Материалы по тегу: инференс
|
11.08.2025 [12:22], Руслан Авдеев
Brookfield: в течение десяти лет мощность ИИ ЦОД вырастет на порядок, а расходы на ИИ-инфраструктуру превысят $7 трлнИнвестиционный гигант Brookfield Asset Management выступил с прогнозом дальнейшего роста рынка дата-центров с небольшим риском «чрезмерного» развития, обусловленного бумом ИИ. Компания уже дала жизнь специальной стратегии развития ИИ-инфраструктуры и опубликовала документ, в котором изложила векторы развития сектора, сообщает Datacenter Dynamics. Сама Brookfield активно вкладывает значительные средства в инфраструктуру ЦОД, только в июне 2025 года она сообщала о готовности выделить $10 млрд на шведский ИИ ЦОД. В феврале она заявляла, что потратит €20 млрд ($23 млрд) на ИИ-инфраструктуру во Франции. Brookfield частично или полностью владеет Compass, Centersquare, Data4, Ascenty, Digtal Connexion и DCI, а также активно инвестирует в энергетику. Основываясь на данных собственного внутреннего исследования, компания пришла к выводу, что общие расходы на ИИ-инфраструктуру превысят $7 трлн в следующие десятилетие. Ранее McKinsey прогнозировала, что на эти цели ещё до конца текущего десятилетия может уйти до до $5 трлн. По прогнозам Brookfield, $4 трлн пойдут на чипы (включая производство и цепочки поставок), $2 трлн — на ЦОД, а $500 млрд — на электроэнергию и сети энергопередачи. Ещё $500 млрд потратят на технологии более общего назначения, вроде выделенных ВОЛС, системы охлаждения и робототехнику. Как сообщают в Brookfield, для ИИ находится всё больше сфер применения, он становится всё более коммерчески привлекательным, а повышение его эффективности приведёт к дальнейшему увеличению спроса. Пока шансы на «перепроизводство» мощностей крайне малы. В компании ожидают, что к концу года ИИ ЦОД («фабрики ИИ») будут располагать мощностями порядка 15 ГВт, тогда как в конце 2024 года речь шла о 7 ГВт. 
Источник изображения: Invest Europe/unsplash.com В следующие десять лет мощности должны вырасти ещё на 75 ГВт, так что к 2034 году их общая мощность приблизится к 82 ГВт. Другими словами, за 10 лет мощности вырастут более чем в 10 раз. Установленная база ИИ-ускорителей с 2024 по 2034 гг. вырастет приблизительно в семь раз, с 7 млн в 2024 году до 45 млн к 2034 году. При этом чипы всё чаще будут применяться не для обучения, а для инференса — к 2030 году на инференс придётся порядка 75 % спроса на ИИ-вычисления. В Brookfield отмечают, что появление сложных ИИ-агентов дополнительно увеличит потребность в инференсе, поэтому всё больше проектов ЦОД будут оптимизироваться именно для инференса, а не для обучения ИИ-моделей. Значительная часть соответствующих проектов будет реализована с помощью компаний, предлагающих «ускоритель как услугу» — вроде CoreWeave. Рост соответствующего рынка вырастет с приблизительно $30 млрд в 2025 году до более $250 млрд к 2034 году, поскольку компании разных масштабов стремятся получить доступ к ИИ-вычислениям без капитальных затрат. В Brookfield подчеркнули, что строителям дата-центров уже стоит вносить изменения в их архитектуру с учётом возможных изменений. Оптимальными в долгосрочной перспективе будут модульные подходы, позволяющие быстро модернизировать систему питания и охлаждения по мере развития чипов и прочих технологий.
03.08.2025 [10:17], Сергей Карасёв
Rebellions и Marvell займутся разработкой решений для суверенного ИИЮжнокорейская компания Rebellions, занимающаяся созданием специализированных ИИ-чипов, объявила о сотрудничестве с американским разработчиком процессоров, микроконтроллеров и телекоммуникационных изделий Marvell Technology. Цель партнёрства — выпуск высокопроизводительных и энергоэффективных ИИ-решений для суверенных платформ в Азиатско-Тихоокеанском регионе и на Ближнем Востоке. Стартап Rebellions основан в 2020 году. Компания проектирует чипы для инференса, способные обеспечить энергоэффективность и высокую производительность при небольших задержках. В январе 2024 года Rebellions провела раунд финансирования Series B, в ходе которого на развитие было привлечено $124 млн. Позднее стартап получил $15 млн от Wa’ed Ventures — венчурного подразделения саудовского нефтегазового и химического гиганта Aramco. Кроме того, фирма Rebellions объявила о слиянии с разработчиком ИИ-чипов Sapeon Korea, который был выделен из SK Telecom в 2016 году. 
Источник изображения: Rebellions В заявлении Rebellions говорится, что инфраструктура ИИ становится всё более важной в плане обеспечения национальной конкурентоспособности. На этом фоне наблюдается переход от стандартизированных архитектур на базе GPU к специализированным системам, построенным с применением ASIC. Такой трансформации способствуют суверенные инициативы и проекты региональных поставщиков облачных услуг, которым требуется инфраструктура, обеспечивающая масштабируемость, эффективность и контроль. Предполагается, что новое партнёрство позволит Rebellions разрабатывать кастомизированные ИИ-ускорители с использованием специализированных платформ Marvell. При этом будут использоваться передовые технологии упаковки чипов, высокоскоростные SerDes-блоки и межкомпонентные соединения. Новые чипы, как ожидается, обеспечат возможность высокопроизводительного и энергоэффективного инференса. В целом, сотрудничество позволит объединить достижения Rebellions в области разработки ИИ-решений с передовыми технологиями интеграции кремниевых компонентов Marvell для создания специализированной инфраструктуры ИИ, отвечающей потребностям государственных организаций.
31.07.2025 [12:37], Руслан Авдеев
Uptime Institute: лишь треть владельцев и операторов ЦОД занимаются обучением ИИ-моделей или инференсомСогласно данным ежегодного глобального опроса, проводимого Uptime Institute, в 2025 году лишь около трети владельцев и операторов ЦОД занимаются задачами, связанными с обучением ИИ-моделей и инференсом, сообщается в докладе организации. В документе отмечается, что те, кто сегодня использует ИИ-технологии, находятся на «ранней стадии развития», но значительно больше игроков намерены последовать их примеру. Новый отчёт является результатом опроса, полученного от более чем 800 владельцев и операторов ЦОД с апреля по май 2025 года, из которых 43 % находятся в Европе и Северной Америке. По информации Uptime Institute, опрошенные представители бизнеса больше всего обеспокоены вопросами затрат (38 % — крайне обеспокоены), а на втором месте — вопросы прогнозирования будущих потребностей в мощностях ЦОД (36 %). На третьем месте — повышение энергоэффективности, на четвёртом — доступность электроэнергии. 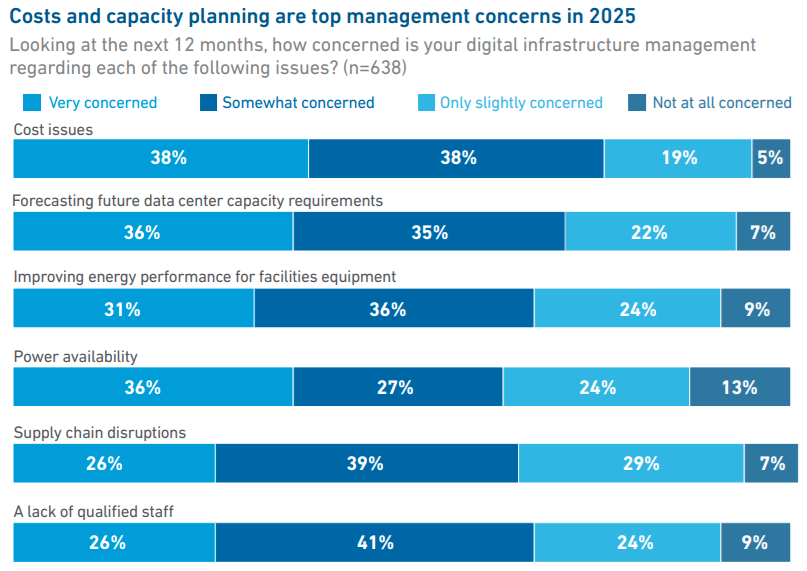
Источник изображения: Uptime Institute Хотя плотность мощности в стойках продолжает расти, в среднем она находится на уровне 10–30 кВт. В Uptime уверены, что лишь немногие проекты используют стойки мощностью более 30 кВт, но «экстремальные» плотности пока встречаются довольно редко. Тем временем уровень PUE по-прежнему остаётся относительно стабильным, среднее значение в текущем году составило 1,54 — уже шестой год подряд оно практически не меняется. 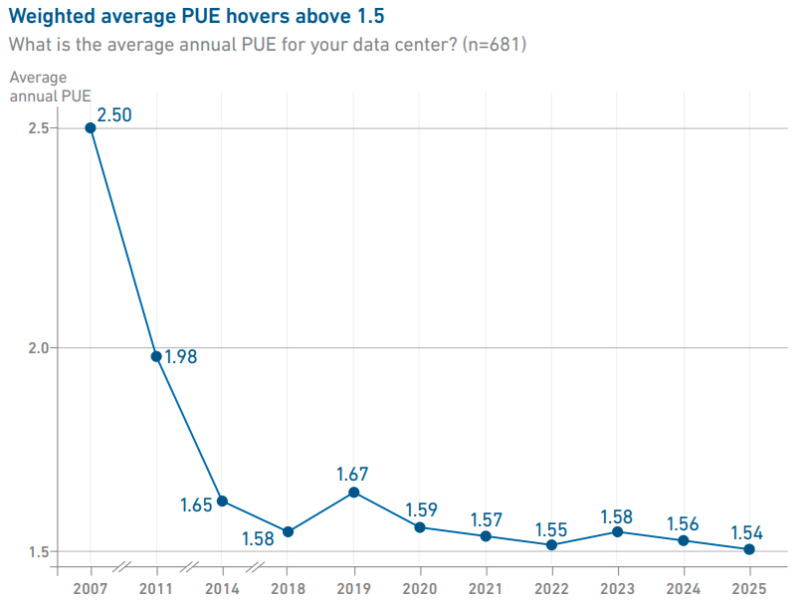
Источник изображения: Uptime Institute Примечательно, что число «значимых» сбоев в работе ЦОД сокращается с учётом общего роста IT-рынка, хотя число публикаций об отказах в работе дата-центров, наоборот, растёт. В отчёте это объясняют просто растущей заметностью и важностью цифровой инфраструктуры в жизни людей. Большинство отключений всё ещё связаны со сбоями электроснабжения (45 %), а также некоторыми другими причинами — впрочем, в 2024 году этот показатель был на уровне 54 %. В отчёте предполагают, что начали окупаться инвестиции в резервирование электропитания и достижения в сфере распределённых и программных архитектур обеспечения отказоустойчивости. Отдельное исследование свидетельствует, что сбои в электропитании в основном связаны с отказами ИБП, а также проблемами с отказами генераторов и переключателями питания. 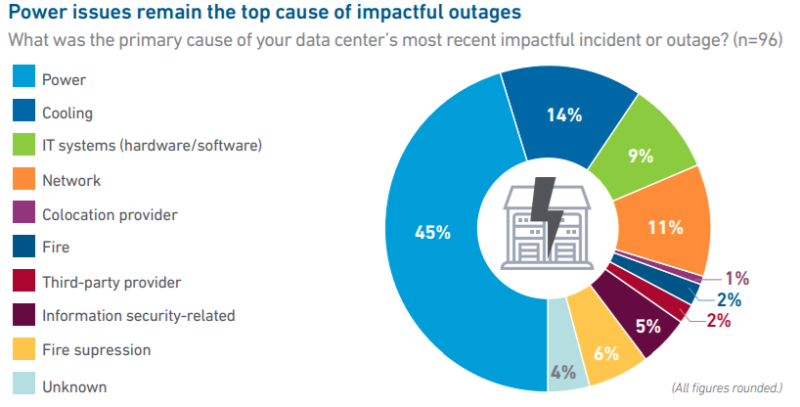
Источник изображения: Uptime Institute Что касается вопроса облачных и локальных вычислений, в Uptime считают, что сейчас около 55 % рабочих нагрузок в той или иной мере размещены вне локальной инфраструктуры, и лишь 45 % приходятся на локальные дата-центры. Вероятно, доля облачных вычислений к 2027 году вырастет до 58 %. Одним из важнейших остаётся кадровый вопрос — почти половина операторов сообщает, что затрудняется с поиском сотрудников, а около 37 % имеют проблемы с удержанием персонала. По словам представителя Uptime Institute, данные организации показывают, что операторам одновременно приходится решать ряд стратегических задач, от прогнозирования технологических изменений до планирования масштабирования бизнеса и подготовки к непредсказуемому спросу на ИИ-вычисления и их поддержку. Подчёркивается, что впервые стало сложнее нанимать и удерживать руководителей старшего звена, чем людей на более низких позициях. Многие опытные руководители уходят на пенсию на фоне нового этапа бурного роста индустрии и нехватки управленцев. 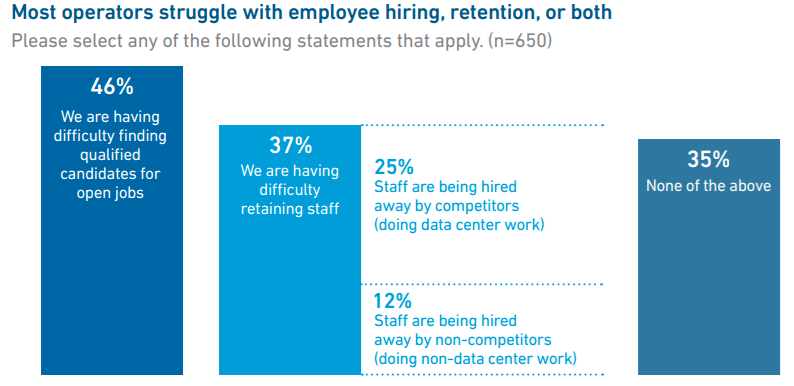
Источник изображения: Uptime Institute В числе прочих выводов — данные о том, что показатели устойчивого развития пострадали из-за коммерческого интереса бизнеса к ИИ и частичного смягчения регуляторных требований в отрасли. В январе 2025 года Uptime Institute сообщал, что развитие ИИ в ЦОД может привести к невыполнению обязательств, взятых операторами по достижению целей устойчивого развития. Также в Uptime отметили использование операторами дата-центров ИИ-решений, в том числе для повышения эффективности объектов (58 %), снижения риска человеческих ошибок (51 %) и повышения производительности труда персонала (48 %).
26.07.2025 [14:55], Сергей Карасёв
В Европе запущена первая метаоблачная ИИ-платформа Fact8raКомпания OpenNebula Systems объявила о запуске Fact8ra — это, как утверждается, первая в Европе платформа «ИИ как услуга» (AI-as-a-Service) на основе мультиоблачной архитектуры. Инициатива является важным этапом на пути формирования европейской суверенной инфраструктуры ИИ. Любопытно, что в Китае создаётся похожая платформа, но по совсем иным причинам — в результате не слишком удачного планирования значительная часть вычислительных мощностей простаивает без дела. Система Fact8ra предлагает многопользовательскую среду для развёртывания частных экземпляров больших языковых моделей (LLM) с открытым исходным кодом. Платформа объединяет НРС-мощности, публичное облако и периферийные ресурсы по всему ЕС. Fact8ra основана на суверенном облачном стеке ИИ, включающем решения OpenNebula, а также другие европейские технологии open source, такие как openSUSE и MariaDB. Поначалу Fact8ra объединит GPU-серверы в восьми странах ЕС: Франции, Германии, Италии, Латвии, Нидерландах, Польше, Испании и Швеции. Отмечается, что Fact8ra способна агрегировать ресурсы поставщиков публичных облачных сервисов, периферийных площадок, суперкомпьютерных центров и финансируемых ЕС фабрик ИИ. В частности, будут объединены мощности Arsys, CloudFerro, IONOS, Leaseweb, OVHcloud, Scaleway, StackScale и Tiscali. Говорится о расширенной поддержке ИИ-ускорителей NVIDIA. 
Источник изображения: OpenNebula Systems Fact8ra поддерживает работу с различными LLM, включая Mistral Nemo 12B, EuroLLM 9B, Salamandra 7B и Italia 9B. Кроме того, реализована интеграция с внешними каталогами ИИ-моделей, в том числе Hugging Face. Поначалу пользователям будут доступны возможности инференса, а затем появятся функции тонкой настройки и обучения моделей ИИ. Fact8ra реализуется как часть программы IPCEI-CIS (Important Project of Common European Interest on Next Generation Cloud Infrastructure and Services) — это европейский проект развития облачной инфраструктуры и услуг следующего поколения. Инициатива стоимостью €3 млрд была одобрена Европейской комиссией в декабре 2023 года. Проект поддерживается 12 государствами-членами ЕС и более чем 120 индустриальными партнёрами. Целями являются стимулирование исследований и увеличение инвестиций в технологии периферийных и облачных вычислений в ЕС, а также создание децентрализованной периферийной инфраструктуры. Ранее в рамках IPCEI-CIS была анонсирована суверенная облачная платформа Virt8ra.
25.07.2025 [09:23], Владимир Мироненко
Импортозамещение по-южнокорейски: LG AI Research выбрала ускорители FuriosaAI RNGD для своих ИИ-серверовКомпания LG AI Research (ИИ-подразделение LG Group) из Южной Кореи заключила соглашение с южнокорейским стартапом FuriosaAI о выпуске серверов с ИИ-ускорителями RNGD для работы с собственным семейством LLM Exaone, сообщил The Register. Как сообщил генеральный директор FuriosaAI Джун Пайк (June Paik) изданию EE Times, серверы LG с чипами RNGD будут ориентированы на предприятия, использующие модели ExaOne в сфере электроники, финансов, телекоммуникаций и биотехнологий. Серверы поступят в продажу в конце этого года. «После тщательного тестирования широкого спектра опций мы пришли к выводу, что RNGD — высокоэффективное решение для развёртывания моделей Exaone», — заявил Киджонг Чон (Kijeong Jeon), руководитель подразделения продуктов LG AI Research. «RNGD обеспечивает убедительное сочетание преимуществ: превосходную производительность в реальных условиях, значительное снижение совокупной стоимости владения и удивительно простую интеграцию», — добавил он. Подобно системам на базе NVIDIA RTX Pro Blackwell, серверы LG RNGD будут включить до восьми ускорителей с интерфейсом PCIe 5.0. Эти системы будут работать на базе того, что FuriosaAI описывает как высокоразвитый программный стек, включающий библиотеку vLLM. LG также предложит собственную платформу агентского ИИ ChatExaone, которая адаптирована для корпоративных сценариев использования. Она объединяет ряд фреймворков для анализа документов, глубоких исследований, анализа данных и RAG. 
Источник изображений: FuriosaAI LG AI Research протестировала работу модели ExaOne-32B на восьмичиповом 4U-сервере c воздушным охлаждением, который был разработан совместно с Supermicro. В 15-кВт стойке можно разместить пять таких серверов. По словам Пайка, LG AI Research протестировала оборудование от нескольких поставщиков оборудования из Южной Кореи и других стран, взяв за основу ускорители NVIDIA A100. «LG AI Research также тестировала облачные решения, но, по их словам, наше решение на данный момент оказалось единственным, отвечающим их требованиям», — сказал Пайк.  Как полагает The Register, выбор для сравнения ускорителя NVIDIA A100, дебютировавшего в 2020 году, а не более свежих моделей, вызван тем, что LG AI Research больше интересует энергоэффективность оборудования, чем производительность. И, как отметил Джун Пайк, хотя за пять лет с момента появления A100 ускорители NVIDIA, безусловно, стали мощнее, но произошло это за счёт увеличения энергопотребления и площади кристалла. 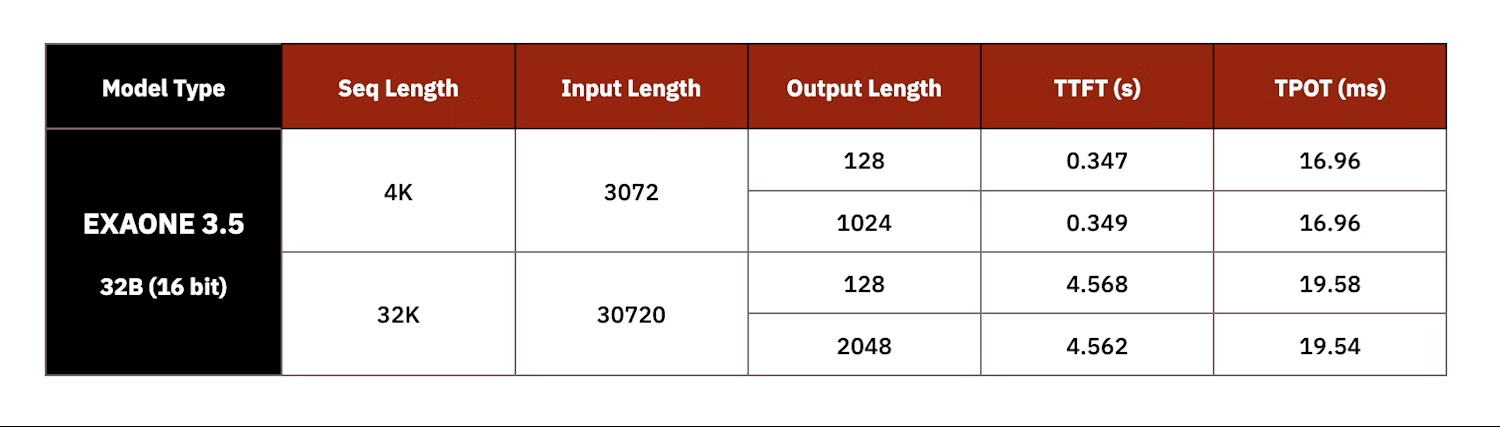 Сообщается, что LG AI фактически использовала четыре PCIe-ускорителя RNGD, задействовав тензорный параллелизм для запуска модели Exaone 32B с 16-бит точностью. По словам Пайка, у LG были очень чёткие целевые показатели производительности, которые она стремилась достичь при валидации чипа. В частности, ограничения включали время до отдачи первого токена (TTFT) — примерно 0,3 с для небольших запросов на 3 тыс. токенов или 4,5 с для более крупных запросов на 30 тыс. токенов. Результат в 60 токенов/с достигается для контекстного окна размером 4 тыс. токенов или 50 токенов/с для контекстного окна размером 32 тыс. токенов.  По словам Пайка, тесты проводились в режиме BF16, поскольку сравниваемые A100 не имеет встроенной поддержки FP8, так что использование RNGD в FP8-режиме позволит удвоить эффективность инференса и снизить TTFT. Кроме того, сервер продемонстрировал в 2,25 раза более высокую производительность инференса LLM на Ватт по сравнению с A100, а полная стойка сможет генерировать в 3,75 раза больше токенов, чем стойка с A100 при том же энергопотреблении. Чип FuriosaAI RNGD обеспечивает производительность 512 Тфлопс (FP8) при TDP 180 Вт. В отличие от ускорителей NVIDIA, оснащённых высокоскоростным интерконнектом NVLink (600 Гбайт/с), FuriosaAI использует интерфейс PCIe 5.0 (128 Гбайт/с). По словам FuriosaAI, чтобы избежать узких мест и накладных расходов, связанных с интерконнектом, компилятор компании помогает оптимизировать процесс обмена данными и собственно вычисления.
24.07.2025 [11:37], Сергей Карасёв
QNAP выпустила ИИ-ускорители для NAS: QAI-M100 и QAI-U100Компания QNAP Systems анонсировала ИИ-ускорители QAI-M100 и QAI-U100, предназначенные для решения различных задач на периферии: это может быть распознавание лиц и объектов, анализ данных в режиме реального времени и пр. Новинки могут использоваться с сетевыми хранилищами QNAP. Изделие QAI-M100 выполнено в форм-факторе M.2 2280 (M+B key) с интерфейсом PCIe 2.0 x1. Задействован процессор Rockchip RK1808 с двумя вычислительными ядрами Arm Cortex-A35, работающими на частоте до 1,6 ГГц. Интегрированный нейропроцессорный блок с поддержкой TensorFlow, Caffe и ONNX обеспечивает производительность до 3 TOPS на операциях INT8. Модуль VPU способен декодировать видеоматериалы H.264 в формате 1080p60 и кодировать 1080p30. Говорится о поддержки памяти LPDDR2/LPDDR3/DDR3/DDR3L/DDR4-800 (в оснащение ускорителя входит 1 Гбайт). В комплект поставки включён тонкий радиатор для рассеяния тепла. В свою очередь, вариант QAI-U100 представляет собой внешний ускоритель в виде USB-брелока с интерфейсом USB 3.2 Gen1. Размеры составляют 92,5 × 29 × 11 мм. Прочие технические характеристики аналогичны устройству типоразмера М.2. 
Источник изображений: QNAP Для работы с новинками требуется NAS под управлением QTS 5.2.1.2930 build 20241025 (или более поздней версией) или QuTS hero h5.2.1.2929 build 20241025 (или выше). Обеспечивается совместимость с софтом QNAP AI Core v3.5.0 (и выше), Multimedia Console v2.7.0 (или более поздними версиями) и QuMagie v1.5.1 (и выше).  Модель QAI-M100 может устанавливать в такие сетевые хранилища QNAP, как TS-435XeU, TS-473A, TS-673A, TS-h765eU и TS-873A. Модификация QAI-U100 может подключаться к различным NAS с количеством отсеков от трёх до 16, включая ТС-332Х, TS-432PXU, TS-432PXU-RP, TS-432X, TS-432XU, TS-432XU-RP, TS-435XeU, TS-473A, TS-632X, TS-673A, TS-h765eU, TS-832PX, TS-832PXU, TS-832PXU-RP, TS-832X, TS-832XU, TS-932PX, TS-932X, TS-h973AX, TS-1232PXU-RP, TS-1232XU, TS-1673AU-RP и др.
23.07.2025 [12:51], Сергей Карасёв
Ускоритель Hailo-10H обеспечивает поддержку генеративного ИИ на периферииКомпания Hailo сообщила о коммерческой доступности изделия Hailo-10H — ИИ-ускорителя второго поколения, ориентированного на работу с генеративными приложениями на периферии. Новинка доступна в виде интегрируемого чипа COB (Chip On Board), а также в виде модулей формата M.2 Key M 2242/2280. По словам компании. при энергопотреблении всего 2,5 Вт новинка способна выдавать более 10 токенов в секунду на моделях с 2 млрд параметров, при этом на отдачу первого токена уходит менее одной секунды. Также чип позволяет детектировать объекты в режиме реального времени в видеопотоке 4K. По заявлениям разработчика, Hailo-10H позволяет использовать большие языковые модели (LLM), визуально-языковые модели (VLM) и другие модели генеративного ИИ локально — без необходимости подключения к облаку. Это выводит ИИ-возможности периферийных устройств на новый уровень. Кроме того, обеспечивается ряд других преимуществ по сравнению с обработкой информации в облаке. В частности, достигается высокий уровень конфиденциальности, поскольку персональные данные не пересылаются на сторонние серверы, а остаются на устройстве. Отпадает также необходимость оплаты облачных вычислительных ресурсов. 
Источник изображений: Hailo Ускоритель Hailo-10H может использоваться в системах с CPU на архитектурах x86 и Arm. Энергопотребление находится на уровне 2,5 Вт. Говорится о совместимости с Linux, Windows и Android, а также с фреймворками TensorFlow, TensorFlow Lite, Keras, PyTorch и ONNX. Изделия в виде модулей М.2 используют интерфейс PCIe 3.0 x4. Объём встроенной памяти LPDDR4/4X составляет 4 или 8 Гбайт. Предусмотрены индустриальный и автомобильный варианты исполнения: в первом случае диапазон рабочих температур простирается от -40 до +85 °C, во втором — от -40 до +105 °C.  Производительность Hailo-10H достигает 40 TOPS в режиме INT4 и 20 TOPS в режиме INT8. Ускоритель полностью совместим с программным стеком Hailo. Среди ключевых сфер применения новинки названы автомобилестроение, телекоммуникации, розничная торговля, информационная безопасность, персональные компьютеры и пр.
19.07.2025 [13:46], Сергей Карасёв
Rockchip анонсировала ИИ-ускоритель RK182X с архитектурой RISC-VКомпания Rockchip, по сообщению ресурса CNX Software, представила в Китае ИИ-ускоритель RK182X, предназначенный для работы с большими языковыми моделями (LLM) и визуально-языковыми моделями (VLM) на периферии. Новинка ориентирована на совместное использование с другими SoC Rockchip. Изделие получило многоядерную архитектуру RISC-V (точное количество ядер пока не раскрывается). В зависимости от модификации задействованы 2,5 или 5 Гбайт памяти DRAM со «сверхвысокой пропускной способностью» (ПСП тоже не раскрывается). Реализована поддержка интерфейсов PCIe 2.0, USB 3.0 и Ethernet. По заявлениям Rockchip, ИИ-ускоритель RK182X способен обрабатывать LLM/VLM, насчитывающие до 7 млрд параметров. В частности, таким моделям требуется примерно 3,5 Гбайт памяти при использовании режимов INT4/FP4. Говорится о совместимости с фреймворками PyTorch, ONNX и TensorFlow, а также форматом HuggingFace GGUF (GPT-Generated Unified Format). 
Источник изображений: CNX Software ИИ-ускоритель спроектирован для применения в связке с такими процессорами Rockchip, как RK3576/RK3588 и другими, вероятно, включая решения RK3668 и RK3688, которые были также представлены вчера. Эти чипы содержат собственный интегрированный NPU-модуль с производительностью 6 TOPS или более для обработки ИИ-нагрузок. 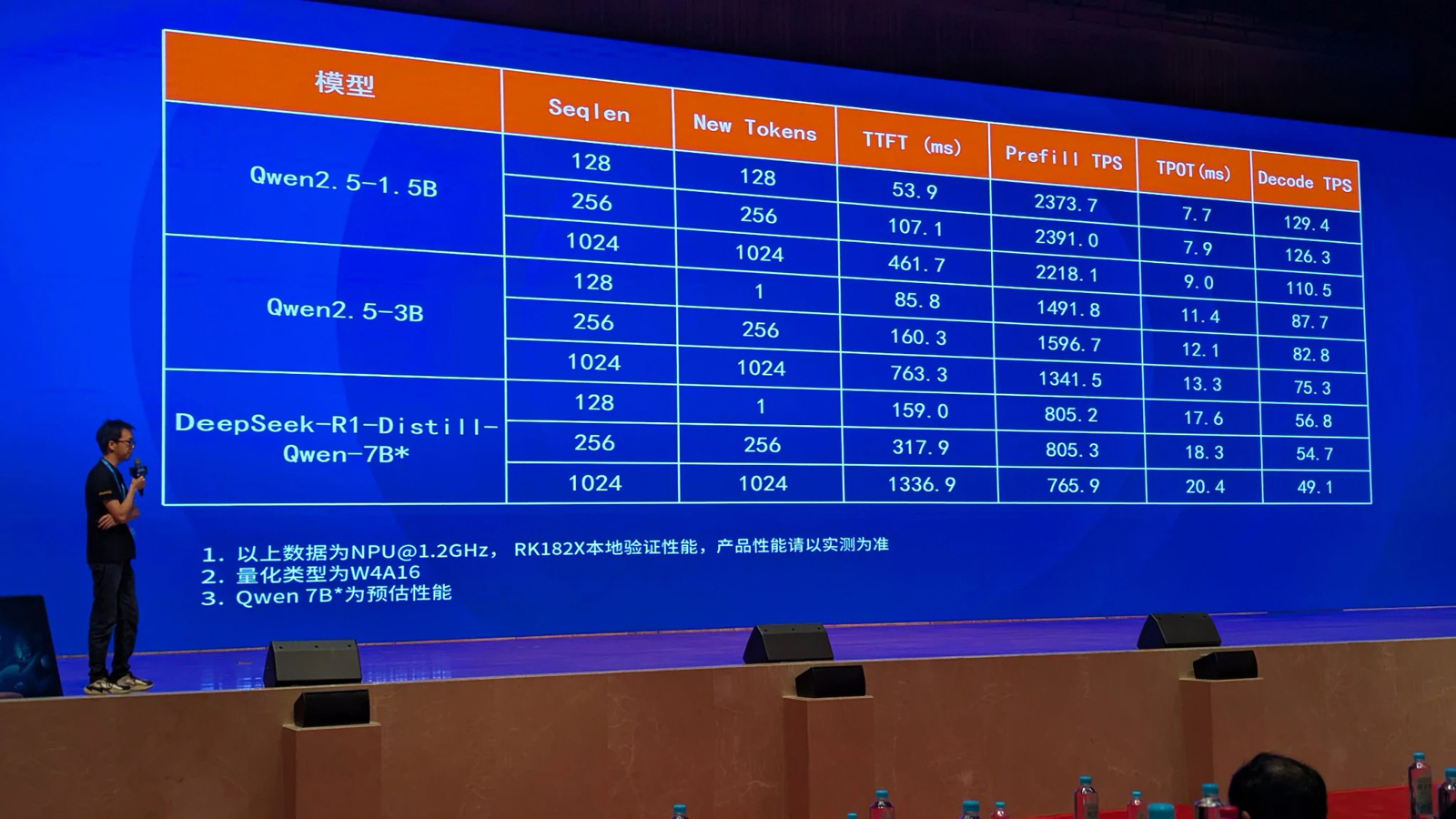 Однако благодаря применению отдельного ускорителя ИИ-быстродействие на определённых задачах может быть повышено в 8–10 раз. Rockchip, в частности, обнародовала скоростные показатели RK182X для таких популярных моделей, как DeepSeek-R1-Distill-Qwen-7B, Qwen2.5-1.5B и Qwen2.5-3B.
13.07.2025 [10:57], Сергей Карасёв
CoreWeave запустила первые общедоступные инстансы на базе NVIDIA RTX Pro 6000 Blackwell Server EditionОператор ИИ-облака CoreWeave объявил о запуске инстансов с ускорителями NVIDIA RTX Pro 6000 Blackwell Server Edition для генеративных приложений, рендеринга в реальном времени и работы с большими языковыми моделями (LLM). Утверждается, что это первые общедоступные облачные экземпляры, построенные на базе названных GPU. Изделия RTX Pro 6000 Blackwell Server Edition на архитектуре Blackwell насчитывают 24 064 ядра CUDA, 752 тензорных ядра пятого поколения и 188 ядер RT четвёртого поколения. В оснащение входят 96 Гбайт памяти GDDR7 с пропускной способностью до 1,6 Тбайт/с. CoreWeave заявляет, что по сравнению с инстансами на основе NVIDIA L40S новые экземпляры обеспечивают 5,6-кратное повышение производительности при LLM-инференсе, 3,5-кратное увеличение быстродействия на операциях преобразования текста в видео и более чем 2-кратное повышение скорости тонкой настройки ИИ-моделей. Заявленная ИИ-производительность в режиме FP4 достигает 3,8 Пфлопс. 
Источник изображения: CoreWeave / NVIDIA Инстансы CoreWeave с ускорителями NVIDIA RTX Pro 6000 Blackwell Server Edition доступны в конфигурациях, насчитывающих до восьми GPU. Задействованы два процессора Intel Xeon поколения Emerald Rapids, а также DPU NVIDIA BlueField-3. Экземпляры предоставляют свыше 7 Тбайт пространства для хранения данных на основе NVMe SSD. Говорится о поддержке служб CoreWeave Observability Services, которые отвечают за детальный мониторинг использования ресурсов, а также предоставляют данные о системных ошибках, температуре и пр. Это помогает быстро обнаруживать и устранять проблемы, минимизируя сбои в рабочих процессах. Новые инстансы доступны посредством CoreWeave Kubernetes Service (CKS) и Slurm on Kubernetes (SUNK) в американском регионе CoreWeave US-EAST-04.
09.07.2025 [16:30], Руслан Авдеев
SambaManaged превратит почти любой ЦОД в ИИ ЦОД всего за три месяцаРазработчик ИИ-ускорителей SambaNova анонсировал решение SambaManaged на базе SN40L. Это первый в отрасли продукт, оптимизированный для инференса, внедрить который можно всего за 90 дней — намного быстрее, чем обычно требуется для систем такого уровня (18–24 мес.), говорит компания. Модульная платформа разработана специально для быстрого развёртывания и позволяет существующим дата-центрам почти немедленно организовать ИИ-инференс с минимальными модификациями инфраструктуры. По мере того, как стремительно растёт спрос на ИИ-задачи, связанные именно с инференсом, традиционные дата-центры сталкиваются с новыми проблемами — на внедрение систем, оптимизированных для таких задач, требуется от полутора до двух лет, много энергии, а также дорогостоящие обновления оборудования. Решение SambaManaged позволяет устранить эти барьеры, быстро развернув прибыльные инференс-сервисы, используя уже имеющуюся силовую и сетевую инфраструктуру. 
Источник изображений: SambaNova SambaManged формируется из стоек SambaRack SN40L-16, каждая из которых включает 16 ускорителей (RDU в терминологии SambaNova) SN40L с BF16-производительностью 10,2 Тфлопс. Платформа оснащена двумя 64-ядерными хост-процессорами, 2 Тбайт DDR4, четырьмя загрузочными 960-Гбайт SSD (RAID1 + два hot-spare) и шестью 7,6-Тбайт NVMe SSD в RAID10 для данных. Энергопотребление составляет всего 7–14,5 кВт (типовое 10 кВт). Стойка весит 485 кг. Рабочая температура — от +15 до +30 °C. Фактически это переименованная платформа DataScale SN40L, только теперь разработчик не говорит о возможности обучения моделей. Как подчёркивают в SambaNova, дата-центры сталкиваются с проблемами энергоснабжения и охлаждения, недостатком компетенций и др. на фоне роста спроса на ИИ. Система SambaManaged обеспечивает высокую ИИ-производительность при низком энергопотреблении и минимальных изменениях инфраструктуры. Преимуществами для ЦОД и облачных провайдеров называются рекордная производительность на каждый затраченный Вт, позволяющая снизить совокупную стоимость владения (TCO) и быстрее вернуть инвестиции. Систему можно внедрить всего за 90 дней. При этом обеспечивается невероятно быстрый инференс с ведущими open source моделями, что позволяет избежать привязки к конкретному вендору и гарантирует совместимость с будущими технологиями. Модульный дизайн позволяет быстро строить даже большие инференс-системы, включая т.н. Token Factory мощностью до 1 МВт (100 стоек). Систему можно масштабировать по мере изменения бизнес-потребностей. Можно выбрать полностью управляемое решение или взять на себя часть контроля за операциями.  SambaManaged уже внедряется крупной публичной компанией в США, потребляющей немало энергии. Платформа обеспечивает максимальную пропускную способность для моделей вроде DeepSeek и ей подобных, помогая клиентам увеличивать доход от инференса и оптимизировать энергоэффективность (PUE). В SambaNova заявляют, что SambaManaged меняет правила игры для организаций, желающих ускорить реализацию ИИ-проектов без ущерба скорости, масштабу или эффективности. Везде, где есть доступ к Сети и электроэнергии, можно обеспечить необходимую инфраструктуру в рекордные сроки. В конце июня 2025 года сообщалось, что SambaNova делает ставку на инференс и партнёрство с облачными провайдерами и госзаказчиками из США. Groq, ещё один поставщик решений для инференса, первым сменил бизнес-подход, отказавшись от продажи ускорителей в пользу формирования целых ИИ ЦОД. Cerebras совместно с партнёрами также создаёт крупные ИИ-суперкомпьютеры и кластеры. |
|