Материалы по тегу: hpc
|
21.05.2023 [22:50], Сергей Карасёв
HPE создаст для Японии суперкомпьютер TSUBAME4.0 производительностью 66,8 ПфлопсКомпания HPE объявила о заключении соглашения с Глобальным научно-информационным вычислительным центром Токийского технологического института (Япония) о создании нового суперкомпьютера под названием TSUBAME4.0. Полностью ввести эту систему в эксплуатацию планируется весной 2024 года. TSUBAME4.0 будет применяться для обучения больших ИИ-моделей и запуска ресурсоёмких приложений в области аналитики данных. В основу суперкомпьютера ляжет платформа HPE Cray XD6500, которая, как утверждается, обеспечивает высокую производительность и специализированные возможности при выполнении нагрузок, связанных с моделированием, а также ИИ. Заявленное пиковое быстродействие TSUBAME4.0 составит 66,8 Пфлопс (FP64). В случае вычислений половинной точности (FP16) показатель достигнет 952 Пфлопс — это в 20 раз больше по сравнению с мощностью суперкомпьютера предыдущего поколения TSUBAME3.0. 
Источник изображения: HPE Вычислительный комплекс TSUBAME4.0 получит 240 узлов, оснащённых двумя процессорами AMD EPYC Genoa, четырьмя ускорителями NVIDIA H100 и 768 Гбайт основной памяти. Говорится о высокой плотности размещения аппаратных компонентов, что позволит уменьшить занимаемую площадь в дата-центре. Задействован 400G-интерконнект NVIDIA Quantum-2 InfiniBand. Отмечается, что в целом архитектура TSUBAME4.0 аналогична системам TSUBAME предыдущих поколений. Благодаря этому возможно использование ранее созданных программных решений, что поможет ускорить реализацию новых НРС-проектов.
17.05.2023 [23:09], Руслан Авдеев
В Нидерландах QMware и QuiX Quantum создадут первый гибридный ЦОД с квантовыми и HPC-технологиямиQMware и QuiX Quantum объявили о создании в нидерландском Энсхеде гибридного дата-центра, в котором сочетается классическая HPC-инфраструктура с квантовыми технологиями. Как сообщает Inside HPC, речь идёт о первой интегрированной гибридной системе такого типа. Ожидается, что ЦОД будет готов к коммерческому использованию уже в августе 2023 года. Пока известно, что проприетарное программное обеспечение QMware позволяет объединить принципиально разные аппаратные вычислительные системы, способные использовать общую память. Повышенные вычислительные мощности позволят обеспечивать более точные результаты, а благодаря QuiX Quantum с её масштабируемой технологией, можно использовать системы для самых разных ресурсоёмких задач. 
Источник изображения: QuiX Quantum Квантовый компьютер компании QuiX Quantum оптимально подходит для гибридной системы, поскольку способен работать при комнатной температуре и легко масштабируется. Для соединения с HPC-инфраструктурой используется оптоволоконное подключение. Управление системой обеспечит унифицированная версия Linux — в сравнении с существующими гибридными решениями новая инфраструктура намного производительнее и экономичнее. Если существующие гибридные системы обычно требуют веб-интеграции квантовой составляющей и HPC-оборудования, то в данном случае этого не требуется, взаимодействие на одной площадке обеспечивает проприетарное железо и ПО Qmware. В результате конечные клиенты получают одновременный доступ к мощностям обоих типов с низкой задержкой. Представителями партнёров ожидают, что использование гибридной инфраструктуры позволит обрабатывать данные в некоторых приложениях до 10 раз быстрее. По словам представителя QuiX Quantum, компания намерена обеспечить использование квантовых технологий в прикладной сфере. По его мнению, оптимизация энергосетей, цепочек поставок или дорожного движения — лишь немногие из сфер, где, возможно, будут применяться гибридные технологии при сотрудничестве с Qmware. Квантовые компьютеры довольно активно покупаются и используются операторами ЦОД, в том числе речь идёт и о гибридных системах. Так, только в марте этого года NVIDIA представила систему DGX Quantum для гибридных квантово-классических вычислений.
16.05.2023 [13:18], Сергей Карасёв
Giga Computing выпустит ЦОД-платформы на базе CPU/GPU с мощностью до 1000 ВтВ распоряжении сетевых источников, по сообщению ресурса VideoCardz, оказалась информация о планах компании Giga Computing (серверное подразделение Gigabyte) по развитию аппаратных платформ для дата-центров на ближайшие несколько лет — вплоть до 2025 года. Судя по обнародованному слайду, Giga Computing в течение нынешнего года и большей части 2024-го будет применять процессоры Intel Xeon поколений Sapphire Rapids-SP/Emerald Rapids-SP с показателем TDP до 350 Вт. К концу 2024 года появятся чипыGranite Rapids, энергопотребление которых будет достигать 500 Вт. Что касается CPU разработки AMD, то в 2023-м компания будет использовать решения с TDP до 400 Вт, а во второй половине следующего года перейдёт на чипы с архитектурой Zen 5 и TDP до 600 Вт. 
Источник изображения: VideoCardz В сегменте GPU энергопотребление ускорителей NVIDIA с интерфейсом PCIe возрастёт с 350–450 Вт в текущем году до 500 Вт в 2024-м. В случае GPU-решений AMD показатель TDP поднимется с 350 Вт до 400 Вт во второй половине 2024-го и 2025 году. Кроме того, Giga Computing намерена взять на вооружение изделия NVIDIA SXM5 с энергопотреблением до 700 Вт. В случае связки CPU+GPU упомянуты такие продукты, как Grace и Grace Hopper с величиной TDP в диапазоне 600–1000 Вт. Они будут применяться в серверах Giga Computing в 2023–2025 гг.
16.05.2023 [09:23], Сергей Карасёв
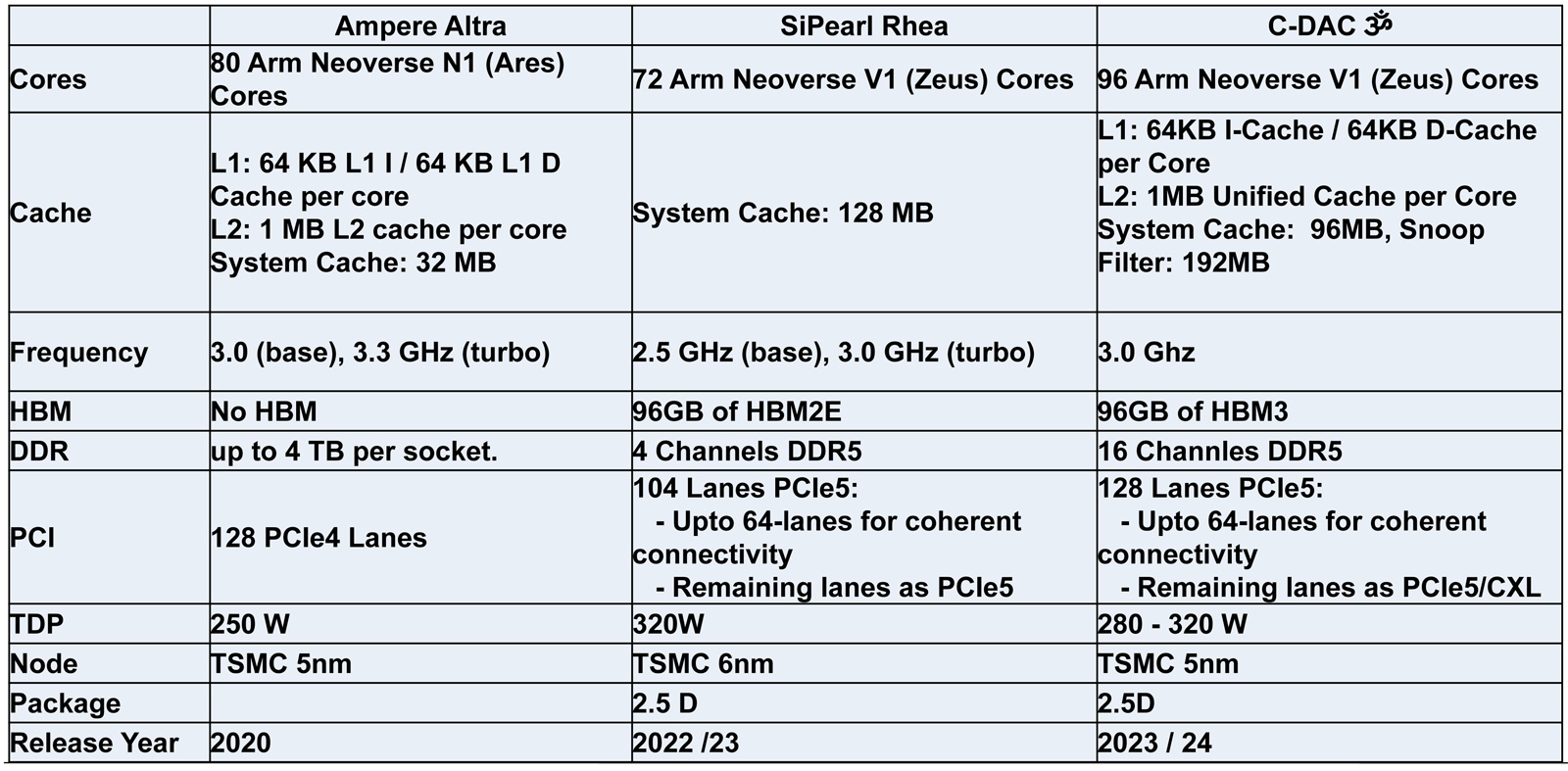
Индия представила свой первый серверный процессор AUM: 96 ядер и 96 Гбайт памяти HBM3Центр развития передовых вычислений (C-DAC) Департамента электроники и информационных технологий Министерства коммуникаций и информационных технологий Индии представил первый в стране процессор для серверов и НРС-систем. Изделие под названием AUM выйдет на коммерческий рынок в текущем или следующем году. Решение имеет чиплетную компоновку на базе двух модулей A48Z, каждый из которых насчитывает 48 вычислительных ядер Zeus с архитектурой Arm. Таким образом, суммарное количество ядер достигает 96. Тактовая частота составляет 3,0 ГГц (до 3,5 ГГц в турбо-режиме); показатель TDP варьируется от 280 до 320 Вт. 
Источник изображений: C-DACC-DAC Новинка будет изготавливаться на предприятии TSMC по 5-нм технологии. Чип содержит 96 Мбайт кеша L2 и 96 Мбайт системного кеша. Изделие получило 96 Гбайт памяти HBM3 и 8-канальный контроллер DDR5-5200; кроме того, имеется доступ к 64 Гбайт памяти HBM3-5600. Таким образом, задействована трёхуровневая подсистема памяти. Упомянуты до 128 линий PCIe 5.0 с поддержкой CXL. 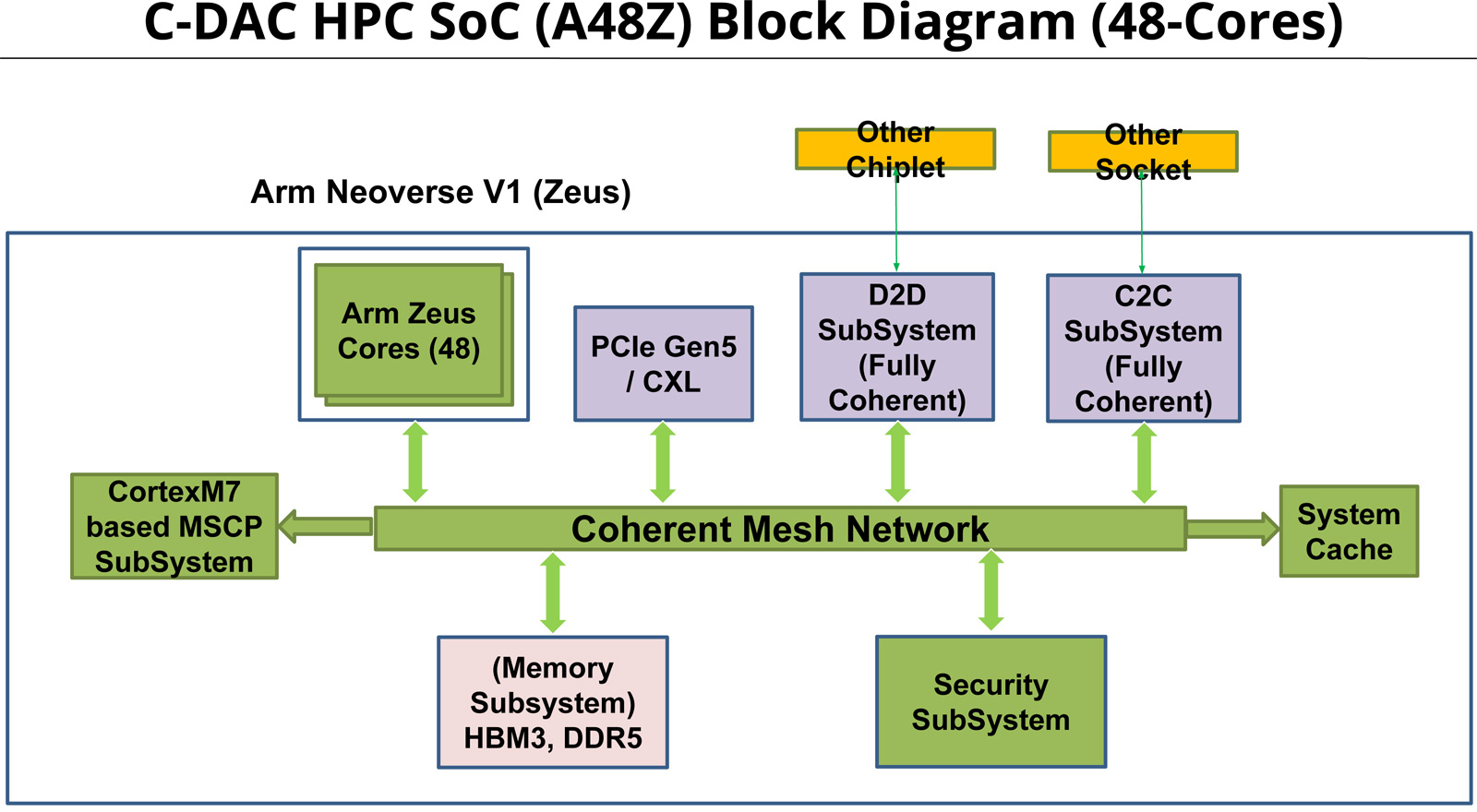 Процессор AUM может применяться в двухсокетных серверах. Заявленная производительность превышает 4,6 Тфлопс в расчёте на разъём. Реализованы различные средства обеспечения безопасности, в том числе функция Secure Boot и криптографические алгоритмы. 
16.05.2023 [09:04], Сергей Карасёв
NTT потратит на развитие инфраструктуры ЦОД более $10 млрд в течение пяти летЯпонская телекоммуникационная корпорация Nippon Telegraph and Telephone (NTT), по сообщению ресурса Datacenter Dynamics, планирует на протяжении пяти лет инвестировать 8 трлн иен (приблизительно $59 млрд) в развитие перспективных направлений. В их числе названы дата-центры, ИИ-платформы и пр. Отмечается, что из указанной суммы не менее 1,5 трлн иен (около $11 млрд) пойдут на расширение или модернизацию инфраструктуры ЦОД. Цифровой бизнес, в который входят ИИ-решения и роботизированные системы, получит на развитие 3 трлн иен ($22 млрд). По оценкам самой NTT, указанные инвестиции позволят в финансовом году, который завершится в марте 2028-го, повысить показатель EBITDA (прибыль до вычета процентов, налогов и амортизационных отчислений) примерно на 20 % по сравнению с предыдущим финансовым годом. Это означает прибыль на уровне 4 трлн иен (приблизительно $29,4 млрд). 
Источник изображения: NTT Сообщается, что в июне текущего года NTT сформирует новую компанию для коммерциализации своей технологии Innovative Optical and Wireless Network (IOWN). Концепция IOWN базируется на использовании оптических коммуникаций, что позволит повысить пропускную способность сетей, уменьшить задержки и энергопотребление. В целом, как ожидается, планируемые вложения помогут NTT укрепить положение на рынке и значительно улучшить финансовые показатели деятельности.
12.05.2023 [15:05], Сергей Карасёв
Для HPC и ИИ: Digital Realty внедрила в своём парижском ЦОД систему прямого жидкостного охлаждения для мощных серверовКомпания Digital Realty развернула в своём дата-центре PAR8 в Ла-Курнёве (находится в 10 км к северу от Парижа) систему прямого жидкостного охлаждения (DLC). Применённое решение снижает эксплуатационные расходы, сокращает энергопотребление и выбросы углерода в атмосферу. По заявлениям Digital Realty, внедрённая технология позволяет клиентам использовать приложения, для которых требуются большие вычислительные ресурсы, в среде, оптимизированной для повышения энергоэффективности. Компания не назвала поставщика DLC-системы, но сообщила, что охлаждение является замкнутым. Парижский дата-центр Digital Realty разработан таким образом, чтобы его можно было адаптировать к меняющимся потребностям клиентов. ЦОД ориентирован прежде всего на выполнение НРС-задач. Утверждается, что благодаря применению концепции DLC клиенты ощутят снижение затрат на обработку данных по сравнению с традиционными методами воздушного охлаждения. 
Источник изображения: Digital Realty ЦОД Digital Realty PAR8 имеет общую площадь объектов приблизительно 26 000 м2. Суммарная мощность достигает 19,2 МВт. Это первый из четырех дата-центров в планируемом Парижском цифровом парке (Paris Digital Park), который предложит 40 000 м2 полезных площадей и до 85 МВт мощности.
12.05.2023 [14:27], Сергей Карасёв
Kao Data построит в Великобритании экологичный 40-МВт ЦОД специально для нагрузок HPC и ИИБританская компания Kao Data, специализирующаяся на HPC-платформах и облачных сервисах, объявила о планах по строительству крупного дата-центра в Манчестере. Этот ЦОД обеспечит мощность до 40 МВт, а начало его коммерческой эксплуатации запланировано на 2025 год. Для строительства дата-центра выбрана бывшая промышленная зона в Кенвуд-Пойнт площадью приблизительно 39 тыс. м2. На территории комплекса расположатся девять залов для оборудования. Инвестиции в проект оцениваются в £350 млн, или приблизительно $440 млн. Предполагается, что объект получит сертификацию OCP Ready и NVIDIA DGX Ready. Площадка предоставит эффективную инфраструктуру для НРС-задач и проектов в области ИИ. Коэффициент PUE нового ЦОД заявлен на уровне 1,2. Питание дата-центр будет на 100 % получать от возобновляемых источников. Для резервных генераторов планируется применение гидрированного растительного масла (HVO) вместо традиционного дизельного топлива. Кроме того, при проектировании ЦОД учитывается возможность утилизации выделяемого тепла. 
Источник изображения: Kao Data Дата-центр в Манчестере станет первой площадкой Kao Data уровня Tier II в Европе. «Мы считаем, что наш объект установит новый стандарт для устойчивых дата-центров в регионе и обеспечит часть базовой инфраструктуры, которая поддерживает как передовые вычислительные кластеры Северной Англии, так и стремление правительства Великобритании стать технологическим и экономическим центром НРС и ИИ», — заявляет Kao Data.
28.04.2023 [12:21], Сергей Карасёв
ВМС США получили суперкомпьютер Nautilus производительностью 8,2 ПфлопсЦентр суперкомпьютерных ресурсов Министерства обороны США (DoD) (Navy DSRC), по сообщению Datacenter Dynamics, получил новую НРС-систему под названием Nautilus: она расположилась в Космическом центре имени Джона Стенниса. Испытания комплекса завершились в апреле 2023 года. Nautilus — это система Penguin TrueHPC, объединяющая 1352 узла. Каждый из них содержит до 128 ядер AMD EPYC Milan и 256 Гбайт памяти. Кроме того, задействованы 16 узлов визуализации на базе NVIDIA A40 и 32 ИИ-узла на основе четырёх ускорителей NVIDIA A100. Используется интерконнект NVIDIA Mellanox Infiniband 200 Гбит/с. В общей сложности в состав Nautilus входят 176 128 ядер и 382 Тбайт памяти. Вместимость хранилища составляет 26 Пбайт. Производительность НРС-комплекса достигает 8,2 Пфлопс. Новый суперкомпьютер является частью Программы модернизации высокопроизводительных вычислений Министерства обороны США (HPCMP). Он поможет в моделировании климата, выполнении исследований в области гидродинамики, химии и пр. 
Источник изображения: US Navy / MC3 Josue L. Escobosa Сообщается также, что центр Navy DSRC модернизировал другой свой суперкомпьютер — систему Narwhal на платформе HPE Cray EX. Этот комплекс получил дополнительно 18 176 вычислительных ядер в составе 128 узлов. Кроме того, добавлены 14 узлов с 1 Тбайт памяти. Таким образом, теперь Narwhal оперирует 308 480 ядрами, а его пиковая производительность достигает 13,6 Пфлопс.
25.04.2023 [20:01], Алексей Степин
Как Aurora, но поменьше: запущен тренировочный суперкомпьютер Sunspot на чипах Intel MaxОдин из самых масштабных проектов в области высокопроизводительных вычислений (HPC), 2-Эфлопс суперкомпьютер Aurora, который планирует вскоре ввести в строй Аргоннская национальная лаборатория (ANL), получил ещё одну тестовую платформу. Новый мини-кластер Sunspot, включающий в себя две стойки будущей машины, является прекрасным полигоном для отладки ПО. Aurora будет состоять из более чем 10 тыс. вычислительных узлов, а Sunspot включает в себя 128 узлов, каждый из которых, впрочем, имеет весьма серьёзную конфигурацию. На борту такой узел несёт пару процессоров Intel Xeon Max (Sapphire Rapids + 64 Гбайт HBM2e), а также шесть ускорителей Intel Max Series (Ponte Vecchio). Sunspot использует в качестве интерконнекта фирменную сеть HPE/Cray Slingshot последнего поколения. 
Источник: Argonne Leadership Computing Facility Как считает глава Argonne Leadership Computing Facility (ALCF), полная идентичность архитектур позволит разработчикам оптимизировать код для максимального использования всех возможностей Sapphire Rapids и Ponte Vecchio. Ранее тестовыми платформами служили кластеры Iris, Arcticus, Florentia самой Аргоннской лаборатории, а также Borealis, принадлежащий Intel. Система Sunspot была запущена ещё в декабре, с тех пор к ней получили доступ более 180 исследователей из 20 команд разработчиков в рамках программ Aurora Early Science Program (ESP) и Exascale Computing Project (ECP). 
Процесс сборки Aurora идёт полным ходом Отмечается, что достигнутые на «железе» Intel Max результаты внушают оптимизм. В ряде научно-технических задач прирост производительности от перехода на ускорители Intel составил от 20 до 70 %, а в разрабатываемом аргоннцами Hardware/Hybrid Accelerated Cosmology Code выигрыш достиг 2,6 раз. Ожидается, что дальнейшая более тонкая оптимизация позволит улучшить результаты. Интересно, что даже после запуска Aurora система Sunspot демонтирована не будет, а станет, как и все предыдущие тестовые платформы ALCF, общедоступным «полигоном для новичков».
22.04.2023 [00:15], Алексей Степин
Ловкость роборук: TopoOpt от Meta✴ и MIT поможет ускорить и удешевить обучение ИИТехнологии искусственного интеллекта (ИИ) сегодня бурно развиваются и требуют всё более серьёзных вычислительных мощностей. Но наряду с наращиванием этих мощностей растут требования и к сетевой подсистеме, поэтому крупные компании и исследовательские организации ищут всё новые способы оптимизации инфраструктуры. Компания Meta✴ в сотрудничестве с Массачусетским технологическим институтом (MIT) и рядом прочих исследовательских организаций опубликовала данные любопытного эксперимента, в котором ИИ-кластер мог менять топологию своего интерконнекта с помощью механической «роборуки». Система получила название TopoOpt, поскольку вычислительные узлы в ней использовали полностью оптическую сеть с оптической же патч-панелью. Эта сеть объединяла 12 вычислительных узлов ASUS ESC4000A-E10, каждый из которых был оснащён ускорителем NVIDIA A100, сетевыми адаптерами HPE и Mellanox ConnectX-5 (100 Гбит/с) с оптическими трансиверами. 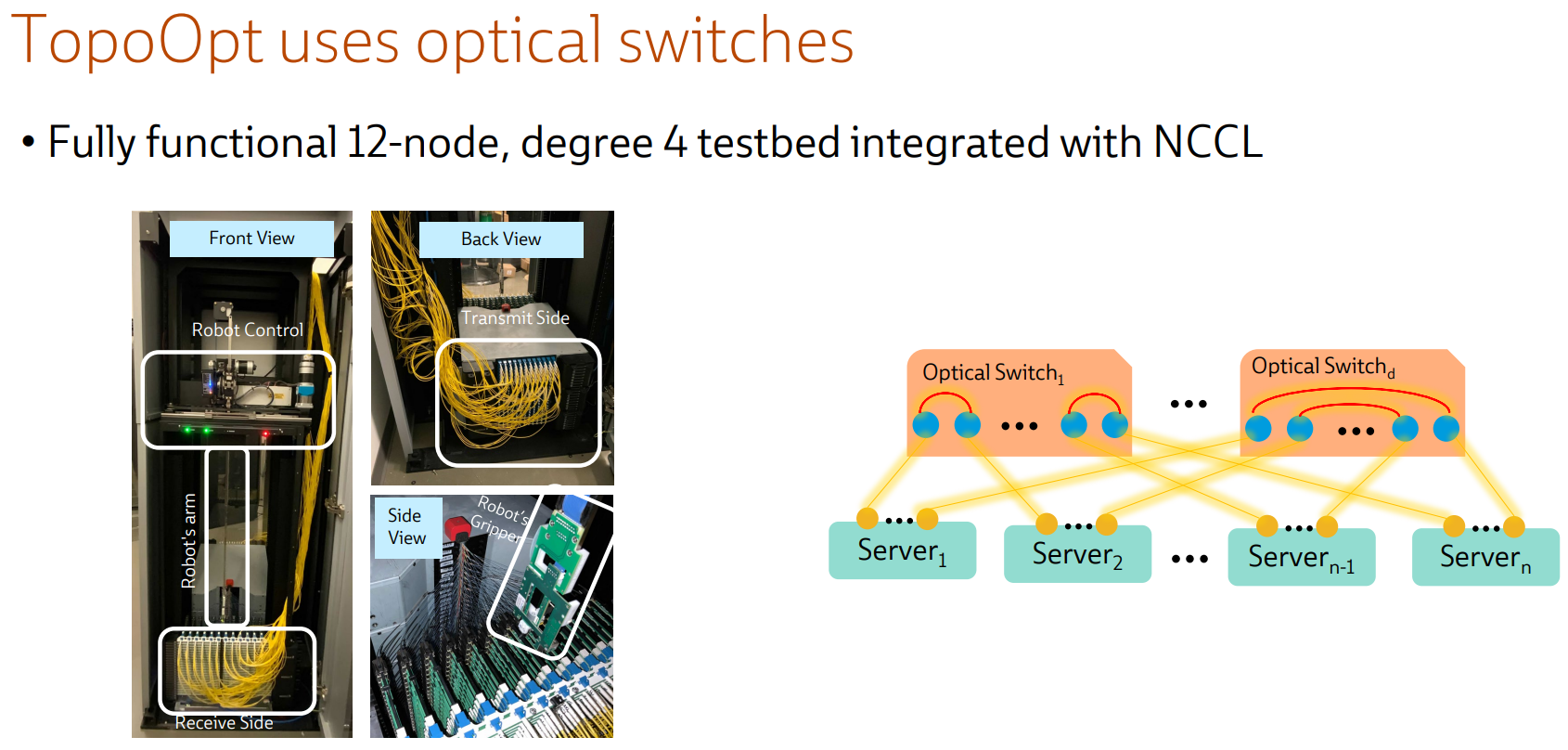
Источник здесь и далее: USENIX Наиболее интересное устройство в эксперименте — оптическая патч-панель Telescent, оснащённая механическим манипулятором, способным производить перекоммутацию на лету. Эта «роборука» работала под управлением специализированного ПО, целью которого ставилось нахождение оптимальной сетевой топологии и сегментации сети применительно к различным задачам машинного обучения. 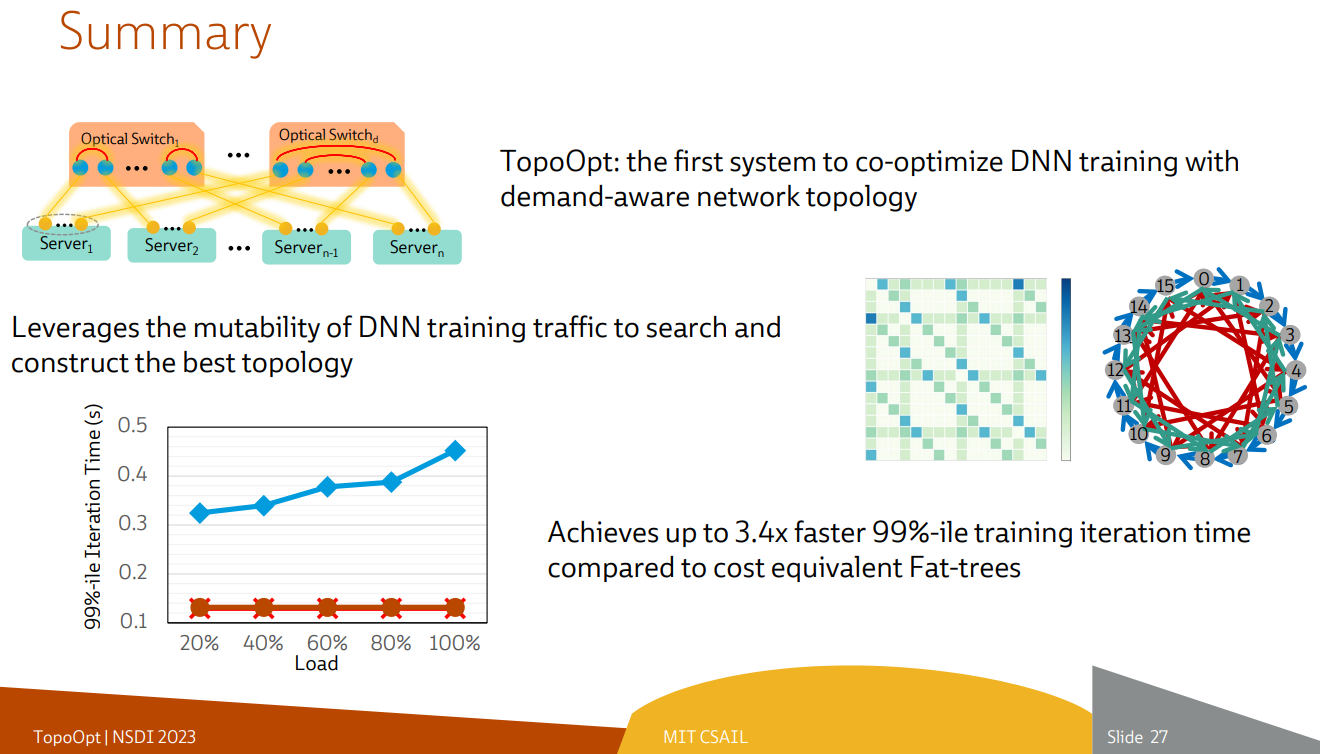
Система с перекоммутируемой оптической сетью не требует энергоёмких высокоскоростных коммутаторов и обеспечивает ряд других преимуществ Такая роботизированная патч-панель не столь расторопна, как оптические коммутаторы Google с микрозеркальной механикой, но стоит впятеро дешевле и имеет больше портов. Опубликованные экспериментальные данные уверенно свидетельствуют о том, что топология «толстого дерева» (fat tree), использующая несколько слоёв коммутаторов, не оптимальна и даже избыточна для ряда нейросетевых задач. К тому же перекоммутируемая оптическая сеть без традиционных высокоскоростных коммутаторов требует меньше оборудования, а значит, может быть не только быстрее сети fat tree в ряде ИИ-задач, но и существенно дешевле в развёртывании и поддержании в рабочем состоянии — как минимум за счёт отсутствия затрат на питание множества коммутаторов. |
|