Лента новостей
|
05.09.2022 [23:00], Алексей Степин
Tesla рассказала подробности о чипах D1 собственной разработки, которые станут основой 20-Эфлопс ИИ-суперкомпьютера DojoКомпания Tesla уже анонсировала собственный, созданный в лабораториях компании процессор D1, который станет основой ИИ-суперкомпьютера Dojo. Нужна такая система, чтобы создать для ИИ-водителя виртуальный полигон, в деталях воссоздающий реальные ситуации на дорогах. Естественно, такой симулятор требует огромных вычислительных мощностей: в нашем мире дорожная обстановка очень сложна, изменчива и включает множество факторов и переменных. До недавнего времени о Dojo и D1 было известно не так много, но на конференции Hot Chips 34 было раскрыто много интересного об архитектуре, устройстве и возможностях данного решения Tesla. Презентацию провел Эмиль Талпес (Emil Talpes), ранее 17 лет проработавший в AMD над проектированием серверных процессоров. Он, как и ряд других видных разработчиков, работает сейчас в Tesla над созданием и совершенствованием аппаратного обеспечения компании. 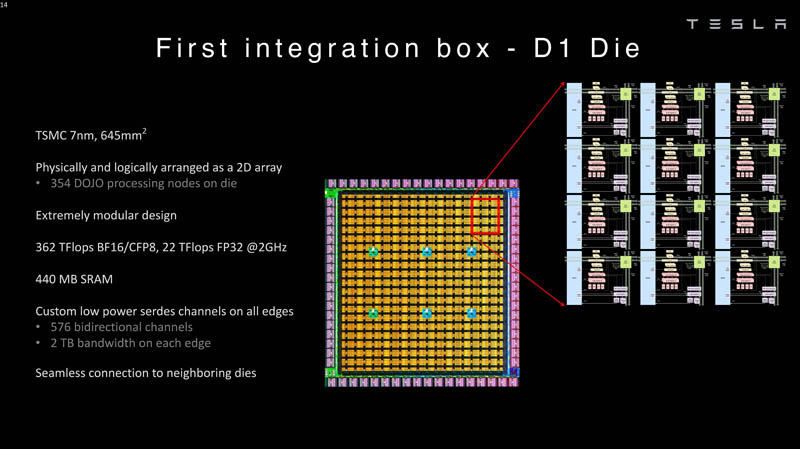
Изображения: Tesla (via ServeTheHome) Главной идеей D1 стала масштабируемость, поэтому в начале разработки нового чипа создатели активно пересмотрели роль таких традиционных концепций, как когерентность, виртуальная память и т.д. — далеко не все механизмы масштабируются лучшим образом, когда речь идёт о построении действительно большой вычислительной системы. Вместо этого предпочтение было отдано распределённой сети хранения на базе SRAM, для которой был создан интерконнект, на порядок опережающий существующие реализации в системах распределённых вычислений. 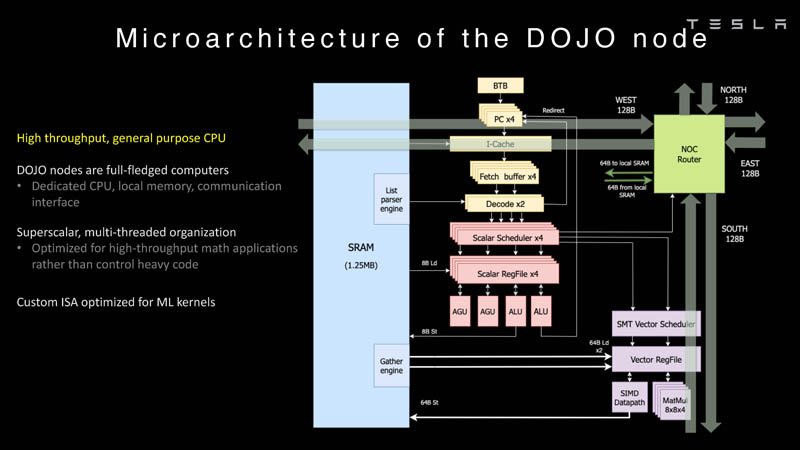 Основой процессора Tesla стало ядро целочисленных вычислений, базирующееся на некоторых инструкциях из набора RISC-V, но дополненное большим количеством фирменных инструкций, оптимизированных с учётом требований, предъявляемых ядрами машинного обучения, используемыми компанией. Блок векторной математики был создан практически с нуля, по словам разработчиков. 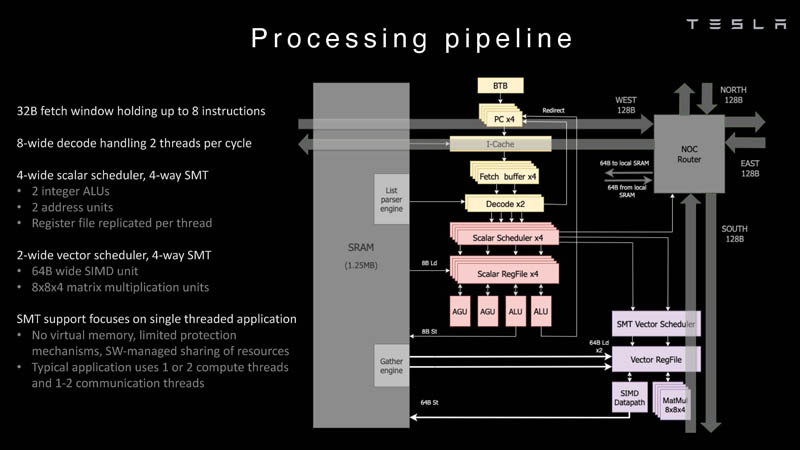 Набор инструкций Dojo включает в себя скалярные, матричные и SIMD-инструкции, а также специфические примитивы для перемещения данных из локальной памяти в удалённую, равно как и семафоры с барьерами — последние требуются для согласования работы c памятью во всей системе. Что касается специфических инструкций для машинного обучения, то они реализованы в Dojo аппаратно. 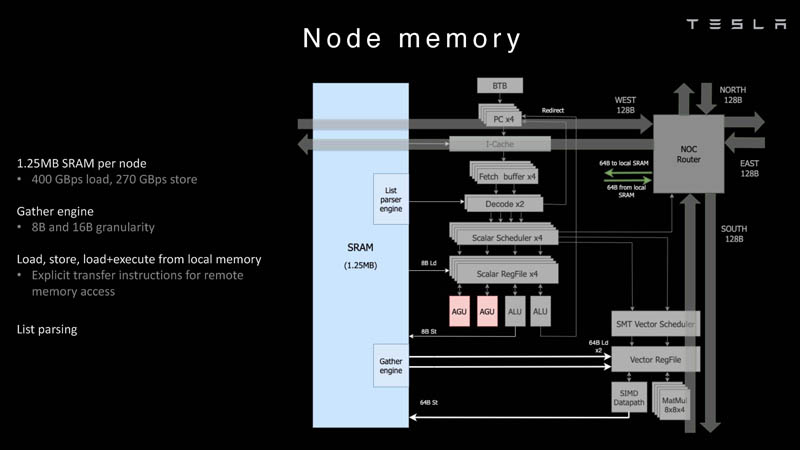 Первенец в серии, чип D1, не является ускорителем как таковым — компания считает его высокопроизводительным процессором общего назначения, не нуждающимся в специфических ускорителях. Каждый вычислительный блок Dojo представлен одним ядром D1 с локальной памятью и интерфейсами ввода/вывода. Это 64-бит ядро суперскалярно. 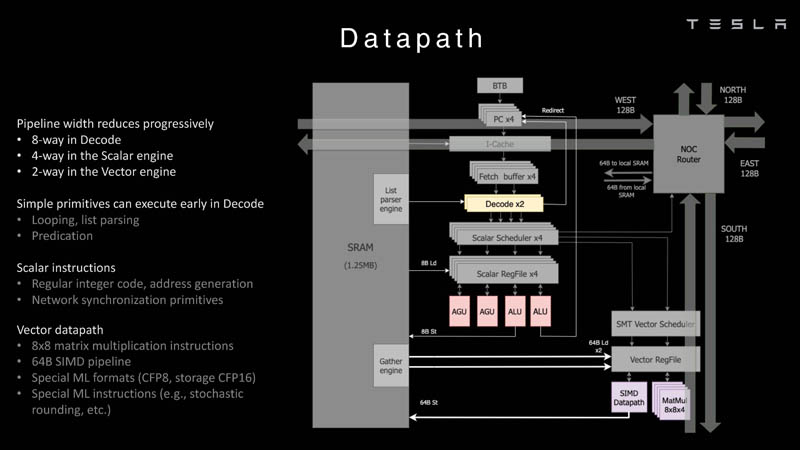 Более того, в ядре реализована поддержка многопоточности (SMT4), которая призвана увеличить производительность на такт (а не изолировать разные задачи друг от друга), поэтому виртуальную память данная реализация SMT не поддерживает, а механизмы защиты довольно ограничены в функциональности. За управление ресурсами Dojo отвечает специализированный программный стек и фирменное ПО. 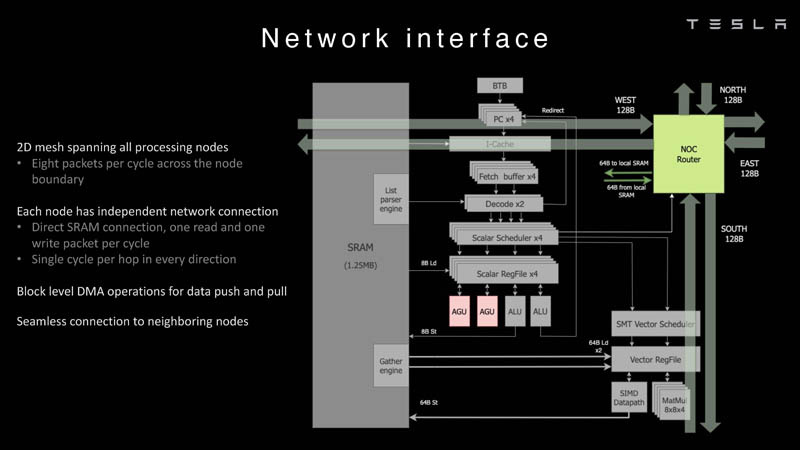 64-бит ядро имеет 32-байт окно выборки (fetch window), которое может содержать до 8 инструкций, что соответствует ширине декодера. Он, в свою очередь, может обрабатывать два потока за такт. Результат поступает в планировщики, которые отправляют его в блок целочисленных вычислений (два ALU) или в векторный блок (SIMD шириной 64 байт + перемножение матриц 8×8×4). 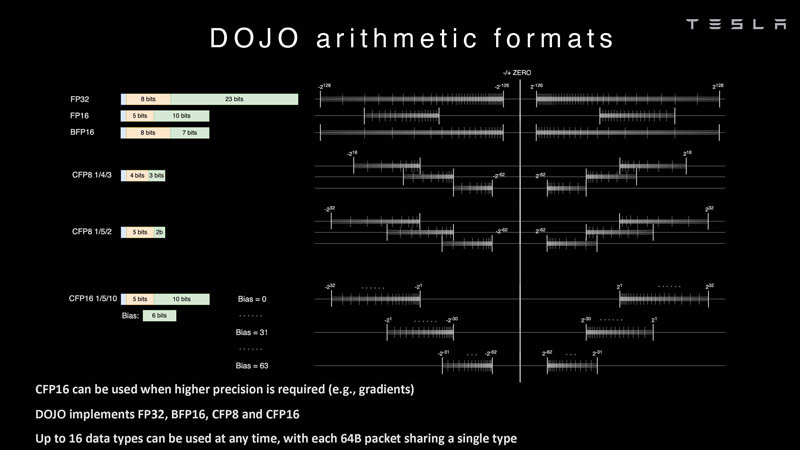 У каждого ядра D1 есть SRAM объёмом 1,25 Мбайт. Эта память — не кеш, но способна загружать данные на скорости 400 Гбайт/с и сохранять на скорости 270 Гбайт/с, причём, как уже было сказано, в чипе реализованы специальные инструкции, позволяющие работать с данными в других ядрах Dojo. Для этого в блоке SRAM есть свои механизмы, так что работа с удалённой памятью не требуют дополнительных операций.  Что касается поддерживаемых форматов данных, то скалярный блок поддерживает целочисленные форматы разрядностью от 8 до 64 бит, а векторный и матричный блоки — широкий набор форматов с плавающей запятой, в том числе для вычислений смешанной точности: FP32, BF16, CFP16 и CFP8. Разработчики D1 пришли к использованию целого набора конфигурируемых 8- и 16-бит представлений данных — компилятор Dojo может динамически изменять значения мантиссы и экспоненты, так что система может использовать до 16 различных векторных форматов, лишь бы в рамках одного 64-байт блока данных он не менялся.  Как уже упоминалось, топология D1 использует меш-структуру, в которой каждые 12 ядер объединены в логический блок. Чип D1 целиком представляет собой массив размером 18×20 ядер, однако доступны лишь 354 ядра из 360 присутствующих на кристалле. Сам кристалл площадью 645 мм2 производится на мощностях TSMC с использованием 7-нм техпроцесса. Тактовая частота составляет 2 ГГц, общий объём памяти SRAM — 440 Мбайт.  Процессор D1 развивает 362 Тфлопс в режиме BF16/CFP8, в режиме FP32 этот показатель снижается до 22 Тфлопс. Режим FP64 векторными блоками D1 не поддерживается, поэтому для многих традиционных HPC-нагрузок данный процессор не подойдёт. Но Tesla создавала D1 для внутреннего использования, поэтому совместимость её не очень волнует. Впрочем, в новых поколениях, D2 или D3, такая поддержка может появиться, если это будет отвечать целям компании. 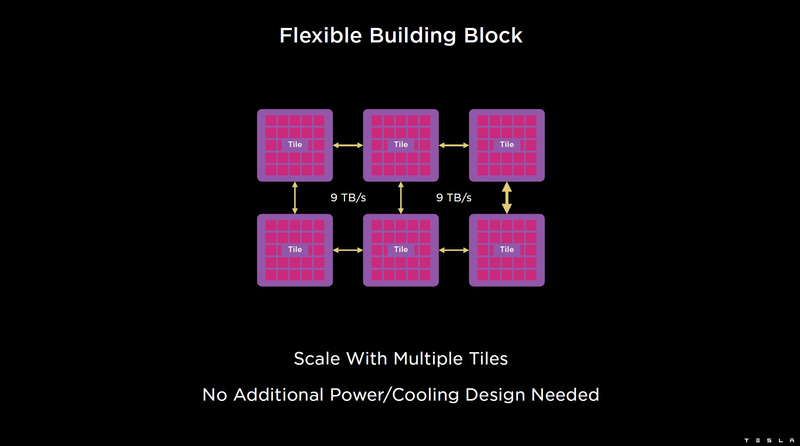 Каждый кристалл D1 имеет 576-битный внешний интерфейс SerDes с совокупной производительностью по всем четырём сторонам, составляющей 18 Тбайт/с, так что узким местом при соединении D1 он явно не станет. Этот интерфейс объединяет кристаллы в единую матрицу 5х5, такая матрица из 25 кристаллов D1 носит название Dojo training tile. 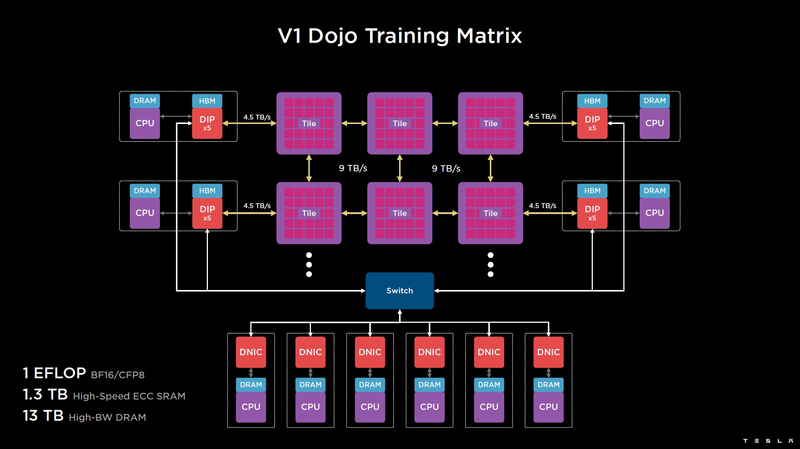 Этот тайл выполнен как законченный термоэлектромеханический модуль, имеющий внешний интерфейс с пропускной способностью 4,5 Тбайт/с на каждую сторону, совокупно располагающий 11 Гбайт памяти SRAM, а также собственную систему питания мощностью 15 кВт. Вычислительная мощность одного тайла Dojo составляет 9 Пфлопс в формате BF16/CFP8. При таком уровне энергопотребления охлаждение у Dojo может быть только жидкостное.  Тайлы могут объединяться в ещё более производительные матрицы, но как именно физически организован суперкомпьютер Tesla, не вполне ясно. Для связи с внешним миром используются блоки DIP — Dojo Interface Processors. Это интерфейсные процессоры, посредством которых тайлы общаются с хост-системами и на долю которых отведены управляющие функции, хранение массивов данных и т.п. Каждый DIP не просто выполняет IO-функции, но и содержит 32 Гбайт памяти HBM (не уточняется, HBM2e или HBM3). 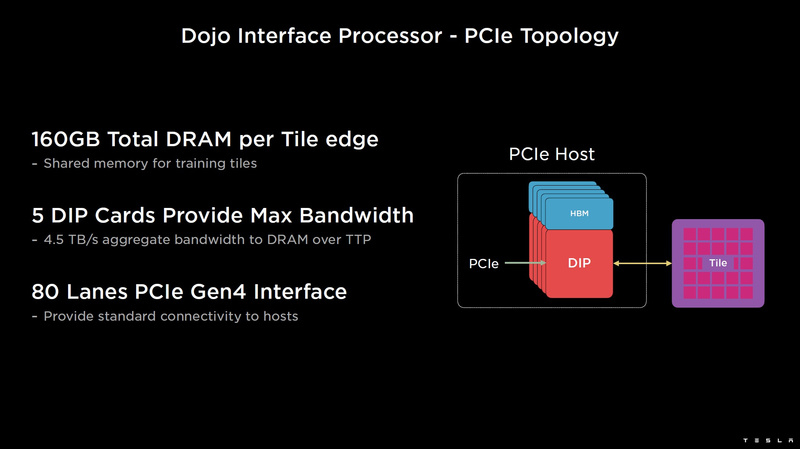 DIP использует полностью свой транспортный протокол (Tesla Transport Protocol, TTP), разработанный в Tesla и обеспечивающий пропускную способность 900 Гбайт/с, а поверх Ethernet — 50 Гбайт/с. Внешний интерфейс у карточек — PCI Express 4.0, и каждая интерфейсная карта несёт пару DIP. С каждой стороны каждого ряда тайлов установлено по 5 DIP, что даёт скорость до 4,5 Тбайт/с от HBM-стеков к тайлу.  В случаях, когда во всей системе обращение от тайла к тайлу требует слишком много переходов (до 30 в случае обращения от края до края), система может воспользоваться DIP, объединённых снаружи 400GbE-сетью по топологии fat tree, сократив таким образом, количество переходов до максимум четырёх. Пропускная способность в этом случае страдает, но выигрывает латентность, что в некоторых сценариях важнее. 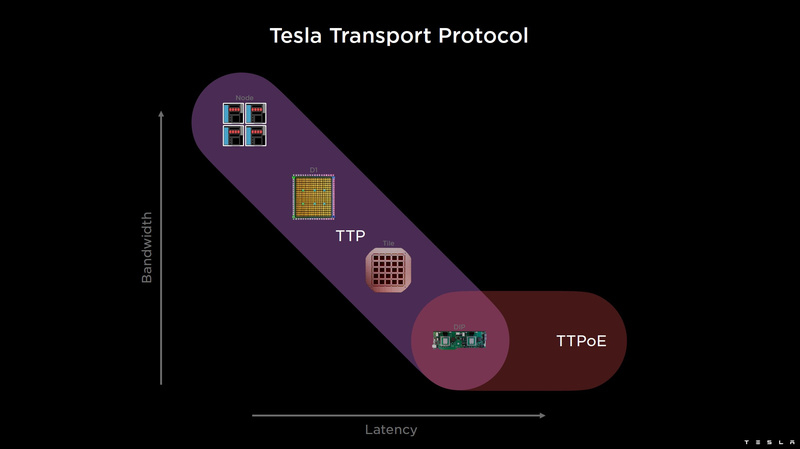 В базовой версии суперкомпьютер Dojo V1 выдаёт 1 Эфлопс в режиме BF16/CFP8 и может загружать непосредственно в SRAM модели объёмом до 1,3 Тбайт, ещё 13 Тбайт данных можно хранить в HBM-сборках DIP. Следует отметить, что пространство SRAM во всей системе Dojo использует единую плоскую адресацию. Полномасштабная версия Dojo будет иметь производительность до 20 Эфлопс. Сколько сил потребуется компании, чтобы запустить такого монстра, а главное, снабдить его рабочим и приносящим пользу ПО, неизвестно — но явно немало. Известно, что система совместима с PyTorch. В настоящее время Tesla уже получает готовые чипы D1 от TSMC. А пока что компания обходится самым большим в мире по числу установленных ускорителей NVIDIA ИИ-суперкомпьютером.
26.08.2022 [12:45], Алексей Степин
Интерконнект NVIDIA NVLink 4 открывает новые горизонты для ИИ и HPCПотребность в действительно быстром интерконнекте для ускорителей возникла давно, поскольку имеющиеся шины зачастую становились узким местом, не позволяя «прокормить» данными вычислительные блоки. Ответом NVIDIA на эту проблему стало создание шины NVLink — и компания продолжает активно развивать данную технологию. На конференции Hot Chips 34 было продемонстрировано уже четвёртое поколение, наряду с новым поколением коммутаторов NVSwitch. 
Изображения: NVIDIA Возможность использования коммутаторов для NVLink появилась не сразу, изначально использовалось соединение блоков ускорителей по схеме «точка-точка». Но дальнейшее наращивание числа ускорителей по этой схеме стало невозможным, и тогда NVIDIA разработала коммутаторы NVSwitch. Они появились вместе с V100 и предлагали до 50 Гбайт/с на порт. Нынешнее же, третье поколение NVSwitch и четвёртое поколение NVLink сделали важный шаг вперёд — теперь они позволяют вынести NVLink-подключения за пределы узла. 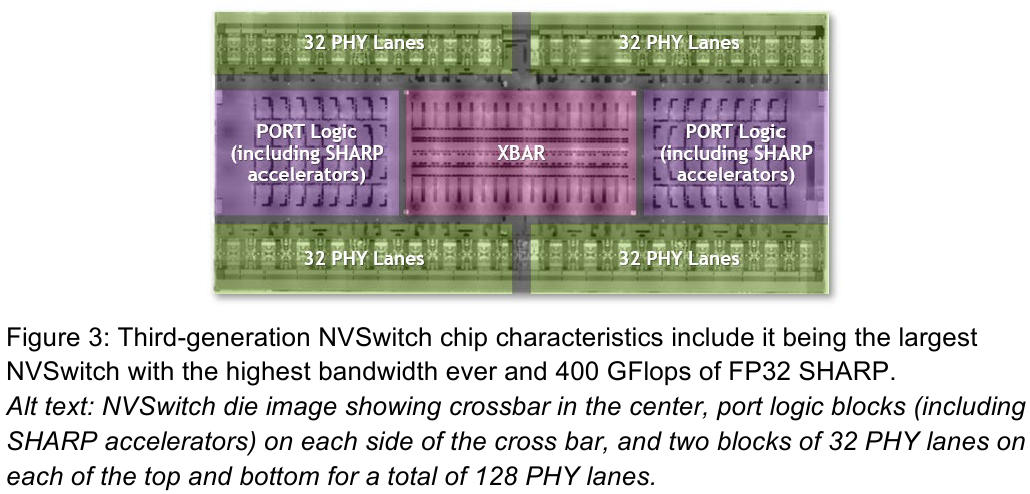 Так, совокупная пропускная способность одного чипа NVSwitch теперь составляет 3,2 Тбайт/с в обе стороны в 64 портах NVLink 4 (x2). Это, конечно, отразилось и на сложности самого «кремния»: 25,1 млрд транзисторов (больше чем у V100), техпроцесс TSMC 4N и площадь 294мм2. Скорость одной линии NVLink 4 осталась равной 50 Гбайт/с, но новые ускорители H100 имеют по 18 линий NVLink, что даёт впечатляющие 900 Гбайт/с. В DGX H100 есть сразу четыре NVSwitch-коммутатора, которые объединяют восемь ускорителей по схеме каждый-с-каждым и дополнительно отдают ещё 72 NVLink-линии (3,6 Тбайт/с). 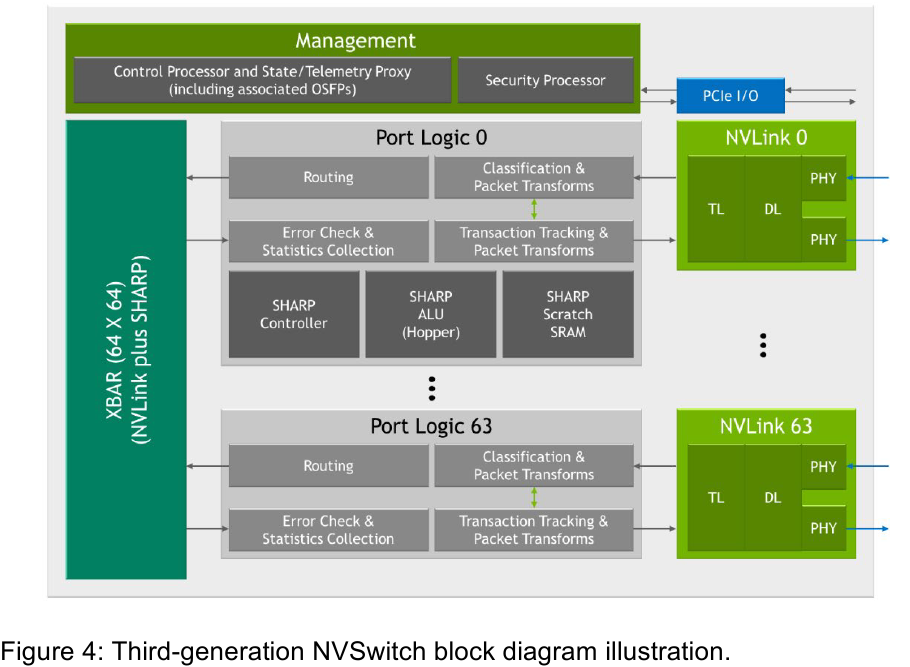 При этом у DGX H100 сохраняются прежние 400G-адаптеры Ethernet/InfiniBand (ConnectX-7), по одному на каждый ускоритель, и пара DPU BlueField-3, тоже класса 400G. Несколько упрощает физическую инфраструктуру то, что для внешних NVLink-подключений используются OSFP-модули, каждый из которых обслуживает 4 линии NVLink. Любопытно, что электрически интерфейсы совместимы с имеющейся 400G-экосистемой (оптической и медной), но вот прошивки для модулей нужны будут кастомные. 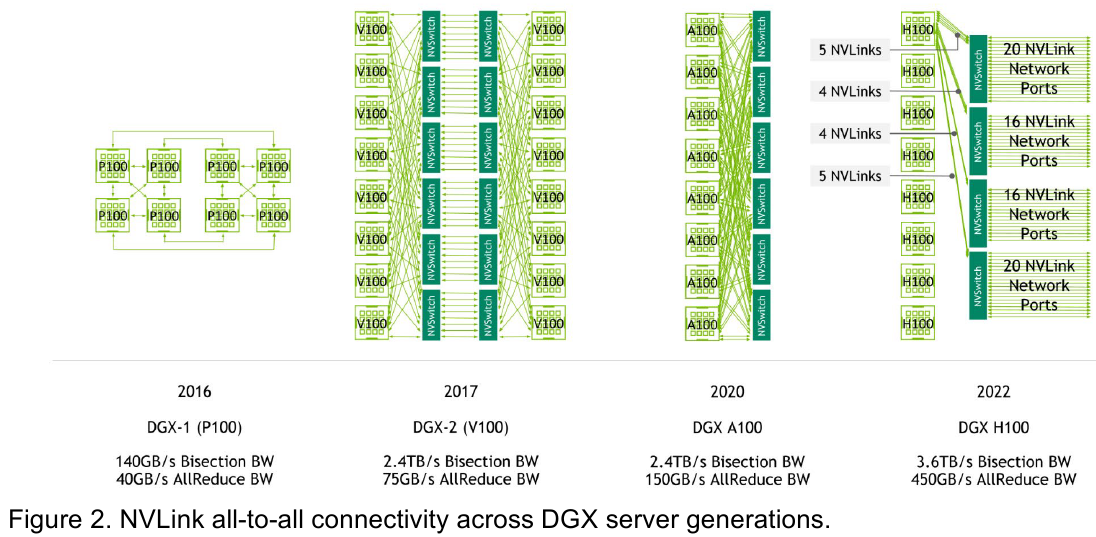 Подключаются узлы DGX H100 к 1U-коммутатору NVLink Switch, включающему два чипа NVSwitch третьего поколения: 32 OSFP-корзины, 128 портов NVLink 4 и агрегированная пропускная способность 6,4 Тбайт/с. В составе DGX SuperPOD есть 18 коммутаторов NVLink Switch и 256 ускорителей H100 (32 узла DGX). Таким образом, можно связать ускорители и узлы 900-Гбайт/с каналом. Как конкретно, остаётся на усмотрение пользователя, но сама NVLink-сеть поддерживает динамическую реконфигурацию на лету. 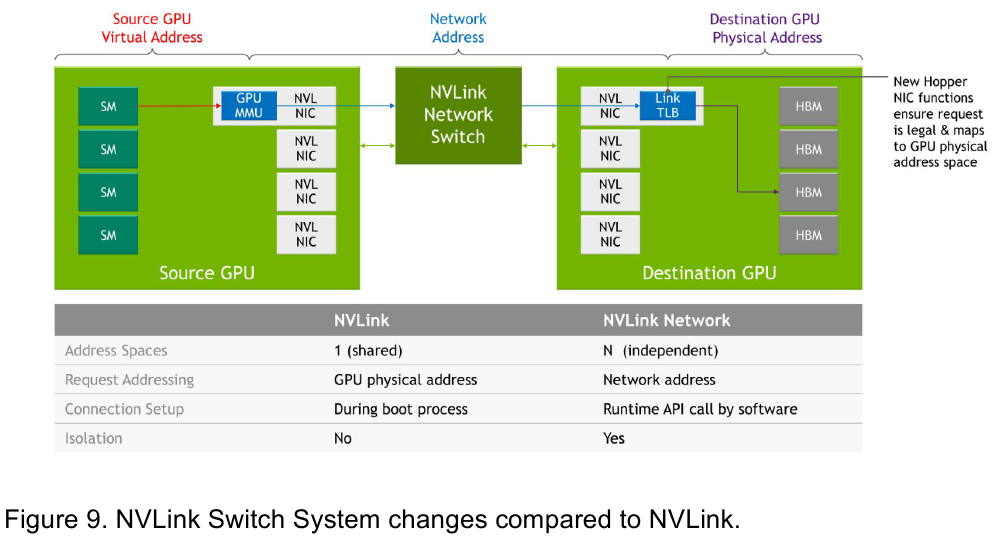 Ещё одна особенность нового поколения NVLink — продвинутые аппаратные SHARP-движки, которые избавляют CPU/GPU от части работ по подготовке и предобработки данных и избавляющие саму сеть от ненужных передач. Кроме того, в NVLink-сети реализованы разделение и изоляция, брандмауэр, шифрование, глубокая телеметрия и т.д. В целом, новое поколение NVLink получило полуторакратный прирост в скорости обмена данными, а в отношении дополнительных сетевых функций он стал трёхкратным. Всё это позволит освоить новые класса HPC- и ИИ-нагрузок, однако надо полагать, что удовольствие это будет недешёвым.
24.08.2022 [22:42], Владимир Мироненко
Untether AI представила ИИ-ускоритель speedAI240 — 1,5 тыс. ядер RISC-V и 238 Мбайт SRAM со скоростью 1 Пбайт/сКомпания Untether AI анонсировала ИИ-архитектуру следующего поколения speedAI (кодовое название «Boqueria»), ориентированную на инференс-нагрузки. При энергоэффективности 30 Тфлопс/Вт и производительности до 2 Пфлопс на чип speedAI устанавливает новый стандарт энергоэффективности и плотности вычислений, говорит компания.  Поскольку at-memory вычисления в ряде задач значительно энергоэффективнее традиционных архитектур, они могут обеспечить более высокую производительность при одинаковых затратах энергии. Первое поколение устройств runAI в 2020 году Untether AI достигла энергоэффективности на уровне 8 Тфлопс/Вт для INT8-вычислений. Новая архитектура speedAI обеспечивает уже 30 Тфлопс/Вт. .jpg)
Изображения: Untether AI (via ServeTheHome) 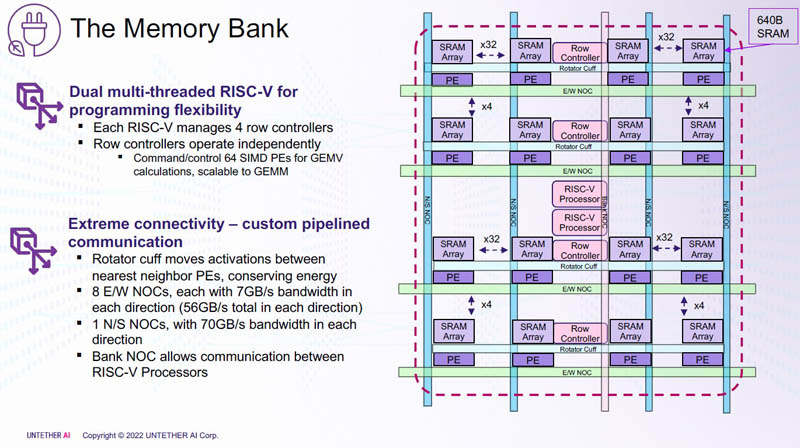 Этого удалось добиться благодаря архитектуре второго поколения, использованию более 1400 оптимизированных 7-нм ядер RISC-V (1,35 ГГц) с кастомными инструкциями, энергоэффективному управлению потоком данных и внедрению поддержки FP8. Вкупе это позволило вчетверо поднять эффективность speedAI по сравнению с runAI. Новинка может быть гибко адаптирована к различным архитектурам нейронных сетей. Концептуально speedAI напоминает ещё один тысячеядерный чип RISC-V — Esperanto ET-SoC-1. 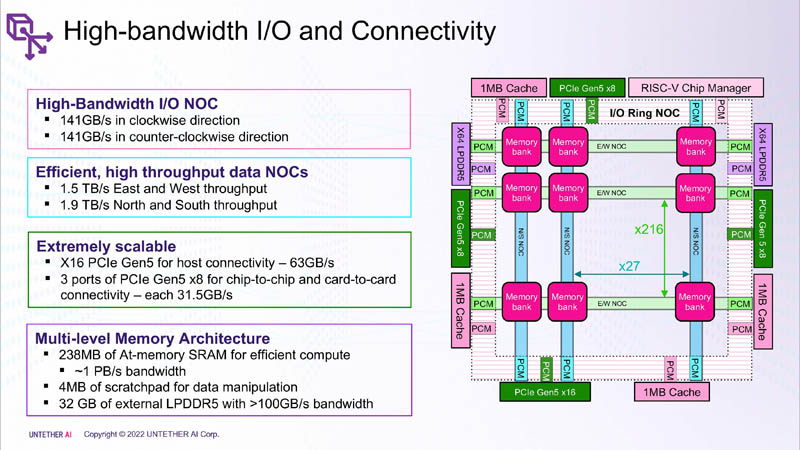 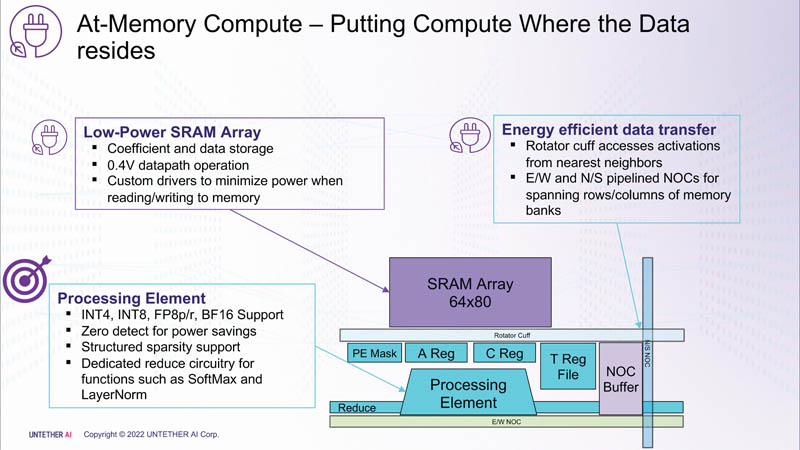 Первый член семейства speedAI — speedAI240 — обеспечивает 2 Пфлопс вычислениях в FP8-вычислениях или 1 Пфлопс для BF16-операций. Благодаря этому обеспечивается самая высокая в отрасли эффективность — например, для модели BERT заявленная производительность составляет 750 запросов в секунду на Вт (qps/w), что, по словам компании, в 15 раз выше, чем у современных GPU. Добиться повышения производительности удалось благодаря тесной интеграции вычислительных элементов и памяти.  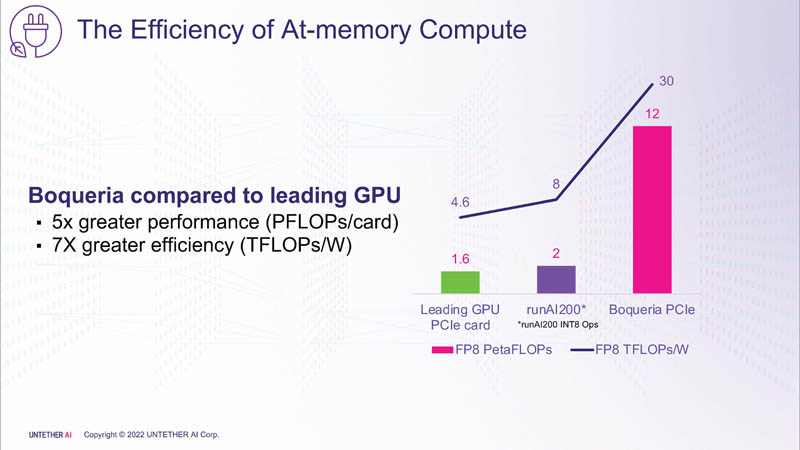 На каждый блок SRAM объёмом 328 Кбайт приходится 512 вычислительных блоков, поддерживающих работу с форматами INT4, INT8, FP8 и BF16. Каждый вычислительный блок имеет два 32-бит (RV32EMC) кастомных ядра RISC-V с поддержкой четырёх потоков и 64 SIMD. Всего есть 729 блоков, так что суммарно чип несёт 238 Мбайт SRAM и 1458 ядер. Блоки провязаны между собой mesh-сетью, к которой также подключены кольцевая IO-шина, несущая четыре 1-Мбайт блока общего кеша, два контроллера LPDRR5 (64 бит) и порты PCIe 5.0: один x16 для подключения к хосту и три x8 для объединения чипов. Суммарная пропускная способность SRAM составляет около 1 Пбайт/с, mesh-сети — от 1,5 до 1,9 Тбайт/с, IO-шины — 141 Гбайт/c в обоих направлениях, а 32 Гбайт DRAM — чуть больше 100 Гбайт/с. PCIe-интерфейсы позволяют объединить до трёх ускорителей, с шестью speedAI240 чипами у каждого. Решения speedAI будут предлагаться как в виде отдельных чипов, так и в составе готовых PCIe-карт и M.2-модулей. Ожидается, что первые поставки избранным клиентам начнутся в первой половине 2023 года.
20.08.2022 [22:30], Алексей Степин
NVIDIA поделилась некоторыми деталями о строении Arm-процессоров Grace и гибридных чипов Grace HopperНа GTC 2022 весной этого года NVIDIA впервые заявила о себе, как о производителе мощных серверных процессоров. Речь идёт о чипах Grace и гибридных сборках Grace Hopper, сочетающих в себе ядра Arm v9 и ускорители на базе архитектуры Hopper, поставки которых должны начаться в первой половине следующего года. Многие разработчики суперкомпьютеров уже заинтересовались новинками. В преддверии конференции Hot Chips 34 компания раскрыла ряд подробностей о чипах. Grace производятся с использованием техпроцесса TSMC 4N — это специально оптимизированный для решений NVIDIA вариант N4, входящий в серию 5-нм процессов тайваньского производителя. Каждый кристалл процессорной части Grace содержит 72 ядра Arm v9 с поддержкой масштабируемых векторных расширений SVE2 и расширений виртуализации с поддержкой S-EL2. Как сообщалось ранее, NVIDIA выбрала для новой платформы ядра Arm Neoverse. 
Источник: NVIDIA Процессор Grace также соответствует ряду других спецификаций Arm, в частности, имеет отвечающий стандарту RAS v1.1 контроллер прерываний (Generic Interrupt Controller, GIC) версии v4.1, блок System Memory Management Unit (SMMU) версии v3.1 и средства Memory Partitioning and Monitoring (MPAM). Базовых кристаллов у Grace два, что в сумме даёт 144 ядра — рекордное количество как в мире Arm, так и x86. 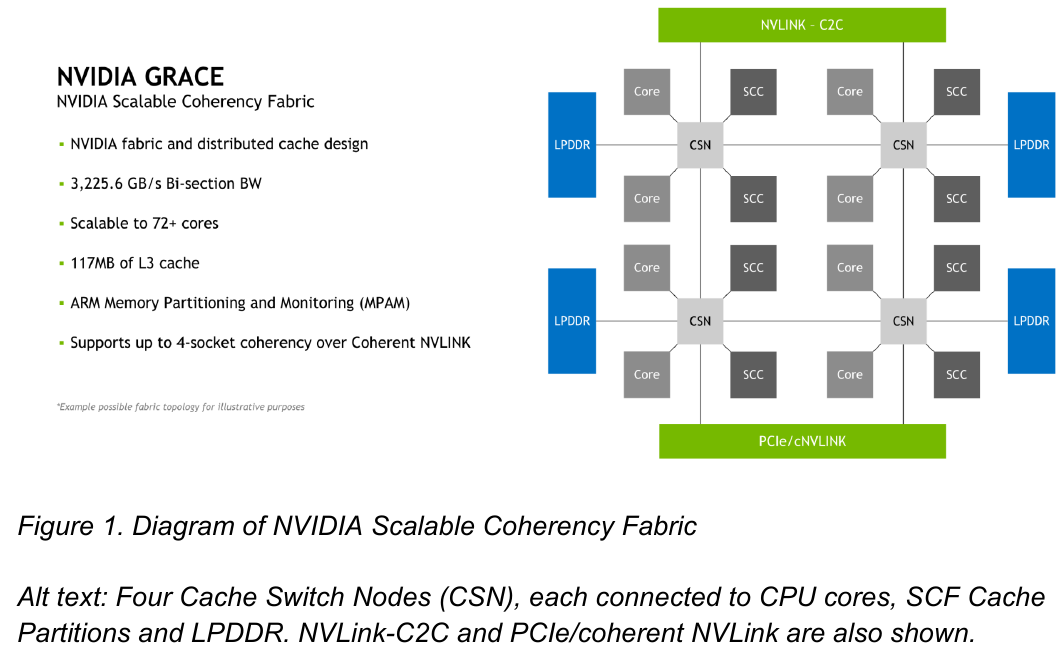
Внутренняя организация кластеров ядр в Grace. Источник: NVIDIA Внутренние блоки Grace соединяются посредством фабрики Scalable Coherency Fabric (SCF), вариации NVIDIA на тему сети CMN-700, применяемой в дизайнах Arm Neoverse. Производительность данного интерконнекта составляет 3,2 Тбайт/с. В случае Grace он предполагает наличие 117 Мбайт кеша L3 и поддерживает когерентность в пределах четырёх сокетов (посредством новой версии NVLink). Но SCF поддерживает масштабирование. Пока что в «железе» она ограничена двумя блоками Grace, а это уже 144 ядра и 234 Мбайт L3-кеша. Ядра и кеш-разделы (SCC) рапределены по внутренней mesh-фабрике SCF. Коммутаторы (CSN) служат интерфейсами для ядер, кеш-разделов и остальными частями системы. Блоки CSN общаются непосредственно друг с другом, а также с контроллерами LPDDR5X и PCIe 5.0/cNVLink/NVLink C2C. 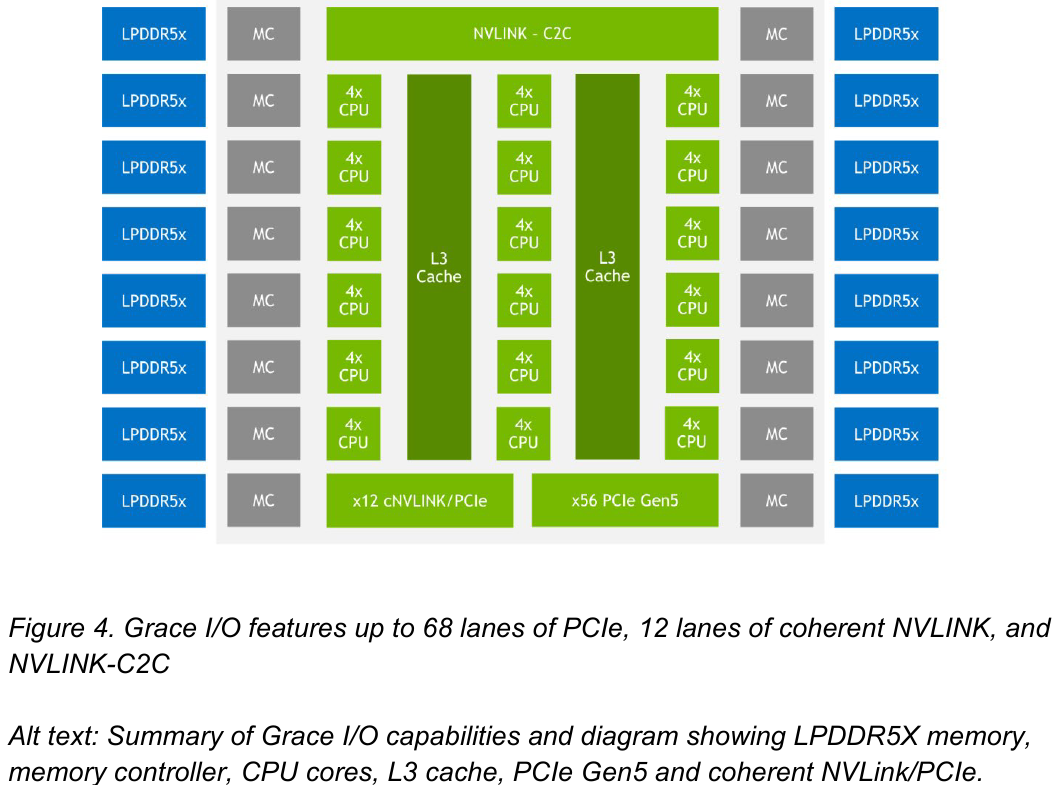
Блок-схема кристалла Grace. Источник: NVIDIA В чипе реализована поддержка PCI Express 5.0. Всего контроллер поддерживает 68 линий, 12 из которых могут также работать в режиме cNVLink (NVLink с когерентностью). x16-интерфейс посредством бифуркации может быть превращен в два x8. Также на приведённой NVIDIA диаграмме можно видеть целых 16 двухканальных контроллеров LPDDR5x. Заявлена ПСП на уровне свыше 1 Тбайт/с для сборки (до 546 Гбайт/с на кристалл CPU). 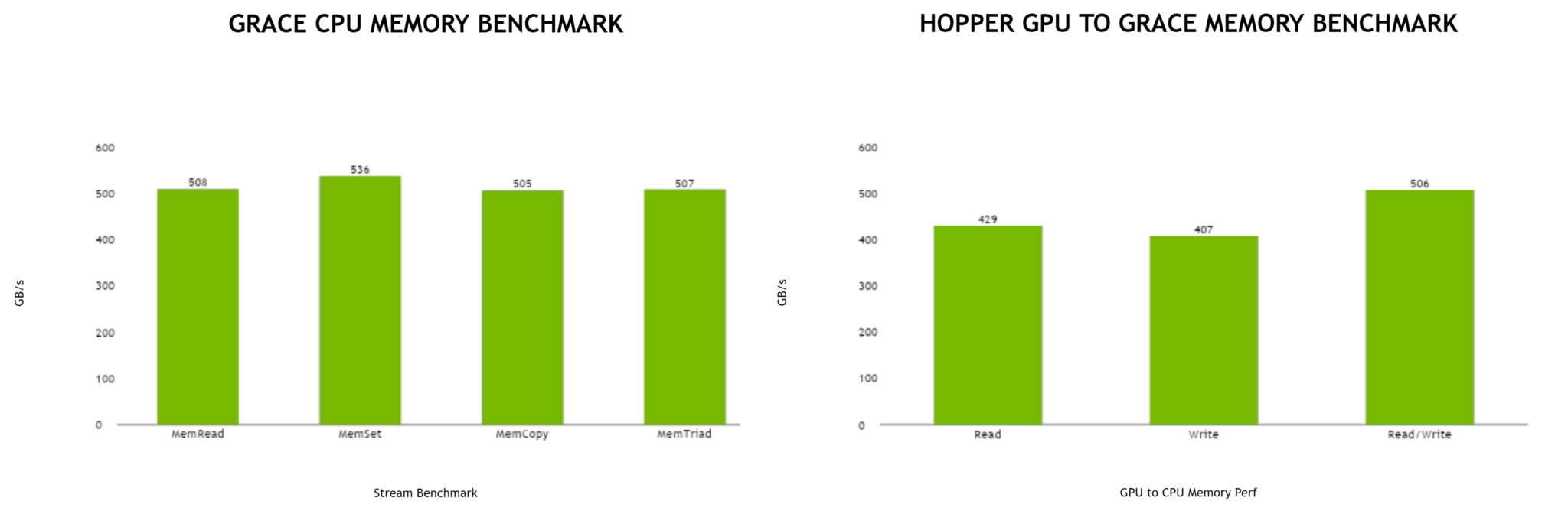
Источник: NVIDIA Основной же межчиповой связи NVIDIA видит новую версию NVLink — NVLink-C2C, которая в семь раз быстрее PCIe 5.0 и способна обеспечить двунаправленную скорость передачи данных на уровне до 900 Гбайт/с, будучи при этом в пять раз экономичнее. Удельное потребление у новинки составляет 1,3 пДж/бит, что меньше, нежели у AMD Infinity Fabric с 1,5 пДж/бит. Впрочем, существуют и более экономичные решения, например, UCIe (~0,5 пДж/бит). 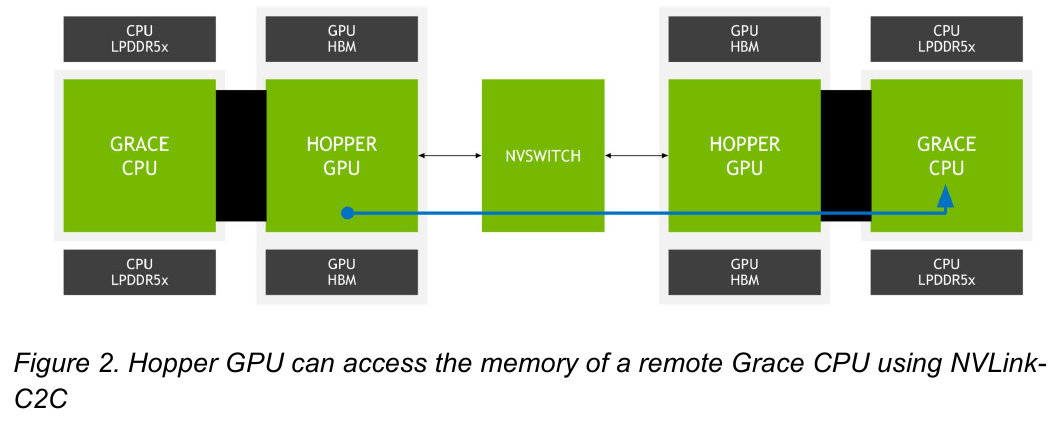
Новый вариант NVLink обеспечит кластер на базе Grace Hopper единым пространством памяти. Источник: NVIDIA NVLink-C2C позволяет реализовать унифицированный «плоский» пул памяти с общим адресным пространством для Grace Hopper. В рамках одного узла возможно свободное обращение к памяти соседей. А вот для объединения нескольких узлов понадобится уже внешний коммутатор NVSwitch. Он будет занимать 1U в высоту, и предоставлять 128 портов NVLink 4 с агрегированной пропускной способностью до 6,4 Тбайт/с в дуплексе. 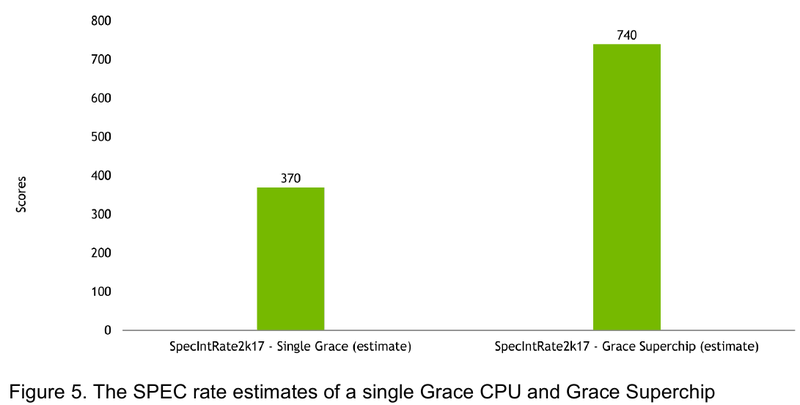
Источник: NVIDIA Производительность Grace также обещает быть рекордно высокой благодаря оптимизированной архитектуре и быстрому интерконнекту. Даже по предварительным цифрам, опубликованным NVIDIA, речь идёт о 370 очках SPECrate2017_int_base для одного кристалла Grace и 740 очках для 144-ядерной сборки из двух кристаллов — и это с использованием обычного компилятора GCC без тонких платформенных оптимизаций. Последняя цифра существенно выше результатов, показанных 128-ядерными Alibaba T-Head Yitian 710, также использующим архитектуру Arm v9, и 64-ядерными AMD EPYC 7773X.
04.08.2022 [15:54], Владимир Мироненко
Разработчик серверных чипов Prodigy с невероятными характеристиками обвинил в своих бедах CadenceКак сообщает The Register, cтартап Tachyum подал в суд на Cadence Design Systems, обвинив компанию в саботаже при выполнении контракта на поставку IP-блоков для будущих 5-нм серверных процессоров Prodigy. По словам Tachyum, старшие 128-ядерные CPU Prodigy с частотой 5,7 ГГц будут втрое быстрее AMD EPYC 7763 и NVIDIA H100. В иске утверждается, что заключённая в 2019 году сделка на предоставление решений Cadence для процессоров Prodigy, была сорвана, поскольку Cadence не смогла предоставить необходимые технологии для вывода продукта на рынок. Заказанные Tachyum блоки не относятся к разряду новшеств, и инженеры Cadence уверяли Tachyum, что стандартные компоненты могли быть без труда интегрированы в процессор. Однако график поставок был нарушен, и дошло даже до того, что Cadence посоветовала Tachyum не использовать её компоненты или вообще приобрести аналоги у других поставщиков. 
Источник изображения: Tachyum Стартап добавил в иске, что Cadence усугубила ущерб, прекратив доступ Tachyum к ПО eDAcard, тем самым вынудив понести расходы на лицензирование другого ПО и переобучение своих инженеров. Срыв сроков и прочие препятствия привели к задержке выхода Prodigy примерно на два года. Tachyum потребовал возместить упущенную выгоду в размере $206 млн и ещё $27 млн дополнительных затрат на поиск альтернативных решений в сжатые сроки. 
Источник изображения: Tachyum Tachyum также указала, что из-за срыва сроков она потеряла возможность получения заказов на поставку чипов для испанского суперкомпьютера MareNostrum 5 стоимостью €151,41 млн. В итоге Барселонский суперкомпьютерный центр (BSC), с которым был подписан меморандум о взаимопонимании, предпочёл компанию Atos. Последняя выбрала ускорители NVIDIA и процессоры Intel, поскольку ни одна европейская компания не могла бы поставить чипы, отвечающие ключевым критериям отбора. В иске Tachyum отмечает, что тогдашний генеральный директор Cadence Лип-Бу Тан (Lip-Bu Tan) входил в совет директоров двух конкурентов Tachyum — SambaNova и Nuvia (поглощена Qualcomm) — и активно участвовал в фондах Walden International и Walden Catalyst, которые инвестировали в другие «кремниевые» стартапы. Ещё один член совета директоров Cadence, Янг Сон (Young Sohn), также является директором одного из этих инвестфондов. По мнению Tachyum, налицо явный конфликт интересов.
02.08.2022 [16:00], Алексей Степин
Опубликованы спецификации Compute Express Link 3.0Мало-помалу стандарт Compute Express Link пробивает себе путь на рынок: хотя процессоров с поддержкой ещё нет, многие из элементов инфраструктуры для нового интерконнекта и базирующихся на нём концепций уже готово — в частности, регулярно демонстрируются новые контроллеры и модули памяти. Но развивается и сам стандарт. В версии 1.1, спецификации на которую были опубликованы ещё в 2019 году, были только заложены основы. Но уже в версии 2.0 CXL получил массу нововведений, позволяющих говорить не просто о новой шине, но о целой концепции и смене подхода к архитектуре серверов. А сейчас консорциум, ответственный за разработку стандарта, опубликовал свежие спецификации версии 3.0, ещё более расширяющие возможности CXL. 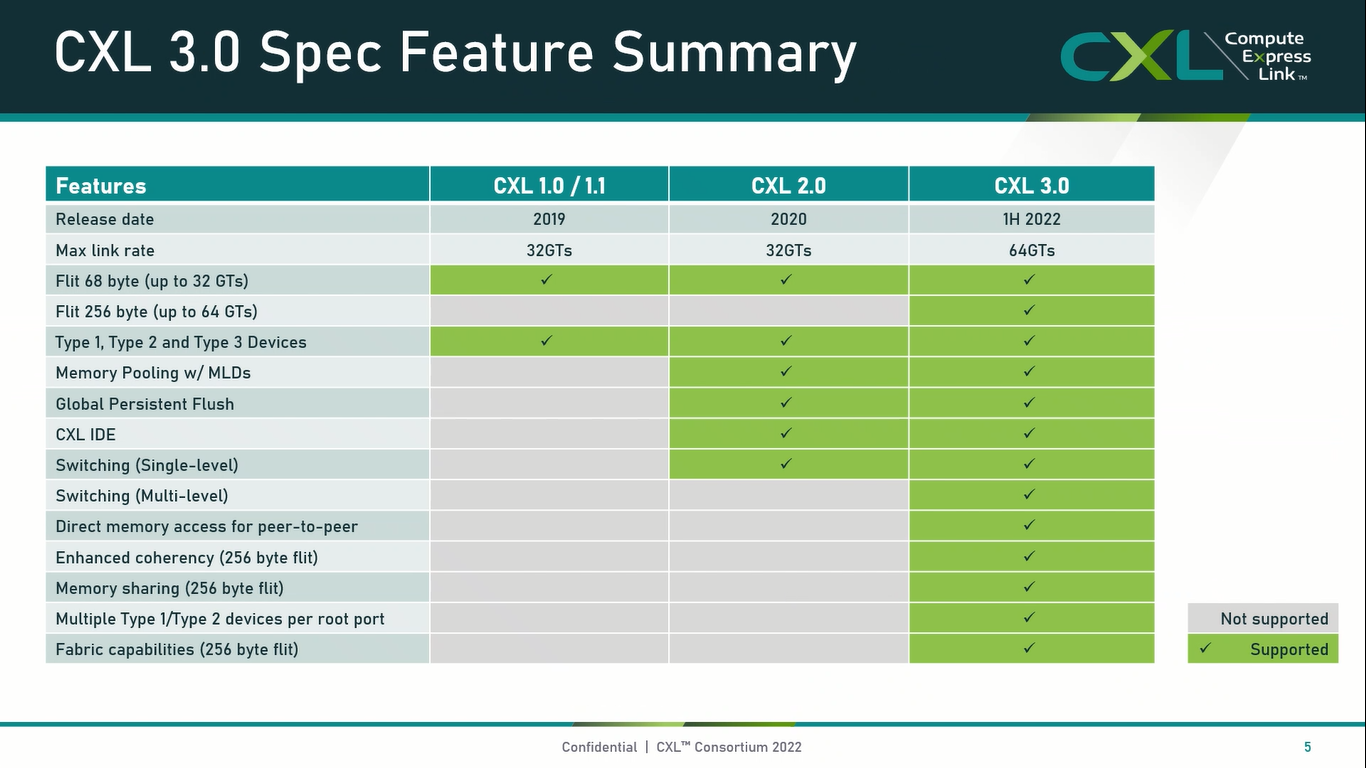
Источник: CXL Consortium И не только расширяющие: в версии 3.0 новый стандарт получил поддержку скорости 64 ГТ/с, при этом без повышения задержки. Что неудивительно, поскольку в основе лежит стандарт PCIe 6.0. Но основные усилия разработчиков были сконцентрированы на дальнейшем развитии идей дезагрегации ресурсов и создания компонуемой инфраструктуры. 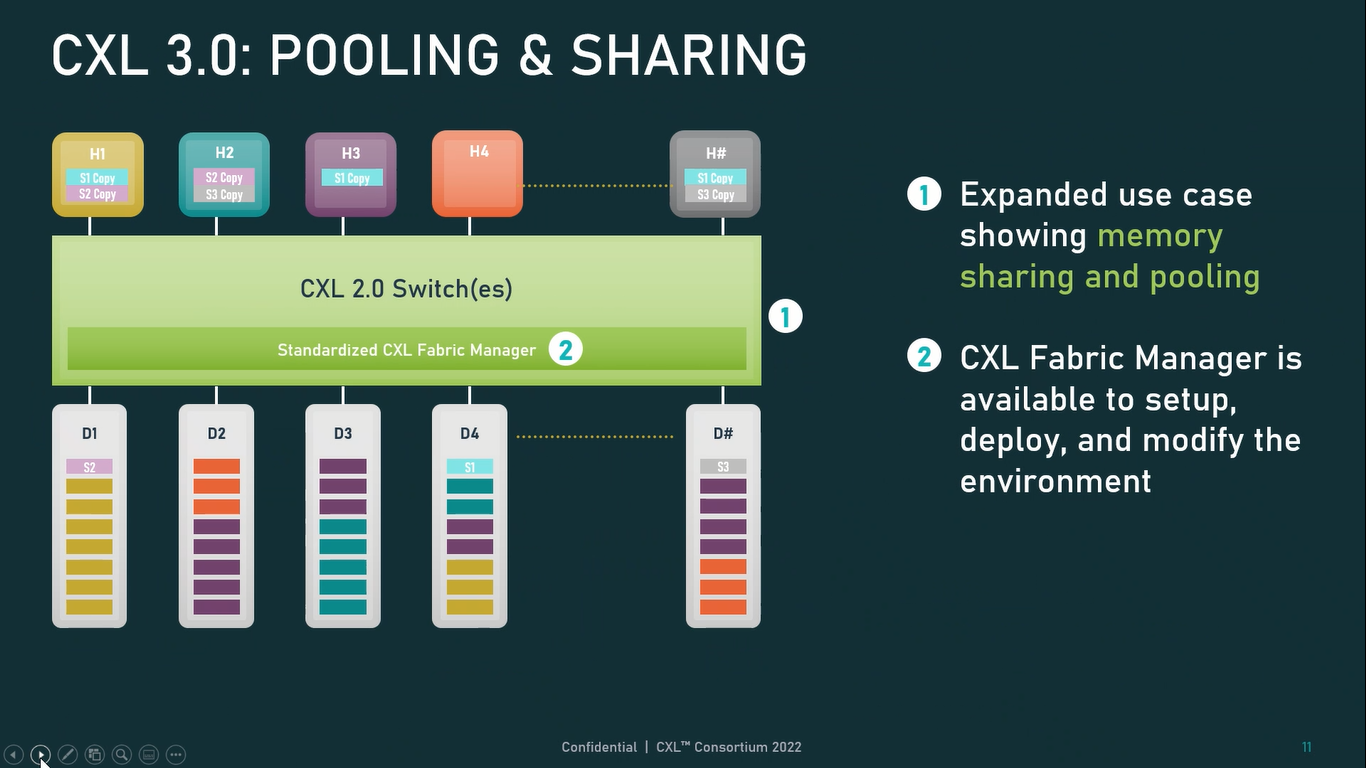 Сама фабрика CXL 3.0 теперь допускает создание и подключение «многоголовых» (multi-headed) устройств, расширены возможности по управлению фабрикой, улучшена поддержка пулов памяти, введены продвинутые режимы когерентности, а также появилась поддержка многоуровневой коммутации. При этом CXL 3.0 сохранил обратную совместимость со всеми предыдущими версиями — 2.0, 1.1 и даже 1.0. В этом случае часть имеющихся функций попросту не будет активирована. 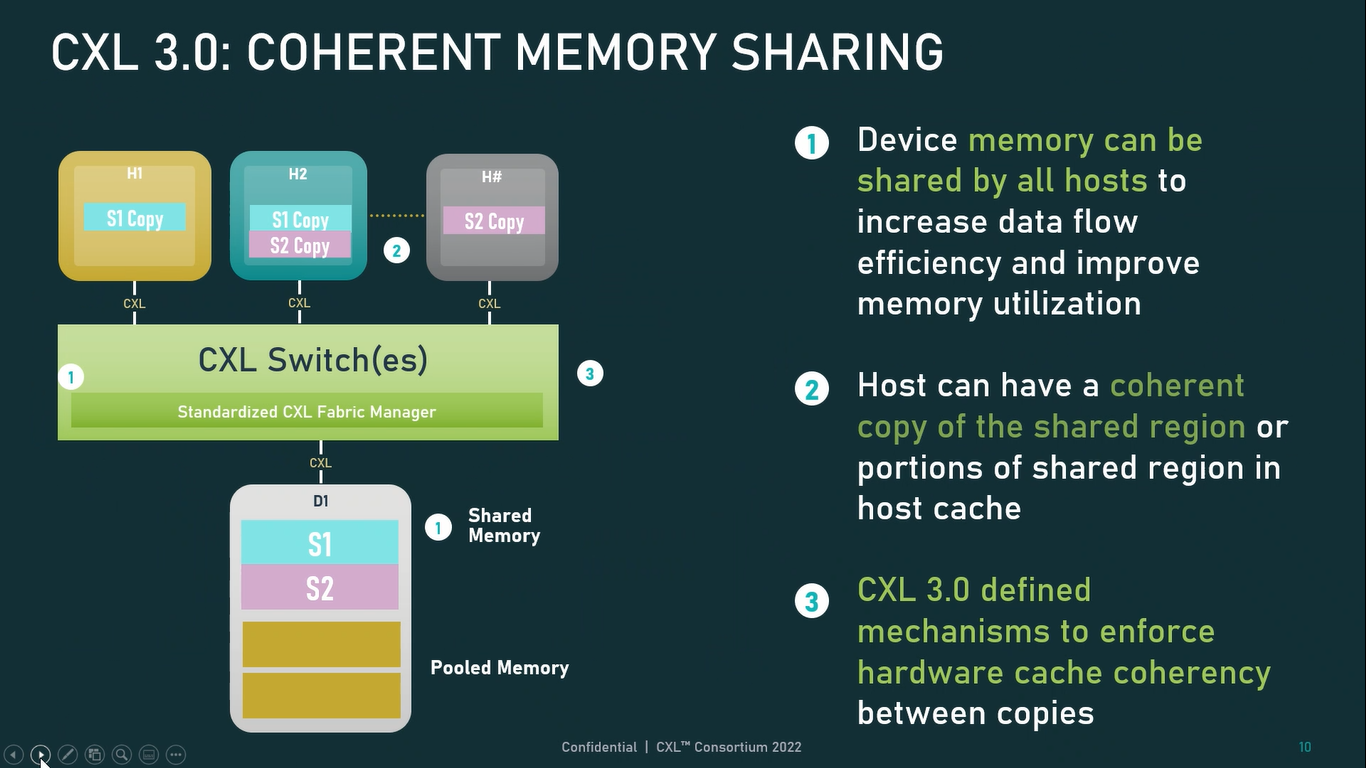 Одно из ключевых новшеств — многоуровневая коммутация. Теперь топология фабрики CXL 3.0 может быть практически любой, от линейной до каскадной с группами коммутаторов, подключенных к коммутаторам более высокого уровня. При этом каждый корневой порт процессора поддерживает одновременное подключение через коммутатор устройств различных типов в любой комбинации. 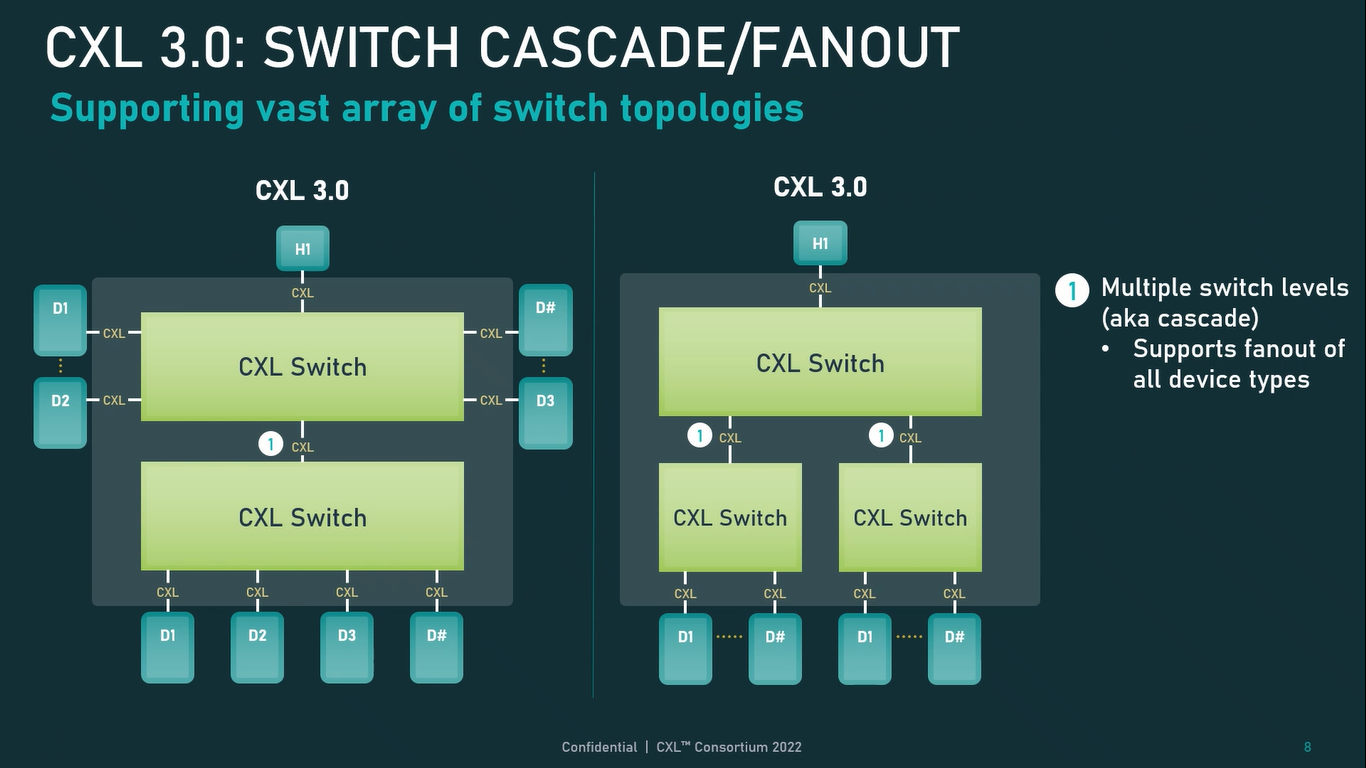 Ещё одним интересным нововведением стала поддержка прямого доступа к памяти типа peer-to-peer (P2P). Проще говоря, несколько ускорителей, расположенных, к примеру, в соседних стойках, смогут напрямую общаться друг с другом, не затрагивая хост-процессоры. Во всех случаях обеспечивается защита доступа и безопасность коммуникаций. Кроме того, есть возможность разделить память каждого устройства на 16 независимых сегментов. 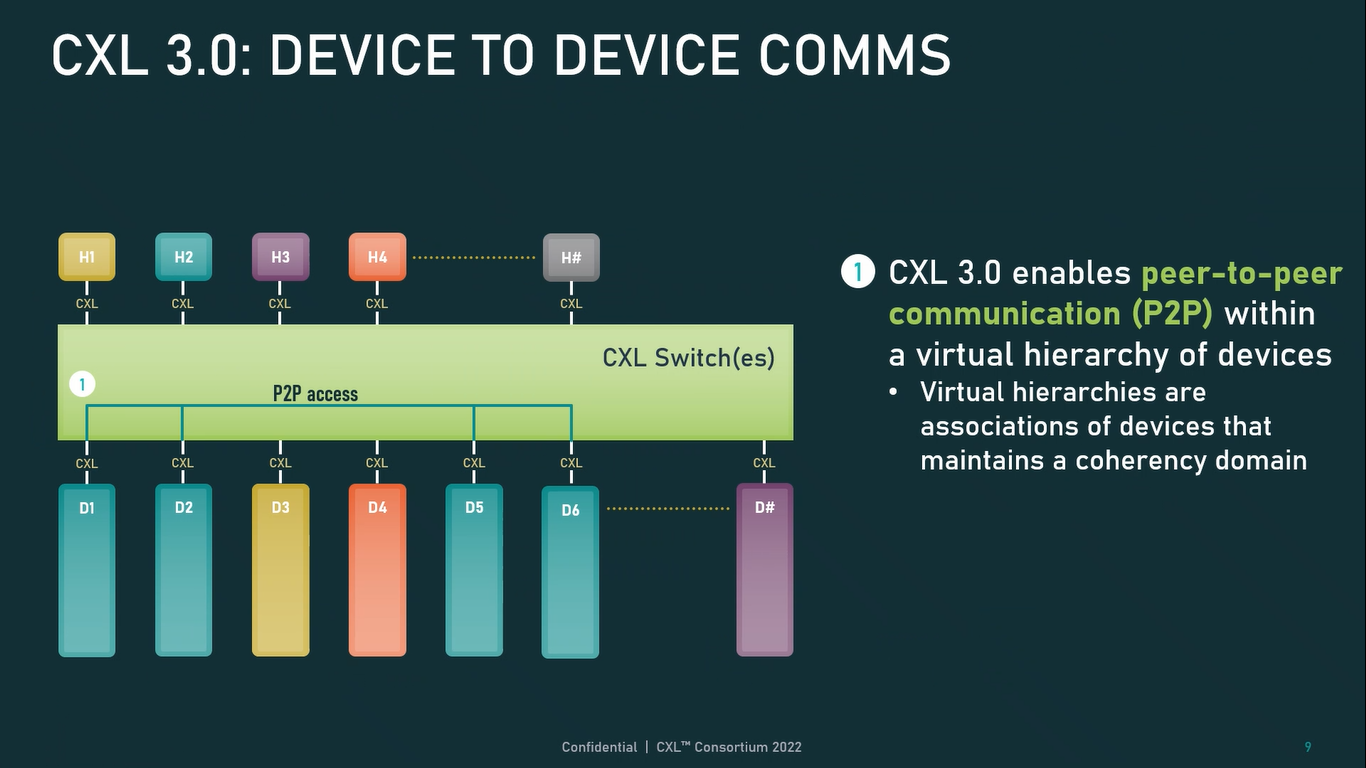 При этом поддерживается иерархическая организация групп, внутри которых обеспечивается когерентность содержимого памяти и кешей (предусмотрена инвалидация). Теперь помимо эксклюзивного доступа к памяти из пула доступен и общий доступ сразу нескольких хостов к одному блоку памяти, причём с аппаратной поддержкой когерентности. Организация пулов теперь не отдаётся на откуп стороннему ПО, а осуществляется посредством стандартизированного менеджера фабрики. 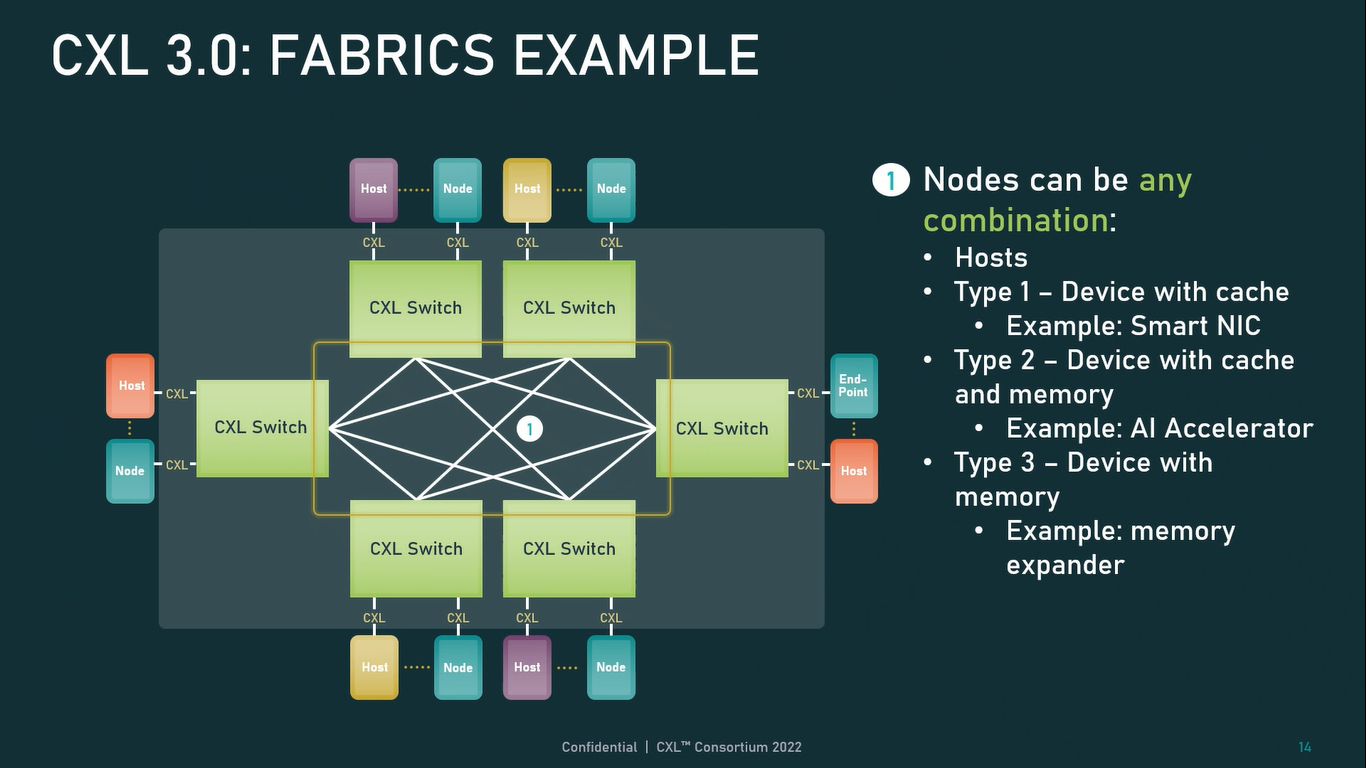 Сочетание новых возможностей выводит идею разделения памяти и вычислительных ресурсов на новый уровень: теперь возможно построение систем, где единый пул подключенной к фабрике CXL 3.0 памяти (Global Fabric Attached Memory, GFAM) действительно существует отдельно от вычислительных модулей. При этом возможность адресовать до 4096 точек подключения скорее упрётся в физические лимиты фабрики. 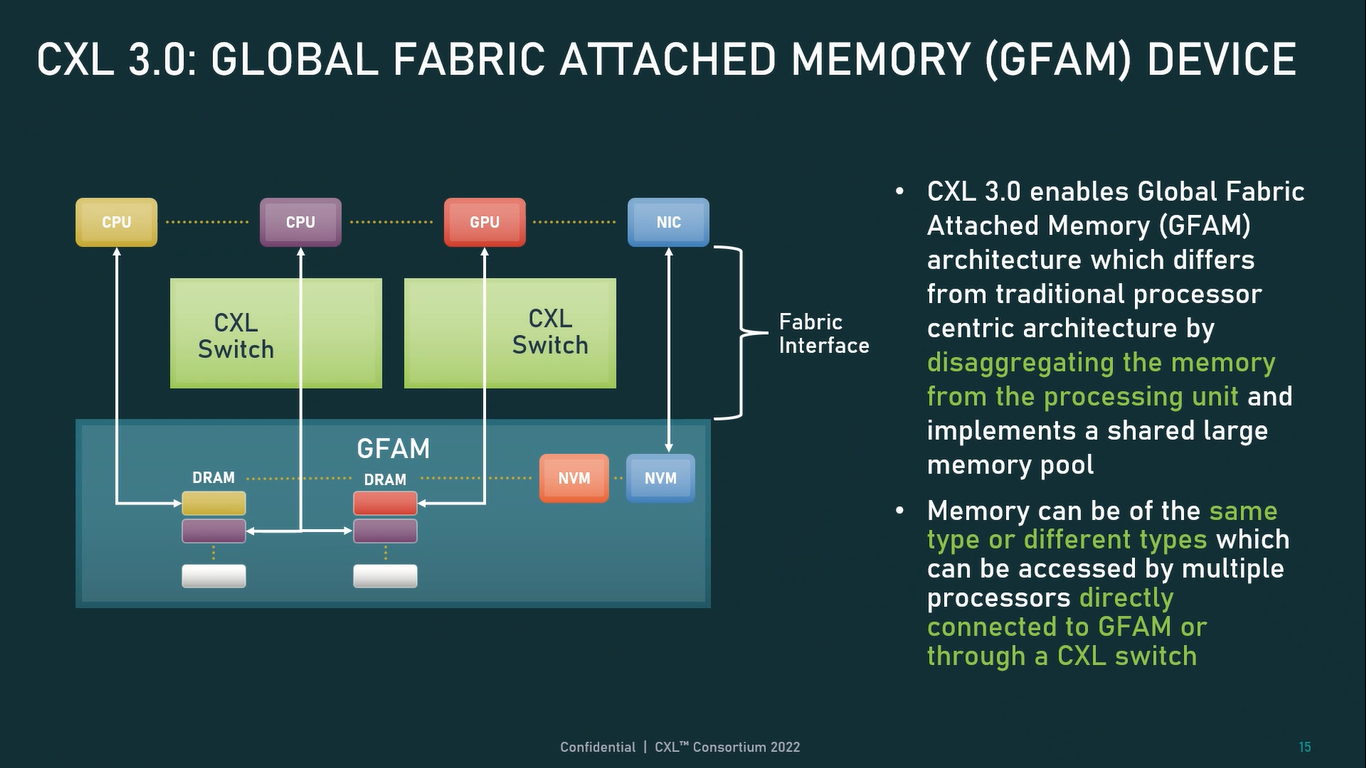 Пул может содержать разные типы памяти — DRAM, NAND, SCM — и подключаться к вычислительным мощностями как напрямую, так и через коммутаторы CXL. Предусмотрен механизм сообщения самими устройствами об их типе, возможностях и прочих характеристиках. Подобная архитектура обещает стать востребованной в мире машинного обучения, в котором наборы данных для нейросетей нового поколения достигают уже поистине гигантских размеров. 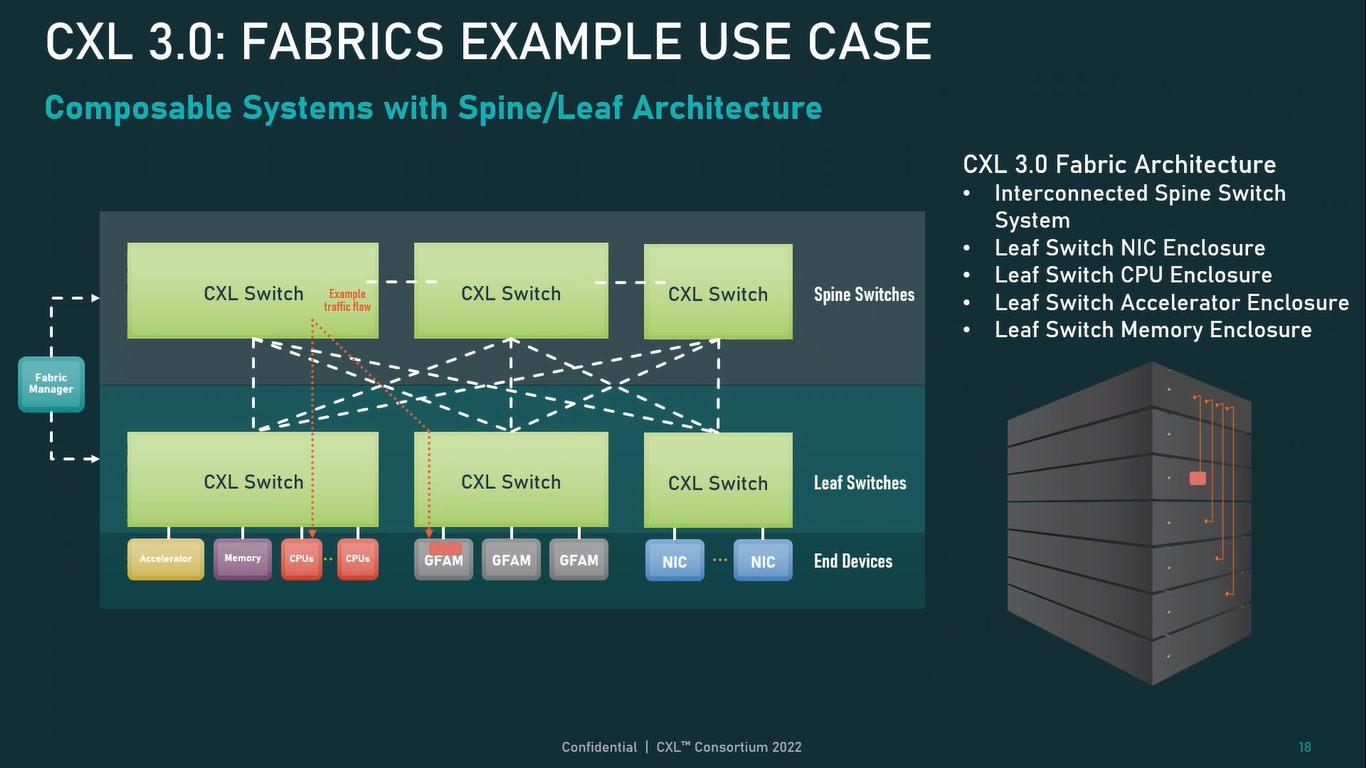 В настоящее время группа CXL уже включает 206 участников, в число которых входят компании Intel, Arm, AMD, IBM, NVIDIA, Huawei, крупные облачные провайдеры, включая Microsoft, Alibaba Group, Google и Meta✴, а также ряд крупных производителей серверного оборудования, в том числе, HPE и Dell EMC.
01.08.2022 [23:00], Игорь Осколков
Великое объединение: спецификации и наработки OpenCAPI и OMI планируется передать консорциуму CXLКонсорциумы OpenCAPI Consortium (OCC) и Compute Express Link (CXL) подписали соглашение, которое подразумевает передачу в пользу CXL всех наработок и спецификаций OpenCAPI и OMI. Если будет получено одобрения всех участвующих сторон, то это будет ещё один шаг в сторону унификации ключевых системных интерфейсов и возможности реализации новых архитектурных решений. Во всяком случае, на бумаге. Консорциумы OpenCAPI (Open Coherent Accelerator Processor Interface) был сформирован в 2016 году с целью создание единого, универсального, скоростного и согласованного интерфейса для связи CPU с ускорителями, сетевыми адаптерами, памятью, контроллерами и устройствами хранения и т.д. Причём в независимости от типа и архитектуры самого CPU. На тот момент новый интерфейс был определённо лучше распространённого тогда PCIe 3.0. С течением времени дела у OpenCAPI шли ни шатко ни валко, однако фактически его использование было ограничено только POWER-платформами от IBM. 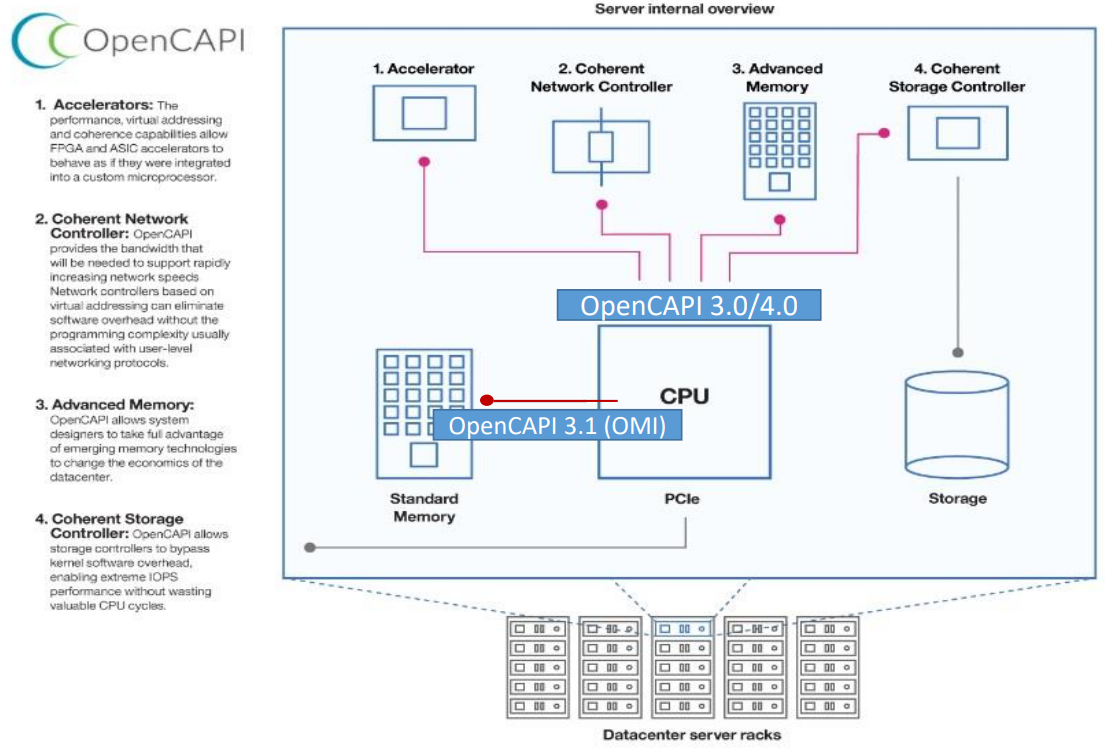
Источник: OpenCAPI Тем не менее, в недрах OpenCAPI родился ещё один очень интересный стандарт — Open Memory Interface (OMI). OMI, если коротко, предлагает некоторую дезагрегацию путём добавления буферной прослойки между CPU и RAM. С одной стороны у OMI есть унифицированный последовательный интерфейс для подключения к CPU, с другой — интерфейсы для подключения какой угодно памяти, на выбор конкретного производителя. 
Источник: Open Memory Interface (OMI) OMI позволяет поднять пропускную способность памяти, не раздувая число контактов и физические размеры и самого CPU, и модулей. Однако и в данном случае массовая поддержка OMI по факту есть только в процессорах IBM POWER10. Концептуально CXL в части работы с памятью повторяет идею OMI, только в данном случае в качестве физического интерфейса используется распространённый PCIe. 
Изображение: SK Hynix Существенная разница c OMI в том, что начальная поддержка CXL будет в грядущих процессорах AMD и Intel. А Samsung и SK Hynix уже готовят соответствующие DDR5-модули. Да и в целом поддержка CXL в индустрии намного шире. Так что консорциуму CXL, по-видимому, осталось поглотить только ещё один конкурирующий стандарт в лице CCIX, как это уже произошло с Gen-Z. Комментируя соглашение, президент консорциума CXL отметил, что сейчас наиболее удачное время для объединения усилий, которое принесёт пользу всей IT-индустрии. Участники OpenCAPI имеют богатый опыт, который поможет улучшить грядущие спецификации CXL и избежать ошибок.
01.08.2022 [15:52], Руслан Авдеев
На крупнейшем в мире рынке ЦОД наметился катастрофический недостаток электроэнергии — дата-центрам не хватает ЛЭПРынок ЦОД Северной Вирджинии продолжают преследовать неприятности. Помимо того, что местные жители активно выступают против старых и новых дата-центров, в местной округе наметилась масштабная нехватка электроэнергии. Как сообщает The Register, в регионе буквально не хватает линий электропередач для снабжения всех ЦОД энергией. По данным Digital Realty, владеющей и обслуживающей более 290 ЦОД, местная энергоснабжающая компания Dominion Energy разослала оповещение ключевым местным потребителям, сообщив, что проблемы с электроснабжением в регионе закончатся не раньше 2026 года. При этом проблема заключается не в нехватке генерирующих мощностей, а именно в дефиците линий электропередач для достаточного энергообеспечения ЦОД. Текущая ёмкость дата-центров в штате составляет порядка 1,7 ГВт. 
Источник изображения: Matthew Henry/unsplash.com Округ Лаудон (Loudoun County) фактически является крупнейшим в мире хабом для дата-центров с общей полезной площадью ЦОД в миллионы квадратных метров. Округ нередко называют «ключевым игроком» в мировой цифровой экономике. Одни только налоги на недвижимость от сектора ЦОД должны составить в фискальном 2023 году почти $600 млн — этого достаточно, чтобы покрыть все расходы властей округа. Проблемы с энергоснабжением могут означать, что многие планируемые проекты переедут в соседние округа Принс-Уильям (Prince William) и Фокир (Fauquier), а то и вовсе в соседний штат Мэриленд. Dominion Energy как минимум частично обслуживает и Принс-Улильям, а вот округ Фредерик в Мэриленде подключен к другой энергосети. 
Источник изображения: Álvaro Serrano/unsplash.com Известно, что беспрецедентный рост нагрузки на сеть Dominion начался в 2018 году на фоне стремительного развития дата-центров и всё ещё не остановился, поэтому в существующие планы развития энергосетей придётся вносить корректировки. На днях Dominion Energy признала, что не сможет обслуживать потребности города Эшберна (Ashburn) в округе Лаудон, где расположена т.н. «Аллея дата-центров». Это будет означать не только остановку уже стартовавших многомиллиардных проектов строительства ЦОД, но и снижение налоговых поступлений. Как сообщает портал DataCenter Dynamics, по прогнозам Wells Fargo, компания может остановить поставки энергии новым ЦОД до 2025 или 2026 года — если проектам, до завершения строительства которых осталось не более полугода, энергии может хватить, то совсем новые объекты, возможно, электричества не получат, несмотря на ранее полученные от Dominion гарантии. А строительство ЦОД, запланированных на 2023-2024 годы, может быть значительно отложено. Впрочем, в Wells Fargo считают, что с нехваткой электричества могут в скором времени столкнуться и уже существующие в регионе кампусы ЦОД.
28.07.2022 [23:13], Алексей Степин
Microsoft и Plug Power успешно протестировали водородные топливные элементы для резервного питания ЦОДДизель-генератор — неотъемлемая часть подсистемы резервного питания любого серьёзного ЦОД, но по природе своей он не может похвастаться нейтральностью выхлопа. Многие ищут традиционным генераторам замену, и в их числе Microsoft. На днях компания сообщила, что ей удалось достичь важной вехи в освоении водородных топливных элементов, которые, по замыслу Microsoft, и должны заменить традиционные дизель-генераторы в принадлежащих ей центрах обработки данных. Компания начала тестирование новой генераторной станции мощностью 3 МВт, построенной на базе топливных ячеек с протонообменной мембраной (PEM). Она способна обеспечивать питание 10 тыс. серверов. С топливными элементами компания экспериментирует давно, ещё с 2013 года, но более ранние разработки использовали природный газ и не по факту не являлись такими уж экологичными. 
Тестовая станция мощностью 3 мВт. Источник: Microsoft/John Brecher Разработать водородные PEM-ячейки компании удалось в сотрудничестве с Plug Power. В течение нескольких недель июня компании совместно протестировали прототип генератора нового поколения. Новая система, выбрасывающая в атмосферу лишь нагретый водяной пар, сработала успешно, так что Plug Power уже работает над созданием коммерческой версии системы. 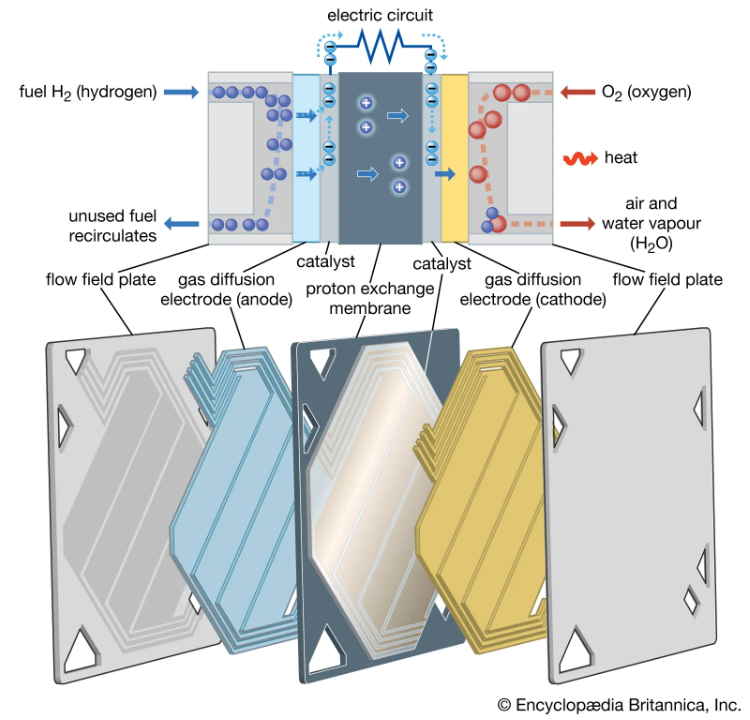
Протонообменная мембрана: конструкция и принцип действия. Источник: Encyclopedia Britannica Первый же экземпляр будет установлен научно-исследовательском центре Microsoft, но пока конкретных сроков пока озвучено не было. У IT-гиганта большие надежды на подобные технологии: к 2030 году компания планирует обновить системы резервного питания во всех своих ЦОД. 
В работе система выделяет только горячий водяной пар. Источник: Microsoft/John Brecher Правда, в полной экологичности водородных топливных элементов есть сомнения: работают они без вредных выбросов, но само их производство может оказаться далеко не таким чистым, как эксплуатация. Тем не менее, администрация США одобрила план стоимостью $8 млрд по развитию производства водорода в рамках программы альтернатив ископаемому топливу. В Европе есть аналогичные инициативы — как совсем скромные (€2,5 млн), так и весьма крупные (€1 млрд).
28.07.2022 [18:12], Руслан Авдеев
Европейские дата-центры хотят снизить потребление воды до 400 мл/кВт·ч, но только к 2040 годуГруппа Climate Neutral Data Centre Pact (CNDCP), объединяющая 90 % европейских операторов ЦОД, предложила добровольно снизить потребление воды до 400 мл на 1 кВт·ч к 2040 году и добиться углеродной нейтральности намного раньше 2050 года. Соответствующая цель уже поставлена ЕС, но операторы намерены добиваться её без законодательного принуждения и с опережением графика, — сообщает Data Center Dynamics. Хотя использование воды способно оказать значительное влияние на экологию, этот фактор часто недооценивают, учитывая только расход энергии. При этом многие ЦОД активно используют воду для охлаждения оборудования, благодаря чему снижается расход всё той же энергии, но растут затраты самой жидкости, что имеет критическое значение для некоторых регионов. Группу CNDCP сформировали в 2021 году с намерением достичь углеродной нейтральности европейских ЦОД к 2030 году, а также обеспечить достойный ответ прочим экологическим вызовам, в том числе снизить расход воды. Для оценки эффективности использования воды используется коэффициент WUE, который отражает расход воды на каждый затраченный киловатт·час электричества. Например, исследование 2016 года показало, что на тот момент WUE для ЦОД в США составлял в среднем 1,8 л/кВт·ч. 
Источник изображения: Christian Lue/unsplash.com Цели поставлены с учётом жизненного цикла уже действующих систем охлаждения, поскольку их немедленная массовая замена может принести больше вреда, чем пользы из-за ущерба экологии в процессе производства самих систем. Поэтому в CNDCP заявили, что все 74 оператора ЦОД, участвовавшие в заключении пакта, добьются потребления не более 400 мл/кВт·ч только к 2040 году. Такой показатель вывели с учётом разницы технологий, климатических и иных условий, характерных для тех или иных ЦОД. 
Источник изображения: Google Отдельные участники рынка уже заявили о намерении добиться положительного водного баланса для своих дата-центров — ЦОД будут отдавать больше чистой воды, чем потреблять. Так, Meta✴ и Microsoft планируют добиться этой цели к 2030 году. Последняя также начала устанавливать станции для очистки сточных вод ЦОД. А вот Google отметилась тем, что пыталась всеми возможными способами скрыть расход воды своими дата-центрами даже от властей. Помимо ограничения расхода воды, подписанты CNDCP предложили ввести и другие цели для дата-центров. Например, уже сформированы две рабочие группы для подготовки к переходу на «циркулярную экономику» со вторичным использованием материалов и переработкой различных ресурсов. В частном порядке аналогичную инициативу уже несколько лет развивает Microsoft в рамках проекта Circular Center. |
|