Материалы по тегу: h200
|
19.08.2024 [10:10], Сергей Карасёв
Gigabyte представила ИИ-серверы с ускорителями NVIDIA H200 и процессорами AMD и IntelКомпания Gigabyte анонсировала HGX-серверы G593-SD1-AAX3 и G593-ZD1-AAX3, предназначенные для задач ИИ и НРС. Устройства, выполненные в форм-факторе 5U, включают до восьми ускорителей NVIDIA H200. При этом используется воздушное охлаждение. 
Источник изображений: Gigabyte Модель G593-SD1-AAX3 рассчитана на два процессора Intel Xeon Emerald Rapids с показателем TDP до 350 Вт, а версия G593-ZD1-AAX3 располагает двумя сокетами для чипов AMD EPYC Genoa с TDP до 300 Вт. Доступны соответственно 32 и 24 слота для модулей оперативной памяти DDR5.  Серверы наделены восемью фронтальными отсеками для SFF-накопителей NVMe/SATA/SAS-4, двумя сетевыми портами 10GbE на основе разъёмов RJ-45 (выведены на лицевую панель) и выделенным портом управления 1GbE (находится сзади). Есть четыре слота FHHL PCIe 5.0 x16 и восемь разъёмов LP PCIe 5.0 x16. Модель на платформе AMD дополнительно располагает двумя коннекторами М.2 для SSD с интерфейсом PCIe 3.0 x4 и x1.  Питание у обоих серверов обеспечивают шесть блоков мощностью 3000 Вт с сертификатом 80 Plus Titanium. Габариты новинок составляют 447 × 219,7 × 945 мм. Диапазон рабочих температур — от +10 до +35 °C. Есть два порта USB 3.2 Gen1 и разъём D-Sub. Массовое производство серверов Gigabyte серии G593 запланировано на II половину 2024 года. Эти системы станут временной заменой (G)B200-серверов, выпуск которых задерживается.
15.07.2024 [09:23], Владимир Мироненко
HPE построит самый мощный в Японии ИИ-суперкомпьютер ABCI 3.0 на базе NVIDIA H200Японский национальный институт передовых промышленных наук и технологий (AIST) объявил о планах по строительству в Касива (Kashiwa, префектура Тиба) нового суперкомпьютера AI Bridging Cloud Infrastructure 3.0 (ABCI 3.0), представляющего собой очередное обновление ИИ-платформы ABCI, запущенной в 2018 году. Новый суперкомпьютер будет предлагаться в качестве облачного сервиса как государственным, так и частным организациям страны, сообщается в блоге NVIDIA. В качестве подрядчика выступает HPE, которая построит систему с использованием платформы Cray XD с ускорителями NVIDIA H200, объединённых 200G-интерконнектом NVIDIA Quantum-2 InfiniBand. HPE не стала раскрывать подробности об общем количестве узлов, стоимости системы и сроках её ввода в эксплуатацию. Как полагает ресурс The Register, речь идёт о системе с 5U-узлами Cray XD670, способными вместить восемь ускорителей NVIDIA H200/H100 и пару Intel Xeon Emerald Rapids. Кроме того, готовится машина ABCI-Q на базе ускорителей NVIDIA H100, ориентированная на исследования в области квантовых и гибридных вычислений. 
Источник изображения: AIST HPE сообщила, что ABCI 3.0, как ожидается, станет самым быстрым ИИ-суперкомпьютером в Японии — примерно 6,2 Эфлопс (FP16?) или 410 Пфлопс (FP64). Проект ABCI 3.0 реализуется при поддержке Министерства экономики, торговли и промышленности Японии (METI) с целью укрепления вычислительных ресурсов страны через Фонд экономической безопасности. Это часть более широкой инициативы METI стоимостью $1 млрд, которая включает в себя как программу ABCI, так и инвестиции в облачные вычисления на базе ИИ.
03.07.2024 [08:32], Владимир Мироненко
Крупный европейский криптомайнер Northern Data обдумывает вывод на биржу подразделений ЦОД и ИИКомпания Northern Data, деятельность которой связана с майнингом криптовалюты, предоставлением услуг высокопроизводительных вычислений (HPC) и ИИ, обдумывает возможность проведения IPO подразделений Taiga и Ardent, предоставляющих услуги облачных вычислений и ЦОД соответственно, пишет Bloomberg. По данным источников Bloomberg, IPO может состояться на площадке Nasdaq. В настоящее время компания ведёт переговоры с банками для проведения публичного размещения акций. По оценкам банков, капитализация этих подразделений может составить $10–$16 млрд. Как и многие компании, занимающиеся майнингом криптовалют, Northern Data рассматривает HPC и ИИ как прибыльное дополнение к своей основной деятельности. В прошлом году Northern Data разделила свой бизнес на три подразделения — Arden, Taiga и Peak Mining, сосредоточив в последнем все операции по майнингу криптовалют. Согласно информации на сайте компании, у неё имеется 11 дата-центров. Peak Mining, американское подразделение компании по майнингу биткоинов, строит и разрабатывает дата-центры суммарной ёмкостью почти 700 МВт, что в случае реализации всех планов сделает его одним из крупнейших майнеров криптовалюты в США. Taiga уже владеет 24,5 тыс. ускорителей NVIDIA, включая H100, A100 и A6000. Они в основном находятся в трёх ЦОД в Швеции и Норвегии и на 100 % запитаны от «зелёных» источников энергии. В понедельник компания объявила, что первой в Европе приобрела 2 тыс. ускорителей NVIDIA H200, дополненных DPU BlueField-3 и ConnectX-7. Они будут размещены в одном из европейских ЦОД с PUE менее 1,2. Запуск первого кластера намечен на IV квартал, а его производительность составит порядка 32 Пфлопс (точность вычислений не указана). Пиковая теоретическая FP64-производительность такого количества ускорителей H200 составляет 68 Пфлопс. 
Источник изображения: Northern Data В свою очередь Ardent занимается дизайном и строительством высокоплотных ЦОД, ориентированных на HPC- и ИИ-нагрузки. Компания использует СЖО, а заявленный уровень PUE не превышает 1,15. При этом Ardent обещает 100 % доступность своих площадок. Как сообщается, Northern Data в ноябре получила кредитное финансирование на сумму €575 млн от компании Tether Group, занимающейся стейблкоинами, а в январе завершила приобретение у Tether компании Damoon за €400 млн, рассчитавшись с помощью облигаций, конвертируемых в акции, выпущенные Northern Data AG. В результате Tether стала основным инвестором Northern Data. Полученные средства Northern Data использует для закупок самых востребованных чипов NVIDIA. Благодаря этому к концу лета компанией будет развёрнуто около 20 тыс. NVIDIA H100.
20.06.2024 [14:54], Владимир Мироненко
HPE и NVIDIA представили совместные решения для ускорения внедрения ИИHewlett Packard Enterprise (HPE) и NVIDIA представили платформу NVIDIA AI Computing by HPE — портфель совместно разработанных решений для ускорения внедрения генеративного ИИ. Ключевым в портфеле является предложение HPE Private Cloud AI. Как указано в пресс-релизе, это первое в своём роде комплексное решение, которое обеспечивает самую глубокую на сегодняшний день интеграцию вычислительных технологий, сетей и ПО NVIDIA с хранилищем, вычислительными ресурсами и облачной платформой HPE GreenLake. Решение предоставляет предприятиям любого размера возможность быстрой и эффективной разработки и развёртывания приложений генеративного ИИ. Решение HPE Private Cloud AI с новой функцией OpsRamp AI Copilot, которая позволяет повысить эффективность ИТ-операций и обработки рабочих нагрузок, включает в себя облачную среду самообслуживания с полным управлением жизненным циклом. Оно доступно в четырёх конфигурациях (Small, Medium, Large и Extra Large) для поддержки рабочих нагрузок ИИ различной сложности. 
Источник изображения: SiliconANGLE HPE Private Cloud AI также поддерживает инференс, точную настройку моделей и их дообучение посредством RAG с использованием собственных данных. Решение сочетает в себе средства контроля конфиденциальности, безопасности, прозрачности и управления данными, в том числе средства ITOps и AIOps. AIOps использует машинное обучение и анализ данных для автоматизации и улучшения ИТ-операций. ITOps включает в себя ряд инструментов, обеспечивающих бесперебойное функционирование ИТ-инфраструктуры организации. 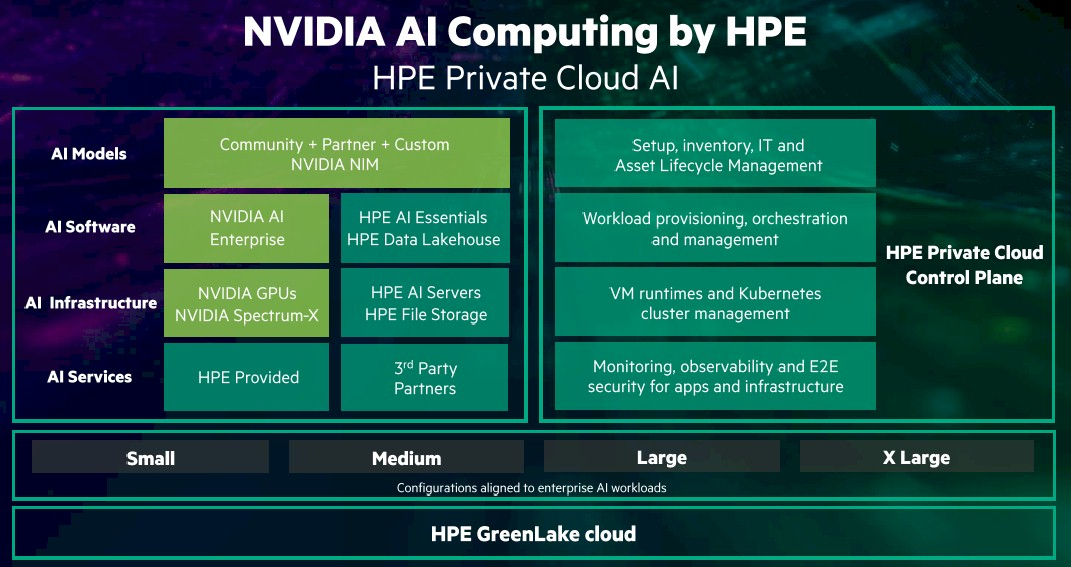
Источник изображения: The Next Platform Конфигурация HPE Private Cloud AI Small, предназначенная для инференса, включает от четырёх до восьми ускорителей NVIDIA L40S, до 248 Тбайт дискового пространства и 100GbE-подключение в стойке мощностью 8 кВт. Конфигурация Medium, предназначенная для инференса и RAG, включает до 16 ускорителей NVIDIA L40S, до 390 Тбайт дискового пространства и 200GbE-подключение в стойке мощностью 17,7 кВт. 
Источник изображения: The Next Platform Конфигурации Large и Extra Large предлагают дополнительные возможности по обработке нагрузок ИИ и ML, а также тонкой настройке ИИ-модели. Конфигурация Large включает до 32 ускорителей NVIDIA H100 NVL, до 1,1 Пбайта дискового пространства и 400GbE-интерконнект в двух стойках мощностью 25 кВт каждая. В свою очередь, конфигурация Extra Large включает до 24 ускорителей NVIDIA GH200 NVL2, до 1,1 Пбайта дискового пространства и 800GbE-интeрконнект в двух стойках мощностью 25 кВт каждая. Стойки могут управляться клиентом самостоятельно или обслуживаться HPE. Каждая конфигурация может работать как автономное локальное решение ИИ или в составе гибридного облака. Используется программная платформа NVIDIA AI Enterprise, включающая микросервисы инференса NIM. Её дополняет ПО HPE AI Essentials. Кроме того, поддержку новых ускорителей NVIDIA получили три аппаратные платформы:
HPE также объявила, что её облачная платформа HPE GreenLake for File Storage прошла сертификацию Nvidia DGX BasePOD и валидацию хранилища NVIDIA OVX, HPE Private Cloud AI, а также анонсированное оборудование будут доступны этой осенью за исключением платформы Cray XD670 на базе NVIDIA H200 NVL, который поступит в продажу этим летом. А после станут доступны и решения на базе Blackwell.
17.06.2024 [22:49], Илья Коваль
Три квантовых компьютера, NVIDIA DGX Quantum, немножко HPC и облако: в Израиле открыт уникальный центр квантовых вычислений IQCC
aws
gh200
grace
hardware
hpc
nvidia
quantum machines
израиль
квантовые вычисления
квантовый компьютер
облако
разработка
Стартап Quantum Machines, разработчик систем управления квантовыми компьютерами, открыл Израильский центр квантовых вычислений (Israeli Quantum Computing Center, IQCC). Площадка, создание которой было частично профинансировано правительством страны, располагается в Тель-Авивском университете. По словам основателей, это первый в мире центр, располагающий квантовыми компьютерами разных типов, которые интегрированы с системой NVIDIA DGX Quantum, HPC-инфраструктурой и облаком. 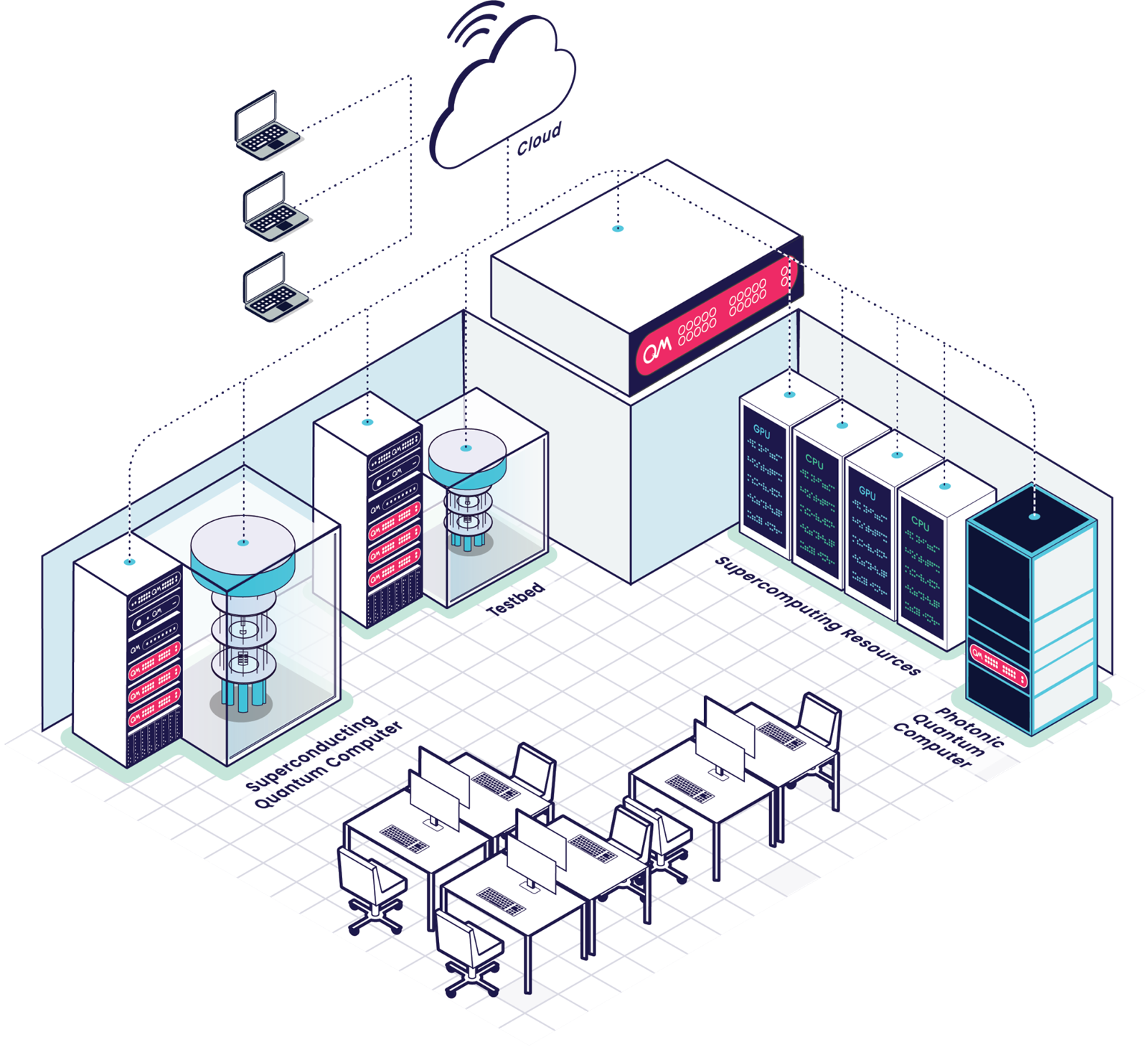
Источник изображений: Quantum Machines Приоритетный доступ со скидкой получат исследовательские организации Израиля, но в целом центр будет открыт для компаний со всего света. Как говорят создатели, IQCC — это лучший в мире полигон для создания новых технологий в области квантовых вычислений, а открытая архитектура площадки позволяет регулярно проводить обновления и упрощает дальнейшее масштабирование возможностей и вычислительных мощностей. Сейчас в IQCC установлены 21-кубитный компьютер Galilee от Quantware на сверхпроводящих кубитах (ещё один такой же используется в качестве тестовой платформы) и фотонный компьютер Negev от ORCA (8 кумод). Системы управляются контроллерами OPX1000 от самой Quantum Machines. HPC-инфраструктура представлена DGX A100, четырьмя GH200 и 128 vCPU на базе AMD EPYC 9334 (Genoa). Дополнительные ресурсы можно арендовать в облаке AWS.  Для Galilee и Negev доступна интеграция с DGX Quantum, платформой для гибридных квантово-классических вычислений, которая была создана NVIDIA и Quantum Machines и впервые в мире развёрнута именно в IQCC. Управлять компьютерами и разрабатывать ПО можно с использованием Qiskit, QUA, OpenQASM3, QBridge, а также Classiq. К системе организован облачный доступ. В ближайшие месяцы в IQCC будут развёрнуты ещё несколько квантовых компьютеров и QPU.
16.06.2024 [16:25], Сергей Карасёв
Холодный приём: новый национальный суперкомпьютер Норвегии разместят в руднике и охладят водой из фьордаВласти Норвегии, по сообщению ресурса HPC Wire, подписали контракт стоимостью Kr225 млн ($21 млн) с корпорацией HPE, предусматривающий создание нового национального суперкомпьютера A2 (постоянное имя системе дадут позже). Он станет самым мощным в истории страны и значительно ускорит исследования и разработки в различных областях, в том числе в сфере ИИ. За закупку и эксплуатацию НРС-систем в Норвегии отвечает государственная компания Sigma2 AS. Вычислительные услуги предоставляются в сотрудничестве с университетами Бергена, Осло, Тромсё, а также Норвежским университетом естественных и технических наук (NTNU) в рамках проекта NRIS. В основу нового суперкомпьютера ляжет платформа HPE Cray EX4000. Известно, что в состав комплекса войдут 76 узлов с четырьмя гибридными суперчипами NVIDIA GH200 (всего 304 ускорителя), 252 узла с двумя 128-ядерными AMD EPYC Turin (64 512 ядер) и 5,3-Пбайт хранилище HPE Cray ClusterStor E1000. Узлы объединит интерконнект HPE Slingshot. Ожидаемая производительность системы составит порядка 10 Пфлопс. 
Источник изображения: Sigma2 Монтаж системы планируется выполнить в течение весны–лета 2025 года. Машина расположится в дата-центре Лефдаль (Lefdal Mine Datacenter, LMD), развёрнутом на базе бывшего рудника. Этот объект имеет большую площадь и предоставляет гибкие возможности в плане масштабирования. Новый суперкомпьютер HPE станет первой национальной высокопроизводительной системой, установленной в этом ЦОД. 
Источник изображения: Sigma2 Несмотря на то, что готовящийся комплекс будет значительно мощнее высокопроизводительных вычислительных систем Sigma2 предыдущего поколения, его энергопотребление окажется меньше примерно на 30 %. Для охлаждения будет использоваться холодная вода из близлежащего фьорда. Нагретая вода затем может быть направлена на нужды местных предприятий, в том числе, например, рыбных ферм. Ожидается, что суперкомпьютер сможет удовлетворить потребности Норвегии в НРС-ресурсах в течение следующих пяти лет. Он будет доступен исследователям по всей стране. В дальнейшем суперкомпьютер может дополнительно получить 119 808 CPU-ядер и/или 224 ускорителя. В целом же Норвегия рассчитывает, что современные ЦОД станут для страны «новой нефтью».
12.06.2024 [18:00], Владимир Мироненко
Уже рутина: NVIDIA снова улучшила результаты в ИИ-бенчмарке MLPerf TrainingВычислительные платформы NVIDIA снова продемонстрировали высокую производительность, на этот раз в свежих тестах MLPerf Training v4.0. Так, суперкомпьютер NVIDIA EOS-DFW более чем утроил свою производительность в LLM-тесте на базе GPT-3 175B по сравнению с прошлогодним результатом. Как сообщается, 11 616 ускорителей NVIDIA H100, объединённых 400G-интерконнектом NVIDIA Quantum-2 InfiniBand, позволили суперкомпьютеру EOS достичь столь значительного результата благодаря более масштабному и комплексному подходу к проектированию системы. А это позволяет более эффективно обучать и запускать крупные модели, экономя время и ресурсы, говорит компания. А более современный ускоритель H200 с улучшенной подсистемой памяти в MLPerf Training быстрее H100 на 14 %, а в GNN-тестах (RGAT) узлы с H200 оказались быстрее узлов с H100 сразу на 47 %. 
Источник изображений: NVIDIA По словам компании, поставщики услуг LLM могут всего за четыре года, инвестировав $1, получить $7, используя модель Llama 3 70B на серверах на базе NVIDIA HGX H200, если исходить из того, что обслуживание обходится в $0,60 за миллион токенов, а пропускная способность HGX H200 составляет 24 тыс. токенов в секунду. 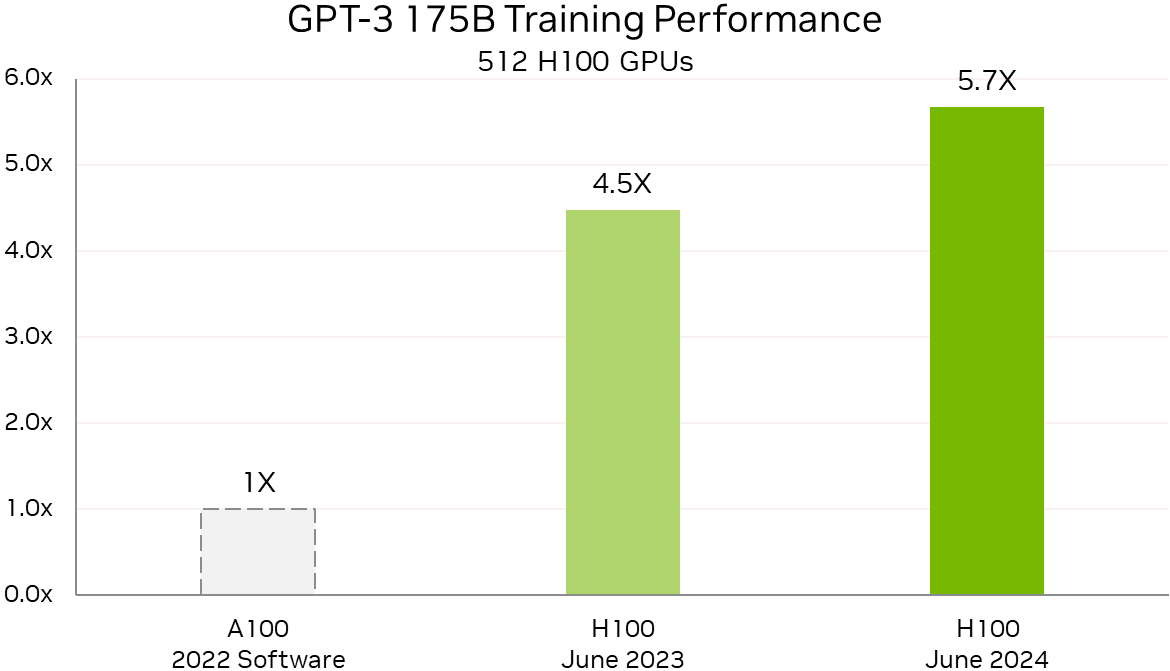 Росту производительности также способствовало совершенствование и оптимизация ПО. Так, кластер из 512 чипов H100 за год стал на 27 % быстрее, а рост производительности с увеличением количества ускорителей теперь более линеен. В новом тесте MLPerf Training по тюнингу LLM (LoRA применительно к Meta✴ Llama 2 70B) системы NVIDIA показали эффективное масштабирование при количестве ускорителей от 8 до 1024. NVIDIA также увеличила производительность обучения Stable Diffusion v2 почти на 80 % при тех же масштабах систем, что были представлены в прошлом тестировании. 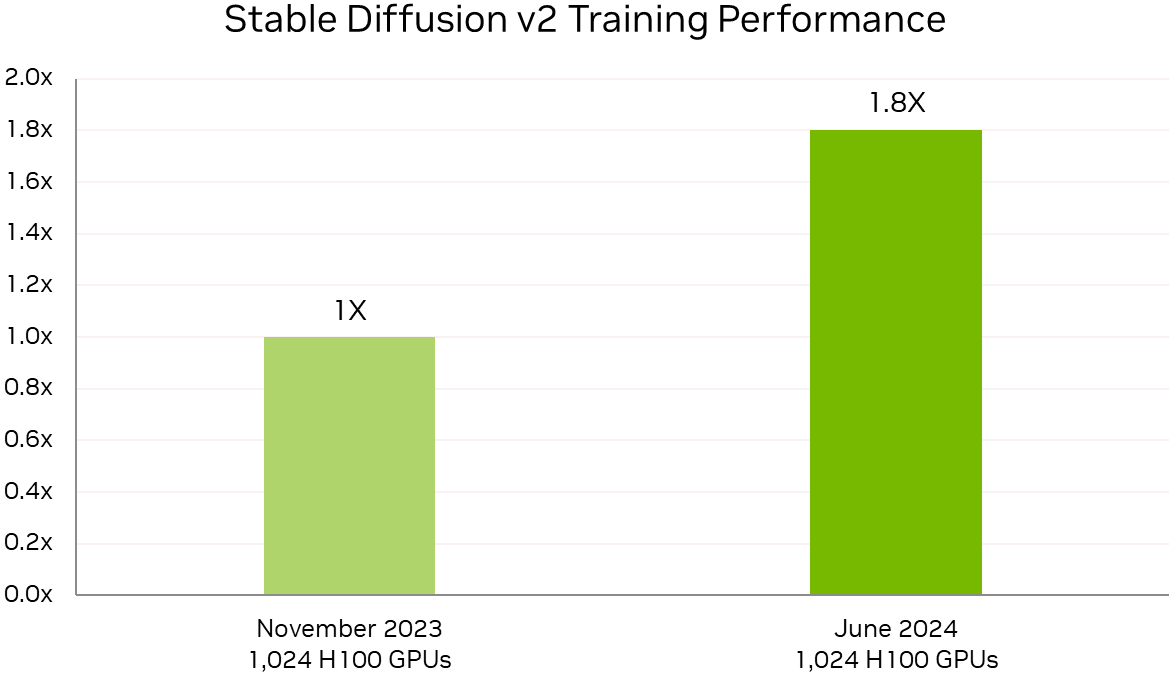 NVIDIA отметила, что для компаний, запускающих приложения на базе LLM, высокая производительность имеет большое значение. Возможность обучать и настраивать более мощные модели — и быстрее их развёртывать и запускать — позволит получить лучшие результаты и более высокий доход. А с выходом платформы NVIDIA Blackwell скоро появится возможность как обучения, так и инференса моделей генеративного ИИ с триллионом параметров.
13.05.2024 [11:12], Сергей Карасёв
Supermicro представила ИИ-серверы на базе Intel Gaudi3 и AMD Instinct MI300XКомпания Supermicro анонсировала новые серверы для задач ИИ и НРС. Дебютировали системы высокой плотности с жидкостным охлаждением, а также устройства, оборудованные высокопроизводительными ускорителями AMD, Intel и NVIDIA. 
Источник изображений: Supermicro В частности, представлены серверы SYS-421GE-TNHR2-LCC и AS-4125GS-TNHR2-LCC в форм-факторе 4U, оснащённые СЖО. Первая из этих моделей рассчитана на установку двух процессоров Intel Xeon Emerald Rapids или Xeon Sapphire Rapids (до 385 Вт), а также 32 модулей DDR5-5600. Второй сервер поддерживает два чипа AMD EPYC 9004 Genoa с показателем TDP до 400 Вт и 24 модуля DDR5-4800.  Обе новинки могут быть оборудованы восемью ускорителями NVIDIA H100 (SXM). В одной стойке могут размещаться до восьми серверов, что в сумме даст 64 ускорителя. При этом общая заявленная производительность такого кластера на операциях FP16 превышает 126 Пфлопс. Серверы оборудованы восемью фронтальными отсеками для SFF-накопителей NVMe. Питание обеспечивают четыре блока мощностью 5250 Вт с сертификатом Titanium. Слоты расширения выполнены по схеме 8 × PCIe 5.0 x16 LP и 2 × PCIe 5.0 x16 FHHL.  На ISC 2024 компания Supermicro также демонстрирует сервер типоразмера 8U, оборудованный ускорителями Intel Gaudi3. Это одна из первых систем такого рода. Кроме того, представлена система AS-8125GS-TNMR2 формата 8U, рассчитанная на восемь ускорителей AMD Instinct MI300X. Этот сервер может комплектоваться двумя процессорами EPYC 9004 с TDP до 400 Вт, 24 модулями оперативной памяти DDR5-4800, фронтальными накопителями SFF (16 × NVMe и 2 × SATA), двумя модулями M.2 NVMe. Установлены шесть блоков питания на 3000 Вт с сертификатом Titanium.  Наконец, Supermicro готовит серверы формата 4U с жидкостным охлаждением, которые могут оснащаться восемью ускорителями NVIDIA H100 и H200. Компания демонстрирует на конференции ISC 2024 и другие системы для приложений ИИ, а также задач НРС.
13.05.2024 [09:00], Сергей Карасёв
Более 200 Эфлопс для ИИ: NVIDIA представила новые НРС-системы на суперчипах Grace HopperКомпания NVIDIA рассказала о новых высокопроизводительных комплексах на основе суперчипов Grace Hopper для задач ИИ и НРС. Отмечается, что суммарная производительность этих систем превышает 200 Эфлопс. Суперкомпьютеры предназначены для решения самых разных задач — от исследований в области изменений климата до сложных научных проектов. Одним из таких НРС-комплексов является EXA1 — HE, который является совместным проектом Eviden (дочерняя структура Atos) и Комиссариата по атомной и альтернативным видам энергии Франции (СЕА). Система использует 477 вычислительных узлов на базе Grace Hopper, а пиковое быстродействие достигает 104 Пфлопс. Ещё одной системой стал суперкомпьютер Alps в Швейцарском национальном компьютерном центре (CSCS). Он использует в общей сложности 10 тыс. суперчипов Grace Hopper. Заявленная производительность на операциях ИИ достигает 10 Эфлопс, и это самый быстрый ИИ-суперкомпьбтер в Европе. Утверждается, что по энергоэффективности Alps в 10 раз превосходит систему предыдущего поколения Piz Daint. 
Источник изображений: NVIDIA В свою очередь, комплекс Helios, созданный компанией НРЕ для Академического компьютерного центра Cyfronet Научно-технического университета AGH в Кракове (Польша), содержит 440 суперчипов NVIDIA GH200 Grace Hopper. Пиковое быстродействие на ИИ-операциях достигает 1,8 Эфлопс.  В список систем на платформе Grace Hopper также входит Jupiter — первый европейский суперкомпьютер экзафлопсного класса. Комплекс расположится в Юлихском исследовательском центре (FZJ) в Германии. Кроме того, в список вошёл комплекс DeltaAI на основе GH200 Grace Hopper, созданием которого занимается Национальный центр суперкомпьютерных приложений (NCSA) при Университете Иллинойса в Урбане-Шампейне (США).  В числе прочих систем названы суперкомпьютер Miyabi в Объединённом центре передовых высокопроизводительных вычислений в Японии (JCAHPC), Isambard-AI в Бристольском университете в Великобритании (5280 × GH200), а также суперкомпьютер в Техасском центре передовых вычислений при Техасском университете в Остине (США), комплекс Venado в Лос-Аламосской национальной лаборатории США (LANL) и суперкомпьютер Recursion BioHive-2 (504 × H100).
26.04.2024 [11:46], Сергей Карасёв
HPE построила самый мощный в Польше суперкомпьютер Helios производительностью 35 ПфлопсКомпания HPE сообщила о создании нового суперкомпьютера под названием Helios для Академического компьютерного центра Cyfronet Научно-технического университета AGH в Кракове (Польша). Вычислительный комплекс будет использоваться для решения ресурсоёмких задач, связанных с ИИ. На сегодняшний день Helios — самая высокопроизводительная система в Польше. Она обеспечивает теоретическую пиковую производительность на уровне 35 Пфлопс, что более чем в четыре раза превосходит показатель предыдущего флагманского суперкомпьютера Cyfronet. Пиковое быстродействие на ИИ-операциях достигает 1,8 Эфлопс. В основу Helios положены узлы HPE Cray EX. Комплекс состоит из трёх сегментов. Один из них предназначен для традиционных вычислений, еще один — для рабочих нагрузок, связанных с обработкой больших данных. Третий сегмент оптимизирован для ИИ-задач: он использует суперчипы NVIDIA. Суперкомпьютер планируется применять при реализации проектов в области химии, медицины, создания передовых материалов, астрономии и защиты окружающей среды. Раздел общего назначения использует процессоры AMD EPYC поколения Genoa. Общее количество вычислительных ядер Zen 4 составляет 75 264, объём оперативной памяти DDR5 — 200 Тбайт. Сегмент для работы с большими данными основан на платформе HPE Cray Supercomputing XD665 с чипами EPYC Genoa, памятью DDR5-4800, быстрыми накопителями NVMe и ускорителями NVIDIA H100, суммарное количество которых равно 24. 
Источник изображения: HPE Наконец, ИИ-раздел объединяет 440 суперчипов NVIDIA GH200 Grace Hopper для компьютерного моделирования с интенсивным использованием графики, поддержки приложений на основе генеративного ИИ и пр. Все компоненты вычислительного комплекса связаны друг с другом посредством 200G-интерконнекта HPE Slingshot. Комплекс Helios оснащён Lustre-хранилищем общей вместимостью 17,5 Пбайт на базе HPE Cray ClusterStor E1000. |
|