Материалы по тегу: nvidia
|
28.05.2021 [00:33], Владимир Мироненко
Perlmutter стал самым мощным ИИ-суперкомпьютером в мире: 6 тыс. NVIDIA A100 и 3,8 ЭфлопсВ Национальном вычислительном центре энергетических исследований США (NERSC) Национальной лаборатории им. Лоуренса в Беркли состоялась торжественная церемония, посвящённая официальному запуску суперкомпьютера Perlmutter, также известного как NERSC-9, созданного HPE в партнёрстве с NVIDIA и AMD. Это самый мощный в мире ИИ-суперкомпьютер, базирующийся на 6159 ускорителях NVIDIA A100 и примерно 1500 процессорах AMD EPYC Milan. Его пиковая производительность в вычислениях смешанной точности составляет 3,8 Эфлопс или почти 60 Пфлопс в FP64-вычислениях. Perlmutter основан на платформе HPE Cray EX с прямым жидкостным охлаждением и интерконнектом Slingshot. В состав системы входят как GPU-узлы, так и узлы с процессорами. Для хранения данных используется файловая система Lustre объёмом 35 Пбайт скорость обмена данными более 5 Тбайт/с, которая развёрнута на All-Flash СХД HPE ClusterStor E1000 (тоже, к слову, на базе AMD EPYC). 
Perlmutter (Phase 1). Фото: NERSC Установка Perlmutter разбита на два этапа. На сегодняшней презентации было объявлено о завершении первого (Phase 1) этапа, который начался в ноябре прошлого года. В его рамках было установлено 1,5 тыс. вычислительных узлов, каждый из которых имеет четыре ускорителя NVIDIA A100, один процессор AMD EPYC Milan и 256 Гбайт памяти. На втором этапе (Phase 2) в конце 2021 года будут добавлены 3 тыс. CPU-узлов c двумя AMD EPYC Milan и 512 Гбайт памяти., а также ещё ещё 20 узлов доступа и четыре узла с большим объёмом памяти. 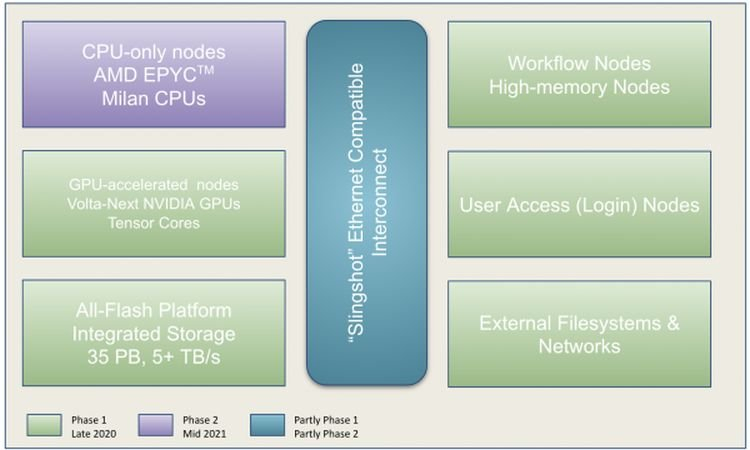
NERSC Также на первом этапе были развёрнуты служебные узлы, включая 20 узлов доступа пользователей, на которых можно подготавливать контейнеры с приложениями для последующего запуска на суперкомпьютере и использовать Kubernetes для оркестровки. Среда разработки будет включать NVDIA HPC SDK в дополнение к наборам компиляторов CCE (Cray Compiling Environment), GCC и LLVM для поддержки различных средств параллельного программирования, таких как MPI, OpenMP, CUDA и OpenACC для C, C ++ и Fortran. 
Фото: DESI Сообщается, что для Perlmutter готовится более двух десятков заявок на вычисления в области астрофизики, прогнозирования изменений климата и в других сферах. Одной из задач для новой системы станет создание трёхмерной карты видимой Вселенной на основе данных от DESI (Dark Energy Spectroscopic Instrument). Ещё одно направление, для которого задействуют суперкомпьютер, посвящено материаловедению, изучению атомных взаимодействий, которые могут указать путь к созданию более эффективных батарей и биотоплива.
15.04.2021 [21:24], Игорь Осколков
DPU BlueField — третий столп будущего NVIDIAВо время открытия GTC’21 наибольшее внимание привлёк, конечно, анонс собственного серверного Arm-процессора NVIDIA — Grace. Говорят, из-за этого даже акции Intel просели, хотя в последних решениях самой NVIDIA процессоры x86-64 были нужны уже лишь для поддержки «обвязки» вокруг непосредственно ускорителей. Да, теперь у NVIDIA есть три точки опоры, три столпа для будущего развития: GPU, DPU и CPU. Причём расположение их именно в таком порядке неслучайно. 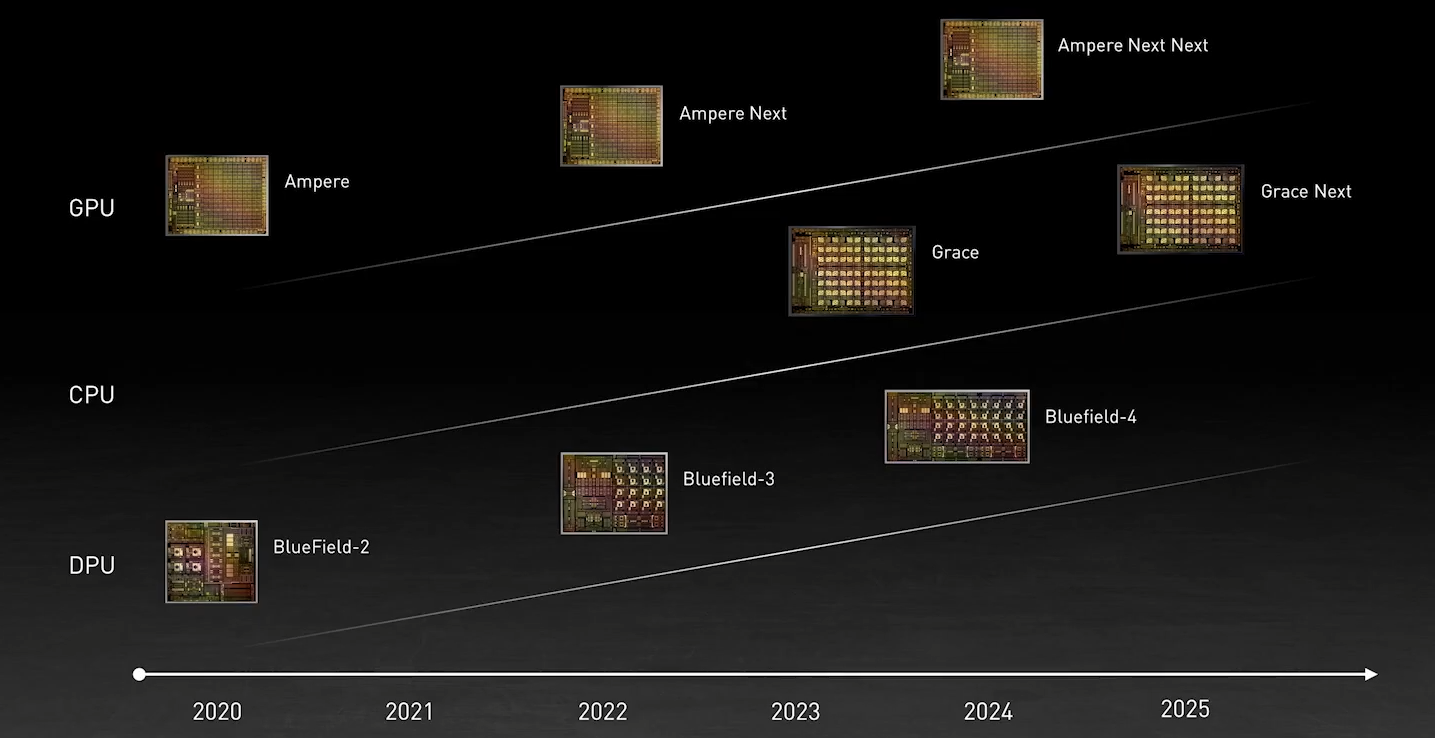 У процессора Grace, который выйдет только в 2023 году, даже по современным меркам «голая» производительность не так уж высока — в SPECrate2017_int его рейтинг будет 300. Но это и неважно потому, что он, как и сейчас, нужен лишь для поддержки ускорителей (которые для краткости будем называть GPU, хотя они всё менее соответствуют этому определению), что возьмут на себя основную вычислительную нагрузку. 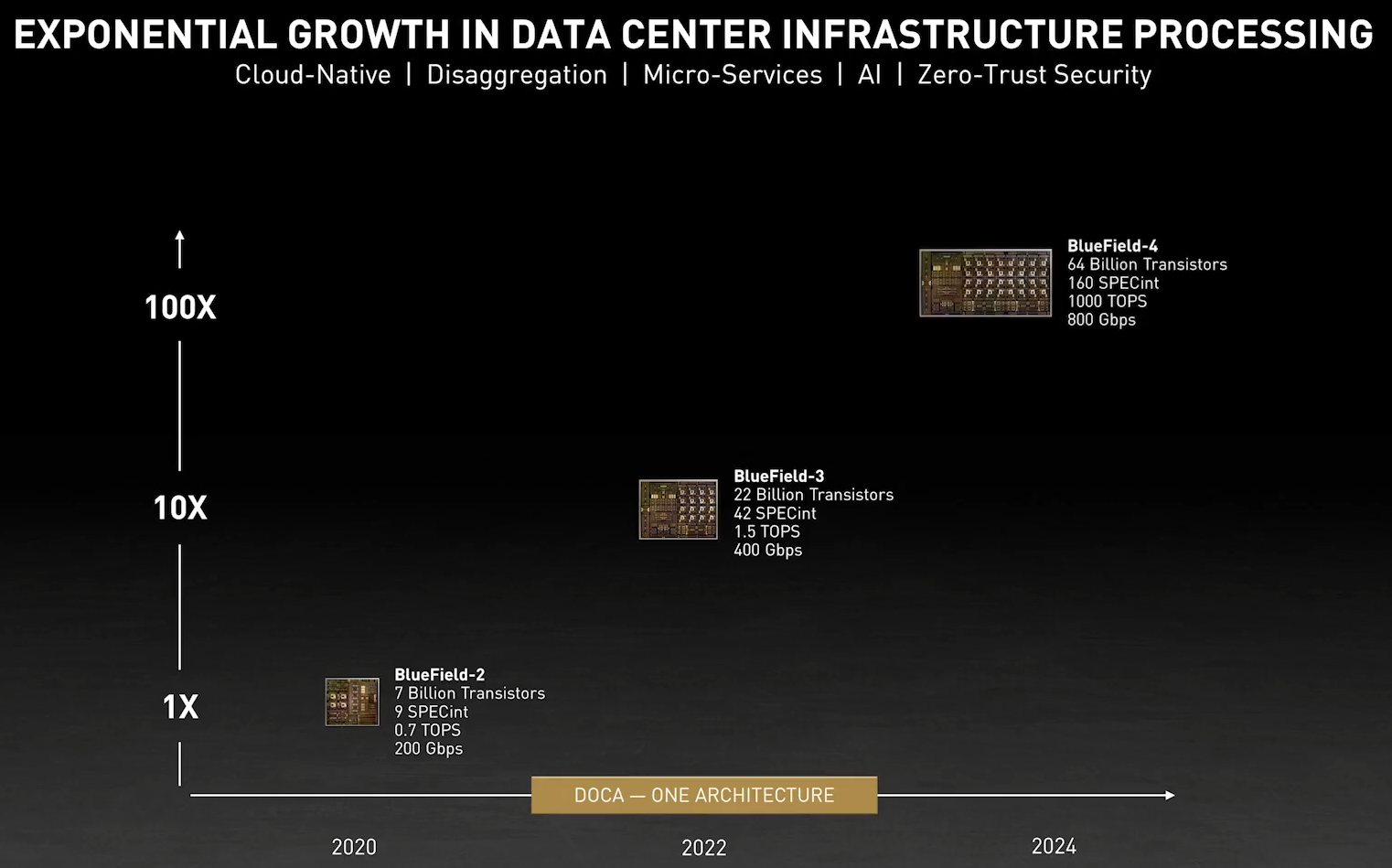 Гораздо интереснее то, что уже в 2024 году появятся BlueField-4, для которых заявленный уровень производительности в том же SPECrate2017_int составит 160. То есть DPU (Data Processing Unit, сопроцессор для данных) формально будет всего лишь в два раза медленнее CPU Grace, но при этом включать 64 млрд транзисторов. У нынешних ускорителей A100 их «всего» 54 млрд, и это один из самых крупных массово производимых чипов на сегодня.  Значительный объём транзисторного бюджета, очевидно, пойдёт не на собственной сетевую часть, а на Arm-ядра и различные ускорители. Анонсированные в прошлом году и ставшие доступными сейчас DPU BlueField-2 намного скромнее. Но именно с их помощью NVIDIA готовит экосистему для будущих комплексных решений, где DPU действительно станут «третьим сокетом», как когда-то провозгласил стартап Fubgible, успевший анонсировать до GTC’21 и собственную СХД, и более общее решение для дата-центров. Однако подход двух компаний отличается. 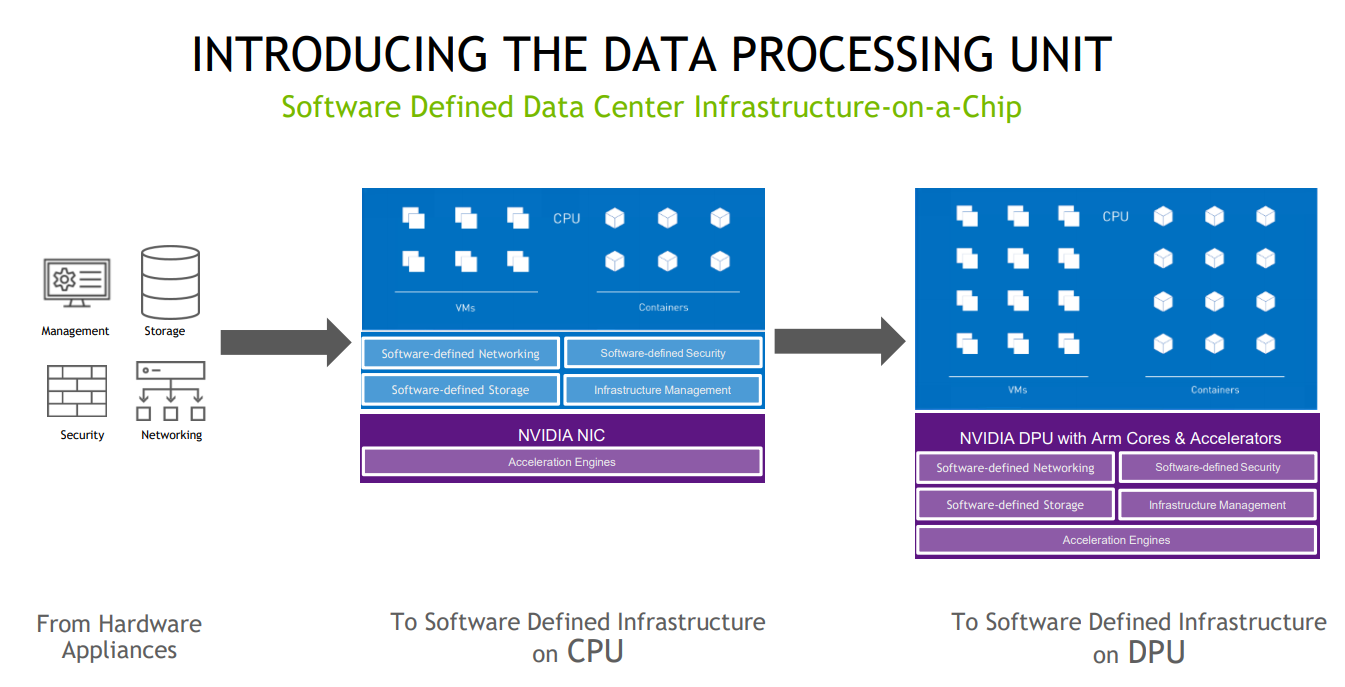 Напомним основные характеристики BlueField-2. Сетевая часть, представленная Mellanox ConnectX-6 Dx, предлагает до двух портов 100 Гбит/с, причём доступны варианты и с Ethernet, и с InfiniBand. Есть отдельные движки для ускорения криптографии, регулярных выражений, (де-)компрессии и т.д. Всё это дополняют 8 ядер Cortex-A78 (до 2,5 ГГц), от 8 до 32 Гбайт DDR4-3200 ECC, собственный PCIe-свитч и возможность подключения M.2/U.2-накопителя. Кроме того, будет вариант BlueField-2X c GPU на борту. Характеристики конкретных адаптеров на базе BlueField-2 отличаются, но, в целом, перед нами полноценный компьютер. А сама NVIDIA называет его DOCA (DataCenter on a Chip Architecture), дата-центром на чипе. 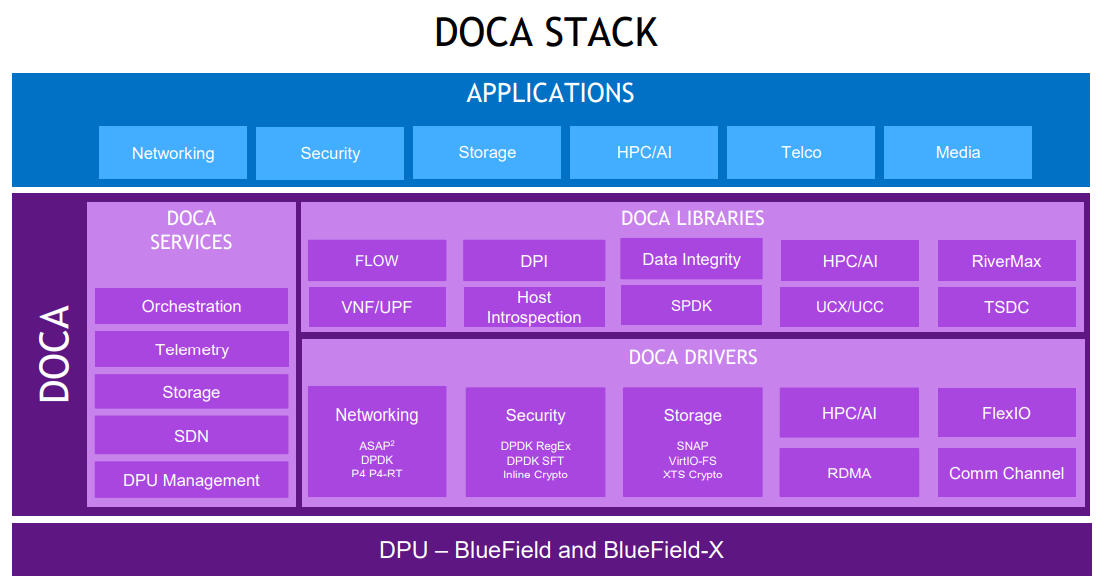 Для работы с ним предлагается обширный набор разработчика DOCA SDK, который включает драйверы, фреймворки, библиотеки, API, службы и собственно среду исполнения. Все вместе они покрывают практически все возможные типовые серверные нагрузки и задачи, а также сервисы, которые с помощью SDK относительно легко перевести в разряд программно определяемых, к чему, собственно говоря, все давно стремятся. NVIDIA обещает, что DOCA станет для DPU тем же, чем стала CUDA для GPU, сохранив совместимость с последующими версиями ПО и «железа». 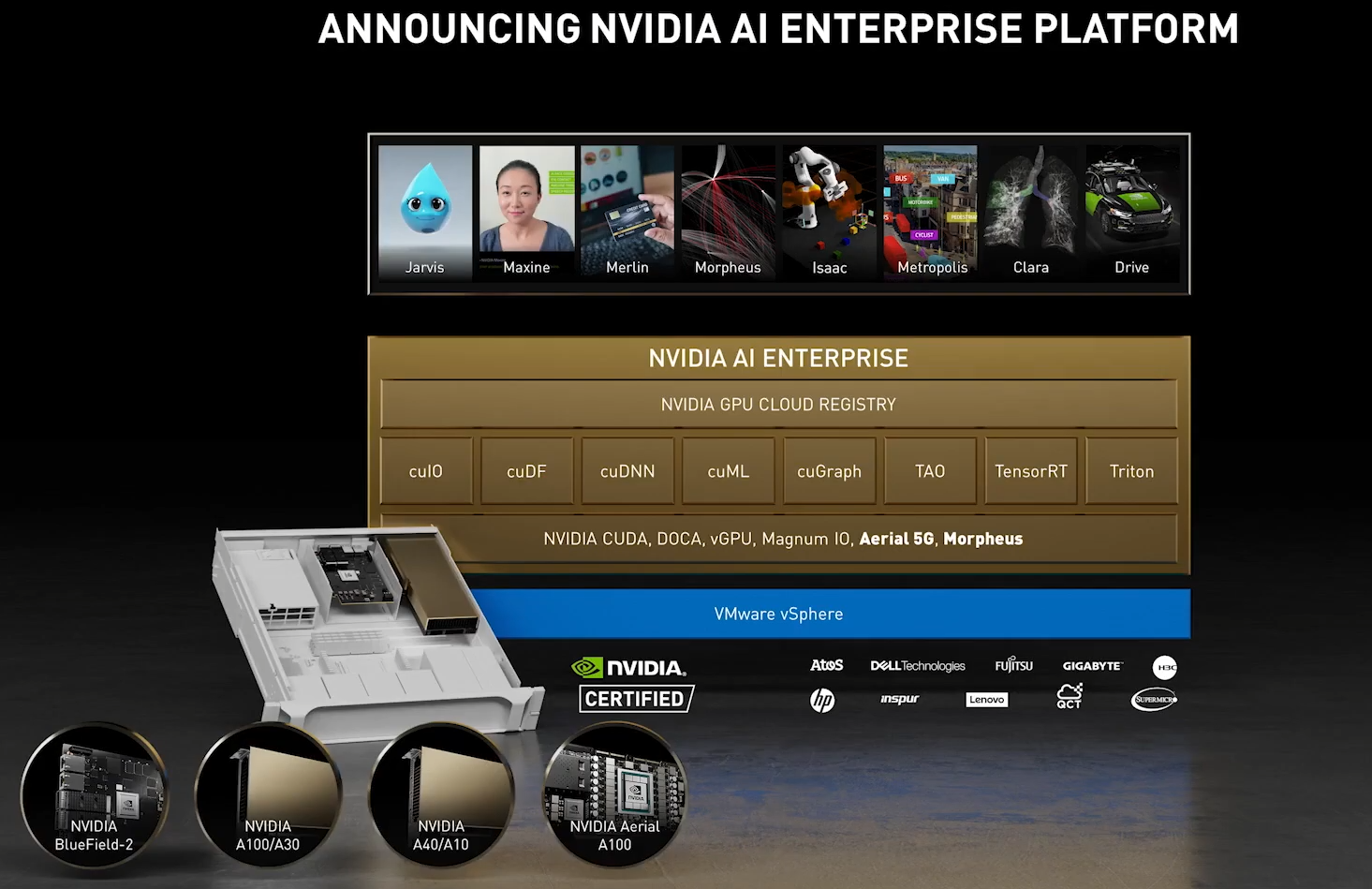 На базе этого программно-аппаратного стека компания уже сейчас предлагает несколько решений. Первое — платформа NVIDIA AI Enterprise для простого, быстрого и удобного внедрения ИИ-решений. В качестве основы используется VMware vSphere, где развёртываются виртуальные машины и контейнеры, что упрощает работу с инфраструктурой, при этом производительность обещана практически такая же, как и в случае bare-metal. 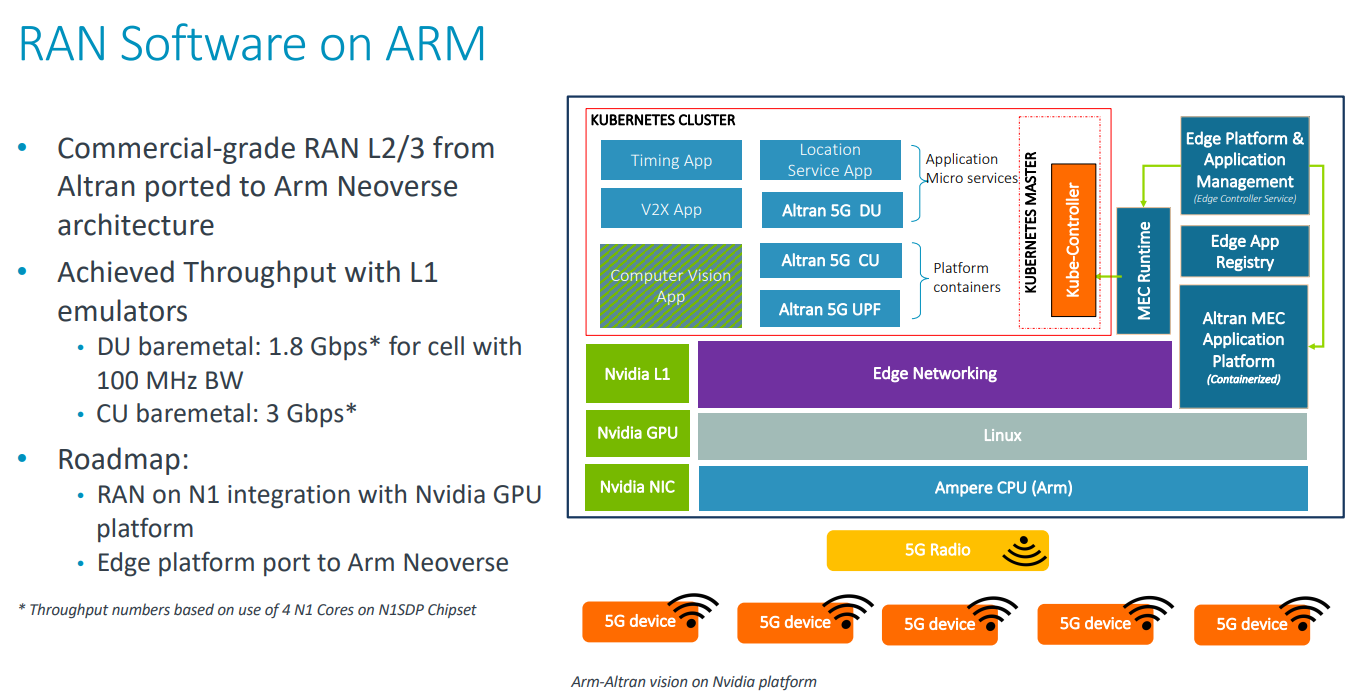 DPU и в текущем виде поддерживают возможность разгрузки для некоторых задач, но VMware вместе с NVIDIA переносят часть типовых задач гипервизора с CPU непосредственно на DPU. Кроме того, VMware продолжает работу над переносом своих решений с x86-64 на Arm, что вполне укладывается в планы развития Arm-экосистемы со стороны NVIDIA. Одним из направлений является 5G, причём работа ведётся по нескольким направлениям. Во-первых, сама Arm разрабатывает периферийную платформу на базе Ampere Altra, дополненных GPU и DPU. 
NVIDIA Aerial A100 Во-вторых, у NVIDIA конвергентное решение — ускоритель Aerial A100, который объединяет в одной карте собственно A100 и DPU. При этом он может использоваться как для ускорения работы собственно радиочасти, так и для обработки самого трафика и реализации различных пограничных сервисов. Там же, где не требуется высокая плотность (как в базовой станции), NVIDIA предлагает использовать более привычную EGX-платформу с раздельными GPU (от A100 и A40 до A30/A10) и DPU. 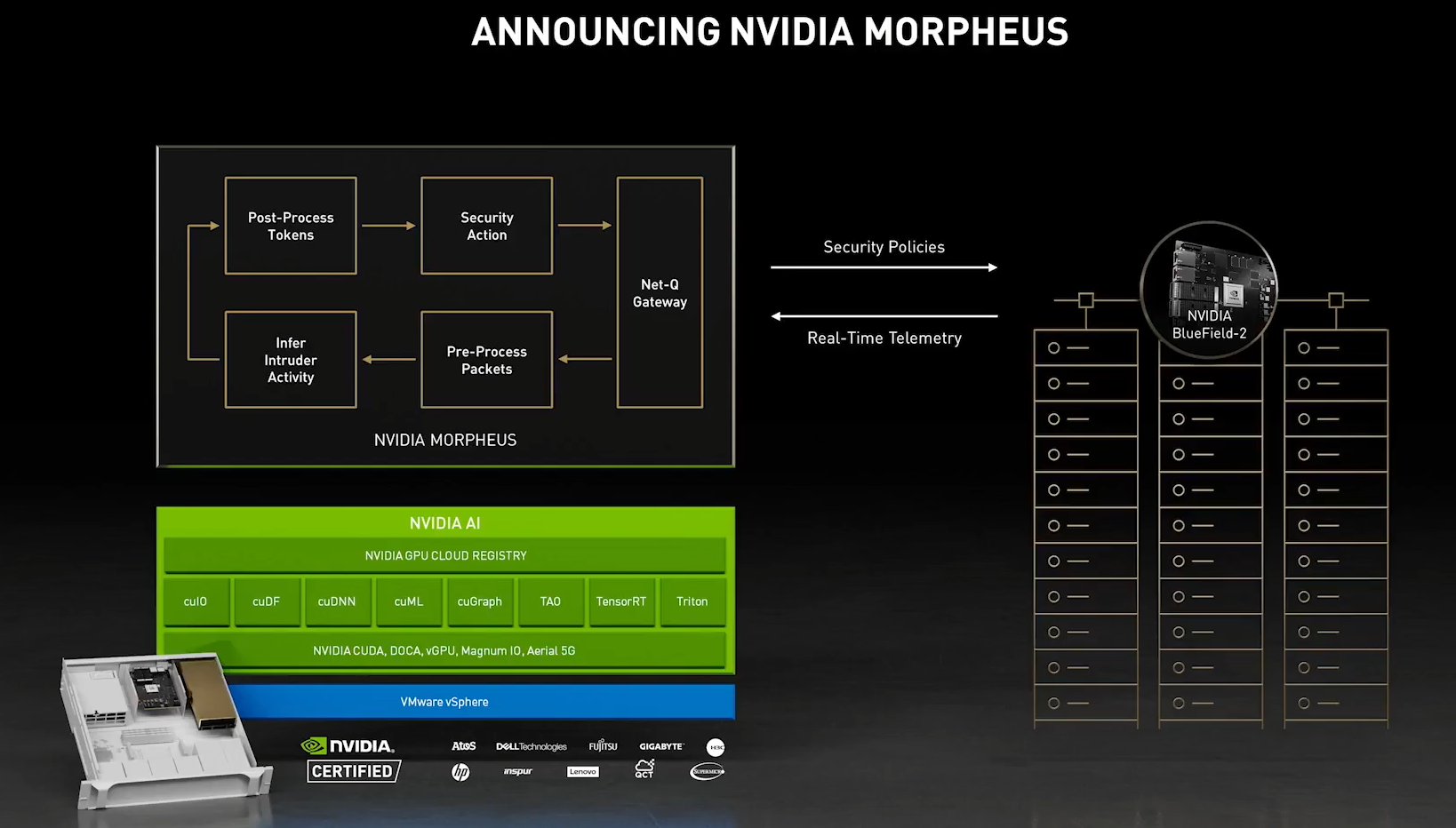 Одним из вариантов комплексного применения таких платформ является проект Morpheus. В его рамках предполагается установка DPU в каждый сервер в дата-центре. Мощностей DPU, в частности, вполне хватает для инспекции трафика, что позволяет отслеживать взаимодействие серверов, приложений, ВМ и контейнеров внутри ЦОД, а также, очевидно, применять различные политики в отношении трафика. DPU в данном случае выступают как сенсоры, данных от которых стекаются в EGX, и, вместе с тем локальными шлюзами безопасности. 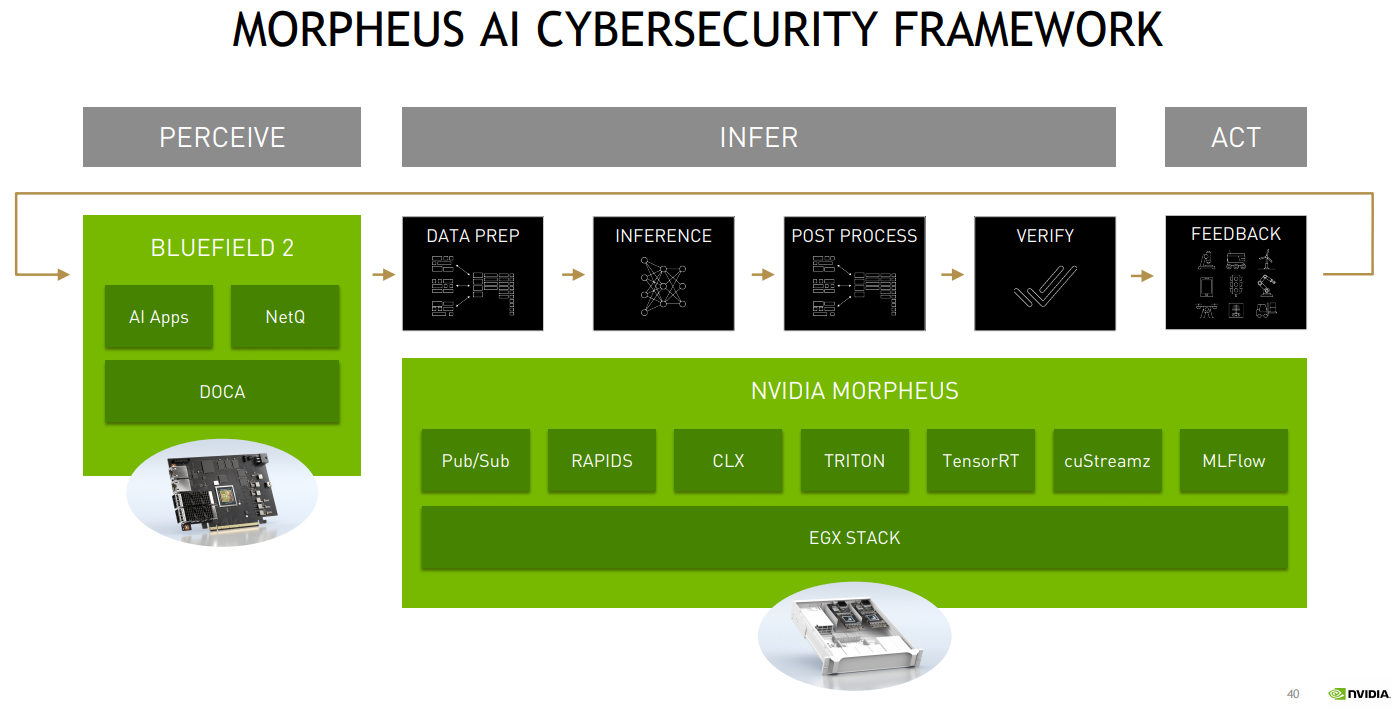 Ручная настройка политик и отслеживание поведения всего парка ЦОД возможны, но не слишком эффективны. Поэтому NVIDIA предлагает как возможность обучения, так и готовые модели (с дообучением по желанию), которые исполняются на GPU внутри EGX и позволяют быстро выявить аномальное поведение, уведомить о нём и отсечь подозрительные приложения или узлы от остальной сети. В эпоху микросервисов, говорит компания, более чем актуально следить за состоянием инфраструктуры внутри ЦОД, а не только на его границе, как было раньше, когда всё внутри дата-центра по умолчанию считалось доверенной средой. 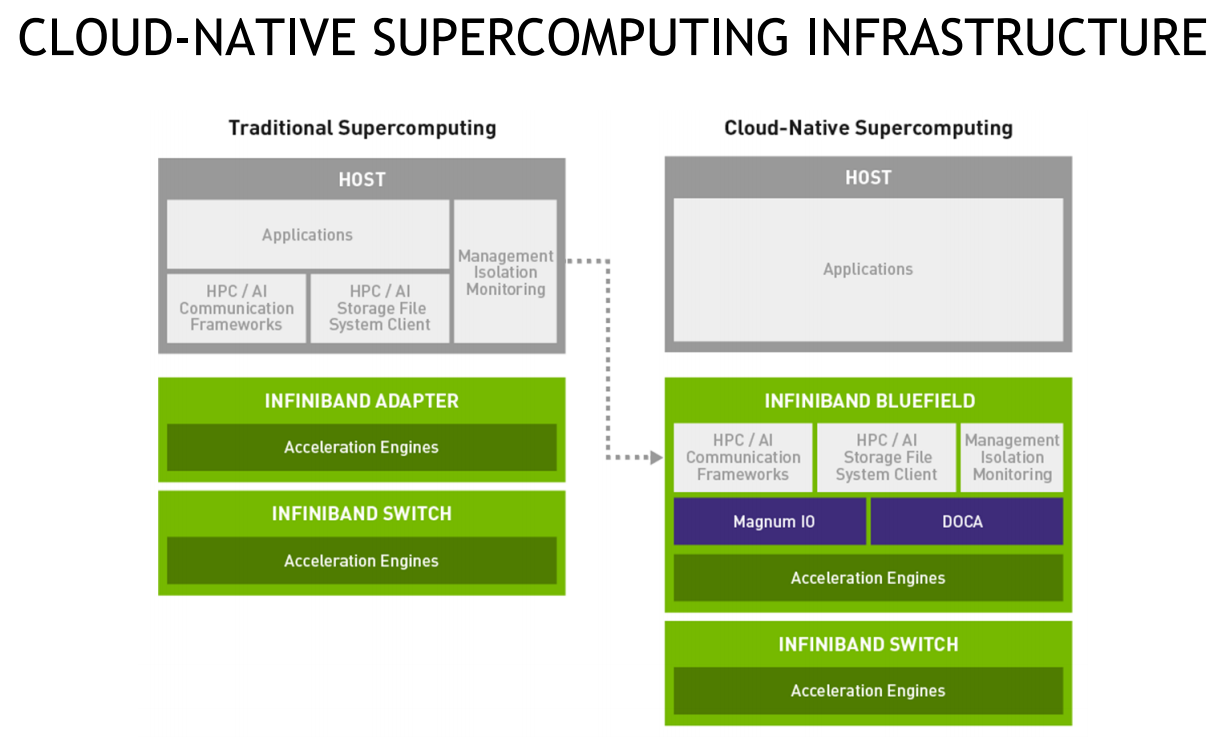 Кроме того, с помощью DPU и DOCA можно перевести инфраструктуру ЦОД на облачную модель и упростить оркестрацию. Но не только ЦОД — обновлённая суперкомпьютерная платформа DGX SuperPOD for Enterprise теперь тоже обзавелась DPU (с InfiniBand) и ПО Base Command, которые позволяют «нарезать» машину на изолированные инстансы с необходимой конфигурацией, упрощая таким образом совместное использование и мониторинг. А это, в свою очередь, повышает эффективность загрузки суперкомпьютера. Base Command выросла из внутренней системы управления Selene, собственным суперкомпьютером NVIDIA, на котором, например, компания обучает модели. 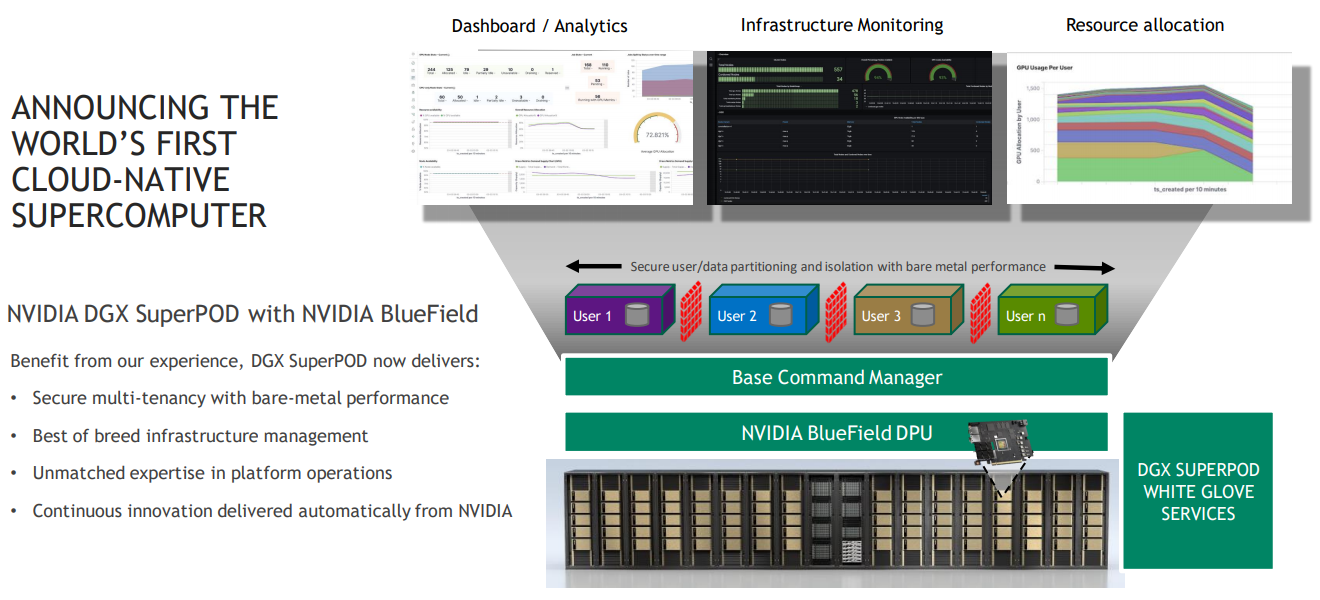 DPU доступны как отдельные устройства, так и в составе сертифицированных платформ NVIDIA и решений партнёров компании, причём спектр таковых велик. Таким образом компания пытается выстроить комплексный подход, предлагая программно-аппаратные решения вкупе с данными (моделями). Аналогичный по своей сути подход исповедует Intel, а AMD с поглощением Xilinx, надо полагать, тоже будет смотреть в эту сторону. И «угрозу» для них представляют не только GPU, но теперь и DPU. А вот новые CPU у NVIDIA, вероятно, на какое-то время останутся только в составе собственных продуктов, в независимости от того, разрешат ли компании поглотить Arm.
12.04.2021 [20:00], Сергей Карасёв
NVIDIA представила младшие серверные ускорители A10 и A30Компания NVIDIA в рамках конференции GPU Technology Conference 2021 анонсировала ускорители A10 и A30, предназначенные для обработки приложений искусственного интеллекта и других задач корпоративного класса. Модель NVIDIA A10 использует 72 ядра RT и может оперировать 24 Гбайт памяти GDDR6 с пропускной способностью до 600 Гбайт/с. Максимальное значение TDP составляет 150 Вт. Новинка выполнена в виде полноразмерной карты расширения с интерфейсом PCIe 4.0: в корпусе сервера устройство займёт один слот расширения. Производительность в вычислениях одинарной точности (FP32) заявлена на уровне 31,2 терафлопса. Новинку можно рассматривать как замену NVIDIA T4.  Модель NVIDIA A30, в свою очередь, получила исполнение в виде двухслотовой карты расширения с интерфейсом PCIe 4.0. Задействованы 24 Гбайт памяти HBM2 с пропускной способностью до 933 Гбайт/с. Показатель TDP равен 165 Вт. Обе новинки используют архитектуру Ampere с тензорными ядрами третьего поколения.  Решения подходят для применения в серверах массового сегмента, рабочих станциях, а также в составе платформы NVIDIA EGX и для периферийных вычислений. 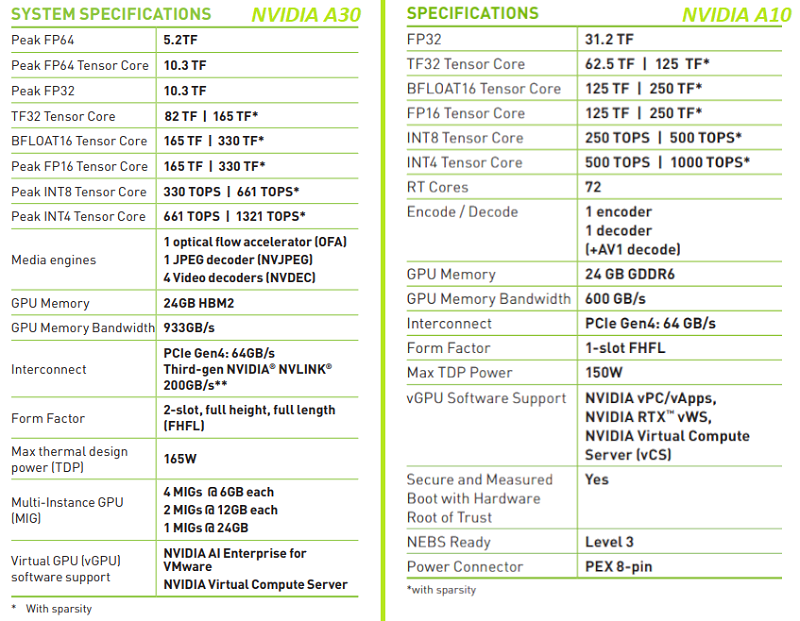
12.04.2021 [19:26], Игорь Осколков
NVIDIA анонсировала серверные Arm-процессоры Grace и будущие суперкомпьютеры на их базеВ рамках GTC’21 NVIDIA анонсировала Arm-процессоры Grace серверного класса, которые станут компаньонами будущих ускорителей компании. Это не означает полный отказ от x86-64, но это позволит компании предложить клиентам более глубоко оптимизированные, а, значит, и более быстрые решения. NVIDIA говорит, что новый CPU позволит на порядок повысить производительность систем на его основе в ИИ и HPC-задачах в сравнении с современными решениями. Процессор назван в честь Грейс Хоппер (Grace Hopper), одного из пионеров информатики и создательницы целого ряда основополагающих концепций и инструментов программирования. И это имя нам уже встречалось в контексте NVIDIA — в конце 2019 года компания зарегистрировала торговую марку Hopper для MCM-решений.  Компания не готова раскрыть полные технически характеристики новинки, которая станет доступна в начале 2023 года, но приводит некоторые интересные детали. В частности, процессор будет использовать Arm-ядра Neoverse следующего поколения (надо полагать, уже на базе ARMv9), которые позволят получить в SPECrate2017_int_base результат выше 300. Для сравнения — система с парой современных AMD EPYC 7763 в том же бенчмарке показывает результат на уровне 800. Вторая особенность Grace — использование памяти LPDRR5X (с ECC, естественно). В сравнении с DDR4 она будет иметь вдвое большую пропускную способность (ПСП) и в 10 раз меньшее энергопотребление. Число и скорость каналов памяти не уточняются, но говорится о суммарной ПСП в более чем 500 Гбайт/с на процессор. А у того же EPYC 7763 теоретический пик ПСП чуть больше 200 Гбайт/с. Очевидно, что другие процессоры к моменту выхода NVIDIA Grace тоже увеличат и производительность, и пропускную способность памяти. Гораздо более интересный вопрос, сколько линий PCIe 5.0 они смогут предложить. Если допустить, что у них будет 128 линий, то общая скорость для них составит чуть больше 500 Гбайт/с. 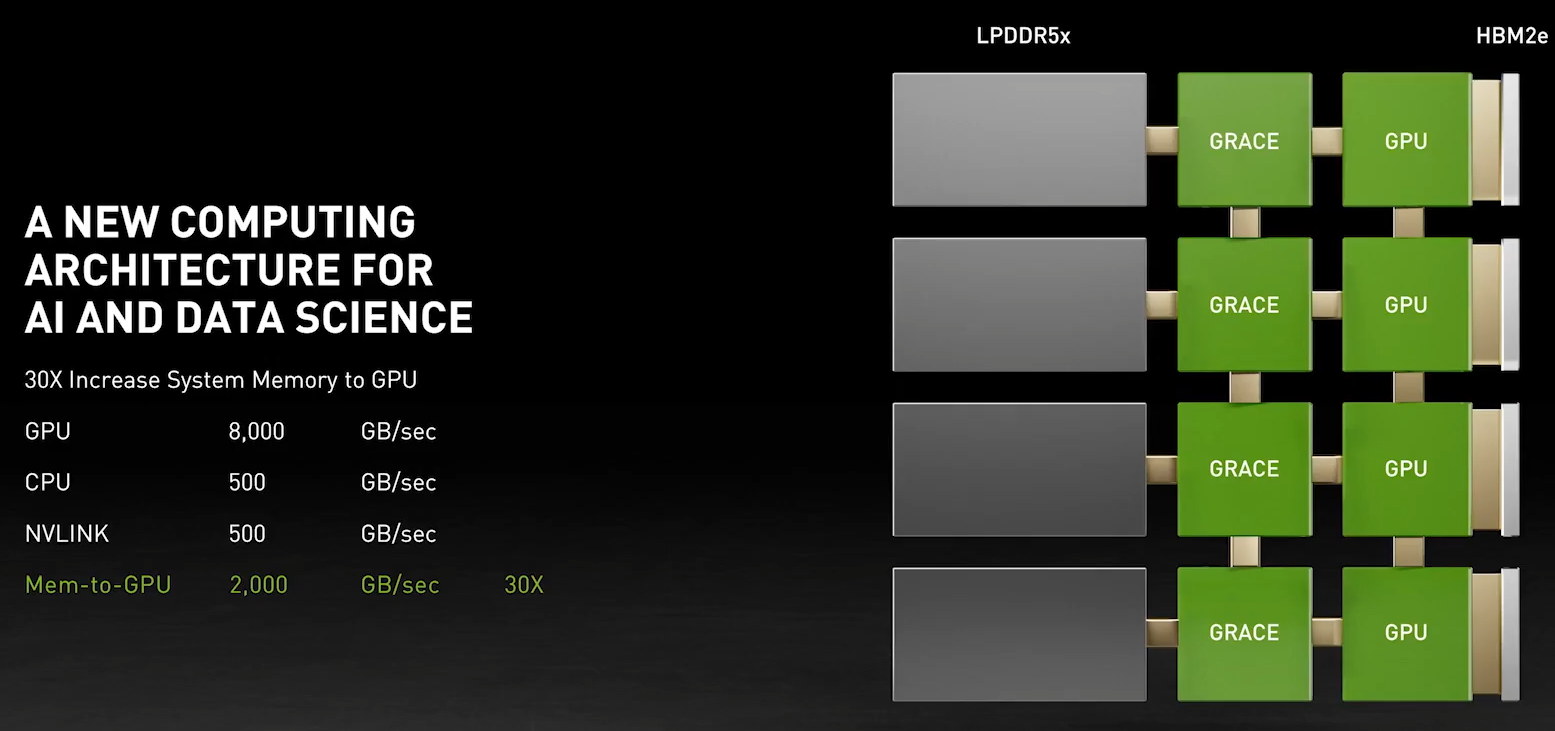 И NVIDIA этого мало — процессоры Grace получат прямое, кеш-когерентное подключение к GPU по NVLInk 4.0 (14x) с суммарной пропускной способностью боле 900 Гбайт/с. GPU тоже, как и прежде, будут общаться напрямую друг с другом по NVLink. Скорость связи между двумя CPU превысит 600 Гбайт/с, а в сборке из четырёх модулей CPU+GPU суммарная скорость обмена данными между системной памятью процессоров и GPU в такой mesh-сети составит 2 Тбайт/с. Но самое интересное тут то, что у памяти CPU (LPDDR5X) и GPU (HBM2e) в такой системе будет единое адресное пространство. Собственно говоря, таким образом компания решает давно назревшую проблему дисбаланса между скоростью обмена данными и доступным объёмом памяти в различных частях вычислительного комплекса. Для сравнения можно посмотреть на архитектуру нынешних DGX A100 или HGX. У каждого ускорителя A100 есть 40 или 80 Гбайт набортной памяти HBM2e (1555 или 2039 Гбайт/с соответственно) и NVLInk-подключение на 600 Гбайт/c, которое идёт к коммутатору NVSwitch, имеющего суммарную пропускную способность 1,8 Тбайт/с. Всего таких коммутаторов шесть, а объединяют они восемь ускорителей. Внутри этой NVLInk-фабрики сохраняется достаточно высокая скорость обмена данными, но как только мы выходим за её пределы, ситуация меняется. 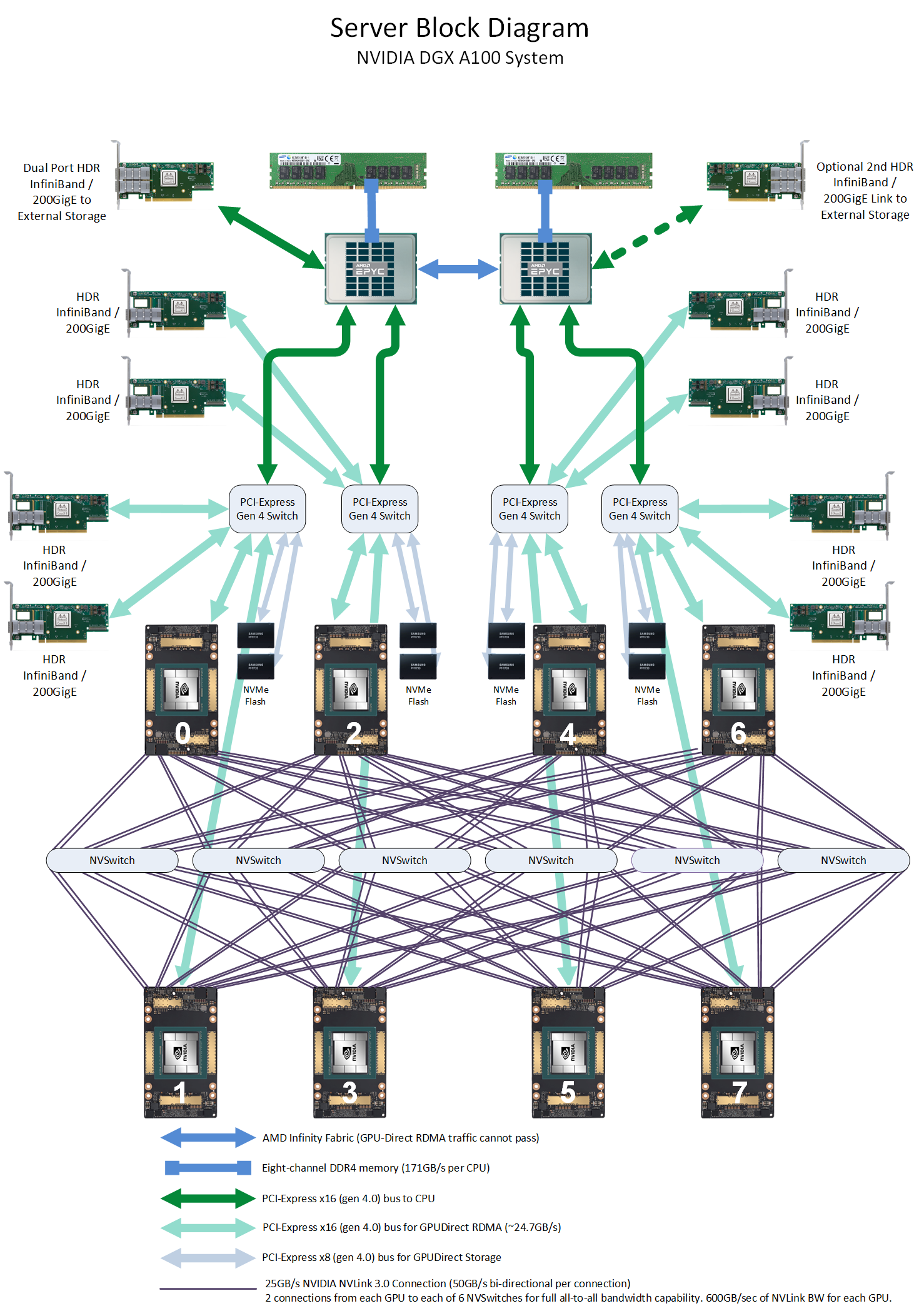
Схема NVIDIA DGX A100. Источник: Microway Каждый ускоритель A100 имеет второй интерфейс — PCIe 4.0 x16 (64 Гбайт/с), который уходит к PCIe-коммутатору, каковых в DGX A100 имеется четыре. Коммутаторы, в свою очередь, объединяют между собой сетевые 200GbE-адаптеры (суммарно в дуплексе до 1,6 Тбайт/с для связи с другими DGX A100), NVMe-накопители и CPU. У каждого CPU может быть довольно много памяти (от 512 Гбайт), но её скорость ограничена упомянутыми выше 200 Гбайт/c.  Узким местом во всей этой схеме является как раз PCIe, поэтому переход исключительно на NVLInk позволит NVIDIA получить большой объём памяти при сохранении приемлемой ПСП, не тратясь лишний раз на дорогую локальную HBM2e у каждого GPU. Впрочем, если компания не переведёт на NVLink и собственные будущие DPU Bluefield-3 (400GbE), которые будут скармливать связке CPU+GPU по, например, GPUDirect Storage данные из внешних NVMe-oF хранилищ и объединять узлы DGX POD, то PCIe 5.0 в составе Grace стоит ждать. Это опять-таки упростит и повысит эффективность масштабирования. 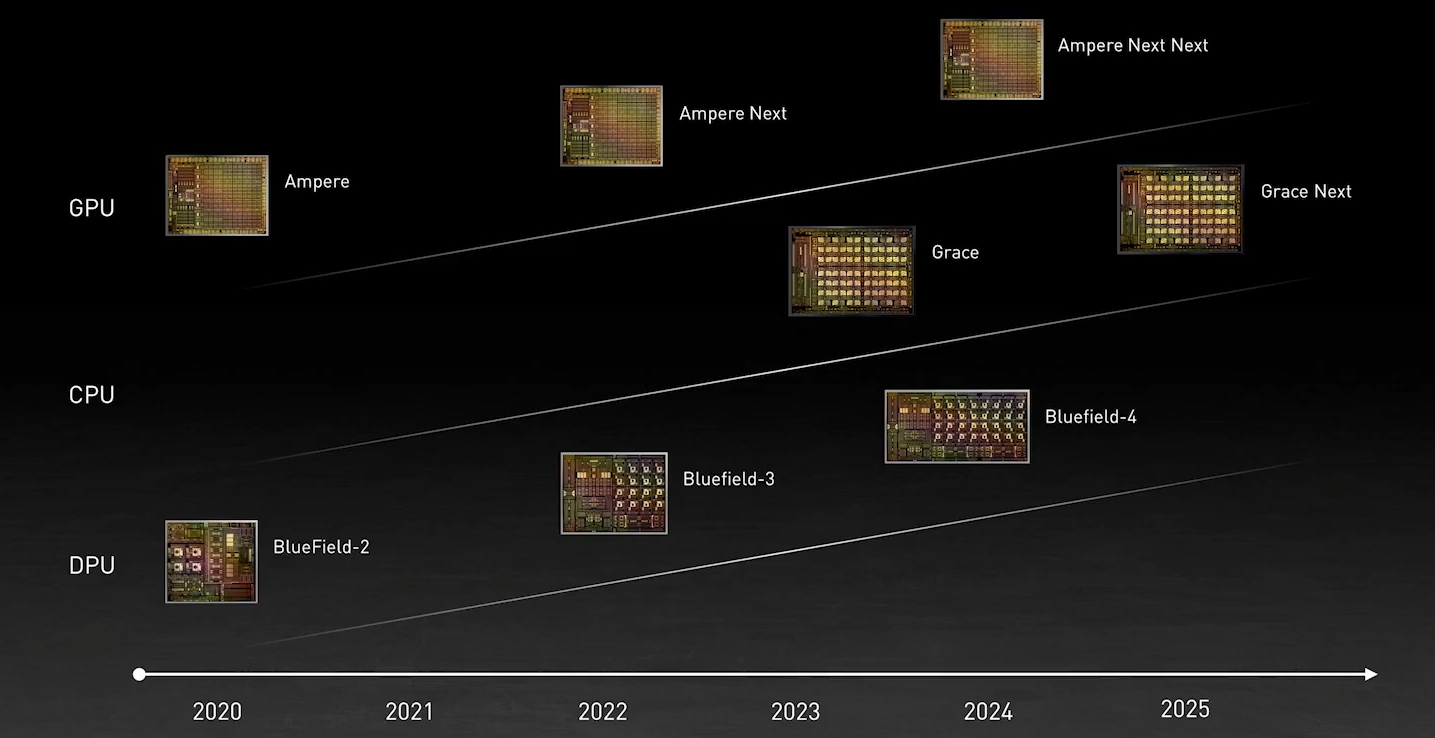 В целом, всё это необходимо из-за быстрого роста объёма ИИ-моделей — в GPT-3 уже 175 млрд параметров, а в течение пары лет можно ожидать модели уже с 0,5-1 трлн параметров. Им потребуются не только новые решения для обучения, но и для инференса. То же касается и физических расчётов — модели становятся всё больше и требовательнее + ИИ здесь тоже активно внедряется. Параллельно с разработкой Grace NVIDIA развивает программную экосистему вокруг Arm и своих решений, готовя почву для будущих систем на их основе.  Одной из такой систем станет суперкомпьютер Alps в Швейцарском национальном компьютерном центре (Swiss National Computing Centre, CSCS), который придёт на смену Piz Daint (12 место в нынешнем рейтинге TOP500). Этот суперкомпьютер серии HPE Cray EX, в частности, сможет в семь раз быстрее обучить модель GPT-3, чем машина NVIDIA Selene (5 место в TOP500). Впрочем, на нём будут выполняться и классические HPC-задачи в области метеорологии, физики, химии, биологии, экономики и так далее. Ввод в эксплуатацию намечен на 2023 год. Тогда же в США появится аналогичная машина от HPE в Лос-Аламосской национальной лаборатории (LANL). Она дополнит систему Crossroads, использующую исключительно процессоры Intel Xeon Sapphire Rapids.
12.04.2021 [19:21], Алексей Степин
NVIDIA анонсировала DPU BlueField-3: 400 Гбит/с, 16 ядер Cortex-A78 и PCIe 5.0Идея «сопроцессора данных», озвученная всерьёз в 2020 году компанией Fungible, продолжает активно развиваться и прокладывать себе дорогу в жизнь. На конференции GTC 2021 корпорация NVIDIA анонсировала новое поколение «умных» сетевых карт BlueField-3, способное работать на скорости 400 Гбит/с. Изначально серия ускорителей BlueField разрабатывалась компанией Mellanox, и одной из целей создания столь продвинутых сетевых адаптеров стала реализация концепции «нулевого доверия» (zero trust) для сетевой инфраструктуры ЦОД нового поколения. Адаптеры BlueField-2 были анонсированы в начале прошлого года. Они поддерживали два 100GbE-порта, микросегментацию, и могли осуществлять глубокую инспекцию пакетов полностью автономно, без нагрузки на серверные ЦП. Шифрование TLS/IPSEC такие карты могли выполнять на полной скорости, не создавая узких мест в сети. 
Кристалл BlueField-3 не уступает в сложности современным многоядерным ЦП — 22 млрд транзисторов Но на сегодня 100 и даже 200 Гбит/с уже не является пределом мечтаний — провайдеры и разработчики ЦОД активно осваивают скорости 400 и 800 Гбит/с. Столь скоростные сети требуют нового уровня производительности от DPU, и NVIDIA вскоре сможет предложить такой уровень: на конференции GTC 2021 анонсировано новое, третье поколение карт BlueField. 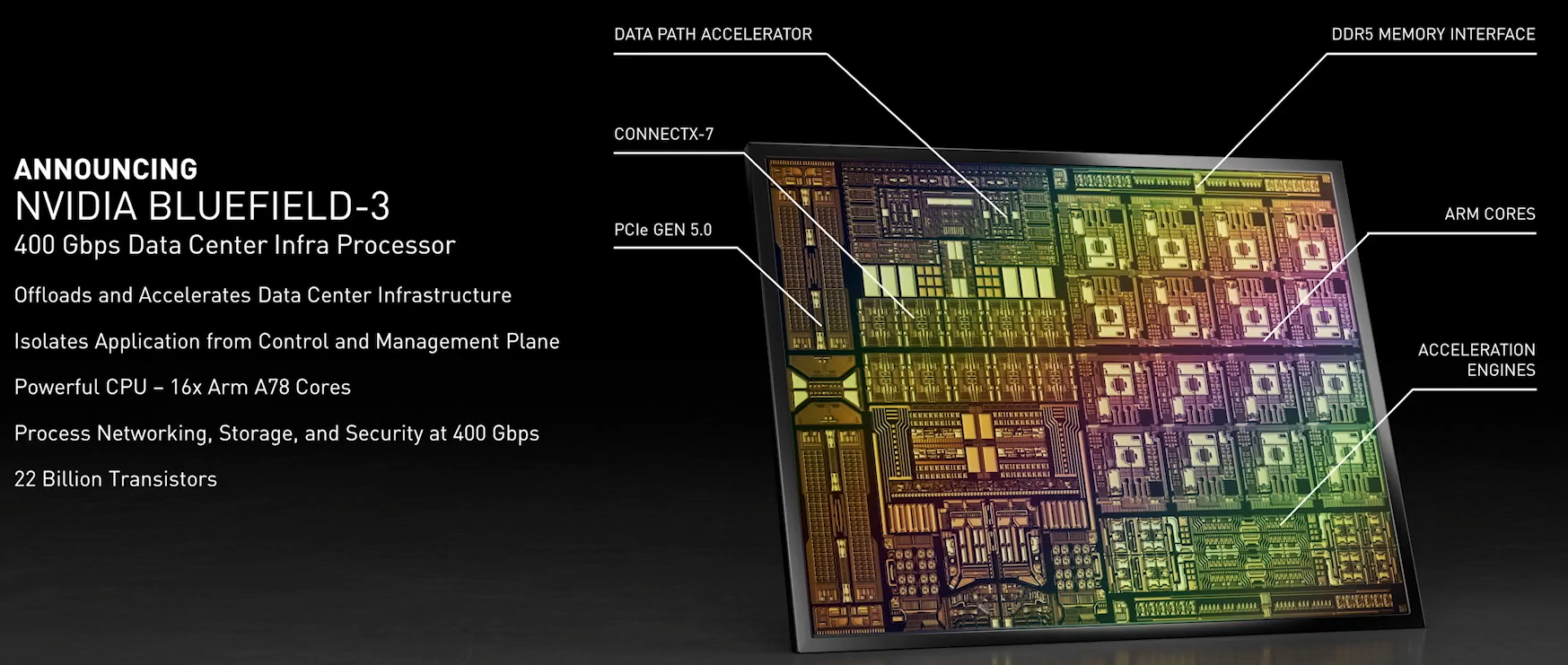 Если BlueField-2 могла похвастаться массивом из восьми ядер ARM Cortex-A72, объединённых когерентной сетью, то BlueField-3 располагает уже шестнадцатью ядрами Cortex-A78 и в четыре раза более мощными блоками криптографии и DPI. Совокупно речь идёт о росте производительности на порядок, что позволяет новинке работать без задержек на скорости 400 Гбит/с — и это первый в индустрии адаптер класса 400GbE со столь продвинутыми возможностями, поддерживающий, к тому же, стандарт PCI Express 5.0. Известно, что столь быстрым сетевым решениям PCIe 5.0 действительно необходим.  С точки зрения поддерживаемых возможностей BlueField-3 обратно совместим с BlueField-2, что позволит использовать уже имеющиеся наработки в области программного обеспечения для DPU. Одновременно с анонсом нового DPU компания представила и открытую программную платформу DOCA, упрощающую разработку ПО для таких сопроцессоров, поскольку они теперь занимаются не просто обработкой сетевого трафика, а оркестрацией работы серверов, приложений и микросервисов в рамках всего дата-центра. 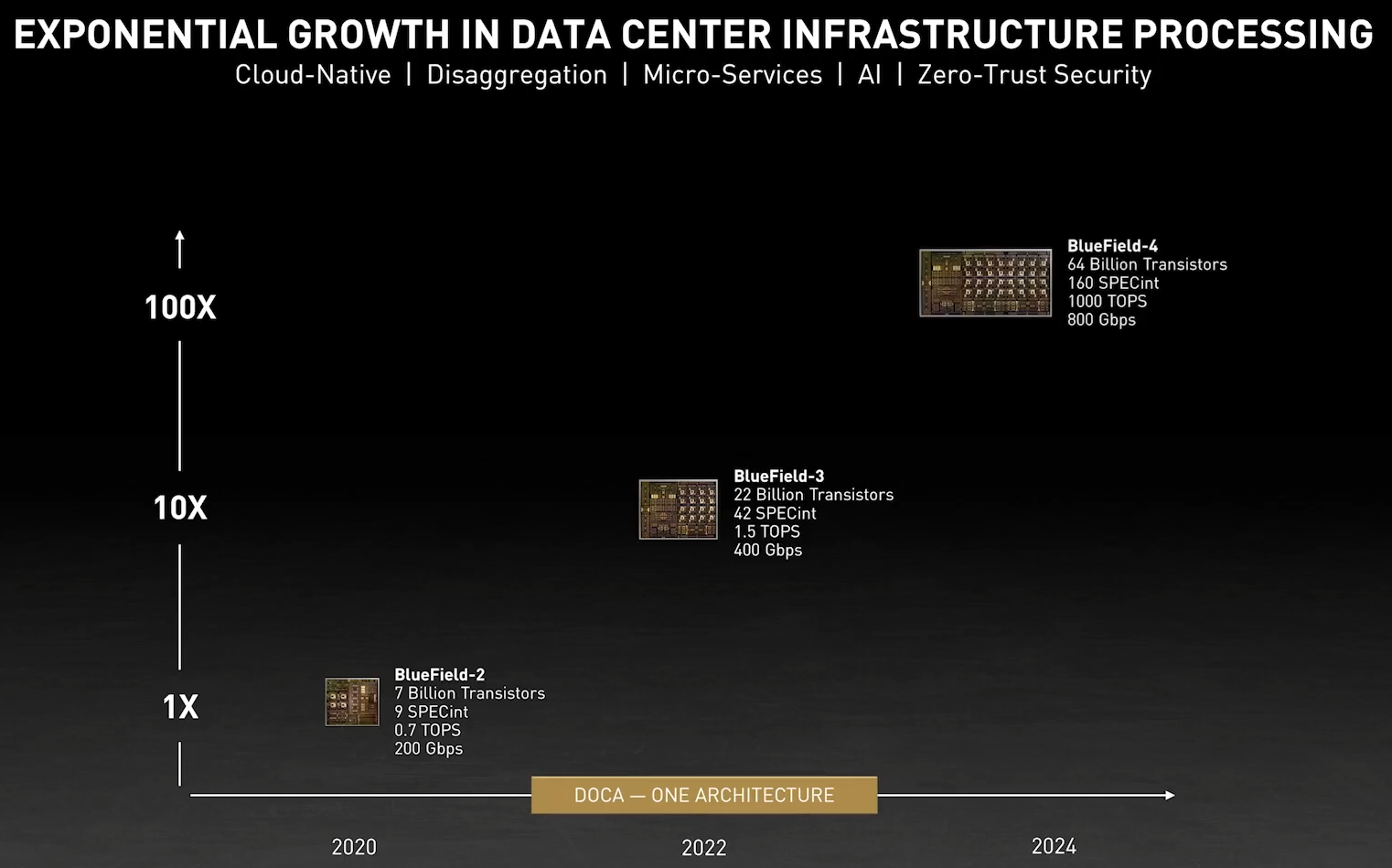 В настоящее время NVIDIA сотрудничает с такими крупными поставщиками серверных решений, как Dell EMC, Inspur, Lenovo и Supermicro, со стороны разработчиков ПО интерес к BlueField проявляют Canonical, VMWare, Red Hat, Fortinet, NetApp и ряд других компаний. О массовом производстве BlueField-3 речи пока не идёт, поставка малыми партиями ожидается в первом квартале 2022 года, но карты BlueField-2 доступны уже сейчас. А в 2024 году появятся BlueField-4 с портами 800 Гбит/с.
23.02.2021 [22:23], Андрей Галадей
Вышло обновление ZLUDA v2, открытой реализации CUDA для GPU IntelРанее мы уже писали об экспериментальнои проекте ZLUDA, развивающем открытую реализацию CUDA для GPU Intel, которая позволила бы нативно исполнять CUDA-приложения на ускорителях Intel без каких-либо модификаций. При этом её разработка ведётся независимо и от Intel, и от NVIDIA. Новинка построена на базе интерфейса Intel oneAPI Level Zero, и может работать на картах Intel UHD/Xe с неплохим уровнем производительности. Однако у первой версии был ряд ограничений. Вчера же вышла вторая версия, которая получила ряд улучшений. Кроме того, автор проекта объявил о переходе на модель непрерывного выпуска релизов.  Основной упор в новой версии сделан на улучшение поддержки Geekbench и работы в Windows-окружении. Собственно говоря, автор прямо говорит, что оптимизация под Geekbench пока является основной целью, а другие CUDA-приложения могут не работать. Кроме того, такое ПО, запущенное с помощью ZLUDA будет работать медленнее, чем на картах NVIDIA, в силу разности архитектур GPU и необходимости эмуляции некоторых возможностей. Подробности приведены на странице проекта.
16.11.2020 [17:00], Игорь Осколков
SC20: NVIDIA представила ускоритель A100 с 80 Гбайт HBM2e и настольный «суперкомпьютер» DGX STATIONNVIDIA представила новую версию ускорителя A100 с увеличенным вдвое объёмом HBM2e-памяти: 80 Гбайт вместо 40 Гбайт у исходной A100, представленной полгода назад. Вместе с ростом объёма выросла и пропускная способность — с 1,555 Тбайт/с до 2 Тбайт/с. В остальном характеристики обоих ускорителей совпадают, даже уровень энергопотребления сохранился на уровне 400 Вт. Тем не менее, объём и скорость работы быстрой набортной памяти влияет на производительность ряда приложений, так что им такой апгрейд только на пользу. К тому же MIG-инстансы теперь могут иметь объём до 10 Гбайт. PCIe-варианта ускорителя с удвоенной памятью нет — речь идёт только об SXM3-версии, которая используется в собственных комплексах NVIDIA DGX и HGX-платформах для партнёров. 
NVIDIA A100 80 Гбайт  Последним ориентировочно в первом квартале следующего года будут предоставлены наборы для добавления новых A100 в существующие решения, включая варианты плат на 4 и 8 ускорителей. У самой NVIDIA обновлению подверглись, соответственно, DGX A100 POD и SuperPOD for Enterprise. Недавно анонсированные суперкомпьютеры Cambridge-1 и HiPerGator на базе SuperPOD одними из первых получат новые ускорители с 80 Гбайт памяти. Ожидается, что HGX-решения на базе новой A100 будут доступны от партнёров компании — Atos, Dell Technologies, Fujitsu, GIGABYTE, Hewlett Packard Enterprise, Inspur, Lenovo, Quanta и Supermicro — в первой половине 2021 года.   Но, пожалуй, самый интересный анонс касается новой рабочей станции NVIDIA DGX STATION A100, которую как раз и можно назвать настольным «суперкомпьютером». В ней используются четыре SXM3-ускорителя A100 с не требующей обслуживания жидкостной системой охлаждения и полноценным NVLink-подключением. Будут доступны две версии, со 160 или 320 Гбайт памяти с 40- и 80-Гбайт A100 соответственно. Базируется система на 64-ядерном процессоре AMD EPYC, который можно дополнить 512 Гбайт RAM.   Для ОС доступен 1,92-Тбайт NVMe M.2 SSD, а для хранения данных — до 7,68 Тбайт NVMe U.2 SSD. Сетевое подключение представлено двумя 10GbE-портами и выделенным портом управления. Видеовыходов четыре, все mini Display Port. DGX STATION A100 отлично подходит для малых рабочих групп и предприятий. В том числе благодаря тому, что функция MIG позволяет эффективно разделить ресурсы станции между почти тремя десятками пользователей. В продаже она появится у партнёров компании в феврале следующего года.  Вероятно, все выпускаемые сейчас A100 c увеличенным объёмом памяти идут на более важные проекты. Новинкам предстоит конкурировать с первым ускорителем на базе новой архитектуры CDNA — AMD Instinct MI100.
05.10.2020 [18:15], Илья Коваль
NVIDIA представила серверный ускоритель A40 с поддержкой виртуализацииНа конференции GTC 2020 компания NVIDIA анонсировала два новых ускорителя: RTX A6000 и A40. Оба являются практически идентичными копиями, но отличаются исполнением — A40 представляет собой привычную полноразмерную двухслотовую карту для серверов с пассивным охлаждением и энергопотреблением 300 Вт. A40 базируется на 8-нм чипе GA102 (10752 CUDA-ядра, 336 Tensor-ядер и 84 RT-ядра), дополненным 48 Гбайт памяти GDDR6 ECC и 384-бит шиной. Наличие NVLink3 позволяет объединить две карты, получив 96 Гбайт общей RAM. Для подключения к хостовой системе используется PCIe 4.0 x16. Увы, частот памяти и ядра, а также уровень производительности компания пока не приводит.  Новинка ориентирована на 3D/CAM и другие системы моделирования и визуализации в виртуализированных окружениях — как и у старшего собрата в A40 есть поддержка до 7 vGPU с объёмом памяти от 1 до 48 Гбайт. А вот поддержки MIG, судя по всему, пока нет. Тем не менее, прочие функциональные блоки никуда не делись, так что карту можно использовать для вычислений и машинного обучения. Также есть один блок кодирования и два блока декодирования видео, которые поддерживают в том числе и AV1.  Из любопытных особенностей отметим, что для питания используется CPU-коннектор ESP (4+4), а не восьмиконтактный PCIe. Кроме того, карта имеет три видеовыхода DisplayPort 1.4, которые по умолчанию отключены — в сервере они всё равно не нужны. Их можно принудительно включить, но тогда будет недоступна функция vGPU. Также в A40 имеется отдельный крипточип CEC 1712 для Secure Boot и прочих функций безопасности, а сама она соответствует NEBS Level 3, что даёт возможность сертифицировать устройства с ней для использования в промышленных (и прочих неблагоприятных) условиях. Поставки новинки начнутся в первом квартале следующего года. Впрочем, как и прежде, она будет ориентирована на OEM-поставщиков оборудования, поэтому увидим мы её скорее в составе готовых продуктов и облаках, а не на полках магазинов.
22.06.2020 [12:39], Илья Коваль
NVIDIA представила PCIe-версию ускорителя A100Как и предполагалось, NVIDIA вслед за SXM4-версией ускорителя A100 представила и модификацию с интерфейсом PCIe 4.0 x16. Обе модели используют идентичный набор чипов с одинаковыми характеристикам, однако, помимо отличия в способе подключения, у них есть ещё два существенных отличия. 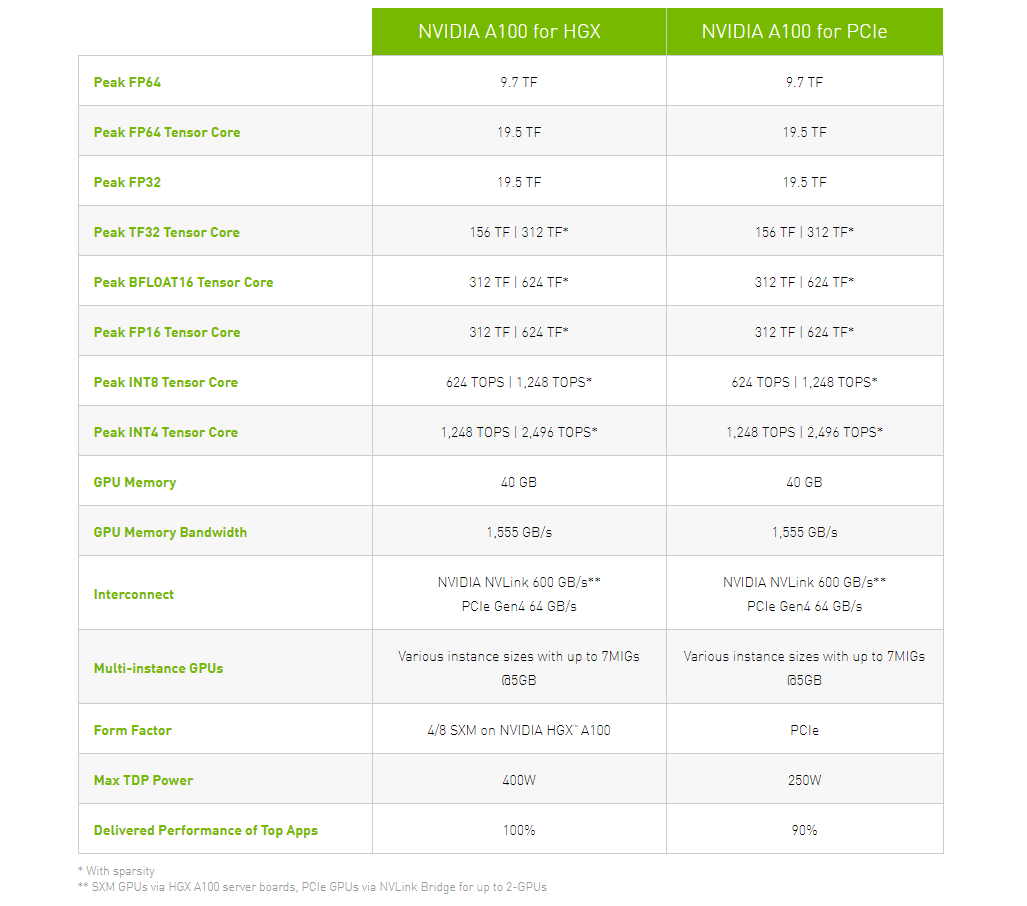 Первое — сниженный с 400 Вт до 250 Вт показатель TDP. Это прямо влияет на величину устоявшейся скорости работы. Сама NVIDIA указывает, что производительность PCIe-версии составит 90% от SXM4-модификации. На практике разброс может быть и больше. Естественным ограничением в данном случае является сам форм-фактор ускорителя — только классическая двухслотовая FLFH-карта с пассивным охлаждением совместима с современными серверами.  Второе отличие касается поддержки быстрого интерфейса NVLink. В случае PCIe-карты посредством внешнего мостика можно объединить не более двух ускорителей, тогда как для SXM-версии есть возможность масштабирования до 8 ускорителей в рамках одной системы. С одной стороны, NVLink в данном случае практически на порядок быстрее PCIe 4.0. С другой — PCIe-версия наверняка будет заметно дешевле и в этом отношении универсальнее. 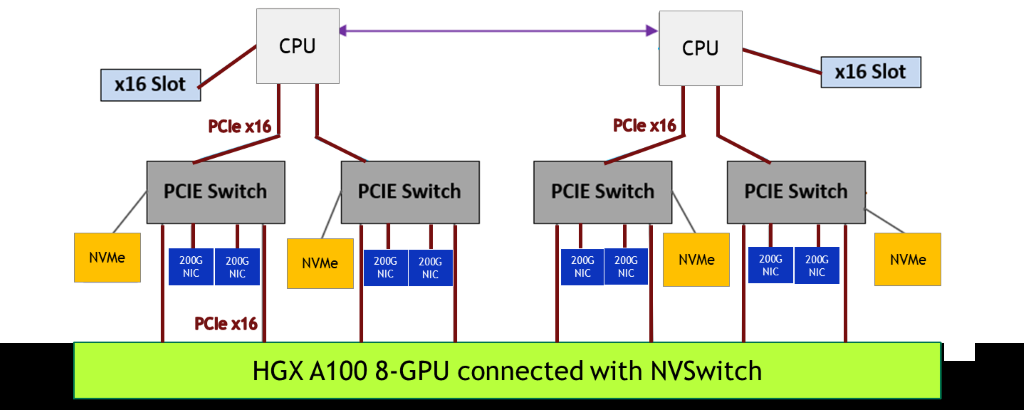 Производители серверов уже объявили о поддержке новых ускорителей в своих системах. Как правило, это уже имеющиеся платформы с возможностью установки 4 или 8 (реже 10) карт. Любопытно, что фактически единственным разумным вариантом для плат PCIe 4.0, как и в случае HGX/DGX A100, является использование платформ на базе AMD EPYC 7002.
14.05.2020 [18:52], Рамис Мубаракшин
NVIDIA представила ускорители A100 с архитектурой Ampere и систему DGX A100 на их основеNVIDIA официально представила новую архитектуру графических процессоров под названием Ampere, которая является наследницей представленной осенью 2018 года архитектуры Turing. Основные изменения коснулись числа ядер — их теперь стало заметно больше. Кроме того, новинки получили больший объём памяти, поддержку bfloat16, возможность разделения ресурсов (MIG) и новые интерфейсы: PCIe 4.0 и NVLink третьего поколения. NVIDIA A100 выполнен по 7-нанометровому техпроцессу и содержит в себе 54 млрд транзисторов на площади 826 мм2. По словам NVIDIA, A100 с архитектурой Ampere позволяют обучать нейросети в 40 раз быстрее, чем Tesla V100 с архитектурой Turing. 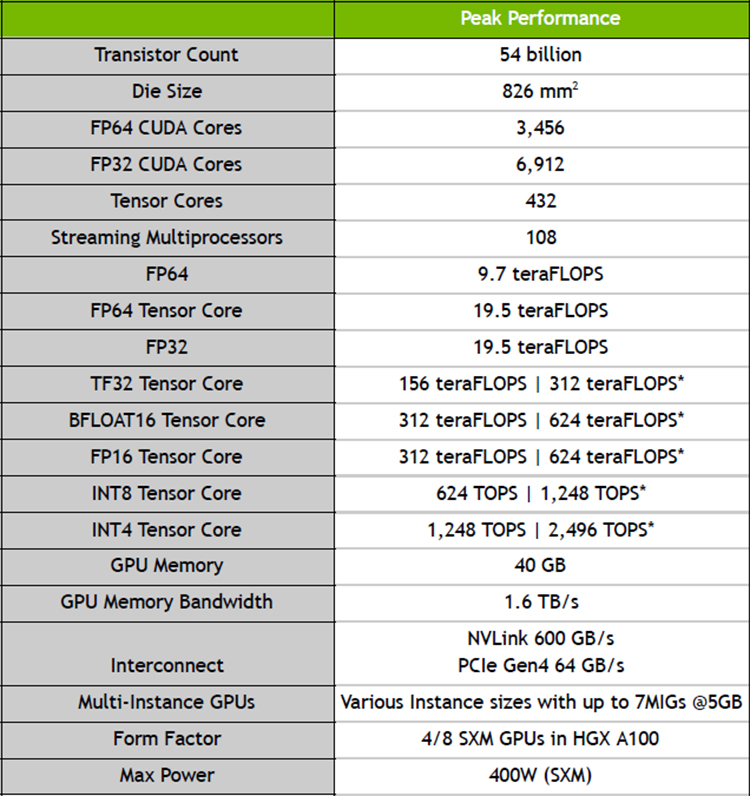
Характеристики A100 Первой основанной на ней вычислительной системой стала фирменная DGX A100, состоящая из восьми ускорителей NVIDIA A100 с NVSwitch, имеющих суммарную производительность 5 Пфлопс. Стоимость одной системы DGX A100 равна $199 тыс., они уже начали поставляться некоторым клиентам. Известно, что они будут использоваться в Аргоннской национальной лаборатории для поддержания работы искусственного интеллекта, изучающего COVID-19 и ищущего от него лекарство. Так как некоторые группы исследователей не могут себе позволить покупку системы DGX A100 из-за ее высокой стоимости, их планируют купить поставщики услуг по облачным вычислений и предоставлять удалённый доступ к высоким мощностям. На данный момент известно о 18 провайдерах, готовых к использованию систем и ускорителей на основе архитектуры Ampere, и среди них есть Google, Microsoft и Amazon. 
Система NVIDIA DGX A100 Помимо системы DGX A100, компания NVIDIA анонсировала ускорители NVIDIA EGX A100, предназначенная для периферийных вычислений. Для сегмента интернета вещей компания предложила плату EGX Jetson Xavier NX размером с банковскую карту. |
|