Материалы по тегу: hpc
|
14.04.2023 [12:07], Сергей Карасёв
Представлен новый суперкомпьютер Gaea C5 производительностью более 10 Пфлопс для исследования климатаОкриджская национальная лаборатория (ORNL) Министерства энергетики США и Национальное управление океанических и атмосферных исследований (NOAA) представили новую НРС-систему Gaea для проведения научных изысканий и моделирования в области климатологии. Комплекс станет пятым суперкомпьютером, который будет установлен в Национальном вычислительном центре климатических исследований в составе ORNL. Ранее на этой площадке уже были развёрнуты четыре системы семейства Gaea. Новый суперкомпьютер получил обозначение C5. Полностью характеристики комплекса не раскрываются. Известно, что в основу положены узлы HPE Cray, а максимальная производительность составляет более 10 Пфлопс. Это практически вдвое превышает мощность двух предыдущих систем вместе взятых. В состав C5 входят восемь шкафов с современными процессорами. Причём один такой шкаф по производительности эквивалентен всей системе С3. 
Источник изображения: ORNL Изначально отгрузку компонентов суперкомпьютера C5 планировалось организовать осенью 2021 года. Однако дефицит комплектующих и сбои в каналах поставок привели к значительным задержкам. В итоге, оборудование было получено только летом 2022-го, после чего начались работы по его монтажу. Затем специалисты приступили к процессу тестирования и приёмки.
14.04.2023 [01:42], Руслан Авдеев
Terve: самый мощный суперкомпьютер Европы позволил создать большую языковую модель для финского языка, притом культурнуюХотя генеративный ИИ активно осваивается миром, и новости о нём поступают со всех концов света, почти ничего не рассказывается об аппаратных мощностях, стоящих за обучением больших языковых моделей (LLM). Как сообщает HPC Wire, ситуацию попытался изменить IT-центр CSC, рассказав о роли европейского суперкомпьютера LUMI в создании LLM для финского языка. Без LUMI обучение модели удалось бы завершить только в 2025 году. Суперкомпьютер LUMI является самым быстрым в Европе и занимает третье место в рейтинге TOP500. LUMI помог в обучении модели TurkuNLP, создававшейся под патронажем учёных из Университета Турку, сумевших сформировать «крупнейшую языковую модель для финского языка за всю историю». Новая ИИ-модель на базе GPT-3 включает 13 млрд параметров — известно, что до TurkuNLP в рамках пилотного проекта создавались и более скромные варианты. Финскому научили и многоязыковую модель BLOOM со 176 млрд параметров. 
Дата-центр LUMI (Фото: Fade Creative) Делить машинное время пришлось со многими другими проектами, по некоторым данным, исследователи временами регистрировали производительность на уровне 75–80 % от расчётной, хотя даже такие показатели признаны неплохими. Поскольку LUMI использует ускорители AMD Instinct MI250X, на их оптимизацию кода под новое «железо» ушло немало времени. Впрочем, группа учёных получила поддержку от команды LUMI User Support Team, AMD и Hugging Face. 
Источник изображения: LUMI Ещё одной нетривиальной задачей стал поиск материалов на финском языке для тренировки модели. Финны — довольно немногочисленный народ, поэтому исходного «сырья» для обучения в мире оцифровано относительно немного. Тексты в электронном виде добывались из всех возможных источников, при этом перед учёными стояла задача отфильтровать контент с ругательствами или материалами, разжигающими ненависть. По данным учёных, им удалось вдвое сократить число спонтанной ругани в сравнении с предыдущими моделями благодаря качественным материалам, использовавшимся для обучения. Перед обучением также пришлось вычистить все персональные данные. Модель опубликована в Сети, но команда уже получила грант на 2 млн GPU-часов в рамках проекта LUMI Extreme Scale, поэтому исследования продолжатся.
13.04.2023 [13:20], Сергей Карасёв
Объём мирового рынка НРС достигнет $62 млрд к 2032 годуСогласно прогнозам аналитиков Future Market Insights, глобальная отрасль HPC в течение ближайших лет будет демонстрировать показатель CAGR (среднегодовой темп роста в сложных процентах) на уровне 4,4 %. В результате, к 2032 году затраты в данной сфере достигнут приблизительно $62 млрд. По оценкам, в 2022-м объём мирового НРС-рынка составил $40 млрд. В течение предстоящих десяти лет спрос будет расти по мере расширения и диверсификации IT-сектора. Аналитики полагают, что всё более востребованными будут становиться гибридные вычислительные среды, что поможет открыть новые перспективы для бизнеса. 
Источник изображения: ORNL Ожидается, что к 2032 году рынок HPC в США достигнет размера в $19,4 млрд, а в Китае — $5,3 млрд. В сегменте аппаратных компонентов в течение указанного периода прогнозируется значение CAGR около 4,3 %. При этом категория наук о жизни и сектор здравоохранения в плане потребности в НРС-ресурсах покажут среднегодовой темп роста в 4,2 % до 2032 года. Отмечается, что росту мировой отрасли НРС способствуют несколько факторов. Это, в частности, потребность в средствах удалённой работы и дистанционного обучения на фоне продолжающейся пандемии COVID-19. Кроме того, стремительно развиваются платформы ИИ и аналитики больших данных. Говорится, что решения в сфере НРС будут широко использоваться правительственными организациями, военными ведомствами, коммунальными и промышленными предприятиями.
11.04.2023 [16:15], Сергей Карасёв
CPU много не бывает: начат монтаж суперкомпьютера Kestrel на базе Intel Xeon Sapphire RapidsВ США, по сообщению ресурса HPC Wire, началось фактическое строительство нового НРС-комплекса — системы Kestrel, контракт на создание которой получила компания HPE. Суперкомпьютер расположится в Национальной лаборатории по изучению возобновляемой энергии (NREL), которая находится в Голдене (штат Колорадо). В окончательном виде НРС-платформа будет содержать 2436 узлов. 2304 модуля — это CPU-блоки, каждый из которых содержит два процессора Intel Xeon Sapphire Rapids и 256 Гбайт RAM. Именно эти узлы в настоящее время доставляются и устанавливаются на площадке NREL. Возможно, также прибудут десять узлов с такими же CPU, но большим объёмом памяти — 2 Тбайт. Одновременно идёт развёртывание интерконнекта HPE Slingshot 11, параллельной ФС ёмкостью 27 Пбайт и корневого хранилища вместимостью 1,2 Пбайт. 
Источник изображения: NREL Позднее в 2023 году в составе Kestrel появятся GPU-узлы: 132 модуля с двумя AMD Epyc Genoa, четырьмя ускорителями NVIDIA H100 и 384 Гбайт памяти, а также 10 блоков с двумя чипами Intel Xeon Sapphire Rapids и двумя ускорителями NVIDIA A40. Изначально монтаж оборудования по проекту Kestrel был запланирован на IV квартал 2022 года. Однако отгрузки задержались из-за сбоя в каналах поставок и сложившейся макроэкономической ситуации. В целом, как ожидается, суперкомпьютер обеспечит пиковую производительность до 44 Пфлопс, что более чем в пять раз превышает мощность его предшественника — комплекса Eagle. Использовать Kestrel планируется при проведении различных исследований в области энергетики — от оптимизации инфраструктуры зарядных станций для электромобилей до создания передовых материалов для солнечных батарей.
08.04.2023 [23:19], Сергей Карасёв
700-Пбайт гибридное хранилище Orion суперкомпьютера Frontier доказало свою эффективностьРесурс insideHPC обнародовал подробности об архитектуре подсистемы хранения данных суперкомпьютера Frontier, установленного в Окриджской национальной лаборатории (ORNL) Министерства энергетики США. Этот комплекс возглавляет нынешний рейтинг TOP500, демонстрируя производительность в 1,102 Эфлопс и пиковое быстродействие в 1,685 Эфлопс. Сообщается, что система хранения Frontier носит название Orion. Она состоит из 50 шкафов с накопителями суммарной вместимостью приблизительно 700 Пбайт. Эти устройства хранения распределены по трёхуровневой схеме, включащей SSD, HDD и другие энергонезависимые решения, на базе которых развёрнуты ФС Lustre и ZFS. Данные возрастом более 90 дней автоматически перемещаются в архив. 
Источник изображения: ORNL Один из уровней, производительный, объединяет 5 400 NVMe SSD, обеспечивающих ёмкость 11,5 Пбайт. Пиковые скорости чтения и записи информации достигают 10 Тбайт/с. Показатель IOPS (количество операций ввода/вывода в секунду) при произвольном чтении и записи превышает 2 млн. Второй уровень содержит 47 700 жёстких дисков (PMR). Их общая вместимость равна 679 Пбайт. Максимальная скорость чтения массива — 4,6 Тбайт/с, скорость записи — 5,5 Тбайт/с. В состав третьего уровня включены 480 устройств NVMe суммарной ёмкостью 10 Пбайт для работы с метаданными. В целом, архитектура соответствует той, что была запланирована изначально. Однако теперь представитель ORNL подтвердил правильность выбранного гибридного подхода к хранению информации, отметив, что одна из выполняемых на суперкомпьютере задач генерирует 80 Пбайт в день и что ему не хотелось бы, чтобы из-за недостаточно быстрого хранилища столь мощная машина простаивала без дела.
07.04.2023 [20:36], Сергей Карасёв
Google заявила, что её ИИ-кластеры на базе TPU v4 и оптических коммутаторов эффективнее кластеров на базе NVIDIA A100 и InfiniBandКомпания Google обнародовала новую информацию о своей облачной суперкомпьютерной платформе Cloud TPU v4, предназначенной для решения задач ИИ и машинного обучения с высокой эффективностью. Система может использоваться в том числе для работы с крупномасштабными языковыми моделями (LLM). Один кластер Cloud TPU Pod содержит 4096 чипов TPUv4, соединённых между собой через оптические коммутаторы (OCS). По словам Google, решение OCS быстрее, дешевле и потребляют меньше энергии по сравнению с InfiniBand. Google также утверждает, что в составе её платформы на OCS приходится менее 5 % от общей стоимости. Причём данная технология даёт возможность динамически менять топологию для улучшения масштабируемости, доступности, безопасности и производительности. Отмечается, что платформа Cloud TPU v4 в 1,2–1,7 раза производительнее и расходует в 1,3–1,9 раза меньше энергии, чем платформы на базе NVIDIA A100 в системах аналогичного размера. Правда, пока компания не сравнивала TPU v4 с более новыми ускорителями NVIDIA H100 из-за их ограниченной доступности и 4-нм архитектуры (по сравнению с 7-нм у TPU v4). 
Изображение: Google Благодаря ключевым инновациям в области интерконнекта и специализированных ускорителей (DSA, Domain Specific Accelerator) платформа Google Cloud TPU v4 обеспечивает почти 10-кратный прирост в масштабировании производительности по сравнению с TPU v3. Это также позволяет повысить энергоэффективность примерно в 2–3 раза по сравнению с современными DSA ML и сократить углеродный след примерно в 20 раз по сравнению с обычными дата-центрами.
05.04.2023 [23:41], Владимир Мироненко
SiPearl привлекла €90 млн на выпуск первого европейского Arm-процессора Rhea для суперкомпьютеровФранцузская компания SiPearl, занимающаяся разработкой энергоэффективного высокопроизводительного Arm-процессора Rhea для европейских суперкомпьютеров, сообщила о завершении раунда финансирования серии А, в ходе которого она привлекла €90 млн. С учётом новых инвестиций объём финансирования SiPearl достиг €110,5 млн. Ожидается, что к концу года компании удастся привлечь ещё больше инвестиций. Сюда входят гранты Евросоюза и Франции на сумму €20,5 млн евро, предоставленные консорциумом European Processor Initiative (EPI), программой EIC Accelerator и регионом Иль-де-Франс. В раунде A приняли участие Arm, Atos Group (через Eviden), Фонд Европейского инновационного совета (€15 млн евро) и правительство Франции через French Tech Souveraineté. Финансирование включает конвертируемые долговые обязательства Европейского инвестиционного банка (ЕИБ) на сумму до €25 млн евро. Rhea на базе Arm Neoverse V1 является специализированным энергоэффективным процессором для высокопроизводительных вычислений (HPC), предназначенным для работы с любыми ускорителями сторонних производителей, в том числе для ИИ и квантовых вычислений. Уже объявлено о заключении соглашений о сотрудничестве с AMD, Intel, NVIDIA и Graphcore. Выпуском Rhea займётся TSMC, а начало коммерческих поставок запланировано на начало 2024 года. 
Фото: SiPearl «Исторически отставая от США и Китая, Европа стала мировым лидером в области высокопроизводительных вычислений благодаря инициативе EuroHPC, впервые включив две системы в четвёрку самых мощных суперкомпьютеров мира: LUMI в Финляндии и Leonardo в Италии. Появление на рынке микропроцессора SiPearl Rhea <…> станет ещё одним решающим шагом на пути к технологической независимости и суверенитету Европы», — заявил Филипп Ноттон (Philippe Notton), генеральный директор и основатель SiPearl, выразив благодарность инвесторам.
05.04.2023 [16:34], Сергей Карасёв
Объём мирового рынка ресурсоёмких вычислений PICaaS в 2027 году превысит $100 млрдКомпания IDC опубликовала свой первый прогноз по мировому рынку ресурсоёмких вычислений, доступ к которым предоставляется по модели «как услуга» (Performance Intensive Computing as a Service, PICaaS). Аналитики полагают, что в ближайшие годы данная отрасль продемонстрирует стремительный рост. По оценкам, в 2021-м объём глобального рынка PICaaS составлял $22,3 млрд. В 2027 году, полагает IDC, расходы достигнут $103,1 млрд. Если этот прогноз оправдается, показатель CAGR (среднегодовой темп роста в сложных процентах) составит 27,9 % в период 2022–2027 гг. IDC определяет сегмент PICaaS как быстроразвивающуюся категорию облачных сервисов, ориентированных на приложения ИИ, аналитику больших данных, инженерно-технические задачи и HPC. Рынок PICaaS включает в себя выручку, получаемую облачными провайдерами от платформ вычислений и хранения информации в рамках моделей IaaS, PaaS и SaaS. В 2022 году на долю PICaaS пришлось около 12,5 % от общего размера облачного сегмента «как услуга», который был оценён в $241,3 млрд. 
Источник изображения: pixabay.com Драйверами рынка PICaaS специалисты IDC называют рост спроса на ресурсоёмкие вычисления и цифровую трансформацию предприятий. Вместе с тем сдерживающими факторами являются сложность управления гибридными средами, нехватка специалистов по технологиям HPC и перенос рабочих нагрузок из общедоступного облака обратно в выделенные IT-среды.
29.03.2023 [22:27], Владимир Мироненко
Cerebras выпустила семь GPT-моделей для генеративного ИИ под открытой лицензией, обучив их на собственных чипахАмериканский производитель ИИ-комплексов Cerebras Systems объявил о выходе 7 больших языковых моделей (LLM) на базе технологии Generative Pre-trained Transformer (GPT) для генеративного ИИ. Это первые публичные LLM, которые прошли обучение с помощью систем CS-2 в суперкластере Cerebras Andromeda на базе фирменных ИИ-чипов Cerebras WSE-2. Другими словами, это одни из первых больших языковых моделей, которые были обучены без использования систем на основе ускорителей, в частности, NVIDIA. Серия из семи открытых моделей GPT со 111, 256, 590 млн, а также 1,3, 2,7, 6,7 и 13 млрпд параметров соответственно доступны на GitHub и Hugging Face. Обучение таких моделей обычно занимает много месяцев, но Cerebras утверждает, что ей удалось справиться всего за несколько недель благодаря Andromeda. Более того, Cerebas удалось снизить стоимость обучения, а также упростить масштабирование без модификации кода и самой модели, что часто требуется при обучении с использованием кластеров традиционных ускорителей. При этом энергоэффективность всего процесса Cerebras смогла повысить. 
Источник изображения: Cerebras Systems Cerebras отметила, что не только предлагает модели, но и инструкции по их обучению под лицензией Apache 2.0. «Мы считаем, что для того, чтобы LLM были открытой и доступной технологией, важно иметь доступ к современным моделям, которые являются открытыми, воспроизводимыми и бесплатными как для исследовательских, так и для коммерческих приложений», — заявила Cerebras. 
Источник изображения: Cerebras Systems Компания заявила, что это первый случай, когда весь набор моделей GPT, обученных с использованием самых современных методов повышения эффективности, стал общедоступным. Поскольку большие языковые модели Cerebras имеют открытый исходный код, их можно использовать как в исследовательских, так и в коммерческих целях. А предварительно обученную модель можно с минимум затрат дообучить под конкретную задачу на пользовательских данных. 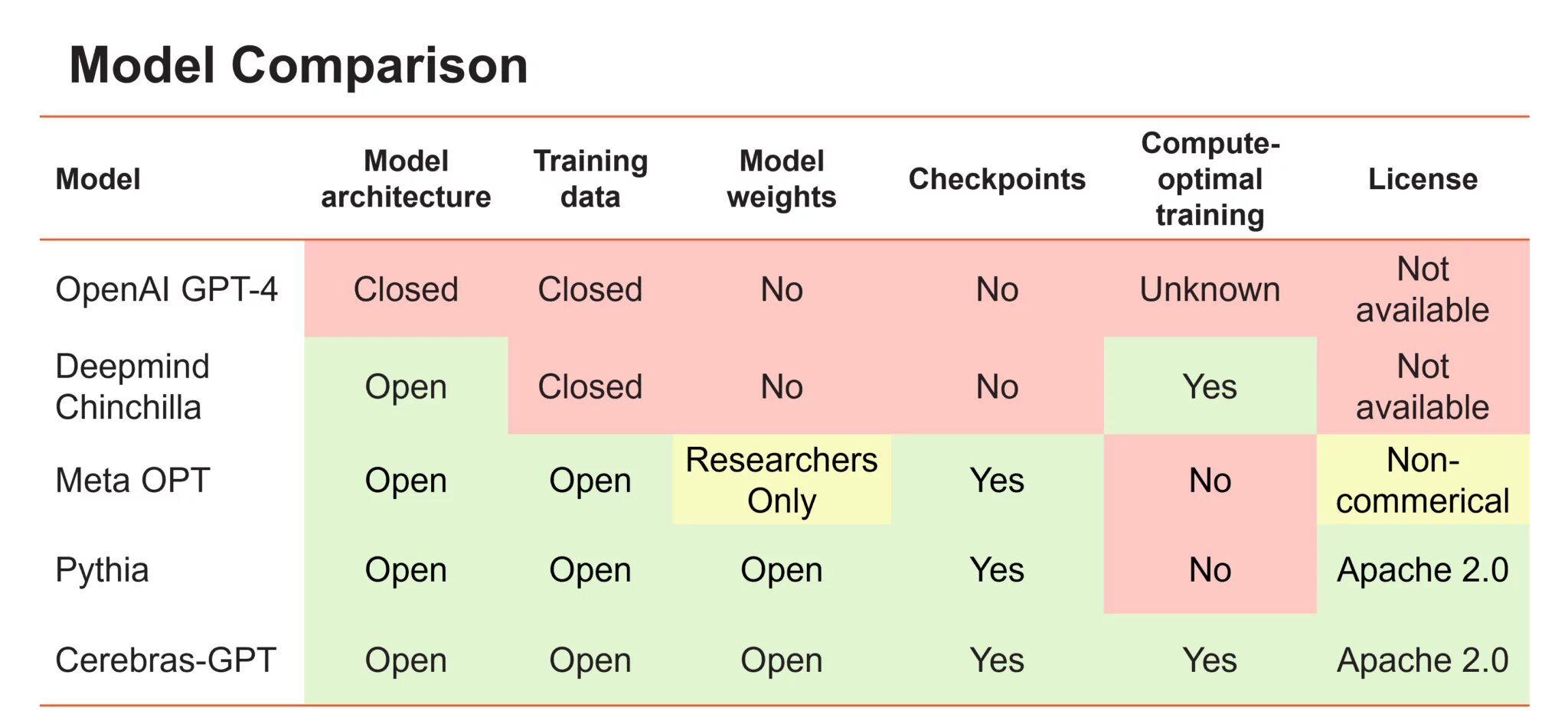
Источник изображения: Cerebras Systems Cerebras отметила, что быстрый рост генеративного ИИ при лидерстве ChatGPT от OpenAI спровоцировал обострение состязания среди производителей ИИ-оборудования для ИИ, взявшихся за создание более мощных и специализированных чипов. Хотя многие из них обещали создать альтернативу ускорителям NVIDIA, пока никому из них не удалось продемонстрировать способность обучать крупномасштабные модели и желание раскрывать наработки под открытыми лицензиями. По словам Cerebras, в связи с конкуренцией доступ к ИИ становится все более закрытым. Так, GPT4 была выпущена без детальной информации об архитектуре модели, параметрах, данных, оборудовании и т.д. Компании создают большие модели с использованием закрытых наборов данных и предлагают выходные данные моделей только через доступ к API.
26.03.2023 [18:59], Сергей Карасёв
Один из последних: в Японии заработал суперкомпьютер Pegasus с 240 Тбайт памяти Optane PMem 300В Центре вычислительных наук Университета Цукубы (University of Tsukuba; префектура Ибараки, Япония), по сообщению HPC Wire, началась эксплуатация HPC-комплекса Pegasus, спроектированного компанией NEC. Это, судя по всему, один из последних суперкомпьютеров, который получит большой объём памяти Optane Pmem, производство которой было остановлено Intel. Система объединяет 120 узлов NEC LX 102Bk-6 на основе одного процессора Xeon Platinum 8468 поколения Sapphire Rapids (48 ядер; 96 потоков; 2,1–3,8 ГГц; 350 Вт), работающего в тандеме со 128 Гбайт оперативной памяти DDR5-4800, дополненных 2 Тбайт памяти Optane PMem 300 (Crow Pass). Любопытно, что по умолчанию часть Optane-памяти отведена под XFS-том (fsdax), но по желанию пользователи могут выбрать и другой режим работы. Кроме того, в состав каждого из узлов входят один PCIe-ускоритель NVIDIA H100. 
Источник изображения: Университет Цукубы Также каждый узел имеет по два накопителя NVMe SSD на 3,2 Тбайт (7 Гбайт/с), а объединены они 200G-интерконнектом Quantum-2 InfiniBand. Дополняет HPC-комплекс гибридное хранилище на базе DDN ES200NV/ES7990X/SS9012, объединяющее NL-SAS HDD вместимостью 18 Тбайт (7200 об/мин) и 1,92-Тбайт NVMe SSD. Суммарная доступная ёмкость составляет приблизительно 7,1 Пбайт, а скорость обмена данными — порядка 40 Гбайт/с. 
Источник изображения: Университет Цукубы Кроме того, применены три дополнительных узла NEC LX 124Rk-2 с двумя чипами Xeon Platinum 8468, 256 Гбайт памяти DDR5, накопителем NVMe SSD и InfiniBand-подключением. Быстродействие Pegasus теоретически достигает 6,5 Пфлопс для вычислений двойной точности. Использовать мощности нового суперкомпьютера планируется в таких областях, как астрофизика, климатология, биология, здравоохранение, Big Data и ИИ. В Университете Цукубы есть ещё один необычный суперкомпьютер Cygnus, объединяющий ускорители NVIDIA Tesla и Intel FPGA. |
|