Материалы по тегу: dpu
|
28.04.2022 [22:54], Алексей Степин
Chelsio представила седьмое поколение сетевых чипов Terminator: 400GbE и PCIe 5.0 x16Компания Chelsio Communications анонсировала седьмое поколение своих сетевых процессоров Terminator с поддержкой 400GbE. От предшественников T7 отличает более развитая вычислительная часть общего назначения, включающая в себя до 8 ядер Arm Cortex-A72, так что их уже можно назвать DPU. Всего представлено пять вариантов 5 чипов (T7, N7, D7, S74 и S72), которые различаются между собой набором движков и ускорителей. Референсная платформа T7 будет доступна в мае, первых же адаптеров на базе новых DPU следует ожидать в III квартале 2022 года. Для задач сжатия, дедупликации или криптографии есть отдельные сопроцессоры. Никуда не делся и привычный для серии Unified Wire встроенный L2-коммутатор. Для подключения к хосту T7 теперь использует шину PCIe 5.0 x16, причём он же содержит и root-комплекс. Более того, имеется и набортный коммутатор+мост PCIe 4.0, и NVMe-интерфейс, и даже поддержка эмуляции NVMe. Всё это, к примеру, позволяет легко и быстро создать NVMe-oF хранилище или мост NVMe-NVMe для компрессии и шифрования данных на лету. Новинка предлагает ускорение работы RoCEv2 и iWARP, FCoE и NVMe/TCP, iSCSI и iSER, а также RAID5/6. Сетевая часть поддерживает разгрузку Open vSwitch и Virt-IO. 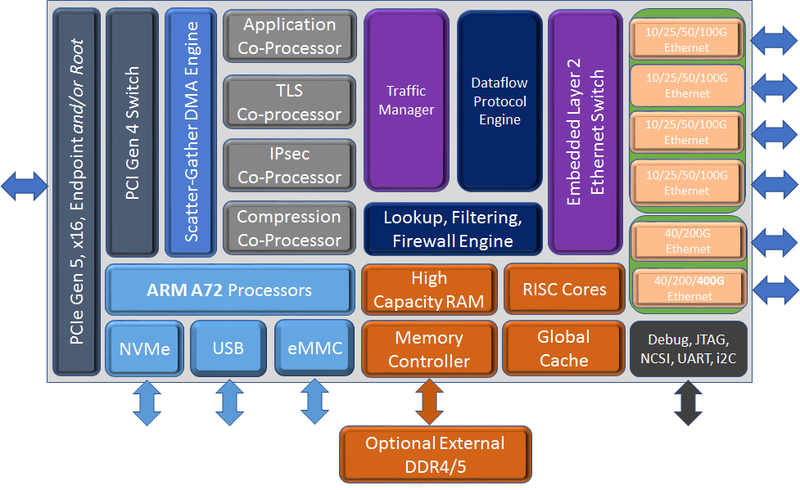
Блок-схема старшего варианта T7 (Изображения: Chelsio Communcations) Впрочем, поддержки P4 тут нет — Chelsio продолжает использовать собственные движки для обработки трафика. Но наработки, сделанные для серий T5 и T6, будет проще перенести на новое поколение чипов. Кроме того, появилась и практически обязательная нынче «глубокая» телеметрия всего проходящего через DPU трафика для повышения управляемости и его защиты. Если и этого окажется мало, то к T7 (и D7) можно напрямую подключить FPGA, а набортную память расширить банками DDR4/5. В пресс-релизе также отмечается, что T7 сможет стать достойной заменой InfiniBand в HРC-системах. 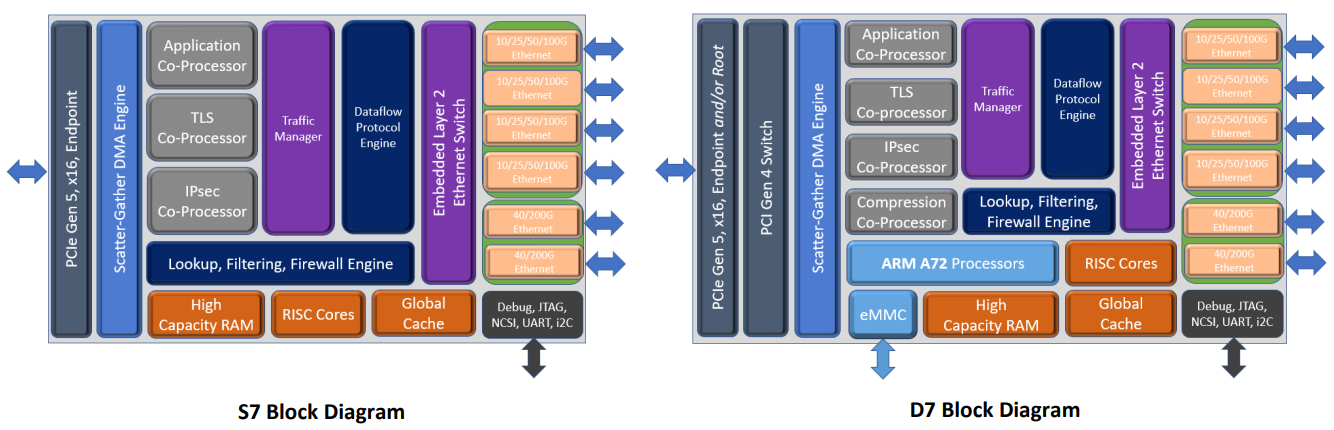 Вариант D7 наиболее близок к T7, но предлагает только 200GbE-подключение, лишён некоторых функций и второстепенных интерфейсов, да и в целом рассчитан на создание СХД. N7, напротив, лишён Arm-ядер и всех функций для работы с хранилищами, нет у него и PCIe-коммутатора и моста. Предлагает он только 200GbE-интерфейсы. Наконец, чипы серии S7 лишены целого ряда второстепенных функций и предоставляют только 100/200GbE-подключение. Они относятся скорее к SmartNIC, поскольку начисто лишены Arm-ядер и некоторых функций. Но зато они и недороги. Кроме того, в седьмом поколении Termintator появилась возможность обойтись без набортной DRAM с сохранением всей функциональности. Так что использование памяти хоста позволит дополнительно снизить стоимость конечных решений, которые будут создавать OEM-производители. Сами чипы производятся с использованием техпроцесса TSMC 12-нм FFC, так что даже у старшей версии чипов типовое энергопотребление не превышает 22 Вт.
19.12.2021 [18:06], Алексей Степин
Nebulon поможет HCI-решениям освоить рынок периферийных вычисленийПо мере внедрения 5G-сетей объёмы данных, добываемых и обрабатываемых на периферии, будут только расти, и здесь новое решение Nebulon для микро-ЦОД окажется весьма к месту. Компания Nebulon была основана лишь 2018 году, а в 2020 году она представила свои первые решения, концептуально очень схожие с тем, что сейчас принято называть DPU. Изначально это были ускорители под названием SPU (Storage Processing Unit), однако впоследствии первое слово заменили на Service, поскольку речь шла уже об облачных системах, и данные платы стали частью того, что сама Nebulon называет «умной инфраструктурой» (Smart Infrastructure). 
Nebulon SPU. Изображения: Nebulon Но у SPU нашлось и ещё одно применение, связанное с периферийной серверной инфраструктурой. Её особенности таковы, что требуют максимальной компактности оборудования, и это, по мнению Nebulon, затрудняет использование классических решений для гиперконвергентной инфраструктуры (HCI), поскольку, по словам Nebulon, она обычно для арбитража, который необходим для стабильности работы, требует наличия в системе минимум трёх узлов. 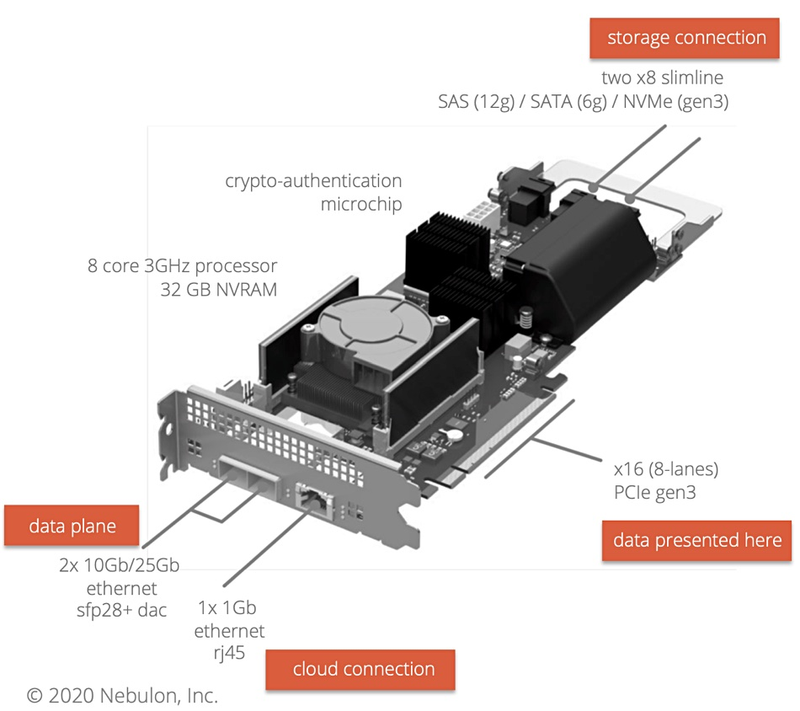 Такой «узел-арбитр» (quorum witness, QW) гарантирует бесперебойную работу системы в том случае, если какой-либо из её основных узлов испытывает проблемы с сетевым подключением. Но в условиях периферии третьему узлу бывает просто негде разместиться, а ведь нужен ещё и сетевой коммутатор. Тут-то на помощь и может прийти ускоритель Nebulon SPU, который можно назвать полноценным «сервером на плате»: он несёт на борту восьмиядерный CPU и 32 Гбайт DRAM. Основным интерфейсом SPU является PCIe 3.0 x16 (8 линий) + ещё два набора по 8 линий могут обслуживать NVMe SSD (но есть и поддержка SAS/SATA). С такой платой HCI-кластер может иметь в составе всего два узла. Коммутатор не требуется, поскольку плата располагает двумя портами 10/25GbE. Интеграцию такого HCI-кластера с облаком, автоматизацию и арбитраж посредством Nebulon ON также берёт на себя SPU. Компания-разработчик назвала данную технологию smartEdge.
29.10.2021 [02:28], Игорь Осколков
Intel объявила о совместной работе с Google над IPU Mount Evans и анонсировала IPDKIntel в рамках мероприятия Innovation раскрыла имя партнёра по разработке IPU Mount Evans — им оказалась компания Google. Впрочем, это не означает, что новинки будут доступны только ей и окажутся оптимизированы только под её задачи. IPU хоть и ориентированы в первую очередь на гиперскейлеров (среди возможных заказчиков называют и Facebook✴), но, по мнению Intel, будут интересны и менее крупным игрокам. Более того, было, наконец, прямо сказано, что ведётся работа и над Project Monterey от VMware. 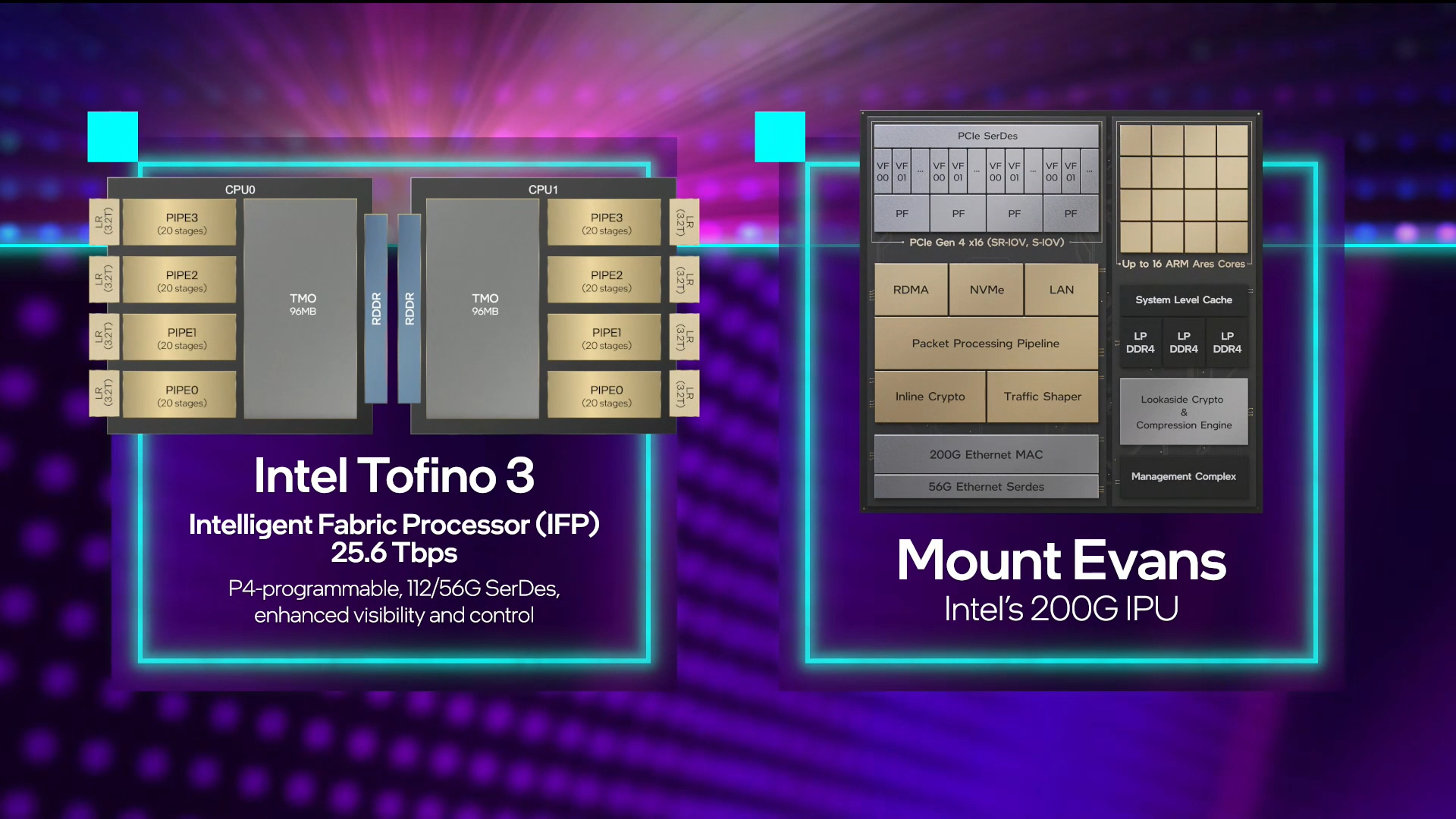 Как пояснил Гвидо Аппенцеллер (Guido Appenzeller), технический директор подразделения Data Platforms Group Intel, название IPU (Infrastructure Processing Unit) было выбрано в противовес всё ещё относительно новому, но более привычному термину DPU (Data Processing Unit) именно потому, что IPU охватывает более широкий спектр задач по работе именно с инфраструктурой, а не только c данными. 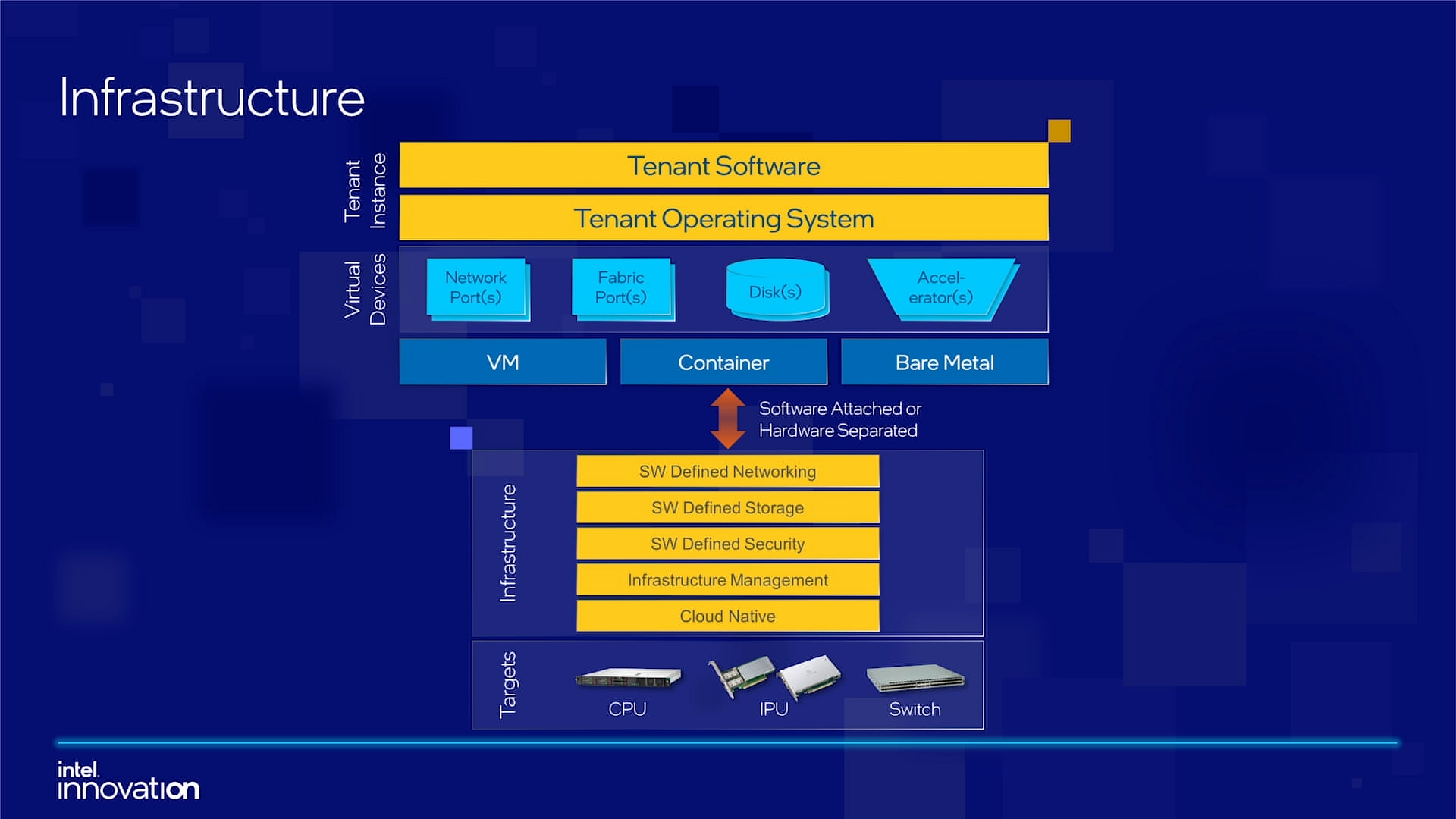 Справедливости ради отметим, что и сами DPU, поначалу чаще ориентированные именно на ускорение работы с СХД и устранению узких мест в передаче данных, уже расширили свою функциональность и практически являются IPU именно в терминологии Intel — этот класс сопроцессоров независим от хост-системы и занимается обслуживанием инфраструктуры, включая работу с сетью и хранилищем, изоляцию и телеметрию, управление нагрузками и т.д. 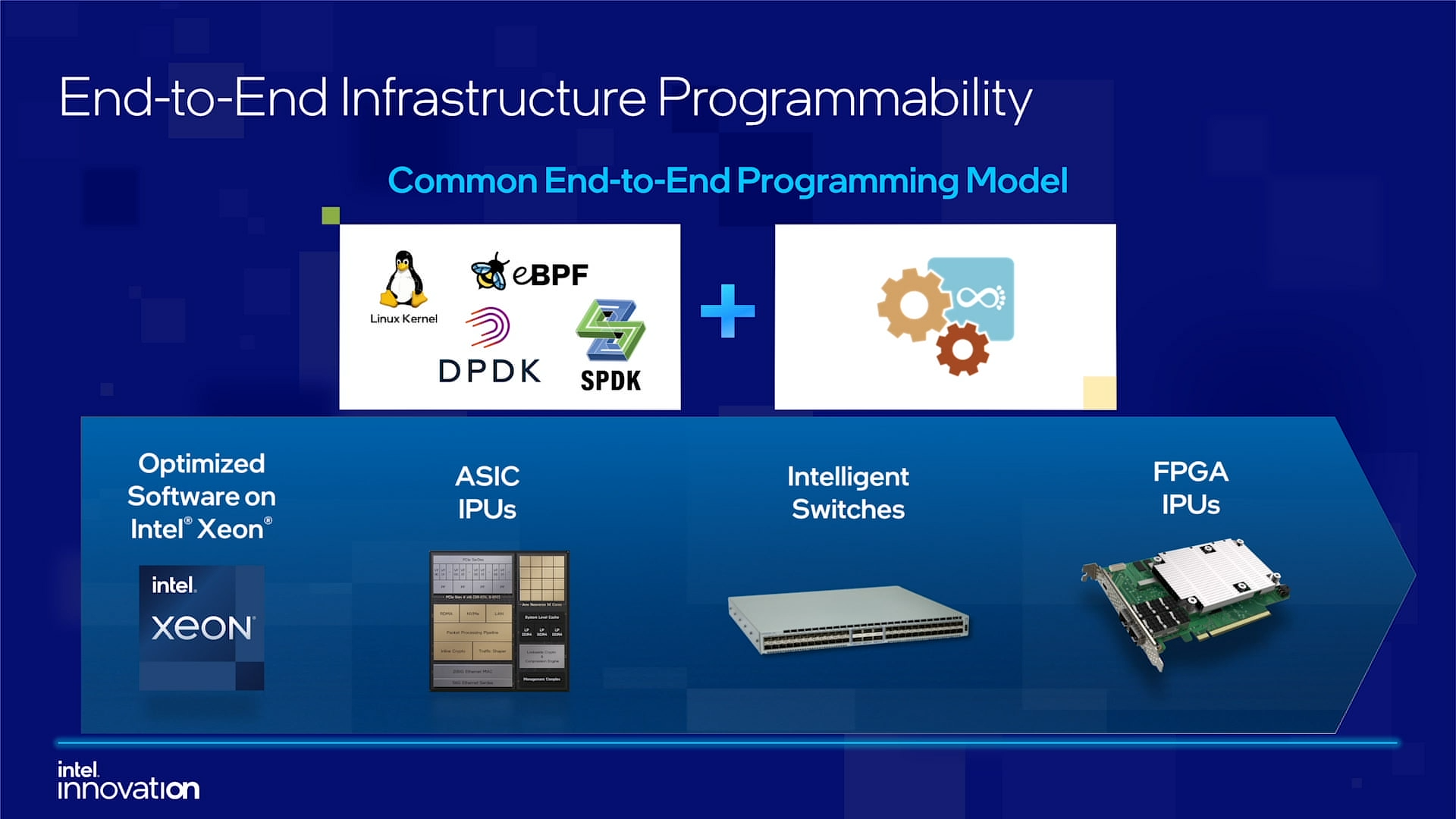 У Intel достаточно богатый опыт работы по сетевому направлению с гиперскейлерами. По словам Аппенцеллера, семь из восьми крупнейших компаний этого класса используют решения Intel во всей или хотя бы в некоторых частях своей инфраструктуры. Так, Microsoft, Baidu и JD полагаются на SmartNIC на базе FPGA. Партнёрство же с Google будет выгодно для обеих компаний. Intel получит заказы, а Google, наконец, обретёт то, что давно есть у Amazon — аналог Nitro. На масштабе в миллионы серверов это очень важно. 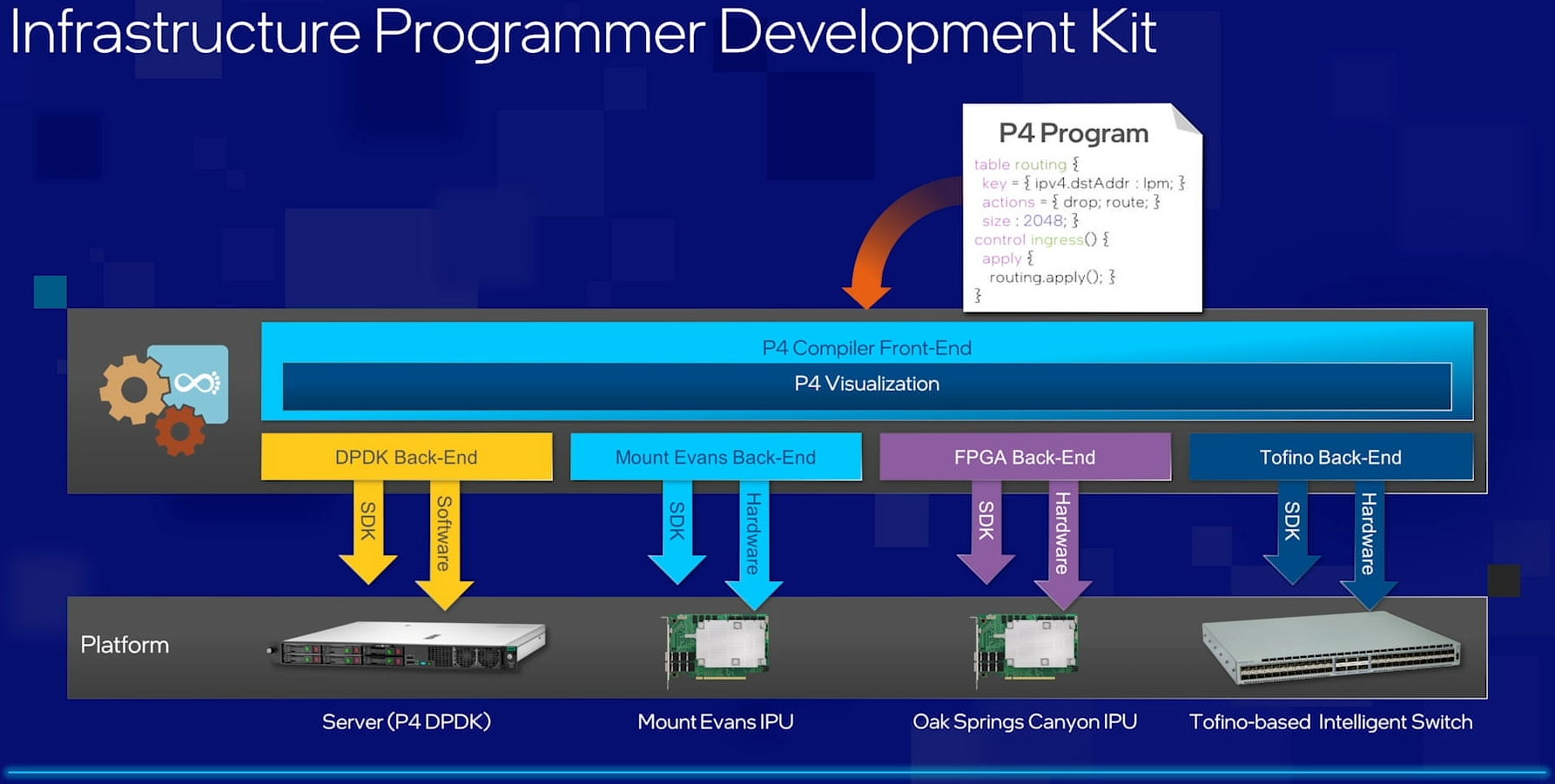 Однако IPU (как аппаратные устройства) — только часть общей картины. Для полноты не хватает как минимум ещё двух компонентов: программного стека и сопутствующей инфраструктуру. Tofino-3 — анонсированный ранее чип или, как его называет сама Intel, Intelligent Fabric Processor — не только поддерживает коммутацию на скорости 25,6 Тбит/с с параллельным сбором телеметрии, но и является полностью P4-программируемым. А это позволяет организовать сквозные мониторинг, управление и оптимизацию трафика для конкретных задач. 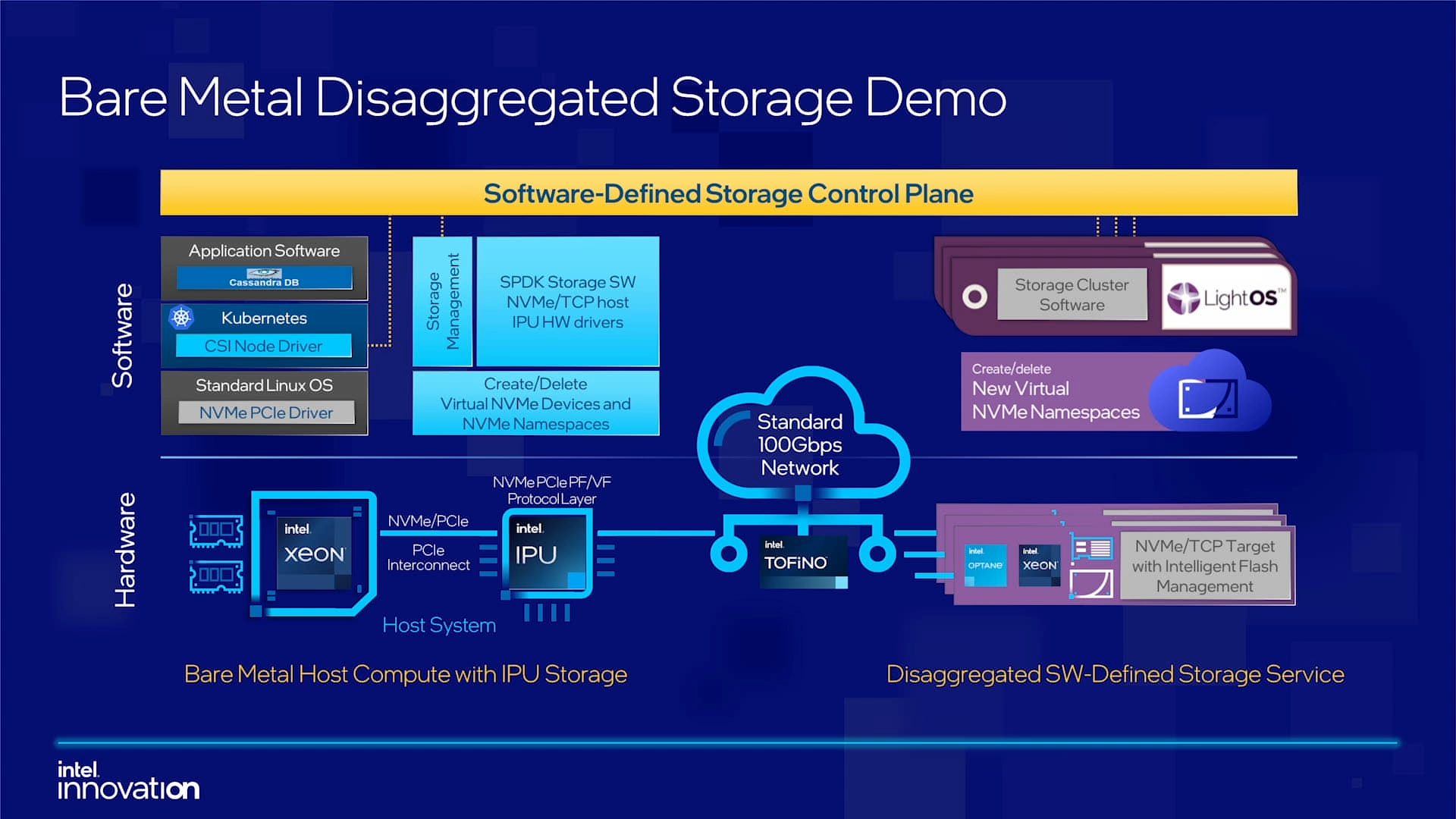 Или, иными словам, IPU и подходящие коммутаторы позволяют сделать всю инфраструктуру практически полностью программно определяемой, но с аппаратной разгрузкой части функций и близкой к bare metal итоговой производительностью. Правда, в качестве демо Intel опять же приводит «классические» примеры с СХД и Open vSwitch, а также сценарии глубокого мониторинга производительности и быстрого поиска проблемных мест в сети. Но этим потенциальные возможности не ограничиваются. 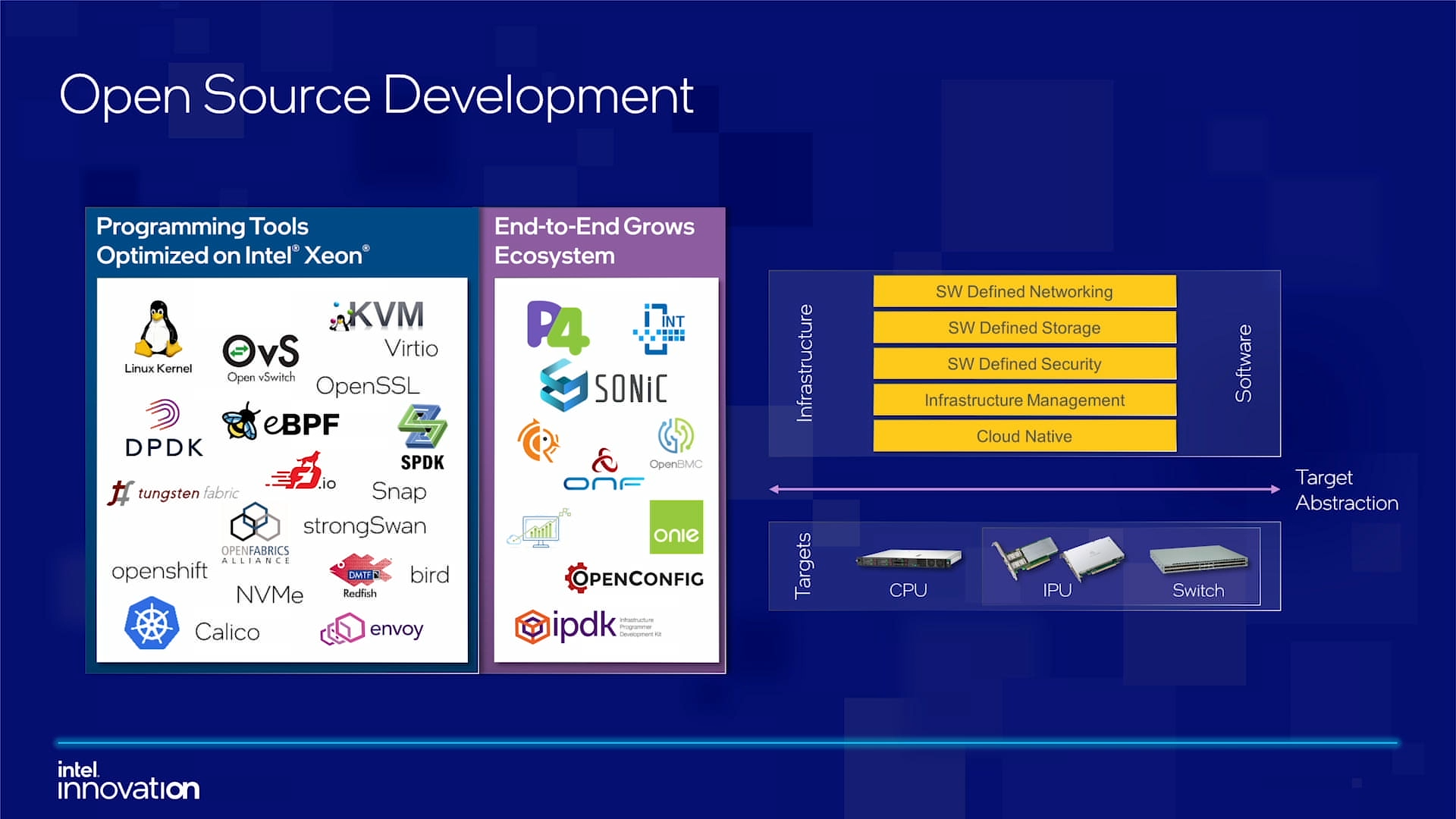 Более того, со стороны ПО и средств разработки жёсткой привязки именно к «железу» Intel нет. Компания представила open source фреймворк IPDK (Infrastructure Programmer Development Kit) для упрощения переноса и, что важно, оптимизации наиболее тяжёлых или нетривиально реализуемых функций ПО на SmartNIC (с FPGA или иной программируемой логикой), IPU/DPU, коммутаторы или CPU. IPDK дополняет уже имеющиеся решения вроде DPDK, SPDK и т.д. возможностями работы с P4.
19.08.2021 [18:04], Алексей Степин
Intel представила IPU Mount Evans и Oak Springs Canyon, а также ODM-платформу N6000 Arrow CreekВесной Intel анонсировала свои первые DPU (Data Processing Unit), которые она предпочитает называть IPU (Infrastructure Processing Unit), утверждая, что такое именования является более корректным. Впрочем, цели у этого класса устройств, как их не называй, одинаковые — перенос части функций CPU по обслуживанию ряда подсистем на выделенные аппаратные блоки и ускорители. Классическая архитектура серверных систем такова, что при работе с сетью, хранилищем, безопасностью значительная часть нагрузки ложится на плечи центральных процессоров. Это далеко не всегда приемлемо — такая нагрузка может отъедать существенную часть ресурсов CPU, которые могли бы быть использованы более рационально, особенно в современных средах с активным использованием виртуализации, контейнеризации и микросервисов. 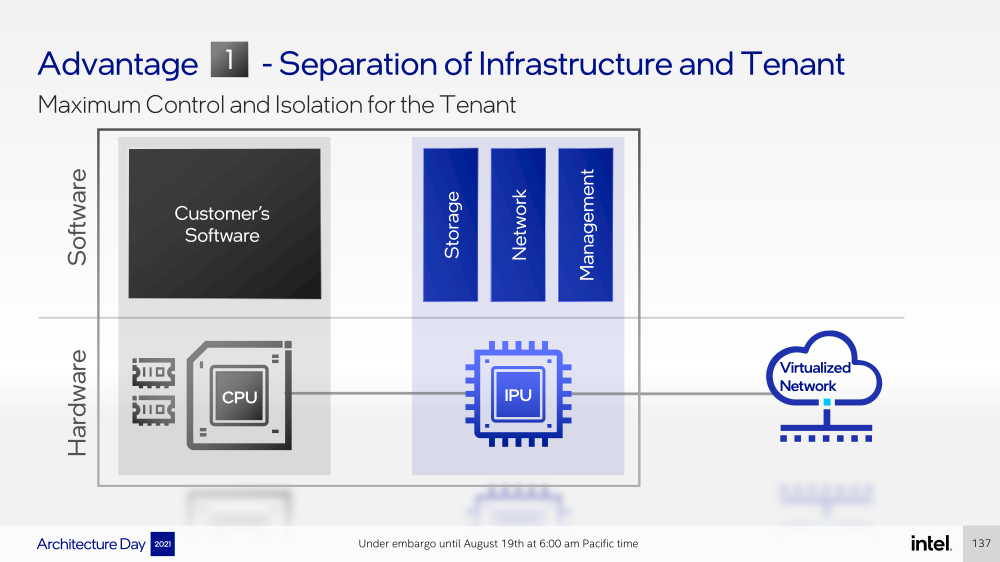 Для решения этой проблемы и были созданы DPU, которые эволюционировали из SmartNIC, бравших на себя «тяжёлые» задачи по обработке трафика и данных. DPU имеют на борту солидный пул вычислительных возможностей, что позволяет на некоторых из них запускать даже гипервизор. Однако Intel IPU имеют свои особенности, отличающие их и от SmartNIC, и от виденных ранее DPU. 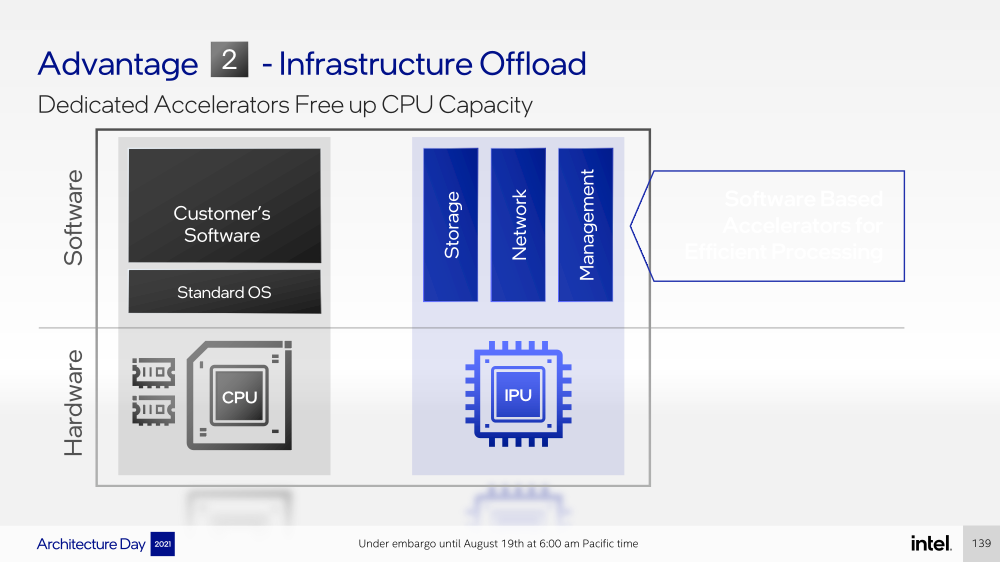 Новый класс сопроцессоров Intel должен взять на себя все заботы по обслуживанию инфраструктуры во всех её проявлениях, будь то работа с сетью, с подсистемами хранения данных или удалённое управление. При этом и DPU, и IPU в отличие от SmartNIC полностью независим от хост-системы. Полное разделение инфраструктуры и гостевых задач обеспечивает дополнительную прослойку безопасности, поскольку аппаратный Root of Trust включён в IPU. 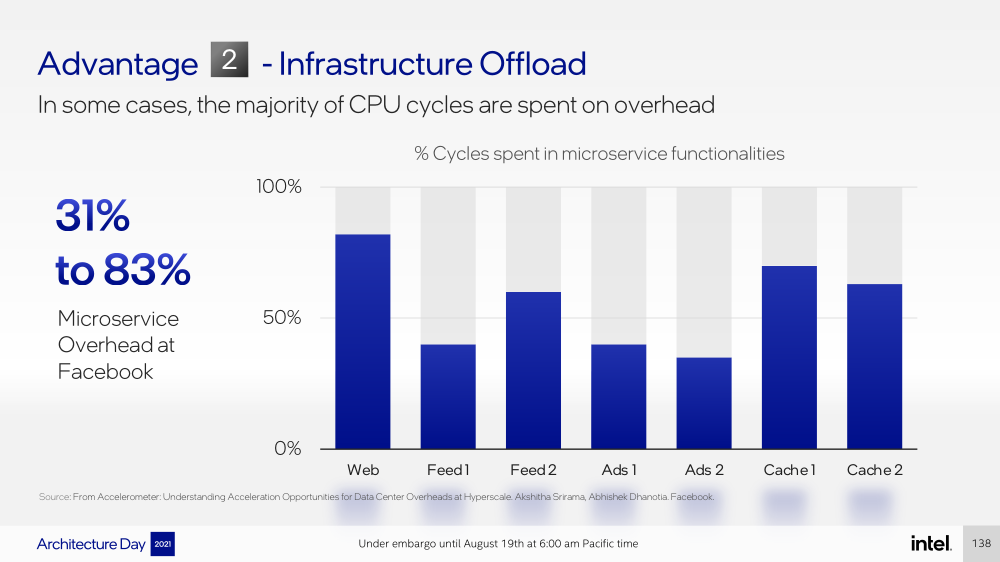 Это не единственное преимущество нового подхода. Компания приводит статистику Facebook✴, из которой видно, что иногда более 50% процессорных тактов серверы тратят на «обслуживание самих себя». Все эти такты могут быть пущены в дело, если за это обслуживание возьмётся IPU. Кроме того, новый класс сетевых ускорителей открывает дорогу к бездисковой серверной инфраструктуре: виртуальные диски создаются и обслуживаются также чипом IPU. 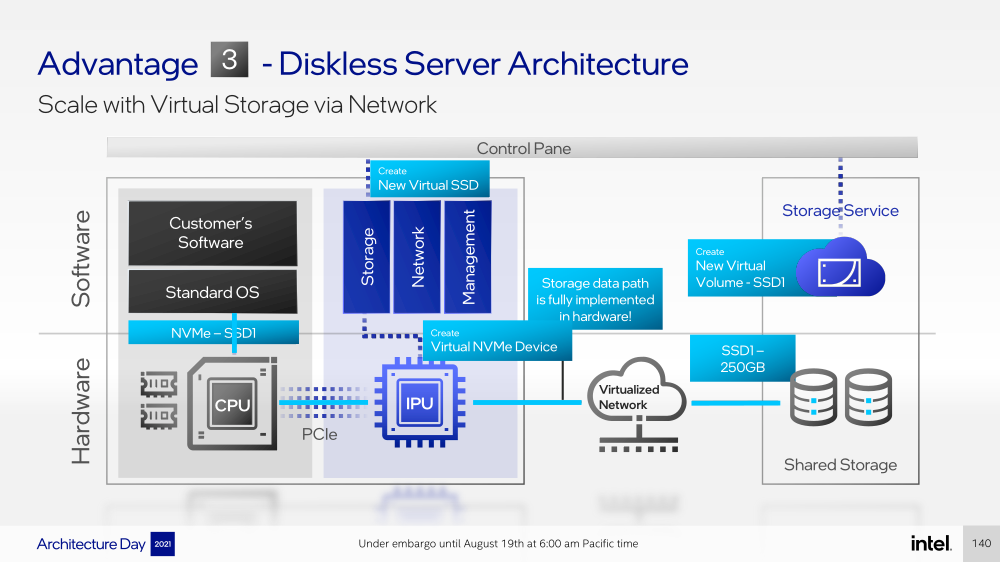 Первый чип в новом семействе IPU, получивший имя Mount Evans, создавался в сотрудничестве с крупными облачными провайдерами. Поэтому в нём широко используется кремний специального назначения (ASIC), обеспечивающий, однако, и нужную степень гибкости, За основу взяты ядра общего назначения Arm Neoverse N1 (до 16 шт.), дополненные тремя банками памяти LPDRR4 и различными ускорителями. 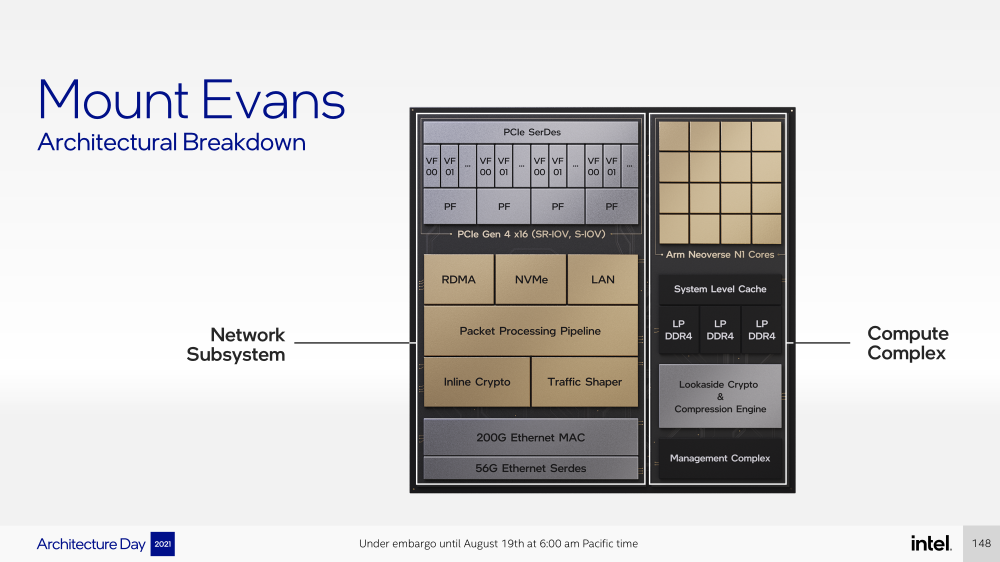 Сетевая часть представлена 200GbE-интерфейсом с выделенным P4-программируемым движком для обработки сетевых пакетов и управления QoS. Дополняет его выделенный IPSec-движок, способный на лету шифровать весь трафик без потери скорости. Естественно, есть поддержка RDMA (RoCEv2) и разгрузки NVMe-oF, причём отличительной чертой является возможность создавать для хоста виртуальные NVMe-накопители — всё благодаря контроллеру, который был позаимствован у Optane SSD.  Дополняют этот комплекс ускорители (де-)компресии и шифрования данных на лету. Они базируются на технологиях Intel QAT и, в частности, предложат поддержку современного алгоритма сжатия Zstandard. Наконец, у IPU будет выделенный блок для независимого внешнего управления. Работать с устройством можно будет посредством привычных SPDK и DPDK. Один IPU Mount Evans может обслуживать до четырёх процессоров. В целом, новинку можно назвать интересной и более доступной альтернативной AWS Nitro.  Также Intel представила платформу Oak Springs Canyon с двумя 100GbE-интерфейсами, которая сочетает процессоры Xeon-D и FPGA семейства Agilex. Каждому чипу которых полагается по 16 Гбайт собственной памяти DDR4. Платформа может использоваться для ускорения Open vSwitch и NVMe-oF с поддержкой RDMA/RocE, имеет аппаратные криптодвижки т.д. Наличие FPGA позволяет выполнять специфичные для конкретного заказчика задачи, но вместе с тем совместимость с x86 существенно упрощает разработку ПО для этой платформы. В дополнение к SPDK и DPDK доступны и инструменты OFS.  Наконец, компания показала и референсную плаформу для разработчиков Intel N6000 Acceleration Development Platform (Arrow Creek). Она несколько отличается от других IPU и относится скорее к SmartNIC, посколько сочетает FPGA Agilex, CPLD Max10 и сетевые контроллеры Intel Ethernet 800 (2 × 100GbE). Дополняет их аппаратный Root of Trust, а также PTP-блок.  Работать с устройством можно также с помощью DPDK и OFS, да и функциональность во многом совпадает с Oak Springs Canyon. Но это всё же платформа для разработки конечных решений ODM-партнёрами Intel, которые могут с её помощью имплементировать какие-то специфические протоколы или функции с ускорением на FPGA, например, SRv6 или Juniper Contrail. IPU могут стать частью высокоинтегрированной ЦОД-платформы Intel, и на этом поле она будет соревноваться в первую очередь с NVIDIA, которая активно продвигает DPU BluefIeld, а вскоре обзаведётся ещё и собственным процессором. Из ближайших интересных анонсов, вероятно, стоит ждать поддержку Project Monterey, о которой уже заявили NVIDIA и Pensando.
30.06.2021 [22:44], Алексей Степин
Marvell анонсировала 5-нм DPU Octeon 10: 36 ядер ARM Neoverse N2, 400GbE, PCIe 5.0 и DDR5Концепция ускорителя для работы с данными, выделенного DPU, продолжает набирать популярность. В последнее время целый ряд компаний представил свои решения. А на днях очередь дошла до крупного разработчика микроэлектроники, компании Marvell, которая анонсировала DPU серии Octeon 10. Новые сопроцессоры построены на основе наиболее совершенного 5-нм техпроцесса TSMC и должны на равных сражаться с такими соперниками, как ускорители NVIDIA BlueField. Сама Marvell известна разработкой собственных вычислительных ядер, однако в Octeon 10 от этого подхода компания отошла, вернувшись к лицензированию ядер ARM — в основу новой серии чипов легли ядра Neoverse N2. 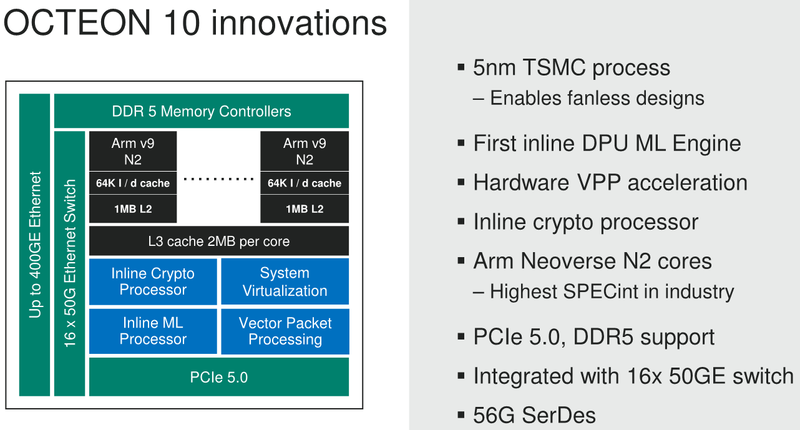 В основе данной архитектуры лежит набор команд ARM v9, появившийся не так уж давно. В сравнении с решениями на базе ARM v8.x эта архитектура может обеспечивать до 40% прироста в производительности, в том числе, за счёт поддержки 128-битных векторных расширений SVE2 и развитой подсистемы кешей. Процессорные ядра в Octeon 10 располагают по 1 и 2 Мбайт кешей второго и третьего уровня на каждое ядро. 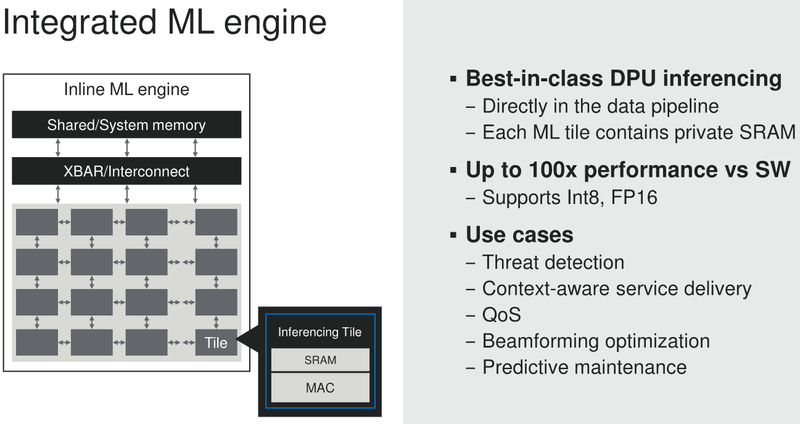 В составе новой SoC также присутствуют блоки ускорения сетевых задач и криптографические акселераторы. Кроме этого, кремний Octeon 10 получил и сетевой коммутатор, обеспечивающий работу 16 портов Ethernet со скоростью 50 Гбит/с. «Прокормить» столь требовательную «семью» непросто, но в плане подсистем ввода-вывода новые DPU также отвечают современным реалиям: они рассчитаны на работу с памятью DDR5-5200 и поддерживают интерфейс PCI Express 5.0, блоки SerDes относятся к поколению 56G. 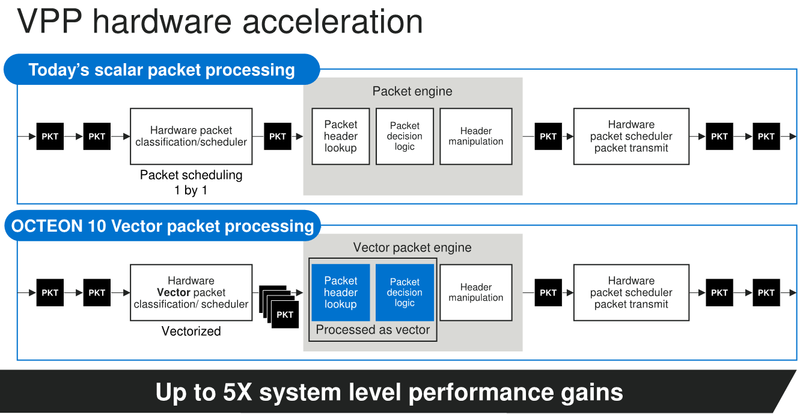 Отдельного упоминания заслуживает движок векторной обработки пакетов (Vector Packet Processing Engine), способный объединять в единую серию сетевые пакеты и «переваривать» их одновременно, как векторные данные. Такой подход позволяет серьёзно снизить латентность, что для DPU очень важно. Имеются в составе Octeon 10 и средства для работы с алгоритмами машинного обучения, причём каждый «тайл», поддерживающий INT8 и FP16, имеет свой объём SRAM. 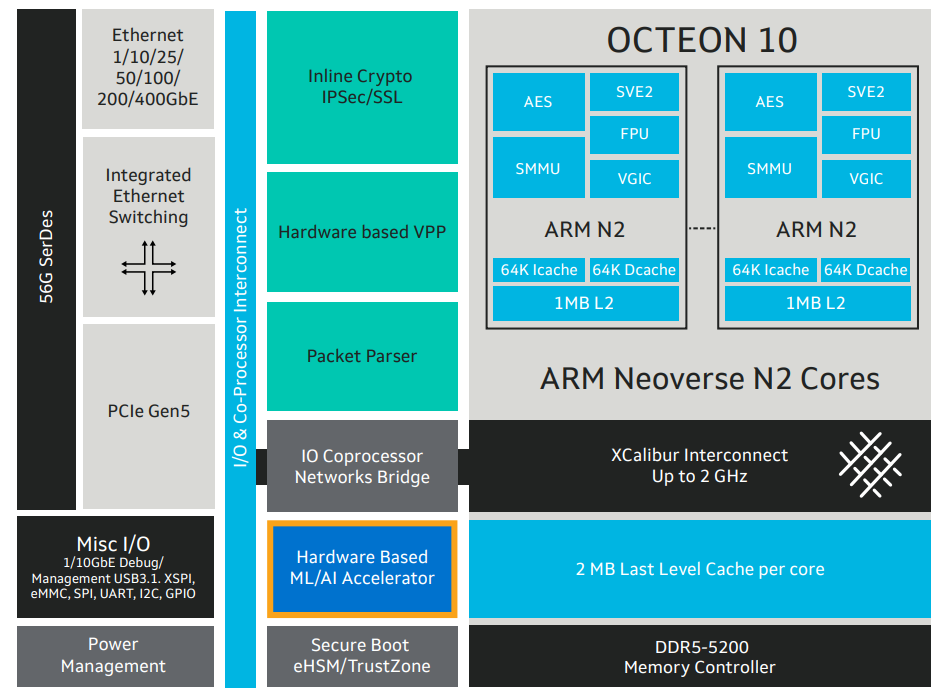 Пока семейство Octeon 10 представлено четырьмя моделями, младшая из которых может содержать до 8 ядер Neoverse N2, а старшая — до 36 таких ядер, причём о масштабировании подсистемы памяти разработчики также подумали и число контроллеров DDR5 в новых чипах варьируется от 2 до 12. Несмотря на столь солидные характеристики, теплопакеты удалось удержать в разумных рамках, и даже у наиболее мощной версии DPU400 TDP составляет всего 60 Ватт. 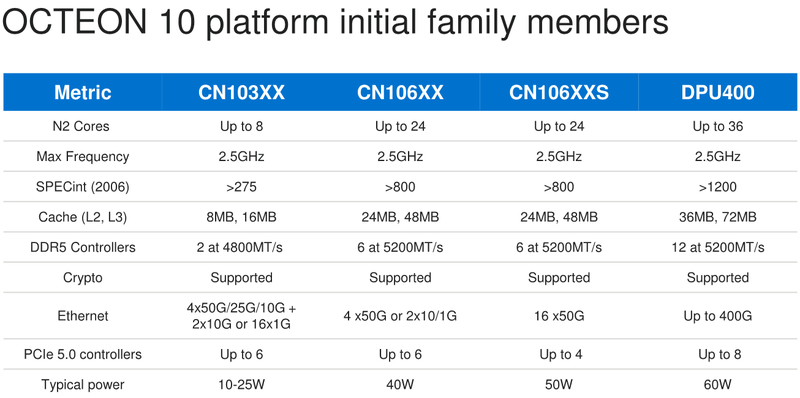 В настоящее время Marvell Octeon 10 уже находится в производстве, первые же партии новых чипов должны поступить к заказчикам во второй половине этого года. Столь многогранные DPU должны найти применение в самых разных сценариях, от поддержания инфраструктуры 5G RAN до работы в составе облачных систем, а также в высокопроизводительных маршрутизаторах.
15.04.2021 [21:24], Игорь Осколков
DPU BlueField — третий столп будущего NVIDIAВо время открытия GTC’21 наибольшее внимание привлёк, конечно, анонс собственного серверного Arm-процессора NVIDIA — Grace. Говорят, из-за этого даже акции Intel просели, хотя в последних решениях самой NVIDIA процессоры x86-64 были нужны уже лишь для поддержки «обвязки» вокруг непосредственно ускорителей. Да, теперь у NVIDIA есть три точки опоры, три столпа для будущего развития: GPU, DPU и CPU. Причём расположение их именно в таком порядке неслучайно. 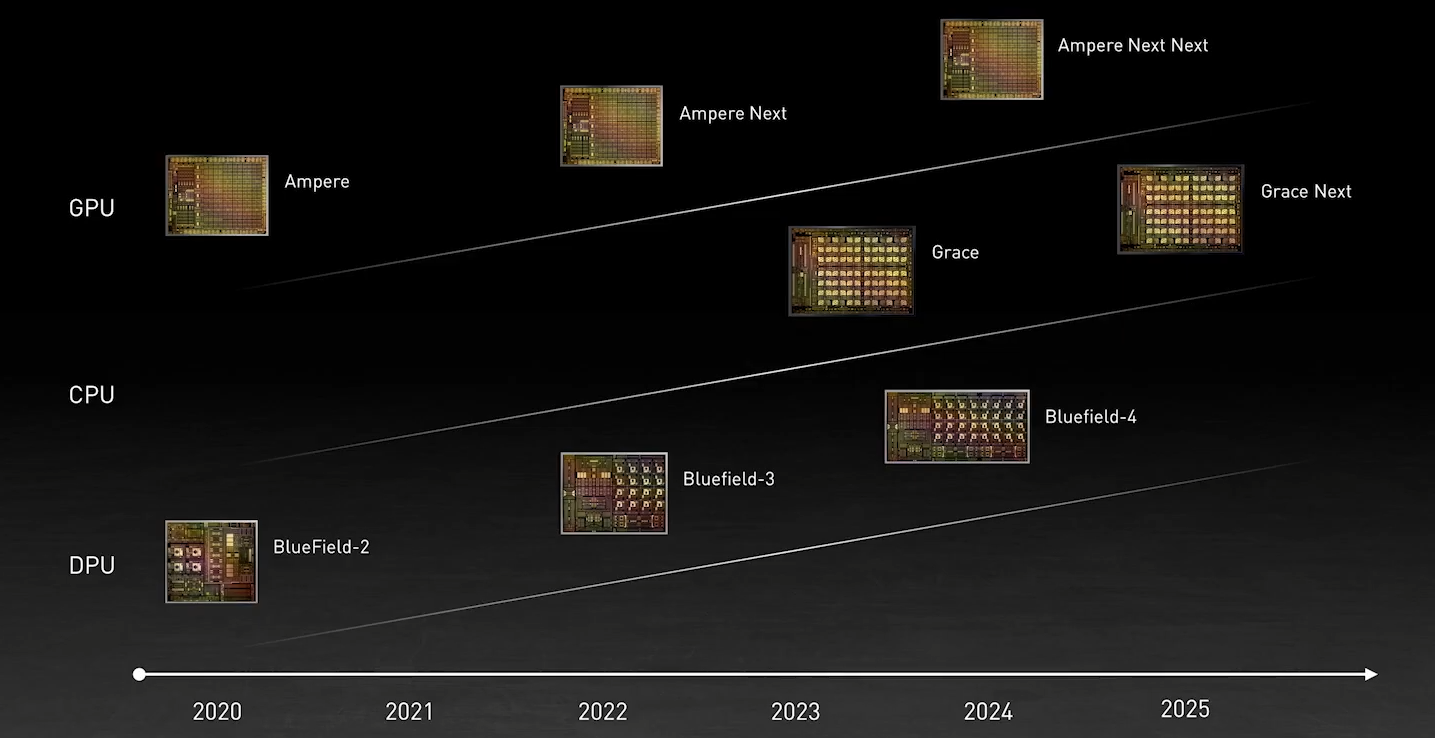 У процессора Grace, который выйдет только в 2023 году, даже по современным меркам «голая» производительность не так уж высока — в SPECrate2017_int его рейтинг будет 300. Но это и неважно потому, что он, как и сейчас, нужен лишь для поддержки ускорителей (которые для краткости будем называть GPU, хотя они всё менее соответствуют этому определению), что возьмут на себя основную вычислительную нагрузку. 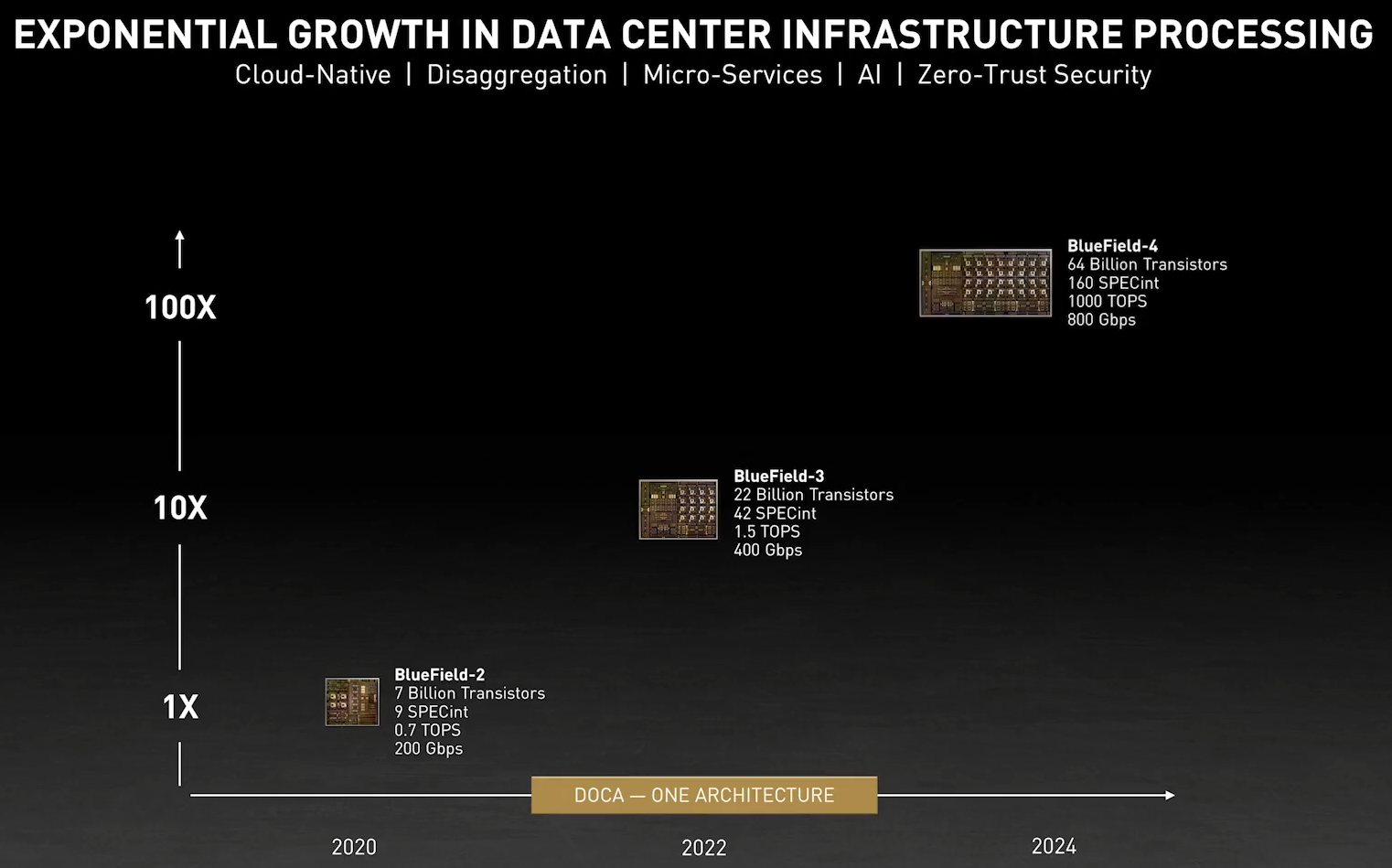 Гораздо интереснее то, что уже в 2024 году появятся BlueField-4, для которых заявленный уровень производительности в том же SPECrate2017_int составит 160. То есть DPU (Data Processing Unit, сопроцессор для данных) формально будет всего лишь в два раза медленнее CPU Grace, но при этом включать 64 млрд транзисторов. У нынешних ускорителей A100 их «всего» 54 млрд, и это один из самых крупных массово производимых чипов на сегодня.  Значительный объём транзисторного бюджета, очевидно, пойдёт не на собственной сетевую часть, а на Arm-ядра и различные ускорители. Анонсированные в прошлом году и ставшие доступными сейчас DPU BlueField-2 намного скромнее. Но именно с их помощью NVIDIA готовит экосистему для будущих комплексных решений, где DPU действительно станут «третьим сокетом», как когда-то провозгласил стартап Fubgible, успевший анонсировать до GTC’21 и собственную СХД, и более общее решение для дата-центров. Однако подход двух компаний отличается. 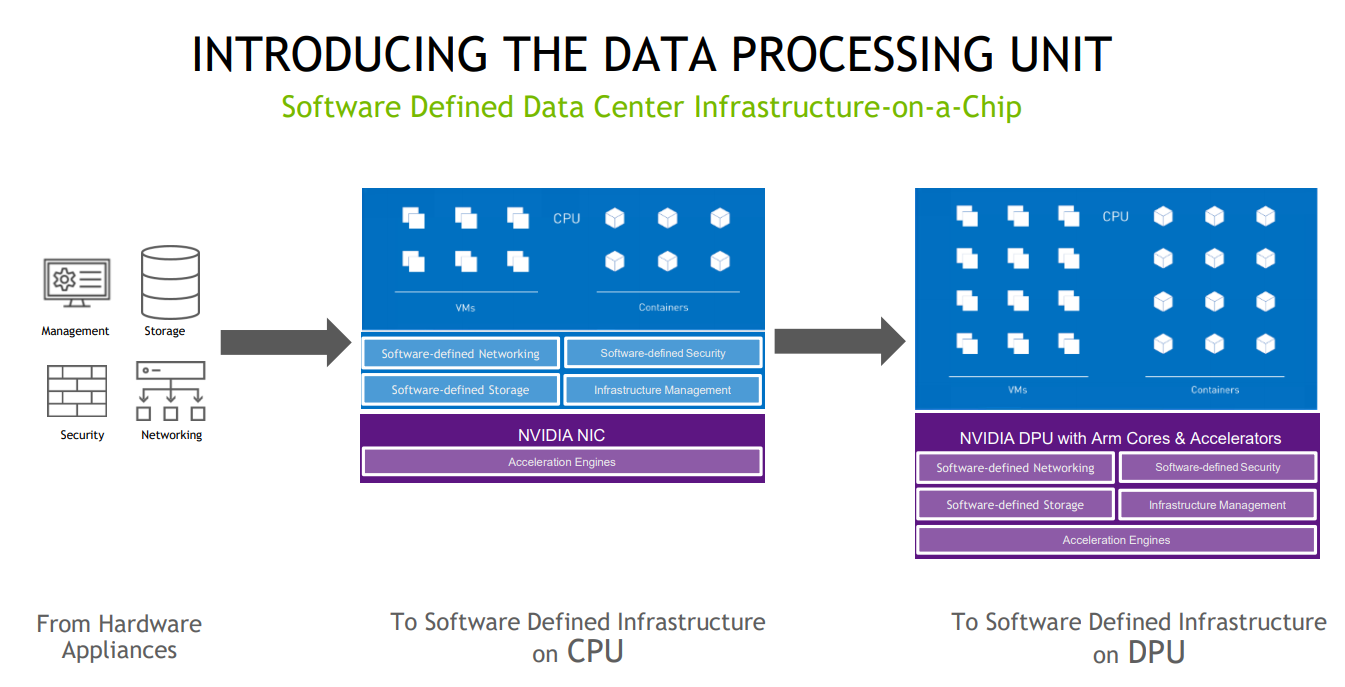 Напомним основные характеристики BlueField-2. Сетевая часть, представленная Mellanox ConnectX-6 Dx, предлагает до двух портов 100 Гбит/с, причём доступны варианты и с Ethernet, и с InfiniBand. Есть отдельные движки для ускорения криптографии, регулярных выражений, (де-)компрессии и т.д. Всё это дополняют 8 ядер Cortex-A78 (до 2,5 ГГц), от 8 до 32 Гбайт DDR4-3200 ECC, собственный PCIe-свитч и возможность подключения M.2/U.2-накопителя. Кроме того, будет вариант BlueField-2X c GPU на борту. Характеристики конкретных адаптеров на базе BlueField-2 отличаются, но, в целом, перед нами полноценный компьютер. А сама NVIDIA называет его DOCA (DataCenter on a Chip Architecture), дата-центром на чипе. 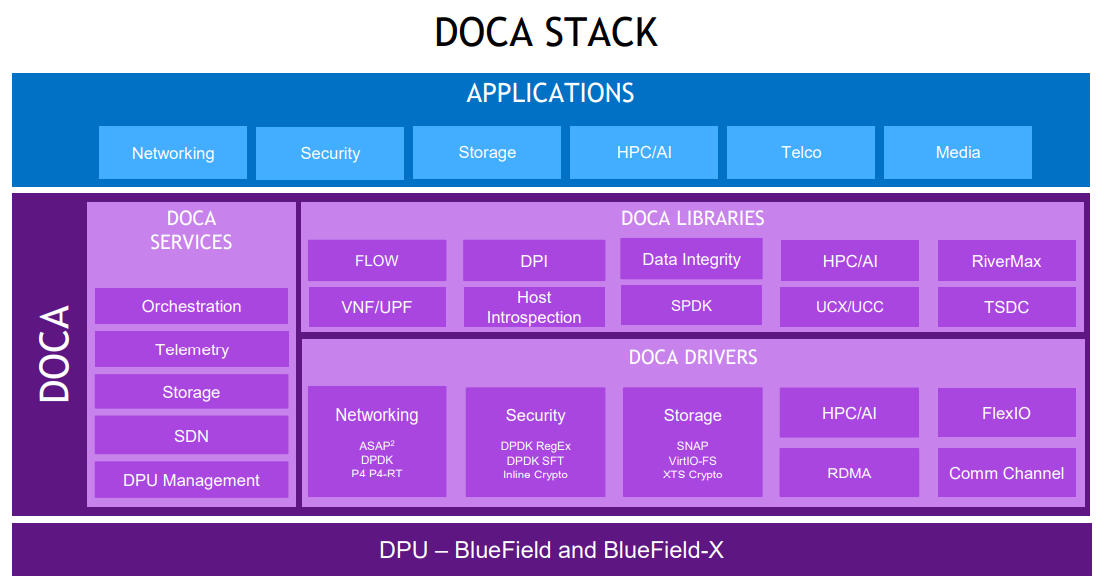 Для работы с ним предлагается обширный набор разработчика DOCA SDK, который включает драйверы, фреймворки, библиотеки, API, службы и собственно среду исполнения. Все вместе они покрывают практически все возможные типовые серверные нагрузки и задачи, а также сервисы, которые с помощью SDK относительно легко перевести в разряд программно определяемых, к чему, собственно говоря, все давно стремятся. NVIDIA обещает, что DOCA станет для DPU тем же, чем стала CUDA для GPU, сохранив совместимость с последующими версиями ПО и «железа». 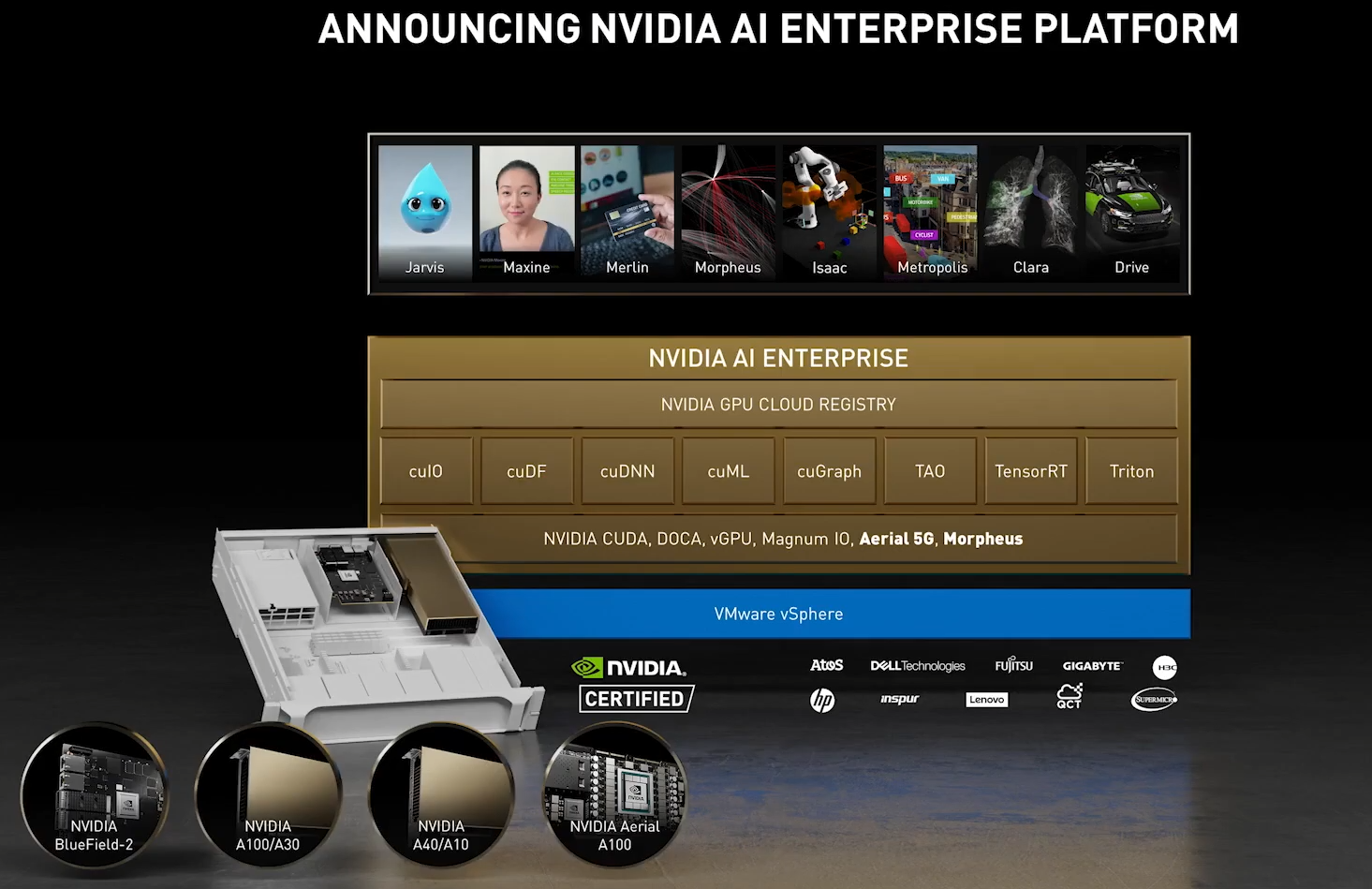 На базе этого программно-аппаратного стека компания уже сейчас предлагает несколько решений. Первое — платформа NVIDIA AI Enterprise для простого, быстрого и удобного внедрения ИИ-решений. В качестве основы используется VMware vSphere, где развёртываются виртуальные машины и контейнеры, что упрощает работу с инфраструктурой, при этом производительность обещана практически такая же, как и в случае bare-metal. 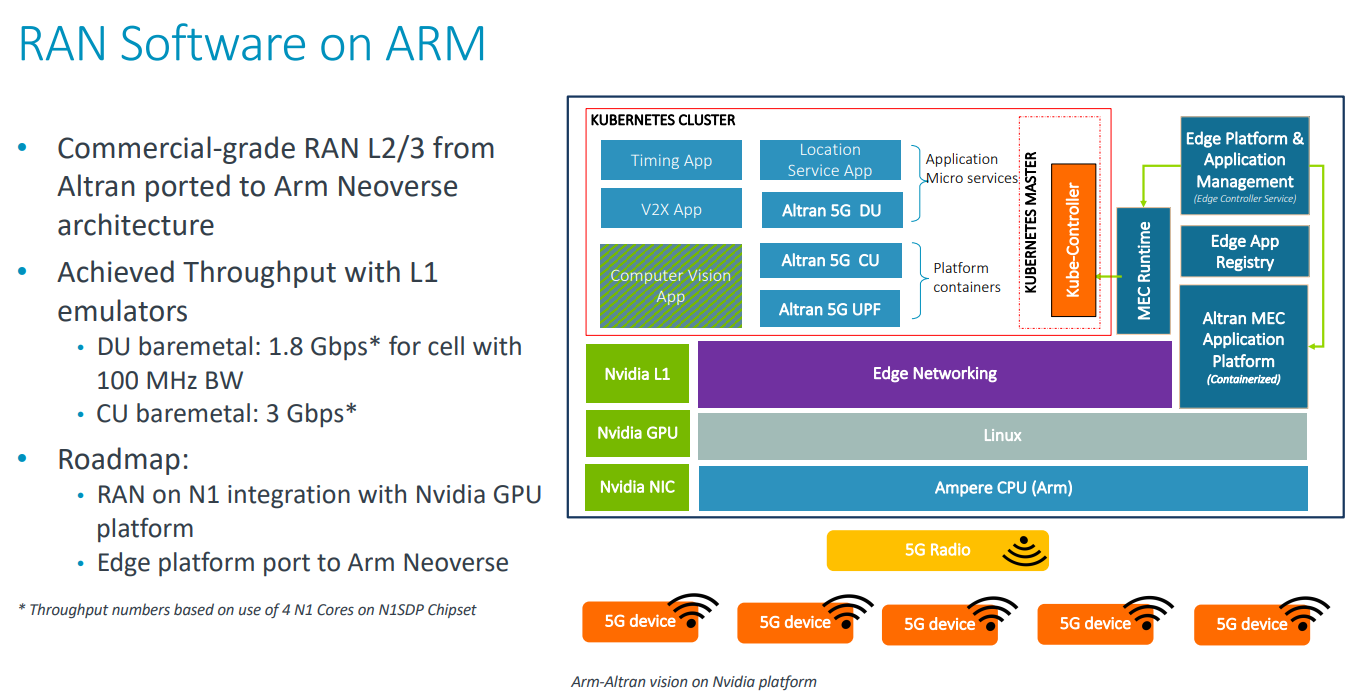 DPU и в текущем виде поддерживают возможность разгрузки для некоторых задач, но VMware вместе с NVIDIA переносят часть типовых задач гипервизора с CPU непосредственно на DPU. Кроме того, VMware продолжает работу над переносом своих решений с x86-64 на Arm, что вполне укладывается в планы развития Arm-экосистемы со стороны NVIDIA. Одним из направлений является 5G, причём работа ведётся по нескольким направлениям. Во-первых, сама Arm разрабатывает периферийную платформу на базе Ampere Altra, дополненных GPU и DPU. 
NVIDIA Aerial A100 Во-вторых, у NVIDIA конвергентное решение — ускоритель Aerial A100, который объединяет в одной карте собственно A100 и DPU. При этом он может использоваться как для ускорения работы собственно радиочасти, так и для обработки самого трафика и реализации различных пограничных сервисов. Там же, где не требуется высокая плотность (как в базовой станции), NVIDIA предлагает использовать более привычную EGX-платформу с раздельными GPU (от A100 и A40 до A30/A10) и DPU. 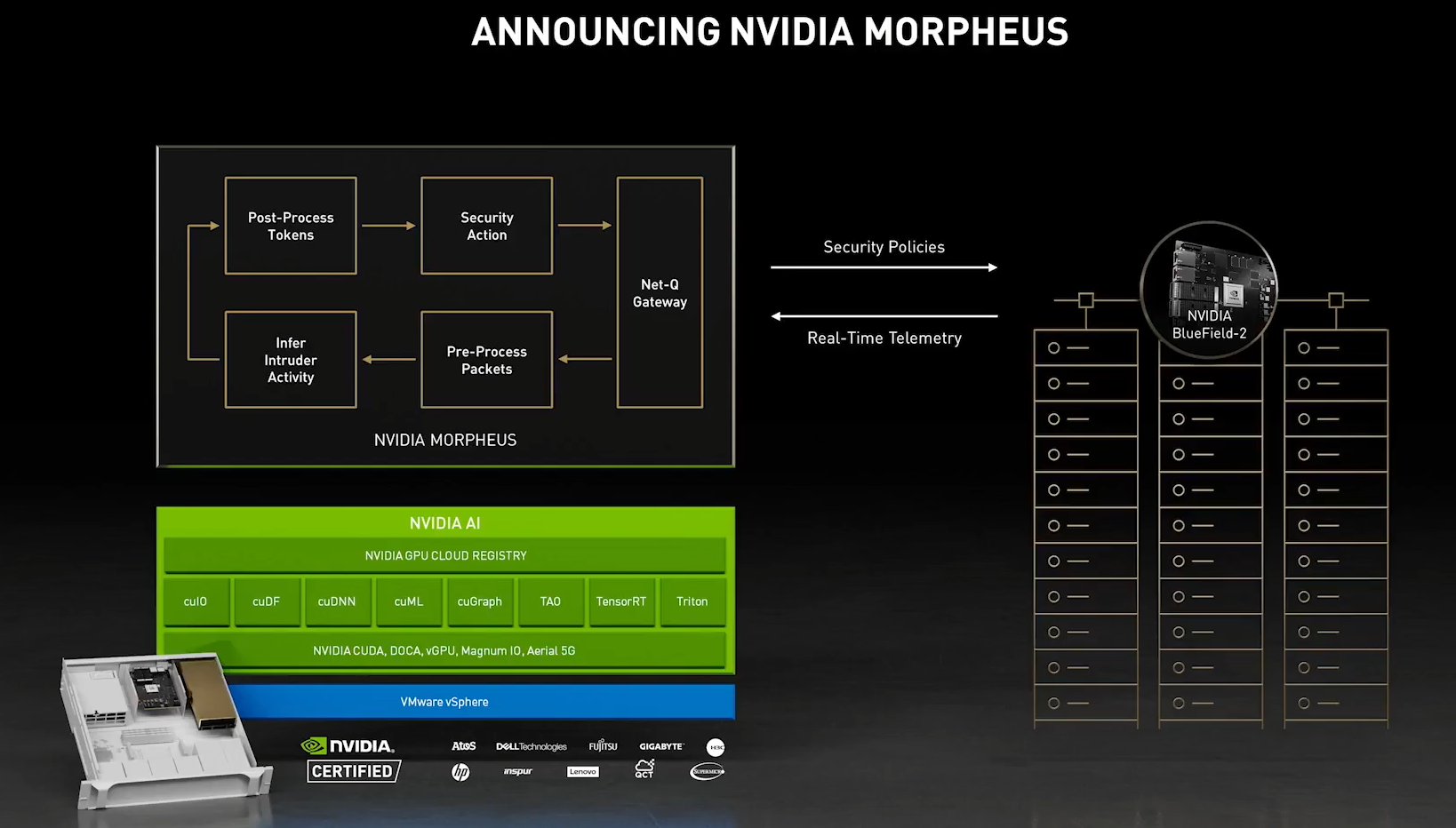 Одним из вариантов комплексного применения таких платформ является проект Morpheus. В его рамках предполагается установка DPU в каждый сервер в дата-центре. Мощностей DPU, в частности, вполне хватает для инспекции трафика, что позволяет отслеживать взаимодействие серверов, приложений, ВМ и контейнеров внутри ЦОД, а также, очевидно, применять различные политики в отношении трафика. DPU в данном случае выступают как сенсоры, данных от которых стекаются в EGX, и, вместе с тем локальными шлюзами безопасности. 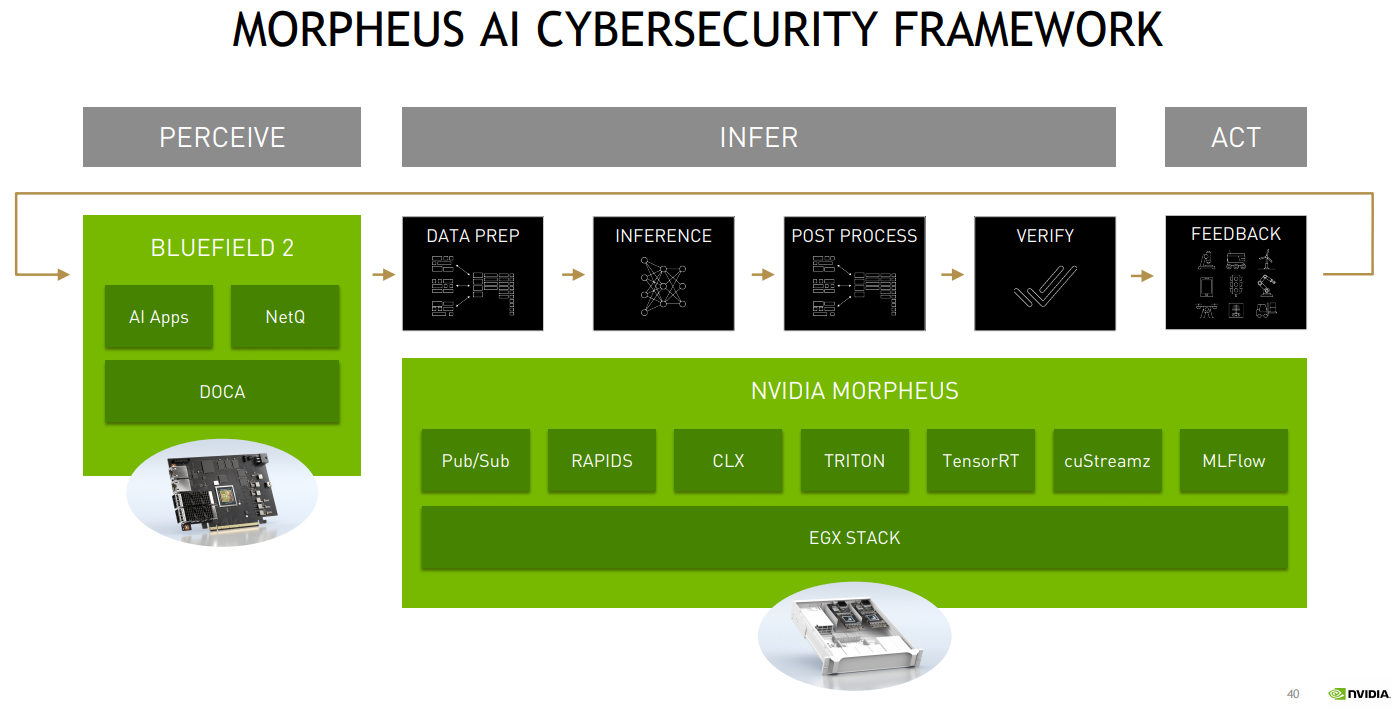 Ручная настройка политик и отслеживание поведения всего парка ЦОД возможны, но не слишком эффективны. Поэтому NVIDIA предлагает как возможность обучения, так и готовые модели (с дообучением по желанию), которые исполняются на GPU внутри EGX и позволяют быстро выявить аномальное поведение, уведомить о нём и отсечь подозрительные приложения или узлы от остальной сети. В эпоху микросервисов, говорит компания, более чем актуально следить за состоянием инфраструктуры внутри ЦОД, а не только на его границе, как было раньше, когда всё внутри дата-центра по умолчанию считалось доверенной средой. 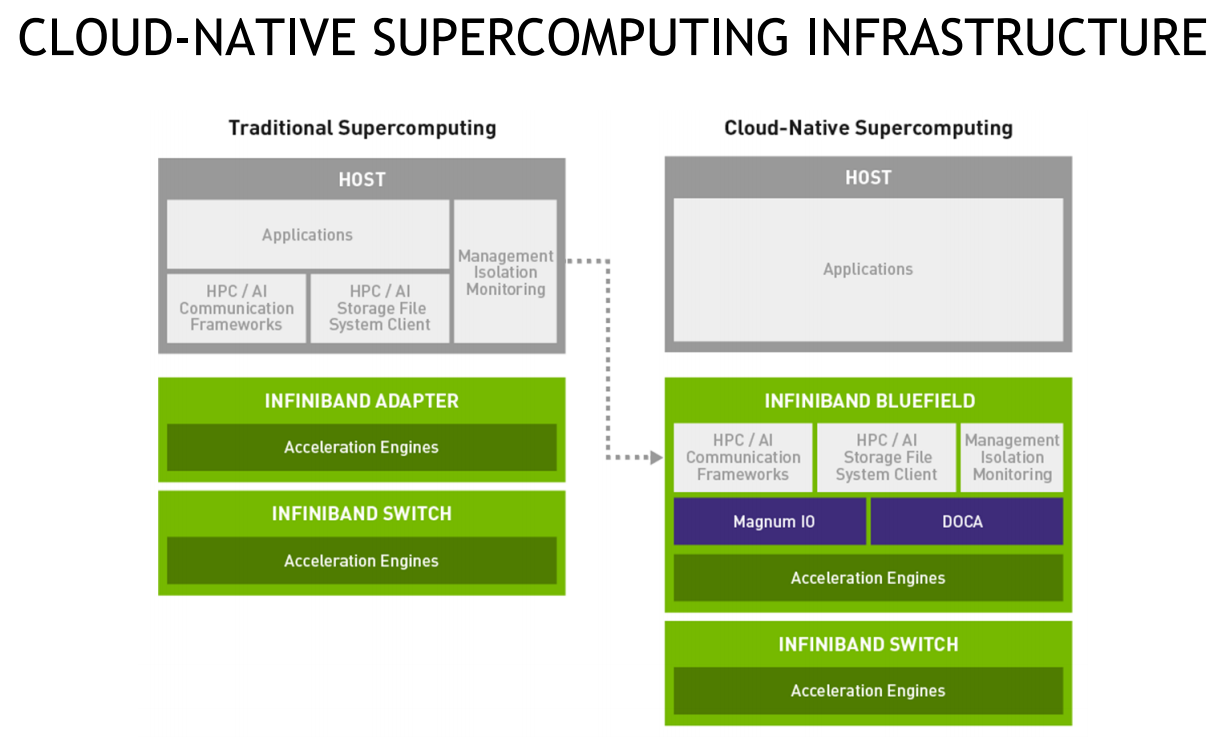 Кроме того, с помощью DPU и DOCA можно перевести инфраструктуру ЦОД на облачную модель и упростить оркестрацию. Но не только ЦОД — обновлённая суперкомпьютерная платформа DGX SuperPOD for Enterprise теперь тоже обзавелась DPU (с InfiniBand) и ПО Base Command, которые позволяют «нарезать» машину на изолированные инстансы с необходимой конфигурацией, упрощая таким образом совместное использование и мониторинг. А это, в свою очередь, повышает эффективность загрузки суперкомпьютера. Base Command выросла из внутренней системы управления Selene, собственным суперкомпьютером NVIDIA, на котором, например, компания обучает модели. 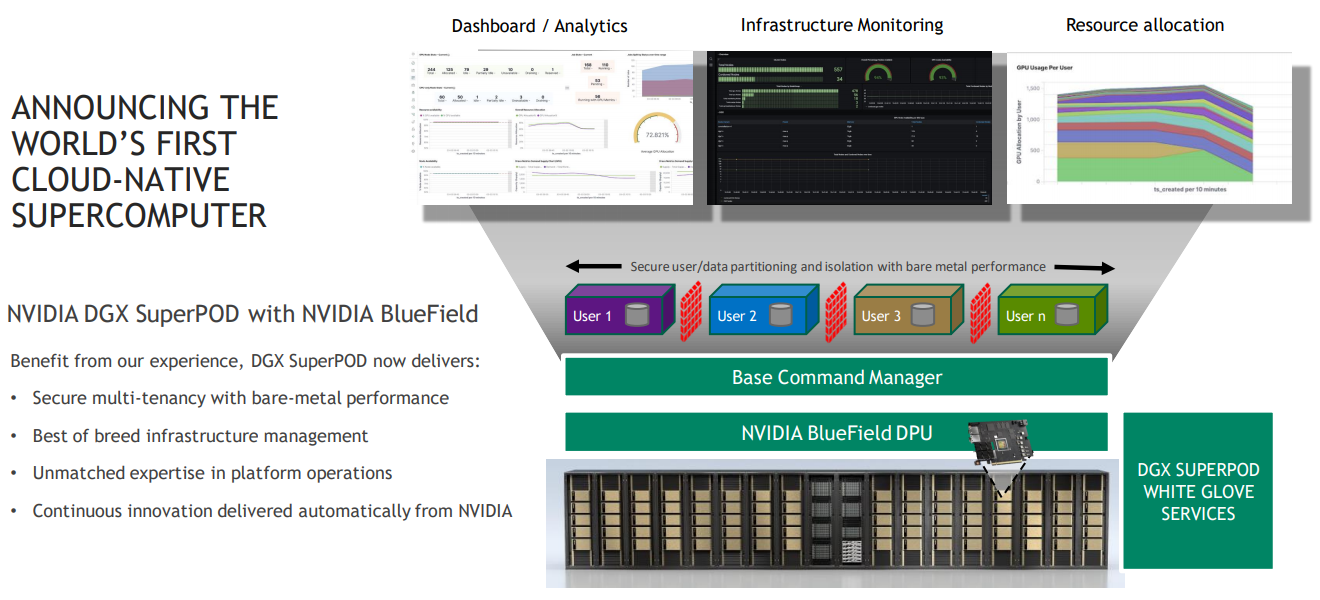 DPU доступны как отдельные устройства, так и в составе сертифицированных платформ NVIDIA и решений партнёров компании, причём спектр таковых велик. Таким образом компания пытается выстроить комплексный подход, предлагая программно-аппаратные решения вкупе с данными (моделями). Аналогичный по своей сути подход исповедует Intel, а AMD с поглощением Xilinx, надо полагать, тоже будет смотреть в эту сторону. И «угрозу» для них представляют не только GPU, но теперь и DPU. А вот новые CPU у NVIDIA, вероятно, на какое-то время останутся только в составе собственных продуктов, в независимости от того, разрешат ли компании поглотить Arm.
12.04.2021 [19:21], Алексей Степин
NVIDIA анонсировала DPU BlueField-3: 400 Гбит/с, 16 ядер Cortex-A78 и PCIe 5.0Идея «сопроцессора данных», озвученная всерьёз в 2020 году компанией Fungible, продолжает активно развиваться и прокладывать себе дорогу в жизнь. На конференции GTC 2021 корпорация NVIDIA анонсировала новое поколение «умных» сетевых карт BlueField-3, способное работать на скорости 400 Гбит/с. Изначально серия ускорителей BlueField разрабатывалась компанией Mellanox, и одной из целей создания столь продвинутых сетевых адаптеров стала реализация концепции «нулевого доверия» (zero trust) для сетевой инфраструктуры ЦОД нового поколения. Адаптеры BlueField-2 были анонсированы в начале прошлого года. Они поддерживали два 100GbE-порта, микросегментацию, и могли осуществлять глубокую инспекцию пакетов полностью автономно, без нагрузки на серверные ЦП. Шифрование TLS/IPSEC такие карты могли выполнять на полной скорости, не создавая узких мест в сети. 
Кристалл BlueField-3 не уступает в сложности современным многоядерным ЦП — 22 млрд транзисторов Но на сегодня 100 и даже 200 Гбит/с уже не является пределом мечтаний — провайдеры и разработчики ЦОД активно осваивают скорости 400 и 800 Гбит/с. Столь скоростные сети требуют нового уровня производительности от DPU, и NVIDIA вскоре сможет предложить такой уровень: на конференции GTC 2021 анонсировано новое, третье поколение карт BlueField. 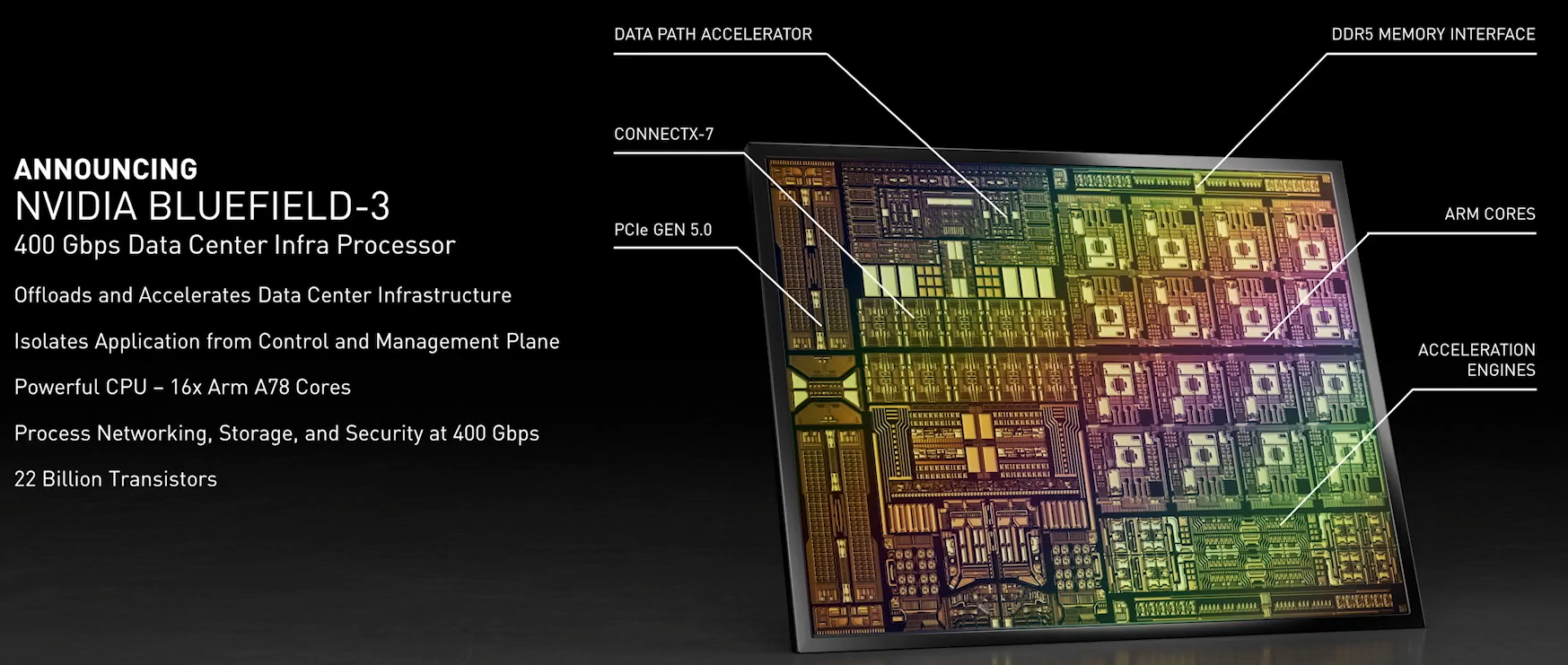 Если BlueField-2 могла похвастаться массивом из восьми ядер ARM Cortex-A72, объединённых когерентной сетью, то BlueField-3 располагает уже шестнадцатью ядрами Cortex-A78 и в четыре раза более мощными блоками криптографии и DPI. Совокупно речь идёт о росте производительности на порядок, что позволяет новинке работать без задержек на скорости 400 Гбит/с — и это первый в индустрии адаптер класса 400GbE со столь продвинутыми возможностями, поддерживающий, к тому же, стандарт PCI Express 5.0. Известно, что столь быстрым сетевым решениям PCIe 5.0 действительно необходим.  С точки зрения поддерживаемых возможностей BlueField-3 обратно совместим с BlueField-2, что позволит использовать уже имеющиеся наработки в области программного обеспечения для DPU. Одновременно с анонсом нового DPU компания представила и открытую программную платформу DOCA, упрощающую разработку ПО для таких сопроцессоров, поскольку они теперь занимаются не просто обработкой сетевого трафика, а оркестрацией работы серверов, приложений и микросервисов в рамках всего дата-центра.  В настоящее время NVIDIA сотрудничает с такими крупными поставщиками серверных решений, как Dell EMC, Inspur, Lenovo и Supermicro, со стороны разработчиков ПО интерес к BlueField проявляют Canonical, VMWare, Red Hat, Fortinet, NetApp и ряд других компаний. О массовом производстве BlueField-3 речи пока не идёт, поставка малыми партиями ожидается в первом квартале 2022 года, но карты BlueField-2 доступны уже сейчас. А в 2024 году появятся BlueField-4 с портами 800 Гбит/с.
16.10.2020 [23:17], Юрий Поздеев
DPU в стиле Intel: сетевые адаптеры с Xeon D, FPGA, HBM и SSDМир сетевых карт становится умнее. Это следующий шаг в дезагрегации ресурсов центров обработки данных. Наличие расширенных возможностей сетевых карт позволяет разгрузить центральный процессор, при этом специализированные сетевые адаптеры обеспечивают более совершенные функции и безопасность. В этой новости мы познакомим вас сразу с двумя адаптерами: Silicom SmartNIC N5010 и Inventec SmartNIC C5020X. Silicom FPGA SmartNIC N5010 предназначена для систем крупных коммуникационных провайдеров. Операторы все чаще стремятся заменить проприетарные форм-факторы от поставщиков телекоммуникационного оборудования на более стандартные варианты. В рамках этого мы видим, что производители ПЛИС не прочи освоить и эту нишу.  В Silicom FPGA SmartNIC N5010 используется Intel Stratix 10 DX с 8 Гбайт памяти HBM. Поскольку пропускная способность памяти становится все большим аспектом производительности системы, HBM будет продолжать распространяться за пределы графических процессоров и FPGA. В SmartNIC и DPU память HBM может использоваться для размещения индексных таблиц поиска и других функций для интенсивных сетевых нагрузок. Помимо HBM SmartNIC N5010 имеет еще 32 Гбайт памяти DDR4 ECC. SmartNIC N5010 потребляет до 225 Вт, что предполагает несколько вариантов исполнения карты, в том числе и с активным охлаждением.  Самая интересная особенность новой карты — 4 сетевых порта по 100 Гбит/с. На плате SmartNIC N5010 установлены две базовые сетевые карты Intel E810 (Columbiaville). На приведенной схеме можно заметить, что используется интерфейс PCIe Gen4 x16, причем их тут сразу два. Для работы четырех 100GbE-портов уже недостаточно одного интерфейса PCIe 4.0 x16. Второй порт PCIe 4.0 x16 может быть подключен через дополнительный кабель к линиям второго процессора, чтобы избежать межпроцессорного взаимодействия для передачи данных.  Вторая новинка, Inventec FPGA SmartNIC C5020X, совмещает на одной плате процессор Intel Xeon D и FPGA Intel Stratix 10. Этот адаптер предназначен для разгрузки центрального процессора в серверах крупных облачных провайдеров. На плате установлен процессор Intel Xeon D-1612 с 32-Гбайт SSD и 16 Гбайт DDR4, подключение к ПЛИС Intel Stratix 10 DX 1100 осуществляется через PCIe 3.0 x8. Нужно отметить, что FPGA Stratix имеет свои собственные 16 Гбайт памяти DDR4, а также обеспечивает сетевые подключения 25/50 Гбит/с и оснащен интерфейсом PCIe 4.0 x8, через который адаптер подключается к хосту. 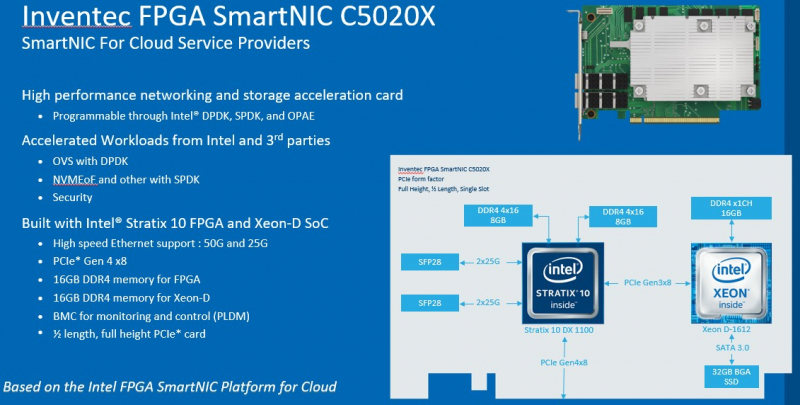 У Inventec уже есть решение на базе Arm (Inventec X250), которое использует ПЛИС Arria 10 GX660 вместе с сетевым адаптером Broadcom Stingray BCM8804, которое имеет аналогичный форм-фактор и TPD не более 75 Вт. Однако для некоторых организаций наличие единой x86 платформы, включая SmartNIC, упрощает развертывание, поэтому вариант C5020X для таких компаний более предпочтителен. Решение получилось очень интересным, однако вряд ли его можно назвать адаптером для массового рынка, как Intel Columbiaville. На примере этого адаптера Intel показала, что может объединить элементы своего портфеля для создания комплексных решений. Inventec FPGA SmartNIC C5020X является хорошей альтернативой предложению на базе Broadcom, что позволит крупным облачным провайдерам диверсифицировать свои платформы.  Несмотря на то, что обе новинки классифицируются как «умные» сетевые адаптеры SmartNIC, вторая, пожалуй, уже ближе к DPU, если сравнивать её с адаптерами NVIDIA DPU, в которых сетевая часть дополнена Arm-процессором и GPU-ускорителем. В данном случае есть и x86-ядра общего назначения, и ускоритель, хотя и на базе ПЛИС. Впрочем, устоявшегося определения DPU и списка критериев соответствия этому классу процессоров пока нет.
19.08.2020 [19:04], Игорь Осколков
Третий сокет: Fungible представляет новый класс процессоров — DPUИдея дезагрегации ресурсов, которые в последнее время становятся всё более разнообразными, далеко не нова. Выделенные аппаратные блоки, которые помогают перемещать данные между ресурсами, тоже в том или ином виде развиваются не первый год. Fungible же решила довести эту концепцию до логического конца, создав DPU (Data Processing Unit).  На конференции HotChips 32 компания рассказала о двух процессорах: Fungible F1 и S1. Первому из них и был посвящён основной доклад. F1 ориентирован на работу с хранилищами и безопасную обработку больших потоков данных, которые требуются современным системам ИИ и аналитики. 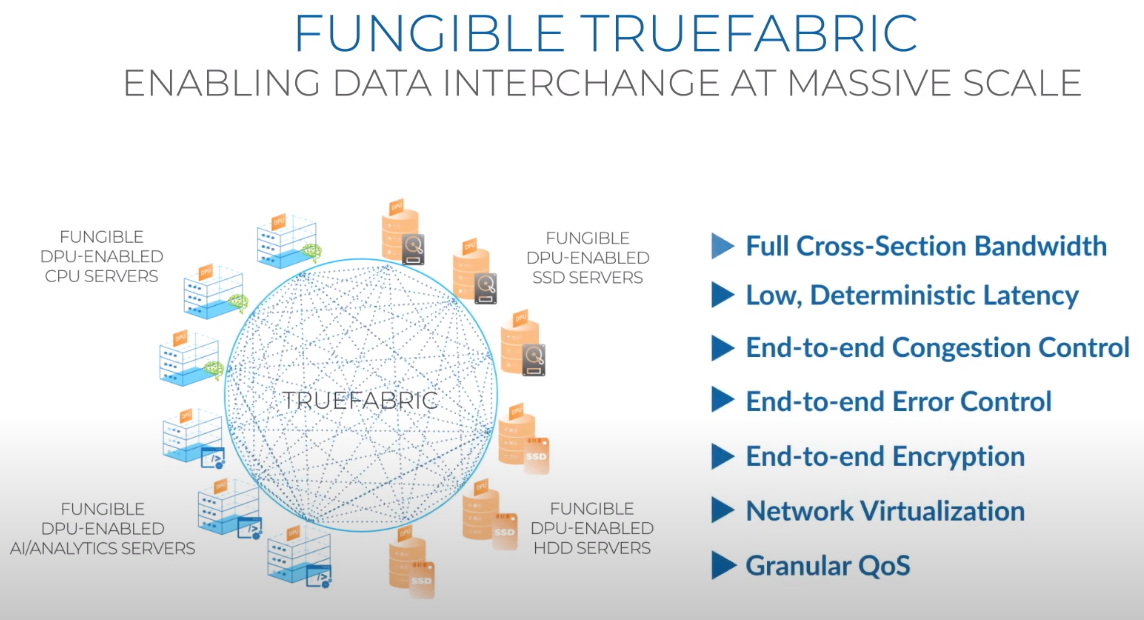 При взгляде «свысока» F1 представляет собой чип c двумя основными интерфейсами: 8 каналов 100GbE и 4 контроллера PCIe 3.0/4.0 x16. Тем не менее, это не просто очередная реализация RDMA или, допустим, NVMe-oF. Со стороны сети предполагается организация общей фабрики между всем узлами, которую разработчики называют TruFabric. 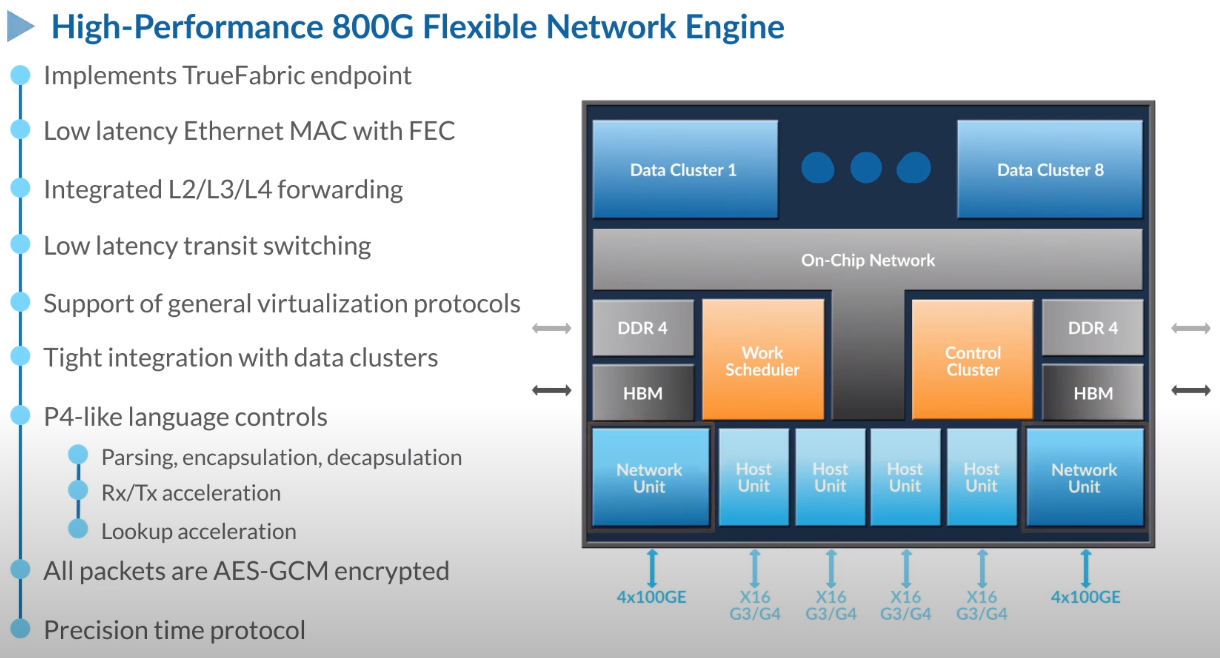 В отличие от многих других решений для фабрики здесь используется стандартный и относительно дешёвый Ethernet, а не PCIe, InfiniBand, Fibre Channel или какой-то проприетарный интерконнект. Весь трафик шифруется, а для реализации собственных функций разгрузки предлагается P4-подобный язык программирования. 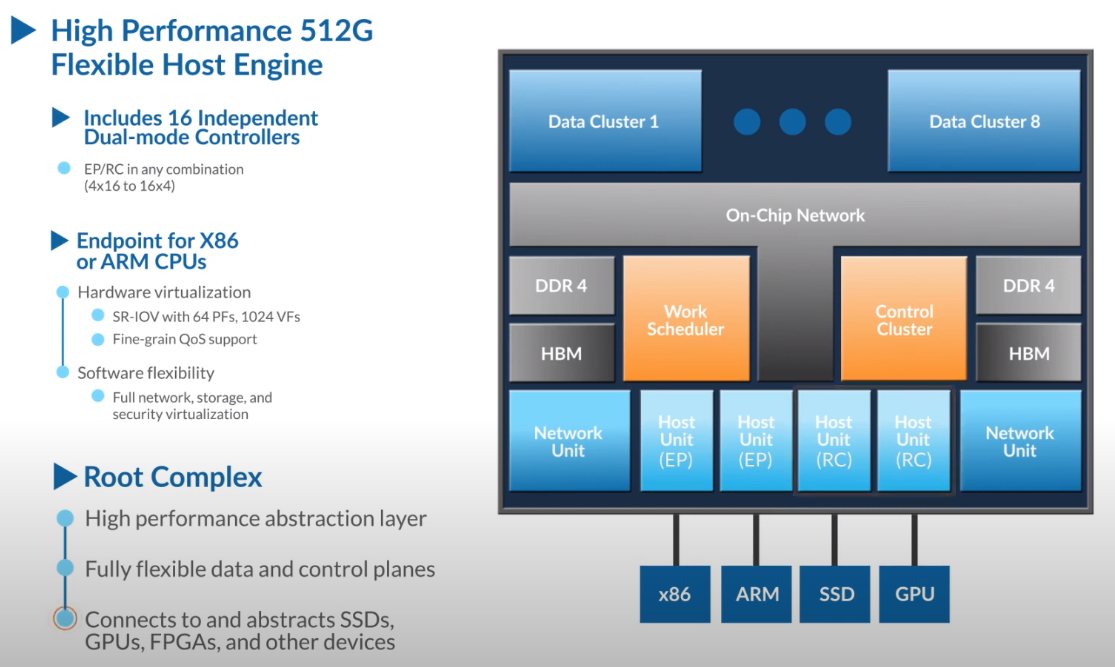 Со стороны PCIe F1 может «представляться» серверу как ещё один адаптер (с SR-IOV), а может предоставлять и собственный root-комплекс для прямого подключения и абстракции других устройств: CPU, GPU, FPGA, NVMe SSD, HDD и так далее. 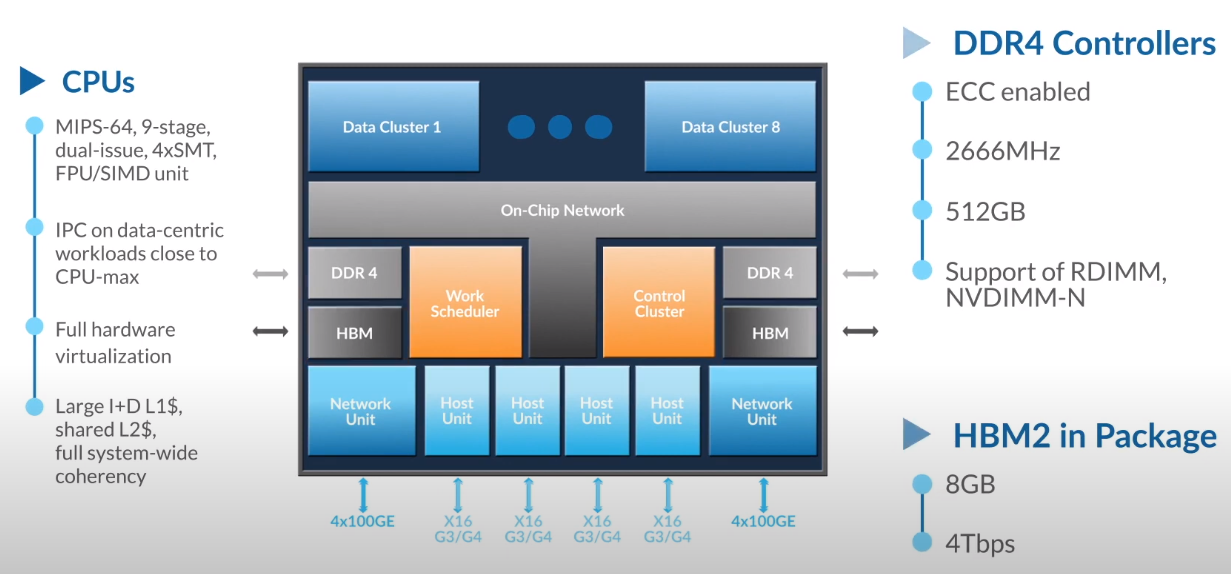 Fungible F1 помимо Ethernet и PCIe включает общий контроллер памяти, планировщик, управляющий блок и собственно блоки обработки данных. Все они объединены внутренней сверхбыстрой шиной. Контроллеры памяти обслуживают 8 Гбайт набортной HBM (4 Тбит/с) + внешние модули DDR4-2666 ECC с поддержкой NVDIMM-N, суммарный объём которых может достигать 512 Гбайт. 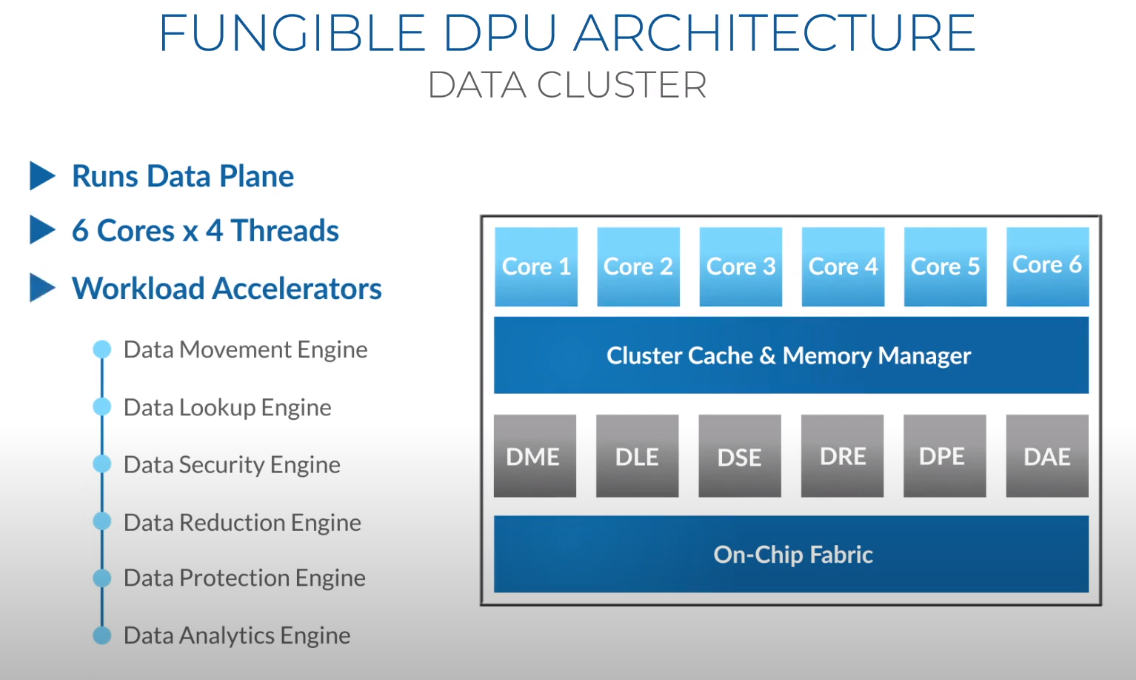 Блоков обработки данных (Data Cluster) в сумме восемь. Каждый из них имеет 6 ядер MIPS-64 общего назначения c SMT4. Их дополняют отдельные аппаратные акселераторы для поиска, передачи и сжатия объёма передаваемых данных, безопасности и защиты информации, а также для аналитики данных. Все ядра и акселераторы имеют общий кеш и менеджер памяти. Суммарно на чип приходится 48 ядер и 192 потока для обработки данных. 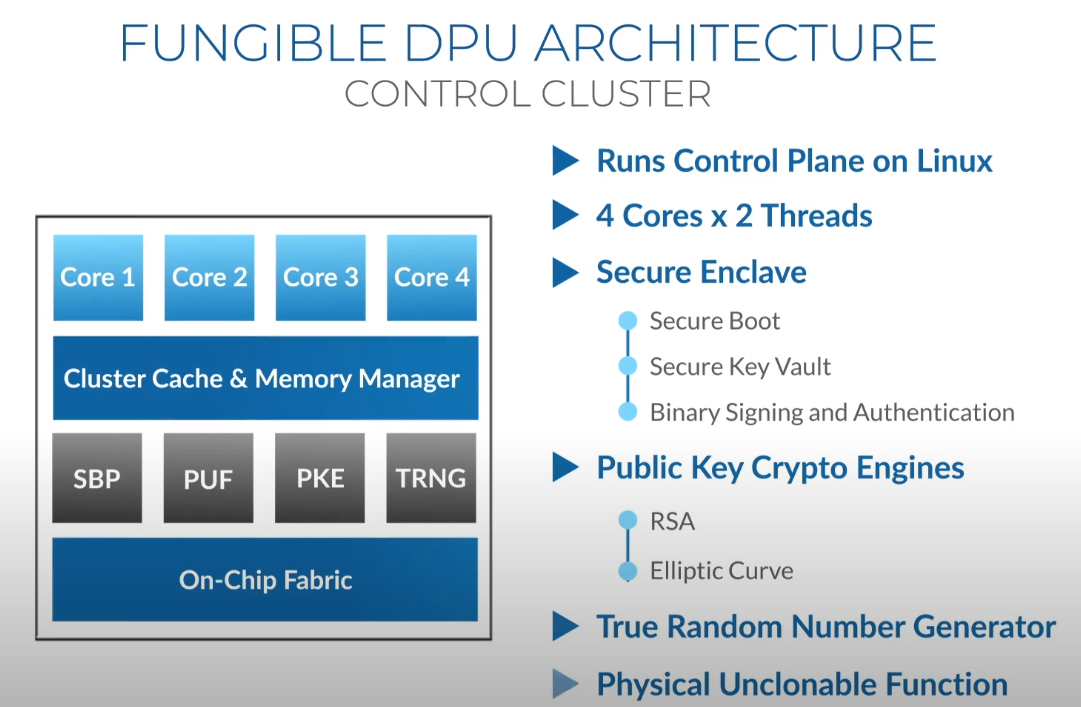 Управляет ими отдельный блок (Control Cluster), включающий 4 ядра MIPS-64 с SMT2, а также модули безопасности: изолированный анклав, генератор случайных чисел, аппаратный акселератор для работы с ключами шифрования. MIPS-ядра также имеют блоки FPU/SIMD и поддержку аппаратной виртуализации. 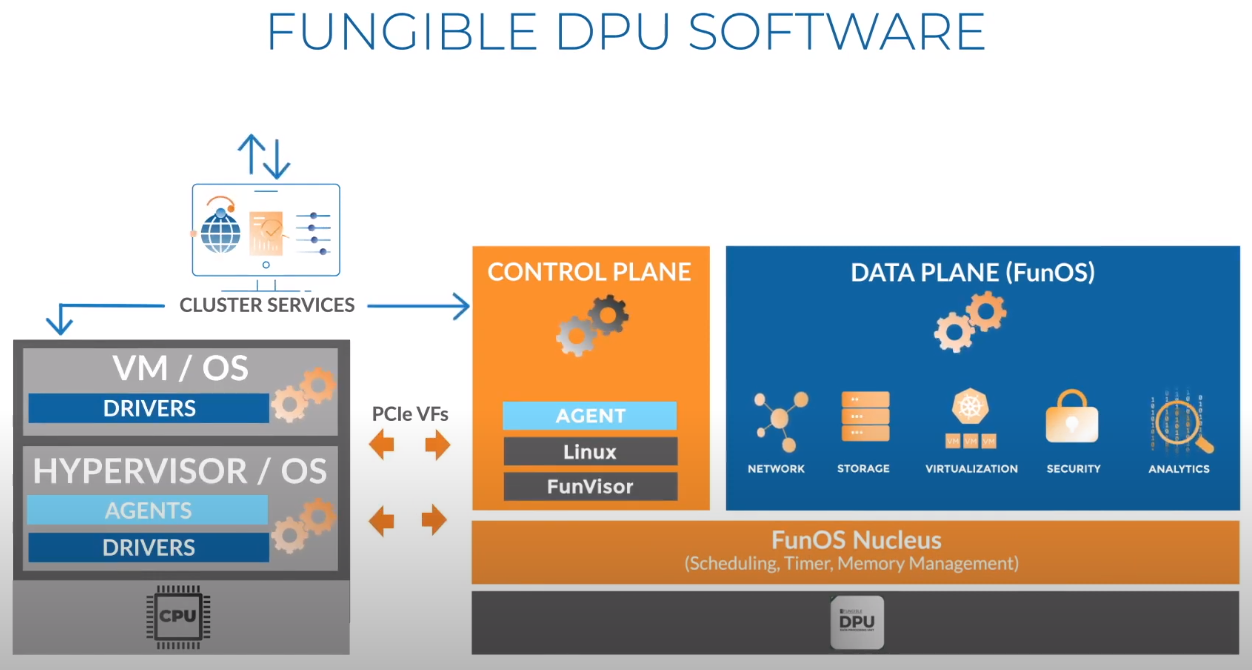 Программная часть представлена мини-ОС FunOS Nucleus, которая обеспечивает самые базовые функции. В блоках Data Cluster «живёт» FunOS, которая обслуживает пять программных стеков: сеть, хранилище, виртуализация, безопасность и аналитика. В Control Cluster работает сверхтонкий гипервизор FunVisor, поверх которого запущен Linux. Для ОС, гипервизора и ВМ, работающим на хост-процессоре x86 или ARM предлагаются драйверы и агенты.  Предварительные тесты действительно показывают значительное ускорение в некоторых нагрузках, а также достаточно высокий уровень производительности самих DPU и TrueFabric. При этом в отличие от SmartNIC и других подобных решений DPU от Fungible обещают быть намного универсальнее и вместе с тем проще в работе. 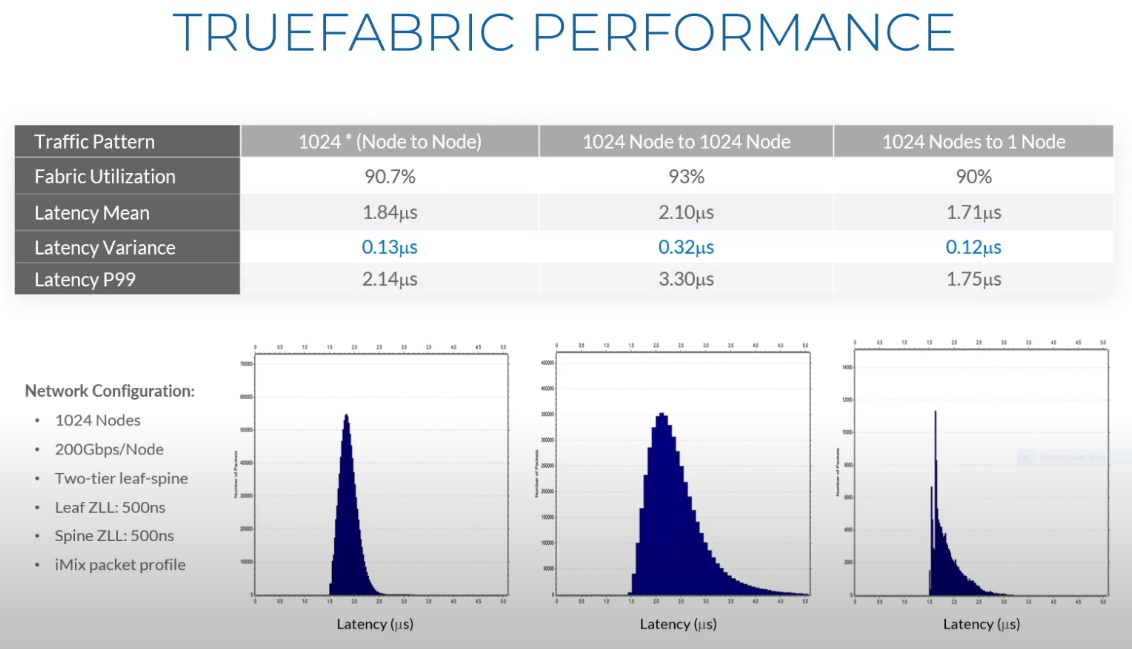 Fungible даже считает, что DPU должны стать одним из ключевых компонентов современных серверов в дата-центре, заняв третий по счёту сокет в системе после CPU и GPU. Таким образом, можно будет на лету «собирать» оптимизированные под конкретные задачи конфигурации из разрозненных ресурсов, объединённых DPU-хабами в единую фабрику. |
|