Материалы по тегу: aist
|
21.06.2025 [08:41], Руслан Авдеев
Через 10 лет ИИ-ускорители получат терабайты HBM и будут потреблять 15 кВт — это изменит подход к проектированию, питанию и охлаждению ЦОДИИ-чипы нового поколения не просто будут быстрее — они станут потреблять беспрецедентно много энергии и потребуют кардинально изменить инфраструктуру ЦОД. По данным учёных, к 2035 году энергопотребление ИИ-ускорителей может вырасти до порядка 15 кВт, из-за чего окажется под вопросом способность инфраструктуры современных ЦОД обслуживать их, сообщает Network World. Исследователи лаборатории TeraByte Interconnection and Package Laboratory (TeraLab), подведомственной Корейскому институту передовых технологий (KAIST), подсчитали, что переход к HBM4 состоится в 2026 году, а к 2038 году появится уже HBM8. Каждый этап развития обеспечит повышение производительности, но вместе с ней вырастут и требования к питанию и охлаждению. В лаборатории полагают, что мощность только одного GPU вырастет с 800 Вт до 1200 Вт к 2035 году. В сочетании с 32 стеками HBM, каждый из которых будет потреблять 180 Вт, общая мощность может увеличиться до 15 360 Вт (в таблице ниже дан расчёт для стеков HBM8, а не HBM7 — прим. ред.). Ожидается, что отдельные модули HBM8 обеспечат ёмкость до 240 Гбайт и пропускную способность памяти до 64 Тбайт/с. В рамках ускорителя можно суммарно получить порядка 5–6 Тбайт HBM с ПСП до 1 Пбайт/с. Это приведёт к изменению конструкции самого ускорителя. Ключевым элементом становятся стеки HBM — процессоры, контроллеры и ускорители будут интегрированы в единую подложку с HBM-модулями. Возможен переход к 3D-упаковке с использованием двусторонних интерпозеров-подложек или даже нескольких интерпозеров на разных «этажах» кристаллов. 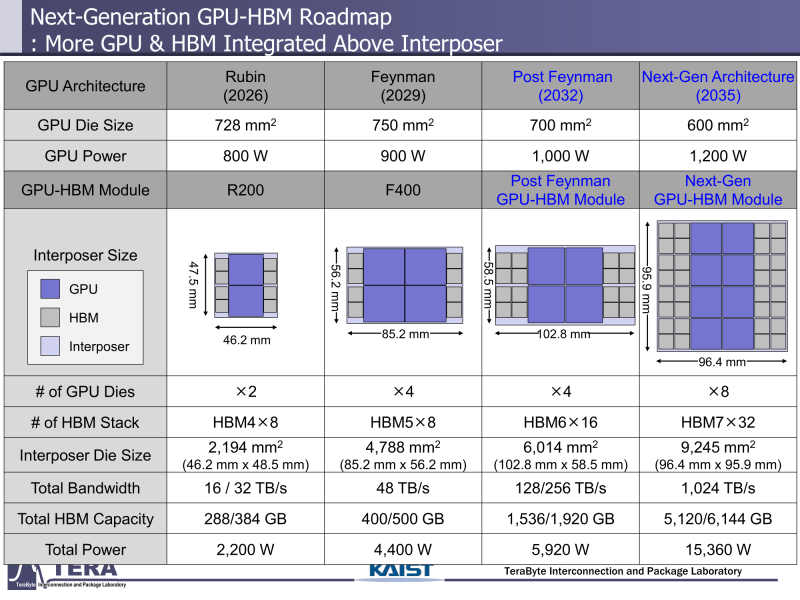
Источник изображений: KAIST Кроме того, для ускорителей придётся разработать и новые системы охлаждения. К уже традиционным прямому жидкостному охлаждению (DLC) и погружным СЖО, вероятно, придётся добавить системы теплоотвода, интегрированные непосредственно в корпуса чипов. Также будут использоваться «жидкостные сквозные соединения» (F-TSVs) для отвода тепла из многослойных чипов, «бесстыковые» соединения Cu–Cu, термодатчики в кристаллах и интеллектуальные системы управления, позволяющие чипам адаптироваться к температурным изменениям. 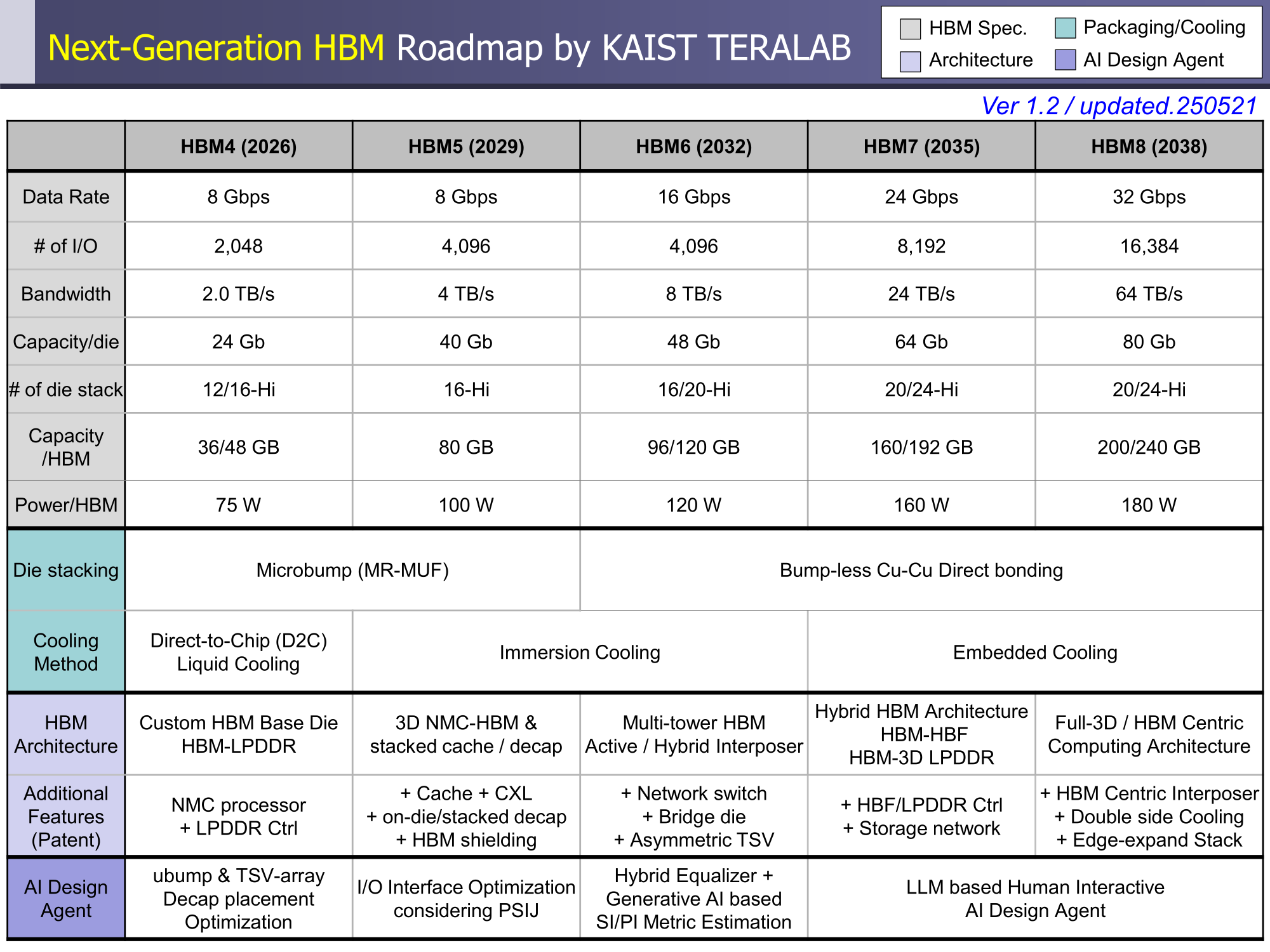 На уровне ЦОД изменится и контур охлаждения, и температурное зонирование всего объекта. В KAIST подчёркивают, что высокую плотность размещения мощностей объекты в большинстве регионов попросту не смогут поддерживать. Пока гиперскейлеры резервируют гигаватты на десятилетия вперёд, региональным коммунальным службам потребуется 7–15 лет на модернизацию ЛЭП. А где-то этого может и не произойти. Так, в Дублине (Ирландия) по-прежнему действует мораторий на строительство новых ЦОД, во Франкфурте-на-Майне похожий запрет действует до 2030 года, а в Сингапуре сегодня доступно всего лишь 7,2 МВт. 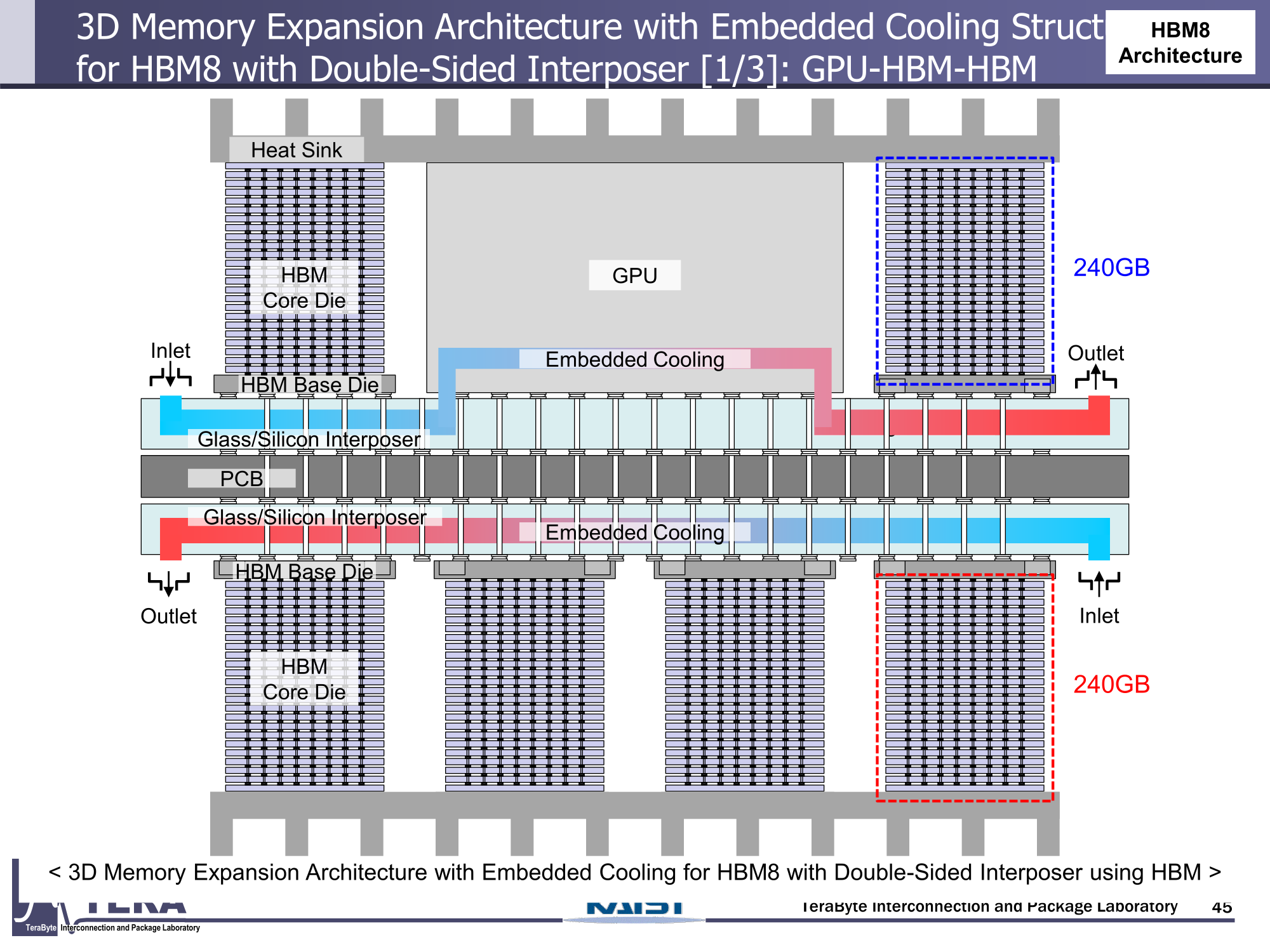 Как считают эксперты, электричество превратилось из одной из статей расходов в определяющий фактор — от его доступности будет зависеть сама возможность реализации ИИ-проектов. На электричество приходится 40-60 % операционных расходов в современной инфраструктуре ИИ, облачной и локальной. Как отмечают в TechInsights, один 15-кВт ускоритель при круглосуточной работе может «съедать» энергии на $20 тыс./год, и это без учёта стоимости охлаждения. 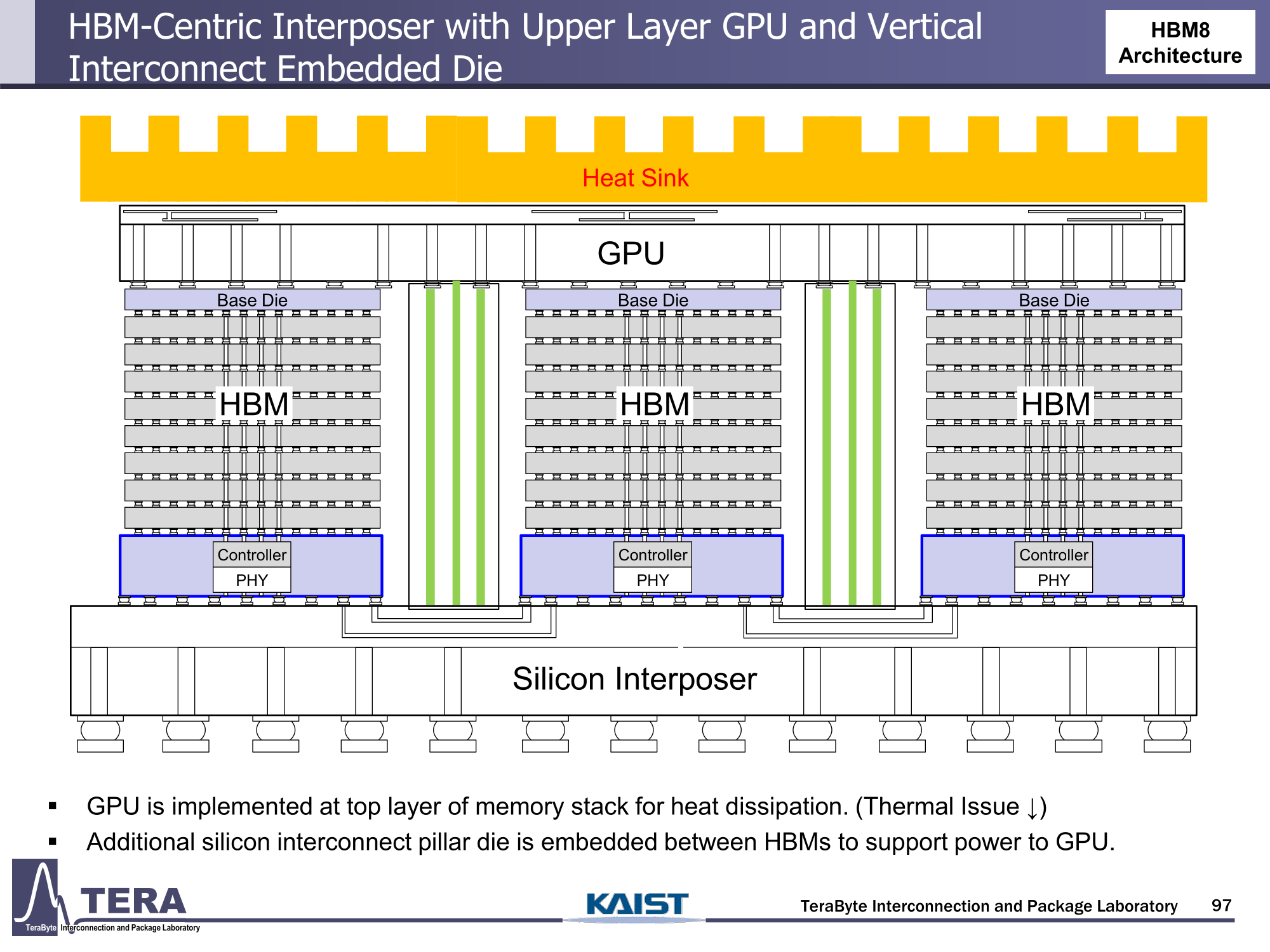 Компании уже вынуждены пересматривать стратегии развёртывания инфраструктуры, учитывая соответствие регуляторным требованиям, региональные тарифы на электроэнергию и др. Гиперскейлеры получают дополнительное преимущество благодаря более низкому PUE, доступу к возобновляемой энергии и оптимизированным схемам закупки энергии. В новой реальности производительность измеряется не только в долларах или флопсах, но и киловаттах. 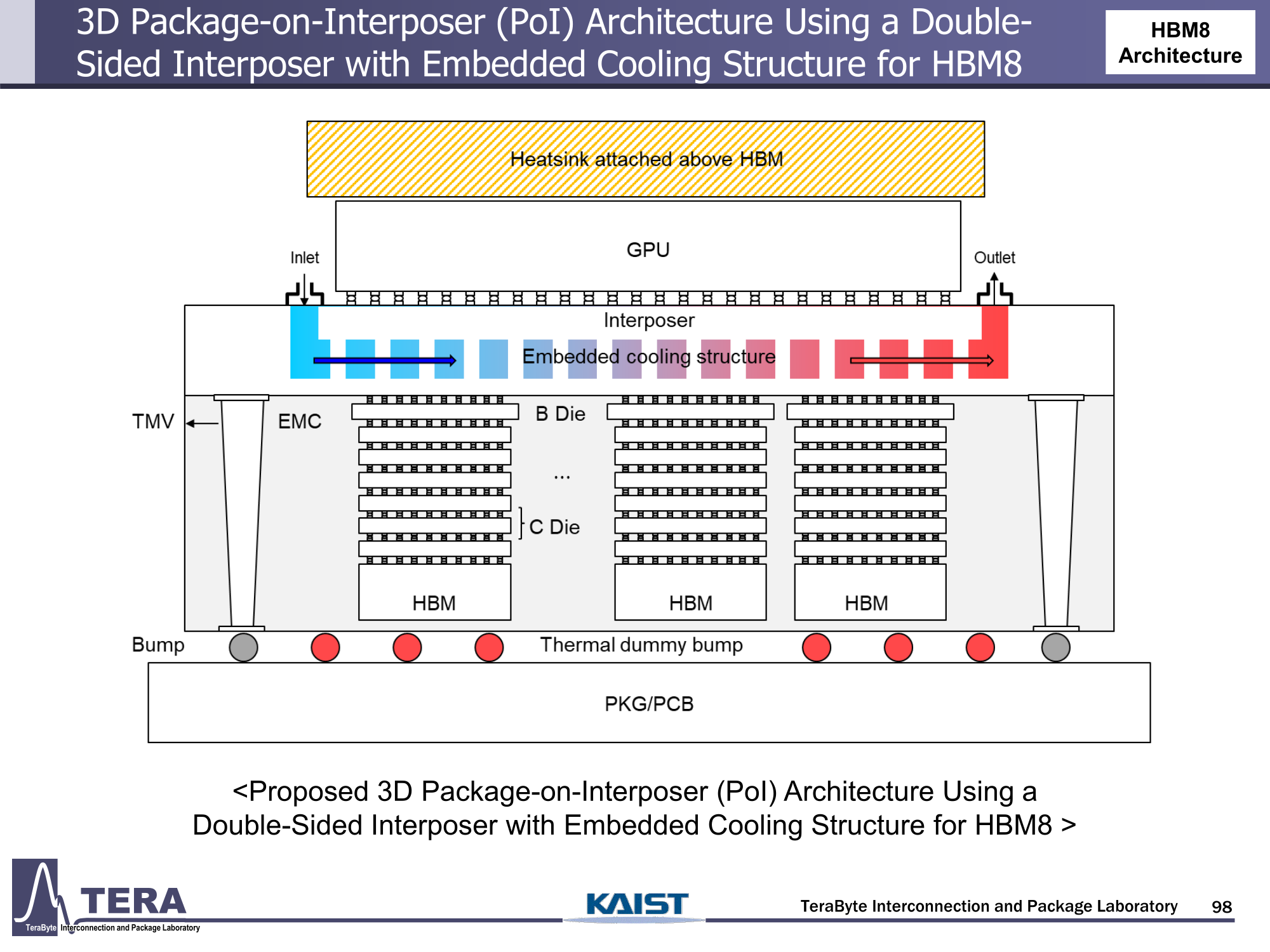 Более того, меняется география рынка ЦОД. Богатые энергией регионы вроде США, Скандинавии или стран Персидского залива привлекают всё больше инвестиций для строительства дата-центров, а регионы со слабыми энергосистемами рискуют превратиться в «ИИ-пустыни», в которых масштабировать мощности невозможно. 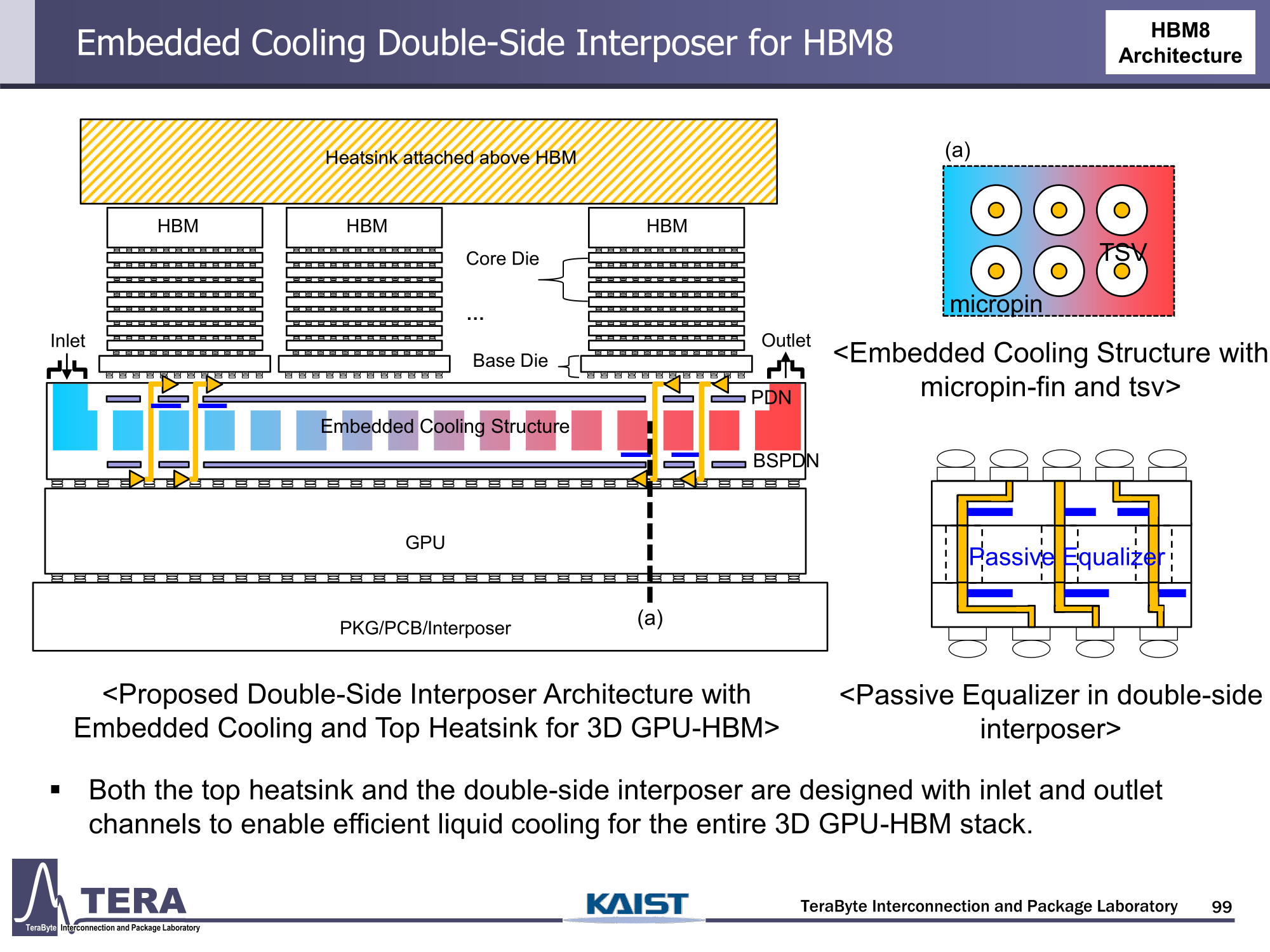 Строителям ИИ-инфраструктуры теперь придётся уделять очень много внимания вопросам энергетики: расходами на электричество, наличие источников энергии, прозрачностью выбросов, близостью ЦОД к электросетям и др. Буквально на днях американский регулятор NERC, отвечающий за надзор за электросетями и сопутствующей инфраструктурой в США, заявил, что подключение к сетям ЦОД в настоящее время весьма рискованно из-за непредсказуемости ЦОД.
15.07.2024 [09:23], Владимир Мироненко
HPE построит самый мощный в Японии ИИ-суперкомпьютер ABCI 3.0 на базе NVIDIA H200Японский национальный институт передовых промышленных наук и технологий (AIST) объявил о планах по строительству в Касива (Kashiwa, префектура Тиба) нового суперкомпьютера AI Bridging Cloud Infrastructure 3.0 (ABCI 3.0), представляющего собой очередное обновление ИИ-платформы ABCI, запущенной в 2018 году. Новый суперкомпьютер будет предлагаться в качестве облачного сервиса как государственным, так и частным организациям страны, сообщается в блоге NVIDIA. В качестве подрядчика выступает HPE, которая построит систему с использованием платформы Cray XD с ускорителями NVIDIA H200, объединённых 200G-интерконнектом NVIDIA Quantum-2 InfiniBand. HPE не стала раскрывать подробности об общем количестве узлов, стоимости системы и сроках её ввода в эксплуатацию. Как полагает ресурс The Register, речь идёт о системе с 5U-узлами Cray XD670, способными вместить восемь ускорителей NVIDIA H200/H100 и пару Intel Xeon Emerald Rapids. Кроме того, готовится машина ABCI-Q на базе ускорителей NVIDIA H100, ориентированная на исследования в области квантовых и гибридных вычислений. 
Источник изображения: AIST HPE сообщила, что ABCI 3.0, как ожидается, станет самым быстрым ИИ-суперкомпьютером в Японии — примерно 6,2 Эфлопс (FP16?) или 410 Пфлопс (FP64). Проект ABCI 3.0 реализуется при поддержке Министерства экономики, торговли и промышленности Японии (METI) с целью укрепления вычислительных ресурсов страны через Фонд экономической безопасности. Это часть более широкой инициативы METI стоимостью $1 млрд, которая включает в себя как программу ABCI, так и инвестиции в облачные вычисления на базе ИИ.
10.03.2024 [21:00], Сергей Карасёв
В Южной Корее создан сверхэффекттивный ИИ-чип, сочетающий классический и нейроморфный подходыИсследователи из Южной Кореи разработали, как утверждается, первый в мире полупроводниковый ИИ-чип, который обладает высоким быстродействием при минимальном энергопотреблении. Изделие, предназначенное для обработки больших языковых моделей (LLM), основано на принципах, имитирующих структуру и функции человеческого мозга. В работе приняли участие специалисты Корейского института передовых технологий (KAIST). Утверждается, что при обработке модели GPT-2 новинка по сравнению с ускорителем NVIDIA A100 затрачивает в 625 раз меньше энергии и занимает в 41 раз меньше физического пространства. Таким образом, южнокорейский ИИ-чип теоретически может применяться даже в смартфонах. Чип производится по 28-нм процессу Samsung Electronics. 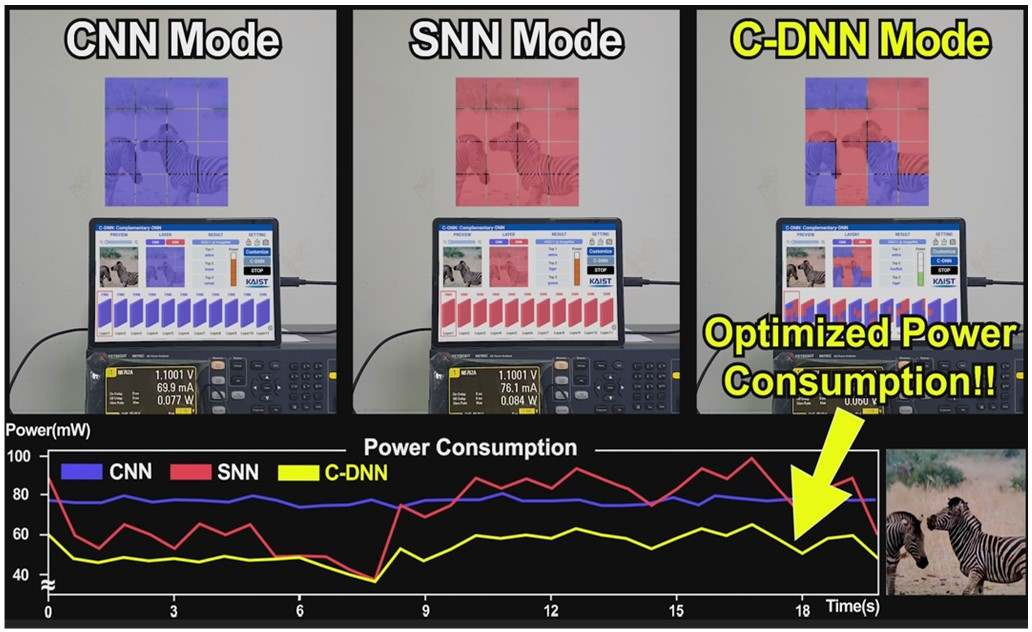
Источник изображений: KAIST Отмечается, что обычно для обработки модели GPT-2 требуются ускорители на базе GPU, потребляющие около 250 Вт энергии. Разработанное изделие требует для этого всего от 40 мВт, а его размеры составляют 4,5 × 4,5 мм. Причём на выполнение операций затрачивается только 0,4 с. Чип наделён 552 Кбайт памяти SRAM. Напряжение питания варьируется от 0,7 до 1,1 В. Тактовая частота варьируется в диапазоне 50–200 МГц. 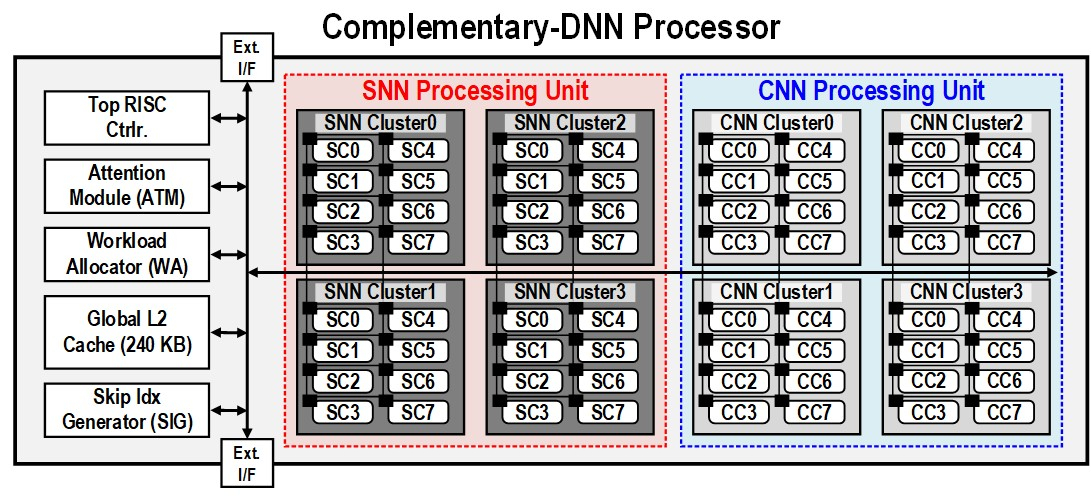 Технология, получившая название C-DNN (Complementary Deep Neural Network) позволяет использовать свёрточные нейронные сети (CNN) и импульсные нейронные сети (SNN), имитирующие процессы, которые задействованы в человеческом мозге при обработке информации. Иными словами, обучение происходит через несколько слоёв нейронных сетей, а потребление энергии варьируется в зависимости от когнитивной нагрузки. Технология минимизирует энергозатраты благодаря использованию DNN для больших входных значений и SNN для меньших. Правда, чип поддерживает максимум INT16. 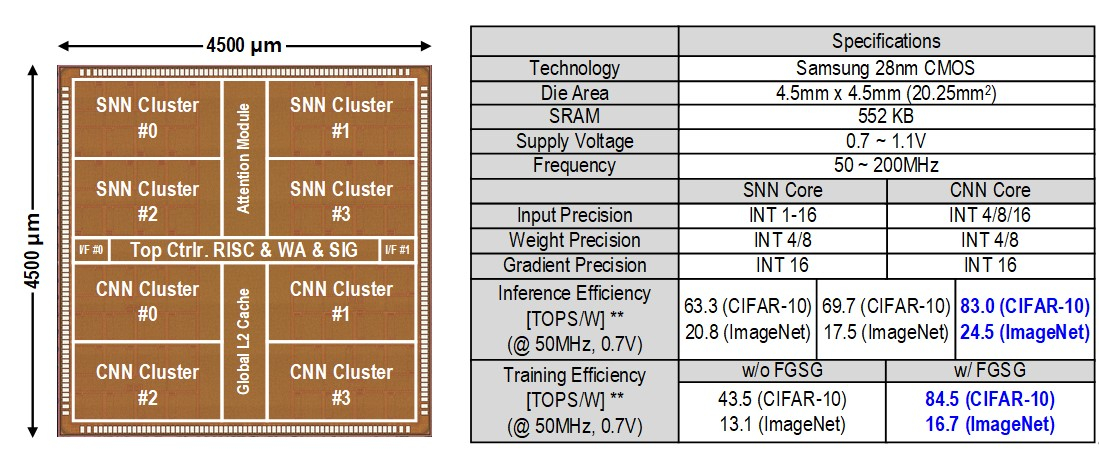 Утверждается, что C-DNN является первым ускорителем, который может поддерживать распределение рабочей нагрузки CNN/SNN, используя компромисс между производительностью и энергопотреблением. Изделие обеспечивает энергоэффективность на уровне 85,8 TOPS/Вт и 79,9 TOPS/Вт для инференса с наборами данных CIFAR-10 и CIFAR-100 соответственно (VGG-16). Энергоэффективность в случае ResNet-50 составляет 24,5 TOPS/Вт. При обучении чип C-DNN демонстрирует энергоэффективность в 84,5 TOPS/Вт и 16,7 TOPS/Вт для CIFAR-10 и ImageNet соответственно. Результаты получены при напряжении 0,7 В и частоте 50 МГц. 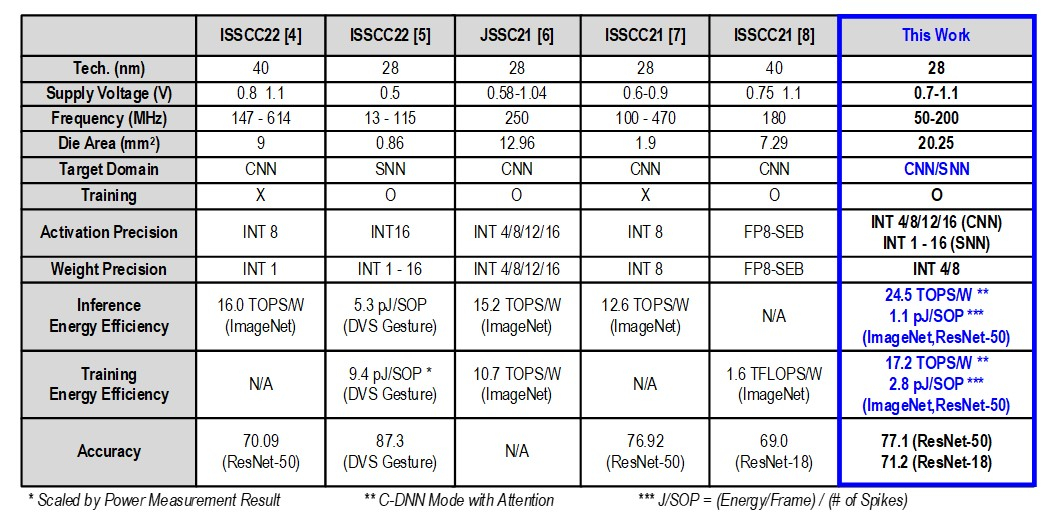 «Нейроморфные вычисления, имитирующие функции мозга, — это технология, которую такие крупные компании, как IBM и Intel, пока по-настоящему не реализовали. Мы гордимся тем, что первыми в мире начали использовать LLM со сверхэффективным нейроморфным ускорением», — говорит руководитель проекта профессора Ю Хой-Джун (Yu Hoi-jun).
16.07.2021 [17:31], Алексей Степин
Японский облачный суперкомпьютер ABCI подвергся модернизацииПопулярность идей машинного обучения и искусственного интеллекта приводит к тому, что многие страны и организации планируют обзавестись HPC-системами, специально предназначенными для этого класса задач. В частности, Токийский университет совместно с Fujitsu модернизировал существующую систему ABCI (AI Bridging Cloud Infrastructure), снабдив её новейшими процессорами Intel Xeon и ускорителями NVIDIA. Как правило, когда речь заходит о суперкомпьютерах Fujitsu, вспоминаются уникальные наработки компании в сфере HPC — процессоры A64FX, но ABCI имеет более традиционную гетерогенную архитектуру. Изначально этот облачный суперкомпьютер включал в себя вычислительные узлы на базе Xeon Gold и ускорителей NVIDIA V100, объединённых 200-Гбит/с интерконнектом. В качестве файловой системы применена разработка IBM — Spectrum Scale. Это одна систем, специально созданных для решения задач искусственного интеллекта, при этом доступная независимым исследователям и коммерческим компаниям. 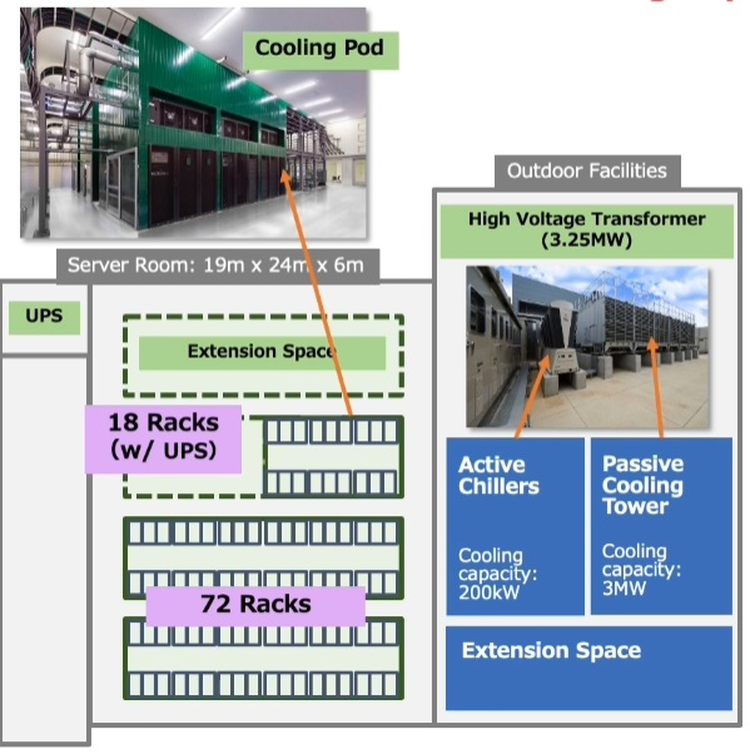 Так, 86% пользователей ABCI не входят в состав Японского национального института передовых технических наук (AIST); их число составляет примерно 2500. Но система явно нуждалась в модернизации. Как отметил глава AIST, с 2019 года загруженность ABCI выросла вчетверо, и сейчас на ней запущено 360 проектов, 60% из которых от внешних заказчиков. Сценарии использования самые разнообразные, от распознавания видео до обработки естественных языков и поиска новых лекарств. 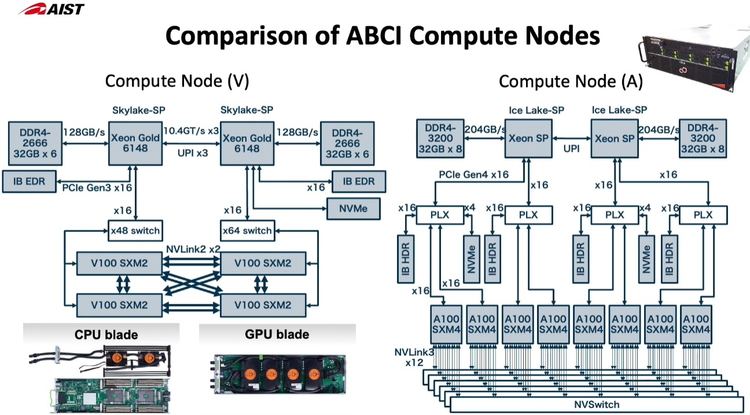
Новые узлы ABCI 2.0 заметно отличаются по архитектуре от старых Как и в большей части систем, ориентированных на машинное обучение, упор при модернизации ABCI был сделан на вычислительную производительность в специфических форматах, включая FP32 и BF16. Изначально в состав ABCI входило 1088 узлов, каждый с четырьмя ускорителями V100 формата SXM2 и двумя процессорами Xeon Gold 6148. После модернизации к ним добавилось 120 узлов на базе пары Xeon Ice Lake-SP и восьми ускорителей A100 формата SXM4. Здесь вместо InfiniBand EDR используется уже InfiniBand HDR. 
Стойка с новыми вычислительными узлами ABCI 2.0 Согласно предварительным ожиданиям, производительность обновлённого суперкомпьютера должна вырасти практически в два раза на задачах вроде ResNet50, в остальных случаях заявлен прирост производительности от полутора до трёх раз. На вычислениях половинной точности речь идёт о цифре свыше 850 Пфлопс, что вплотную приближает ABCI к системам экза-класса. Разработчики также надеются повысить энергоэффективность системы путём применения специфических ускорителей, включая ASIC, но пока речь идёт о связке Intel + NVIDIA. ABCI и сейчас можно назвать экономичной системой — при максимальной общей мощности комплекса 3,25 МВт сам суперкомпьютер при полной нагрузке потребляет лишь 2,3 МВт. Поскольку система ориентирована на предоставление вычислительных услуг сторонним заказчикам, модернизировано и системное ПО, в котором упор сместился в сторону контейнеризации. |
|