Материалы по тегу: инференс
|
13.10.2025 [12:14], Сергей Карасёв
IBM представила ускоритель Spyre Accelerator для ИИ-инференсаКорпорация IBM объявила о том, что с конца текущего месяца специализированные ИИ-ускорители Spyre Accelerator станут доступны в составе серверов z17 и LinuxONE 5. А в начале декабря такими картами начнут комплектоваться системы POWER11. О подготовке Spyre Accelerator стало известно в августе прошлого года. Это детище исследовательского подразделения IBM Research. Ускоритель ориентирован на задачи инференса с низкой задержкой. В частности, устройство подходит для работы с генеративными приложениями и ИИ-агентами. 
Источник изображения: IBM Изделие представляет собой плату расширения с интерфейсом PCIe 5.0 x16, в состав которой входит нейропроцессор IBM с 32 ядрами. Кроме того, есть 128 Гбайт памяти LPDDR5. Ускоритель насчитывает в общей сложности 25,6 млрд транзисторов; при производстве применяется 5-нм технология. Заявленное энергопотребление находится на уровне 75 Вт. 
Источник изображения: IBM IBM отмечает, что при использовании традиционных CPU и GPU для решения ресурсоёмких задач в области ИИ возникают сложности с масштабированием и эффективностью. Изделия Spyre Accelerator проектировались с тем, чтобы помочь в устранении указанных недостатков. При необходимости можно объединить до 16 плат в кластер в системе POWER11 и до 48 плат в составе z17. Вкупе с процессорами Telum II, которые лежат в основе z17 и LinuxONE 5, компании смогут одновременно запускать несколько ИИ-моделей. При этом возможен локальный инференс, что минимизирует обращения к сторонним сервисам: это сокращает задержки и способствует повышению безопасности. В качестве потенциальных заказчиков Spyre Accelerator называются финансовые организации, предприятия розничной торговли, государственные структуры, учреждения из сферы здравоохранения, промышленные предприятия и пр.
13.10.2025 [00:30], Владимир Мироненко
Вложи $5 млн — получи $75 млн: NVIDIA похвасталась новыми рекордами в комплексном бенчмарке InferenceMAX v1
b200
gb200
hardware
nvidia
open source
semianalysis
бенчмарк
ии
инференс
рекорд
финансы
энергоэффективность
NVIDIA сообщила о результатах, показанных суперускорителем GB200 NVL72, в новом независимом ИИ-бенчмарке InferenceMAX v1 от SemiAnalysis. InferenceMAX оценивает реальные затраты на ИИ-вычисления, определяя совокупную стоимость владения (TCO) в долларах на миллион токенов для различных сценариев, включая покупку и владение GPU в сравнении с их арендой. InferenceMAX опирается на инференс популярных моделей на ведущих платформах, измеряя его производительность для широкого спектра вариантов использования, а результаты может перепроверить любой желающий, говорят авторы бенчмарка. Суперускоритель GB200 NVL72 победил во всех категориях бенчмарка InferenceMAX v1. Чипы NVIDIA Blackwell показали наилучшую окупаемость инвестиций — вложение в размере $5 млн приносят $75 млн дохода от токенов DeepSeek R1, обеспечивая 15-кратную окупаемость (год назад NVIDIA обещала ROI на уровне 700 %). Также ускорители поколения Blackwell отличаются самой низкой совокупной стоимостью владения. например, оптимизация ПО NVIDIA B200 позволила добиться стоимости всего в два цента на миллион токенов на OpenAI gpt-oss-120b, обеспечив пятикратное снижение стоимости одного токена всего за два месяца. NVIDIA B200 первенствовал и по пропускной способности и интерактивности, обеспечив 60 тыс. токенов в секунду на ускоритель и 1 тыс. токенов в секунду на пользователя в gpt-oss с новейшим стеком NVIDIA TensorRT-LLM. NVIDIA сообщила, что постоянно повышает производительность путём оптимизации аппаратного и программного стека. Первоначальная производительность gpt-oss-120b на системе NVIDIA DGX Blackwell B200 с библиотекой NVIDIA TensorRT LLM уже была лидирующей на рынке, но команды NVIDIA и сообщество разработчиков значительно оптимизировали TensorRT LLM для ускорения исполнения открытых больших языковых моделей (LLM). 
Источник изображений: NVIDIA Компания отметила, что выпуск TensorRT LLM v1.0 стал значительным прорывом в повышении скорости инференса LLM благодаря распараллеливанию и оптимизации IO-операций. А у недавно вышедшей модели gpt-oss-120b-Eagle3-v2 используется спекулятивное декодирование — интеллектуальный метод, позволяющий предсказывать несколько токенов одновременно. Это уменьшает задержку и обеспечивает получение ещё более быстрых результатов — пропускная способность выросла втрое, до 100 токенов в секунду на пользователя (TPS/пользователь), а общая производительность на ускоритель выросла с 6 до 30 тыс. токенов. 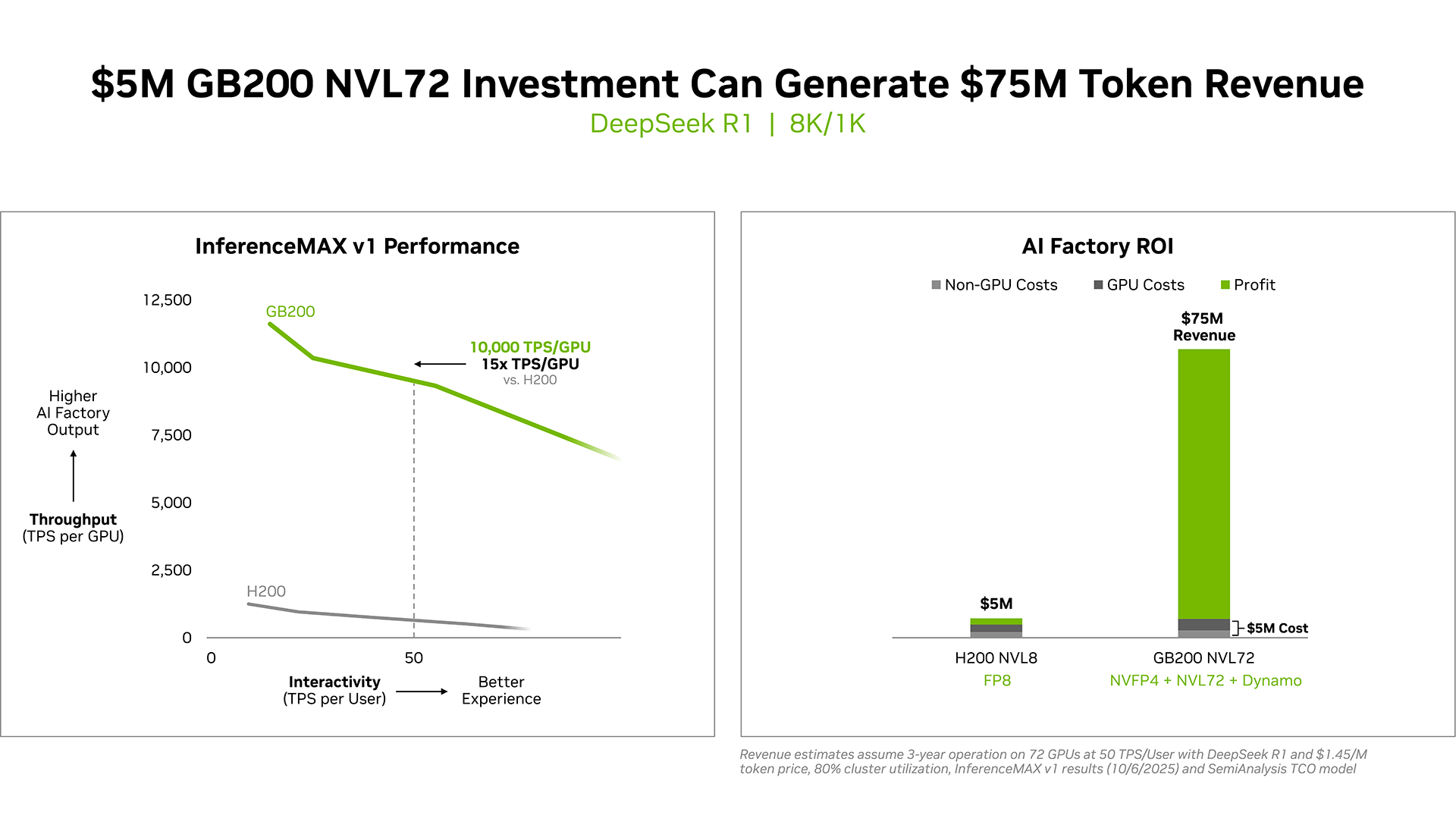 Для моделей с «плотной» архитектурой (Dense AI), таких как Llama 3.3 70b, которые требуют значительных вычислительных ресурсов из-за большого количества параметров и одновременного использования всех параметров в процессе инференса, NVIDIA Blackwell B200 достиг нового рубежа производительности в бенчмарке InferenceMAX v1, отметила NVIDIA. Суперускоритель показал более 10 тыс. токенов/с (TPS) на GPU при 50 TPS на пользователя, т.е. вчетверо более высокую пропускную способность на GPU по сравнению с NVIDIA H200. 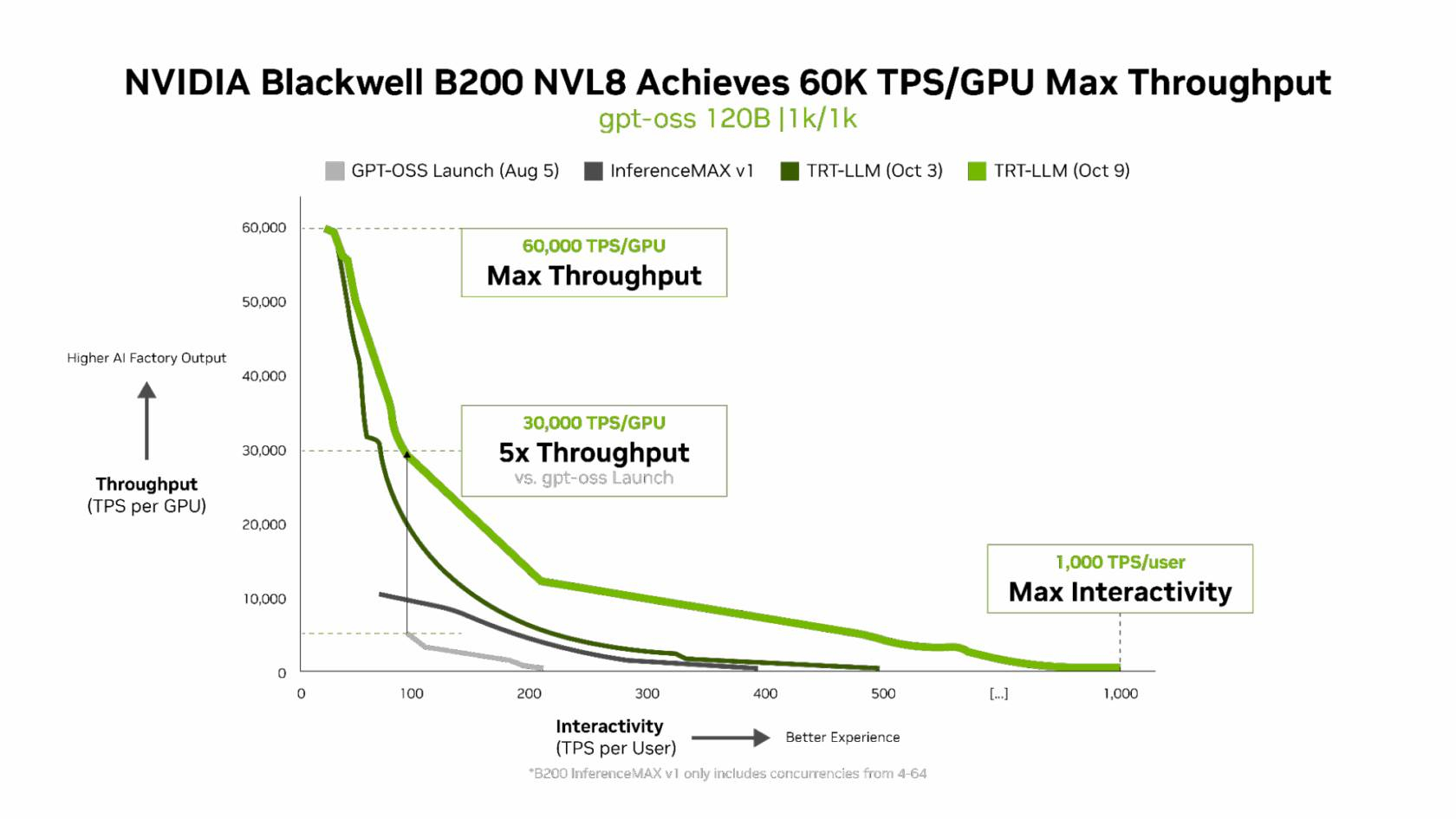 NVIDIA подчеркнула, что такие показатели, как количество токенов на Вт, стоимость на миллион токенов и TPS/пользователь не уступают по важности пропускной способности. Фактически, для ИИ-фабрик с ограниченной мощностью ускорители с архитектурой Blackwell обеспечивают до 10 раз лучшую производительность на МВт по сравнению с предыдущим поколением и позволяют получать более высокий доход от токенов. 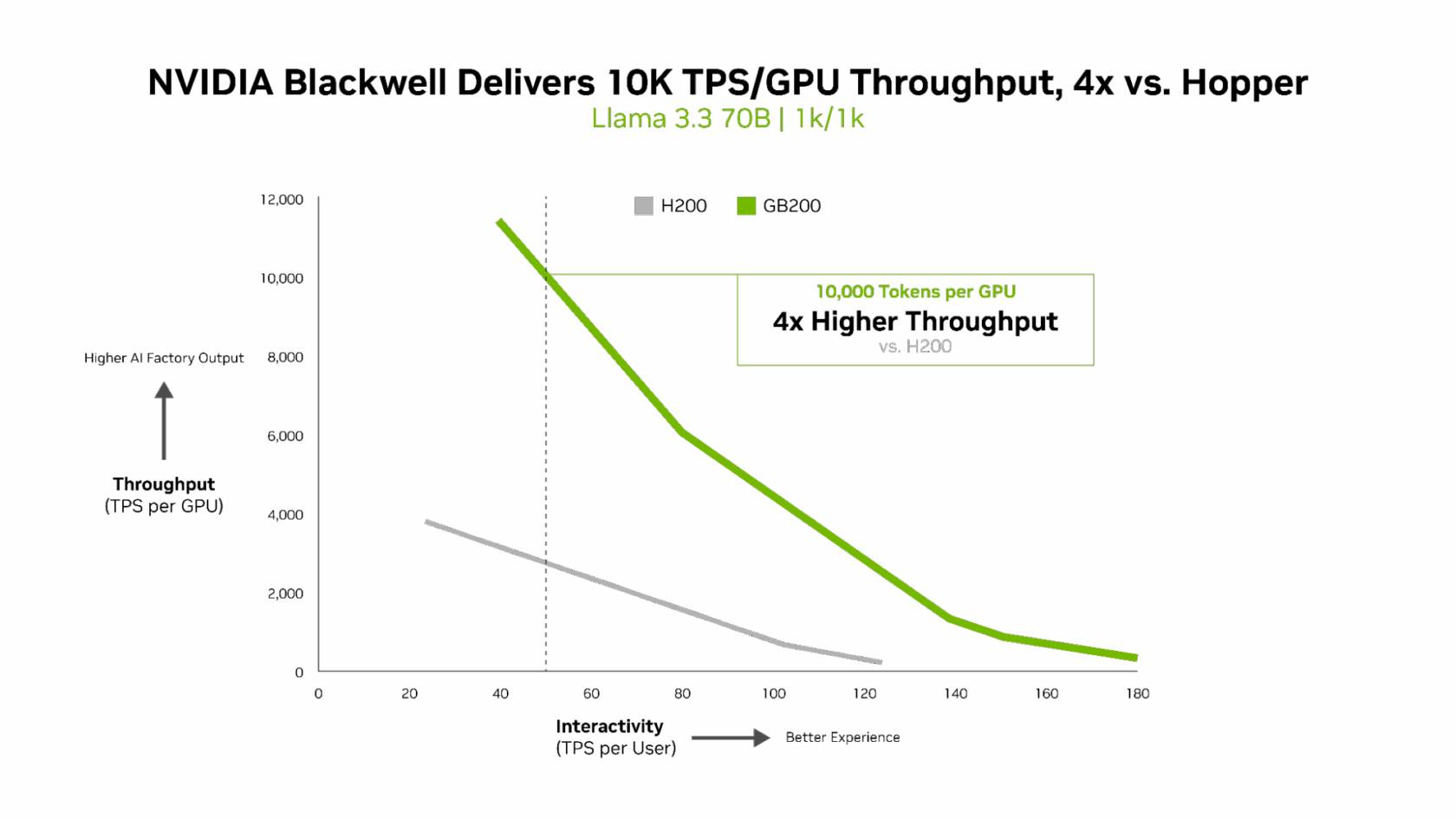 Компания отметила, что стоимость обработки одного токена (Cost per Token) имеет решающее значение для оценки эффективности ИИ-модели и напрямую влияет на эксплуатационные расходы. NVIDIA утверждает, что в целом архитектура NVIDIA Blackwell позволила снизить стоимость обработки миллиона токенов в 15 раз по сравнению с предыдущим поколением. 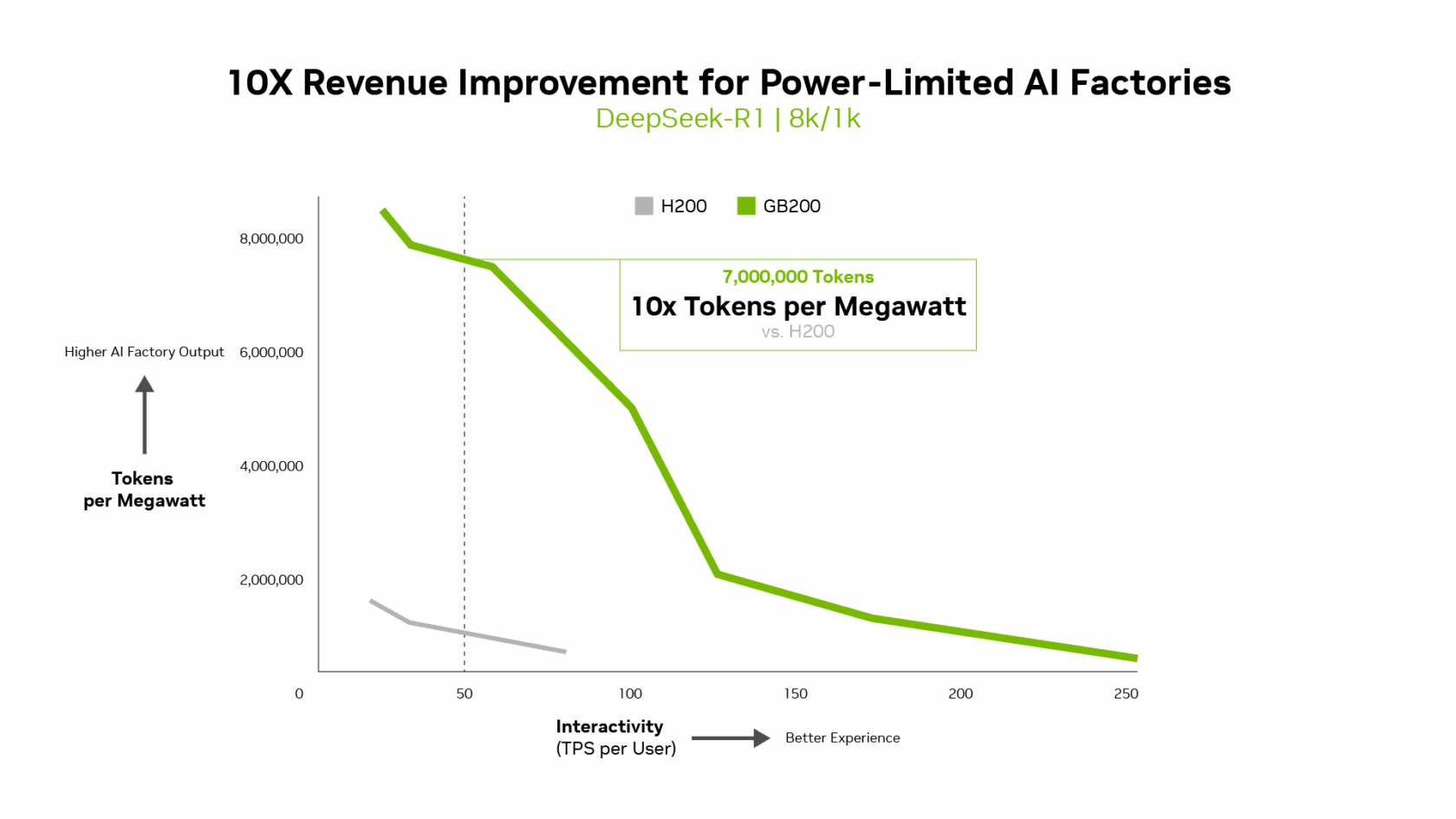 В InferenceMAX используется метод оценки эффективности Pareto front, определяющий наилучшее (компромиссное) сочетание различных факторов для оценки производительности ускорителя. Это показывает, насколько Blackwell лучше конкурентов справляется с балансом стоимости, энергоэффективности, пропускной способности и скорости отклика. Системы, оптимизированные только для одной метрики, могут демонстрировать пиковую производительность «в вакууме», но такая «экономика» не масштабируется в производственных средах. 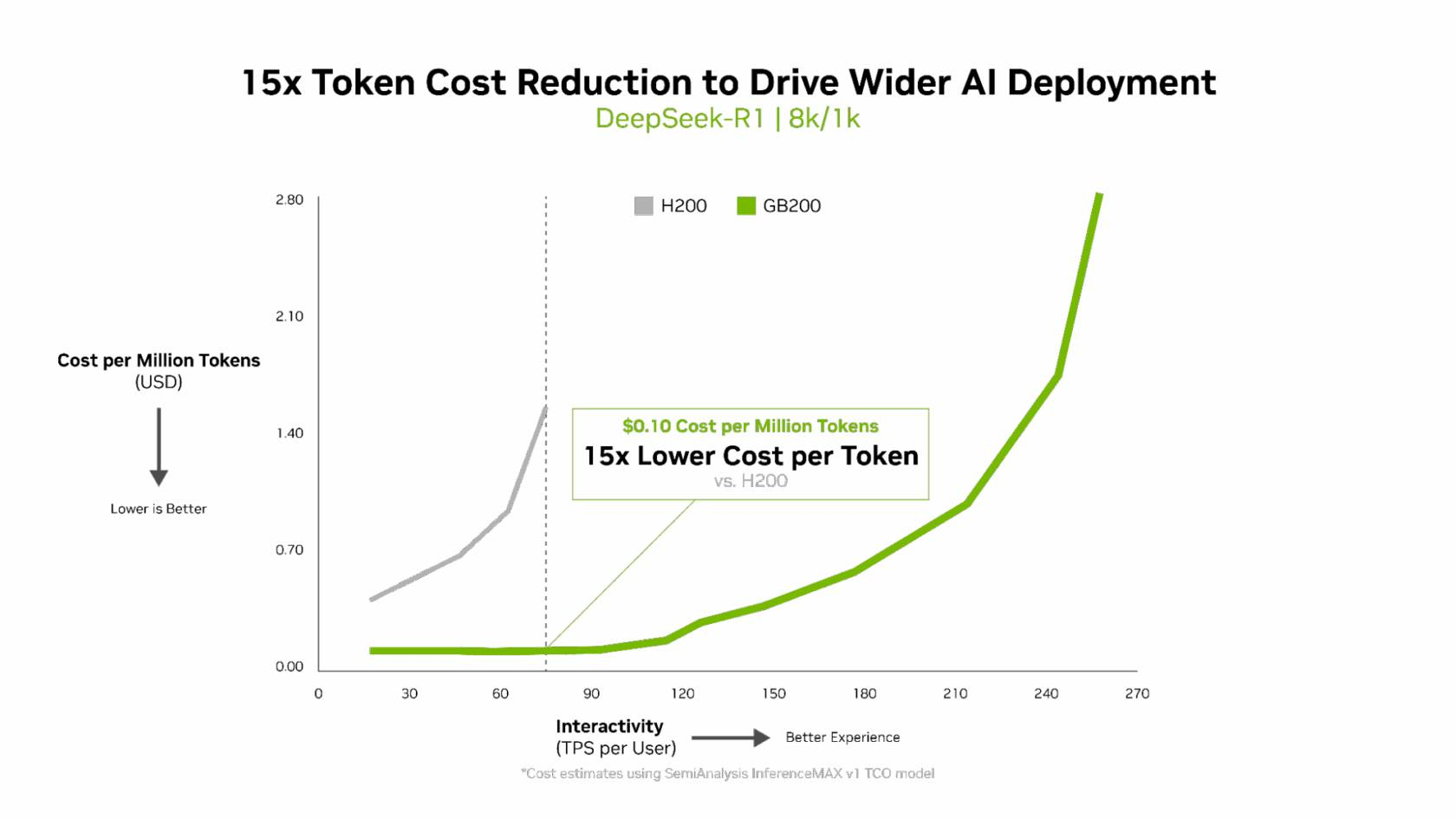 Компания отметила, что ИИ переходит от экспериментальных пилотных проектов к ИИ-фабрикам — инфраструктуре, которая производит интеллектуальные решения, преобразуя данные в токены и решения в режиме реального времени. Фреймворк NVIDIA Think SMART помогает предприятиям ориентироваться в этом переходе, демонстрируя, как полнофункциональная платформа инференса обеспечивает измеримую окупаемость инвестиций. Обещая 15-кратную окупаемость инвестиций и непрерывный рост производительности за счёт ПО, NVIDIA не просто лидирует в текущей гонке ИИ-технологий, но и задаёт правила для следующего этапа, где экономика будет определять победителей рынка, пишет The Tech Buzz. Для предприятий, делающих ставку на конкурирующие платформы в своих стратегиях по развёртыванию ИИ, результаты таких бенчмарков должны побудить к пересмотру выбора ИИ-инфраструктуры.
10.10.2025 [10:11], Сергей Карасёв
Intel готовит новый GPU-ускоритель, оптимизированный для инференсаКорпорация Intel в ходе мероприятия Intel Tech Tour Arizona сообщила о подготовке новых ИИ-ускорителей на базе GPU. Речь идёт об изделиях, специально оптимизированных для задач инференса. Кроме того, компания поделилась планами по развитию ИИ-продуктов в целом. Ранее предполагалось, что в 2025 году Intel выведет на рынок ускорители Falcon Shores. Изначально планировалось, что это будут гибридные решения, содержащие блоки CPU и GPU. Однако впоследствии Intel сделала выбор в пользу конфигурации исключительно на основе GPU. А затем корпорация и вовсе заявила, что на коммерческом рынке изделия Falcon Shores не появятся. Вместо этого Intel решила сфокусировать внимание на выпуске ускорителей Jaguar Shores. Войдёт ли готовящийся к выпуску GPU для инференса в семейство Jaguar Shores, пока не ясно. Подробности о новинке Intel обещает раскрыть в ходе предстоящего мероприятия 2025 OCP Global Summit, которое пройдёт с 13 по 16 октября в Сан-Хосе (Калифорния, США). На сегодняшний день известно, что устройство получит улучшенную память с высокой пропускной способностью. Изделие будет ориентировано на корпоративный сектор. 
Источник изображения: Intel «Мы активно работаем над оптимизированным для инференса GPU, о котором подробнее расскажем на конференции OCP», — сообщил технический директор Intel Сачин Катти (Sachin Katti). Кроме того, Intel объявила о намерении перейти на ежегодный график выпуска ИИ-продуктов следующего поколения. Предполагается, что это поможет укрепить позиции на глобальном рынке ИИ, на котором корпорация уступила позиции NVIDIA. При этом Intel подчёркивает, что на ближайшую перспективу Jaguar Shores является основным приоритетом в области развития высокопроизводительных решений для ИИ-инфраструктуры.
02.10.2025 [13:10], Руслан Авдеев
Meta✴ приобрела Rivos, разработчика RISC-V-ускорителей, совместимых с CUDAMeta✴ Platforms приобрела занимающийся разработкой ИИ-чипов на базе RISC-V стартап Rivos. Это должно ускорить разработку собственных полупроводников и снизить зависимость от сторонних поставщиков, сообщает Silicon Angle. Условия покупки пока неизвестны, но ключевой инвестор стартапа, Walden Catalyst, с гордостью сообщил о сделке, а нынешний генеральный директор Intel Лип-Бу Тан (Lip-Bu Tan), имевший прямое отношение к созданию и развитию стартапа, поздравил команду. Стартап был основан в 2021 году, а в 2023-м к нему присоединились около полусотни бывших инженеров Apple. Meta✴ будет использовать опыт Rivos для расширения работ над семейством собственных ИИ-ускорителей Meta✴ Training and Inference Accelerator (MTIA). Впрочем, Rivos использовала комплексный подход, разрабатывая CPU и GPUGPU-чипы с кеш-когерентностью и унифицированным доступом к памяти (DDR и HBM), дополненные интегрированным 800G-интерконнектом на базе Ultra Ethernet. Это похоже на подход NVIDIA при создании суперускорителей. В 2025 году Rivos выпустила на TSMC тестовый чип, работающий на частоте 3,1 ГГц и программный стек, совместимый с NVIDIA CUDA. Изначальная стратегия предполагала создание энергоэффективного ИИ-ускорителя с частотой до 3,5 ГГц, совместимого с существующей экосистемой, который планировалось продавать гиперскейлерам (хотя бы одному). Первую коммерческую платформу компания собиралась выпустить в следующем году, она позволила бы перекомпилировать, а не переписывать с нуля приложения, созданные для платформ NVIDIA. Компания также принимала участие в создании RISC-V RVA23 Profile. 
Источник изображения: Rivos Хотя Meta✴ не раскрыла стоимость сделки, вероятно, речь идёт о миллиардных тратах. В августе сообщалось, что стартап вёл переговоры с инвесторами о возможном раунде финансирования в объёме $300–$400 млн, а то и $500 млн, что повысило бы оценку стоимости компании до более чем $2 млрд. ИИ-проекты Meta✴ полагаются преимущественно на сторонние аппаратные решения. Компания потратила миллиарды долларов на покупку ускорителей, в основном NVIDIA, и потратит ещё миллиарды на аренду ИИ-инфраструктуры у сторонних игроков. В частности, буквально на днях она подписала новую сделку с CoreWeave на $14,2 млрд. В этом году капзатраты могут достигнуть $72 млрд, а выпуск собственных чипов позволил бы компании сэкономить миллиарды долларов, снизив зависимость от NVIDIA и облачных операторов. 
Источник изображения: Rivos По словам Constellation Research, Meta✴ является единственным крупным ИИ-предприятием, почти полностью зависящим от инфраструктурных решений NVIDIA. Имеются данные, что компания уже взаимодействовала с Rivos некоторое время, поэтому и решила приобрести стартап целиком. Если инициатива увенчается успехом, это поможет Meta✴ снизить расходы как на обучение, так и на инференс. Также сообщается, что Meta✴ работает с TSMC над выпуском своего нового чипа, и уже отправила на производство необходимую документацию для выпуска пробных образцов для оценки их эффективности.
29.09.2025 [17:53], Владимир Мироненко
Euclyd разрабатывает ИИ-ускоритель Craftwerk с фирменной памятью UBM: 1 Тбайт и 8 Пбайт/сСтартап Euclyd, вышедший из скрытого режима (stealth mode), рассказал на саммите AI Infra Summit некоторые подробности о разрабатываемом чипе, который обеспечит более низкое энергопотребление и более низкую стоимость в расчёте на токен по сравнению с существующими решениями, пишет ресурс EE Times. Сама компания называет его первым в мире «кремнием» для агентного ИИ. Ингольф Хелд (Ingolf Held), соучредитель и вице-президент по продуктам Euclyd, сообщил ресурсу EE Times, что чип представляет собой огромную конструкцию из множества чиплетов, объединённых в модуль SiP (System-in-Package) под названием Craftwerk. Он будет включать 16 384 SIMD-блоков и обеспечивать производительность до 8 Пфлопс (FP16) или 32 Пфлопс (FP4). Эти вычислительные элементы разработаны Euclyd с нуля. В устройстве будет использоваться кремниевый интерпозер с максимально крупными размерами (примерно 100 × 100 мм) с 2,5D- и 3D-компонентами. 
Источник изображений: Euclyd «Мы разработаем его сами — мы не будем наследовать ничего от Arm или RISC-V, и он будет полностью программируемым с помощью наших собственных инструментов», — сказал он. По словам Хелда, дизайн будет поддерживать программируемость, чтобы гарантировать возможность ускорения будущих нагрузок, будь то мультимодальный инференс, логические рассуждения, рекуррентные модели, модели пространства состояний или диффузионные модели. Euclyd объединит вычислительные чиплеты с кастомной памятью Ultra Bandwidth Memory (UBM) — 1 Тбайт DRAM с пропускной способностью 8000 Тбайт/с в той же упаковке Craftwerk. По словам Хелда, ИИ-ускорители со SRAM работают быстро, но при их использовании приходится разделять обработку ИИ-нагрузки между множеством чипов из-за малого объёма такой памяти. HBM имеет достаточную ёмкость, но её пропускная способность мала для решения задач, поставленных Euclyd. И хотя UBM от Euclyd отличается кастомным дизайном, для её изготовления не потребуется какой-то экзотический технологический процесс. Craftwerk позволит реализовать многоагентные рабочие процессы на одном кристалле кремния с TDP в пределах 3 кВт, отметил Хелд. По словам компании, NVIDIA DGX-B200 может обрабатывать 1038 токенов/с для одного пользователя Llama4-Maverick (400B), Cerebras предлагает 2554 токена/с для одного пользователя, а один SiP Craftwerk будет обрабатывать 20 тыс. токенов/с для одного пользователя. Стойка Euclyd будет включать 16 хост-процессоров и 32 модуля Craftwerk в шасси с жидкостным охлаждением с общим TDP 125 кВт. По оценкам Euclyd, в типичном многопользовательском сценарии эта система будет предлагать 7,68 млн токенов/с для Llama4-Maverick. 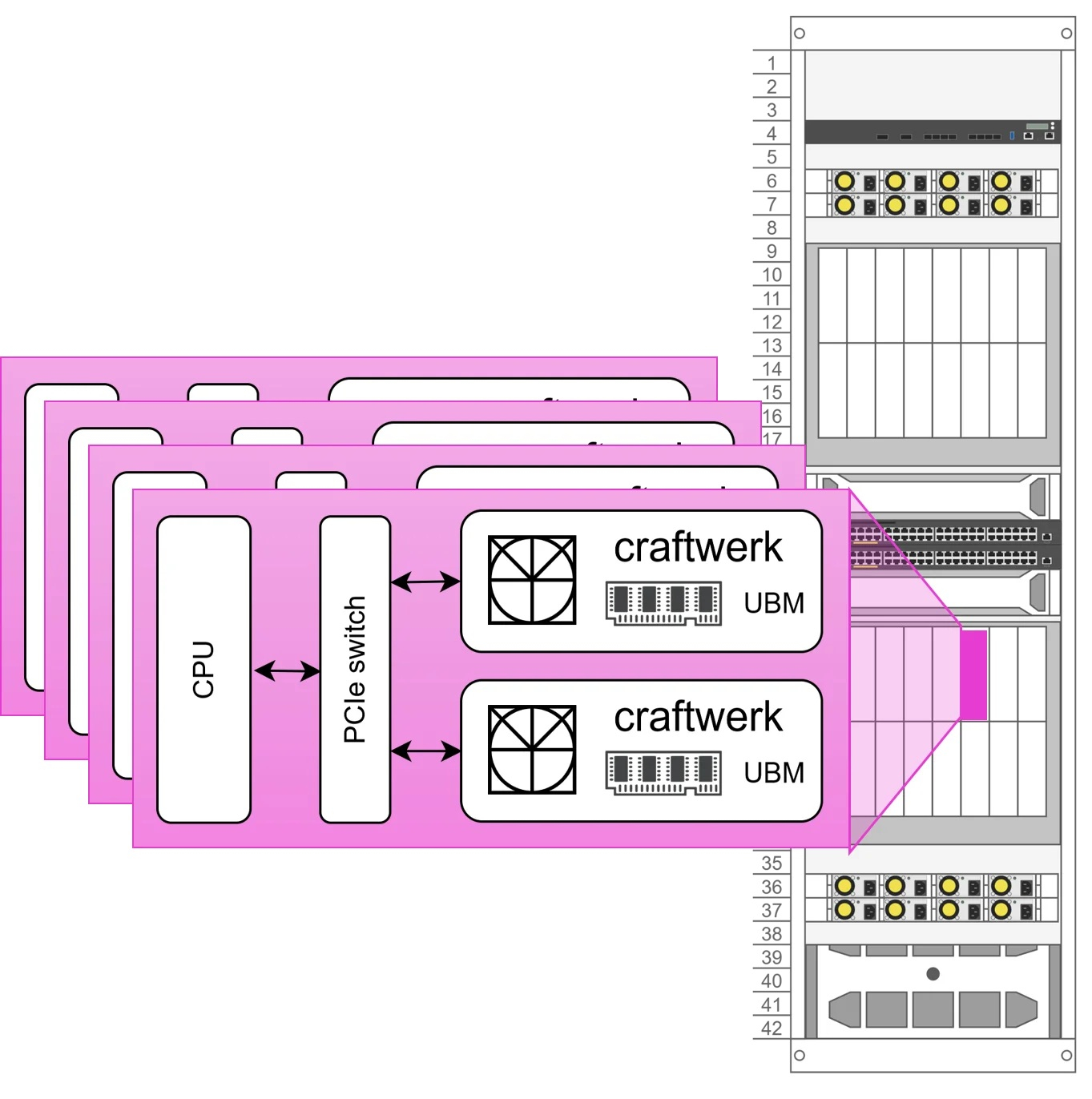 На данный момент у Euclyd три частных инвестора: Питер Веннинк (Peter Wennink, бывший генеральный директор ASML), Федерико Фаггин (Federico Faggin, один из изобретателей микропроцессора и основатель Zilog и Synaptics) и Стивен Шурман (Steven Schuurman, основатель Elastic). В ближайшее время компания планирует привлечь венчурный капитал для запуска производства и масштабирования, но, по словам Хелда, посевного финансирования должно быть достаточно для демонстрации работоспособности кремниевых чипов. Сооснователь и консультант Euclyd Атул Синха (Atul Sinha) заявил EE Times, что Европа лучшее место для талантливых дизайнеров, чем Кремниевая долина. Он подтвердил, что Euclyd планирует оставаться в юрисдикции Нидерландов со штаб-квартирой ИТ-кампусе Эйндховена, где также находится штаб-квартира NXP. «Чего люди не понимают, так это то, что в Европе есть места, где действительно есть значительный набор технологий и кадровая база, — сказал Синха. — Для полупроводников Эйндховен, безусловно, на первом месте. Я бы сказал, что лучше места нет».
26.09.2025 [11:35], Сергей Карасёв
Стартап FuriosaAI представил ИИ-сервер NXT RNGD с производительностью 4 ПфлопсЮжнокорейский стартап FuriosaAI анонсировал высокопроизводительный сервер NXT RNGD для ресурсоёмких нагрузок ИИ. Утверждается, что в сценариях частного облака и локальных дата-центров новинка обеспечивает большую эффективность и меньшую стоимость владения по сравнению с решениями, оборудованными ускорителями на базе GPU. Система NXT RNGD заключена в корпус форм-фактора 4U. Она оснащена восемью специализированными ускорителями RNGD, которые выполнены в виде карт расширения PCIe 5.0 x16. Каждая из карт располагает 48 Гбайт памяти HBM3 с пропускной способностью до 1,5 Тбайт/с и 256 Мбайт памяти SRAM (384 Тбайт/с). Таким образом, суммарный объём памяти HBM3 составляет 384 Гбайт. 
Источник изображения: FuriosaAI Ускорители RNGD обладают ИИ-производительностью до 512 Тфлопс в режиме FP8 и до 512 TOPS в режиме INT8. Таким образом, сервер NXT RNGD демонстрирует показатели до 4 Пфлопс и 4 тыс. TOPS соответственно. При этом общая потребляемая мощность составляет 3 кВт против 10,2 кВт у NVIDIA DGX H100. Таким образом, как отмечает FuriosaAI, стандартная серверная стойка мощностью 15 кВт способна вместить до пяти систем NXT RNGD, в то время как в случае NVIDIA DGX H100 может поддерживаться работа только одной машины. Среди других преимуществ платформы NXT RNGD разработчик называет простоту и удобство развёртывания в любом месте (в том числе с ограничениями по доступной мощности), суверенитет данных (подходит для приложений с обработкой конфиденциальной информации), гибкость в плане новых вариантов использования (доступен комплект SDK) и существенное снижение совокупной стоимости владения. В настоящее время сервер предлагается для тестирования клиентам по всему миру. Приём заказов на NXT RNGD начнётся в 2026 году.
23.09.2025 [15:49], Руслан Авдеев
За ИИ в дальнюю дорогу: Китай строит собственный децентрализованный вариант StargateКитай строит крупный кластер ЦОД на острове в городе Уху (Wuhu) на реке Янцзы в рамках проекта, который уже называют «китайским Stargate». Впрочем, по масштабам с оригинальным Stargate он пока не сопоставим, сообщает The Financial Times. Кластер в Уху — лишь часть более масштабного плана Пекина по укреплению своих позиций в качестве ИИ-сверхдержавы. Новый шаг сделан в ответ на усилия США по сохранению лидерства в сфере ИИ. По оценкам Epoch AI, на Америку сегодня приходится до ¾ мировых вычислительных мощностей, на Китай — пока лишь 15 %. В марте Пекин представил план, согласно которому в отдалённых от побережья западных регионах будут сосредоточены ЦОД, специализирующиеся на обучении ИИ-моделей — они не требуют столь малого времени отклика, как ЦОД для инференса, которые строятся ближе к ключевым населённым пунктам. Одним из примеров последних стал «остров данных» (Data Island) в Уху для четырёх ИИ ЦОД компаний Huawei, China Telecom, China Unicom и China Mobile, которые будут обслуживать богатые города в дельте Янцзы: Шанхай, Ханчжоу, Нанкин и Сучжоу. 
Источник изображения: Ryan Moulton/unsplash.com Всего в Уху построили ЦОД 15 компаний, общий объём инвестиций составил ¥270 млрд юаней ($37 млрд). Местное правительство предлагает субсидии, покрывающие до 30 % затрат на ИИ-чипы, в других регионах субсидии значительно скромнее. ЦОД в Уланчаб во Внутренней Монголии будет обслуживать Пекин и Тяньцзинь, ЦОД в Гуйчжоу будут обеспечивать сервисами Гуанчжоу, а Цинъян в Ганьсу будет обслуживать Чэнду и Чунцин. Оптимизация работы ЦОД призвана компенсировать невыгодное положение КНР в сравнении с США, на руку которым играет и жёсткий экспортный контроль, не позволяющий Китаю закупать передовые ИИ-ускорители и связанное оборудование. Китайским производителям вроде Huawei и Cambricon нелегко заполнить пустующую нишу, в том числе из-за ограниченных производственных мощностей в КНР. Китайским ЦОД приходится полагаться на менее производительные отечественные решения или закупать чипы на чёрном рынке — в КНР уже имеется сеть посредников, скрытно импортирующих решения NVIDIA. Один из поставщиков — базирующаяся в Уху компания Gate of the Era, закупающая партии серверов с ускорителями Blackwell для китайских ЦОД. Не так давно стало известно о гигантском ИИ ЦОД для 115 тыс. ускорителей NVIDIA, расположенном на окраине пустыни Гоби в Синьцзяне. В самой NVIDIA утверждают, что контрабанда ускорителей обречена на провал с технической и экономической точки зрения. 
Источник изображения: Nuno Alberto/unsplash.сom Инициатива East Data, West Computing, которая предполагала строительство ЦОД в богатых энергоресурсами отдалённых провинциях вроде Ганьсу и Внутренней Монголии, оказалась не вполне успешной. Недостаток технических компетенций и локального спроса, а также дороговизна каналов связи до востока страны привли к тому, что эти ИИ ЦОД не используются на полную мощность, а то и вовсе проставивают. Во многих случаях закупка чипов субсидировалась местными властями, которые не горят желанием отдавать ускорители кому-то ещё. Поэтому Пекин рассчитывает использовать сетевые технологии China Telecom и Huawei для объединения мощностей разрозненных ускорителей на разных объектах, создав децентрализованный вычислительный кластер. Китайские телеком-гиганты применяют сетевое оборудование для «трансляции» вычислительных мощностей с запада на восток страны. Тем не менее, эксперты DC Byte считают, что использование множества небольших ЦОД менее эффективно, чем одного нового крупного дата-центра.
12.09.2025 [23:07], Владимир Мироненко
Intel Arc Pro впервые поучаствовали в бенчмарках MLPerf Inference, но в лидерах предсказуемо осталась NVIDIAMLCommons объявил результаты набора бенчмарков MLPerf Inference v5.1. Последний раунд демонстрирует, насколько быстро развивается инференс и соответствующие бенчмарки, пишет ресурс HPCwire. В этом раунде было рекордное количество заявок — 27. Представлены результаты сразу пяти новых ускорителей: AMD Instinct MI355X, Intel Arc Pro B60 48GB Turbo, NVIDIA GB300, NVIDIA RTX 4000 Ada 20GB, NVIDIA RTX Pro 6000 Blackwell Server Edition. Всего же количество результатов MLPerf перевалило за 90 тыс. результатов. В текущем раунде были представлены три новых бенчмарка: тест рассуждений на основе модели DeepSeek-R1, тест преобразования речи в текст на основе Whisper Large v3 и небольшой тест LLM на основе Llama 3.1 8B. Как отметил ресурс IEEE Spectrum, бенчмарк на основе модели Deepseek R1 671B (671 млрд параметров), более чем в 1,5 раза превышает самый крупный бенчмарк предыдущего раунда на основе Llama 3.1 405B. В модели Deepseek R1, ориентированной на рассуждения, большая часть вычислений выполняется во время инференса, что делает этот бенчмарк ещё более сложным. Что касается самого маленького бенчмарка, основанного на Llama 3.1 8B, то, как поясняют в MLCommons, в отрасли растёт спрос на рассуждения с малой задержкой и высокой точностью. SLM отвечают этим требованиям и являются отличным выбором для таких задач, как реферирование текста или периферийные приложения. В свою очередь бенчмарк преобразования голоса в текст, основанный на Whisper Large v3, был разработан в ответ на растущее количество голосовых приложений, будь то смарт-устройства или голосовые ИИ-интерфейсы. 
Источник изображения: NVIDIA NVIDIA вновь возглавила рейтинг MLPerf Inference, на этот раз с архитектурой Blackwell Ultra, представленной платформой NVIDIA GB300 NVL72, которая установила рекорд, увеличив пропускную способность DeepSeek-R1 на 45 % по сравнению с предыдущими системами GB200 NVL72 (Blackwell). NVIDIA также продемонстрировала высокие результаты в бенчмарке Llama 3.1 405B, который имеет более жёсткие ограничения по задержке. NVIDIA применила дезагрегацию, разделив фазы работы с контекстом и собственно генерацию между разными ускорителями. Этот подход, поддерживаемый фреймворком Dynamo, обеспечил увеличение в 1,5 раза пропускной способности на один ускоритель по сравнению с традиционным обслуживанием на системах Blackwell и более чем в 5 раз по сравнению с системами на базе Hopper. 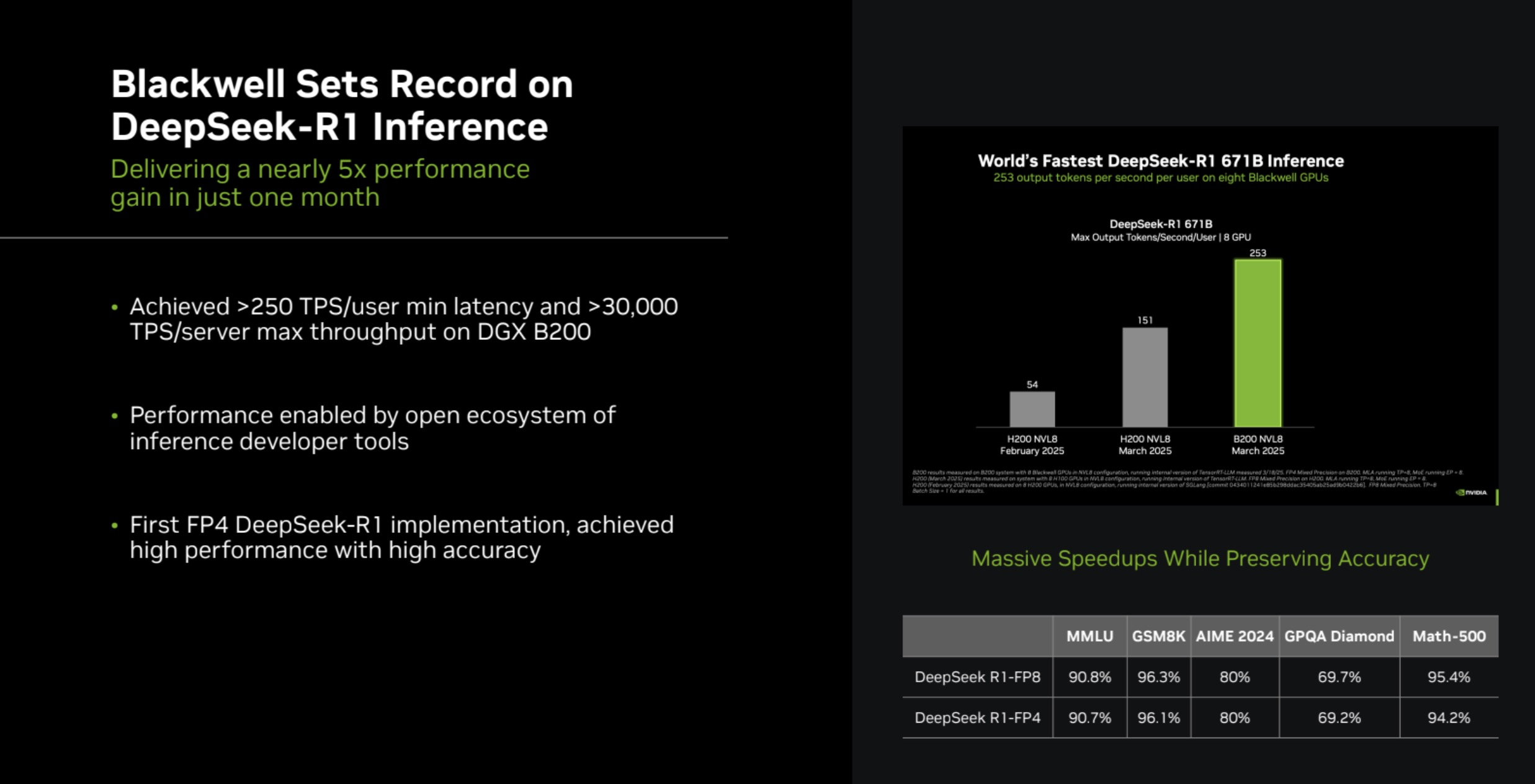
Источник изображения: NVIDIA NVIDIA назвала «дезагрегированное обслуживание» одним из ключевых факторов успеха, помимо аппаратных улучшений при переходе к Blackwell Ultra. Также свою роль сыграло использованием фирменного 4-бит формата NVFP4. «Мы можем обеспечить точность, сопоставимую с BF16», — сообщила компания, добавив, что при этом потребляется значительно меньше вычислительной мощности. Для работы с контекстом NVIDIA готовит соускоритель Rubin CPX. В более компактных бенчмарках решения NVIDIA также продемонстрировали рекордную пропускную способность. Компания сообщила о более чем 18 тыс. токенов/с на один ускоритель в бенчмарке Llama 3.1 8B в автономном режиме и 5667 токенов/с на один ускоритель в Whisper. Результаты были представлены в офлайн-, серверных и интерактивных сценариях, при этом NVIDIA сохранила лидерство в расчете на GPU во всех категориях. 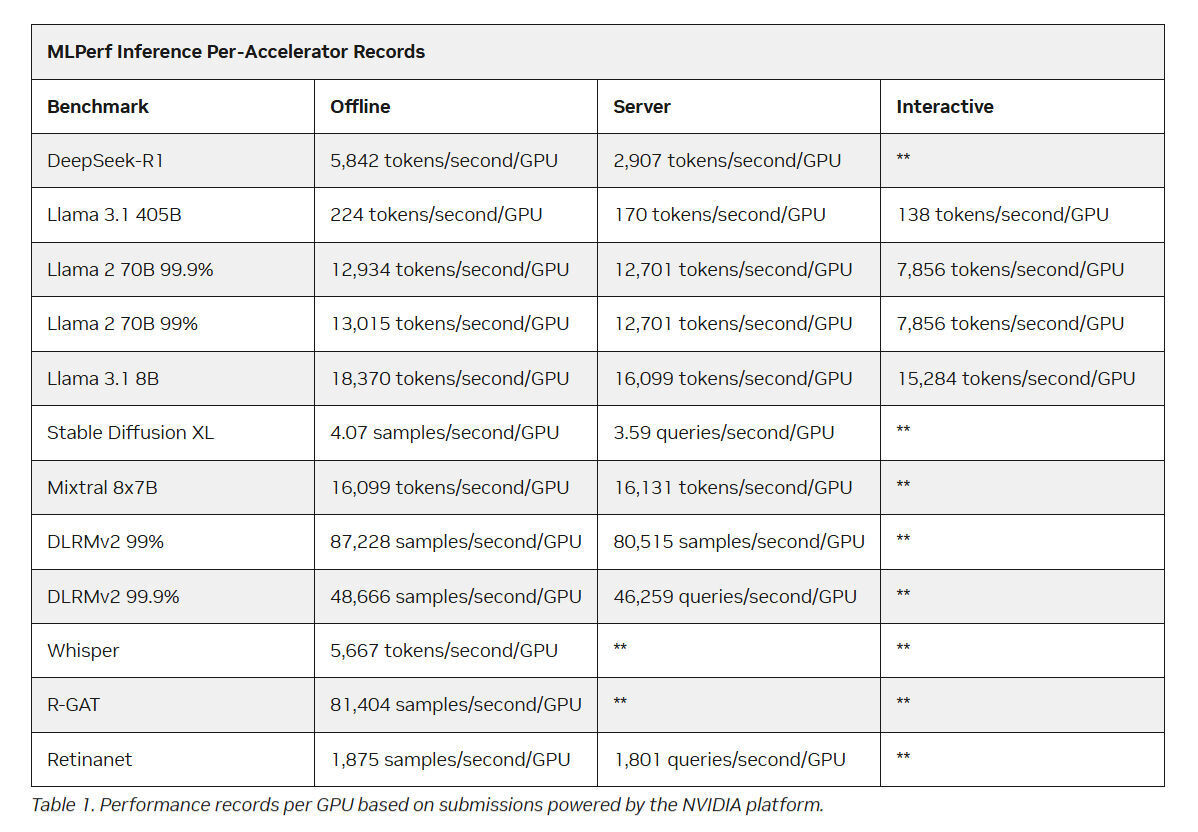
Источник изображения: NVIDIA/TechPowerUp AMD представила результаты AMD Instinct MI355X только в «открытой» категории, где разрешены программные модификации модели. Ускоритель MI355X превзошёл в бенчмарке Llama 2 70B ускоритель MI325X в 2,7 раза по количеству токенов/с. В этом раунде AMD также впервые обнародовала результаты нескольких новых рабочих нагрузок, включая Llama 2 70B Interactive, MoE-модель Mixtral-8x7B и генератор изображений Stable Diffusion XL. 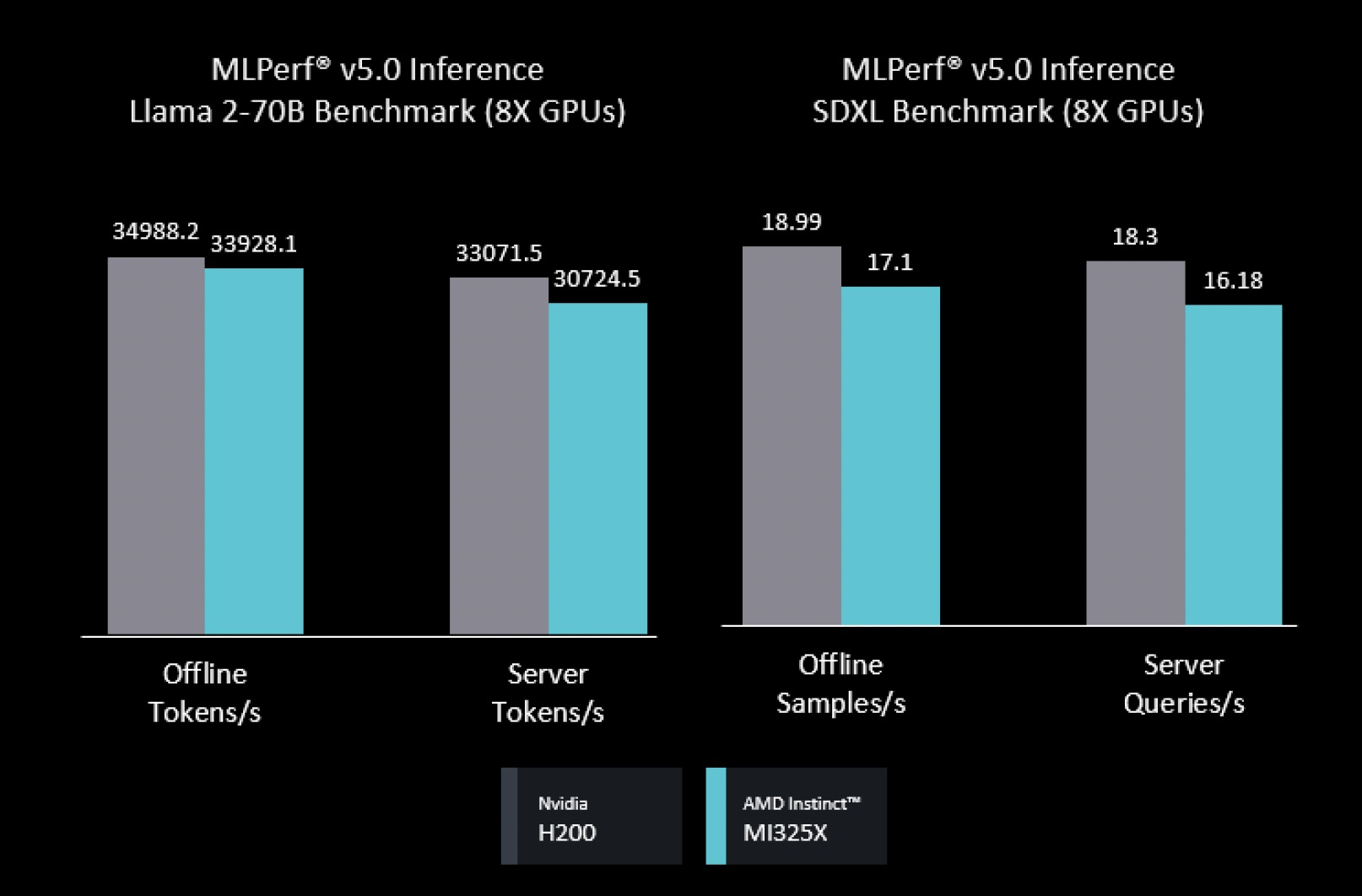
Источник изображения: AMD/ServeTheHome В число «закрытых» заявок AMD входили системы на базе ускорителей AMD MI300X и MI325X. Более продвинутый MI325X показал результаты, схожие с показателями систем на базе NVIDIA H200 на Llama 2 70b, в комбинированном тесте MoE и тестах генерации изображений. Кроме того, компанией была представлена первая гибридная заявка, в которой ускорители AMD MI300X и MI325X использовались для одной и той же задачи инференса — бенчмарка на базе Llama 2 70b. Возможность распределения нагрузки между различными типами ускорителей — важный шаг, отметил IEEE Spectrum. В этом раунде впервые был представлен и ускоритель Intel Arc Pro. Для бенчмарков использовалась видеокарта MaxSun Intel Arc Pro B60 Dual 48G Turbo, состоящая из двух GPU с 48 Гбайт памяти, в составе платформы Project Battlematrix, которая может включать до восьми таких ускорителей. Система показала результаты на уровне NVIDIA L40S в небольшом тесте LLM и уступила ему в тесте Llama 2 70b. 
Источник изображения: Intel Следует также отметить, что в этом раунде, как и в предыдущем, участвовала Nebius (ранее Yandex N.V.). Компания отметила, что результаты, полученные на односерверных инсталляциях, подтверждают, что Nebius AI Cloud обеспечивает «высочайшие» показатели производительности для инференса базовых моделей, таких как Llama 2 70B и Llama 3.1 405B. В частности, Nebius AI Cloud установила новый рекорд производительности для NVIDIA GB200 NVL72. По сравнению с лучшими результатами предыдущего раунда, её однохостовая инсталляция показала прирост производительности на 6,7 % и 14,2 % при работе с Llama 3.1 405B в автономном и серверном режимах соответственно. «Эти два показателя также обеспечивают Nebius первое место среди других разработчиков MLPerf Inference v5.1 для этой модели в системах GB200», — сообщила компания.
10.09.2025 [13:35], Сергей Карасёв
NVIDIA представила соускоритель Rubin CPX со 128 Гбайт GDDR7 для масштабных задач ИИ-инференсаNVIDIA неожиданно анонсировала чип Rubin CPX — GPU нового класса, спроектированный для масштабных задач ИИ-инференса и работы с моделями, использующими длинный контекст. Поставки решения планируется организовать в конце 2026 года. Чип Rubin CPX выполнен в виде монолитного кристалла и оснащён 128 Гбайт памяти GDDR7. Заявленная ИИ-производительность достигает 30 Пфлопс в режиме NVFP4. Предусмотрены по четыре блока NVENC и NVDEC для кодирования и декодирования видеоматериалов. Новинка дополнит другие ускорители компании. Оркестрацией нагрузок будет заниматься платформа NVIDIA Dynamo, распределяющая нагрузки между подходящими для каждой задачи ускорителями. 
Источник изображений: NVIDIA Изделие Rubin CPX предназначено для использования вместе с Arm-процессорами Vera и ускорителями Rubin в составе новой стоечной платформы NVIDIA Vera Rubin NVL144 CPX. Эта система будет объединять 144 чипа Rubin CPX, 144 чипа Rubin и 36 процессоров Vera (88 кастомных 3-нм Arm-ядер). Говорится об использовании суммарно 100 Тбайт памяти с агрегированной пропускной способностью 1,7 Пбайт/с. Общая производительность на операциях NVFP4 — до 8 Эфлопс, что примерно в 7,5 раза больше по сравнению с системами NVIDIA GB300 NVL72. Задействована система жидкостного охлаждения. Кроме того, NVIDIA планирует выпуск двухстоечного решения, включающего стойку Vera Rubin NVL144 CPX и «обычную» стойку Vera Rubin NVL144.  «Платформа Vera Rubin ознаменует собой новый скачок производительности в области вычислений ИИ, предлагая как GPU следующего поколения Rubin, так и чип нового класса CPX. Это первый CUDA GPU, специально разработанный для ИИ с длинным контекстом, когда модели одновременно обрабатывают миллионы токенов», — отмечает Дженсен Хуанг (Jensen Huang), основатель и генеральный директор NVIDIA. 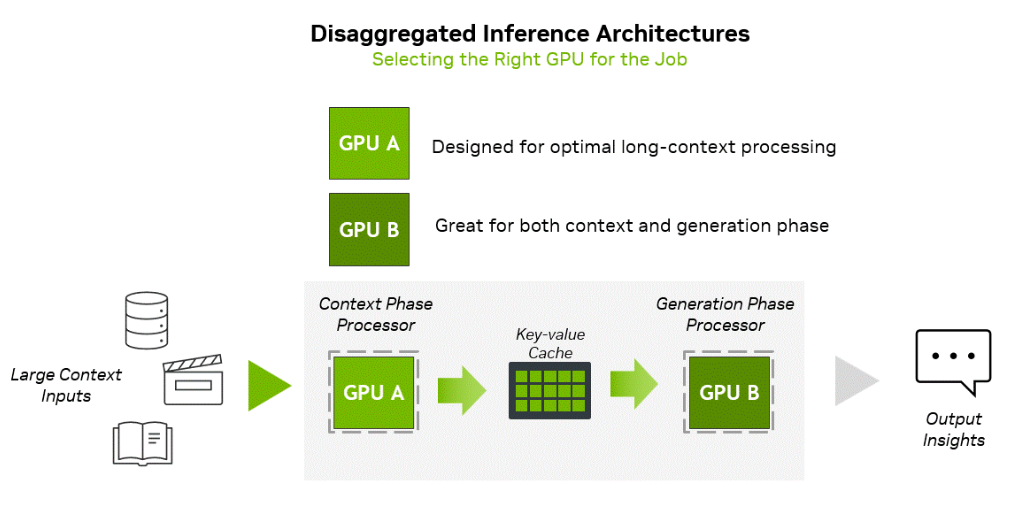 Основная задача Rubin CPX — работа с контекстом в больших моделях и создание KV-кеша. Эта операция ограничена вычислительными способностями чипа, тогда как генерация токенов зависит уже от пропускной способности памяти и интерконнекта для быстрого обмена данными. NVIDIA предложила разделить эти этапы и на аппаратном уровне. CPX лишён HBM, зато операции возведения в степень он делает втрое быстрее, чем Blackwell Ultra.
09.09.2025 [15:46], Сергей Карасёв
d-Matrix представила 400GbE-адаптер JetStream для объединения своих ИИ-ускорителейСтартап d-Matrix анонсировал специализированную IO-карту JetStream, предназначенную для распределения нагрузок ИИ-инференса между серверами в дата-центре. Устройство ориентировано на использование в связке с ускорителями d-Matrix Corsair, архитектура которых основана на модифицированных ячейках SRAM для вычислений в памяти (DIMC). JetStream использует стандарт Ethernet, благодаря чему обладает совместимостью с уже существующими коммутаторами. Новинка выполнена в виде платы расширения с интерфейсом PCIe 5.0 х16. Используются корзины QSFP-DD. Могут быть задействованы два 200GbE-порта со скоростью 200 Гбит/с или один 400GbE-порт. Архитектура серверов d-Matrix для ИИ-инференса предполагает установку ускорителей Corsair с DMX-мостом между каждыми двумя такими картами для обеспечения высокой пропускной способности без использования PCIe. Затем пары ускорителей объединяются посредством коммутатора PCIe. В эталонном дизайне один NIC JetStream обслуживает до четырёх экземпляров Corsair. d-Matrix утверждает, что сетевую задержку в такой конфигурации удалось сократить до 2 мкс. 
Источник изображений: d-Matrix По заявлениям d-Matrix, карты JetStream могут применяться в существующих ЦОД без необходимости замены дорогостоящих инфраструктурных компонентов. В связке с ИИ-ускорителями Corsair и ПО d-Matrix Aviator решения JetStream способны справляться с ИИ-моделями, насчитывающими более 100 млрд параметров. При этом, как утверждает разработчик, обеспечивается в 10 раз более высокая производительность, в три раза лучшая экономическая эффективность и втрое большая энергоэффективность по сравнению с решениями на базе GPU. 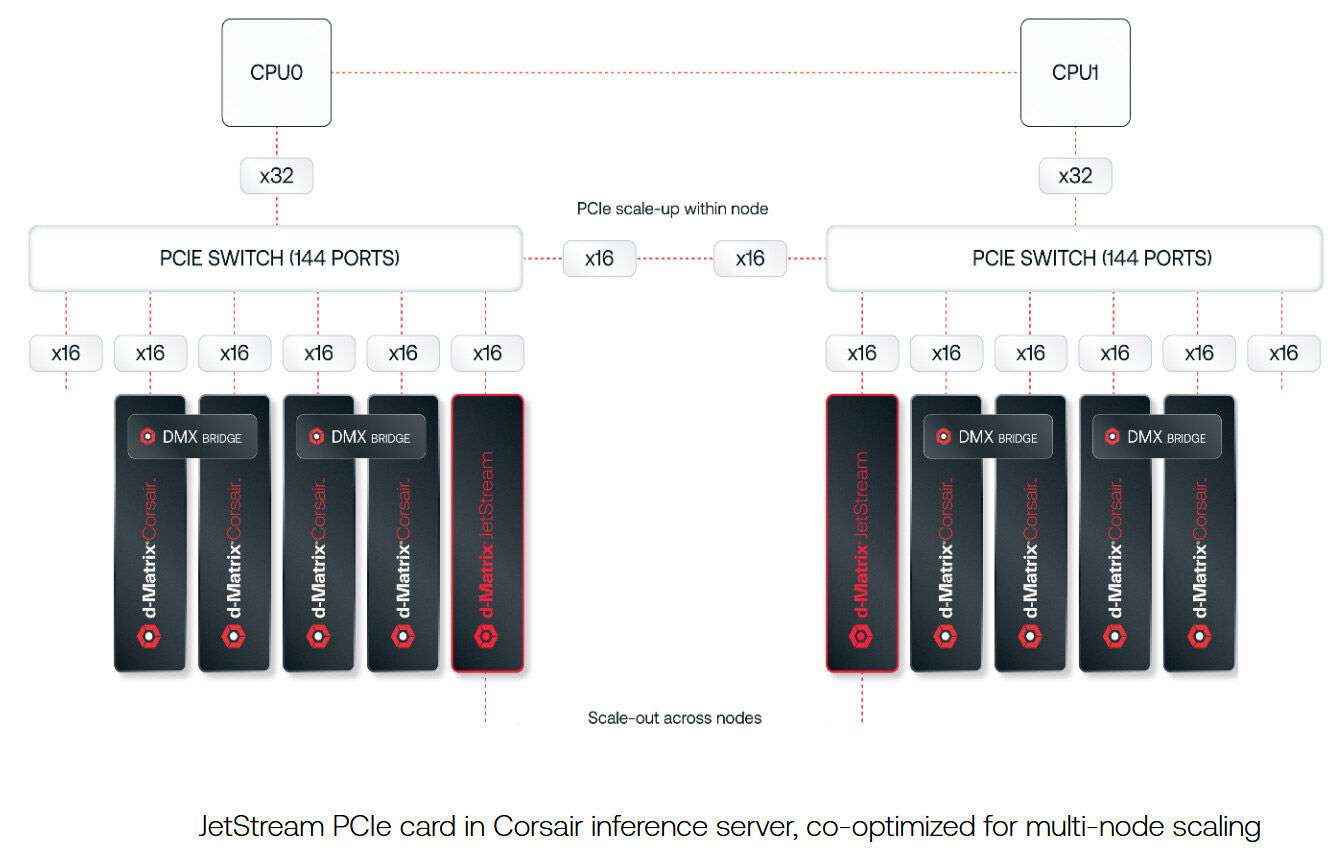 Энергопотребление JetStream составляет около 150 Вт. Адаптер оснащён системой охлаждения с радиатором и тепловыми трубками, которые охватывают зону QSFP-DD. Пробные поставки новинки уже начались, а массовое производство запланировано на конец текущего года. |
|