Материалы по тегу: hpc
|
27.07.2024 [23:44], Алексей Степин
Не так просто и не так быстро: учёные исследовали особенности работы памяти и NVLink C2C в NVIDIA Grace HopperГибридный ускоритель NVIDIA Grace Hopper объединяет CPU- и GPU-модули, которые связаны интерконнектом NVLink C2C. Но, как передаёт HPCWire, в строении и работе суперчипа есть некоторые нюансы, о которых рассказали шведские исследователи. Им удалось замерить производительность подсистем памяти Grace Hopper и интерконнекта NVLink в реальных сценариях, дабы сравнить полученные результаты с характеристиками, заявленными NVIDIA. Напомним, для интерконнекта изначально заявлена скорость 900 Гбайт/с, что в семь раз превышает возможности PCIe 5.0. Память HBM3 в составе GPU-части имеет ПСП до 4 Тбайт/с, а вариант с HBM3e предлагает уже до 4,9 Тбайт/с. Процессорная часть (Grace) использует LPDDR5x с ПСП до 512 Гбайт/с. В руках исследователей оказалась базовая версия Grace Hopper с 480 Гбайт LPDDR5X и 96 Гбайт HBM3. Система работала под управлением Red Hat Enterprise Linux 9.3 и использовала CUDA 12.4. В бенчмарке STREAM исследователям удалось получить следующие показатели ПСП: 486 Гбайт/с для CPU и 3,4 Тбайт/с для GPU, что близко к заявленным характеристиками. Однако результат скорость NVLink-C2C составила всего 375 Гбайт/с в направлении host-to-device и лишь 297 Гбайт/с в обратном направлении. Совокупно выходит 672 Гбайт/с, что далеко от заявленных 900 Гбайт/с (75 % от теоретического максимума). 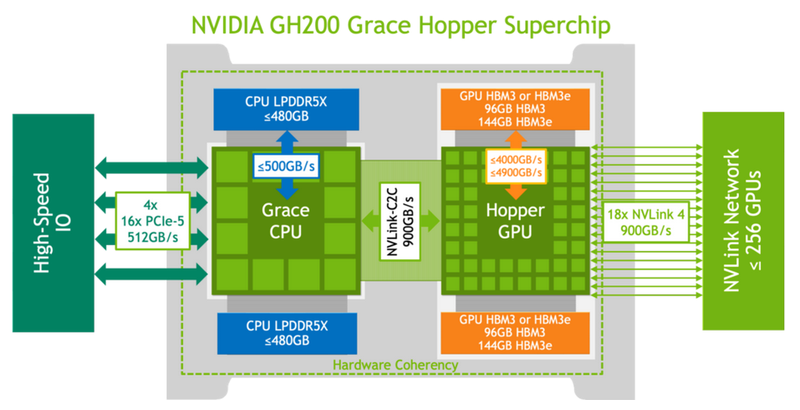
Источник: NVIDIA Grace Hopper в силу своей конструкции предлагает два вида таблицы для страниц памяти: общесистемную (по умолчанию страницы размером 4 Кбайт или 64 Кбайт), которая охватывает CPU и GPU, и эксклюзивную для GPU-части (2 Мбайт). При этом скорость инициализации зависит от того, откуда приходит запрос. Если инициализация памяти происходит на стороне CPU, то данные по умолчанию помещаются в LPDDR5x, к которой у GPU-части есть прямой доступ посредством NVLink C2C (без миграции), а таблица памяти видна и GPU, и CPU. 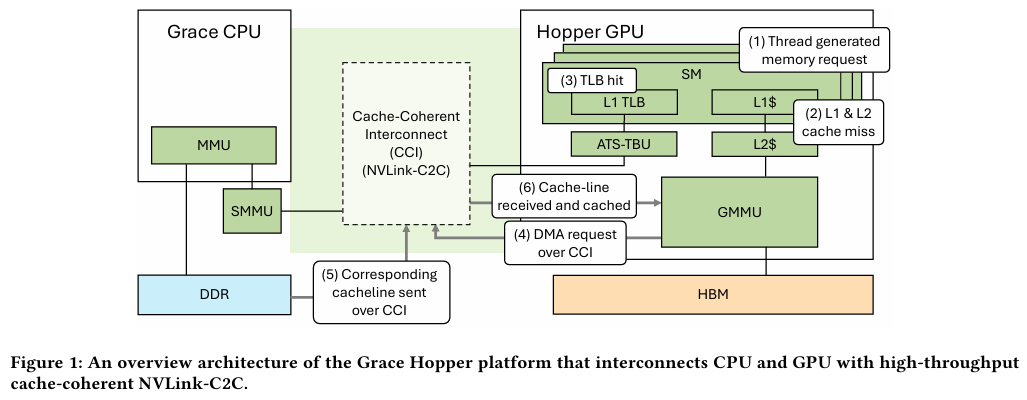
Источник: arxiv.org Если же памятью управляет не ОС, а CUDA, то инициализацию можно сразу организовать на стороне GPU, что обычно гораздо быстрее, а данные поместить в HBM. При этом предоставляется единое виртуальное адресное пространство, но таблиц памяти две, для CPU и GPU, а сам механизм обмена данными между ними подразумевает миграцию страниц. Впрочем, несмотря на наличие NVLink C2C, идеальной остаётся ситуация, когда GPU-нагрузке хватает HBM, а CPU-нагрузкам достаточно LPDDR5x. 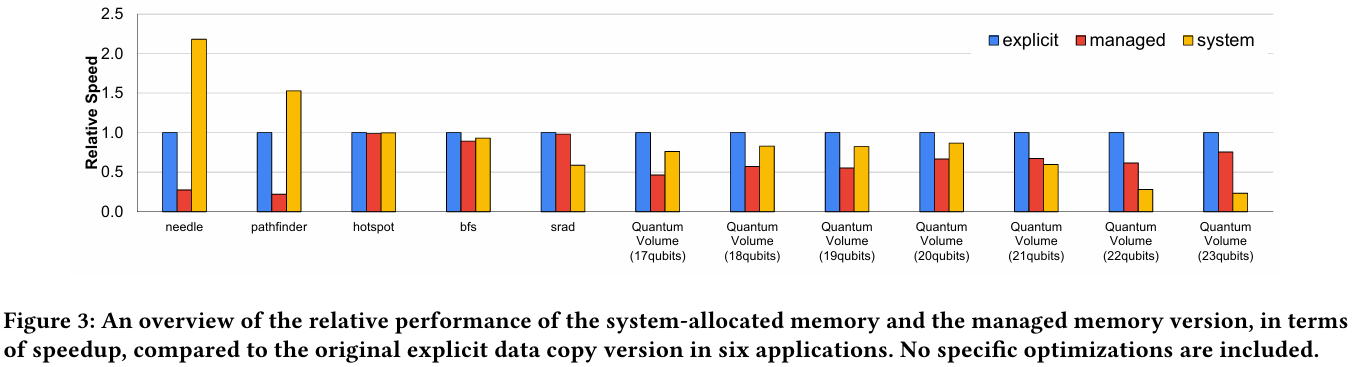
Источник: arxiv.org Также исследователи затронули вопрос производительности при использовании страниц памяти разного размера. 4-Кбайт страницы обычно используются процессорной частью с LPDDR5X, а также в тех случаях, когда GPU нужно получить данные от CPU через NVLink-C2C. Но как правило в HPC-нагрузках оптимальнее использовать 64-Кбайт страницы, на управление которыми расходуется меньше ресурсов. Когда же доступ в память хаотичен и непостоянен, страницы размером 4 Кбайт позволяют более тонко управлять ресурсами. В некоторых случаях возможно двукратное преимущество в производительности за счёт отсутствия перемещения неиспользуемых данных в страницах объёмом 64 Кбайт. В опубликованной работе отмечается, что для более глубокого понимания механизмов работы унифицированной памяти у гетерогенных решений, подобных Grace Hopper, потребуются дальнейшие исследования.
27.07.2024 [10:30], Сергей Карасёв
Аргоннская национальная лаборатория намерена создать СХД ёмкостью 400 Пбайт за $20 млнАргоннская национальная лаборатория (ANL) Министерства энергетики США (DOE) обнародовала запрос на создание нового кластера хранения данных для своего парка суперкомпьютеров. Как сообщает ресурс Datacenter Dynamics, реализация проекта может обойтись в $15–$20 млн. Речь идёт о создании СХД, которая обеспечит ёмкость и производительность, необходимые для поддержания работы действующих НРС-комплексов, а также будущих суперкомпьютеров. Отмечается, что на площадке Argonne Leadership Computing Facility (ALCF) развёрнуты несколько высокопроизводительных параллельных файловых систем для обработки данных, генерируемых исследователями и инженерами. Это, в частности две системы Lustre вместимостью 100 Пбайт с пропускной способностью 650 Гбайт/с. Обе они используют интерконнект Infiniband HDR. 
Источник изображения: DOE Новая СХД будет обладать ёмкостью на уровне 400 Пбайт. В число требований входят IOPS-производительность до 240 млн, пиковая пропускная способность в 6 Тбайт/с, совместимость с POSIX и возможность одновременного монтирования до 30 тыс. узлов. Поставщик должен обеспечивать поддержку в течение пяти лет. Предполагается, что платформа будет использоваться суперкомпьютером Aurora, который в нынешнем рейтинге TOP500 занимает второе место с быстродействием 1,012 Эфлопс. Кроме того, доступ к СХД получит НРС-комплекс Polaris: его пиковая производительность составляет около 44 Пфлопс. Проектируемая СХД должна обеспечивать «надёжность и масштабируемость, необходимые для следующего поколения HPC и ИИ». Поставку платформы исполнителю работ необходимо осуществить ко II или к IV кварталу 2025 года, если дополнительные полгода позволят внедрить новые технологии.
25.07.2024 [09:57], Сергей Карасёв
Илон Маск показал ИИ-суперкомпьютер Dojo на основе чипов Tesla D1Глава Tesla Илон Маск (Elon Musk), по сообщению ресурса Tom's Hardware, обнародовал фотографии вычислительного комплекса Dojo, который будет использоваться для разработки инновационных автомобильных технологий, а также для обучения автопилота. Tesla, напомним, начала создание ИИ-суперкомпьютера Dojo в июле 2023 года. Основой системы послужат специализированные чипы собственной разработки Tesla D1. Дата-центр Dojo, расположенный в штаб-квартире Tesla в Остине (Техас, США), по своей конструкции напоминает бункер. В апреле нынешнего года сообщалось, что при строительстве ЦОД компания Маска столкнулась с трудностями, связанными в том числе с доставкой необходимых материалов. Как теперь сообщается, Tesla намерена ввести Dojo в эксплуатацию до конца 2024 года. По производительности этот суперкомпьютер будет сопоставим с кластером из 8 тыс. ускорителей NVIDIA H100. По словам Маска, это «не слишком много, но и не тривиально». Для сравнения: мощнейший ИИ-суперкомпьютер компании xAI, также курируемой Илоном Маском, объединит 100 тыс. карт H100. 
Источник изображений: Илон Маск Отмечается, что чипы Tesla D1 специально ориентированы на машинное обучение и анализ видеоданных. Поэтому систему Dojo планируется использовать прежде всего для совершенствования технологии автономного вождения Tesla путём обработки видеоданных, полученных от автомобилей компании. В свою очередь, «ИИ-гигафабрика» xAI поможет в развитии чат-ботов Grok следующего поколения.  Маск также сообщил, что компания Tesla намерена «удвоить усилия» по разработке и развертыванию Dojo из-за высоких цен на оборудование NVIDIA. Вместе с тем финансовый директор Tesla Вайбхав Танеджа (Vaibhav Taneja) заявил, что, несмотря на снижение капвложений во II квартале 2024 года, компания по-прежнему ожидает, что соответствующие затраты превысят $10 млрд.
23.07.2024 [01:20], Владимир Мироненко
Стартап xAI Илона Маска запустил ИИ-кластер в Теннеси [Обновлено]Илон Маск объявил в соцсети X (ранее Twitter) о запуске стартапом xAI в дата-центре в Мемфисе «самого мощного в мире кластера для обучения ИИ», который будет использоваться для создания «самого мощного в мире по всем показателям искусственного интеллекта к декабрю этого года», пишет Tom's Hardware. Однако, судя по всему, на практике сейчас работает лишь очень небольшая часть кластера. «Отличная работа команды @xAI, команды @X, @Nvidia и компаний поддержки, которые начали обучение с кластером Memphis Supercluster примерно в 4:20 утра по местному времени. 100 тыс. H100 с жидкостным охлаждением в единой RDMA-фабрике — это самый мощный кластер обучения ИИ в мире!», — сообщил миллиардер в своём аккаунте. Как указали в xAI, новая вычислительная система будет использоваться для обучения новой версии @grok, которая будет доступна премиум-подписчикам @x. Ранее появились сообщения о том, что оборудование для ИИ-кластера будут поставлять Dell и Supermicro. Комментируя нынешнее заявление Маска, гендиректор Supermicro Чарльз Лян (Charles Liang) подтвердил, что большая часть оборудования для ИИ-кластера была поставлена его компанией. 
Источник изображений: xAI В мае этого года Маск поделился планами построить гигантский суперкомпьютер для xAI для работы над следующей версией чат-бота Grok, который будет включать 100 тыс. ускорителей Nvidia H100. А в следующем году Илон Маск планирует запустить ещё один кластер, который будет содержать 300 тыс. ускорителей NVIDIA B200. Для его создания Маск намеревался привлечь Oracle, планируя выделить $10 млрд на аренду ИИ-серверов компании, но затем отказался от этой идеи, так как его не устроили предложенные Oracle сроки реализации проекта. Как отметил ресурс Tom's Hardware, новый ИИ-кластер стартапа xAI превосходит все суперкомпьютеры из TOP500 с точки зрения количества ускорителей. Самые мощные в мире суперкомпьютеры, такие как Frontier (37 888 ускорителей AMD), Aurora (60 000 ускорителей Intel) и Microsoft Eagle (14 400 ускорителей NVIDIA), похоже, значительно уступают кластеру xAI. Впрочем, технические детали о сетевой фабрике нового кластера пока не предоставлены.  Но, как выясняется, не всё в заявлении Маска соответствует действительности. Аналитик Dylan Patel (Дилан Пател) из SemiAnalysis обвинил Маска во лжи, поскольку в настоящее время кластеру доступно 7 МВт мощности, чего хватит для работы примерно 4 тыс. ускорителей. С 1 августа будет доступно 50 МВт, если xAI наконец подпишет соглашение с властями Теннесси. А подстанция мощностью 150 МВт все ещё находится в стадии строительства, которое завершится в IV квартале 2024 года. Как отмечает местное издание commercial appeal, поскольку речь идёт об объекте мощностью более 100 МВт, для его подключения требуется разрешение коммунальных компаний Memphis Light, Gas and Water (MLGW) и Tennessee Valley Authority (TVA). Контракт на подключение ЦОД к энергосети с TVA не был подписан. Более того, для охлаждения ЦОД, по оценкам MLGW, потребуется порядка 4,9 тыс. м3 воды ежедневно. UPD: Дилан Пател удалил исходный твит, но уточнил текущее положение дел. От энергосети кластер сейчас потребляет 8 МВт, однако рядом с площадкой установлены мобильные генераторы (14 × 2,5 МВт), так что сейчас в кластере активны около 32 тыс. ускорителей, а в полную силу он зарабатает в IV квартале. Если контракт с TVA будет подписан, то к 1 августу кампус получит ещё 50 МВт от сети, а к концу году будет подведено 200 МВт. Для работы 100 тыс. H100 требуется порядка 155 МВт.
17.07.2024 [11:21], Руслан Авдеев
Smart Global Holdings (SGH) сменит имя на Penguin SolutionsНа мероприятии Nasdaq MarketSite Analyst Day специалист по HPC-решениям Smart Global Holdings (SGH) объявил о намерении стать Penguin Solutions, Inc. HPCWire сообщает, что необычный ребрендинг продолжит трансформацию калифорнийской компании, идущую уже несколько лет. «Новая» Pengiun Solutions позиционирует себя как эксперт по комплексным инфраструктурным решениям в области ИИ. По словам представителя SGH, ИИ становится драйвером обеспечения конкурентных преимуществ во всех отраслях экономики. Большие языковые модели (LLM), ИИ-аналитика, симуляции и другие связанные темы приобретают критически важное значение, поэтому предприятия любого масштаба стремятся к внедрению систем искусственного интеллекта. В компании отмечают, что ИИ-инфраструктура невероятно сложна и значительно отличается от традиционных корпоративных IT-решений, требует новых технологических навыков, которые у многих организаций всё ещё отсутствуют. Зачастую сложность ИИ-технологий ведёт к их медленному внедрению, использованию неэффективных систем и нереализованной прибыли на инвестиции. 
Источник изображения: Businesswire/SGH SGH поглотила Penguin Solutions в 2018 году, так что теперь у неё есть более 25 лет опыта работы с HPC-системами. Компания внедрила и управляет более 75 тыс. ускорителей — она фактически уже является доверенным партнёром для многих клиентов, желающих использовать возможности ИИ. Решение SGH поменять имя строится на заработанной ранее репутации и знаменует новую для компании эру. Ожидается, что SGH завершит своё превращение в Penguin Solutions в этом году после одобрения акционерами. Cree LED — подразделение SGH, сохранит свою идентичность и продолжит вести дела под прежним именем. Ребрендинг — не единственное важное изменение для компании в этом году. Южнокорейская SK Holdings намерена вложить $200 млн в развитие её бизнеса в обмен на акции.
17.07.2024 [11:21], Руслан Авдеев
SK Telecom инвестирует $200 млн в Smart Global Holdings (Penguin Solutions) для совместной работы над ИИ- и HPC-инфраструктуройЮжнокорейская телекоммуникационая компания SK Telecom вложит $200 млн в бизнес Smart Global Holdings (SGH), связанный с системами искусственного интеллекта и инфраструктурными ИИ-проектами. По данным Datacenter Dynamics, в обмен на инвестиции SK получит часть акций SGH. В дальнейшем компании намерены совместно работать над использованием «взаимодополняющих возможностей» для расширения спектра предложений клиентам и создания дифференцированных комплексных решений и сервисов в области ИИ и дата-центров, предлагать передовые решения для рынка памяти и периферийных ИИ-серверов на базе NPU-чипов. Калифорнийская SGH уже продаёт ряд платформ и сервисов для HPC, ИИ, машинного обучения, отказоустойчивых вычислений и Интернета вещей, в том числе периферийные и облачные решения. Благодаря приобретению в 2018 году бизнеса Penguin Solutions компания предлагает интегрированные ИИ-решения для ЦОД, от разработки ИИ-кластеров до внедрения и поддержки эксплуатации таких продуктов. Совсем недавно компания объявила о ребрнединге — теперь SGH почти полностью уходит под «зонтик» Penguin Solutions, компания должна сменить имя до конца текущего года. Стоит отметить, что Penguin Solutions известна как поставщик HPC-решений для государственных и военных ведомств США. 
Источник изображения: Alexander Schimmeck/unsplash.com Глава SGH поприветствовал SK Telecom в качестве нового стратегического инвестора, заявив, что новость стала свидетельством возможностей Penguin Solutions по внедрению в больших масштабах «фабрик ИИ», ПО и прочих решений. Ожидается, что сотрудничество принесёт немало выгоды и акционерам. Ранее в текущем году SGH приняла участие в раунде финансирования серии C другой компании — Lambda Labs, привлёкшей $320 млн. SK Telecom получит 200 тыс. привилегированных акций в SGH, которые она сможет конвертировать в простые акции по цене $32,81 каждая. Компания расширяет своё ИИ-портофолио. В прошлом году она инвестировала $100 млн в Anthropic, стоящей за серией LLM Claude. По словам представителя SK Telecom, инвестиции и дальнейшее сотрудничество укрепит позиции южнокорейского гиганта в сфере ИИ.
05.07.2024 [16:42], Руслан Авдеев
TotalEnergies запустила гибридный суперкомпьютер Pangea 4 для ускорения «зелёного перехода»Французская нефтегазовая компания TotalEnergies ввела в эксплуатацию гибридный суперкомпьютер Pangea 4. Машина находится в Научно-техническом центре Жана Феже в По (Jean Féger Scientific and Technical Center at Pau) на юго-западе Франции и состоит из вычислительных мощностей, размещённых на самой площадке, и облачных ресурсов Pangea@Cloud. Pangea 4 компактнее и энергоэффективнее предшественницы Pangea II — она использует на 87 % меньше энергии. Компания не раскрывает производительность новой машины, хотя и указывает, что она вдвое производительнее одной из предыдущих машин. Машина Pangea III с теоретической пиковой FP64-производительностью 31,7 Пфлопс, ставшая в своё время самым мощным индустриальным суперкомпьютером, продолжит свою работу. Pangea 4 была создана HPE, которая также строит суперкомпьютер HPC6 для итальянской нефтегазовой компании Eni. 
Источник изображения: TotalEnergies Pangea 4 будет использоваться не только для традиционных геофизических расчётов, но и для проектов по улавливанию и захоронению CO2, моделированию биотоплива и полимеров, расчётов механик снижения метановых выбросов, моделирования воздушных потоков для проектирования ветроэнергетических установок и т.д. А комбинация on-premise вычислений с облачными отвечает растущим запросам бизнеса, особенно с сфере новой энергетики — для того, чтобы помочь реализовать стратегию «зелёного перехода». Впрочем, приверженность компании «зелёным» ценностям находится под вопросом. TotalEnergies входит в одну из семи крупнейших нефтяных компаний. В прошлом году исследователи Oil Change International сообщили, что TotalEnergies занимала третье место по одобрению новых проектов расширения нефте- и газодобычи и использовала рекордную выручку для удвоения инвестиций в ископаемое топливо.
02.07.2024 [23:55], Алексей Степин
15 тыс. ускорителей на один ЦОД: Alibaba Cloud рассказала о сетевой фабрике, используемой для обучения ИИAlibaba Cloud раскрыла ряд сведений технического характера, касающихся сетевой инфраструктуры и устройства своих дата-центров, занятых обработкой ИИ-нагрузок, в частности, обслуживанием LLM. Один из ведущих инженеров компании, Эньнань Чжай (Ennan Zhai), опубликовал доклад «Alibaba HPN: A Data Center Network for Large Language Model Training», который будет представлен на конференции SIGCOMM в августе этого года. В качестве основы для сетевой фабрики Alibaba Cloud выбрала Ethernet, а не, например, InfiniBand. Новая платформа используется при обучении масштабных LLM уже в течение восьми месяцев. Выбор обусловлен открытостью и универсальностью стека технологий Ethernet, что позволяет не привязываться к конкретному вендору. Кроме того, меньше шансы пострадать от очередных санкций США. Отмечается, что традиционный облачный трафик состоит из множества относительно небыстрых потоков (к примеру, менее 10 Гбит/с), тогда как трафик при обучении LLM включает относительно немного потоков, имеющих периодический характер со всплесками скорости до очень высоких значений (400 Гбит/с). При такой картине требуются новые подходы к управлению трафиком, поскольку традиционные алгоритмы балансировки склонны к перегрузке отдельных участков сети. 
Источник здесь и далее: Alibaba Cloud Разработанная Alibaba Cloud альтернатива носит название High Performance Network (HPN). Она учитывает многие аспекты работы именно с LLM. Например, при обучении важна синхронизация работы многих ускорителей, что делает сетевую инфраструктуру уязвимой даже к единичным точкам отказа, особенно на уровне внутристоечных коммутаторов. Alibaba Cloud использует для решения этой проблемы парные коммутаторы, но не в стековой конфигурации, рекомендуемой производителями. 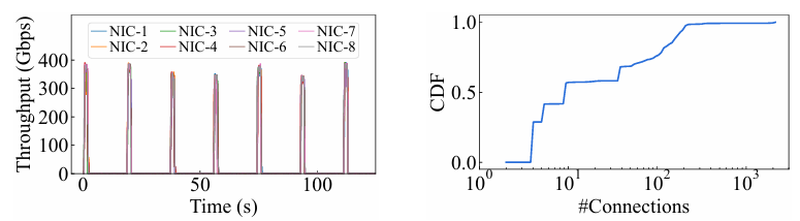
Характер трафика при обучении LLM Каждый хост содержит восемь ИИ-ускорителей и девять сетевых адаптеров. Каждый из NIC имеет по паре портов 200GbE. Девятый адаптер нужен для служебной сети. Между собой внутри хоста ускорители общаются посредством NVLink на скорости 400–900 Гбайт/с, а для общения с внешним миром каждому из них полагается свой 400GbE-канал с поддержкой RDMA. При этом порты сетевых адаптеров подключены к разным коммутаторам из «стоечной пары», что серьёзно уменьшает вероятность отказа. 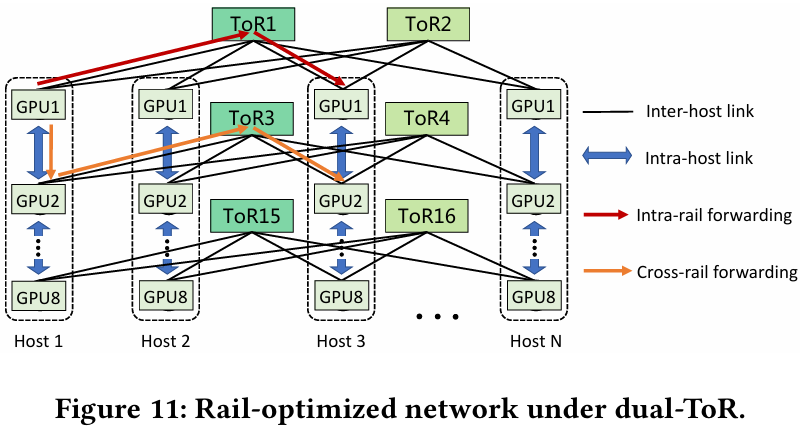 В докладе говорится, что Alibaba Cloud использует современные одночиповые коммутаторы с пропускной способностью 51,2 Тбит/с. Этим условиям отвечают либо устройства на базе Broadcom Tomahawk 5 (март 2023 года), либо Cisco Silicon One G200 (июнь того же года). Судя по использованию выражения «начало 2023 года», речь идёт именно об ASIC Broadcom. 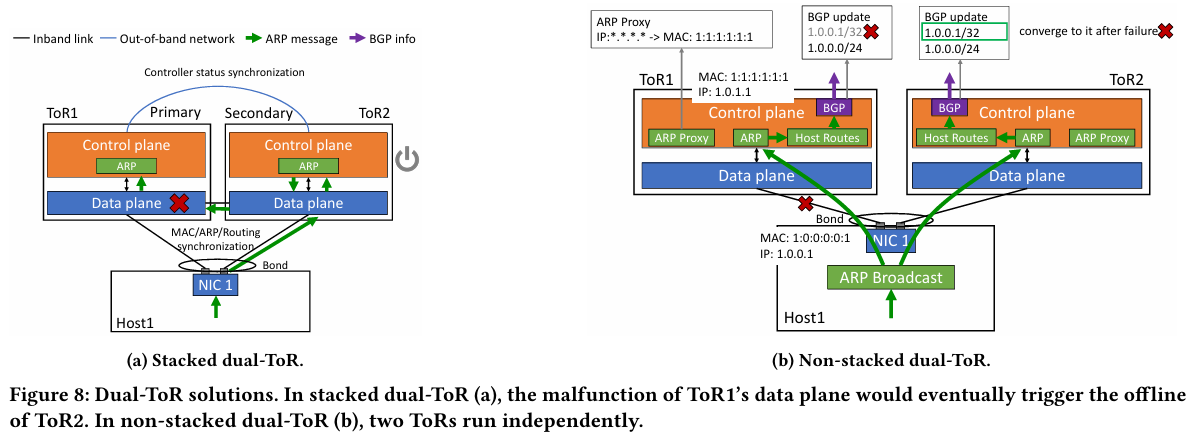 Своё предпочтение именно одночиповых коммутаторов компания объясняет просто: хотя многочиповые решения с большей пропускной способностью существуют, в долгосрочной перспективе они менее надёжны и стабильны в работе. Статистика показывает, что аппаратные проблемы у подобных коммутаторов возникают в 3,77 раза чаще, нежели у одночиповых. 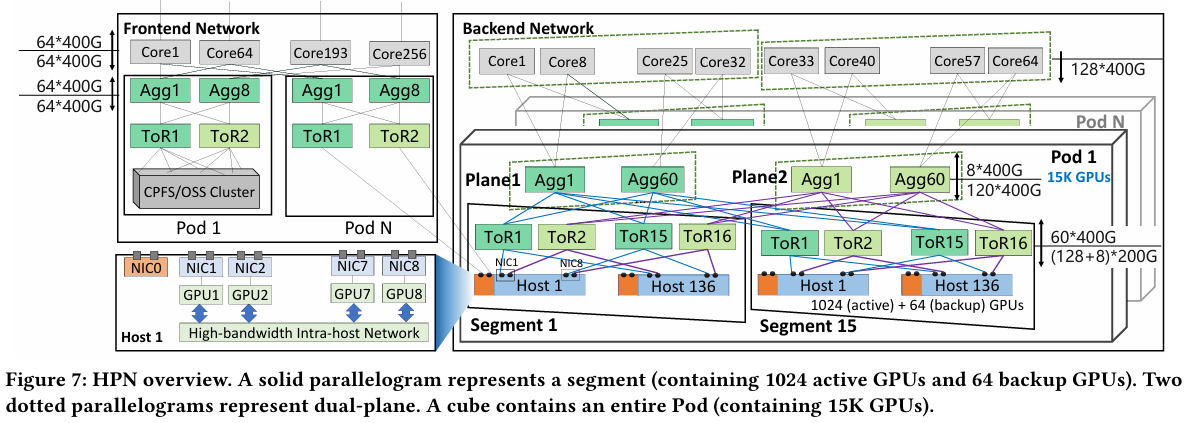 Одночиповые решения класса 51,2 Тбит/с выделяют много тепла, но ни один поставщик оборудования не смог предложить Alibaba Cloud готовые решения, способные удерживать температуру ASIC в пределах 105 °C. Выше этого порога срабатывает автоматическая защита. Поэтому для охлаждения коммутаторов Alibaba Cloud создала собственное решение на базе испарительных камер. 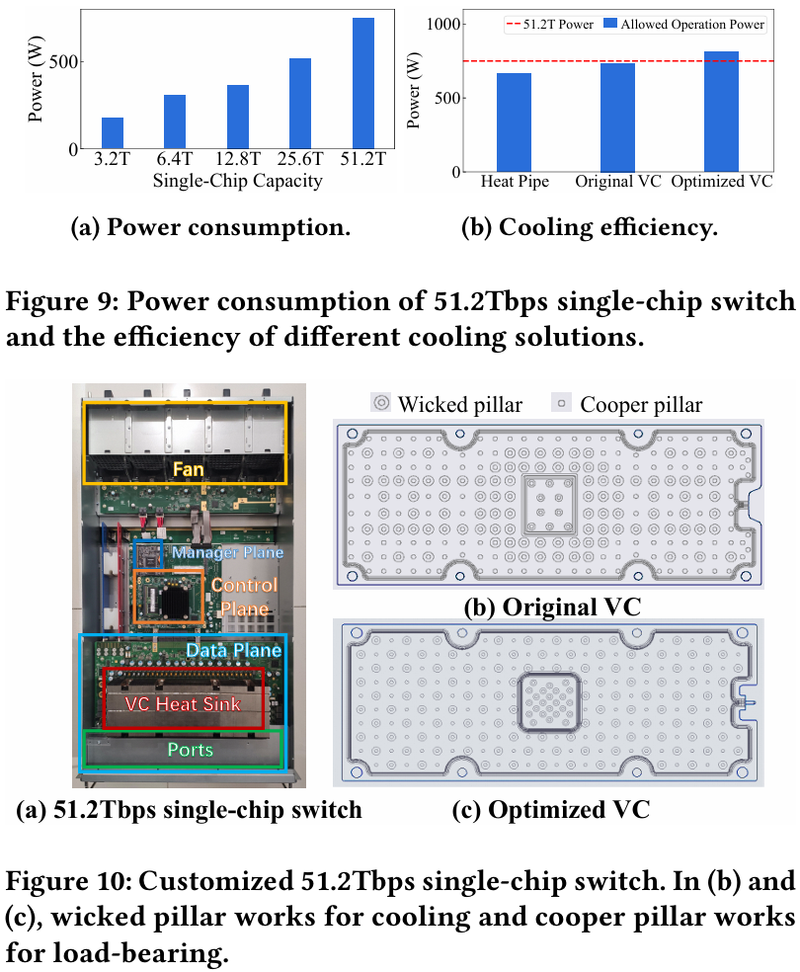 Сетевая фабрика позволяет создавать кластеры, каждый из которых содержит 15360 ускорителей и располагается в отдельном здании ЦОД. Такое высокоплотное размещение позволяет использовать оптические кабели длиной менее 100 м и более дешёвые многомодовые трансиверы, которые дешевле одномодовых примерно на 70 %. Ёмкость такого дата-центра составляет около 18 МВт. 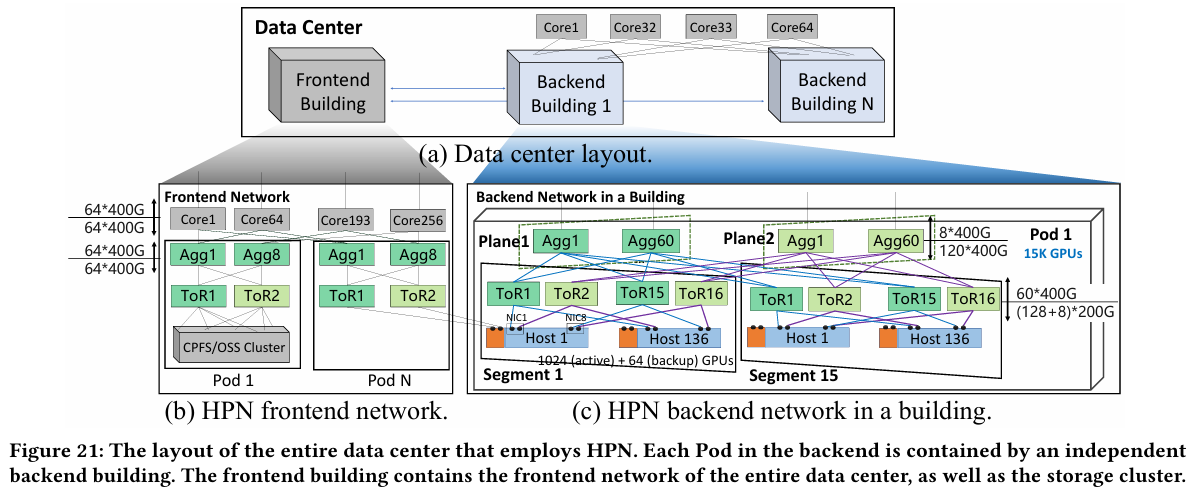 Но есть у HPN и недостаток: использование топологии с двумя внутристоечными коммутаторами и другие особенности архитектуры усложняют кабельную подсистему, поэтому инженеры поначалу столкнулись с ростом ошибок при подключении сетевых интерфейсов. В настоящее время активно используются тесты, позволяющие проверить каждое подключение на соответствие идентификаторов портов и коммутаторов рабочим схемам. Отмечается, что параметры Ethernet-коммутаторов удваиваются каждые два года, поэтому компания уже разрабатывает сетевую архитектуру следующего поколения, рассчитанную на применение будущих ASIC 102,4 Тбит/с. По словам Alibaba Cloud, обучение LLM с сотнями миллиардов параметров потребует огромного распределённого кластера, количество ускорителей в котором исчисляется миллионами. И ему требуется соответствующая сетевая инфраструктура.
30.06.2024 [14:28], Сергей Карасёв
В Австралии запущен ИИ-суперкомпьютер Virga [Обновлено]Государственное объединение научных и прикладных исследований Австралии (CSIRO) сообщило о вводе в эксплуатацию высокопроизводительного вычислительного комплекса Virga. Система, предназначенная для ИИ-задач, ускорит научные открытия, а также поможет развитию промышленности и экономики страны. Суперкомпьютер располагается в дата-центре Hume компании CDC в Канберре. Его созданием занималась компания Dell: в основу положены серверы PowerEdge XE9640, оснащённые двумя процессорами Intel Xeon Sapphire Rapids 8452Y (36C/72T, 2,0/3,2 ГГц, 300 Вт), до 512 Гбайт RAM и четырьмя 61,44-Тбайт NVMe SSD. Задействованы ИИ-ускорители NVIDIA H100 с 96 Гбайт памяти HBM3 — всего 448 шт. Система занимает 14 стоек, а в качестве интерконнекта используется Infiniband NDR. Dell заключила контракт на создание Virga в 2023 году: сумма изначально составляла $9,65 млн, однако фактическое строительство комплекса обошлось в $10,85 млн. Новый суперкомпьютер придёт на смену НРС-системе CSIRO предыдущего поколения под названием Bracewell, но унаследует от неё BeeGFS-хранилище, также построенное на оборудовании Dell. В нынешнем рейтинге TOP500 машина занимает 72 место с пиковой и практической FP64-производительностью 18,46 Пфлопс и 14,94 Пфлопс соответственно. Комплекс Virga получил своё имя в честь метеорологического эффекта «вирга» — это дождь, который испаряется, не достигая земли: видеть его можно в виде полос, выходящих из-под облаков. Систему Virga планируется использовать для таких задач, как прогнозирование пожаров, разработка вакцин нового поколения, проектирование гибких солнечных панелей, анализ медицинских изображений и пр. 
Источник изображения: CSIRO Пока подробные технические характеристики Virga и показатели быстродействия не раскрываются. Отмечается лишь, что в составе комплекса применена гибридная система прямого жидкостного охлаждения. Говорится также, что CDC оперирует двумя кампусами дата-центров Hume. Площадка Hume Campus One объединяет три ЦОД и имеет мощность 21 МВт, тогда как в состав Hume Campus Two входят два объекта суммарной мощностью 51 МВт.
27.06.2024 [12:58], Сергей Карасёв
В Японии запущен суперкомпьютер TSUBAME4.0 с ускорителями NVIDIA H100 для ИИ-задачГлобальный научно-информационный вычислительный центр (GSIC) Токийского технологического института (Tokyo Tech) в Японии объявил о вводе в эксплуатацию вычислительного комплекса TSUBAME4.0, созданного компанией HPE. Новый суперкомпьютер будет применяться в том числе для задач ИИ. В основу машины легли 240 узлов HPE Cray XD665. Каждый из них несёт на борту два процессора AMD EPYC Genoa и четыре ускорителя NVIDIA H100 SXM5 (94 Гбайт HBM2e). Объём оперативной памяти DDR5-4800 составляет 768 Гбайт. Задействован интерконнект Infiniband NDR200. Вместимость локального накопителя NVMe SSD — 1,92 Тбайт. В состав НРС-комплекса входит подсистема хранения данных HPE Cray ClusterStor E1000. Сегмент на основе HDD имеет ёмкость 44,2 Пбайт — это в 2,8 раза больше по сравнению с суперкомпьютером предыдущего поколения TSUBAME 3.0. Кроме того, имеется SSD-раздел ёмкостью 327 Тбайт. Пиковая производительность TSUBAME4.0 достигает 66,8 Пфлопс (FP64), что в 5,5 больше по отношению к системе третьего поколения. Быстродействие на операциях половинной точности (FP16) поднялось в 20 раз по сравнению с TSUBAME3.0 — до 952 Пфлопс. 
Источник изображения: Tokyo Tech На сегодняшний день TSUBAME4.0 является вторым по производительности суперкомпьютером в Японии после Fugaku. Эта система в нынешнем рейтинге TOP500 занимает четвёртое место с показателем 442 Пфлопс. Лидером в мировом масштабе является американский комплекс Frontier — 1,21 Эфлопс. |
|