Материалы по тегу: software
|
27.06.2025 [12:37], Руслан Авдеев
Digital Realty выбрала HPE Private Cloud для модернизации своего парка ЦОД по всему мируКомпания HPE объявила о том, что оператор ЦОД Digital Realty намерен стандартизировать свою инфраструктуру по всему миру, которая включает 300 ЦОД в 25 странах и регионах, взяв за основу HPE Private Cloud Business Edition, сообщает пресс-служба компании. В результате Digital Realty сможет обрабатывать огромные объёмы данных, одновременно упростив управление ЦОД, повысив уровень безопасности и надёжности. Как заявил представитель Digital Realty, компания владеет и управляет передовыми ЦОД по всему миру, что требует технологий для масштабирования в соответствии с ростом потребностей клиентов. HPE Private Cloud Business Edition обеспечит такое масштабирование и оптимизированное управление инфраструктурой с предсказуемой стоимостью владения. Модернизация дата-центров поможет Digital Realty повысить операционную эффективность и управление рабочими нагрузками с минимизацией затрат. HPE позволяет полностью автоматизировать настройку инфраструктуры и управление жизненным циклом ЦОД, что даст Digital Realty возможность уделять меньше внимания решению инфраструктурных вопросов и больше концентрироваться на обеспечении бизнес-результатов для клиентов. 
Источник изображения: HPE Как заявили в HPE, Digital Realty стала исключительным технологическим и колокейшн-партнёром компании, оказав огромное доверие технологиям частных облаков, предлагаемым HPE. По данным HPE, HPE Private Cloud Business Edition снижает совокупную стоимость владения до 2,5 раз в сравнении с решениями конкурентов, а с помощью ПО HPE Morpheus VM Essentials и СХД HPE Alletra Storage MP B10000 управление ЦОД значительно упрощается. Работая с партнёром HPE, компанией Infradax, Digital Realty уже оценила некоторые решения для хранения данных, после чего приняла решение о полной интеграции продуктов HPE. HPE и World Wide Technology (WWT) будут сотрудничать в деле развёртывания новых решений в дата-центрах Digital Realty по всему миру.
26.06.2025 [09:21], Владимир Мироненко
За сокет, а не ядра: HPE предлагает доступные лицензии на Morpheus VM Essentials, чтобы привлечь недовольных политикой BroadcomВ своём выступлении на конференции HPE Discover 2025 глава HPE Антонио Нери (Antonio Neri, на фото ниже) коснулся вопросов лицензирования решения Morpheus VM Essentials и инструментов для него, пишет ServeTheHome. Это решение было создано HPE после приобретения Morpheus Data путём объединения функций Morpheus со своим собственным предложением виртуализации на основе KVM с целью привлечения клиентов VMware, недовольных лицензионной политикой Broadcom. Решение Morpheus VM Essentials предназначено для тех, кто находится в начале миграции с VMware, хотя HPE всячески старается не упоминать название данного продукта Broadcom. Далее клиенты могут воспользоваться версией Morpheus VM Enterprise, также им будут предложены конфигурации HPE Private Cloud. 
Источник изображений: HPE HPE имеет ряд инструментов профилирования и калькуляторы стоимости, которые помогают клиентам рассчитывать экономию затрат благодаря переносу рабочих нагрузок в Morpheus. В версии Enterprise можно сравнивать различные опции хостинга для определённого типа машин в разных публичных облаках и собственных ЦОД.  Говоря о лицензировании следует отметить тот факт, что у HPE Morpheus Essentials меньше возможностей, пишет ServeTheHome. Например, клиент можете управлять только локальными кластерами виртуализации на базе Morpheus KVM и кластерами VMware через интеграцию с vCenter. Говорить об этом можно скорее как о замене небольших развёртываний VMware с немногочисленными серверами с ESXi под управлением vCenter. Однако преимущество заключается в том, что это решение намного дешевле по сравнению с VMware. 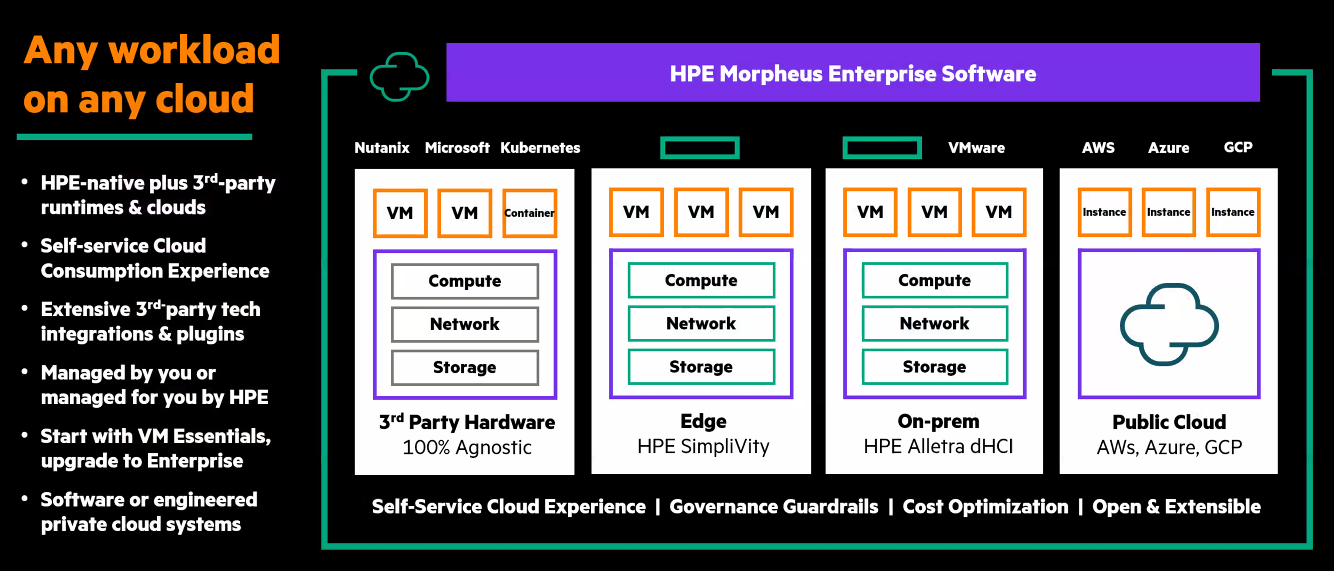 Как сообщили в компании ресурсу ServeTheHome, цена решения Essential по прейскуранту составляет около $600 за сокет, а полная версия Enterprise — порядка $2500 за сокет. Это ключевое преимущество HPE, поскольку стоимость лицензий VMware после появления AMD EPYC стала рассчитываться исходя из количества ядер. А после поглощения Broadcom продукты и вовсе стали предлагаться исключительно по подписке.
25.06.2025 [17:06], Руслан Авдеев
HPE делает ставку на повсеместное использование ИИ-агентовИИ-агенты окончательно укрепились в корпоративной повестке. Главной темой мероприятия HPE Discover в 2025 году стало массовое внедрение ИИ-агентов, причём независимо от того, насколько зрелыми являются эти технологии, сообщает The Register. Хотя немало внимания по традиции уделялось «железу», в выступлении главы HPE Антонио Нери (Antonio Neri) акцент был сделан именно на архитектуру ИИ-агентов GreenLake Intelligence. По данным самой компании, внедрение агентов предполагается везде, где только можно. HPE заявила, что GreenLake Intelligence должна стать ключевой «точкой взаимодействия» с ИИ-агентами во всей экосистеме HPE, управляемой с помощью гибридной облачной платформы HPE GreenLake. В ходе выступления привели ряд примеров. Так, сетевые продукты HPE Aruba получат поддержку новой «агентной mesh-технологии», стоящей за мультимодальным помощником. Такой помощник сможет анализировать причины сетевых сбоев и с помощью разных ИИ-агентов предлагать, что именно должен сделать человек для устранения проблемы, не просто сообщая о неисправности, но и подсказывая решение. Функции ИИ-агента появятся и в платформе управления IT-инфраструктурой OpsRamp, системах хранения данных и прочих бизнес-направлениях. ИИ-агенты будут использоваться для автоматизации управления затратами, обеспечения экоустойчивого развития и поддержки бизнес-услуг — для выполнения рутинных задач без участия человека. 
Источник изображения: Emilipothèse/unsplash.com Правда, внедрение ИИ-агентов в экосистему HPE вовсе не означает, что они полностью автономны. Пока ИИ не способен полностью взять рутину на себя. HPE подчёркивает, что хотя агенты и называются автономными, окончательное решение пока всё-таки остаётся за человеком. Тем не менее, некоторые сценарии уже отрабатываются автономно — вроде исправления сетевых ошибок, сбоев в хранении данных и др., но во многих других областях успехи не столь очевидны. По мнению HPE, в течение следующего года в сфере внедрения ИИ-агентов ожидаются значительные успехи, хотя год назад о таких технологиях вообще почти не велось разговоров. В компании подчёркивают, что таким системам нужно постепенно эволюционировать. И дело даже не в «железе», ведь оно уже готово к этому — дело за программным обеспечением. С прошлого года HPE и NVIDIA уже предлагают «ИИ-фабрики» AI Factory для корпоративных клиентов на базе HPE Private Cloud AI, а теперь появляются и новые варианты, включая Composable для провайдеров и компаний гиперскейл-уровня и Sovereign для правительств и клиентов с повышенными требованиями к безопасности и суверенитету данных. Сама NVIDIA уже представила проект AI-Q Blueprint Platform для создания продвинутых ИИ-агентов.
25.06.2025 [13:34], Руслан Авдеев
SambaNova делает ставку на инференс и партнёрство с облачными провайдерами и госзаказчикамиРазработчик ИИ-ускорителей SambaNova Systems объявил о стратегическом изменении профиля деятельности. Теперь основное внимание будет уделено инференсу, а не обучению ИИ-моделей, сообщает EE Times со ссылкой на главу компании Родриго Ляна (Rodrigo Liang). Тот считает, что в ближайшие годы инференс станет ключевым направлением в ИИ-секторе. Переосмысление стратегии привело к увольнению 77 сотрудников в апреле 2025 года. Компания всё ещё будет поддерживать обучение ИИ-моделей, но признаёт, что спрос на крупные кластеры для этих целей заметно снизился. Многие клиенты переходят на открытые модели, адаптируя и дообучая их — разработчики не желают создавать свои LLM с нуля. Поэтому теперь SambaNova будет предоставлять предприятиям и правительственным структурам инструменты для развёртывания открытых и доработанных моделей, в том числе «рассуждающих». Основными клиентами компании сегодня являются крупные предприятия и «суверенные» государственные заказчики, заинтересованные в сокращении затрат. У госзаказчиков особые требования, в частности — независимость от США и других стран. Кроме того, они используют модели, обученные на локальных данных и ориентированные на специфику национальных экономик. Поскольку стойки компании потребляют всего по 10 кВт, позволить их себе могут даже страны со слабой энергетической инфраструктурой. 
Источник изображения: Magnet.me/unsplash.com Хотя у SambaNova есть собственная облачная инфраструктура с поддержкой открытых моделей, компания не намерена строить крупные кластеры для инференса. Вместо этого она организует партнёрство с облачными провайдерами, предоставляя им технологии для создания ИИ-облаков. Некоторыми партнёрами стали региональные облачные провайдеры, намеренные развернуть собственные ИИ-экосистемы. Платформа SambaNova Cloud играет роль демонстрационной площадки и не претендует на конкуренцию с другими провайдерами, являясь шаблоном, по образцу которого можно развёртывать аналогичные схемы «под ключ». Технологии SambaNova позволяют запускать до 100 разных копий Llama-70B в одной стойке. Это отличный вариант для компаний, которым нужны разные варианты моделей для финансового, юридического и других отделов, для разных целей. По словам компании, у конкурентов для каждой версии модели требуется стойка на 140 кВт, в то время как SambaNova позволяет использовать стойки на 10 кВт для запуска множества моделей, причём переключение с одной на другую осуществляется «за миллисекунду». Это позволяет компаниям экономить значительные средства. Осенью 2024 года SambaNova объявила о запуске самой быстрой на тот момент облачной платформы для ИИ-инференса. В этом она соревнуется с Cerebras и Groq, которые пытаются составить конкуренцию NVIDIA. Стоит отметить, что Groq также сменила бизнес-подход, отказавшись от продажи отдельных ускорителей в пользу оснащения целых ИИ ЦОД для инференса. Cerebras совместно с партнёрами создаёт крупные ИИ-суперкомпьютеры и кластеры. От обучения моделей она не отказывается.
23.06.2025 [14:46], Владимир Мироненко
Broadcom представила VMware Cloud Foundation 9 — основу основ для современного частного облака
broadcom
kubernetes
nvidia
software
vmware
виртуализация
ии
информационная безопасность
частное облако
Broadcom объявила о выходе платформы VMware Cloud Foundation (VCF) 9.0, которая предоставляет клиентам согласованную операционную модель для частного облака, охватывающую ЦОД, периферию и управляемую облачную инфраструктуру. VCF 9.0 сочетает в себе гибкость и масштабируемость публичных облаков с безопасностью, производительностью, архитектурным контролем и низкой совокупной стоимостью владения (TCO) локальных сред. VCF 9.0 является единой унифицированной платформой с поддержкой традиционных, современных и ИИ-приложений, говорит компания. Согласованные операции, управление и контроль в среде частного облака, а также возможность самообслуживания позволяет разработчикам сосредоточиться на своих приложениях, а не на инфраструктуре. Именно для этого при создании VCF 9.0 была выбрана совершенно новая архитектура. VCF 9.0 получила унифицированный интерфейс для администраторов облака, обеспечивающий целостное представление о его работе. Новое приложение Quick Start значительно сокращает время и сложность настройки. Встроенные политики управления и предварительно настроенные шаблоны помогают поддерживать соответствие требованиям всем развёртываниям, сокращая ручные задачи и гарантируя повторяемость инфраструктуры. Разработчики получают доступ к автоматизированным и эластичным самообслуживаемым IaaS. 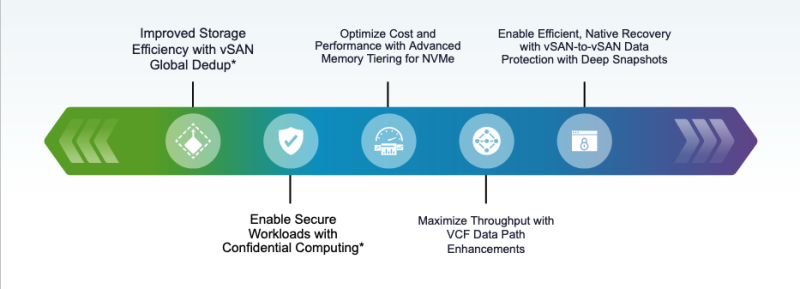
Источник изображений: Broadcom Встроенная службы vSphere Kubernetes Service (VKS) позволяет одинаково работать как с виртуальными машинами (ВМ), так и с контейнерами. Унифицированный подход позволяет клиентам создавать, развёртывать и запускать контейнеризированные и виртуализированные рабочие нагрузки вместе, снижая потребность в сложных стеках DevOps и интеграциях. VCF 9.0 предлагает явные преимущества в плане прогнозируемости и прозрачности затрат по сравнению с публичным облаком, позволяя организациям получить полное представление о совокупной стоимости владения и обеспечивая чёткую видимость рентабельности инвестиций в инфраструктуру, говорит Broadcom.  Ключевой особенностью VCF 9.0 является и новая панель управления SecOps, обеспечивающая консолидированное представление безопасности платформы и управления данными, включая интегрированные политики соответствия и нормативные ограничения для согласованного управления. VMware vDefend обеспечивает встроенное обнаружение и реагирование на угрозы, микросегментацию на уровне зон и приложений, сокращение поверхности атак и принудительное применение принципа нулевого доверия в VCF. vDefend расширяет возможности как администраторов инфраструктуры, так и владельцев VPC, оптимизирует миграцию и обеспечивает последовательное предотвращение угроз в многоэкземплярных развёртываниях VCF. Обновления коснулись и подсистем хранения и сетей. Расширенное многоуровневое хранение для NVMe позволяет обеспечить снижение до 38 % совокупной стоимости владения, а VMware vSAN ESA с Global Dedupe позволяет на 34 % снизить совокупную стоимость владения хранилищем. Новая защита данных vSAN-to-vSAN с «глубокими» снапшотами обеспечивает более эффективное восстановление после сбоев или атак программ-вымогателей. VCF обеспечивает практически нулевую потерю производительности по сравнению с bare metal, поддерживая при этом vMotion без простоев для рабочих ИИ-нагрузок.  VMware Live Recovery обеспечивает унифицированное управление кибер- и аварийным восстановлением во всех развертываниях VCF с повышенным суверенитетом данных за счёт локальных изолированных сред восстановления. Поддерживает до 200 неизменяемых снапшотов на ВМ и обеспечивает более эффективное масштабирование за счёт возможности расширения хранилища независимо от вычислений с помощью кластеров хранения vSAN. Наконец, в VMware NSX обеспечен трёхкратный рост производительности коммутации VMware Private AI Foundation с NVIDIA повышает кибербезопасность, позволяя развернуть облаки с поддержкой изоляции (air gap) и GPU-as-a-Service. В службе также появилась видимость профилей vGPU и новые инструменты мониторинга (v)GPU. А Model Runtime упрощает использование и масштабирование ИИ-моделей, в то время как Agent Builder Service обеспечивает более эффективное создание ИИ-агентов.  VMware Data Services Manager (DSM) предлагает поддержку PostgreSQL и MySQL с Microsoft SQL Server в Tech Preview. Интеграция с VCF Automation позволяет ИТ-отделам предоставлять DBaaS, а дополнительные усовершенствования повышают эффективность для управления большими парками баз данных. Еще одним ключевым обновлением является интеграция балансировщика нагрузки VMware Avi с VMware Cloud Foundation (VCF) 9.0. Он обеспечивает единую облачную операционную модель для балансировки по всем рабочим нагрузкам, предлагает plug-and-play балансировку для ВМ и Kubernetes, а также единый API для администраторов и разработчиков инфраструктуры.
20.06.2025 [00:00], Владимир Мироненко
Управлять данными, а не хранилищами: Pure Storage представила унифицированную облачную платформу Enterprise Data CloudPure Storage представила платформу Enterprise Data Cloud (EDC), которая предлагает простой, гибкий и унифицированный способ управления данными и хранилищами, позволяя организациям сосредоточиться на бизнес-задачах, а не на инфраструктуре. EDC позволяет управлять блочными, файловыми и объектными нагрузками в локальных, облачных и гибридных средах. Компания отметила, что использование традиционных моделей хранения влечёт за собой фрагментацию, разрозненность и неконтролируемое разрастание данных. Enterprise Data Cloud (EDC) предназначена для решения этих проблем, предоставляя виртуализированное облако данных с единым контролем, охватывающим различные среды. Такой подход обеспечивает интеллектуальное, автономное управление данными и управление во всём массиве данных, позволяя компаниям снизить риски, затраты и эксплуатационную неэффективность. 
Источник изображений: Pure Storage «Пришло время прекратить управлять хранилищем и начать управлять данными. Поскольку ИИ увеличивает потенциальную ценность корпоративных данных, а киберугрозы ставят их под угрозу, архитектуры хранения данных и инструменты для управления данными не поспевают за развитием», — сообщил в пресс-релизе председатель и генеральный директор Pure Storage Чарльз Джанкарло (Charles Giancarlo). Как отметил ресурс Computer Weekly, EDC представляет собой объединение существующих архитектурных элементов и систем Pure Storage: Purity OS, которая является общей для всех массивов компании; Fusion, которая позволяет обнаруживать и управлять ресурсами хранения; Pure1, которая позволяет управлять парком оборудования с точки зрения производительности и детального управления ресурсами; подписка Evergreen.  В основе платформы лежит решение Pure Fusion, объединяющее хранилища как пул адаптируемых ресурсов и рассматривающее все массивы как конечные точки в единой сети данных. Это позволяет администраторам управлять парком СХД через единый интерфейс и развёртывать рабочие нагрузки с использованием интеллектуальных шаблонов, которые автоматизируют такие параметры, как качество обслуживания, уровни защиты и требования к производительности. Слой Fusion изначально встроен в массивы Pure. Администраторы получили большую гибкость в реагировании на конкретные потребности каждой рабочей нагрузки и больше не должны предварительно планировать и настраивать развёртывания, что снижает риск несоответствия и повышает отказоустойчивость, гарантируя, что ресурсы для рабочих нагрузок будут подготовлены правильно с самого начала. 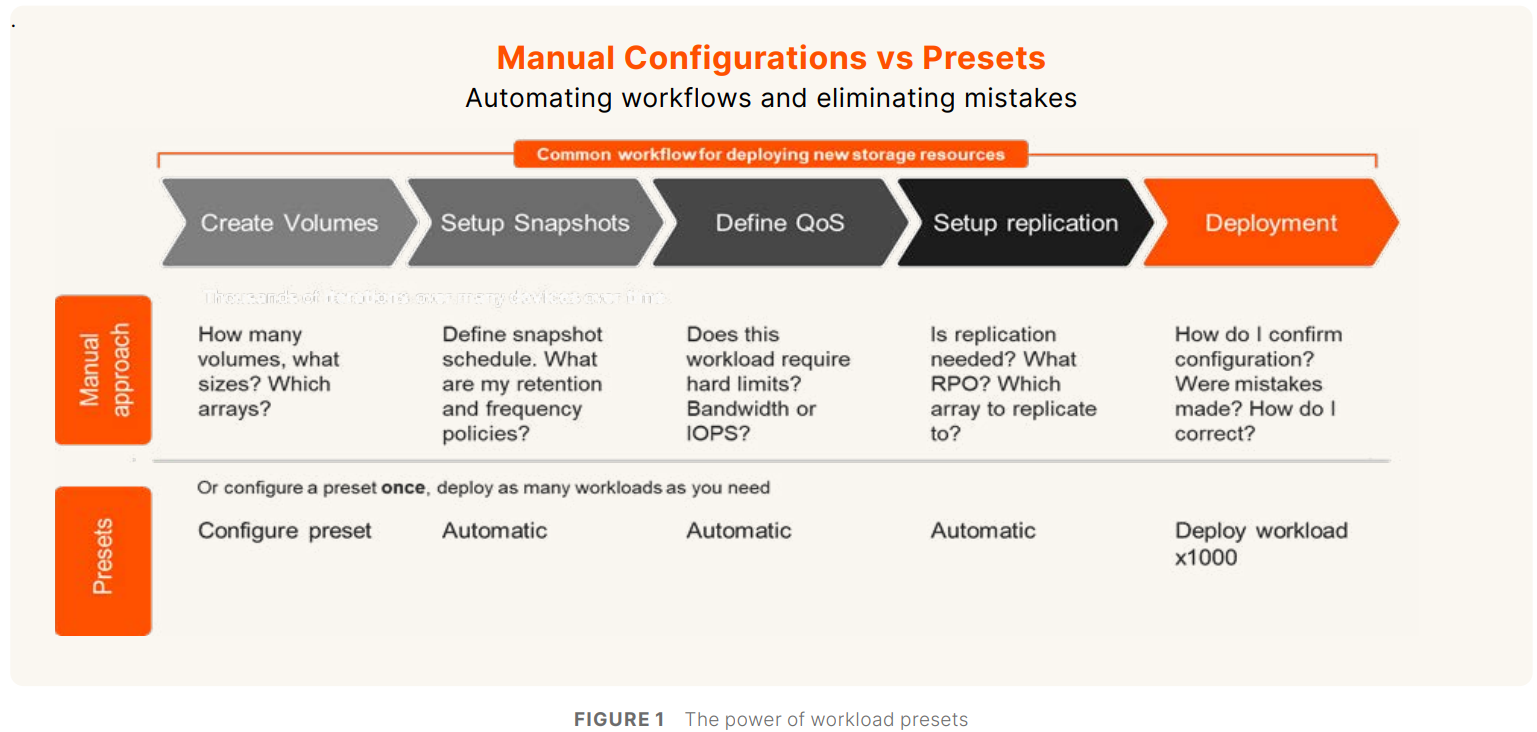 Чтобы устранить проблемы, возникающие из-за ручных операций по подготовке, миграции и многого другого, автоматизация охватывает весь стек платформы с возможностями оркестрации на основе политик и самообслуживания. Встроенное соответствие требованиям и улучшенная киберустойчивость ещё больше минимизируют риск путём использования политик безопасности и управления. Эти новые возможности полностью переопределяют интеллектуальное управление хранением, считает компания. EDC поддерживает готовые сценарии для формирования рабочих процессов, которые интегрируют хранилище с вычислениями, сетями и приложениями, чтобы обеспечить сложные развёртывания, такие как репликация базы данных в нескольких ЦОД и в публичном облаке в рамках одной задачи. 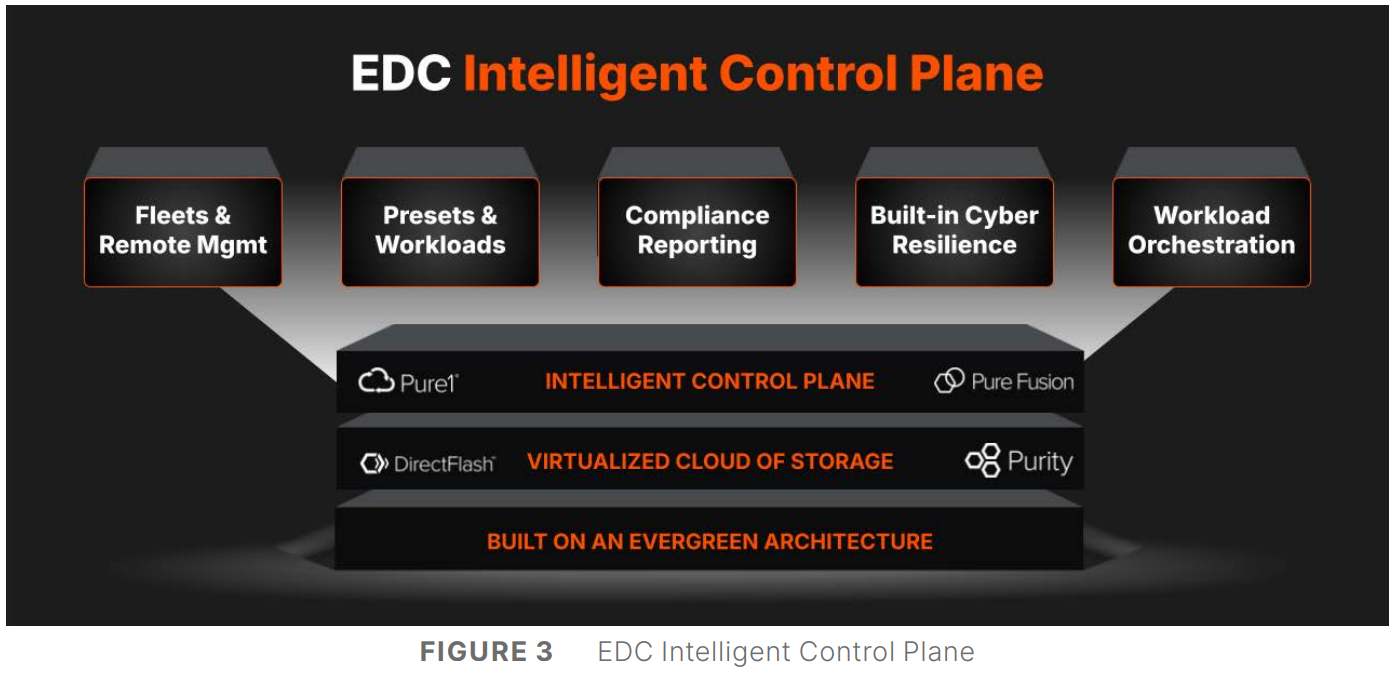 Чад Кенни (Chadd Kenney), вице-президент Pure Storage по технологиям, рассказал, что автоматизированные функции решают некоторые из рутинных задач развёртывания. «Если у кого-то есть приложение, которому требуется Oracle, администратор должен изучить парк массивов хранения, выяснить, какой из них способен принять новую рабочую нагрузку, а затем настроить его, убедившись в работоспособности репликации, наличии снапшотов и корректности политики качества обслуживания, — говорит Кенни. — Шаблоны позволяют вам задавать все конфигурации разом». Платформа предоставляет организованные шаблоны для рабочих процессов, созданные на основе тысяч существующих коннекторов для сторонних приложений и продуктов, в том числе от Cisco, Microsoft, VMware, ServiceNow и Slack. Шаблоны охватывают конфигурации хранилищ, вычислительных ресурсов, сетей, баз данных и приложений. Можно использовать готовые шаблоны от самой Pure и партнёров или создавать свои. 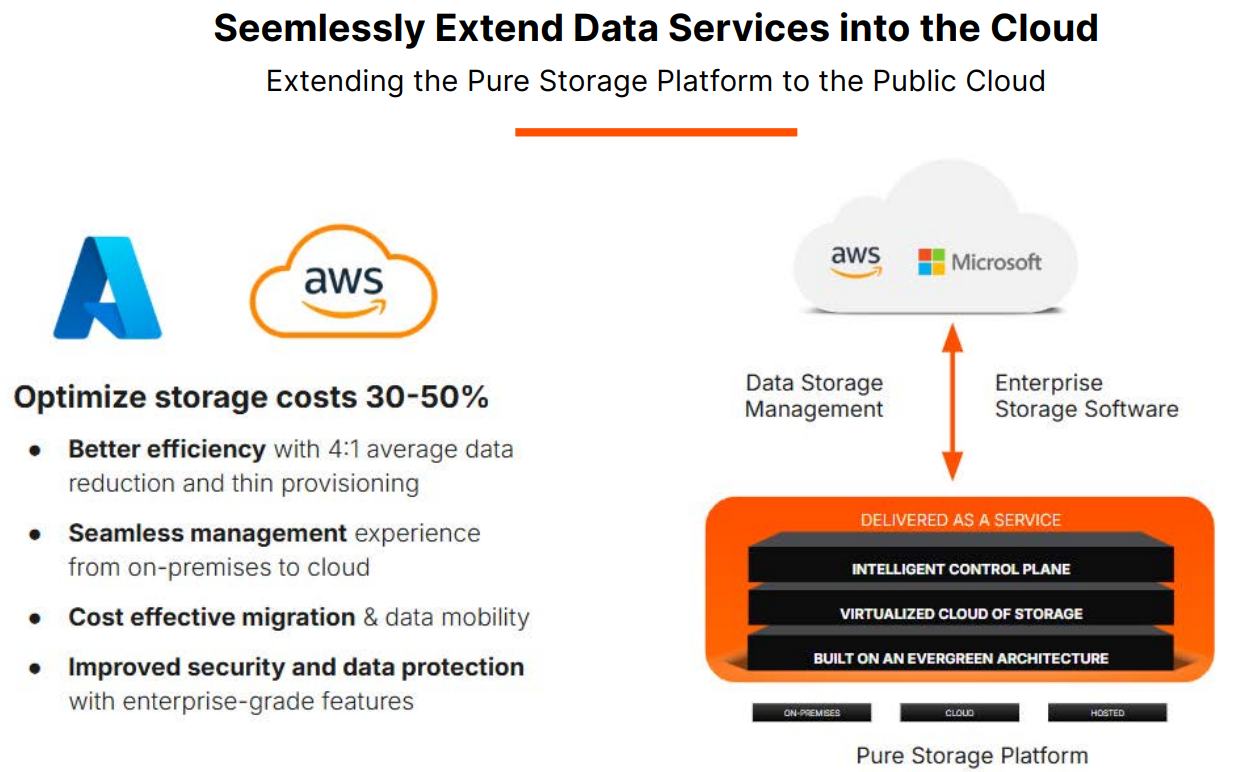 Платформа включает в себя центр оркестрации с шаблонами автоматизации для таких функций, как DRaaS и предоставление данных, и имеет интеграцию с Rubrik Security Cloud и Crowdstrike Logscale. Например, Pure Fusion по сигналу от Rubrik автоматически маркирует снимки, отправляет их на сканирование и быстро выявляет среди них наиболее подходящие для восстановления. В случае с CrowdStrike компания предлагает первое в своём роде проверенное, локальное, устойчивое, безопасное и высокопроизводительное хранилище для Falcon LogScale. Кроме того, платформа предлагает расширенные возможности восстановления сред VMware. Наконец, интеллектуальный помощник компании AI Copilot, отслеживает в реальном времени телеметрию всего EDC, что позволяет ему мгновенно реагировать на запросы по производительности на уровне парка, предоставлять сценарии конфигурации и поддерживать быструю корректировку политики без вмешательства человека, заявила Pure Storage. «В течение 10 секунд он обработает все данные 100 различных систем, даст вам ответ и предоставит сценарий для развёртывания нагрузки», — рассказал Кенни.
17.06.2025 [23:55], Владимир Мироненко
AMD анонсировала платформу ROCm 7.0, облако для разработчиков AMD Developer Cloud и программу Radeon Test DriveAMD вместе с ускорителями Instinct MI350X/MI355X представила 7-ю версию своего открытого программного стека ROCm (Radeon open compute). Как сообщает компания, ROCm 7.0 предназначен для удовлетворения растущих потребностей рабочих нагрузок генеративного ИИ и HPC, одновременно расширяя возможности разработчиков за счёт доступности, эффективности и активного сотрудничества сообщества. По данным AMD, платформа ROCm 7 предлагает более чем в 3,5 раза большую производительность инференса, чем ROCm 6, и в 3 раза большую эффективность обучения. Это стало возможным благодаря улучшениям производительности и поддержке типов данных с меньшей точностью, таких как FP4 и FP6. Дальнейшие улучшения в коммуникационных стеках позволили оптимизировать использование ускорителя и перемещение данных. ROCm 7 поддерживает распределённый инференс, а также фреймворки SGLang, vLLM и llm-d. Платформа ROCm 7 создавалась совместно с этими партнёрами, включая разработку общих интерфейсов и примитивов для обеспечения эффективного распределённого инференса на платформах AMD. 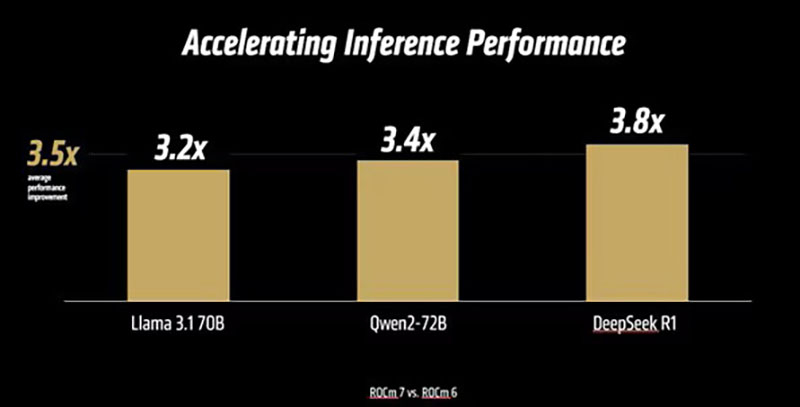
Источник изображений: AMD Вместе с ROCm 7 компания представила MLOps-платформу ROCm Enterprise AI для бесперебойных ИИ-операций в корпоративном сегменте. Платформа предлагает инструменты для тонкой настройки модели и интеграции как со структурированными, так и неструктурированными рабочими процессами. AMD заявила, что работает с партнёрами по экосистеме над созданием эталонных реализаций для таких приложений, как чат-боты и обобщение документов. 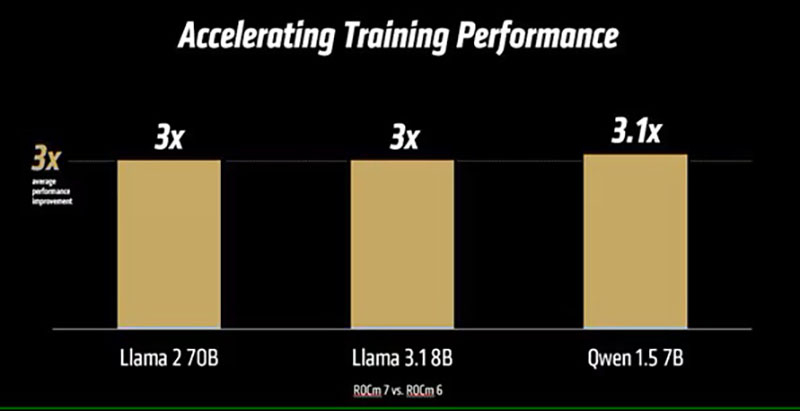 AMD отметила, что тесное партнёрство гарантирует разработчикам доступ к лучшим в своем классе инструментам, постоянному улучшению производительности и открытой среде для быстрой итерации и развёртывания. Также AMD представила партнёров экосистемы ROCm, которые используют преимущества данной платформы:
Кроме того, AMD представила «простую в использовании платформу для разработчиков» AMD Developer Cloud, обеспечивающую быстрый доступ к AMD Instinct с возможностью масштабирования от одного (192 Гбайт памяти) до восьми AMD Instinct MI300X (1536 Гбайт памяти). Сообщается, что конфигурации с одним ускорителем в основном используются для рабочих нагрузок инференса на «лёгких» моделях, тогда как максимальная конфигурация обеспечивает распределённое обучение, тонкую настройку и высокопроизводительный инференс для крупномасштабных моделей.  AMD сообщила, что платформа AMD Developer Cloud была разработана с учётом четырёх основных целей:
По словам компании, AMD Developer Cloud предполагает различные варианты использования. Решение идеально подходит для независимых разработчиков AI/ML, работающих над низкоуровневым программированием, разработкой ядер (kernel) или корпоративных приложений и проектов, нацеленных на нативную поддержку AMD. Также платформу можно использовать для мероприятий и хакатонов, обеспечивая масштабируемую поддержку образовательных и практических мероприятий с предоставлением кредитов на использование ускорителей во время семинаров, хакатонов, конкурсов и демонстраций.  Также с выходом ROCm 7 появилась поддержка ноутбуков и рабочих станциях на Windows с видеокартами Radeon и процессорами Ryzen AI. С этим связан ещё один важный анонс — компания представила программу ROCm on Radeon Test Drive, которая будет запущена этим летом партнёрстве с различными поставщиками оборудования (первыми стали Colfax и System76), чтобы упростить разработчикам возможность опробовать ROCm на GPU Radeon, передаёт Phoronix. В рамках Radeon Test Drive предоставляется возможность удалённо протестировать GPU Radeon (PRO).
15.06.2025 [23:29], Владимир Мироненко
Большая жатва: AMD назначила вице-президентом по ИИ гендиректора ИИ-стартапа Lamini, в который сама же и вложиласьAMD продолжает укреплять команду специалистов в сфере ИИ за счёт привлечения талантливых разработчиков, а также поглощения ИИ-стартапов. На минувшей неделе Шарон Чжоу (Sharon Zhou, вторая справа на фото ниже), соучредитель и гендиректор ИИ-стартапа Lamini (PowerML Inc.) сообщила в соцсети X, что она и несколько сотрудников присоединяются к AMD. Комментируя переход, представитель AMD сообщил ресурсу CRN, что это было наймом специалистов, а не приобретением команды, как это было в случае с разработчиком ИИ-чипов Untether AI, который фактически прекратил существование после сделки. В настоящее время неизвестно, какой будет дальнейшая судьба Lamini, которую в прошлом году покинул Грег Диамос (Greg Diamos), бывший архитектор ПО NVIDIA CUDA, основавший компанию вместе с Чжоу в 2022 году. До основания Lamini Чжоу работала менеджером по ML-продуктам в Google, менеджером по продуктам в ИИ-стартапах Kensho Technologies и Tamr, а также занимала должность внештатного преподавателя компьютерных наук в Стэнфордском университете, где она получила докторскую степень по этой же специальности. В AMD её назначили на должность вице-президента по ИИ. 
Источник изображения: Sharon Zhou/X Платформа Lamini позволяет компаниям настраивать и кастомизировать большие языковые модели (LLM) с использованием собственных данных. В частности, Lamini предложила новый подход под названием Mixture of Memory Experts (MoME), направленный на повышение производительности LLM и фактической точности путем радикального снижения частоты галлюцинаций с 50 % до 5 %. Утверждается, что этот подход позволяет значительно сократить объём вычислительных ресурсов для обучения LLM, а также продолжительность этого процесса. В 2023 году AMD представила Lamini как одного из первых независимых поставщиков ПО, поддержавших её ускорители Instinct. В сентябре того же года Lamini сообщила, что использует более чем 100 ускорителей серии Instinct MI200 и что платформа AMD ROCm «достигла программного паритета» с NVIDIA CUDA. До определённого момента ИИ-платформа Lamini была единственной коммерческой платформой, целиком и полностью работающей на базе AMD Instinct.  В прошлом году стартап привлек финансирование в размере $25 млн от нескольких инвесторов, включая венчурное подразделение AMD, Эндрю Ына (Andrew Ng), гендиректора Dropbox Дрю Хьюстона (Drew Houston), и Лип-Бу Тана (Lip-Bu Tan), который в начале этого года стал гендиректором Intel. Помимо команды Untether AI, AMD приобрела в течение последних нескольких неделе разработчика систем кремниевой фотоники Enosemi и стартапа Brium, специализирующегося на инструментах оптимизации ИИ ПО для различной аппаратной инфраструктуры.
14.06.2025 [17:04], Владимир Мироненко
Scale AI получила от Meta✴ более $14 млрд, но потеряла гендиректора и рискует лишиться крупных контрактов с Gooogle, Microsoft, OpenAI и xAIИИ-стартап Scale AI, занимающийся подготовкой, оценкой и разметкой данных для обучения ИИ-моделей, объявил о крупной инвестиционной сделке с Meta✴, по результатм которой его рыночная стоимость превысила $29 млрд. Сделка существенно расширит коммерческие отношения Scale и Meta✴. Также её условиями предусмотрен переход гендиректора Scale AI Александра Ванга (Alexandr Wang) и ещё ряда сотрудников в Meta✴. Вместо Ванга, который останется в совете директоров стартапа, временно исполняющим обязанности гендиректора Scale AI назначен Джейсон Дроги (Jason Droege), директор по стратегии, имеющий «20-летний опыт создания и руководства знаковыми технологическими компаниями, включая Uber Eats и Axon». Представитель Scale AI уточнил в интервью ресурсу CNBC, что Meta✴ вложит в компанию $14,3 млрд, в результате чего получит в ней 49-% долю акций, но без права голоса. «Мы углубим совместную работу по созданию данных для ИИ-моделей, а Александр Ванг присоединится к Meta✴ для работы над нашими усилиями по созданию суперинтеллекта», — рассказал представитель Meta✴. Переманивая Ванга, который не имея опыта в R&D, сумел с нуля создать крупный бизнес в сфере ИИ, гендиректор Meta✴ Марк Цукерберг (Mark Zuckerberg) делает ставку на его организаторские способности, полагая, что укрепить позиции Meta✴ в сфере ИИ под силу опытному бизнес-лидеру, больше похожему на Сэма Альтмана (Sam Altman), чем на учёных, стоящих у руля большинства конкурирующих ИИ-лабораторий, пишет Reuters. 
Источник изображения: Scale AI Инвестиции в Scale AI станут вторыми по величине в истории Meta✴ после приобретения WhatsApp за $19 млрд. Однако сделка может оказаться не совсем выгодной для Scale AI, предупреждает Reuters, поскольку многие компании, являющиеся клиентами Scale AI, могут отказаться от дальнейшего сотрудничества из-за опасений по поводу того, что Ванг, оставаясь в совете директоров стартапа, будет предоставлять Meta✴ внутреннюю информацию о приоритетах конкурентов. Представитель Scale AI заверил, что инвестиции Meta✴ и переход Ванга не повлияют на клиентов стартапа, и что Meta✴ не будет иметь доступа к его какой-либо деловой информации или данным. Тем не менее, по словам источников Reuters, Google, один их крупнейших клиентов Scale AI, планирует разорвать отношения со стартапом. Источники сообщили, что Google планировала потратить $200 млн только в этом году на услуги Scale AI по подгтовке и разметке данных людьми. После объявления о сделке поисковый гигант уже провёл переговоры с несколькими конкурентами Scale AI. Scale AI получила в 2024 году размере $870 млн, из них около около $150 млн от Google, утверждают источники. По их словам, другие крупные клиенты, включая Microsoft, OpenAI и xAI, тоже планируют отказаться от услуг Scale AI. Официальных подтверждений этой информации пока не поступало. А финансовый директор OpenAI заявил в пятницу, что компания, которой источники тоже приписывают намерение отказаться от услуг Scale AI, продолжит работать со стартапом, как с одним из своих многочисленных поставщиков данных.
07.06.2025 [16:24], Владимир Мироненко
AMD впервые приняла участие в бенчмарке MLPerf Training, но до рекордов NVIDIA ей ещё очень далекоКонсорциум MLCommons объявил новые результаты бенчмарка MLPerf Training v5.0, отметив быстрый рост и эволюцию в области ИИ, а также рекордное количество общих заявок и увеличение заявок для большинства тестов по сравнению с бенчмарком v4.1. MLPerf Training v5.0 предложил новый бенчмарк предварительной подготовки большой языковой модели на основе Llama 3.1 405B, которая является самой большой ИИ-моделью в текущем наборе тестов обучения. Он заменил бенчмарк на основе gpt3 (gpt-3-175B), входивший в предыдущие версии MLPerf Training. Целевая группа MLPerf Training выбрала его, поскольку Llama 3.1 405B является конкурентоспособной моделью, представляющей современные LLM, включая последние обновления алгоритмов и обучение на большем количестве токенов. Llama 3.1 405B более чем в два раза больше gpt3 и использует в четыре раза большее контекстное окно. Несмотря на то, что бенчмарк на основе Llama 3.1 405B был представлен только недавно, на него уже подано больше заявок, чем на предшественника на основе gpt3 в предыдущих раундах, отметил консорциум. 
Источник изображения: NVIDIA MLCommons сообщил, что рабочая группа MLPerf Training регулярно добавляет новые рабочие нагрузки в набор тестов, чтобы гарантировать, что он отражает тенденции отрасли. Результаты бенчмарка Training 5.0 показывают заметный рост производительности для новых бенчмарков, что указывает на то, что отрасль отдаёт приоритет новым рабочим нагрузкам обучения, а не старым. Тест Stable Diffusion показал увеличение скорости в 2,28 раза для восьмичиповых систем по сравнению с версией 4.1, вышедшей шесть месяцев назад, а тест Llama 2.0 70B LoRA увеличил скорость в 2,10 раза по сравнению с версией 4.1; оба превзошли исторические ожидания роста производительности вычислений с течением времени в соответствии с законом Мура. Более старые тесты в наборе показали более скромные улучшения производительности. 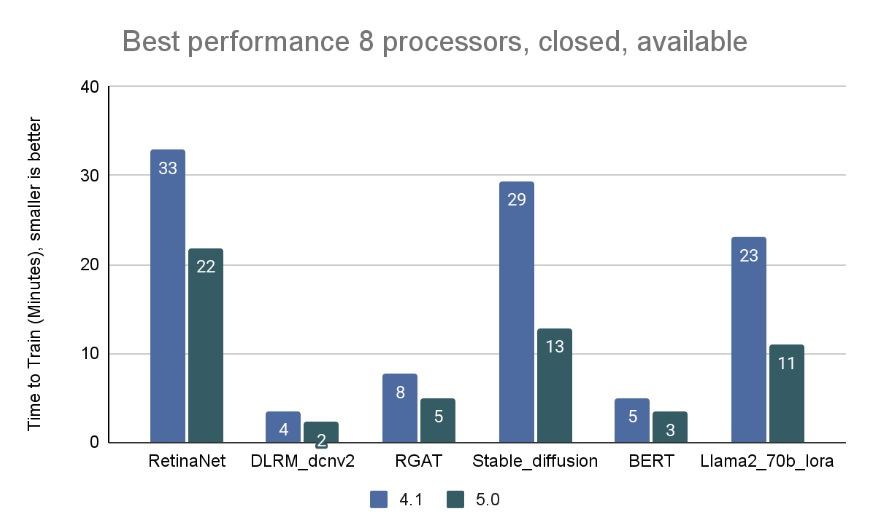
Источник изображений: MLCommons На многоузловых 64-чиповых системах тест RetinaNet показал ускорение в 1,43 раза по сравнению с предыдущим раундом тестирования v3.1 (самым последним, включающим сопоставимые масштабные системы), в то время как тест Stable Diffusion показал резкое увеличение в 3,68 раза. «Это признак надёжного цикла инноваций в технологиях и совместного проектирования: ИИ использует преимущества новых систем, но системы также развиваются для поддержки высокоприоритетных сценариев», — говорит Шрия Ришаб (Shriya Rishab), сопредседатель рабочей группы MLPerf Training. 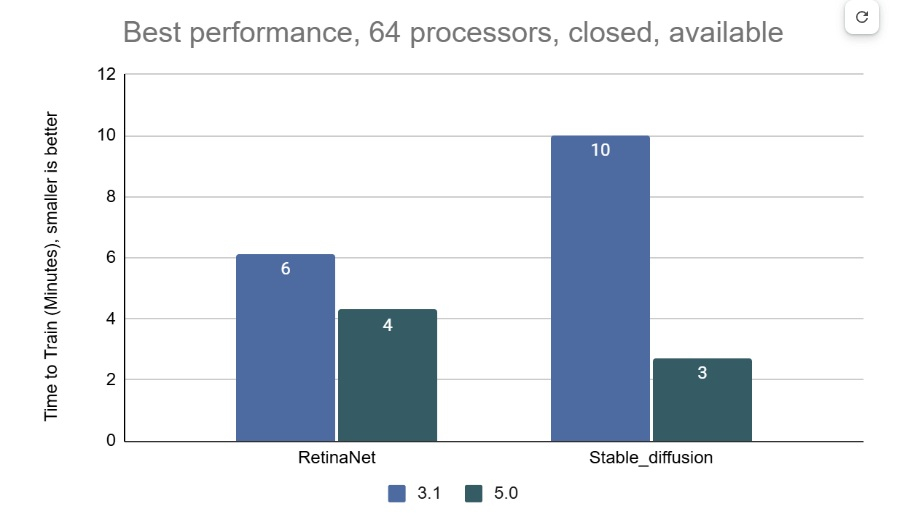 В заявках на MLPerf Training 5.0 использовалось 12 уникальных чиповых, все в категории коммерчески доступных. Пять из них стали общедоступными с момента выхода последней версии набора тестов MLPerf Training:
Заявки также включали три новых семейства процессоров:
Кроме того, количество представленных многоузловых систем увеличилось более чем в 1,8 раза по сравнению с версией бенчмарка 4.1. Хиуот Касса (Hiwot Kassa), сопредседатель рабочей группы MLPerf Training, отметил растущее число провайдеров облачных услуг, предлагающих доступ к крупномасштабным системам, что делает доступ к обучению LLM более демократичным. 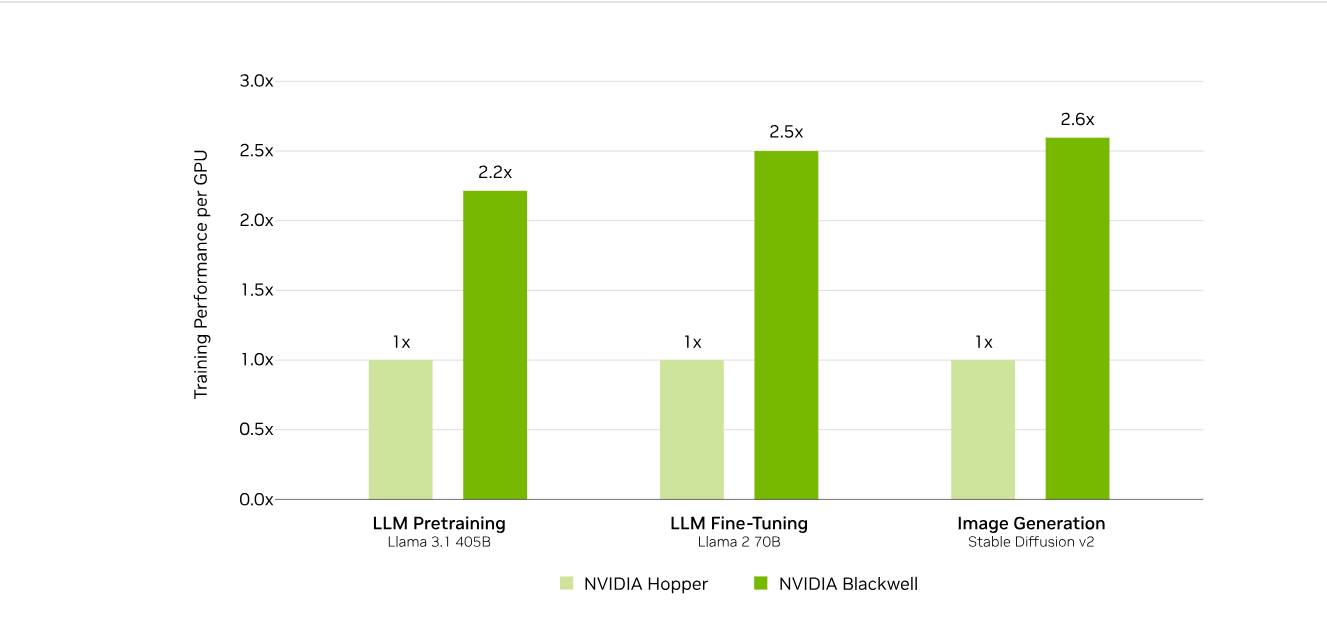
Источник изображений: NVIDIA Последние результаты MLPerf Training 5.0 от NVIDIA показывают, что её ускорители Blackwell GB200 демонстрируют рекордные результаты по времени обучения, демонстрируя, как стоечная конструкция «ИИ-фабрики» компании может быстрее, чем раньше, превращать «сырые» вычислительные мощности в развёртываемые модели, пишет ресурс HPCwire. Раунд MLPerf Training v5.0 включает 201 результат от 20 организаций-участников: AMD, ASUS, Cisco, CoreWeave, Dell, GigaComputing, Google Cloud, HPE, IBM, Krai, Lambda, Lenovo, MangoBoost, Nebius, NVIDIA, Oracle, QCT, SCITIX, Supermicro и TinyCorp. «Мы бы особенно хотели поприветствовать впервые подавших заявку на участие в MLPerf Training AMD, IBM, MangoBoost, Nebius и SCITIX, — сказал Дэвид Кантер (David Kanter), руководитель MLPerf в MLCommons. — Я также хотел бы выделить первый набор заявок Lenovo на результаты тестов энергопотребления в этом раунде — энергоэффективность в системе обучения ИИ-систем становится всё более важной проблемой, требующей точного измерения». 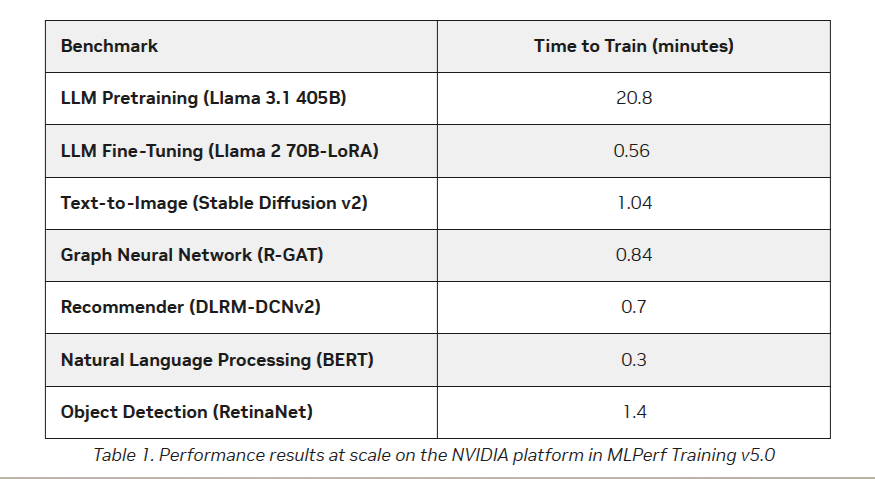 NVIDIA представила результаты кластера на основе систем GB200 NVL72, объединивших 2496 ускорителей. Работая с облачными партнерами CoreWeave и IBM, компания сообщила о 90-% эффективности масштабирования при расширении с 512 до 2496 ускорителей. Это отличный результат, поскольку линейное масштабирование редко достигается при увеличении количества ускорителей за пределами нескольких сотен. Эффективность масштабирования в диапазоне от 70 до 80 % уже считается солидным результатом, особенно при увеличении количества ускорителей в пять раз, пишет HPCwire. В семи рабочих нагрузках в MLPerf Training 5.0 ускорители Blackwell улучшили время сходимости «до 2,6x» при постоянном количестве ускорителей по сравнению с поколением Hopper (H100). Самый большой рост наблюдался при генерации изображений и предварительном обучении LLM, где количество параметров и нагрузка на память самые большие.  Хотя в бенчмарке проверялась скорость выполнения операций, NVIDIA подчеркнула, что более быстрое выполнение задач означает меньшее время аренды облачных инстансов и более скромные счета за электроэнергию для локальных развёртываний. Хотя компания не публиковала данные об энергоэффективности в этом бенчмарке, она позиционировала Blackwell как «более экономичное» решение на основе достигнутых показателей, предполагая, что усовершенствования дизайна тензорных ядер обеспечивают лучшую производительность на Ватт, чем у поколения Hopper. Также HPCwire отметил, что NVIDIA была единственным поставщиком, представившим результаты бенчмарка предварительной подготовки LLM на основе Llama 3.1 405B, установив начальную точку отсчёта для обучения с 405 млрд параметров. Это важно, поскольку некоторые компании уже выходят за рамки 70–80 млрд параметров для передовых ИИ-моделей. Демонстрация проверенного рецепта работы с 405 млрд параметров даёт компаниям более чёткое представление о том, что потребуется для создания ИИ-моделей следующего поколения. 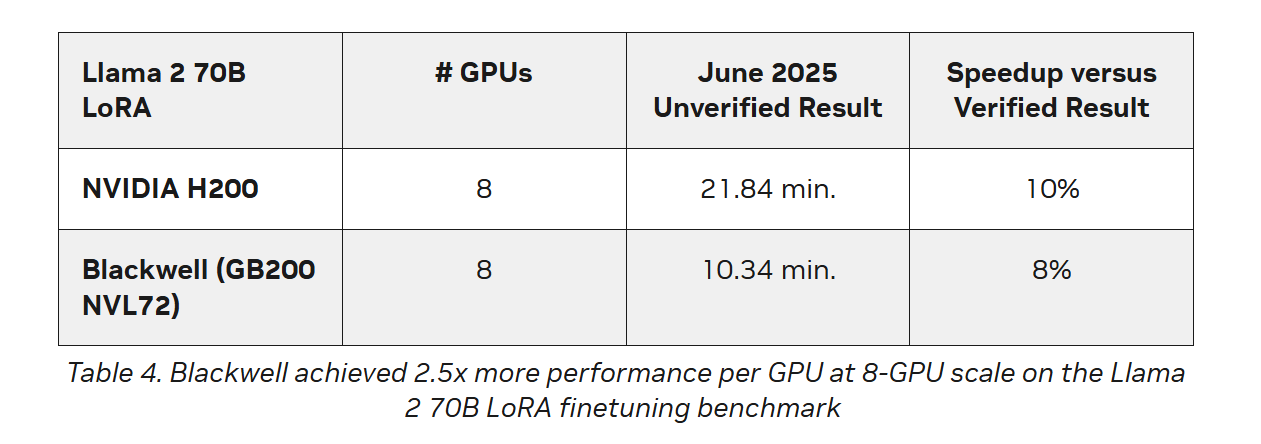 В ходе пресс-конференции Дэйв Сальватор (Dave Salvator), директор по ускоренным вычислительным продуктам в NVIDIA, ответил на распространенный вопрос: «Зачем фокусироваться на обучении, когда в отрасли в настоящее время все внимание сосредоточено на инференсе?». Он сообщил, что тонкая настройка (после предварительного обучения) остается ключевым условием для реальных LLM, особенно для предприятий, использующих собственные данные. Он обозначил обучение как «фазу инвестиций», которая приносит отдачу позже в развёртываниях с большим объёмом инференса. Этот подход соответствует более общей концепции «ИИ-фабрики» компании, в рамках которой ускорителям даются данные и питание для обучения моделей. А затем производятся токены для использования в реальных приложениях. К ним относятся новые «токены рассуждений» (reasoning tokens), используемые в агентских ИИ-системах. 
 NVIDIA также повторно представила результаты по Hopper, чтобы подчеркнуть, что H100 остаётся «единственной архитектурой, кроме Blackwell», которая показала лидерские показатели по всему набору MLPerf Training, хотя и уступила Blackwell. Поскольку инстансы на H100 широко доступны у провайдеров облачных сервисов, компания, похоже, стремится заверить клиентов, что существующие развёртывания по-прежнему имеют смысл. 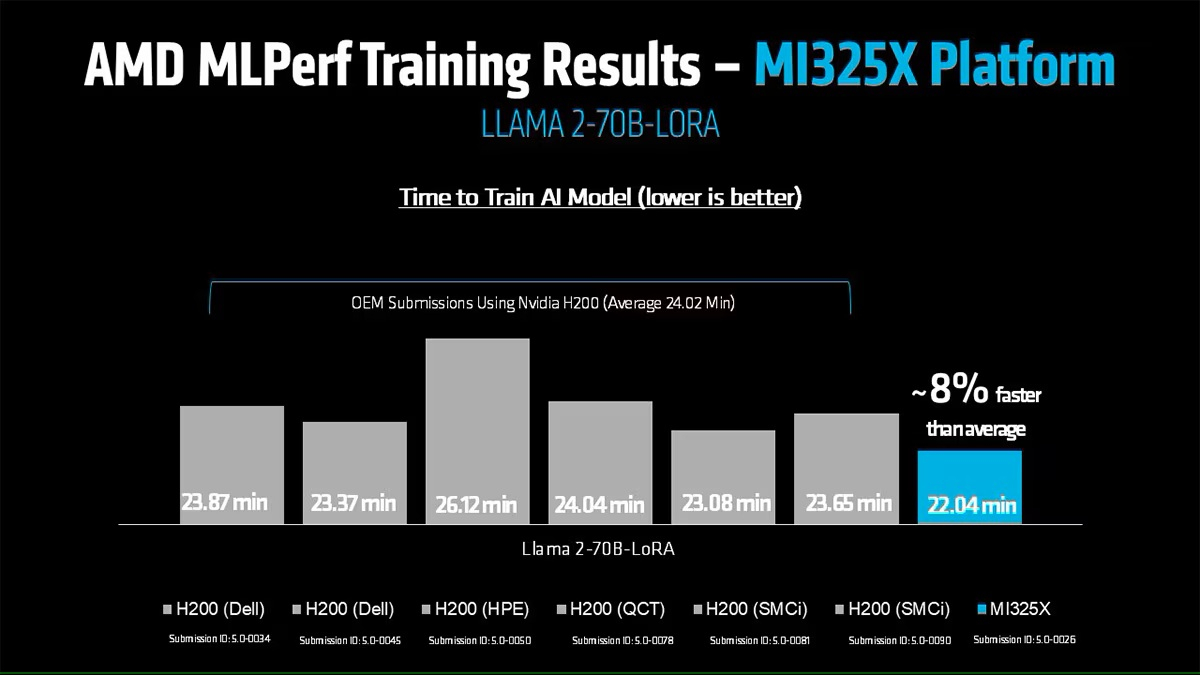
Источник изображений: AMD AMD, со своей стороны, продемонстрировала прирост производительности поколения чипов. В тесте Llama2 70B LoRA она показала 30-% прирост производительности AMD Instinct MI325X по сравнению с предшественником MI300X. Основное различие между ними заключается в том, что MI325X оснащён почти на треть более быстрой памятью.  В самом популярном тесте, тонкой настройке LLM, AMD продемонстрировала, что её новейший ускоритель Instinct MI325X показывает результаты наравне с NVIDIA H200. Это говорит о том, что AMD отстает от NVIDIA на одно поколение, отметил ресурс IEEE Spectrum. 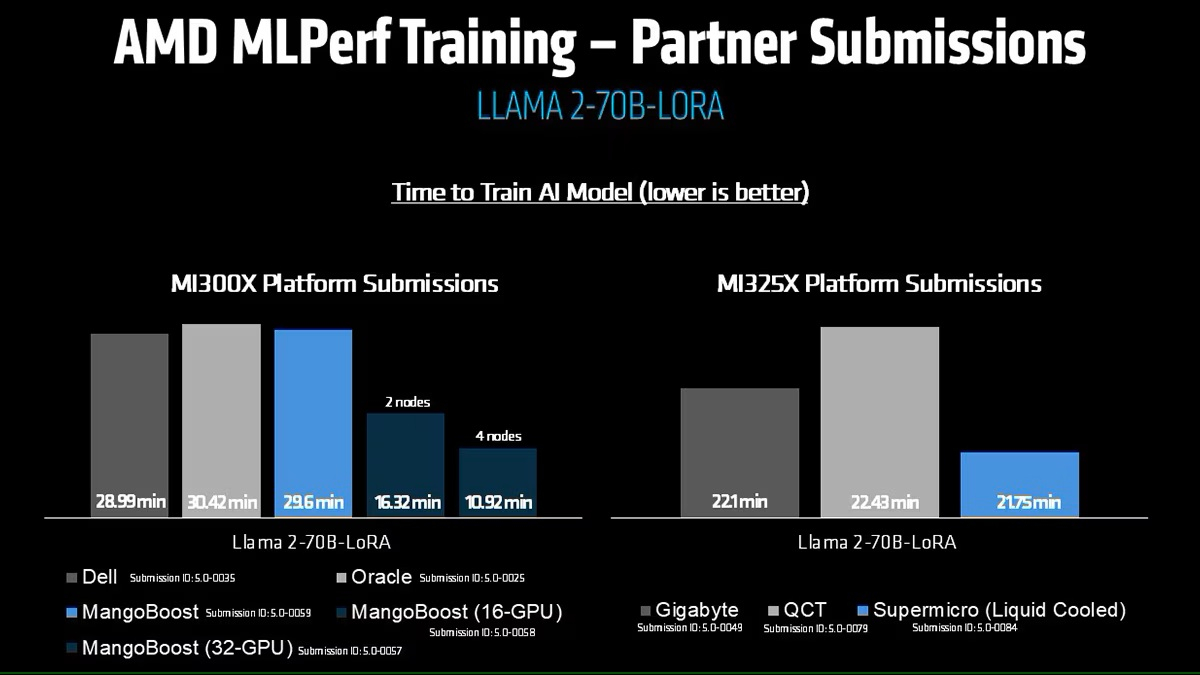 AMD впервые представила результаты MLPerf Training, хотя в предыдущие годы другие компании представляли результаты в этом тесте, используя ускорители AMD. В свою очередь, Google представила результаты лишь одного теста, задачи генерации изображений, с использованием Trillium TPU. Тест MLPerf также включает тест на энергопотребление, измеряющий, сколько энергии уходит на выполнение каждой задачи обучения. В этом раунде лишь Lenovo включила измерение этого показателя в свою заявку, что сделало невозможным сравнение между компаниями. Для тонкой настройки LLM на двух ускорителях Blackwell требуется 6,11 ГДж или 1698 КВт·ч — примерно столько энергии уходит на обогрев небольшого дома зимой. |
|