Материалы по тегу: hpc
|
15.03.2023 [15:02], Сергей Карасёв
SiFive, компания-разработчик RISC-V решений, присоединилась к проекту OpenMPКомпания SiFive, разработчик процессоров на архитектуре RISC-V, вошла в Наблюдательный совет за архитектурой OpenMP Architecture Review Board (ARB) — группы ведущих поставщиков оборудования и ПО, а также исследовательских организаций, занимающихся продвижением концепции параллельного программирования. OpenMP, или Open Multi-Processing, — это открытый стандарт для распараллеливания программ на языках C, C++ и Fortran. Вычисления организуются за счёт многопоточности в многопроцессорных системах. Реализована поддержка аппаратных ускорителей. Предполагается, что членство SiFive в OpenMP ARB поможет в расширении моделей программирования в области встраиваемых систем. Какие-либо другие подробности сотрудничества не раскрываются. 
Источник изображения: SiFive Отмечается, что благодаря решениям SiFive клиенты могут ускорить внедрение инноваций, а также дифференцировать свои технологии и продукты. «Открытые стандарты обеспечивают гибкость, взаимодействие и инновации, и SiFive рада присоединиться к OpenMP ARB и поддержать эти усилия», — отметила Элис Чан (Alice Chan), вице-президент по программному обеспечению SiFive.
13.03.2023 [18:43], Сергей Карасёв
ИИ-инстансы ND H100 v5 в облаке Microsoft Azure позволят объединить тысячи ускорителей NVIDIA H100Корпорация Microsoft сообщила о том, что на базе облачной платформы Azure станут доступны высокопроизводительные масштабируемые инстансы ND H100 v5 для нагрузок, связанных со сложными ИИ-моделями, в частности, с генеративными приложениями на основе нейросетей. ND H100 v5 могут использоваться при реализации таких проектов, как чат-бот ChatGPT на базе нейросети. Этот бот использует языковую модель OpenAI GPT-3, насчитывающую 175 млрд параметров. 
Фото: Microsoft Система предусматривает использование ускорителей NVIDIA H100. Восемь таких GPU объединены посредством NVSwitch и NVLink 4.0. Возможно масштабирование до тысяч ускорителей при помощи сети на базе NVIDIA Quantum-2 InfiniBand, которая обеспечивает пропускную способность до 400 Гбит/с в расчёте на GPU (до 3,2 Тбит/с на виртуальную машину). В составе ND H100 v5 применяются процессоры Intel Xeon Sapphire Rapids, обеспечивающие интерфейс PCIe 5.0 и 16 каналов DDR5-4800. Ранее NVIDIA планировала массово разворачивать в облаках специализированные HPC/ИИ-системы на базе H100.
10.03.2023 [01:11], Владимир Мироненко
Великобритания хочет построить собственный суперкомпьютер на отечественных чипах за почти $1 млрдНа этой неделе премьер-министр Великобритании Риши Сунак (Rishi Sunak) представил программу, которая позволит стране «укрепить своё место в качестве мировой сверхдержавы в области науки и технологий к 2030 году». Одним из главных проектов программы должно стать создание HPC-системы, способной соперничать по мощности с самым производительным суперкомпьютером в мире Frontier (без учёта китайских OceanLight и Tianhe-3), установленным в США. По словам источников, министерство финансов пока не дало согласия на финансирование проекта. Согласно данным источников ресурса Bloomberg, в настоящее время канцлер казначейства Великобритании обсуждает предложение Департамента науки, инноваций и технологий, созданного в феврале, вложить £800 млн ($946 млн) в создание суперкомпьютера. Frontier, к примеру, обошёлся США в $600 млн. Как утверждают в департаменте, суперкомпьютер обеспечит финансовый импульс отечественной технологической отрасли, поскольку, как предполагается, вычислительная система будет построена британскими фирмами с использованием чипов и систем, созданных британскими же производителями. То есть участие американской HPE и французской Atos, построивших многие из самых мощных суперкомпьютеров в мире, не предполагается. Ресурс The Register допустил, что ответственность за создание суперкомпьютера возложат на британский стартап Graphcore, который уже работает над ИИ-суперкомпьютером Good Machine. Стоит эта система около $120 млн, а производительность её составляет 10 Эфлопс в вычислениях пониженной точности (не FP64). The Register также допускает участие в проекте Arm, поскольку в Великобритании был запущен в работу первый в мире Arm-суперкомпьютер Isambarad, а японский Fugaku возглавлял TOP500. Ещё одним потенциальным участником проекта называется американская NVIDIA, которая также задействует Arm-ядра в новейших чипах Grace Superchip и Grace Hopper. 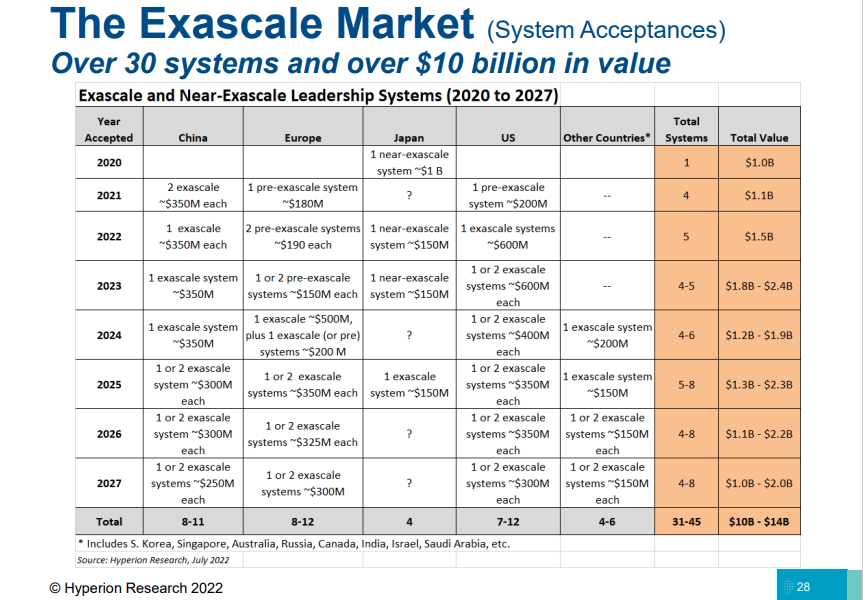
Источник: Hyperion Research Ситуация с мощными машинами усугубляется тем, что Великобритания в связи с Brexit'ом покинула консорциум EuroHPC, в создании которого принимала активное участие. Суперкомпьютеры EuroHPC уже занимают третье (финский LUMI от HPE) и четвёртое (итальянский Leonardo от Atos) место в последнем TOP500. В скором времени EuroHPC будут развёрнуты самый мощный европейский ИИ-суперкомпьютер MareNostrum-5, первый экзафлопсный суперкомпьютер JUPITER и шесть квантовых компьютеров. При этом Евросоюз активно вкладывается в создание собственных CPU и ускорителей, а также СХД.
06.03.2023 [16:30], Владимир Мироненко
Новые задержки у Intel: выпуск ускорителей Rialto Bridge отменён, а Falcon Shores — отложенКомпания Intel опубликовала в конце прошлой недели письмо вице-президента и главы подразделения Super Compute Group Джеффа Маквея (Jeff McVeigh), в котором, помимо обновлённой информации о состоянии линейки продуктов серверных ускорителей вычислений Intel и их принятии клиентами, было объявлено о ряде кардинальных изменений планов компании по поводу будущих продуктов этой категории. В частности, Intel отказалась от производства ускорителей серии Rialto Bridge, выход которых был намечен на текущий год. Вместо этого компания сразу перейдёт к выпуску чипов Falcon Shores с более новой версией архитектуры Intel Xe. Правда, их выход теперь запланирован на 2025 год вместо 2024-го. Следует также отметить, что если ранее Intel планировала выпуск Falcon Shores в форм-факторе гибридных (XPU) чипов, объединяющих CPU, ускорители и память на основе чиплетов (тайлов в терминологии Intel), то теперь первыми появятся HPC-ускорители следующего поколения без CPU-ядер. Компания пояснила ресурсу ServeTheHome, что по-прежнему придерживается планов по выпуску гибридных (XPU) чипов Falcon Shores, но они увидят свет немного позже. Это означает, что как минимум до 2026 года NVIDIA и AMD будут опережать Intel в деле внедрения архитектур следующего поколения. 
Источник изображения: Intel Как отметил ресурс AnandTech, положительным моментом является то, что Intel не отказывается от архитектуры Xe, которая используется во многих её продуктах, от встроенной графики до HPC-ускорителей, что подчёркивает её важность и жизнеспособность. Отмена Rialto Bridge в сочетании с задержкой Falcon Shores является серьёзной неудачей для Intel, но в итоге она просто заменяет одну итерацию Xe другой, более продвинутой. Изменения планов Intel также коснулись семейства серверных ускорителей Intel Flex для облачных игр и кодирования мультимедиа, поскольку Intel отказалась от запуска Lancaster Sound (также известного как Next Sound) в пользу следующего поколения ускорителей Melville Sound, разработка которых будет ускорена. Intel не назвала точной даты презентации данного решения. Ранее его выход ожидался в те же сроки, что и у Falcon Shores. Согласно Intel, изменения планов относительно Intel Flex позволят ей соответствовать двухлетнему графику выпуска серверных ускорителей. Её конкуренты, NVIDIA и AMD, последние годы работают в таком же режиме. По словам Intel, это изменение «соответствует ожиданиям клиентов в отношении внедрения новых продуктов и даёт время для развития их экосистем».
23.02.2023 [18:48], Руслан Авдеев
Южная Корея предоставила учёным новый 35-Пфлопс ИИ-суперкомпьютерЮжнокорейское Министерство науки и информационных технологий ввело в эксплуатацию новый суперкомпьютер вычислительной мощностью 35 Пфлопс и стоимостью почти $35 млн. Как сообщает DataCenter Dynamics, суперкомпьютер расположен в ЦОД Research Data Center хаба AI Innovation Hub, находящегося на территории кампуса Университета Кореи в Сеуле, и предназначен для решения научных задач. По данным издания, в спонсируемом государством проекте принимает участие 631 учёный и ислледователь. Одновременно нагружать суперкомпьютер задачами смогут порядка 100 исследователей. В министерстве считают, что новый проект поможет Южной Корее поддерживать на должном уровне вычислительные мощности в быстро меняющемся ИИ-секторе. По словам представителя министерства, власти не пожалеют ресурсов на поддержку исследований в этой сфере. 
Источник изображения: Ciaran O'Brien/unsplash.com В 2021 году Южная Корея объявила о намерении создать собственные чипы, которые впоследствии станут основой отечественных серверов и суперкомпьютеров. Речь в том числе про ИИ-ускорители, развитие которых было, в частности, поручено SK Group (Sapeon), Rebellions, FuriosaAI — все три компании уже анонсировали свои решения, а SK не так давно удвоила производительность своего ИИ-суперкомпьютера Titan.
22.02.2023 [21:09], Алексей Степин
AMD опубликовала доклад об энергетических перспективах зеттафлопсных суперкомпьютеров: до 100 МВт и к 2035 годуЧеловечество преуспело в гонке за экзафлопсами. Следующий барьер лежит в области 1 Зфлопс, что потребует нарастить производительность ещё на три порядка. Но вместе с производительностью растёт и потребляемая мощность. Перспективам такого роста был посвящён доклад главы AMD, Лизы Су (Lisa Su), сделанный на конференции ISSCC. Компания не слишком оптимистична в своих оценках: хотя статистика говорит, что с 1995 года производительность HPC-систем удваивалась примерно каждые 1,2 года, удельная энергоэффективность Гфлопс/Вт росла куда медленнее — цикл удвоения составляет 2,2 года. Сегодня TOP500 возглавляет Frontier с показателями 1,102 Эфлопс и 21,1 МВт. При сохранении данного уровня энергоэффективности достижение 1 Зфлопс потребует 21 ГВт. То есть для его питания потребуется 21 энергоблок АЭС, мощностью 1000 МВт каждый. 
Источник здесь и далее: HPCWire Даже при сохранении существующего темпа увеличения энергоэффективности к 2035 году этот показатель достигнет лишь 2140 Гфлопс/Вт, так что гипотетический зетта-кластер всё равно потребует 500 МВт. Вряд ли можно назвать практичным суперкомпьютер, требующий для себя отдельный энергоблок АЭС. В качестве реалистичной цифры было названо 100 МВт, что требует эффективности порядка 10000 Гфлопс/Вт. Достичь её будет непросто: на слайдах, показанных AMD, видно, что одного прогресса в техпроцессах явно будет недостаточно. 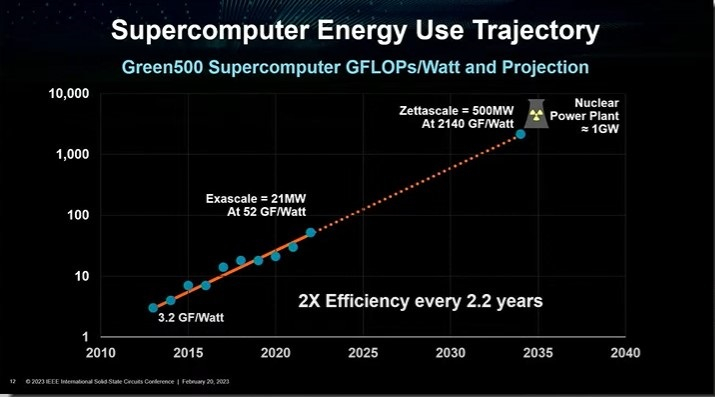 Потребуются существенные архитектурные оптимизации, массовый переход на чиплетные технологии, совершенствование интерконнекта, а также оптимизация аппаратной и программной части на основе ИИ. Подсистема памяти не просто вырастет в объёмах, но и станет «умной» благодаря переносу части вычислений на уровень DRAM. Здесь AMD активно сотрудничает с таким крупным производителем, как Samsung Electronics — компании уже создали уникальный ИИ-суперкомпьютер, скрестив «умную» память HBM-PIM и ускорители Instinct, и развивают SmartSSD. 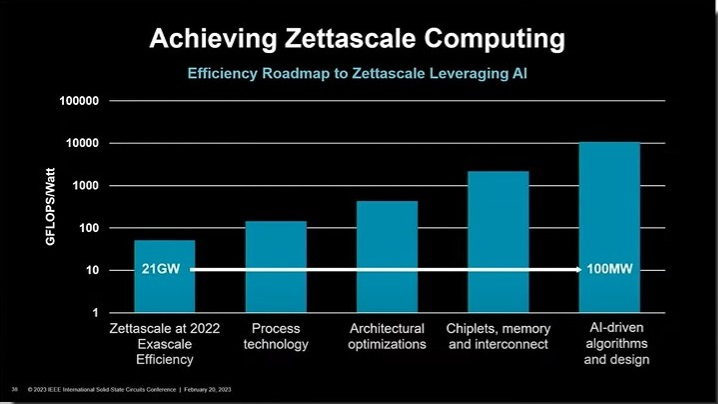 Неплохим примером комплексного подхода к решению вышеописанной проблемы, по мнению AMD, является APU Instinct MI300, который уже совсем скоро станет основой самых мощных суперкомпьютеров. Впрочем, пока что загадывать наперёд спешат не все специалисты. Так, США готовятся к созданию суперкомпьютеров производительностью от 10–20 Эфлопс, которые будут потреблять 20–60 МВт. А некоторые и вовсе считают, что будущие экзафлопсные HPC-системы и вовсе станут последними в своём роде.
22.02.2023 [15:07], Владимир Мироненко
Trendforce прогнозирует рост спроса на серверную память DRAM благодаря развитию рынка ИИ и HPCАналитическая компания Trendforce сообщила прогноз развития рынка DRAM в 2023 году, согласно которому память для серверов обгонит чипы памяти для мобильных устройств по доле в общем выпуске DRAM. По данным Trendforce, во второй половине 2022 года рынок памяти находился в состоянии свободного падения: в III квартале средние цены на DRAM снизились на 31 %, в IV квартале — ещё на 34 %. В этом году Trendforce даёт консервативный прогноз относительно роста поставок смартфонов и увеличения объёма DRAM в них. Рост среднего установленного объёма памяти DRAM в смартфонах, который начал заметно замедляться ещё в 2022 году, станет более ограниченным, а мобильная DRAM будет виновником сокращения доли всего рынка DRAM, отметили аналитики. Причиной аналитики называют образовавшиеся складские запасы, что повлияло на аппаратные спецификации разрабатываемых смартфонов. TrendForce ожидает, что в ближайшие годы прирост среднего объёма DRAM в смартфонах будет ниже 10 % год к году. 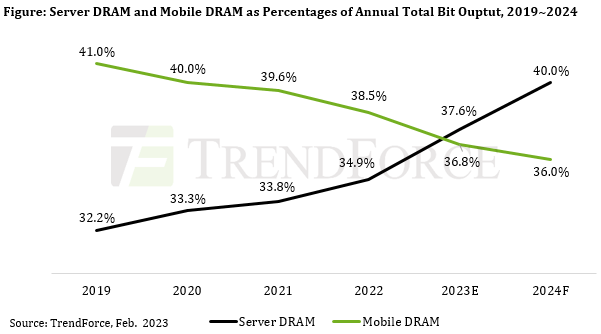
Источник: Trendforce А вот на серверном рынке ситуация иная. Появление новых приложений, связанных с ИИ и высокопроизводительными вычислениями (HPC), влечёт за собой потребность в большем объёме памяти. Поэтому TrendForce полагает, что серверная память будет составлять наибольшую часть общего объёма производства на рынке DRAM в течение следующих нескольких лет. TrendForce также отметила, что память DRAM для серверов обладает определённой степенью эластичности по цене, которая меняется в соответствии со спросом, а контрактные цены на неё значительно снизились с III квартала 2022 года. TrendForce прогнозирует, что средний установленный объём DRAM в серверах увеличится в этом году на 12,1 % в годовом исчислении. По оценкам TrendForce, серверная память в этом году займёт около 37,6 % рынка, тогда как мобильная DRAM— около 36,8 %. То есть серверная DRAM обгонит мобильную DRAM. TrendForce также считает, что к 2025 году SSD корпоративного класса будут представлять самый большой сегмент рынка флеш-памяти NAND. Снижение цен стимулировало спрос на неё со стороны производителей смартфонов и серверов, утверждает компания. В связи с этим рост установленного объёма флеш-памяти NAND на одно устройство должен превысить 20 % как для смартфонов, так и для корпоративных твердотельных накопителей.
15.02.2023 [19:03], Алексей Степин
SK Telecom удвоила мощность ИИ-суперкомпьютера Titan, ответственного за работу корейского варианта GPT-3Южная Корея — одна из стран, наиболее активно вкладывающих массу ресурсов в развитие собственной суперкомпьютерной инфраструктуры, в том числе, в разработку собственных процессоров и ускорителей. Уделяет она серьёзное внимание и модернизации существующих HPC-систем, что актуально в свете бурного развития ИИ, особенно нейросетевых языковых моделей. Крупный южнокорейский телеком-провайдер, компания SK Telecom объявила серьёзной модернизации суперкомпьютера Titan, который является «мозгом» для ИИ-модели Aidat (A dot) — корейского варианта знаменитой GPT-3. Впервые эта сеть дебютировала в мае прошлого года в качестве ИИ-помощника SK, помогающего с рекомендациями для выбора аудио- и видеоконтента владельцам смартфонов. 
Источник: SK Telecom Titan не имеет отношения к уже демонтированному кластеру Окриджской национальной лаборатории — это система, базирующаяся на серверах HPE Apollo 6500 с процессорами AMD EPYC 7763 (64C/128T, 2,45 ГГц) и в ноябре 2022 года занявшая 92 место в TOP500 с результатом 6,29 Пфлопс. Суперкомпьютер использует ускорители NVIDIA A100 (80 Гбайт) и интерконнект InfiniBand HDR. Деталей о обновлении системы SK Telecom практически не раскрывает, но известно, что количество ускорителей доведено до 1040, и это позволило достичь модернизированному кластеру пиковой производительности на уровне 17,1 Пфлопс, что более чем вдвое превосходит предыдущий показатель. Компания отмечает, что апгрейд позволит использовать ещё более сложные модели, что должно улучшить качество ответов Aidat.
10.02.2023 [14:14], Сергей Карасёв
Atos построит суперкомпьютер для Общества Макса Планка на базе новейших AMD EPYC Genoa и Instinct MI300AКомпания Atos объявила о заключении контракта на создание и установку нового высокопроизводительного комплекса для Общества научных исследований имени Макса Планка. В основу системы ляжет суперкомпьютерная платформа BullSequana XH3000 с новейшими процессорами AMD EPYC и ускорителями Instinct. Стоимость проекта превышает €20 млн. Суперкомпьютер будет эксплуатироваться Вычислительным и информационным центром Общества Макса Планка (MPCDF) в Гархинге недалеко от Мюнхена (Германия). Систему планируется применять для решения задач в области астрофизики, биологических исследований, разработки передовых материалов, физики плазмы и технологий ИИ. Комплекс получит систему прямого жидкостного охлаждения (DLC) без вентиляторов. Коэффициент эффективности использования энергии (PUE) составит менее 1,05, что намного ниже по сравнению с другими HPC-установками. В суперкомпьютере будут применяться чипы AMD EPYC Genoa и ускорители Instinct MI300A. Система будет включать 768 процессорных узлов и 192 узла с ускорителями. В состав комплекса войдёт хранилище IBM SpectrumScale. 
Источник изображения: Atos Узлы CPU планируется поставить в III квартале 2023 года, тогда как развёртывание узлов с ускорителями ожидается в первой половине 2024 года. По производительности новый суперкомпьютер в три раза превзойдёт нынешний комплекс Cobra, который используется в MPCDF и также базируется на технологиях Atos. Его пиковое быстродействие достигает 11,4 Пфлопс.
09.02.2023 [17:56], Сергей Карасёв
IBM представила облачный ИИ-суперкомпьютер VelaКорпорация IBM анонсировала HPC-систему под названием Vela — это облачный суперкомпьютер, оптимизированный для задач ИИ. В основу положены процессоры Intel Xeon Cascade Lake, а также ускорители NVIDIA. Сообщается, что Vela заработала ещё в мае 2022 года. Она базируется на облачной платформе IBM Cloud, но в настоящее время суперкомпьютер предназначен для использования только исследовательским сообществом IBM. Каждый из узлов комплекса оснащён двумя процессорами Intel Xeon Cascade Lake (в данном случае IBM отказалась от собственных чипов POWER10) и восемью ускорителями NVIDIA A100 (80 Гбайт). Объём оперативной памяти составляет 1,5 Тбайт. Задействованы четыре NVMe SSD, каждый вместимостью 3,2 Тбайт. Каждая пара ускорителей подключена посредством двух 100GbE-интерфейсов к ToR-коммутатору, каждый из которых, в свою очередь, через два канала 100GbE соединён с магистральными коммутаторами. При создании системы IBM сделала выбор в пользу конфигурации на основе виртуальных машин (ВМ). Утверждается, что хотя «голое железо» предпочтительнее для достижения максимальной производительности, подход с применением ВМ даёт большую гибкость. Использование виртуальных машин, в частности, обеспечивает возможность динамического масштабирования кластеров ИИ и перераспределения ресурсов. При этом создателям удалось снизить «штраф» к производительности до менее чем 5 %. 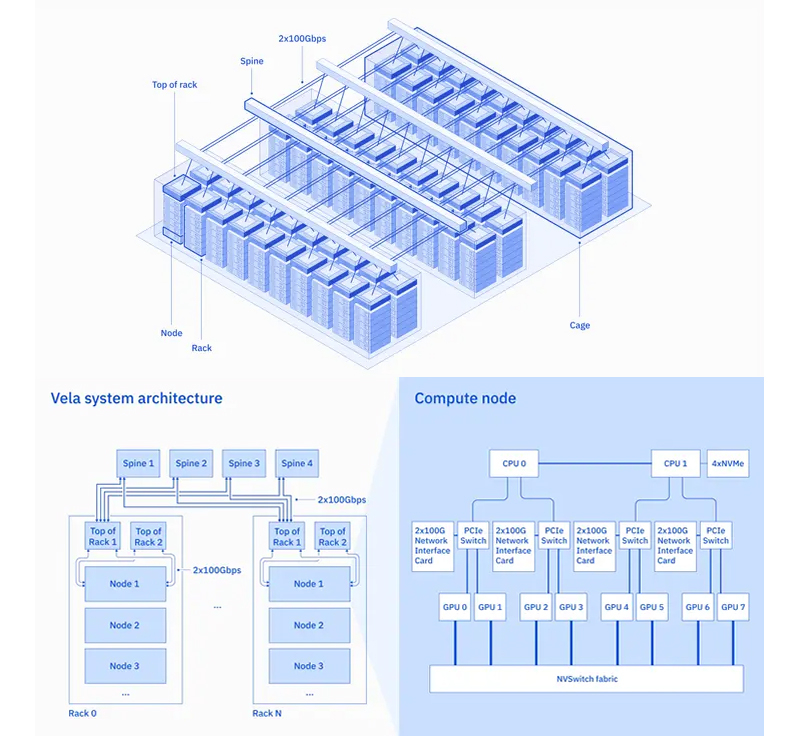
Источник изображения: IBM В состав Vela входят 60 стоек. Если верить диаграмме выше, каждая стойка содержит шесть узлов, что в сумме даёт 360 узлов и 2880 ускорителей NVIDIA A100. Система изначально интегрирована в среду IBM Cloud VPC, а это означает, что ИИ-нагрузки могут задействовать любые из более чем 200 сервисов IBM Cloud. В перспективе на базе Vela могут быть созданы другие суперкомпьютеры. «Хотя эта работа проделана с прицелом на обеспечение производительности и гибкости для крупномасштабных рабочих нагрузок ИИ, инфраструктура была разработана таким образом, чтобы её можно было развернуть в любом из наших мировых дата-центров любого масштаба», — заявляет IBM. |
|
