Материалы по тегу: ускоритель
|
07.10.2023 [00:44], Сергей Карасёв
Стартап Lemurian Labs, созданный выходцами из NVIDIA, AMD и Intel, намерен совершить революцию в мире ИИСтартап Lemurian Labs, специализирующийся, как он сам говорит, на решении вычислительных проблем, связанных с использованием ИИ, по сообщению HPCwire, провёл начальный раунд финансирования, в ходе которого привлечено $9 млн. Средства предоставили Oval Park Capital, Good Growth Capital, Raptor Group, Alumni Ventures и др. В команду Lemurian Labs входят бывшие специалисты Google, Microsoft, NVIDIA, AMD и Intel. Компания ставит перед собой задачу создать принципиально новый подход к обработке алгоритмов ИИ с целью снижения энергопотребления и затрат. 
Источник изображений: Lemurian Labs Стартап отмечает, что платформы ИИ развиваются с беспрецедентной скоростью. Это приводит к стремительному увеличению масштаба моделей, что порождает необходимость в огромных вычислительных ресурсах. В результате, аппаратные платформы потребляют непомерное количество энергии, что делает разработку ИИ чрезвычайно дорогостоящей и экологически неустойчивой. Например, развёртывание GPT3 в масштабах поисковика Google потребует 400 МВт и более $100 млрд. Кроме того, создаётся дефицит ускорителей. Впрочем, компания и сама намерена создать программно-аппаратный комплекс. 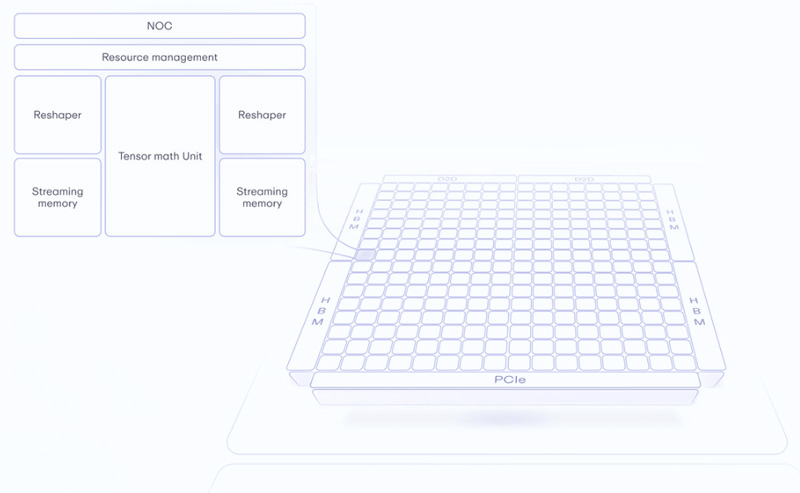 Lemurian Labs предлагает решить проблему путём создания специализированной платформы, использующей новый формат данных PAL8 (Parallel Adaptive Logarithm, или параллельный адаптивный логарифм). Она, по словам создателей, позволит ускорить рабочие нагрузки ИИ, увеличив пропускную способность по сравнению с GPU-решениями почти в 20 раз при ⅒ от общей стоимости. Вкупе с сопутствующим ПО станет возможным значительное увеличение производительности без роста потребляемой мощности, что позволит с высокой эффективностью разрабатывать ресурсоёмкие ИИ-приложения. 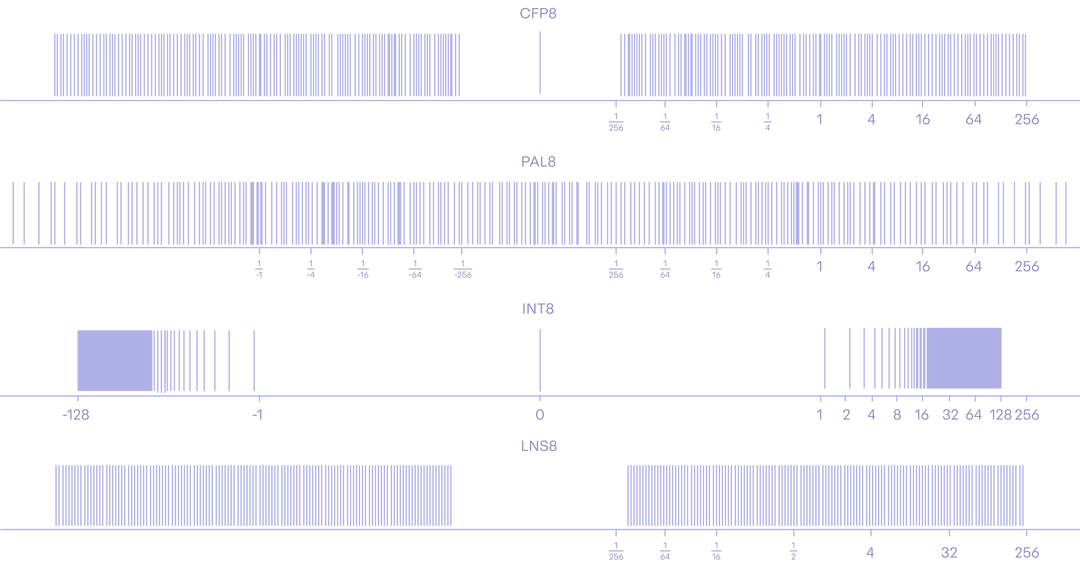 Компания создаёт специализированный компилятор, который динамически распределяет задачи для максимального использования ресурсов оборудования. Это делает написание кода для кластера из 1 тыс. узлов таким же простым, как и для одного. Вместе с тем новый тип данных не только даёт лучшее представление чисел по сравнению с FP-форматами, но и обеспечивает десятикратное увеличение эффективности, позволяя обойти существующие ограничения, связанные с параллельными вычислениями. Плюс к этому задействована многоуровневая архитектура памяти, оптимизирующая потоки данных с целью увеличения пропускной способности и эффективности без ущерба для универсальности.
03.10.2023 [17:09], Руслан Авдеев
Microsoft: приобрести ИИ-ускорители NVIDIA становится всё проще и прощеКак заявил недавно на конференции Code Conference технический директор Microsoft Кевин Скотт (Kevin Scott), приобрести ускорители компании NVIDIA для ИИ и HPC-вычислений уже не так сложно, как ещё несколько месяцев назад. По данным портала Tom’s Hardware, проблема доступности и поставок активно решается производителем. По словам того же Скотта, ещё не так давно спрос намного превышал предложение всех производителей ускорителей. Хотя дефицит ещё не исчез, ситуация улучшается буквально с каждой неделей. В последнее время драйвером огромного спроса на ускорители были техногиганты, включая Microsoft, активно осваивающие рынок ИИ-продуктов, в том числе для сторонних клиентов. Для тренировки больших языковых моделей (LLM), обычно используются ускорители именно NVIDIA, в результате чего спрос на них в 2023 году стремительно взлетел, а рост стоимости акций «зелёных» с начала года составил 190 %. 
Источник изображения: NVIDIA В ходе недавнего отчёта о доходах NVIDIA сообщила о намерении повысить объёмы поставок в следующем году. Параллельно появилась информация о том, что трафик одного из самых популярных чат-ботов, ChatGPT от OpenAI, существенно падал в течение трёх месяцев подряд. OpenAI использует облачную платформу Microsoft Azure, так что нагрузка на неё в последнее время не столь велика. По словам Скотта, занимающегося в числе прочего и распределением ресурсов, эта задача в последние кварталы была чрезвычайно трудной, но теперь выполнять свои обязанности стало намного легче. Скотт не стал комментировать слухи о том, что Microsoft якобы разрабатывает собственные ИИ-чипы, но подтвердил, что компания прилагает немалые усилия в работе над полупроводниковыми проектами и инвестировала в них немало средств. При этом он признал, что в последние годы NVIDIA остаётся ведущим партнёром Microsoft в ИИ-секторе, но подчеркнул, что компания будет выбирать наилучшие решения для своих систем, какое бы происхождение они ни имели.
02.10.2023 [15:57], Сергей Карасёв
AMD представила ускоритель Alveo UL3524 для брокерских и биржевых приложенийКомпания AMD анонсировала специализированный ускоритель Alveo UL3524 на базе FPGA, ориентированный на финтех-сферу. Решение, как утверждается, позволяет трейдерам, хедж-фондам, брокерским конторам и биржам совершать операции с задержками наносекундного уровня. В основу новинки положен чип FPGA Virtex UltraScale+, выполненный по 16-нм технологии. Конфигурация включает 64 трансивера с ультранизкой задержкой, 780 тыс. LUT и 1680 DSP. Отмечается, что Alveo UL3524 обеспечивает в семь раз меньшую задержку по сравнению с FPGA предыдущего поколения. В частности, инновационная архитектура трансиверов с оптимизированными сетевыми ядрами позволяет добиться показателя менее 3 нс. 
Источник изображения: AMD Ускоритель может использоваться в комплексе с платформой разработки Vivado Design Suite. AMD также предоставляет разработчикам среду FINN с открытым исходным кодом, что позволяет внедрять в высокопроизводительные трейдинговые системы модели ИИ с низкими задержками. Ускоритель выполнен в виде однослотовой карты расширения с интерфейсом PCIe 4.0 x16. Задействован система пассивного охлаждения, а показатель TDP заявлен на отметке 125 Вт. Предусмотрены четыре сетевых порта QSFP-DD. Карта несёт на борту 16 Гбайт памяти DDR4-2666 и 72 Мбайт памяти QDR II+. Весит ускоритель 832 г.
30.09.2023 [23:18], Алексей Степин
Intel отказалась от ИИ-ускорителей Habana GrecoОдним из столпов своей ИИ-платформы Intel сделала разработки поглощённой когда-то Habana Labs. Но если ускорители Gaudi2 оказались конкурентоспособными, то ветку инференс-решений Goya/Greco было решено свернуть. Любопытно, что на мероприятии Intel Innovation 2023 имя Habana Labs не упоминалось, а использовалось исключительно название Intel Gaudi. Дела у данной платформы, базирующейся на ускорителе Gaudi2, обстоят неплохо. Так, в частности, она имеет поддержку FP8-вычислений и, согласно данным Intel, не только серьёзно опережает NVIDIA A100, но успешно соперничает с H100. Фактически в тестах MLPerf только Intel смогла составить хоть какую-то серьёзную конкуренцию NVIDIA. 
Изображение: Intel Однако не все разработки Habana имеют счастливую судьбу. В 2022 году одновременно с Gaudi2 был анонсирован и инференс-ускоритель Greco, поставки которого должны были начаться во II полугодии 2023 года. Но сейчас, похоже, данная платформа признана бесперспективной. Intel не только убрала все упоминания Greco со своего сайта и ни словом не обмолвилась о них на мероприятии, но и подчистила Linux-драйвер несколько дней назад. А вот появление Gaudi3 уже не за горами.
29.09.2023 [13:05], Сергей Карасёв
Разработчик ИИ-чипов Kneron получил $49 млн инвестицийКомпания Kneron, специализирующаяся на разработке ИИ-технологий, объявила о проведении расширенного раунда инвестиций Series B, в ходе которого на развитие привлечено $49 млн. Таким образом, общая сумма вложений в рамках указанной финансовой программы достигла $97 млн. Стартап Kneron из Сан-Диего разрабатывает чипы, которые можно использовать в умных автомобилях, роботах и других подключённых устройствах с ИИ-функциями. Компания заявляет, что приложения машинного обучения, использующие её чипы, могут стабильно работать даже без доступа в интернет. 
Источник изображения: Kneron Одно из изделий Kneron — специализированный ИИ-чип KL730. Он объединяет четырёхъядерный CPU на архитектуре Arm и акселератор для задач инференса. Реализована поддержка интерфейсов SD, USB и Ethernet. Заявленная производительность достигает 4 TOPS. При этом обеспечивается высокая энергоэффективность. Средства на развитие в ходе раунда Series B предоставили Foxconn and HH-CTBC Partnership (Foxconn Co-GP Fund), Alltek, Horizons Ventures, Liteon Technology Corp, Adata и Palpilot. Деньги будут использованы в том числе для ускорения разработки ИИ-решений для автомобильной сферы. В целом, на сегодняшний день стартап Kneron получил финансовую поддержку в размере $190 млн.
25.09.2023 [21:13], Алексей Степин
Разработка RISC-V платформы MEEP для будущих европейских суперкомпьютеров завершенаЕвропейский Союз продолжает активно развивать собственное видение суперкомпьютеров ближайшего будущего, в основу которых ляжет архитектура RISC-V. За три с половиной года работы проекта Marenostrum Experimental Exascale Platform (MEEP) создана новая платформа, детально описывающая различные блоки и свойства таких HPC-систем. Выбор микроархитектуры RISC-V в качестве основы MEEP вполне оправдан — она является открытой и позволяет разработчикам не зависеть от проприетарных наборов инструкций и аппаратных решений. Таким образом ЕС планирует достигнуть автономии в сфере супервычислений, обзаведясь собственной платформой. 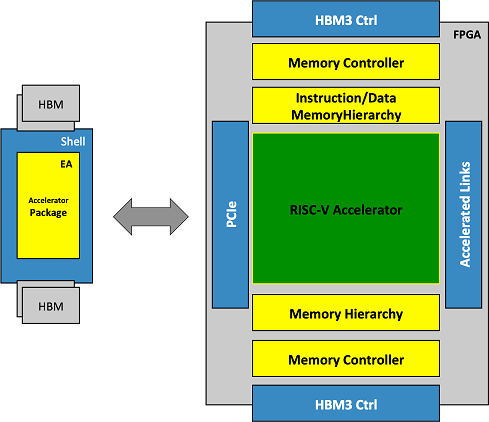
Высокоуровневое описание эмулируемого ускорителя В основе проекта MEEP лежит ядро Accelerated Memory and Compute Engine (ACME), изначально спроектированное с прицелом на применение высокоскоростной памяти HBM3 и состоящее из тайлов памяти (Memory Tile) и вычислительных тайлов VAS, объединённых меш-интерконнектом. Воплощение дизайна ACME в реальный кремний пока ещё дело будущего, но уже очевидно, что процессоры, разработанные в рамках проекта MEEP, будут иметь чиплетную компоновку. 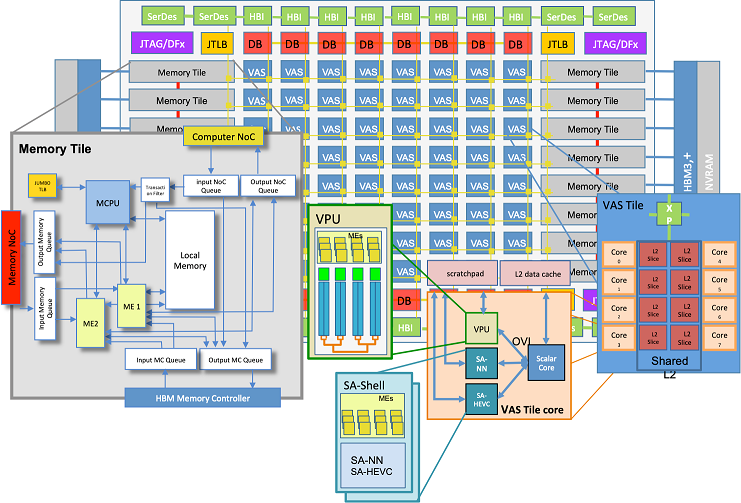
Архитектура ACME и её строительные блоки В конструкции ACME на долю Memory Tile выпадают все операции с подсистемами памяти, включая построение иерархических массивов, использующих разные типы памяти, в том числе MRAM и HBM3. Модули VAS включают себя по 8 процессорных ядер со своими разделами L2-кеша. Каждое такое ядро состоит из нескольких отдельных блоков: скалярного RISC-V, блока векторных операций, а также блоков ускорителей двух типов — SA-HEVC для обработки видео и SA-NN для нейросетевых задач, в частности, инференса. 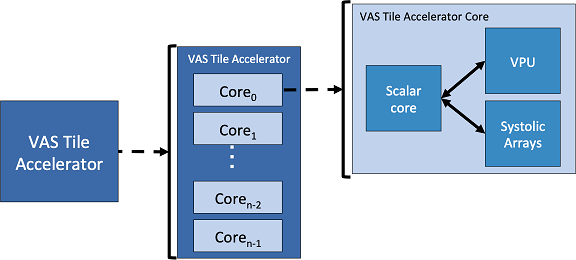
Схема работы ускорителей в составе блоков VAS По сути, каждый модуль VAS представляет собой вполне законченный многоядерный процессор RISC-V, способный работать со всеми современными форматами данных, автоматически распознающий расширенные инструкции и выполняющий их с помощью соответствующих ускорителей в своём составе. Платформа, созданная в рамках проекта MEEP, уже функционирует как эмулируемый с помощью FPGA Xilinx полноценный прототип. Он позволяет не только вести разработку и отладку ПО для новой европейской суперкомпьютерной экосистемы, но и производить валидацию аппаратных компонентов для будущих ускорителей/процессоров с архитектурой ACME.
20.09.2023 [20:05], Алексей Степин
SambaNova представила ИИ-ускоритель SN40L с памятью HBM3, который в разы быстрее GPUБум больших языковых моделей (LLM) неизбежно порождает появление на рынке нового специализированного класса процессоров и ускорителей — и нередко такие решения оказываются эффективнее традиционного подхода с применением GPU. Компания SambaNova Systems, разработчик таких ускорителей и систем на их основе, представила новое, третье поколение ИИ-процессоров под названием SN40L. Осенью 2022 года компания представила чип SN30 на базе уникальной тайловой архитектуры с программным управлением, уже тогда вполне осознавая тенденцию к увеличению объёмов данных в нейросетях: чип получил 640 Мбайт SRAM-кеша и комплектовался оперативной памятью объёмом 1 Тбайт. 
Источник изображений здесь и далее: SambaNova (via EE Times) Эта наработка легла и в основу новейшего SN40L. Благодаря переходу от 7-нм техпроцесса TSMC к более совершенному 5-нм разработчикам удалось нарастить количество ядер до 1040, но их архитектура осталась прежней. Впрочем, с учётом реконфигурируемости недостатком это не является. Чип SN40L состоит из двух больших чиплетов, на которые приходится 520 Мбайт SRAM-кеша, 1,5 Тбайт DDR5 DRAM, а также 64 Гбайт высокоскоростной HBM3. Последняя была добавлена в SN40L в качестве буфера между сверхбыстрой SRAM и относительно медленной DDR. Это должно улучшить показатели чипа при работе в режиме LLM-инференса. Для эффективного использования HBM3 программный стек SambaNova был соответствующим образом доработан. 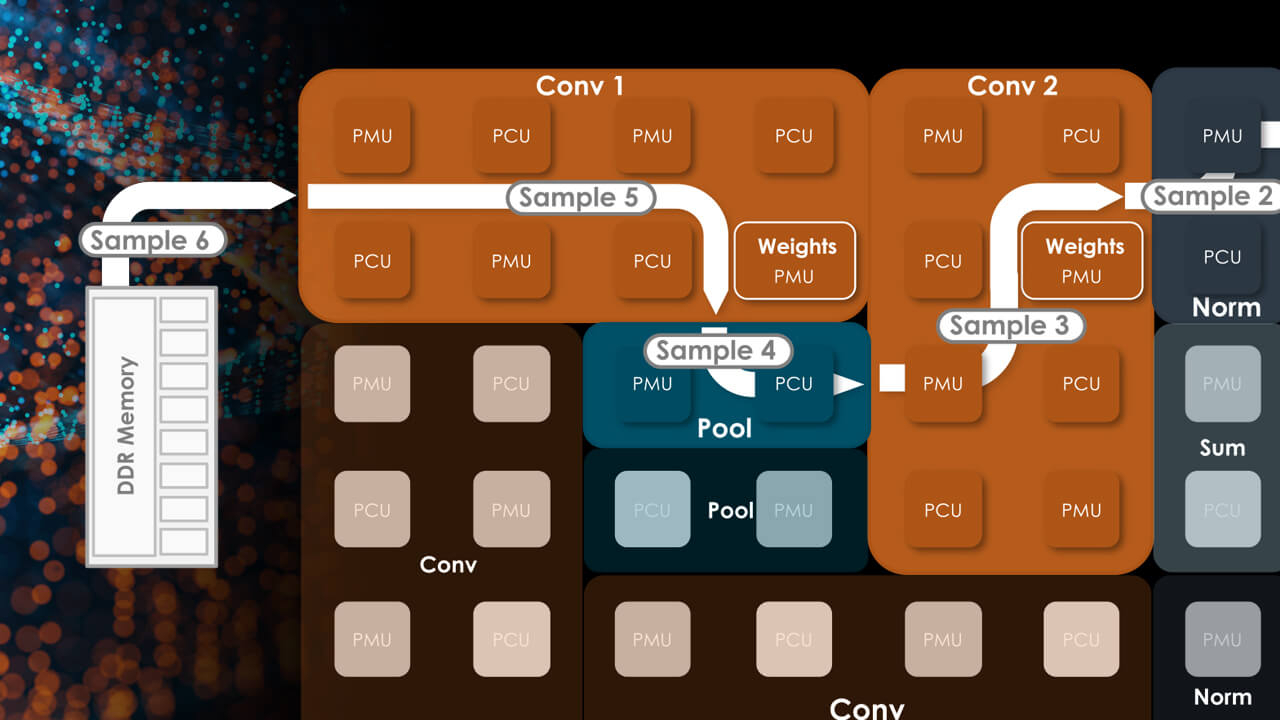
Тайловая архитектура SambaNova состоит из вычислительных тайлов PCU, SRAM-тайлов PMU, управляющей логики и меш-интерконнекта По сведениям SambaNova, восьмипроцессорная система на базе SN40L сможет запускать и обслуживать ИИ-модель поистине титанических «габаритов» — с 5 трлн параметров и глубиной запроса более 256к. В описываемой модели речь идёт о наборе экспертных моделей с LLM Llama-2 в качестве своеобразного дирижёра этого оркестра. Архитектура с традиционными GPU потребовала бы для запуска этой же модели 24 сервера с 8 ускорителями каждый; впрочем, модель ускорителей не уточняется. Как и прежде, сторонним клиентам чипы SN40L и отдельные вычислительные узлы на их основе поставляться не будут. Компания продолжит использовать модель Dataflow-as-a-Service (DaaS) — расширяемую платформу ИИ-сервисов по подписке, включающей в себя услуги по установке оборудования, вводу его в строй и управлению в рамках сервиса. Однако SN40L появится в рамках этой услуги позднее, а дебютирует он в составе облачной службы SambaNova Suite.
19.09.2023 [00:13], Владимир Мироненко
NeuroBlade интегрирует SQL-ускорители SPU с VeloxСтартап NeuroBlade, специализирующийся на разработке решений для ускорения анализа данных, объявил о сотрудничестве с сообществом Velox компании Meta✴ Platforms с целью интеграции ускорителя SQL Processing Unit (SPU) в новый унифицированный фреймворк для работы с данными. Как отметили в NeuroBlade, полная интеграция SPU NeuroBlade в Velox обеспечивает ускорение обработки данных более чем в 10 раз, помимо трёхкратного повышения производительности, уже достигнутого Velox за счет оптимизации ПО. Цель проекта заключается в том, чтобы дать компаниям возможность эффективно обрабатывать огромные наборы данных, говорится в пресс-релизе. 
Источник изображения: NeuroBlade Элад Сити (Elad Sity), гендиректор и соучредитель NeuroBlade, подчеркнул важность совместных усилий, которые «знаменуют эпоху, когда организации смогут умело управлять растущими объёмами данных, повышать производительность аналитики и получать значительные конкурентные преимущества». Velox представляет собой унифицированный open source движок, который объединяет различные программные оптимизации в области обработки запросов в единую высокопроизводительную библиотеку, а в будущем и в самостоятельный фреймворк. Velox уже совместим с Presto и Apache Spark. Интеграция SPU NeuroBlade в Velox достигается за счёт новых API Velox, которые позволят произвольно переносить выполнение части запросов на ускоритель. Как отмечается в пресс-релизе, CPU с трудом справляются с аналитическими запросами, скорость которых превышает 2–3 Гбайт/с, из-за ограничений в обработке данных и сложности запросов. SPU NeuroBlade позволяет решить эту проблему, поскольку предлагает специализированный процессор, который обеспечивает аппаратную обработку сложных запросов и работу с памятью и хранилищем, что позволяет разгрузить CPU и добиться постоянной пропускной способности при обработке больших данных и снизить задержки.
17.09.2023 [19:04], Сергей Карасёв
NVIDIA за квартал отгрузила 900 тонн ускорителей H100Во II четверти 2024 финансового года, которая была закрыта 30 июля, компания NVIDIA реализовала продукцию для дата-центров на сумму около $10,32 млрд — это на 171 % больше результата за предыдущий год. Аналитики Omdia, как сообщает ресурс Tom's Hardware, подсчитали, что за эти три месяца NVIDIA отгрузила свыше 300 тыс. флагманских ускорителей H100. Изделия H100 на архитектуре Hopper предназначены для ресурсоёмких приложений ИИ, а также задач НРС. Однако из-за стремительного развития платформ генеративного ИИ такие ускорители оказались в дефиците: выполнение новых заказов откладывается до 2024 года. 
Источник изображения: NVIDIA По оценкам Omdia, во II квартале NVIDIA поставила более 900 тонн ускорителей H100. В своих расчётах аналитики полагают, что вес одного устройства с радиатором охлаждения превышает 3 кг. Таким образом, получается, что в течение рассматриваемого периода компания реализовала более 300 тыс. изделий. Ускорители H100 предлагаются в нескольких вариантах исполнения — в виде карты расширения PCIe и в формате модуля SXM. При этом масса (с учётом радиатора) различается: так, например, для карты она указана на отметке 1,2 кг. В случае SXM-изделий показатель не приводится, но, как отмечает Tom's Hardware, он не превышает 2 кг. Если предположить, что 80 % поставок H100 составляют модули, а 20 % — карты, то средний вес одного ускорителя должен составить около 1,84 кг. Omdia заявляет, что оценила общую массу в 900 тонн на основе количества H100, которые, по её мнению, NVIDIA поставила во II квартале. Таким образом, как отмечается, фактически суммарный вес может оказаться меньше, но речь всё равно идёт о сотнях тонн. Omdia прогнозирует, что до конца 2023 года темпы отгрузок Н100 сохранятся. Иными словами, NVIDIA сможет за год поставить около 1,2 млн таких ускорителей, а их суммарный вес достигнет 3600 тонн.
16.09.2023 [21:40], Сергей Карасёв
Cadence представила 7-нм ИИ-ядро Neo NPU с производительностью до 80 TOPSКомпания Cadence Design Systems, разработчик IP-блоков, по сообщению CNX-Software, создала ядро Neo NPU (Neural Processing Unit) — нейропроцессорный узел, предназначенный для решения ИИ-задач с высокой энергетической эффективностью. Решение подходит для создания SoC умных сенсоров, IoT-устройств, носимых гаджетов, систем оказания помощи водителю при движении (ADAS) и пр. Утверждается, что производительность Neo NPU может масштабироваться от 8 GOPS до 80 TOPS в расчёте на ядро. В случае многоядерных конфигураций быстродействие может исчисляться сотнями TOPS. Ядро Neo NPU способно справляться как с классическими ИИ-задачами, так и с нагрузками генеративного ИИ. Говорится о поддержке INT4/8/16 и FP16 для свёрточных нейронных сетей (CNN), рекуррентных нейронных сетей (RNN) и трансформеров. 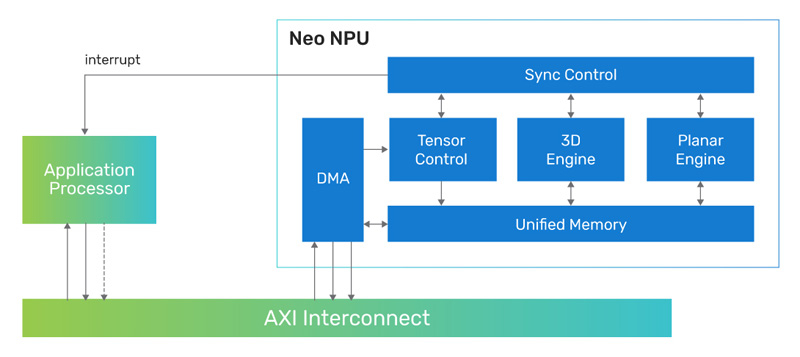
Источник изображения: Cadence Для Neo NPU предполагается применение 7-нм технологии производства. Стандартная тактовая частота — 1,25 ГГц. Утверждается, что по сравнению с ядрами первого поколения Cadence AI IP изделие Neo NPU обеспечивает 20-кратный прирост производительности. Скорость инференса в расчёте на ватт в секунду возрастает в 5–10 раз. Разработчикам будет предлагаться комплект NeuroWeave (SDK) с поддержкой TensorFlow, ONNX, PyTorch, Caffe2, TensorFlow Lite, MXNet, JAX, а также Android Neural Network Compiler, TF Lite Delegates и TensorFlow Lite Micro. Решение Neo NPU станет доступно в декабре 2023 года. |
|