Материалы по тегу: llm
|
24.03.2025 [01:37], Владимир Мироненко
NVIDIA анонсировала ИИ-модели Llama Nemotron с регулируемым «уровнем интеллекта»NVIDIA анонсировала новое семейство ИИ-моделей Llama Nemotron с расширенными возможностями рассуждения. Основанные на моделях Llama с открытым исходным кодом от Meta✴ Platforms, модели от NVIDIA предназначены для предоставления разработчикам основы для создания продвинутых ИИ-агентов, которые могут от имени своих пользователей независимо или с минимальным контролем работать в составе связанных команд для решения сложных задач. «Агенты — это автономные программные системы, предназначенные для рассуждений, планирования, действий и критики своей работы», — сообщила Кари Бриски (Kari Briski), вице-президент по управлению программными продуктами Generative AI в NVIDIA на брифинге с прессой, пишет VentureBeat. «Как и люди, агенты должны понимать контекст, чтобы разбивать сложные запросы, понимать намерения пользователя и адаптироваться в реальном времени», — добавила она. По словам Бриски, взяв Llama за основу, NVIDIA оптимизировала модель с точки зрения требований к вычислениям, сохранив точность ответов. 
Источник изображений: NVIDIA NVIDIA сообщила, что улучшила новое семейство моделей рассуждений в ходе дообучения, чтобы улучшить многошаговые математические расчёты, кодирование, рассуждения и принятие сложных решений. Это позволило повысить точность ответов моделей до 20 % по сравнению с базовой моделью и увеличить скорость инференса в пять раз по сравнению с другими ведущими рассуждающими open source моделями. Повышение производительности инференса означают, что модели могут справляться с более сложными задачами рассуждений, имеют расширенные возможности принятия решений и позволяют сократить эксплуатационные расходы для предприятий, пояснила компания. Модели Llama Nemotron доступны в микросервисах NVIDIA NIM в версиях Nano, Super и Ultra. Они оптимизированы для разных вариантов развёртывания: Nano для ПК и периферийных устройств с сохранением высокой точности рассуждения, Super для оптимальной пропускной способности и точности при работе с одним ускорителем, а Ultra — для максимальной «агентской точности» в средах ЦОД с несколькими ускорителями. Как сообщает NVIDIA, обширное дообучение было проведено в сервисе NVIDIA DGX Cloud с использованием высококачественных курируемых синтетических данных, сгенерированных NVIDIA Nemotron и другими открытыми моделями, а также дополнительных курируемых наборов данных, совместно созданных NVIDIA. Обучение включало 360 тыс. часов инференса с использованием ускорителей H100 и 45 тыс. часов аннотирования человеком для улучшения возможностей рассуждения. По словам компании, инструменты, наборы данных и методы оптимизации, используемые для разработки моделей, будут в открытом доступе, что предоставит предприятиям гибкость в создании собственных пользовательских рвссуждающих моделей.  Одной из ключевых функций NVIDIA Llama Nemotron является возможность включать и выключать опцию рассуждения. Это новая возможность на рынке ИИ, утверждает компания. Anthropic Claude 3.7 имеет несколько схожую функциональность, хотя она является закрытой проприетарной моделью. Среди моделей с открытым исходным кодом IBM Granite 3.2 тоже имеет переключатель рассуждений, который IBM называет «условным рассуждением». Особенность гибридного или условного рассуждения заключается в том, что оно позволяет системам исключать вычислительно затратные этапы рассуждений для простых запросов. NVIDIA продемонстрировала, как модель может задействовать сложные рассуждения при решении комбинаторной задачи, но переключаться в режим прямого ответа для простых фактических запросов. NVIDIA сообщила, что целый ряд партнёров уже использует модели Llama Nemotron для создания новых мощных ИИ-агентов. Например, Microsoft добавила Llama Nemotron и микросервисы NIM в Microsoft Azure AI Foundry. SAP SE использует модели Llama Nemotron для улучшения возможностей своего ИИ-помощника Joule и портфеля решений SAP Business AI. Кроме того, компания использует микросервисы NVIDIA NIM и NVIDIA NeMo для повышения точности завершения кода для языка ABAP. ServiceNow использует модели Llama Nemotron для создания ИИ-агентов, которые обеспечивают повышение производительности и точности исполнения задач предприятий в различных отраслях. Accenture сделала рассуждающие модели NVIDIA Llama Nemotron доступными на своей платформе AI Refinery. Deloitte планирует включить модели Llama Nemotron в свою недавно анонсированную платформу агентского ИИ Zora AI. Atlassian и Box также работают с NVIDIA, чтобы гарантировать своим клиентам доступ к моделям Llama Nemotron.
23.02.2025 [22:52], Владимир Мироненко
Alibaba в ближайшие три года инвестирует в ИИ и облака $52 млрд — больше, чем за десять лет до этогоAlibaba Group Holding Limited сообщила финансовые результаты III квартала 2024 финансового года, закончившегося 31 декабря 2024 года, которые превысили прогнозы аналитиков. Выручка компании составила ¥280,15 млрд ($38,38 млрд), что на 8 % больше результата аналогичного квартала предыдущего финансового года и выше консенсус-прогноза 17 аналитиков, опрошенных LSEG, в размере ¥279,34 млрд. Инвесторы позитивно оценили квартальные итоги, а также планы китайского технологического гиганта больше инвестировать в электронную коммерцию и ИИ. Благодаря этому на торгах Гонконгской фондовой биржи акции Alibaba поднялись в цене более чем на 10 %, достигнув самого высокого уровня за более чем три года, пишет Reuters. Американские депозитарные расписки компании выросли примерно на 12 % на утренних торгах в Нью-Йорке после публикации результатов, демонстрируя самый большой однодневный процентный прирост с сентября прошлого года, сообщила газета The Wall Street Journal. Согласно Reuters, стоимость акции Alibaba выросла с начала года на 60 %. Чистая прибыль (GAAP), причитающаяся держателям обыкновенных акций, составила ¥48,95 млрд ($6,71 млрд), что значительно превышает прошлогодний результат в размере ¥14,43 млрд ($1,98 млрд) и консенсус-прогноз аналитиков от LSEG в размере ¥40,6 млрд ($5,56 млрд). Чистая прибыль (GAAP) на разводнённую акцию составила ¥2,55 ($0,35). Скорректированная чистая прибыль (Non-GAAP) за квартал составила ¥51,07 млрд ($7,0 млрд), что на 6 % больше результата за III квартал 2023 финансового года. Скорректированная разводнённая прибыль на акцию (Non-GAAP) составила ¥2,67 ($0,37), превысив на 13 % прошлогодний показатель. 
Источник изображений: Alibaba Скорректированная EBITA выросла на 33 % в годовом исчислении до ¥3,14 млрд ($430 млн). Рост произошёл в основном за счёт сдвига в ассортименте продукции в сторону более прибыльных публичных облачных продуктов и повышения операционной эффективности, что частично компенсировалось ростом инвестиций в развитие клиентской базы и технологий. Международный бизнес электронной коммерции, включающий платформу AliExpress, B2B-площадку Alibaba.com и другие региональные платформы, остался одним из самых быстрорастущих в компании, увеличив выручку на 32 % до ¥37,76 млрд ($5,18 млрд). Выручка подразделения Cloud Intelligence Group компании Alibaba выросла на 13 % с ¥28,07 млрд ($3,85 млрд) в прошлом году до ¥31,74 млрд ($4,35 млрд). Как сообщает компания, рост был обусловлен увеличением внедрения продуктов, связанных с ИИ, выручка от которых сохраняла трехзначный процентный годовой рост шестой квартал подряд. Компания подчеркнула приверженность продвижению мультимодального ИИ и open source. В январе 2025 года Alibaba открыла исходный код Qwen2.5-VL, мультимодальной модели следующего поколения, и запустила флагманскую MoE-модель Qwen2.5-Max. Обе модели доступны пользователям и предприятиям через Qwen Chat и собственную платформу Bailian. С августа 2023 года компания открыла целый ряд различных LLM Qwen. По состоянию на 31 января 2025 года на Hugging Face было разработано более 90 тыс. производных моделей на основе семейства Qwen, что делает его одним из крупнейших семейств ИИ-моделей.  Alibaba добилась «значительных успехов» в развитии своего облачного бизнеса в области ИИ после запуска своей флагманской модели Qwen 2.5-Max AI Foundation, сообщила компания Barclays в заметке для инвесторов, добавив, что наблюдается резкий рост спроса на инференс, на который приходится до 70 % всех заказов клиентов. Глава Alibaba Эдди Ву (Eddie Wu) сообщил на встрече с аналитиками, что ИИ — это «та возможность для трансформации отрасли, которая появляется только раз в несколько десятилетий». Он также сказал, что Alibaba вложит в течение следующих трёх лет больше средств в ИИ и облачные вычисления, чем за последнее десятилетие, но не назвал точную сумму. По оценкам Barclays, запланированные инвестиции превысят ¥270 млрд ($37,0 млрд). В этом месяце Alibaba Cloud открыла второй ЦОД в Таиланде в рамках стратегии по расширению присутствия в Юго-Восточной Азии, сообщил ресурс Data Center Dynamics. UPD 24.02.2024: компания официально объявила о намерении инвестировать не менее ¥380 млрд ($52,44 млрд) в облачную и ИИ-инфраструктуру в течение трёх лет.
13.02.2025 [23:58], Руслан Авдеев
Big Data для Большого Брата: глава Oracle предложил собрать все-все данные американцев и обучить на них сверхмощный «присматривающий» ИИ
big data
llm
oracle
software
база данных
государство
ии
информационная безопасность
конфиденциальность
сша
По словам главы Oracle Ларри Эллисона (Larry Ellison), если правительства хотят, чтобы ИИ повысил качество обслуживания и защиту граждан, то необходимо собрать буквально всю информацию о них, включая даже ДНК, в единой базе, которую и использовать для обучения ИИ, сообщает The Register. Таким мнением Эллисон поделился с бывшим премьер-министром Великобритании Тони Блэром (Tony Blair) на мероприятии World Governments Summit в Дубае. Глава Oracle считает, что вскоре искусственный интеллект изменит жизнь каждого обитателя Земли во всех отношениях. По его мнению, нужно сообщить правительству как можно больше информации. Для этого необходимо свести воедино все национальные данные, включая геопространственные данные, информацию об экономике, электронные медицинские записи, в т.ч. информацию о ДНК, сведения об инфраструктуре и др. Т.е. передать буквально всё, обучить на этом массиве ИИ, а потом задавать ему любые вопросы. Подобный проект первым можно реализовать в США, говорит Эллисон. Результатами, по мнению мультимиллиардера, станет рост качества здравоохранения благодаря персонализации медицинской помощи, возможность прогнозировать урожайность и оптимизировать на этой основе производство продовольствия. Можно будет анализировать качество почв, чтобы дать рекомендации фермерам — где именно вносить удобрения и улучшать орошение и др. По словам Эллисона, когда все данные будут храниться в одном месте, можно будет лучше заботиться о пациентах и населении в целом, управлять всевозможными социальными сервисами и избавиться от мошенничества. 
Источник изображения: ev / Unsplash Конечно, такая система баз данных может стать предшественницей тотальной системы наблюдения — о необходимости чего-то подобного мультимиллиардер говорил ещё в прошлом году, намекая, что реализовать такой проект могла бы именно Oracle. Постоянный надзор за населением в режиме реального времени с анализом данных системами машинного обучения Oracle, по его словам, позволит всем «вести себя наилучшим образом». Oracle уже является крупным правительственным и военным подрядчиком в США и готова помочь другим странам реализовать подобные всеобъемлющие ИИ-проекты. Все данные, конечно, предполагается поместить в одну большую систему за авторством Oracle. Как заявил Эллисон, Oracle уже строит ЦОД ёмкостью 2,2 ГВт и стоимостью $50–$100 млрд. Именно на таких площадках будет учиться «сверхмощный» ИИ. Поскольку такие модели очень дороги, свои собственные клиентам, вероятно, обучать и не придётся, зато такие площадки позволят сделать несколько разных крупных моделей. В мире всего несколько компаний, способных обучать модели такого масштаба. В их числе, конечно, Oracle с собственной инфраструктурой. Компания присоединилась к ИИ-мегапроекту Stargate, реализация которого в течение следующих четырёх лет обойдётся в $500 млрд.
06.02.2025 [16:46], Руслан Авдеев
Индия должна стать лидером в создании малых «рассуждающих» ИИ-моделей, заявил Сэм АльтманНа заключительном этапе азиатского турне глава OpenAI Сэм Альтман (Sam Altman) заявил, что Индия способна стать одним из лидеров в гонке ИИ, особенно — в деле создании малых «рассуждающих» моделей (SLM). Альтман выразил интерес к динамичной экосистеме местных разработчиков, которая может стать ключевым элементом расширения OpenAI, сообщает DigiTimes. По словам Альтмана, Индия стала вторым по величине рынком для компании, поскольку за последний год число пользователей утроилось. Во время визита Альтман встретился с представителями правительства страны. Хотя затраты на разработку новых моделей по-прежнему высоки, Альтман признал, что прогресс в области ИИ может значительно снизить зависимость от дорогостоящего оборудования, а отдача от вложений в ИИ будет расти экспоненциально. Это приведёт к ежегодному десятикратному снижению стоимости «единиц интеллекта» — условного измерения вычислительной эффективности ИИ. По словам бизнесмена, мир достиг стадии невероятного прогресса в сфере «дистилляции» моделей. 
Источник изображения: Shubhangee Vyas/unsplash.com Хотя обучение даже малых моделей остаётся довольно дорогим, именно небольшие модели с возможностью «рассуждений» приведут буквально к взрыву креативности. И Индия должна быть на переднем крае прогресса. Альтман особенно выделил потенциал проектов в здравоохранении и образовании, где ИИ способен стать движущей силой преобразований. Сейчас индийские компании обратили внимание на открытые модели, включая DeepSeek. Стоит отметить, что в ходе визита в Индию в июне 2023 года Альтман охарактеризовал шансы страны на создание ИИ-моделей уровня ChatGPT как «совершенно безнадёжные». Теперь же он приятно удивлён достижениями Индии в этой области. Глава OpenAI отдельно пояснил, что прежние высказывания относились к трудностям конкуренции с IT-гигантами при создании экономически эффективных моделей. Альтман отдельно подчеркнул, что стоимость API OpenAI значительно упала, и намекнул, что в будущем тоже возможно появление open source инициатив. Индия активно продвигает ИИ-проекты в рамках инициативы IndiaAI, подкреплённой инвестициями в объёме ₹103,7 млрд рупий ($1,2 млрд). Местную большую языковую модель (LLM) власти намерены создать в течение десяти месяцев. Представители Министерства коммуникаций и информационных технологий Индии заявили, что создание базовой структуры уже завершено, теперь усилия разработчиков направлены на создание вариантов моделей, соответствующих уникальным языковым и культурным требованиям страны.
03.02.2025 [15:21], Сергей Карасёв
Реальные затраты DeepSeek на создание ИИ-моделей на порядки выше заявленных, но достижений компании это не умаляетКитайский стартап DeepSeek наделал много шума в Кремниевой долине, анонсировав «рассуждающую» ИИ-модель DeepSeek R1 c 671 млрд параметров. Утверждается, что при её обучении были задействованы только 2048 ИИ-ускорителей NVIDIA H800, а затраты на данные работы составили около $6 млн. Это бросило вызов многим западным конкурентам, таким как OpenAI, а акции ряда крупных ИИ-компаний начали падать в цене. Однако, как сообщает ресурс SemiAnalysis, фактические расходы DeepSeek на создание ИИ-инфраструктуры и обучение нейросетей могут быть гораздо выше. Стартап DeepSeek берёт начало от китайского хедж-фонда High-Flyer. В 2021 году, ещё до введения каких-либо экспортных ограничений, эта структура приобрела 10 тыс. ускорителей NVIDIA A100. В мае 2023 года с целью дальнейшего развития направления ИИ из High-Flyer была выделена компания DeepSeek. После этого стартап начал более активное расширение вычислительной ИИ-инфраструктуры. По данным SemiAnalysis, на сегодняшний день DeepSeek имеет доступ примерно к 10 тыс. изделий NVIDIA H800 и 10 тыс. NVIDIA H100. Кроме того, говорится о наличии около 30 тыс. ускорителей NVIDIA H20, которые совместно используются High-Flyer и DeepSeek для обучения ИИ, научных исследований и финансового моделирования. Таким образом, в общей сложности DeepSeek может использовать до 50 тыс. ускорителей NVIDIA при работе с ИИ, что в разы больше заявленной цифры в 2048 ускорителей. 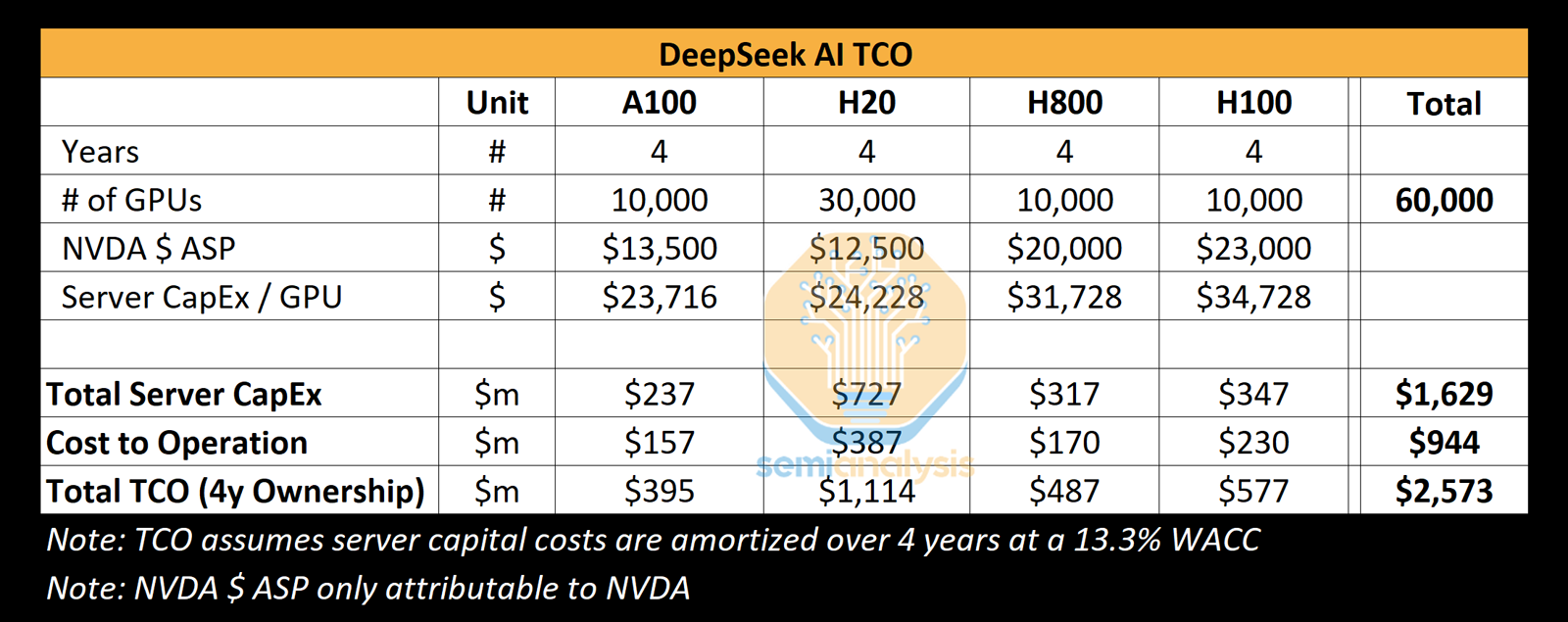
Источник изображения: SemiAnalysis Кроме того, SemiAnalysis сообщает, что общие капитальные затраты на ИИ-серверы для DeepSeek составили около $1,6 млрд, тогда как операционные расходы могут достигать $944 млн. Это подрывает заявления о том, что DeepSeek заново изобрела процесс обучения ИИ и инференса с существенно меньшими инвестициями, чем лидеры отрасли. Цифра в $6 млн не учитывает затраты на исследования, тюнинг модели, обработку данных и пр. На самом деле, как подчёркивается, DeepSeek потратила более $500 млн на разработки с момента своего создания. И всё же DeepSeek имеет ряд преимуществ перед другими участниками глобального ИИ-рынка. В то время как многие ИИ-стартапы полагаются на внешних поставщиков облачных услуг, DeepSeek эксплуатирует собственные дата-центры, что позволяет быстрее внедрять инновации и полностью контролировать разработку, оптимизируя расходы. Кроме того, DeepSeek остаётся самофинансируемой компанией, что обеспечивает гибкость и позволяет более оперативно принимать решения. Плюс к этому DeepSeek нанимает специалистов исключительно из Китая, уделяя особое внимание не формальным записям в аттестатах, а практическим навыкам работы и способностям эффективно выполнять поставленные задачи. Некоторые ИИ-исследователи в DeepSeek зарабатывают более $1,3 млн в год, что говорит об их высочайшей квалификации.
03.02.2025 [09:20], Руслан Авдеев
The Register: Успех DeepSeek показал важность обдуманных инвестиций в ИИ, но потребность в развитии инфраструктуры никуда не денетсяШок, вызванный недавним триумфом китайского ИИ-стартапа DeepSeek, представившего дешёвые и эффективные ИИ-модели, заставил многих усомниться в результативности масштабных вложений в инфраструктуру на базе дорогих ИИ-ускорителей, сообщает The Register. Тем не менее эксперты уверены, что отказываться от инвестиций было бы нецелесообразно. На прошлой неделе акции ряда крупнейших американских ИИ-брендов после дебюта весьма эффективной модели DeepSeek R1, использующей, со слов создателей, сравнительно мало ускорителей NVIDIA, буквально обрушились в цене. Из-за этого многие эксперты усомнились в том, что траты миллиардов на аппаратную инфраструктуру для ИИ себя оправдывают, если Китай способен добиться хороших результатов, используя не самое мощное оборудование. Например, NVIDIA «в моменте» потеряла $600 млрд рыночной стоимости. Настоящая истерия наложилась на растущее беспокойство в связи с тем, что всё больше денег тратится на инфраструктуру и её поддержку, а особенной отдачи пока не видно. Впрочем, паника может быть неуместной, поскольку обрушение акций прекратилось, а DeepSeek обвиняется в использовании ИИ-моделей Anthropic и OpenAI. Как отмечает The Register, нет и реальных подтверждений того, что производительность моделей DeepSeek находится на уровне лучших из актуальных моделей, а также того, что на обучение китайского ИИ ушло всего $6 млн. По оценкам SemiAnalysis, доступная DeepSeek инфраструктура гораздо больше, чем утверждает компания, и стоит более чем $1,5 млрд. 
Источник изображения: Etienne Girardet/unsplash.com По словам экспертов Omdia, опасения относительно «сокрушительных» инноваций DeepSeek сильно преувеличены. В компании подтверждают, что китайский стартап использовал некоторые «гениальные инновации», но они приведут лишь к массовому использованию аналогичных решений и строительству новой ИИ-инфраструктуры. В Omdia прогнозируют, что в ближайшие годы рынок ИИ-инфраструктуры, скорее всего, значительно вырастет. В компании полагают, что до 2028 года поставки серверов для инференса будут расти на 17 % ежегодно. В TrendForce придерживаются несколько иного мнения и предполагают, что в будущем организации всё же станут более строго оценивать инвестиции в инфраструктуру ИИ и станут применять более эффективные модели для того, чтобы снизить зависимость от доступности ускорителей. Также не исключается, что чаще будут использоваться кастомные ASIC вместо сторонних ИИ-ускорителей и спрос на «классические» модели может претерпеть с 2025 года заметные изменения. Если раньше индустрия полагалась в первую очередь на масштабирование моделей, увеличение объёмов данных и повышение производительности оборудования, то теперь стратегия меняется. DeepSeek прибегла к «дистилляции» моделей, повышению скорости инференса и снижения зависимости от оборудования. Не так давно генеральный директор IBM Арвинд Кришна (Arvind Krishna) объявил, что деятельность DeepSeek подтвердила правильность подхода к ИИ его собственной компании, считающей, что модели могут быть меньше, как и время их обучения. При использовании подобных подходов затраты на инференс могут снизиться в 30 раз, что очень хорошо для корпоративных клиентов. Ещё в 2023 году компания начала развивать серию «экономичных» базовых моделей Granite. Вероятно, по этому пути пойдут и другие. 
Источник изображения: SemiAnalysis Gartner также сообщает, что именно эффективное масштабирование ИИ будет целесообразнее простого наращивания вычислительных ресурсов. Впрочем, китайский ИИ не устанавливает новый стандарт эффективности моделей, поскольку те соответствуют показателям уже существующих, но не превосходят их. Кроме того, нет доказательств, что добавление дополнительных вычислительных ресурсов и данных не имеет значения. The Register прогнозирует, что продукты и технологии DeepSeek не вызовут резкого падения спроса на ИИ-инфраструктуру, поэтому инвесторам NVIDIA и строителям ЦОД, вероятно, можно не бояться того, что «пузырь» ИИ лопнет, как этого ожидают некоторые эксперты. Во всяком случае одни из крупнейших инвесторов в сектор ЦОД — Blackstone и Brookfield — заявили, что следят за успехами DeepSeek, но отказываться от инвестиций не собираются. Тем не менее, успех китайского стартапа напоминает о том, что «всегда можно сделать ещё лучше» и экстенсивное вливание денег и вычислительных ресурсов не всегда лучший вариант.
31.01.2025 [08:46], Владимир Мироненко
Почти половина бизнеса IBM теперь приходится на ПО — компания делает ставку на ИИ и open sourceИнвесторы поддержали стратегию развития IBM направления, касающегося развёртывания технологий ИИ, что нашло выражение в росте акций после публикации компанией отчёта за IV квартал и 2024 финансовый год, завершившийся 31 декабря, пишет газета The Wall Street Journal. Также свою роль сыграло то, что основные показатели IBM превысили прошлогодние результаты и прогнозы Уолл-стрит. Ранее IBM объявила, что приняла подход открытых инноваций к ИИ, открыв исходный код своих решений. В мае компания выпустила открытые модели Granite Foundation, а до этого она вместе с NASA сделала открытой базовую ИИ-модель для анализа спутниковых данных и выложила её на Hugging Face. Финансовый директор IBM Джеймс Кавано (James Kavanaugh) отметил, что стратегия open source делает технологию более экономически эффективной и более простой в масштабировании. Это соответствует подходу китайского стартапа DeepSeek, ИИ-модели которого вызвали шок на рынке. Общая выручка IBM за IV квартал увеличилась на 1 % до $17,6 млрд, что соответствует ожиданиям аналитиков, опрошенных LSEG. При этом скорректированная прибыль на разведённую акцию (Non-GAAP) составила $3,92 при прогнозе аналитиков $3,75. Чистая прибыль (GAAP) IBM за квартал составила $2,92 млрд или $3,09 на разведённую акцию, тогда как годом ранее эти показатели равнялись $3,29 млрд и $3,55 на акцию. 
Источник изображений: IBM Подразделение ПО увеличило выручку в годовом исчислении на 10 % до $7,92 млрд, чему способствовал рост выручки Red Hat на 16 %. Платформа OpenShift обеспечила почти половину этого объёма. Выручка подразделения по автоматизации увеличилась на 15 %, подразделения по обработке данных и ИИ — на 4 %. Компания отметила, что объём бизнеса в сфере генеративного ИИ теперь составляет более $5 млрд, что почти на $2 млрд больше, чем кварталом ранее. Гендиректор IBM Арвинд Кришна (Arvind Krishna) сообщил, что на ПО теперь приходится около 45 % бизнеса IBM с годовым оборотом более $15 млрд и двузначным ростом. 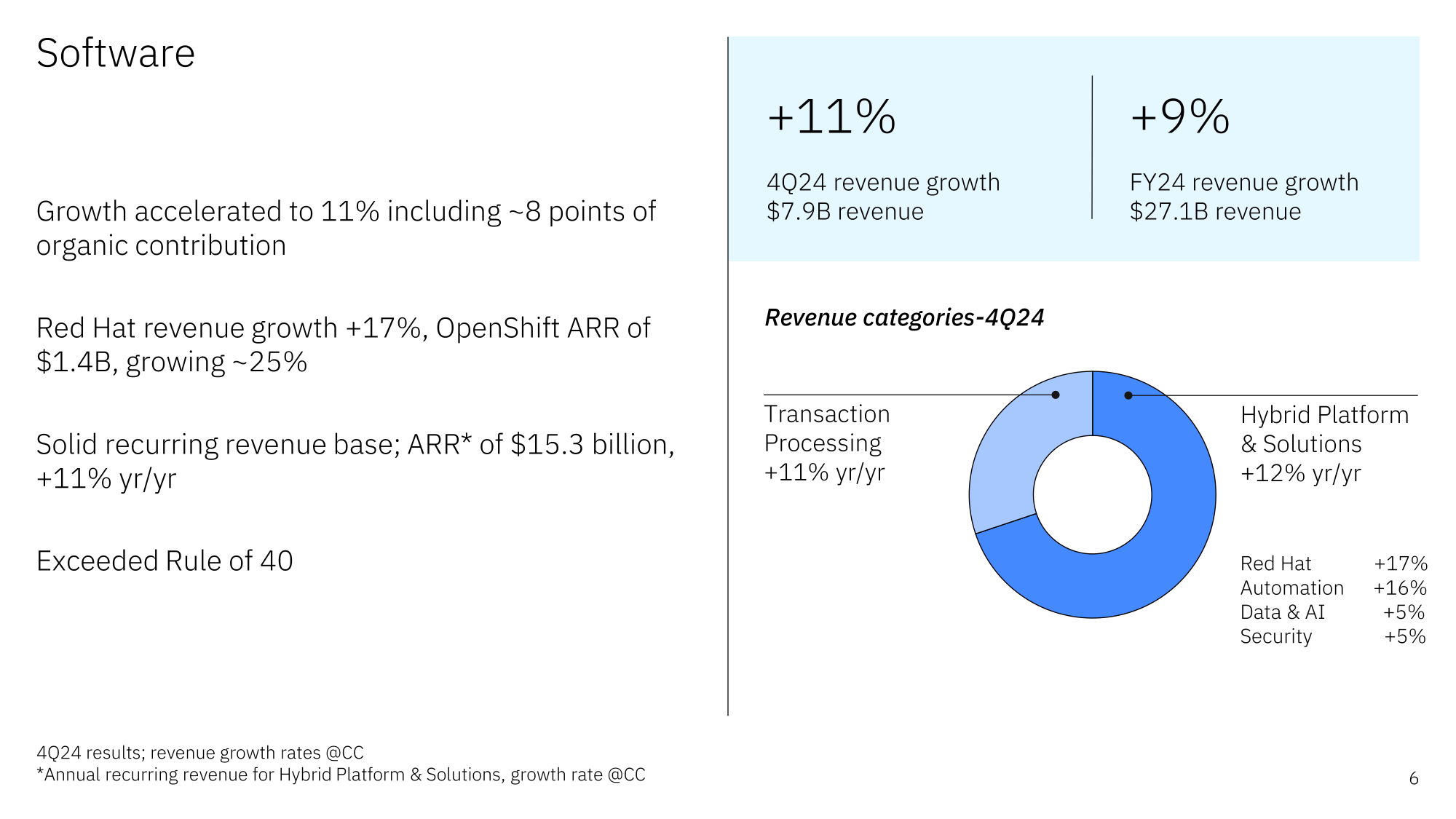 Продажи консалтингового подразделения IBM снижаются четвёртый квартал подряд, на это раз на 2 % до $5,18 млрд. Клиенты продолжают перенаправлять средства из традиционных консалтинговых проектов в проекты, ориентированные на ИИ, сообщил Кавано, отметив, что скорее всего, это временно. «Мы завершили год с самым высоким в истории зафиксированным количеством заказов за квартал, рост — на 23 %, — сказал он. — Мы по-прежнему имеем дело с очень динамичной средой вокруг того, как клиенты расставляют приоритеты в расходах». Около 80 % заказов поступает от консалтингового подразделения, а остальное — от подразделения ПО. 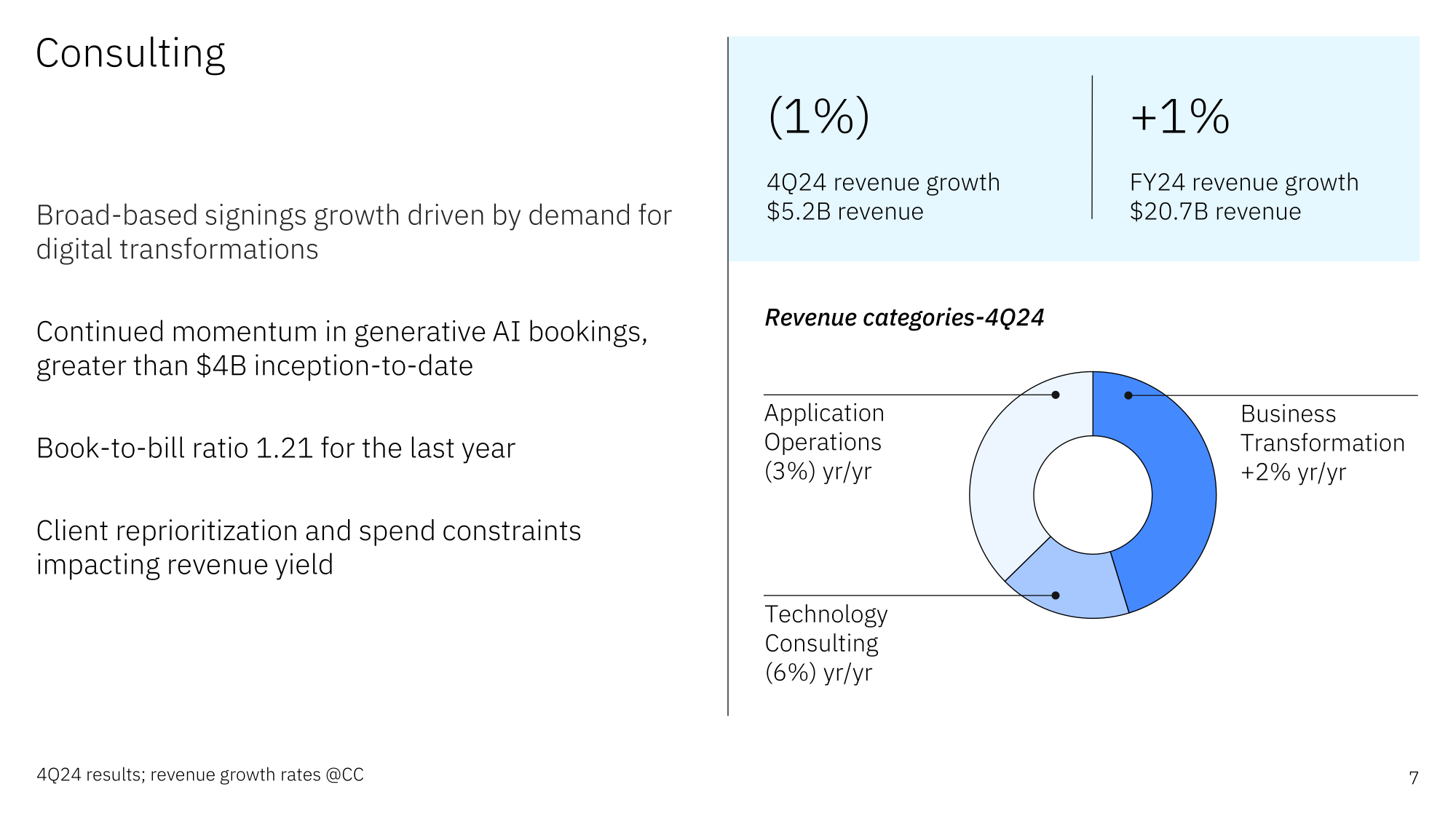 Выручка инфраструктурного подразделения снизилась в отчётном квартале на 7,6 % до $4,26 млрд, что отражает приближающееся окончание трёхлетнего жизненного цикла мейнфреймов z16, продажи которых упали на 21 %. Ожидается, что следующее поколение z17 выйдет в середине года, что обеспечит рост доходов во II полугодии 2025-го. 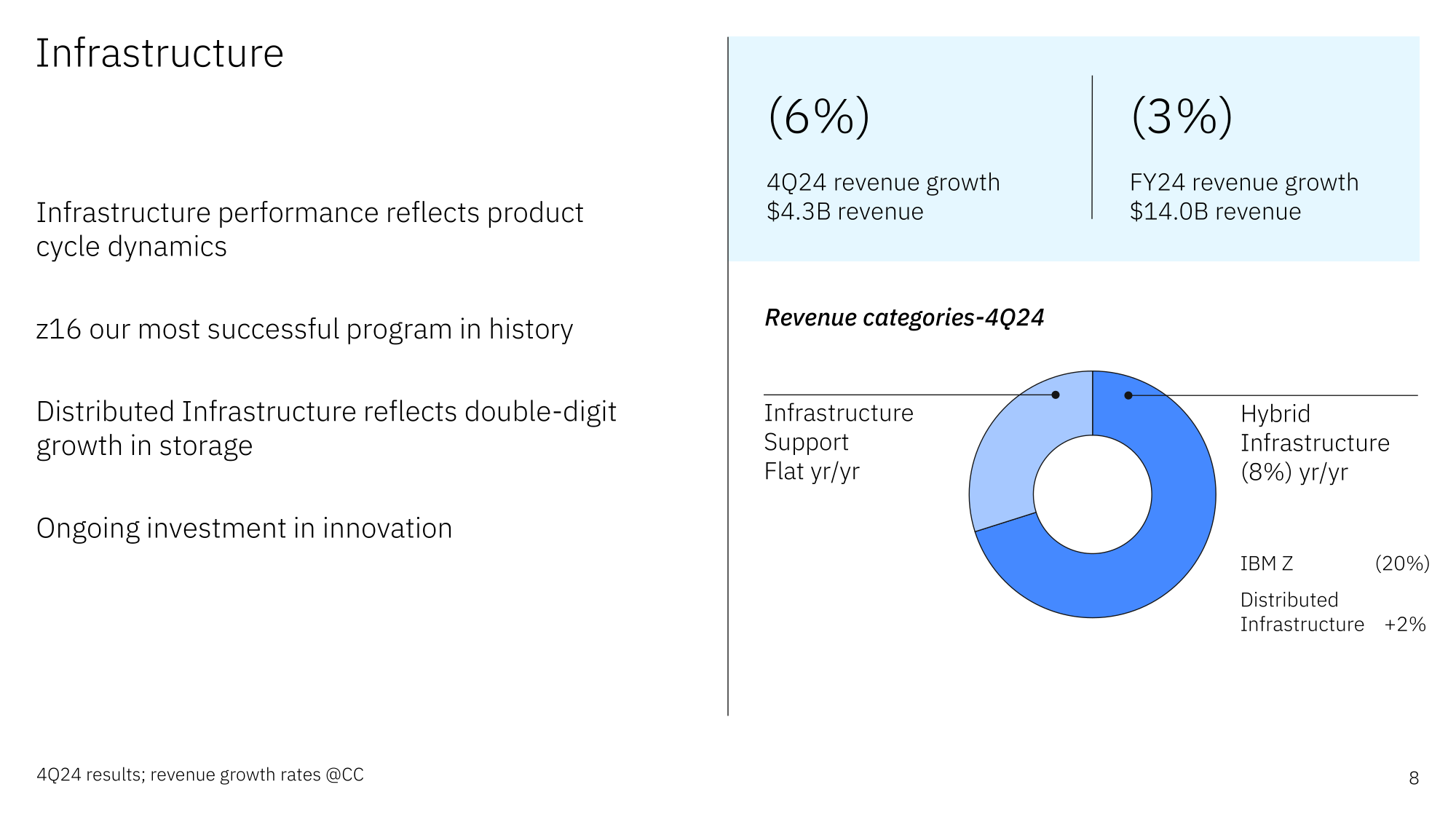 За весь 2024 финансовый год выручка IBM составила $62,8 млрд, превысив показатель 2023 финансового года на 1 %. Подразделение ПО увеличило выручку на 8 %, а у консалтингового подразделения этот показатель снизился на 1 %. У инфраструктурного подразделения выручка упала больше — на 4 %. В 2025 году IBM ожидает рост выручки не менее чем на 5 %. После публикации финансового отчёта акции компании выросли на внебиржевых торгах на 9 %, сообщил ресурс SiliconANGLE. За последние 12 месяцев цена акции IBM увеличилась на 22 %. Как отмечает The Register, компания сэкономила $3,5 млрд на операционных расходах в прошлом году и намеревается сэкономить столько же в 2025-м, что косвенно указывает на новую волну увольнений. В 2024 году их было как минимум две. Сведения о размере штата компания не обновляла уже больше года.
24.01.2025 [23:38], Владимир Мироненко
Платформа GenAI от DigitalOcean упростит создание ИИ-агентовОблачный провайдер DigitalOcean представил платформу GenAI, которая позволяет использовать базовые модели от сторонних поставщиков для создания и развёртывания агентов ИИ за считанные минуты без необходимости глубоких знаний в области ИИ или машинного обучения. Как сообщает DigitalOcean, интуитивно понятная работа в GenAI позволяет клиентам вне зависимости от уровня подготовки настраивать агентов с доступом к надёжным конвейерам данных и многоагентным командам. DigitalOcean GenAI позволяет компаниям создавать чат-боты на основе базовых моделей сторонних поставщиков (Anthropic, Meta✴, Mistral и др.) для анализа документов, семантического поиска, создания изображений и т.д. Платформа создана так, чтобы быть независимой от фреймворков. Платформа упрощает и создание агентов, специфичных для конкретных вариантов использования, привнося контекстные данные в базовые LLM. Клиенты смогут не только извлекать неструктурированные данные из файлов, но и структурированные данные из баз данных или обращаясь к API, чтобы дополнять подсказки и задействовать Retrieval Augmented Generation (RAG), обеспечивая агентам доступ к точной и актуальной информации. С помощью вызываемых функций можно дописать кастомный код, чтобы расширить возможности своего агента. 
Источник изображения: DigitalOcean Встроенные ограничители (guardrails) позволяют повысить достоверность ответов агента, помогая отфильтровывать неправильные или ненадлежащие результаты. А возможность частных подключений и наличие готового интерфейса для чат-ботов упрощают запуск этих агентов на веб-сайте клиента. В будущем появится возможность обращаться к источникам данным по URL, поддержка конвейеров AgentOps и CI/CD, тонкая настройка моделей и многое другое.
23.01.2025 [13:29], Руслан Авдеев
В Nebius AI Studio появились открытые ИИ-модели для преобразования текста в изображениеИИ-компания Nebius B.V. (бывшая Yandex N.V.) анонсировала обновление платформы «инференс как услуга» для разработчиков. В частности, добавлены новые open source модели, предназначенные для преобразования текста в изображение, сообщает Silicon Angle. В скором времени в сервисе появятся модели для преобразования текста в видео. Nebius AI Studio представляет собой гибкую, удобную для пользователей среду для разработчиков, решивших заняться созданием ИИ-приложений, говорит компания. Помимо обеспечения доступа к обширному набору больших языковых моделей (LLM), решение является одним из самых доступных с точки зрения стоимости. Поскольку компания управляет своей собственной облачной инфраструктурой, она может обеспечить одну из самых низких цен за токен на рынке, подчёркивает Nebius. Кроме того, предлагается гибкая ценовая модель — чем больше ресурсов потребляется, тем они дешевле. 
Источник изображения: Nebius Ранее компания называлась Yandex N.V. — это была родительская структура российского «Яндекса». Позже она продала поисковый и некоторые другие бизнесы, но сохранила ЦОД за пределами России (и даже намерена строить новые) и, наконец, превратилась в облачный инфраструктурный ИИ-сервис. На этой инфраструктуре и работает Nebius AI Studio. Обновление добавило модели Flux Schnell и Flux Dev, разработанные ИИ-стартапом Black Forest Labs Inc. — позиционирующим себя как одного из конкурентов OpenAI. Разработчики, создающие ИИ-приложения в Nebius AI Studio, смогут напрямую интегрировать в них новые модели. В компании утверждают, что она обеспечивает одну из самых высоких скоростей рендеринга — изображения создаются за секунды. Приложения, создаваемые с использованием Nebius AI Studio, могут поддерживать обработку до 100 млн токенов в минуту, сообщает пресс-служба компании.
13.01.2025 [23:15], Владимир Мироненко
Полупроводниковая отрасль США раскритиковала новые ограничения на экспорт ИИ-чипов и ИИ-моделейАдминистрация США объявила в понедельник о введении в действие правила AI Diffusion rule («Правило распространения ИИ»), которым теперь будет регулироваться режим экспортного контроля ИИ-технологий. 20 близким союзникам и партнерам США будет предоставлен беспрепятственный доступ к ИИ-чипам и мощным ИИ-моделям. При этом требования лицензирования теперь касаются большинства других стран, пишет Financial Times. Как сообщается, цель новых ограничений — затруднить для Китая использование других стран для обхода существующих ограничений США и получения технологий, которые могут быть использованы для укрепления военной мощи КНР — от моделирования ядерного оружия до разработки гиперзвуковых ракет. Новое правило предлагает трёхуровневую систему лицензирования для чипов, используемых в ИИ ЦОД. Верхний уровень (Tier I) включает членов G7, а также Австралию, Новую Зеландию, Южную Корею, Тайвань, Нидерланды и Ирландию, которые не будут подвергаться ограничениям. Страны Tier II, не подпадающие под контроль вооружений, смогут получить до 1700 новейших ИИ-ускорителей без специального разрешения. Если нужно больше чипов, придётся подать заявку на получение специальной лицензии. Также лицензия потребуется для получения доступа к самым мощным закрытым моделям ИИ. Для получения лицензии компании должны будут иметь адекватное обеспечение физической защиты и кибербезопасности. 
Источник изображения: silvia trigo / Unsplash Третий уровень (Tier III) включает такие страны, как Китай, Иран, Россия и Северная Корея, на которые также распространяется эмбарго на поставки оружия. Эти страны подпадают под полный запрет на поставку продвинутых технолгий ИИ. Новым правилом также впервые ограничивается их доступ к передовым ИИ-моделям. Вместе с тем правило не распространяется на деятельность в цепочке поставок, включая проектирование, производство и хранение чипов. Администрация Байдена заявила, что правило также не будет ограничивать доступ к моделям ИИ с открытым исходным кодом, таким как Llama от Meta✴. «Полупроводники, которые питают [ИИ], и мощные модели, как мы все знаем, являются технологией двойного назначения, — отметила министр торговли США Джина Раймондо (Gina Raimondo) перед объявлением нового правила. — Они используются во многих коммерческих приложениях, но также могут использоваться нашими противниками для ядерного моделирования, разработки биологического оружия и развития своих армий». Введение ограничений на международные продажи ИИ-технологий в критический момент для отрасли вызвало яростную реакцию со стороны полупроводниковой промышленности США, отметила Financial Times. На прошлой неделе Ассоциация полупроводниковой промышленности США (SIA) и Фонд информационных технологий и инноваций США (ITIF), комментируя подготовку властями этого правила с предварительным названием Export Control Framework for Artificial Intelligence Diffusion (Рамки экспортного контроля для распространения ИИ), выступили с заявлениями, в которых говорилось, что его введение даст иностранным конкурентам лишь преимущество перед американскими компаниями. 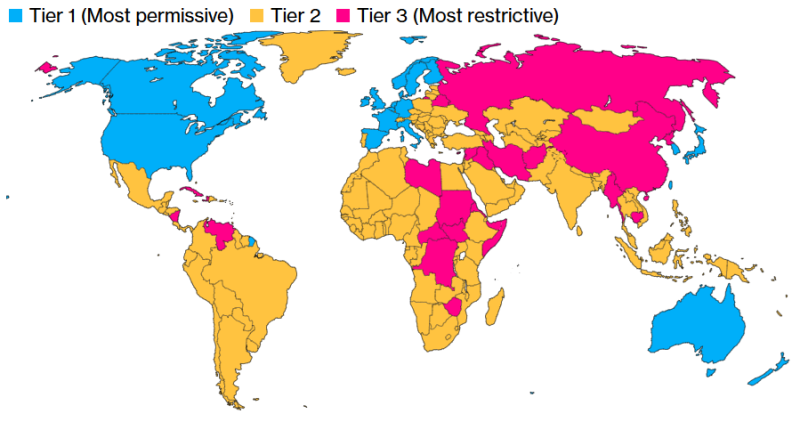
Источник изображения: Bloomberg «Отрасль по-прежнему обеспокоена настойчивостью администрации в публикации сложного и значимого правила такого рода — без каких-либо предварительных консультаций с индустрией или другими заинтересованными сторонами — в последние дни срока полномочий президента Байдена», — написал Джейсон Оксман (Jason Oxman), президент Совета индустрии информационных технологий (ITI) министру торговли Раймондо за несколько дней до публикации правила, сообщил ресурс WTTLonline. Исполнительный вице-президент Oracle Кен Глак (Ken Gluck) заявил в блоге, что новое ограничение администрации Байдена войдет в историю как «одно из самых разрушительных, когда-либо ударявших по технологической отрасли США». NVIDIA назвала новое правило «беспрецедентным и ошибочным». «Хотя эти правила и замаскированы под “антикитайские” меры, они никак не повысят безопасность США. Вместо того чтобы смягчить любую угрозу, они лишь ослабят глобальную конкурентоспособность Америки, подрывая инновации, обеспечивавшие лидерство США», — сообщила компания. |
|