Лента новостей
|
04.10.2022 [22:57], Алексей Степин
Intel Labs представила нейроморфный ускоритель Kapoho Point — 8 млн электронных нейронов на 10-см платеКомпания Intel уже не первый год развивает направление нейроморфных процессоров — чипов, имитирующих поведение нейронов головного мозга. Уже во втором поколении, Loihi II, процессор получил 128 «ядер», эквивалентных 1 млн «цифровых нейронов», однако долгое время этот чип оставался доступен лишь избранным разработчикам Intel Neuromorphic Research Community через облако. Но ситуация меняется, пусть и спустя пять лет после анонса первого нейроморфного чипа: компания объявила о выпуске платы Kapoho Point, оснащённой сразу восемью процессорами Loihi II. Напомним, что они производятся с использованием техпроцесса Intel 4 и состоят из 2,3 млрд транзисторов, образующих асинхронную mesh-сеть из 128 нейроморфных ядер, модель работы которых задаётся на уровне микрокода. 
Источник изображений: Intel Labs Площадь кристалла нейроморфоного процессора Intel второго поколения составляет всего 31 мм2. Судя по всему, активного охлаждения Loihi II не требует: даже в первой реализации в виде PCIe-платы Oheo Gulch кулером оснащалась только управляющая ПЛИС, но не сам нейроморфный чип. В своём интервью ресурсу AnandTech Майк Дэвис (Mike Davies), глава проекта, отметил, что в реальных сценариях, выполняемых в человеческом масштабе времени, речь идёт о цифре порядка 100 милливатт, хотя в более быстром масштабе чип, естественно, может потреблять и больше. 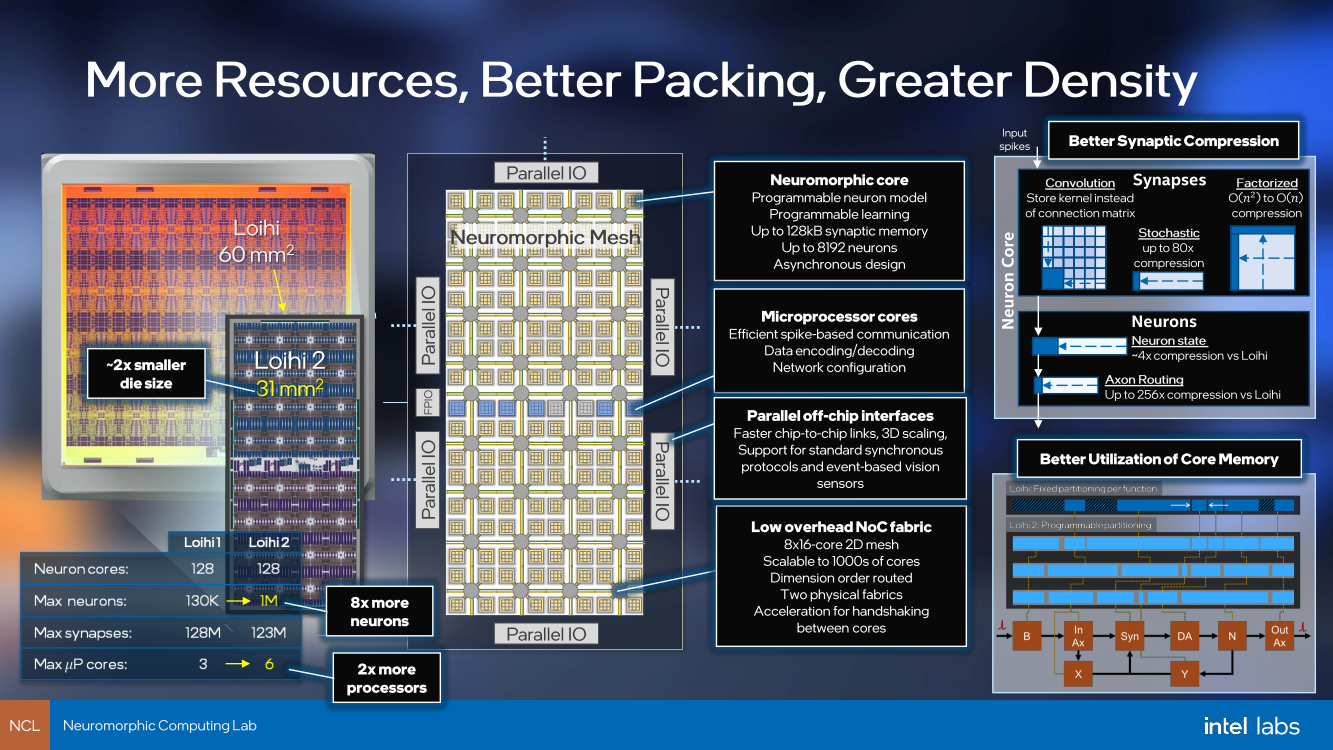
Архитектура и особенности строения Loihi II. По нажатию открывается полноразмерная версия Новый модуль, по словам компании, способен эмулировать до 1 млрд синапсов, а в задачах оптимизации с большим количеством переменных (до 8 миллионов, эквивалентно количеству «нейронов»), где нейроморфная архитектура Intel очень сильна, он может опережать традиционные процессоры в 1000 раз. Каждое ядро имеет свой небольшой пул быстрой памяти объёмом 192 Кбайт. Шесть выделенных ядер отвечают за управление нейросетью Loihi II; также в составе чипа имеются аппаратные ускорители кодирования-декодирования данных. Новинка изначально создана модульной: благодаря интерфейсному разъёму несколько плат Kapoho Point можно устанавливать одна над другой. Поддерживаются «бутерброды» толщиной до 8 плат, в деле опробован, однако, вдвое более тонкий вариант, но даже четыре Kapoho Point дают 32 миллиона нейронов в совокупности. Для коммуникации с внешним миром используется интерфейс Ethernet: в чипе реализована поддержка скоростей от 1 (1000BASE-KX) до 10 Гбит/с (10GBase-KR). Размеры каждой платы невелики, всего 4×4 дюйма (102×102 мм). 
Платы Kapoho Point позволяют легко расширять нейросеть на базе Loihi II В отличие от первого поколения Loihi, доступ к которому можно было получить лишь виртуально, через облако, системы на базе Kapoho Point уже доставлены избранным клиентам Intel, и речь идёт о реальном «железе». В число первых клиентов входит Исследовательская лаборатория ВВС США (Air Force Research Laboratory, AFRL), для задач которой такие достоинства Loihi II, как компактность и экономичность являются решающими. 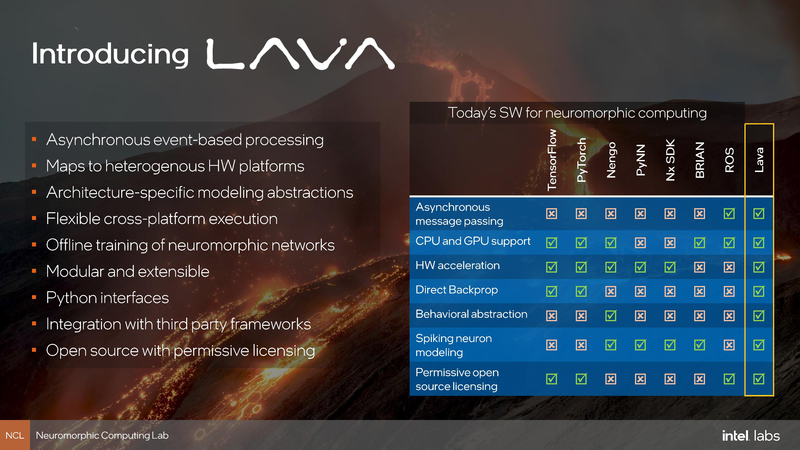
Возможности SDK Lava Одновременно с анонсом Kapoho Point компания Intel обновила и фреймворк Lava. В отлчиие от SDK первого поколения Nx новая открытая программная платформа разработки сделана аппаратно-независимой, что позволит разрабатывать нейро-приложения не только на платформе, оснащённой чипами Loihi II.
28.09.2022 [12:37], Алексей Степин
AMD анонсировала Ryzen Embedded V3000 — процессоры для встраиваемых систем с архитектурой Zen 3Семейство процессоров AMD Ryzen Embedded V получило долгожданное обновление: компания представила чипы V3000 с архитектурой Zen 3. Процессоры предназначены для широкого круга задач и могут использоваться в системах хранения данных, маршрутизаторах, сетевых брандмауэрах и коммутаторах — для этого у них достаточно как производительности, так и возможностей подсистем ввода-вывода. Новые чипы отличаются высокой энергоэффективностью: их номинальный теплопакет составляет от 15 до 45 Ватт в зависимости от модели; более тонкая настройка TDP позволяет регулировать потребление в диапазоне 10-54 Ватта. Это очень полезная возможность для периферийных систем, часто обходящихся пассивным охлаждением в виде оребренного корпуса. 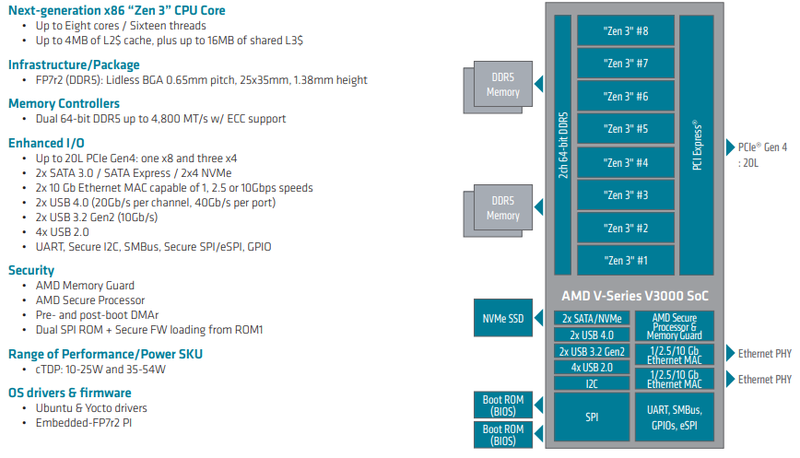
Источник изображений здесь и далее: AMD Всего в серии Ryzen Embedded V3000 представлено пять новых процессоров с количеством ядер от четырёх до восьми. Они отличаются базовой частотой от 1,9 до 3,5 ГГц, объёмами кешей, а также диапазоном рабочих температур: например, в серии есть модель V3C18I, способная функционировать в окружающей среде с температурой от -40 до +105 °C. В остальном новые процессоры очень похожи: все они используют компактные корпуса BGA, у всех максимальная частота в турборежиме составляет 3,8 ГГц, все чипы способны работать с памятью DDR5-4800, имеют 20 линий PCIe 4.0 и два интегрированных MAC-блока 10GbE. 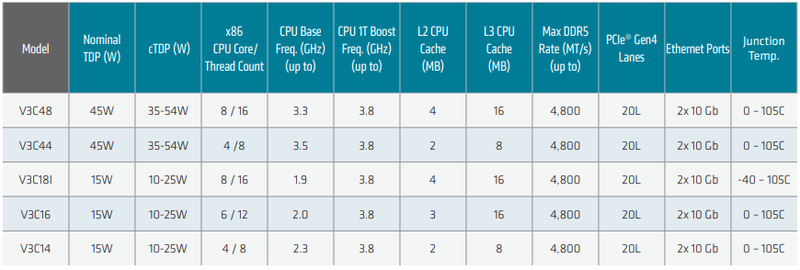
Модельный ряд Ryzen Embedded V3000 Новые процессоры AMD могут похвастаться повышенной защищённостью за счёт поддержки технологий AMD Memory Guard и AMD Platform Secure Boot. Компания-производитель рассчитывает на долгую службу новинок — жизненный цикл Ryzen Embedded V3000 составляет 10 лет. Также они будут иметь драйверную поддержку для будущих версий Linux Ubuntu и Yocto. Поставки новых чипов Ryzen Embedded V3000 ведущим OEM- и ODM-производителям оборудования уже начаты. AMD считает, что эти процессоры станут идеально сбалансированным выбором для СХД и сетевых устройств, как сочетающие в себе достаточно высокую производительность и низкий уровень тепловыделения, особенно важный в ограниченном пространстве серверных стоек.
23.09.2022 [19:58], Алексей Степин
Google заявила, что использует процессоры SiFive Intelligence X280 на RISC-V вместе со своим TPUАрхитектура RISC-V продолжает понемногу набирать популярность и завоевывать внимание ведущих игроков на рынке информационных технологий. На мероприятии AI Hardware Summit в совместном выступлении ведущего архитектора SiFive и архитектора Google TPU было отмечено, что Google уже использует процессоры с ядрами Intelligence X280. Эти ядра — один из вариантов воплощения архитектуры RISC-V, из продвигаемых SiFive. Анонс Intelligence X280 состоялся ещё в апреле 2021 года, когда SiFive выпустила апдейт 21G1, основной упор в котором был сделан на максимизацию характеристик уже существующих ядер RISC-V в области операций с плавающей запятой. 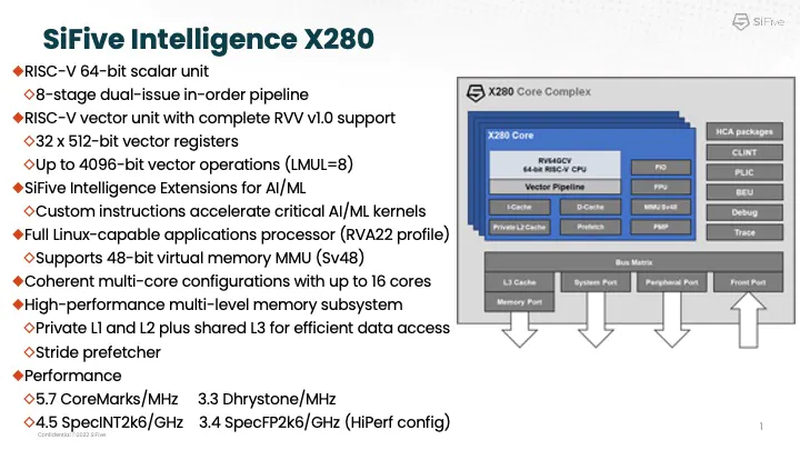
Процессорное ядро Intelligence X280 и его возможности. Источник: SiFive Как следует из названия, данный вариант процессора оптимизирован под задачи машинного интеллекта: ядра RISC-V в нём дополнены векторными конвейерами RISC-V Vector (RVV) с производительностью 4,5 Тфлопс BF16 и 9,2 Топс INT8 на ядро. Одной из самых интересных технологий в Intelligence X280 является интерфейс Vector Coprocessor Interface eXtension (VCIX). 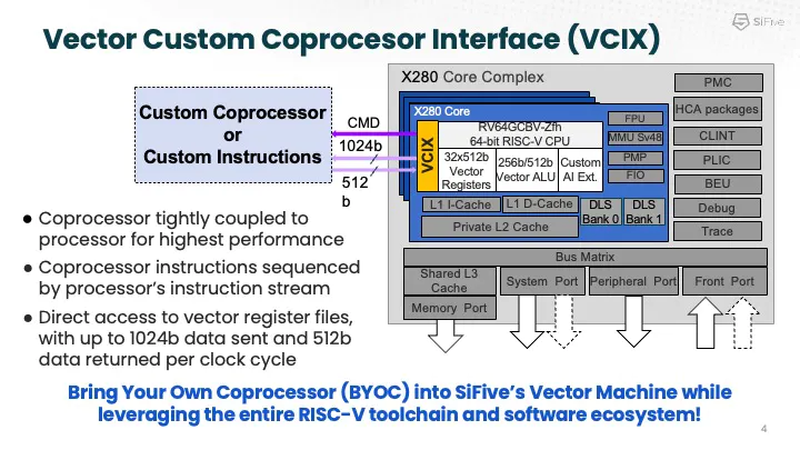
Устройство VCIX. Источник: SiFive Он позволяет подключать внешние ускорители векторных операций напрямую к регистровому файлу X280, минуя основную шину и кеши. Такой подход минимизирует накладные расходы и не требует использования специальных средств при программировании системы, поскольку связка из X280 и подключённого по VCIX ускорителя работает полностью прозрачно в рамках стандартных средств разработки SiFive. 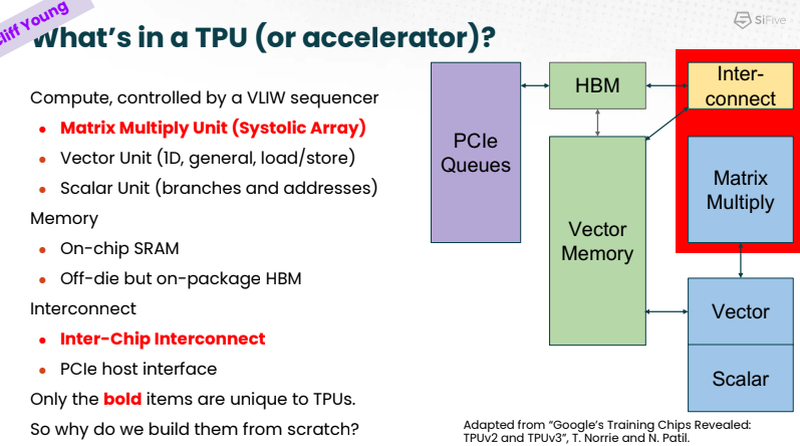
Сильные стороны Google TPU. Источник: SiFive На саммите в Санта-Кларе разработчики SiFive и Google TPU рассказали, что процессоры Intelligence X280 используются в качестве хост-процессоров к ускорителям систолической векторной математики Google MXU; правда, о масштабах внедрения RISC-V в Google сведений приведено не было. 
Разделение труда Intelligence X280 и Google TPU. Источник: SiFive Ранее уже появлялась информация, что Google активно тестирует ASIC сторонних разработчиков в связке со своим TPU, в частности, чипы Broadcom, дабы разгрузить его от второстепенных задач и сделать упор на сильных сторонах — матричной математике и быстром интерконнекте. Похоже, SiFive Intelligence X280 решает задачу интеграции подобного рода задач более изящно: как отметил в выступлении Клифф Янг (Cliff Young), архитектор Google TPU, с помощью VCIX можно построить машину, позволяющую усидеть на двух стульях (build a machine that lets you have your cake and eat it too).
21.09.2022 [19:32], Алексей Степин
NVIDIA представила ускорители L40 и новую Omniverse-платформу OVX на их основеНа конференции GTC 2022 NVIDIA анонсировала второе поколение систем для симуляции и запуска «цифровых двойников» OVX. Это вовсе не развлечение: использование точных моделей реальных физических объектов, пространств и устройств потенциально весьма выгодно, поскольку симуляция городского квартала для обучения автопилотов или фабрики для оценки взаимодействия роботов с живыми работниками априори будет стоить намного меньше, нежели проведение натурных испытаний. Зачастую такие симуляции используют тензорные и матричные вычисления, поэтому основой новой платформы OVX стали новые ускорители NVIDIA L40 с архитектурой Ada Lovelace, располагающие ядрами трассировки лучей третьего поколения и тензорными ядрами четвёртого поколения. Они поддерживают как классический трассировку лучей (ray tracing), так и трассировку путей (path tracing), что важно для корректной симуляции поведения различных материалов. 
NVIDIA L40. Здесь и далее источник изображений: NVIDIA Физически L40 представляют собой двухслотовую FHFL-плату расширения PCIe с пассивным охлаждением — теплопакет новинки ограничен рамками 300 Вт. Объём оперативной памяти GDDR6 составляет 48 Гбайт, вдвое больше, нежели у игровых GeForce RTX 4090, и, в отличие от последних, поддерживается совместная работа двух карт в режиме NVLink, что может оказаться полезным в симуляциях с большим объёмом данных. Для вывода изображения служат четыре порта DP 1.4a. 
NVIDIA OVX Server Каждый сервер NVIDIA OVX будет содержать 8 ускорителей L40 и три сетевых адаптера ConnectX-7 с портами класса 200GbE и поддержкой шифрования сетевого трафика на лету. От 4 до 16 таких серверов составят OVX POD, а 32 или более —кластер SuperPOD. Такие кластеры станут домом для новой облачной платформы NVIDIA Omniverse Cloud, услуги которой компания планирует предоставлять робототехникам, создателям автономных транспортных средств, «умной инфраструктуры» и вообще всем, кому нужна точная симуляция сложных объектов и систем с качественной визуализацией результатов.
21.09.2022 [01:10], Алексей Степин
NVIDIA представила платформу IGX для «умной» промышленности и медициныПомимо новых GPU с архитектурой Ada компания NVIDIA на конференции GTC 2022 анонсировала множество новинок и не последней из них стала новая периферийная платформа IGX, призванная вывести «умную» промышленность на новый уровень. Главный упор в IGX сделан на обеспечении повышенной безопасности, причём как информационной, так и физической. Использовать совместный труд роботов в промышленности пытаются уже давно, но до недавних пор такие решения были нестандартными и весьма дорогостоящими. IGX призвана обеспечить безопасность, стандартизацию и высокий уровень производительности, достаточный для современной робототехники. Сердцем платформы IGX являются высокоинтегрированные модули серии Jetson AGX Orin, сочетающие в себе достаточно мощный процессор общего назначения, GPU-ускоритель, ускорители ИИ, машинного зрения, а также отдельный сопроцессор sMCU, отвечающий за обеспечение безопасности в проактивном режиме. Последний работает в комплексе с новыми программными расширениями, легко интегрируемыми в большинство коммерческих ОС благодаря сопутствующему программному стеку NVIDIA AI Enterprise. 
NVIDIA IGX. Здесь и далее источник изображений: NVIDIA Что касается проактивной защиты, то, к примеру, получив сигнал с видеокамер о том, что человек приближается к «зоне ответственности» роботов, система автоматически изменит траекторию движения последних, предупредит сотрудников, а также на основании полученных данных скорректирует поведение роботов в дальнейшем. Также с помощью технологии «цифровых двойников» можно будет провести симуляцию, дабы заранее выяснить возможные точки потенциально опасных столкновений машин и людей. 
NVIDIA IGX сделает подобные сценарии безопасными Производительность центрального модуля IGX составляет 275 Топс в режиме INT8. Обеспечение сетевых возможностей возложено на плечи современного сетевого адаптера ConnectX-7, гарантирующего прецизионные тайминги, позволяющие использовать платформу не только в промышленности, но и в медицине, где вопросы безопасности и точности жизненно важны. Естественно, индустрия нового поколения не может обойтись без унифицированных средств управления и обеспечения кибербезопасности. Весь комплекс решений на базе новой платформы IGX может развёртываться и управляться с единой консоли с помощью облачной системы NVIDIA Fleet Command. За безопасность при этом отвечает выделенный контроллер. На более высоком уровне за интеграцию новой платформы в единую экосистему отвечает фреймворк NVIDIA Metropolis, с помощью которого можно создавать по-настоящему крупномасштабные комплексы, включая целые «умные города». 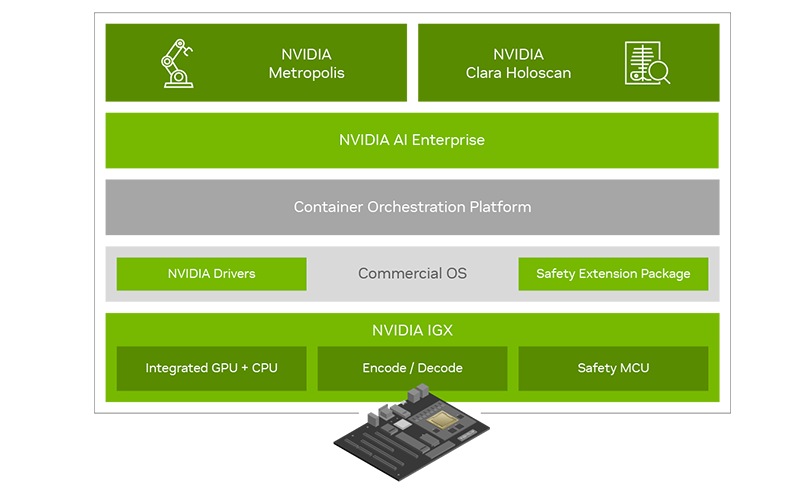
Программно-аппаратный состав новой платформы Отдельного упоминания заслуживает то, что новая платформа NVIDIA IGX избрана в качестве основы разработчиками медицинских систем, в частности, цифровой и робо-хирургии, такими как Activ Surgical, Moon Surgical и Proximie. Это стало возможным как благодаря аппаратным свойствам платформы, таким как низкая латентность и гарантированное время отклика, так и сочетанию фреймворков MONAI и Clara Holoscan.  Первый позволяет обучать специфические ИИ-модели на основании массивов медицинских данных. Эти модели затем могут интегрироваться с помощью Clara Holoscan SDK в реальные системы ультразвукового сканирования, эндоскопии или робохирургии. Помимо встроенных средств ускорения IGX, Clara Holoscan поддерживает и внешние ускорители NVIDIA RTX A6000, а технология Rivermax обеспечит передачу видеоданных для робота-хирурга на скорости 100 Гбит/с прямо в набортную память GPU. 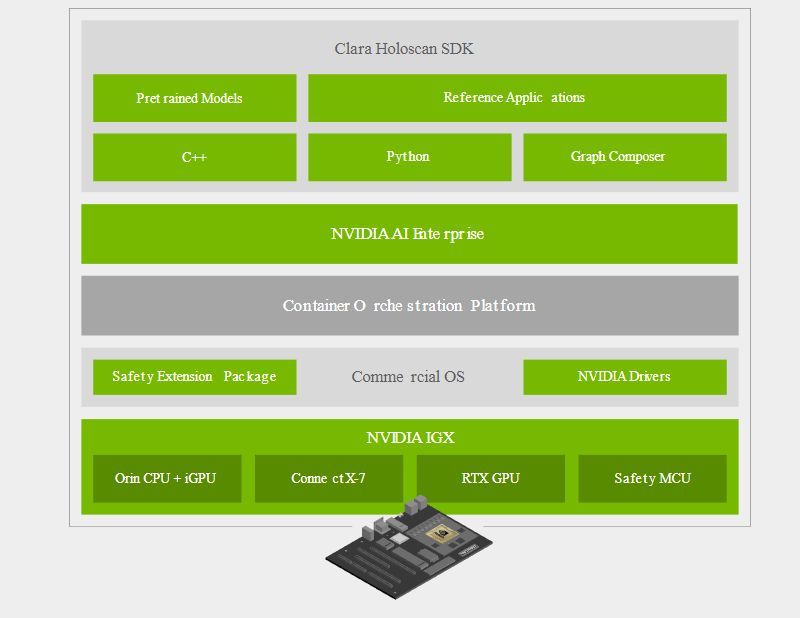 Комплекты разработчика IGX Orin будут доступны заказчикам в начале следующего года. Уже достигнуты соглашения с производителями встраиваемого оборудования ADLINK, Advantech, Dedicated Computing, Kontron, Leadtek, MBX, Onyx, Portwell, Prodrive Technologies и YUAN; уже испытывает новинку в деле Siemens. Также NVIDIA сотрудничает с Canonical, Red Hat и SUSE в целях обеспечения долговременной поддержки платформы, срок которой составит не менее 10 лет.
16.09.2022 [22:58], Алексей Степин
SambaNova Systems представила второе поколение ИИ-систем DataScale — SN30 с 5 Гбайт SRAM и 8 Тбайт DRAMСтартап SambaNova, решивший бросить вызов NVIDIA, представил второе поколение систем машинного обучения — DataScale SN30. В основе лежит собственная разработка компании, ускоритель Cardinal SN30, для обозначения которого SambaNova использует термин Reconfigurable Data Flow Unit (RDU). На новинку уже обратили внимание такие организации, как Аргоннская национальная лаборатория (ANL) и Ливерморская национальная лаборатория им. Э. Лоуренса (LLNL). Cardinal SN30 состоит из 86 млрд транзисторов и производится с использованием 7-нм техпроцесса TSMC. Главной его особенностью является возможность реконфигурации: создатели уподобляют этот процессор сложным FPGA. Последним он уступает в степени гибкости, поскольку не может менять конфигурацию на уровне отдельных логических вентилей, зато выигрывает в скорости перепрограммирования и уровне энергопотребления. За это отвечает фирменный программный стек. 
Источник: HPCwire Большой упор SambaNova сделала на объёме локальной памяти, поскольку современные модели машинного обучения имеют тенденцию к гигантомании. Только SRAM-кеша у Cardinal SN30 640 Мбайт, а объём DRAM составляет 1 Тбайт. По своим параметрам SN30 вдвое превосходит чип первого поколения, SN10, но имеет такую же тайловую архитектуру с программным управлением. 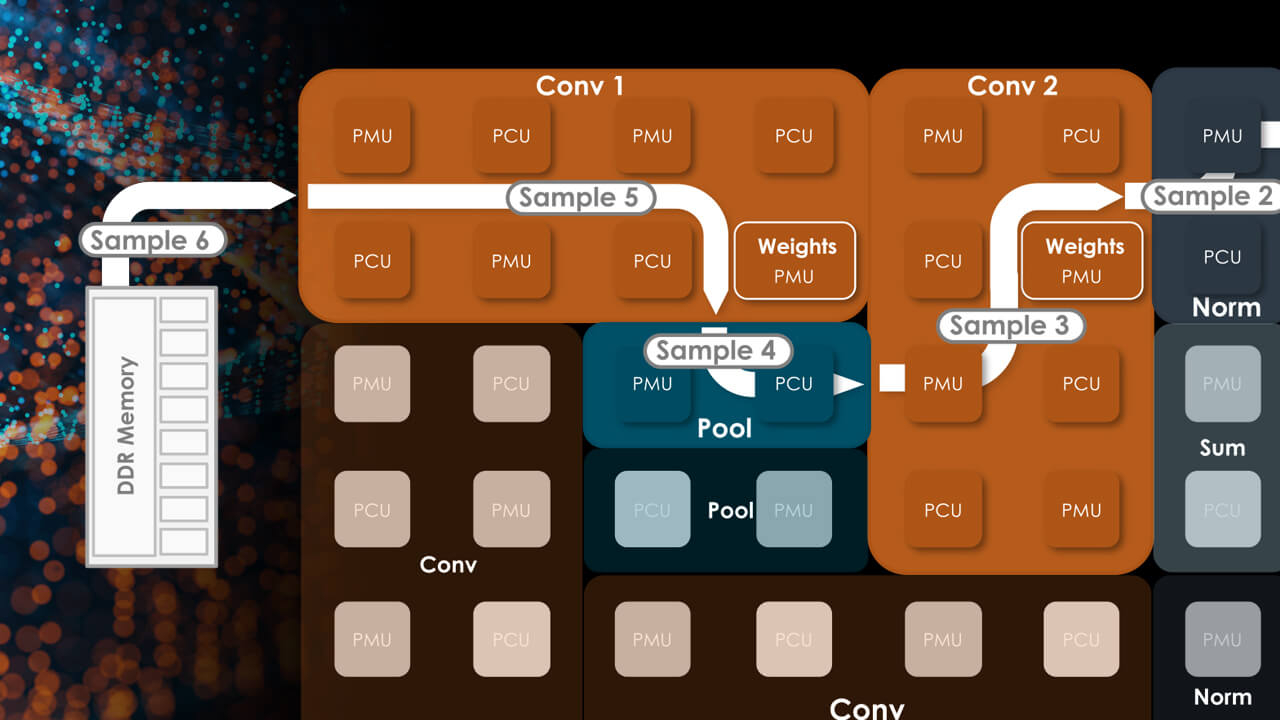
Здесь и далее источник изображений: SambaNova Каждый тайл содержит блоки PCU, отвечающие за вычисления, блоки PMU, содержащие SRAM и обслуживающую логику, а также mesh-интерконнект, обслуживаемый блоками коммутаторов. Такой подход к построению процессора весьма напоминает Tesla D1, у которых вычислительные блоки похожим образом чередуются с блоками быстрой SRAM-памяти. Отдельно ускорители компания не поставляет, минимальная конфигурация готовой 42U-системы DataScale включает в себя 8 чипов SN30.  Комплектация может включать в себя от одного до трёх узлов SN30. Воспользоваться возможностями DataScale можно и в виде услуги, поскольку новинка легко интегрируется в облачные среды и полностью поддерживает платформу Kubernetes. Полный список провайдеров ещё уточняется, на сегодняшний момент партнерами SambaNova являются Aicadium, Cirrascale и ORock.  Высокая производительность в режиме BF16 является главным достоинством новинки — по словам вице-президента SambaNova, каждый чип развивает 688 Тфлопс. Это более чем вдвое выше показателя A100, составляющего 312 Тфлопс. По словам компании, DataScale SN30 вшестеро производительнее NVIDIA DGX A100 (40 Гбайт) и эффективнее всего проявляет себя при обучении сверхбольших моделей вроде GPT-3 с её 13 млрд параметров. Однако нельзя не отметить, что, во-первых, сравнение идёт со старым продуктом NVIDIA, которая вот-вот представит DGX H100, а во-вторых, SambaNova не упоминает в явном виде энергопотребление одного узла SN30.
14.09.2022 [22:28], Игорь Осколков
Arm анонсировала серверные ядра Neoverse V2 Demeter, именно они легли в основу процессоров NVIDIA GraceArm анонсировала новые ядра в серии Neoverse, принадлежащие к семейству Armv9 — Neoverse V2 с кодовым названием Demeter (Деметра). В семействе Neoverse V-ядра относятся к высокопроизводительным решениям, ориентированным на гиперскейлеров, облачных провайдеров и поставщиков HPC-решений. Одним из первых продуктов на базе новой платформы станет 72-ядерный серверный процессор NVIDIA Grace, выход которого запланирован на следующий год. 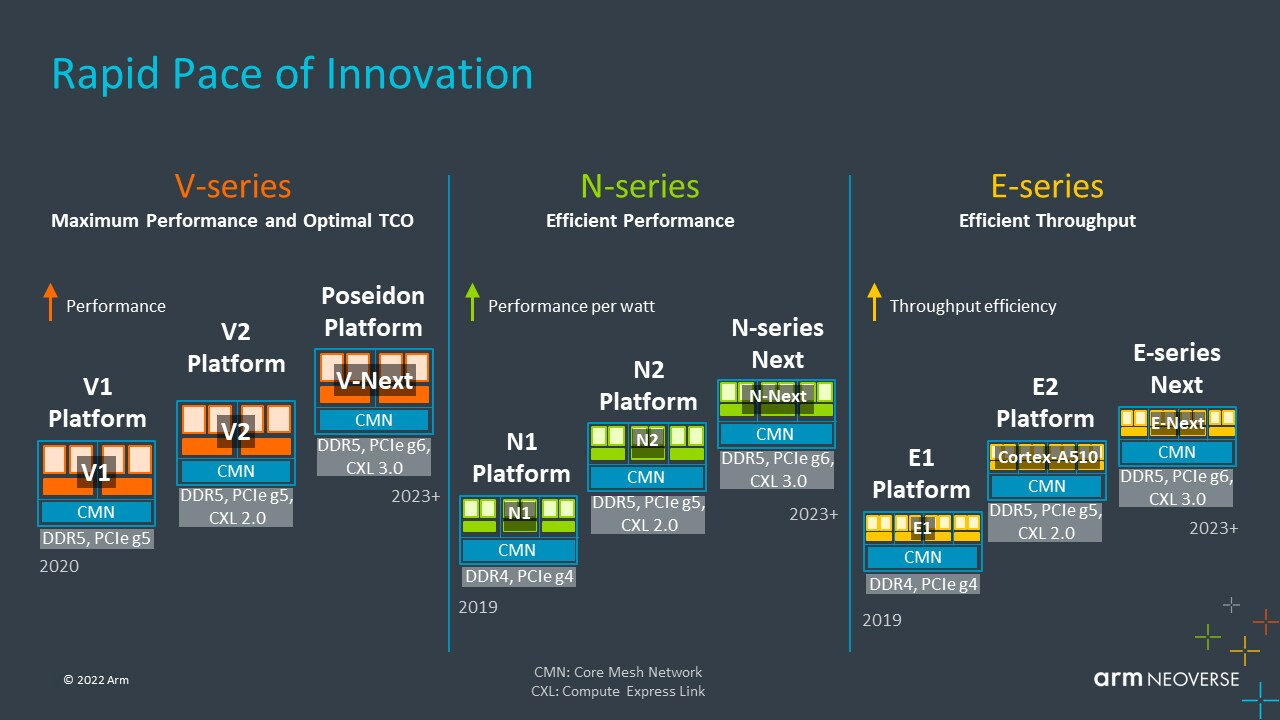
Источник: Arm Arm пока что не приводит точные характеристики V2-ядер, но говорит о возросшей производительности как целочисленных вычислений, так и вычислений с плавающей запятой. Для новинок заявлена поддержка SVE2-инструкций, наличие четырёх 128-бит векторных блоков, а также блоки для работы с матрицами и поддержка BF16/INT8. Кроме того, ядра получат увеличенный до 2 Мбайт L2-кеш, а также новые механизмы аппаратной защиты и, по-видимому, улучшенные криптографические движки. 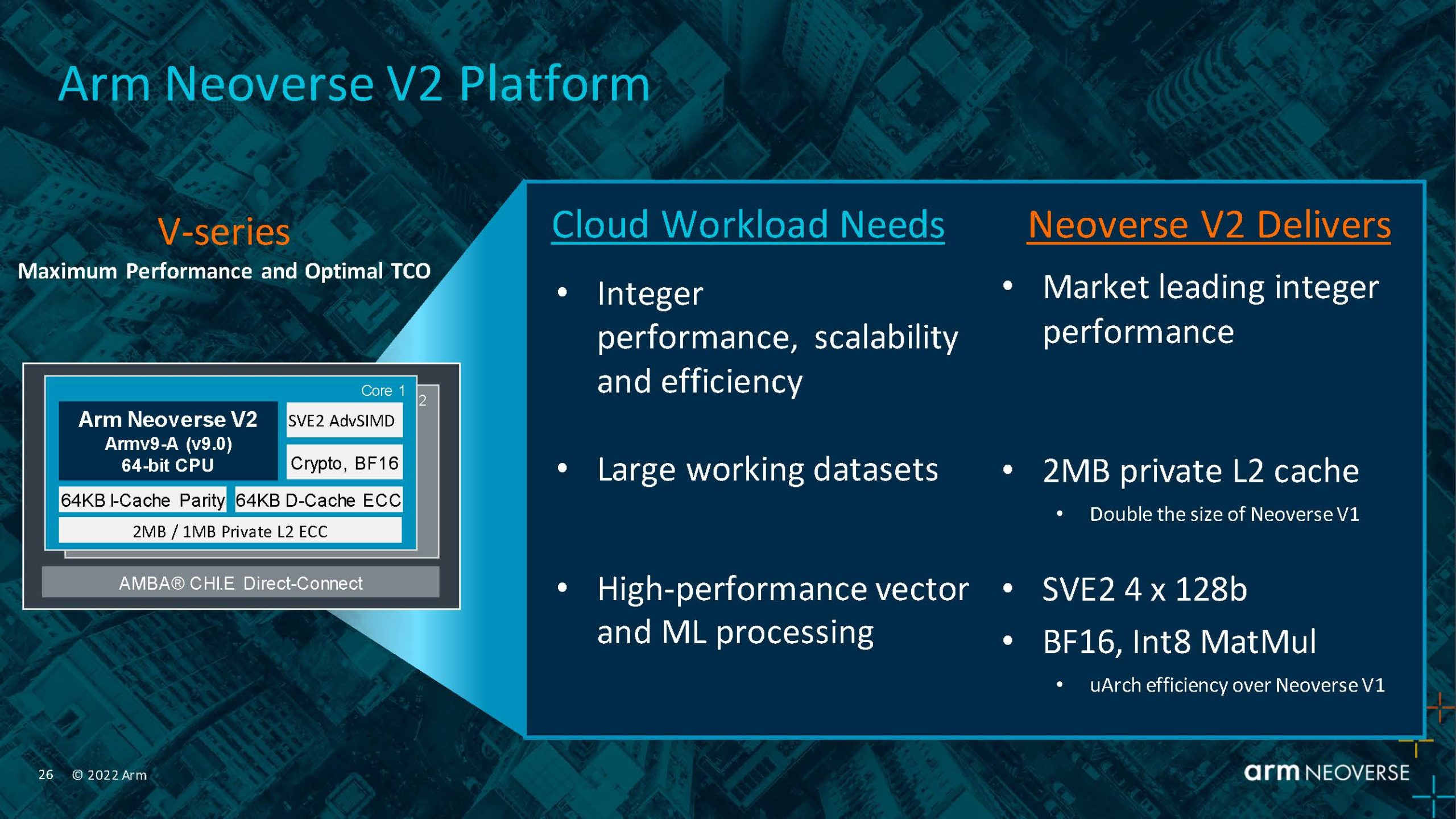
Источник: ServeTheHome  Объединять ядра и кеши будет когерентная mesh-шина CMN-700 с суммарной пропускной способностью до 4 Тбайт/с, которая может обслуживать до 512 Мбайт кеш-памяти. А за обслуживание связей с другими кристаллами всё так же будет отвечать шина AMBA CHI. Будет предложена поддержка (LP)DDR5(X), CXL 2.0, PCIe 5.0 и UCIe. Также Arm пообещала и далее вкладываться в развитие инициативы SystemReady и совместную с партнёрами оптимизацию системного и прикладного ПО — всё ради упрощения перехода конечных пользователей с x86 на Arm. 
Источник: ServeTheHome  Впрочем, как отмечает ServeTheHome, в ходе презентации Arm напирала скорее на прирост эффективности с точки зрения именно целочисленных вычислений, что актуально для облаков. x86-лагерь сдавать позиции в этой области не хочет — конкуренцию Arm составят AMD EPYC Bergamo и Intel Xeon Sierra Forest. Но в 2023 году Arm представит следующее поколение высокопроизводительных ядер Neoverse V3 (Poseidon) c PCIe 6.0 и CXL 3.0, а также «сбалансированную» платформу Neoverse N3 и энергоэффективные ядра Neoverse E следующего поколения.
14.09.2022 [17:35], Руслан Авдеев
Cargill представила NatureCool 2000, жидкость растительного происхождения для иммерсионных СЖОКак сообщает DataCenter Dynamics, американская продовольственная компания Cargill разработала жидкость NatureCool 2000 для погружных СЖО, которая является более экологичной альтернативой для составов, полученных в результате перегонки углеводородов, поскольку на 90 % состоит из растительных масел. Разработчики подчёркивают, что, поскольку она получена из растений с естественным образом «связанным» углеродом, её можно назвать углеродно-нейтральной. Кроме того, новинка является биоразлагаемой. 
Источник изображения: Robert Anderson/unsplash.com При этом показатели NatureCool 2000 не только не уступают самым передовым синтетическим альтернативам, но и превосходят их по теплоотдаче на 10 %. Кроме того, жидкость соответствует всем необходимым стандартам безопасности. В частности, говорится о том, что температура вспышки составляет 325°C, а сама жидкость гаснет после устранения источника высокой температуры, тогда как традиционные синтетические жидкости в этом случае могут продолжать гореть. 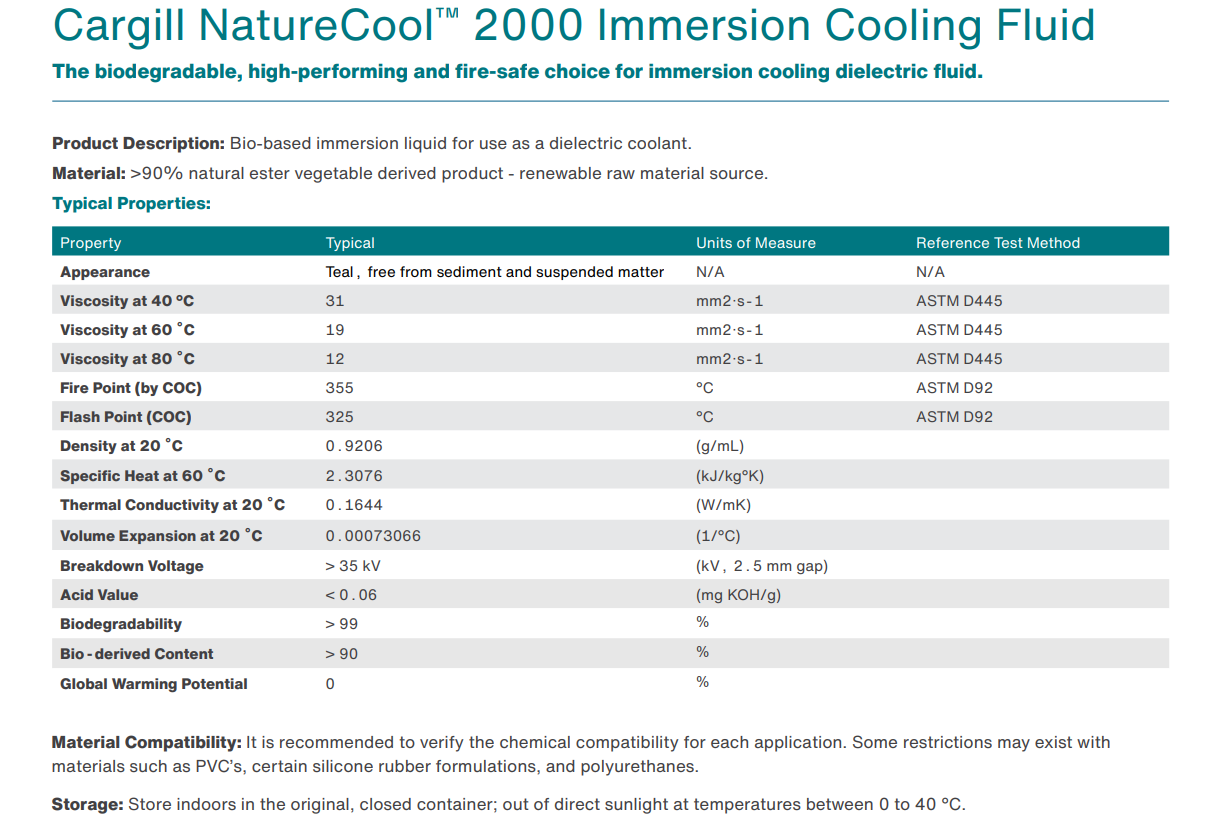
Источник: Cargill Известно, что Cargill уже присоединилась к инициативе Open Compute Project, причём члены команды продовольственной компании принимают активное участие в развитии спецификаций погружных СЖО. Cargill постепенно осваивает нишу продуктов для ЦОД, хотя пока подобный профиль деятельности не является основным для компании.
08.09.2022 [23:04], Игорь Осколков
Серверная Вирджиния: один-единственный штат США всё ещё обгоняет по ёмкости сверхкрупных дата-центров и Европу, и КитайПо оценкам аналитиков Synergy Research Group, к концу II квартала 2022 года число дата-центров гиперскейлеров превысило 800 шт., а к концу 2026 года их станет в полтора раза больше. Причём расти будет не только количество таких ЦОД, но и их мощность. При этом 53 % ёмкости ЦОД гиперскейлеров приходится на США, а оставшаяся доля практически поровну поделена между Европой, Китаем и остальным миром. Наиболее крупные игроки на этом рынке — «большая тройка» облачных провайдеров (Amazon, Google, Microsoft). У каждой из этих компаний имеется более 130 дата-центров, причем не менее 25 в каждом из трёх основных регионов, Североамериканском, Азиатско-Тихоокеанском и Европейском. По мощности дата-центров лидируют компании Amazon, Google, Microsoft, Facebook✴, Alibaba и Tencent. Всего же в исследовании Synergy Research Group учитывались дата-центры 19 крупнейших компаний, оказывающих облачные и иные интернет-услуги. 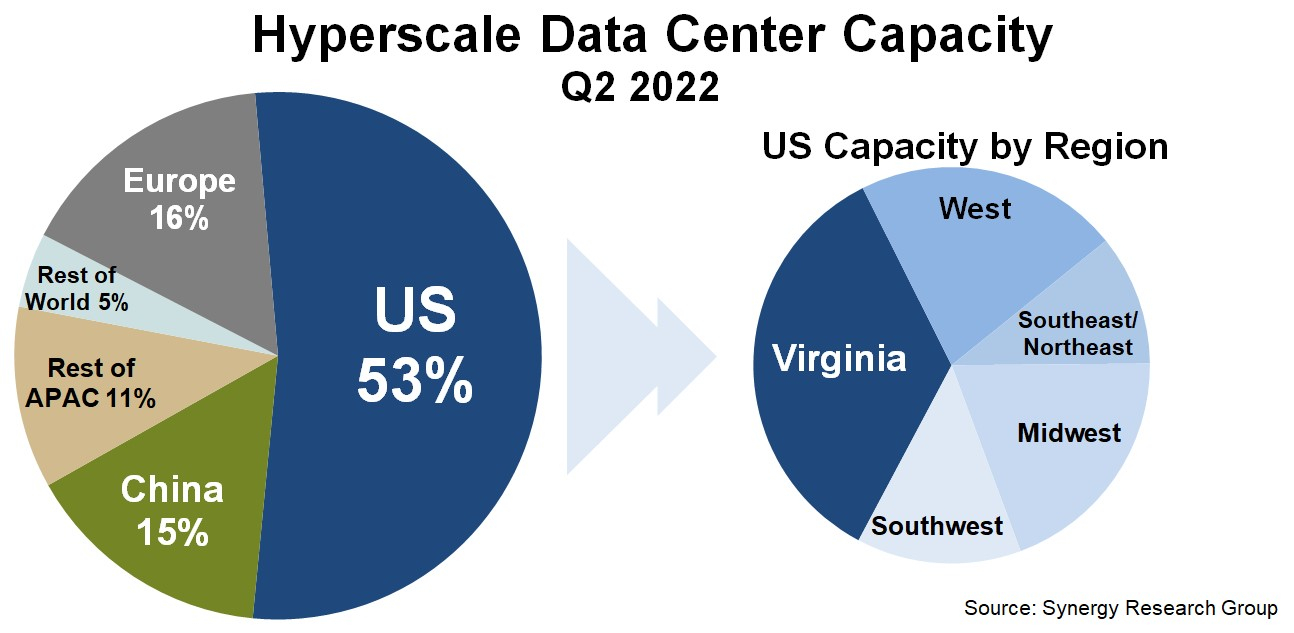
Источник: Synergy Research Group По мощности дата-центров лидируют компании Amazon, Google, Microsoft, Facebook✴, Alibaba и Tencent. При этом, как и прежде, более трети мощностей в США приходится на один-единственный штат — Вирджинию, которая обгоняет по этому показателю Европу и Китай. Здесь находится так называемая Аллея дата-центров, охватывающая округи Лаудон (Loudoun), Принс-Уильям (Prince William) и Фэрфакс (Fairfax). ЦОД в основном концентрируются вокруг городов Эшберн (Ashburn), Стерлинг (Sterling), Манассас (Manassas) и Шантийи (Chantilly). 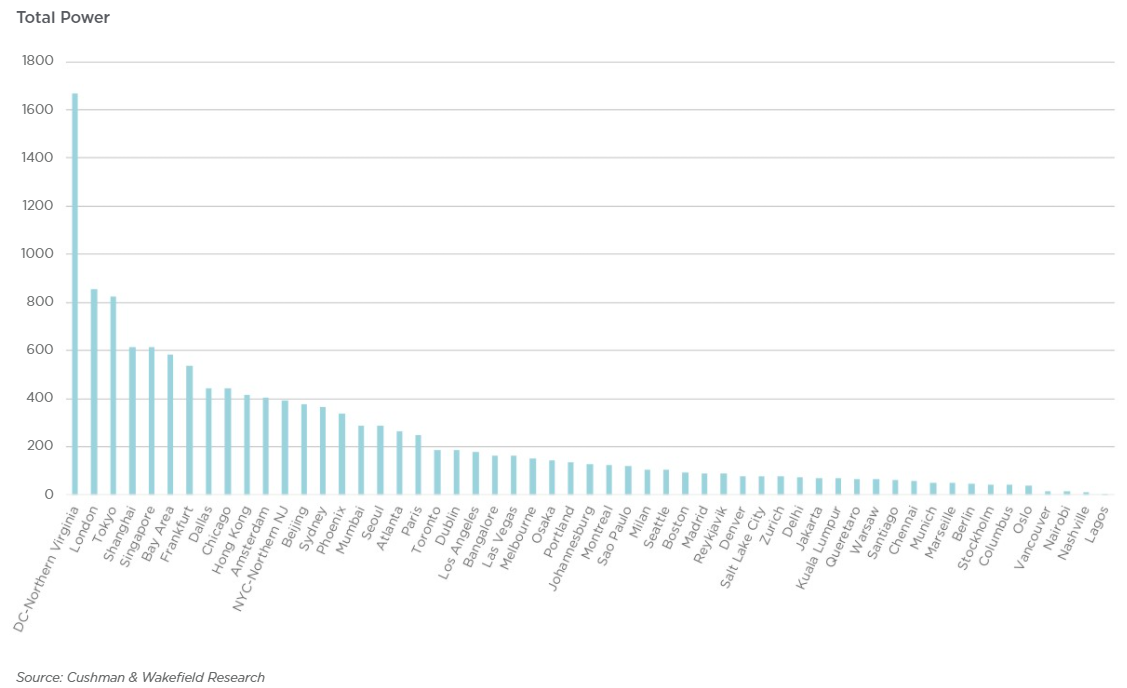
Источник: Cushman & Wakefield Research Суммарная ёмкость ЦОД в штате достигла 1,7 ГВт. В частности, Amazon именно здесь размещает значительную часть своих ЦОД. Другими крупными игроками на локальном рынке являются Microsoft, Meta✴, Google, ByteDance. Столь привлекательной для операторов ЦОД Вирджиния стала в силу доступности площадей и энергии, развитой инфраструктуры, а также особенностей местного законодательства, в том числе налоговых послаблений. Правда, теперь местные жители жалуются на «катастрофический шум» от дата-центров, а возможностей энергосети стало не хватать. Что касается других регионов, то в Европе ведущими рынками для гиперскейлеров остаются Ирландия и Нидерланды, где в последнее время также наметился кризис — обе страны больше не рады крупным игрокам, которые один за другим отменяют или приостанавливают проекты по созданию и развитию ЦОД. Китайский рынок остаётся относительно изолированным, поскольку он включает по большей части дата-центры местных IT-гигантов: Alibaba, Tencent и Baidu. В целом же аналитики прогнозируют, что в течение следующих пяти лет важность ключевых на текущий момент рынков ЦОД несколько снизится.
06.09.2022 [22:47], Алексей Степин
Кремниевая фотоника Lightmatter Passage объединит чиплеты на скорости 96 Тбайт/сНа конференции Hot Chips 34 компания Lightmatter, занимающаяся созданием фотонного ИИ-процессора, рассказала о своей новой разработке, Lightmatter Passage, открывающей для чиплетов эру фотоники. Как известно, переход на чиплеты позволил разработчикам сложных чипов сравнительно малой кровью обойти ограничения, накладываемые технологиями на создание монолитных кристаллов большой площади. Однако современный высокоскоростной межчиплетный интерконнект всё равно весьма сложен и потребляет сравнительно много энергии. И по мере роста количества чиплетов на общей подложке проблема будет лишь обостряться. 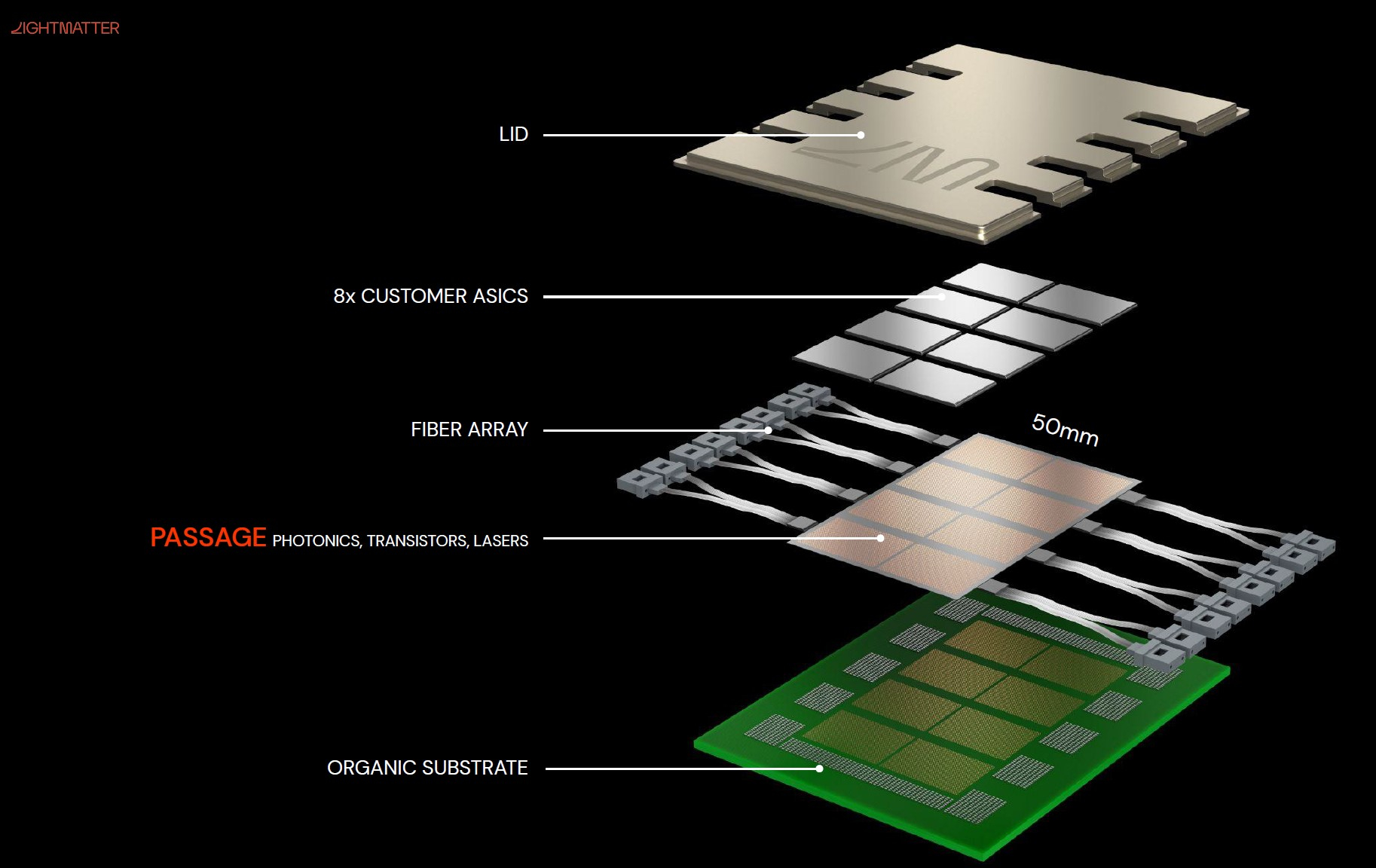
Изображения: Lightmatter (via ServeTheHome) Но технология Lightmatter Passage, призванная заменить электрический интерконнект оптическим, позволит эту проблему обойти. По сути, Passage — универсальная кремниевая прослойка, содержащая в своём составе лазеры, оптические модуляторы, фотодетекторы, волноводы, а также классические транзисторы для сопутствующей логики. Поверх этой прослойки Lightmatter и предлагает размещать чиплеты любой архитектуры. 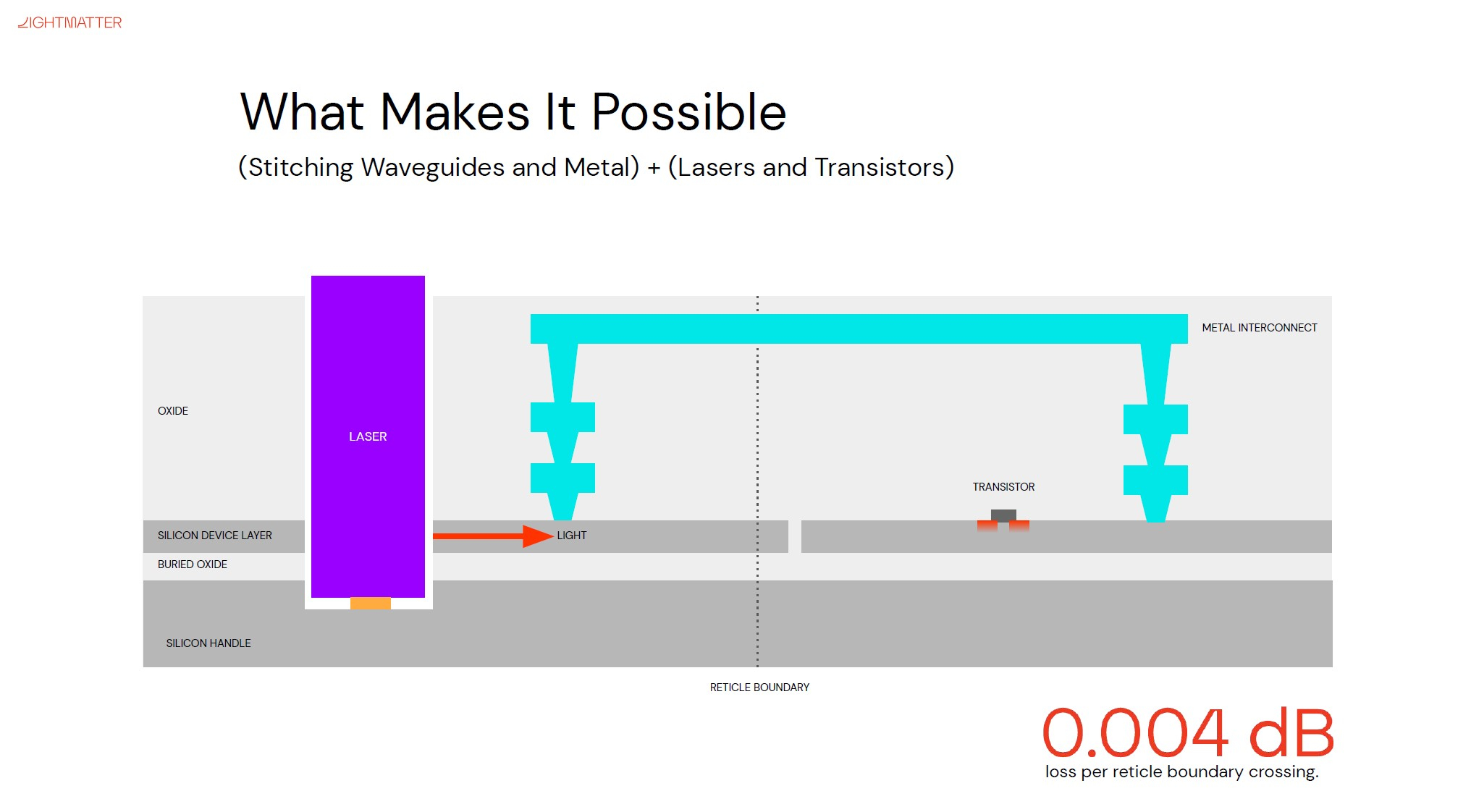 Электрическая часть Passage имеет изменяемую конфигурацию и в текущей реализации поддерживает установку до 48 чиплетов (в виде матрицы 6×8). Производится такая прослойка из 300-мм кремниевой пластины SOI, верхний и нижний слои Passage имеют классические контакты для чиплетов и установки на PCB соответственно. При этом максимальная подводимая электрическая мощность может достигать 700 Вт. Вся же коммуникация чиплетов между собой происходит внутри и является оптической. 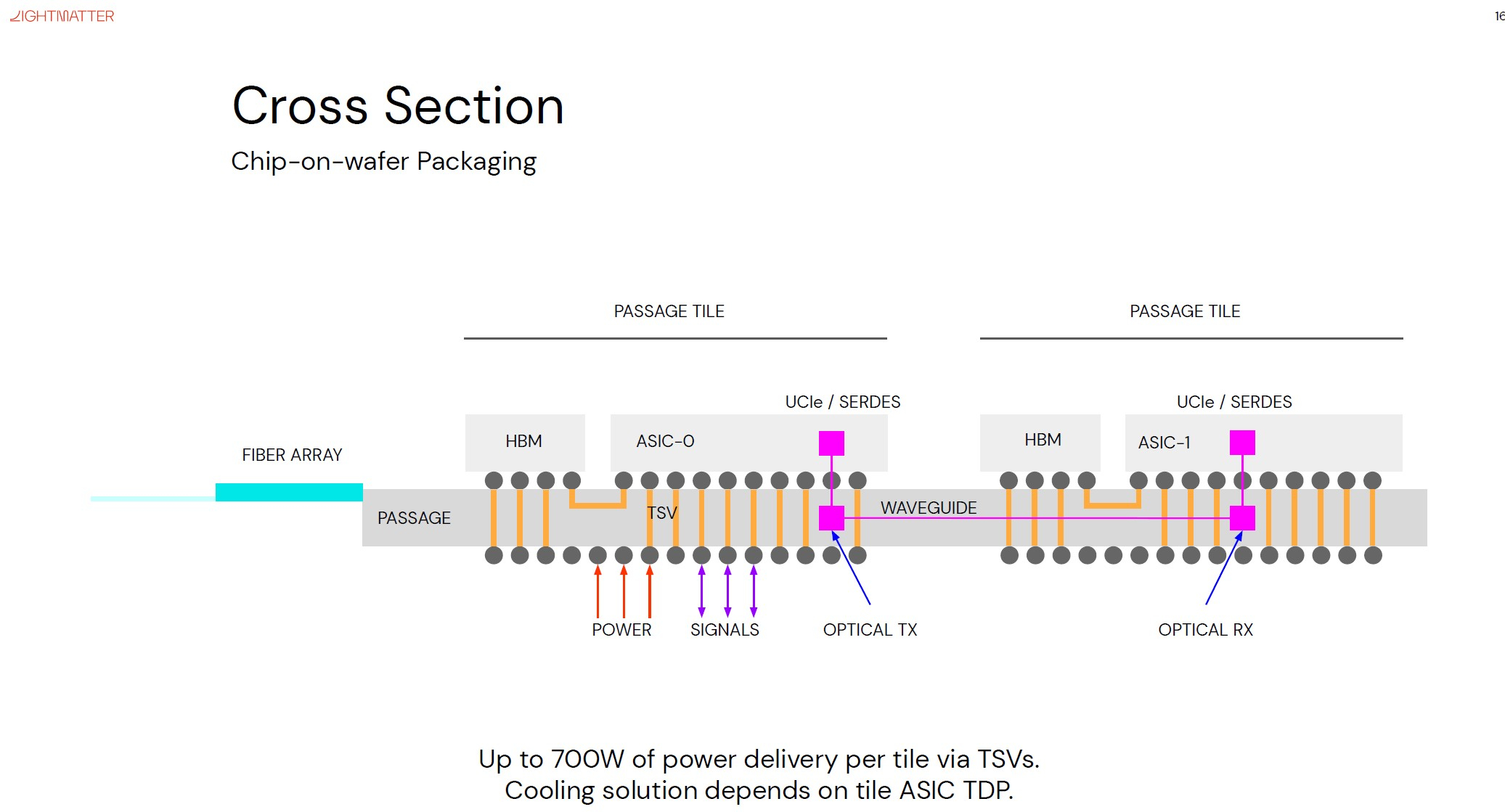 Матрица фотонных волноводов, плотность которой в 40 раз выше, чем у традиционных оптоволоконные технологий, обеспечивает латентность одного перехода на уровне менее 2 нс. Как заявляют разработчики, расстояние между чиплетами при этом роли не играет — для любого сочетания пары точек «входа» и «выхода» сигнала значение задержки одинаково. Высокая плотность волноводов позволяет «накормить» каждый чиплет потоком данных до 96 Тбайт/с, а внешние каналы Passage позволяют связать чипы с другими компонентами системы на скоростях до 16 Тбайт/с. 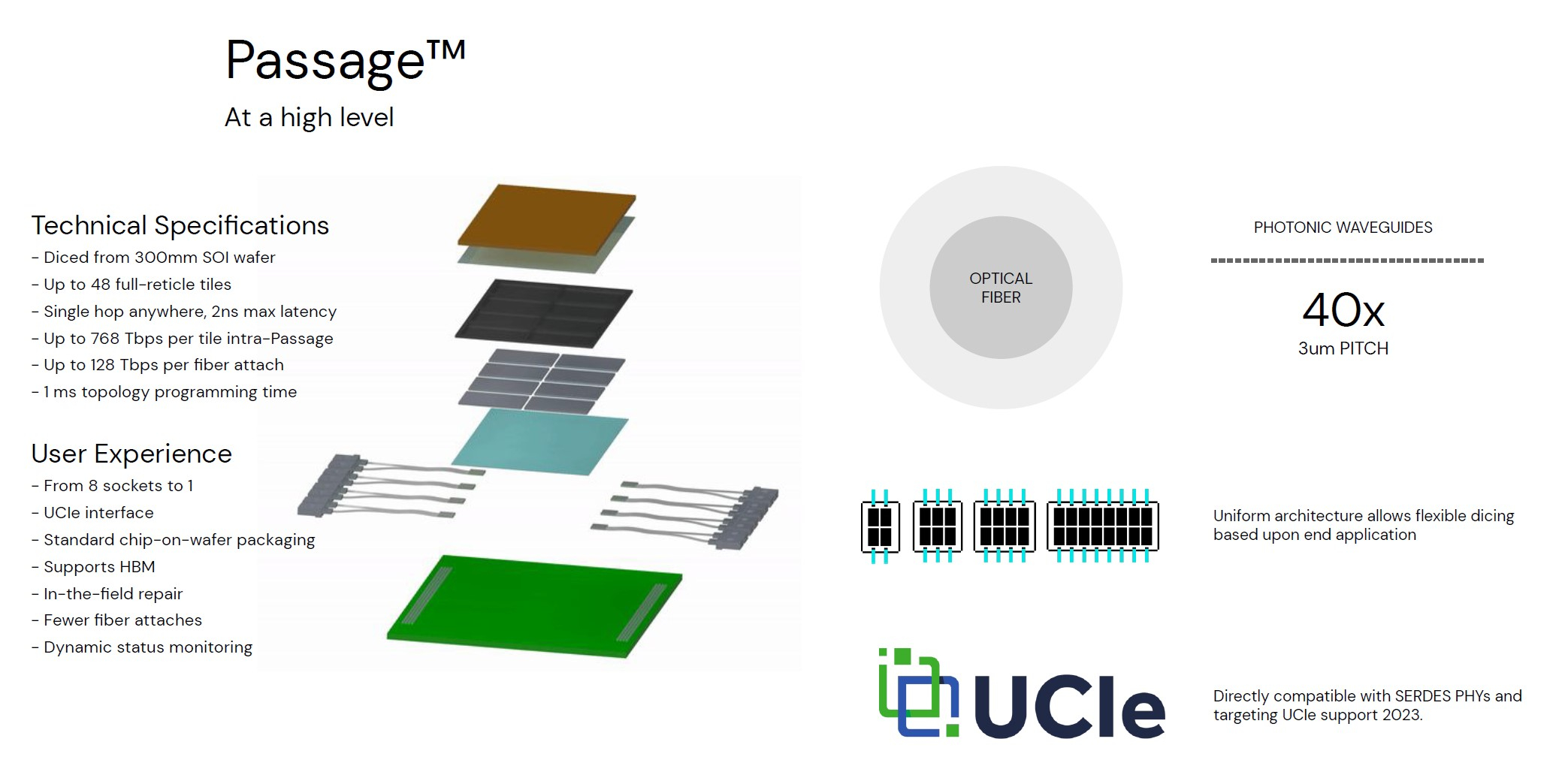 Основой данной технологии является фирменная разработка компании, позволяющая точно «сшивать» в пределах нескольких слоев SOI-кремния электрические соединения с многочисленными волноводами. Уже существующая в кремнии тестовая реализация Passage потребляет 21 Вт, позволяет устанавливать до 48 чиплетов площадью по 800 мм2, обеспечивает каждое посадочное место 32 каналами с пропускной способностью 1024 Тбит/с, причём топологию интерконнекта можно динамически менять.  Тестовая подложка Passage, полученная из 300-мм пластины, содержит 288 лазеров мощностью 50 мВт каждый. Всего в состав системы входит 150 тыс. компонентов, и это заявка на абсолютный рекорд для фотонных чипов. Кроме того, новая технология совместима со стандартом UCIe — говорится о скорости 32 Гбит/с на линию. Впрочем, в случае простого SerDes-соединения, как считают создатели, этот показатель можно поднять до 112 Гбит/с. |
|