Материалы по тегу: ускоритель
|
16.09.2023 [21:40], Сергей Карасёв
Cadence представила 7-нм ИИ-ядро Neo NPU с производительностью до 80 TOPSКомпания Cadence Design Systems, разработчик IP-блоков, по сообщению CNX-Software, создала ядро Neo NPU (Neural Processing Unit) — нейропроцессорный узел, предназначенный для решения ИИ-задач с высокой энергетической эффективностью. Решение подходит для создания SoC умных сенсоров, IoT-устройств, носимых гаджетов, систем оказания помощи водителю при движении (ADAS) и пр. Утверждается, что производительность Neo NPU может масштабироваться от 8 GOPS до 80 TOPS в расчёте на ядро. В случае многоядерных конфигураций быстродействие может исчисляться сотнями TOPS. Ядро Neo NPU способно справляться как с классическими ИИ-задачами, так и с нагрузками генеративного ИИ. Говорится о поддержке INT4/8/16 и FP16 для свёрточных нейронных сетей (CNN), рекуррентных нейронных сетей (RNN) и трансформеров. 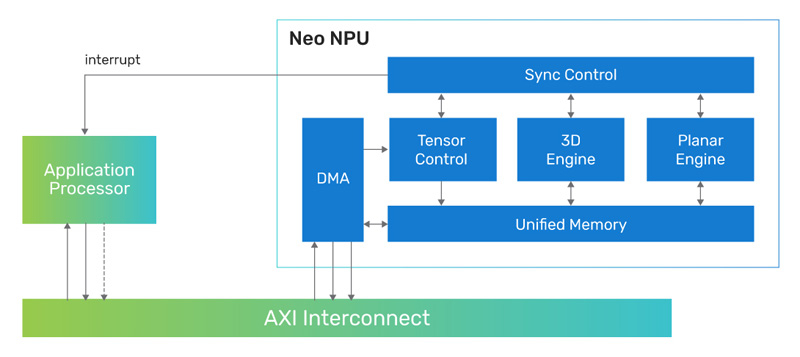
Источник изображения: Cadence Для Neo NPU предполагается применение 7-нм технологии производства. Стандартная тактовая частота — 1,25 ГГц. Утверждается, что по сравнению с ядрами первого поколения Cadence AI IP изделие Neo NPU обеспечивает 20-кратный прирост производительности. Скорость инференса в расчёте на ватт в секунду возрастает в 5–10 раз. Разработчикам будет предлагаться комплект NeuroWeave (SDK) с поддержкой TensorFlow, ONNX, PyTorch, Caffe2, TensorFlow Lite, MXNet, JAX, а также Android Neural Network Compiler, TF Lite Delegates и TensorFlow Lite Micro. Решение Neo NPU станет доступно в декабре 2023 года.
15.09.2023 [20:52], Алексей Степин
Groq назвала свои ИИ-чипы TSP четырёхлетней давности идеальными для LLM-инференсаТензорный процессор TSP, разработанный стартапом Groq, был анонсирован ещё осенью 2019 года и его уже нельзя назвать новым. Тем не менее, как сообщает Groq, TSP всё ещё является достаточно мощным решением для инференса больших языковых моделей (LLM). Теперь Groq позиционирует своё детище как LPU (Language Processing Unit) и продвигает его в качестве идеальной платформы для запуска больших языковых моделей (LLM). Согласно имеющимся данным, в этом качестве четырёхлетний процессор проявляет себя весьма неплохо. Groq открыто хвастается своим преимуществом над GPU, но в последних раундах MLPerf участвовать не желает. 
Источник изображений здесь и далее: Groq В своё время Groq разработала не только сам тензорный процессор, но и дизайн ускорителя на его основе, а также продумала вопрос взаимодействия нескольких TSP в составе вычислительного узла с дальнейшим масштабированием до уровня мини-кластера. Именно для такого кластера и опубликованы свежие данные о производительности Groq в сфере LLM. 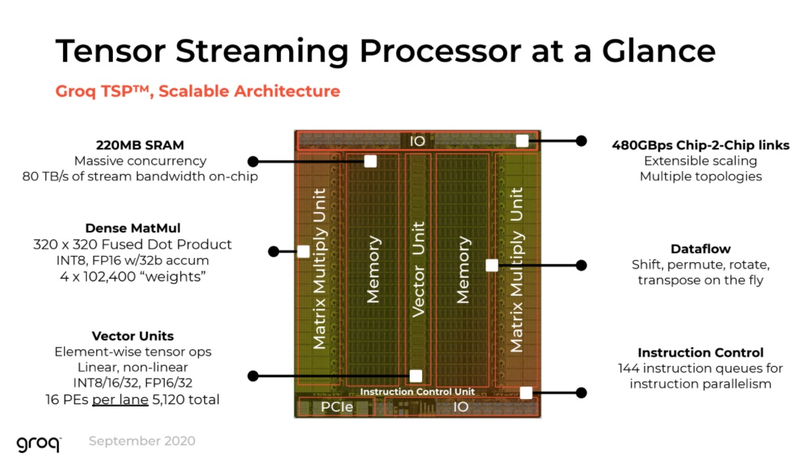 Система разработки, содержащая в своём составе 640 процессоров Groq TSP, была успешно использована для запуска модели Meta✴ Llama-2 с 70 млрд параметров. Как показали результаты тестов, модель на данной платформе работает с производительностью 240 токенов в секунду на пользователя. Для адаптации и развёртывания Llama-2, по словам создателей Groq, потребовалось всего несколько дней. В настоящее время усилия Groq будут сконцентрированы на адаптации имеющейся платформы в сфере LLM-инференса, поскольку данный сектор рынка растёт быстрее, нежели сектор обучения ИИ-моделей. Для LLM-инференса важнее умение эффективно масштабировать потоки небольших блоков (8–16 Кбайт) на большое количество чипов. 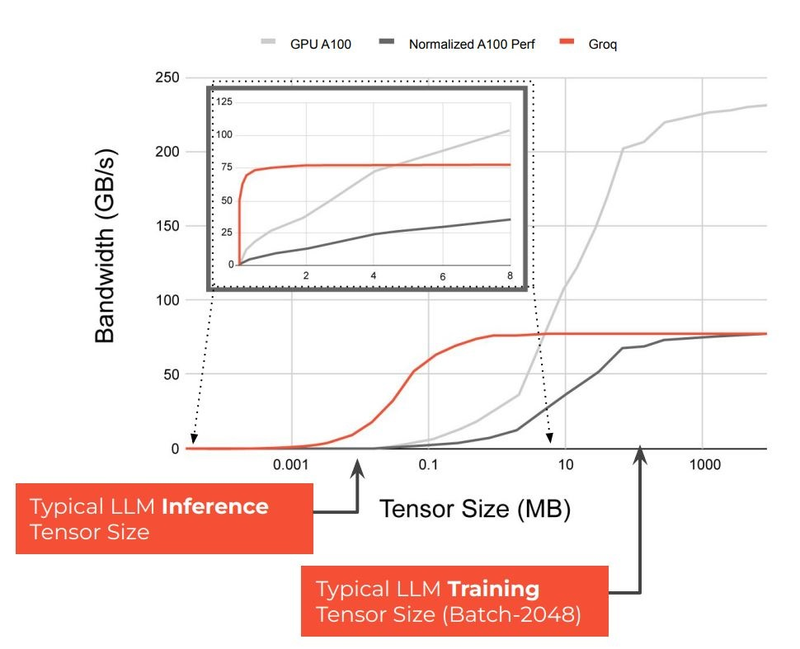 В этом Groq TSP превосходит NVIDIA A100: если в сравнении двух серверов выиграет решение NVIDIA, то уже при 40 серверах показатели латентности у Groq TSP будут намного лучше. В распоряжении Groq имеется пара 10-стоечных кластеров с 640 процессорами, один из которых используется для разработки, а второй — в качестве облачной платформы для клиентов Groq в области финансовых услуг. Работает система Groq и в Аргоннской национальной лаборатории (ALCF), где она используется для исследований в области термоядерной энергетики.  В настоящее время Groq TSP производятся на мощностях GlobalFoundries, а упаковка чипов происходит в Канаде, но компания работает над вторым поколением своих процессоров, которое будет производиться уже на заводе Samsung в Техасе. Параллельно Groq работает над созданием 8-чипового ускорителя на базе TSP первого поколения. Это делается для уплотнения вычислений, а также для более полного использования проприетарного интерконнекта и обхода ограничений, накладываемых шиной PCIe 4.0. Также ведётся дальнейшая оптимизация ПО для кремния первого поколения. 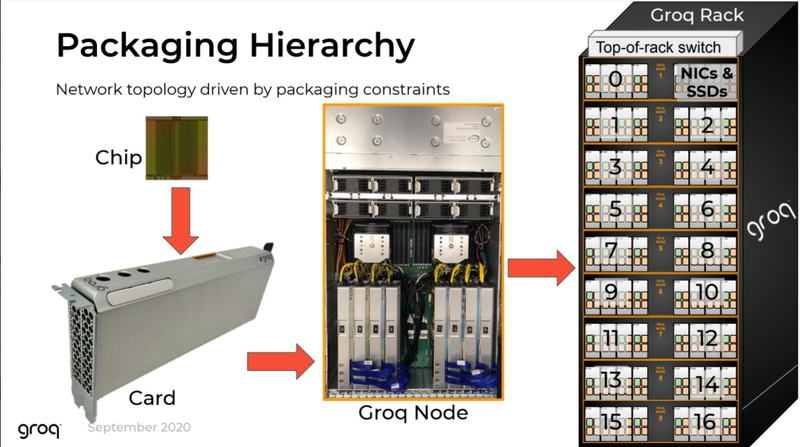 Простота и скорость разработки ПО для платформы Groq TSP объясняется историей создания этого процессора — начала Groq с создания компилятора и лишь затем принялась за проектирование кремния с учётом особенностей этого компилятора. Перекладывание на плечи компилятора всех задач оркестрации вычислений позволило существенно упростить дизайн TSP, а также сделать предсказуемыми показатели производительности и латентности ещё на этапе сборки ПО. При этом архитектура Groq TSP вообще не предусматривает использования «ядер» (kernels), то есть не требует блоков низкоуровневого кода, предназначенного для общения непосредственно с аппаратной частью. В случае с TSP любая задача разбивается на набор небольших инструкций, реализованных в кремнии и выполняемых непосредственно чипом. 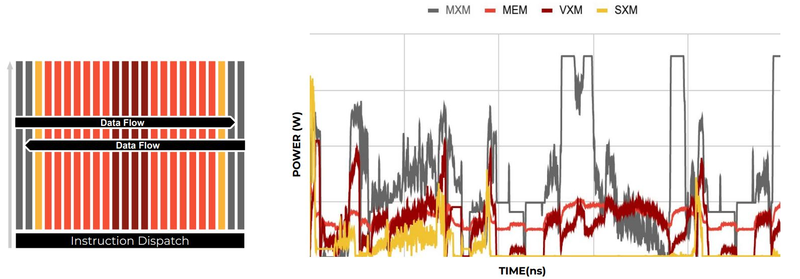
Компилятор Groq позволяет визуализировать и предсказывать энергопотребление с точностью до наносекунд. Источник: Groq Предсказуемость Groq TSP распространяется и на энергопотребление: оно полностью профилируется ещё на этапе компиляции, так что пики и провалы можно спрогнозировать с точностью вплоть до наносекунд. Это позволяет добиться от платформы более надёжного функционирования, избежав так называемой «тихой» порчи данных — сбоев, происходящих в результате резких всплесков энергетических и тепловых параметров кремния. 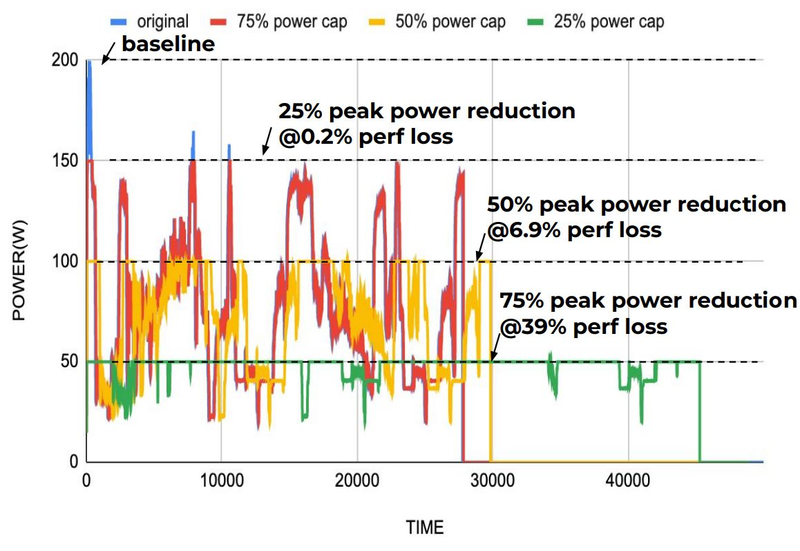
Энергопотребление Groq TSP поддаётся тонкой настройке на уровне программного обеспечения. Источник: Groq Что касается будущего LLM-инференса, то Groq считает, что этой отрасли есть, куда расти. В настоящее время LLM дают ответ на запрос сразу, и затем пользователи могут уточнить его в последующих итерациях, но в будущем они начнут «рефлексировать» — то есть, «продумывать» несколько вариантов одновременно, используя совокупный результат для более точного «вывода» и ответа. Разумеется, такой механизм потребует больших вычислительных мощностей, и здесь масштабируемая и предсказуемая архитектура Groq TSP может прийтись как нельзя более к месту.
13.09.2023 [15:04], Сергей Карасёв
ИИ-стартап Axelera представил платформу Metis AI для периферийных вычисленийМолодая компания Axelera AI B.V. сообщила о начале поставок платформы Metis AI, разработанной специально для ускорения ИИ-задач на периферии. Стартап, основанный в 2021 году, получил финансирование на сумму более $50 млн. Чип Axelera основан на открытой архитектуре RISC-V. В базовом варианте платформа Metis AI обеспечивает производительность до 39,3 TOPS. Увеличив тактовую частоту, быстродействие можно довести до 48,16 TOPS. Изделие предлагается в различных вариантах исполнения, включая карты расширения PCIe (FHHL), модули М.2 2280 и полноценные системы для задач машинного зрения. В частности, карты PCIe AI Edge доступны в версиях с одним и несколькими чипами с общей производительностью до 856 TOPS. Утверждается, что платформа Metis AI обладает высокой энергетической эффективностью — это важно при организации ИИ-вычислений на периферии. 
Источник изображений: Axelera AI B.V. Изделия Metis AI используют чипы Axelera Metis AIPU, содержащие четыре ядра для in-memory вычислений. Объём SRAM-кеша L1 составляет 16 Мбайт, кеша L2 — 32 Мбайт. Диапазон рабочих температур простирается от -40 до +85 °C. Гарантирована совместимость с Ubuntu 20.04/22.04 и Yocto. Разработчикам доступен набор инструментов Voyager SDK и фирменный компилятор TVM, который включает в себя средства оптимизации.  Модуль Axelera M.2 в формате 2280 наделён 512 Мбайт памяти LPDDR4x и одним чипом Axelera Metis AIPU. Энергоэффективность достигает 15 TOPS в расчёте на 1 Вт. Задействовано пассивное охлаждение; интерфейс подключения — PCIe 3.0 х4. Цена составляет €150. В свою очередь, карты Axelera PCIe AI Edge доступны в версиях с одним (+1 Гбайт набортной RAM) и четырьмя чипами Axelera Metis AIPU: в первом случае быстродействие достигает 214 TOPS (INT8), во втором — 856 TOPS. Устройства выполнены в виде однослотовых карт с интерфейсом PCIe 3.0 х4 и PCIe 3.0 х16. Применена система активного охлаждения с вентилятором. Цена составляет около €200 и €500 соответственно.
07.09.2023 [23:02], Сергей Карасёв
Разработчик ускорителей для генеративного ИИ D-Matrix привлёк на развитие $110 млнСтартап D-Matrix, по сообщению ресурса SiliconAngle, провёл крупный раунд финансирования Series B, в ходе которого на развитие привлечено $110 млн. Данную программу возглавила инвестиционная фирма Temasek, базирующаяся в Сингапуре. Компания D-Matrix создаёт чипы и платформы, предназначенные для развертывания систем генеративного ИИ. Стартап проектирует микросхемы со специализированной чиплетной архитектурой, использующей концепцию «цифровых вычислений в памяти» (DIMC). Это позволяет перенести полностью программируемую память непосредственно на чип, что даёт возможность уменьшить задержки и повысить эффективность. 
Источник изображения: D-Matrix Отмечается, что большие языковые модели, такие как Llama 2 от Meta✴ Platform и ChatGPT от OpenAI, обучаются на огромных массивах данных. Именно для оптимизации этого процесса и предназначены решения D-Matrix. В частности, изделие под названием Jayhawk II, как утверждает стартап, позволяет повысить эффективность обучения в 10–20 раз по сравнению с GPU и уменьшить затраты в 10–20 раз. В нынешнем раунде финансирования D-Matrix приняли участие существующие инвесторы в лице Playground Global, венчурного фонда M12 корпорации Microsoft, Nautilus Venture Partners и Entrada Ventures. К ним присоединились Industry Ventures, Ericsson Ventures, Marlan Holdings, Mirae Asset и Samsung Ventures. Стартап D-Matrix в апреле 2022 года получил $44 млн в рамках предыдущего раунда финансирования, возглавляемого M12 и компанией SK hynix Inc. Таким образом, общая сумма привлечённых средств достигла $154 млн.
07.09.2023 [21:25], Алексей Степин
Cerebras готова к построению масштабных ИИ-кластеров CS-2 с 163 млн ядерНа прошедшей недавно конференции Hot Chips 2023 компания Cerebras, создатель самого большого в мире ИИ-процессора WSE-2, рассказала о своём видении будущего ИИ-систем. По мнению Cerebras, сфокусировать внимание стоит не столько на наращивании сложности отдельных чипов, сколько на решениях проблем, связанных с масштабированием кластеров. Свою презентацию Cerebras начала с любопытных фактов: за прошедшие пять лет сложность ИИ-моделей возросла в 40 тыс. раз. И этот темп явно опережает темпы развития чипов-ускорителей. Хотя налицо прогресс и в техпроцессах (5x), и в архитектуре (14x), и во внедрении более эффективных для ИИ форматов данных, но наибольший прирост производительности обеспечивает именно возможность эффективного масштабирования. 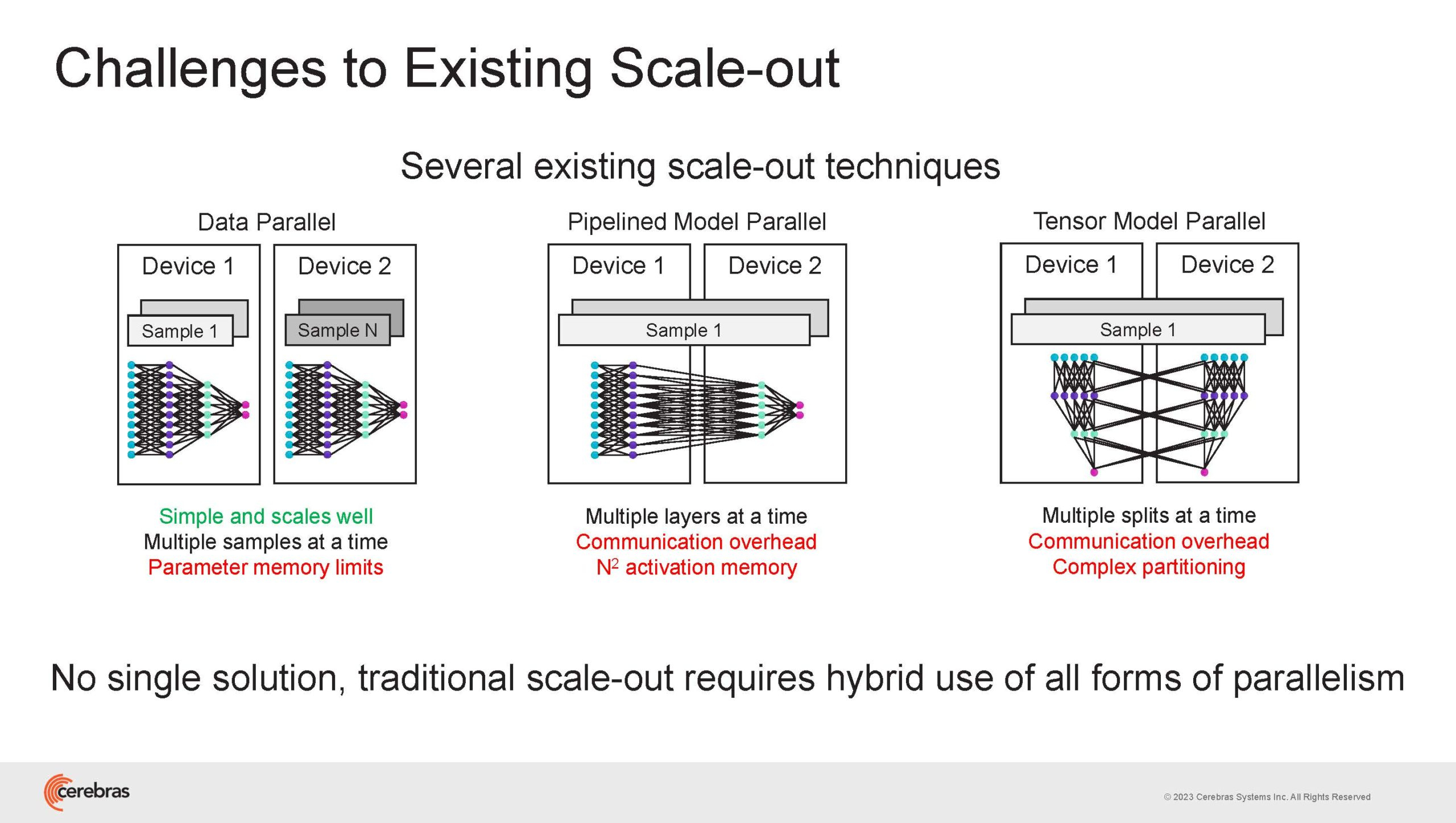
Источник изображений здесь и далее: Cerebras (via ServeTheHome) Однако и этого недостаточно — 600-кратный прирост от кластеризации явно теряется на фоне 40-тыс. усложнения самих нейросетей. А дальнейший рост масштабов ИИ-комплексов в их классическом виде, состоящих из множества «малых» ускорителей, неизбежно приводит к проблемам с организацией памяти, интерконнекта и вычислительных мощностей. 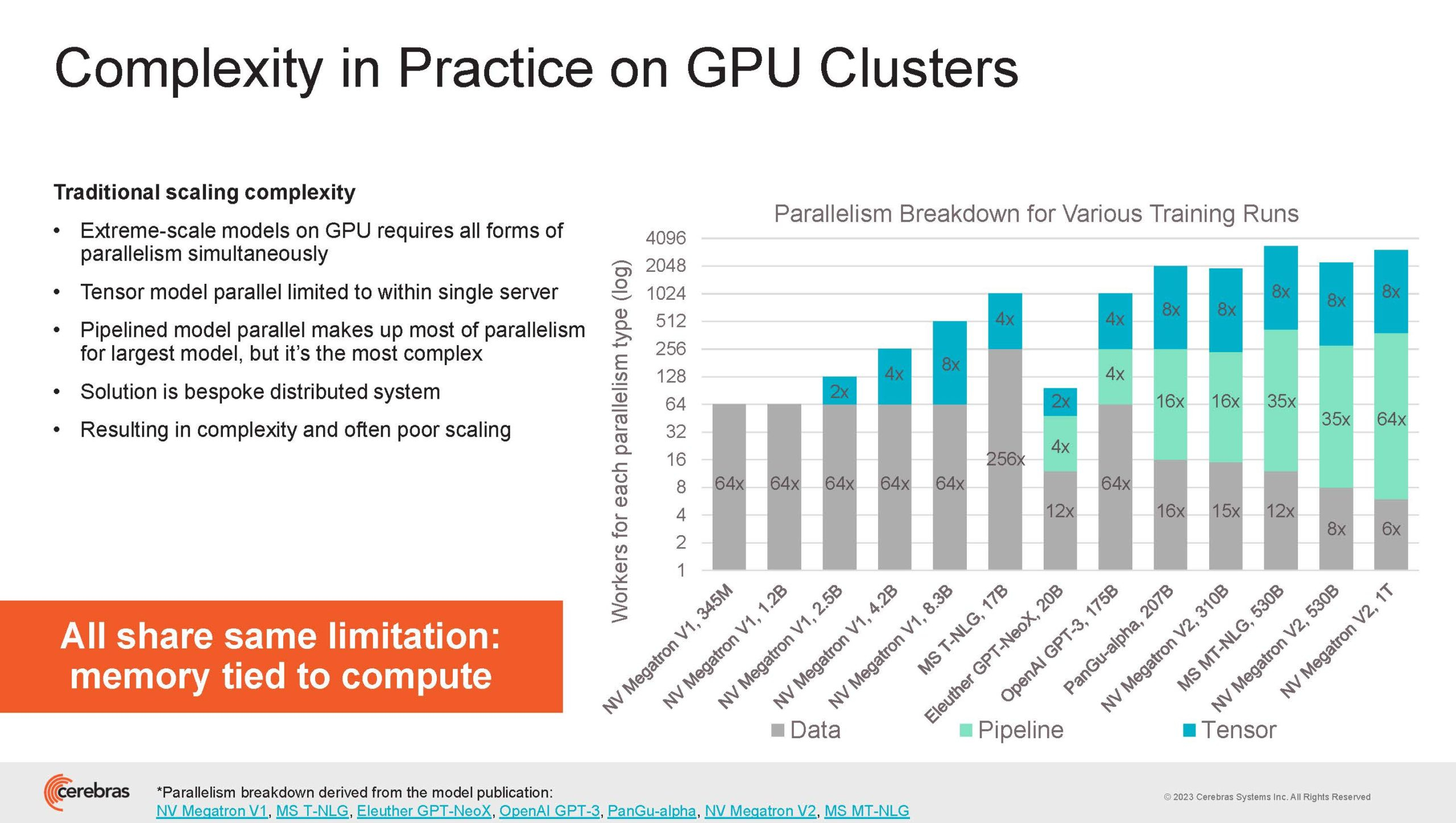 В итоге решение любой задачи в таких системах часто упирается в необходимость тончайшей, но при этом далеко не всегда эффективной оптимизации разделения ресурсов. При этом разные методы масштабирования имеют свои проблемы — узким местом могут оказаться и память, и интерконнект, и конкретный подход к организации кластера. 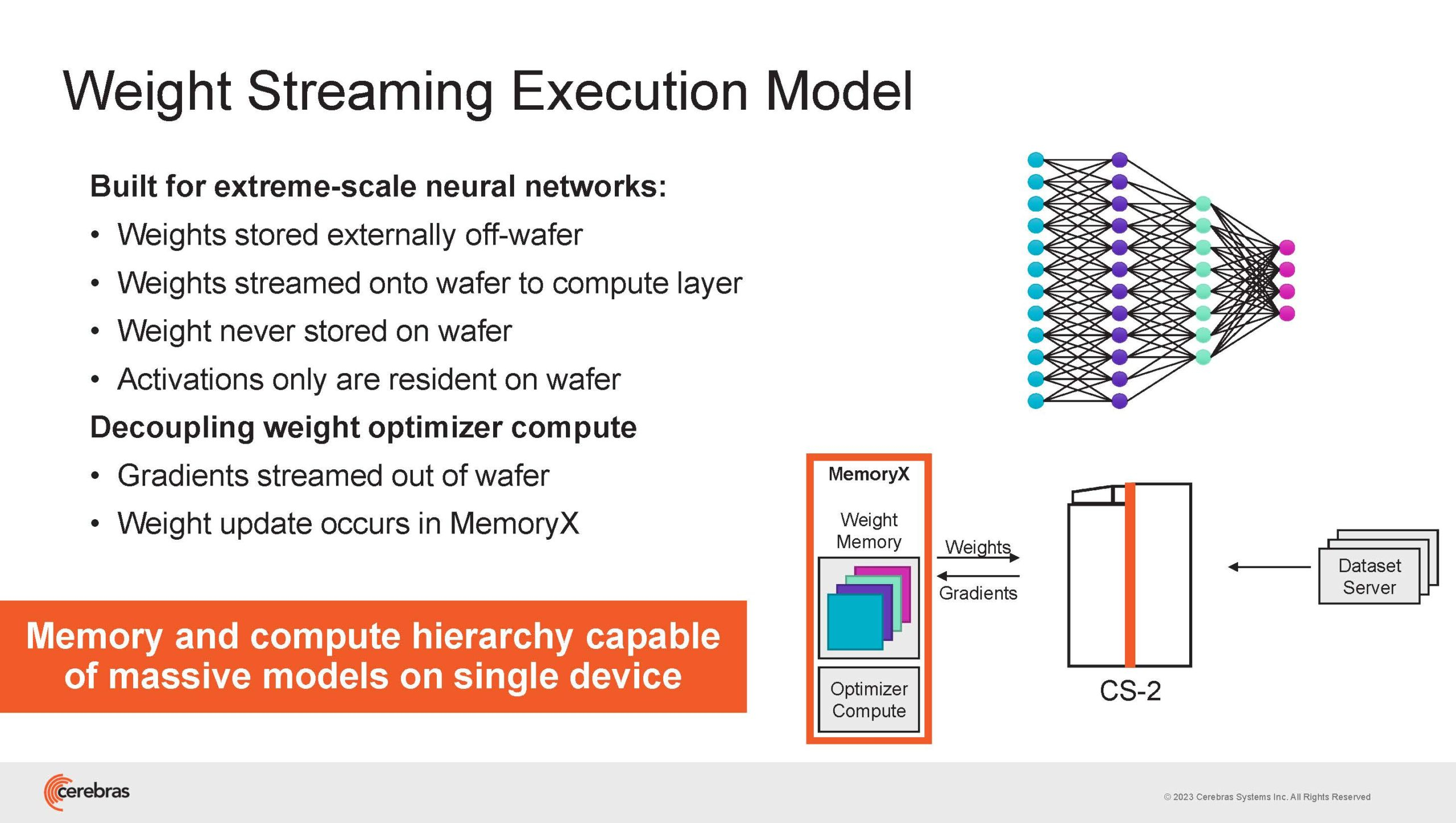 Cerebras же предлагает совершенно иной подход. Выход компания видит в создании огромных чипов-кластеров, таких, как 7-нм Cerebras WSE-2. Этот чип на сегодня можно назвать самым большим в индустрии: его площадь составляет более 45 тыс. мм2, при этом он содержит 2,6 трлн транзисторов и имеет 850 тыс. ядер, дополненных 40 Гбайт сверхбыстрой памяти. Что интереснее, кластер на базе CS-2 представляется с точки зрения исполняемой модели, как единая система. 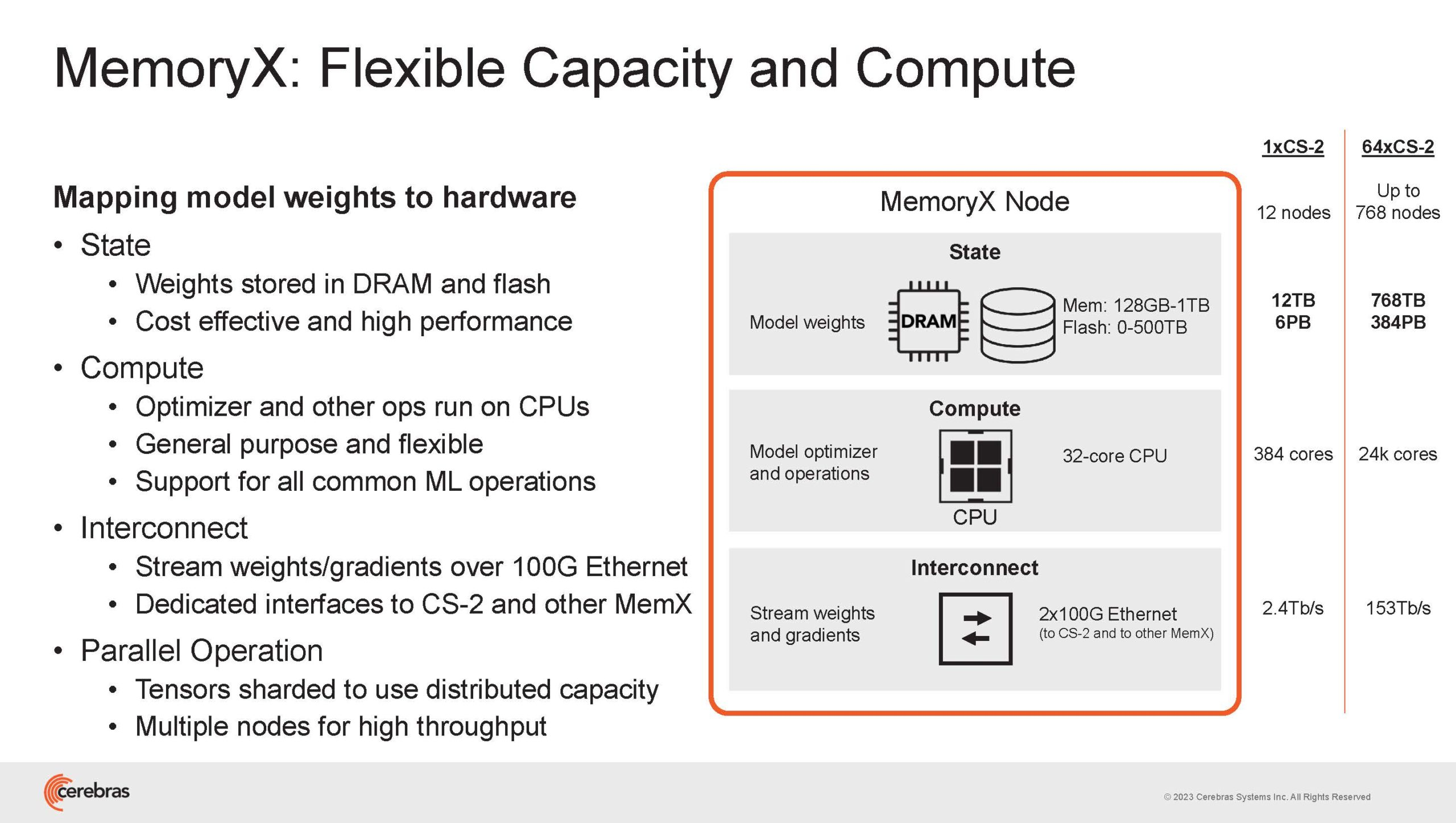 Сама по себе сложность WSE-2 и платформы CS-2 на его основе такова, что позволяет запускать модели практически любых размеров, благо весовые коэффициенты чип в себе не хранит, а подгружает извне с помощью подсистемы MemoryX. При этом сама по себе платформа CS-2 допускает и дальнейшее масштабирование: с помощью интерконнекта SwarmX в единый кластер можно объединить до 192 таких машин, что в теории позволит поднять производительность до 8+ Эфлопс. 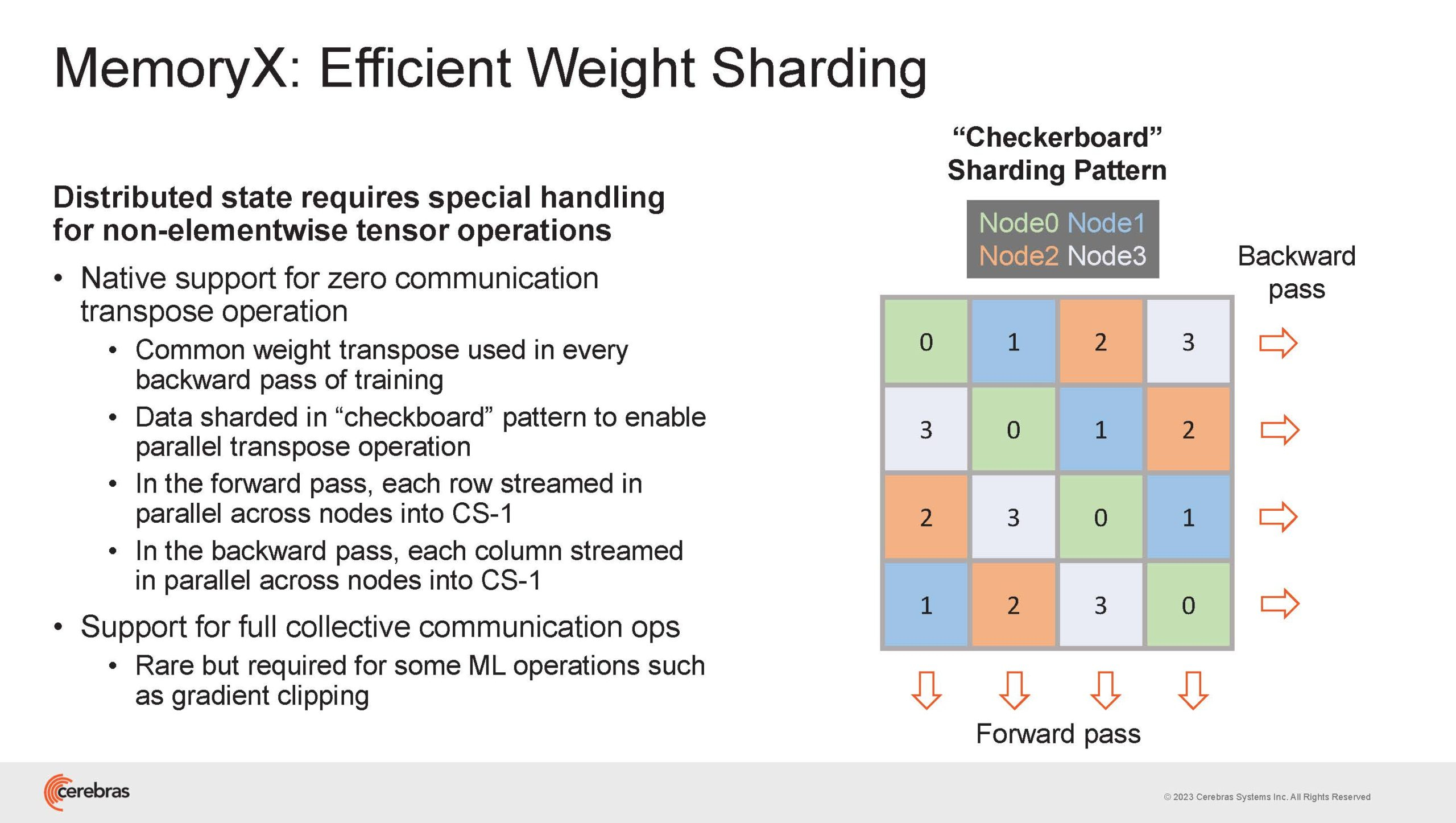 Подсистема MemoryX включает в себя 12 узлов, за оптимизацию модели в ней отвечают 32-ядерные процессоры, а веса хранятся как в DRAM, так и во флеш-памяти — объёмы этих подсистем составляют 12 Тбайт и 6 Пбайт соответственно. Каждый узел имеет по 2 порта 100GbE — один для закачки данных в CS-2, второй для общения с другими MemoryX в кластере. Оптимизация данных производится на процессорах MemoryX, «мегачипы» CS-2 для этого не используются. 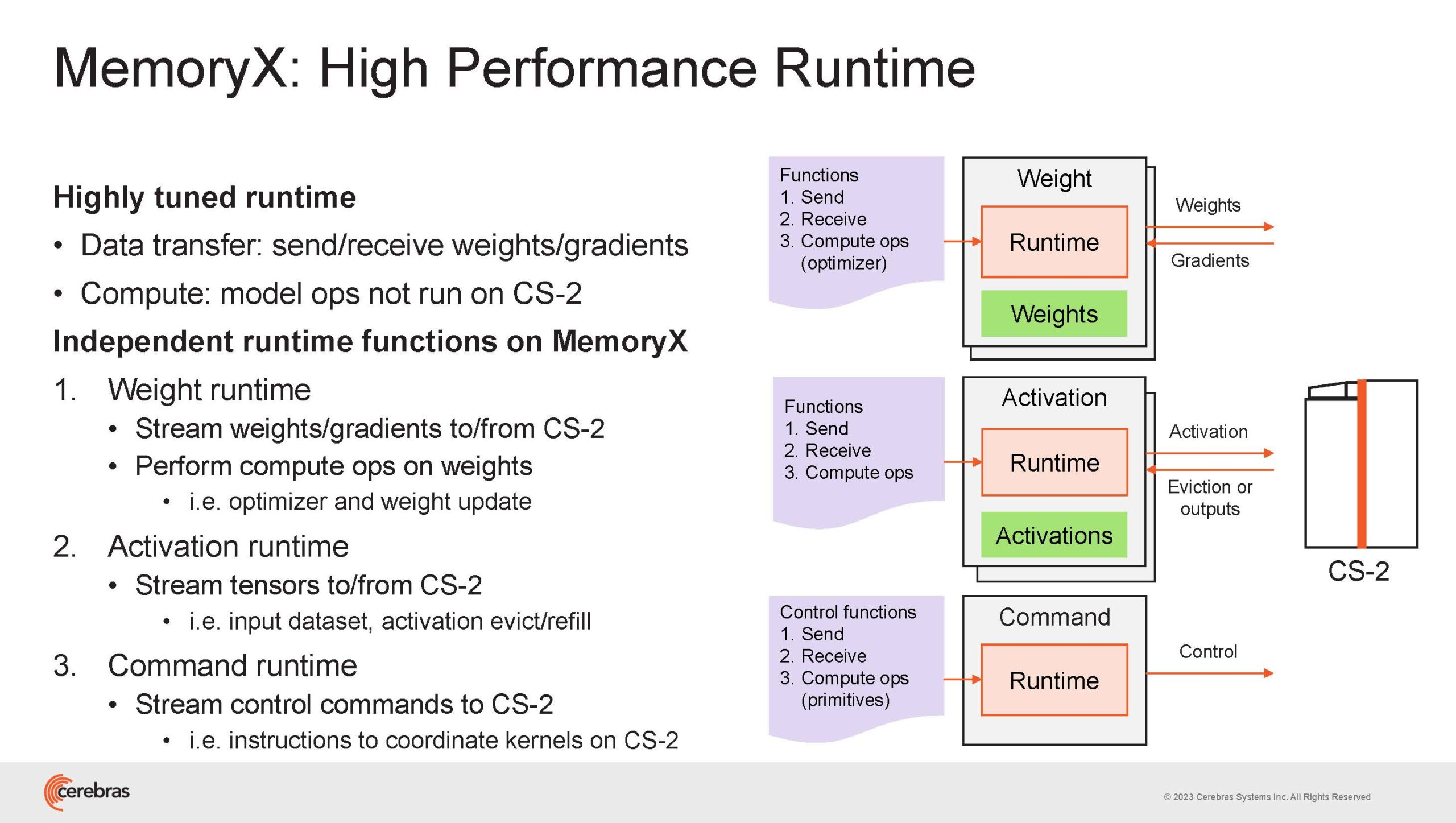 Подсистема интерконнекта SwarmX базируется на 100GbE с поддержкой RoCE DRMA, но имеет ряд особенностей: на каждые четыре системы CS-2 приходтся 12 узлов SwarmX c производительностью интерконнекта 7,2 Тбит/с. Трансляция и редуцирование данных осуществляются с коэффициентом 1:4, причём и здесь используются силы собственных 32-ядерных процессоров, а не ресурсы CS-2. Топологически SwarmX имеет двухслойную конфигурацию spine-leaf и обеспечивает соединение типа all-to-all, при этом каждая CS-2 имеет свой канал с пропускной способностью 1,2 Тбит/с. 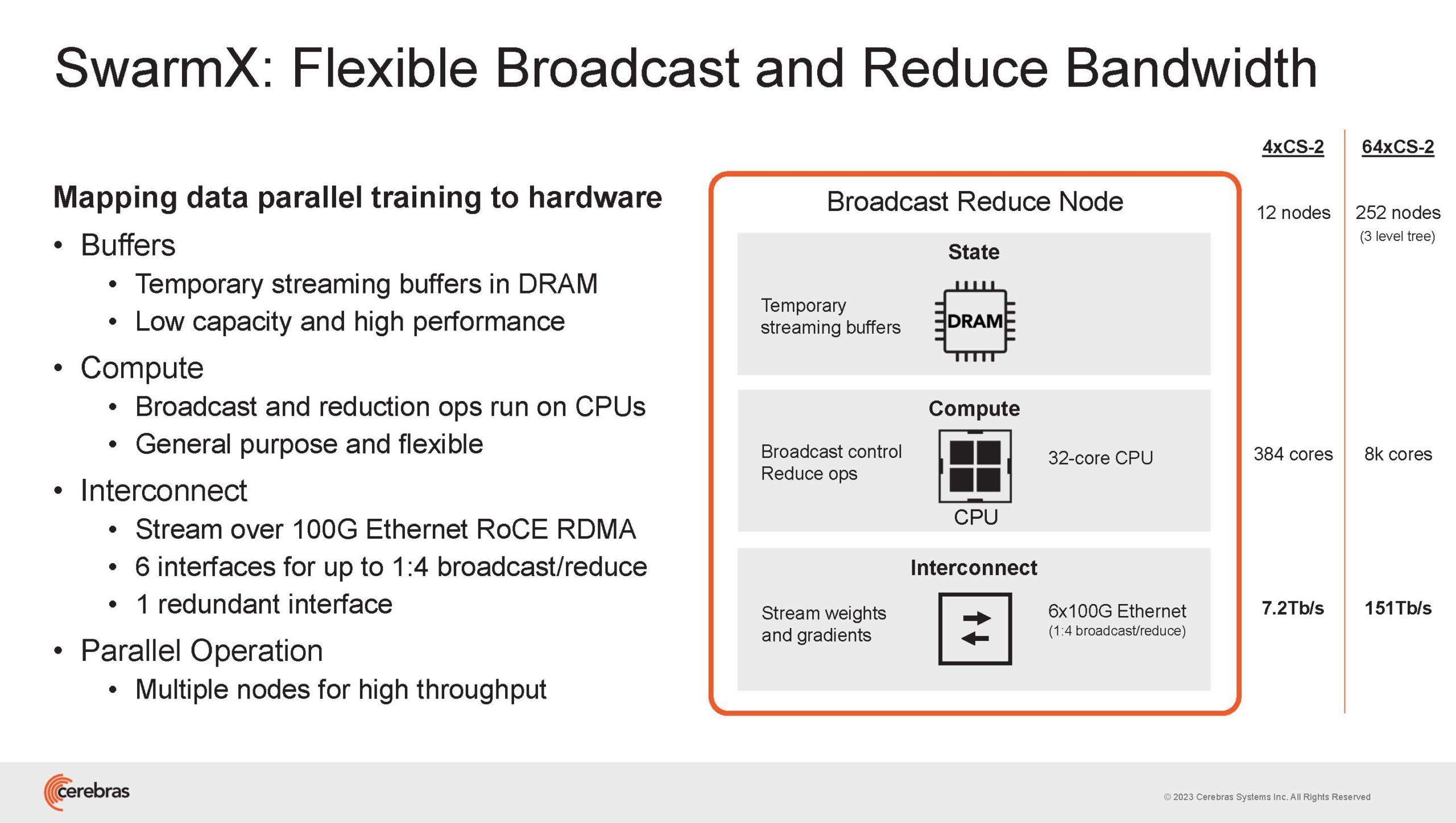 Сочетание MemoryX и SwarmX позволяет делать кластеры на базе CS-2 крайне гибкими: размер модели ограничивается лишь ёмкостью узлов MemoryX, а степень параллелизма — их количеством. При этом интерконнект обладает достаточной степенью избыточности, чтобы говорить об отсутствии единых точек отказа. 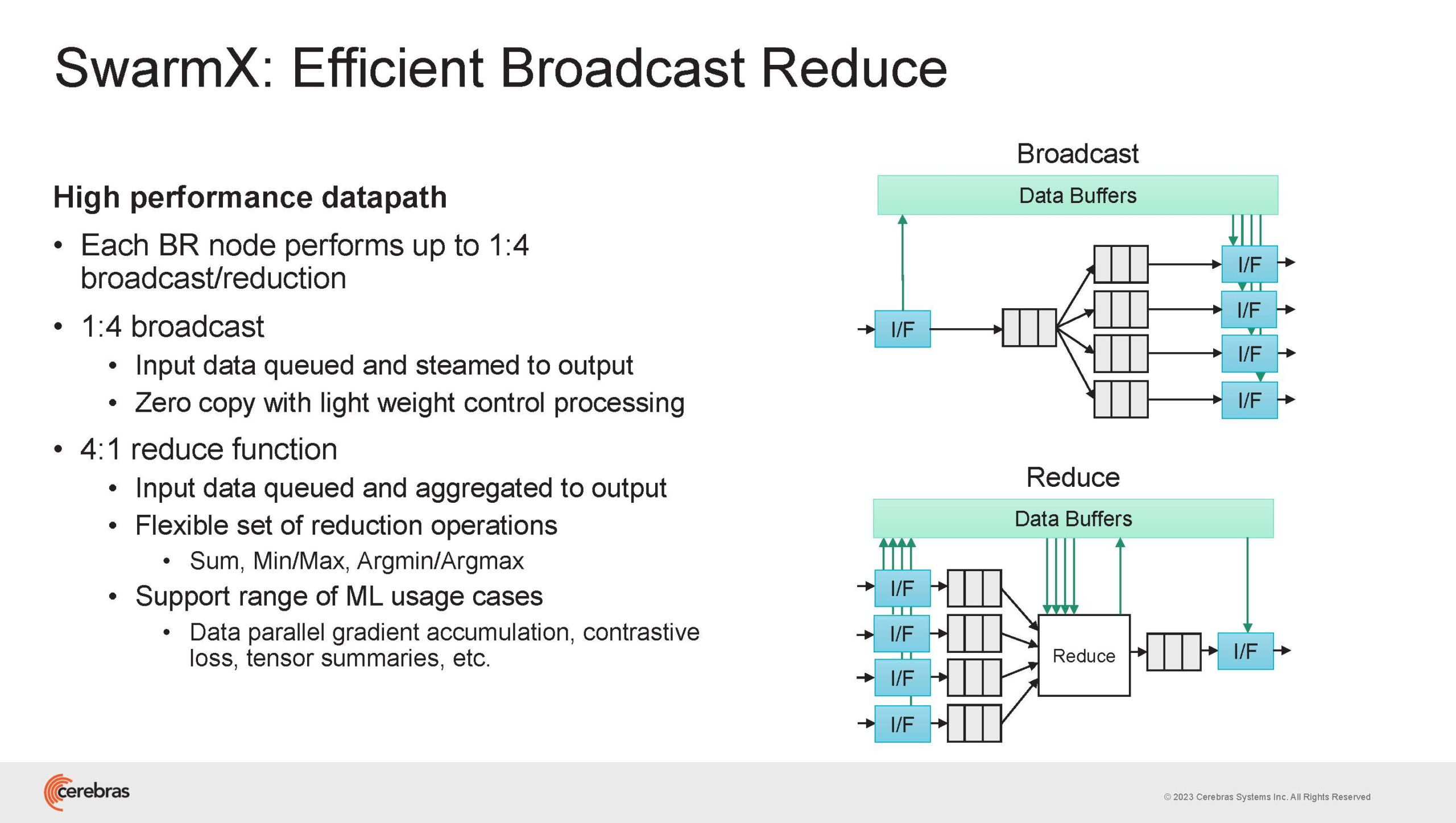 Таким образом, Cerebras имеет на руках всё необходимое для запуска самых сложных моделей искусственного интеллекта. Уже сравнительно немолодой кластер Andromeda, включающий всего 16 платформ CS-2, способен «натаскивать» за считанные недели нейросети размерностью до 13 млрд параметров. При этом масштабирование по размеру модели не требует серьёзного вмешательства в программный код, в отличие от классического подхода для ускорителей NVIDIA. Фактически для сетей и с 1, и со 100 млрд параметров используется один и тот же код. 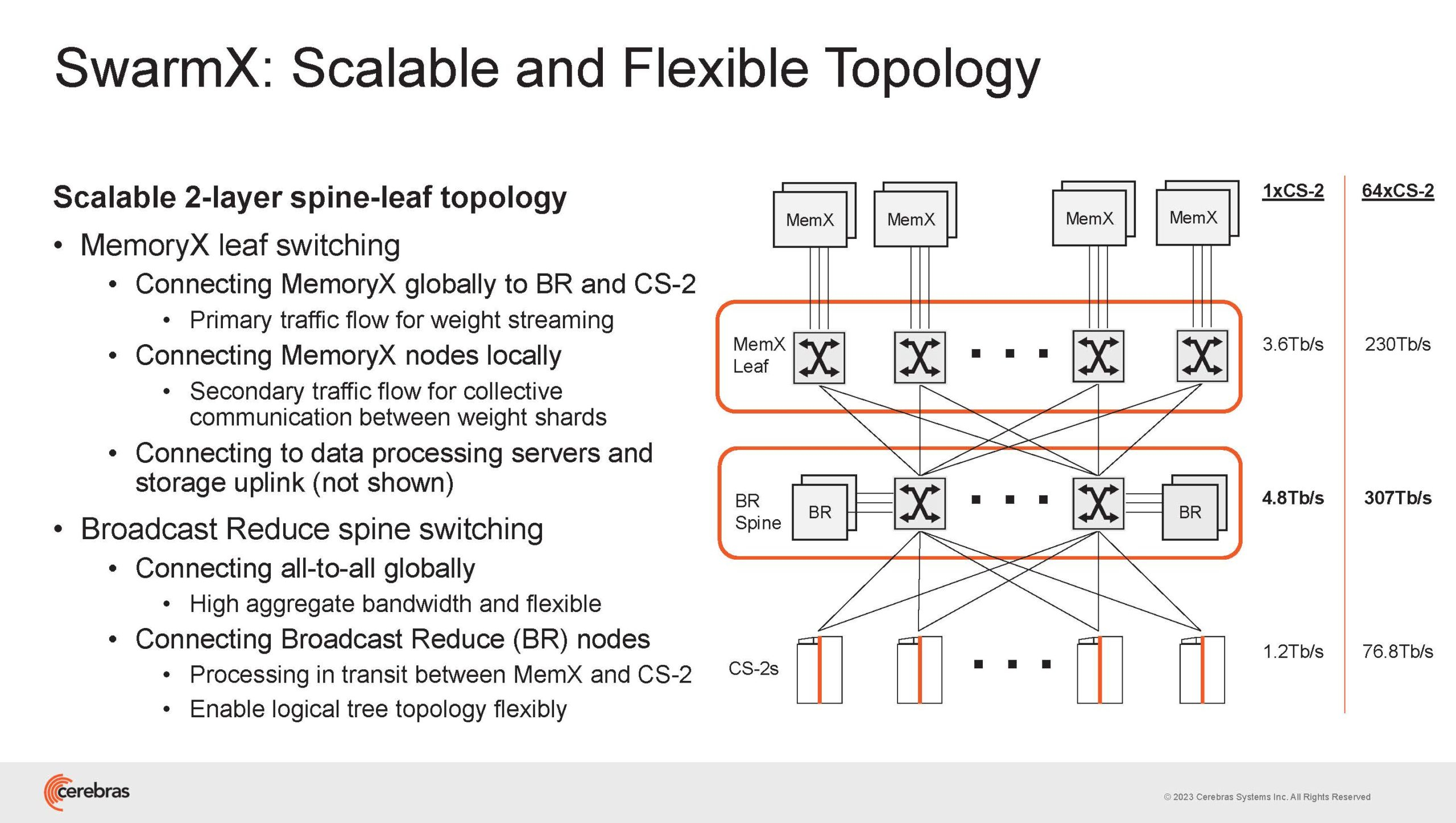 Более мощный 64-узловой комплекс Condor Galaxy 1 (CG-1), располагающий 54 млн ИИ-ядер и развивающий до 4 Эфлопс уже доказал, что подход к масштабированию, продвигаемый Cerebras, оправдывает себя. Он успешно обучил первую публичную модель с 3 млрд параметров, причём по возможностям она приближается к моделям с 7 млрд параметров. И это не предел: напомним, в текущем воплощении сочетание подсистем MemoryX и интерконнекта SwarmX допускает объединение в единый кластер до 192 узлов CS-2. 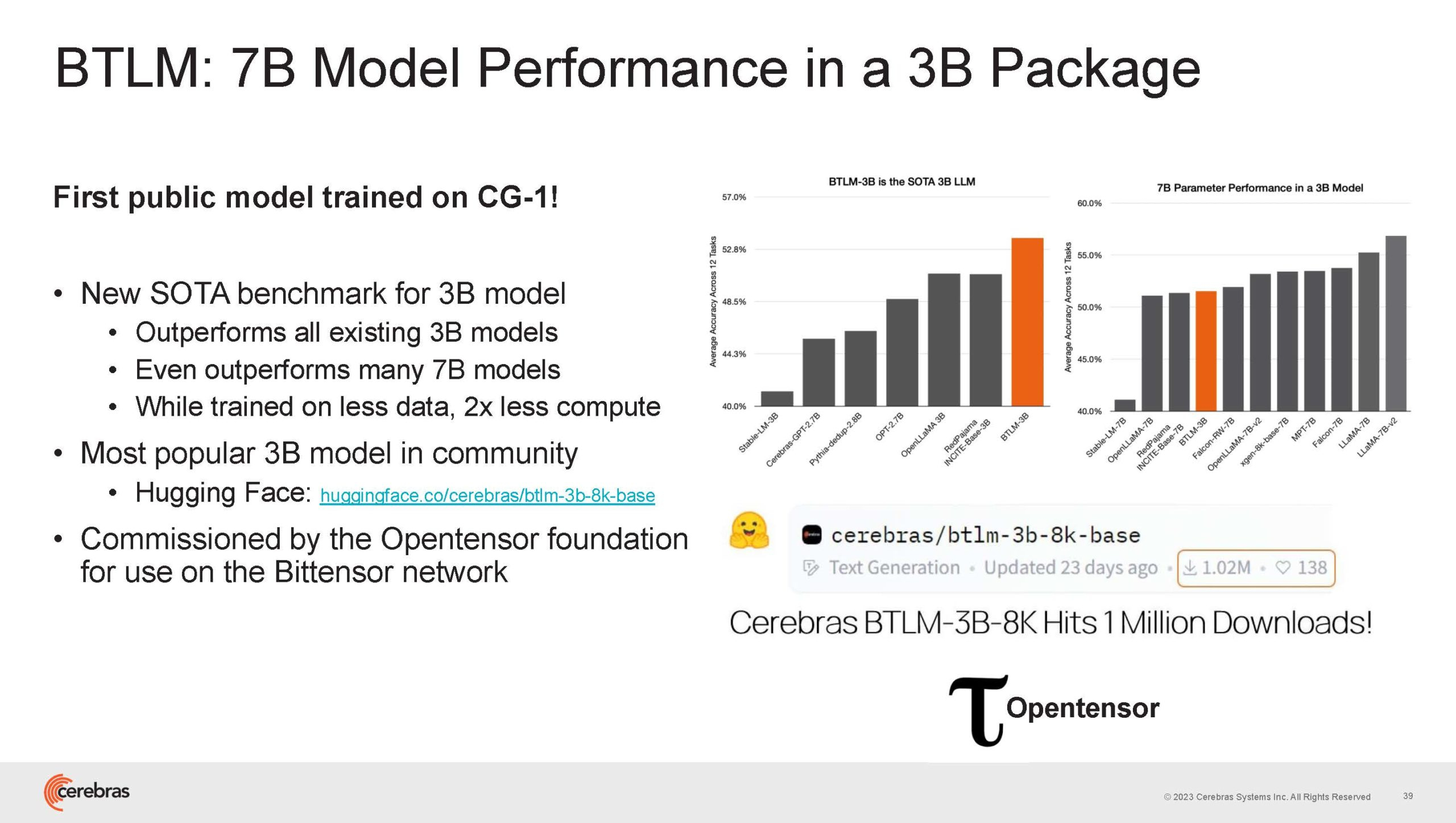 Компания считает, что она полностью готова к наплыву ещё более сложных нейросетей, а предлагаемая ей архитектура в явном виде лишена многих узких мест, свойственных традиционным GPU-архитектурам. Насколько успешным окажется такой подход в более отдалённой перспективе, покажет время.
30.08.2023 [16:04], Алексей Степин
Google Cloud анонсировала новое поколение собственных ИИ-ускорителей TPU v5eКак известно, Google Cloud использует в своей инфраструктуре не только сторонние ускорители, но и TPU собственной разработки. Эти кастомные ASIC компания продолжает активно развивать — она анонсировала предварительную доступность виртуальных машин с новейшими TPU v5e, разработка которых заняла более двух лет. Сам чип TPU v5e позиционируется Google как эффективный со всех точек зрения ускоритель, предназначенный для обучения нейросетей или инференс-систем среднего и большого классов. В сравнении с TPU v4 он, по словам Google, обеспечивает вдвое более высокую производительность в пересчёте на доллар для обучения больших языковых моделей (LLM) и генеративных нейросетей. Для инференс-систем преимущество по тому же критерию составляет 2,5x. В сравнении с аналогичными решениями на базе других чипов, например, GPU, выигрыш может составить и 4x. Каждый чип TPU v5e включает четыре блока матричных вычислений, по одному блоку для скалярных и векторных расчётов, а также HBM2-память. 
Источник изображения: Google Компания отмечает, что не экономит на технических характеристиках TPU v5e в угоду рентабельности. Кластеры могут включать до 256 чипов TPU v5e, объединённых высокоскоростным интерконнектом с совокупной пропускной способностью более 400 Тбит/с. Производительность такой платформы составляет 100 Попс (Петаопс) в INT8-вычислениях. Правда, здесь есть нюанс: INT8-производительности TPU v5e составляет 393 Тфлопс против 275 Тфлопс у v4, но вот BF16-производительность у TPU v4 составляет те же 275 Тфлопс, тогда как у v5e этот показатель равен уже 197 Тфлопс. 
Источник изображения: Google В настоящее время для предварительного тестирования доступно уже восемь вариантов инстансов на базе v5e, а в зависимости от конфигурации количество TPU может составлять от 1 до более чем 250. В рамках платформы обеспечена полная интеграция с Google Kubernetes Engine, собственной платформой Vertex AI, а также с большинством современных фреймворков, включая PyTorch, TensorFlow и JAX. Работа с TPU v5e будет значительно дешевле, чем с TPU v4 — $1,2/час против $3,4/час (за чип). 
Источник изображения: Google В настоящее время машины с TPU v5e доступны только в североамериканском регионе (us-west4), но в дальнейшем возможность их использования появится в регионах EMEA (Нидерланды) и APAC (Сингапур). Также Google предлагает опробовать технологию Multislice, позволяющей объединять в единый комплекс десятки тысяч TPU v5e или TPU v4, где каждый «слайс» может содержать до 3072 чипов TPU (v4). В максимальной конфигурации можно развернуть 64 инстанса, работающих с 256 кластерами TPU v5e. Сама компания уже использует новые чипы для своего поисковика и Google Photos.
10.08.2023 [16:49], Руслан Авдеев
В ожидании новых санкций: китайские гиперскейлеры заказали ускорители NVIDIA на $5 млрдКитайские IT-гиганты начали массовые закупки ускорителей NVIDIA, стремясь обеспечить развитие собственной ИИ-инфраструктуры. Как сообщает Financial Times, только в этом году местным клиентам будут поставлены соответствующие чипы на $1 млрд и ещё на $4 млрд — в следующем. В Китае только ByteDance уже владеет 10 тыс. ускорителей NVIDIA, а ещё почти 70 тыс. чипов A800 должны быть поставлены в следующем году. По данным Financial Times, один лишь этот заказ оценивается в $700 млн. Сопоставимые закупки сделали или готовы сделать и другие техногиганты из Поднебесной. В связи с тем, что США ввели ограничения на поставку своих продуктов и технологий в КНР, покупателям из Поднебесной пришлось согласиться на очевидно дискриминационные предложения — для страны выпускаются урезанные варианты ускорителей в лице A800 и H800. Не исключено, что США и их союзники и дальше будут ужесточать экспортную политику, поэтому местные компании принялись активно закупать хотя бы A800 — пока не запретили поставлять и их, что невероятно усложнит обучение больших языковых моделей (LLM). 
Источник изображения: NVIDIA По данным DataCenter Dynamics, прошлым вечером акции NVIDIA упали на 4 % на фоне опасений, что регуляторы США прибегнут к новым ограничительным мерам в отношении китайских компаний и организаций. Дело в том, что президент США уже издал указ, предусматривающий в отношении Китая дальнейшие ограничения, связанные с технологиями ИИ, квантовыми вычислениями и экспортом технологий, связанных с производством чипов. Производители прибегают к различным уловкам для того, чтобы обойти американские санкции. Так, Intel изменила модельный ряд Xe и представила ИИ-ускоритель Habana Gaudi 2 для китайских покупателей. Готовит особые ускорители и AMD.
09.08.2023 [18:00], Алексей Степин
NVIDIA анонсировала L40S — новый универсальный ускоритель на базе Ada LovelaceКорпорация NVIDIA обновила серию укорителей L40, представленных осенью прошлого года в рамках платформы OVX. Новинка под названием NVIDIA L40S позиционируется как универсальный ускоритель в форм-факторе двухслотовой FHFL-карты расширения с интерфейсом PCIe 4.0 x16, пригодный для решения практически любых задач. Во многом L40S повторяет L40 — она также базируется на архитектуре Ada Lovelace, оснащена графическим процессором AD102, дополненным 48 Гбайт памяти GDDR6 ECC (384 бит, 864 Гбайт/с). В составе ускорителя работают 18176 ядер CUDA, 142 RT-ядра третьего поколения и 568 тензорных ядер четвёртого поколения. То есть в этом отличий от L40 нет. Но значение TDP у новинки выше на 50 Вт и составляет 350 Вт, она все ещё имеет пассивное охлаждение. 
Источник изображений здесь и далее: NVIDIA При этом L40S умудряется быть практически вдвое быстрее L40 во всех форматах вычислений с использованием тензорных ядер, а вот без Tensor Core её FP32-производительность выросла минимально — с 90,5 до 91,6 Тфлопс. Поддержкой NVLink-мостика новинка так и не обзавелась. L40S оснащён четырьмя портами DP 1.4a с поддержкой NVIDIA Mosaic и Quadro Sync. Также доступны профили vGPU для vDWS, GRID vApps/vPC, vCS. Имеется поддержка Secure Boot с Root of Trust и соответствие стандарту NEBS Level 3.  Таким образом, новинка подходит не только в качестве ускорителя для обучения ИИ-моделей или инференс-систем, но и в качестве основы для систем рендеринга 3D-графики, визуализации или создания и запуска приложений для мета-вселенных. NVIDIA отмечает, что в ИИ-задачах L40S опережает A100 в 1,2–1,7 раза, а наличие трёх движков NVENC/NVDEC с поддержкой AV1 позволяет использовать новый ускоритель в качестве эффективной платформы транскодирования видео.
08.08.2023 [23:15], Игорь Осколков
NVIDIA представила обновлённый вариант гибридного ускорителя GH200 с 141 Гбайт памяти HBM3eВсего два с небольшим месяца назад NVIDIA объявила о начале массового производства гибридных суперчипов Grace Hopper GH200 и анонсировала 1-Эфлопс ИИ-суперкомпьютер на их основе. Первые решения на базе этих чипов станут доступны до конца текущего года, а уже во II квартале 2024 года появится новая версия Grace Hopper, которая получит 141 Гбайт набортной памяти HBM3e. В этом и заключается их отличие от оригинальных GH200, которые оснащаются 96 Гбайт HBM3. Помимо увеличения объёма памяти выросла и её пропускная способность, с 4 до 5 Тбайт/с. Ну и если заявленный объём LPDDR5x в 500 Гбайт не является округлением исходных 480 Гбайт, то и здесь тоже есть небольшой прирост. При этом производительность новой версии осталась на прежнем уровне — 4 Пфлопс с Transformer Engine (без явного указания точности вычислений). Тем не менее, прирост ПСП и объёма памяти положительно скажется как на процессе обучения ИИ-моделей, так и, что особенно важно, на инференсе. 
Изображение: NVIDIA Прочие технические характеристики новинок компания пока не раскрыла, но сообщила о сохранении совместимости с платформой NVIDIA MGX и возможности объединения множества суперчипов и узлов посредством NVLink. Новинке придётся соревноваться с ускорителями AMD Instinct MI300A, которые должны появиться на рынке чуть раньше.
05.08.2023 [22:34], Сергей Карасёв
Hailo представила ИИ-ускорители Hailo-8 Century с производительностью до 208 TOPSСтартап Hailo Technologies, разработчик ИИ-чипов, анонсировал изделие начального уровня Hailo-8L, а также семейство ускорителей Hailo-8 Century, выполненных в виде карт расширения с интерфейсом PCle х16. Чип Hailo-8L предназначен для работы с приложениями, которым не требуется слишком высокое ИИ-быстродействие. Он обеспечивает производительность на уровне 13 TOPS. Выделяется простота интеграции с оборудованием; изделию не требуется внешняя память. Стандартное энергопотребление составляет 1,5 Вт. 
Источник изображения: Hailo Technologies Низкопрофильные карты Hailo-8 Century в зависимости от варианта исполнения имеют половинную или полную длину. Они несут на борту от 2 до 16 чипов Hailo-8, что обеспечивает быстродействие от 52 до 208 TOPS. Энергопотребление при этом варьируется от 10 до 65 Вт. Говорится, что ускорители Hailo-8 Century предоставляют лучшую в своём классе энергетическую эффективность с показателем 400 FPS/Вт в ResNet50. Стоимость Century начинается с $249 за версию с быстродействием 52 TOPS. Гарантирована совместимость с Linux и Windows, а также с фреймворками Tensorflow (Lite), Keras, Pytorch и ONNX. Все представленные изделия имеют широкий диапазон рабочих температур — от -40 до +85 °C. Решения уже доступны для предварительного заказа. |
|