Материалы по тегу: hpc
|
30.08.2024 [12:43], Сергей Карасёв
Fujitsu займётся созданием ИИ-суперкомпьютера Fugaku Next зеттафлопсного уровняМинистерство образования, культуры, спорта, науки и технологий Японии (MEXT) объявило о планах по созданию преемника суперкомпьютера Fugaku, который в своё время возглавлял мировой рейтинг ТОР500. Ожидается, что новая система, рассчитанная на ИИ-задачи, будет демонстрировать FP8-производительность зеттафлопсного уровня (1000 Эфлопс). В нынешнем списке TOP500 Fugaku занимает четвёртое место с FP64-быстродействием приблизительно 442 Пфлопс. Реализацией проекта Fugaku Next займутся японский Институт физико-химических исследований (RIKEN) и корпорация Fujitsu. Создание системы начнётся в 2025 году, а завершить её разработку планируется к 2030-му. На строительство комплекса MEXT выделит ¥4,2 млрд ($29,06 млн) в первый год, тогда как общий объём государственного финансирования, как ожидается, превысит ¥110 млрд ($761 млн). MEXT не прописывает какой-либо конкретной архитектуры для суперкомпьютера Fugaku Next, но в документации ведомства говорится, что комплекс может использовать CPU со специализированными ускорителями или комбинацию CPU и GPU. Кроме того, требуется наличие передовой подсистемы хранения, способной обрабатывать как традиционные рабочие нагрузки ввода-вывода, так и ресурсоёмкие нагрузки ИИ. 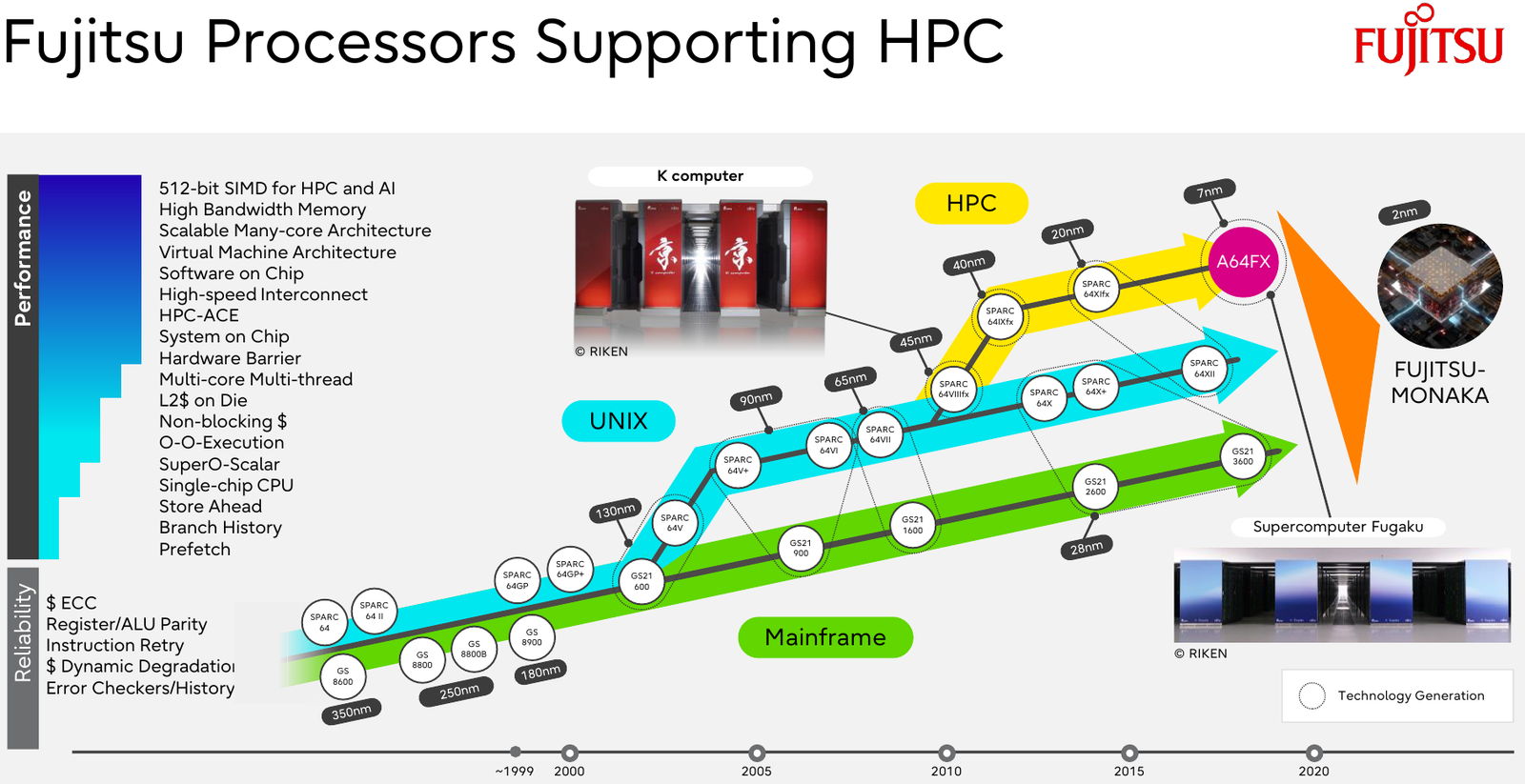
Источник изображения: Fujitsu Предполагается, что каждый узел Fugaku Next обеспечит пиковую производительность в «несколько сотен Тфлопс» для вычислений с двойной точностью (FP64), около 50 Пфлопс для вычислений FP16 и примерно 100 Пфлопс для вычислений FP8. Для сравнения, узлы системы Fugaku демонстрирует быстродействие FP64 на уровне 3,4 Тфлопс и показатель FP16 около 13,5 Тфлопс. Для Fugaku Next предусмотрено применение памяти HBM с пропускной способностью в несколько сотен Тбайт/с против 1,0 Тбайт/с у Fugaku. По всей видимости, в состав Fugaku Next войдут серверные процессоры Fujitsu следующего поколения, которые появятся после изделий MONAKA. Последние получат чиплетную компоновку с кристаллами SRAM и IO-блоками ввода-вывода, обеспечивающими поддержку DDR5, PCIe 6.0 и CXL 3.0. Говорится об использовании 2-нм техпроцесса.
24.08.2024 [14:02], Сергей Карасёв
Суперкомпьютер Cray-1 из коллекции сооснователя Microsoft Пола Аллена уйдёт с молоткаАукционный дом Christie's объявил три аукциона под общим названием Gen One — Innovations from the Paul G. Allen Collection: с молотка уйдут сотни предметов, связанных с компьютерной историей, из коллекции сооснователя Microsoft Пола Аллена (Paul Allen). Аллен основал Microsoft вместе с Биллом Гейтсом в 1975 году. В 1983-м он покинул эту корпорацию, занявшись инвестированием, а в 2011 году стал одним из основателей компании Stratolaunch Systems. Аллен скончался в 2018 году в возрасте 65 лет. 
Источник изображений: Christie's Из коллекции Пола Аллена на аукцион Christie's выставлен, в частности, суперкомпьютер Cray-1, анонсированный в 1975 году. Эта машина с начальной стоимостью почти $8 млн (сейчас это чуть больше $46 млн) обладает производительностью 160 Мфлопс. Система имеет уникальную С-образную форму, благодаря которой удалось уменьшить количество проводов внутри корпуса. За время производства было построено всего около 80 экземпляров Cray-1. Выставленная на аукцион система была выведена из эксплуатации и использовалась в качестве демонстрационного образца Cray Research. Это один из семнадцати экземпляров, которые, как считается, сохранились на сегодняшний день. И это первый суперкомпьютер Cray-1, выставленный на торги. Оценочная стоимость лота составляет $150–$250 тыс.  В коллекцию также входит суперкомпьютер Cray-2 1985 года. Как и его предшественник, эта система имеет цилиндрическую С-образную форму. Комплекс с ценой около $16 млн на момент выхода (сейчас это около $47 млн) обеспечивает быстродействие в 1,9 Гфлопс. Всего было продано 25 таких суперкомпьютеров. Эта конкретная модель, проданная REI, считается самой долговечной системой Cray-2: она была выведена из эксплуатации в 1999 году. Ожидается, что цена на аукционе окажется в диапазоне $250–$350 тыс. С молотка также уйдёт суперкомпьютер CDC 6500 1967 года, который оценивается в $200–$300 тыс. Это была первая система, способная выполнять 1 млн инструкций в секунду. Изначально её цена составляла $8 млн (почти $75 млн в современной валюте). На аукцион выставлены несколько мейнфреймов: среди них — DEC PDP10 KA10 и KI10 производства 1968 и 1974 годов соответственно, а также IBM 7090 от 1959 года.  На торги выставлены различные настольные компьютеры (например, Xerox Star 1108 Personal Computer), ранние компьютеры Apple, шифровальная машина Enigma времен Второй мировой войны, микрокомпьютеры (такие как SOL-20 Terminal Microcomputer и MITS Altair 8800b Microcomputer), цифровой компьютер Kenbak-1, персональный компьютер Пола Аллена Compaq и многие другие экспонаты, имеющие историческую ценность. С молотка также уйдут записи Microsoft, произведения научной фантастики, обеденное меню с «Титаника», метеорит, письмо Альберта Эйнштейна президенту Рузвельту с предупреждением об опасности ядерного оружия и скафандр, который носил астронавт Эд Уайт в 1965 году.
23.08.2024 [15:00], Владимир Мироненко
США готовят новые ограничения для тех, кто сотрудничает с Китаем в сфере суперкомпьютеровСША намерены ужесточить ограничения для создания в Китае суперкомпьютеров с участием своих граждан, резидентов и компаний, пишет ресурс HPCwire. В июле был опубликован законопроект, подготовленный Управлением по безопасности инвестиций (Office of Investment Security, OIS), согласно которому гражданам и постоянным резидентам США будет запрещено заниматься деятельностью, связанной с суперкомпьютерами, со странами и территориями, вызывающими обеспокоенность правительства США, к котором причислены Китай, Гонконг и Макао. Они также должны будут сообщать о любых транзакциях, связанных с этой деятельностью. Проект «Положений, касающихся инвестиций США в определённые технологии и продукты национальной безопасности в странах, вызывающих обеспокоенность», был открыт для обсуждения до 5 августа, но комментарии различных экспертов и организаций поступают до сих пор. 
Источник изображения: Dark Light2021 / Unsplash Деятельность в сфере суперкомпьютеров, регулируемая этим законопроектом, «включает разработку, установку, продажу или производство любого суперкомпьютера, оснащённого передовыми интегральными схемами, которые могут обеспечить теоретическую вычислительную мощность от 100 Пфлопс двойной точности (FP64) или от 200 Пфлопс одинарной точности (FP32) объёмом 1178 м3 или меньше». Проще говоря, речь идёт о достаточно высокоплотных HPC-решениях. Кроме того, граждане и резиденты США будут обязаны информировать правительство об определённых транзакциях, касающихся HPC-сферы, если они занимают должность в иностранной компании, например, партнёра, менеджера или инвестиционного консультанта. Им также вменяется обязанность отслеживать и не допускать проведения иностранными организациями транзакций с Китаем в контексте суперкомпьютеров. Некоторые представители компьютерной отрасли США восприняли законопроект негативно, заявив, что предлагаемые ограничения являются произвольными. Другим не понравилось расширение государственного надзора, что, как им кажется, задушит инновации в области ИИ. Также утверждается, что закон не учитывает влияние на конкурентоспособность американских технологических компаний на мировом рынке. 
Источник изображения: Ronan Furuta / Unsplash В частности, новые правила могут отразиться на производителе ИИ-чипов Cerebras, заключившем партнёрское соглашение о создании девяти ИИ-суперкомпьютеров Condor Galaxy для G42, базирующейся в ОАЭ. Однако, согласно сообщениям, G42 также поставляет технологии в Китай. Это, впрочем, не помешало ей заключить ещё и $1,5-млрд соглашение с Microsoft. Венчурная компания a16z, которая сама сдаёт ускорители в аренду, обратилась к правительству с просьбой исключить пункт о производительности из регулирования. Она инвестировала в сотни ИИ-стартапов, которым требуется огромная вычислительная мощность. По словам, a16z требования к производительности ИИ-систем стремительно поменялись всего за несколько лет. Поэтому любые ограничения, введённые сейчас, могут очень быстро оказаться неактуальными. Ассоциация полупроводниковой промышленности (SIA) предупредила, что американские чипмейкеры будут вынуждены уступить свою долю рынка иностранным конкурентам. И в отсутствие инвестиционной активности США в странах, которые вызывают обеспокоенность, появятся зарубежные инвесторы. Это может «подорвать лидерство США и стратегическое преимущество в таких критически важных технологических секторах, как полупроводники, и других стратегических отраслях, которые зависят от полупроводников», — заявила SIA. 
Источник изображения: Kayla Kozlowski / Unsplash В свою очередь, Национальная ассоциация венчурного капитала (NVCA) сообщила, что предлагаемые правила несут с собой значительное бремя расходов на венчурные инвестиции США по всем направлениям. Расходы на соблюдение правил могут составить до $100 млн/год, что намного больше оценки Министерства финансов США в $10 млн/год. NVCA отметила, что многие стартапы в значительной мере полагаются в своей стратегии на ИИ, и бремя соответствия регуляторным правилам увеличит их расходы на ведение бизнеса и на «каждую из примерно пятнадцати тысяч венчурных инвестиций, сделанных в США». Также вызывает вопросы расплывчатость списка лиц, которым вменяется в обязанность соблюдать новые правила. Все предыдущие санкции хоть и затормозили, но не помешали созданию китайских суперкомпьютеров, в том числе на чипах собственной разработки. Кроме того, все американские чипмейкеры после очередного введения ограничений корректировали спецификации своих продуктов, чтобы не лишаться крупного и важного для них рынка Китая.
20.08.2024 [23:30], Руслан Авдеев
Суперкомпьютер с лабораторией: Пентагон создаёт новый комплекс защиты США от биологических угрозНовейший проект Министерства обороны США объединит суперкомпьютер и т.н. лабораторию быстрого реагирования (RRL, Rapid Response Laboratory). The Register сообщает, что проект призван укрепить биологическую защиту Соединённых Штатов. Расположенная на территории Ливерморской национальной лаборатории им. Э. Лоуренса (Lawrence Livermore National Laboratory, LLNL) в Калифорнии, машина строится при сотрудничестве с Национальным агентством ядерной безопасности США (National Nuclear Security Agency, NNSA) и будет основана на той же архитектуре, что и грядущий экзафлопсный суперкомпьютер El Capitan на базе ускорителей AMD Instinct MI300A. Спецификации аппаратного обеспечения и ПО не раскрываются. Машина будет использоваться как военными, так и гражданскими специалистами для крупномасштабных симуляций, ИИ-моделирования, классификации угроз, а при сотрудничестве с новой биологической лабораторией — для ускорения разработки контрмер. Некоторые из них, как ожидается, будут чрезвычайно важными, поскольку решения можно будет находить в течение дней, если не часов. Впрочем, новые вычислительные мощности военные биологи намерены использовать на регулярной основе. Конечно, как отмечает The Register, инструменты для разработки средств борьбы могут использоваться и для создания биологического оружия, хотя в самом Пентагоне о подобном применении суперкомпьютера не упоминают. 
Источник изображения: Lawrence Livermore National Laboratory Концепция биологической защиты США представляет собой комплекс мер для борьбы как с естественными, так и рукотворными биологическими угрозами военным и гражданским лицам, природным ресурсам, источникам пищи и воды и т.п., воздействие на которые может негативно сказаться на возможностях воюющей стороны. Поскольку биологические угрозы имеют важное значение для самых разных ведомств, суперкомпьютер будет доступен и прочим правительственным агентствам США, а также союзникам Соединённых Штатов, академическим исследователям и промышленным компаниям. Лаборатория RRL будет находиться буквально в «шаговой доступности» от суперкомпьютера. Она станет дополнением к проекту Пентагона Generative Unconstrained Intelligent Drug Engineering (GUIDE). GUIDE занимается разработкой медицинских и биологических контрмер с использованием машинного обучения для создания анител, структурной биологии, биоинформатики, молекулярного моделирования и т.д. Новый суперкомпьютер позволит Пентагону быстрые и многократные тесты моделируемых вакцин и лекарств. RRL автоматизирована и снабжена роботами и иными инструментами для изучения строения и свойств молекул, для редактирования структуры белков и т.д. По словам экспертов LLNL, лаборатория, подключённая к суперкомпьютеру, позволит изменить всю систему распознавания биологических угроз и ответа на них.
16.08.2024 [14:45], Руслан Авдеев
Эдинбургский университет лоббирует создание первого в Великобритании экзафлопсного суперкомпьютера, от которого новое правительство решило отказатьсяКоманда Эдинбургского университета активно лоббирует выделение учреждению £800 млн ($1,02 млрд) для строительства суперкомпьютера экзафлопсного класса. Ранее новое британское правительство фактически отказалось продолжать реализацию некогда уже одобренного проекта, ссылаясь на дефицит бюджета. Ожидалось, что страна выделит почти миллиард долларов на строительство передового суперкомпьютера, причём изначально речь шла об использовании отечественных компонентов. В октябре 2023 года было объявлено, что именно Эдинбург станет пристанищем первой в Великобритании вычислительной машины экзафлопсного уровня. Суперкомпьютер должен был заработать уже в 2025 году. Университет даже успел потратить £31 млн ($38 млн) на строительство нового крыла Advanced Computing Facility. 
Источник изображения: Adam Wilson/unsplash.com Однако в начале августа 2024 года британское правительство объявило, что не будет выделять £1,3 млрд ($1,66 млрд) на ранее одобренные технологические и ИИ-проекты. На тот момент представитель Министерства науки, инноваций и технологий (Department for Science, Innovation, and Technology) заявил, что властям приходится принимать «трудные и необходимые» решения. По данным СМИ, вице-канцлер Эдинбургского университета сэр Питер Мэтисон (Peter Mathieson) пытается лично лоббировать среди министров выделение средств на обещанный суперкомпьютер. В письме сотрудникам университета он отметил, что диалог с Министерством науки, инноваций и технологий продолжится и будет взаимодействовать с академическими и промышленными кругами для возобновления инвестиций. По словам учёного, университет десятки лет был лидером в HPC-сфере Великобритании и до сих пор остаётся центром реализации суперкомпьютерных и ИИ-проектов. Если средства всё-таки удастся выбить у британских чиновников и система заработает, она будет в 50 раз производительнее нынешней системы ARCHER2. Тем временем в материковой Европе ведётся активная работа над собственными проектами. В частности, начались работы по строительству суперкомпьютера экзафлопсного уровня класса Jupiter на Arm-чипах и ускорителях NVIDIA. Впрочем, весной этого года Великобритания вновь присоединилась к EuroHPC, так что со временем страна сможет поучаствовать в европейских HPC-проектах.
15.08.2024 [12:19], Руслан Авдеев
Исландский проект IceCloud представил частное облако под ключ с питанием от ГеоТЭС и ГЭСКонсорциум компаний запустил пилотный проект облачного сервиса IceCloud на базе исландского ЦОД с необычными возможностями. The Register сообщает, что дата-центр будет полностью снабжаться возобновляемой энергией для того, чтобы его клиенты смогли достичь своих экологических, социальных и управленческих обязательств (ESG). Проект IceCloud Integrated Services представляет собой частное облако с широкими возможностями настройки для того, чтобы предложить клиентам экономичную масштабируемую платформу, в том числе для ИИ и прочих ресурсоёмких задачах. В консорциум на равных правах входят британский поставщик ЦОД-инфраструктур Vesper Technologies (Vespertec), разработчик облачного ПО Sardina Systems и оператор Borealis Datacenter из Исландии. Vespertec занимается созданием кастомных серверов, хранилищ и сетевых решений, в том числе стандарта OCP. Sardina отвечает за облачную платформу Fish OS. Это дистрибутив OpenStack для частных облачных сервисов, интегрированный с Kubernetes и сервисом хранения данных Ceph. Предполагается, что облачная платформа не будет имитировать AWS и Azure. Решение ориентировано на корпоративных клиентов с задачами, требующими высокой производительности, малого времени отклика и высокого уровня доступности. 
Источник изображения: Robert Lukeman/unsplash.com Таких предложений на рынке уже немало, но IceCloud на базе ЦОД Borealis Datacenter позволит клиентам использовать исключительно возобновляемую энергию и экономить на охлаждении благодаря прохладному местному климату. Выполнение компаниями-клиентами ESG-обязательств, а также снижение на 50 % энергопотребления вне периодов часов пиковых нагрузок и снижение потребления на 38 % в целом ведёт к существенному снижению стоимости эксплуатации облака, говорят авторы проекта. 
Источник изображения: Vespertec До заключения контракта на обслуживание в облаке IceCloud с клиентом ведутся переговоры для выяснения его потребностей в программном и аппаратном обеспечении и пр. После этого клиенту делается индивидуальное пакетное предложение. Перед окончательным принятием решения клиент может протестировать сервис и, если его всё устраивает, он получит персонального менеджера. Эксперты подтверждают, что размещение ЦОД на севере имеет три ключевых преимущества. Низкие температуры окружающей среды позволяют экономить на охлаждении, обеспечивая низкий индекс PUE. Сам регион богат возобновляемой энергией и, наконец, в Исландии не так тесно в сравнении с популярными европейскими локациями ЦОД во Франкфурте, Лондоне, Амстердаме, Париже и Дублине.
08.08.2024 [17:50], Руслан Авдеев
Виртуальный суперкомпьютер Fugaku теперь можно запустить в облаке AWSЯпонская научная группа RIKEN Center for Computational Science представила виртуальную версию принадлежащего ей Arm-суперкомпьютера, которую можно развернуть в облаке AWS. По данным The Register, суперкомпьютер считался самым производительным в мире в 2020 году, пока его не потеснила первая экзафлопсная машина Frontier двумя годами позже. 
Источник изображения: RIKEN Центр намерен упростить желающим использование системы Fugaku, поэтому в RIKEN и решили создать виртуального двойника, способного работать в облаке или даже на суперкомпьютерах, принадлежащих другим компаниям. Представители центра сообщили, что построить машину из 160 тыс. узлов недостаточно, ведь необходимы ещё и программные решения. Другими словами, в облаке полностью воспроизвели программную HPC-экосистему Fugaku, которая включает массу оптимизированных для Arm пакетов и специализированного ПО. Первая версия Virtual Fugaku доступна в виде Singularity-образа. Она предназначена для запуска на Arm-процессорах Amazon Graviton3E, которые оптимизированы для задач HPC/ИИ. Как и процессоры Fujitsu A64FX, используемые в Fugaku, они предлагают инструкции Scalable Vector Extension (SVE). Основная ОС — RHEL 8.10. ПО собрано с использованием GCC 14.1 и библиотеки OpenMPI, которая поддерживает EFA. В Amazon крайне довольны выбором AWS в качестве базовой платформы для Virtual Fugaku. 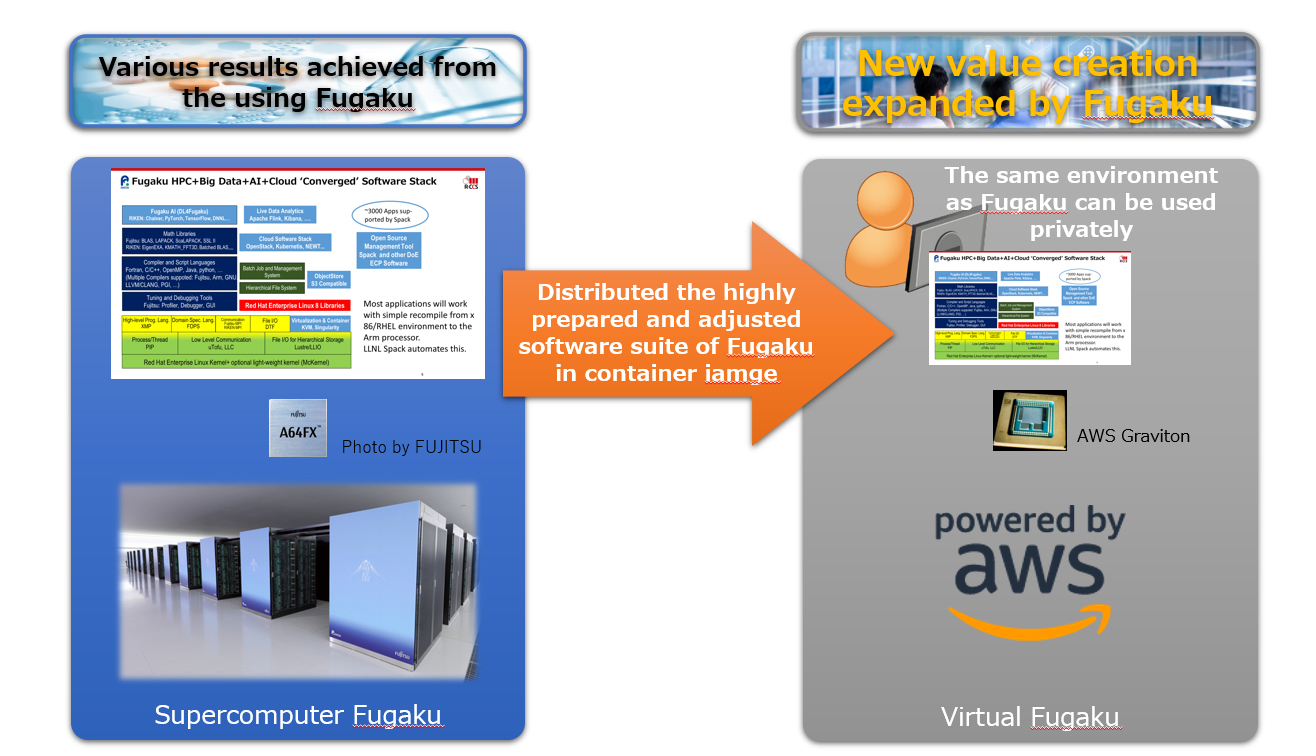
Источник изображения: RIKEN В будущем возможно портирование Virtual Fugaku и на другие архитектуры, но на какие бы платформы его ни перенесли, в RIKEN надеются, что инстансы «продолжат дело» своего родителя. Исследователи заявили, что результаты использования Fugaku, включая разработки, связанные с контролем заболеваний, созданием новых материалов и лекарств, хорошо известны. В ходе эксплуатации специалисты получили богатый опыт обращения с суперкомпьютером и намерены поделиться им с обществом. В RIKEN даже рассматривают Virtual Fugaku как стандартную платформу для использования программных HPC-решений — если суперкомпьютерные центры по всему миру примут этот формат, пользователи оценят богатство библиотеки ПО. Впрочем, некоторые эксперты считают, что такая концепция не вполне жизнеспособна — HPC-задачи часто связаны с использованием оборудования, оптимизированного под конкретные цели, поэтому маловероятно, что одна программная платформа подойдёт всем заинтересованным сторонам.
03.08.2024 [21:10], Владимир Мироненко
В Великобритании отложили планы по строительству экзафлопсного суперкомпьютера — нет денегНовый состав правительства Великобритании, сформированный в июле, отменил решение предыдущей администрации о выделении £1,3 млрд на финансирование технологических и ИИ-проектов, включая строительство в Центре передовых вычислений Эдинбургского университета (ACF) экзафлопсного суперкомпьютера при поддержке национального центра AI Research Resource (AIRR), который должен был быть запущен в эксплуатацию в 2025 году. Об этом сообщил ресурс DatacenterDynamics (DCD). В прошлом году правительство консерваторов выделило £800 млн на экзафлопсный суперкомпьютер и £500 млн на дополнительное финансирование AIRR. Однако нынешнее лейбористское правительство заявило, что в планах расходов предыдущего правительства не было выделено нового финансирования для этой программы, и поэтому проекты не будут продолжены. 
Источник изображения: EPCC В Центре передовых вычислений Эдинбургского университета (ACF) уже есть суперкомпьютер, и после объявления в октябре 2023 года о предстоящем строительстве нового, им был израсходован £31 млн на строительство дополнительного помещения в здании для центра Edinburgh Parallel Computing Centre (EPCC). Что дальше будет с этим проектом пока неясно. Отвечая на просьбу DCD прокомментировать ситуацию, представитель Департамента науки, инноваций и технологий Великобритании (DSIT) заявил, что в правительстве по-прежнему привержены созданию технологической инфраструктуры, но приходится принимать сложные решения для восстановления экономической стабильности и реализации национальной миссии по росту экономики. Следует отметить, что в прошлом месяце правительство Великобритании объявило о планах инвестировать £100 млн в пять новых центров квантовых исследований в Глазго, Эдинбурге, Бирмингеме, Оксфорде и Лондоне.
31.07.2024 [11:21], Сергей Карасёв
Vertiv представила модульные дата-центры высокой плотности для ИИ-нагрузокКомпания Vertiv представила модульную платформу MegaMod CoolChip, предназначенную для построения дата-центров высокой плотности для задач ИИ. Утверждается, что данное решение позволяет сократить время развёртывания вычислительных мощностей примерно в два раза по сравнению с традиционным строительством. Отмечается, что стремительное развитие генеративного ИИ, машинного обучения и НРС-приложений приводит к необходимости изменения обычной концепции ЦОД. Из-за большого количества мощных ускорителей требуется внедрение более эффективных систем охлаждения. В случае MegaMod CoolChip реализуется гибридный подход с воздушным и жидкостным охлаждением. Инфраструктура MegaMod CoolChip может включать в себя блоки распределения охлаждающей жидкости Vertiv XDU, стойки с поддержкой СЖО Vertiv Liquid-cooled Rack, решения Vertiv Air Cooling, стоечные блоки распределения питания Vertiv rPDU и пр. Модульная архитектура MegaMod CoolChip предусматривает возможность установки до 12 стоек в ряд. Мощность каждой из них может превышать 100 кВт. 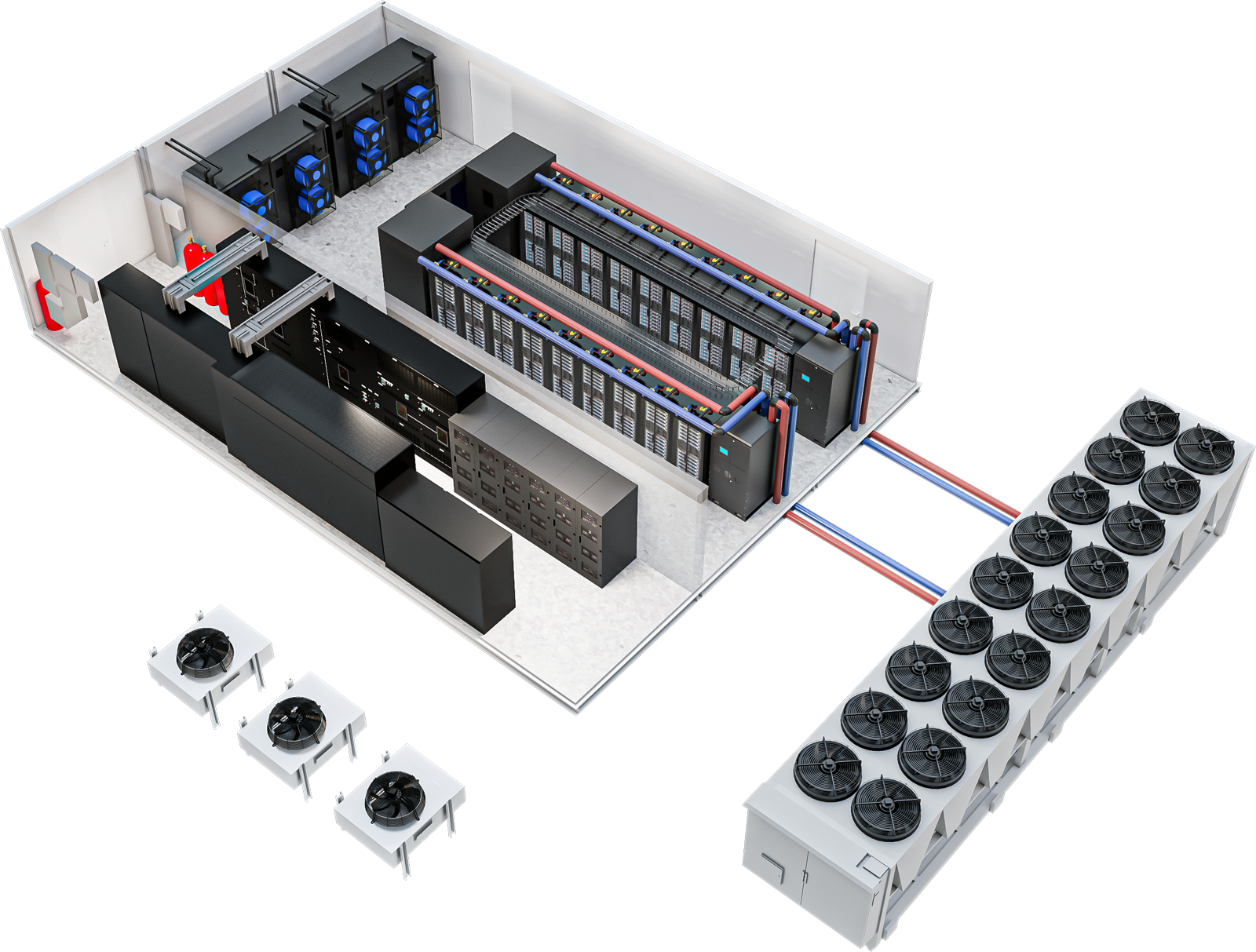
Источник изображения: Vertiv MegaMod CoolChip поставляется в виде отдельных блоков, которые монтируются непосредственно на месте размещения дата-центра. Возможны различные варианты организации воздушно-жидкостного охлаждения. Для СЖО используется технология однофазного прямого жидкостного охлаждения Direct-To-Chip. Возможно резервирование охлаждающих систем по схеме N+1.
29.07.2024 [08:11], Сергей Карасёв
Инсбрукский университет запустил гибридный квантово-классический суперкомпьютерИнсбрукский университет имени Леопольда и Франца (UIBK) в Австрии объявил о том, что его НРС-комплекс LEO5 интегрирован с квантовый системой IBEX Q1 компании AQT. Таким образом, сформирован гибридный квантово-классический суперкомпьютер, который, как утверждается, открывает совершенно новые возможности для решения сложных научных и промышленных задач и создания вычислительных платформ следующего поколения. Машина LEO5, запущенная в 2023 году, объединяет 63 узла, каждый из которых содержит два процессора Intel Xeon 8358 (Ice Lake-SP) с 32 ядрами. Применён интерконнект Infiniband HDR100. В состав 36 узлов входят ускорители NVIDIA — A30, A40 или A100. Производительность достигает 300 Тфлопс на операциях FP64 и 740 Тфлопс на операциях FP32. 
Источник изображения: UIBK В свою очередь, лазерная квантовая система IBEX Q1, разработанная специалистами AQT (дочерняя структура UIBK), не требует для работы экстремального охлаждения. Утверждается, что она может функционировать при комнатной температуре, а энергопотребление составляет менее 2 кВт. Квантовое оборудование размещено в двух кастомизированных стойках. Проект по созданию гибридного суперкомпьютера реализован в рамках инициативы HPQC (High-Performance integrated Quantum Computing), финансируемой австрийским Агентством по продвижению и стимулированию прикладных исследований, технологий и инноваций (FFG). Новая платформа, как отмечается, создаёт основу для будущих гетерогенных инфраструктур, ориентированных на решение сложных задач. «Успешная интеграция квантового компьютера в высокопроизводительную вычислительную среду знаменует собой важную веху для австрийских и европейских исследований и развития технологий в целом», — говорит Генриетта Эгерт (Henrietta Egerth), управляющий директор FFG. |
|