Материалы по тегу: бенчмарк
|
13.10.2025 [00:30], Владимир Мироненко
Вложи $5 млн — получи $75 млн: NVIDIA похвасталась новыми рекордами в комплексном бенчмарке InferenceMAX v1
b200
gb200
hardware
nvidia
open source
semianalysis
бенчмарк
ии
инференс
рекорд
финансы
энергоэффективность
NVIDIA сообщила о результатах, показанных суперускорителем GB200 NVL72, в новом независимом ИИ-бенчмарке InferenceMAX v1 от SemiAnalysis. InferenceMAX оценивает реальные затраты на ИИ-вычисления, определяя совокупную стоимость владения (TCO) в долларах на миллион токенов для различных сценариев, включая покупку и владение GPU в сравнении с их арендой. InferenceMAX опирается на инференс популярных моделей на ведущих платформах, измеряя его производительность для широкого спектра вариантов использования, а результаты может перепроверить любой желающий, говорят авторы бенчмарка. Суперускоритель GB200 NVL72 победил во всех категориях бенчмарка InferenceMAX v1. Чипы NVIDIA Blackwell показали наилучшую окупаемость инвестиций — вложение в размере $5 млн приносят $75 млн дохода от токенов DeepSeek R1, обеспечивая 15-кратную окупаемость (год назад NVIDIA обещала ROI на уровне 700 %). Также ускорители поколения Blackwell отличаются самой низкой совокупной стоимостью владения. например, оптимизация ПО NVIDIA B200 позволила добиться стоимости всего в два цента на миллион токенов на OpenAI gpt-oss-120b, обеспечив пятикратное снижение стоимости одного токена всего за два месяца. NVIDIA B200 первенствовал и по пропускной способности и интерактивности, обеспечив 60 тыс. токенов в секунду на ускоритель и 1 тыс. токенов в секунду на пользователя в gpt-oss с новейшим стеком NVIDIA TensorRT-LLM. NVIDIA сообщила, что постоянно повышает производительность путём оптимизации аппаратного и программного стека. Первоначальная производительность gpt-oss-120b на системе NVIDIA DGX Blackwell B200 с библиотекой NVIDIA TensorRT LLM уже была лидирующей на рынке, но команды NVIDIA и сообщество разработчиков значительно оптимизировали TensorRT LLM для ускорения исполнения открытых больших языковых моделей (LLM). 
Источник изображений: NVIDIA Компания отметила, что выпуск TensorRT LLM v1.0 стал значительным прорывом в повышении скорости инференса LLM благодаря распараллеливанию и оптимизации IO-операций. А у недавно вышедшей модели gpt-oss-120b-Eagle3-v2 используется спекулятивное декодирование — интеллектуальный метод, позволяющий предсказывать несколько токенов одновременно. Это уменьшает задержку и обеспечивает получение ещё более быстрых результатов — пропускная способность выросла втрое, до 100 токенов в секунду на пользователя (TPS/пользователь), а общая производительность на ускоритель выросла с 6 до 30 тыс. токенов. 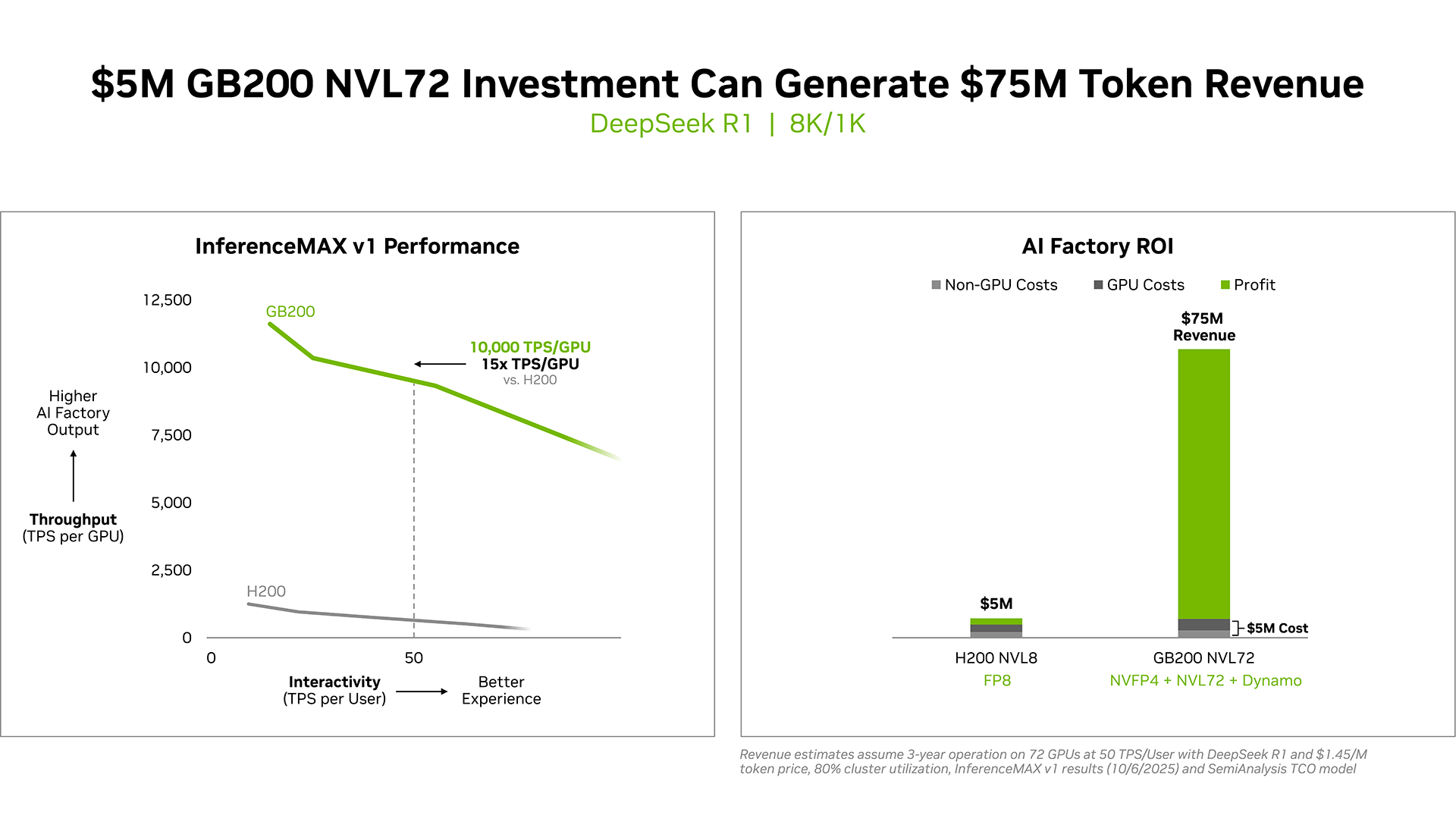 Для моделей с «плотной» архитектурой (Dense AI), таких как Llama 3.3 70b, которые требуют значительных вычислительных ресурсов из-за большого количества параметров и одновременного использования всех параметров в процессе инференса, NVIDIA Blackwell B200 достиг нового рубежа производительности в бенчмарке InferenceMAX v1, отметила NVIDIA. Суперускоритель показал более 10 тыс. токенов/с (TPS) на GPU при 50 TPS на пользователя, т.е. вчетверо более высокую пропускную способность на GPU по сравнению с NVIDIA H200. 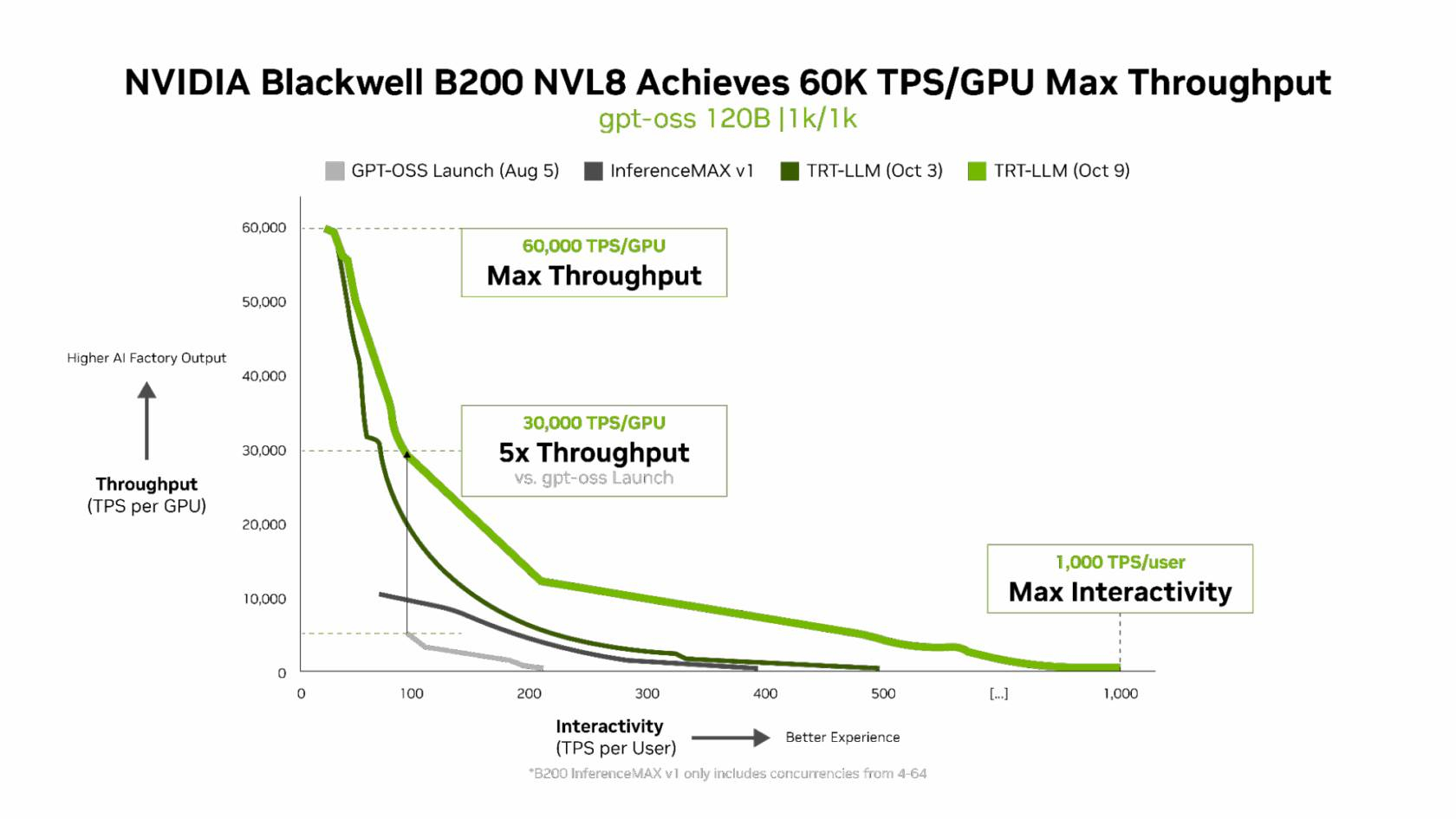 NVIDIA подчеркнула, что такие показатели, как количество токенов на Вт, стоимость на миллион токенов и TPS/пользователь не уступают по важности пропускной способности. Фактически, для ИИ-фабрик с ограниченной мощностью ускорители с архитектурой Blackwell обеспечивают до 10 раз лучшую производительность на МВт по сравнению с предыдущим поколением и позволяют получать более высокий доход от токенов. 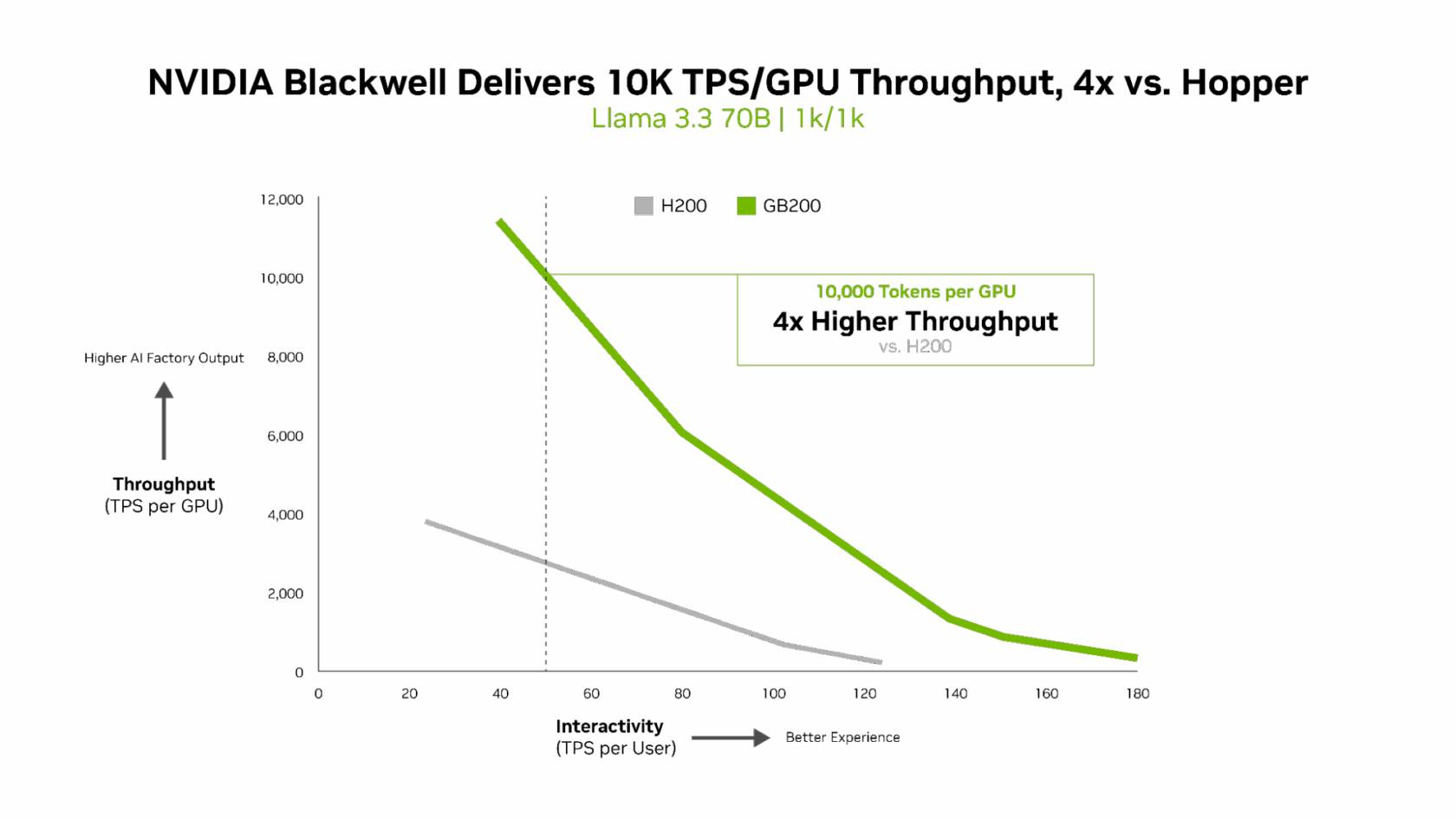 Компания отметила, что стоимость обработки одного токена (Cost per Token) имеет решающее значение для оценки эффективности ИИ-модели и напрямую влияет на эксплуатационные расходы. NVIDIA утверждает, что в целом архитектура NVIDIA Blackwell позволила снизить стоимость обработки миллиона токенов в 15 раз по сравнению с предыдущим поколением. 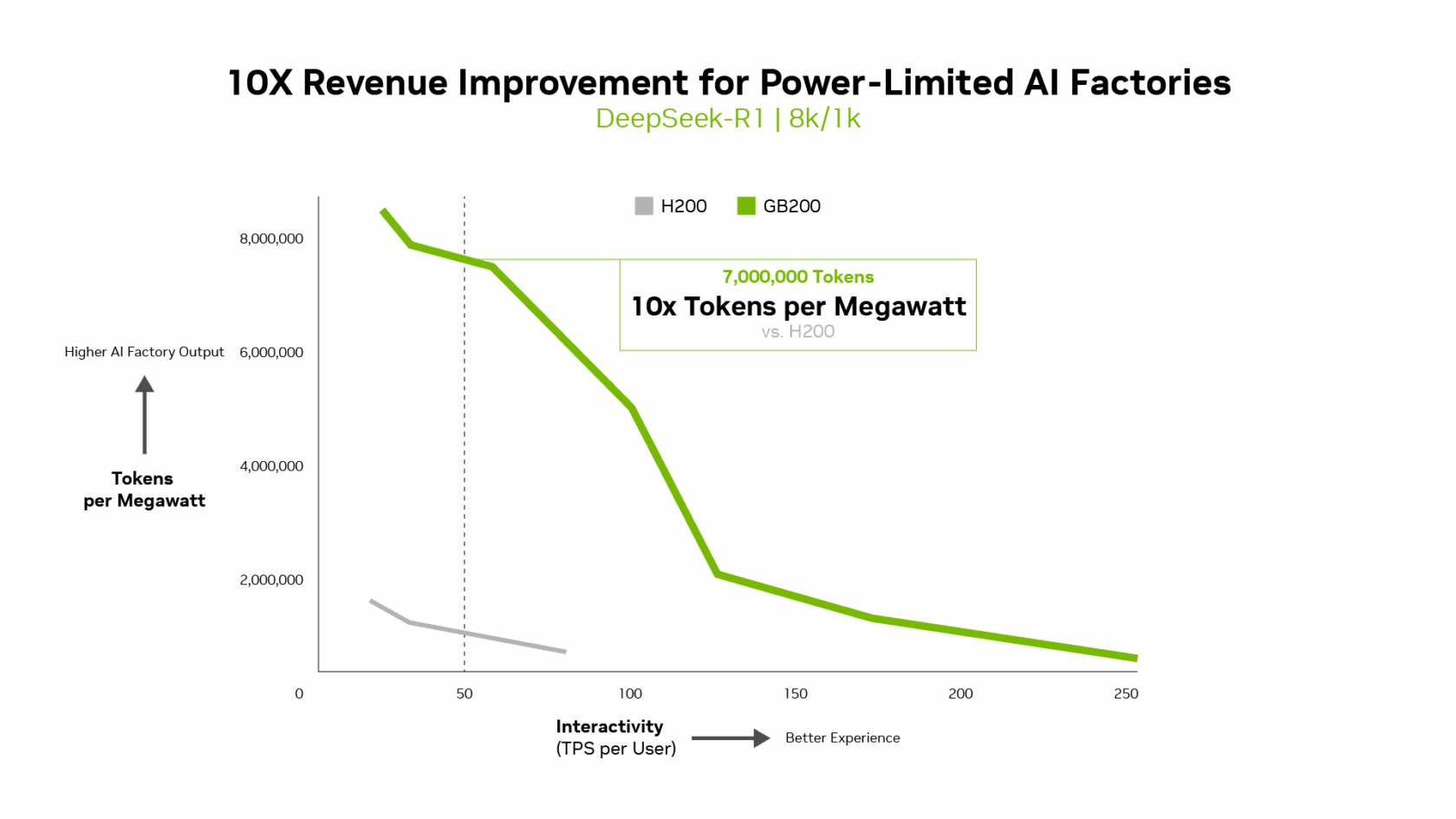 В InferenceMAX используется метод оценки эффективности Pareto front, определяющий наилучшее (компромиссное) сочетание различных факторов для оценки производительности ускорителя. Это показывает, насколько Blackwell лучше конкурентов справляется с балансом стоимости, энергоэффективности, пропускной способности и скорости отклика. Системы, оптимизированные только для одной метрики, могут демонстрировать пиковую производительность «в вакууме», но такая «экономика» не масштабируется в производственных средах. 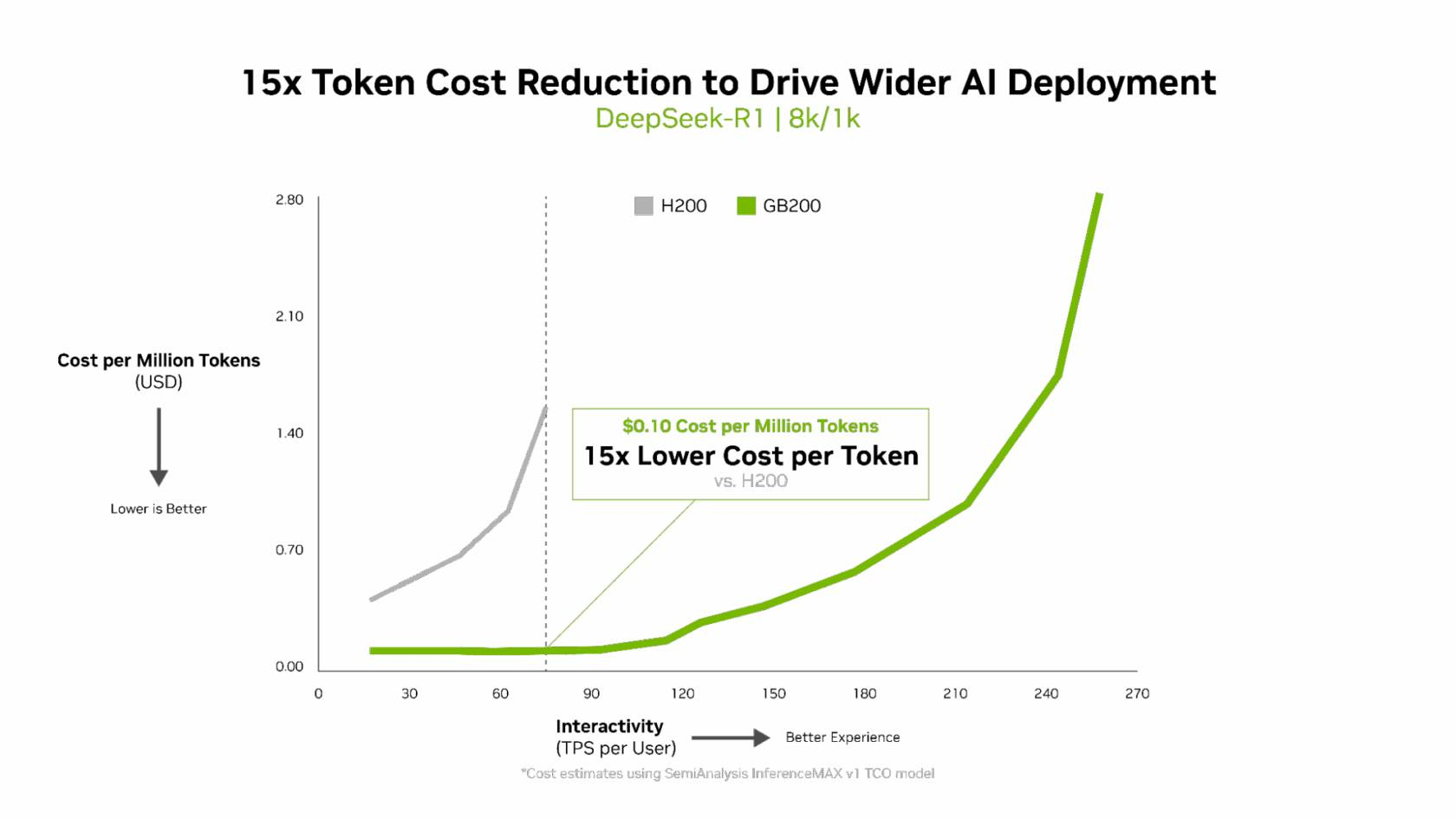 Компания отметила, что ИИ переходит от экспериментальных пилотных проектов к ИИ-фабрикам — инфраструктуре, которая производит интеллектуальные решения, преобразуя данные в токены и решения в режиме реального времени. Фреймворк NVIDIA Think SMART помогает предприятиям ориентироваться в этом переходе, демонстрируя, как полнофункциональная платформа инференса обеспечивает измеримую окупаемость инвестиций. Обещая 15-кратную окупаемость инвестиций и непрерывный рост производительности за счёт ПО, NVIDIA не просто лидирует в текущей гонке ИИ-технологий, но и задаёт правила для следующего этапа, где экономика будет определять победителей рынка, пишет The Tech Buzz. Для предприятий, делающих ставку на конкурирующие платформы в своих стратегиях по развёртыванию ИИ, результаты таких бенчмарков должны побудить к пересмотру выбора ИИ-инфраструктуры.
12.09.2025 [23:07], Владимир Мироненко
Intel Arc Pro впервые поучаствовали в бенчмарках MLPerf Inference, но в лидерах предсказуемо осталась NVIDIAMLCommons объявил результаты набора бенчмарков MLPerf Inference v5.1. Последний раунд демонстрирует, насколько быстро развивается инференс и соответствующие бенчмарки, пишет ресурс HPCwire. В этом раунде было рекордное количество заявок — 27. Представлены результаты сразу пяти новых ускорителей: AMD Instinct MI355X, Intel Arc Pro B60 48GB Turbo, NVIDIA GB300, NVIDIA RTX 4000 Ada 20GB, NVIDIA RTX Pro 6000 Blackwell Server Edition. Всего же количество результатов MLPerf перевалило за 90 тыс. результатов. В текущем раунде были представлены три новых бенчмарка: тест рассуждений на основе модели DeepSeek-R1, тест преобразования речи в текст на основе Whisper Large v3 и небольшой тест LLM на основе Llama 3.1 8B. Как отметил ресурс IEEE Spectrum, бенчмарк на основе модели Deepseek R1 671B (671 млрд параметров), более чем в 1,5 раза превышает самый крупный бенчмарк предыдущего раунда на основе Llama 3.1 405B. В модели Deepseek R1, ориентированной на рассуждения, большая часть вычислений выполняется во время инференса, что делает этот бенчмарк ещё более сложным. Что касается самого маленького бенчмарка, основанного на Llama 3.1 8B, то, как поясняют в MLCommons, в отрасли растёт спрос на рассуждения с малой задержкой и высокой точностью. SLM отвечают этим требованиям и являются отличным выбором для таких задач, как реферирование текста или периферийные приложения. В свою очередь бенчмарк преобразования голоса в текст, основанный на Whisper Large v3, был разработан в ответ на растущее количество голосовых приложений, будь то смарт-устройства или голосовые ИИ-интерфейсы. 
Источник изображения: NVIDIA NVIDIA вновь возглавила рейтинг MLPerf Inference, на этот раз с архитектурой Blackwell Ultra, представленной платформой NVIDIA GB300 NVL72, которая установила рекорд, увеличив пропускную способность DeepSeek-R1 на 45 % по сравнению с предыдущими системами GB200 NVL72 (Blackwell). NVIDIA также продемонстрировала высокие результаты в бенчмарке Llama 3.1 405B, который имеет более жёсткие ограничения по задержке. NVIDIA применила дезагрегацию, разделив фазы работы с контекстом и собственно генерацию между разными ускорителями. Этот подход, поддерживаемый фреймворком Dynamo, обеспечил увеличение в 1,5 раза пропускной способности на один ускоритель по сравнению с традиционным обслуживанием на системах Blackwell и более чем в 5 раз по сравнению с системами на базе Hopper. 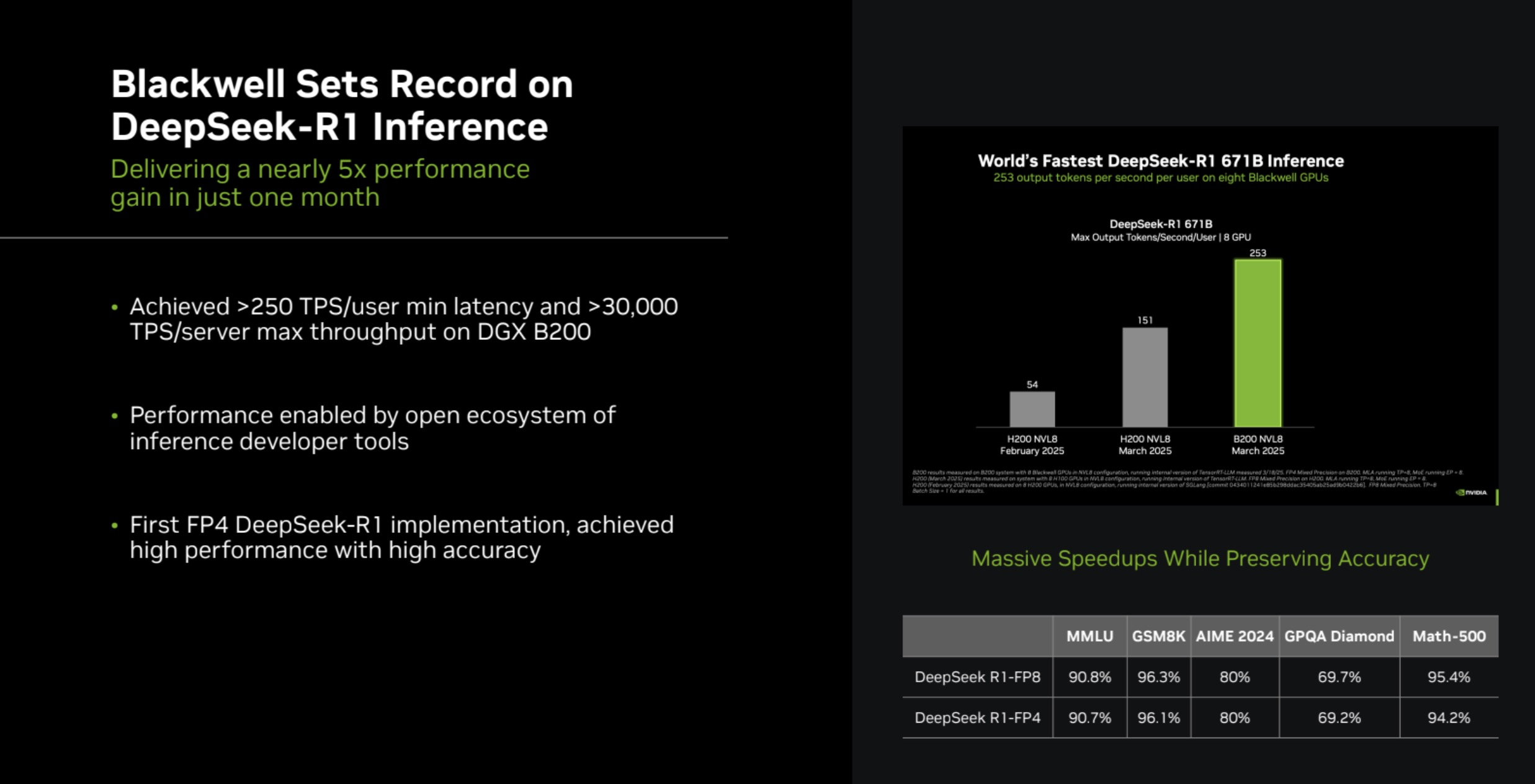
Источник изображения: NVIDIA NVIDIA назвала «дезагрегированное обслуживание» одним из ключевых факторов успеха, помимо аппаратных улучшений при переходе к Blackwell Ultra. Также свою роль сыграло использованием фирменного 4-бит формата NVFP4. «Мы можем обеспечить точность, сопоставимую с BF16», — сообщила компания, добавив, что при этом потребляется значительно меньше вычислительной мощности. Для работы с контекстом NVIDIA готовит соускоритель Rubin CPX. В более компактных бенчмарках решения NVIDIA также продемонстрировали рекордную пропускную способность. Компания сообщила о более чем 18 тыс. токенов/с на один ускоритель в бенчмарке Llama 3.1 8B в автономном режиме и 5667 токенов/с на один ускоритель в Whisper. Результаты были представлены в офлайн-, серверных и интерактивных сценариях, при этом NVIDIA сохранила лидерство в расчете на GPU во всех категориях. 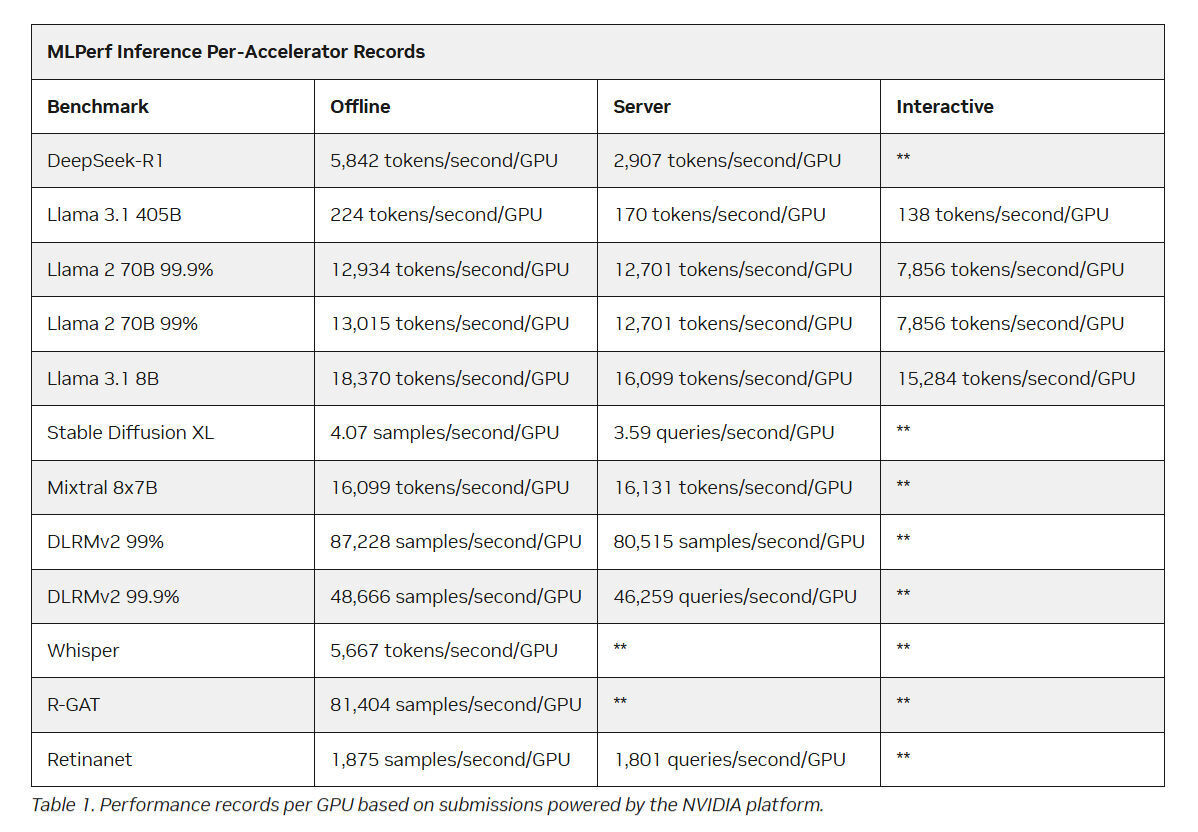
Источник изображения: NVIDIA/TechPowerUp AMD представила результаты AMD Instinct MI355X только в «открытой» категории, где разрешены программные модификации модели. Ускоритель MI355X превзошёл в бенчмарке Llama 2 70B ускоритель MI325X в 2,7 раза по количеству токенов/с. В этом раунде AMD также впервые обнародовала результаты нескольких новых рабочих нагрузок, включая Llama 2 70B Interactive, MoE-модель Mixtral-8x7B и генератор изображений Stable Diffusion XL. 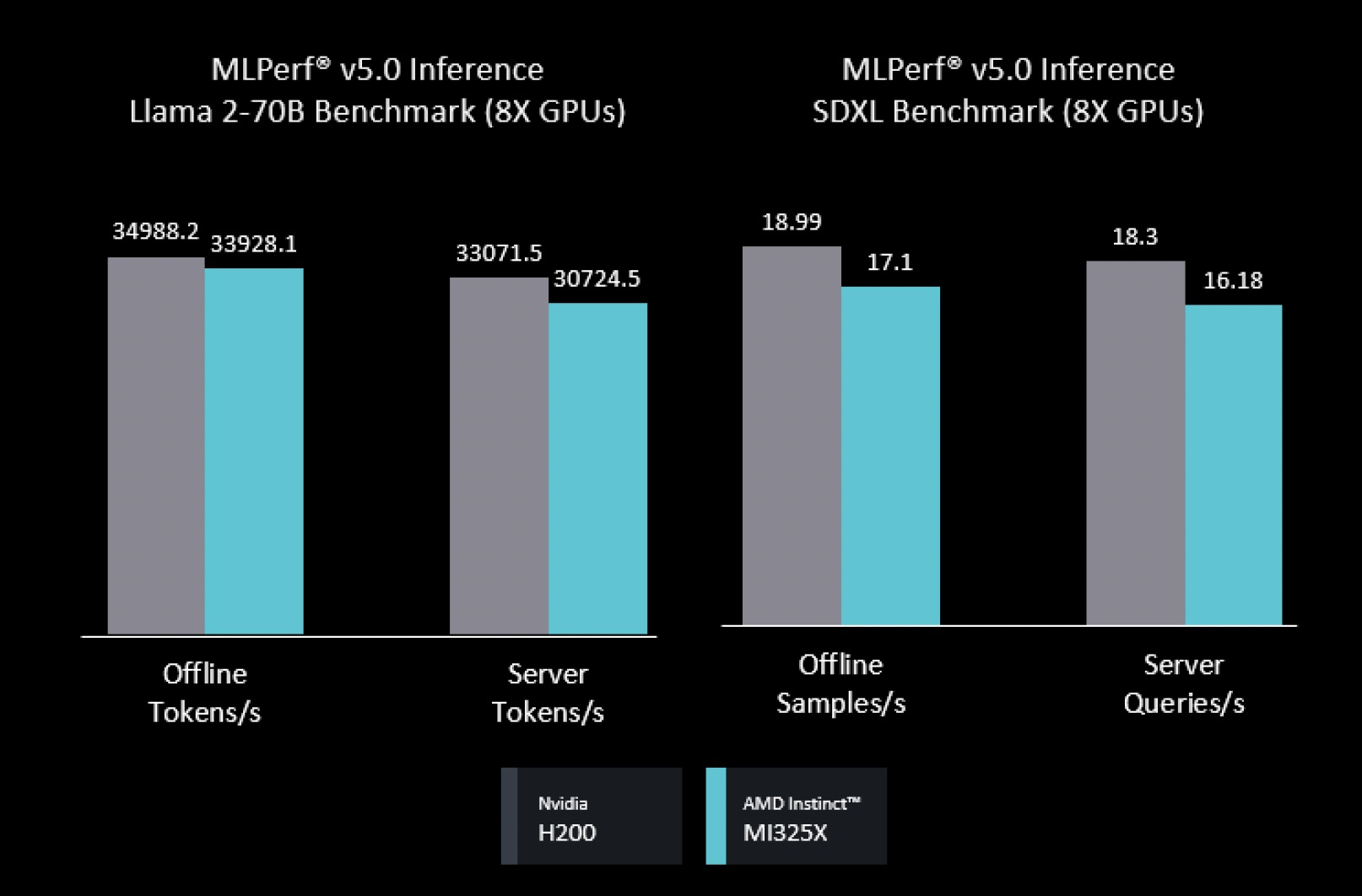
Источник изображения: AMD/ServeTheHome В число «закрытых» заявок AMD входили системы на базе ускорителей AMD MI300X и MI325X. Более продвинутый MI325X показал результаты, схожие с показателями систем на базе NVIDIA H200 на Llama 2 70b, в комбинированном тесте MoE и тестах генерации изображений. Кроме того, компанией была представлена первая гибридная заявка, в которой ускорители AMD MI300X и MI325X использовались для одной и той же задачи инференса — бенчмарка на базе Llama 2 70b. Возможность распределения нагрузки между различными типами ускорителей — важный шаг, отметил IEEE Spectrum. В этом раунде впервые был представлен и ускоритель Intel Arc Pro. Для бенчмарков использовалась видеокарта MaxSun Intel Arc Pro B60 Dual 48G Turbo, состоящая из двух GPU с 48 Гбайт памяти, в составе платформы Project Battlematrix, которая может включать до восьми таких ускорителей. Система показала результаты на уровне NVIDIA L40S в небольшом тесте LLM и уступила ему в тесте Llama 2 70b. 
Источник изображения: Intel Следует также отметить, что в этом раунде, как и в предыдущем, участвовала Nebius (ранее Yandex N.V.). Компания отметила, что результаты, полученные на односерверных инсталляциях, подтверждают, что Nebius AI Cloud обеспечивает «высочайшие» показатели производительности для инференса базовых моделей, таких как Llama 2 70B и Llama 3.1 405B. В частности, Nebius AI Cloud установила новый рекорд производительности для NVIDIA GB200 NVL72. По сравнению с лучшими результатами предыдущего раунда, её однохостовая инсталляция показала прирост производительности на 6,7 % и 14,2 % при работе с Llama 3.1 405B в автономном и серверном режимах соответственно. «Эти два показателя также обеспечивают Nebius первое место среди других разработчиков MLPerf Inference v5.1 для этой модели в системах GB200», — сообщила компания.
07.06.2025 [16:24], Владимир Мироненко
AMD впервые приняла участие в бенчмарке MLPerf Training, но до рекордов NVIDIA ей ещё очень далекоКонсорциум MLCommons объявил новые результаты бенчмарка MLPerf Training v5.0, отметив быстрый рост и эволюцию в области ИИ, а также рекордное количество общих заявок и увеличение заявок для большинства тестов по сравнению с бенчмарком v4.1. MLPerf Training v5.0 предложил новый бенчмарк предварительной подготовки большой языковой модели на основе Llama 3.1 405B, которая является самой большой ИИ-моделью в текущем наборе тестов обучения. Он заменил бенчмарк на основе gpt3 (gpt-3-175B), входивший в предыдущие версии MLPerf Training. Целевая группа MLPerf Training выбрала его, поскольку Llama 3.1 405B является конкурентоспособной моделью, представляющей современные LLM, включая последние обновления алгоритмов и обучение на большем количестве токенов. Llama 3.1 405B более чем в два раза больше gpt3 и использует в четыре раза большее контекстное окно. Несмотря на то, что бенчмарк на основе Llama 3.1 405B был представлен только недавно, на него уже подано больше заявок, чем на предшественника на основе gpt3 в предыдущих раундах, отметил консорциум. 
Источник изображения: NVIDIA MLCommons сообщил, что рабочая группа MLPerf Training регулярно добавляет новые рабочие нагрузки в набор тестов, чтобы гарантировать, что он отражает тенденции отрасли. Результаты бенчмарка Training 5.0 показывают заметный рост производительности для новых бенчмарков, что указывает на то, что отрасль отдаёт приоритет новым рабочим нагрузкам обучения, а не старым. Тест Stable Diffusion показал увеличение скорости в 2,28 раза для восьмичиповых систем по сравнению с версией 4.1, вышедшей шесть месяцев назад, а тест Llama 2.0 70B LoRA увеличил скорость в 2,10 раза по сравнению с версией 4.1; оба превзошли исторические ожидания роста производительности вычислений с течением времени в соответствии с законом Мура. Более старые тесты в наборе показали более скромные улучшения производительности. 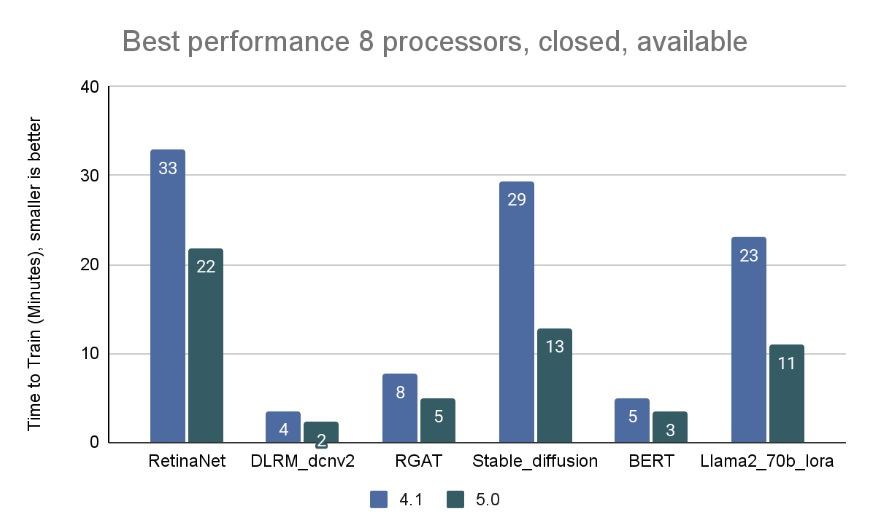
Источник изображений: MLCommons На многоузловых 64-чиповых системах тест RetinaNet показал ускорение в 1,43 раза по сравнению с предыдущим раундом тестирования v3.1 (самым последним, включающим сопоставимые масштабные системы), в то время как тест Stable Diffusion показал резкое увеличение в 3,68 раза. «Это признак надёжного цикла инноваций в технологиях и совместного проектирования: ИИ использует преимущества новых систем, но системы также развиваются для поддержки высокоприоритетных сценариев», — говорит Шрия Ришаб (Shriya Rishab), сопредседатель рабочей группы MLPerf Training. 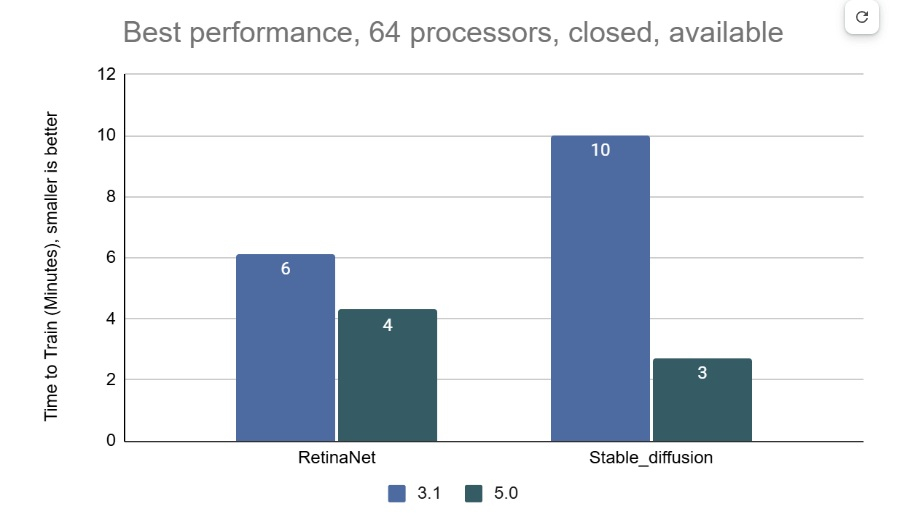 В заявках на MLPerf Training 5.0 использовалось 12 уникальных чиповых, все в категории коммерчески доступных. Пять из них стали общедоступными с момента выхода последней версии набора тестов MLPerf Training:
Заявки также включали три новых семейства процессоров:
Кроме того, количество представленных многоузловых систем увеличилось более чем в 1,8 раза по сравнению с версией бенчмарка 4.1. Хиуот Касса (Hiwot Kassa), сопредседатель рабочей группы MLPerf Training, отметил растущее число провайдеров облачных услуг, предлагающих доступ к крупномасштабным системам, что делает доступ к обучению LLM более демократичным. 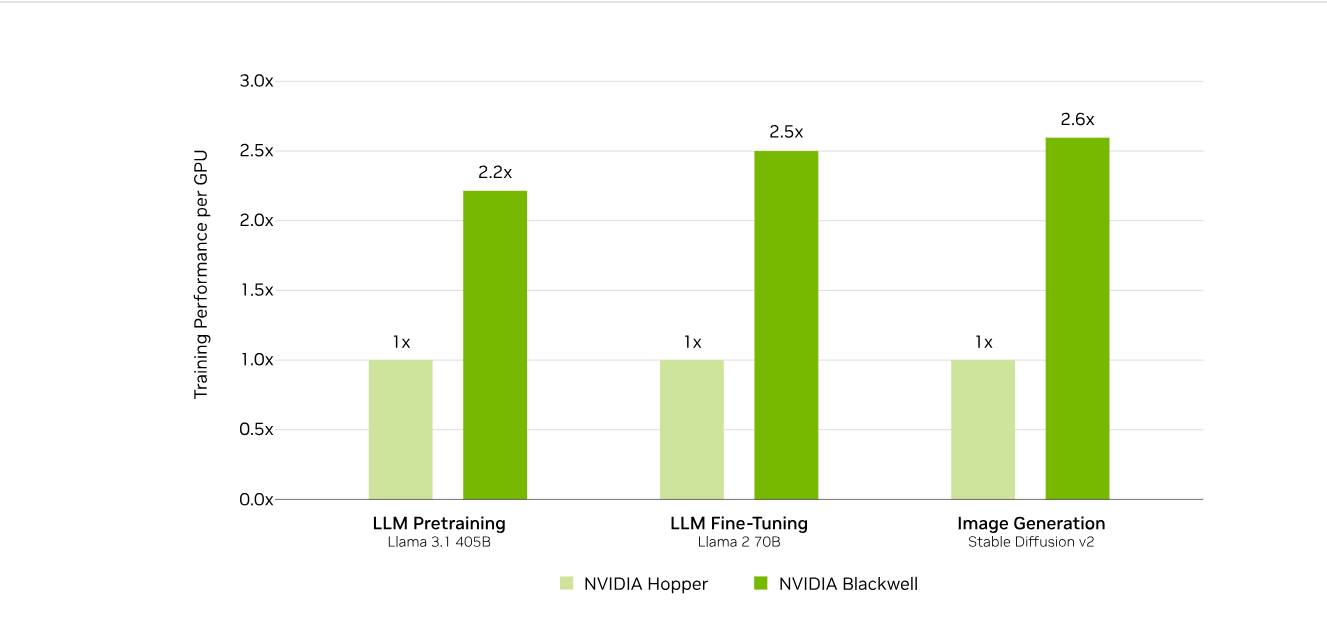
Источник изображений: NVIDIA Последние результаты MLPerf Training 5.0 от NVIDIA показывают, что её ускорители Blackwell GB200 демонстрируют рекордные результаты по времени обучения, демонстрируя, как стоечная конструкция «ИИ-фабрики» компании может быстрее, чем раньше, превращать «сырые» вычислительные мощности в развёртываемые модели, пишет ресурс HPCwire. Раунд MLPerf Training v5.0 включает 201 результат от 20 организаций-участников: AMD, ASUS, Cisco, CoreWeave, Dell, GigaComputing, Google Cloud, HPE, IBM, Krai, Lambda, Lenovo, MangoBoost, Nebius, NVIDIA, Oracle, QCT, SCITIX, Supermicro и TinyCorp. «Мы бы особенно хотели поприветствовать впервые подавших заявку на участие в MLPerf Training AMD, IBM, MangoBoost, Nebius и SCITIX, — сказал Дэвид Кантер (David Kanter), руководитель MLPerf в MLCommons. — Я также хотел бы выделить первый набор заявок Lenovo на результаты тестов энергопотребления в этом раунде — энергоэффективность в системе обучения ИИ-систем становится всё более важной проблемой, требующей точного измерения». 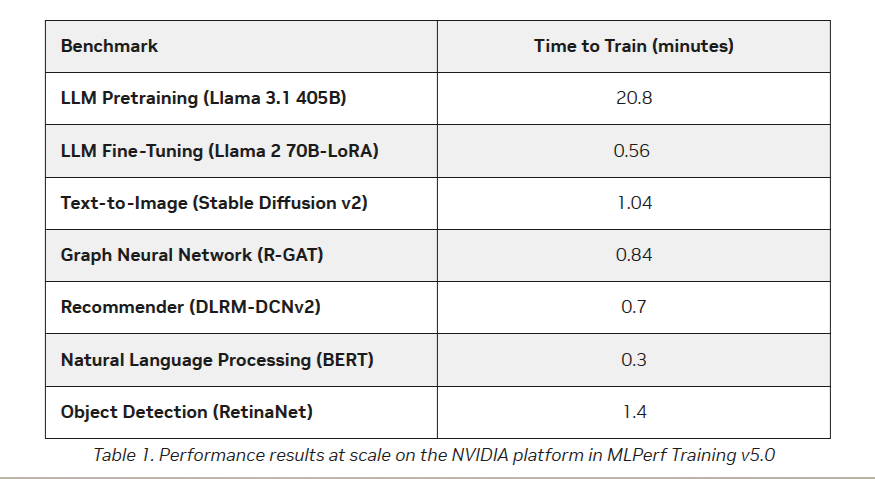 NVIDIA представила результаты кластера на основе систем GB200 NVL72, объединивших 2496 ускорителей. Работая с облачными партнерами CoreWeave и IBM, компания сообщила о 90-% эффективности масштабирования при расширении с 512 до 2496 ускорителей. Это отличный результат, поскольку линейное масштабирование редко достигается при увеличении количества ускорителей за пределами нескольких сотен. Эффективность масштабирования в диапазоне от 70 до 80 % уже считается солидным результатом, особенно при увеличении количества ускорителей в пять раз, пишет HPCwire. В семи рабочих нагрузках в MLPerf Training 5.0 ускорители Blackwell улучшили время сходимости «до 2,6x» при постоянном количестве ускорителей по сравнению с поколением Hopper (H100). Самый большой рост наблюдался при генерации изображений и предварительном обучении LLM, где количество параметров и нагрузка на память самые большие.  Хотя в бенчмарке проверялась скорость выполнения операций, NVIDIA подчеркнула, что более быстрое выполнение задач означает меньшее время аренды облачных инстансов и более скромные счета за электроэнергию для локальных развёртываний. Хотя компания не публиковала данные об энергоэффективности в этом бенчмарке, она позиционировала Blackwell как «более экономичное» решение на основе достигнутых показателей, предполагая, что усовершенствования дизайна тензорных ядер обеспечивают лучшую производительность на Ватт, чем у поколения Hopper. Также HPCwire отметил, что NVIDIA была единственным поставщиком, представившим результаты бенчмарка предварительной подготовки LLM на основе Llama 3.1 405B, установив начальную точку отсчёта для обучения с 405 млрд параметров. Это важно, поскольку некоторые компании уже выходят за рамки 70–80 млрд параметров для передовых ИИ-моделей. Демонстрация проверенного рецепта работы с 405 млрд параметров даёт компаниям более чёткое представление о том, что потребуется для создания ИИ-моделей следующего поколения. 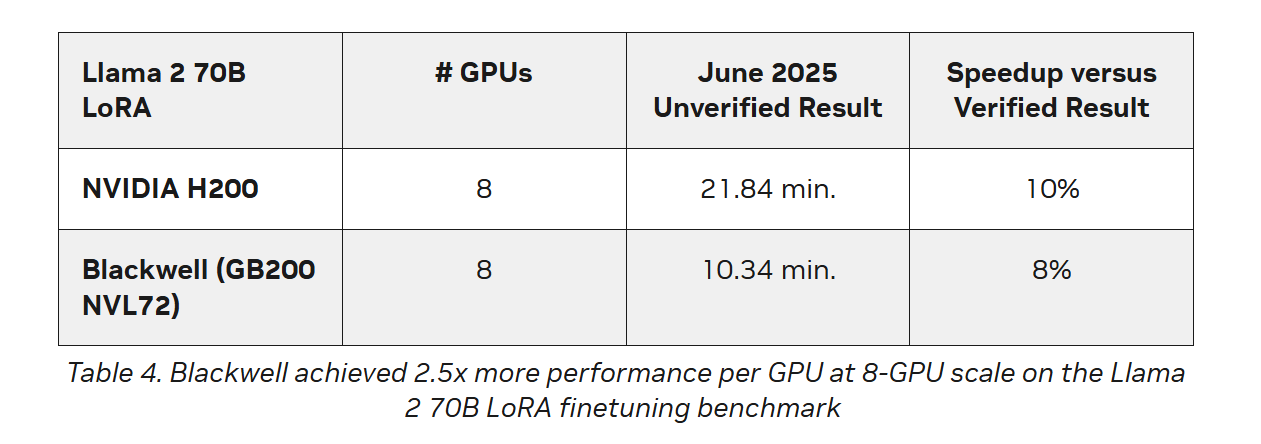 В ходе пресс-конференции Дэйв Сальватор (Dave Salvator), директор по ускоренным вычислительным продуктам в NVIDIA, ответил на распространенный вопрос: «Зачем фокусироваться на обучении, когда в отрасли в настоящее время все внимание сосредоточено на инференсе?». Он сообщил, что тонкая настройка (после предварительного обучения) остается ключевым условием для реальных LLM, особенно для предприятий, использующих собственные данные. Он обозначил обучение как «фазу инвестиций», которая приносит отдачу позже в развёртываниях с большим объёмом инференса. Этот подход соответствует более общей концепции «ИИ-фабрики» компании, в рамках которой ускорителям даются данные и питание для обучения моделей. А затем производятся токены для использования в реальных приложениях. К ним относятся новые «токены рассуждений» (reasoning tokens), используемые в агентских ИИ-системах. 
 NVIDIA также повторно представила результаты по Hopper, чтобы подчеркнуть, что H100 остаётся «единственной архитектурой, кроме Blackwell», которая показала лидерские показатели по всему набору MLPerf Training, хотя и уступила Blackwell. Поскольку инстансы на H100 широко доступны у провайдеров облачных сервисов, компания, похоже, стремится заверить клиентов, что существующие развёртывания по-прежнему имеют смысл. 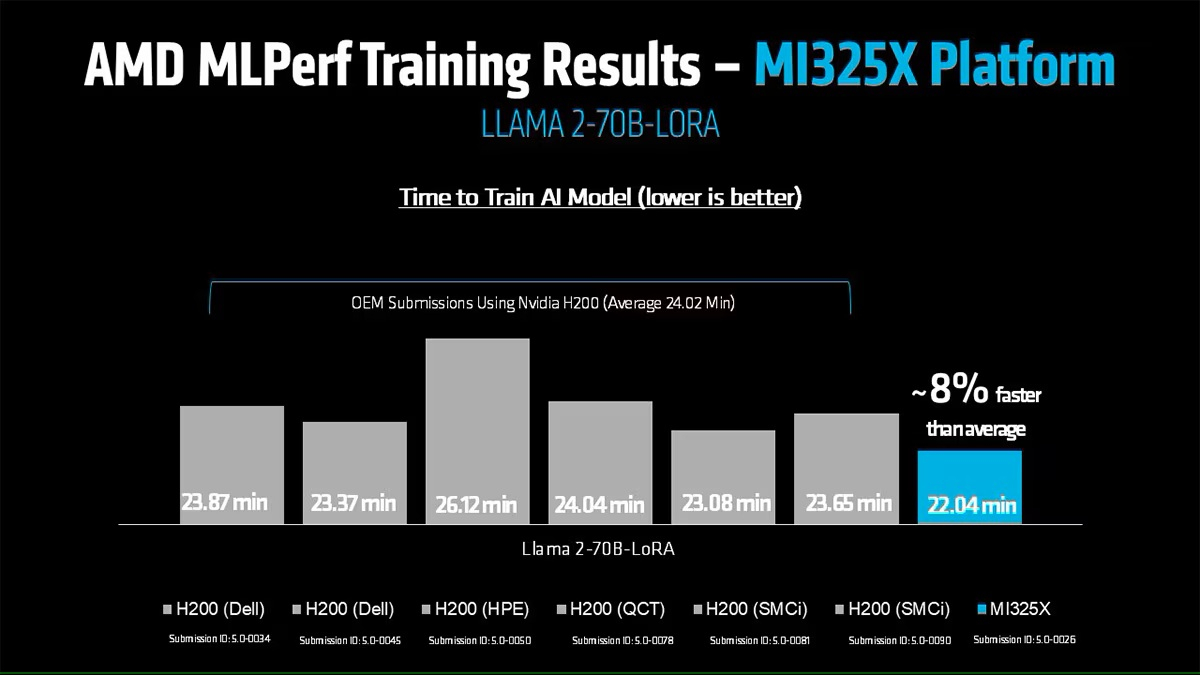
Источник изображений: AMD AMD, со своей стороны, продемонстрировала прирост производительности поколения чипов. В тесте Llama2 70B LoRA она показала 30-% прирост производительности AMD Instinct MI325X по сравнению с предшественником MI300X. Основное различие между ними заключается в том, что MI325X оснащён почти на треть более быстрой памятью.  В самом популярном тесте, тонкой настройке LLM, AMD продемонстрировала, что её новейший ускоритель Instinct MI325X показывает результаты наравне с NVIDIA H200. Это говорит о том, что AMD отстает от NVIDIA на одно поколение, отметил ресурс IEEE Spectrum. 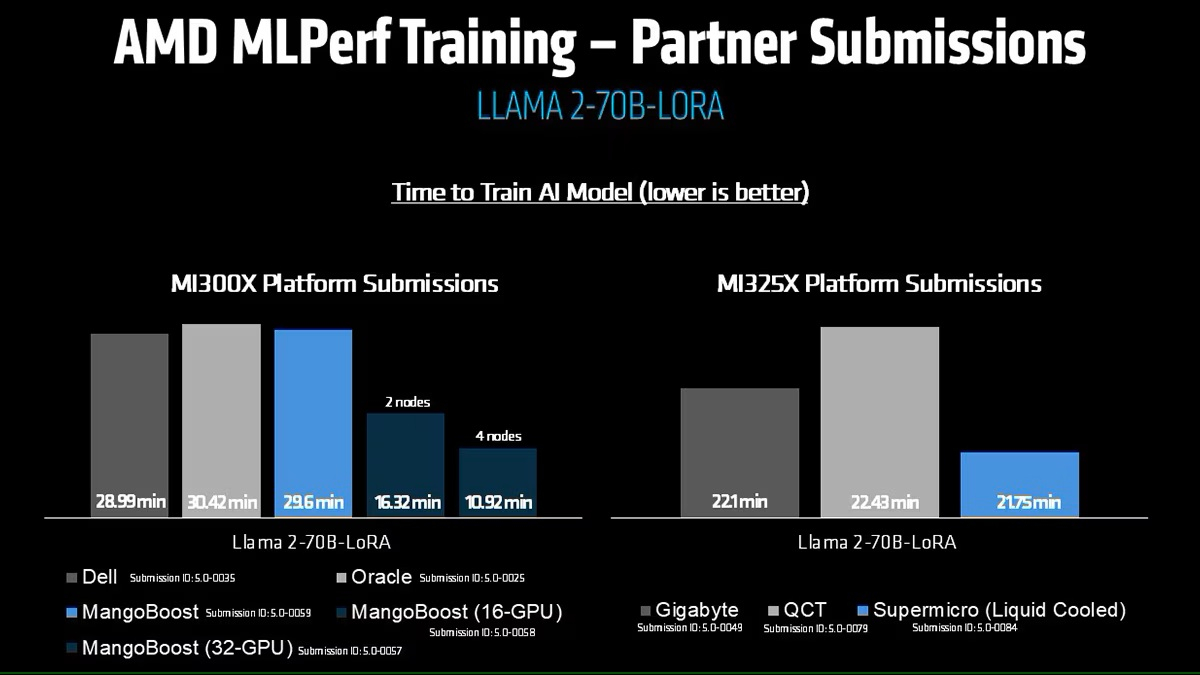 AMD впервые представила результаты MLPerf Training, хотя в предыдущие годы другие компании представляли результаты в этом тесте, используя ускорители AMD. В свою очередь, Google представила результаты лишь одного теста, задачи генерации изображений, с использованием Trillium TPU. Тест MLPerf также включает тест на энергопотребление, измеряющий, сколько энергии уходит на выполнение каждой задачи обучения. В этом раунде лишь Lenovo включила измерение этого показателя в свою заявку, что сделало невозможным сравнение между компаниями. Для тонкой настройки LLM на двух ускорителях Blackwell требуется 6,11 ГДж или 1698 КВт·ч — примерно столько энергии уходит на обогрев небольшого дома зимой.
21.05.2025 [10:39], Владимир Мироненко
GPU-маркетплейс NVIDIA DGX Cloud Lepton упростит доступ к дефицитным ИИ-ускорителямNVIDIA анонсировала GPU-маркетплейс NVIDIA DGX Cloud Lepton, которая позволит разработчикам со всего мира, создающим агентские и другие ИИ-приложения использовать NVIDIA Blackwell и другие модели ускорителей в глобальной сети партнёрских облаков (NCP): CoreWeave, Crusoe, Firmus, Foxconn, GMI Cloud, Lambda, Nebius, Nscale, Softbank и Yotta Data Services. Ожидается, что ведущие провайдеры облачных услуг и другие GPU-маркетплейсы также присоединятся к DGX Cloud Lepton. Разработчики смогут использовать вычислительные мощности ускорителй в определённых регионах как для вычислений по требованию, так и на постоянной основе. «NVIDIA DGX Cloud Lepton свяжет нашу сеть глобальных поставщиков облачных GPU с разработчиками в сфере ИИ, — заявил основатель и генеральный директор NVIDIA Дженсен Хуанг (Jensen Huang). — Вместе с нашими NCP мы строим ИИ-фабрику планетарного масштаба». По замыслу NVIDIA, платформа DGX Cloud Lepton поможет решить критическую задачу обеспечения разработчиков надёжными, высокопроизводительными ресурсами ускорителей путём унификации доступа к облачным ИИ-сервисам и мощностям собственных ускорителей. Платформа интегрирована с программным стеком NVIDIA, включая микросервисы NIM и NeMo, Blueprints и Cloud Functions. 
Источник изображений: NVIDIA В числе основных преимуществ новой платформы компания назвала:
А для самих провайдеров, участвующих в DGX Cloud Lepton, предоставляется ПО для управления, которое обеспечивает диагностику состояния ускорителей в реальном времени и автоматизирует анализ первопричин возникших проблем, избавляя от ручной диагностики и сокращая время простоев.  NVIDIA также анонсировала инициативу Exemplar Clouds, предназначенную для стандартизации прозрачного сравнительного анализа облачной ИИ-инфраструктуры. Это предложение должно решить серьёзную проблему, с которой сталкиваются разработчики и предприятия, развёртывающие рабочие ИИ-нагрузки — прогнозирование эффективности, надёжности и ценовой эффективности облачной платформы. Exemplar Clouds использует NVIDIA DGX Cloud Benchmarking, комплексный набор инструментов и рекомендаций для оптимизации производительности облачных ИИ-нагрузок и количественной оценки связи между стоимостью и производительностью.
04.04.2025 [10:26], Владимир Мироненко
Бенчмарк MLPerf Inference 5.0 показал, что ускорители AMD Instinct MI325X не уступают NVIDIA H200Консорциум MLCommons опубликовал результаты тестирования различных аппаратных решений в бенчмарке MLPerf Inference 5.0, о чём сообщил ресурс IEEE Spectrum. Он отметил, что ускорители NVIDIA с архитектурой Blackwell превзошли все остальные чипы, но последняя версия ускорителей Instinct от AMD — Instinct MI325X — оказалась на уровне конкурирующего решения NVIDIA H200. Сопоставимые результаты были получены в основном в тестах одной из маломасштабных больших языковых моделей (LLM) — Llama2 70B. Чтобы лучше отражать особенности развития ИИ, консорциум добавил три новых теста MLPerf — всего доступно 11 бенчмарков. Добавлены два теста для LLM. Популярная и относительно компактная Llama2 70B уже является устоявшимся эталоном MLPerf, но консорциум решил включить тест, имитирующий скорость реагирования, ожидаемую пользователями от чат-ботов. Поэтому был добавлен новый эталон Llama2-70B Interactive, который ужесточает требования к оборудованию: системы должны выдавать не менее 25 токенов в секунду при задержке на ответ не более 450 мс. С учётом роста популярности «агентного ИИ» в MLPerf решили добавить тестирование LLM с характеристиками, необходимыми для таких задач. В итоге была выбрана Llama3.1 405B. Эта модель имеет широкое контекстное окно — 128 тыс. токенов, что в 30 раз больше, чем у Llama2 70B. Третий новый бенчмарк — RGAT — представляет собой графовую сеть. Он классифицирует информацию в сети. Например, набор данных для тестирования RGAT состоит из научных статей, связанных между собой авторами, учреждениями и областями исследований, что составляет 2 Тбайт данных. RGAT должен классифицировать статьи по почти 3000 темам. 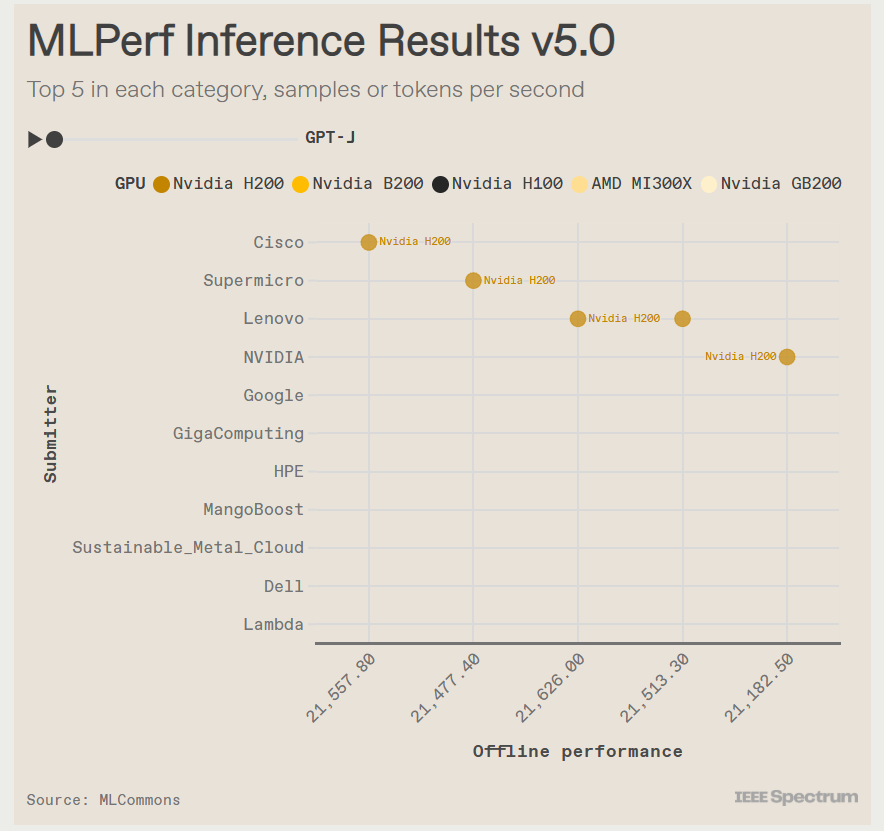
Источник изображения: IEEE Spectrum В этом раунде тестов поступили заявки от NVIDIA и 15 компаний-партнёров, включая Dell, Google и Supermicro. Оба ускорителя NVIDIA с архитектурой Hopper первого и второго поколения — H100 и H200 — показали хорошие результаты. «Мы смогли добавить ещё 60 % производительности за последний год, — у Hopper, которая была запущена в производство в 2022 году, сообщил Дэйв Сальватор (Dave Salvator), один из директоров NVIDIA. — У неё всё ещё есть некоторый запас производительности». Лидером же оказался B200 с архитектурой Blackwell. B200 содержит на 36 % больше памяти HBM, чем у H200, но, что ещё важнее, он может выполнять ключевые математические операции, используя FP4 вместо FP8 у Hopper. В тесте Llama3.1 405B система от Supermicro с восемью B200 выдала почти в четыре раза больше токенов в секунду, чем система с восемью H200 от Cisco. И та же система Supermicro была в три раза быстрее самого быстрого сервера на H200 в интерактивной версии Llama2 70B. NVIDIA использовала суперчип GB200 — сочетание ускорителей Blackwell и процессоров Grace — чтобы продемонстрировать эффективность интерконнекта NVLink, который позволяет работать множеству узлов как один ускоритель. В непроверенном результате, которым компания поделилась с журналистами, стойка GB200 NVL72 выдавала 869 200 токенов в секунду в Llama2 70B. Самая быстрая система текущего раунда MLPerf Inference — сервер NVIDIA B200 — показала 98 443 токена в секунду. Ускоритель Instinct MI325X позиционируется AMD как конкурент H200. Он имеет ту же архитектуру, что и предшественник MI300, но оснащён увеличенным объёмом памяти HBM с более высокой пропускной способностью — 256 Гбайт и 6 Тбайт/с (рост на 33 % и 13 % соответственно). AMD оптимизировала ПО, что позволило увеличить скорость инференса DeepSeek-R1 в 8 раз. В тесте Llama2 70B компьютеры с восемью MI325X отставали от аналогичных систем на базе H200 всего на 3–7 %. В задачах генерации изображений система MI325X показала отличия в пределах 10 % от системы на H200. Также сообщается, что партнёр AMD, компания Mangoboost, продемонстрировала почти четырёхкратное увеличение производительности в тесте Llama2 70B, запустив вычисления на четырёх узлах. 
Источник изображения: ML Commons Intel традиционно использует в тестах только процессорные системы, чтобы показать, что для некоторых рабочих нагрузок GPU не требуются. В этот раз были представлены первые данные по чипам Intel Xeon 6900P и 6700P (Granite Rapids), выпускаемым по техпроцессу Intel 3. Компьютер с двумя Xeon 6 показал результат в 40 285 семплов в секунду в тесте распознавания изображений, что составляет около одной трети производительности системы Cisco с двумя NVIDIA H100. По сравнению с результатами Xeon 5 в октябре 2024 года новый процессор демонстрирует прирост в 80 % в данном тесте и ещё большее ускорение в задачах обнаружения объектов и медицинской визуализации. С 2021 года, когда Intel начала представлять результаты Xeon, её процессоры достигли 11-кратного прироста производительности в тесте ResNet. Intel отказалась от участия в категории ускорителей: её конкурент для H100 — Gaudi 3 — не появился ни в текущих результатах MLPerf, ни в версии 4.1, выпущенной в октябре 2024 года. Чип Google TPU v6e также продемонстрировал свои возможности, хотя результаты были ограничены задачей генерации изображений. При 5,48 запроса в секунду система с четырьмя TPU показала прирост в 2,5 раза по сравнению с аналогичным компьютером, использующим TPU v5e, в результатах за октябрь 2024 года. Тем не менее 5,48 запроса в секунду — это примерно те же показатели, что и у аналогичного по размеру компьютера Lenovo с NVIDIA H100.
25.12.2024 [01:00], Владимир Мироненко
Гладко было на бумаге: забагованное ПО AMD не позволяет раскрыть потенциал ускорителей Instinct MI300XАналитическая компания SemiAnalysis опубликовала результаты исследования, длившегося пять месяцев и выявившего большие проблемы в ПО AMD для работы с ИИ, из-за чего на данном этапе невозможно в полной мере раскрыть имеющийся у ускорителей AMD Instinct MI300X потенциал. Проще говоря, из-за забагованности ПО AMD не может на равных соперничать с лидером рынка ИИ-чипов NVIDIA. При этом примерно три четверти сотрудников последней заняты именно разработкой софта. Как сообщает SemiAnalysis, из-за обилия ошибок в ПО обучение ИИ-моделей с помощью ускорителей AMD практически невозможно без значительной отладки и существенных трудозатрат. Более того, масштабирование процесса обучения как в рамках одного узла, так и на несколько узлов показало ещё более существенное отставание решения AMD. И пока AMD занимается обеспечением базового качества и простоты использования ускорителей, NVIDIA всё дальше уходит в отрыв, добавляя новые функции, библиотеки и повышая производительность своих решений, отметили исследователи. 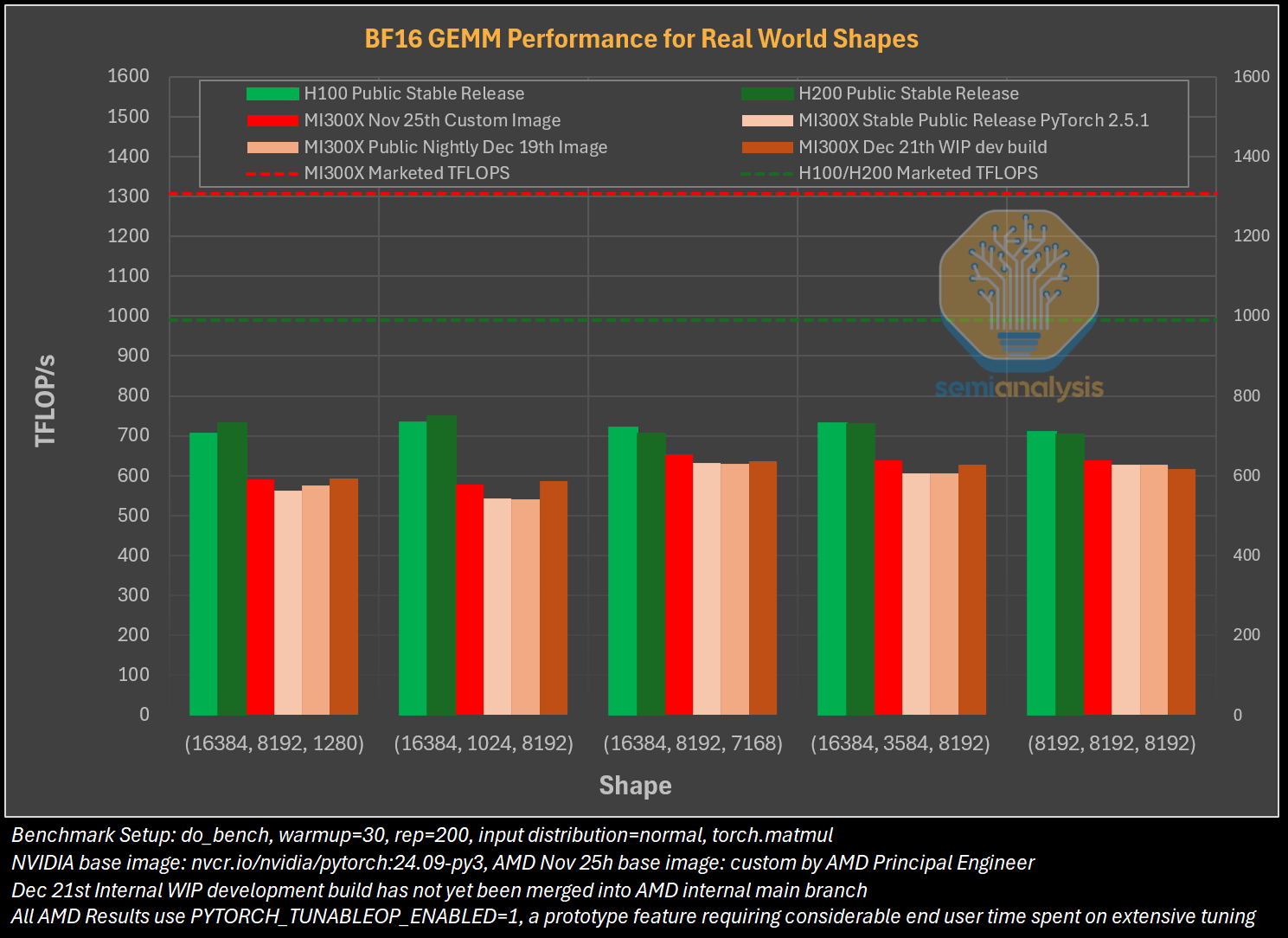
Источник изображений: SemiAnalysis На бумаге чип AMD Instinct MI300X выглядит впечатляюще с FP16-производительностью 1307 Тфлопс и 192 Гбайт памяти HBM3 в сравнении с 989 Тфлопс и 80 Гбайт памяти у NVIDIA H100. К тому же чипы AMD предлагают более низкую общую стоимость владения (TCO) благодаря более низким ценам и использованию более дешёвого интерконнекта на базе Ethernet. Но проблемы с софтом сводят это преимущество на нет и не находят реализации на практике. При этом исследователи отметили, что в NVIDIA H200 объём памяти составляет 141 Гбайт, что означает сокращение разрыва с чипами AMD по этому параметру. Кроме того, внутренняя шина xGMI лишь формально обеспечивает пропускную способность 448 Гбайт/с для связки из восьми ускорителей MI300X. Фактически же P2P-общение между парой ускорителей ограничено 64 Гбайт/с, тогда как для объединения H100 используется NVSwitch, что позволяет любому ускорителю общаться с другим ускорителем на скорости 450 Гбайт/с. А включённый по умолчанию механизм NVLink SHARP делает часть коллективных операций непосредственно внутри коммутатора, снижая объём передаваемых данных. 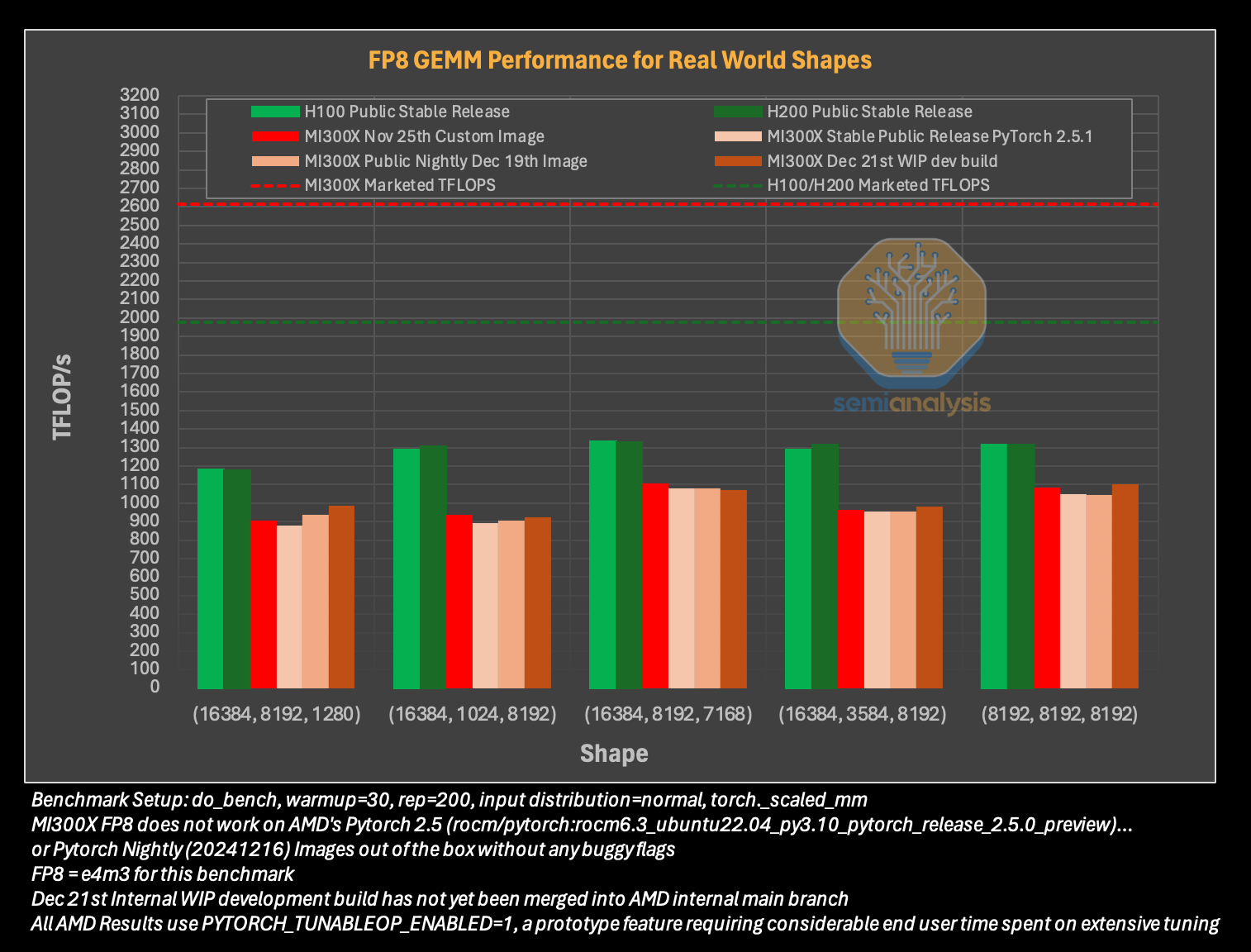 Как отметили в SemiAnalysis, сравнение спецификаций чипов двух компаний похоже на «сравнение камер, когда просто сверяют количество мегапикселей», и AMD просто «играет с числами», не обеспечивая достаточной производительности в реальных задачах. Чтобы получить пригодные для аналитики результаты тестов, специалистам SemiAnalysis пришлось работать напрямую с инженерами AMD над исправлением многочисленных ошибок, в то время как системы на базе NVIDIA работали сразу «из коробки», без необходимости в дополнительной многочасовой отладке и самостоятельной сборке ПО. В качестве показательного примера SemiAnalysis рассказала о случае, когда Tensorwave, крупнейшему провайдеру облачных вычислений на базе ускорителей AMD, пришлось предоставить целой команде специалистов AMD из разных отделов доступ к оборудованию с её же ускорителями, чтобы те устранили проблемы с софтом. Обучение с использованием FP8 в принципе не было возможно без вмешательства инженеров AMD. Со стороны NVIDIA был выделен только один инженер, за помощью к которому фактически не пришлось обращаться. 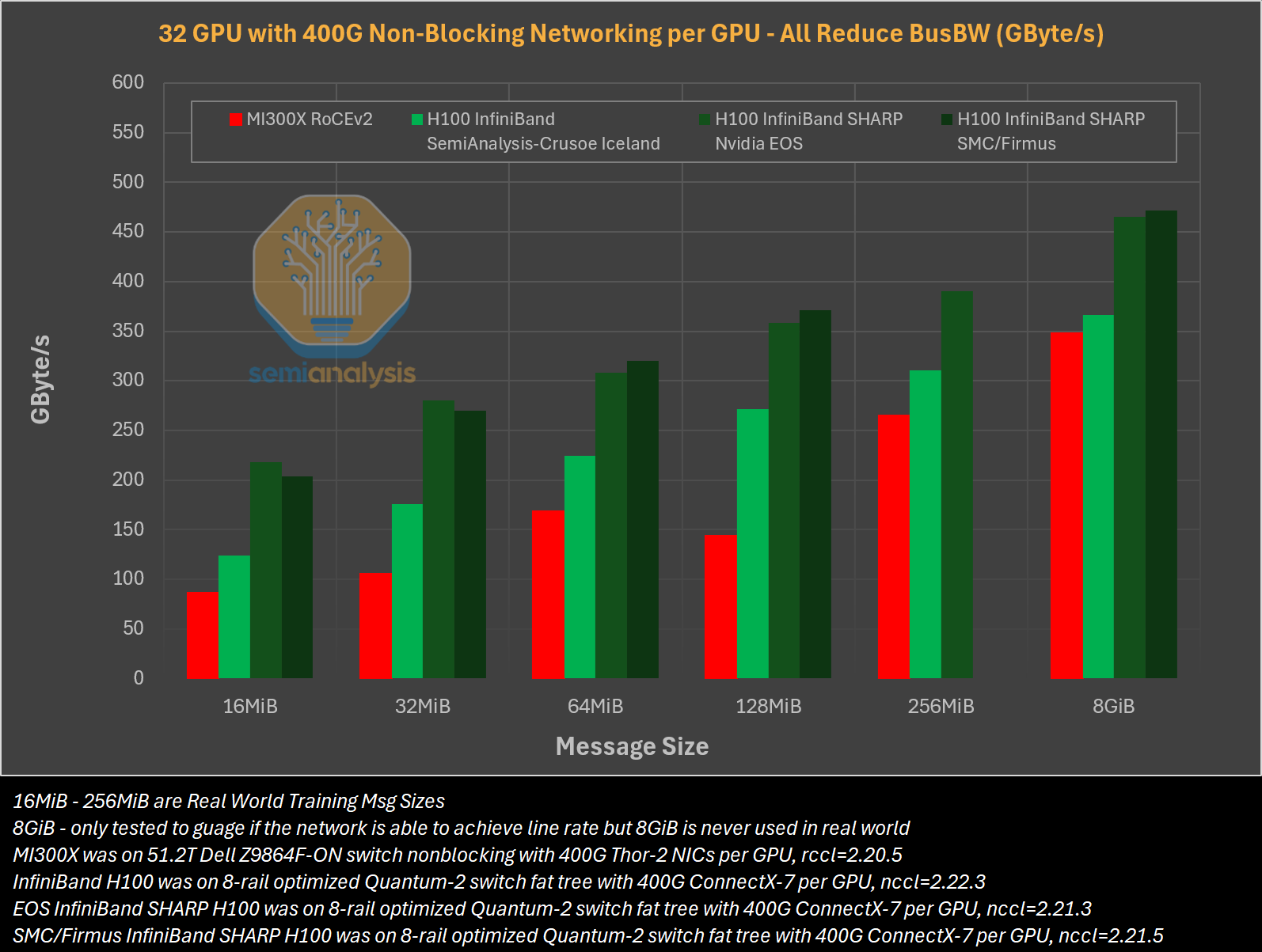 У AMD есть лишь один выход — вложить значительные средства в разработку и тестирование ПО, считают в SemiAnalysis. Аналитики также предложили выделить тысячи чипов MI300X для автоматизированного тестирования, как это делает NVIDIA, и упростить подготовку окружения, одновременно внедряя лучшие настройки по умолчанию. Проблемы с ПО — основная причина, почему AMD не хотела показывать результаты бенчмарка MLPerf и не давала такой возможности другим. В SemiAnalysis отметили, что AMD предстоит немало сделать, чтобы устранить выявленные проблемы. Без серьёзных улучшений своего ПО AMD рискует еще больше отстать от NVIDIA, готовящей к выпуску чипы Blackwell следующего поколения. Для финальных тестов Instinct использовался специально подготовленный инженерами AMD набор ПО, который станет доступен обычным пользователям лишь через один-два квартала. Речь не идёт о Microsoft или Meta✴, которые самостоятельно пишут ПО для Instinct. Один из автором исследования уже провёл встречу с главой AMD Лизой Су (Lisa Su), которая пообещала приложить все усилия для исправления ситуации.
29.11.2024 [10:15], Сергей Карасёв
Система Cerebras с ускорителями WSE установила рекорд в молекулярной динамике, превзойдя суперкомпьютер FrontierАмериканский стартап Cerebras Systems, специализирующийся на создании чипов для систем машинного обучения и других ресурсоёмких задач, объявил об установлении нового мирового рекорда производительности в области молекулярной динамики. В эксперименте приняли участие Сандийские национальные лаборатории (SNL), Ливерморская национальная лаборатория имени Лоуренса (LLNL) и Лос-Аламосская национальная лаборатория (LANL) в составе Министерства энергетики США (DOE). Вычисления выполнялись на системе, оснащённой фирменными ускорителями Cerebras Wafer Scale Engine (WSE). Говорится, что впервые в истории молекулярной динамики исследователи достигли результата более 1 млн шагов моделирования в секунду (timesteps per second, TPS). В частности, показано значение на уровне 1,1 млн TPS на платформе Cerebras CS-2, оборудованной чипами WSE-2, которые насчитывают 850 тыс. тензорных ядер и несут на борту 40 Гбайт памяти SRAM. Для сравнения: в случае суперкомпьютера экзафлопсного класса Frontier, который в нынешнем рейтинге TOP500 занимает второе место, результат составляет 1470 TPS. Таким образом, система Cerebras обеспечивает 748-кратный выигрыш в быстродействии на задачах молекулярной динамики. При этом энергопотребление комплекса Cerebras составляет 27 кВт против 21 МВт у Frontier. 
Источник изображения: Cerebras Кроме того, комплекс Cerebras превзошел Anton 3 — самый мощный в мире специализированный суперкомпьютер для молекулярной динамики. Anton 3 использует 512 кастомных ASIC, а его энергопотребление находится на уровне 400 кВт. Показатель быстродействия Anton 3 достигает 980 тыс. TPS. То есть, система Cerebras показывает выигрыш примерно в 20 %. Предполагается, что ускорители Cerebras предоставят качественно новые возможности для исследований в различных областях, включая разработку материалов следующего поколения, перспективных лекарственных препаратов и решений в сфере возобновляемой энергетики. Нужно отметить, что ранее Сандийские национальные лаборатории запустили ИИ-систему Kingfisher на чипах Cerebras WSE-3. А сама компания Cerebras развернула «самую мощную в мире» ИИ-платформу для инференса.
14.11.2024 [23:07], Владимир Мироненко
Google и NVIDIA показали первые результаты TPU v6 и B200 в ИИ-бенчмарке MLPerf TrainingУскорители Blackwell компании NVIDIA опередили в бенчмарках MLPerf Training 4.1 чипы H100 более чем в 2,2 раза, сообщил The Register. По словам NVIDIA, более высокая пропускная способность памяти в Blackwell также сыграла свою роль. Тесты были проведены с использование собственного суперкомпьютера NVIDIA Nyx на базе DGX B200. Новые ускорители имеют примерно в 2,27 раза более высокую пиковую производительность в вычисления FP8, FP16, BF16 и TF32, чем системы H100 последнего поколения. B200 показал в 2,2 раза более высокую производительность при тюнинге модели Llama 2 70B и в два раза большую производительность при предварительном обучении (Pre-training) модели GPT-3 175B. Для рекомендательных систем и генерации изображений прирост составил 64 % и 62 % соответственно. Компания также отметила преимущества используемой в B200 памяти HBM3e, благодаря которой бенчмарк GPT-3 успешно отработал всего на 64 ускорителях Blackwell без ущерба для производительности каждого GPU, тогда как для достижения такого же результата понадобилось бы 256 ускорителей H100. Впрочем, про Hopper компания тоже не забывает — в новом раунде компания смогла масштабировать тест GPT-3 175B до 11 616 ускорителей H100. 
Источник изображений: NVIDIA Компания отметила, что платформа NVIDIA Blackwell обеспечивает значительный скачок производительности по сравнению с платформой Hopper, особенно при работе с LLM. В то же время чипы поколения Hopper по-прежнему остаются актуальными благодаря непрерывным оптимизациям ПО, порой кратно повышающим производительность в некоторых задач. Интрига в том, что в этот раз NVIDIA решила не показывать результаты GB200, хотя такие системы есть и у неё, и у партнёров.  В свою очередь, Google представила первые результаты тестирования 6-го поколения TPU под названием Trillium, о доступности которого было объявлено в прошлом месяце, и второй раунд результатов ускорителей 5-го поколения TPU v5p. Ранее Google тестировала только TPU v5e. По сравнению с последним вариантом, Trillium обеспечивает прирост производительности в 3,8 раза в задаче обучения GPT-3, отмечает IEEE Spectrum.  Если же сравнивать результаты с показателями NVIDIA, то всё выглядит не так оптимистично. Система из 6144 TPU v5p достигла контрольной точки обучения GPT-3 за 11,77 мин, отстав от системы с 11 616 H100, которая выполнила задачу примерно за 3,44 мин. При одинаковом же количестве ускорителей решения Google почти вдвое отстают от решений NVIDIA, а разница между v5p и v6e составляет менее 10 %. 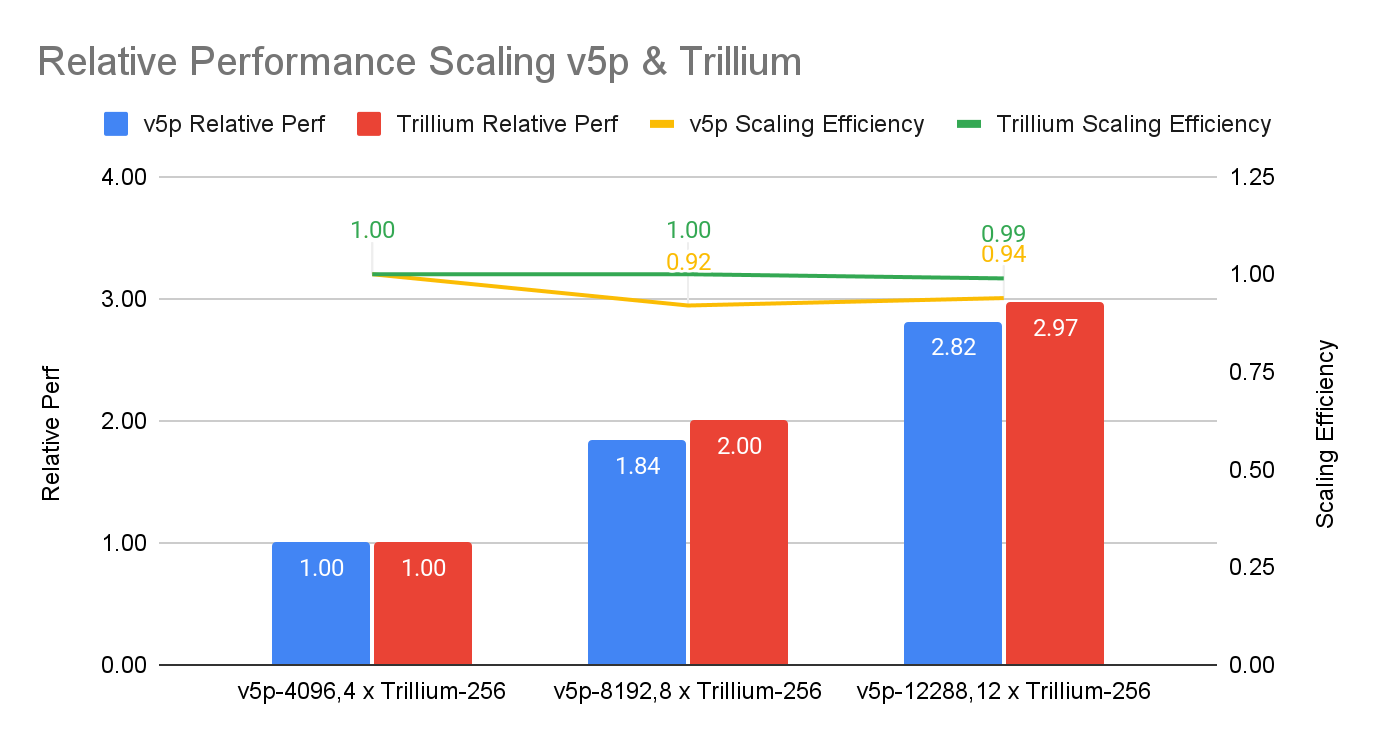
Источник изображения: Google В тесте Stable Diffusion система из 1024 TPU v5p заняла второе место, завершив работу за 2,44 мин, тогда как система того же размера на основе NVIDIA H100 справилась с задачей за 1,37 мин. В остальных тестах на кластерах меньшего масштаба разрыв остаётся примерно полуторакратным. Впрочем, Google упирает на масштабируемость и лучшее соотношение цены и производительности в сравнении как с решениями конкурентов, так и с собственными ускорителями прошлых поколений. Также в новом раунде MLPerf появился единственный результат измерения энергопотребления во время проведения бенчмарка. Система из восьми серверов Dell XE9680, каждый из которых включал восемь ускорителей NVIDIA H100 и два процессора Intel Xeon Platinum 8480+ (Sapphire Rapids), в задаче тюнинга Llama2 70B потребила 16,38 мДж энергии, потратив на работу 5,05 мин. — средняя мощность составила 54,07 кВт.
29.08.2024 [01:00], Владимир Мироненко
NVIDIA вновь показала лидирующие результаты в ИИ-бенчмарке MLPerf InferenceNVIDIA сообщила, что её платформы показали самые высокие результаты во всех тестах производительности уровня ЦОД в бенчмарке MLPerf Inference v4.1, где впервые дебютировал ускоритель семейства Blackwell. Ускоритель NVIDIA B200 (SXM, 180 Гбайт HBM) оказался вчетверо производительнее H100 на крупнейшей рабочей нагрузке среди больших языковых моделей (LLM) MLPerf — Llama 2 70B — благодаря использованию механизма Transformer Engine второго поколения и FP4-инференсу на Tensor-ядрах. Впрочем, именно B200 заказчики могут и не дождаться. Ускоритель NVIDIA H200, который стал доступен в облаке CoreWeave, а также в системах ASUS, Dell, HPE, QTC и Supermicro, показал лучшие результаты во всех тестах в категории ЦОД, включая последнее дополнение к бенчмарку, LLM Mixtral 8x7B с общим количеством параметров 46,7 млрд и 12,9 млрд активных параметров на токен, использующую архитектуру Mixture of Experts (MoE, набор экспертов). 
Источник изображения: NVIDIA Как отметила NVIDIA, MoE приобрела популярность как способ привнести большую универсальность в LLM, поскольку позволяет отвечать на широкий спектр вопросов и выполнять более разнообразные задачи в рамках одного развёртывания. Архитектура также более эффективна, поскольку активируются только несколько экспертов на инференс — это означает, что такие модели выдают результаты намного быстрее, чем высокоплотные (Dense) модели аналогичного размера. Также NVIDIA отмечает, что с ростом размера моделей для снижения времени отклика при инференсе объединение нескольких ускорителей становится обязательными. По словам компании, NVLink и NVSwitch уже в поколении NVIDIA Hopper предоставляют значительные преимущества для экономичного инференса LLM в реальном времени. А платформа Blackwell ещё больше расширит возможности NVLink, позволив объединить до 72 ускорителей. 
Источник изображения: NVIDIA Заодно компания в очередной раз напомнила о важности программной экосистемы. Так, в последнем раунде MLPerf Inference все основные платформы NVIDIA продемонстрировали резкий рост производительности. Например, ускорители NVIDIA H200 показали на 27 % большую производительность инференса генеративного ИИ по сравнению с предыдущим раундом. А Triton Inference Server продемонстрировал почти такую же производительность, как и у bare-metal платформ. Наконец, благодаря программным оптимизациям в этом раунде MLPerf платформа NVIDIA Jetson AGX Orin достигла более чем 6,2-кратного улучшения пропускной способности и 2,5-кратного улучшения задержки по сравнению с предыдущим раундом на рабочей нагрузке GPT-J LLM. По словам NVIDIA, Jetson способен локально обрабатывать любую модель-трансформер, включая LLM, модели класса Vision Transformer и, например, Stable Diffusion. А вместо разработки узкоспециализированных моделей теперь можно применять универсальную GPT-J-6B модель для обработки естественного языка на периферии.
01.08.2024 [23:55], Алексей Степин
Arm-процессоры AWS Graviton4 успешно конкурируют с актуальными Intel Xeon, а иногда обгоняют даже AMD EPYCВсего за пять лет Amazon успела разработать и внедрить четыре поколения серверных Arm-процессоров Graviton. 4-нм Graviton4 получили 96 ядер и 12 каналов памяти DDR5-5600, а также поддержку PCIe 5.0. Всё это дало AWS основание утверждать, что Graviton4 производительнее предшественника на 30 %, а пропускная способность памяти у него выше на 75 %. Насколько это соответствует истине, выяснил ресурс Phoronix, который заодно сравнил новинки с другими современными процессорами. В тестировании Phoronix приняли участие следующие модели Graviton:

Источник: AWS Платформа Graviton в последней итерации выглядит вполне достойно. Она использует современный набор инструкций Arm, а по количеству ядер и каналов памяти сопоставима с новейшими решениями Intel и AMD. Производительность по мере смены поколений у Graviton растёт практически линейно, за исключением перехода от первого поколения ко второму, что легко объясняется возросшим сразу вчетверо количеством ядер. Что касается Graviton4, то новые процессоры в среднем быстрее Graviton3 примерно в 1,55 раза, а первенца серии они превосходят в 10,4 раза. В некоторых случаях выигрыш выходит далеко за рамки теоретических 1,5x, поскольку у Graviton4 более совершенная архитектура, новее набор инструкций, вдвое больший объем кеша на ядро и существенно более производительная подсистема памяти. Такое поведение, к примеру, характерно для тестов srsRAN, задач криптографии и особенно работы с базами данных. 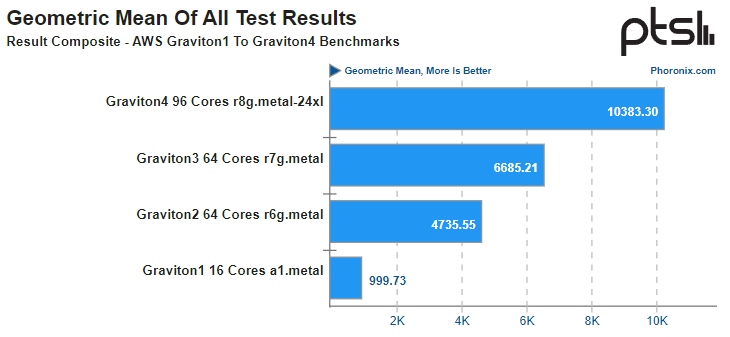
Источник здесь и далее: Phoronix В другом исследовании Phoronix процессорам Graviton4 довелось столкнуться с серьёзными соперниками из мира x86, включая 128-ядерный AMD EPYC 9754 (Bergamo) и 144-ядерные Intel Xeon 67xx (Sierra Forest), а также с ближайшим конкурентом по Arm-платформе, 128-ядерным процессором Ampere Altra Max. К сожалению, метрик энергопотребления в текущей версии инстанса r8g.metal-24xl получить не удалось, но и без этого результаты получены весьма интересные. С первых тестов очевидно, что Altra Max уже не соперник современным решениям, несмотря на сопоставимое количество ядер — сказывается не самая новая архитектура. А вот Graviton4 чувствует себя неплохо и в тестах на компиляцию может опережать даже AMD EPYC 9754. Хороша новинка и в базах данных, она лишь немного уступает процессорам Genoa и зачастую опережает 144-ядерное решение Intel c E-ядрами. И даже в HPC-нагрузках, для которых характерно активное использование FP-вычислений у Graviton4 всё хорошо! Неплохо себя детище AWS чувствует и в сценариях (де-)компрессии данных и кодировании видео. 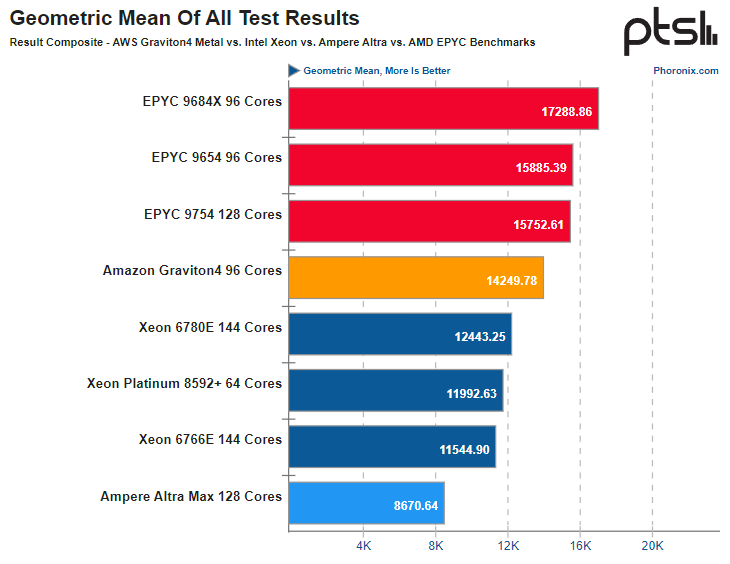 В итоговом зачёте AWS Graviton4 уверенно занимает место в середине таблицы, опережая оба Xeon — и 64-ядерный Platinum 8592+ (Emerald Rapids), и 144-ядерный Xeon 6780E, но до уровня AMD EPYC 9754 всё же несколько недотягивая. Это вполне даёт основание считать, что платформа AWS Graviton достигла зрелости. Она вполне конкурентоспособна даже на фоне x86-монстров. Более того, на сегодня Graviton4 можно считать самым продвинутым серверным процессором с архитектурой AArch64. Впрочем, вскоре предстоят сражения с Granite Rapids, Turin и AmpereOne (а на подходе ещё и Aurora с HBM). |
|