Материалы по тегу: ускоритель
|
31.01.2025 [06:24], Сергей Карасёв
Intel решила не поставлять ускорители Falcon Shores на рынокСо-генеральный директор Intel Мишель Джонстон Холтхаус (Michelle Johnston Holthaus) дала комментарии по поводу ускорителей Falcon Shores, которые должны были поступить в продажу в 2025 году. По её словам, эти изделия не появятся на коммерческом рынке. Ожидалось, что Falcon Shores выйдут после ускорителей Rialto Bridge, которые должны были прийти на смену Ponte Vecchio. Но в марте 2023 года Intel отменила выпуск Rialto Bridge. Тогда же сообщалось, что дебют Falcon Shores откладывается. После того, как гендиректор Intel Пэт Гелсингер (Pat Gelsinger) подал в отставку, будущее Falcon Shores оказалось под вопросом. Пытаясь прояснить ситуацию, Intel заявила, что планы по выпуску этих решений сохраняются — их планировалось поставлять в качестве GPU, а не гибридных ускорителей, как говорилось изначально. Однако в конце 2024 года появилась информация, что Intel рассматривает Falcon Shores как тестовый продукт. 
Источник изображения: Intel Как теперь заявила Холтхаус, Intel действительно использует Falcon Shores «в качестве внутреннего тестового чипа» — без планов по его выводу на коммерческий рынок. По её словам, основное внимание будет уделено ускорителям Jaguar Shores, которые, как предполагается, помогут разработать «системное решение в масштабе стойки» для укрепления позиций в области дата-центров, ориентированных на задачи ИИ. «ИИ ЦОД являются привлекательным рынком для нас. Но мы пока не закрепились в данном сегменте должным образом. Поэтому мы упрощаем дорожную карту и концентрируем ресурсы», — сказала Холтхаус. Она также добавила, что заказчики хотят получить полномасштабное стоечное решение, а не просто чипы. Ожидается, что проект Falcon Shores поможет в создании комплексной платформы, охватывающей системные компоненты, сеть и память. Вероятно, речь идёт об аналоге суперускорителей NVIDIA GB200 NVL72. В целом, Intel пытается скорректировать план дальнейшей работы после ряда неудач. Корпорация катастрофически отстала от NVIDIA и AMD по продажам ИИ-ускорителей — так, объём реализации Gaudi не достиг даже $500 млн. На этом фоне Intel приходится в спешном порядке менять стратегию.
28.01.2025 [18:40], Владимир Мироненко
«Рынки ошибаются»: DeepSeek не угрожает NVIDIA и другим американским IT-гигантам
deepseek
fortune
hardware
nvidia
анализ рынка
ии
инференс
китай
прогноз
санкции
сша
ускоритель
финансы
Рост популярности ИИ-технологий способствовал росту рыночной стоимости NVIDIA выше $3 трлн. Однако её акции обрушились в понедельник на 17 %, вызвав падение рыночной стоимости компании почти на $600 млрд, после анонса китайским стартапом DeepSeek ИИ-моделей V3 и R1, способных соперничать с лучшими моделями любой американской компании, хотя и были обучены за малую часть стоимости на менее продвинутых чипах NVIDIA H800 и A100, пишет Fortune. Также в начале недели приложение AI Assistant стартапа DeepSeek вышло на первое место в рейтинге самых популярных бесплатных приложений в интернет-магазине в Apple App Store в США, опередив ИИ-чат-бот ChatGPT от OpenAI. Более того, модель DeepSeek R1, призванная бросить вызов модели «рассуждений» OpenAI o1, можно запустить на рабочей станции, а не в ЦОД. Поскольку мощные ускорители NVIDIA являются одной из самых больших статей расходов на разработку самых передовых моделей ИИ, инвесторы начали пересматривать свои представления относительно вложений в ИИ-бизнес. Да, DeepSeek явно потряс рынок ИИ, однако разговоры о крахе NVIDIA могут быть преждевременными, равно как и заявления о том, что успех DeepSeek означает, что США следует отказаться от политики, направленной на ограничение доступа Китая к самым передовым ИИ-чипам, предупреждают аналитики Fortune. DeepSeek утверждает, что использует 10 тыс. ускорителей NVIDIA A100, а также чипы H800, что на порядок меньше, чем используют американские компании для обучения своих самых передовых ИИ-моделей. Например, Xai Илона Маска (Elon Musk) построила вычислительный кластер Colossus в Теннесси на базе 100 тыс. ускорителей NVIDIA H100, его планирует расширить до 1 млн чипов. 
Источник изображения: Heather Wilde / Unsplash Это дало повод некоторым экспертам утверждать, что введение ограничений США подстегнуло инновации в Китае. В Fortune считают такие умозаключения недальновидными и утверждают, что влияние DeepSeek может, как это ни парадоксально звучит на первый взгляд, увеличить спрос на передовые чипы ИИ — как NVIDIA, так и её конкурентов. Причина отчасти заключена в феномене, известном как парадокс Джевонса (Jevons Paradox). Парадокс Джевонса, также известный как эффект отскока, назван в честь британского экономиста XIX века Уильяма Стэнли Джевонса (William Stanley Jevons), который заметил: когда технический прогресс делает использование ресурса более эффективным, общее потребление этого ресурса имеет тенденцию к увеличению. Это имеет смысл, если спрос на что-либо относительно эластичен — снижающаяся из-за повышения эффективности цена создаёт ещё больший спрос на продукт. Одной из причин слабого внедрения ИИ-моделей в крупных организациях была их дороговизна. Это особенно касалось новых «рассуждающих» моделей, таких как o1 от OpenAI. Модели DeepSeek гораздо дешевле конкурентов в эксплуатации, так что теперь компании могут позволить себе развёртывать их для многих сценариев использования. В масштабах отрасли это может привести к резкому росту спроса на вычислительную мощность. В понедельник гендиректор Microsoft Сатья Наделла (Satya Nadella) и бывший гендиректор Intel Пэт Гелсингер (Pat Gelsinger) указали на это в сообщениях в социальных сетях. Наделла напрямую сослался на парадокс Джевонса, в то время как Гелсингер сказал, что «вычисления подчиняются» тому, что он назвал «законом газа». «Если сделать его значительно дешевле, рынок для него расширится… это сделает ИИ гораздо более широко распространенным, — написал он. — Рынки ошибаются». 
Источник изображения: Mark Daynes / Unsplash В Fortune задались вопросом: «Какая именно вычислительная мощность потребуется?». Топовые ускорители NVIDIA оптимизированы для обучения крупнейших больших языковых моделей (LLM), таких как GPT-4 от OpenAI или Claude 3-Opus от Anthropic. Для инференса чипы NVIDIA меньше подходят, чем изделия конкурентов, включая AMD и, например, Groq, чипы которых позволяют исполнять ИИ-нагрузки быстрее и намного эффективнее. Google и Amazon также создают свои собственные чипы ИИ, некоторые из которых оптимизированы для инференса. NVIDIA сейчас занимает более 80 % рынка ИИ-вычислений на базе ЦОД (если исключить кастомные ASIC облачных провайдеров, её доля может составить до 98 %) и вряд ли утратит доминирование быстро или полностью, отметили в Fortune. Ёе ускорители также могут использоваться для инференса, а программная платформа CUDA имеет большое и лояльное сообщество разработчиков, которое вряд ли откажется от него в одночасье. Если общий спрос на ИИ-чипы увеличится из-за парадокса Джевонса, общие доходы NVIDIA всё равно смогут вырасти даже при падении доли на рынке из-за увеличившегося рынка. Ещё одна причина, по которой спрос на передовые ИИ-чипы, вероятно, продолжит рост, связана с особенностями работы моделей рассуждений, таких как R1. В то время как способности предыдущих типов LLM росли по мере увеличения доступной вычислительной мощности во время обучения, то модели рассуждений зависят от вычислительных ресурсов во время инференса — чем их больше, тем лучше ответы. 
Источник изображения: Kayla Kozlowski / Unsplash Запустив R1 на ноутбуке, можно получить хороший ответ на сложный математический вопрос, скажем, через час, в то время как при использовании ускорителей в облаке на тот же ответ уйдут считанные секунды. Для многих бизнес-приложений задержка или время, необходимое модели для ответа, имеет большое значение. И чтобы сократить время выполнения задачи, по-прежнему будут нужны передовые ИИ-ускорители. Кроме того, многие эксперты сомневаются в правдивости заявления DeepSeek о том, что её модель V3 была обучена примерно на 2048 урезанных ускорителях NVIDIA H800 или что её модель R1 была обучена на столь малом количестве чипов. Александр Ван (Alexandr Wang), генеральный директор Scale AI, сообщил в интервью CNBC, что, по его данным, DeepSeek тайно получила доступ к кластеру из 50 тыс. ускорителей H100. Также известно, что хедж-фонд HighFlyer, которому принадлежит DeepSeek, успел закупить до введения санкций значительное количество менее производительных ускорителей NVIDIA. Так что вполне возможно, что NVIDIA находится в лучшем положении, чем предполагают паникующие инвесторы, и что проблема с экспортным контролем США заключается не в политике, а в её реализации, подытожили аналитики Fortune.
28.01.2025 [00:14], Владимир Мироненко
Дороговизна и высокое энергопотребление ИИ-ускорителей NVIDIA открыли новые горизонты для Marvell и BroadcomВзрывной рост популярности ChatGPT и других решений на базе генеративного ИИ вызвал беспрецедентный спрос на вычислительные мощности, что привело к дефициту ИИ-ускорителей, пишет DIGITIMES. NVIDIA занимает львиную долю рынка ИИ-чипов, а ведущие поставщики облачных услуг, такие как Google, Amazon и Microsoft, активно занимаются проектами по разработке собственных ускорителей, стремясь снизить свою зависимость от внешних поставок. Всё большей популярностью у крупных облачных провайдеров пользуются ASIC, поскольку они стремятся оптимизировать чипы под свои конкретные требования, отметил DIGITIMES. ASIC обеспечивают высокую производительность и энергоэффективность в узком спектре задач, что делает их альтернативой универсальным ускорителям NVIDIA. Несмотря на доминирование NVIDIA на рынке, высокое энергопотребление её чипов в сочетании с высокой стоимостью позволило ASIC занять конкурентоспособную нишу. Особенно хорошо ASIC подходят для обучения и инференса ИИ-моделей, предлагая значительно более высокие показатели производительности в пересчёте на 1 Вт по сравнению с GPU общего назначения. Также ASIC предоставляют заказчикам больший контроль над своим технологическим стеком. На рынке разработки ASIC основными конкурентами являются Broadcom и Marvell, которые используют разные технологии и стратегические подходы. 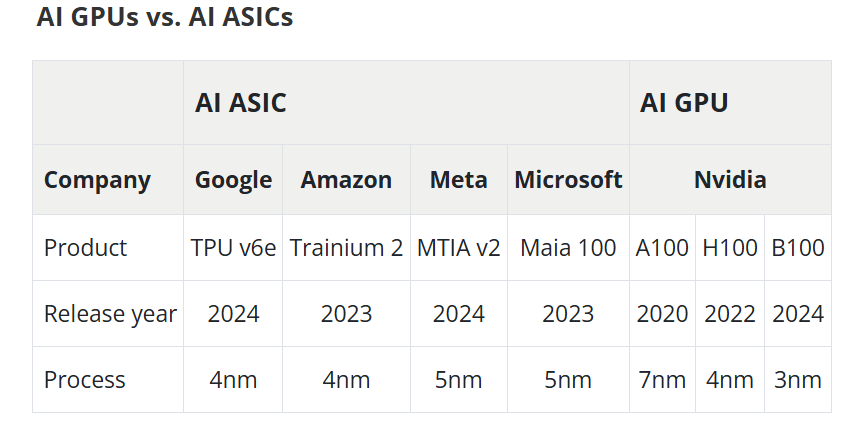
Источник изображений: DIGITIMES Marvell укрепила свои позиции на рынке, в частности, благодаря партнёрству с Google в разработке серверных Arm-чипов, расширив при этом стратегическое сотрудничество со своим основным клиентом — Amazon. TPU v6e от Google представляет собой самую передовую ASIC ИИ среди чипов, разработанных четырьмя ведущими облачными провайдерам, приближаясь по производительности к H100. Однако она всё ещё отстает от ускорителей NVIDIA примерно на два года, утверждает DIGITIMES. Созданный Marvell и Amazon ускоритель Trainium 2 по производительности находится между NVIDIA A100 и H100. В ходе последнего отчёта о финансовых результатах Marvell поделилась прогнозом значительного роста выручки от ASIC, начиная с 2024 года (2025 финансовый год), обусловленного Trainium 2 и Google Axion. В частности, совместный с Amazon проект Marvell Inferential ASIC предполагается запустить в массовое производство в 2025 году (2026 финансовый год), в то время как Microsoft Maia, как ожидается, начнет приносить доход с 2026 года (2027 финансовый год). 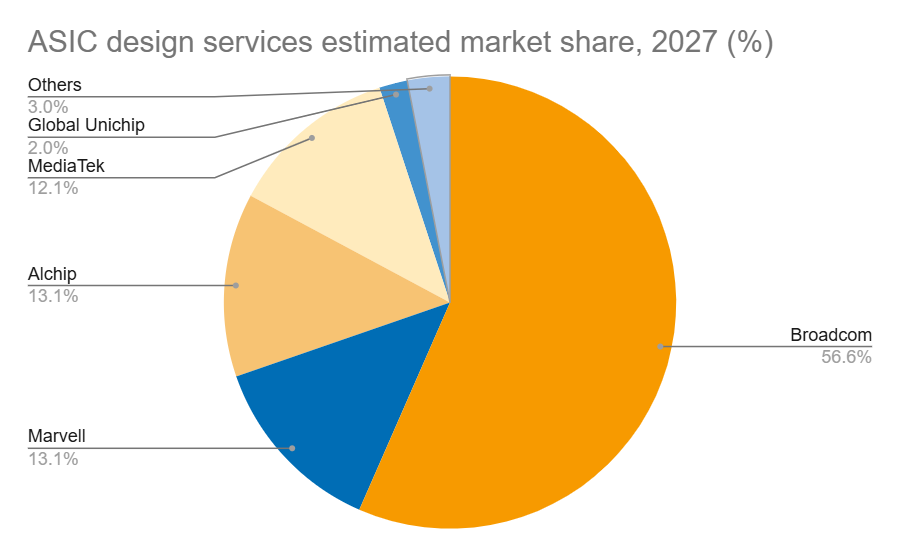 Как утверждают в Morgan Stanley, хотя бизнес Marvell по производству кастомных чипов является ключевым драйвером роста его подразделения по разработке решений для ЦОД, он также несёт в себе значительную неопределённость. Краткосрочные прогнозы Morgan Stanley для продуктов Marvell/Trainium положительны, что подтверждается возросшими мощностями TSMC по упаковке чипов методом CoWoS, планами Amazon по расширению производства и уверенностью Marvell в рыночном спросе. Однако в долгосрочной перспективе конкурентная среда создает проблемы. Появление компаний вроде WorldChip Electronics в секторе вычислительных чипов может заставить Marvell переориентироваться на сетевые решения. Кроме того, потенциальное снижение прибыли от Trainium после 2026 года означает, что Marvell нужно будет обеспечить запуск новых проектов для поддержания динамики роста, говорят аналитики. Broadcom и Marvell являют собой примеры разных стратегий развития в секторе ASIC, отмечает DIGITIMES. Broadcom отдаёт приоритет крупномасштабной интеграции и проектированию платформ, подкрепляя свой подход значительными инвестициями в НИОКР и сложной технологической интеграцией. В свою очередь, Marvell развивается за счёт стратегических приобретений, например, Cavium, Avera и Innovium, благодаря чему расширяет своё портфолио технологий.
24.01.2025 [14:33], Сергей Карасёв
Бывший гендиректор Intel Пэт Гелсингер инвестировал средства в ИИ-стартап FractileЭкс-гендиректор Intel Пэт Гелсингер, по сообщению TrendForce, стал инвестором британского стартапа Fractile.ai, который специализируется на разработках в области ИИ. Сумма, которую предоставил бывший глава Intel на развитие этой компании, не раскрывается. Fractile.ai основана в 2022 году Уолтером Гудвином (Walter Goodwin) — специалистом, получившим докторскую степень в области искусственного интеллекта и робототехники в Оксфордском университете. Стартап разрабатывает специализированные ИИ-чипы, использующие метод вычислений в оперативной памяти. Такой подход может существенно повысить скорость инференса и выполнения других задач, связанных с интенсивными вычислениями. Утверждается, что по сравнению с традиционными ИИ-ускорителями на базе GPU решения Fractile.ai обеспечат ряд значительных преимуществ. В частности, говорится, что новые чипы позволят поднять производительность больших языковых моделей (LLM) в 100 раз при одновременном 10-кратном снижении затрат по сравнению с решениями NVIDIA. При этом чипы Fractile.ai обеспечат в 20 раз более высокую производительность в расчёте на 1 Вт затрачиваемой энергии по сравнению с любым другим оборудованием ИИ, представленным в настоящее время на рынке. 
Источник изображения: Intel Однако пока Fractile.ai не изготовила тестовые образцы изделий, а оценка их характеристик и возможностей проводится путём компьютерного моделирования. Тем не менее, Гелсингер говорит, что ни один подход в отношении ИИ-вычислений не воодушевляет его больше, чем тот, который предлагает Fractile.ai. По его словам, для дальнейшего масштабирования ИИ большое значение имеет снижение как энергопотребления, так и стоимости вычислений. Отмечается также, что стартап Fractile.ai ранее привлек в общей сложности $17,5 млн финансирования. В число инвесторов входят Kindred Capital, NATO Innovation Fund, Oxford Science Enterprises и несколько бизнес-ангелов.
23.01.2025 [19:45], Руслан Авдеев
ByteDance намерена потратить $12 млрд на ИИ-ускорители в 2025 годуКитайская ByteDance намерена потратить в 2025 году более $12 млрд на ИИ-инфраструктуру. Она делает ставку на использование передовых технологий для роста, хотя и находится под давлением американских властей, намеренных заставить её продать часть популярной социальной сети TikTok, сообщает The Financial Times. Правда, огромный бюджет на новые закупки планировали до последних изменений американской политики. В частности, по данным источников, компания намерена выделить ¥40 млрд ($5,5 млрд) на покупку ИИ-чипов в 2025 году. Это вдвое больше, чем было потрачено на эти же цели в 2024-м. Около 60 % заказов компании на чипы в Китае придётся на местных производителей вроде Huawei и Cambricon (в основном для инференса), остальное достанется NVIDIA. По некоторым данным, Пекин неофициально рекомендовал китайским бизнесам закупать не менее 30 % чипов у производителей из Поднебесной. За первые три квартала выручка NVIDIA в Китае, включая Гонконг, составила $11,6 млрд, или 13 % от общих денежных поступлений. ByteDance является крупнейшим покупателем в Китае, но может приобретать для китайских ЦОД только модели H20, соответствующие американским экспортным ограничениям. По данным Omdia, в 2024 году компания заказала около 230 тыс. чипов NVIDIA, в основном именно H20. Ещё столько же купила Tencent. Для сравнения — в тот же период Microsoft приобрела 485 тыс. чипов семейства Hopper, а Meta✴ — 224 тыс. 
Источник изображения: Danie LIU/unsplash.com Также ByteDance планирует инвестировать около $6,8 млрд за пределами Китая, чтобы нарастить возможности обучения ИИ-моделей с использованием передовых чипов NVIDIA. Но с этим могут возникнуть проблемы из-за недавнего ужесточения США экспортного контроля, призванного сдержать технологическое развитие Китая. В любом случае компания является одним из лидеров ИИ-гонки в Китае и активно наращивает соответствующую инфраструктуру. Она уже развернула вычислительные мощности в Юго-Восточной Азии (в частности, Малайзии). Хотя китайским компаниям сильно ограничен доступ к ИИ-чипам NVIDIA, они сохранили доступ к ним, арендуя мощности в «нейтральных» странах. Эту лазейку закрыла предыдущая администрация США. Хотя Трамп может пересмотреть эти правила, если их всё же будут строго придерживаться, это серьёзно ограничит доступ ByteDance к вычислениям. По данным источников, в этом году ByteDance заключила много соглашений об аренде вычислительных мощностей. Их должно хватить для обеспечения большинства потребностей компании в 2025 году, но что может случиться после, пока неизвестно. Судьба TikTok в США пока остаётся под вопросом. У соцсети есть 75 дней, чтобы определиться со стратегией работы или уйти из страны. Власти США хотят, чтобы американское подразделение TikTok продало долю в 50 %, пригрозив новыми санкциями в случае отказа. Ситуация может помешать планам ByteDance по выходу на биржу (IPO). Не так давно компания предварительно оценила себя приблизительно в $300 млрд. UPD: По данным Reuters, капитальные затраты компании в 2025 году составят ¥150 млрд ($20,64 млрд). Срос на ресурсы привёл к тому, что компания стала одним из крупнейших клиентов Microsoft в Азии в сфере облачных вычислений. Ведущим приложением компании является чат-бот Duobao с 75 млн пользователей, имеется бот для преобразования текстов в видео Jimeng, а также инструмент Kouzi для разработчиков ботов и сервис Maoxing, обеспечивающий эмоциональную поддержку людям. Некоторые приложения компании доступны за рубежом — Duobao известен на международном рынке как Cici, а Jimeng — как Dreamina.
22.01.2025 [08:08], Руслан Авдеев
Ускорители Ascend не готовы состязаться с чипами NVIDIA в деле обучения ИИ, но за эффективность инференса Huawei будет бороться всеми силамиХотя на китайском рынке ИИ-ускорителей по-прежнему доминирует NVIDIA, Huawei намерена отнять у неё значительную его долю. Для этого китайский разработчик намерен помочь китайским ИИ-компаниям внедрять чипы собственного производства для инференса, сообщает The Financial Times. Для обучения ИИ-моделей китайские производители в массе своей применяют чипы NVIDIA. Huawei пока не готова заменить продукты NVIDIA в этом деле из-за ряда технических проблем, в том числе из-за проблем с интерконнектом ускорителей при работе с крупными моделями. Предполагается, что в будущем именно инференс станет пользоваться большим спросом, если темпы обучения ИИ-моделей замедлятся, а приложения вроде чат-ботов будут распространены повсеместно. Если инференс нужен постоянно, то к обучению ИИ-моделей прибегают лишь время от времени. По словам сотрудников и клиентов Ascend, компания сосредоточена на менее сложном, но, возможно, более прибыльном пути. Но поскольку ускорители NVIDIA и Huawei используют разные программные экосистемы, последняя предлагает бизнесам ПО для обеспечения совместимости. Продукция Huawei продвигается при поддержке китайского правительства, внутри страны именно эта компания считается наиболее серьёзным конкурентом NVIDIA. И хотя китайские компании всё более ограничены в доступе к аппаратным решениям NVIDIA из-за санкций, они охотно покупают даже урезанные чипы H20, которые всё равно считают более предпочтительным вариантом, чем китайские альтернативы. 
Источник изображения: Huawei Задача Huawei — убедить разработчиков отказаться от платформы CUDA, во многом благодаря которой NVIDIA и смогла добиться успеха на рынке. От проблем с ПО страдает и AMD — по словам экспертов, именно оно не позволяет раскрыть потенциал ускорителей Instinct MI300X. Впрочем, готовящаяся к релизу версия Huawei Ascend 910C должна решить эти проблемы, поскольку новое поколение ускорителей получит ПО, упрощающее работу разработчиков. Тем временем китайские Baidu и Cambricon добились определённых успехов в разработке собственных ИИ-ускорителей, а ByteDance обратилась за помощью к Broadcom. По оценкам SemiAnalysis, в прошлом году NVIDIA заработала $12 млрд на продажах своей продукции в Китае, поставив 1 млн ускорителей H20, т.е. вдвое больше, чем Ascend 910B. Впрочем, отрыв, по словам экспертов, быстро сокращается, поскольку Huawei наращивает производство. Отмечается, что рост доли Huawei на рынке ИИ-ускорителей отчасти сдерживается лишь недостаточным предложением её продукции. По мнению экспертов, наращивать производство будет трудно, поскольку Китайское вынужден использовать устаревшее оборудование из-за санкций США. Специализация на инференсе может свидетельствовать и об особом векторе развития китайских ИИ-систем, отличающемся от американского. Китайские компании не участвуют в гонке Meta✴, xAI и OpenAI по созданию мегакластеров на базе решений NVIDIA. Зато большей эффективности в задачах инференса можно добиться даже с более слабыми чипами. Снизив стоимость работы ИИ-моделей, можно будет сохранять конкурентоспособность даже в таких условиях. В прошлом месяце китайский стартап DeepSeek представил ИИ-модель V3, обеспечивающую низкие затраты на обучение и инференс в сравнении с сопоставимыми по возможностям моделями из США. DeepSeek утверждает, что Huawei успешно адаптировала V3 к Ascend. Ранее сообщалось, что Huawei охотно направляет к клиентам специалистов для помощи с переходом с NVIDIA на Ascend.
20.01.2025 [15:59], Сергей Карасёв
Индия может столкнуться с дефицитом ИИ-ускорителей из-за новой политики СШАВ то время как крупные корпорации, специализирующиеся на ИИ, присматриваются к Индии в поисках выгодных возможностей, недавние меры экспортного контроля США вызвали обеспокоенность по поводу дальнейшего расширения вычислительных мощностей в этой стране, передаёт DIGITIMES. Напомним, администрация США ввела в действие требование AI Diffusion rule («Правило распространения ИИ»), которое предусматривает лицензирование ИИ-чипов, используемых в дата-центрах. Фактически все страны разделены на три уровня. Верхний предполагает неограниченный доступ к ИИ-чипам и мощным ИИ-моделям: такими привилегиями смогут воспользоваться члены G7 и некоторые другие государства. Страны второго уровня, к которым относится Индия, смогут получить до 1700 новейших ИИ-ускорителей без специального разрешения. В целом же им разрешено приобретать вычислительную мощность, эквивалентную до 320 тыс. передовых GPU в течение следующих двух лет. Государства третьего уровня, такие как Китай, Иран, Россия и Северная Корея, подпадают под полный запрет на поставку современных ИИ-решений. 
Источник изображения: unsplash.com / Levi Meir Clancy По оценкам, общая вычислительная ИИ-мощность в Индии на сегодняшний день эквивалентна 25 тыс. передовых GPU. Страна анонсировала инициативу IndiaAI, в рамках которой планируется приобрести около 10 тыс. ускорителей для дальнейшего расширения экосистемы ИИ. Это позволит удовлетворить потребности в ресурсах в краткосрочной перспективе. Однако из-за значительного размера рынка Индии в будущем, как ожидается, возникнет необходимость в закупке гораздо большего количества ИИ-чипов. Президент Индийской ассоциации электроники и полупроводниковой продукции (IESA) Ашок Чандак (Ashok Chandak) заявил, что масштабные ИИ ЦОД, которым требуются сотни тысяч ускорителей, могут столкнуться с задержками развития или необходимостью сокращения запланированной вычислительной ёмкости. Такая ситуация негативно отразится на конкурентоспособности местных предприятий на мировом рынке. Кроме того, обязательное лицензирование может привести к бюрократическим проблемам и увеличению расходов. Эксперты говорят, что решение американских властей ввести ограничения на приобретение Индией передовых ИИ-чипов несколько удивительно, учитывая, что в последние годы США активно поддерживали усилия этой страны по развитию ее полупроводникового потенциала в контексте геополитической напряжённости. С другой стороны, новая мера экспортного контроля вполне объяснима с точки зрения исторических связей Индии и России. Аналитики считают, что введённые меры экспортного контроля могут ускорить усилия Индии по разработке собственных ИИ-решений.
20.01.2025 [07:53], Владимир Мироненко
SRAM, да и только: d-Matrix готовит ИИ-ускоритель CorsairСтартап d-Matrix создал ИИ-ускоритель Corsair, оптимизированный для быстрого пакетного инференса больших языковых моделей (LLM). Архитектура ускорителя основана на модифицированных ячейках SRAM для вычислений в памяти (DIMC), работающих на скорости порядка 150 Тбайт/с. Новинка, по словам компании, отличается производительностью и энергоэффективностью, пишет EE Times. Массовое производство Corsair начнётся во II квартале. Среди инвесторов d-Matrix — Microsoft, Nautilus Venture Partners, Entrada Ventures и SK hynix. d-Matrix фокусируется на пакетном инференсе с низкой задержкой. В случае Llama3-8B сервер d-Matrix (16 четырёхчиплетных ускорителей в составе восьми карт) может производить 60 тыс. токенов/с с задержкой 1 мс/токен. Для Llama3-70B стойка d-Matrix (128 чипов) может производить 30 тыс. токенов в секунду с задержкой 2 мс/токен. Клиенты d-Matrix могут рассчитывать на достижение этих показателей для размеров пакетов порядка 48–64 (в зависимости от длины контекста), сообщила EE Times руководитель отдела продуктов d-Matrix Шри Ганесан (Sree Ganesan). 
Источник изображений: d-Matrix Производительность оптимизирована для исполнения моделей в расчёте до 100 млрд параметров на одну стойку. По словам Ганесан, это реалистичный сценарий использования LLM. В таких сценариях решение d-Matrix обеспечивает 10-кратное преимущество в интерактивности (время до получения токена) по сравнению с решениями на базе традиционных ускорителей, таких как NVIDIA H100. Corsair ориентирован на модели размером менее 70 млрд параметров, подходящих для генерации кода, интерактивной генерации видео или агентского ИИ, которые требуют высокой интерактивности в сочетании с пропускной способностью, энергоэффективностью и низкой стоимостью.  Ранние версии архитектуры d-Matrix использовали MAC-блоки на базе SRAM-ячеек, дополненных большим количеством транзисторов для операций умножения. Сложение же выполнялось в аналоговом виде с использованием разрядных линий, измерения тока и аналого-цифрового преобразования. В 2020 году компания выпустила чиплетную платформу Nighthawk на основе этой архитектуры. «[Nighthawk] продемонстрировал, что мы можем значительно повысить точность по сравнению с традиционными аналоговыми решениями, но мы всё ещё отстаем на пару процентных пунктов от традиционных решений типа GPU», — сказал EE Times генеральный директор d-Matrix Сид Шет (Sid Sheth). 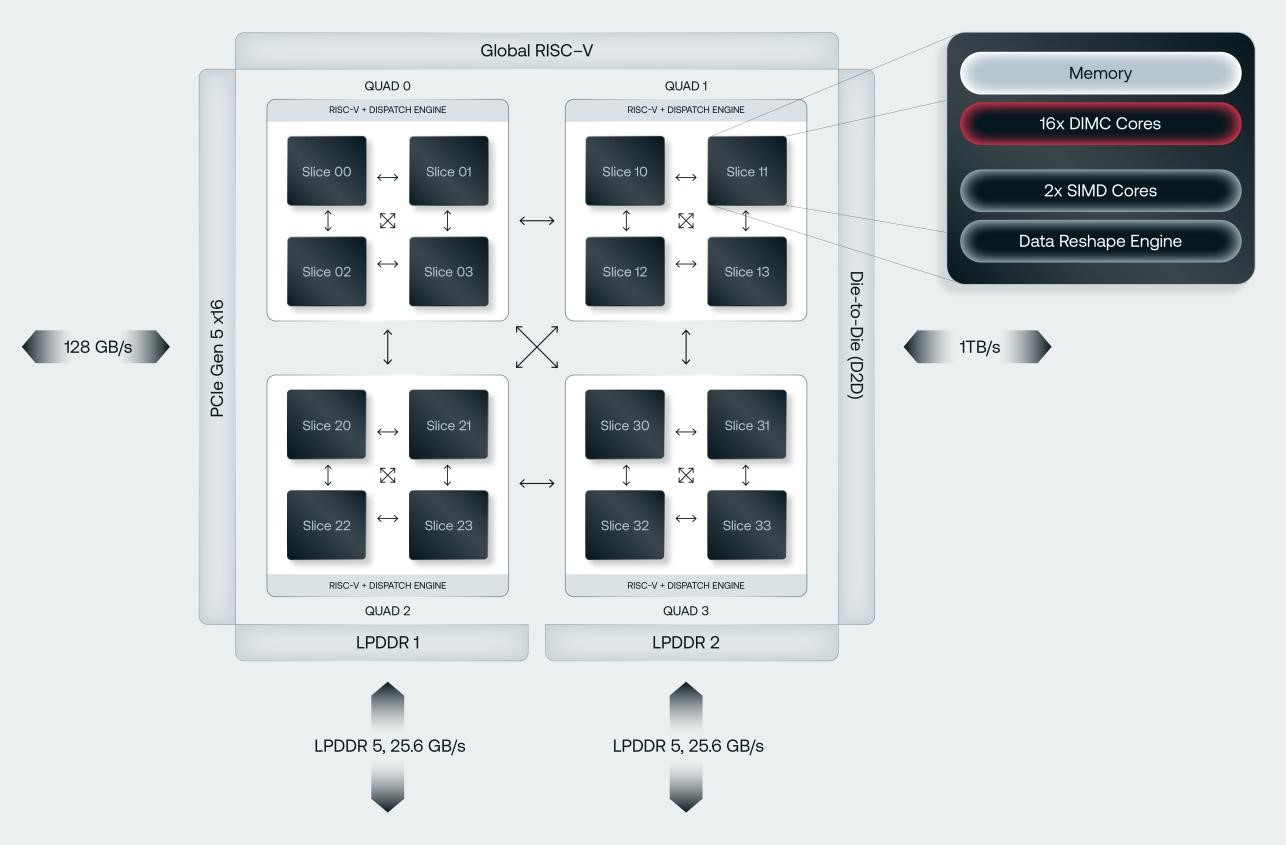 Однако потенциальным клиентам не понравилось, что при таком подходе возможно снижение точности, так что в Corsair компания вынужденно сделала выбор в пользу полностью цифрового сумматора. ASIC d-Matrix включает четыре чиплета, каждый из которых содержит по четыре вычислительных блока, объединённых посредством DMX Link по схеме каждый-с-каждым, и по одному планировщику и RISC-V ядру. Внутри каждого вычислительного блока есть 16 DIMC-ядер, состоящих из наборов SRAM-ячеек (64×64), а также два SIMD-ядра и движок преобразования данных. Суммарно доступен 1 Гбайт SRAM с пропускной способностью 150 Тбайт/с. 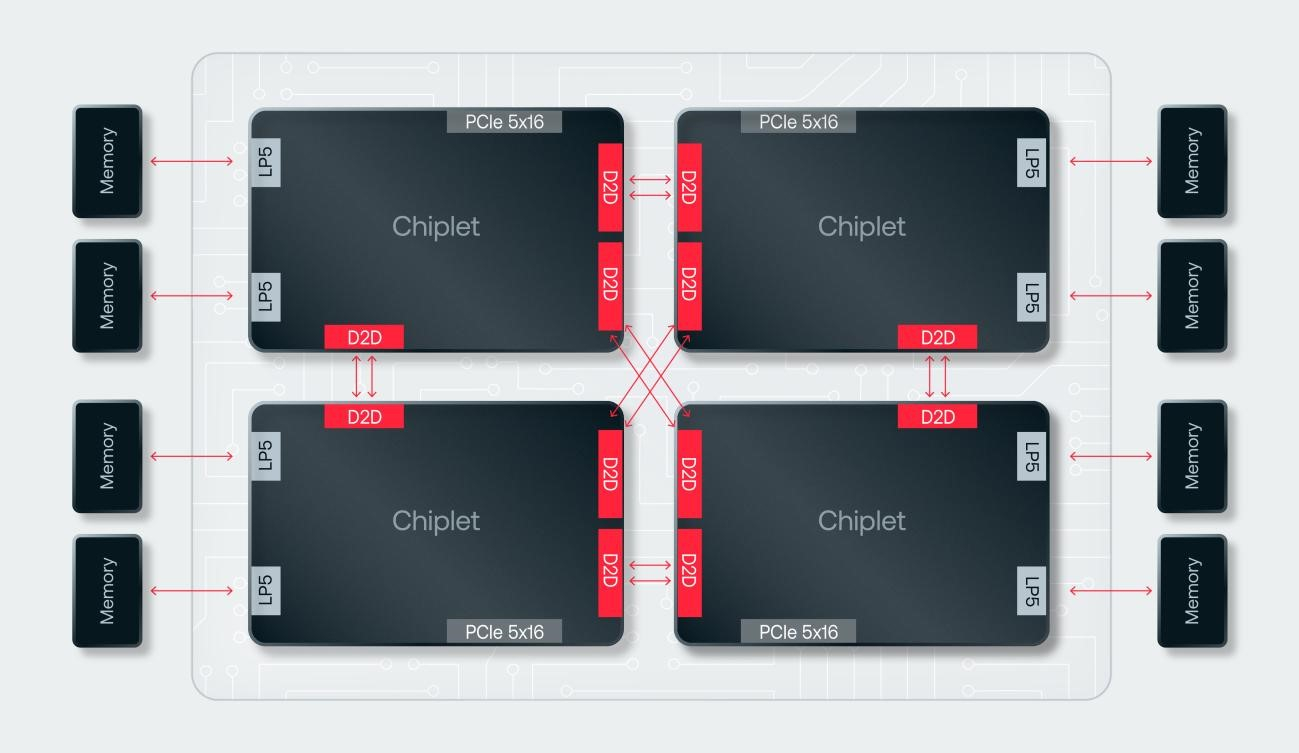 ASIC объединён со 128 Гбайт LPDDR5 (до 400 Гбайт/с) посредством органической подложки (без дорогостоящего кремниевого интерпозера). Хотя текущее поколение ASIC включает только четыре чиплета именно из-за ограничений подложки, в будущем их количество увеличится. Внешние интерфейсы ASIC представлены стандартным PCIe 5.0 x16 (128 Гбайт/с) и фирменным интерконнектом DMX Link (1 Тбайт/с) для объединения чиплетов. 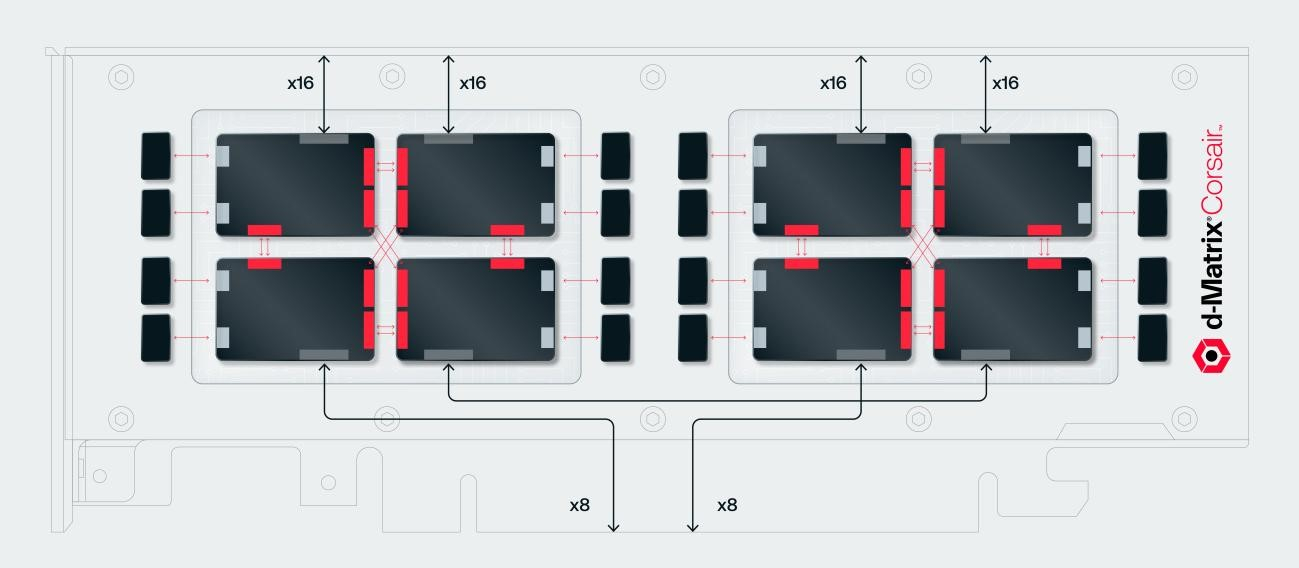 FHFL-карта Corsair включает два ASIC d-Matrix (т.е. всего восемь чиплетов) и имеет TDP на уровне 600 Вт. Ускоритель работает с форматами данных OCP MX (Microscaling Formats) и обеспечивает до 2400 Тфлопс в MXINT8-вычислениях или 9600 Тфолпс в случае MXINT4. Две карты Corsair можно объединить посредством 512-Гбайт/с мостика DMX Bridge. Их, по словам компании, достаточно для задействования тензорного параллелизма. Дальнейшее масштабирование возможно посредством PCIe-коммутации. Именно поэтому d-Matrix работает с GigaIO и Liqid. В одно шасси можно поместить восемь карт Corsair, а в стойку, которая будет потреблять порядка 6–7 кВт — 64 карты. 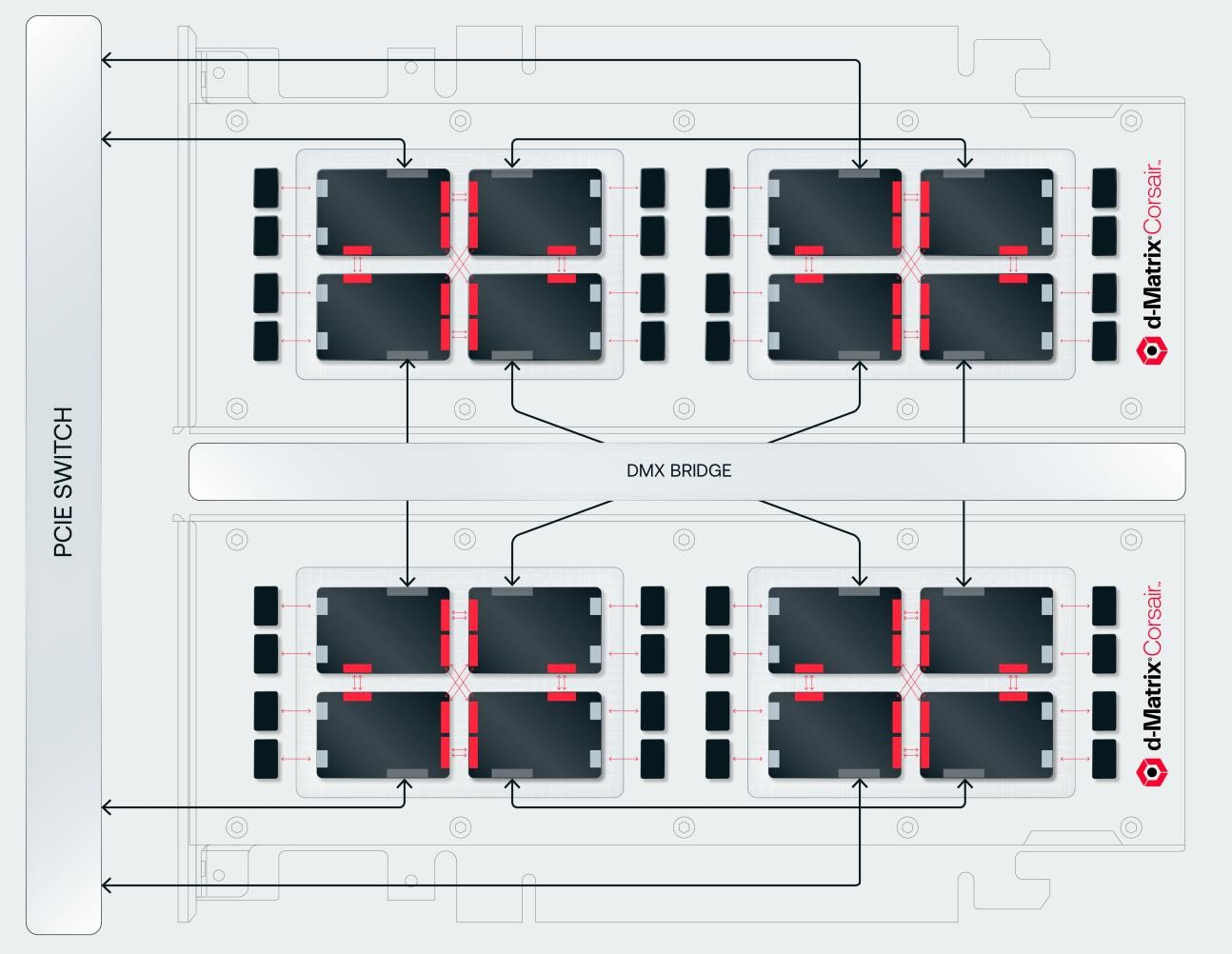 d-Matrix уже разрабатывает ASIC следующего поколения Raptor, который должен выйти в 2026 году. Raptor будет ориентирован на «думающие» модели и получит ещё больше памяти за счёт размещения DRAM непосредственно поверх вычислительных чиплетов. SRAM-чиплеты Raptor также перейдут с 6-нм техпроцесса TSMC, который используется при изготовлении Corsair, к 4 нм без существенных изменений микроархитектуры. По словам компании, она потратила два года на работу с TSMC, чтобы создать 3D-упаковку для нового поколения ASIC. 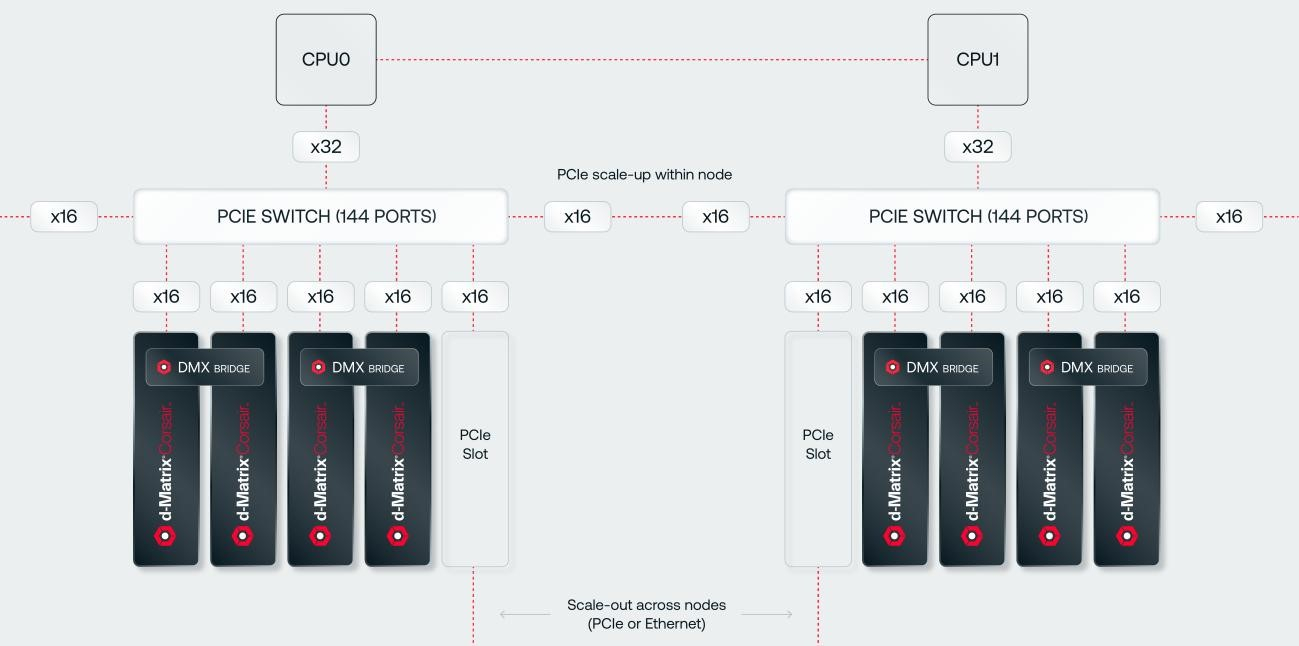 Как отмечает EETimes, команда разработчиков ПО d-Matrix в два раза больше команды разработчиков оборудования (120 против 60). Стратегия компании в области ПО заключается в максимальном использовании open source экосистемы, включая PyTorch, OpenAI Triton, MLIR, OpenBMC и т.д. Вместе они образуют программный стек Aviator, который отвечает за конвертацию моделей в числовые форматы d-Matrix, применяет к ним фирменные методы разрежения, компилирует их, распределяет нагрузку по картам и серверам, а также управляет исполнением моделей, включая обслуживание большого количества запросов.
17.01.2025 [15:02], Владимир Мироненко
Аналитики снизили рейтинг акций AMD из-за более низких ожиданий по продажам ускорителейАкции Advanced Micro Devices (AMD) могут потерять своё конкурентное преимущество, сообщил аналитик Wolfe Research Крис Касо (Chris Caso), понизив рейтинг акций производителя чипов с Buy (покупать) до Peer Perform (нейтральный), сообщает ресурс Barron's. Аналитик отметил, что после вчерашнего отчёта TSMC о прибыли выросли акции всех компаний по производству оборудования для изготовления пластин — Lam Research, KLA Corporation и Applied Materials. А у AMD, для которой TSMC производит чипы, такого же роста не наблюдалось. Наоборот, её акции упали в четверг на 1,3 % до $118,44. Понизив рейтинг акций AMD, Крис Касо также снял свою целевую цену в $210 за акцию, пояснив свой шаг более низкими, чем прогнозировалось, ожиданиями относительно доходов компании от производства ускорителей для ЦОД. Ускорители являются одним из ключевых продуктов AMD, и Касо утверждает, что бизнес компании по этому направлению «работает ниже ожиданий». Аналитик выразил мнение, что ситуация улучшится после выхода во II половине 2025 года ускорителей AMD Instinct MI350. 
Источник изображения: AMD Ранее в этом месяце рейтинг AMD снизили Goldman Sachs и HSBC. Аналитики Goldman понизили свой рейтинг с «Покупать» (Buy) до «Нейтральный» (Peer Perform), сославшись на скромный рост продаж ускорителей для ЦОД на фоне жесткой конкуренции, в то время как команда HSBC понизила рейтинг AMD с «Покупать» (Buy) до «Сокращать позицию» (Reduce) из-за опасений, что акции могут упасть ещё ниже после трёхмесячного спада. Wolfe Research снизила прогнозы выручки и прибыли AMD за I квартал до $6,6 млрд и $0,80 на акцию соответственно, по сравнению с более ранними прогнозами выручки в $7,04 млрд и прибыли в $0,93 на акцию. Скорректированные цифры оказались ниже ожиданий Уолл-стрит в $7,04 млрд по выручке и $0,95 по прибыли на акцию. Компания тоже снизила свой годовой прогноз по выручке и прибыли до $29,9 млрд и $4,19 на акцию соответственно с предыдущих $33,6 млрд и $5,33 на акцию при консенсус-прогнозе аналитиков выручки в размере $32,3 млрд и прибыли в $5,02 на акцию.
16.01.2025 [16:16], Руслан Авдеев
США вводят очередные ограничения на выпуск и экспорт современных чиповМинистерство торговли США вводит новый пакет экспортных ограничений, призванных помешать Китаю и другим странам закупать передовые чипы, сообщает Silicon Angle. В частности, ограничения коснутся предприятий, выпускающих микросхемы, а также работающих по заказу других организаций. Так, новые меры коснутся TSMC и Samsung Electronics, а также упаковщиков чипов, включая ту же TSMC. Новые правила предусматривают получение производителями чипов и упаковщиками полупроводников лицензий на экспорт «определённых передовых чипов» в ряд регионов. Власти откажутся от подобных требований, если производитель чипов получит технические аттестации от доверенных участников цепочек поставок. Так, разработчики чипов могут получить от американских властей статус «одобренных» или «авторизованных». Если разработчик подтверждает, что его чипы не достигают по своим характеристикам установленных США порогов производительности, лицензионные требования к ним отменяются. То же касается фабрик и компаний-упаковщиков. Если характеристики производимых чипов не превышают определённого порога, новые экспортные ограничения не применяются. 
Источник изображения: CHUTTERSNAP/unsplash.com Объявлено и о ряде других нормативных изменений. В частности, запускается процесс утверждения компаний в перечне одобренных дизайн-центров и поставщиков чипов и услуг OSAT (Outsourced Semiconductor Assembly and Test). Также оптимизированы процедуры раскрытия информации в случаях, если производитель принимает заказ клиента, потенциально способного перенаправить продукцию в Китай. В связи с новыми правилами в чёрный список Entity List отправятся 16 новых организаций, включая некоторые ИИ-компании, поддерживающие развитие производства передовых чипов в Китае. Одной из таких компаний стала Sophgo — в прошлом году выяснилось, что она якобы передала выпущенную для неё продукцию компании Huawei, давно пребывающей в американском чёрном списке, после чего TSMC прекратила выполнение её заказов и поставки. Министерство торговли вводит новые правила всего через несколько дней после того, как администрация уходящего президента США ввела глобальные ограничения на поставки ИИ-чипов и передовых моделей ИИ. Ранее американские власти уже вводили санкции, ограничивающие возможности китайской полупроводниковой индустрии. Речь идёт о закупках чипов NVIDIA, памяти HBM и других компонентов. Не щадят и союзников. Нидерландской ASML запрещено поставлять в КНР оборудование для DUV-литографии, на котором можно изготавливать 5- и 7-нм полупроводники. |
|