Лента новостей
|
26.12.2022 [16:49], Руслан Авдеев
Су-вид в стиле Qarnot: как приготовить ужин с помощью сервераФранцузская компания Qarnot предоставляет услуги высокопроизводительных вычислений компаниям вроде Adobe, Societe Generale, Illumination и Fix Studio. Изюминкой её деятельности является акцент на использовании тепла серверов в разных целях — на этот раз его применили для приготовления ужина. 
Фото: Clément Pellegrini/LinkedIn Вычислительные кластеры Qarnot OBx, по данным компании, позволяют использовать до 96 % выделяемого серверами тепла для нагрева, например, воды. Один из них и использовала Qarnot, подойдя к вопросу использования тепла с кулинарной изобретательностью. Так, в ёмкости c циркулирующей горячей водой появились утка, говядина и лосось. Чтобы охлаждающая жидкость не превратилась в бульон, продукты разместили в вакуумированной упаковке. Пока система занималась 3D-рендерингом, температура в ёмкости поддерживалась на уровне +55 °C. Этого вполне достаточно, чтобы использовать французскую технологию приготовления мяса sous vide — она предусматривает приготовление блюд при относительно невысоких температурах. Правда, процесс приготовления в этом случае затягивается. Разумеется, в данном случае речь идёт лишь о демонстрации возможностей решений Qarnot. Компания активно продаёт отработанное тепло, но оно обычно применяется более традиционными способами, преимущественно для отопления жилых и коммерческих зданий. По словам технического директора компании, её решения снижают энергозатраты на отопление на 65 %, а сопутствующие выбросы углерода — на 81 %. В 2018 году компания представила «криптообогреватели», представляющие собой комбинацию вычислительного устройства и обогревателя для дома, а в 2020 году предложила отапливать дома с помощью б/у серверов.
20.12.2022 [17:06], Владимир Мироненко
В результате судебного разбирательства выяснилось, что на один ЦОД Google приходится четверть объёма потребления питьевой воды американского городкаGoogle раскрыла объёмы потребления воды своих ЦОД. На этот шаг компания пошла после судебного процесса между местной газетой The Oregonian и властями Даллеса (штат Орегон), которые пытались сохранить данную информацию в секрете. В прошлом году The Oregonian затребовала данные о водопотреблении у Google, но не получила их и обратилась к городским властям. Муниципалитет отказался предоставлять эту информацию, объявив её коммерческой тайной, после чего газета подала к нему иск. В итоге городским властям пришлось пойти на попятную. Выяснилось, что в течение 2021 года на объектах поисковой компании в Даллесе было израсходовано около 1,2 млрд л воды, что гораздо меньше по сравнению с 3,8 млрд л, израсходованными инфраструктурой ЦОД Google в Каунсил-Блаффсе (штат Айова). В целом в 2021 году потребление воды на объектах Google в США составило 12,4 млрд л, а за пределами США — 4,4 млрд л. Сама компания считает, что это не так уж и много, утверждая, что общее годовое потребление воды её дата-центрами сопоставимо с расходом воды на обслуживание 29 полей для гольфа на юго-западе США. Google уточнила, что речь идёт о питьевой воде и указанные объёмы не включают воду из других источников, например, морскую воду. По данным The Oregonian, потребление воды ЦОД Google в Даллесе почти утроилось за последние пять лет и теперь составляет более четверти всего объёма воды, используемой в городе. Эти цифры будут расти, поскольку компания планирует построить в городе ещё два ЦОД. Следует также отметить, что Даллес находится в засушливом регионе и здесь наблюдается пик многолетней засухи. 
Изображение: Google Исполнительный директор некоммерческой правозащитной группы WaterWatch Джон ДеВоу (John DeVoe) заявил, что увеличение потребления ЦОД воды в два или три раза в течение следующего десятилетия может иметь серьёзные последствия для обитателей водоёмов и других водопользователей в районе Даллеса. Он отметил, что потребление воды в городе удвоилось с 2002 по 2021 год, что поставило под угрозу протекающую здесь реку и отдельные виды обитающих в ней рыб. ДеВоу уточнил, что на долю Google приходится до 29 % всего городского потребления воды. В свою очередь, Google и городские власти заявили, что заключённый контракт учитывает потребности города в воде и что компания обязуется выделить $28,5 млн на модернизацию систем поставки воды. Кроме того, она передала городу права на использование воды на своих промышленных землях в обмен на большее количество воды из городских резервуаров. Город обязался предоставить Google больше воды для новых ЦОД, начав перекачку не использовавшихся ранее подземных вод. Понимая, что у общественности растёт обеспокоенность по поводу значительных объёмов расхода воды ЦОД, технологические компании весьма неохотно делятся такой информацией. Согласно исследованию Uptime Institute, лишь около половины компаний сообщает об использовании воды или выбросах углекислого газа в ЦОД.
14.12.2022 [15:31], Сергей Карасёв
Microsoft купила разработчика необычного оптоволокна LumenisityКорпорация Microsoft объявила о заключении соглашения о покупке компании Lumenisity, базирующейся в Великобритании. Этот стартап, основанный в 2017 году, специализируется на разработке решений для высокоскоростной передачи данных с применением технологии полого оптоволокна HCF (Hollow Core Fiber). Компания Lumenisity создана как дочерняя структура Исследовательского центра оптоэлектроники (ORC) Саутгемптонского университета. Конструкцией HCF предусмотрено наличие заполненного воздухом канала, окружённого кольцом стеклянных трубок, похожим на соты. Свет проходит не через обычное волокно, а через воздушный канал, так что, по словам Lumenisity, он распространяется по HCF-кабелям примерно на 47 % быстрее, чем через волокно из кварцевого стекла. Хотя это и не новая технология, интерес к ней растёт по мере улучшения пропускной способности и надёжности. 
Источник изображения: Microsoft Такая конструкция позволяет не только повысить скорость передачи данных и снизить задержки, но и открывает путь к созданию протяжённых ВОЛС без использования репитеров благодаря более низким потерям энергии. Кроме того, Lumenisity говорит, что её решение дешевле аналогов и лучше защищено от вторжений. Microsoft заявляет, что приобретение Lumenisity расширит возможности по дальнейшей оптимизации глобальной облачной инфраструктуры Azure. Lumenisity привлекла на развитие в общей сложности около $15,5 млн, а недавно открыла производственное предприятие HCF в Ромси, Великобритания. Финансовые условия сделки не раскрываются. Важно отметить, что волокно Lumenisity не требует для развёртывания специального оборудования и работает со многими оптическими системами, которые сегодня используются в телекоммуникационных сетях. По всей видимости, Microsoft будет применять технологию Lumenisity для объединения своих ЦОД. Также Microsoft по неподтверждённым пока официально данным приобрела Fungible, разработчика DPU. Компания, судя по всему, намерена задействовать эти DPU только для собственных нужд.
13.12.2022 [21:52], Алексей Степин
Ventana анонсировала первый по-настоящему серверный RISC-V процессор Veyron V1: 192 ядра с частотой 3,6 ГГцАрхитектура RISC-V достаточно молода и обычно ассоциируется с экономичными чипами на платах, подобных Raspberry Pi. Однако технически она позволяет создавать и мощные процессоры, способные поспорить с лучшими решениями на базе архитектур Arm и x86. На саммите RISC-V компания Ventana Micro Systems анонсировала целое семейство высокопроизводительных процессоров, первенцем в котором стал чип Veyron V1, который, по словам разработчиков, сможет потягаться в однопоточной производительности с самыми современными CPU класса High-End. 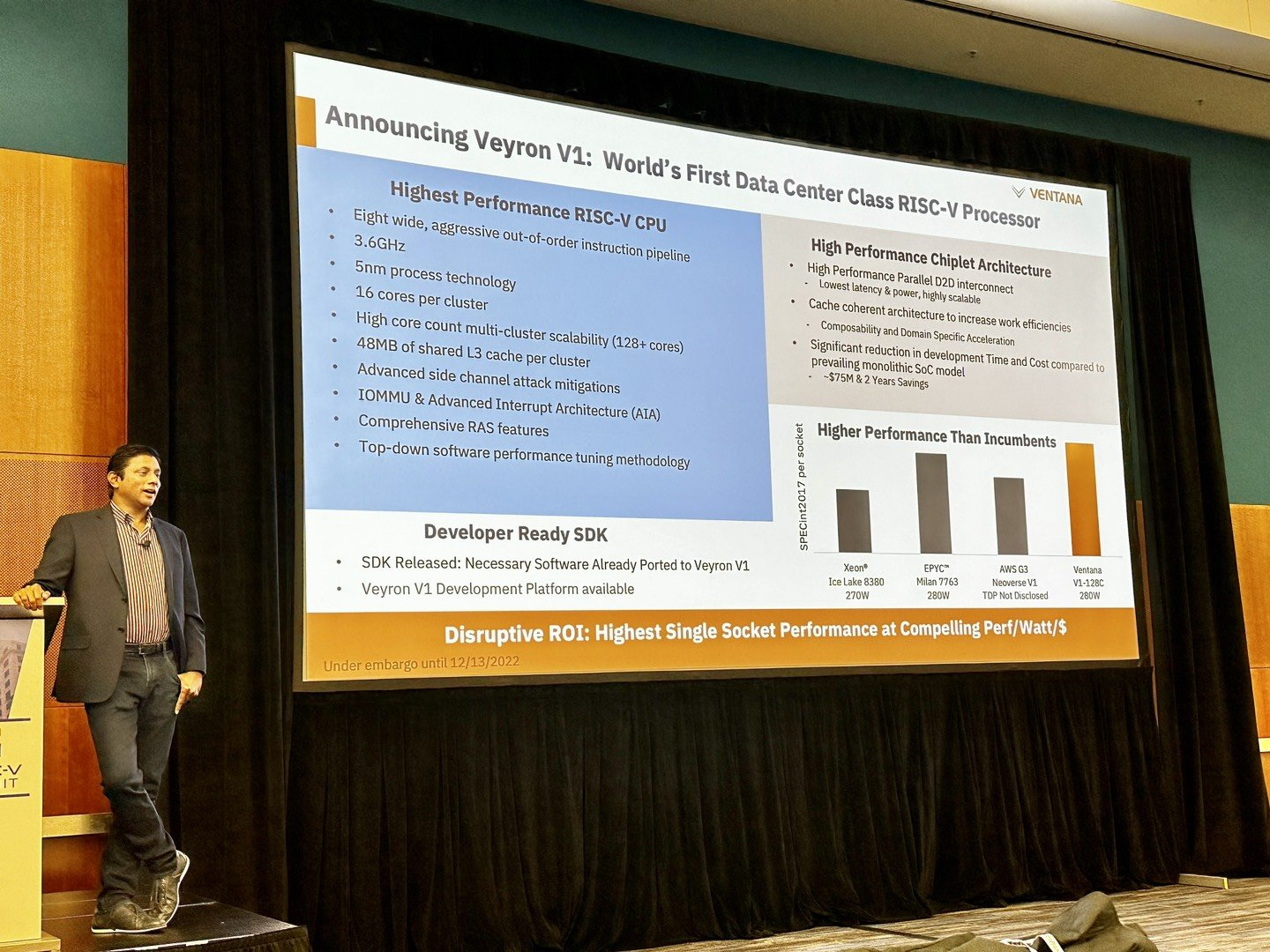
Veyron V1 должен стать самым быстрым процессором с архитектурой RISC-V. Источник: Twitter@risc_v Новинка нацелена на рынок гиперскейлеров, причём благодаря чиплетному дизайну новый процессор изначально разрабатывался как кастомизируемый под задачи заказчика. Veyron V1 будет предлагаться в виде своеобразного набора-конструктора, включающего в себя один или несколько вычислительных чиплетов Veyron, I/O-хаба и интерконнекта, позволяющего связать все компоненты воедино. Это, по словам разработчиков, должно серьёзно ускорить и удешевить процесс внедрения новой процессорной платформы, снизив расходы на разработку чипов на 75 %, а время создания — до не более чем двух лет. 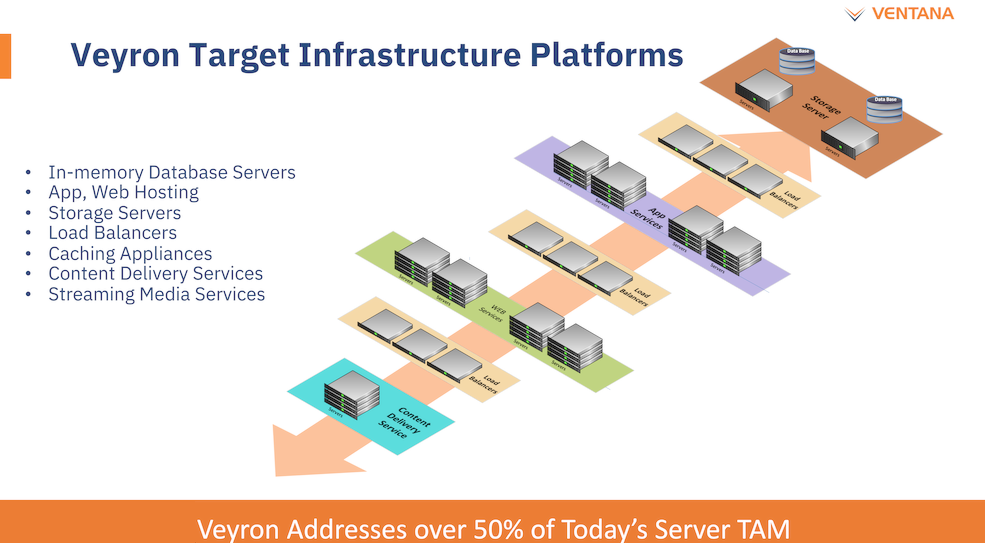
Платформа Veyron V1 универсальна и покрывает широкий спектр задач. Источник здесь и далее: StorageReview Вычислительный чиплет Veyron V1 использует продвинутые 64-битные ядра RISC-V и располагает 2 Мбайт кеша L2, а также многопоточным контроллером памяти. Предусмотрены конфигурации чиплета с 6, 8, 12 или 16 ядрами с частотой в районе 3 ГГц, что сопоставимо с решениями Google и AWS. Использоваться процессор может не только в ЦОД, но и в различных встраиваемых системах, базовых станциях 5G или даже клиентских рабочих станциях. 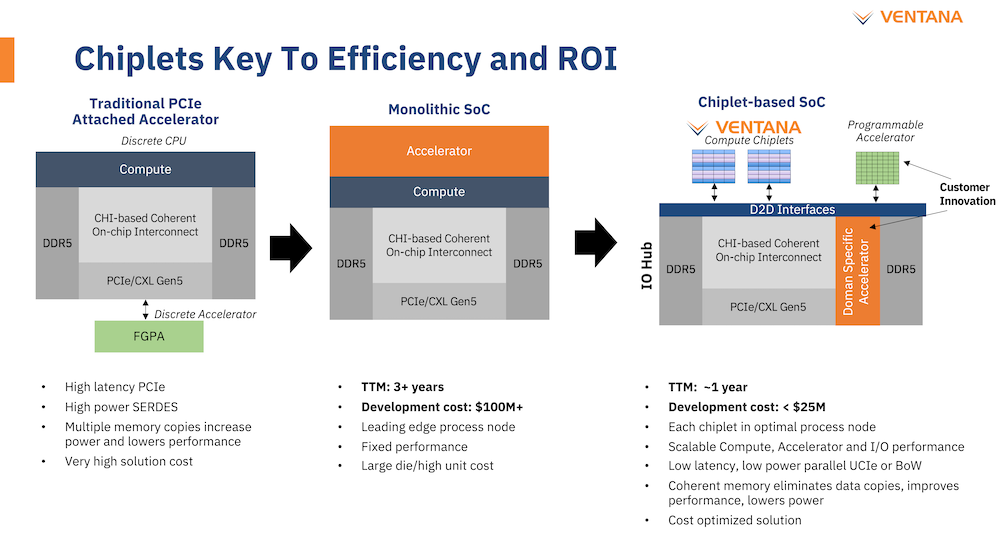
Чиплетная архитектура ускорит цикл разработки и внедрения, а также упростит задачу подключения кастомных ускорителей Архитектурно дизайн Veyron V1 использует агрессивный конвейер шириной восемь инструкций и с внеочередным исполнением. Чип способен работать на частоте до 3,6 ГГц благодаря использованию 5 нм техпроцесса TSMC. I/O-хаб может производиться с использованием более дешёвых 12 или даже 16-нм техпроцессов. Для соединения компонентов процессора разработан специальный низколатентный интерконнект D2D. 
Платформа разработки Veyron V1 и её технические характеристики Каждый чиплет включает в себя до 16 ядер, предусмотрена возможность масштабирования процессора до 192 ядер в 12 чиплетах. Общий объём разделяемого кеша L3 составляет 48 Мбайт. Заявлен высокий уровень защищённости архитектуры от атак по сторонним каналам. Разработчики заявляют о беспрецедентно низком энергопотреблении: 128 ядер V1 уложатся в 280 Вт; AMD EPYC 7763 потребляет столько же при вдвое меньшем числе ядер. 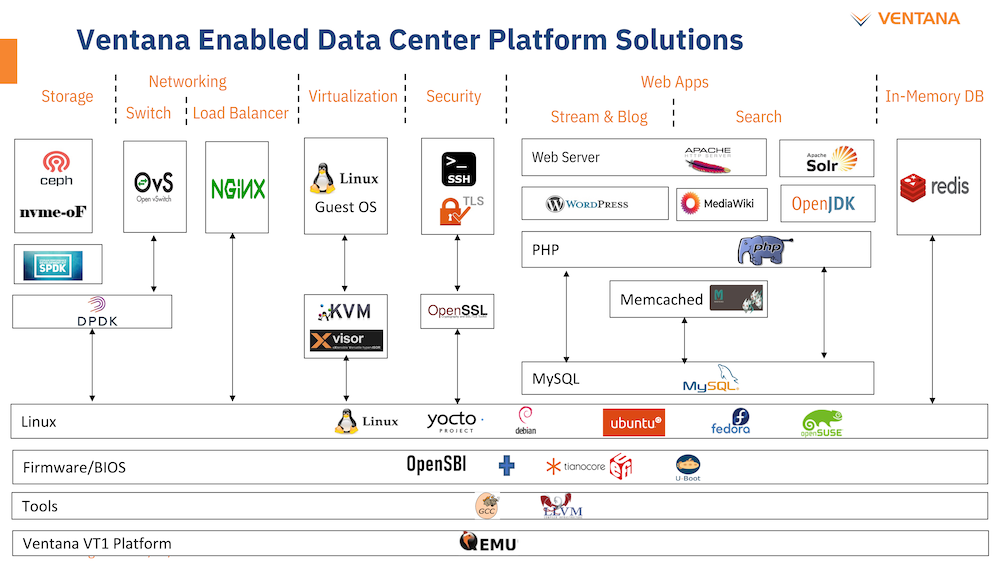
Ventana поддержит новую платформу на всех уровнях разработки системного и прикладного ПО Анонс Ventana нельзя назвать «бумажным» — компания говорит о доступности комплектов разработчика, причём сразу в двух типах шасси: в настольном и в серверном корпусе высотой 2U. Конфигурация включает в себя 16-ядерную версию V1, 128 гбайт памяти DDR5, подключенной с помощью интерфейса CXL (PCIe 5.0) x16, два свободных слота расширения PCIe 5.0 x16, загрузочный накопитель NVMe M.2 и 8 NVMe SFF SSD формата 2,5" для хранения данных. Для удалённого управления предусмотрен 1GbE-порт. 
Большая часть критически важного программного обеспечения уже портирована на архитектуру RISC-V Компания не забыла и о поддержке со стороны программного обеспечения: платформы разработчика Ventana Veyron V1 будут сопровождаться полноценным SDK с основным ПО, уже портированным на новую архитектуру. В список входят компиляторы GCC и LLVM, отладчик OpenOCD/GDB, исходные коды и бинарные файлы загрузчиков U-Boot и Tianocore UEFI EDK2.1. Поддерживается ряд дистрибутивов Linux, а также другое системное и прикладное ПО. Ожидается, что новые системы будут доступны в начале следующего года.
30.11.2022 [16:55], Алексей Степин
AWS представила пятое поколение аппаратных гипервизоров NitroНа днях крупный провайдер облачных услуг, компания Amazon Web Services представила новые варианты инстансов на базе новейших процессоров Graviton3E, но данный чип — не единственная новинка AWS. Одновременно с Graviton3E было представлено и пятое поколение аппаратных гипервизоров Nitro, существенно выигрывающих по ключевым показателям у решений предыдущего, четвёртого поколения. 
Здесь и далее источник изображений: ServeTheHome Главная идея Nitro — сочетание «кремния» гипервизора, DPU и сопроцессора безопасности с поддержкой Root of Trust в едином чипе. В системах AWS плата с чипом Nitro полностью управляет распределением вычислительных ресурсов и памяти, избавляя от этой нагрузки хост-процессоры. По результатам тестов, проведённых AWS, производительность облачных инстансов с использованием ускорителей Nitro практически не отличается от производительности классической bare metal-системы.  AWS Nitro v5 использует кастомный кристалл, разработанный Annapurna Labs. По сравнению с Nitro v4, количество транзисторов было удвоено, но за счёт этого удалось на 60 % поднять скорость обработки сетевых пакетов, на 30 % снизить латентность, а также, благодаря продвинутому техпроцессу, обеспечить лучшую удельную производительность. 
Платы AWS Nitro v5 используют проприетарные разъёмы Улучшились и другие характеристики: на 50 % выросла пропускная способность памяти и вдвое возросла производительность подсистемы PCI Express. Платы Nitro v5 станут сердцем новых инстансов C7gn, где обеспечат полную изоляцию критически важных подсистем, таких, как прошивки BIOS, BMC и накопителей от гостевого доступа извне и позволят обновлять эти прошивки без влияния на клиентские нагрузки.  Также они возьмут на себя обслуживание сетей VPC/EBS, включая переход на использование SRD вместо TCP, и накопителей Nitro SSD. AWS уже объявила о возможности предварительного тестирования систем C7gn на базе Nitro v5 и новейших процессоров Graviton3/3E.
29.11.2022 [17:12], Алексей Степин
AWS представила Arm-процессор Graviton3E, оптимизированный для задач ИИ и HPCОдин из крупнейших облачных провайдеров, компания Amazon Web Services объявила о доступности новых инстансов EC2 на базе процессора Graviton3E. Новый чип — наследник анонсированного в конце 2021 года Graviton3, 5-нм 64-ядерного процессора на дизайне Arm Neoverse V1 (Zeus) с поддержкой DDR5 и PCI Express 5.0. Graviton3 использует набор команд Armv8.4 c расширениями Neon (4×128 бит) и SVE (2×256 бит) и поддерживает работу с популярными в сфере машинного обучения форматами данных INT8 и BF16. В сравнении c Graviton2 процессор быстрее на 25-60 % при сохранении аналогичного уровня тепловыделения. Дизайн серверов AWS предусматривает наличие трёх процессоров на узел высотой 1U. 
Изображения: AWS Новый процессор Graviton3E представляет собой дальнейшее развитие Graviton3. Чип оптимизирован с учётом потребностей рынка высокопроизводительных вычислений и основное внимание в его архитектуре уделено повышению производительности на операциях с плавающей запятой и вычислениях с использованием векторной математики. AWS, к сожалению, пока не раскрывает деталей относительно архитектуры Graviton3E, но прирост производительности на векторных операциях относительно обычного Graviton3 может достигать 35 %. Помимо классического теста HPL новый процессор хорошо проявляет себя в тестах, имитирующих медико-биологические и финансовые задачи.  Сценарии нагрузок, характерные для HPC, как правило, активно оперируют перемещением крупных объемов данных. Чтобы оптимизировать этот процесс, в новых инстансах AWS использует сеть на базе Elastic Fabric с новыми адаптерами Elastic Network Adapter (ENA). Такая сеть оперирует т. н. Scalable Reliable Datagram (SRD) вместо всем привычных TCP-пакетов. SRD позволяет организовать повторную отправку пакетов за микросекунды вместо миллисекунд в классическом Ethernet. Сердцем же новых инстансов AWS стало пятое поколение аппаратных гипервизоров Nitro 5. В сравнении с предыдущим поколением, Nitro 5 обладает вдвое более высокой вычислительной производительностью, на 50 % повышенной пропускной способностью памяти, а также позволяет обрабатывать на 60 % больше сетевых пакетов при сниженной на 30 % латентности. 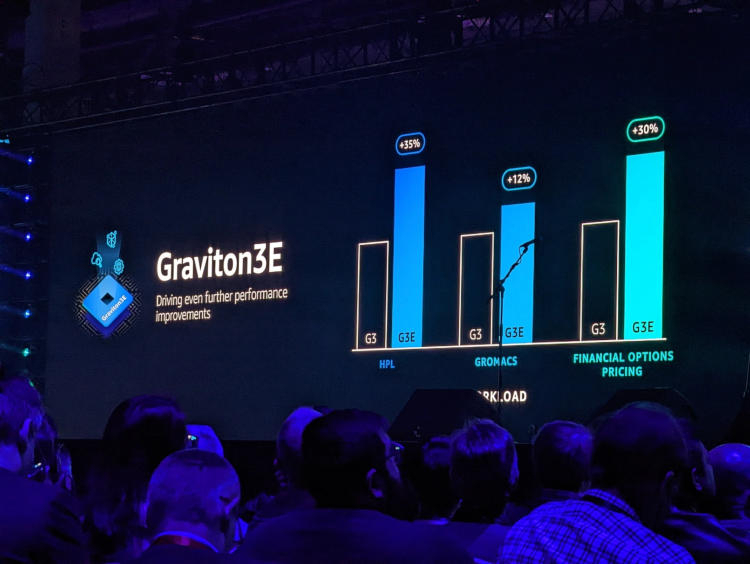
Здесь и далее источник изображений: AWS Инстансы Hpc7g с процессорами Graviton3E получат внутреннюю сеть с пропускной способностью 200 Гбит/с и станут доступны в различных конфигурациях вплоть до 64 vCPU и 128 ГиБ памяти. Аналогичные параметры имеют инстансы C7gn, предназначенные для задач с интенсивным сетевым трафиком: виртуальных маршрутизаторов, сетевых экранов, балансировщиков нагрузки и т.п. Также компания анонсировала инстансы R7iz, в которых используются процессоры Intel Xeon Scalable четвёртого поколения (Sapphire Rapids) с постоянной частотой всех ядер 3,9 ГГц. Они могут иметь конфигурацию до 128 vCPU с 1 ТиБ памяти.
29.11.2022 [12:20], Сергей Карасёв
В Италии официально запущен суперкомпьютер Leonardo — четвёртая по мощности HPC-система в миреСовместная инициатива по высокопроизводительным вычислениям в Европе EuroHPC JU и некоммерческий консорциум CINECA, состоящий из 69 итальянских университетов и 21 национальных исследовательских центров, провели церемонию запуска суперкомпьютера Leonardo. В основу комплекса положены платформы Atos BullSequana X2610 и X2135. Система Leonardo состоит из двух секций — общего назначения и с ускорителями вычислений (Booster). Когда строительство системы будет завершено, первая будет включать 1536 узлов, каждый из которых содержит два процессора Intel Xeon Sapphire Rapids с 56 ядрами и TDP в 350 Вт, 512 Гбайт оперативной памяти DDR5-4800, интерконнект NVIDIA InfiniBand HDR100 и NVMe-накопитель на 8 Тбайт. 
Источник изображения: HPCwire Секция Booster объединяет 3456 узлов, каждый из которых содержит один чип Intel Xeon 8358 с 32 ядрами, 512 Гбайт ОЗУ стандарта DDR4-3200, четыре кастомных ускорителя NVIDIA A100 с 64 Гбайт HBM2-памяти, а также два адаптера NVIDIA InfiniBand HDR100. Кроме того, в состав комплекса входят 18 узлов для визуализации: 6,4 Тбайт NVMe SSD и два ускорителя NVIDIA RTX 8000 (48 Гбайт) в каждом. Вычислительный комплекс объединён фабрикой с топологией Dragonfly+. 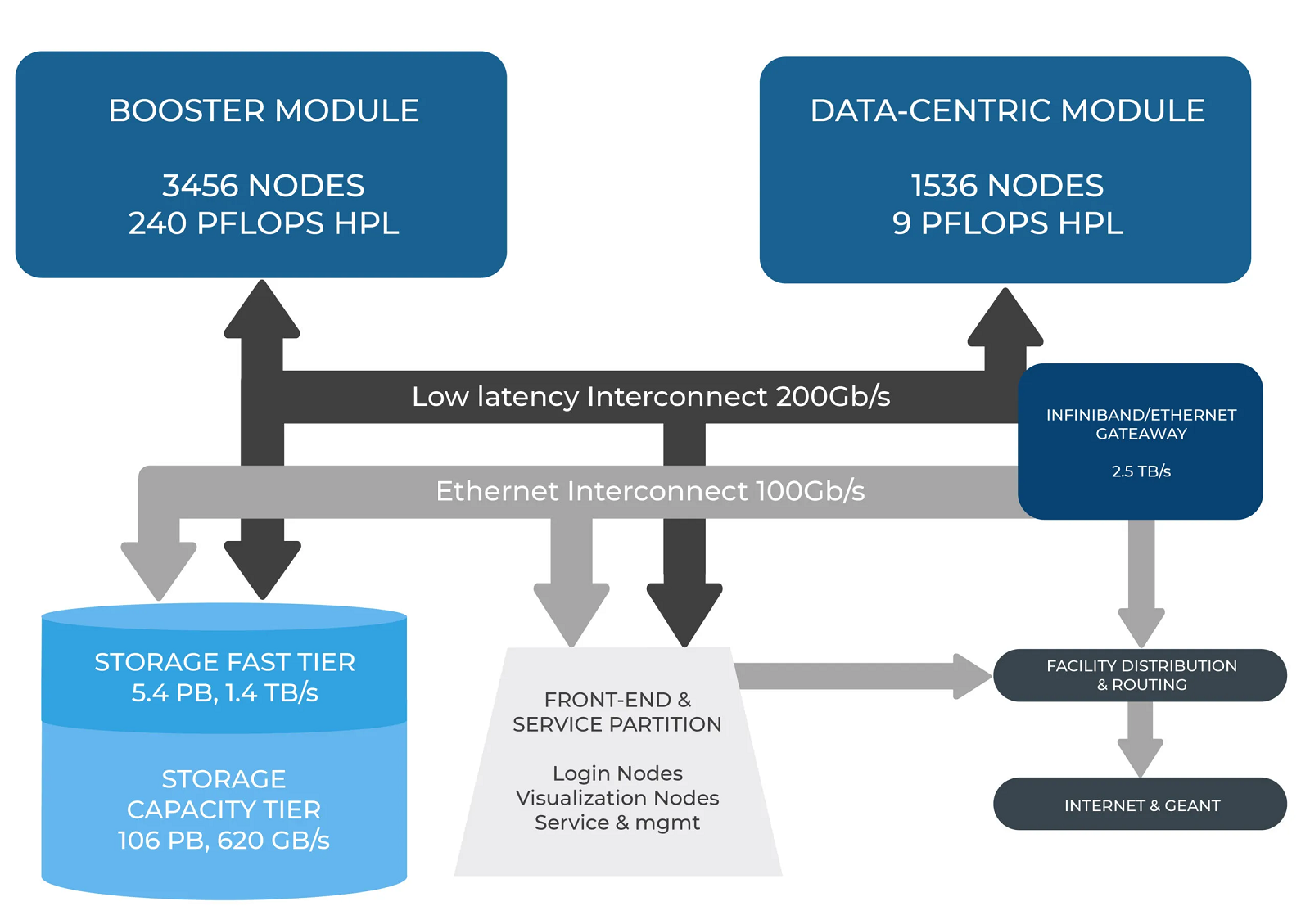
Источник: CINECA Для хранения данных служит двухуровневая система. Производительный блок (5,4 Пбайт, 1400 Гбайт/с) содержит 31 модуль DDN Exascaler ES400NVX2, каждый из которых укомплектован 24 NVMe SSD вместимостью 7,68 Тбайт и четырьмя адаптерами InfiniBand HDR. Второй уровень большой ёмкости (106 Пбайт, чтение/запись 744/620 Гбайт/с) состоит из 31 массива DDN EXAScaler SFA799X с 82 SAS HDD (7200 PRM) на 18 Тбайт и четырьмя адаптерами InfiniBand HDR. Каждый из массивов включает два JBOD-модуля с 82 дисками на 18 Тбайт. Для хранения метаданных используются 4 модуля DDN EXAScaler SFA400NVX: 24 × 7,68 Тбайт NVMe + 4 × InfiniBand HDR. 
Изображение: CINECA В настоящее время Leonardo обеспечивает производительность более 174 Пфлопс. Ожидается, что суперкомпьютер будет полностью запущен в первой половине 2023 года, а его пиковое быстродействие составит 250 Пфлопс. Уже сейчас система занимает четвёртое место в последнем рейтинге самых мощных суперкомпьютеров мира TOP500. В Европе Leonardo является второй по мощности системой после LUMI. Leonardo оборудован системой жидкостного охлаждения для повышения энергоэффективности. Кроме того, предусмотрена возможность регулировки энергопотребления для обеспечения баланса между расходом электричества и производительностью. Суперкомпьютер ориентирован на решение высокоинтенсивных вычислительных задач, таких как обработка данных, ИИ и машинное обучение. Половина вычислительных ресурсов Leonardo будет предоставлена пользователям EuroHPC.
14.11.2022 [00:00], Игорь Осколков
Игра по новым правилам: AMD представила Genoa, четвёртое поколение серверных процессоров EPYCВсего за десять лет AMD совершила почти невозможное — практически полностью потеряла серверный рынок, а теперь не просто успешно его отвоёвывает, но и предлагает комплексное портфолио решений. Анонс четвёртого поколения процессоров EPYC под кодовым именем Genoa — это не технологическая победа над Intel, поскольку AMD даже не думала бороться с Sapphire Rapids и уж тем более с Ice Lake-SP, а ориентировалась на Granite Rapids. Но годовая задержка с выпуском Sapphire Rapids позволила AMD не только в более спокойном темпе доделывать чипы Genoa, которые вышли на полгода позже, чем задумывалось ранее, но и поработать с разработчиками и заказчиками. Компании удалось вернуть их доверие — победа в умах гораздо важнее, чем просто технологическое превосходство. А оно неоспоримо. 
Источник: AMD EPYC Genoa заключены в корпус 72×75 мм, содержат до 90 млрд транзисторов и состоят из 13 чиплетов: 12 CCD, изготовленных по 5-нм техпроцессу TSMC плюс один, изрядно увеличившийся в размерах, IO-блок, сделанный там же, но уже по 6-нм нормам. Отказ от услуг GlobalFoundries, которая так и не смогла освоить тонкие техпроцессы, случился как нельзя кстати, поскольку IO-блок становится крайне важным компонентом при таком количестве ядер, которые необходимо вовремя накормить данными. И Genoa интересны в первую очередь с точки зрения полноты и разнообразия IO, а не рекордного количества ядер. IO-чиплет оснащён новыми SerDes-блоками, которые обслуживают и PCIe 5.0, и Infinity Fabric 3.0 (IF/GMI3). Формально каждому чипу полагается 128 линий PCIe 5.0, но реальная конфигурация чуть сложнее. Во-первых, у каждого чипа есть ещё восемь (2 x4) бонусных линий PCIe 3.0 для подключения нетребовательных устройств и обвязки, но в 2S-конфигурации таких линий будет только 12. Во-вторых, для 2S можно задействовать три (3Link) или четыре (4Link) IF-подключения, получив 160 или 128 свободных линий PCIe 5.0 соответственно. 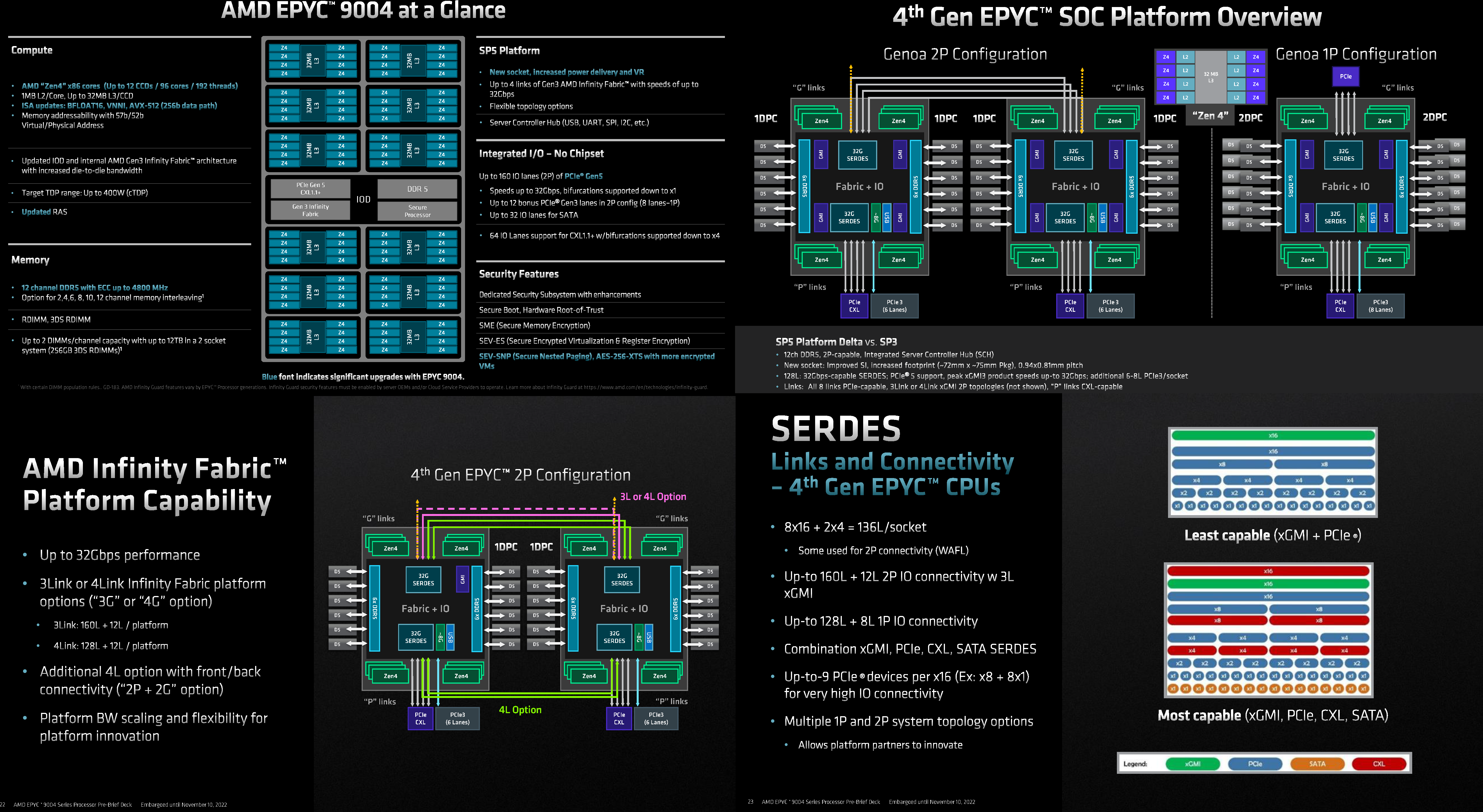
Изображения: AMD (via SemiAnalysis) В-третьих, каждый root-комплекс x16 может быть поделён между девятью устройствами (вплоть до x8 + восемь x1). Часть линий можно отдать на SATA (до 32 шт.), хотя это довольно расточительно. Но главное не это! Из 128 линий 64 поддерживают в полном объёме CXL 1.1 и частично CXL 2.0 Type 3, причём возможна бифуркация вплоть до x4. Ради такой поддержки CXL выход Genoa задержался на два квартала, но оно того определённо стоило — к процессору можно подключать RAM-экспандеры. И решения SK Hynix уже валидированы для новой платформы. CXL-память будет выглядеть как NUMA-узел (без CPU) — задержки обещаны примерно те же, что и при обращении к памяти в соседнем сокете, а пропускная способность одного CXL-подключения x16 почти эквивалентна двум каналам DDR5. При этом для CXL-памяти прозрачно поддерживаются всё те же функции безопасности, включая SME/SEV/SNP (теперь ключей стало аж 1006, а алгоритм обновлён до 256-бит AES-XTS). Отдельно для CXL-памяти внедрена поддержка SMKE (secure multi-key encryption), с помощью которой гипервизор может оставлять зашифрованными выбранные области SCM-устройств (до 64 ключей) между перезагрузками. 
Изображения: AMD (via SemiAnalysis) Такая гибкость при работе с памятью крайне важна для тех же гиперскейлеров. DDR5 по сравнению с DDR4 вчетверо плотнее, вполовину быстрее и… пока значительно дороже. И здесь AMD снова пошла им навстречу, добавив поддержку 72-бит памяти, а не только стандартной 80-бит, сохранив и расширив механизмы коррекции ошибок. 10-% разница в количестве DRAM-чипов при сохранении той же ёмкости на масштабах в десятки и сотни тысяч серверов выливается в круглую сумму. Кроме того, в Genoa сглажена разница в производительности между одно- и двухранговыми модулями с 25 % (в случае Milan) до 4,5 %. Что примечательно, AMD удалось сохранить сопоставимый уровень задержки обращений к памяти между поколениями CPU: 118 нс против 108 нс, из которых только 3 нс приходится на IO-блок, а 10 нс уже на саму память. Теоретическая пиковая пропускная способность памяти составляет 460,8 Гбайт/с на сокет. Однако тут есть нюансы. Genoa имеет 12 каналов памяти DDR5-4800, которые способны вместить до 6 Тбайт RAM. Однако сейчас фактически доступен только режим 1DPC, а вот 2DPC, судя по всему, появится только в следующем году. Genoa поддерживает модули (3DS) RDIMM и предлагает чередование с шагом в 2, 4, 6, 8, 10 или 12 каналов. 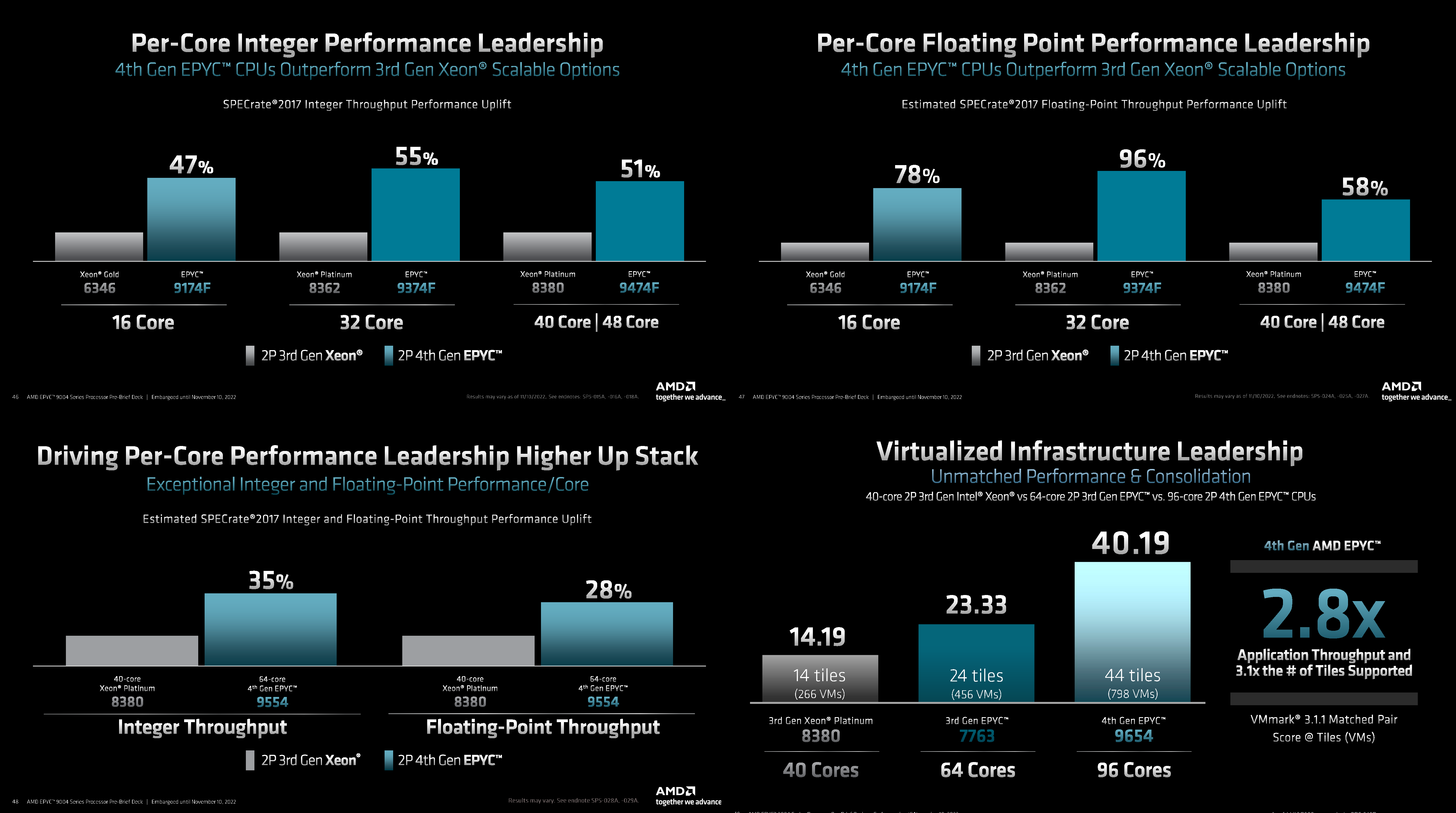
Изображения: AMD (via SemiAnalysis)
Каждый чип можно разбить на два (NPS2) или четыре (NPS4) равных NUMA-домена, а при большом желании и «прибить» L3-кеш к ядрам в том же CCD, получив уже 12 доменов. Но, по словам AMD, это нужно лишь в редких случаях, чтобы выжать ещё несколько процентов производительности. И это снова возвращает нас к особенностям IO-блока. Дело в том, что у каждого CCD есть сразу два GMI-порта. Но в конфигурациях с 8 и 12 CCD используется только один из них, а вот в случае 4 CCD — оба. Интересно, задействует ли AMD «лишние» порты для подключения других блоков. Впрочем, AMD, имея столь гибкие возможности конфигурации моделей, ограничилась относительно скромным начальным набором CPU, которые включает всего 18 моделей с числом ядер от 16 до 96, из которых четыре имеют индекс P (односокетные, чуть дешевле) и четыре — F (выше частота, больше объём L3-кеша). Модельный ряд условно делится на три группы: повышенная производительность на ядро (F-серия), повышенная плотность ядер и повышенный показатель TCO (с относительно малым количеством ядер). 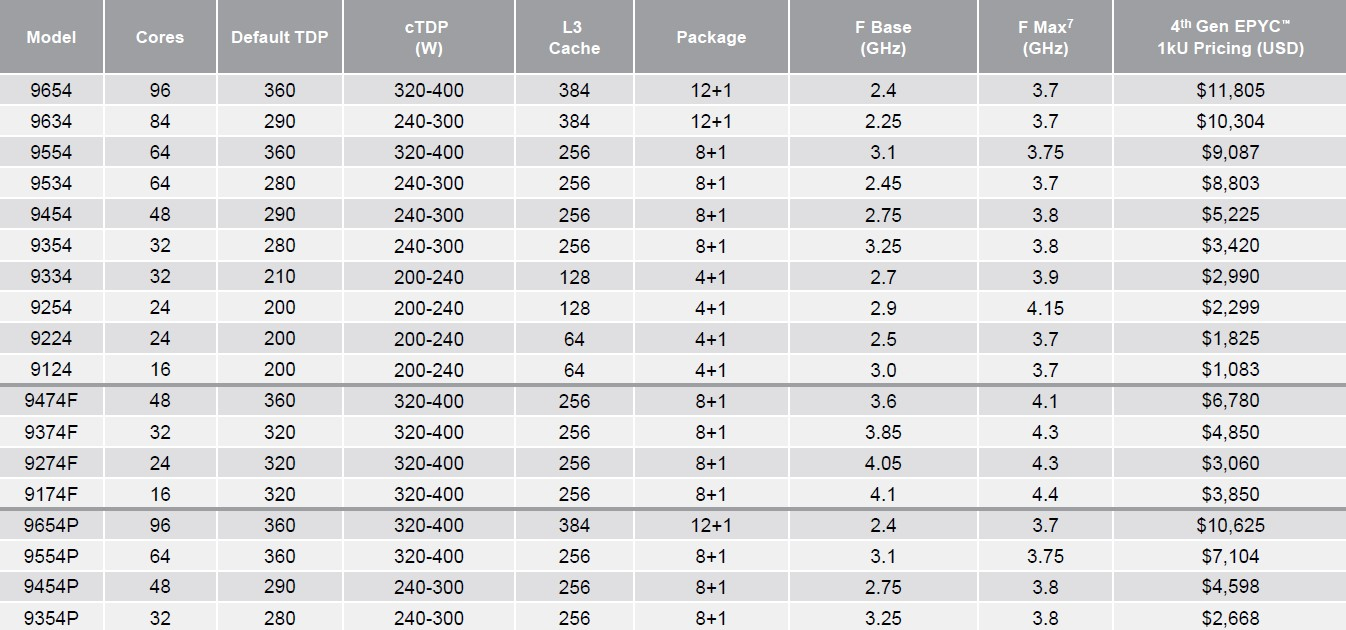
Источник: AMD (via ServeTheHome) На первый взгляд может показаться, что и цены на новинки заметно выросли, но это не совсем так. Например, у топовых моделей условная стоимость одного ядра (а их стала в полтора раза больше) так и крутится около «магического» значения в $123. Но с учётом возросшей производительности на ценовую политику AMD просто грех жаловаться. Прирост IPC между Zen3 и Zen4 составил 14 %, в том числе благодаря увеличению L2-кеша до 1 Мбайт на ядро (L1 и L3 остались без изменений), но не только. Есть и другие улучшения. Например, обновлённый контроллер прерываний AVIC позволяет практически полностью насытить не только 200G, но 400G NIC. С учётом чуть возросших частот и просто катастрофической разнице в количестве ядер топовый вариант Genoa не только значительно обгоняет Milan, но и в два-три раза быстрее старшего Ice Lake-SP. Дело ещё в и том, что Genoa обзавелись поддержкой AVX-512, в том числе инструкций VNNI (DL Boost), которыми так долго хвасталась Intel, а также BF16. Но реализация сделана иначе. У Intel используются «полноценные» 512-бит блоки, дорогие с точки зрения энергопотребления и затрат кремния. AMD же пошла по старому пути, используя 256-бит операции и несколько циклов, что позволяет не так агрессивно сбрасывать частоты. 
Изображения: AMD (via SemiAnalysis) Переход на новый техпроцесс, а также обновлённые подсистемы мониторинга и управления питанием позволили сохранить TDP в разумных пределах от 200 Вт до 360 Вт (cTDP до 400 Вт), что всё ещё позволяет обойтись воздушным охлаждением — всего + 80 Вт для старших процессоров при полуторакратном росте числа ядер. Таким образом, AMD имеет полное право заявлять, что Genoa лидирует по производительности, плотности размещения вычислительных мощностей, энергоэффективности и, в целом, по уровню TCO. У Intel же пока преимущество в более высокой доступности продукции в сложившейся геополитической обстановке. Отдельный вопрос, как AMD будет распределять имеющиеся мощности по выпуску Genoa между гиперскейлерами, корпоративным сектором и HPC-сегментом. Впрочем, компания в любом случае меняет рынок, иногда неожиданным образом. В частности, VMware, которая когда-то из-за EPYC изменила политику лицензирования, была вынуждена дополнительно оптимизировать свои продукты для Genoa. В конце концов, где вы раньше видели 2S-платформу со 192 ядрами и 384 потоками?
10.11.2022 [17:15], Владимир Мироненко
HPE анонсировала недорогие, энергоэффективные и компактные суперкомпьютеры Cray EX2500 и Cray XD2000/6500Hewlett Packard Enterprise анонсировала суперкомпьютеры HPE Cray EX и HPE Cray XD, которые отличаются более доступной ценой, меньшей занимаемой площадью и большей энергоэффективностью по сравнению с прошлыми решениями компании. Новинки используют современные технологии в области вычислений, интерконнекта, хранилищ, питания и охлаждения, а также ПО. 
Изображение: HPE Суперкомпьютеры HPE обеспечивают высокую производительность и масштабируемость для выполнения ресурсоёмких рабочих нагрузок с интенсивным использованием данных, в том числе задач ИИ и машинного обучения. Новинки, по словам компании, позволят ускорить вывода продуктов и сервисов на рынок. Решения HPE Cray EX уже используются в качестве основы для больших машин, включая экзафлопсные системы, но теперь компания предоставляет возможность более широкому кругу организаций задействовать супервычисления для удовлетворения их потребностей в соответствии с возможностями их ЦОД и бюджетом. В семейство HPE Cray вошли следующие системы:
Все три системы задействуют те же технологии, что и их старшие собратья: интерконнект HPE Slingshot, хранилище Cray Clusterstor E1000 и пакет ПО HPE Cray Programming Environment и т.д. Система HPE Cray EX2500 поддерживает процессоры AMD EPYC Genoa и Intel Xeon Sapphire Rapids, а также ускорители AMD Instinct MI250X. Модель HPE Cray XD6500 поддерживает чипы Sapphire Rapids и ускорители NVIDIA H100, а для XD2000 заявлена поддержка AMD Instinct MI210. 
Изображение: Intel В качестве примеров выгод от использования анонсированных суперкомпьютеров в разных отраслях компания назвала:
10.11.2022 [01:55], Игорь Осколков
Intel объединила HBM-версии процессоров Xeon Sapphire Rapids и ускорители Xe HPC Ponte Vecchio под брендом MaxВ преддверии SC22 и за день до официального анонса AMD EPYC Genoa компания Intel поделилась некоторыми подробностями об HBM-версии процессоров Xeon Sapphire Rapids и ускорителях Ponte Vecchio, которые теперь входят в серию Intel Max. 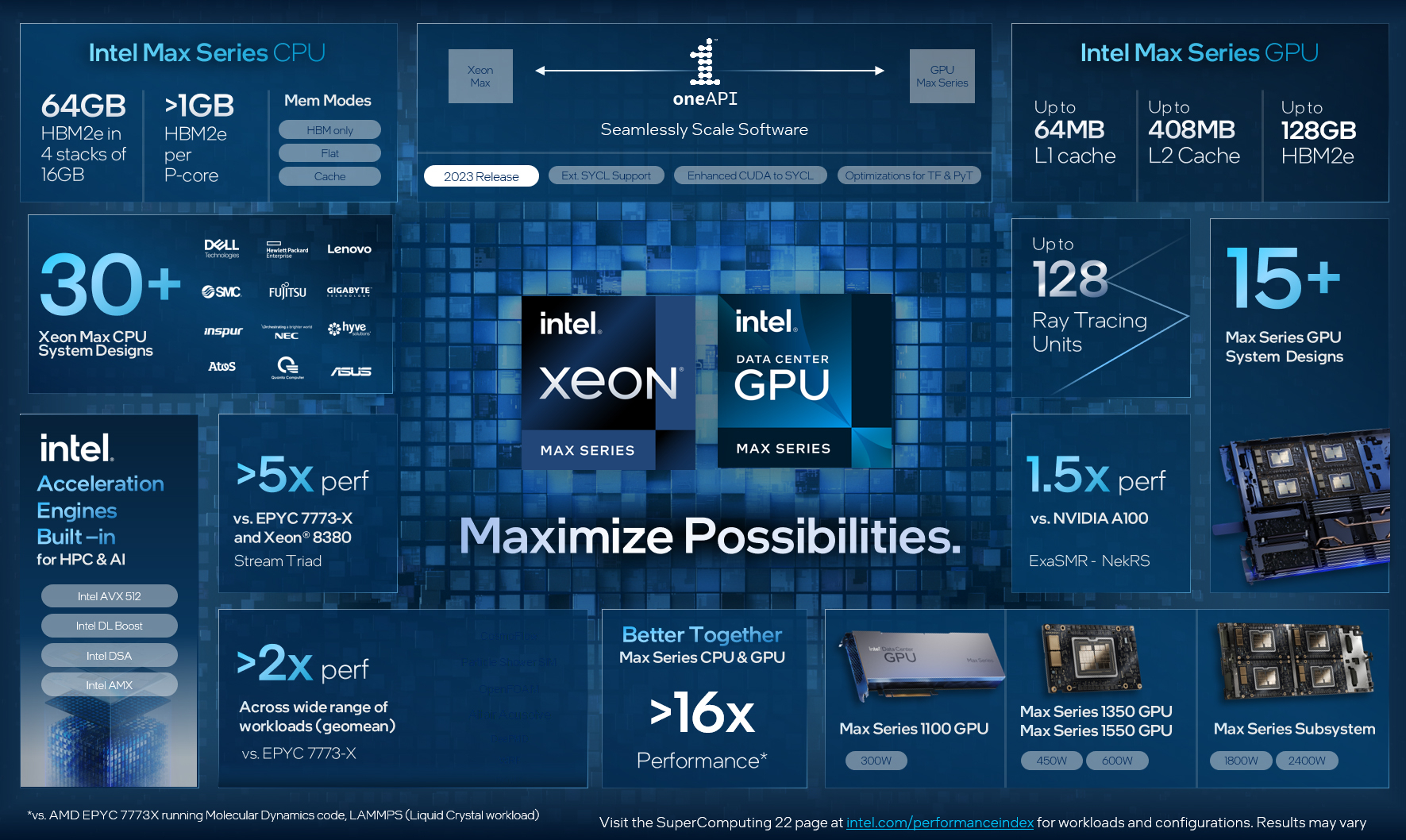
Изображения: Intel Intel Xeon Max предложат до 56 P-ядер, 112,5 Мбайт L3-кеша, 64 Гбайт HBM2e-памяти (четыре стека) с пропускной способностью порядка 1 Тбайт/с, 8 каналов памяти (DDR5-4800 в случае 1DPC, суммарно до 6 Тбайт), а также интерфейсы PCIe 5.0, CXL 1.1, UPI 2.0 и целый ряд различных технологий ускорения для задач HPC и ИИ: AVX-512, DL Boost, AMX, DSA, QAT и т.д. Заявленный уровень TDP составляет 350 Вт.  Первым процессором с набортной HBM-памятью был Arm-чип Fujitsu A64FX (48 ядер, 32 Гбайт HBM2), лёгший в основу суперкомпьютера Fugaku. Intel поднимает планку, давая более 1 Гбайт быстрой памяти на каждое ядро. А поскольку процессор состоит из четырёх отдельных чиплетов, возможно создание четырёх NUMA-доменов с выделенными HBM- и DDR-контроллерами. Но и монолитный режим тоже имеется. А поддержка CXL даёт возможность задействовать RAM-экспандеры. 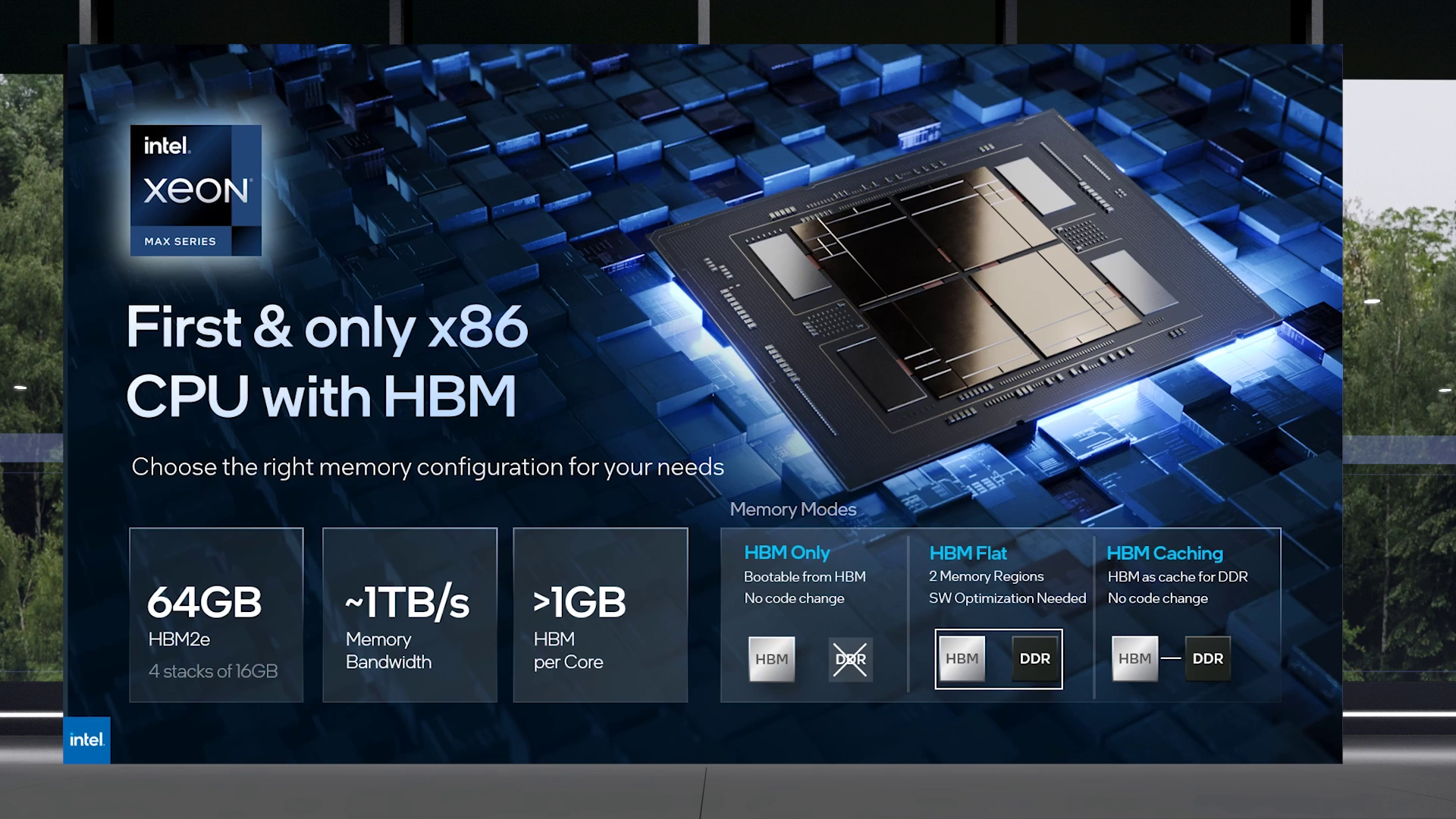 Intel Xeon Max поддерживают 2S-платформы, что суммарно даёт уже 128 Гбайт HBM-памяти, которых вполне хватит для целого ряда задач. Новые процессоры действительно могут обходиться без DIMM. Но есть и два других режима. В первом HBM-память работает в качестве кеша для обычной памяти, и для системы это происходит прозрачно, так что никаких модификаций для ПО (как в случае отсутствия DIMM вообще) не требуется. Во втором режиме HBM и DDR представлены как отдельные пространства, так что тут дорабатывать ПО придётся, зато можно добиться более эффективного использования обоих типов памяти.
В презентации Intel сравнивает новые Xeon Max с AMD EPYC Milan-X – в зависимости от задачи прирост составляет от +20 % до 4,8 раз. Но, во-первых, уже сегодня эти тесты потеряют всякий смысл в связи с презентацией EPYC Genoa (которые, к слову, должны получить AVX-512), а во-вторых, в следующем году AMD обещает представить Genoa-X с 3D V-Cache. Intel же явно не оставляет попытки создать как можно более универсальный процессор.  Что касается Ponte Vecchio, которые теперь называются Max GPU, то практически ничего нового относительно строения и особенностей данных ускорителей Intel не сказала: до 128 ядер Xe (только теперь стало известно об аппаратном ускорении трассировки лучей, что важно для визуализации), 64 Мбайт L1-кеша и аж 408 Мбайт L2-кеша (из них 120 Мбайт приходится на Rambo-кеш в двух стеках), 16 линий Xe Link, 8 HBM2e-контроллеров на 128 Гбайт памяти и пиковая FP64-производительность на уровне 52 Тфлопс. Все эти характеристики относятся к старшей модели Max Series 1550 в OAM-исполнении с TDP в 600 Вт.  Max Series 1350 предложит 112 ядер Xe и 96 Гбайт HBM2e, но и TDP у этой модели составит всего 450 Вт. Для обеих OAM-версий также будут доступны готовые блоки из четырёх ускорителей (по примеру NVIDIA RedStone), объединённых по схеме «каждый с каждым», так что в сумме можно получить 512 Гбайт HBM2e с ПСП в 12,8 Тбайт/с. Ну а самый простой ускоритель в серии называется Max Series 1100. Это 300-Вт PCIe-плата с 56 Xe-ядрами, 48 Гбайт HBM2e и мостиками Xe Link.  Intel утверждает, что ускорители Max до двух раз быстрее NVIDIA A100 в некоторых задачах, но и здесь история повторяется — нет сравнения с более современными H100. Хотя предварительный доступ к этим ускорителям у Intel есть, поскольку именно Sapphire Rapids являются составной частью платформы DGX H100. В целом, Intel прямо говорит, что наибольшей эффективности вычислений позволяет добиться связка CPU и GPU серии Max в сочетании с oneAPI. Всего на базе решений данной серии готовится более 40 продуктов.
Пока что приоритетным для Intel проектом является 2-Эфлопс суперкомпьютер Aurora, для которого пока что создан тестовый кластер Sunspot со 128 узлами, содержащими ускорители Max. Следующим ускорителем Intel станет Rialto Bridge, который появится в 2024 году. Также компания готовит гибридные (XPU) чипы Falcon Shores, сочетающие CPU, ускорители и быструю память. Аналогичный подход применяют AMD и NVIDIA. |
|
