Материалы по тегу: sc20
|
20.11.2020 [16:45], Сергей Карасёв
NEC выводит на рынок векторный ускоритель SX-Aurora TSUBASA Vector Engine 2.0Компания NEC сообщила о том, что с января следующего года заказчикам по всему миру станет доступен акселератор Vector Engine 2.0 серии SX-Aurora TSUBASA, анонсированный ещё летом. Изделие Type 20B выполнено в виде двухслотовой карты расширения с интерфейсом PCIe. Оно содержит восемь векторных блоков с частотой 1,6 ГГц, обеспечивающих производительность на уровне 2,45 Тфлопс FP64, и 48 Гбайт памяти HBM2 с пропускной способностью приблизительно 1,53 Тбайт/с. При этом энергопотребление находится на уровне 200 Вт. Также есть версия ускорителя Type 20A, которая имеет 10 векторных блоков и производительность 3,07 Тфлопс FP64.  Благодаря векторной архитектуре крупные объёмы данных можно обрабатывать в пределах каждого цикла. Это открывает широкие возможности при решении задач в области искусственного интеллекта, машинного обучения, интенсивных научных вычислений и пр. 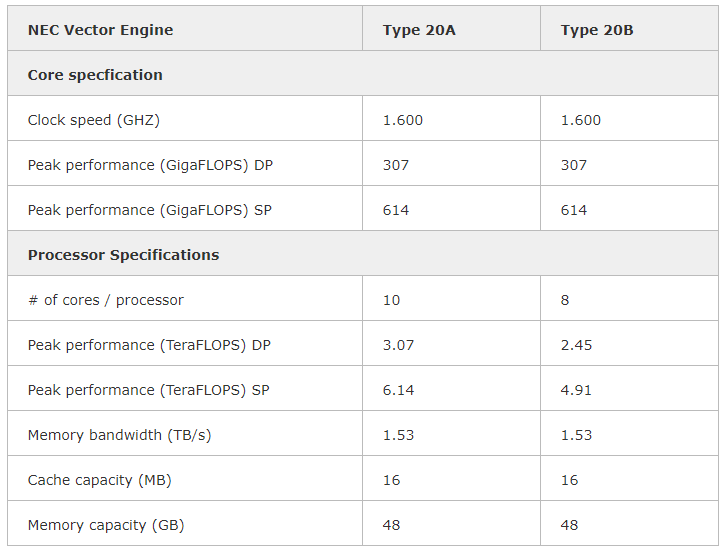 Векторный ускоритель Vector Engine 2.0 может использоваться в составе стандартных серверов и рабочих станций с архитектурой х86 от сторонних поставщиков оборудования. Таким образом, заказчики смогут сформировать вычислительную платформу в соответствии со своими требованиями и объёмом финансирования. Данное решение, по словам NEC, ориентировано на предприятия малого и среднего бизнеса, у которых есть потребность в формировании платформы высокопроизводительных вычислений (HPC).
18.11.2020 [00:17], Владимир Мироненко
SC20: РСК представила all-flash СХД Tornado AFS с функцией высокой доступностиГруппа компаний РСК, российский разработчик HPC-решений, представила на всемирной виртуальной суперкомпьютерной выставке SC20 целый ряд новых решений. В частности, было объявлено, что высокоплотные и энергоэффективные вычислительные узлы «РСК Торнадо» будут поддерживать 10-нм серверные процессоры Intel с кодовым наименованием Ice Lake-SP, намеченные к выпуску в начале 2021 года. Как ожидается, новые чипы получат поддержку интерфейса PCI Express 4.0 и памяти Intel Optane DC второго поколения. Также была представлена интеллектуальная СХД Tornado AFS с поддержкой функции высокой доступности для создания систем хранения с большим объемом данных. Решение отличается высокой надёжностью и доступностью данных благодаря объединению узлов Tornado AFS в функциональные пары, так как в случае выхода из строя одного из узлов работа обеспечивается с помощью второго.  Это обеспечивает надёжное хранение данных объёмом до 2 Пбайт в форм-факторе 2U с помощью 64-х NVMe SSD в форм-факторе E1.L. Также используются процессоры семейства Intel Xeon Scalable 2-го поколения, твердотельные диски Optane SSD и модули энергонезависимой PMem-памяти Optane DC Persistent Memory (DCPMM). В RSC Tornado AFS используется 100 % жидкостное охлаждение в режиме «горячая вода» с показателем эффективности использования электроэнергии PUE на уровне 1,04. РСК подтвердила заявленную ранее поддержку DAOS в решениях RSC Storage on-Demand и объявила о переходе на обновлённую платформу оркестрации «РСК БазИС» для создания высокопроизводительных составных архитектур хранения данных. Это позволит вместо жёсткого регламентирования конфигурации применять компонуемый подход для управления DAOS. Использование высокопроизводительных адаптеров с поддержкой RDMA, NVMe-накопителей и памяти Optane DCPMM позволит произвести такую дезагрегацию и дальнейшую компоновку «по запросу» без снижения производительности. Такой подход позволит заметно увеличить допустимый объем системы хранения данных благодаря отмене ограничений по объёму PMem в DAOS. При этом благодаря компонуемости, неиспользуемые в какой-то момент времени диски можно подключить к другому серверу на основе DAOS или Lustre. В дополнение можно разделить серверы с DAOS и серверы c NVMe-дисками на два пула, тем самым максимально устранив ограничения аппаратной архитектуры сервера (нехватку линий шины PCIe, используемой как накопителями, так и сетевыми адаптерами, а также физических ограничений шасси сервера по размещению дополнительных устройств и их охлаждению). РСК также разработала пользовательский интерфейс для RSC Storage on-Demand, позволяющий быстро создать сложную многоуровневую компонуемую систему хранения «по требованию». Новый интерфейс поддерживает создание параллельных файловых систем Lustre, распределённых объектных систем хранения DAOS и их комбинаций.
16.11.2020 [20:44], Алексей Степин
Подробности об архитектуре AMD CDNA ускорителей Instinct MI100Лидером в области использования графических архитектур для вычислений долгое время была NVIDIA, однако давний соперник в лице AMD вовсе не собирается сдавать свои позиции. В ответ на анонс архитектуры Ampere и ускорителей нового поколения A100 на её основе компания AMD сегодня ответила своим анонсом первого в мире ускорителя на основе архитектуры CDNA — сверхмощного процессора Instinct MI100. Достаточно долго подход к проектированию графических чипов оставался унифицированным, однако быстро выяснилось, что то, что хорошо для игр, далеко не всегда хорошо для вычислений, а некоторые возможности для областей применения, не связанных с рендерингом 3D-графики, попросту избыточны. Примером могут служить модули растровых операций (RBE/ROP) или наложения текстур. Произошло то, что должно было произойти: слившиеся на какое-то время воедино ветви эволюции «графических» и «вычислительных» процессоров вновь начали расходиться. И новый процессор AMD Instinct MI100 относится к чисто вычислительной ветви развития подобного рода чипов.  Теперь AMD имеет в своём распоряжении две основных архитектуры, RDNA и CDNA, которые и представляют собой вышеупомянутые ветви развития GPU. Естественно, новый процессор Instinct MI100 унаследовал у своих собратьев по эволюции многое — в частности, блоки исполнения скалярных и векторных инструкций: в конце концов, всё равно, работают ли они для расчёта графики или для вычисления чего-либо иного. Однако новинка содержит и ряд отличий, позволяющих ей претендовать на звание самого мощного и универсального в мире ускорителя на базе GPU. 
Схема эволюции графических процессоров: налицо дивергенция признаков AMD в последние годы существенно укрепила свои позиции, и это отражается в создании собственной единой IP-инфраструктуры: новый чип выполнен с использованием 7-нм техпроцесса и все системы интерконнекта, как внутренние, так и внешние, в MI100 базируются на шине AMD Infinity второго поколения. Внешние каналы имеют ширину 16 бит и оперируют на скорости 23 Гт/с, однако если в предыдущих моделях Instinct их было максимум два, то теперь количество каналов Infinity Fabric увеличено до трёх. Это позволяет легко организовывать системы на базе четырёх MI100 с организацией межпроцессорного общения по схеме «все со всеми», что минимизирует задержки. 
Ускорители Instinct MI100 получили третий канал Infinity Fabric Общую организацию внутренней архитектуры процессор MI100 унаследовал ещё от архитектуры GCN; его основу составляют 120 вычислительных блоков (compute units, CU). При принятой AMD схеме «64 шейдерных блока на 1 CU» это позволяет говорить о 7680 процессорах. Однако на уровне вычислительного блока архитектура существенно переработана, чтобы лучше отвечать требованиям, предъявляемым современному вычислительному ускорителю. В дополнение к стандартным блокам исполнения скалярных и векторных инструкций добавился новый модуль матричной математики, так называемый Matrix Core Engine, но из кремния MI100 удалены все блоки фиксированных функций: растеризации, тесселяции, графических кешей и, конечно, дисплейного вывода. Универсальный движок кодирования-декодирования видеоформатов, однако, сохранён — он достаточно часто используется в вычислительных нагрузках, связанных с обработкой мультимедийных данных. 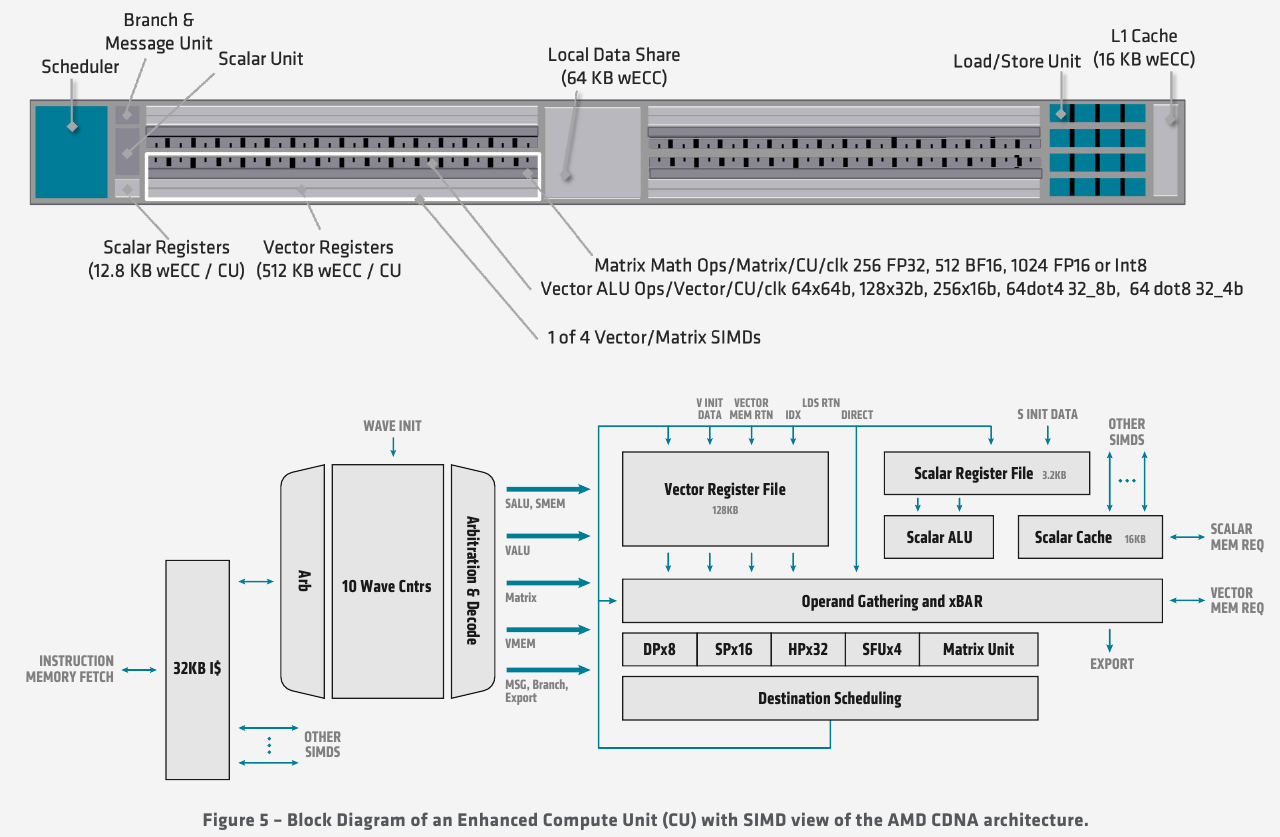
Структурная схема вычислительных модулей в MI100 Каждый CU содержит в себе по одному блоку скалярных инструкций со своим регистровым файлом и кешем данных, и по четыре блока векторных инструкций, оптимизированных для вычислений в формате FP32 саналогичными блоками. Векторные модули имеют ширину 16 потоков и обрабатывают 64 потока (т.н. wavefront в терминологии AMD) за четыре такта. Но самое главное в архитектуре нового процессора — это новые блоки матричных операций. Наличие Matrix Core Engines позволяет MI100 работать с новым типом инструкций — MFMA (Matrix Fused Multiply-Add). Операции над матрицами размера KxN могут содержать смешанные типы входных данных: поддерживаются режимы INT4, INT8, FP16, FP32, а также новый тип Bfloat16 (bf16); результат, однако, выводится только в форматах INT32 или FP32. Поддержка столь многих типов данных введена для универсальности и MI100 сможет показать высокую эффективность в вычислительных сценариях разного рода. 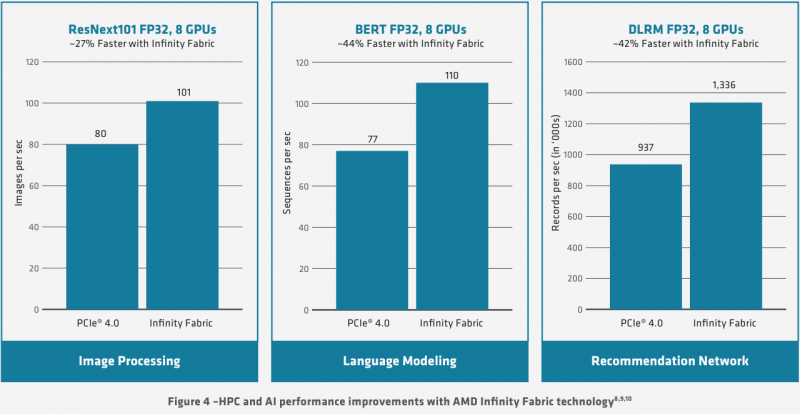
Использование Infinity Fabric 2.0 позволило ещё более увеличить производительность MI100 Каждый блок CU имеет свой планировщик, блок ветвления, 16 модулей load-store, а также кеши L1 и Data Share объёмами 16 и 64 Кбайт соответственно. А вот кеш второго уровня общий для всего чипа, он имеет ассоциативность 16 и объём 8 Мбайт. Совокупная пропускная способность L2-кеша достигает 6 Тбайт/с. Более серьёзные объёмы данных уже ложатся на подсистему внешней памяти. В MI100 это HBM2 — новый процессор поддерживает установку четырёх или восьми сборок HBM2, работающих на скорости 2,4 Гт/с. Общая пропускная способность подсистемы памяти может достигать 1,23 Тбайт/с, что на 20% быстрее, нежели у предыдущих вычислительных ускорителей AMD. Память имеет объём 32 Гбайт и поддерживает коррекцию ошибок. 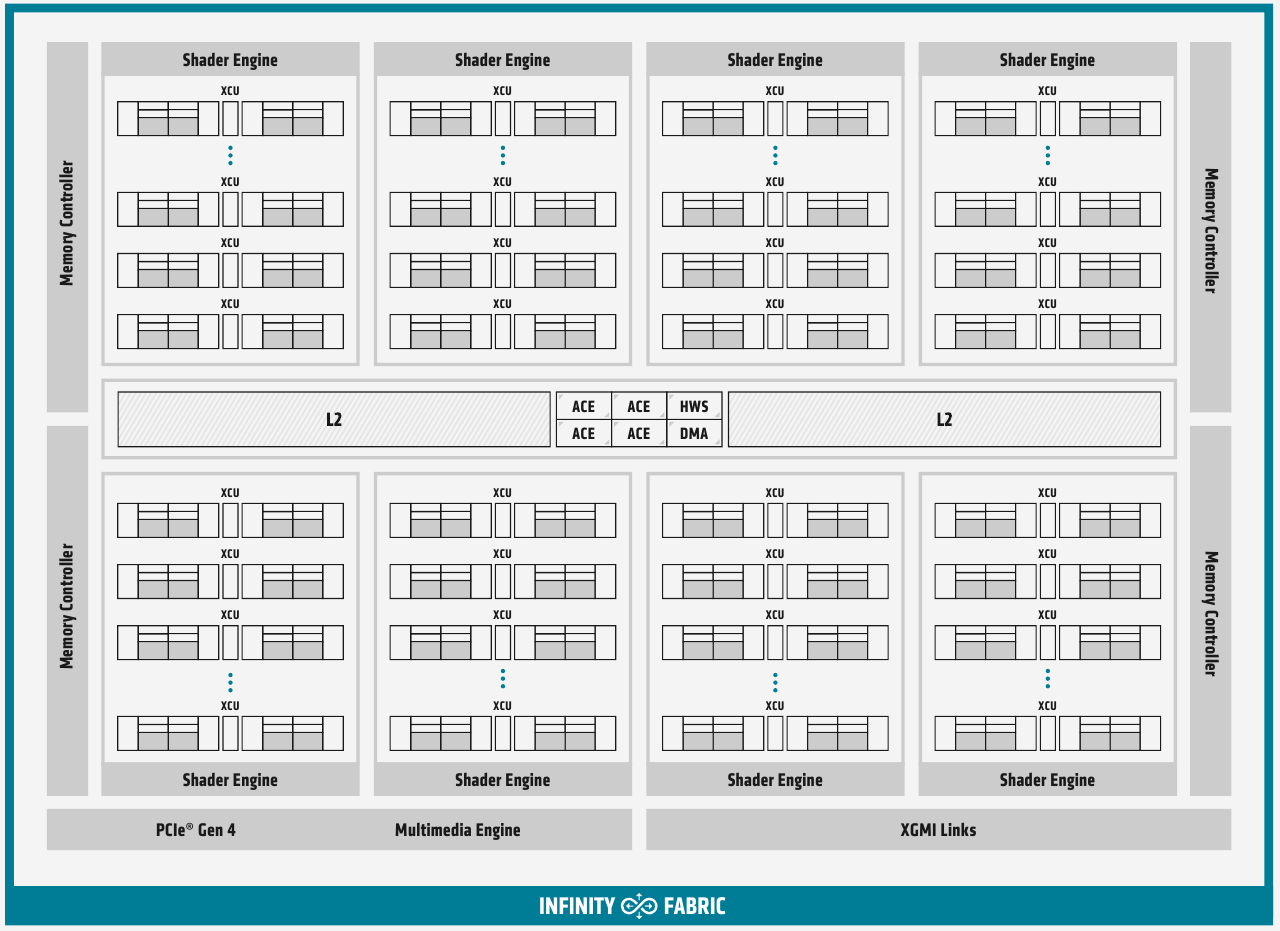
Общая блок-схема Instinct MI100 «Мозг» чипа Instinct MI100 составляют четыре командных процессора (ACE на блок-схеме). Их задача — принять поток команд от API и распределить рабочие задания по отдельным вычислительным модулям. Для подключения к хост-процессору системы в составе MI100 имеется контроллер PCI Express 4.0, что даёт пропускную способность на уровне 32 Гбайт/с в каждом направлении. Таким образом, «уютнее всего» ускоритель Instinct MI100 будет чувствовать себя совместно с ЦП AMD EPYC второго поколения, либо в системах на базе IBM POWER9/10. Избавление от лишних архитектурных блоков и оптимизация архитектуры под вычисления в как можно более широком числе форматов позволяют Instinct MI100 претендовать на универсальность. Ускорители с подобными возможностями, как справедливо считает AMD, станут важным строительным блоком в экосистеме HPC-машин нового поколения, относящихся к экзафлопсному классу. AMD заявляет о том, что это первый ускоритель, способный развить более 10 Тфлопс в режиме двойной точности FP64 — пиковый показатель составляет 11,5 Тфлопс. 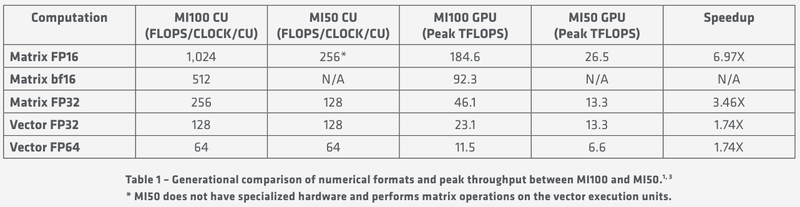
Удельные и пиковые показатели производительности MI100 В менее точных форматах новинка пропорционально быстрее, и особенно хорошо ей даются именно матричные вычисления: для FP32 производительность достигает 46,1 Тфлопс, а в новом, оптимизированном под задачи машинного обучения bf16 — и вовсе 92,3 Тфлопс, причём, ускорители Instinct предыдущего поколения таких вычислений выполнять вообще не могут. В зависимости от типов данных, превосходство MI100 перед MI50 варьируется от 1,74х до 6,97x. Впрочем, NVIDIA A100 в этих задача всё равно заметно быстрее, а вот в FP64/FP32 проигрывают.
16.11.2020 [17:00], Игорь Осколков
SC20: NVIDIA представила ускоритель A100 с 80 Гбайт HBM2e и настольный «суперкомпьютер» DGX STATIONNVIDIA представила новую версию ускорителя A100 с увеличенным вдвое объёмом HBM2e-памяти: 80 Гбайт вместо 40 Гбайт у исходной A100, представленной полгода назад. Вместе с ростом объёма выросла и пропускная способность — с 1,555 Тбайт/с до 2 Тбайт/с. В остальном характеристики обоих ускорителей совпадают, даже уровень энергопотребления сохранился на уровне 400 Вт. Тем не менее, объём и скорость работы быстрой набортной памяти влияет на производительность ряда приложений, так что им такой апгрейд только на пользу. К тому же MIG-инстансы теперь могут иметь объём до 10 Гбайт. PCIe-варианта ускорителя с удвоенной памятью нет — речь идёт только об SXM3-версии, которая используется в собственных комплексах NVIDIA DGX и HGX-платформах для партнёров. 
NVIDIA A100 80 Гбайт  Последним ориентировочно в первом квартале следующего года будут предоставлены наборы для добавления новых A100 в существующие решения, включая варианты плат на 4 и 8 ускорителей. У самой NVIDIA обновлению подверглись, соответственно, DGX A100 POD и SuperPOD for Enterprise. Недавно анонсированные суперкомпьютеры Cambridge-1 и HiPerGator на базе SuperPOD одними из первых получат новые ускорители с 80 Гбайт памяти. Ожидается, что HGX-решения на базе новой A100 будут доступны от партнёров компании — Atos, Dell Technologies, Fujitsu, GIGABYTE, Hewlett Packard Enterprise, Inspur, Lenovo, Quanta и Supermicro — в первой половине 2021 года.   Но, пожалуй, самый интересный анонс касается новой рабочей станции NVIDIA DGX STATION A100, которую как раз и можно назвать настольным «суперкомпьютером». В ней используются четыре SXM3-ускорителя A100 с не требующей обслуживания жидкостной системой охлаждения и полноценным NVLink-подключением. Будут доступны две версии, со 160 или 320 Гбайт памяти с 40- и 80-Гбайт A100 соответственно. Базируется система на 64-ядерном процессоре AMD EPYC, который можно дополнить 512 Гбайт RAM.   Для ОС доступен 1,92-Тбайт NVMe M.2 SSD, а для хранения данных — до 7,68 Тбайт NVMe U.2 SSD. Сетевое подключение представлено двумя 10GbE-портами и выделенным портом управления. Видеовыходов четыре, все mini Display Port. DGX STATION A100 отлично подходит для малых рабочих групп и предприятий. В том числе благодаря тому, что функция MIG позволяет эффективно разделить ресурсы станции между почти тремя десятками пользователей. В продаже она появится у партнёров компании в феврале следующего года.  Вероятно, все выпускаемые сейчас A100 c увеличенным объёмом памяти идут на более важные проекты. Новинкам предстоит конкурировать с первым ускорителем на базе новой архитектуры CDNA — AMD Instinct MI100. |
|