Материалы по тегу: инференс
|
08.09.2025 [19:09], Сергей Карасёв
Axelera AI представила ускоритель Metis M.2 Max для ИИ-задач на периферииСтартап Axelera AI B.V. из Нидерландов анонсировал ускоритель Metis M.2 Max, предназначенный для ИИ-инференса на периферии. Новинка может использоваться, в частности, для работы с большими языковыми моделями (LLM) и визуально-языковыми моделями (VLM). Metis M.2 Max представляет собой улучшенную версию изделия Metis M.2, дебютировавшего в 2023 году. В основу положен чип Axelera Metis AIPU, содержащий четыре ядра с открытой архитектурой RISC-V: ИИ-производительность достигает 214 TOPS на операциях INT8. Ускорители выполнены в форм-факторе M.2 2280, а для обмена данными служит интерфейс PCIe 3.0 x4. У модели Metis M.2 Max по сравнению с оригинальной версией в два раза повысилась пропускная способность памяти (точные значения не приводятся). Её объём в зависимости от модификации составляет 1, 4, 8 или 16 Гбайт. Реализованы расширенные средства обеспечения безопасности, включая защиту целостности прошивки. Новинка будет предлагаться в вариантах со стандартным и расширенным диапазоном рабочих температур: в первом случае он простирается от -20 до +70 °C, во втором — от -40 до +85 °C. Благодаря этому, как утверждается, Metis M.2 Max подходит для применения в самых разных областях, в том числе в промышленном секторе, розничной торговле, в сферах здравоохранения и общественной безопасности и пр. 
Источник изображения: Axelera AI Разработчикам компания Axelera AI предлагает комплект Voyager SDK, который позволяет полностью раскрыть потенциал чипа Metis AIPU и упрощает развёртывание коммерческих приложений. Продажи ИИ-ускорителя Metis M.2 Max начнутся в IV квартале текущего года. Устройство будет поставляться отдельно и в комплекте с опциональным низкопрофильным радиатором охлаждения.
08.09.2025 [17:26], Владимир Мироненко
d-Matrix начала тестирование чипа Pavehawk с поддержкой 3DIMCСтартап d-Matrix объявил о разработке новой реализации технологии 3D-вычислений в памяти (3DIMC), которая обещает в 10 раз ускорить работу ИИ-моделей и в 10 раз повысить энергоэффективность по сравнению с текущим отраслевым стандартом HBM4, пишет ресурс SiliconANGLE. Технический директор Судип Бходжа (Sudeep Bhoja) сообщил в блоге, что первый чип компании с поддержкой 3DIMC, d-Matrix Pavehawk, разработка которого заняла более двух лет, сейчас проходит тестирование. В Pavehawk логический блок, изготовленный с использованием 5-нм техпроцесса TSMC, располагается поверх чипа памяти и интегрирован с ним посредством технологии F2F (face-to-face). По словам Бходжи, отраслевые тесты показывают, что производительность вычислений растёт примерно в 3 раза каждые два года, в то время как пропускная способность памяти — всего в 1,6 раза. Этот разрыв постоянно увеличивается, память уже стала узким местом в масштабировании ИИ. Компания утверждает, что простое увеличение количества ускорителей в ЦОД не решит проблему «стены памяти». 
Источник изображений: d-Matrix/ServeTheHome HPCwire цитирует гендиректора: d-Matrix Сида Шета (Sid Sheth): «Модели быстро развиваются, и традиционные системы памяти HBM становятся очень дорогими, энергоёмкими и ограниченными по пропускной способности». По его словам, узким местом ИИ-инференса является память, а не только количество операций с плавающей запятой, но 3DIMC меняет правила игры. «Стекируя память в трёх измерениях и обеспечивая её более тесную интеграцию с вычислениями, мы значительно сокращаем задержку, увеличиваем пропускную способность и открываем новые возможности повышения эффективности», — подчеркнул он. Компания отметила, что инференс, а не обучение, быстро становится доминирующей рабочей ИИ-нагрузкой. По словам Бходжи, CoreWeave недавно заявила, что 50 % её рабочих нагрузок теперь приходится на инференс, и аналитики прогнозируют, что в течение следующих двух-трех лет инференс будет составлять более 85 % всех корпоративных рабочих ИИ-нагрузок. Он подчеркнул, что компания не занимается перепрофилированием архитектур, созданных для обучения ИИ-моделей, — она с нуля разрабатывает решения, ориентированные на инференс. 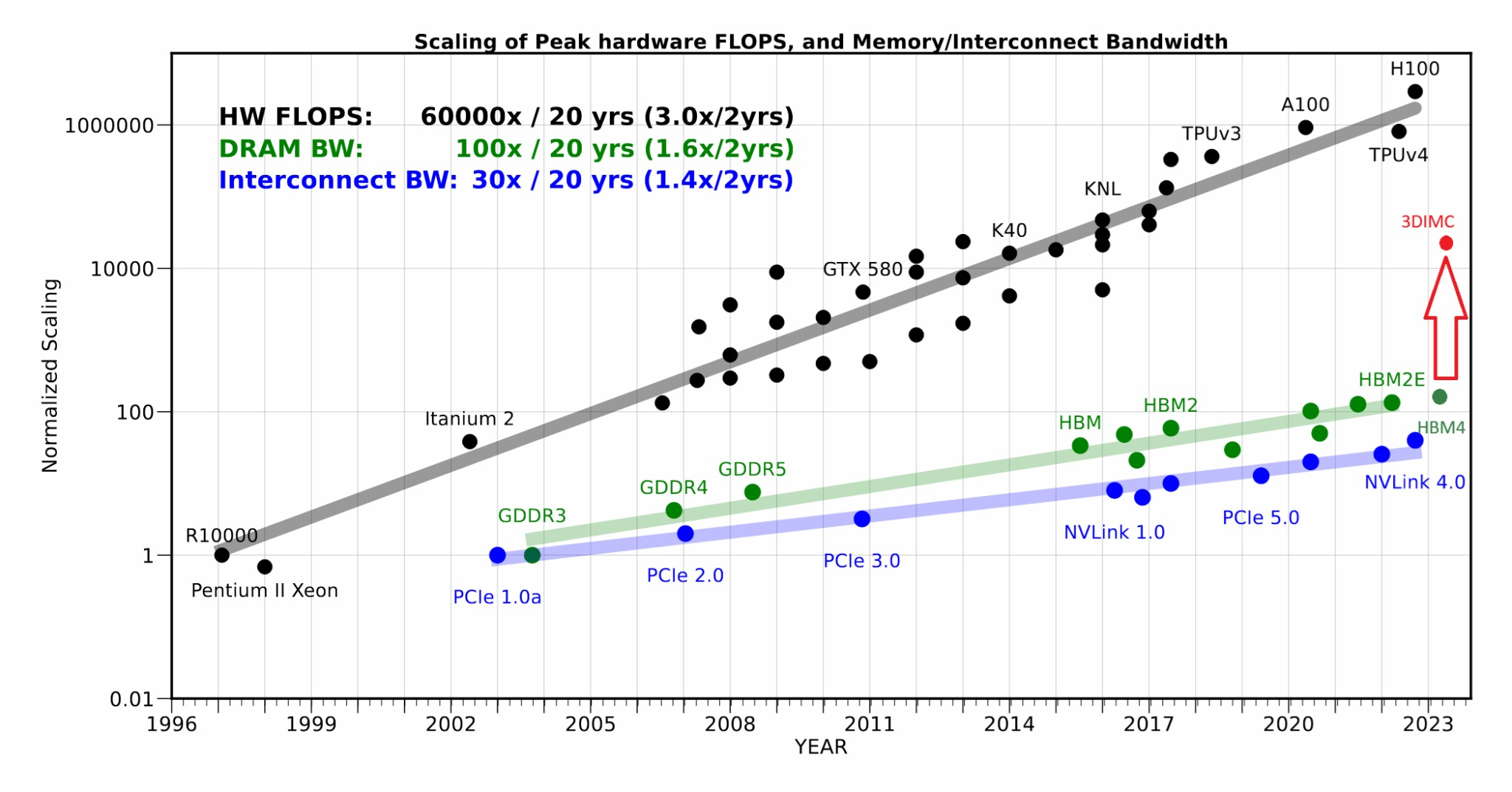 Бходжа сообщил, что первые пользователи ИИ-ускорителей Corsair, среди которых есть и гиперскейлеры, и неооблака, убедились, что архитектура с упором на память может значительно повысить пропускную способность, энергоэффективность и скорость генерации токенов по сравнению с GPU. Он также отметил, что конструкция на основе чиплетов обеспечивает не только большую пропускную способность памяти, но и «невероятную» гибкость, позволяя внедрять технологии памяти нового поколения быстрее и эффективнее, чем монолитные архитектуры. Бходжа заявил, что 3DIMC на порядок увеличит пропускную способность памяти и производительность для задач ИИ-инференса и обеспечит провайдерам сервисов и предприятиям возможность масштабировать их эффективно и экономично по мере появления новых моделей и приложений. С выводом Pavehawk на рынок компания занялось созданием следующего поколения архитектуры обработки в оперативной памяти, использующей 3DMIC, под названием Raptor. 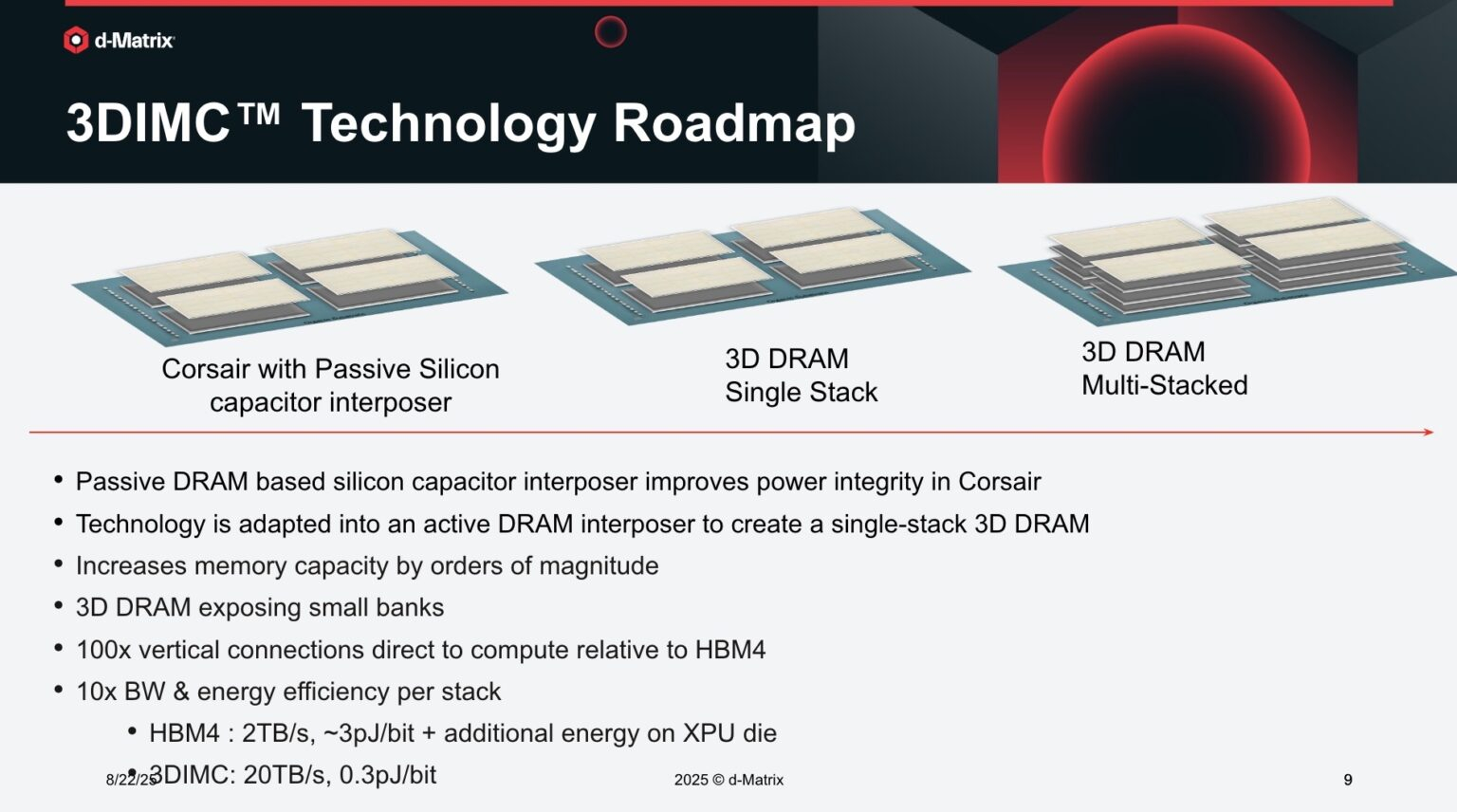 «Наша архитектура следующего поколения Raptor будет включать 3DIMC и опираться на опыт, полученный нами и нашими клиентами в ходе тестирования Pavehawk. Благодаря вертикальному размещению памяти и тесной интеграции с вычислительными чиплетами, Raptor обещает преодолеть барьер в области памяти и выйти на совершенно новый уровень производительности и совокупной стоимости владения», — утверждает Бходжа. Он добавил, что, поставив требования к памяти во главу угла при разработке своих решений — от Corsair до Raptor и далее — компания гарантирует, что инференс будет быстрее, доступнее и стабильнее при масштабировании. d-Matrix провела два раунда финансирования. В раунде A в 2022 году было привлечено $44 млн, а в раунде B в 2023 году – $110 млн, что в общей сложности составляет $154 млн. Компания сотрудничает с поставщиком решений компонуемых систем GigaIO.
08.09.2025 [09:29], Сергей Карасёв
DE-CIX запустила первую в мире платформу обмена ИИ-трафикомОператор точек обмена трафиком DE-CIX объявил о запуске первой в мире специализированной платформы, призванной обеспечить высокоскоростное и надёжное взаимодействие между агентами, сетями и приложениями на базе ИИ. Инфраструктура сформирована в рамках первой фазы проекта AI Internet Exchange (AI-IX). К платформе уже подключены более 50 сетей, ориентированных на задачи ИИ. Это, в частности, провайдеры инференс-услуг и GPUaaS, а также поставщики облачных сервисов. AI-IX, как утверждается, обеспечивает отказоустойчивое и высокозащищённое соединение с низкими задержками, специально предназначенное для сценариев использования ИИ в режиме реального времени. Это могут быть мультимодальные агенты, робототехнические устройства, системы автономного вождения и пр. Платформа использует проприетарную масштабируемую систему маршрутизации. Вторая фаза проекта AI-IX предполагает поддержку Ultra Ethernet для формирования географически распределённой среды обучения ИИ. Задачей консорциума Ultra Ethernet, созданного в июле 2023 года, является разработка ИИ/HPC-интерконнекта на базе Ethernet. DE-CIX отмечает, что с появлением Ultra Ethernet меняется подход к проектированию инфраструктуры для ресурсоёмких вычислений. Становится возможным объединение географически распределённых узлов, что предоставляет компаниям новые возможности в плане создания отказоустойчивой и более экономичной частной инфраструктуры ИИ. 
Источник изображения: DE-CIX В целом, как подчёркивает DE-CIX, пиринговые сети ИИ предлагают ряд преимуществ как для задач инференса, так и для обучения моделей. Среди них — снижение затрат, повышение безопасности, увеличение производительности и повышение гибкости.
31.08.2025 [15:51], Руслан Авдеев
Alibaba разработала собственный ИИ-ускоритель для инференсаНа фоне нарастающего давления со стороны китайских властей, стремящихся избавиться от зависимости от ИИ-чипов NVIDIA и и других западных аналогов, Alibaba разработала собственный ИИ-ускоритель. В пятницу появились данные, что новейший чип китайского IT-гиганта ориентирован на инференс, сообщает The Register. Подразделения Alibaba T-Head довольно давно работает над собственными ИИ-решениями. В 2019 году он представила вариант Hanguang 800, но в отличие от современных моделей NVIDIA и AMD, он в первую очередь предназначен для классических ML-моделей машинного обучения (таких как ResNet), а не для современных больших языковых моделей (LLM). Утверждается, что новый чип будет справляться с более разнообразными нагрузками. В обозримом будущем для обучения Alibaba, вероятно, будет по-прежнему использовать ускорители NVIDIA. По имеющимся данным, в отличие от ускорителей Huawei Ascend, продукт Alibaba совместим с программной платформой NVIDIA, что позволяет лишь немного переработать используемый код. При этом использование инструментов CUDA не является необходимым для инференса. Alibaba, вероятно, ориентируется на более высокоуровневые варианты вроде PyTorch или TensorFlow. Так или иначе, чип придётся выпускать в Китае из-за санкций США. Кто именно займётся непосредственно выпуском не указывается, но весьма вероятно, что речь идёт о SMIC. Кроме того, Китаю запрещено продавать высокоскоростную память HBM2e и более новые версии — если они уже не интегрированы в готовый ускоритель. Это значит, что Alibaba или будет использовать «медленную» память GDDR или LPDDR, а также накопленные запасы HBM, пока не появятся собственные аналоги. 
Источник изображения: Alibaba Новости об очередных полупроводниках китайского производства появились на фоне призывов китайского правительства не использовать ускорители NVIDIA H20 из соображений безопасности. Впрочем, NVIDIA, которой не так давно вновь разрешили поставлять H20 в Китай, все обвинения решительно отрицает. По некоторым данным, ведётся разработка нового ускорителя семейства Blackwell, специально для Китая. Впрочем, в текущем квартале компания всё равно не рассчитывает на доходы в КНР, поскольку механизмы возобновления продажи и взимания 15-процентной экспортной пошлины ещё не отработаны. Тем временем китайские лидеры ИИ-отрасли ищут альтернативы продуктам компании. DeepSeek переориентировала свои модели на использование нового поколения китайских чипов. Компания не назвала поставщика, но, по некоторым данным, перенести обучение на Ascend не удалось. Впрочем, сама Huawei старается ускорить и инференс. Стартап Enflame, поддерживаемый Tencent, разрабатывает новый ускоритель L600, который получит 144 Гбайт (3,6 Тбайт/с) и поддержку FP8-вычислений. MetaX анонсировала модель C600 со 144 Гбайт HBM3e, но производство, вероятно, будет ограничено имеющимися резервами памяти. Наконец, Cambricon Technologies также работает над собственным ускорителем Siyuan 690, который, как ожидается, будет лучше NVIDIA H100.
28.08.2025 [13:03], Руслан Авдеев
Китайский бизнес переходит на подержанные ускорители NVIDIA A100 и H100 из-за проблем с поставками H20Китайская ИИ-индустрия постепенно переходит на восстановленные или подержанные ИИ-ускорители NVIDIA A100 и H100 после того, как очередные экспортные ограничения на NVIDIA H20 заставили компании искать альтернативы этому продукту. Искусственно ослабленный ускоритель H20 должен был сохранить присутствие NVIDIA на китайском рынке, но чип фактически «оказался на обочине» даже после того, как на его продажи вновь дали зелёный свет после временного запрета — китайские регуляторы поставили под сомнение его безопасность, сообщает Tom’s Hardware со ссылкой на Digitimes. Всё это привело к стремительному росту спроса на старые модели A100 и H100, китайские компании проводят некую «реконфигурацию» таких ускорителей для использования в недорогих, но высокопроизводительных системах инференса. Последний требует значительно меньше ресурсов, чем обучение ИИ-моделей, рабочие нагрузки могут эффективно выполняться на относительно слабом оборудовании. Именно поэтому даже A100 с 80 Гбайт HBM2e (2 Тбайт/с), представленный ещё в 2020 году, в некоторых случаях остаётся вполне востребованным. Хотя архитектура Ampere уступает Hopper по пиковой производительности, она всё ещё эффективна для инференса благодаря относительно большому объёму памяти и развитой экосистеме ПО CUDA. Для чат-ботов и рекомендательных систем экономически эффективно использовать системы без самых современных чипов. Представленные в 2022 году H100 значительно производительнее A100 в задачах, связанных с обучением. В то же время H20 изначально был оптимизирован для менее ресурсоёмкого инференса, но его возможности урезали так сильно, что производительность в сравнении с H100 у этой модели ниже в 3–7 раз, а в задачах, связанных с вычислениями FP64, он медленнее более чем в 30 раз. Другими словами, даже A100 всё ещё могут быть привлекательнее для китайских покупателей, чем новые H20. 
Источник изображения: NVIDIA Поскольку пока никому не удалось создать что-то сопоставимое с программной экосистемой NVIDIA CUDA, старые GPU вполне востребованы. Тем более что оборудование для инференса менее требовательно во всех отношениях, а китайские ЦОД, по-видимому, не испытывают проблем с энергий и готовы платит за восстановленную устаревшую электронику, даже с пониженной надёжностью. В результате NVIDIA оказалась в странном положении. Компания в своё время списала $5,5 млрд из-за нераспроданных запасов H20 — когда в США решили полностью запретить их поставки в Китай. После снятия запрета компания резко нарастила выпуск H20, но теперь столкнулась уже с нежеланием властей КНР видеть эти чипы в стране. Тем не менее, её ускорители по-прежнему являются одним из главных катализаторов бума ИИ в Китае. Другими словами, чипы компании по-прежнему доминируют на рынке Поднебесной, но активность на теневых рынках может снизить выгоду от бизнеса с Китаем. Впрочем, уже появилась информация о разработке нового ускорителя на основе современной архитектуры Blackwell — хотя и тоже ослабленного.
24.08.2025 [23:18], Сергей Карасёв
NeuReality готовит чип NR2 для оркестрации инференсаКомпания NeuReality раскрыла предварительную информацию об изделии NR2 — чипе второго поколения, предназначенном специально для оркестрации инференса. Изделие представляет собой более эффективную альтернативу связке CPU и NIC в высокопроизводительных системах ИИ. Чип первого поколения NR1 дебютировал в июне нынешнего года. Изделие может применяться в связке с любым GPU или ИИ-ускорителем. При этом, как утверждается, NR1 позволяет повысить эффективность использования GPU почти до 100 % по сравнению со средним показателем в 30–50 % при традиционном сочетании CPU и NIC в современных серверах. В состав NR1 входят четыре декодера видео/изображений, 16 DSP для аудио/речи, 16 векторных DSP общего назначения, два порта 10/25/50/100GbE и пр. Характеристики NR2 на данный момент полностью не раскрываются. Известно, что в основу решения положена платформа Arm Neoverse Compute Subsystems (CSS) V3. Чип может объединять до 128 ядер, оптимизированных для масштабных рабочих нагрузок обучения моделей ИИ и инференса. По сравнению с оригинальной версией в NR2 реализована более глубокая интеграция между CPU-блоком и NIC для координации ИИ-моделей в реальном времени, дезагрегации на основе микросервисов, потоковой передачи токенов, оптимизации KV-кеша и оркестровки. 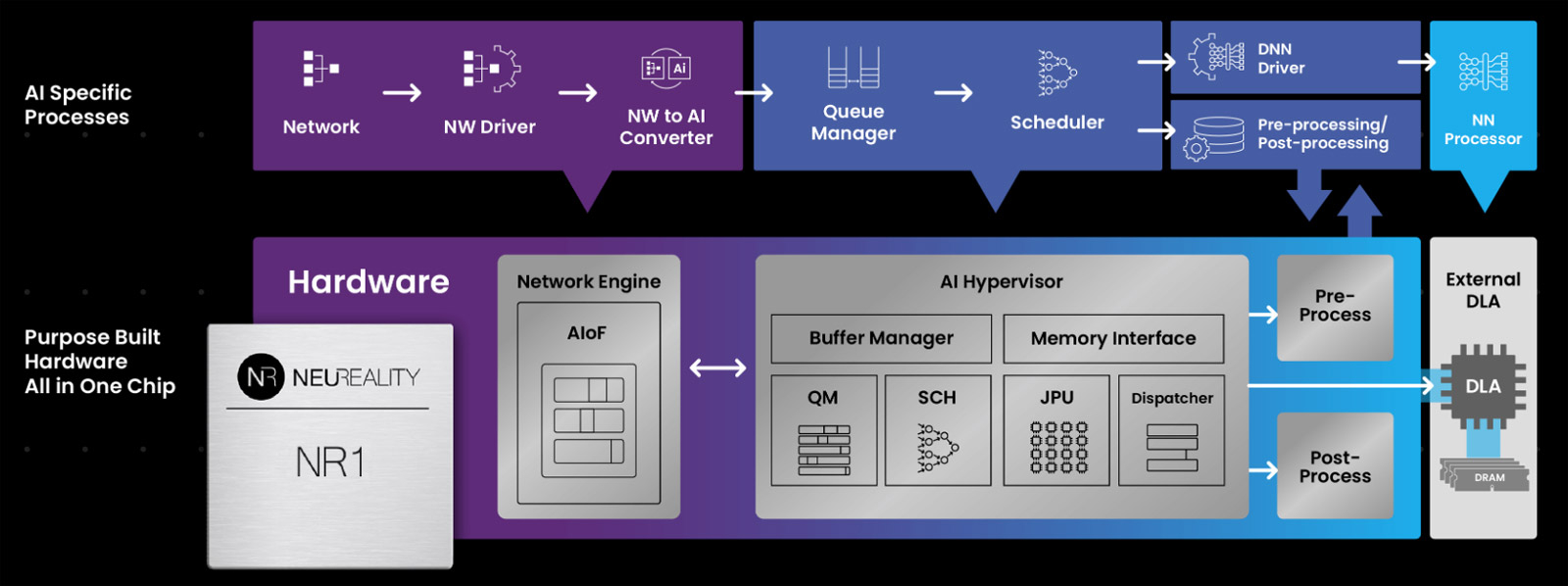
Источник изображения: NeuReality В целом, как отмечает NeuReality, чипы серии NR представляют собой качественно новый класс изделий, способных управлять рабочими нагрузками инференса с непревзойдённой эффективностью. Гипервизор ИИ в сочетании с ядрами Arm Neoverse обеспечивает оптимальную оркестровку и максимальную загрузку доступных ресурсов.
22.08.2025 [17:23], Руслан Авдеев
Google: медианный промпт Gemini потребляет 0,24 Вт·ч энергии и 0,26 мл водыКомпания Google опубликовала документ, в котором описывается методология измерения потребления энергии и воды, а также выбросов и воздействия на окружающую среду ИИ Gemini. Как утверждают в Google, «медианное» потребление энергии на одно текстовое сообщение в Gemini Apps составляет 0,24 Вт·ч, выбросы составляют 0,03 г эквивалента углекислого газа (CO2e), а воды расходуется 0,26 мл. В компании подчёркивают, что показатели намного ниже в сравнении со многими публичными оценками, а на каждый запрос тратится электричества столько же, сколько при просмотре телевизора в течение девяти секунд. Google на основе данных о сокращении выбросов в ЦОД и декарбонизации энергопоставок полагает, что за последние 12 месяцев энергопотребление и общий углеродный след сократились в 33 и 44 раза соответственно. В компании надеются, что исследование внесёт вклад в усилия по разработке эффективного ИИ для общего блага. Методологии расчёта энергопотребления учитывает энергию, потребляемую активными ИИ-ускорителями (TPU), CPU, RAM, а также затраты простаивающих машин и общие расходы ЦОД. При этом из расчёта исключаются затраты на передачу данных по внешней сети, энергия устройств конечных пользователей, расходы на обучение моделей и хранение данных. 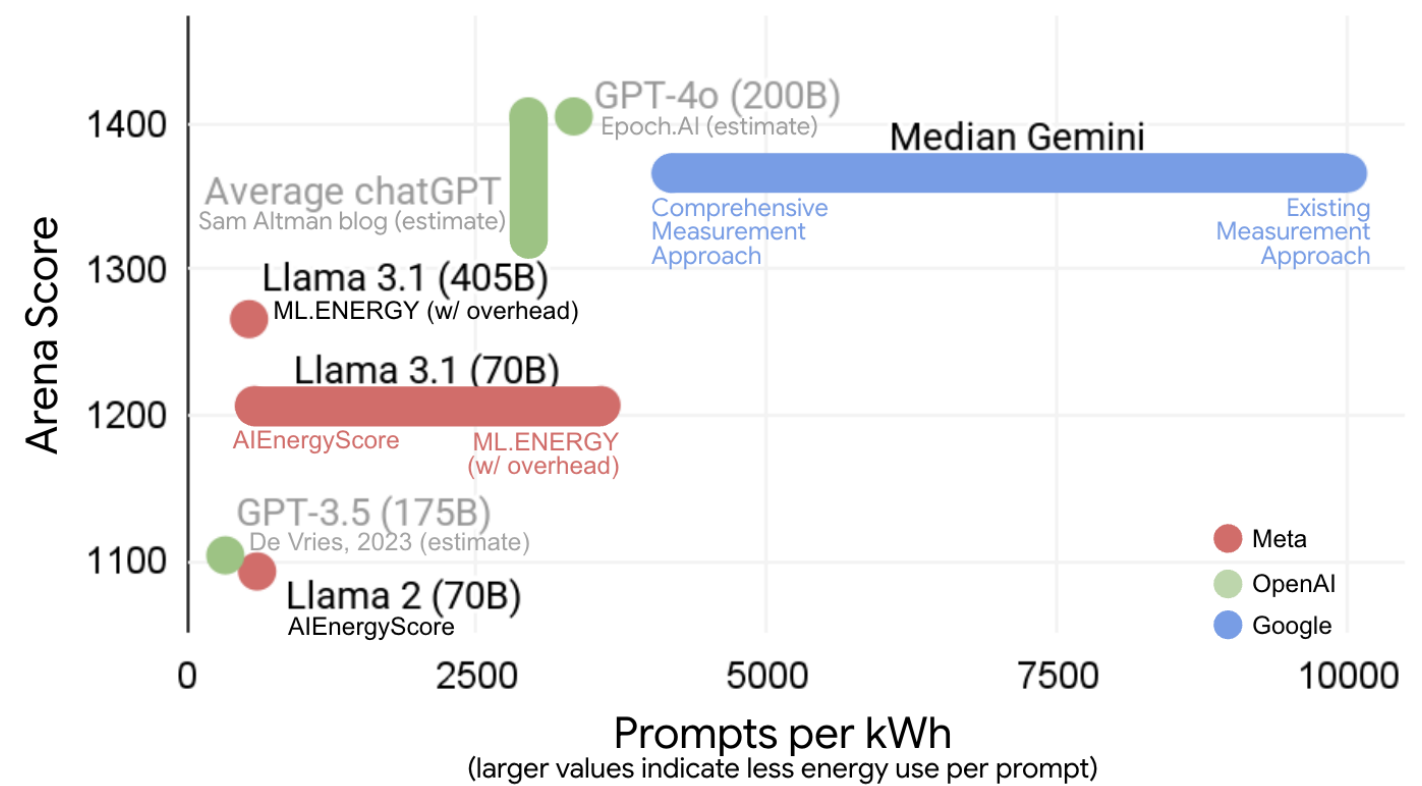
Источник изображений: Google Впрочем, по мнению некоторых экспертов, данные вводят в заблуждение, поскольку часть информации не учитывается. Так, не принимается в расчёт «косвенное» использование воды, поскольку считается только вода, которую ЦОД применяют для охлаждения, хотя значительная часть водопотребления приходится на генерирующие мощности, а не на их потребителей. Кроме того, при учёте углеродных выбросов должны приниматься во внимание не купленные «зелёные сертификаты», а реальное загрязняющее действие ЦОД в конкретной локации с учётом использования «чистой» и «обычной» энергии в местной электросети. 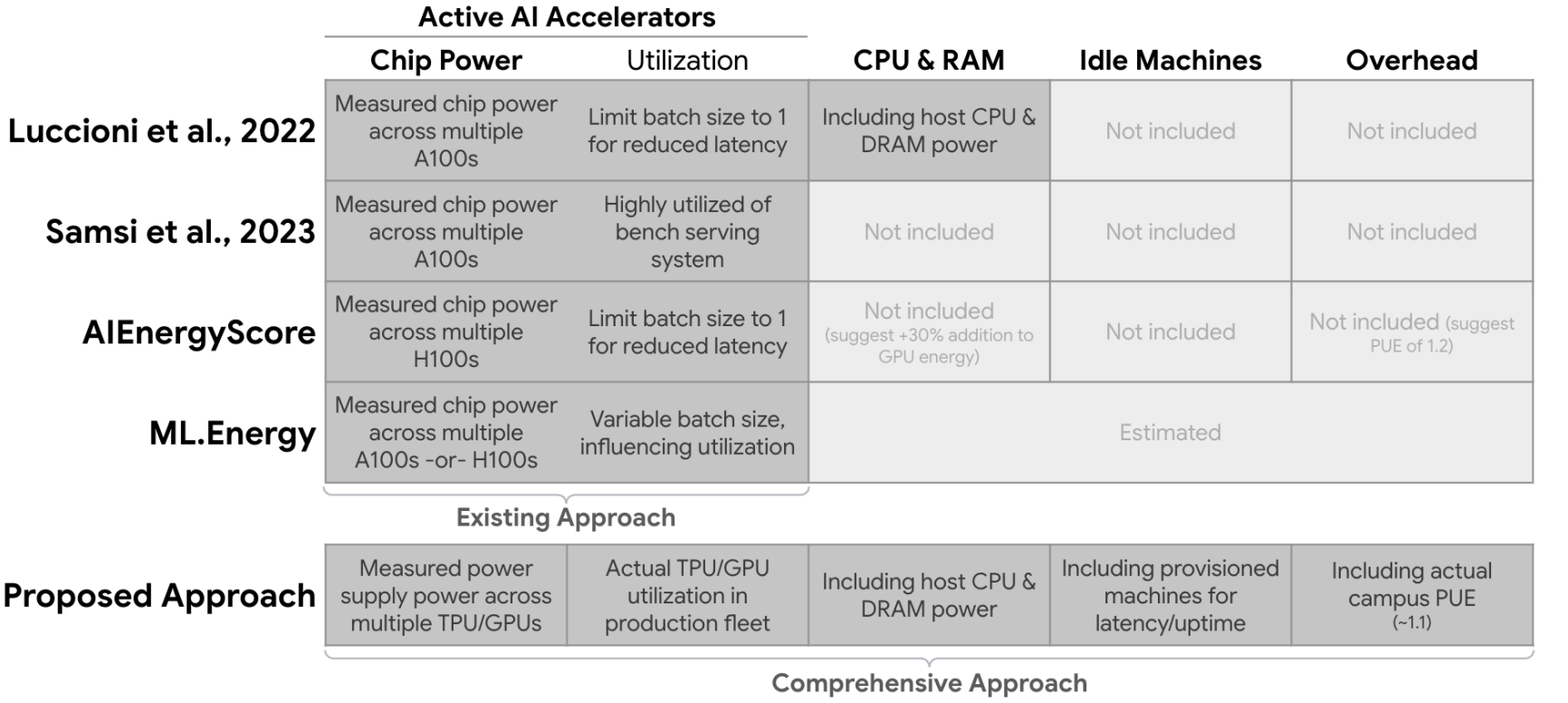 OpenAI также недавно оказалась в центре внимания экспертов и общественности, поскольку появилась информация, что её новейшая модель GPT-5 потребляет более 18 Вт·ч электроэнергии, до 40 Вт·ч на ответ средней длины. Сам глава компании Сэм Альтман (Sam Altman) объявил, что в среднем на выполнение запроса тратится около 0,34 Вт∙ч и около 0,32 мл воды. Это несколько больше, чем заявленные показатели Google Gemini, однако, согласно расчётам исследователей, эти цифры, скорее всего, актуальны для GPT-4o.
22.08.2025 [16:33], Владимир Мироненко
Почти как у самой NVIDIA: NVLink Fusion позволит создавать кастомные ИИ-платформыТехнологии NVIDIA NVLink и NVLink Fusion позволят вывести производительность ИИ-инференса на новый уровень благодаря повышенной масштабируемости, гибкости и возможностям интеграции со сторонними чипами, которые в совокупности отвечает стремительному росту сложности ИИ-моделей, сообщается в блоге NVIDIA. С ростом сложности ИИ-моделей выросло количество их параметров — с миллионов до триллионов, что требует для обеспечения их работы значительных вычислительных ресурсов в виде кластеров ускорителей. Росту требований, предъявляемых к вычислительным ресурсам, также способствует внедрение архитектур со смешанным типом вычислений (MoE) и ИИ-алгоритмов рассуждений с масштабированием (Test-time scaling, TTS). NVIDIA представила интерконнект NVLink в 2016 году. Пятое поколение NVLink, вышедшее в 2024 году, позволяет объединить в одной стойке 72 ускорителя каналами шириной 1800 Гбайт/с (по 900 Гбайт/с в каждую сторону), обеспечивая суммарную пропускную способность 130 Тбайт/с — в 800 раз больше, чем у первого поколения.  Производительность NVLink зависит от аппаратных средств и коммуникационных библиотек, в частности, от библиотеки NVIDIA Collective Communication Library (NCCL) для ускорения взаимодействия между ускорителями в топологиях с одним и несколькими узлами. NCCL поддерживает вертикальное и горизонтальное масштабирование, а также включает в себя автоматическое распознавание топологии и оптимизацию передачи данных. 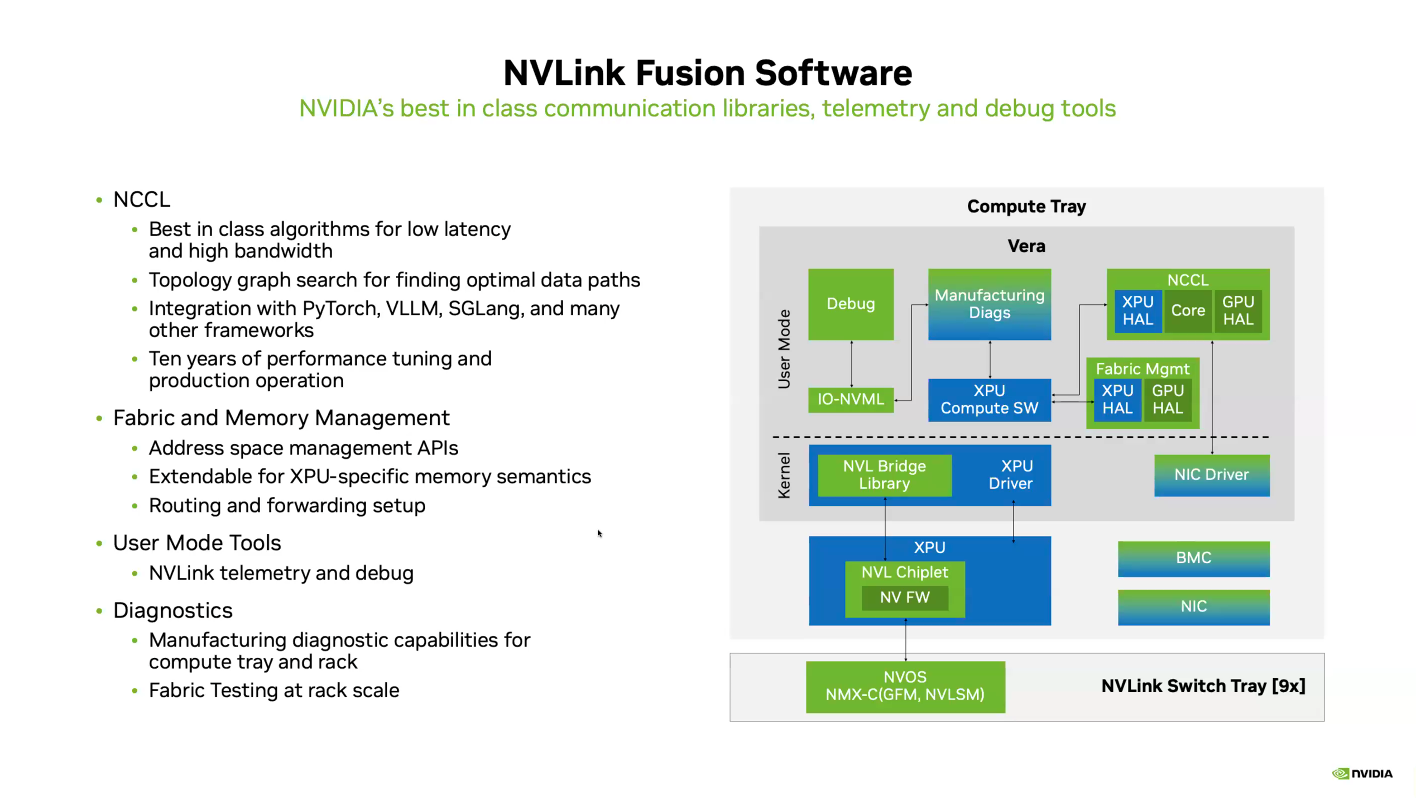 Технология NVLink Fusion призвана обеспечить гиперскейлерам доступ ко всем проверенным в производстве технологиям масштабирования NVLink. Она позволяет интегрировать кастомные микросхемы (CPU и XPU) с технологией вертикального и горизонтального масштабирования NVIDIA NVLink и стоечной архитектурой для развёртывания кастомных ИИ-инфраструктур. 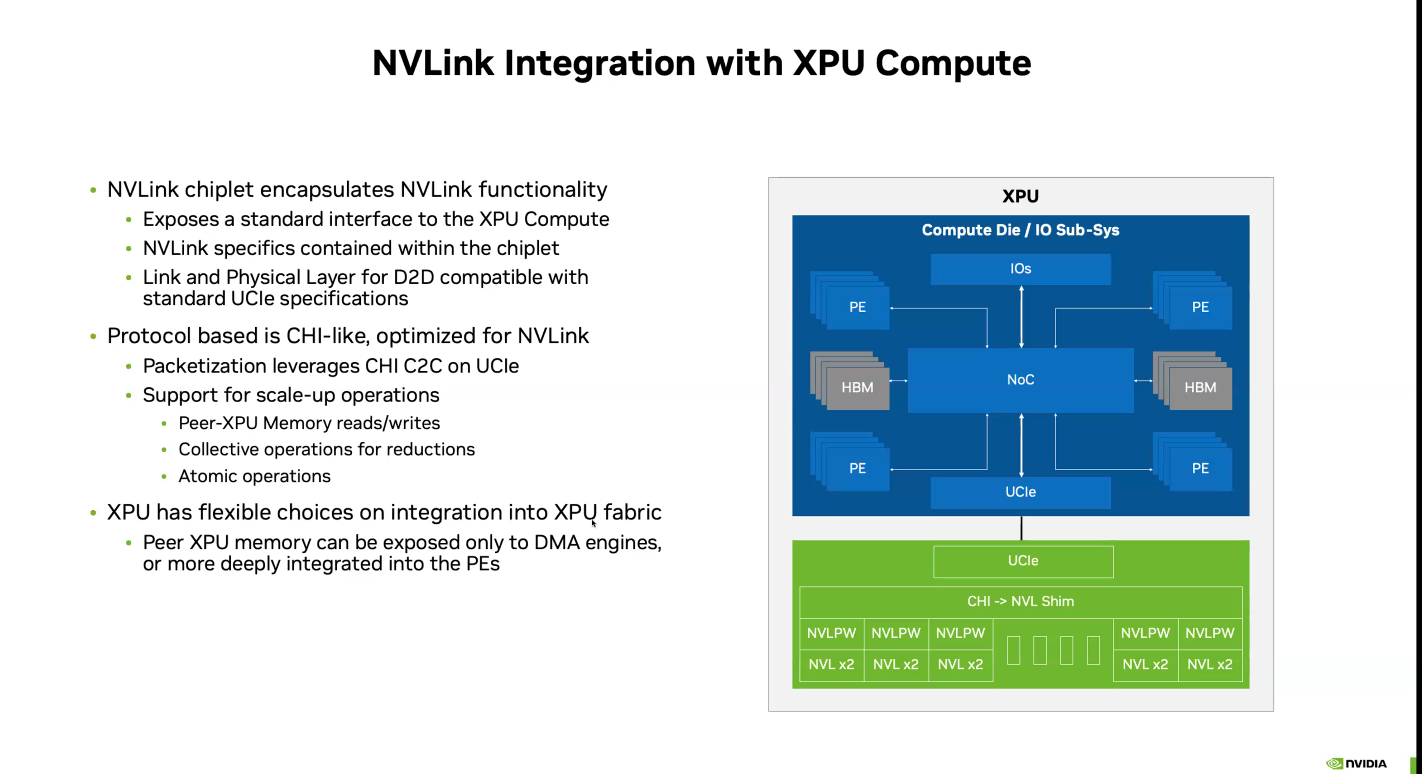 Технология охватывает NVLink SerDes, чиплеты, коммутаторы и стоечную архитектуру, предлагая универсальные решения для конфигураций кастомных CPU, кастомных XPU или комбинированных платформ. Модульное стоечное решение OCP MGX, позволяющее интегрировать NVLink Fusion с любым сетевым адаптером, DPU или коммутатором, обеспечивает заказчикам гибкость в построении необходимых решений, заявляет NVIDIA. 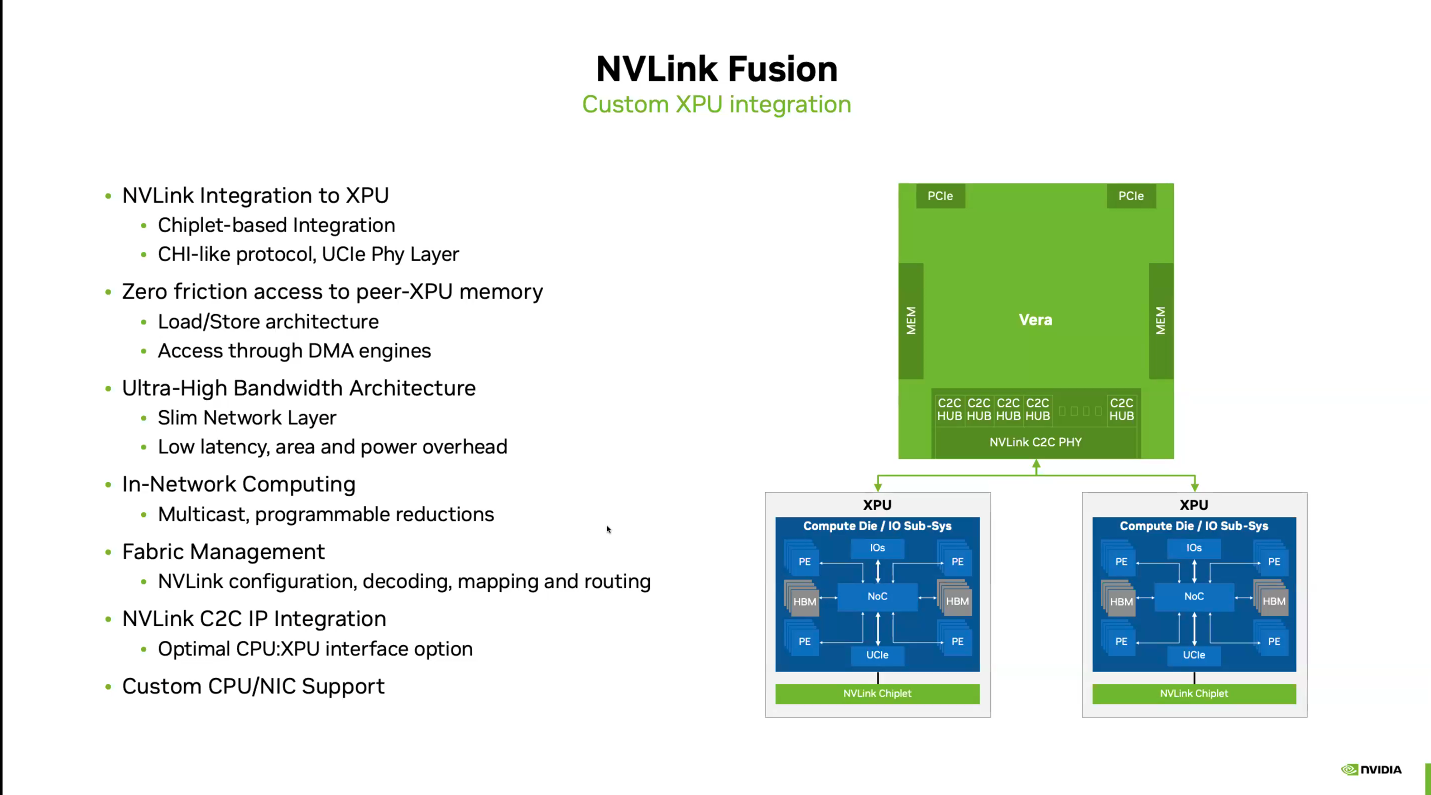 NVLink Fusion поддерживает конфигурации с кастомными CPU и XPU с использованием IP-блоков и интерфейса UCIe, предоставляя заказчикам гибкость в реализации интеграции XPU на разных платформах. Для конфигураций с кастомными CPU рекомендуется интеграция с IP NVLink-C2C для оптимального подключения и производительности GPU. При этом предлагаются различные модели доступа к памяти и DMA. 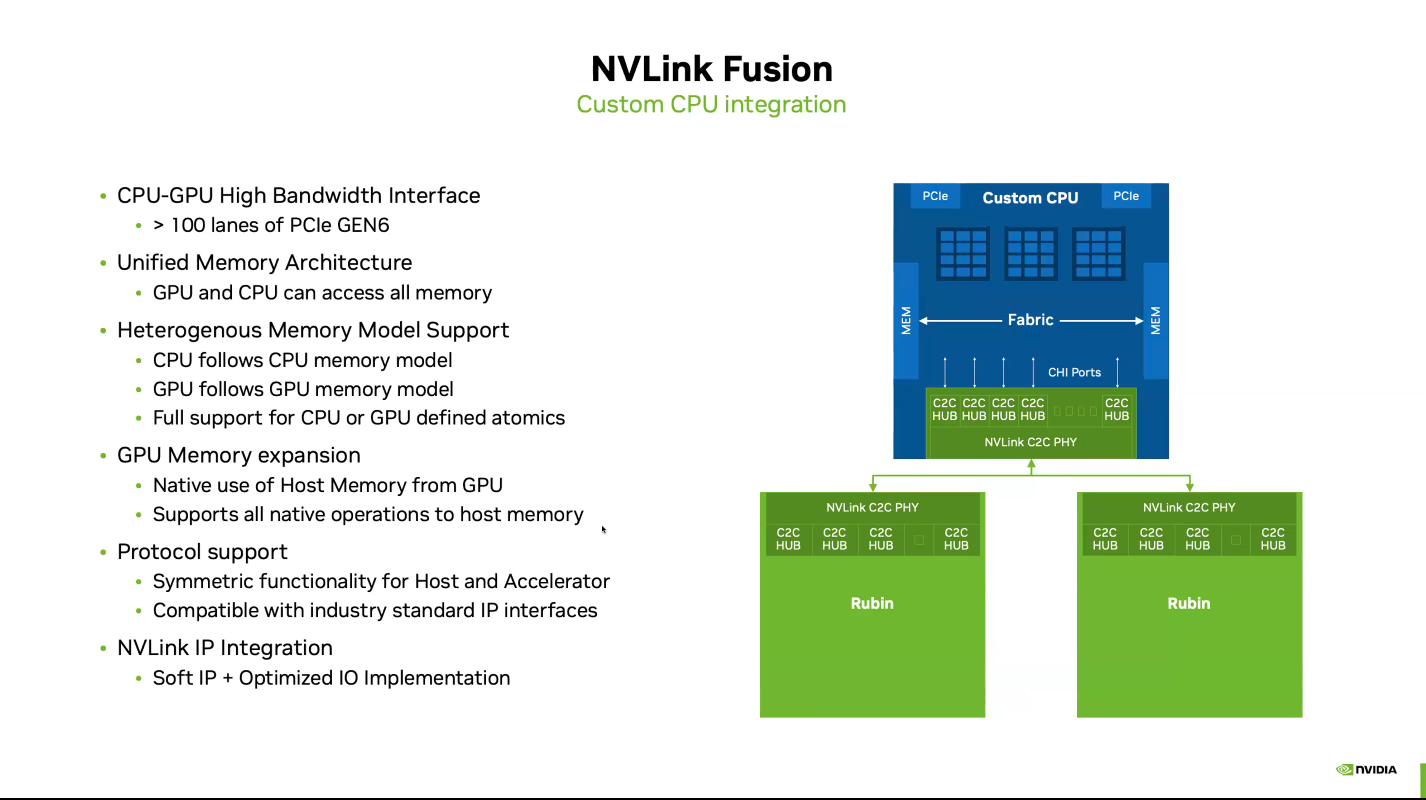 NVLink Fusion использует преимущества обширной экосистемы кремниевых чипов, в том числе от партнёров по разработке кастомных полупроводников, CPU и IP-блоков, что обеспечивает широкую поддержку и быструю разработку новых решений. Основанная на десятилетнем опыте использования технологии NVLink и открытых стандартах архитектуры OCP MGX, платформа NVLink Fusion предоставляет гиперскейлерам исключительную производительность и гибкость при создании ИИ-инфраструктур, подытожила NVIDIA.  При этом основным применением NVLink Fusion с точки зрения NVIDIA, по-видимому, должно стать объединение сторонних чипов с её собственными, а не «чужих» чипов между собой. Более открытой альтернативой NVLink должен стать UALink с дальнейшим масштабированием посредством Ultra Ethernet.
14.08.2025 [17:29], Руслан Авдеев
Умнее, но прожорливее: GPT-5 потребляет до 20 раз больше энергии, чем предыдущие моделиНедавно представленной модели OpenAI GPT-5 в сравнении с ChatGPT образца середины 2023 года для обработки идентичного запроса потребуется до 20 раз больше энергии, сообщает The Guardian. Официальную информацию об энергопотреблении OpenAI, как и большинство её конкурентов, не публикует. В июне 2025 года глава компании Сэм Альтман (Sam Altman) сообщил, что речь идёт о 0,34 Вт∙ч и 0,00032176 л на запрос, но о какой именно модели идёт речь, не сообщалось. Документальные подтверждения этих данных тоже отсутствуют. По словам представителя Университета штата Иллинойс (University of Illinois), GPT-5 будет потреблять намного больше энергии в сравнении с моделями-предшественницами как при обучении, так и при инференсе. Более того, в день премьеры GPT-5 исследователи из Университета Род-Айленда (University of Rhode Island) выяснили, что модель может потреблять до 40 Вт∙ч для генерации ответа средней длины из приблизительно 1 тыс. токенов. Для сравнения, в 2023 году на обработку одного запроса уходило порядка 2 Вт∙ч. Сейчас среднее потребление GPT-5 составляет чуть более 18 Вт∙ч на запрос, что выше, чем у любых других сравнивавшихся учёными моделей, за исключением апрельской версии «рассуждающей» o3 и DeepSeek R1. Предыдущая модель GPT-4o потребляет значительно меньше. 18 Вт∙ч эквивалентны 18 минутам работы лампочки накаливания. С учётом того, что ChatGPT обрабатывает около 2,5 млрд запросов ежедневно, за сутки тратится энергии, достаточной для снабжения 1,5 млн домохозяйств в США. 
Источник изображения: Dean Brierley / Unsplash В целом учёные не удивлены, поскольку GPT-5 в разы производительнее своих предшественниц. Летом 2025 года ИИ-стартап Mistral опубликовал данные, в которых выявлена «сильная корреляция» между масштабом модели и её энергопотреблением. По её данным, GPT-5 использует на порядок больше ресурсов, чем GPT-3. При этом многие предполагают, что даже GPT-4 в 10 раз больше GPT-3. Впрочем, есть и дополнительные факторы, влияющие на потребление ресурсов. Так, GPT-5 использует более эффективное оборудование и новую, более экономичную экспертную архитектуру с оптимизацией расхода ресурсов на ответы, что в совокупности должно снизить энергопотребление. С другой стороны, в случае с GPT-5 речь идёт о «рассуждающей» модели, способной работать с видео и изображениями, поэтому реальное потребление ресурсов, вероятно, будет очень высоким. Особенно в случае длительных рассуждений. 
Источник изображения: Tim King / Unsplash Чтобы посчитать энергопотребление, группа из Университета Род-Айленда умножила среднее время, необходимое модели для ответа на запрос на среднюю мощность, потребляемую моделью в ходе работы. Важно отметить, что это только примерные оценки, поскольку достоверную информацию об использовании моделями конкретных чипов и распределении запросов найти очень трудно. Озвученная Альтманом цифра в 0,34 Вт∙ч практически совпадает с данными, рассчитанными для GPT-4o. Учёные подчёркивают необходимость большей прозрачности со стороны ИИ-бизнесов по мере выпуска всё более производительных моделей. В университете считают, что OpenAI и её конкуренты должны публично раскрыть информацию о воздействии GPT-5 на окружающую среду. Ещё в 2023 году сообщалось, что на обучение модели уровня GPT-3 требуется около 700 тыс. л воды, а на диалог из 20-50 вопросов в ChatGPT уходило около 500 мл. В 2024 году сообщалось, что на генерацию ста слов у GPT-4 уходит до трёх бутылок воды.
13.08.2025 [13:24], Руслан Авдеев
Южнокорейский разработчик ИИ-чипов DeepX объединился с Baidu для выхода на рынок КНРЮжнокорейская DeepX, разрабатывающая ИИ-ускорители, заключила соглашение с китайским гиперскейлером Baidu. Компании намерены оптимизировать разрабатываемую Bailu ИИ-платформу Ernie LLM для оборудования DeepX, сообщает EE Times. В DeepX заявляют, что речь идёт о первом официальном сотрудничестве компании с одной из ключевых китайских ИИ-экосистем. Интеграция ускорителей DeepX с моделями Baidu PaddlePaddle и Ernie позволят южнокорейской компании получить прямой доступ к одному из крупнейших сообществ разработчиков ИИ в Китае. Это ускорит выход стартапа на китайский рынок и обеспечит надёжную проверку его технологий одним из мировых лидеров в сфере искусственного интеллекта. Недавно компания привлекла Morgan Stanley для управления очередным раундом финансирвоания. В прошлом году в ходе раунда финансирования серии C компания привлекла порядка $80 млн, теперь, по данным Bloomberg, она намерена получить значительно больше — незадолго до выхода на IPO в 2027 году. Компания считает себя конкурентом NVIDIA в некоторых секторах. PaddlePaddle представляет собой открытую платформу для глубокого обучения, разработанную компанией Baidu. Она является ключевым фреймворком для ИИ в Китае и представляет собой аналог западным решениям вроде PyTorch или Jax. PaddlePaddle включает готовые предобученные модели, инструменты для разработки и оптимизации ИИ-приложений. В экосистеме PaddlePaddle более 10 млн разработчиков и 200 тыс. предприятий, которые работают над сценариями использования ИИ для обработки зрения, речи и естественного языка. Также предлагается «бесшовная интеграция» с китайскими облачными платформами. 
Источник изображения: DeepX Китай — один из крупнейших быстрорастущих рынков ИИ в мире, особенно в сфере промышленного ИИ, робототехники и умных устройств. Выход на китайский рынок при поддержке Baidu даёт DeepX возможность быстро масштабировать внедрение. Поэтому изначально партнёрство в рамках технологической системы PaddlePaddle будет сосредоточено на промышленном ИИ. Планируется, что компании станут совместно разрабатывать промышленные продукты, обеспечив совместимость технологий. Сообщается, что компании сосредоточатся на промышленных приложениях для распознавания символов (OCR), дронов, робототехники, также изучаются и варианты инновационного использования — в умных городах, автопромышленности и потребительской электронике. Сотрудничество закладывает основу для широкого внедрения ИИ в секторах, где энергоэффективность имеет критически важное значение. Перед подписанием соглашения DeepX продемонстрировала работу ускорителя DX-M1 с моделями Baidu — PP-OCR пятого поколения и VLM. Теперь команды Baidu, включая PaddlePaddle и Ernie, будут адаптировать свои модели для чипов DX-M1 и будущего DX-M2. Прототипы DX-M2, выполненные по 2-нм техпроцессу Samsung, собираются использовать для демонстрации крупной модели ERNIE-4.5-VL-28B-A3B. DeepX также собрала 10 моделей на базе OpenVino для DX-M1, чтобы их можно было использовать совместно с экосистемой PaddlePaddle. По имеющимся данным, существующие клиенты DeepX в Китае работают в сфере промышленных ПК, робототехники и модулей интеллектуальных камер. Благодаря экосистеме Baidu предполагается ускорить коммерческое внедрение, начиная с текущего года. |
|