Материалы по тегу: hpc
|
07.02.2023 [19:37], Руслан Авдеев
Регулирование оборота «вечных» PFAS-химикатов и отказ 3M от их выпуска могут значительно повлиять на будущее погружных СЖОПерфторалкильные и полифторалкильные вещества (PFAS, «вечные химикаты»), вероятно, представляют угрозу для здоровья людей, хотя их вредоносность по многим параметрам пока не получила документальных подтверждений. Тем не менее, как сообщает портал HPC Wire, PFAS привлекают всё больше внимания регуляторов, а принятые против них в ЕС меры грозят всей полупроводниковой индустрии. Теперь этими веществами заинтересовались и американские регуляторы, включая Агентство по охране окружающей среды США (EPA), что может привести к изменению перспектив развития HPC-индустрии. Дело в том, что PFAS используются в двухфазных системах погружного охлаждения. В частности, речь идёт о жидкостях Novec и Fluorinert компании 3M, также применяемых при выпуске полупроводников и в других сферах. В конце 2022 года 3M заявила, что намерена полностью отказаться от их производства уже к 2025 году и уже остановила крупнейший завод по их выпуску в Бельгии. Действия регуляторов и отказ 3M от производства может привести к серьёзным изменениям в HPC-индустрии, поскольку поставит под угрозу бесперебойность поставок необходимых компонентов и материалов. 
Источник изображения: 3M Но есть и другие факторы. Так, крупные международные производители СЖО будут ориентироваться на страны с наиболее жёсткими регуляторными нормами, даже если на других рынках условия более благоприятны. А крупные заказчики вроде Google и Microsoft, декларирующие достижение определённых целей по защите окружающей среды, могут отказаться от PFAS просто из-за репутационных рисков, даже если PFAS будут вполне легальны. По мнению экспертов Motivair, ужесточение контроля за PFAS может представлять угрозу широкомасштабному распространению технологий двухфазного погружного охлаждения. Впрочем, далеко не все уверены, что новые ограничения могут изменить тренды на рынке HPC, поскольку многие игроки здесь применяют, по их словам, эффективные и безопасные системы на основе других технологий СЖО и химикатов. Как сообщает DataCenter Dynamics, по данным производителя иммерсионных СЖО LiquidStack, большее влияние ограничения на использование PFAS могут оказать на полупроводниковую отрасль, где подобные вещества широко применяются в процессе производства. В компании утверждают, что имеется немало альтернатив жидкостям 3M, хотя как минимум некоторые из них тоже являются PFAS.
27.01.2023 [11:57], Алексей Степин
PEZY Computing всё-таки выпустила процессор PEZY-SC3 — 4096 кастомных ядер и 19,7 Тфлопс FP64Японская компания PEZY Computing, являющаяся разработчиком процессоров с любопытными архитектурными решениями, ещё в 2017 году столкнулась с обвинениями в мошенничестве. Однако, похоже ей удалось преодолеть трудности. В Twitter появился ряд любопытных цифр, описывающих процессор PEZY-SC3, в том числе данные о техпроцессе, производительности нового чипа в Linpack, а также об энергоэффективности новинки. 
PEZY-SC3. Источник здесь и далее: Twitter Напомним, в отличие от широко распространённого принципа SIMD (одна инструкция, множество данных), чипы PEZY-SC используют MIMD (много инструкций, множество данных), предусматривающую независимую асинхронную работу множества сравнительно несложных ядер; уже в первом поколении PEZY-SC их было 1024. Благодаря MIMD чип удалось сделать достаточно простым, сэкономив транзисторный бюджет на блоках типа планировщика внеочередного исполнения инструкций. Третье поколение, как и планировалось ранее, использует техпроцесс TSMC класса 7 нм и состоит из 4096 кастомных RISC-подобных ядер, что делает процессор PEZY-SC3 похожим на GPU. Для управления этим вычислительным массивом в составе чипа имеется два шестиядерных кластера с архитектурой MIPS64. Площадь кристалла новинки равна 786 мм2, максимальное тепловыделение — 470 Вт. 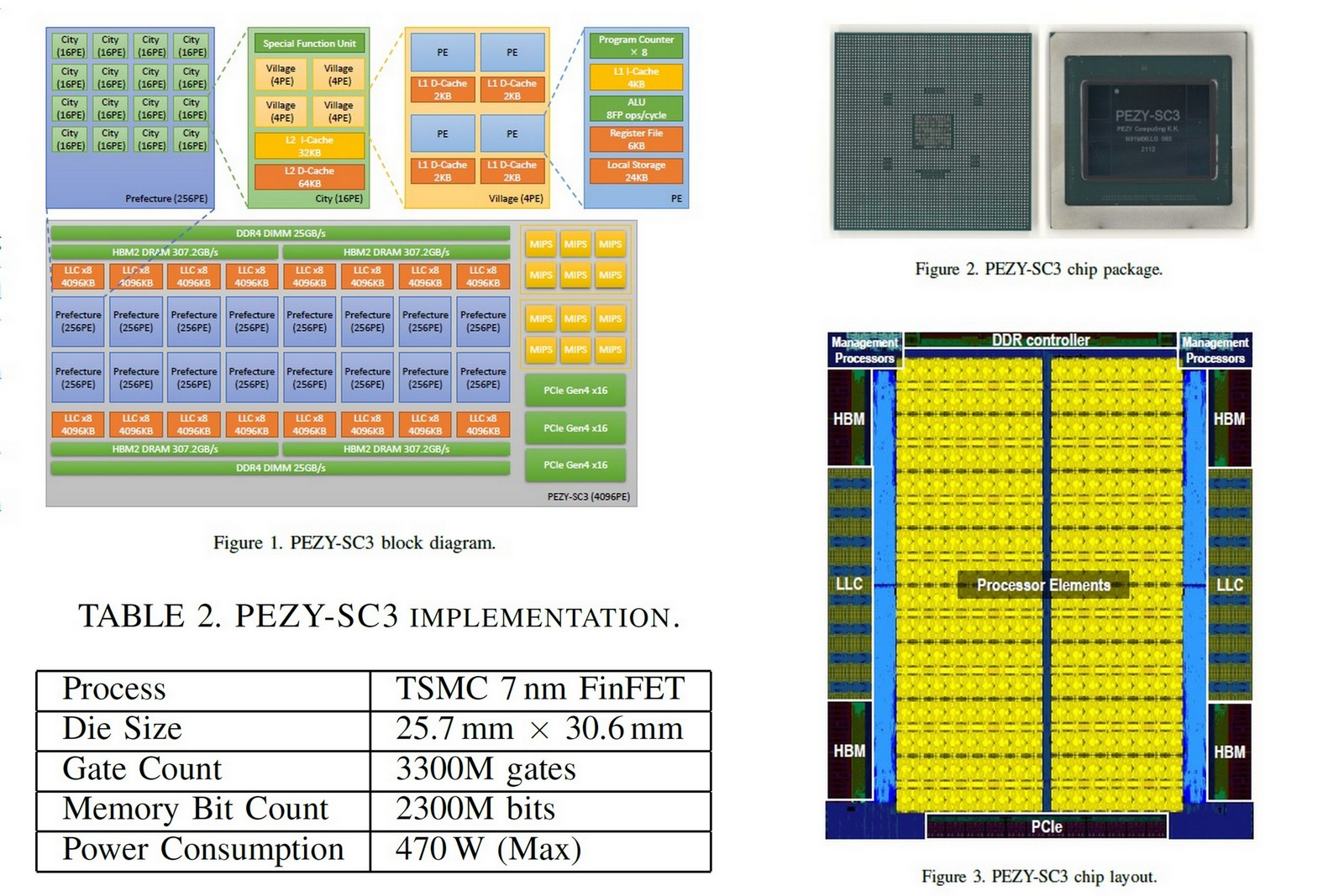
Структура кристалла и архитектура PEZY-SC3. Полноразмерное изображение доступно по клику PEZY-SC3 реализует многоуровневую архитектуру памяти, предусматривающую одновременное использование HBM2 и DDR4. Есть четыре стека HBM2 c пропускной способностью 307,2 Гбайт/с каждый, что совокупно дает 1,23 Тбайт/с — больше, чем у Intel Xeon Max (приблизительно 1 Тбайт/с). Ещё 50 Гбайт/с обеспечивает классическая память DDR4. Производительность PEZY-SC3 составляет 19,7 Тфлопс в режиме FP64, для FP32 и FP16 заявлено 39,3 и 76,8 Тфлопс соответственно, что существенно превосходит показатели NVIDIA A100. Специфических блоков тензорных вычислений японский процессор не имеет, но отличается большей универсальностью, нежели решение NVIDIA. 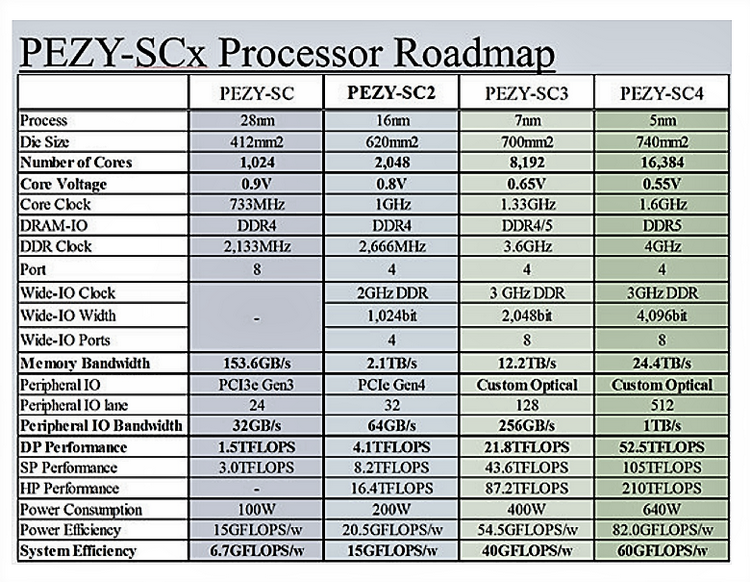
Старые планы PEZY. По ряду параметров PEZY-SC3 с ранее опубликованными данными не совпадает: в частности, ядер у него в два раза меньше Чип PEZY-SC3 неплохо проявил себя с точки зрения энергоэффективности, показав в тесте Linpack эффективность 24,6 Гфлопс/Вт, что позволило занять ему 12 место в рейтинге Green500. Выше на момент публикации результатов в ноябре 2021 года в список вошли только системы с ускорителями NVIDIA A100. Благодаря своей универсальности, PEZY-SC3 хорошо подходит для сложных научных вычислений, да и потенциал энергоэффективности до конца не исчерпан и может быть повышен при дальнейшей оптимизации ПО с учётом особенностей архитектуры MIMD.
24.01.2023 [21:55], Руслан Авдеев
Большой системе — большой монитор: разрешение дисплея Stallion в техасском суперкомпьютерном центре выросло до 597 МПиксХотя дисплей Stallion Техасского университета в Остине и без того имел одно из самых высоких разрешений в мире, университетская лаборатория TACC POB Visualization Laboratory обновила оборудование, позволяющее в мельчайших деталях рассматривать важные для учёных изображения. Речь идёт, например, как о снимках звёздного неба, сделанных космическими телескопами, так и о новых вариантах вируса COVID-19. Новый Stallion, пришедший на замену системе, установленной ещё в 2008 году, работает в паре с кластером, предлагающим пользователям более 74 Гбайт графической памяти (ускорители NVIDIA Quadro K5000), 1,28 Тбайт оперативной памяти и 19 Тбайт постоянной памяти, а также 232 ядра CPU. За вывод изображения и управление «распределённым» дисплеем отвечает ПО DisplayCluster и MostPixelsEver. Обновлённый дисплей, состоит из восемнадцати (6×3) 65″ QLED-панелей Samsung, каждая — с разрешением 8К. После обновления суммарное разрешение дисплея увеличилось со 328 до 597 МПикс, а его яркость выросла. 
Источник изображения: TACC По мнению учёных, даже старый Stallion уже «менял правила игры», а его новая версия стала ещё лучше — теперь, к примеру, можно в мельчайших деталях рассматривать объекты вроде развалин древнего камбоджийского мегаполиса Ангкора. Исследователи способны будут разглядеть даже те детали, которые раньше остались бы незамеченными. В частности, активно пользуется новой технологией команда Cosmic Evolution Early Release Science Survey (CEERS), изучающая данные, снятые телескопом «Джеймс Уэбб» — даже на небольшом фрагменте можно разглядеть огромное количество незаметных ранее галактик, включая самые отдалённые из известных сегодня.
17.01.2023 [15:09], Сергей Карасёв
В Венгрии запущен суперкомпьютер Komondor с производительностью 5 ПфлопсГосударственное агентство по развитию информационных технологий (KIFU) объявило о запуске суперкомпьютера Komondor в кампусе Дебреценского университета (Венгрия). Это самый мощный венгерский вычислительный комплекс: его производительность достигает почти 5 Пфлопс. Стоимость проекта оценивается в $12,8 млн. В основу положены платформа HPE Cray EX и 100G-интерконнект (Slingshot 11). Тестирование суперкомпьютера началось в сентябре 2022 года. Архитектура Komondor предполагает наличие CPU- и GPU-разделов, а также специализированного блока для задач ИИ и аналитики данных. Раздел CPU объединяет 140 узлов, каждый из которых содержит два процессора AMD EPYC 7763 (64 ядра; 2,45–3,50 ГГц; 256 Мбайт кеша L3; 280 Вт): суммарная производительность данного сегмента составляет 0,7 Пфлопс. GPU-составляющая включает 50 узлов на чипах EPYC 7763: каждый из узлов наделён четырьмя ускорителями NVIDIA A100, а общее быстродействие равно 4 Пфлопс. 
Источник изображения: KIFU Кроме того, в состав системы включены ИИ-блок и модуль Big Data. Первый состоит из двух узлов HPE Apollo 6500 Gen10, содержащих по два процессора EPYC 7763 и по восемь ускорителей NVIDIA A100. Второй модуль использует узел SMP/NUMA с 12 процессорами Intel Xeon Gold 6254 (18 ядер; 3,1–4,0 ГГц; 200 Вт). Суперкомпьютер также имеет хранилище на 10 Пбайт. Тепло, генерируемое вычислительным комплексом, будет использоваться для обогрева близлежащего муниципального бассейна. Около трёх четвертей ресурсов системы будут доступны исследователям по всей стране, а остальная часть — бизнесу. Заявленная потребляемая мощность — около 300 кВт. В ноябрьском рейтинге TOP500 суперкомпьютер Komondor находится на 199-й позиции.
05.01.2023 [22:25], Алексей Степин
AMD продемонстрировала на CES 2023 гигантский APU Instinct MI300: 13 чиплетов в LGA-упаковкеНа CES 2023 компания AMD впервые показала публике новый APU Instinct MI300. На сегодняшний момент MI300 — крупнейший и самый сложный чип, когда-либо созданный в стенах Advanced Micro Devices. Он насчитывает 146 млрд транзисторов, составляющих ядра CPU и GPU, вспомогательную логику, I/O-контроллер, а также память HBM3. По сложности новинка, таким образом, превосходит и Intel Xeon Max (100 млрд транзисторов), и гибрид NVIDIA Grace Hopper (80 млрд транзисторов). Все компоненты чипа объединены посредством 4-го поколения Infinity Fabric, физически же чиплеты разнесены не только по горизонтали, но и по вертикали, причём сами чиплеты производятся с использованием разных техпроцессов. В составе MI300 имеется 4 чиплета, выполненных по технологии 6 нм, на которых, в свою очередь, располагаются ещё 9 чиплетов, но уже использующих вышеупомянутый 5-нм техпроцесс. 
Источник: AMD/YouTube 6-нм чиплетамы образуют активную подложку, которая включает I/O-контроллер (в том числе для работы с памятью) и вспомогательную логику, а более совершенный 5-нм техпроцесс использован для вычислительных ядер. CPU-ядер с архитектурой Zen 4 в составе нового процессора 24. К сожалению, именно о CDNA-ядрах говорится мало и не озвучивается даже их число. С учётом того, что в Zen 4 используются 8-ядерные чиплеты, 3 из 9 «верхних» блоков MI300 именно процессорные.  Также на снимке можно разглядеть 8 сборок HBM3, суммарный объём которых составляет 128 Гбайт. Теоретически это может означать эффективную ширину шины вплоть до 8192 бит и пропускную способность в районе 5 Тбайт/с или даже больше. Такое сочетание позволит MI300 в 8 раз опередить MI250X в ИИ-задачах (правда, речь о разреженных FP8-вычислениях), и это при пятикратном превосходстве в энергоэффективности. Последнюю цифру озвучивала и Intel, говоря о своих APU Falcon Shores, выход которых намечен на 2024 год.  Конкретные значения энергопотребления и тепловыделения пока остаются тайной, но MI300, согласно Tom's Hardware, получил LGA-упаковку (SH5), напоминающую таковую у новеньких EPYC Genoa. Также на презентации было указано, что работоспособный кремний MI300 уже получен и находится в настоящее время в лабораториях AMD. Иными словами, у «красных» всё идёт по плану — официальный анонс состоится во второй половине нынешнего, 2023 года. Впрочем, MI300 будет дорогим и редким чипом.
17.12.2022 [12:36], Сергей Карасёв
Европа выделит €270 млн на развитие экосистемы RISC-VСовместная инициатива по высокопроизводительным вычислениям в Европе EuroHPC JU сообщила о намерении провести конкурс на финансирование проектов в области создания HPC-систем на архитектуре RISC-V. Предложения будут приниматься с 26 января по 4 апреля 2023 года. Европейский союз планирует выделить €270 млн на развитие экосистемы RISC-V. Речь идёт как об аппаратных решениях, так и о сопутствующем ПО. В частности, будет изучаться подход, основанный на чиплетах: это позволит применять процессоры RISC-V в паре с ускорителями в одном корпусе микросхемы. 
Источник изображения: HPC Wire Инициатива нацелена на уменьшение зависимости Европы от изделий с архитектурами x86 и Arm. В начале 2022 года консорциум EuroHPC JU объявил о выделении €141 млн на развитие собственных CPU, ускорителей и суперкомпьютеров. Речь шла в том числе о решениях на основе RISC-V. В Европейском союзе уже принят Закон о чипах, нацеленный на формирование новой экосистемы производства микросхем: в документе содержатся неоднократные упоминания архитектуры RISC-V. Научные учреждения в Европе создали экспериментальные системы на основе RISC-V. К примеру, пользователи могут получить доступ к платформам SUPER-V в Барселонском суперкомпьютерном центре (BSC) и ExCALIBUR в Эдинбургском университете. А Европейская инициатива по процессорам разработала ускорители машинного обучения RISC-V, которые в ближайшие годы появятся на экзафлопсных суперкомпьютерах. BSC и Intel совместно проектируют суперкомпьютерный чип с архитектурой RISC-V. В целом, интерес к RISC-V со стороны IT-компаний стремительно растёт. В течение последнего времени решения в данной сфере представили сразу несколько разработчиков. Так, Ventana Micro Systems анонсировала целое семейство высокопроизводительных процессоров, первенцем в котором стал чип Veyron V1. У MIPS появилось высокопроизводительное ядро eVocore P8700 на основе RISC-V, у SiFive — ядро Performance P670. Компания Andes представила RISC-V чипы AndesCore AX60 для ИИ, 5G и ЦОД.
16.12.2022 [15:26], Сергей Карасёв
В Аргентине появится 15,7-Пфлопс суперкомпьютер на платформе Intel MaxМинистр науки, технологий и инноваций Аргентины Даниэль Фильмус (Daniel Filmus) и министр обороны страны Хорхе Тайана (Jorge Taiana) рассказали о новом комплексе высокопроизводительных вычислений, который планируется ввести в эксплуатацию весной 2023 года. Безымянный пока суперкомпьютер расположится в вычислительном центре Национальной метеорологической службы Аргентины. Созданием системы занимаются специалисты Lenovo. Отличительной особенностью системы станет то, что они будет использовать исключительно процессоры и ускорители Intel Max. Комплекс объединит 5120 ядер процессоров Intel Max (HBM-версии чипов Xeon Sapphire Rapids) суммарной производительностью около 440 Тфлопс. Кроме того, будут задействованы 296 ускорителей Intel Max (Ponte Vecchio) с общим быстродействием 15,3 Пфлопс. Таким образом, пиковая производительность суперкомпьютера в целом составит примерно 15,7 Пфлопс. С таким показателем он мог бы претендовать на 82-е место в нынешнем рейтинге TOP500. Система получит 1,66 Пбайт памяти, 400G-сеть и систему прямого жидкостного охлаждения. Потребляемая мощность составит приблизительно 233 кВт. 
Источник изображения: Intel Суперкомпьютер планируется применять для широкого спектра научных задач, таких как разработка лекарственных препаратов, биоинформатика, наука о данных, искусственный интеллект и моделирование атмосферы. Нужно отметить, что сейчас Национальная метеорологическая служба Аргентины использует HPC-систему Huayra Muyu с пиковым быстродействием 370 Тфлопс.
14.12.2022 [20:39], Алексей Степин
AMD и Samsung создали уникальный экспериментальный ИИ-суперкомпьютер, скрестив «умную» память HBM-PIM и ускорители InstinctКонцепция вычислений в памяти (in-memory computing) имеет ряд преимуществ при построении HPC-систем, и компания Samsung сделала в этой области важный шаг. Впервые на практике южнокорейский гигант совместил в экспериментальном суперкомпьютере свои чипы in-memory с ускорителями AMD Instinct. Согласно заявлениям Samsung, такое сочетание даёт существенный прирост производительности при обучении «тяжёлых» ИИ-моделей. При этом улучшаются и показатели энергоэффективности. Новая система насчитывает 96 ускорителей AMD Instinct MI100, каждый из которых дополнен фирменной памятью HBM-PIM с функциями processing-in-memory. В состав системы входит 12 вычислительных узлов с 8 ускорителями в каждом. Шестёрка узлов связана с другой посредством коммутаторов InfiniBand. Используется 16 линков со скоростью 200 Гбит/с. 
Здесь и далее источник изображений: Samsung Кластер Samsung нельзя назвать рекордсменом, но результаты получены весьма обнадёживающие: в задаче обучения языковой модели Text-to-Test Transfer Transformer (T5), разработанной Google, использование вычислительной памяти позволило снизить время обучения в 2,5 раза, а потребление энергии при этом сократилось в 2,7 раза. 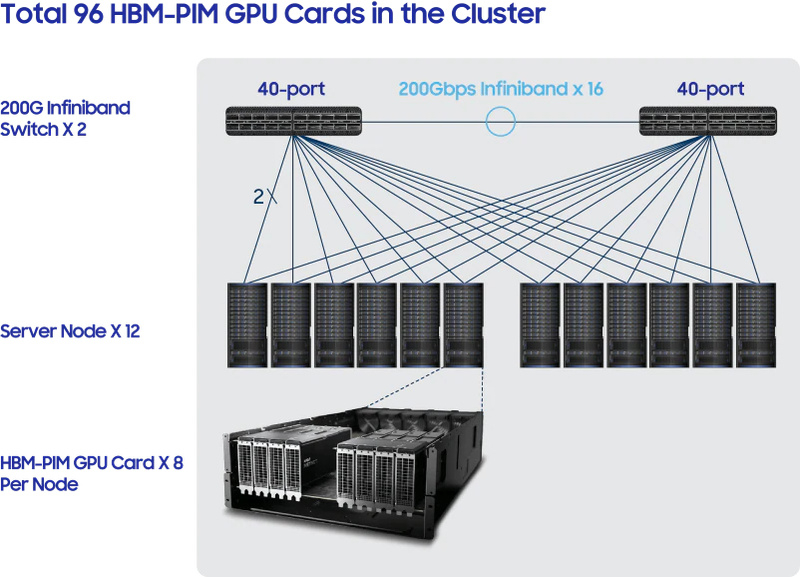 Технология весьма дружественна к экологии: по словам Samsung, такой кластер с памятью HBM-PIM способен сэкономить 2100 ГВт·час в год, что в пересчёте на «углеродный след» означает снижение выбросов на 960 тыс. т за тот же период. Для поглощения аналогичных объёмов углекислого газа потребовалось бы 10 лет и 16 млн. деревьев.  Компания уверена в своей технологии вычислений в памяти и посредством SYCL уже подготовила спецификации, позволяющие разработчикам ПО использовать все преимущества HBM-PIM. Также Samsung активно работает над похожей концепцией PNM (processing-near-memory), которая найдёт своё применение в модулях памяти CXL. 
Устройство Samsung HBM-PIM Работы по внедрению PIM и PNM Samsung ведёт давно, ещё на конференции Hot Chips 33 в прошлом году она объявила, что намерена оснастить вычислительными ускорителями все типы памяти — не только HBM2/3, но и DDR4/5. Тогда же впервые был продемонстрирован рабочий образец HBM-PIM, где каждый чип был оснащён ускорителем с FP16-производительностью 1,2 Тфлопс. Таким образом, первая HPC-система с технологией PIM полностью доказала работоспособность концепции вычислений в памяти. Samsung намеревается активно продвигать технологии PIM и PNM как в ИТ-индустрии, так и в академической среде, главном потребителе ресурсов суперкомпьютеров и кластерных систем.
29.11.2022 [17:12], Алексей Степин
AWS представила Arm-процессор Graviton3E, оптимизированный для задач ИИ и HPCОдин из крупнейших облачных провайдеров, компания Amazon Web Services объявила о доступности новых инстансов EC2 на базе процессора Graviton3E. Новый чип — наследник анонсированного в конце 2021 года Graviton3, 5-нм 64-ядерного процессора на дизайне Arm Neoverse V1 (Zeus) с поддержкой DDR5 и PCI Express 5.0. Graviton3 использует набор команд Armv8.4 c расширениями Neon (4×128 бит) и SVE (2×256 бит) и поддерживает работу с популярными в сфере машинного обучения форматами данных INT8 и BF16. В сравнении c Graviton2 процессор быстрее на 25-60 % при сохранении аналогичного уровня тепловыделения. Дизайн серверов AWS предусматривает наличие трёх процессоров на узел высотой 1U. 
Изображения: AWS Новый процессор Graviton3E представляет собой дальнейшее развитие Graviton3. Чип оптимизирован с учётом потребностей рынка высокопроизводительных вычислений и основное внимание в его архитектуре уделено повышению производительности на операциях с плавающей запятой и вычислениях с использованием векторной математики. AWS, к сожалению, пока не раскрывает деталей относительно архитектуры Graviton3E, но прирост производительности на векторных операциях относительно обычного Graviton3 может достигать 35 %. Помимо классического теста HPL новый процессор хорошо проявляет себя в тестах, имитирующих медико-биологические и финансовые задачи.  Сценарии нагрузок, характерные для HPC, как правило, активно оперируют перемещением крупных объемов данных. Чтобы оптимизировать этот процесс, в новых инстансах AWS использует сеть на базе Elastic Fabric с новыми адаптерами Elastic Network Adapter (ENA). Такая сеть оперирует т. н. Scalable Reliable Datagram (SRD) вместо всем привычных TCP-пакетов. SRD позволяет организовать повторную отправку пакетов за микросекунды вместо миллисекунд в классическом Ethernet. Сердцем же новых инстансов AWS стало пятое поколение аппаратных гипервизоров Nitro 5. В сравнении с предыдущим поколением, Nitro 5 обладает вдвое более высокой вычислительной производительностью, на 50 % повышенной пропускной способностью памяти, а также позволяет обрабатывать на 60 % больше сетевых пакетов при сниженной на 30 % латентности. 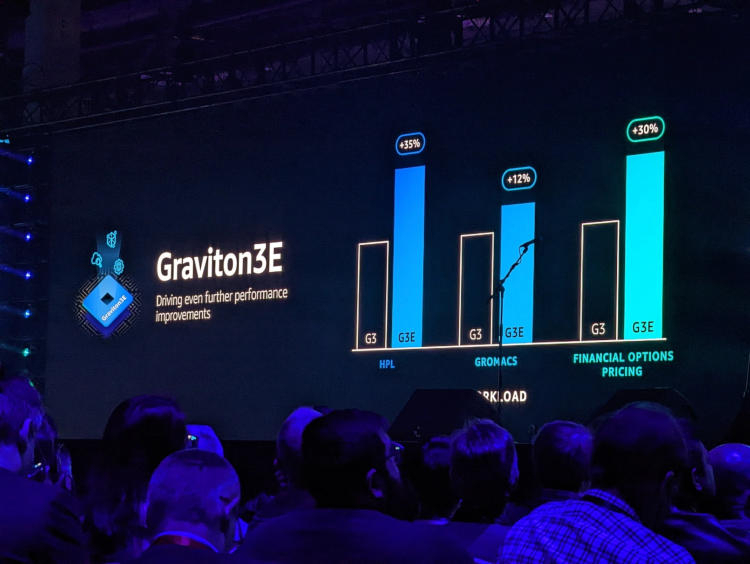
Здесь и далее источник изображений: AWS Инстансы Hpc7g с процессорами Graviton3E получат внутреннюю сеть с пропускной способностью 200 Гбит/с и станут доступны в различных конфигурациях вплоть до 64 vCPU и 128 ГиБ памяти. Аналогичные параметры имеют инстансы C7gn, предназначенные для задач с интенсивным сетевым трафиком: виртуальных маршрутизаторов, сетевых экранов, балансировщиков нагрузки и т.п. Также компания анонсировала инстансы R7iz, в которых используются процессоры Intel Xeon Scalable четвёртого поколения (Sapphire Rapids) с постоянной частотой всех ядер 3,9 ГГц. Они могут иметь конфигурацию до 128 vCPU с 1 ТиБ памяти.
29.11.2022 [12:20], Сергей Карасёв
В Италии официально запущен суперкомпьютер Leonardo — четвёртая по мощности HPC-система в миреСовместная инициатива по высокопроизводительным вычислениям в Европе EuroHPC JU и некоммерческий консорциум CINECA, состоящий из 69 итальянских университетов и 21 национальных исследовательских центров, провели церемонию запуска суперкомпьютера Leonardo. В основу комплекса положены платформы Atos BullSequana X2610 и X2135. Система Leonardo состоит из двух секций — общего назначения и с ускорителями вычислений (Booster). Когда строительство системы будет завершено, первая будет включать 1536 узлов, каждый из которых содержит два процессора Intel Xeon Sapphire Rapids с 56 ядрами и TDP в 350 Вт, 512 Гбайт оперативной памяти DDR5-4800, интерконнект NVIDIA InfiniBand HDR100 и NVMe-накопитель на 8 Тбайт. 
Источник изображения: HPCwire Секция Booster объединяет 3456 узлов, каждый из которых содержит один чип Intel Xeon 8358 с 32 ядрами, 512 Гбайт ОЗУ стандарта DDR4-3200, четыре кастомных ускорителя NVIDIA A100 с 64 Гбайт HBM2-памяти, а также два адаптера NVIDIA InfiniBand HDR100. Кроме того, в состав комплекса входят 18 узлов для визуализации: 6,4 Тбайт NVMe SSD и два ускорителя NVIDIA RTX 8000 (48 Гбайт) в каждом. Вычислительный комплекс объединён фабрикой с топологией Dragonfly+. 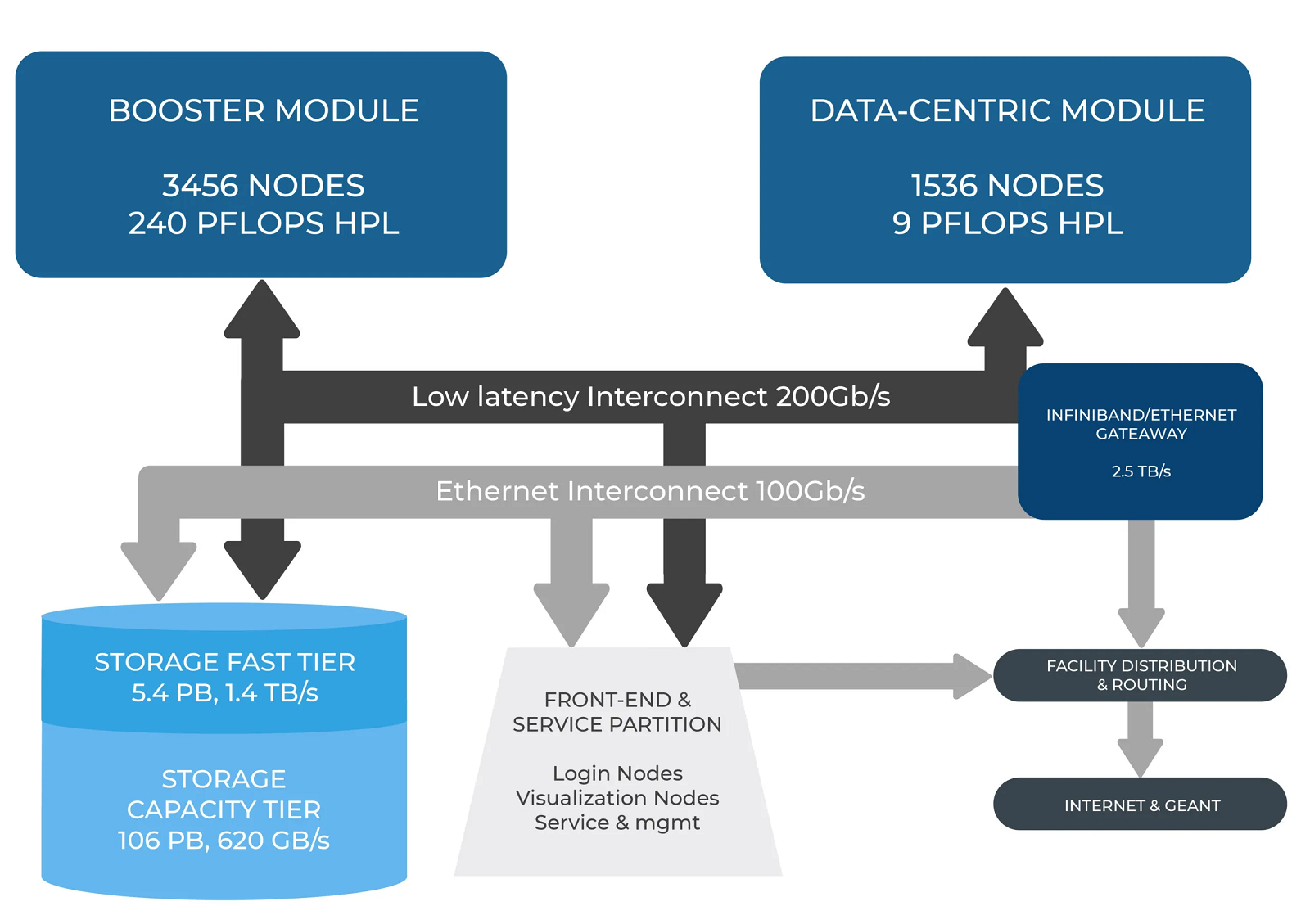
Источник: CINECA Для хранения данных служит двухуровневая система. Производительный блок (5,4 Пбайт, 1400 Гбайт/с) содержит 31 модуль DDN Exascaler ES400NVX2, каждый из которых укомплектован 24 NVMe SSD вместимостью 7,68 Тбайт и четырьмя адаптерами InfiniBand HDR. Второй уровень большой ёмкости (106 Пбайт, чтение/запись 744/620 Гбайт/с) состоит из 31 массива DDN EXAScaler SFA799X с 82 SAS HDD (7200 PRM) на 18 Тбайт и четырьмя адаптерами InfiniBand HDR. Каждый из массивов включает два JBOD-модуля с 82 дисками на 18 Тбайт. Для хранения метаданных используются 4 модуля DDN EXAScaler SFA400NVX: 24 × 7,68 Тбайт NVMe + 4 × InfiniBand HDR. 
Изображение: CINECA В настоящее время Leonardo обеспечивает производительность более 174 Пфлопс. Ожидается, что суперкомпьютер будет полностью запущен в первой половине 2023 года, а его пиковое быстродействие составит 250 Пфлопс. Уже сейчас система занимает четвёртое место в последнем рейтинге самых мощных суперкомпьютеров мира TOP500. В Европе Leonardo является второй по мощности системой после LUMI. Leonardo оборудован системой жидкостного охлаждения для повышения энергоэффективности. Кроме того, предусмотрена возможность регулировки энергопотребления для обеспечения баланса между расходом электричества и производительностью. Суперкомпьютер ориентирован на решение высокоинтенсивных вычислительных задач, таких как обработка данных, ИИ и машинное обучение. Половина вычислительных ресурсов Leonardo будет предоставлена пользователям EuroHPC. |
|