Материалы по тегу: суперкомпьютер
|
16.11.2023 [21:31], Сергей Карасёв
Суперкомпьютер ISEG отделившейся от «Яндекса» компании Nebius стал одним из самых мощных в мире
gigabyte
h100
hardware
hpc
intel
nebius
nvidia
sapphire rapids
top500
xeon
нидерланды
суперкомпьютер
Компания Nebius N.V. со штаб-квартирой в Нидерландах, созданная бывшими сотрудниками «Яндекса», вошла в первую двадцатку ноябрьского рейтинга мощнейших суперкомпьютеров мира TOP500 со своей НРС-системой ISEG. Этот вычислительный комплекс, названный в честь сооснователя «Яндекса» Ильи Сегаловича, расположился на 16-й строке списка. 
Источник изображения: Nebius В основу ISEG положены HGX-узлы Gigabyte G593-SD0 с двумя процессорами Intel Xeon Sapphire Rapids и восемью ускорителями NVIDIA H100 (SXM). В частности, задействованы чипы Platinum 8468 (48 ядер; 96 потоков; 2,1–3,8 ГГц; 350 Вт). Общее количество ядер в составе суперкомпьютера достигает 218 880. Применён интерконнект Infiniband NDR400. Производительность ISEG достигает 46,54 Пфлопс (FP64), пиковое быстродействие — 86,79 Пфлопс. С такими показателями система оставляет далеко позади все российские суперкомпьютеры. В частности, самый мощный НРС-комплекс РФ — «Червоненкис» компании «Яндекс» — располагается только на 36-й позиции с результатом 21,53 Пфлопс. Таким образом, по быстродействию этот суперкомпьютер уступает системе ISEG более чем в два раза. 
Источник изображения: Nebius Forbes отмечает, что в процессе создания ISEG интеллектуальная собственность и технологии «Яндекса» не использовались. Тестирование суперкомпьютера для рейтинга TOP500 проводилось с ОС Ubuntu Linux 20.04. Энергопотребление системы составило 1,32 МВт. В списке Green500 машина занимает 15-е место.
15.11.2023 [13:57], Сергей Карасёв
Французский суперкомпьютер Adastra одним из первых получит новейшие ускорители AMD Instinct MI300AФранцузское национальное агентство по высокопроизводительным вычислениям (GENCI), по сообщению HPCwire, проводит масштабное обновление суперкомпьютера Adastra, о запуске которого было объявлено два года назад. После апгрейда система сможет решать сложные задачи в области ИИ. Комплекс Adastra находится под управлением Национального вычислительного центра высшего образования Франции (CINES). Система использует платформу HPE Cray EX235A с оптимизированными процессорами AMD EPYC Milan (64 ядра; 2,0 ГГц) и ускорителями AMD Instinct MI250X. Апгрейд предусматривает использование гибридных чипов Instinct MI300A в составе платформы HPE Cray EX4000, оснащённой 14 серверами HPE Cray EX255a Accelerator Blade. В общей сложности будут задействованы 28 узлов, каждый из которых содержит четыре чипа Instinct MI300A. Таким образом, суммарное количество использованных изделий Instinct MI300A равно 112. Задействован 200G-интерконнект HPE Slingshot 11. Об итоговой производительности обновлённого суперкомпьютера Adastra данных пока нет. Но в прежнем виде система занимает 17-ю строку в ноябрьском рейтинге TOP500 с быстродействием 46,1 Пфлопс (FP64). А в мировом рейтинге самых энергоэффективных НРС-систем GREEN500 комплекс Adastra находится на третьей позиции с показателем 58,021 Гфлопс/Вт. 
Изображение: GENCI
14.11.2023 [19:26], Сергей Карасёв
TACC получит ИИ-суперкомпьютер Vista с суперчипами NVIDIA GH200 Grace HopperТехасский центр передовых вычислений (TACC) при Техасском университете в Остине (США) на конференции по высокопроизводительным вычислениям SC23 анонсировал суперкомпьютер Vista, ориентированный на задачи ИИ и машинного обучения. Запуск этого комплекса в эксплуатацию запланирован на начало 2024 года. Отмечается, что Vista станет связующим звеном между нынешним суперкомпьютером TACC Frontera и будущей системой TACC Horizon, проект которой финансируется Национальным научным фондом (NSF). Ввод Horizon в строй намечен на 2025 год: ожидается, что этот комплекс будет на порядок быстрее Frontera. Что касается Vista, то эта система знаменует собой переход от традиционной архитектуры х86, которая применяется во Frontera и системах Stampede, в пользу Arm. В частности, будут задействованы суперчипы NVIDIA GH200 Grace Hopper, которые содержат 72-ядерный Arm-процессор NVIDIA Grace и ускоритель NVIDIA H200. В составе Vista чипами GH200 будут оборудованы немногим более половины всех вычислительных узлов. Оставшиеся узлы получат процессор NVIDIA Grace CPU Superchip, содержащий два кристалла Grace в одном модуле (144 ядра). 
Источник изображения: TACC Для Vista предусмотрено использование 400G-интерконнекта NVIDIA Quantum-2 InfiniBand. Компания VAST Data предоставит для суперкомпьютера высокопроизводительное флеш-хранилище, подключенное к Stampede3. Вычислительные узлы будут производиться компанией Gigabyte, а интеграцию обеспечит Dell.
14.11.2023 [18:50], Сергей Карасёв
Запущены суперкомпьютеры Dawn, SuperMUC-NG и Crossroads на базе Intel Data Center GPU Max и Xeon Sapphire Rapids
hardware
hpc
intel
intel max
intel xe
sapphire rapids
sc23
xeon
великобритания
германия
суперкомпьютер
сша
Корпорация Intel на конференции по высокопроизводительным вычислениям SC23 рассказала о новых суперкомпьютерах, попавших в ноябрьский рейтинг TOP500. Речь, в частности, идёт о вычислительных комплексах Dawn (Phase 1), SuperMUC-NG (Phase 2) и Crossroads. Система Dawn, созданная специалистами Intel, Dell Technologies и Кембриджского университета, рассчитана на задачи ИИ. В основу положены серверы Dell PowerEdge XE9640 с жидкостным охлаждением. В общей сложности задействованы 256 узлов, в состав которых входят 512 процессоров Intel Xeon Sapphire Rapids — Platinum 8468 с 48 ядрами (96 потоков; 2,1–3,8 ГГц; 350 Вт). Суперкомпьютер Dawn использует 1024 ускорителя Intel Data Center GPU Max 1550. Общий объём памяти DDR составляет 256 Тбайт, а её пропускная способность достигает 157 Тбайт/с. Кроме того, задействовано 128 Тбайт памяти НВМ с пропускной способностью до 3,3 Пбайт/с. Подсистема хранения данных вместимостью 3 Пбайт обеспечивает скорость до 2 Тбайт/с. Агрегированная пропускная способность сети — до 25,6 Тбайт/с. Заявленная производительность достигает 19,46 Пфлопс (FP64). Это соответствует 41-му месту в ноябрьском рейтинге ТОР500. Пиковое быстродействие — 53,85 Пфлопс. Система установлена в лаборатории Cambridge Open Zettascale Lab (Великобритания). 
Источник изображения: Intel В свою очередь, комплекс SuperMUC-NG (Phase 2) смонтирован в Суперкомпьютерном центре Лейбница Баварской академии наук (Германия). Этот суперкомпьютер базируется на серверах Lenovo ThinkSystem SD650-I V3 Neptune DWC с прямым жидкостным охлаждением. Установлены 240 узлов, в состав которых входят в общей сложности 480 процессоров Intel Xeon Platinum 8480L (56 ядер; 112 потоков; 2,0–3,8 ГГц; 350 Вт) и 960 ускорителей Data Center GPU Max. 
Источник изображения: Intel Комплекс SuperMUC-NG (Phase 2) оперирует 123 Тбайт памяти DDR с пропускной способностью до 147 Тбайт/с. Память НВМ такого же объёма обеспечивает пропускную способность до 3,1 Пбайт/с. Применено хранилище на 1 Пбайт со скоростью 750 Гбайт/с. Пропускная способность сети — до 12 Тбайт/с. Суперкомпьютер обладает производительностью 17,19 Пфлопс (FP64): в списке ТОР500 система располагается на 52-й строке. Наконец, суперкомпьютер Crossroads размещён в Лос-Аламосской национальной лаборатории (LANL) Министерства энергетики США. Система обладает производительностью 30,03 Пфлопс (FP64). Задействованы 2600 чипов Intel Xeon CPU Max 9480 с 56 ядрами и памятью HBM. Система находится на 24-м месте рейтинга ТОР500. Всего же в новой редакци рейтинга есть 20 новых машин на базе Sapphire Rapids, из которых пять используют Max-версию процессоров, а также четыре системы с ускорителями Data Center GPU Max.
14.11.2023 [02:35], Игорь Осколков
Ноябрьский TOP500: запоздалый рассвет IntelСвежая, 62-ая по счёту редакция рейтинга TOP500 самых производительных суперкомпьютеров мира среди тех, кто пожелал в нём участвовать (это снова отсылка к Китаю) принесла не очень много изменений, но зато интересных. Первое место по-прежнему удерживает AMD-система Frontier с показателем 1,194 Эфлопс и всё такой же приличной энергоэффективностью на уровне 52,59 Гфлопс/Вт, которая с лета обновлений не получала. А вот второе место… Второе место, наконец-то, досталось суперкомпьютеру Aurora, с анонса которого прошло восемь лет, а архитектура и заявленная производительность неоднократно пересматривались. Формально машина, использующая процессоры Intel Xeon Max с HBM-памятью и ускорители Data Center GPU Max (Ponte Vecchio), объединённых интерконнектом HPE Slingshot 11 (как у Frontier), была смонтирована ещё летом этого года, но процесс ввода в эксплуатацию этой уникальной системы завершится только в 2024 году. К тому моменту Aurora должна достичь заявленной производительности 2 Эфлопс. Столько же предложит AMD-система El Capitan. 
Фото: Intel Но для Intel и Аргоннской национальной лаборатории (ANL) попадание в лидеры TOP500, похоже, стало делом принципа — за потраченные деньги (суммарно $500 млн) и время надо отчитаться. Поэтому в тесте участвовала лишь половина машины, которая добралась до отметки 585,34 Пфлопс. При этом разница между фактической и теоретической пиковой производительностью составляет почти два раза, а сама система уже потребляет больше Frontier и в Green500 находится в конце третьего десятка с показателем 23,71 Гфлопс/Вт. Так что простор для оптимизаций ещё есть. В целом, в свежем рейтинге сразу два десятка из полсотни новичков рейтинга используют Sapphire Rapids, причём пять систем ещё и Xeon Max, но ускорителями Intel Xe обзавелось лишь четыре системы. У AMD же сейчас есть десяток систем с Instinct MI250X (и ещё одна с MI210) и пять систем EPYC Genoa. Всего на EPYC’ах разных поколений базируется 140 систем против 331 на базе Xeon. Ускорителями NVIDIA оснащено 166 машин в списке, из которых только десять имеют новые H100, причём одна в необычной конфигурации. Без акселераторов обходятся 314 машин. 
Фото: Microsoft Третье место заняла облачная система, которые в TOP500 встречаются всё чаще, а в будущем и вовсе станут неизбежны. Эта Microsoft Azure Eagle на базе инстансов NDv5 (Intel Xeon Platinum 8480C + NVIDIA H100 + Infiniband NDR400) набрала 561,2 Пфлопс. Впрочем, технически классические и облачные HPC-системы становятся всё ближе — суперкомпьютер NVIDIA EOS, который построен на ровно тех же компонентах, что Eagle, и который в TOP500 занял девятое место (121,4 Пфлопс), фактически тоже использует облачную архитектуру. А на примере MLPerf обе компании показали эффективность масштабирования нагрузок. Пятое место досталось финской системе LUMI, которая после очередного апгрейда набрала 379,7 Пфлопс. Наконец, на восьмом месте с показателем 138,2 Пфлопс закрепился европейский суперкомпьютер MareNostrum 5 с непростой судьбой. Точнее, его GPU-часть (ACC), поскольку CPU-часть (GPP) набрала 40,1 Пфлопс. ACC использует узлы Eviden BullSequana XH3000 с Intel Xeon Platinum 8460Y+ и ускорителями NVIDIA H100, но с 64 Гбайт памяти. GPP базируется на узлах Lenovo ThinkSystem SD650 v3 с Intel Xeon Platinum 8480+. Объединяет всю систему интерконнект Infiniband NDR200. 
Изображение: NVIDIA Fugaku, некогда самая мощная машина, да ещё и на Arm, опустилась на четвёртую строчку рейтинга. Правда, в HPCG ей равных всё равно нет (16 Пфлопс), а второе и третье места достались Frontier (14,05 Пфлопс) и LUMI (4,59 Пфлопс). В Green500 семь машин из первой десятки представлены опять-таки связками AMD EPYC + Instinct, хотя лидерство всё ещё за Henri (Intel Xeon Ice Lake-SP + NVIDIA H100). Результаты HPL-MxP (ранее HPL-AI) с июня не обновлялись, так что в тройку лидеров входят Frontier (9,95 Эфлопс), LUMI (2,35 Эфлопс) и Fugaku (2 Эфлопс). Тройка лидеров среди производителей по количеству машин включает Lenovo (169 шт.), HPE (103 шт.) и Eviden (48 шт.), но по производительности с большим отрывом лидирует HPE (34,9 %), а за ней уже идут Eviden (9,8 %) и Lenovo (8,6 %). Впрочем, Китай, где как раз много однотипных машин Lenovo, направляет всё меньше заявок на включение в рейтинг, а США — всё больше. По суммарной производительности суперкомпьютеров Штаты тоже лидируют — 53 % от всего списка.
13.11.2023 [22:05], Сергей Карасёв
200+ Эфлопс: суперчип NVIDIA Grace Hopper ляжет в основу более 40 ИИ-суперкомпьютеровКомпания NVIDIA сообщила о том, что её суперчип GH200 Grace Hopper ляжет в основу более чем 40 ИИ-суперкомпьютеров по всему миру, которые используются в исследовательских центрах, на облачных площадках и пр. Отмечается, что в скором времени станут доступны десятки новых НРС-систем на базе GH200. Этот суперчип позволяет решать самые сложные научные задачи на базе ИИ, которые требуют обработки терабайт данных. В совокупности вычислительные системы на базе GH200, как сообщается, обеспечат ИИ-производительность около 200 Эфлопс. В частности, HPE объявила, что интегрирует GH200 в суперкомпьютеры HPE Cray. Узлы EX254n оснащаются двумя модулями Quad GH200 с четырьмя суперчипами в каждом, обеспечивая возможность масштабирования до десятков тысяч узлов. Аналогичный подход используется и в платформе Eviden BullSequana XH3000, которую Юлихский исследовательский центр (FZJ) в Германии получит в составе Jupiter — первого европейского суперкомпьютера экзафлопсного класса. 
Источник изображения: NVIDIA Объединённый центр передовых высокопроизводительных вычислений в Японии (JCAHPC) намерен использовать суперчип в своём суперкомпьютере следующего поколения. Техасский центр передовых вычислений при Техасском университете в Остине (США) оборудует суперчипами НРС-систему Vista. Национальный центр суперкомпьютерных приложений при Университете Иллинойса в Урбане-Шампейне будет использовать решения GH200 в составе ИИ-платформы DeltaAI. А Британия получит ИИ-суперкомпьютер Isambard-AI на основе этого суперчипа, который разместится в Бристольском университете. 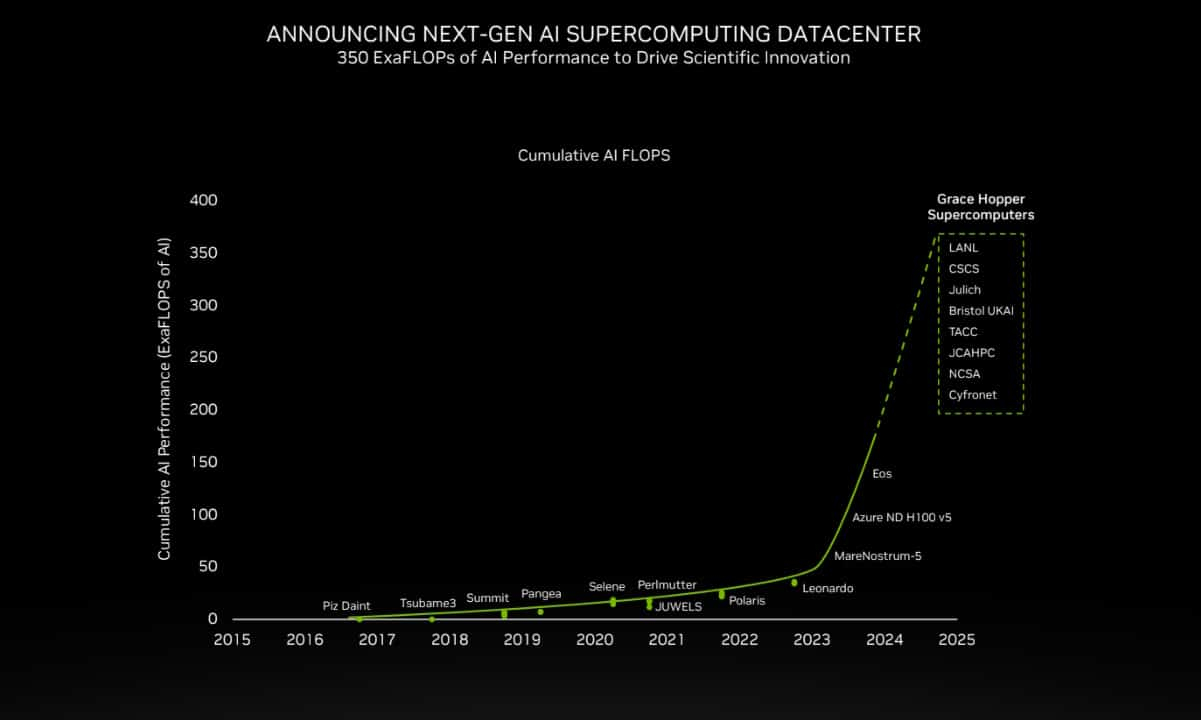
Источник изображения: NVIDIA Все эти системы присоединяются к ранее анонсированным платформам на базе GH200 от Швейцарского национального суперкомпьютерного центра (CSCS) и SoftBank Corp. GH200 уже доступен у некоторых поставщиков облачных услуг, таких как Lambda и Vultr. CoreWeave объявила о планах открыть инстансы GH200 в I квартале 2024 года. Другие производители систем, такие как ASRock Rack, ASUS, Gigabyte и Ingrasys, начнут поставки серверов с этими суперчипами к концу года.
13.11.2023 [17:00], Сергей Карасёв
Первый в Европе экзафлопсный суперкомпьютер Jupiter получит 24 тыс. гибридных суперчипов NVIDIA Grace HopperКомпания NVIDIA в ходе конференции по высокопроизводительным вычислениям SC23 сообщила о том, что её суперчип GH200 Grace Hopper станет одной из ключевых составляющих НРС-системы Jupiter — первого европейского суперкомпьютера экзафлопсного класса. 
Узел BullSequana XH3000 (Источник здесь и далее: NVIDIA) Jupiter — проект Европейского совместного предприятия по развитию высокопроизводительных вычислений (EuroHPC JU). Комплекс расположится в Юлихском исследовательском центре (FZJ) в Германии. В создании суперкомпьютера участвуют NVIDIA, ParTec, Eviden и SiPearl. Архитектура системы модульная, что позволяет адаптировать её под разные классы задач. В основу одного из основных блоков Jupiter ляжет платформа Eviden BullSequana XH3000 с прямым жидкостным охлаждением, а в состав каждого узла войдут модули Quad GH200. Общее количество суперчипов составит 23752. В качестве интерконнекта будет применяться NVIDIA Quantum-2 InfiniBand. Быстродействие на операциях обучения ИИ составит до 93 Эфлопс, а FP64-производительность должна достичь 1 Эфлопс. При этом общая потребляемая мощность Jupiter составит всего 18,2 МВт.  Применять систему Jupiter планируется для решения наиболее сложных задач. Среди них — моделирование климата и погоды в высоком разрешении (на базе NVIDIA Earth-2), создание новых лекарственных препаратов (NVIDIA BioNeMo и NVIDIA Clara), исследования в области квантовых вычислений (NVIDIA cuQuantum и CUDA Quantum), промышленное проектирование (NVIDIA Modulus и NVIDIA Omniverse). Ввод Jupiter в эксплуатацию запланирован на 2024 год.
08.11.2023 [20:00], Игорь Осколков
Счёт на секунды: ИИ-суперкомпьютер NVIDIA EOS с 11 тыс. ускорителей H100 поставил рекорды в бенчмарках MLPerf TrainingВместе с публикацией результатов MLPerf Traning 3.1 компания NVIDIA официально представила новый ИИ-суперкомпьютер EOS, анонсированный ещё весной прошлого года. Правда, с того момента машина подросла — теперь включает сразу 10 752 ускорителя H100, а её FP8-производительность составляет 42,6 Эфлопс. Более того, практически такая же система есть и в распоряжении Microsoft Azure, и её «кусочек» может арендовать каждый, у кого найдётся достаточная сумма денег. 
Изображения: NVIDIA Суммарно EOS обладает порядка 860 Тбайт памяти HBM3 с агрегированной пропускной способностью 36 Пбайт/с. У интерконнекта этот показатель составляет 1,1 Пбайт/с. В данном случае 32 узла DGX H100 объединены посредством NVLink в блок SuperPOD, а за весь остальной обмен данными отвечает 400G-сеть на базе коммутаторов Quantum-2 (InfiniBand NDR). В случае Microsoft Azure конфигурация машины практически идентичная с той лишь разницей, что для неё организован облачный доступ к кластерам. Но и сам EOS базируется на платформе DGX Cloud, хотя и развёрнутой локально.   В рамках MLPerf Training установила шесть абсолютных рекордов в бенчмарках GPT-3 175B, Stable Diffusion (появился только в этом раунде), DLRM-dcnv2, BERT-Large, RetinaNet и 3D U-Net. NVIDIA на этот раз снова не удержалась и добавила щепотку маркетинга на свои графики — когда у тебя время исполнения теста исчисляется десятками секунд, сравнивать свои результаты с кратно меньшими по количеству ускорителей кластерами несколько неспортивно. Любопытно, что и на этот раз сравнивать H100 приходится с Habana Gaudi 2, поскольку Intel не стесняется показывать результаты тестов. 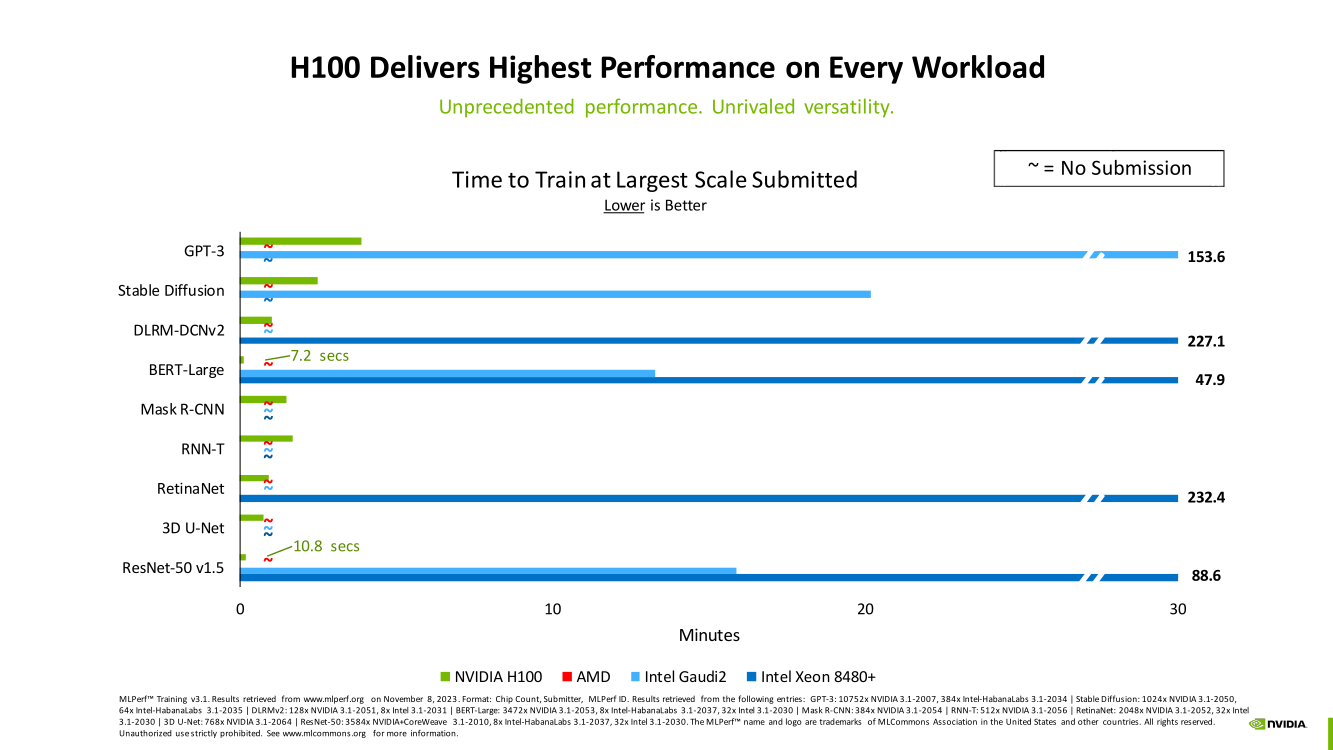 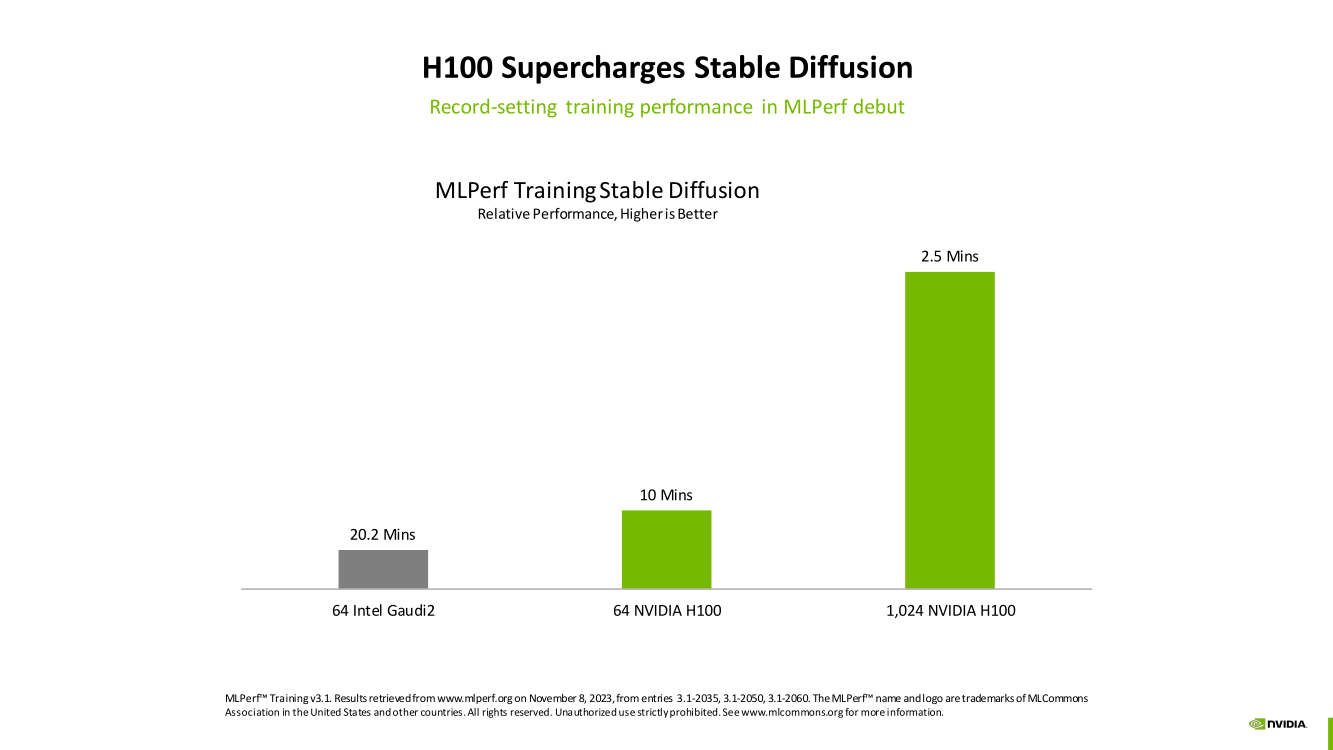 NVIDIA очередной раз подчеркнула, что рекорды достигнуты благодаря оптимизациям аппаратной части (Transformer Engine) и программной, в том числе совместно с MLPerf, а также благодаря интерконнекту. Последний позволяет добиться эффективного масштабирования, близкого к линейному, что в столь крупных кластерах выходит на первый план. Это же справедливо и для бенчмарков из набора MLPerf HPC, где система EOS тоже поставила рекорд. 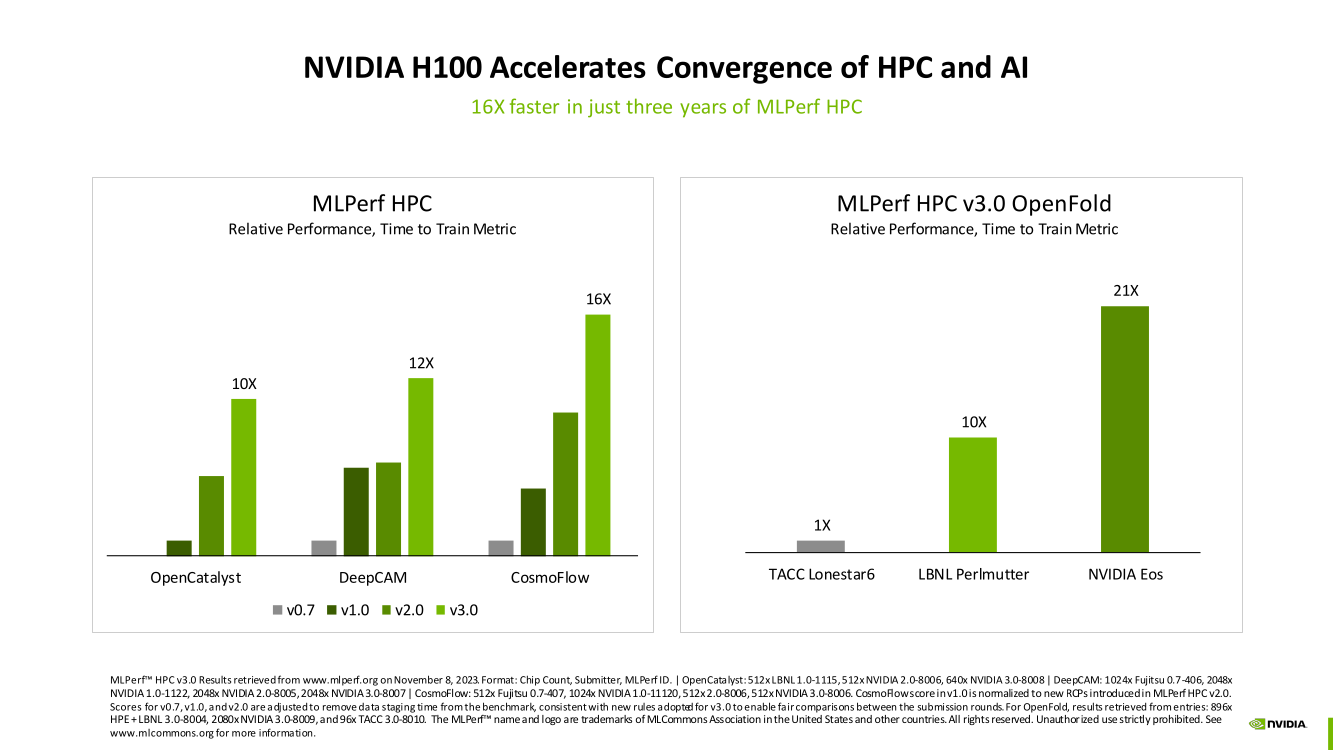
03.11.2023 [01:01], Владимир Мироненко
В Великобритании появится ИИ-суперкомпьютер Dawn, разработанный Dell, Intel и Кембриджским университетомDell Technologies, Intel и Кембриджский университет объявили о создании в Великобритании разработанного совместными усилиями суперкомпьютера Dawn. Запуск будет осуществляться в два этапа. Первый будет выполнен в течение двух месяцев, то есть до конца года. На втором этапе, который буде завершён в 2024 году, производительность Dawn будет увеличена в десять раз, будет завершена в следующем году. Подробные характеристики Dawn будут объявлены на SC23 в этом месяце. Суперкомпьютер Dawn установлен в лаборатории Cambridge Open Zettascale Lab. Как сообщает Dell, это будет самое мощное суперкомпьютерное ИИ-облако на базе OpenStack, разработанное совместно с британской SME StackHPC. Машина использует серверы Dell PowerEdge XE9640 с процессорами Sapphire Rapids и ускорителями Max. Всего задействовано более 1 тыс. ускорителей. Платформа Scientific OpenStack с открытым исходным кодом обеспечит полностью оптимизированную для ИИ и моделирования облачную HPC-среду. Отмечена и поддержка Intel oneAPI для гетерогенных вычислений. Предполагается, что суперкомпьютер будет использоваться для выполнения сложных вычислительных задач в области академических и промышленных исследований, здравоохранения, инжиниринга и моделирования климата. 
Изображение: Intel В следующем году в Великобритании также будет построен суперкомпьютер Isambard-AI, который вместе с Dawn будет включён в проект AI Research Resource (AIRR), созданный британским правительством для оказания помощи национальным разработчикам ИИ. Isambard-AI и Isambard-3 будут построены HPE с использованием Arm-чипов NVIDIA Grace и Grace Hopper. При этом и Dell, и HPE одновременно заявили, что именно их детища будут самыми быстрыми ИИ-суперкомпьютерами в стране.
02.11.2023 [21:49], Руслан Авдеев
Британия получит 200-Пфлопс ИИ-суперкомпьютер Isambard-AI на гибридных Arm-чипах NVIDIA GH200Правительство Великобритании о выделении £225 млн ($273 млн) на строительство самого мощного в стране суперкомпьютера Isambard производительностью более 200 Пфлопс в FP64-вычислениях и более 21 Эфлопс в ИИ-задачах. Как сообщает The Register, новая машина на базе тысяч гибридных Arm-суперчипов NVIDIA Grace Hopper (GH200) разместится в Бристольском университете и будет построена HPE. Ожидается, что машина будет введена в эксплуатацию в следующем году и поможет в выполнении самых разных задач, от автоматизированной разработки лекарств до анализа климатических изменений, от изучения и внедрения нейросетей в робототехнике до задач, связанных с обеспечением национальной безопасности и обработкой больших данных. Isambard-AI войдёт в десятку самых быстрых суперкомпьютеров мира. Пока что самый быстрый суперкомпьютер Великобритании — это 20-Пфлопс система Archer2, занимающая 30-ю позицию в рейтинге TOP500 и введённая в строй всего пару лет назад. Isambard-AI получит 5448 гибридных чипов NVIDIA GH200 GraceHopper с 96/144 Гбайт HBM-памяти. Используется платформа HPE Cray EX с интерконнектом Slingshot 11 и СЖО. 25-Пбайт хранилище использует СХД Cray ClusterStor E1000. Система будет размещена в ЦОД с автономным охлаждением, а система утилизации избыточного тепла позволит обогревать близлежащие здания. Первыми выгодоприобретателями проекта Isambard-AI станут команды Frontier AI Task Force и AI Safety Institute, намеренные смягчить угрозу со стороны ИИ национальной безопасности Великобритании. 
Изображение: HPE Компанию Isambard-AI составит ранее анонсированный Arm-суперкомпьютер Isambard-3, который также построит HPE. Эту машину введут в эксплуатацию следующей весной, она обеспечит британским учёным ранний доступ к вычислительным мощностям на первом этапе реализации проекта Isambard-AI. Isambard-3 получит 384 суперчипа NVIDIA Grace, а его пиковое быстродействие в FP64-вычислениях составит 2,7 Пфлопс. Всего в различные ИИ-проекты британские власти вложат порядка £900 млн ($1,1 млрд). В частности, вместе с Isambard-AI был объявлен и суперкомпьютер Dawn, который разместится в Кембридже. Хотя ранее NVIDIA описывала Isambard-AI как самый быстрый в стране, создатели Dawn утверждают, что быстрейшим будет именно он. Система будет полагаться на серверы Dell PowerEdge XE9640 с процессорами Sapphire Rapids и ускорителями Max. |
|