Материалы по тегу: ии
|
10.06.2025 [14:44], Руслан Авдеев
В обход Stargate: Oracle рассчитывает найти для OpenAI 5 ГВт на обучение ИИ к концу 2026 годаКомпания Oracle намерена расширить присутствие на рынке дата-центров в США для поддержки рабочих нагрузок OpenAI. Как сообщают аналитики TD Cowen, особое внимание уделяется отдельным объектам мощностью порядка 1 ГВт, энергия которым будет доступна уже в конце 2026 и начале 2027 гг., сообщает Datacenter Dynamics. Партнерство Oracle и OpenAI отчасти обусловлено предпочтением OCI SuperClaster с RDMA-интерконнектом, обеспечивающим высокую пропускную способность и низкие задержки. Сотрудничество также способствует развитию уже существующего проекта OpenAI на базе кампуса Abilene Stargate в Абилине (Техас), построенном Crusoe и Oracle. Вместе с тем TD Cowen полагает, что новая пятилетняя сделка не связана со Stargate и была заключена напрямую между Oracle и OpenAI. В её рамках Oracle закупит мощности ЦОД, соответствующие требованиям OpenAI. За них Oracle будет взимать плату в размере $2,60–$3,00 за каждый ускоритель в час, при этом цены будут зависеть от типа чипов. Всего будет развёрнуто около 2,3 млн ускорителей. Ранее OpenAI заявляла, что намерена не только сотрудничать с партнёрами, но строить и собственные дата-центры. В TD Cowen пока не знают, есть ли у Oracle эксклюзивные права на обслуживание этих 5 ГВт или за них придётся побороться с другими провайдерами. Также известно, что OpenAI подписала соглашение на $12 млрд с CoreWeave, а затем ещё на $4 млрд. Не исключено, что последняя также поборется за контракт. 
Источник изображений: Oracle В TD Cowen считают, что вне зависимости от того, кто будет исполнителем, предоставившим необходимые 5 ГВт, это позволит отрасли аренды ЦОД в США добиться рекордных показателей уже в 2025 году. Впрочем, в компании сомневаются, что к концу 2026 году в стране наберётся пять полностью запитанных площадок мощностью 1 ГВт каждая — не считая тех мощностей, которыми располагают некоторые бывшие майнеры криптовалют, сейчас преобразующие их для HPC.  По оценкам компании, капитальные затраты на ускорители составят $92 млрд (из расчёта $42 тыс./шт.), капитальные затраты на ЦОД составят ещё $67 млрд (из расчёта $13,5 млн/МВт). В сумме получает $159 млрд, так что не исключено привлечение сторонних инвесторов. Хотя сделка не обсуждалась в рамках проекта Stargate, вполне возможно, что часть средств будет получено именно от него. На Stargate в США рассчитывают потратить до $500 млрд, также планируется реализация аналогичных проектов по всему миру. Так, в ОАЭ намерены реализовать такой проект. В TD Cowen рассчитывают, что мощность Stargate за рубежом составит 5 ГВт, проект будет подкреплён инвестициями со стороны ряда стран, по некоторым данным, рассматривались Израиль и Малайзия. Сейчас эмиссар OpenAI совершает поездку по Азиатско-Тихоокеанскому региону, ведя переговоры в Индии, Южной Корее, Австралии и Сингапуре. В Европе OpenAI ведёт переговоры с Великобританией, Францией и Германией.
10.06.2025 [12:15], Руслан Авдеев
Нейроморфный суперкомпьютер SpiNNaker2, способный имитировать до 180 млн нейронов, прописался в Сандийских национальных лабораторияхНемецкая SpiNNcloud Systems, занимающаяся разработкой нейроморфных суперкомпьютеров, ввела в эксплуатацию в Сандийских национальных лабораториях (Sandia National Laboratories, SNL) суперкомпьютер SpiNNaker2, созданный по подобию человеческого мозга. Это имеет большое значение для развития вычислительной техники и выполнения задач, связанных с обеспечением национальной безопасности, сообщает Silicon Angle. SNL — это научно-исследовательский комплекс правительства США, занимающийся проектами в области национальной безопасности, энергетики и передовых технологических инноваций. Sandia управляется одним из специализированных подразделений Министерства энергетики США (DoE) и более всего известна проектами, связанными с ядерным арсеналом Соединённых Штатов и обеспечением его сохранности и эффективности. Суперкомпьютер SpiNNaker2 анонсировали в мае 2024 года. Он представляет собой высокопроизводительную нейроморфную компьютерную систему, основанную на принципах работы человеческого мозга. Платформа создана разработчиком архитектур Arm и SpiNNaker1 Стивом Фербером (Steve Furber) и использует множество чипов с низким энергопотреблением для ИИ-вычислений и выполнения других задач. 
Источник изображения: SpiNNcloud Systems Как сообщает Datacenter Dynamics, система использует тысячи Arm-ядер для имитации работы нейронов мозга. В Sandia National Labs развёрнута одна из крупнейших в мире конфигураций SpiNNaker из 24 плат о 175 104 ядрами, способная моделировать 150–180 млн нейронов, что делает её одной из пяти самых мощных нейроморфных платформ в мире для исследований в области ИИ и нейротехнологий. Впрочем, от человеческого мозга со 100 млрд нейронов система, по данным Blocks & Files, пока ещё сильно отстаёт. SpiNNaker2 использует высокопараллельную архитектуру из 48 чипов SpiNNaker2 на плату, каждый из которых имеет по 152 ядра на основе Arm, 20 Мбайт SRAM и специализированные ускорители. Конструкция обеспечивает эффективные вычисления, позволяющие системе выполнять сложные симуляции с более низким энергопотреблением в сравнении с ИИ-ускорителями традиционного типа. Высокая эффективность SpiNNaker2 делает его особенно ценным для выполнения задач в сфере обеспечения национальной безопасности. Каждая плата оснащена 96 Гбайт оперативной памяти LPDDR4. В конфигурации с 90 платами система имеет 8640 Гбайт DRAM, а в максимальном варианте (1440 плат) — 138 240 Гбайт. Архитектура использует высокоскоростную межчиповую связь, что вообще исключает необходимость в централизованном хранилище данных, а огромный объём памяти позволяет эффективно моделировать крупномасштабные нейронные сети. 
Источник изображения: SpiNNcloud Systems SpiNNaker2 интегрирован в существующие HPC-системы и работает без ОС или дисков, достигая высокой скорости работы за счет хранения данных в SRAM и DRAM. Система использует стандартные параллельные порты для загрузки и выгрузки данных, а её текущая максимальная конфигурация включает более 10,5 млн ядер, что позволяет моделировать нейронные сети в режиме «биологического реального времени». По словам представителя Sandia, хотя системы на базе классических ускорителей способны повысить эффективность суперкомпьютеров в сравнении с обычными CPU, системы на основе «архитектуры» человеческого мозга вроде SpiNNaker2 — ещё более привлекательная альтернатива. В SpiNNcloud заявляют, что система поддерживает и следующего поколения алгоритмов систем генеративного ИИ, обеспечивая значительно более эффективный путь развития машинного обучения с применением «динамической разреженности» (dynamic sparsity). По данным сайта SpiNNcloud, в скором будущем появится чип SpiNNext, в 78 раз более энергетически эффективный, чем традиционные ИИ-ускорители.
10.06.2025 [12:15], Владимир Мироненко
«Это полное безумие»: SAP не видит смысла в строительстве Европой собственной облачной инфраструктурыКристиан Кляйн (Christian Klein), гендиректор немецкого разработчика ПО SAP, самой дорогой публичной компании Европы с рыночной стоимостью $342,4 млрд, не видит смысла в построении на континенте собственной облачной инфраструктуры в противовес созданной здесь американскими гиперскейлерами. «Конкурентоспособность европейской автомобильной или химической промышленности не будет достигнута путем строительства 20 различных ЦОД во Франции и попыток конкурировать с американскими гиперскейлерами. Это полное безумие, и это суверенитет, реализованный совершенно неправильно», — цитирует The Register заявление Кляйна, сделанное на конференции для инвесторов на прошлой неделе, организованной инвестиционным банком BNP Paribas. «Нам нужны лучшие (сервисы) здесь, в Европе, для применения ИИ, для применения интеллектуального ПО, чтобы быть лучшими, чтобы производить намного лучшие, намного более быстрые, лучшие автомобили и быть намного более эффективными в управлении нашими цепочками поставок», — сказал он. Кляйн отметил, что в Европе большие проблемы с ценами на энергоносители, поэтому строительство большего количества ЦОД — не лучшее решение. SAP готова предоставить клиентам различные уровни безопасности данных и суверенитета данных, но «полностью нейтральна на уровне инфраструктуры», — заявил он на конференции. С помощью ИИ и хранилища данных SAP предлагает клиентам «полный суверенитет сверху донизу», сообщил Кляйн. 
Источник изображения: Geoffrey Moffett/unsplash.com На фоне всё более враждебной риторики США по поводу европейской политики и норм управления европейские лидеры недавно анонсировали «Международную цифровую стратегию» (International Digital Strategy). В то время как американские гиперскейлеры AWS, Google и Microsoft пытаются развеять опасения по поводу суверенитета данных, заверяя, что способны обеспечить безопасное хранение данных европейских клиентов, некоторые европейские политики по-прежнему обеспокоены готовностью администрации США игнорировать судебные постановления, пишет The Register. SAP не одинока в своих сомнениях по поводу целесообразности разделения на уровне облачной инфраструктуры, отметил The Register. В прошлом месяце эксперты сообщили ресурсу, что для европейских организаций «на практике почти невозможно» воспроизвести инфраструктуру, созданную крупными американскими провайдерами облачных сервисов в Европе.
09.06.2025 [14:27], Руслан Авдеев
Евросоюз ограничит использование воды дата-центрамиЕвропейский союз обнародовал планы по повышению устойчивости всего блока к засухам и улучшения качества воды. В Еврокомиссии подчёркивают, что около трети земель Европы ежегодно сталкиваются с нехваткой воды, поэтому новая стратегия появилась вполне своевременно. В числе прочего предусмотрено развитие контроля за использованием водных ресурсов IT-сектором, сообщает Bloomberg. Работать над учреждением стандартов производительности для ограничения использования водных ресурсов в дата-центрах будет Еврокомиссия — как свидетельствуют материалы стратегии водной экоустойчивости, представленной в прошлую среду, регион столкнётся с вероятным дефицитом воды в ближайшие десятилетия. Общая цель ЕС — повысить эффективность использования воды минимум на 10 % к 2030 году. В последние годы нехватка воды ударила по Евросоюзу, поскольку повышение летних температур не могло не отразиться на качестве поставок этого важнейшего ресурса. 
Источник изображения: Microsoft Засухи нанесли серьёзный ущерб атомной энергетике Франции и усложнили доставку товаров по обмелевшей реке Рейн — одному из ключевых торговых путей Европы. При этом управление водными ресурсами в Евросоюзе фрагментировано, в числе прочего ему мешают запутанные системы водоснабжения и стареющие резервуары/водохранилища. В апреле уже сообщалось, что доступ к чистой воде становится одной из главных забот для операторов ИИ ЦОД всего мира. В мае было анонсировано, что в рамках стратегии ЕС по водной экоустойчивости Water Resilience Strategy Евросоюз разработает новые лимиты потребления воды дата-центрами. По-видимому, они буду жёстче обозначенных ранее.
09.06.2025 [14:02], Руслан Авдеев
Перегрев, плохое ПО и сила привычки: китайские компании не горят желанием закупать ИИ-ускорители HuaweiНесмотря на дефицит передовых ИИ-ускорителей на китайском рынке, китайская компания Huawei, выпустившая модель Ascend 910C, может столкнуться с проблемами при её продвижении. Она рассчитывала помочь китайскому бизнесу в преодолении санкций на передовые полупроводники, но перспективы нового ускорителя остаются под вопросом, сообщает The Information. Китайские гиганты вроде ByteDance, Alibaba и Tencent всё ещё не разместили крупных заказов на новые ускорители. Основная причина в том, что экосистема NVIDIA доминирует во всём мире (в частности, речь идёт о программной платформе CUDA), а решения Huawei недостаточно развиты. В результате компания продвигает продажи государственным структурам (при поддержке самих властей КНР) — это косвенно свидетельствует о сложности выхода на массовый рынок. Китайский бизнес годами инвестировал в NVIDIA CUDA для ИИ- и HPC-задач. Соответствующий инструментарий, библиотеки и сообщество разработчиков — настолько развитая экосистема, что альтернатива в лице Huawei CANN (Compute Architecture for Neural Networks) на её фоне выглядит весьма слабо. У многих компаний всё ещё хранятся огромные запасы ускорителей NVIDIA, накопленные в преддверии очередного раунда антикитайских санкций, поэтому у их владельцев нет стимула переходить на новые и незнакомые решения. Они скорее предпочтут оптимизировать программный стек, как это сделала DeepSeek, чтобы повысить утилизацию имеющегося «железа». Если бы, например, та же DeepSeek перешла на ускорители Huawei, это подтолкнуло бы к переходу и других разработчиков, но пока этого не происходит. Кроме того, некоторые компании вроде Tencent и Alibaba не желают поддерживать продукты конкурентов, что усложняет Huawei продвижение её ускорителей. 
Источник изображения: Huawei Есть и технические проблемы. Самый передовой ускоритель Huawei Ascend 910C периодически перегревается, поэтому возникла проблема доверия к продукции. Поскольку сбои во время длительного обучения модели обходятся весьма дорого. Кроме того, он не поддерживает ключевой для эффективного обучения ИИ формат FP8. Ascend 910С представляет собой сборку из двух чипов 910B. Он обеспечивает производительность на уровне 800 Тфлопс (FP16) и пропускную способность памяти 3,2 Тбайт/с, что сопоставимо с параметрами NVIDIA H100. Также Huawei представила кластер CloudMatrix 384. Наконец, проблема в собственно американских санкциях. В мае 2025 года Министерство торговли США предупредило, что использование чипов Huawei без специального разрешения может расцениваться, как нарушение экспортных ограничений — якобы в продуктах Huawei незаконно используются американские технологии. Такие ограничения особенно важны для компаний, ведущих международный бизнес — даже если они китайского происхождения. Хотя NVIDIA ограничили продажи в Китае, она по-прежнему демонстрирует рекордные показатели. По данным экспертов UBS, у компании есть перспективные проекты суммарной мощностью «десятки гигаватт» — при этом, каждый гигаватт ИИ-инфраструктуры, по заявлениям NVIDIA, приносит ей $40–50 млрд. Если взять вероятную очередь проектов на 20 ГВт с периодом реализации два-три года, то только сегмент ЦОД может обеспечить NVIDIA около $400 млрд годовой выручки. Это подчеркивает доминирующее положение компании на рынке аппаратного обеспечения для ИИ.
09.06.2025 [12:52], Руслан Авдеев
AWS запустила свой первый облачный регион на Тайване и намерена вложить $5 млрд в инфраструктуру островаAmazon Web Services (AWS) запустила на Тайване новый облачный регион. AWS Asia Pacific в Тайбэе (Taipei) — первый регион компании на острове и 15-й — в Азиатско-Тихоокеанском географическом регионе, сообщает Datacenter Dynamics. Reuters добавляет, что AWS потратит $5 млрд на развитие нового региона, чтобы поддержать строительство ЦОД и сетей. АWS анонсировала регион в июне 2024 года, отметив, что инвестирует в Тайвань «миллиарды долларов» в следующие 15 лет. AWS официально присутствует на Тайване с 2014 года, когда был открыт филиал AWS в Тайбэе. В том же году компания запустила в регионе локацию для периферийных вычислений Amazon CloudFront, вторая заработала в 2018 году. В том же году запущены две локации AWS Direct Connect, а в 2020 году заработали два AWS Outposts. В 2022 года в Тайбэе заработала специальная зона Local Zones. С запуском нового облачного региона AWS развернула на Тайване третью локацию AWS Direct Connect. Точка Direct Connect находится в дата-центре Chief Telecom HD около тайваньской столицы. По данным AWS, клиенты, подключающие свои сети к AWS на новой площадке, получают частный прямой доступ к всем публичным облачным регионам AWS Regions кроме тех, что находятся на территории материкового Китая. Локация обеспечивает выделенные каналы связи 10/100 Гбит/с. 
Источник изображения: Jack Brind/unsplash.com Среди первых клиентов нового региона — Gamania Group, Chunghwa Telecom, Cathay Financial Holdings. Как заявляет партнёр AWS, компания Nextlink Technology, инвестиции IT-гиганта в местную инфраструктуру помогут цифровой трансформации тайваньских компаний, ускорят развитие различных отраслей. В компании заявили, что намерены сотрудничать с AWS для дальнейшей помощи корпорациям, желающим воспользоваться преимуществами региона AWS Asia Pacific. Это локальное преимущество поможет удовлетворить потребности клиентов в локализации данных, низкой задержке доступа и высокой производительности. Google также располагает собственным регионом на острове. Гиперскейлер приобрёл 15 га в уезде Чжанхуа (Changhua County) в 2011 году, построил свой первый ЦОД в 2013 году и запустил облачный регион Google Cloud Platform (GCP) в 2014 году. В 2019 году компания объявила, что будет строить вторую площадку в городе Тайнань (Tainan). Microsoft анонсировала планы создания облачного региона Taipei Azure в 2020 году, но запуск всё ещё планируется «скоро». Ранее облачным регионом на Тайване управляла китайская Alibaba, но в 2022 году проект был свёрнут. В текущем году AWS уже запустила новые облачные регионы в Таиланде и Мексике, а в мае объявила, что намерена инвестировать $4 млрд в регион ЦОД в Чили.
07.06.2025 [16:24], Владимир Мироненко
AMD впервые приняла участие в бенчмарке MLPerf Training, но до рекордов NVIDIA ей ещё очень далекоКонсорциум MLCommons объявил новые результаты бенчмарка MLPerf Training v5.0, отметив быстрый рост и эволюцию в области ИИ, а также рекордное количество общих заявок и увеличение заявок для большинства тестов по сравнению с бенчмарком v4.1. MLPerf Training v5.0 предложил новый бенчмарк предварительной подготовки большой языковой модели на основе Llama 3.1 405B, которая является самой большой ИИ-моделью в текущем наборе тестов обучения. Он заменил бенчмарк на основе gpt3 (gpt-3-175B), входивший в предыдущие версии MLPerf Training. Целевая группа MLPerf Training выбрала его, поскольку Llama 3.1 405B является конкурентоспособной моделью, представляющей современные LLM, включая последние обновления алгоритмов и обучение на большем количестве токенов. Llama 3.1 405B более чем в два раза больше gpt3 и использует в четыре раза большее контекстное окно. Несмотря на то, что бенчмарк на основе Llama 3.1 405B был представлен только недавно, на него уже подано больше заявок, чем на предшественника на основе gpt3 в предыдущих раундах, отметил консорциум. 
Источник изображения: NVIDIA MLCommons сообщил, что рабочая группа MLPerf Training регулярно добавляет новые рабочие нагрузки в набор тестов, чтобы гарантировать, что он отражает тенденции отрасли. Результаты бенчмарка Training 5.0 показывают заметный рост производительности для новых бенчмарков, что указывает на то, что отрасль отдаёт приоритет новым рабочим нагрузкам обучения, а не старым. Тест Stable Diffusion показал увеличение скорости в 2,28 раза для восьмичиповых систем по сравнению с версией 4.1, вышедшей шесть месяцев назад, а тест Llama 2.0 70B LoRA увеличил скорость в 2,10 раза по сравнению с версией 4.1; оба превзошли исторические ожидания роста производительности вычислений с течением времени в соответствии с законом Мура. Более старые тесты в наборе показали более скромные улучшения производительности. 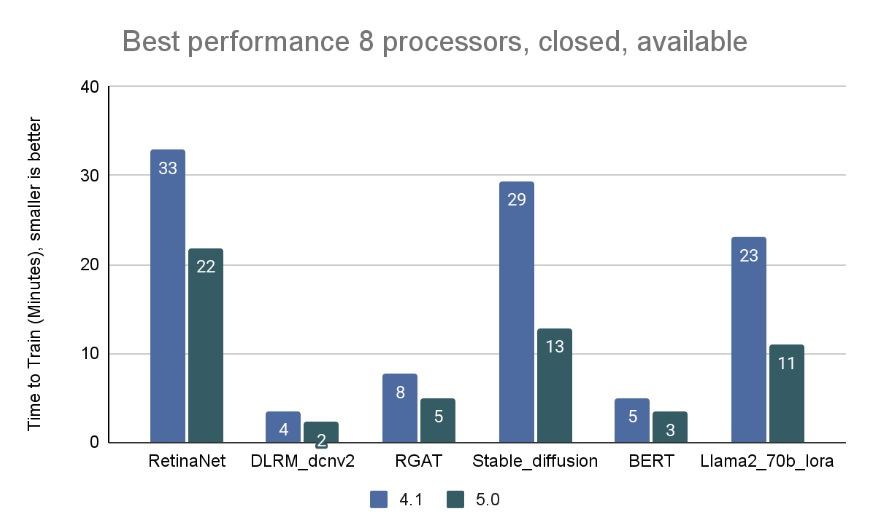
Источник изображений: MLCommons На многоузловых 64-чиповых системах тест RetinaNet показал ускорение в 1,43 раза по сравнению с предыдущим раундом тестирования v3.1 (самым последним, включающим сопоставимые масштабные системы), в то время как тест Stable Diffusion показал резкое увеличение в 3,68 раза. «Это признак надёжного цикла инноваций в технологиях и совместного проектирования: ИИ использует преимущества новых систем, но системы также развиваются для поддержки высокоприоритетных сценариев», — говорит Шрия Ришаб (Shriya Rishab), сопредседатель рабочей группы MLPerf Training. 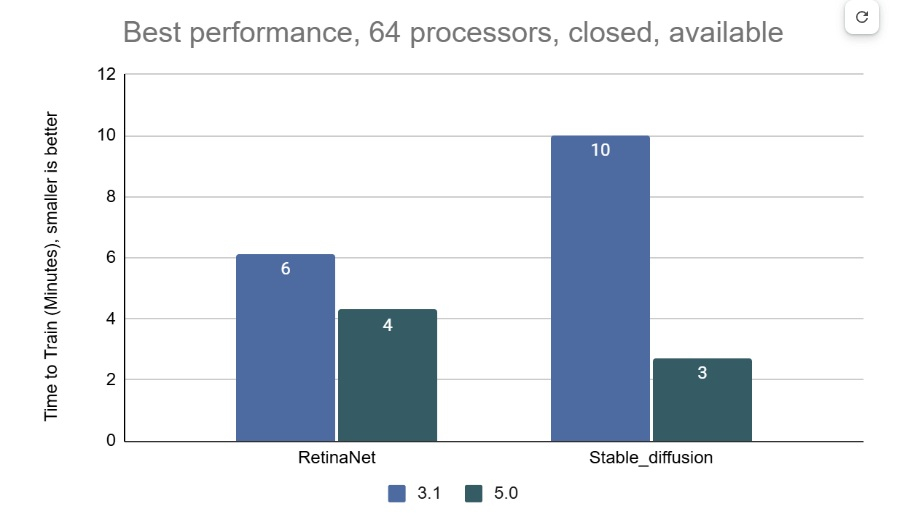 В заявках на MLPerf Training 5.0 использовалось 12 уникальных чиповых, все в категории коммерчески доступных. Пять из них стали общедоступными с момента выхода последней версии набора тестов MLPerf Training:
Заявки также включали три новых семейства процессоров:
Кроме того, количество представленных многоузловых систем увеличилось более чем в 1,8 раза по сравнению с версией бенчмарка 4.1. Хиуот Касса (Hiwot Kassa), сопредседатель рабочей группы MLPerf Training, отметил растущее число провайдеров облачных услуг, предлагающих доступ к крупномасштабным системам, что делает доступ к обучению LLM более демократичным. 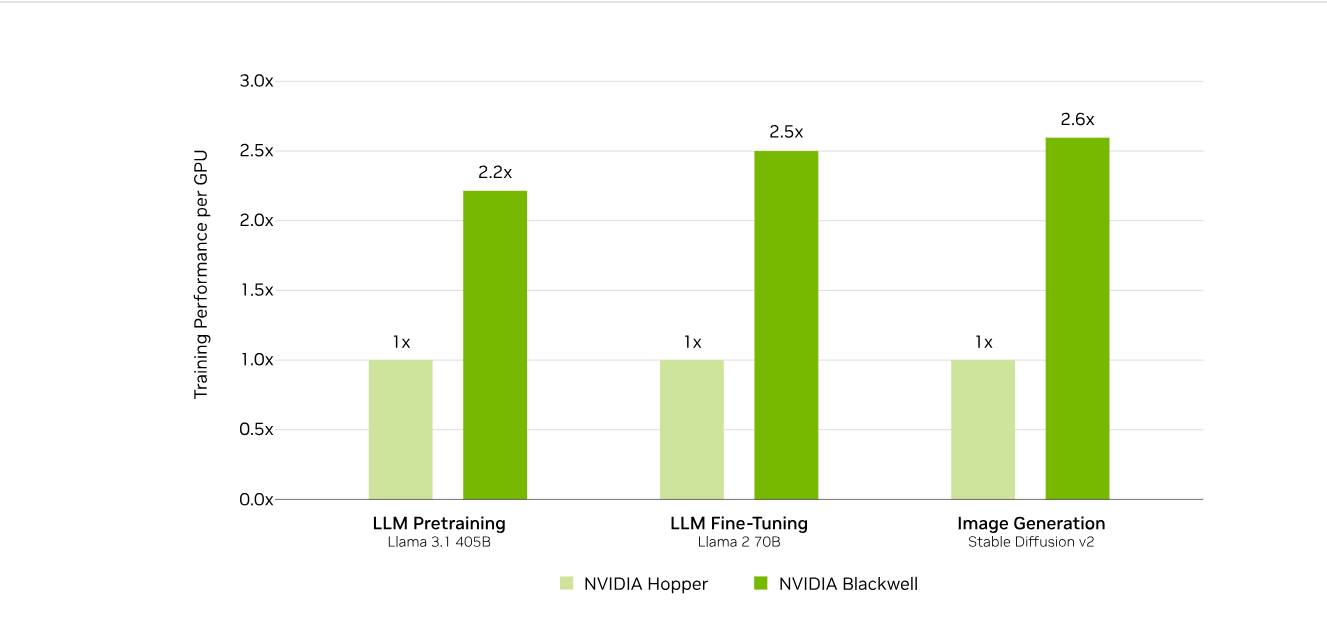
Источник изображений: NVIDIA Последние результаты MLPerf Training 5.0 от NVIDIA показывают, что её ускорители Blackwell GB200 демонстрируют рекордные результаты по времени обучения, демонстрируя, как стоечная конструкция «ИИ-фабрики» компании может быстрее, чем раньше, превращать «сырые» вычислительные мощности в развёртываемые модели, пишет ресурс HPCwire. Раунд MLPerf Training v5.0 включает 201 результат от 20 организаций-участников: AMD, ASUS, Cisco, CoreWeave, Dell, GigaComputing, Google Cloud, HPE, IBM, Krai, Lambda, Lenovo, MangoBoost, Nebius, NVIDIA, Oracle, QCT, SCITIX, Supermicro и TinyCorp. «Мы бы особенно хотели поприветствовать впервые подавших заявку на участие в MLPerf Training AMD, IBM, MangoBoost, Nebius и SCITIX, — сказал Дэвид Кантер (David Kanter), руководитель MLPerf в MLCommons. — Я также хотел бы выделить первый набор заявок Lenovo на результаты тестов энергопотребления в этом раунде — энергоэффективность в системе обучения ИИ-систем становится всё более важной проблемой, требующей точного измерения». 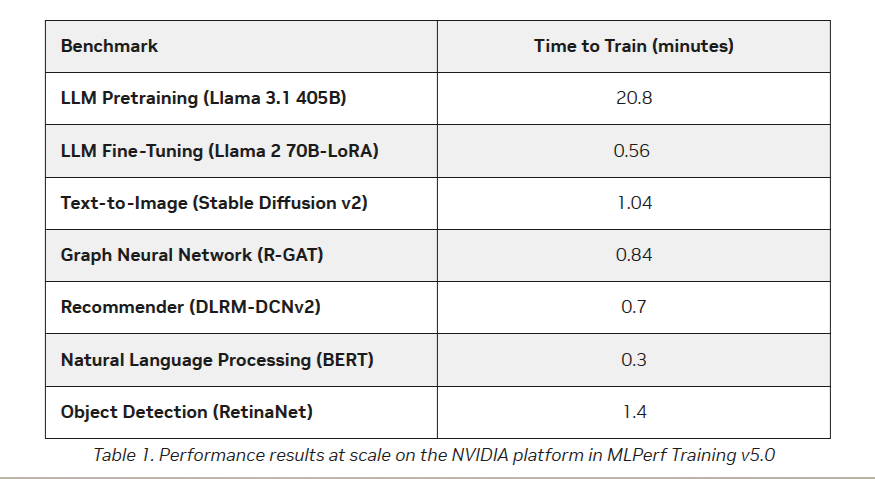 NVIDIA представила результаты кластера на основе систем GB200 NVL72, объединивших 2496 ускорителей. Работая с облачными партнерами CoreWeave и IBM, компания сообщила о 90-% эффективности масштабирования при расширении с 512 до 2496 ускорителей. Это отличный результат, поскольку линейное масштабирование редко достигается при увеличении количества ускорителей за пределами нескольких сотен. Эффективность масштабирования в диапазоне от 70 до 80 % уже считается солидным результатом, особенно при увеличении количества ускорителей в пять раз, пишет HPCwire. В семи рабочих нагрузках в MLPerf Training 5.0 ускорители Blackwell улучшили время сходимости «до 2,6x» при постоянном количестве ускорителей по сравнению с поколением Hopper (H100). Самый большой рост наблюдался при генерации изображений и предварительном обучении LLM, где количество параметров и нагрузка на память самые большие.  Хотя в бенчмарке проверялась скорость выполнения операций, NVIDIA подчеркнула, что более быстрое выполнение задач означает меньшее время аренды облачных инстансов и более скромные счета за электроэнергию для локальных развёртываний. Хотя компания не публиковала данные об энергоэффективности в этом бенчмарке, она позиционировала Blackwell как «более экономичное» решение на основе достигнутых показателей, предполагая, что усовершенствования дизайна тензорных ядер обеспечивают лучшую производительность на Ватт, чем у поколения Hopper. Также HPCwire отметил, что NVIDIA была единственным поставщиком, представившим результаты бенчмарка предварительной подготовки LLM на основе Llama 3.1 405B, установив начальную точку отсчёта для обучения с 405 млрд параметров. Это важно, поскольку некоторые компании уже выходят за рамки 70–80 млрд параметров для передовых ИИ-моделей. Демонстрация проверенного рецепта работы с 405 млрд параметров даёт компаниям более чёткое представление о том, что потребуется для создания ИИ-моделей следующего поколения. 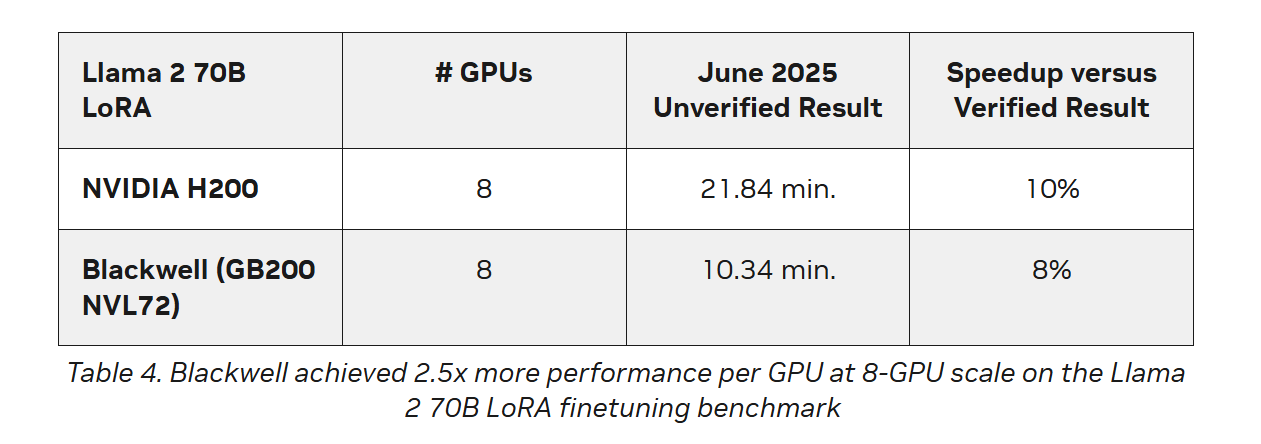 В ходе пресс-конференции Дэйв Сальватор (Dave Salvator), директор по ускоренным вычислительным продуктам в NVIDIA, ответил на распространенный вопрос: «Зачем фокусироваться на обучении, когда в отрасли в настоящее время все внимание сосредоточено на инференсе?». Он сообщил, что тонкая настройка (после предварительного обучения) остается ключевым условием для реальных LLM, особенно для предприятий, использующих собственные данные. Он обозначил обучение как «фазу инвестиций», которая приносит отдачу позже в развёртываниях с большим объёмом инференса. Этот подход соответствует более общей концепции «ИИ-фабрики» компании, в рамках которой ускорителям даются данные и питание для обучения моделей. А затем производятся токены для использования в реальных приложениях. К ним относятся новые «токены рассуждений» (reasoning tokens), используемые в агентских ИИ-системах. 
 NVIDIA также повторно представила результаты по Hopper, чтобы подчеркнуть, что H100 остаётся «единственной архитектурой, кроме Blackwell», которая показала лидерские показатели по всему набору MLPerf Training, хотя и уступила Blackwell. Поскольку инстансы на H100 широко доступны у провайдеров облачных сервисов, компания, похоже, стремится заверить клиентов, что существующие развёртывания по-прежнему имеют смысл. 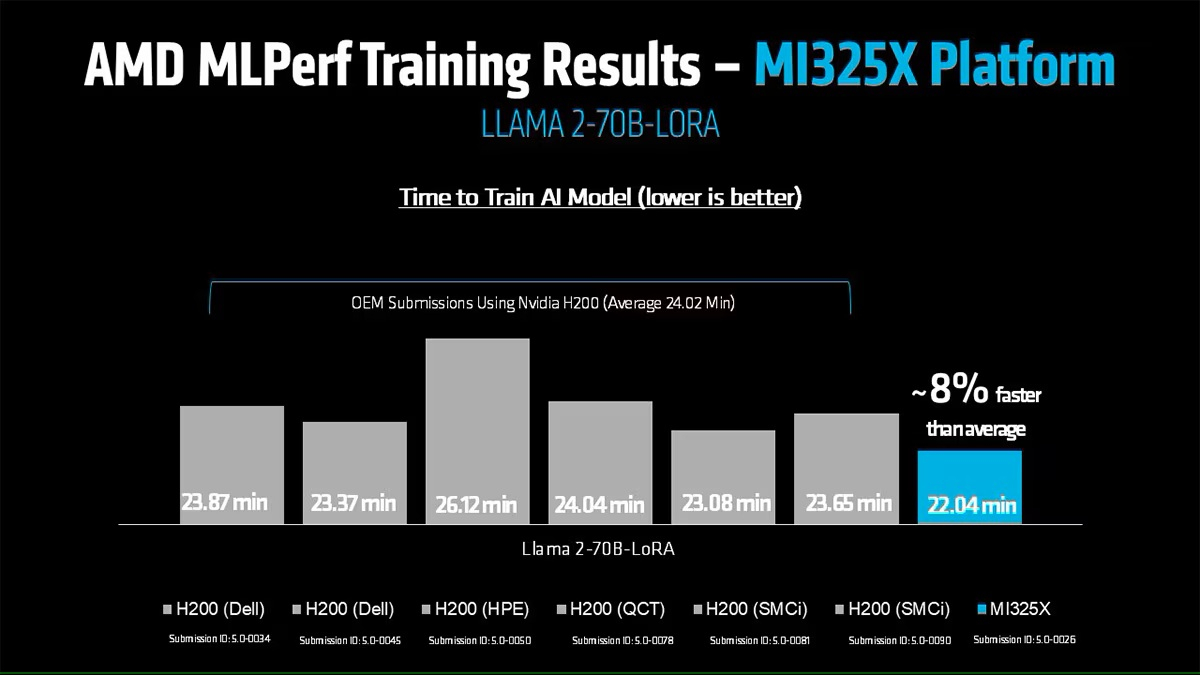
Источник изображений: AMD AMD, со своей стороны, продемонстрировала прирост производительности поколения чипов. В тесте Llama2 70B LoRA она показала 30-% прирост производительности AMD Instinct MI325X по сравнению с предшественником MI300X. Основное различие между ними заключается в том, что MI325X оснащён почти на треть более быстрой памятью.  В самом популярном тесте, тонкой настройке LLM, AMD продемонстрировала, что её новейший ускоритель Instinct MI325X показывает результаты наравне с NVIDIA H200. Это говорит о том, что AMD отстает от NVIDIA на одно поколение, отметил ресурс IEEE Spectrum. 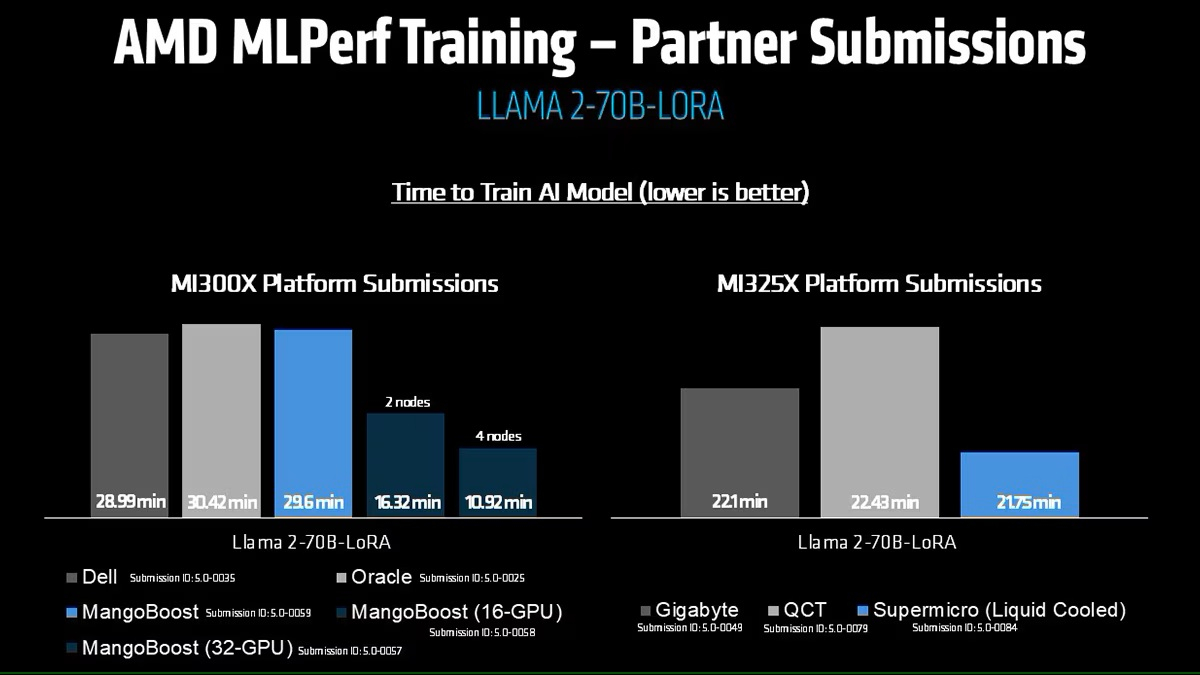 AMD впервые представила результаты MLPerf Training, хотя в предыдущие годы другие компании представляли результаты в этом тесте, используя ускорители AMD. В свою очередь, Google представила результаты лишь одного теста, задачи генерации изображений, с использованием Trillium TPU. Тест MLPerf также включает тест на энергопотребление, измеряющий, сколько энергии уходит на выполнение каждой задачи обучения. В этом раунде лишь Lenovo включила измерение этого показателя в свою заявку, что сделало невозможным сравнение между компаниями. Для тонкой настройки LLM на двух ускорителях Blackwell требуется 6,11 ГДж или 1698 КВт·ч — примерно столько энергии уходит на обогрев небольшого дома зимой.
06.06.2025 [18:46], Руслан Авдеев
AMD продолжает шоппинг: компания купила стартап Brium для борьбы с доминированием NVIDIAВ последние дни компания AMD активно занимается покупками компаний, так или иначе задействованных в разработке ИИ-технологий. Одним из последних событий стала покупка стартапа Brium, специализирующегося на инструментах разработки и оптимизации ИИ ПО, сообщает CRN. AMD, по-видимому, всерьёз обеспокоилась развитием программной экосистемы после того, как выяснилось, что именно ПО не даёт раскрыть весь потенциал ускорителей Instinct. О покупке Brium, в состав которой входят «эксперты мирового класса в области компиляторов и программного обеспечения для ИИ», было объявлено в минувшую среду. Финансовые условия сделки пока не разглашаются. По словам представителя AMD, передовое ПО Brium укрепит возможности IT-гиганта «поставлять в высокой степени оптимизированные ИИ-решения», включающие ИИ-ускорители Instinct, которые играют для компании ключевую роль в соперничестве с NVIDIA. Дополнительная информация изложена в пресс-релизе AMD. В AMD уверены, что разработки Brium в области компиляторных технологий, фреймворков для выполнения моделей и оптимизации ИИ-инференса позволят улучшить эффективность и гибкость ИИ-платформы нового владельца. Главное преимущество, которое AMD видит в Brium — способность стартапа оптимизировать весь стек инференса до того, как модель начинает обрабатываться аппаратным обеспечением. Это позволяет снизить зависимость от конкретных конфигураций оборудования и обеспечивает ускоренную и эффективную работу ИИ «из коробки». В частности, команда Brium «немедленно» внесёт вклад в ключевые проекты вроде OpenAI Triton, WAVE DSL и SHARK/IREE, имеющие решающее значение для более быстрой и эффективной эксплуатации ИИ-моделей на ускорителях AMD Instinct. У технического директора Brium Квентина Коломбета (Quentin Colombet) десятилетний опыт разработки и оптимизации компиляторов для ускорителей в Google, Meta✴ и Apple. 
Источник изображения: AMD Компания сосредоточится на внедрении новых форматов данных вроде MX FP4 и FP6, которые уменьшают объём вычислений и снижают энергопотребление, сохраняя приемлемую точность моделей. В результате разработчики могут добиться более высокой производительности ИИ-моделей, снижая затраты на оборудование и повышая энергоэффективность. Покупка Brium также поможет ускорить создание open source инструментов. Это даст возможность AMD лучше адаптировать свои решения под специфические потребности клиентов из разных отраслей. Так, Brium успешно адаптировала Deep Graph Library (DGL) — фреймворк для работы с графовыми нейронными сетями (GNN) — под платформу AMD Instinct, что дало возможность эффективно запускать передовые ИИ-приложения в области здравоохранения. Такого рода компетенции повышают способность AMD предоставлять оптимальные решения для отраслей с высокой добавленной стоимостью и расширять охват рынка. Brium — лишь одно из приобретений AMD за последние дни для усиления позиций в соперничестве с NVIDIA, доминирование которой на рынке ИИ позволило получить в прошлом году выручку, более чем вдвое превышавшую показатели AMD и Intel вместе взятых. В числе последних покупок — стартап Enosemi, работающий над решениями в сфере кремниевой фотоники, поставщик инфраструктуры ЦОД ZT Systems, а также софтверные стартапы Silo AI, Nod.ai и Mipsology. Кроме того, совсем недавно компания купила команду Untether AI, не став приобретать сам стартап.
06.06.2025 [17:58], Руслан Авдеев
AMD купила команду разработчика ИИ-чипов Untether AI, но не саму компанию, которая тут же закрыласьКомпания AMD объявила об очередной за несколько дней корпоративной покупке. Она наняла неназванное количество сотрудников Untether AI, разрабатывающей ИИ-чипы для энергоэффективного инференса в ЦОД и на периферии, сообщает Silicon Angle. Первым информацией о сделке поделился представитель рекрутинговой компании SBT Industries, специализирующейся на полупроводниковой сфере. Позже в AMD подтвердили, что компания приобрела «талантливую команду инженеров по аппаратному и программному ИИ-обеспечению» у Untether AI. Новые сотрудники помогут оптимизировать разработку компиляторов и ядер ИИ-систем, а также улучшить проектирование чипсетов, их проверку и интеграцию. Вероятно, сделку завершили в прошлом месяце, причём в команду не вошёл глава Untether Крис Уокер (Chris Walker), перешедший в стартап из Intel и возглавивший его в начале 2024 года. Судя по информации из соцсетей, Уокер покинул компанию в мае. Сделка довольно необычна, поскольку никаких активов компании не покупалось, но Untether AI уже объявила о закрытии бизнеса и поставок или поддержки чипов speedAI и ПО imAIgine Software Development Kit (SDK). 
Источник изображения: Untether AI Untether AI была основана 2018 году в Торонто (Канада). В июле 2021 года стартап привлёк $125 млн в раунде финансирования, возглавленном венчурным подразделением Intel Capital. Компания разрабатывала энергоэффективные чипы для инференса для периферийных решений, потребляющих мало энергии. В одной упаковке объединялись модули для вычислений и память. В октябре 2024 года начала продажи чипа speedAI240 Slim (развитие speedAI240). speedAI240 Slim, по данным компании, втрое энергоэффективнее аналогов в сегменте ЦОД. Помимо Intel, Untether AI имела партнёрские отношения с Ampere Computing, Arm Holdings и NeuReality. Буквально в минувшем апреле Уокер сообщил журналистам, что компания отметила большой спрос на свои чипы для инференса со стороны покупателей, ищущих альтернативы продуктам NVIDIA с более высокой энергоёмкостью. Более того, в прошлом году компания договорилась с индийской Ola-Krutrim о совместной разработке ИИ-ускорителей не только для инференса, но и для тюнинга ИИ-моделей. Покупка состоялась всего через два дня после объявления о приобретении малоизвестного стартапа Brium, специализировавшегося на инструментах разработки и оптимизации ИИ ПО. Вероятно, AMD заинтересована в использовании его опыта для оптимизации инференса на отличном от NVIDIA оборудовании. Сделка с Brium состоялась всего через шесть дней после того, как AMD объявила о покупке разработчика систем кремниевой фотоники Enosemi. Это поможет AMD нарастить компетенции в соответствующей сфере, поскольку всё больше клиентов пытаются объединять тысячи ускорителей для поддержки интенсивных ИИ-нагрузок.
05.06.2025 [17:27], Руслан Авдеев
1 Тбит/с на 4,7 тыс. км: Nokia протестировала сверхбыструю квантово-защищённую сеть для ИИ-суперкомпьютеровNokia, финский центр CSC (Finnish IT Center for Science) и ассоциация образовательных и исследовательских учреждений Нидерландов SURF успешно испытали сверхбыструю (1,2 Тбит/с) квантово-безопасную магистраль передачи данных между Амстердамом и Каяани (Kajaani, Финляндия). Эксперимент направлен на подготовку инфраструктуры для HPC- и ИИ-систем, каналы связи которой защищены от взлома квантовыми компьютерами будущего, сообщает Converge. Испытание, проведённое в мае 2025 года, позволило установить связь по ВОЛС на расстоянии более 3,5 тыс. км, а длина одного из тестовых маршрутов через Норвегию составила 4,7 тыс. км (1 Тбит/с). Инициатива рассчитана на поддержку и развитие возможностей финского ИИ-суперкомпьютера LUMI-AI. Также речь идёт о поддержке будущих ИИ-фабрик (AI Factories), которым потребуются защищённые каналы со сверхвысокой пропускной способностью. Тестовый запуск включал передачу синтезированных и реальных исследовательских данных «с диска на диск» через пять исследовательских и образовательных сетей, включая SURF (Нидерланды), NORDUnet (преимущественно скандинавские страны), Sunet (Швеция), SIKT (Норвегия) и Funet (Финляндия). Эксперимент подтвердил возможность обработки огромных непрерывных потоков данных, необходимых для современных нагрузок, обучения и эксплуатации ИИ-моделей. 
Источник изображения: LUMI В сети использовали маршрутизаторы Nokia IP/MPLS с поддержкой FlexE (Flexible Ethernet) для гибкого разделения физических интерфейсов на логические каналы с гарантированной пропускной способностью и квантово-защищённой передачу данных. Новая веха свидетельствует о готовности европейской инфраструктуры к интенсивному использованию данных, в том числе пакетов климатической информации петабайтных объёмов, информации для обучения ИИ-моделей и т.д. Эксперимент также подтвердил возможность безопасных, дальних многодоменных передач между разными сетями или административными границами. Это насущная потребность для современных международных проектов, где данные нужно передавать через разные сети без ущерба производительности и безопасности. По словам финских исследователей, исследовательские сети проектируются с учётом потребностей будущего. В ЦОД CSC в Каяани уже размещен общеевропейский суперкомпьютер LUMI, а с реализацией подпроекта LUMI-AI и ввода других ИИ-фабрик EuroHPC наличие надёжной и масштабируемой системы связи Европе просто необходима. |
|