Материалы по тегу: суперкомпьютер
|
04.10.2023 [19:19], Алексей Степин
8 Зфлопс и сотни Пбайт DRAM для ИИ: Tachyum пообещала построить невиданный суперкомпьютер на чипах Prodigy, которых пока никто не виделКомпания Tachyum, разработавшая, по её утверждению, новый тип универсальных процессоров, сочетающих в себе свойства CPU, GPU и TPU заявила о первом крупном заказе на поставку этих чипов, известных под именем Prodigy. Процессоры будут использованы для создания HPC/ИИ-системы производительностью более 50 Эфлопс (точность не указана), а в ИИ-задачах и вовсе обещаны 8 Зфлопс. Благодаря характеристикам Prodigy, новая система в 25 раз превзойдёт быстрейшие современные суперкомпьютеры, вошедшие в строй в этом году, а в области ИИ сможет использовать модели, превосходящие ChatGPT4 по сложности в 25 тыс. раз. Столь серьёзный прирост производительности, по словам разработчиков, обещает прорывы во многих научных и технических отраслях. Детали контракта, к сожалению, не разглашаются. Известно лишь, что компания-заказчик располагается в США. 
Источник изображений здесь и далее: Tachyum Как сказано в официальном пресс-релизе Tachyum, человеческий мозг состоит из примерно 100 млрд нейронов и 200 триллионов синаптических связей межу ними. Если принять одно такое соединение за несколько байт, полная имитация мозга потребует 100 Тбайт памяти. Компания говорит о системе с сотнями петабайт DRAM, что заведомо превзойдёт возможности мозга.  Начало работ над новым суперкомпьютером запланировано на 2024 год, в строй машина должна войти уже в 2025 году. Вот некоторые из её технических характеристик:
В программной части предполагается использование нового типа данных Tachyum AI (TAI), обещающего выдающуюся эффективность именно в обработке видео и LLM. А универсальная природа процессора Prodigy должна сделать ЦОД на его основе более простым и требующим меньше разнообразного оборудования, что должно положительно сказаться как на стоимости постройки, так и на эксплуатационных расходах.  Напомним, что не так давно Tachyum объявила об изменении характеристик Prodigy: количество ядер было увеличено со 128 до 192, объём кеша вырос соответственно со 128 до 192 Мбайт. Были расширены также коммуникационные средства чипа: число трансиверов SerDes подросло с 64 до 96. Площадь кристалла при использовании 5-нм техпроцесса должна составить 600 мм2. Однако есть одно существенное «но»: несмотря на внушительные цифры производительности и заявления Tachyum, процессоры Prodigy существуют только на бумаге и в виде эмулируемой с помощью FPGA платформы с небольшим количеством ядер. Похоже, с их воплощением в кремний имеются проблемы. Остаётся надеяться, что они будут успешно решаться: демонстрация первых образцов Prodigy всё ещё запланирована на 2023 год.
29.09.2023 [22:57], Руслан Авдеев
Французская iliad Group приобрела ИИ-кластер NVIDIA DGX SuperPOD из 1016 ускорителей H100 и задумала создать универсальный ИИФранцузская ГК iliad Group заявила о приобретении системы NVIDIA DGX SuperPOD для предоставления участникам европейского рынка IT «самого мощного» в регионе облачного ИИ-суперкомпьютера, включающего 1016 ускорителей H100 (127 систем DGX последнего поколения). За покупку отвечал облачный провайдер Scaleway, а сама машина разместилась в ЦОД Datacenter 5 в окрестностях Парижа. 
Фото: iliad Group Это только первый шаг компании на пути к достижению краткосрочной цели по предоставлению новых вычислительных мощностей клиентам. Для того, чтобы удовлетворить любые запросы клиентов, Scaleway обеспечила предоставление вычислительных мощностей небольшими блоками, по паре связанных серверов DGX H100 в каждом. В ближайшие месяцы Scaleway продолжит наращивать вычислительные способности платформы. Кроме того, iliad анонсировала создание в Париже ИИ-лаборатории, в которую уже инвестировано более €100 млн. Её главой стал миллиардер Ксавье Ниль (Xavier Niel), фактически контролирующий iliad Group. Лаборатория, как сообщается, привлекла известных исследователей из крупнейших международных компаний. Основной целью лаборатории станет помощь в создании универсального ИИ, а результаты исследований в этом направлении будут доступны публично.
25.09.2023 [21:13], Алексей Степин
Разработка RISC-V платформы MEEP для будущих европейских суперкомпьютеров завершенаЕвропейский Союз продолжает активно развивать собственное видение суперкомпьютеров ближайшего будущего, в основу которых ляжет архитектура RISC-V. За три с половиной года работы проекта Marenostrum Experimental Exascale Platform (MEEP) создана новая платформа, детально описывающая различные блоки и свойства таких HPC-систем. Выбор микроархитектуры RISC-V в качестве основы MEEP вполне оправдан — она является открытой и позволяет разработчикам не зависеть от проприетарных наборов инструкций и аппаратных решений. Таким образом ЕС планирует достигнуть автономии в сфере супервычислений, обзаведясь собственной платформой. 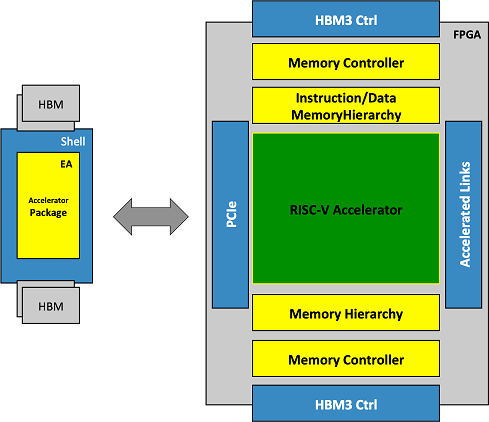
Высокоуровневое описание эмулируемого ускорителя В основе проекта MEEP лежит ядро Accelerated Memory and Compute Engine (ACME), изначально спроектированное с прицелом на применение высокоскоростной памяти HBM3 и состоящее из тайлов памяти (Memory Tile) и вычислительных тайлов VAS, объединённых меш-интерконнектом. Воплощение дизайна ACME в реальный кремний пока ещё дело будущего, но уже очевидно, что процессоры, разработанные в рамках проекта MEEP, будут иметь чиплетную компоновку. 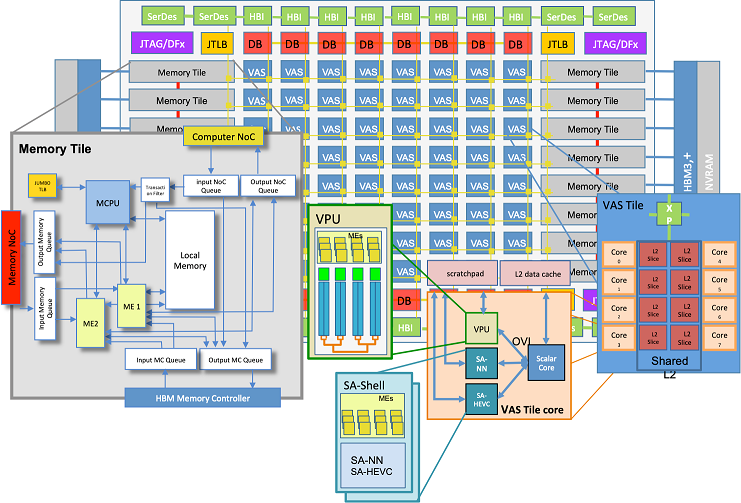
Архитектура ACME и её строительные блоки В конструкции ACME на долю Memory Tile выпадают все операции с подсистемами памяти, включая построение иерархических массивов, использующих разные типы памяти, в том числе MRAM и HBM3. Модули VAS включают себя по 8 процессорных ядер со своими разделами L2-кеша. Каждое такое ядро состоит из нескольких отдельных блоков: скалярного RISC-V, блока векторных операций, а также блоков ускорителей двух типов — SA-HEVC для обработки видео и SA-NN для нейросетевых задач, в частности, инференса. 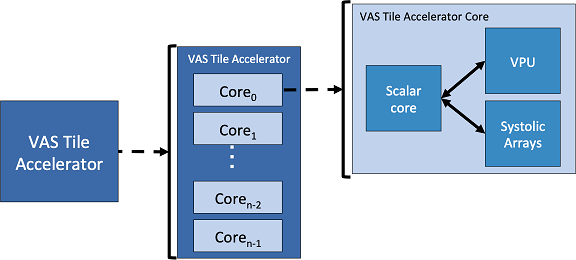
Схема работы ускорителей в составе блоков VAS По сути, каждый модуль VAS представляет собой вполне законченный многоядерный процессор RISC-V, способный работать со всеми современными форматами данных, автоматически распознающий расширенные инструкции и выполняющий их с помощью соответствующих ускорителей в своём составе. Платформа, созданная в рамках проекта MEEP, уже функционирует как эмулируемый с помощью FPGA Xilinx полноценный прототип. Он позволяет не только вести разработку и отладку ПО для новой европейской суперкомпьютерной экосистемы, но и производить валидацию аппаратных компонентов для будущих ускорителей/процессоров с архитектурой ACME.
22.09.2023 [12:29], Сергей Карасёв
Цукерберг создаст суперкомпьютер для биомедицинских исследований на ускорителях NVIDIA H100«Инициатива Чан Цукерберг» (CZI), благотворительная организация основателя Facebook✴ Марка Цукерберга (Mark Zuckerberg), намерена создать высокопроизводительный вычислительный кластер с ускорителями NVIDIA. Об этом сообщает ресурс Datacenter Dynamics. Говорится, что в основу платформы лягут более тысячи изделий NVIDIA H100. Кластер планируется использовать для биомедицинских исследований с применением средств ИИ. Суперкомпьютер будет использоваться для разработки открытых моделей человеческих клеток. При этом планируется применять прогностические методы, обученные на больших наборах данных, таких как те, которые интегрированы в программный инструмент Chan Zuckerberg CELL by GENE (CZ CELLxGENE). Модели также будут обучаться на данных, полученных исследовательскими институтами CZ Science, таких как атлас расположения и взаимодействия белков OpenCell и клеточный атлас Tabula Sapiens, созданный Биоцентром Чана Цукерберга в Сан-Франциско (Biohub San Francisco). 
Источник изображения: pixabay.com Разработка цифровых моделей, способных предсказывать поведение различных типов клеток, поможет исследователям лучше понять здоровое состояние организма и изменения, происходящие при различных заболеваниях.
22.09.2023 [10:59], Сергей Карасёв
Intel создаст мощнейший ИИ-суперкомпьютер с тысячами ускорителей Habana Gaudi2Корпорация Intel, по сообщению сайта Datacenter Dynamics, намерена создать один из самых мощных в мире суперкомпьютеров для работы с генеративным ИИ. Ресурсы платформы будет использовать компания Stability AI, реализующая проекты в соответствующей сфере. В основу НРС-платформы лягут процессоры Xeon. Кроме того, говорится об использовании приблизительно 4000 ускорителей Gaudi2. Проект Intel и Stability AI поможет компаниям укрепить позиции на рынке генеративного ИИ. О сроках запуска системы в эксплуатацию и её предполагаемой производительности ничего не сообщается. Ранее Intel обнародовала результаты тестирования Gaudi2 в бенчмарке GPT-J (входит в MLPerf Inference v3.1), основанном на большой языковой модели (LLM) с 6 млрд параметров. По оценкам, Gaudi2 может стать альтернативой решению NVIDIA H100 на ИИ-рынке. 
Источник изображения: pixabay.com Тем не менее, H100 по-прежнему превосходит конкурентов в плане обработки ИИ-задач. Ранее NVIDIA анонсировала программное обеспечение TensorRT-LLM с открытым исходным кодом, специально разработанное для ускорения исполнения больших языковых моделей (LLM). По оценкам NVIDIA, применение TensorRT-LLM позволяет вдвое увеличить производительность ускорителя H100 в тесте GPT-J 6B. При использовании модели Llama2 прирост быстродействия по сравнению с А100 достигает 4,6x.
19.09.2023 [15:07], Сергей Карасёв
Исследовательская лаборатория ВВС США получила суперкомпьютер Raider мощностью 12 ПфлопсВысокопроизводительный вычислительный комплекс для Исследовательской лаборатории ВВС США (AFRL), по сообщению ресурса Datacenter Dynamics, прибыл на базу Райт-Паттерсон в Огайо. Суперкомпьютер, построенный Penguin Computing, получил название Raider. 
Изображения: AFRL Новая НРС-система имеет производительность приблизительно 12 Пфлопс. Raider является частью более широкой программы модернизации высокопроизводительных вычислений Министерства обороны и будет доступен ВВС, армии и флоту США. Суперкомпьютер примерно в четыре раза мощнее своего предшественника — комплекса Thunder, запущенного в 2015 году: у этой системы производительность составляет 3,1 Пфлопс. Использовать Raider планируется прежде всего для решения сложных задач в области моделирования различных процессов.  В опубликованных в прошлом году документах говорится, что Raider должен был получить 189 тыс. вычислительных ядер. Предполагалось, что система будет включать 356 узлов различного назначения и конфигурации и получит процессоры AMD EPYC 7713 (Milan), 44 Тбайт RAM, 152 ускорителя NVIDIA A100, 200G-интерконнект InfiniBand HDR и 20-Пбайт хранилище. Однако заявленная производительность этой системы составляла 6,11 Пфлопс, так что характеристики суперкомпьютера явно скорректировали. В дополнение к Raider Исследовательская лаборатория ВВС США заказала два других суперкомпьютера — TI-23 Flyer и TI-Raven, которые, как ожидается, будут обеспечивать производительность на уровне 14 Пфлопс. Ввод этих систем в эксплуатацию запланирован на 2024 год.
14.09.2023 [22:40], Руслан Авдеев
NVIDIA и Xanadu построят симулятор квантового компьютера на базе обычного суперкомпьютераКомпания NVIDIA начала сотрудничество с канадской Xanadu Quantum Technologies для того, чтобы запустить крупномасштабную симуляцию квантовых вычислений на суперкомпьютере. Как сообщает Silicon Angle, исследователи используют новейший фреймворк PennyLane компании Xanadu и разработанное NVIDIA ПО cuQuantum для создания квантового симулятора. PennyLane представляет собой фреймворк с открытым кодом, предназначенный для «гибридных квантовых вычислений», а инструменты cuQuantum для разработки программного обеспечения позволяют организовать симулятор квантовых вычислений, используя высокопроизводительные кластеры ускорителей. Вычислительных ресурсов действительно требуется немало, поскольку для воспроизведения работы квантовой модели из около 30 кубитов потребовалось 256 ускорителей NVIDIA A100 в составе суперкомпьютера Perlmutter. 
Источник изображения: geralt/pixabay.com Как заявляют в Xanadu, комбинация PennyLane и cuQuantum позволяет значительно увеличить число симулированных кубитов — ранее подобных возможностей просто не было. Тесты cuQuantum с одним ускорителем показали повышение производительности симуляции на порядок. Уже к концу текущего года учёные рассчитывают масштабировать технологию до 1 тыс. узлов с использованием 4 тыс. ускорителей, что позволит создать симуляцию более 40 кубитов. 
Источник изображения: Xanadu Учёные утверждают, что крупными симуляциями в результате смогут пользоваться даже стажёры. Всего планируется реализация не менее шести проектов с использованием соответствующей технологии для изучения физики высоких энергий, систем машинного обучения, развития материаловедения и химии. Xanadu уже сейчас работает с Rolls-Royce над разработкой квантовых алгоритмов, позволяющих создавать более эффективные двигатели, а также с Volkswagen Group над проектами по созданию эффективных аккумуляторов.
14.09.2023 [18:26], Руслан Авдеев
Британский ИИ-суперкомпьютер Isambard-3 станет одним из самых мощных в ЕвропеВ Великобритании будет реализован новый амбициозный проект в сфере вычислительных технологий. Как сообщает Network World, власти страны объявили о строительстве нового суперкомпьютера, а всего в различные проекты с учётом создания центра по исследованию систем искусственного интеллекта (ИИ) будет вложено £900 млн ($1,1 млрд). Isambard-3 пообещали разместить на площадке в Бристоле в этом году. Машина будет включать тысячи передовых ускорителей и станет одним из самых мощных суперкомпьютеров Европы. Бристоль уже является одним из центров исследований ИИ-систем. На базе Бристольского университета будет создан национальный центр AI Research Resource (AIRR или Isambard-AI) для поддержки исследований в сфере ИИ, в том числего его безопасного использования. 
Источник изображения: franganillo/pixabay.com Суперкомпьютер и AIRR финансируются за счёт средств, выделить которые британское правительство пообещало ещё в марте текущего года. Британские власти ожидают, что центр в Бристоле станет «катализатором» для научных открытий и позволит Великобритании держаться в числе лидеров разработки ИИ, а суперкомпьютер поможет экспертам и исследователям использовать «меняющий правила» потенциал ИИ-систем. Отметим, что ранее Великобритания покинула EuroHPC в связи с Brexit'ом, что несколько затормозило развитие HPC-сферы в стране. Пока не раскрываются технические детали нового суперкомпьютера, хотя первые данные о его спецификациях появились ещё в мае. Правда, тогда речь шла только об использовании Arm-процессоров NVIDIA Grace. Это уже третье поколение HPC-систем на базе Arm, Isambard и Isambard 2 базировались на Cavium ThunderX2 и Fujitsu A64FX соответственно, причём основным поставщиком всех трёх систем является HPE/Cray.
13.09.2023 [13:45], Сергей Карасёв
«Тренировочный» суперкомпьютер Polaris показал высокое быстродействие СХД в тестах MLPerf Storage AIАргоннская национальная лаборатория Министерства энергетики США сообщила о том, что вычислительный комплекс Polaris, предназначенный для решения ИИ-задач, устанавливает высокие стандарты производительности СХД в бенчмарке MLPerf Storage AI. Суперкомпьютер Polaris, разработанный в сотрудничестве с Hewlett Packard Enterprise (HPE), объединяет 560 узлов, соединенных между собой посредством интерконнекта HPE Slingshot. Каждый узел содержит четыре ускорителя NVIDIA A100 и два накопителя NVMe вместимостью 1,6 Тбайт каждый. Задействована платформа хранения HPE ClusterStor E1000, которая предоставляет 100 Пбайт полезной ёмкости на 8480 накопителях. Заявленная скорость передачи данных достигает 659 Гбайт/с. Вычислительный комплекс смонтирован на площадке Argonne Leadership Computing Facility (ALCF). Пиковая производительность составляет около 44 Пфлопс. 
Источник изображения: ALCF Быстродействие Lustre-хранилища оценивалась с использованием двух рабочих нагрузок MLPerf Storage AI — UNet3D и Bert. Данные размещались как в основном хранилище, так и на NVMe-накопителях в составе узлов суперкомпьютера, что позволило эмулировать различные рабочие нагрузки ИИ. В тесте UNet3D с интенсивным вводом-выводом суперкомпьютер достиг пиковой пропускной способности в 200 Гбайт/с для основного хранилища HPE ClusterStor E1000. В случае NVMe-накопителей продемонстрирован результат на уровне 800 Гбайт/с. Менее интенсивная рабочая нагрузка Bert также показала высокие результаты, что говорит о возможности эффективного выполнения современных ИИ-задач.
12.09.2023 [13:42], Сергей Карасёв
Суперкомпьютер Dojo может увеличить рыночную стоимость Tesla на $500 млрдАналитики Morgan Stanley, по сообщению Datacenter Dynamics, полагают, что запуск суперкомпьютера Dojo позволит Tesla увеличить свою рыночную стоимость на $500 млрд. Иными словами, капитализация компании Илона Маска может подняться приблизительно на 60 %. Tesla намерена до конца 2024 года потратить на проект Dojo более $1 млрд. Этот вычислительный комплекс поможет в разработке инновационных технологий для роботизированных автомобилей. В составе системы будут применяться чипы собственной разработки Tesla D1. В перспективе производительность Dojo планируется довести до 100 Эфлопс. По состоянию на сентябрь 2023 года рыночная капитализация Tesla составляет около $778 млрд при стоимости ценных бумаг примерно $248. Отмечается, что цена акций компании в течение нынешнего года уже выросла более чем вдвое после снижения в 2022-м. Morgan Stanley прогнозирует, что после ввода системы Dojo в эксплуатацию стоимость ценных бумаг Tesla поднимется примерно на 60 % — до $400. 
Источник изображения: Tesla «Чем больше мы анализировали проект Dojo, тем больше осознавали потенциальную возможность недооценки акций Tesla», — сказал аналитик Morgan Stanley Адам Джонас (Adam Jonas). Предполагается, что Dojo поможет ускорить развитие технологий автопилотирования, а также усилит позиции Tesla в сегменте облачных сервисов. Ранее генеральный директор Tesla Илон Маск заявлял, что компания разрабатывает систему отчасти из-за того, что не может получить достаточное количество ускорителей на базе GPU для удовлетворения своих потребностей. |
|