Материалы по тегу: инференс
|
01.12.2023 [23:19], Алексей Степин
Broadcom представила первый сетевой коммутатор со встроенным ИИ-движкомКомпания Broadcom представила Trident 5-X12 — первый сетевой коммутатор, снабжённый ИИ-движком, который поможет избавиться от сетевых заторов и ускорить обучение ИИ. Новый сетевой процессор относится к семейству StrataXGS и имеет маркировку BCM78800. Он предназначен в первую очередь для компактных ToR-коммутаторов нового поколения. Это первый сетевой ASIC, дополненный инференс-движком NetGNT (Networking General-purpose Neural-network Traffic-analyzer). NetGNT может быть «натаскан» на распознавание ситуации, потенциально ведущей к сетевому затору. К примеру, в сценариях, характерных для обучения нейросетей, часто встречается ситуация, когда множество потоков пакетов прибывает одновременно на один порт, что и вызывает затор. Но движок Broadcom способен предсказать и заранее предотвратить такое развитие событий. 
Источник изображений здесь и далее: Broadcom Trident 5-X12 также имеет расширенную систему телеметрии и располагает объёмными FIB с гибким распределением. Реализованы множественные механизмы распределения нагрузки и предотвращения заторов. Новинка относится к программируемым решениям (NPL), причём готовые сценарии предлагает и сама Broadcom. В рамках API сохранена совместимость с предыдущими решениями компании. Возможно использование SONiC. 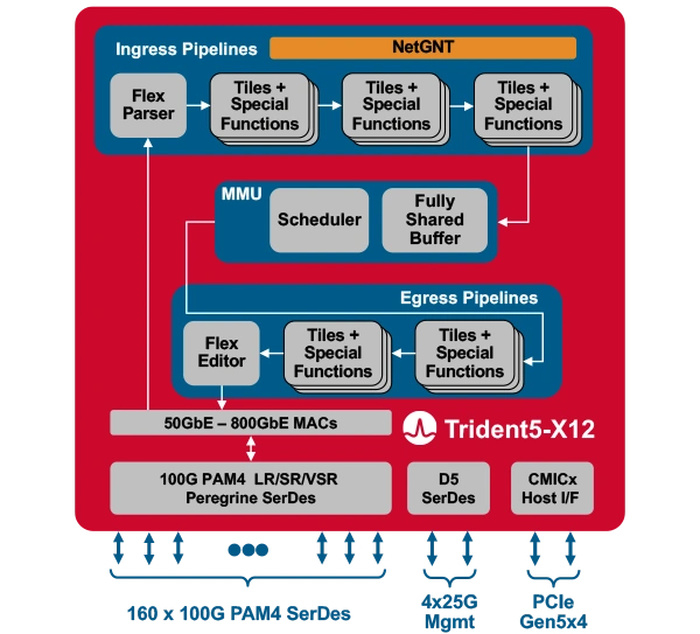 Чип оснащён 160 100G-блоками SerDes (PAM-4) и позволяет среди прочего реализовывать смешанные конфигурации — например, с 24 портами 400G и 8 портами 800G в 1U-шасси. При этом совокупная пропускная способность составляет 16 Тбит/с, однако благодаря 5-нм техпроцессу энергопотребление у новинки в пересчёте на порт на четверть ниже, нежели у Trident 4-X9.
30.11.2023 [03:10], Игорь Осколков
ИИ в один клик: llamafile позволяет запустить большую языковую модель сразу в шести ОС и на двух архитектурахMozilla представила первый релиз инструмента llamafile, позволяющего упаковать веса большой языковой модели (LLM) в исполняемый файл, который без установки можно запустить практически на любой современной платформе, причём ещё и с поддержкой GPU-ускорения в большинстве случаев. Это упрощает дистрибуцию и запуск моделей на ПК и серверах. llamafile распространяется под лицензией Apache 2.0 и использует открытые инструменты llama.cpp и Cosmopolitan Libc. Утилита принимает GGUF-файл с весами модели, упаковывает его и отдаёт унифицированный бинарный файл, который запускается в macOS, Windows, Linux, FreeBSD, OpenBSD и NetBSD. Готовый файл предоставляет либо интерфейс командной строки, либо запускает веб-сервер с интерфейсом чат-бота. 
Источник: GitHub / Mozilla Ocho Поддерживаются платформы x86-64 и ARM64, причём в первом случае автоматически определяется тип CPU и по возможности используются наиболее современные векторные инструкции. llamafile может использовать ускорители NVIDIA, а в случае платформы Apple задействовать Metal. Разработчики успешно протестировали инструмент в Linux (в облаке Google Cloud) и Windows с картой NVIDIA, в macOS и на NVIDIA Jetson. Впрочем, некоторые нюансы всё же есть. Так, в Windows размер исполняемого файла не может превышать 4 Гбайт, поэтому большие модели вынужденно хранятся в отдельном файле. В macOS на платформе Apple Silicon перед первым запуском всё же придётся установить Xcode, а в Linux, возможно, понадобится обновить некоторые компоненты. Подробности и примеры готовых моделей можно найти в репозитории проекта.
19.11.2023 [03:00], Сергей Карасёв
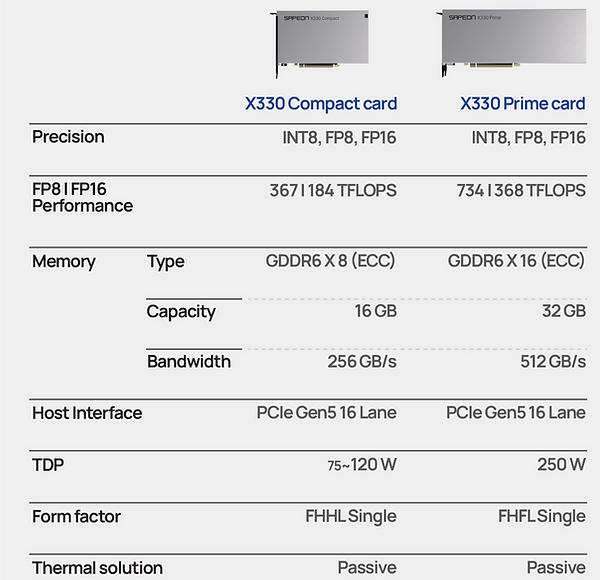
Южнокорейский стартап Sapeon представил 7-нм ИИ-чип X330ИИ-стартап Sapeon, поддерживаемый южнокорейским телекоммуникационным гигантом SK Group, анонсировал чип X330, предназначенный для инференса и обслуживания больших языковых моделей (LLM). Изделие ляжет в основу специализированных ускорителей для дата-центров. Sapeon заявляет, что новый нейропроцессор (NPU) обеспечивает примерно вдвое более высокую производительность и в 1,3 раза лучшую энергоэффективность, чем продукты конкурентов, выпущенные в этом году. По сравнению с предыдущим решением самой компании — Sapeon X220 — достигается увеличение быстродействия в четыре раза и повышение энергоэффективности в два раза. 
Изображения: Sapeon Новинка будет изготавливаться на TSMC по 7-нм технологии. Массовое производство запланировано на I полугодие 2024 года. На базе чипа будут предлагаться два ускорителя — X330 Compact Card и X330 Prime Card. Оба имеют однослотовое исполнение и оснащаются системой пассивного охлаждения. Для подключения применяется интерфейс PCIe 5.0 х16. Карты могут осуществлять вычисления INT8, FP8 и FP16.  Модель X330 Compact Card уменьшенной длины несёт на борту 16 Гбайт памяти GDDR6 с пропускной способностью до 256 Гбайт/с. Заявленная производительность на операциях FP8 и FP16 достигает соответственно 367 и 184 Тфлопс. Энергопотребление варьируется в диапазоне от 75 до 120 Вт. Полноразмерная модификация X330 Prime Card получила 32 Гбайт памяти GDDR6 с пропускной способностью до 512 Гбайт/с. Заявленное быстродействие FP8 и FP16 составляет до 734 и 368 Тфлопс. Энергопотребление — 250 Вт. 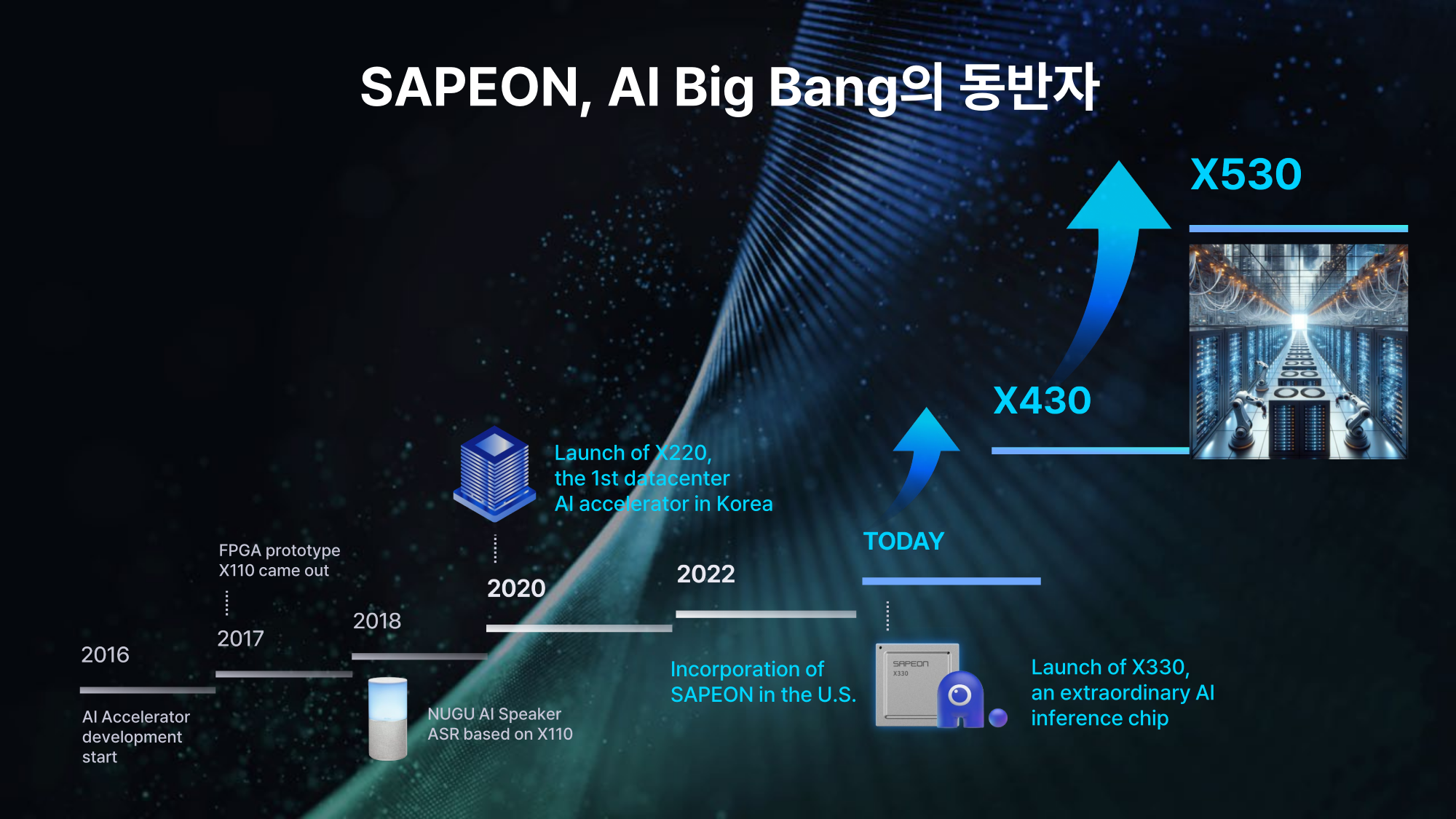 Группа SK в последнее время активно вкладывается в развитие ИИ, инвестируя напрямую или через дочерние структуры как в софт, так и в железо. С ней, в частности, связан ещё один южнокорейский разработчик ИИ-чипов Rebellions, также поддерживаемый правительством страны, которое намерено к 2030 году довести долю отечественных ИИ-чипов в местных дата-центрах до 80 %. Делается это для того, чтобы снизить зависимость от иностранных решений и избежать дефицита. Сама же Sapeon готовит ещё минимум два поколения своих чипов.
19.11.2023 [01:46], Сергей Карасёв
В облаке Cirrascale появились ИИ-ускорители Qualcomm Cloud AI 100Компания Cirrascale Cloud Services сообщила о том, что в её облаке AI Innovation Cloud стали доступны инстансы на основе специализированных ИИ-ускорителей Qualcomm Cloud AI 100. Сервис предназначен для инференса, обработки больших языковых моделей (LLM), генеративных ИИ-систем, приложений машинного зрения и т. п. Решение Qualcomm Cloud AI 100, выполненное в виде однослотовой 75-Вт карты PCIe с пассивынм охлаждением. Ускоритель поддерживает вычисления FP16/32 и INT8/16. Задействованы 16 ядер Qualcomm AI Cores и 16 Гбайт памяти LPDDR4x-2133 с пропускной способностью 136,5 Гбайт/с. Qualcomm Cloud AI 100 обеспечивает быстродействие до 350 TOPS на операциях INT8 и до 175 Тфлопс при вычислениях FP16. Cirrascale Cloud Services предлагает инстансы на базе одной, двух, четырёх и восьми карт Qualcomm Cloud AI 100. Количество vCPU варьируется от 12 до 64, объём оперативной памяти — от 48 до 384 Гбайт. Во всех случаях задействован SSD вместимостью 1 Тбайт (NVMe). 
Источник изображения: Qualcomm / Lenovo Разработчики могут использовать комплект Qualcomm Cloud AI SDK, который предлагает различные инструменты в области ИИ — от внедрения предварительно обученных моделей до развёртывания приложений глубокого обучения. Стоимость инстансов варьируется от $329 до $2499 в месяц (при оформлении годовой подписки — от $259 до $2019 в месяц).
15.11.2023 [15:52], Сергей Карасёв
NeuReality представила «сервер на чипе» и другие аппаратные ИИ-решения для инференсаКомпания NeuReality на конференции по высокопроизводительным вычислениям SC23 представила полностью интегрированное решение NR1 AI Inference, предназначенное для ИИ-платформ. Изделие спроектировано специально для ускорения инференса и снижения нагрузки на аппаратные ресурсы. Утверждается, что благодаря использованию технологий NeuReality операторы крупных дата-центров могут на 90 % сократить затраты на выполнение операций ИИ. При этом производительность по сравнению с традиционными системами на основе CPU больше на порядок. Впрочем, конкретные цифры не приводятся. 
Источник изображений: NeuReality В продуктовое семейство NeuReality входит решение NR1, которое разработчик называет «сервером на чипе» со встроенным нейросетевым движком. По заявлениям NeuReality, это первый в мире «сетевой адресуемый процессор» — NAPU (Network Addressable Processing Unit). Этот специализированный чип, ориентированный на задачи инференса, обладает возможностями виртуализации и сетевыми функциями.  Изделие NR1 является основой вычислительного модуля NR1-M AI Inference Module, выполненного в виде полноразмерной двухслотовой карты расширения PCIe. Модуль может подключаться к внешнему ускорителю глубокого обучения (DLA). Наконец, анонсирован сервер NR1-S AI Inference Appliance, который оснащается картами NR1-M AI Inference Module. NeuReality отмечает, что данная система позволяет снизить стоимость и энергопотребление почти в 50 раз на операциях инференса по сравнению со стандартными платформами.
01.11.2023 [13:43], Руслан Авдеев
Из-за нехватки ИИ-ускорителей NVIDIA южнокорейский IT-гигант Naver Corporation вынужден перейти на CPU IntelСпрос на ИИ-ускорители NVIDIA так высок, что производитель чипов не может удовлетворить его в полной мере. В результате, как сообщает The Korean Economic Daily, создатель ведущего поискового портала Южной Кореи — компания Naver Corporation — для ряда ИИ-нагрузок перешла с использования ускорителей NVIDIA на Intel Xeon Sapphire Rapids, как из-за дефицита, так и по причине роста цен на продукцию. По данным СМИ, Naver Corp. начала использовать решения Intel для ИИ-серверов картографического сервиса Naver Place. Корейский IT-гигант использует ИИ-модель для распознавания ложных данных в случаях, когда пользователи ведут поиск по ключевым запросам вроде «ближайшие рестораны» в приложении Naver Map. Ранее именно продукты NVIDIA применялись для обработки таких данных. Впрочем, речь идёт в первую очередь об инференсе, а для обучения моделей компания всё равно вынуждена использовать ИИ-ускорители. Приобрести ИИ-ускорители NVIDIA, включая H100, стало очень сложно, а цены на последние с начала года выросли в Южной Корее вдвое. Но даже если у вас есть средства, время с момента размещения заказа на ускорители до их получения уже увеличилось до 52 недель, так что быстро обновить парк серверов не выйдет. При этом ускорители способны справляться с ИИ-задачами на порядок быстрее CPU. 
Источник изображения: Naver Как утверждают отраслевые эксперты, Intel усовершенствовала технологии работы с ИИ-системами, желая угодить клиентам, ищущим альтернативы ускорителям NVIDIA. Например, Naver в течение месяца тестировала ИИ-сервер на основе процессоров компании перед его вводом в эксплуатацию. Вероятно, южнокорейский IT-гигант продолжит использовать CPU Intel новых поколений. По мнению экспертов, сотрудничество Naver и Intel может привести к ослаблению позиций NVIDIA на рынке чипов для ИИ-вычислений. По некоторым данным, Microsoft объединила усилия с AMD, чтобы помочь последней в экспансии на рынке ИИ-процессоров. Компании сотрудничают для конкуренции с NVIDIA, контролирующей около 80 % мирового рынка ИИ-чипов.
20.09.2023 [20:05], Алексей Степин
SambaNova представила ИИ-ускоритель SN40L с памятью HBM3, который в разы быстрее GPUБум больших языковых моделей (LLM) неизбежно порождает появление на рынке нового специализированного класса процессоров и ускорителей — и нередко такие решения оказываются эффективнее традиционного подхода с применением GPU. Компания SambaNova Systems, разработчик таких ускорителей и систем на их основе, представила новое, третье поколение ИИ-процессоров под названием SN40L. Осенью 2022 года компания представила чип SN30 на базе уникальной тайловой архитектуры с программным управлением, уже тогда вполне осознавая тенденцию к увеличению объёмов данных в нейросетях: чип получил 640 Мбайт SRAM-кеша и комплектовался оперативной памятью объёмом 1 Тбайт. 
Источник изображений здесь и далее: SambaNova (via EE Times) Эта наработка легла и в основу новейшего SN40L. Благодаря переходу от 7-нм техпроцесса TSMC к более совершенному 5-нм разработчикам удалось нарастить количество ядер до 1040, но их архитектура осталась прежней. Впрочем, с учётом реконфигурируемости недостатком это не является. Чип SN40L состоит из двух больших чиплетов, на которые приходится 520 Мбайт SRAM-кеша, 1,5 Тбайт DDR5 DRAM, а также 64 Гбайт высокоскоростной HBM3. Последняя была добавлена в SN40L в качестве буфера между сверхбыстрой SRAM и относительно медленной DDR. Это должно улучшить показатели чипа при работе в режиме LLM-инференса. Для эффективного использования HBM3 программный стек SambaNova был соответствующим образом доработан. 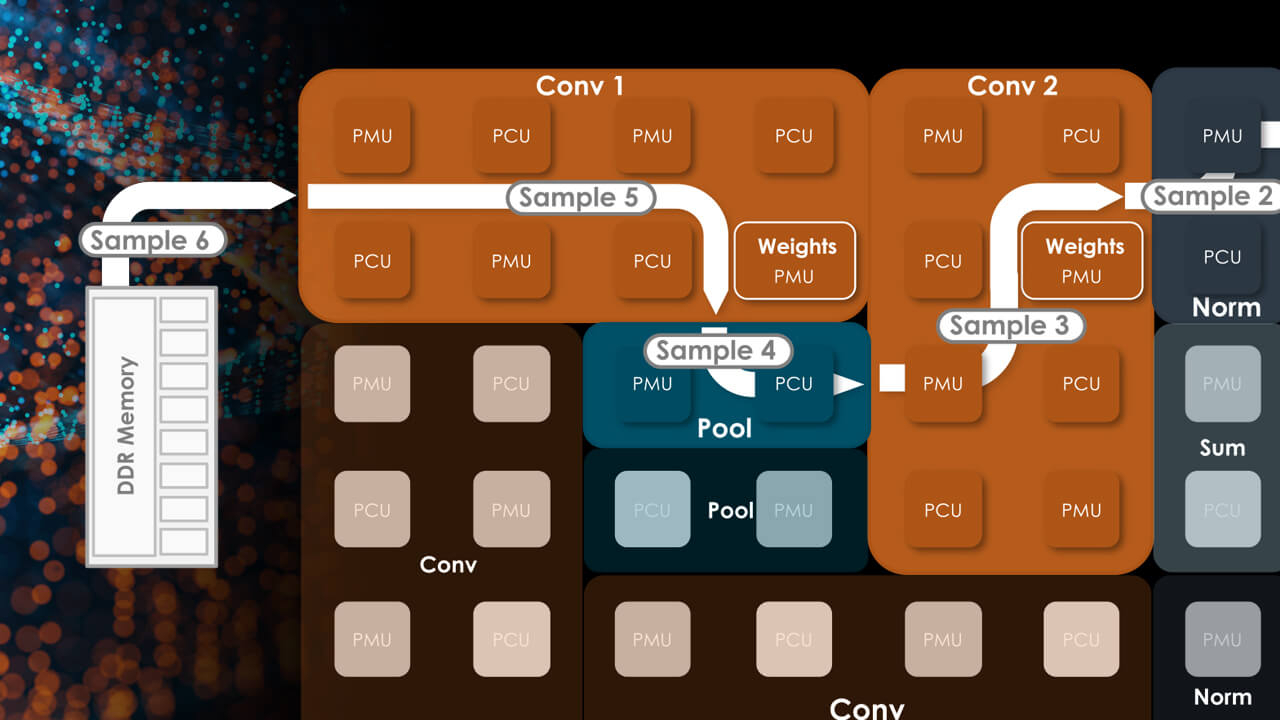
Тайловая архитектура SambaNova состоит из вычислительных тайлов PCU, SRAM-тайлов PMU, управляющей логики и меш-интерконнекта По сведениям SambaNova, восьмипроцессорная система на базе SN40L сможет запускать и обслуживать ИИ-модель поистине титанических «габаритов» — с 5 трлн параметров и глубиной запроса более 256к. В описываемой модели речь идёт о наборе экспертных моделей с LLM Llama-2 в качестве своеобразного дирижёра этого оркестра. Архитектура с традиционными GPU потребовала бы для запуска этой же модели 24 сервера с 8 ускорителями каждый; впрочем, модель ускорителей не уточняется. Как и прежде, сторонним клиентам чипы SN40L и отдельные вычислительные узлы на их основе поставляться не будут. Компания продолжит использовать модель Dataflow-as-a-Service (DaaS) — расширяемую платформу ИИ-сервисов по подписке, включающей в себя услуги по установке оборудования, вводу его в строй и управлению в рамках сервиса. Однако SN40L появится в рамках этой услуги позднее, а дебютирует он в составе облачной службы SambaNova Suite.
21.03.2023 [19:45], Игорь Осколков
Толстый и тонкий: NVIDIA представила самый маленький и самый большой ИИ-ускорители L4 и H100 NVLНа весенней конференции GTC 2023 компания NVIDIA представила два новых ИИ-ускорителя, ориентированных на инференес: неприличной большой H100 NVL, фактически являющийся парой обновлённых ускорителей H100 в формате PCIe-карты, и крошечный L4, идущий на смену T4. 
Изображения: NVIDIA NVIDIA H100 NVL действительно выглядит как пара H100, соединённых мостиками NVLink. Более того, с точки зрения ОС они выглядят как пара независимых ускорителей, однако ПО воспринимает их как единое целое, а обмен данными между двумя картам идёт в первую очередь по мостикам NVLink (600 Гбайт/с). Новинка создана в первую очередь для исполнения больших языковых ИИ-моделей, в том числе семейства GPT, а не для их обучения. 
NVIDIA H100 NVL Однако аппаратно это всё же не просто пара обычных H100 PCIe. По уровню заявленной производительности NVL-вариант вдвое быстрее одиночного ускорителя H100 SXM, а не PCIe — 3958 и 7916 Тфлопс в разреженных (в обычных показатели вдвое меньше) FP16- и FP8-вычислениях на тензорных ядрах соответственно, что в 2,6 раз больше, чем у H100 PCIe. Кроме того, NVL-вариант получил сразу 188 Гбайт HBM3-памяти с суммарной пропускной способностью 7,8 Тбайт/с. 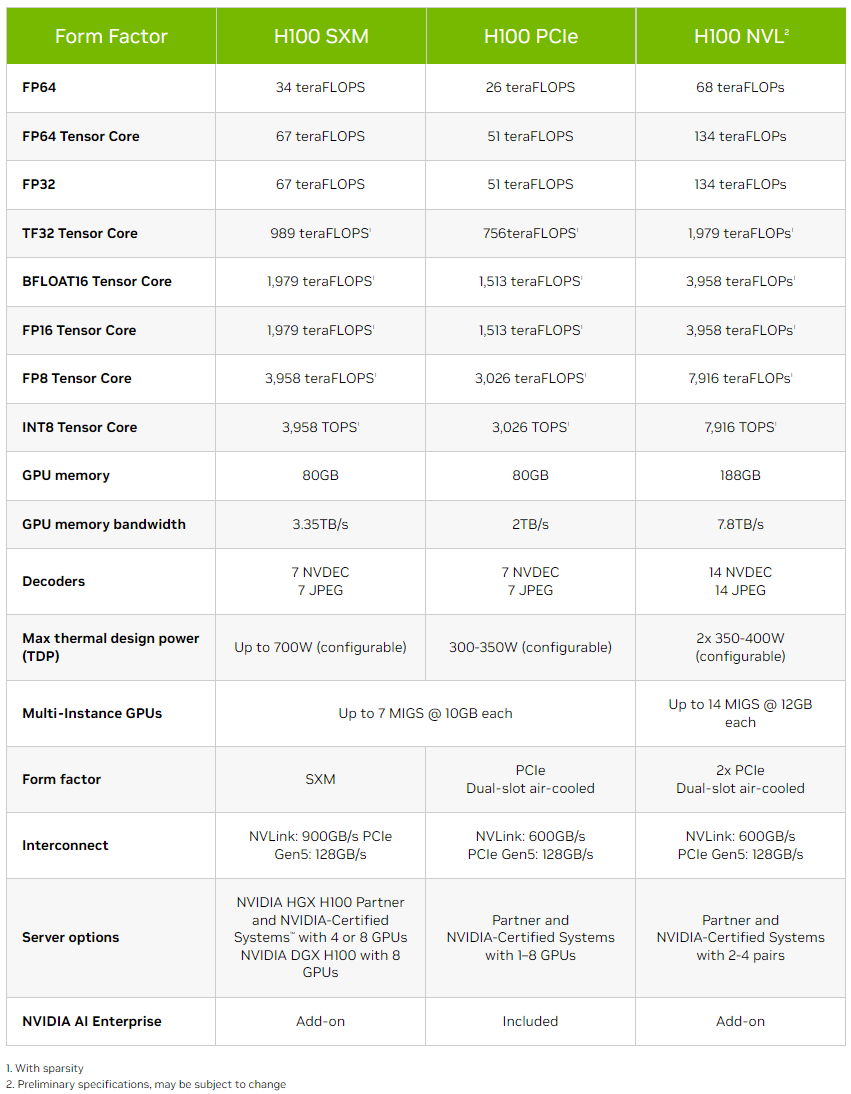 NVIDIA утверждает, что форм-фактор H100 NVL позволит задействовать новинку большему числу пользователей, хотя четыре слота и TDP до 800 Вт подойдут далеко не каждой платформе. NVIDIA H100 NVL станет доступна во второй половине текущего года. А вот ещё одну новинку, NVIDIA L4 на базе Ada, в ближайшее время можно будет опробовать в облаке Google Cloud Platform, которое первым получило этот ускоритель. Кроме того, он же будет доступен в рамках платформы NVIDIA Launchpad, да и ключевые OEM-производители тоже взяли его на вооружение. 
NVIDIA L4 Сама NVIDIA называет L4 поистине универсальным серверным ускорителем начального уровня. Он вчетверо производительнее NVIDIA T4 с точки зрения графики и в 2,7 раз — с точки зрения инференса. Маркетинговые упражнения компании при сравнении L4 с CPU оставим в стороне, но отметим, что новинка получила новые аппаратные ускорители (де-)кодирования видео и возможность обработки 130 AV1-потоков 720p30 для мобильных устройств. С L4 возможны различные сценарии обработки видео, включая замену фона, AR/VR, транскрипцию аудио и т.д. При этом ускорителю не требуется дополнительное питание, а сам он выполнен в виде HHHL-карты. 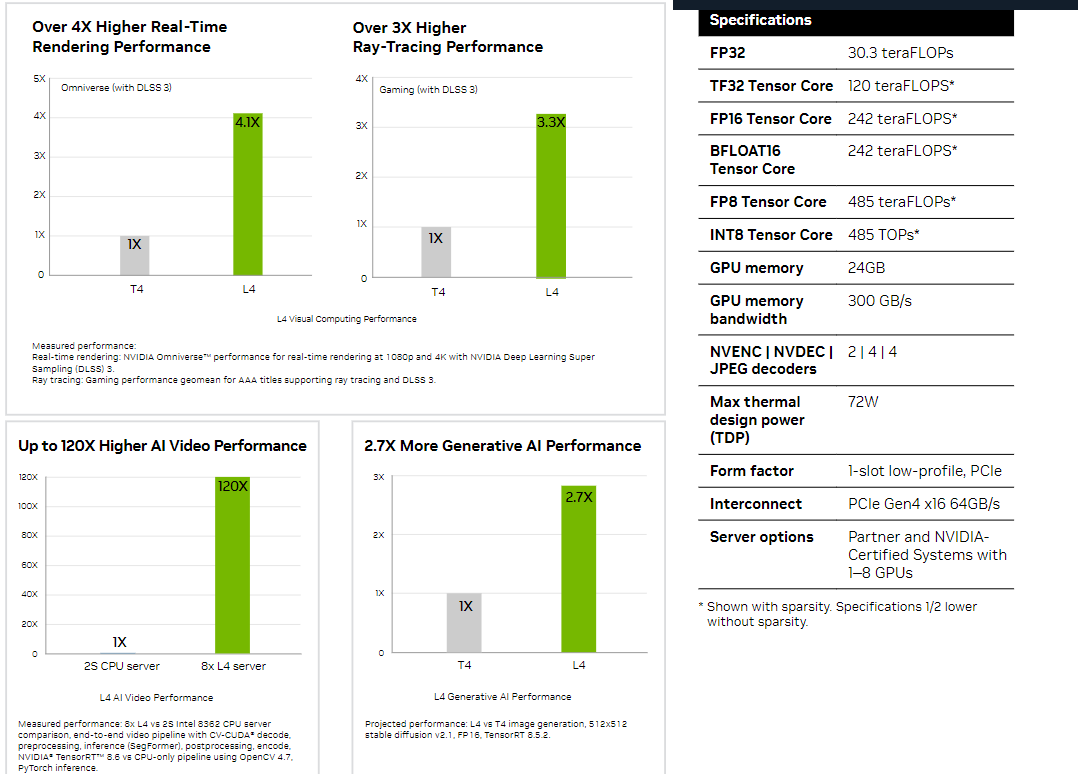
24.08.2022 [22:42], Владимир Мироненко
Untether AI представила ИИ-ускоритель speedAI240 — 1,5 тыс. ядер RISC-V и 238 Мбайт SRAM со скоростью 1 Пбайт/сКомпания Untether AI анонсировала ИИ-архитектуру следующего поколения speedAI (кодовое название «Boqueria»), ориентированную на инференс-нагрузки. При энергоэффективности 30 Тфлопс/Вт и производительности до 2 Пфлопс на чип speedAI устанавливает новый стандарт энергоэффективности и плотности вычислений, говорит компания.  Поскольку at-memory вычисления в ряде задач значительно энергоэффективнее традиционных архитектур, они могут обеспечить более высокую производительность при одинаковых затратах энергии. Первое поколение устройств runAI в 2020 году Untether AI достигла энергоэффективности на уровне 8 Тфлопс/Вт для INT8-вычислений. Новая архитектура speedAI обеспечивает уже 30 Тфлопс/Вт. .jpg)
Изображения: Untether AI (via ServeTheHome) 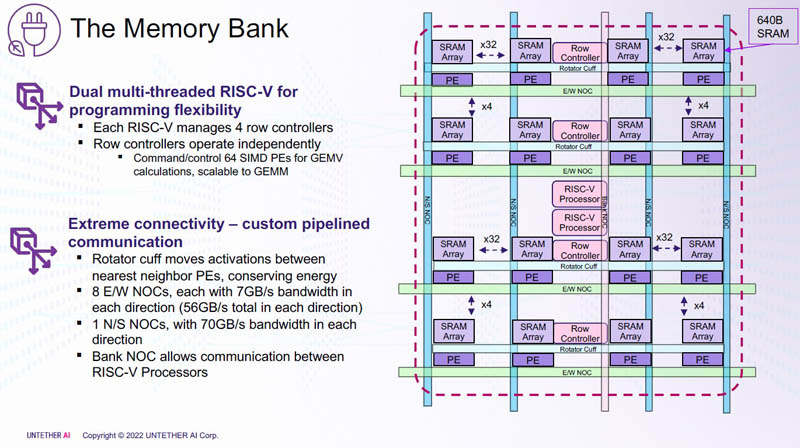 Этого удалось добиться благодаря архитектуре второго поколения, использованию более 1400 оптимизированных 7-нм ядер RISC-V (1,35 ГГц) с кастомными инструкциями, энергоэффективному управлению потоком данных и внедрению поддержки FP8. Вкупе это позволило вчетверо поднять эффективность speedAI по сравнению с runAI. Новинка может быть гибко адаптирована к различным архитектурам нейронных сетей. Концептуально speedAI напоминает ещё один тысячеядерный чип RISC-V — Esperanto ET-SoC-1. 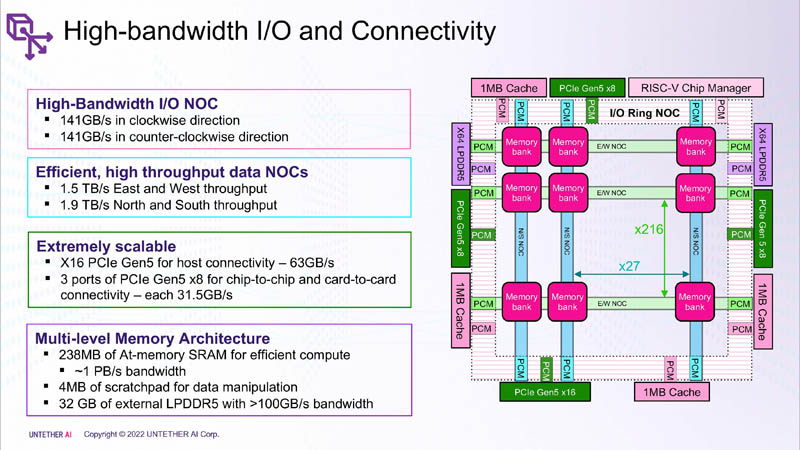 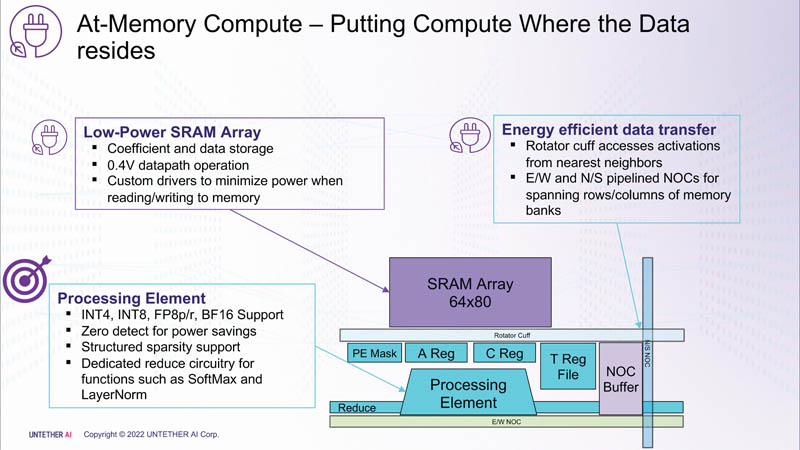 Первый член семейства speedAI — speedAI240 — обеспечивает 2 Пфлопс вычислениях в FP8-вычислениях или 1 Пфлопс для BF16-операций. Благодаря этому обеспечивается самая высокая в отрасли эффективность — например, для модели BERT заявленная производительность составляет 750 запросов в секунду на Вт (qps/w), что, по словам компании, в 15 раз выше, чем у современных GPU. Добиться повышения производительности удалось благодаря тесной интеграции вычислительных элементов и памяти.  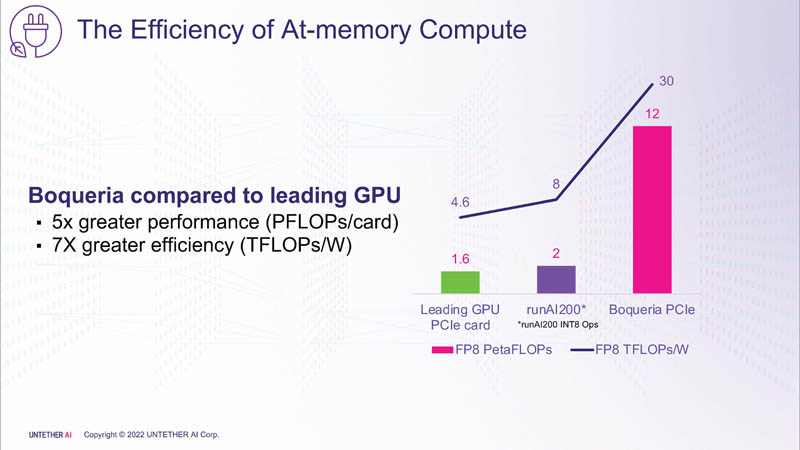 На каждый блок SRAM объёмом 328 Кбайт приходится 512 вычислительных блоков, поддерживающих работу с форматами INT4, INT8, FP8 и BF16. Каждый вычислительный блок имеет два 32-бит (RV32EMC) кастомных ядра RISC-V с поддержкой четырёх потоков и 64 SIMD. Всего есть 729 блоков, так что суммарно чип несёт 238 Мбайт SRAM и 1458 ядер. Блоки провязаны между собой mesh-сетью, к которой также подключены кольцевая IO-шина, несущая четыре 1-Мбайт блока общего кеша, два контроллера LPDRR5 (64 бит) и порты PCIe 5.0: один x16 для подключения к хосту и три x8 для объединения чипов. Суммарная пропускная способность SRAM составляет около 1 Пбайт/с, mesh-сети — от 1,5 до 1,9 Тбайт/с, IO-шины — 141 Гбайт/c в обоих направлениях, а 32 Гбайт DRAM — чуть больше 100 Гбайт/с. PCIe-интерфейсы позволяют объединить до трёх ускорителей, с шестью speedAI240 чипами у каждого. Решения speedAI будут предлагаться как в виде отдельных чипов, так и в составе готовых PCIe-карт и M.2-модулей. Ожидается, что первые поставки избранным клиентам начнутся в первой половине 2023 года.
10.05.2022 [22:46], Игорь Осколков
Intel анонсировала ИИ-ускорители Habana Gaudi2 и GrecoНа мероприятии Intel Vision было анонсировано второе поколение ИИ-ускорителей Habana: Gaudi2 для задач глубокого обучения и Greco для инференс-систем. Оба чипа теперь производятся с использованием 7-нм, а не 16-нм техпроцесса, но это далеко не единственное улучшение. Gaudi2 выпускается в форм-факторе OAM и имеет TDP 600 Вт. Это почти вдвое больше 350 Вт, которые были у Gaudi, но второе поколение чипов значительно отличается от первого. Так, объём набортной памяти увеличился втрое, т.е. до 96 Гбайт, и теперь это HBM2e, так что в итоге и пропускная способность выросла с 1 до 2,45 Тбайт/с. Объём SRAM вырос вдвое, до 48 Мбайт. Дополняют память DMA-движки, способные преобразовывать данные в нужную форму на лету. 
Изображения: Intel/Habana В Gaudi2 имеется два основных типа вычислительных блоков: Matrix Multiplication Engine (MME) и Tensor Processor Core (TPC). MME, как видно из названия, предназначен для ускорения перемножения матриц. TPC же являются программируемыми VLIW-блоками для работы с SIMD-операциями. TPC поддерживают все популярные форматы данных: FP32, BF16, FP16, FP8, а также INT32, INT16 и INT8. Есть и аппаратные декодеры HEVC, H.264, VP9 и JPEG.  Особенностью Gaudi2 является возможность параллельной работы MME и TPC. Это, по словам создателей, значительно ускоряет процесс обучения моделей. Фирменное ПО SynapseAI поддерживает интеграцию с TensorFlow и PyTorch, а также предлагает инструменты для переноса и оптимизации готовых моделей и разработки новых, SDK для TPC, утилиты для мониторинга и оркестрации и т.д. Впрочем, до богатства программной экосистемы как у той же NVIDIA пока далеко. 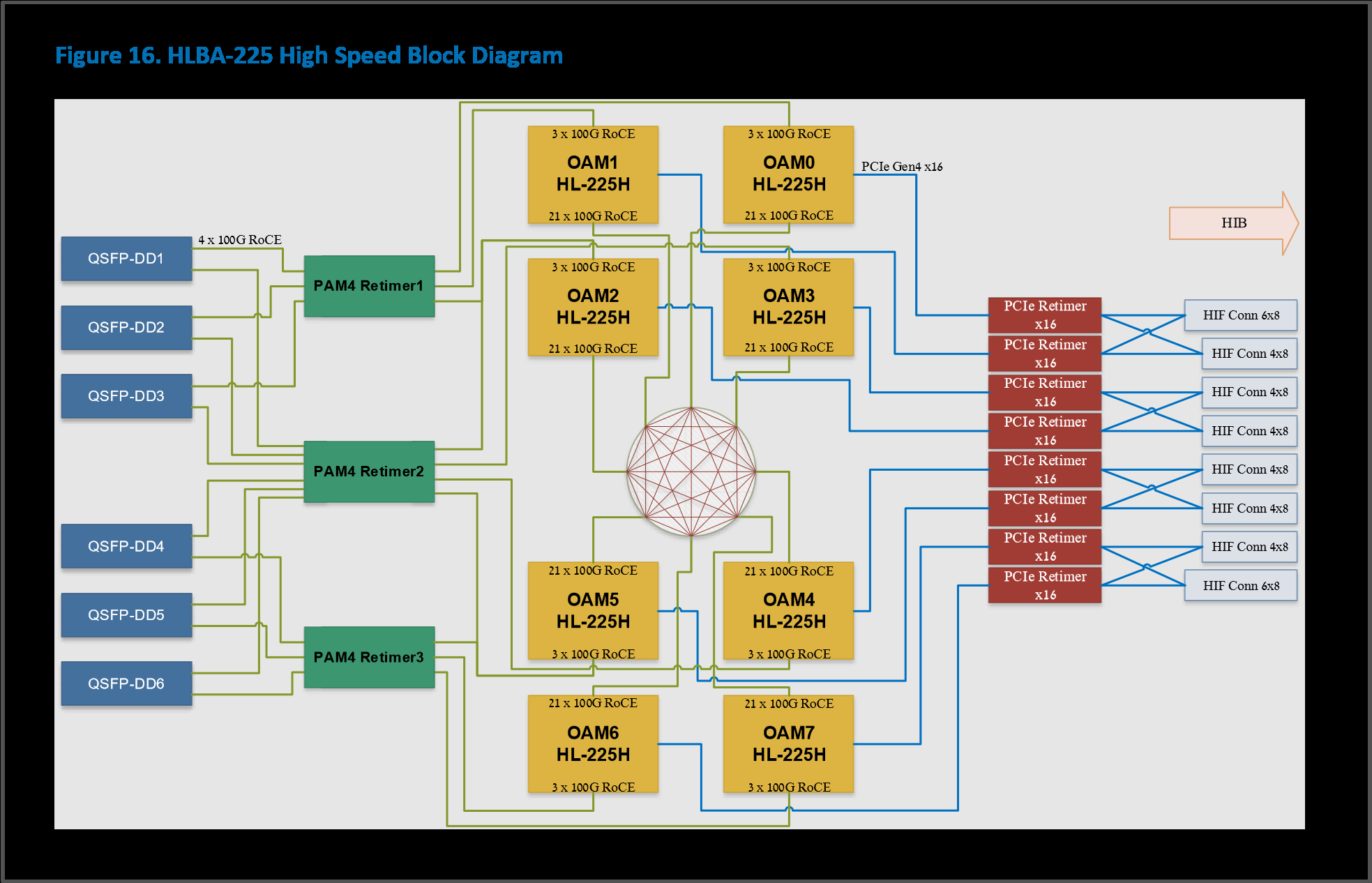 Интерфейсная часть новинок включает PCIe 4.0 x16 и сразу 24 (ранее было только 10) 100GbE-каналов с RDMA ROcE v2, которые используются для связи ускорителей между собой как в пределах одного узла (по 3 канала каждый-с-каждым), так и между узлами. Intel предлагает плату HLBA-225 (OCP UBB) с восемью Gaudi2 на борту и готовую ИИ-платформу, всё так же на базе серверов Supermicro X12, но уже с новыми платами, и СХД DDN AI400X2. 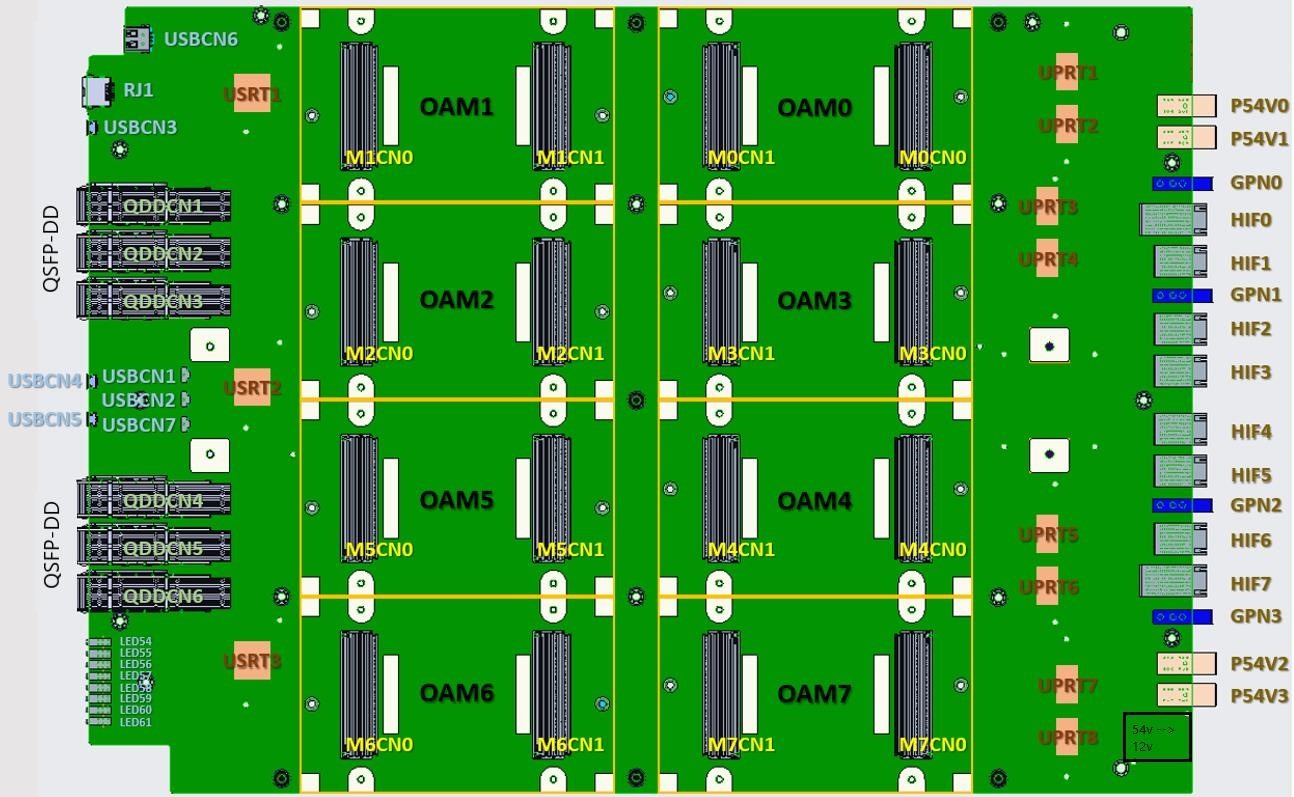 Наконец, самое интересное — сравнение производительности. В ряде популярных нагрузок новинка оказывается быстрее NVIDIA A100 (80 Гбайт) в 1,7–2,8 раз. На первый взгляд результат впечатляющий. Однако A100 далеко не новы. Более того, в III квартале этого года ожидается выход ускорителей H100, которые, по словам NVIDIA, будут в среднем от трёх до шести раз быстрее A100, а благодаря новым функциям прирост в скорости обучения может быть и девятикратным. Ну и в целом H100 являются более универсальными решениями. 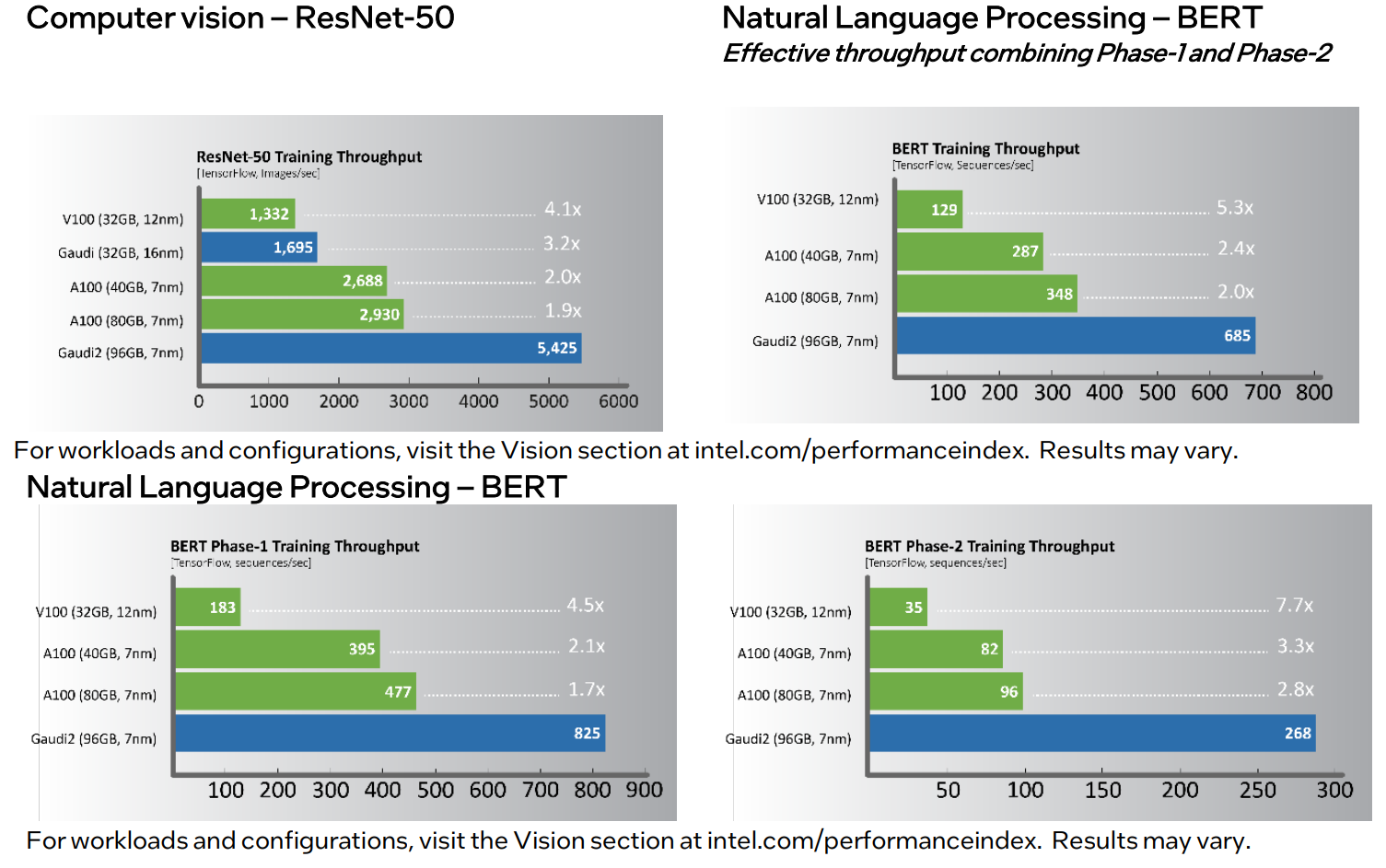 Gaudi2 уже доступны клиентам Habana, а несколько тысяч ускорителей используются самой Intel для дальнейшей оптимизации ПО и разработки чипов Gaudi3. Greco будут доступны во втором полугодии, а их массовое производство намечено на I квартал 2023 года, так что информации о них пока немного. Например, сообщается, что ускорители стали намного менее прожорливыми по сравнению с Goya и снизили TDP с 200 до 75 Вт. Это позволило упаковать их в стандартную HHHL-карту расширения с интерфейсом PCIe 4.0 x8.  Объём набортной памяти всё так же равен 16 Гбайт, но переход от DDR4 к LPDDR5 позволил впятеро повысить пропускную способность — с 40 до 204 Гбайт/с. Зато у самого чипа теперь 128 Мбайт SRAM, а не 40 как у Goya. Он поддерживает форматы BF16, FP16, (U)INT8 и (U)INT4. На борту имеются кодеки HEVC, H.264, JPEG и P-JPEG. Для работы с Greco предлагается тот же стек SynapseAI. Сравнения производительности новинки с другими инференс-решениями компания не предоставила.  Впрочем, оба решения Habana выглядят несколько запоздалыми. В отставании на ИИ-фронте, вероятно, отчасти «виновата» неудачная ставка на решения Nervana — на смену так и не вышедшим ускорителям NNP-T для обучения пришли как раз решения Habana, да и новых инференс-чипов NNP-I ждать не стоит. Тем не менее, судьба Habana даже внутри Intel не выглядит безоблачной, поскольку её решениям придётся конкурировать с серверными ускорителями Xe, а в случае инференс-систем даже с Xeon. |
|
{kind=link}