Материалы по тегу: nvidia
|
06.10.2025 [14:00], Сергей Карасёв
HP представила компактный «ИИ-суперкомпьютер» ZGX Nano G1n AI Station на основе NVIDIA GB10Компания HP анонсировала рабочую станцию ZGX Nano G1n AI Station небольшого форм-фактора, предназначенную для работы с ИИ, включая «тонкую» настройку языковых моделей, инференс и агентные приложения. Основой новинки служит суперчип NVIDIA GB10 Grace Blackwell. В целом решение практически не отличается от систем на базе GB10 других вендоров. Устройство заключено в корпус с габаритами 150 × 150 × 51 мм, а масса составляет 1,25 кг. В состав чипа GB10 входят 20-ядерный процессор Grace (10 × Arm Cortex-X925 и 10 × Arm Cortex-A725) и ускоритель Blackwell. Имеется 128 Гбайт унифицированной системной памяти LPDDR5x, пропускная способность которой достигает 273 Гбайт/с. Компьютер может быть оборудован SSD типоразмера M.2 вместимостью 1 или 4 Тбайт (NVMe OPAL). В оснащение входят сетевой контроллер 10GbE (Realtek RTL8127), адаптер NVIDIA ConnectX-7 200GbE, беспроводной модуль MediaTek MT7925 с поддержкой Wi-Fi 7 (2×2) / Bluetooth 5.4. В тыльной части корпуса располагаются разъём USB Type-C для подачи питания, три порта USB Type-C (20 Гбит/с), гнездо RJ45 (10GbE), два порта QSFP и интерфейс HDMI 2.1a. 
Источник изображения: HP На устройстве применяется программная платформа NVIDIA DGX OS на базе Ubuntu, оптимизированная специально для задач ИИ. Заявленная производительность достигает 1000 TOPS на операциях FP4. Возможна работа с ИИ-моделями, насчитывающими до 200 млрд параметров. Кроме того, два экземпляра ZGX Nano G1n AI Station могут быть объединены в одну систему, что позволит использовать ИИ-модели, оперирующие 405 млрд параметров. Продажи компактного ИИ-суперкомпьютера начнутся текущей осенью.
04.10.2025 [12:56], Сергей Карасёв
Fujitsu и NVIDIA создадут вычислительную ИИ-инфраструктуру нового поколенияЯпонская корпорация Fujitsu объявила о расширении стратегического сотрудничества с NVIDIA с целью создания полнофункциональной инфраструктуры ИИ следующего поколения, в состав которой войдут ИИ-агенты. Предполагается, что инициатива поможет ускорить развитие таких отраслей, как здравоохранение, производство, робототехника и др. Партнёры намерены работать по ряду направлений. В частности, Fujitsu и NVIDIA займутся созданием передовой вычислительной инфраструктуры для задач ИИ. Речь идёт об объединении серверных процессоров Fujitsu Monaka на архитектуре Arm с высокопроизводительными GPU разработки NVIDIA. Для этого будет задействована технология NVLink Fusion, позволяющая применять скоростные интерконнекты NVLink со сторонними чипами. Конечной целью является предоставление комплексной экосистемы HPC-ИИ с интегрированным софтом Fujitsu для Arm-процессоров и NVIDIA CUDA. Кроме того, сотрудничество предусматривает создание «саморазвивающейся» платформы ИИ-агентов. Она, как ожидается, обеспечит высокую производительность и безопасность. Планируется внедрение механизма, который позволит агентам и моделям ИИ развиваться автономно с возможностью оптимизации под запросы конкретных отраслей. В конечном итоге, такие агенты будут предоставляться заказчикам в виде микросервисов NVIDIA NIM. 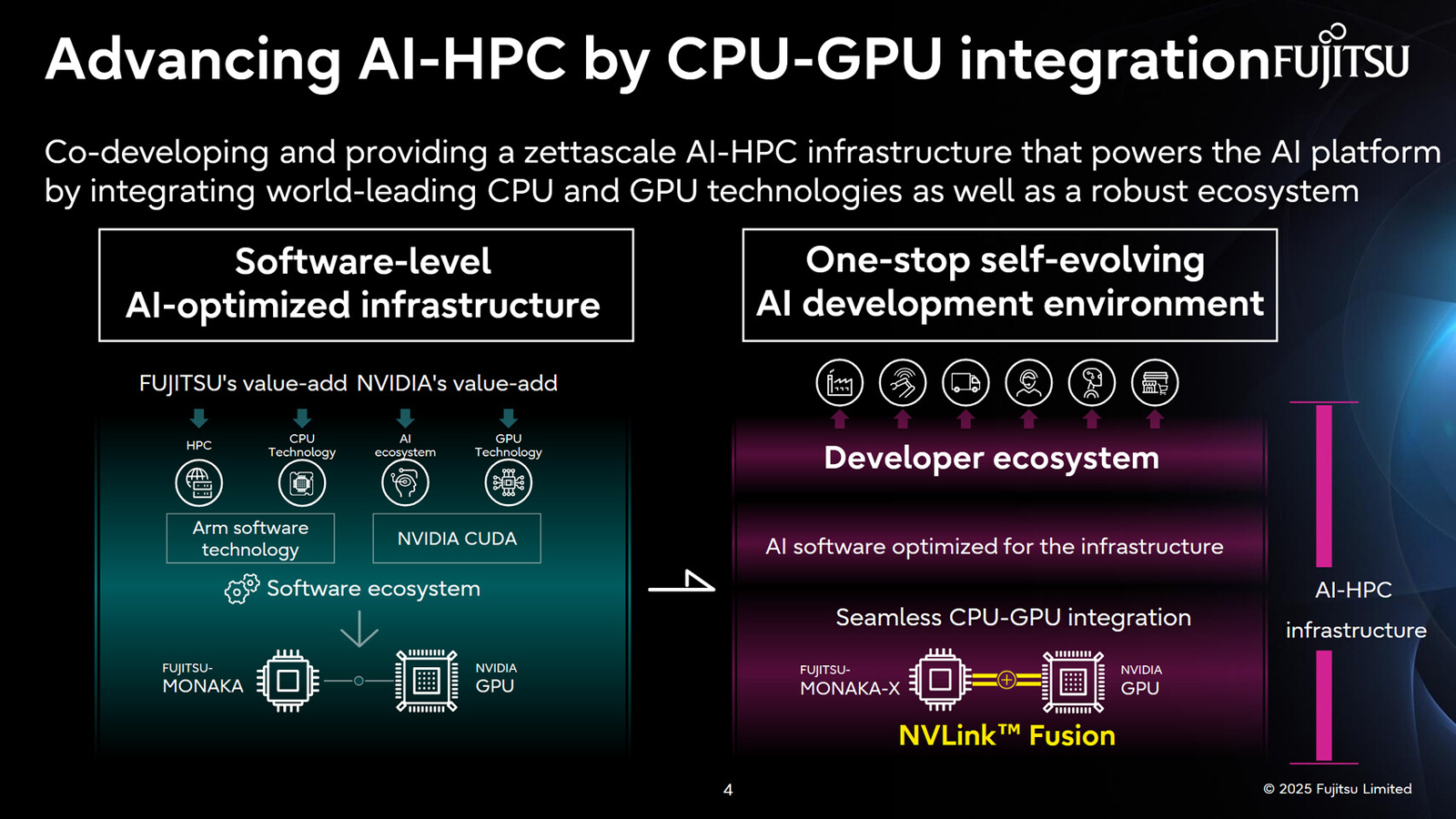
Источник изображений: Fujitsu Ещё одним направлением сотрудничества названо формирование партнёрской экосистемы для расширения использования агентов и моделей ИИ. Планируется также разработка передовых квантовых технологий, включая гибридные квантово-классические вычислительные системы на основе чипов Monaka и НРС-решений NVIDIA.  В целом, как отмечается, к 2030 году спрос на вычислительные мощности для ИИ в Японии вырастет в 320 раз по сравнению с 2020-м. На этом фоне местные компании, включая Fujitsu, SoftBank и KDDI, активно реализуют различные проекты, направленные на развитие рынка ИИ.
03.10.2025 [15:57], Руслан Авдеев
Задержки поставок ИИ-чипов в ОАЭ на десятки миллиардов долларов расстраивают NVIDIAСпустя пять месяцев после заключения многомиллиардной сделки по поставке ИИ-ускорителей в ОАЭ, процесс её реализации фактически заморожен. Это обескураживает как главу NVIDIA Дженсена Хуанга (Jensen Huang), так и некоторых чиновников из Белого дома, сообщает The Wall Street Journal. В рамках сделки, анонсированной в мае, ОАЭ пообещали инвестировать в США большие средства в обмен на обещание поставок сотен тысяч ИИ-ускорителей ежегодно. Однако спустя месяцы после переговоров инвестиции так и не стартовали. Будущее соглашения сейчас в руках министра торговли США Говарда Лютника (Howard Lutnick), в своё время поддержавшего сделку. Разрешение Министерства торговли имеет критическое значение, поскольку именно оно должно дать NVIDIA и другим производителям право на поставку ИИ-чипов в ОАЭ. По некоторым данным, министр оказывает давление на Эмираты, чтобы те, наконец, вложили в экономику США обещанные средства — иначе судьба поставок ускорителей в страну окажется под вопросом. Президент США Дональд Трамп (Donald Trump) одобрил сделку с ОАЭ в ходе майского турне, в надежде продвинуть собственные ИИ-технологии вместо китайских. На тот момент было заявлено, что Белый дом подготовил сделки с ОАЭ на сумму $200 млрд, включая соглашение о помощи в развитии американских технологий и производства. 
Источник изображения: Darcey Beau / Unsplash Результаты переговоров имеют немалое значение для Лютника, поскольку того и так критикуют за введение высоких импортных пошлин и платы $100 тыс. за визу H-1B, по которой в США въезжали попадали многие технические специалисты. Давление оказывает и NVIDIA, которая крайне заинтересована в расширении поставок. Хуанг и его соратники неоднократно жаловались на политику Лютника и медленный прогресс в одобрении экспорта. Правда, точных данных о том, что именно он заморозил поставки, пока нет. В ОАЭ придерживаются позиции, что в ответ на миллиардные инвестиции в страну должны поставлять ускорители NVIDIA на миллиарды долларов. По данным чиновников, как минимум $1 млрд будет вложен в США в обмен на поставки чипов на $1 млрд к концу года. По некоторым сведениям, за чипы ОАЭ будет расплачиваться отдельно и без учёта инвестиций. ОАЭ демонстрирует приверженность идее инвестиций в американские ЦОД и даже вели дела с представителями семьи самого Трампа. Что касается инвестиций, США стремятся поощрять вложения в американскую экономику не только со стороны Эмиратов. Так, недавно была заключена сделка с Японией, которая обязалась инвестировать в США $550 млрд, в специальный фонд поднадзорный министру торговли. Тем временем NVIDIA стремится добиться экспортных лицензий на поставку чипов и в Китай. В своё время у производителей потребовали отчислять 15 % от выручки за поставки в эту страну урезанных версий ускорителей. В рамках соглашения с ОАЭ, большинство чипов в страну будет поставляться представительствам американских компаний. Некоторые чиновники бьют тревогу в связи с участием в сделке G42 из Абу-Даби. Есть опасения, что прямые поставки чипов ей приведут к перепродаже их в Китай, с которым у компании были довольно тесные связи. Пока Министерство торговли не планирует поставок G42, но это не исключено в будущем.
02.10.2025 [21:02], Владимир Мироненко
Microsoft потратит $33 млрд на доступ к 100+ тыс. NVIDIA GB300 в неооблаках, но со временем хочет перейти на свои ИИ-ускорителиВ Сети появились новые подробности о сделке стоимостью до $19,4 млрд, заключённой Microsoft с Nebius Group NV в начале сентября. Как сообщает Bloomberg со ссылкой на информированные источники, Microsoft получит пятилетний доступ к выделенной инфраструктуре на базе более чем 100 тыс. суперускорителей NVIDIA GB300. Ранее сообщалось, что речь идёт о мощностях нового ЦОД Nebius в Вайнленде (Нью-Джерси, США). Как пишет Forbes, Nebius отличается от многих облачных провайдеров тем, что фокусируется только на рабочих нагрузках ИИ и МО, что позволяет лучше оптимизировать архитектуру ЦОД в отличие от гиперскейлеров, которые занимаются решением множества задач. Кроме того, Nebius отличается от других неооблаков, таких как CoreWeave, тем, что предоставляет инструменты и сервисы для разработчиков, которые позволяют совершенствовать ИИ-модели, выполнять инференс и разрабатывать кастомные решения, а не просто фокусируется на «чистой» вычислительной мощности. При этом Nebius начала наращивать вычислительные мощности ещё до того, как возник спрос на эти ресурсы, отметил Forbes. Подобные контракты Microsoft заключила с ещё несколькими неооблаками (neocloud), включая CoreWeave, Nscale и Lambda, на общую сумму в $33 млрд, и они обеспечивают её большую выгоду. Вместо того, чтобы тратить огромные ресурсы на строительство собственных ЦОД, Microsoft обращается к проверенному поставщику ИИ-инфраструктуры, благодаря чему может быстрее совершенствовать свою ИИ-инфраструктуру с меньшими первоначальными затратами, используя высвободившиеся мощности для предоставления клиентам прибыльных услуг на базе ИИ. Вдобавок такой подход позволяет Microsoft быстрее менять стратегию, чем при использовании собственных дата-центров. В начале бума ИИ Microsoft арендовала мощности даже у Oracle, своего прямого конкурента, для поддержки ИИ-функций в поиске Bing. 
Источник изображения: Nebius/Bloomberg Эти сделки также устраняют для Microsoft значительную часть финансовых рисков, связанных со строительством собственных ЦОД. Она не только сразу получает необходимые мощности для своих ИИ-сервисов, вместо того чтобы тратить годы на строительство ЦОД, но и перекладывает на других вопросы строительства, финансирования и управление этими ЦОД, что даёт компании большую финансовую гибкость. Так, Microsoft может отнести некоторые затраты к операционным, а не капитальным, что, по словам аналитика Bernstein Марка Мёрдлера (Mark Moerdler), даёт потенциальные преимущества для денежного потока, налогообложения и способа представления прибыли в финотчётах. Компания использует серверы неооблаков не только для обучения ИИ-моделей, но и для сложного инференса. Сделки с неооблаками становятся популярными и у конкурентов Microsoft, хотя им далеко до её масштабов. В мае 2025 года OpenAI расширила с конкурирующей с Nebius компанией CoreWeave контракт стоимостью $11,9 млрд на $4 млрд, после чего заключила ещё одно соглашение на $6,5 млрд, увеличив общую сумму соглашений до $22,4 млрд. Ещё один технологический гигант Meta✴ подписал сделку с CoreWeave на сумму в $14,2 млрд, обеспечив себе доступ к её облачным ИИ-сервисов на период до 2031 года. Вместе с тем в долгосрочной перспективе Microsoft намерена переключиться на ИИ-ускорители собственной разработки, которые обеспечивают лучший показатель TCO, передаёт CNBC. Два года назад компания представила первые ИИ-чипы Maia 100. Следующее поколение этих чипов, как ожидается, появится в 2026 году. При этом компания сосредоточится не на чипах в отдельности, а будет использовать более системный подход, учитывающий вопросы охлаждения, интерконнекта и т.д. Пока что, признаёт Microsoft, в течение многих лет решения NVIDIA обеспечивали лучшее соотношение цены к производительности.
29.09.2025 [11:10], Руслан Авдеев
Канадский рынок дата-центров вырастет почти на порядок — до 10,3 ГВтКанада готовится к новой фазе развития рынка дата-центров. В отчёте аналитического агентства DC Byte говорится, что общая ёмкость рынка ЦОД в обозримом будущем вырастет до 10,3 ГВт с нынешних введённых в эксплуатацию 1,4 ГВт. Проекты общей мощностью 8,9 ГВт находятся на разных этапах реализации, их них 6,9 ГВт — на ранних этапах без фактического начала строительства. Во многом будущий рост объясняется серией анонсов, состоявшихся во II полугодии 2024 года. В том числе речь идёт о проекте инвестора, бизнесмена и шоумена Кевином О’Лири (Kevin O’Leary) Wonder Valley в провинции Альберта. В своё время было заявлено, что речь идёт о строительстве 55 объектов мощностью 100 МВт каждый с питанием от природного газа. Это крупнейший проект, на который приходится 5,6 ГВт от общего плана (по другим данным — 7,5 ГВт). В DC Byte отмечают, что речь идёт о новом этапе роста, связанном с бумом ИИ и ориентированных на ускорители дата-центров. Тем не менее, они должны заработать не раньше 2027 года, а пока же рынок всё ещё ориентирован на «традиционные» дата-центры, где лидируют Vantage, Cologix и Compass. 93 % IT-нагрузок ЦОД страны приходится на Торонто, Монреаль и провинцию Альберту (столица Эдмонтон). При этом в Канаде 60 % местной генерации приходится на ГЭС, т.е. «зелёную» энергетику, что при соблюдении некоторых условий, не может не привлекать глобальных игроков. Впрочем, природного газа здесь тоже хватает, и на него тоже делают ставку. 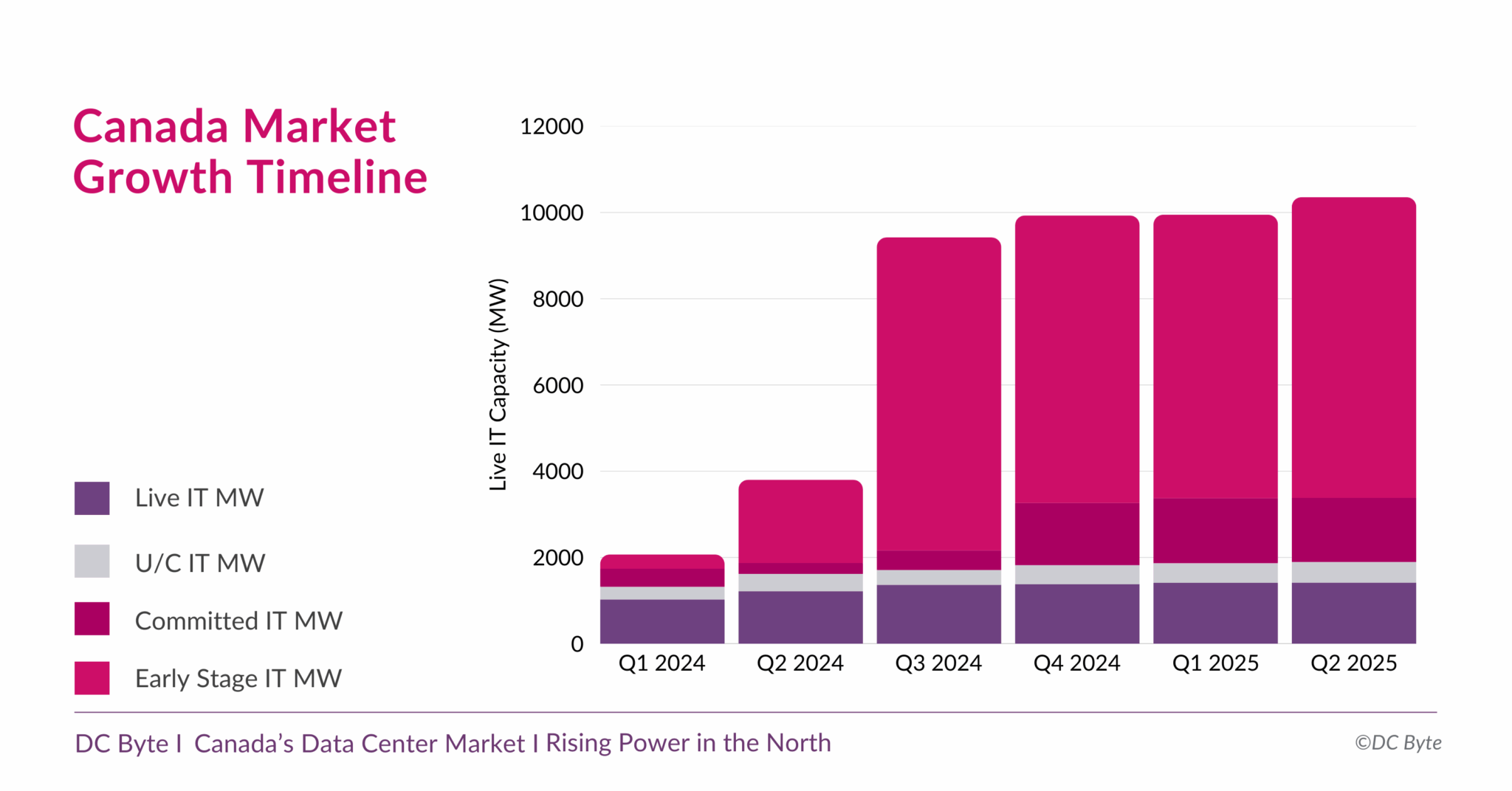
Источник изображения: DC Byte Пока же местные проекты отличает скромность. Так, совокупная мощность сети ИИ ЦОД Bell AI Fabric, планируемой Bell Canada и Telus, составит 500 МВт. Впрочем, на конференции All In Canada AI Ecosystem в Монреале Канада представила стратегию развития суверенного ИИ, подчеркнув важность цифрового суверенитета и экономической независимости, и анонсировала открытие первой ИИ-фабрики Telus, построенной при поддержке NVIDIA и HPE. Фабрика обеспечивает полный цикл работы с ИИ — от обучения моделей до инференса, с хранением данных внутри страны и питанием от возобновляемой энергии на 99 %. 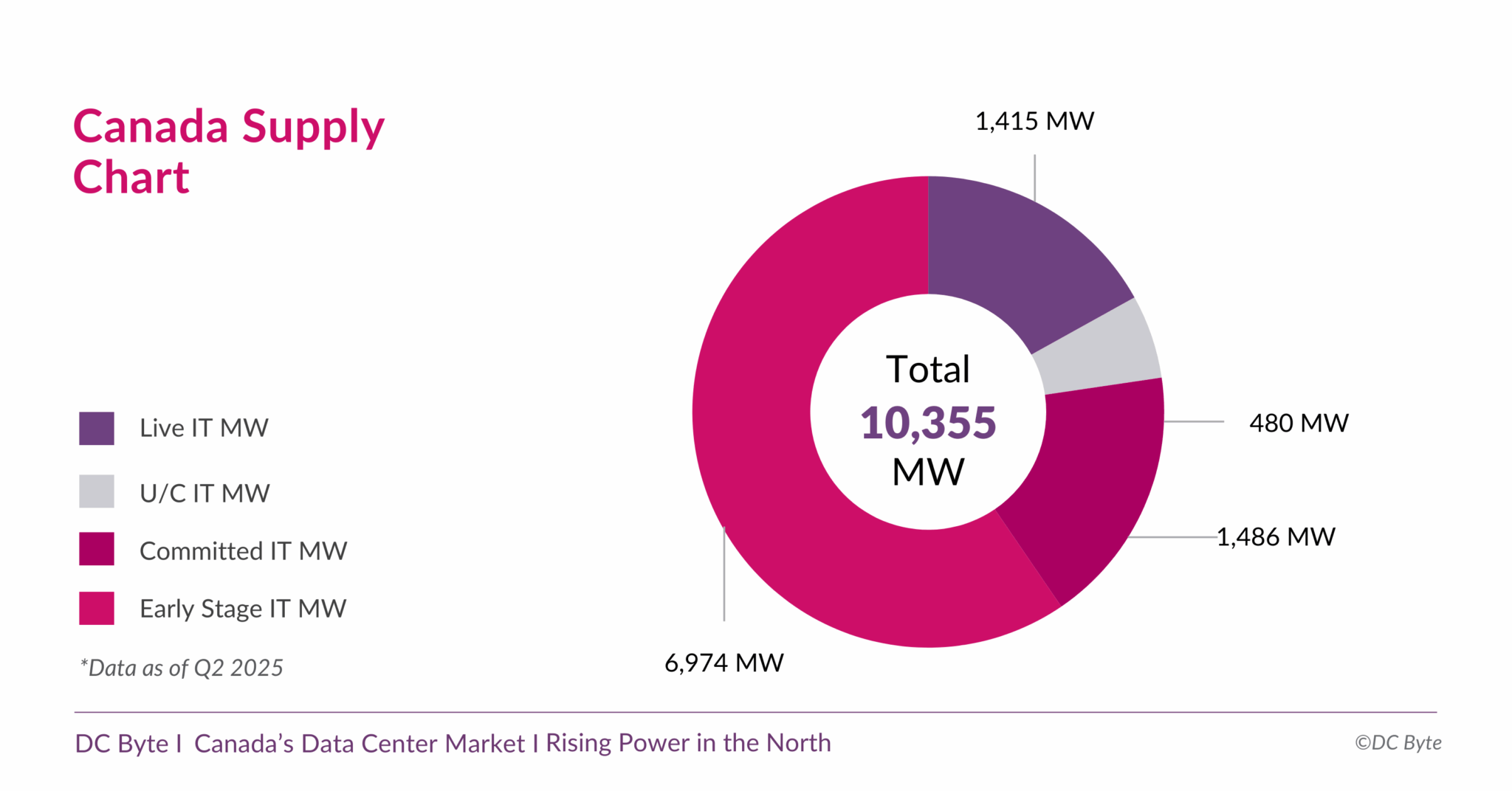
Источник изображения: DC Byte Тогда AMD и канадская Cohere объявили о расширении сотрудничества в сфере ИИ. В частности, ключевые «безопасные» решения последней, включая Command A, Vision, Translate и North, будут доступны на ИИ-инфраструктуре на базе ускорителей Instinct. Благодаря этому корпоративные и государственные клиенты, включая канадские проекты «суверенного ИИ», получат больше возможностей выбора ИИ-инструментов. AMD станет использовать платформу Cohere North для решения собственных инженерных и бизнес-задач.
28.09.2025 [12:30], Сергей Карасёв
«Зелёная» энергия для «зелёных» ускорителей: Lambda и ECL впервые запитали NVIDIA GB300 NVL72 от водородаОблачный провайдер Lambda и стартап ECL объявили о развёртывании первых в отрасли систем NVIDIA GB300 NVL72 с питанием от водорода. Высокопроизводительная платформа предназначена для обучения базовых ИИ-моделей, инференса и других ресурсоёмких задач. ECL специализируется на создании автономных модульных дата-центров с питанием от водорода, при возведении которых применяются технологии 3D-печати. Первым ЦОД компании стал объект MV1 мощностью 1 МВт на площадке в Маунтин-Вью (Калифорния, США). Кроме того, ECL заявила о намерении построить ИИ ЦОД TerraSite-TX1 мощностью 1 ГВт к востоку от Хьюстона (Техас, США). Как сообщается, системы NVIDIA GB300 NVL72 компании Lambda смонтированы на базе модульного дата-центра MV1. Эта площадка отличается нулевым потреблением воды и нулевым уровнем выбросов вредных газов в атмосферу. Питание обеспечивается исключительно от водородных топливных элементов. Развёрнутые устройства GB300 NVL72 разработаны компанией Supermicro. Они обладают мощностью 142 кВт. Для отвода тепла применяется система прямого жидкостного охлаждения, вода для которой поступает от водородных топливных элементов, на которых вырабатывается в качество побочного продукта при генерации электричества. Задействованы централизованные блоки распределения охлаждающей жидкости (CDU). Утверждается, что это первое в отрасли подобное сочетание инфраструктуры на базе ускорителей NVIDIA с водородным источником «зеленой» энергии. 
Источник изображения: Lambda Отмечается, что развёртывание систем NVIDIA GB300 NVL72, масса которых составляет примерно 1800 кг, сопряжено с серьёзными трудностями. Лишь немногие дата-центры способны справиться с требованиями к плотности мощности и охлаждению. Водородные топливные элементы рассматриваются в качестве одного из наиболее перспективных способов решение проблемы питания таких объектов. При этом становится возможным устойчивое развитие облачных ИИ-платформ.
27.09.2025 [15:32], Сергей Карасёв
Майнинговая компания Iren увеличила мощность ИИ-облака, закупив тысячи ускорителей NVIDIA и AMD за $674 млнКриптомайнинговая компания Iren (ранее известная как Iris Energy), по сообщению Datacenter Dynamics, увеличила количество ИИ-ускорителей в своём облаке примерно в два раза. Стоимость приобретённого оборудования оценивается в $674 млн. Компании прочат статус серьёзного игрока на рынке неооблаков. Компания находится в процессе перехода от майнинга криптовалют к облачному бизнесу на базе ИИ. В частности, закуплены 7100 ускорителей NVIDIA B300 и 4200 изделий NVIDIA B200, а также 1100 AMD Instinct MI350X. В результате, общее количество ускорителей в составе платформы Iren достигло приблизительно 23 тыс. Новое оборудование в ближайшие месяцы будет развёрнуто в кампусе Iren в городе Принс-Джордже (Prince George) в северной части провинции Британская Колумбия в Канаде. В настоящее время на этой площадке ведётся строительство вычислительного комплекса с жидкостным охлаждением мощностью 10 МВт (ИТ-нагрузка), который сможет поддерживать более 4500 суперускорителей NVIDIA GB300. В конце августа нынешнего года Iren сообщила о приобретении 1200 ускорителей NVIDIA B300 для серверов с воздушным охлаждением и 1200 изделий NVIDIA GB300 для систем с жидкостным охлаждением: стоимость данной партии составила примерно $168 млн. Эти чипы также предназначены для ЦОД в Принс-Джордже. Тогда говорилось, что Iren привлекла финансирование в размере около $96 млн для покупки GB300: средства получены по схеме лизинга сроком на два года. 
Источник изображения: Iren В настоящее время Iren управляет пятью кампусами ЦОД общей мощностью 810 МВт, расположенными в Северной Америке: два в Техасе (США) и три в Британской Колумбии (Канада). Ещё 2,1 ГВт находятся в стадии строительства, причём 2 ГВт из них приходится на новый кампус в Техасе. Как отмечает Дэниел Робертс (Daniel Roberts), соучредитель и содиректор Iren, удвоение парка GPU позволит удовлетворить растущие потребности клиентов в масштабируемых вычислительных мощностях.
26.09.2025 [10:33], Руслан Авдеев
Media Stream AI построит в Манчестере 2-МВт ИИ ЦОД с охлаждением водой из местного каналаБританская медиакомпания Media Stream AI (MSAI) намерена открыть в Солфорде (Salford, Большой Манчестер) дата-центр в популярном «творческом» районе Media City. Объект мощностью 2 МВт будет использовать для охлаждения воду из канала Рочдейл (Rochdale), сообщает Datacenter Dynamics. Система охлаждения будет состоять из замкнутого контура с теплообменниками и драйкулеров. При поддержке Lenovo объект стоимостью £50 млн ($67,3 млн) сможет обеспечить плотность стоек на уровне 30–60 кВт при PUE менее 1,2. На площадке планируется разместить 1,1 тыс. ускорителей NVIDIA H200 в составе серверов Lenovo ThinkSystem с СЖО Neptune. В будущем возможно расширение до 2,3 тыс. ускорителей. Объект должен заработать в I квартале 2026 года. Компания намерена создать там же собственную виртуальную продакшн-студию и робототехническую лабораторию. Media Stream AI рассчитывает предоставлять ИИ-сервисы медиакомпаниям и работникам творческих профессий. На сайте стартапа объявлено, что он намерен предоставить доступ к ускорителям NVIDIA L4, A10G, A4000, A5000, A100, H100 и L40. Также компания намерена развернуть к концу 2026 года площадки в Германии и Франции. Более того, MSAI заключила соглашение с властями Ямайки о строительстве и эксплуатации первого на острове ИИ ЦОД. 
Источник изображения: Jonny Gios/unsplash.com Прецеденты использования похожих систем охлаждения есть. Например, Digital Realty использует для охлаждения ЦОД во Франции и Великобритании проточную речную воду. Green Mountain намерена развернуть систему охлаждения речной водой на своём новом объекте в Германии. Речное охлаждение также используют Denv-R во Франции и Nautilus в Калифорнии. Наконец, сеть европейских супермаркетов Lidl объявила, что один из её ЦОД в Германии тоже использует охлаждение речной водой, а норвежский оператор дата-центров Polar утверждает, что для охлаждения одного из своих ЦОД намерен использовать близлежащую реку. Участвуют в подобных проектах и гиперскейлеры. Площадка Google в Финляндии использует для охлаждения и морскую воду.
24.09.2025 [16:55], Владимир Мироненко
OpenAI арендует, а не купит чипы у NVIDIA в рамках $100-млрд сделкиВ СМИ появились новые подробности о сделке NVIDIA и OpenAI, в рамках которой чипмейкер инвестирует в OpenAI $100 млрд. Как сообщает газета The Financial Times, переговоры прошли напрямую между гендиректором NVIDIA Дженсеном Хуангом (Jensen Huang) и главой OpenAI Сэмом Альтманом (Sam Altman). Главы компаний обсуждали подробности соглашения практически без официальных консультаций с банками, которые обычно выступают посредниками в подобных случаях. По данным The Information, в числе обсуждаемых вопросов было применение новой бизнес-модели лизинга чипов. Вместо того чтобы напрямую приобретать ускорители NVIDIA, OpenAI фактически будет брать у NVIDIA чипы в аренду с постепенной оплатой, что потенциально снизит первоначальные затраты на 10–15 % в течение пяти лет. Точные условия аренды или лизинга не разглашаются. У кого останутся чипы после окончания срока действия договора, тоже не говорится. 
Источник изображения: NVIDIA Данный подход отражает более широкую тенденцию в ИИ-отрасли, где капиталоёмкая ИИ-инфраструктура рассматривается скорее как услуга, чем как основной актив. Такая бизнес-модель позволяют компаниям быстро масштабироваться без значительных капитальных затрат, в то время как NVIDIA обеспечивает себе долгосрочные источники дохода. Как отметил Альтман, сделка знаменует собой «новую модель финансирования <…>, при которой мы можем платить постепенно, а не покупать всё сразу». «Чипы и системы составляют огромную [долю] стоимости, и оплатить её авансом сложно», — добавил он. По словам аналитиков, действия Хуанга, направленные на то, чтобы сделать NVIDIA «предпочтительным стратегическим партнёром OpenAI в области вычислений и сетевых технологий», затруднят переход ИИ-разработчиков на конкурирующие чипы. Также укрепляет позиции компании в отрасли программная платформа NVIDIA CUDA, ставшая стандартным инструментом написания ИИ-приложений. Удерживая ИИ-разработчиков в своей экосистеме, Хуанг инвестирует в OpenAI, а также в десятки других стартапов, занимающихся ИИ-приложениями, облачными вычислениями, робототехникой и здравоохранением, что «многократно окупится для NVIDIA в будущем», говорят эксперты.
23.09.2025 [01:00], Владимир Мироненко
NVIDIA инвестирует в OpenAI $100 млрд, которые в основном пойдут на покупку её же ускорителейNVIDIA и OpenAI объявили о подписании соглашения о намерениях в рамках стратегического партнёрства, согласно которому NVIDIA поставит OpenAI ускорители для развёртывания ИИ-инфраструктуры мощностью не менее 10 ГВт, что позволит обучать и запускать модели следующего поколения на пути к созданию суперинтеллекта. Для поддержки планов OpenAI, включающих строительство нескольких дата-центров, NVIDIA обязалась инвестировать в неё до $100 млрд, но поэтапно и по мере развёртывания новых ИИ-кластеров NVIDIA. Запуск первого этапа запланирован на II половину 2026 года с началом поставок платформы Vera Rubin. Первые $10 млрд от NVIDIA станут доступны после того, как стороны достигнут окончательного соглашения о покупке OpenAI её ИИ-платформ. Ожидается, что детали нового этапа стратегического партнёрства будут определены в ближайшие недели. Проект не связан со Stargate. Агентство Reuters отметило взаимовыгодный характер сделки, в результате которой NVIDIA получает долю в крупнейшей в мире компании в области ИИ, уже являющейся её важным клиентом. В свою очередь, OpenAI получает необходимые денежные средства и доступ для покупки передовых чипов, которые необходимы ей в первую очередь для сохранения своего доминирования в условиях растущей конкуренции. По словам источника Reuters, близкого к OpenAI, сделка будет включать две отдельные, но взаимосвязанные транзакции. Стартап сам заплатит NVIDIA за чипы, в то время как деньги NVIDIA пойдут на приобретение миноритарной доли акций. 
Источник изображения: Lucas Jennis / Wikipedia Согласно пресс-релизу, OpenAI будет сотрудничать с NVIDIA в качестве приоритетного стратегического партнёра в области вычислений и сетевых технологий для реализации планов по развитию ИИ-фабрик. Компании будут совместно оптимизировать свои планы по разработке ПО OpenAI для моделирования и инфраструктуры, а также аппаратного и программного обеспечения NVIDIA. Напомним, что NVIDIA поддержала OpenAI в раунде финансирования на $6,6 млрд в октябре 2024 года. Генеральный директор NVIDIA Дженсен Хуанг (Jensen Huang) сообщил телеканалу CNBC, что 10 ГВт эквивалентны от 4 до 5 млн GPU. По его словам, именно такой объём компания поставит в этом году, что «вдвое больше, чем в прошлом году». «Спрос на ускорители NVIDIA фактически является неотъемлемой частью разработки передовых ИИ-моделей», — заявил аналитик eMarketer Джейкоб Борн (Jacob Bourne), отметив, что подобные сделки также должны снизить опасения по поводу потери продаж в Китае. Он добавил, что это также опровергает предположение о том, что конкурирующие производители чипов или кастомные разработки крупных технологических платформ способны потеснить NVIDIA. Масштаб инвестиций NVIDIA может привлечь внимание антимонопольных органов, пишет Reuters. Министерство юстиции США и Федеральная торговая комиссия США (FTC) достигли соглашения в середине 2024 года, которое открыло путь для потенциальных расследований роли Microsoft, OpenAI и NVIDIA в ИИ-индустрии. Однако администрация Дональда Трампа (Donald Trump) пока придерживается более мягкого подхода к вопросам конкуренции по сравнению с предыдущей администрацией. Инвестиции NVIDIA последовали за недавним раундом вторичного финансирования, в ходе которого OpenAI получила у ряда инвесторов оценку в $500 млрд. |
|