Материалы по тегу: dpu
|
08.12.2023 [16:17], Сергей Карасёв
Marvell представила новые DPU серии Octeon 10Компания Marvell расширила семейство чипов Octeon 10, анонсировав изделия CN102 и CN103, которые относятся к классу DPU (Data Processing Unit). Новинки предназначены для построения высокопроизводительного сетевого оборудования, в частности, брандмауэров, маршрутизаторов, устройств SD-WAN, малых сот 5G, коммутаторов и пр. Представленные чипы объединяют до восьми 64-битных ядер Arm Neoverse N2 с частотой до 2,7 ГГц. Объём кеш-памяти L2/L3 составляет 8/16 Мбайт. Заявлена поддержка DDR5-5600 и интерфейсов PCIe 3.0 (у CN102) и PCIe 5.0 (только CN103). Изделия производятся по 5-нм техпроцессу. Утверждается, что они обеспечивают в три раза более высокую производительность по сравнению с решениями Marvell DPU предыдущего поколения при одновременном снижении энергопотребления на 50 % — до 25 Вт. Чипы могут применяться в качестве разгрузочного сопроцессора или в качестве основного процессора в сетевых устройствах. 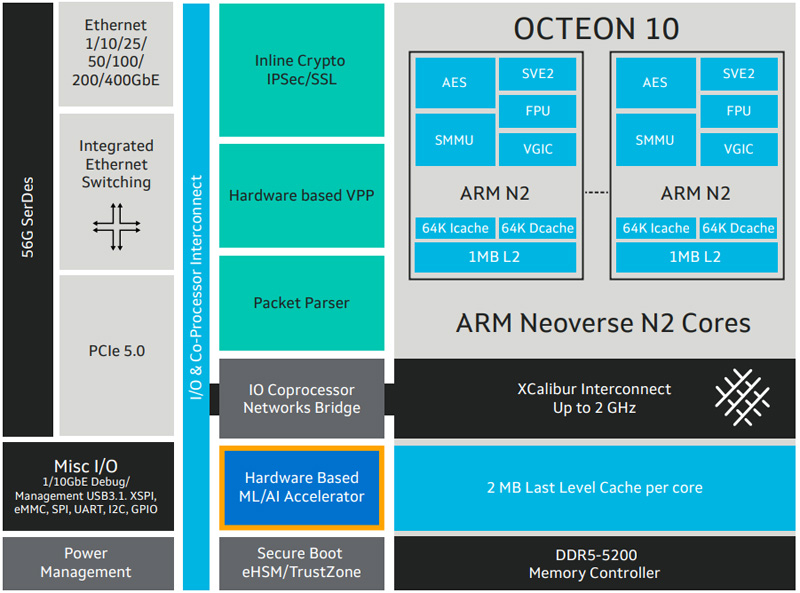
Источник изображения: Marvell Модель CN102 имеет поддержку сетевых портов в следующей конфигурации: 4 × 10GbE + 2 × 10GbE или 16 × 1GbE. У версии CN103 схема такова: 4 × 50/25/10GbE + 2 × 10GbE или 16 × 1GbE. Энергопотребление составляет соответственно 10–20 Вт и 10–25 Вт. Старшая версия получила SerDes-блоки 56G. Среди прочего упомянуты аппаратное ускорение пакетов с оптимизацией VPP, поддержка IPsec и Secure Boot. Показатель SPECint (2017) достигает 37. Поставки образов Octeon 10 CN102 и CN103 уже начались, а массовое производство запланировано на IV квартал 2023-го и на I четверть 2024 года соответственно.
26.11.2023 [22:48], Сергей Карасёв
Nebulon представила ускорители Medusa2 на базе DPU NVIDIA BlueField-3Компания Nebulon анонсировала специализированные ускорители обработки сервисов (Services Processing Unit, SPU) — устройства серии Medusa2. Эти решения обеспечивают разгрузку, ускорение и изоляцию широкого спектра процессов в работе сети, СХД и подсистемы безопасности, включая обнаружение программ-вымогателей. В основу Medusa2 лёг DPU BlueField-3 разработки NVIDIA с шестнадцатью ядрами Arm Cortex-A78, тогда как первое поколение укорителей, изначально называвшихся Storage Processing Unit, было выполнено на собственной аппаратной платформе. Nebulon Medusa2 представляют собой карты расширения с интерфейсом PCIe 5.0 (х8). Они оснащены 48 Гбайт памяти DDR5 с пропускной способностью до 80 Гбайт/с. SPU подключается напрямую к внутренним накопителям NVMe (а также SAS и SATA). Ускорители оснащены двумя сетевыми портами 10/25/50/100GbE и портом управления 1GbE. 
Источник изображения: Nebulon SPU создает на сервере безопасную зону, отделённую от ОС и приложений — область Nebulon Secure Enclave. При этом платформа nebOS разгружает ресурсы, беря на себя выполнение таких задач, как дедупликация и сжатие данных, шифрование (AES), моментальные снимки, зеркалирование и пр. Обеспечена интеграция со средами VMware vSphere, Microsoft Server/Hyper-V и Linux/KVM. Medusa2 SPU не зависит от ОС и приложений и не требует установки каких-либо дополнительных драйверов или программных агентов. Предусмотрен криптографический сопроцессор со сверхзащищенным аппаратным хранилищем ключей и криптографическими контрмерами, которые усиливают защиту от любых потенциальных угроз, связанных с ПО. Например, обнаружение программ-вымогателей осуществляется менее чем за 2,5 мин., а на восстановление после атак таких зловредов требуется менее 4 мин. Реализованы средства безопасной загрузки. В целом, компания сравнивает свои SPU с AWS Nitro. Также анонсирован компактный ускоритель Medusa2i для edge-серверов. Он, как и старший собрат, использует DPU BlueField-3, но количество ядер Cortex-A78 уменьшено до 8, а объём памяти DDR5 — до 24 Гбайт. Возможна установка четырёх SSD формата M.2 вместимостью до 32 Тбайт каждый. Утверждается, что благодаря Medusa2 количество рабочих нагрузок на один сервер может быть увеличено на 33 %, что снижает эксплуатационные расходы и затраты на приобретение лицензий на ПО. При этом требования к мощности и площади дата-центра снижаются на 25 %. Интерес к ускорителям проявили Dell, HPE, Lenovo и Supermicro.
22.11.2023 [11:18], Сергей Карасёв
NVIDIA представила сетевой ускоритель SuperNIC для гипермасштабируемых ИИ-нагрузокКомпания NVIDIA анонсировала аппаратное решение SuperNIC — это сетевой ускоритель нового типа, предназначенный для масштабных рабочих нагрузок ИИ в системах на базе Ethernet. Устройство обеспечивает скорость передачи данных до 400 Гбит/с с использованием RDMA (RoCE). Новинка выполнена на основе DPU BlueField-3: это часть сетевой 400G/800G-платформы Spectrum-X, которая предусматривает использование коммутаторов на базе ASIC NVIDIA Spectrum-4 (51,2 Тбит/с). Отмечается, что сообща BlueField-3 SuperNIC и Spectrum-4 составляют основу вычислительной системы, специально разработанной для ускорения ИИ-нагрузок. При этом платформа Spectrum-X обеспечивает высокую эффективность сети, превосходя по производительности традиционные среды Ethernet. По заявления NVIDIA, DPU предоставляет множество расширенных функций, таких как высокая пропускная способность, подключение с небольшой задержкой и пр. 
Источник изображения: NVIDIA Среди ключевых особенностей SuperNIC называются: высокоскоростное переупорядочение пакетов; расширенный контроль перегрузок с использованием данных в реальном времени и специализированных сетевых алгоритмов; возможность программирования ввода-вывода (I/O); энергоэффективный низкопрофильный дизайн; полная оптимизация для ИИ (включая вычисления, сети, хранилище, системное ПО, коммуникационные библиотеки). В одной системе могут быть задействованы до восьми SuperNIC, что позволяет добиться соотношения 1:1 с GPU. А это даёт возможность максимизировать производительность при выполнении сложных задач ИИ.
16.11.2023 [02:43], Алексей Степин
Microsoft представила 128-ядерый Arm-процессор Cobalt 100 и ИИ-ускоритель Maia 100 собственной разработкиГиперскейлеры ради снижения совокупной стоимости владения (TCO) и зависимости от сторонних вендоров готовы вкладываться в разработку уникальных чипов, изначально оптимизированных под их нужды и инфраструктуру. К небольшому кругу компаний, решившихся на такой шаг, присоединилась Microsoft, анонсировавшая Arm-процессор Azure Cobalt 100 и ИИ-ускоритель Azure Maia 100. 
Изображения: Microsoft Первопроходцем в этой области стала AWS, которая разве что память своими силами не разрабатывает. У AWS уже есть три с половиной поколения Arm-процессоров Graviton и сразу два вида ИИ-ускорителей: Trainium для обучения и Inferentia2 для инференса. Крупный китайский провайдер Alibaba Cloud также разработал и внедрил Arm-процессоры Yitian и ускорители Hanguang. Что интересно, в обоих случаях процессоры оказывались во многих аспектах наиболее передовыми. Наконец, у Google есть уже пятое поколение ИИ-ускорителей TPU.  Microsoft заявила, что оба новых чипа уже производятся на мощностях TSMC с использованием «последнего техпроцесса» и займут свои места в ЦОД Microsoft в начале следующего года. Как минимум, в случае с Maia 100 речь идёт о 5-нм техпроцессе, вероятно, 4N. В настоящее время Microsoft Azure находится в начальной стадии развёртывания инфраструктуры на базе новых чипов, которая будет использоваться для Microsoft Copilot, Azure OpenAI и других сервисов. Например, Bing до сих пор во много полагается на FPGA, а вся ИИ-инфраструктура Microsoft крайне сложна.  Microsoft приводит очень мало технических данных о своих новинках, но известно, что Azure Cobalt 100 имеет 128 ядер Armv9 Neoverse N2 (Perseus) и основан на платформе Arm Neoverse Compute Subsystem (CSS). По словам компании, процессоры Cobalt 100 до +40 % производительнее имеющихся в инфраструктуре Azure Arm-чипов, они используются для обеспечения работы служб Microsoft Teams и Azure SQL. Oracle, вложившаяся в своё время в Ampere Comptuing, уже перевела все свои облачные сервисы на Arm.  Чип Maia 100 (Athena) изначально спроектирован под задачи облачного обучения ИИ и инференса в сценариях с использованием моделей OpenAI, Bing, GitHub Copilot и ChatGPT в инфраструктуре Azure. Чип содержит 105 млрд транзисторов, что больше, нежели у NVIDIA H100 (80 млрд) и ставит Maia 100 на один уровень с Ponte Vecchio (~100 млрд). Для Maia организован кастомный интерконнект на базе Ethernet — каждый ускоритель располагает 4,8-Тбит/с каналом для связи с другими ускорителями, что должно обеспечить максимально эффективное масштабирование.  Сами Maia 100 используют СЖО с теплообменниками прямого контакта. Поскольку нынешние ЦОД Microsoft проектировались без учёта использования мощных СЖО, стойку пришлось сделать более широкой, дабы разместить рядом с сотней плат с чипами Maia 100 серверами и большой радиатор. Этот дизайн компания создавала вместе с Meta✴, которая испытывает аналогичные проблемы с текущими ЦОД. Такие стойки в настоящее время проходят термические испытания в лаборатории Microsoft в Редмонде, штат Вашингтон.  В дополнение к Cobalt и Maia анонсирована широкая доступность услуги Azure Boost на базе DPU MANA, берущего на себя управление всеми функциями виртуализации на манер AWS Nitro, хотя и не целиком — часть ядер хоста всё равно используется для обслуживания гипервизора. DPU предлагает 200GbE-подключение и доступ к удалённому хранилищу на скорости до 12,5 Гбайт/с и до 650 тыс. IOPS.  Microsoft не собирается останавливаться на достигнутом: вводя в строй инфраструктуру на базе новых чипов Cobalt и Maia первого поколения, компания уже ведёт активную разработку чипов второго поколения. Впрочем, совсем отказываться от партнёрства с другими вендорами Microsoft не намерена. Компания анонсировала первые инстансы с ускорителями AMD Instinct MI300X, а в следующем году появятся инстансы с NVIDIA H200. 
19.10.2023 [01:40], Алексей Степин
Axiado представила новый класс сопроцессоров — TCUНа мероприятии 2023 OCP Global Summit компания Axiado представила новый класс аппаратных сопроцессоров — TCU (Trusted Control/Compute Unit), предназначенный для управления и защиты IT-инфраструктуры от различного рода атак. Защитных механик в мире ИТ существует множество, но и киберпреступники постоянно совершенствуют методы атак, задействуя порой самые экзотические атак по сторонним каналам, к примеру, используя механизмы динамического управления напряжением и частотой в современных процессорах. Не всегда спасает положение даже подход «нулевого доверия» (Zero Trust), поскольку программная реализация также уязвима ко взлому или утере ключей. 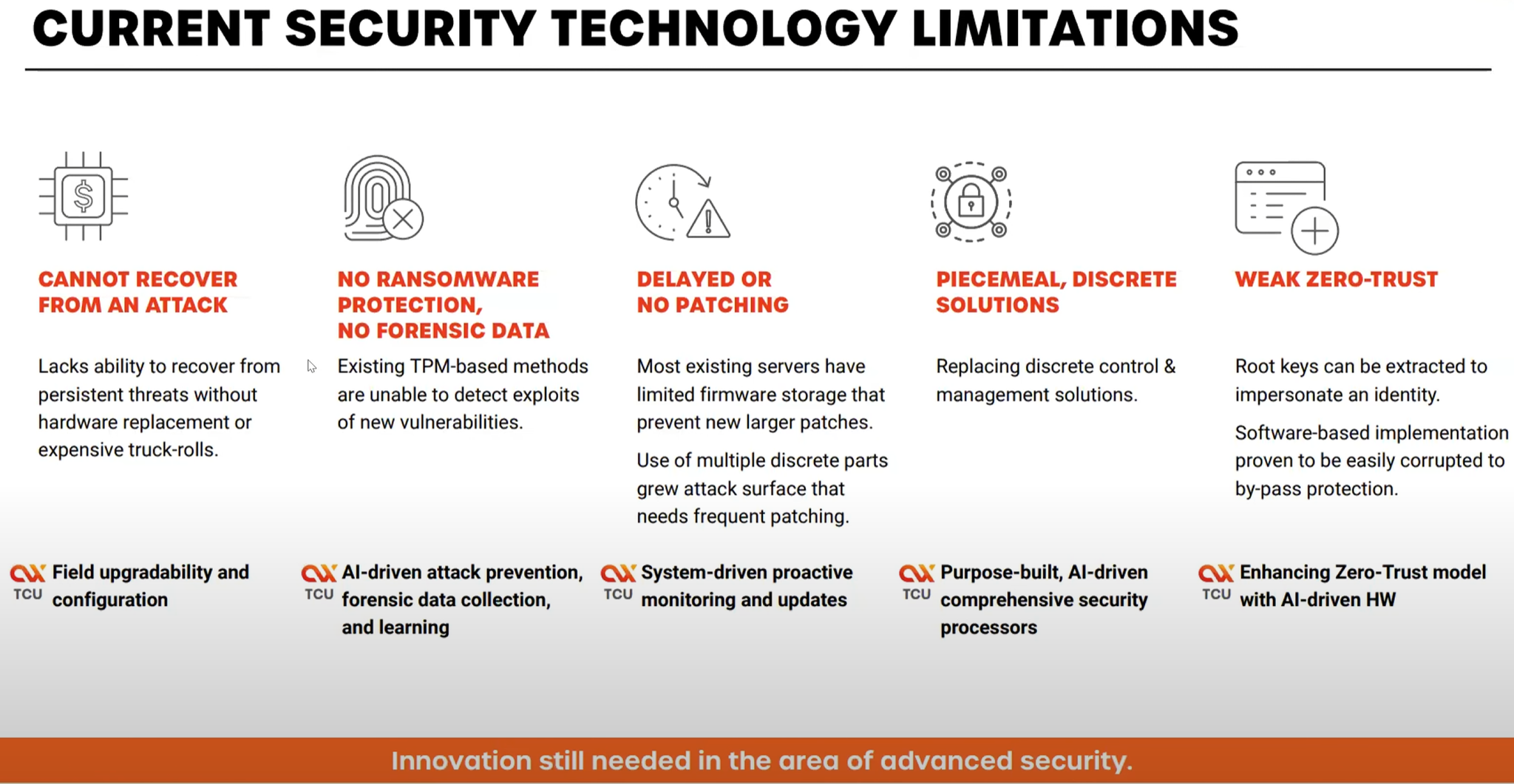
Источник изображений здесь и далее: OCP/Axiado 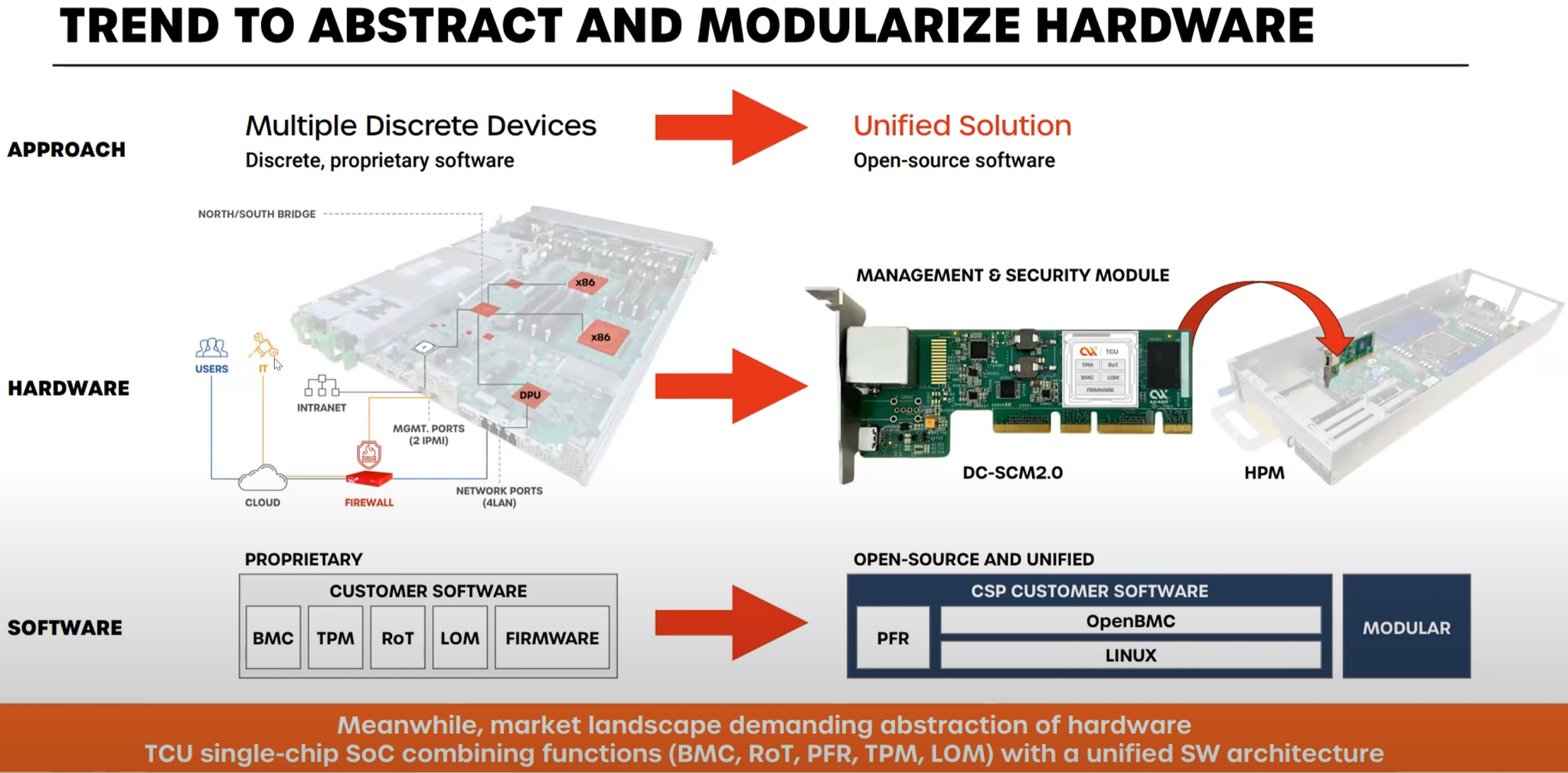 Решение Axiado — аппаратный контроль в реальном времени, использующий ИИ, который позволяет предсказывать и предотвращать разного рода атаки, дообучаясь в процессе. Последнее, по мнению компании, быть на шаг впереди злоумышленников и предотвращать возможный взлом ещё на этапе первых подозрительных действий, производимых в системе. Чипы серии AX2000/3000 способны выполнять и другие функции: Platform Root of Trust, BMC или TPM. При этом предполагается использование модульной и открытой программной архитектуры на основе PFR (Platform Firmware Resilence) и OpenBMC.  Чипы Axiado AX2000/3000 содержат четыре инференс-движка общей мощностью 4 Топс, четыре ядра общего назначения Arm Cortex A53, а также модули доверенного и привилегированного исполнения, блок брандмауэра и криптодвижок. Большая часть модулей решения Axiado работает под управлением открытой ОС реального времени Zephyr. Клиент легко может доработать платформу собственными модулями. 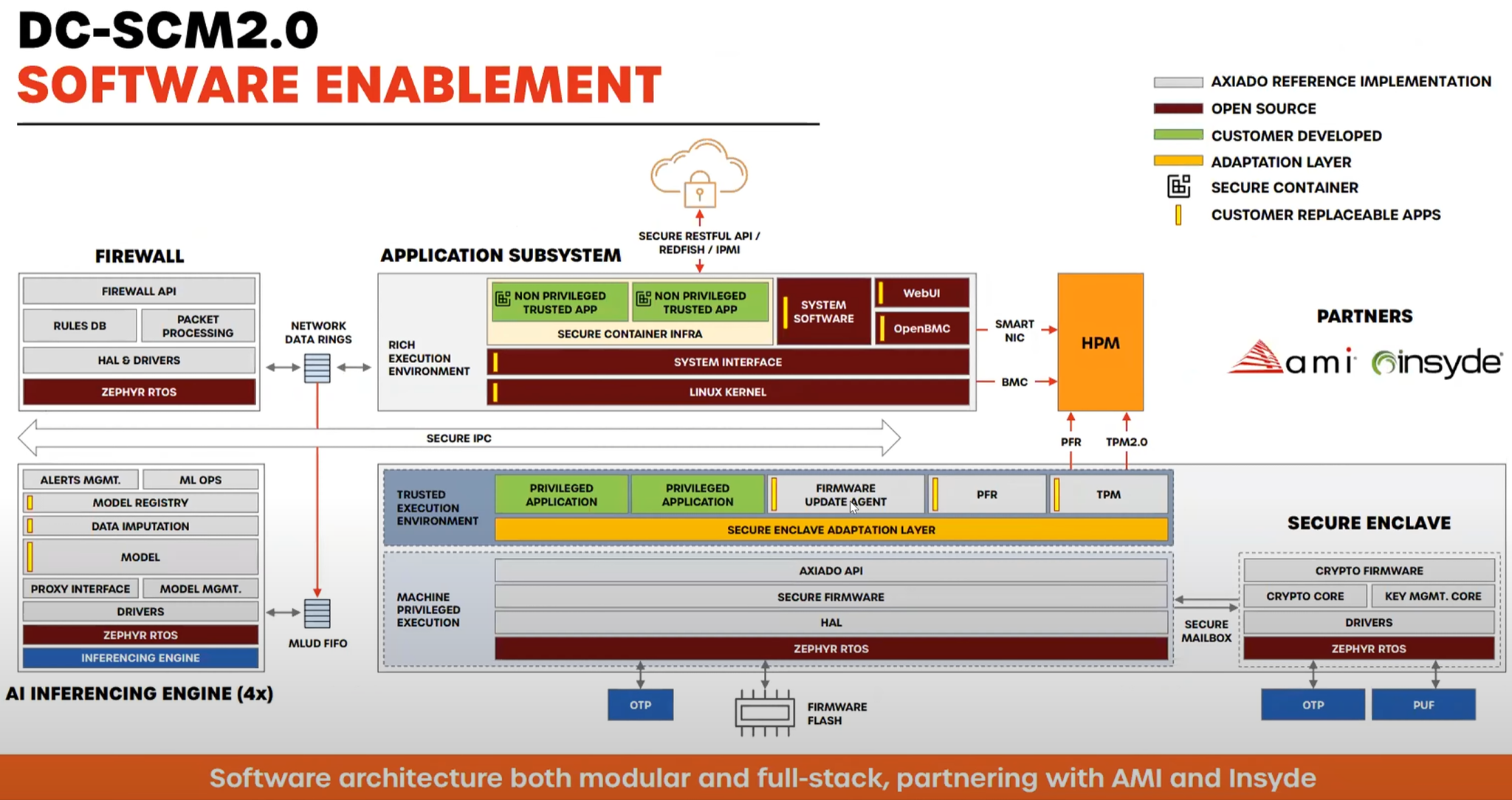 Axiado активно сотрудничает с OCP и уже разработала несколько вариантов адаптеров на базе TCU для продвигаемых консорциумом серверных форм-факторов. В портфолио компании представлены адаптеры DC-SCM 2.0 (Secure Control Module) как в вертикальном, так и в горизонтальном форм-факторах, а также в виде классического PCIe-адаптера NCM (Network Compute Module).  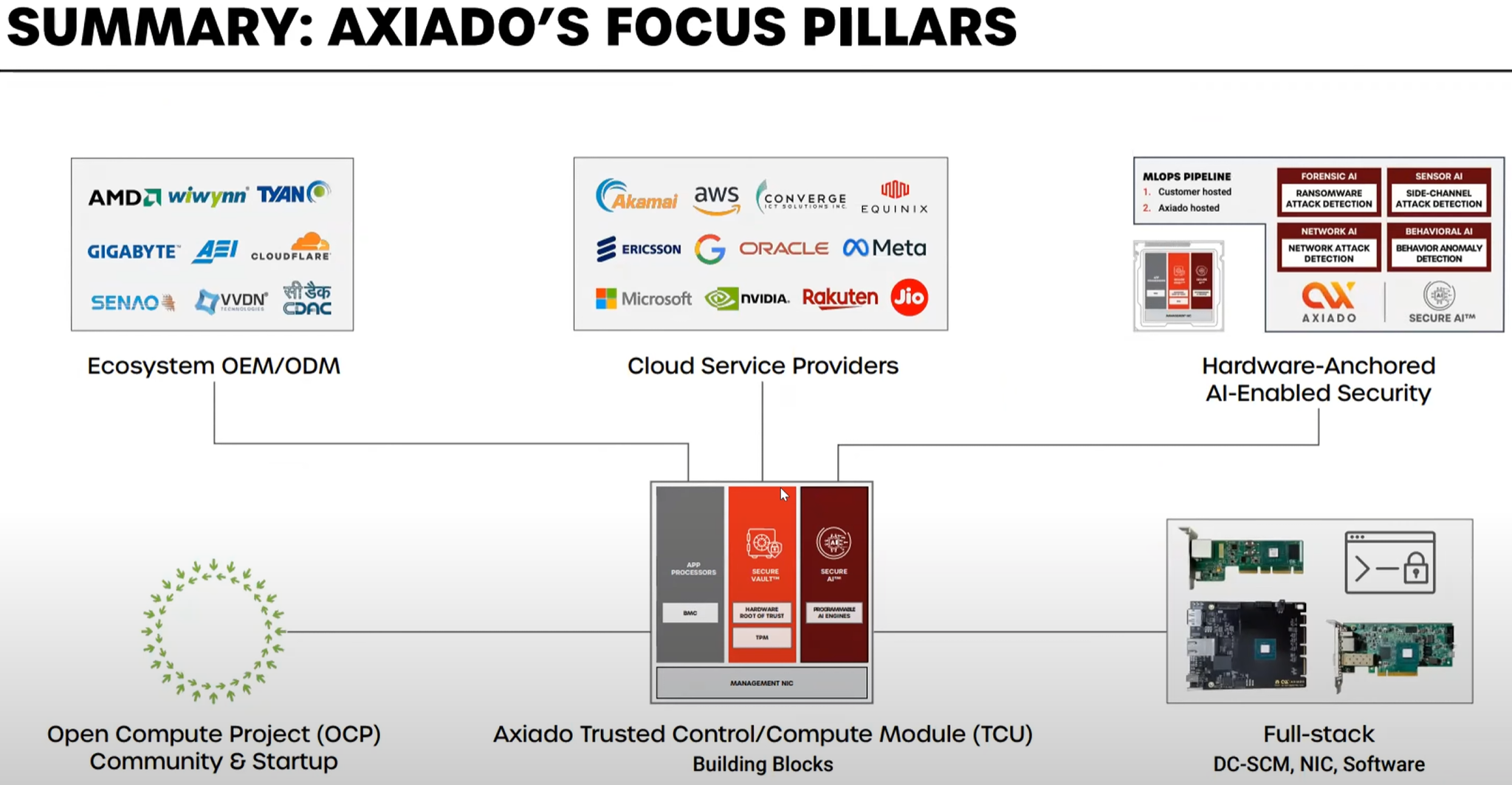 Компания уже успела договориться о сотрудничестве с GIGABYTE, VVDN, Wiwynn, Senao и Tyan. Но этим список партнёров Axiado не ограничивается: в её решениях заинтересованы также крупные облачные провайдеры, включая AWS, Microsoft, Google и Meta✴, а также ряд других компаний и системных интеграторов.
21.07.2023 [23:10], Алексей Степин
Microsoft предлагает протестировать DPU MANA с Azure BoostКрупные облачные провайдеры давно осознали пользу, которую могут принести DPU и активно применяют подобного рода решения. В частности, AWS давно использует платформу Nitro, Google разработала DPU при поддержке Intel, а Microsoft активно готовит к запуску собственную платформу под названием MANA. Основой MANA является кастомный чип SoC, разработанный специально с учётом обеспечения высокой пропускной способности, стабильности подключения и низкой латентности. DPU на его основе обеспечивает пропускную способность до 200 Гбит/с, а также поддерживает подключение удалённого хранилища данных на скоростях до 10 Гбайт/с при производительности до 400 тыс. IOPS. Отметим, что ранее AMD заявила о появлении DPU Pensando в облаке Azure, а сама Microsoft в прошлом году поглотила разработчика DPU Fungible. 
Изображение: Microsoft MANA является частью услуги Azure Boost и берёт на себя управление всеми аспектами виртуализации, включая работу с сетью и данными, а также функции управления хост-системой. Перенос этих функций на отдельную платформу не просто улучшает производительность и масштабируемость, но и обеспечивает дополнительный слой безопасности. MANA уже задействованы в инфраструктуре Azure и подтвердили высочайшую скорость при работе с внешними хранилищами данных для инстансов Ebsv5, а также отличную пропускную способность и низкую латентность сетевого канала для всех инстансов семейств Ev5 и Dv5. MANA поддерживает Windows и Linux, а для более тонкой работы с аппаратной частью ускорителя можно задействовать DPDK. В части информационной безопасности следует отметить наличие криптоядра, соответствующего стандартам FIPS 140. В настоящее время сервис Azure Boost доступен в качестве превью. Компания приглашает к сотрудничеству партнёров и клиентов с высокими запросами к характеристикам сетевого канала и хранилищ.
29.05.2023 [07:30], Сергей Карасёв
NVIDIA представила модульную архитектуру MGX для создания ИИ-систем на базе CPU, GPU и DPUКомпания NVIDIA на выставке Computex 2023 представила архитектуру MGX, которая открывает перед разработчиками серверного оборудования новые возможности для построения HPC-систем, платформ для ИИ и метавселенных. Утверждается, что MGX закладывает основу для быстрого создания более 100 вариантов серверов при относительно небольших затратах. Концепция MGX предусматривает, что разработчики на первом этапе проектирования выбирают базовую системную архитектуру для своего шасси. Далее добавляются CPU, GPU и DPU в той или иной конфигурации для решения определённых задач. Таким образом, на базе MGX может быть построена серверная система для уникальных рабочих нагрузок в области наук о данных, больших языковых моделей (LLM), периферийных вычислений, обработки графики и видеоматериалов и пр. Говорится также, что благодаря гибридной конфигурации на одной машине могут выполняться задачи разных типов, например, и обучение ИИ-моделей, и поддержание работы ИИ-сервисов. 
Источник изображений: NVIDIA Одними из первых системы на архитектуре MGX выведут на рынок компании Supermicro и QCT. Первая предложит решение ARS-221GL-NR с NVIDIA Grace, а вторая — сервер S74G-2U на базе NVIDIA GH200 Grace Hopper. Эти платформы дебютируют в августе нынешнего года. Позднее появятся MGX-платформы ASRock Rack, ASUS, Gigabyte, Pegatron и других производителей.  Архитектура MGX совместима с нынешним и будущим оборудованием NVIDIA, включая H100, L40, L4, Grace, GH200 Grace Hopper, BlueField-3 DPU и ConnectX-7. Поддерживаются различные форм-факторы систем: 1U, 2U и 4U. Возможно применение воздушного и жидкостного охлаждения.
10.01.2023 [17:11], Сергей Карасёв
Microsoft подтвердила поглощение DPU-разработчика Fungible, но сумму сделки так и не назвалаКорпорация Microsoft официально объявила о заключении соглашения по покупке компании Fungible — молодого разработчика DPU (Data Processing Unit). О сумме сделки ничего не сообщается. Слухи о том, что редмондский гигант проявляет интерес к Fungible, появились в середине декабря 2022 года. Тогда говорилось, что приобретение стартапа обойдётся Microsoft приблизительно в $190 млн. Решения Fungible помогут Microsoft поднять производительность её дата-центров. По условиям соглашения, команда Fungible присоединится к подразделению разработки ЦОД-инфраструктур Microsoft. Специалисты компании сосредоточатся на создании нескольких специализированных DPU, а также на сетевых инновациях и улучшении аппаратных систем. «Технологии Fungible помогают создать высокопроизводительную, масштабируемую, дезагрегированную, горизонтально масштабируемую инфраструктуру ЦОД с высокими показателями надёжности и безопасности», — говорится в заявлении Microsoft. 
Источник изображения: Fungible Добавим, что Fungible была основана в 2015 году выходцами из Xerox PARC Прадипом Синдху (Pradeep Sindhu, сооснователь и бывший глава Juniper Networks) и Бертраном Серле (Bertrand Serlet, работал в Apple и Parallels, основал Upthere). Стартап привлёк более $300 млн инвестиций, но в последнее время дела у него шли не слишком хорошо. По слухам, после неудачной попытки продать компанию Meta✴ стартап был вынужден уволить часть сотрудников и сократить портфолио решений. Fungible, как и ряд аналогичных проектов, по мере развития перешёл от создания сверхбыстрых хранилищ к идее переноса на DPU иных инфраструктурных задач по примеру AWS Nitro (собственная разработка Amazon). Однако, как утверждают некоторые источники, сложность разработки ПО негативно сказалась на популярности решений Fungible. Например, Google пошла по другому пути и заручилась поддержкой Intel.
30.11.2022 [16:55], Алексей Степин
AWS представила пятое поколение аппаратных гипервизоров NitroНа днях крупный провайдер облачных услуг, компания Amazon Web Services представила новые варианты инстансов на базе новейших процессоров Graviton3E, но данный чип — не единственная новинка AWS. Одновременно с Graviton3E было представлено и пятое поколение аппаратных гипервизоров Nitro, существенно выигрывающих по ключевым показателям у решений предыдущего, четвёртого поколения. 
Здесь и далее источник изображений: ServeTheHome Главная идея Nitro — сочетание «кремния» гипервизора, DPU и сопроцессора безопасности с поддержкой Root of Trust в едином чипе. В системах AWS плата с чипом Nitro полностью управляет распределением вычислительных ресурсов и памяти, избавляя от этой нагрузки хост-процессоры. По результатам тестов, проведённых AWS, производительность облачных инстансов с использованием ускорителей Nitro практически не отличается от производительности классической bare metal-системы.  AWS Nitro v5 использует кастомный кристалл, разработанный Annapurna Labs. По сравнению с Nitro v4, количество транзисторов было удвоено, но за счёт этого удалось на 60 % поднять скорость обработки сетевых пакетов, на 30 % снизить латентность, а также, благодаря продвинутому техпроцессу, обеспечить лучшую удельную производительность. 
Платы AWS Nitro v5 используют проприетарные разъёмы Улучшились и другие характеристики: на 50 % выросла пропускная способность памяти и вдвое возросла производительность подсистемы PCI Express. Платы Nitro v5 станут сердцем новых инстансов C7gn, где обеспечат полную изоляцию критически важных подсистем, таких, как прошивки BIOS, BMC и накопителей от гостевого доступа извне и позволят обновлять эти прошивки без влияния на клиентские нагрузки.  Также они возьмут на себя обслуживание сетей VPC/EBS, включая переход на использование SRD вместо TCP, и накопителей Nitro SSD. AWS уже объявила о возможности предварительного тестирования систем C7gn на базе Nitro v5 и новейших процессоров Graviton3/3E.
19.06.2022 [13:32], Алексей Степин
Alibaba Cloud представила свой вариант DPU — Cloud Infrastructure Processing Unit (CIPU)С учётом стремительно наступающей эры DPU/IPU не вызывает удивления, что такой китайский гигант, как Alibaba Cloud, представил своё видение «универсального сетевого сопроцессора», использовав схожий термин Cloud Infrastructure Processing Unit (CIPU). На ежегодном саммите компании Alibaba Cloud анонсировала новый чип, являющийся дальнейшим развитием идей, ранее воплощённых в умном сетевом адаптере X-Dragon, разрабатывавшемся как аналог AWS Nitro. Пока об архитектуре Alibaba CIPU известно не так много, но физически это обычная двухслотовая плата расширения с интерфейсом PCI Express. 
Источник: @ogawa_tter Судя по имеющимся данным, в основе лежит четвёртое поколение архитектуры X-Dragon, обеспечившее 20% прирост производительности в сравнении с предыдущим поколением этих процессоров. Что более интересно, в основе новой итерации X-Dragon лежит дуэт технологий Elastic RDMA (eRDMA) и Shared Memory Communications over RDMA (SMC-R). Он позволяет новому ускорителю обращаться к памяти хост-системы напрямую на уровне ядра фирменных ОС Alibaba Cloud Linux 3 и Anolis OS. Для приложений, использующих TCP, всё выглядит прозрачно, но латентность при этом удалось понизить до 5 мкс. 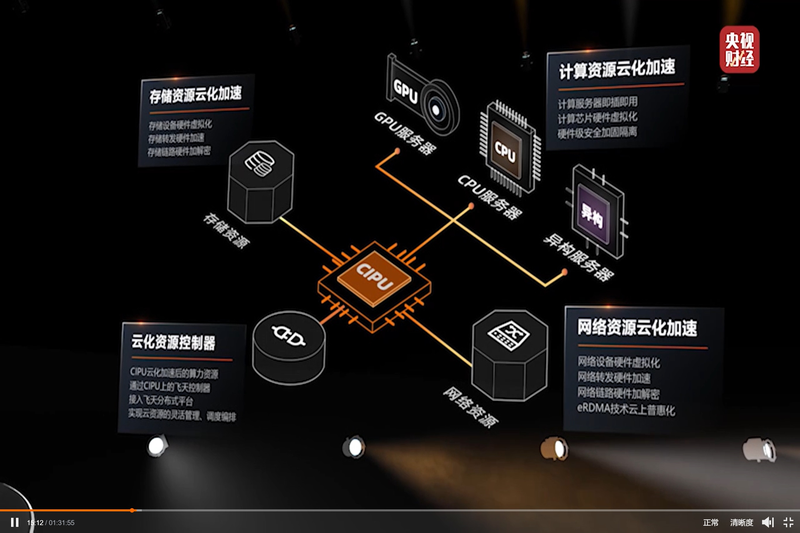
Источник: @ogawa_tter Новые сопроцессоры полностью совместимы со стеком технологий RDMA over Converged Ethernet (RoCE), причём поддерживается даже iWARP, довольно редкий вариант, встречавшийся ранее в адаптерах Intel и Chelsio. Реализации iWARP могут быть сложнее RoCE, т.к. используют многослойную архитектуру и ряд твиков, а в итоге нередко показывают менее высокую производительность. Но благодаря поддержке обеих технологий новое решение Alibaba получилось поистине универсальным. 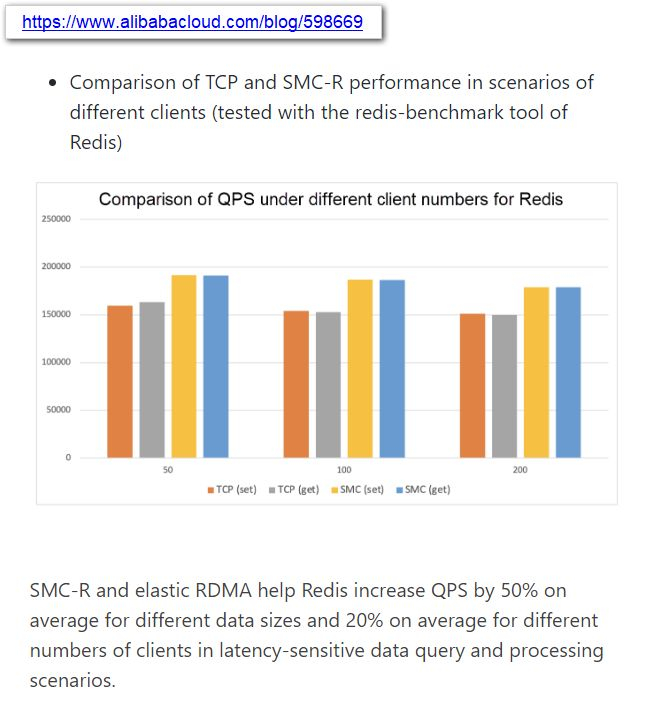
Источник: @ogawa_tter Результаты тестов весьма обнадёживают: в частности, для Redis ускорители CIPU за счёт SMC-R позволили поднять количество обрабатываемых запросов на 50%, а в сценариях с данными, чувствительными к латентности, прирост составил 20%. Исходя из опубликованных в японском блоге Tadashi Ogawa, это действительно полноценный IPU, могущий стать мостом между сетью, подсистемами хранения данных, CPU, GPU и прочими ускорителями. Компания активно развивает собственную аппаратную инфраструктуру и в прошлом году уже представила 128-ядерный 5-нм процессор Yitian 710 на базе набора инструкций Armv9 c 8 каналами DDR5, поддержкой PCIe 5.0 (96 линий) и при этом способный работать на частотах до 3,2 ГГц. |
|