Материалы по тегу: hpc
|
07.06.2023 [15:28], Сергей Карасёв
HPE создаст новую HPC-систему c процессорами Intel Max для Университета штата Нью-Йорк в Стони-БрукеУниверситет штата Нью-Йорк в Стони-Бруке анонсировал проект нового НРС-комплекса, который планируется использовать при проведении исследований в таких областях, как инженерия, физика, социальные и биологические науки. Созданием суперкомпьютера займутся специалисты компании HPE. В основу платформы лягут серверы HPE ProLiant DL360 Gen11 на процессорах Intel Xeon Sapphire Rapids. В том числе будут задействованы узлы на базе Intel Xeon Max. Утверждается, что применение этих решений позволит повысить плотность компоновки оборудования и уменьшить площадь дата-центра — в том числе благодаря возможности развёртывания СЖО. Помимо НРЕ и Intel, в проекте принимает участие системный интегратор ComnetCo. Эта фирма и раньше сотрудничала с Университетом штата Нью-Йорк в Стони-Бруке; кроме того, она имеет опыт взаимодействия с исследовательскими организациями и государственными заказчиками. Управление НРС-платформой возьмут на себя Институт передовых вычислительных наук (IACS) и Отдел информационных технологий (DoIT) в составе университета. 
Отмечается, что Университет штата Нью-Йорк в Стони-Бруке станет первым академическим учреждением в США, развернувшим суперкомпьютерную платформу с процессорами Xeon Max на серверах HPE ProLiant. Доступ к ресурсам платформы планируется предоставлять в масштабах всего кампуса. Сведений о производительности системы на данный момент нет.
06.06.2023 [13:33], Сергей Карасёв
Университет FAU в Германии получит суперкомпьютерный центр стоимостью €260 млнМинистр науки Германии Маркус Блюм (Markus Blume), по сообщению Datacenter Dynamics, подписал документ о создании в стране нового суперкомпьютерного центра стоимостью приблизительно €260 млн. Площадка НРС расположится в Эрлангене (земля Бавария). Говорится, что комплекс станет дочерней структурой существующего суперкомпьютерного центра в Лейбнице. Управление будущей системой, равно как и уже действующей, будет осуществлять Университет имени Фридриха — Александра в Эрлангене и Нюрнберге (FAU). Это учреждение на сегодняшний день инвестировало в суперкомпьютерные технологии в общей сложности более €1,5 млрд. 
Источник изображения: FAU «Проект выводит FAU в высшую лигу с точки зрения вычислительной инфраструктуры и инвестиций. Мы открываем новые горизонты в области высокопроизводительной обработки данных. Ключевым моментом здесь является взаимодействие: все университеты и все дисциплины — от гуманитарных наук до квантовых исследований — получат выгоду от суперкомпьютерного центра», — сказал господин Блюм. Сроки строительства НРС-комплекса и его предполагаемая мощность пока не разглашаются. Но отмечается, что расходы на оборудование, работы и оплату труда сотрудников в течение первых десяти лет после старта проекта покроют федеральные и местные власти. Ресурсы суперкомпьютера планируется использовать при реализации исследовательских проектов в различных сферах. Речь, в частности, идёт о залачах на базе ИИ.
01.06.2023 [18:50], Сергей Карасёв
NVIDIA создаст ИИ-суперкомпьютеры Taipei-1 и Israel-1Компания NVIDIA в ходе выставки Computex 2023 представила HPC-комплексы Taipei-1 и Israel-1. Первый из названных суперкомпьютеров ориентирован на решение сложных задач в области ИИ и промышленных метавселенных, а второй будет выступать в качестве испытательного полигона для тестирования новых решений. Основа Taipei-1 — 64 системы NVIDIA DGX H100. Это полностью оптимизированная аппаратная и программная платформа, включающая поддержку новых программных решений NVIDIA для ИИ. Конфигурация узлов включает восемь ускорителей H100, два DPU BlueField-3 и 2 Тбайт памяти. Кроме того, в состав Taipei-1 войдут 64 системы NVIDIA OVX , которые предназначены для построения крупномасштабных цифровых двойников. Клиентам будет доступен облачный сервис DGX Cloud, а софт NVIDIA Base Command поможет в мониторинге рабочих нагрузок. Ведущие тайваньские образовательные и научно-исследовательские институты одними из первых получат доступ к Taipei-1 для развития здравоохранения, больших языковых моделей (LLM), климатологии, робототехники, интеллектуального производства и промышленных проектов. Использовать мощности суперкомпьютера, в частности, планирует Национальный тайваньский университет. 
Изображение: NVIDIA В свою очередь, комплекс Israel-1 станет самым мощным ИИ-суперкомпьютером в Израиле. Машина объединит 256 серверов Dell PowerEdge XE9680 на основе NVIDIA HGX H100. В общей сложности будут задействованы 2560 изделий BlueField-3 DPU и 80 коммутаторов Spectrum-4. Общее пиковое быстродействие системы составит 130 Пфлопс, а производительность на ИИ-операциях — до 8 Эфлопс.  Любопытно, что на выставке также удалось обнаружить упоминание пока что не анонсированной машины Taiwania 4, о которой писали зарубежные СМИ. В частности, говорится, что система получит 44 узла со 144-ядерными Arm-чипами Grace, которые будут объединены интеконнектом NVIDIA Quantum-2 InfiniBand NDR. Созданием суперкомпьютера займётся ASUS, а расположится он в тайваньском Национальном центре высокопроизводительных вычислений (NCHC).
01.06.2023 [18:32], Сергей Карасёв
ASUS представила Arm-сервер RS720QN-E11-RS24U на базе архитектуры NVIDIA MGXКомпания ASUS в рамках выставки Computex 2023 анонсировала сервер RS720QN-E11-RS24U типоразмера 2U с высокой плотностью компоновки элементов. Новинка использует передовую модульную архитектуру NVIDIA MGX, которая позволяет комбинировать CPU, GPU и DPU в нужном сочетании для решения определённых задач в области ИИ и НРС.  Сервер несёт на борту процессор NVIDIA Grace CPU Superchip, насчитывающий 144 ядра Arm. Чип функционирует в тандеме с оперативной памятью LPDDR5 объёмом 256/512 Гбайт. Во фронтальной части расположены 24 отсека для SFF-накопителей NVMe. Кроме того, возможна установка SSD-модулей М.2 22110 с интерфейсом PCIe 5.0 х4.  Модель RS720QN-E11-RS24U располагает двумя сетевыми портами 1GbE (контроллер Intel I350) и выделенным сетевым портом управления. Питание обеспечивают блоки мощностью 3600 Вт с сертификатом 80 PLUS Titanium. Сервер имеет габариты 800 × 444 × 88,15 мм. В системе охлаждения задействованы вентиляторы с возможностью горячей замены.
31.05.2023 [21:48], Руслан Авдеев
Колумбия превратит ЦОД Tayra в сильнейший в стране суперкомпьютерКолумбийские власти приняли решение превратить недостаточно загруженный ЦОД в самый мощный в стране суперкомпьютер. Как сообщает портал DataCenter Dynamics, на эти цели они готовы выделить $330 тыс. Сравнительно небольшие инвестиции позволят поднять производительность имеющейся платформы с 17 до 130 Тфлопс. Речь идёт об объекте Tayra, находящемся колумбийском Центре биоинформатики и вычислительной биологии (BIOS) в Валье-дель-Каука. Сегодня вычислительными мощностями обеспечиваются государственные ведомства, образовательные учреждения и бизнес. Как сообщил представитель местных властей, сейчас фактически имеется система стоимостью 17 млрд песо (около $4 млн), которая буквально ничего не делает. Поэтому было решено потратить ещё 1,5 млрд песо на то, чтобы комплекс по-настоящему заработал. 
Валье-дель-Каука. Источник изображения: Alexander Schimmeck/unsplash.com Новый суперкомпьютер, которых в Латинской Америке совсем немного, как ожидается, поможет создать экосистему для инноваций. Он будет использоваться для решения социодемографических задач, для более точных предсказаний погоды, а также в исследованиях окружающей среды и климата. Хотя для Колумбии появление суперкомпьютера является важным шагом в развитии страны, производительности машины не хватит для попадания в рейтинг TOP500.
29.05.2023 [14:50], Владимир Мироненко
Hyperion Research: рынок HPC вырос в 2022 году на 4 %, а ИИ и облака ускорят его развитиеСогласно исследованию Hyperion Research, о результатах которого было объявлено в ходе конференции ISC 2023, рынок HPC-вычислений вырос в 2022 году в годовом исчислении на 4 %. Гендиректор Hyperion Эрл Джозеф (Earl Joseph) отметил, что на фоне всех проблем цепочек поставок и экономических последствий темпы роста рынка оказались ниже прогнозов аналитиков. В своей оценке роста Hyperion Research учла показатели последнего квартального отчёта лидера рынка ускорителей NVIDIA, результаты которого значительно превзошли прогнозы, благодаря чему акции NVIDIA выросли на 25 %. Согласно расчётам Hyperion Research, ключевым драйвером отрасли HPC в течение следующих четырёх лет будет долгосрочный рост использования генеративного ИИ, в результате чего среднегодовой темп роста сектора в период 2021–2026 годов составит 17,9 %. 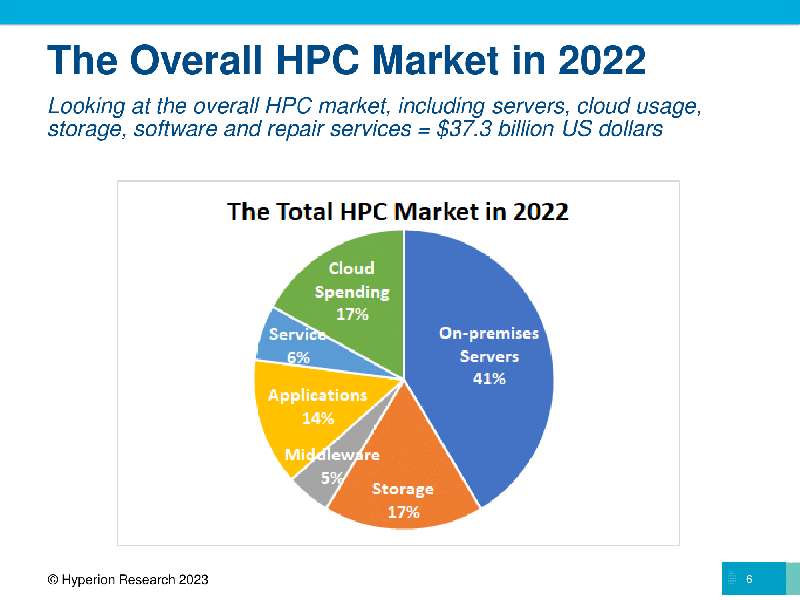
Источник изображений: Hyperion Research По словам Джозефа, 4-процентный рост HPC относится ко всему рынку, включая локальные серверы, СХД, промежуточное ПО и сервисы приложений, а также расходы на выполнение рабочих нагрузок HPC в облаке. Он отметил, что ожидания роста рынка на 6 или 7 % не оправдались, поскольку «некоторые показатели (например, реальные поступления) сократились с 2022 по 2023 год». Общие выручка отрасли выросла за счёт сегмента суперкомпьютеров на сумму $7,3 млрд (системы стоимостью более $500 тыс.), а доходы от экзафлопсных и предэкзафлопсных систем стимулировали рост рынка. По данным Hyperion Research, HPE сохранила лидерство на рынке HPC-серверов, на втором месте — Dell. Выручка HPE от продажи серверов в 2022 году составила $5,1 млрд, а у Dell — $3,6 млрд. За ними следуют Lenovo ($1,2 млрд), Inspur ($1,1 млрд) и Sugon с $600 млн. Замыкают рейтинг IBM, Atos (Eviden), Fujitsu, NEC и Penguin. 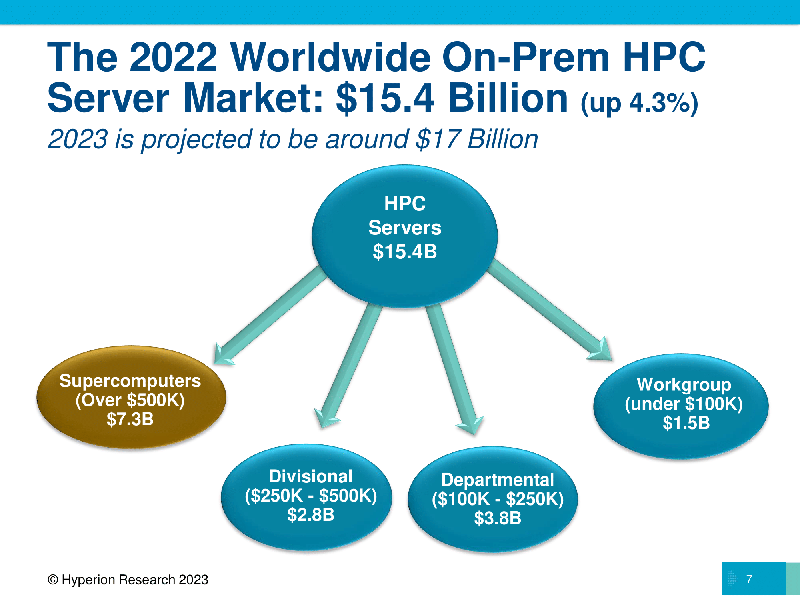 Если рассматривать сегментам локальных систем, то крупнейшим был сектор государственных лабораторий ($3,3 млрд), за ним следуют университеты и академические учреждения ($2,7 млрд), CAE ($1,8 млрд), оборонная отрасль ($1,6 млрд) и биологические науки ($1,1 млрд). Если государственные лаборатории и оборонную отрасль объединить в одну государственную категорию, её объём составил бы почти $5 млрд. Hyperion Research прогнозирует «пристойный рост» HPC-рынка в 2023 году, чему будет способствовать запуск нескольких систем эксафлопсного класса, а также рост расходов на ИИ и облачные HPC-решения. В этом году на HPC-рынке выручка от продажи локальных систем, как ожидается, составит примерно $17 млрд, а общие расходы на локальные HPC — $33 млрд. Как ожидают аналитики Hyperion Research, расходы на облачные HPC-решения вырастут с $6,3 млрд в 2022 году до $7,4 млрд в этом году, к 2026 году этот показатель достигнет $11,6 млрд. В период 2020–2026 гг. облачные HPC будут иметь среднегодовой темп роста в пределах 17,9 %. 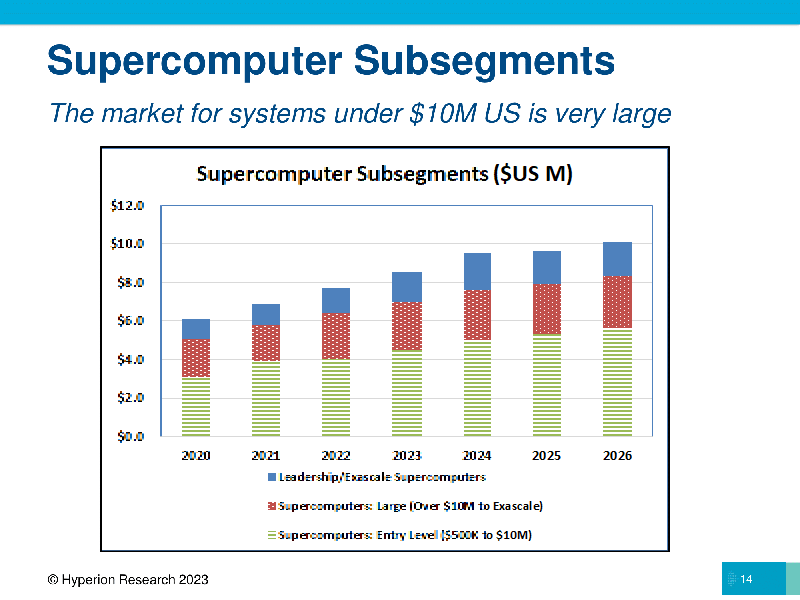 Джозеф заявил, что Hyperion Research ожидает «поворотный момент» в росте облачных HPC-решений, частично обусловленный расширением использования ИИ. «Мы ожидаем примерно 18-процентный рост за пятилетний период, что является просто феноменальным ростом на рынке. Мы ожидаем, что к 2026 году расходы на высокопроизводительные вычисления в облаке составят порядка $12 млрд», — сообщил он. В 2022 году Европа оставалась растущим регионом HPC (две из четырёх лучших систем в списке TOP500 самых мощных суперкомпьютеров мира находятся на континенте). Hyperion Research сообщила, что в 2023 году в целом по региону EMEA (Европа, Ближний Восток и Африка) сектор суперкомпьютерных серверов достигнет $2,2 млрд, составив $2,9 млрд в 2026 году при среднегодовом темпе роста в 2022–2026 годах на уровне 9,3 %.
29.05.2023 [07:30], Сергей Карасёв
NVIDIA представила 1-Эфлопс ИИ-суперкомпьютер DGX GH200: 256 суперчипов Grace Hopper и 144 Тбайт памятиКомпания NVIDIA анонсировала вычислительную платформу нового типа DGX GH200 AI Supercomputer для генеративного ИИ, обработки огромных массивов данных и рекомендательных систем. HPC-платформа станет доступна корпоративным заказчикам и организациям в конце 2023 года. Платформа представляет собой готовый ПАК и включает, в частности, наборы ПО NVIDIA AI Enterprise и Base Command. Для платформы предусмотрено использование 256 суперчипов NVIDIA GH200 Grace Hopper, объединённых при помощи NVLink Switch System. Каждый суперчип содержит в одном модуле Arm-процессор NVIDIA Grace и ускоритель NVIDIA H100. Задействован интерконнект NVLink-C2C (Chip-to-Chip), который, как заявляет NVIDIA, значительно быстрее и энергоэффективнее, нежели PCIe 5.0. В результате, скорость обмена данными между CPU и GPU возрастает семикратно, а затраты энергии сокращаются примерно в пять раз. Пропускная способность достигает 900 Гбайт/с. 
Источник изображений: NVIDIA Технология NVLink Switch позволяет всем ускорителям в составе системы функционировать в качестве единого целого. Таким образом обеспечивается производительность на уровне 1 Эфлопс (~ 9 Пфлопс FP64), а суммарный объём памяти достигает 144 Тбайт — это почти в 500 раз больше, чем в одной системе NVIDIA DGX A100. Архитектура DGX GH200 AI Supercomputer позволяет добиться 10-кратного увеличения общей пропускной способности по сравнению с HPC-платформой предыдущего поколения.  Ожидается, что Google Cloud, Meta✴ и Microsoft одними из первых получат доступ к суперкомпьютеру DGX GH200, чтобы оценить его возможности для генеративных рабочих нагрузок ИИ. В перспективе собственные проекты на базе DGX GH200 смогут реализовывать крупнейшие провайдеры облачных услуг и гиперскейлеры. Для собственных нужд NVIDIA до конца 2023 года построит суперкомпьютер Helios, который посредством Quantum-2 InfiniBand объединит сразу четыре DGX GH200.
29.05.2023 [07:30], Сергей Карасёв
NVIDIA начала массовое производство суперчипов Grace Hopper для генеративного ИИКомпания NVIDIA в ходе выставки Computex 2023 сообщила о начале серийного производства суперчипов GH200 Grace Hopper, предназначенных для построения НРС-систем и платформ генеративного ИИ. Ожидается, что изделия возьмут на вооружение ведущие облачные провайдеры и гиперскейлеры, включая Google, Meta✴ и Microsoft. В состав Grace Hopper входят 72-ядерный Arm-процессор NVIDIA Grace и ускоритель NVIDIA H100 с 96 Гбайт HBM3. Объём общей для обоих кристаллов памяти составляет 576 Гбайт (480 Гбайт LPDDR5x). Кристаллы соединены между собой шиной NVLink-C2C, обеспечивающей пропускную способность 900 Гбайт/с: это приблизительно в семь раз больше по сравнению с PCIe 5.0. Заявленный уровень производительности GH200 — 4 Пфлопс с использованием Transformer Engine. «Генеративный ИИ быстро трансформирует IT-пространство, предоставляя новые возможности и ускоряя открытия в здравоохранении, финансах, бизнес-сфере и многих других отраслях. С началом серийного выпуска суперчипов Grace Hopper производители по всему миру вскоре представят ускоренные инфраструктуры для решения ИИ-задач корпоративного класса на основе уникальных массивов данных», — сказал Иэн Бак (Ian Buck), вице-президент HPC-подразделения NVIDIA. 
Источник изображения: NVIDIA Говорится, что в число производителей серверов с ускорителями NVIDIA входят такие компании, как Cisco, Dell Technologies, Gigabyte, HPE, Lenovo, Supermicro, Eviden (Atos). Среди тайваньских партнёров компании были названы AAEON, Advantech, Aetina, ASRock Rack, ASUS, GIGABYTE, Ingrasys, Inventec, Pegatron, QCT, Tyan, Wistron и Wiwynn. Изделия NVIDIA H100 уже применяют в составе своих платформ облачные провайдеры AWS, Cirrascale, CoreWeave, Google Cloud, Lambda, Microsoft Azure, Oracle Cloud, Paperspace и Vultr. 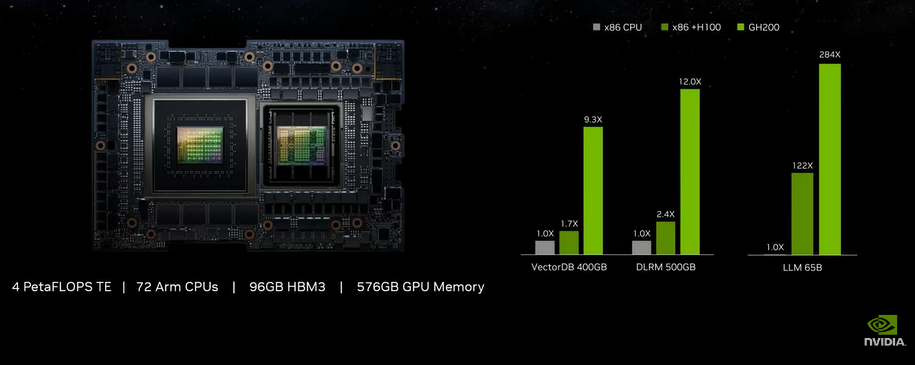
Источник изображения: NVIDIA Системы нового поколения на базе NVIDIA Grace, Hopper и Ada Lovelace обеспечат поддержку полного набора ПО NVIDIA, включая NVIDIA AI Enterprise, NVIDIA Omniverse и NVIDIA RTX. Платформы на основе суперчипов GH200 Grace Hopper станут доступны позднее в текущем году.
29.05.2023 [07:30], Сергей Карасёв
NVIDIA представила модульную архитектуру MGX для создания ИИ-систем на базе CPU, GPU и DPUКомпания NVIDIA на выставке Computex 2023 представила архитектуру MGX, которая открывает перед разработчиками серверного оборудования новые возможности для построения HPC-систем, платформ для ИИ и метавселенных. Утверждается, что MGX закладывает основу для быстрого создания более 100 вариантов серверов при относительно небольших затратах. Концепция MGX предусматривает, что разработчики на первом этапе проектирования выбирают базовую системную архитектуру для своего шасси. Далее добавляются CPU, GPU и DPU в той или иной конфигурации для решения определённых задач. Таким образом, на базе MGX может быть построена серверная система для уникальных рабочих нагрузок в области наук о данных, больших языковых моделей (LLM), периферийных вычислений, обработки графики и видеоматериалов и пр. Говорится также, что благодаря гибридной конфигурации на одной машине могут выполняться задачи разных типов, например, и обучение ИИ-моделей, и поддержание работы ИИ-сервисов. 
Источник изображений: NVIDIA Одними из первых системы на архитектуре MGX выведут на рынок компании Supermicro и QCT. Первая предложит решение ARS-221GL-NR с NVIDIA Grace, а вторая — сервер S74G-2U на базе NVIDIA GH200 Grace Hopper. Эти платформы дебютируют в августе нынешнего года. Позднее появятся MGX-платформы ASRock Rack, ASUS, Gigabyte, Pegatron и других производителей.  Архитектура MGX совместима с нынешним и будущим оборудованием NVIDIA, включая H100, L40, L4, Grace, GH200 Grace Hopper, BlueField-3 DPU и ConnectX-7. Поддерживаются различные форм-факторы систем: 1U, 2U и 4U. Возможно применение воздушного и жидкостного охлаждения.
24.05.2023 [18:36], Сергей Карасёв
AMD показала узлы грядущего 2-Эфлопс суперкомпьютера El Capitan на базе новейших APU Instinct MI300AКомпания AMD в ходе суперкомпьютерной конференции ISC 2023, по сообщению ресурса Tom's Hardware, продемонстрировала компоненты суперкомпьютера El Capitan, который после ввода в эксплуатацию сможет претендовать на звание самого высокопроизводительного комплекса в мире. Новая НРС-машина расположится в Ливерморской национальной лаборатории им. Э. Лоуренса (LLNL) Министерства энергетики США. В основу лягут гибридные чипы Instinct MI300, а производительность превысит 2 Эфлопс (FP64). Для сравнения: самый мощный на сегодняшний день суперкомпьютер Frontier, установленный в Национальной лаборатории Окриджа, обладает быстродействием около 1,194 Эфлопс. На ISC 2023 Бронис Р. де Супински (Bronis R. de Supinski), технический директор LLNL, показал блейд-серверы, которые войдут в состав El Capitan. Устройство, изготовленное компанией HPE, объединяет четыре модуля Instinct MI300 с жидкостным охлаждением. Решение выполнено в форм-факторе 1U. 
Источник изображений: LLNL / Tom's Hardware Супински также показал фотографию лаборатории AMD в Остине, где испытываются рабочие образцы Instinct MI300. Таким образом, как отмечается, новые чипы практически готовы для использования в коммерческих системах. В частности, ввод суперкомпьютера El Capitan в эксплуатацию запланирован на вторую половину 2023 года. Тестовые кластеры El Capitan на базе AMD EPYC Milan и Instinct MI250X ещё в прошлом году попали в TOP500.  Любопытно, что Супинкси в ходе выступления назвал Instinct MI300 несколько другим именем — Instinct MI300A. Однако не ясно, является ли это специальной модификацией для El Capitan или более формальным индексом продукта. Супински отметил, что решение может работать в нескольких разных режимах, но основная конфигурация предусматривает единый домен памяти и домен NUMA, что обеспечивает общий доступ к памяти для всех ядер CPU и GPU.  Для El Capitan предусмотрено использование фирменного хранилища Rabbit. Оно включает 4U-узлы на основе 18 быстрых SSD, которые подключены к плате Rabbit-S, обеспечивающей коммутацию с вычислительной частью. За работу СХД отвечает контроллер Rabbit-P с чипом EPYC.  Администрации по национальной ядерной безопасности США (NNSA), которая будет использовать El Capitan, пришлось модифицировать энергетическую инфраструктуру для одновременной работы нового суперкомпьютера и действующего комплекса Sierra. Общая мощность увеличена с 45 МВт до 85 МВт, а ещё 15 МВт зарезервировано для системы охлаждения. Таким образом, суммарно доступны 100 МВт, хотя El Capitan будет потреблять менее 40 МВт. |
|