Материалы по тегу: ускоритель
|
29.11.2023 [03:43], Владимир Мироненко
AWS представила 96-ядерный Arm-процессор Graviton4 и ИИ-ускоритель Trainium2Amazon Web Services представила Arm-процессор нового поколения Graviton4 и ИИ-ускоритель Trainium2, предназначенный для обучения нейронных сетей. Всего к текущему моменту компания выпустила уже 2 млн Arm-процессоров Graviton, которыми пользуются более 50 тыс. клиентов. «Graviton4 представляет собой четвёртое поколение процессоров, которое мы выпустили всего за пять лет, и это самый мощный и энергоэффективный чип, который мы когда-либо создавали для широкого спектра рабочих нагрузок», — отметил Дэвид Браун (David Brown), вице-президент по вычислениям и сетям AWS. По сравнению с Graviton3 новый чип производительнее на 30 %, включает на 50 % больше ядер и имеет на 75 % выше пропускную способность памяти. 
Изображение: AWS Graviton4 будет иметь до 96 ядер Neoverse V2 Demeter (2 Мбайт L2-кеша на ядро) и 12 каналов DDR5-5600. Кроме того, новый чип получит поддержку шифрования трафика для всех своих аппаратных интерфейсов. Процессор изготавливается по 4-нм техпроцессу TSMC и, вероятно, имеет чиплетную компоновку. Возможно, это первый CPU компании, ориентированный на работу в двухсокетных платформах. 
Изображение: AWS Поначалу Graviton4 будет доступен в инстансах R8g (пока в статусе превью), оптимизированных для приложений, интенсивно использующих ресурсы памяти — высокопроизводительные базы данных, in-memory кеши и Big Data. Эти инстансы будут поддерживать более крупные конфигурации, иметь в три раза больше vCPU и в три раза больше памяти по сравнению с инстансами Rg7, которые имели до 64 vCPU и 512 Гбайт ОЗУ. 
Amazon Trainium2 (Изображение: AWS) В свою очередь, Trainium 2 предназначен для обучения больших языковых моделей (LLM) и базовых моделей. Сообщается, что ускоритель в сравнении с Trainium 1 вчетверо производительнее и при этом имеет в 3 раза больший объём памяти и в 2 раза более высокую энергоэффективность. Инстансы EC2 Trn2 получат 16 ИИ-ускорителей с возможностью масштабирования до 100 тыс. единиц в составе EC2 UltraCluster, которые суммарно дадут 65 Эфлопс, то есть по 650 Тфлопс на ускоритель. Как утверждает Amazon это позволит обучать LLM с 300 млрд параметров за недели вместо месяцев. Со временем на Graviton4 заработает SAP HANA Cloud, портированием и оптимизацией этой платформы уже занимаются. Oracle также перенесла свою СУБД на Arm, а заодно перевела все свои облачные сервисы на чипы Ampere, в которую в своё время инвестировала. Microsoft же пошла по пути AWS и недавно анонсировала 128-ядерый Arm-процессор (Neoverse N2) Cobalt 100 и ИИ-ускоритель Maia 100 собственной разработки. Всё это может представлять отдалённую угрозу для AMD и Intel. С NVIDIA же все всё равно пока что продолжают дружбу — именно в инфраструктуре AWS, как ожидается, появится самый мощный в мире ИИ-суперкомпьютер на базе новых GH200.
28.11.2023 [22:20], Игорь Осколков
NVIDIA анонсировала суперускоритель GH200 NVL32 и очередной самый мощный в мире ИИ-суперкомпьютер Project CeibaAWS и NVIDIA анонсировали сразу несколько новых совместно разработанных решений для генеративного ИИ. Основным анонсом формально является появление ИИ-облака DGX Cloud в инфраструктуре AWS, вот только облако это отличается от немногочисленных представленных ранее платформ DGX Cloud тем, что оно первом получило гибридные суперчипах GH200 (Grace Hoppper), причём в необычной конфигурации. 
Изображения: NVIDIA В основе AWS DGX Cloud лежит платформа GH200 NVL32, но это уже не какой-нибудь сдвоенный акселератор вроде H100 NVL, а целая, готовая к развёртыванию стойка, включающая сразу 32 ускорителя GH200, провязанных 900-Гбайт/с интерконнектом NVLink. В состав такого суперускорителя входят 9 коммутаторов NVSwitch и 16 двухчиповых узлов с жидкостным охлаждением. По словам NVIDIA, GH200 NVL32 идеально подходит как для обучения, так и для инференса действительно больших LLM с 1 трлн параметров.  Простым перемножением количества GH200 на характеристики каждого ускорителя получаются впечатляющие показатели: 128 Пфлопс (FP8), 20 Тбайт оперативной памяти, из которых 4,5 Тбайт приходится на HBM3e с суммарной ПСП 157 Тбайтс, и агрегированная скорость NVLink 57,6 Тбайт/с. И всё это с составе одного EC2-инстанса! Да, новая платформа использует фирменные DPU AWS Nitro и EFA-подключение (400 Гбит/с на каждый GH200). Новые инстансы, пока что безымянные, можно объединять в кластеры EC2 UltraClasters.  Одним из таких кластеров станет Project Ceiba, очередной самый мощный в мире ИИ-суперкомпьютер с FP8-производительность 65 Эфлопс, объединяющий сразу 16 384 ускорителя GH200 и имеющий 9,1 Пбайт памяти, а также агрегированную пропускную способность интерконнекта на уровне 410 Тбайт/с (28,8 Тбайт/с NVLink). Он и станет частью облака AWS DGX Cloud, которое будет доступно в начале 2024 года. В скором времени появятся и EC2-инстансы попроще: P5e с NVIDIA H200, G6e с L40S и G6 с L4. 
28.11.2023 [18:11], Руслан Авдеев
NVIDIA продала более 500 тыс. ИИ-ускорителей H100, но менее дефицитными они не сталиВ III квартале 2024 фискального года, завершившегося в октябре 2023-го, компания NVIDIA заработала впечатляющие $14,5 млрд на решениях для дата-центров. Как сообщает Tom’s Hardware, значительная часть выручки приходится на передовые ускорители H100 для ИИ и HPC-систем. Данные опубликовала компания Omdia, отслеживающая активность на рынке IT-решений. Согласно её анализу, крупнейшими покупателями ускорителей H100 стали гиперскейлеры вроде Meta✴ и Microsoft, значительно обогнавших по объёмам закупок Google, Amazon, Oracle и Tencent. Если Microsoft и Meta✴ приобрели по 150 тыс. ускорителей, то их «коллеги» по IT-рынку — по 50 тыс. При этом гиперскейлерам отдаётся очевидный приоритет при выполнении заказов. В Omdia пришли к выводу, что до конца года будет поставлено почти 650 тыс. H100. В то же время срок выполнения новых заказов на серверы на базе ускорителей компании вырос с 36 до 52 недель. Так, Dell, HPE и Lenovo не могут полностью удовлетворить свои потребности в ускорителях для своих серверов в кратчайшие сроки. В итоге год к году поставки серверов в количественном выражении рухнут на 17–20 %, однако общая выручка поднимется на 6–8 %. 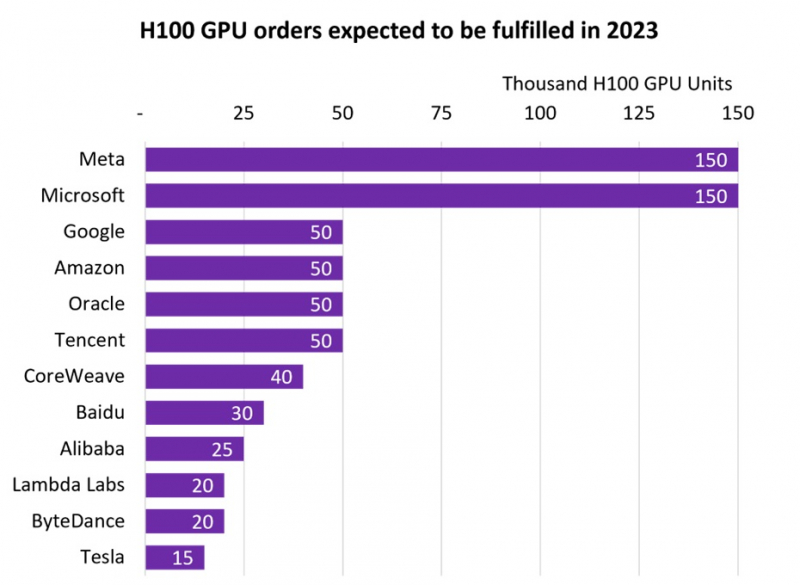
Источник изображения: Omdia В 2027 году рынок серверов должен вырасти до $195,6 млрд, причём основное предпочтение будет отдаваться специализированным вариантам под конкретные задачи, оснащённым специальными сопроцессорами. Запрос на серверы с кастомными конфигурациями становится новой нормой по мере того, как заказчики осознали экономическую эффективность применения сопроцессоров и ускорителей. Пионерами в этой сфере стали компании, связанные с ИИ и медиаконтентом, но привлекательность таких решений, как ожидается, в ближайшем будущем будет оценена и в других секторах.
21.11.2023 [00:34], Руслан Авдеев
Cerebras раскритиковала NVIDIA за «вооружение» Китая ИИ-ускорителямиГлава Cerebras Эндрю Фельдман (Andrew Feldman) подверг критике NVIDIA за попытки компании уложиться в нормы, установленные новыми экспортными ограничениями США в отношении Китая, чтобы продолжить поставки ИИ-ускорителей в Поднебесную. Как передаёт The Register, такое поведение Фельдман назвал «неамериканским» и сравнил техногиганта с торговцем ИИ-оружием. По словам Фельдмана, NVIDIA буквально единолично «вооружила» Китай, поставив огромное количество ускорителей. Хотя компания действовала в рамках закона, это не снимает с неё моральной ответственности. Сама Cerebras тоже разрабатывает чипы для систем машинного обучения и других ресурсоёмких задач, но намерена соблюдать «дух, а не букву» введённых в октябре США новых правил, ограничивающих поставки ИИ-оборудования в США. Правила и без того фактически отрезают Пекин от поставок разработанных в США передовых ускорителей, но уже ходят слухи, что NVIDIA готовит новые продукты для того, чтобы обойти и эти ограничения. Раньше она уже выпустила «ухудшенные» A800 и H800, теперь тоже попавшие под ограничения. Неанонсированные чипы H20, L20 и L2 якобы представляют собой менее производительные версии более быстрых вариантов, поставляющихся для стран, не попавших под санкции. NVIDIA уже предупреждала, что новые ограничения способны сказаться на её финансовых результатах. 
Фото: Cerebras Вместе с тем сама Cerebras в этом году заключила контракт на $900 млн для строительства девяти ИИ-суперкомпьютеров на чипах WSE-2 для компании G42 из ОАЭ, которую неоднократно обвиняли в связях со структурами, занятых, к примеру, шпионажем в пользу властей ОАЭ. В данном случае компания не усматривает моральной дилеммы. Cerebras с самого начала приняла решение не вести дел с Китаем, а также обещает соблюдать рекомендации американских госорганов, касающиеся поставок полупроводников на Ближний Восток. Фельдман считает, что компании не должны пытаться обойти ограничения. В частности, компания отслеживала, чтобы её чипы «не поставлялись в одно место на Ближнем Востоке, чтобы вскоре исчезнуть и появиться совсем в другом, там, куда они не должны были бы поставляться». Как заявляют в Cerebras, когда вы пытаетесь обойти правила, вы выглядите «не по-американски». Конечно, обойти санкционные ограничения пытается не только NVIDIA, но и, например, Intel, которая ранее в этом году представила ухудшенную версию ускорителей Habana Gaudi для продажи на китайском рынке — правда, новейшие ограничения, похоже, не дадут поставлять в Китай и их. Некоторые сигналы о желании обойти санкции поступают и от AMD, хотя нет точных данных, когда начнутся продажи адаптированных под санкции решений и начнутся ли они вообще.
19.11.2023 [22:42], Сергей Карасёв
16 ускорителей на один сервер: Liqid и Dell представили платформу UltraStack L40SКомпания Liqid в партнёрстве с Dell Technologies анонсировала эталонную архитектуру UltraStack L40S для формирования систем с высокой плотностью компоновки GPU и иных ускорителей — до 16 шт. на один сервер. Такие платформы могут использоваться для ИИ-приложений, работы с большими языковыми моделями (LLM), задач НРС и пр. Новинка доступна в конфигурациях UltraStack x8 и UltraStack x16. В качестве хост-сервера в составе решения выступает Dell PowerEdge R760xa на базе Intel Xeon Sapphire Rapids: применены два процессора Xeon Gold 6430 (32 ядра; 64 потока; 1,9 ГГц). Объём оперативной памяти в первом случае составляет 1 Тбайт, во втором — 2 Тбайт. К серверу подключаются модули Liqid PCIe Chassis. Версия UltraStack x8 использует два таких модуля: задействованы восемь ускорителей NVIDIA L40S с 48 Гбайт памяти GDDR6 и SSD-хранилище вместимостью 30 Тбайт (NVMe). Вариант UltraStack x16 комплектуется тремя модулями Liqid PCIe Chassis: объединены 16 карт NVIDIA L40S, а ёмкость хранилища составляет 60 Тбайт. 
Источник изображения: Liqid Платформа UltraStack L40S предполагает применение восьми двухпортовых сетевых адаптеров NVIDIA ConnectX-7 (16 × 200 Гбит/с), DPU BlueField-3, двух хост-адаптеров Liqid Gen 4.0 x16 HBA, а также коммутатора PCIe 4.0 на 24/48 портов. Среднее энергопотребление UltraStack x8 заявлено на уровне 4,5 кВт, UltraStack x16 — 7,5 кВт. Система базируется на ПО Liqid Matrix. Компания Liqid утверждает, что по сравнению с четырьмя серверами формата 2U, каждый из которых содержит четыре ускорителя NVIDIA L40S, её система UltraStack с 16 такими картами обеспечивает на 35 % более высокую производительность, сокращение энергопотребления на 35 % и снижение общей стоимости владения на 25 %.
19.11.2023 [03:00], Сергей Карасёв
Южнокорейский стартап Sapeon представил 7-нм ИИ-чип X330ИИ-стартап Sapeon, поддерживаемый южнокорейским телекоммуникационным гигантом SK Group, анонсировал чип X330, предназначенный для инференса и обслуживания больших языковых моделей (LLM). Изделие ляжет в основу специализированных ускорителей для дата-центров. Sapeon заявляет, что новый нейропроцессор (NPU) обеспечивает примерно вдвое более высокую производительность и в 1,3 раза лучшую энергоэффективность, чем продукты конкурентов, выпущенные в этом году. По сравнению с предыдущим решением самой компании — Sapeon X220 — достигается увеличение быстродействия в четыре раза и повышение энергоэффективности в два раза. 
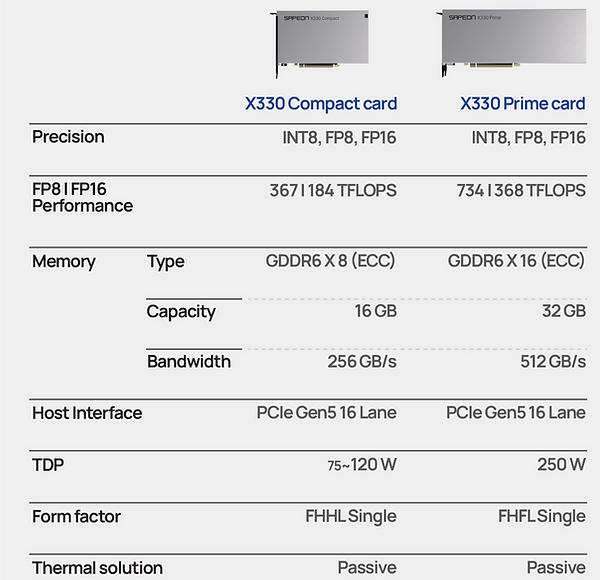
Изображения: Sapeon Новинка будет изготавливаться на TSMC по 7-нм технологии. Массовое производство запланировано на I полугодие 2024 года. На базе чипа будут предлагаться два ускорителя — X330 Compact Card и X330 Prime Card. Оба имеют однослотовое исполнение и оснащаются системой пассивного охлаждения. Для подключения применяется интерфейс PCIe 5.0 х16. Карты могут осуществлять вычисления INT8, FP8 и FP16.  Модель X330 Compact Card уменьшенной длины несёт на борту 16 Гбайт памяти GDDR6 с пропускной способностью до 256 Гбайт/с. Заявленная производительность на операциях FP8 и FP16 достигает соответственно 367 и 184 Тфлопс. Энергопотребление варьируется в диапазоне от 75 до 120 Вт. Полноразмерная модификация X330 Prime Card получила 32 Гбайт памяти GDDR6 с пропускной способностью до 512 Гбайт/с. Заявленное быстродействие FP8 и FP16 составляет до 734 и 368 Тфлопс. Энергопотребление — 250 Вт.  Группа SK в последнее время активно вкладывается в развитие ИИ, инвестируя напрямую или через дочерние структуры как в софт, так и в железо. С ней, в частности, связан ещё один южнокорейский разработчик ИИ-чипов Rebellions, также поддерживаемый правительством страны, которое намерено к 2030 году довести долю отечественных ИИ-чипов в местных дата-центрах до 80 %. Делается это для того, чтобы снизить зависимость от иностранных решений и избежать дефицита. Сама же Sapeon готовит ещё минимум два поколения своих чипов.
17.11.2023 [14:02], Руслан Авдеев
Tencent накопила достаточно ускорителей NVIDIA H800 для поддержания ИИ-разработок в условиях антикитайских санкцийПосле ужесточения антикитайских санкций 17 октября со стороны США бизнес и государственные структуры КНР лишились возможности приобретать даже ухудшенные версии ускорителей NVIDIA. Тем не менее, как сообщает DigiTimes, многие китайские участники рынка успели закупить большое количество ускорителей до вступления новых запретов в силу. По словам президента Tencent Мартина Лау (Martin Lau), перспектива введения более строгих санкций сподвигла компанию к более рациональному использованию уже имеющихся чипов, а также поиску альтернатив на местном рынке, где разработка подобных решений ведётся ударными темпами. В своё время NVIDIA на фоне санкций пришлось наладить для Китая вместо ускорителей A100 и H100 выпуск моделей A800 и H800 с искусственно заниженной производительностью. Но теперь и их экспорт в Поднебесную попал под запрет. Как заявил Лау журналистам, Tencent уже закупила достаточно ускорителей NVIDIA для дальнейшего развития ИИ-платформы Hunyuan. Ожидается, что компании удастся обучить ещё как минимум два поколения ИИ-моделей. В результате, как считают в руководстве Tencent, новейшие антикитайские санкции не смогут повлиять на возможность развития ИИ-технологий компании в краткосрочной перспективе. 
Источник изображения: NVIDIA Инвесторам сообщили, что Hunyuan уже может готовить резюме встреч, проводимых на похожей на Zoom платформе Tencent Meeting, даёт рекомендации программистам компании и повышает эффективность создания игр. Также ИИ способен выступать в роли копирайтера для рекламодателей, позволяя более аккуратно адаптировать рекламу под целевую аудиторию, увеличивая её эффективность. В частности, это позволило улучшить показатели видеорекламы Tencent. В обозримом будущем Лау рассчитывает, что ИИ позволит и отвечать на вопросы клиентов — это позволит объединить рекламу и продажи. Как подчеркнул Лау, фактически Tencent находится в числе китайских компаний с самыми большими запасами чипов H800 — в своё время именно она первой начала приобретать их у NVIDIA. В частности поэтому она накопила большие запасы, так что новые запреты способны лишь слегка замедлить работы. По словам Лау, наиболее эффективной будет комбинированная схема, при которой наиболее производительные чипы оставят для тренировки ИИ-моделей, а варианты с меньшей производительностью будут применяться для инференса. Впрочем, несмотря на принятые меры, в Tencent признают, что антикитайские санкции США негативно скажутся на облачном ИИ-сервисе компании. Тем не менее, Лау уверен, что если запасы H800 начнут иссякать, они будут пополнены за счёт китайских решений. Как сообщает The Register, пока таких фактически не существует. Но, судя по всему, в Tencent уверены, что скоро варианты, способные бросить вызов американскому превосходству, окажутся в китайском распоряжении. В III квартале выручка китайского техногиганта составила $21,5 млрд и выросла год к году на 10 %. Операционная прибыль упала на 6 %, но всё ещё составляет $6,8 млрд. Компания принимает ряд мер по оптимизации бизнеса и сейчас её социальные платформы WeChat и QQ насчитывают по 1,336 млрд и 558 млн активных пользователей соответственно, наблюдается небольшой рост год к году. Рост доходов руководство объясняет эффективностью видео- и игрового сервисов.
16.11.2023 [02:43], Алексей Степин
Microsoft представила 128-ядерый Arm-процессор Cobalt 100 и ИИ-ускоритель Maia 100 собственной разработкиГиперскейлеры ради снижения совокупной стоимости владения (TCO) и зависимости от сторонних вендоров готовы вкладываться в разработку уникальных чипов, изначально оптимизированных под их нужды и инфраструктуру. К небольшому кругу компаний, решившихся на такой шаг, присоединилась Microsoft, анонсировавшая Arm-процессор Azure Cobalt 100 и ИИ-ускоритель Azure Maia 100. 
Изображения: Microsoft Первопроходцем в этой области стала AWS, которая разве что память своими силами не разрабатывает. У AWS уже есть три с половиной поколения Arm-процессоров Graviton и сразу два вида ИИ-ускорителей: Trainium для обучения и Inferentia2 для инференса. Крупный китайский провайдер Alibaba Cloud также разработал и внедрил Arm-процессоры Yitian и ускорители Hanguang. Что интересно, в обоих случаях процессоры оказывались во многих аспектах наиболее передовыми. Наконец, у Google есть уже пятое поколение ИИ-ускорителей TPU.  Microsoft заявила, что оба новых чипа уже производятся на мощностях TSMC с использованием «последнего техпроцесса» и займут свои места в ЦОД Microsoft в начале следующего года. Как минимум, в случае с Maia 100 речь идёт о 5-нм техпроцессе, вероятно, 4N. В настоящее время Microsoft Azure находится в начальной стадии развёртывания инфраструктуры на базе новых чипов, которая будет использоваться для Microsoft Copilot, Azure OpenAI и других сервисов. Например, Bing до сих пор во много полагается на FPGA, а вся ИИ-инфраструктура Microsoft крайне сложна.  Microsoft приводит очень мало технических данных о своих новинках, но известно, что Azure Cobalt 100 имеет 128 ядер Armv9 Neoverse N2 (Perseus) и основан на платформе Arm Neoverse Compute Subsystem (CSS). По словам компании, процессоры Cobalt 100 до +40 % производительнее имеющихся в инфраструктуре Azure Arm-чипов, они используются для обеспечения работы служб Microsoft Teams и Azure SQL. Oracle, вложившаяся в своё время в Ampere Comptuing, уже перевела все свои облачные сервисы на Arm.  Чип Maia 100 (Athena) изначально спроектирован под задачи облачного обучения ИИ и инференса в сценариях с использованием моделей OpenAI, Bing, GitHub Copilot и ChatGPT в инфраструктуре Azure. Чип содержит 105 млрд транзисторов, что больше, нежели у NVIDIA H100 (80 млрд) и ставит Maia 100 на один уровень с Ponte Vecchio (~100 млрд). Для Maia организован кастомный интерконнект на базе Ethernet — каждый ускоритель располагает 4,8-Тбит/с каналом для связи с другими ускорителями, что должно обеспечить максимально эффективное масштабирование.  Сами Maia 100 используют СЖО с теплообменниками прямого контакта. Поскольку нынешние ЦОД Microsoft проектировались без учёта использования мощных СЖО, стойку пришлось сделать более широкой, дабы разместить рядом с сотней плат с чипами Maia 100 серверами и большой радиатор. Этот дизайн компания создавала вместе с Meta✴, которая испытывает аналогичные проблемы с текущими ЦОД. Такие стойки в настоящее время проходят термические испытания в лаборатории Microsoft в Редмонде, штат Вашингтон.  В дополнение к Cobalt и Maia анонсирована широкая доступность услуги Azure Boost на базе DPU MANA, берущего на себя управление всеми функциями виртуализации на манер AWS Nitro, хотя и не целиком — часть ядер хоста всё равно используется для обслуживания гипервизора. DPU предлагает 200GbE-подключение и доступ к удалённому хранилищу на скорости до 12,5 Гбайт/с и до 650 тыс. IOPS.  Microsoft не собирается останавливаться на достигнутом: вводя в строй инфраструктуру на базе новых чипов Cobalt и Maia первого поколения, компания уже ведёт активную разработку чипов второго поколения. Впрочем, совсем отказываться от партнёрства с другими вендорами Microsoft не намерена. Компания анонсировала первые инстансы с ускорителями AMD Instinct MI300X, а в следующем году появятся инстансы с NVIDIA H200. 
15.11.2023 [15:52], Сергей Карасёв
NeuReality представила «сервер на чипе» и другие аппаратные ИИ-решения для инференсаКомпания NeuReality на конференции по высокопроизводительным вычислениям SC23 представила полностью интегрированное решение NR1 AI Inference, предназначенное для ИИ-платформ. Изделие спроектировано специально для ускорения инференса и снижения нагрузки на аппаратные ресурсы. Утверждается, что благодаря использованию технологий NeuReality операторы крупных дата-центров могут на 90 % сократить затраты на выполнение операций ИИ. При этом производительность по сравнению с традиционными системами на основе CPU больше на порядок. Впрочем, конкретные цифры не приводятся. 
Источник изображений: NeuReality В продуктовое семейство NeuReality входит решение NR1, которое разработчик называет «сервером на чипе» со встроенным нейросетевым движком. По заявлениям NeuReality, это первый в мире «сетевой адресуемый процессор» — NAPU (Network Addressable Processing Unit). Этот специализированный чип, ориентированный на задачи инференса, обладает возможностями виртуализации и сетевыми функциями.  Изделие NR1 является основой вычислительного модуля NR1-M AI Inference Module, выполненного в виде полноразмерной двухслотовой карты расширения PCIe. Модуль может подключаться к внешнему ускорителю глубокого обучения (DLA). Наконец, анонсирован сервер NR1-S AI Inference Appliance, который оснащается картами NR1-M AI Inference Module. NeuReality отмечает, что данная система позволяет снизить стоимость и энергопотребление почти в 50 раз на операциях инференса по сравнению со стандартными платформами.
14.11.2023 [03:20], Алексей Степин
Intel показала результаты тестов ускорителя Max 1550 и рассказала о будущих чипах Gaudi3 и Falcon ShoresВ рамках SC23 корпорация Intel продемонстрировала ряд любопытных слайдов. На них присутствуют результаты тестирования ускорителя Max 1550 с архитектурой Xe, а также планы относительно следующего поколения ИИ-ускорителей Gaudi. 
Изображение: Intel При этом компания применила иной подход, нежели обычно — вместо демонстрации результатов, полученных в стенах самой Intel, слово было предоставлено Аргоннской национальной лаборатории Министерства энергетики США, где летом этого года было завершён монтаж суперкомпьютера экза-класса Aurora, занимающего нынче второе место в TOP500.  В этом HPC-кластере применены OAM-модули Max 1550 (Ponte Vecchio) с теплопакетом 600 Вт. Они содержат в своём составе 128 ядер Xe и 128 Гбайт памяти HBM2E. Интерфейс Xe Link позволяет общаться напрямую восьми таким модулям, что обеспечивает более эффективную масштабируемость. 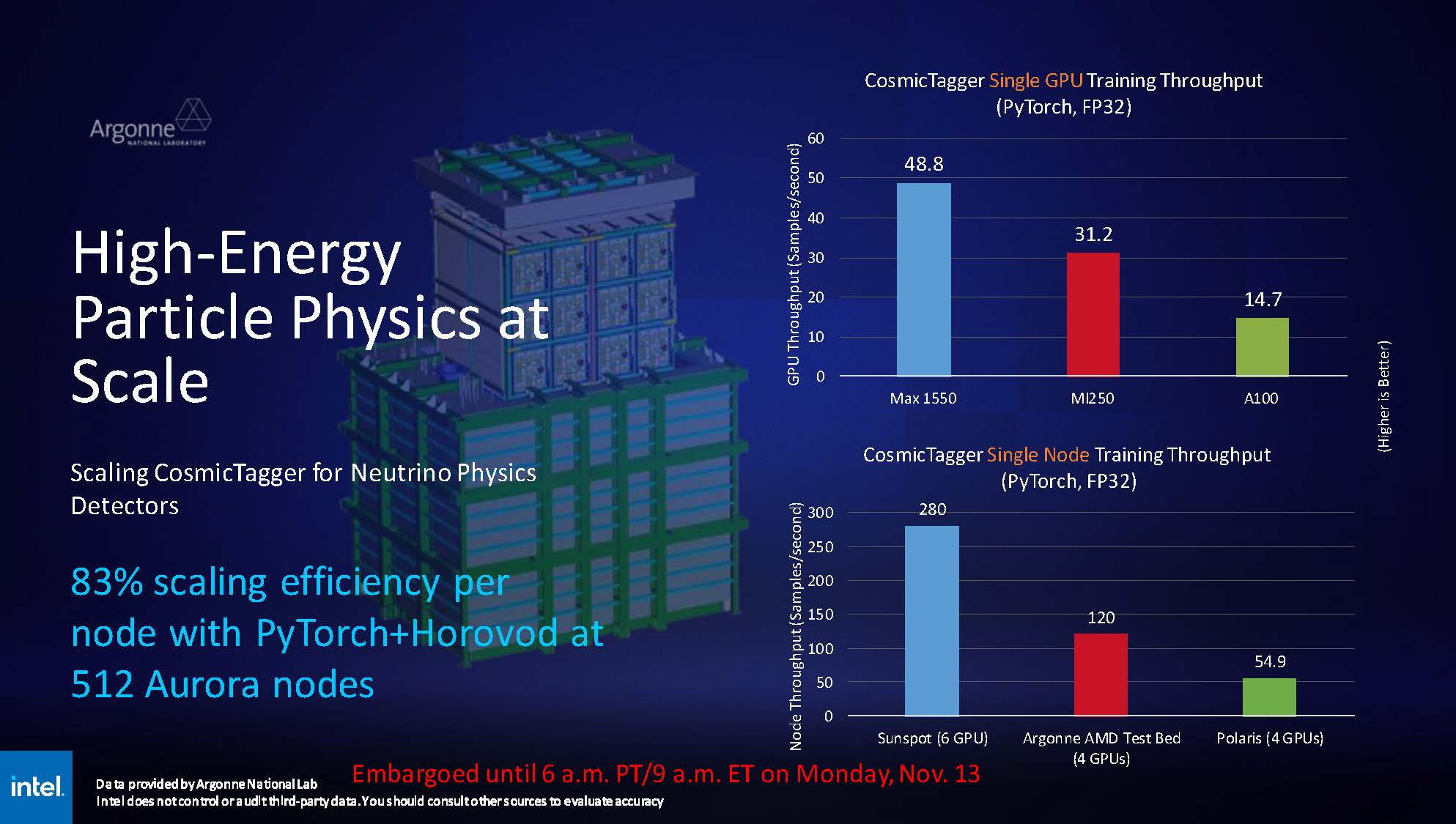
Источник изображений здесь и далее: Intel via ServeTheHome Хотя настройка вычислительного комплекса Aurora ещё продолжается, уже имеются данные о производительности Max 1550 в сравнении с AMD Instinct MI250 и NVIDIA A100. В тесте физики высоких частиц, использующих сочетание PyTorch+Horovod (точность вычислений FP32), ускорители Intel уверенно заняли первое место, а также показали 83% эффективность масштабирования на 512 узлах Aurora.  В тесте, симулирующем поведение комплекса кремниевых наночастиц, ускорители Max 1550, также оказались первыми как в абсолютном выражении, так и в пересчёте на 128-узловой тест в сравнении с системами Polaris (четыре A100 на узел) и Frontier (четыре MI250 на узел). Написанный с использованием Fortran и OpenMP код доказал работоспособность и при масштабировании до более чем 500 вычислительных узлов Aurora. 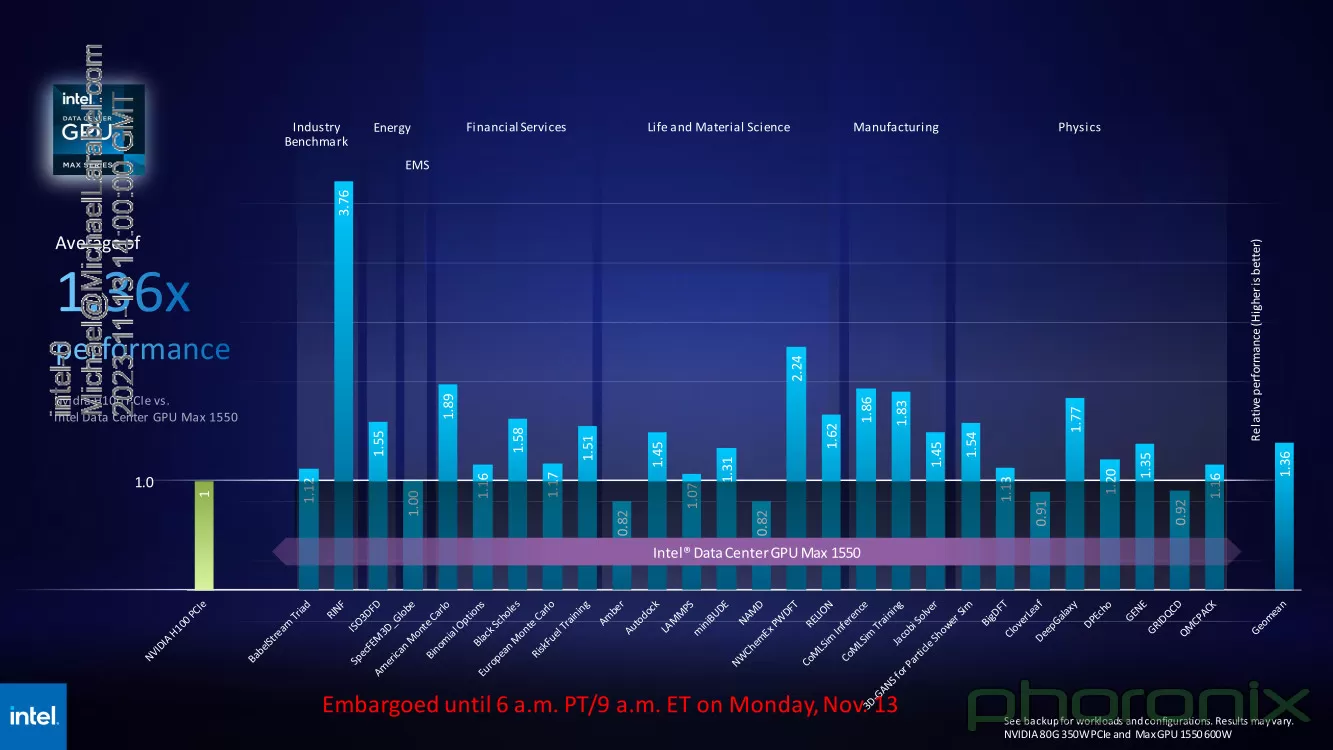
Источник изображения: Intel via Phoronix В целом, ускорители Intel Max 1550 демонстрируют хорошие результаты и не уступают NVIDIA H100: в некоторых задачах их относительная эффективность составляет не менее 0,82, но в большинстве других тестов этот показатель варьируется от 1,0 до 3,76. Очевидно, что у H100 появился достойный соперник, который, к тому же, имеет меньшую стоимость и большую доступность. Но сама NVIDIA уже представила чипы (G)H200, а AMD готовит Instinct MI300.  Системы на базе Intel Max доступны в различном виде: как в облаке Intel Developer Cloud, так и в составе OEM-решений. Supermicro предлагает сервер с восемью модулями OAM, а Dell и Lenovo — решения с четырьями ускорителями в этом же формате. PCIe-вариант Max 1100 доступен от вышеуказанных производителей, а также у HPE. 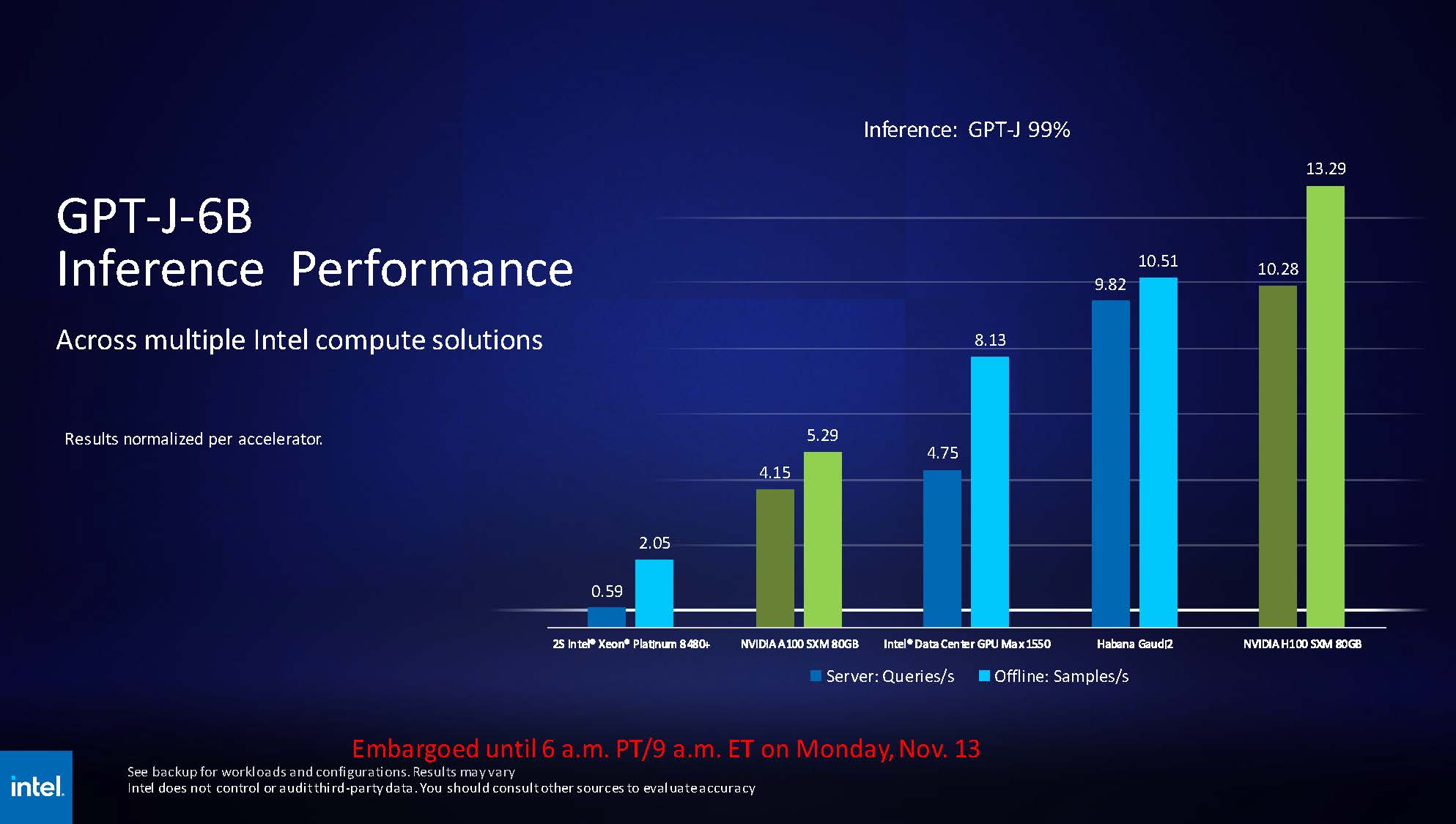 Помимо ускорителей Max, Intel привела и новые данные о производительности ИИ-сопроцессоров Gaudi2. Компания продолжает активно совершенствовать и оптимизировать программную экосистему Gaudi. В результате, в инференс-системе на базе модели GPT-J-6B результаты ускорителей Gaudi2 уже сопоставимы с NVIDIA H100 (SXM 80 Гбайт), а A100 существенно уступает как Gaudi2, так и Max 1550.  Но самое интересное — это сведения о планах относительно следующего поколения Gaudi. Теперь известно, что Gaudi3 будет производиться с использованием 5-нм техпроцесса. Новый чип будет в четыре раза быстрее в вычислениях BF16, а также получит вдвое более мощную подсистему памяти и в 1,5 раза больше памяти HBM. Увидеть свет он должен в 2024 году. 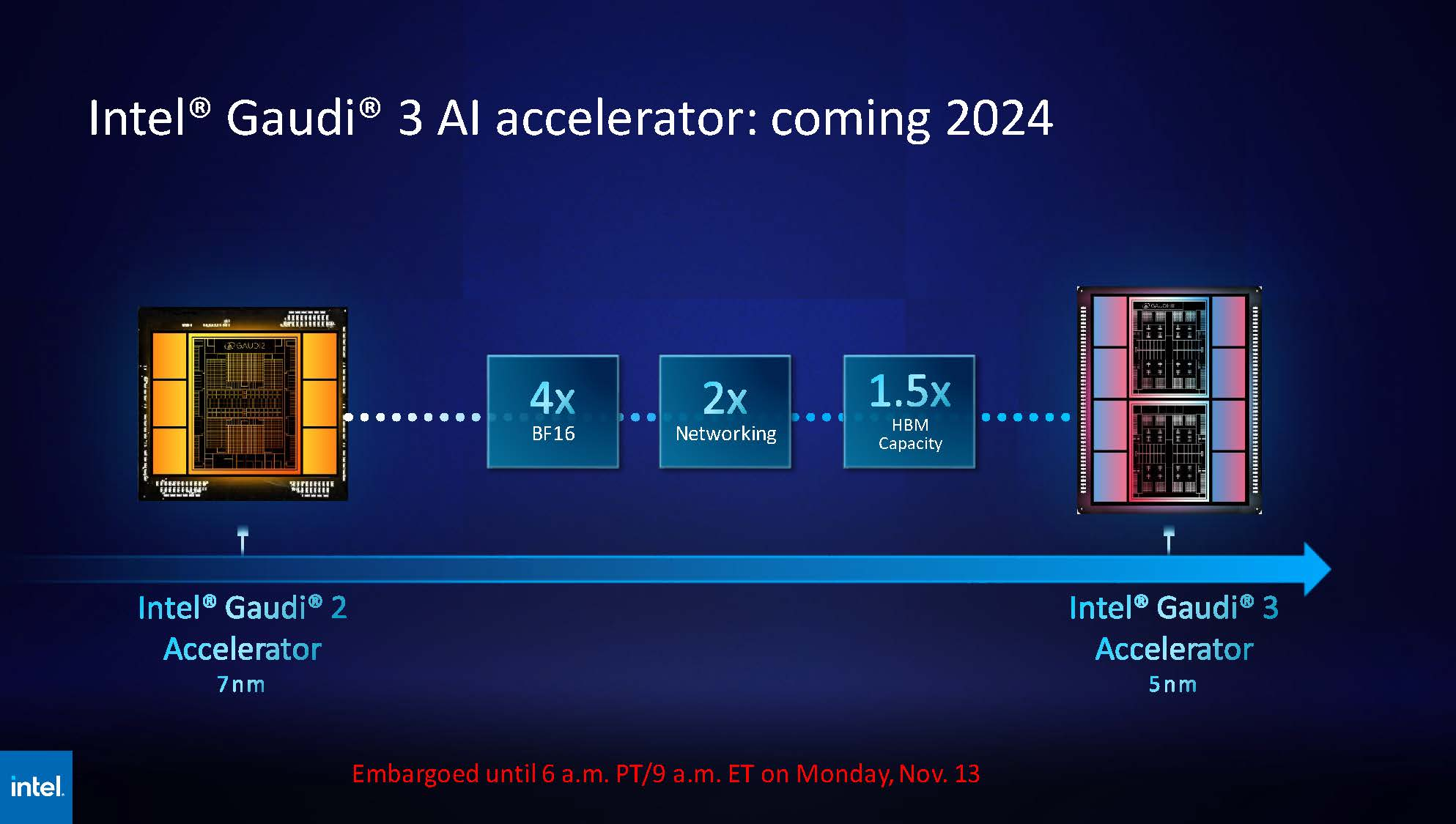 Заодно компания напомнила, что процессоры Xeon Emerald Rapids будут представлены ровно через месяц, а Granite Rapids появятся в 2024 году. В 2025 появится чип Falcon Shores, который теперь должен по задумке Intel сочетать в себе GPU и ИИ-сопроцессор. Он объединит архитектуры Habana и Xe в единое решение с тайловой компоновкой, памятью HBM3 и полной поддержкой CXL. 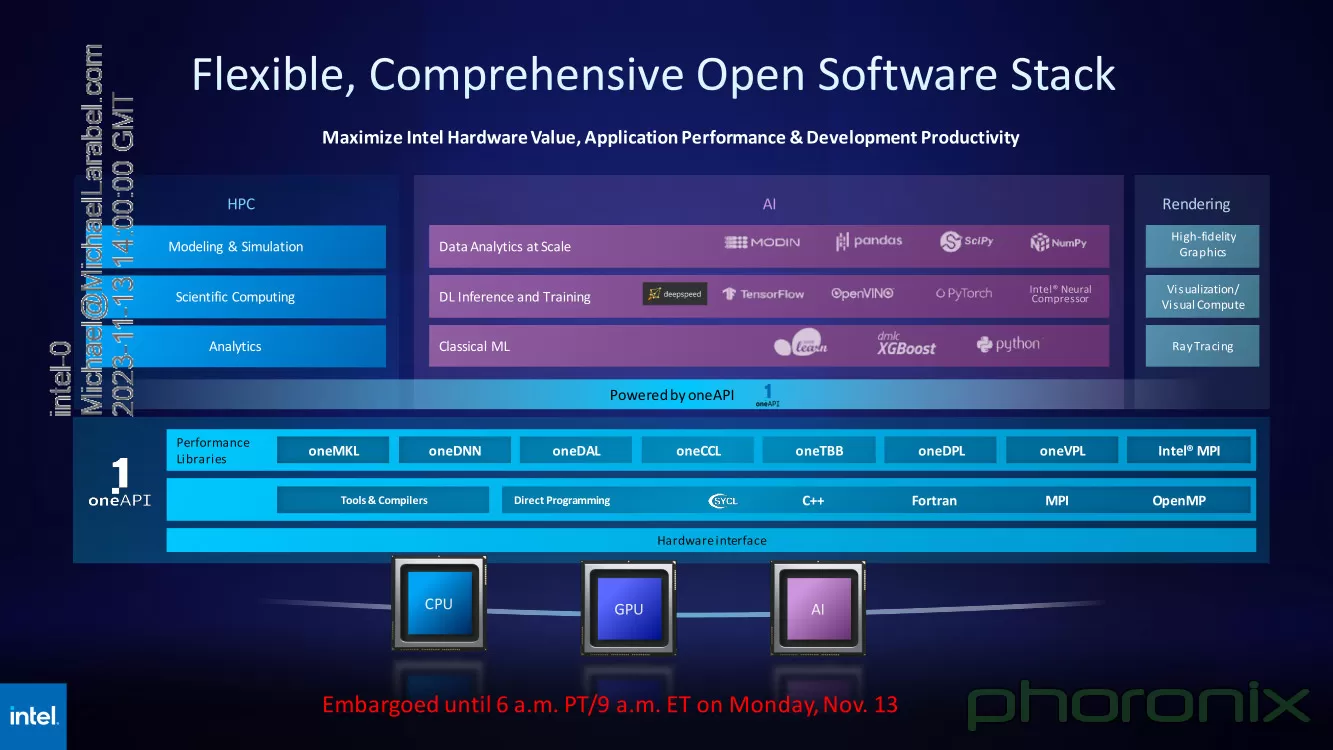
Источник изображения: Intel via Phoronix Следует отметить, что такая унификация вполне реальна: Intel весьма активно развивает универсальный, гибкий и открытый стек технологий в рамках проекта oneAPI. В него входят все необходимые инструменты — от компиляторов и системных библиотек до средств интеграции с популярными движками аналитики данных, моделями и библиотеками искусственного интеллекта. |
|

{kind=link}