Материалы по тегу: h100
|
17.11.2023 [14:02], Руслан Авдеев
Tencent накопила достаточно ускорителей NVIDIA H800 для поддержания ИИ-разработок в условиях антикитайских санкцийПосле ужесточения антикитайских санкций 17 октября со стороны США бизнес и государственные структуры КНР лишились возможности приобретать даже ухудшенные версии ускорителей NVIDIA. Тем не менее, как сообщает DigiTimes, многие китайские участники рынка успели закупить большое количество ускорителей до вступления новых запретов в силу. По словам президента Tencent Мартина Лау (Martin Lau), перспектива введения более строгих санкций сподвигла компанию к более рациональному использованию уже имеющихся чипов, а также поиску альтернатив на местном рынке, где разработка подобных решений ведётся ударными темпами. В своё время NVIDIA на фоне санкций пришлось наладить для Китая вместо ускорителей A100 и H100 выпуск моделей A800 и H800 с искусственно заниженной производительностью. Но теперь и их экспорт в Поднебесную попал под запрет. Как заявил Лау журналистам, Tencent уже закупила достаточно ускорителей NVIDIA для дальнейшего развития ИИ-платформы Hunyuan. Ожидается, что компании удастся обучить ещё как минимум два поколения ИИ-моделей. В результате, как считают в руководстве Tencent, новейшие антикитайские санкции не смогут повлиять на возможность развития ИИ-технологий компании в краткосрочной перспективе. 
Источник изображения: NVIDIA Инвесторам сообщили, что Hunyuan уже может готовить резюме встреч, проводимых на похожей на Zoom платформе Tencent Meeting, даёт рекомендации программистам компании и повышает эффективность создания игр. Также ИИ способен выступать в роли копирайтера для рекламодателей, позволяя более аккуратно адаптировать рекламу под целевую аудиторию, увеличивая её эффективность. В частности, это позволило улучшить показатели видеорекламы Tencent. В обозримом будущем Лау рассчитывает, что ИИ позволит и отвечать на вопросы клиентов — это позволит объединить рекламу и продажи. Как подчеркнул Лау, фактически Tencent находится в числе китайских компаний с самыми большими запасами чипов H800 — в своё время именно она первой начала приобретать их у NVIDIA. В частности поэтому она накопила большие запасы, так что новые запреты способны лишь слегка замедлить работы. По словам Лау, наиболее эффективной будет комбинированная схема, при которой наиболее производительные чипы оставят для тренировки ИИ-моделей, а варианты с меньшей производительностью будут применяться для инференса. Впрочем, несмотря на принятые меры, в Tencent признают, что антикитайские санкции США негативно скажутся на облачном ИИ-сервисе компании. Тем не менее, Лау уверен, что если запасы H800 начнут иссякать, они будут пополнены за счёт китайских решений. Как сообщает The Register, пока таких фактически не существует. Но, судя по всему, в Tencent уверены, что скоро варианты, способные бросить вызов американскому превосходству, окажутся в китайском распоряжении. В III квартале выручка китайского техногиганта составила $21,5 млрд и выросла год к году на 10 %. Операционная прибыль упала на 6 %, но всё ещё составляет $6,8 млрд. Компания принимает ряд мер по оптимизации бизнеса и сейчас её социальные платформы WeChat и QQ насчитывают по 1,336 млрд и 558 млн активных пользователей соответственно, наблюдается небольшой рост год к году. Рост доходов руководство объясняет эффективностью видео- и игрового сервисов.
16.11.2023 [21:31], Сергей Карасёв
Суперкомпьютер ISEG отделившейся от «Яндекса» компании Nebius стал одним из самых мощных в мире
gigabyte
h100
hardware
hpc
intel
nebius
nvidia
sapphire rapids
top500
xeon
нидерланды
суперкомпьютер
Компания Nebius N.V. со штаб-квартирой в Нидерландах, созданная бывшими сотрудниками «Яндекса», вошла в первую двадцатку ноябрьского рейтинга мощнейших суперкомпьютеров мира TOP500 со своей НРС-системой ISEG. Этот вычислительный комплекс, названный в честь сооснователя «Яндекса» Ильи Сегаловича, расположился на 16-й строке списка. 
Источник изображения: Nebius В основу ISEG положены HGX-узлы Gigabyte G593-SD0 с двумя процессорами Intel Xeon Sapphire Rapids и восемью ускорителями NVIDIA H100 (SXM). В частности, задействованы чипы Platinum 8468 (48 ядер; 96 потоков; 2,1–3,8 ГГц; 350 Вт). Общее количество ядер в составе суперкомпьютера достигает 218 880. Применён интерконнект Infiniband NDR400. Производительность ISEG достигает 46,54 Пфлопс (FP64), пиковое быстродействие — 86,79 Пфлопс. С такими показателями система оставляет далеко позади все российские суперкомпьютеры. В частности, самый мощный НРС-комплекс РФ — «Червоненкис» компании «Яндекс» — располагается только на 36-й позиции с результатом 21,53 Пфлопс. Таким образом, по быстродействию этот суперкомпьютер уступает системе ISEG более чем в два раза. 
Источник изображения: Nebius Forbes отмечает, что в процессе создания ISEG интеллектуальная собственность и технологии «Яндекса» не использовались. Тестирование суперкомпьютера для рейтинга TOP500 проводилось с ОС Ubuntu Linux 20.04. Энергопотребление системы составило 1,32 МВт. В списке Green500 машина занимает 15-е место.
16.11.2023 [16:23], Сергей Карасёв
В облаке Microsoft Azure появились первые в отрасли ИИ-инстансы на базе NVIDIA H100 NVLКорпорация Microsoft объявила о том, что на базе облака Azure стали доступны виртуальные машины NC H100 v5 для HPC-вычислений и нагрузок ИИ. Это, как отмечается, первые в отрасли облачные инстансы на базе ускорителей NVIDIA H100 NVL. Данное решение объединяет два PCIe-ускорителя H100, соединённых посредством NVIDIA NVLink. Объём памяти HBM3 составляет 188 Гбайт, а заявленная FP8-производительность (с разреженностью) достигает почти 4 Пфлопс. Инстансы H100 v5 основаны на платформе AMD EPYC Genoa. В зависимости от реализации, доступны 40 или 80 vCPU и 320 и 640 Гбайт памяти соответственно. В первом случае задействован один ускоритель NVIDIA H100 NVL с 94 Гбайт памяти HBM3, во втором — два ускорителя с суммарно 188 Гбайт памяти HBM3. Пропускная способность сетевого подключения — 40 и 80 Гбит/с. 
Источник изображения: NVIDIA В отличие от виртуальных машин серии ND, рассчитанных на самые крупные модели ИИ, инстансы NC оптимизированы для обучения и инференса моделей меньшего размера, которым не требуются сверхмасштабные массивы данных. Виртуальные машины Azure NC H100 v5 также хорошо подходят для определённых НРС-нагрузок: это гидродинамика, молекулярная динамика, квантовая химия, прогнозирование погоды и моделирование климата, а также финансовая аналитика. В 2024 году Microsoft добавит в облако Azure виртуальные машины с новейшими ускорителями NVIDIA H200: оно смогут обрабатывать более крупные модели ИИ без увеличения задержки. А уже сейчас клиентам Azure стал доступен сервис DGX Cloud.
13.11.2023 [16:16], Сергей Карасёв
OSS представила защищённый ИИ-сервер Gen 5 AI Transportable на базе NVIDIA H100Компания One Stop Systems (OSS) на конференции по высокопроизводительным вычислениям SC23 представила сервер Gen 5 AI Transportable, предназначенный для решения задач ИИ и машинного обучения на периферии. Устройство, рассчитанное на монтаж в стойку, выполнено в корпусе уменьшенной глубины. Новинка соответствует американским военным стандартам в плане устойчивости к ударам, вибрации, диапазону рабочих температур и пр. Сервер может применяться в составе мобильных дата-центров, на борту грузовиков, самолётов и подводных лодок. Возможна установка четырёх ускорителей NVIDIA H100 и до 16 NVMe SSD суммарной вместимостью до 1 Пбайт. Говорится о поддержке до 35 одновременных ИИ-нагрузок. Кроме того, могут применяться сетевые решения стандарта 400 Гбит/с. При необходимости можно подключить NAS-хранилище в усиленном исполнении. 
Источник изображения: OSS Для сервера доступны различные варианты охлаждения: воздушное, автономное жидкостное или внешний теплообменник с жидкостным контуром. Поддерживаются различные варианты организации питания с переменным и постоянным током для использования на суше, в воздухе и море. При использовании СЖО ускорители H100, по всей видимости, комплектуются водоблоком EK-Pro NVIDIA H100 GPU WB. Реализована фирменная архитектура Open Split-Flow: она обеспечивает высокую эффективность охлаждения даже при небольшой скорости потока жидкости, что позволяет применять не слишком мощные помпы или помпы, работающие с невысокой скоростью. Микроканалы, фрезерованные на станке с ЧПУ, обладают минимальным гидравлическим сопротивлением потоку. Водоблок имеет однослотовое исполнение. 
Источник изображения: EKWB Предусмотрено проприетарное ПО U-BMC (Unified Baseboard Management Controller) для динамического управления скоростью вентиляторов, мониторинга системы и пр. Сервер подходит для монтажа в большинство 19″ стоек.
09.11.2023 [01:35], Руслан Авдеев
Microsoft из-за прожорливости Bing Chat пришлось договориться об аренде ИИ-ускорителей NVIDIA у OracleТочно неизвестно, велик ли спрос на ИИ-сервисы Microsoft или у компании просто недостаточно вычислительных ресурсов, но IT-гиганту пришлось договариваться с Oracle об использовании ИИ-ускорителей в ЦОД последней. Как сообщает The Register, речь идёт о применении оборудования Oracle для «разгрузки» некоторых языковых моделей Microsoft, применяемых в Bing. Во вторник компании анонсировали многолетнее соглашение. Как сообщают в Microsoft, одновременное использование компанией как Oracle Cloud, так и Microsoft Azure расширит возможности клиентов и ускорит работу с поисковыми сервисами. Сотрудничество связано с тем, что Microsoft надо всё больше вычислительных ресурсов для заявляемого «взрывного роста» её ИИ-сервисов, а у Oracle как раз имеются десятки тысяч ускорителей NVIDIA A100 и H100 для аренды. 
Источник изображения: cliff1126/pixabay.com Служба Oracle Interconnect обеспечивает взаимодействие с облаком Microsoft Azure, что позволяет работающим в Azure сервисам взаимодействовать с ресурсами Oracle Cloud Infrastructure (OCI). Раньше такое решение уже применялось, но для сторонних клиентов двух компаний. Теперь Microsoft применяет Interconnect наряду с Azure Kubernetes Service для организации работы ИИ-узлов в облаке Oracle на благо Bing Chat. Microsoft ещё в феврале интегрировала чат-бота Bing Chat в свой поисковый сервис и свой браузер. Не так давно добавилась и возможность, например, генерировать изображения прямо в процессе диалога. При этом использование больших языковых моделей требует огромного числа ускорителей для их тренировки, но для инференса необходимы ещё большие вычислительные мощности. 
Фото: Microsoft В Oracle утверждают, что облачные суперкластеры компании, которые, вероятно, будет использовать Microsoft, могут масштабироваться до 32 768 ИИ-ускорителей A100 или 16 384 ускорителей H100 с использованием RDMA-сети с ультранизкой задержкой. Дополнением является хранилище петабайтного класса. В самой Microsoft избегают говорить, сколько именно узлов Oracle нужно компании, причём, похоже, не намерены делать этого и в будущем. Конкуренты сотрудничают уже не в первый раз. В сентябре Oracle сообщала о намерении размещать системы с базами данных в ЦОД Azure. Более того, ещё в мае 2023 года Microsoft и Oracle изучали возможность аренды ИИ-серверов друг у друга на случай, если у них вдруг не будет хватать вычислительных мощностей для крупных облачных клиентов. Ранее ходили слухи, что похожие соглашения Microsoft подписала с CoreWeave и Lambda Labs, к которым NVIDIA более благосклонна в вопросах поставки ускорителей. Попутно Microsoft ищет более экономичные альтернативы языковым моделям OpenAI.
08.11.2023 [20:00], Игорь Осколков
Счёт на секунды: ИИ-суперкомпьютер NVIDIA EOS с 11 тыс. ускорителей H100 поставил рекорды в бенчмарках MLPerf TrainingВместе с публикацией результатов MLPerf Traning 3.1 компания NVIDIA официально представила новый ИИ-суперкомпьютер EOS, анонсированный ещё весной прошлого года. Правда, с того момента машина подросла — теперь включает сразу 10 752 ускорителя H100, а её FP8-производительность составляет 42,6 Эфлопс. Более того, практически такая же система есть и в распоряжении Microsoft Azure, и её «кусочек» может арендовать каждый, у кого найдётся достаточная сумма денег. 
Изображения: NVIDIA Суммарно EOS обладает порядка 860 Тбайт памяти HBM3 с агрегированной пропускной способностью 36 Пбайт/с. У интерконнекта этот показатель составляет 1,1 Пбайт/с. В данном случае 32 узла DGX H100 объединены посредством NVLink в блок SuperPOD, а за весь остальной обмен данными отвечает 400G-сеть на базе коммутаторов Quantum-2 (InfiniBand NDR). В случае Microsoft Azure конфигурация машины практически идентичная с той лишь разницей, что для неё организован облачный доступ к кластерам. Но и сам EOS базируется на платформе DGX Cloud, хотя и развёрнутой локально.   В рамках MLPerf Training установила шесть абсолютных рекордов в бенчмарках GPT-3 175B, Stable Diffusion (появился только в этом раунде), DLRM-dcnv2, BERT-Large, RetinaNet и 3D U-Net. NVIDIA на этот раз снова не удержалась и добавила щепотку маркетинга на свои графики — когда у тебя время исполнения теста исчисляется десятками секунд, сравнивать свои результаты с кратно меньшими по количеству ускорителей кластерами несколько неспортивно. Любопытно, что и на этот раз сравнивать H100 приходится с Habana Gaudi 2, поскольку Intel не стесняется показывать результаты тестов. 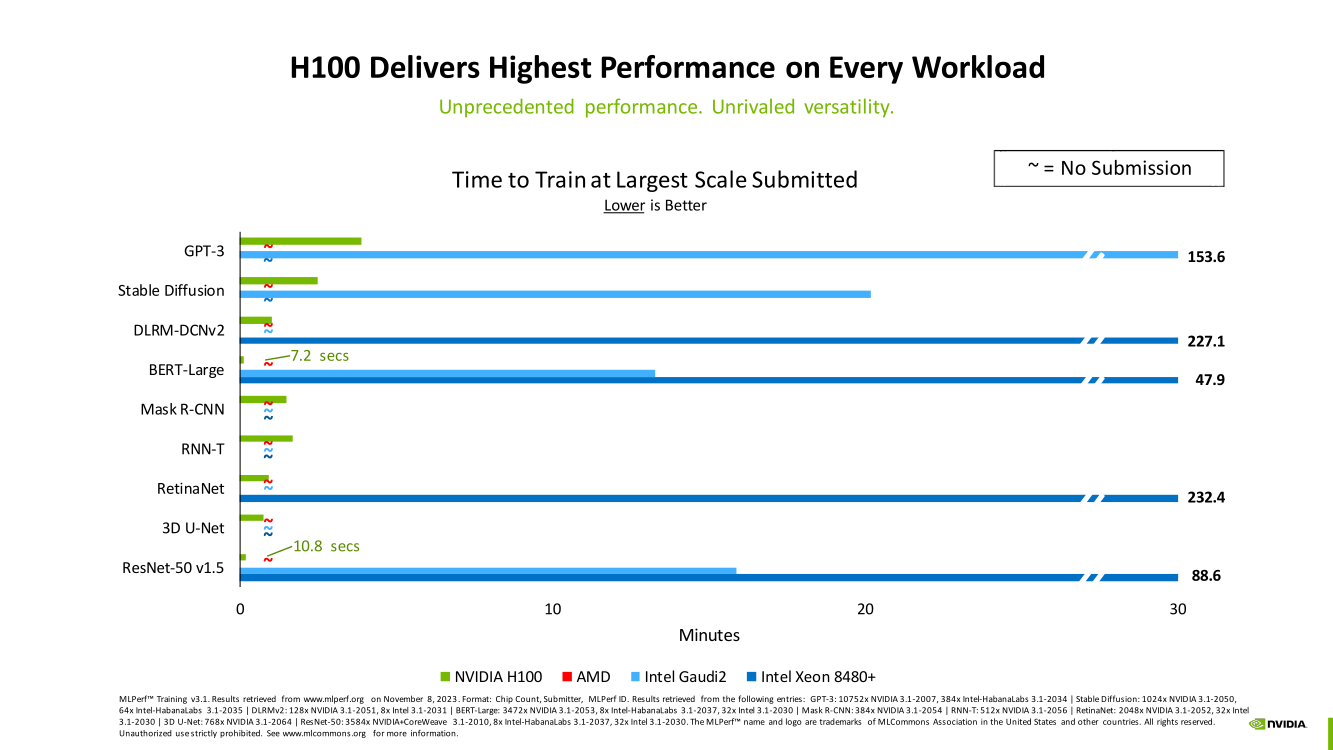 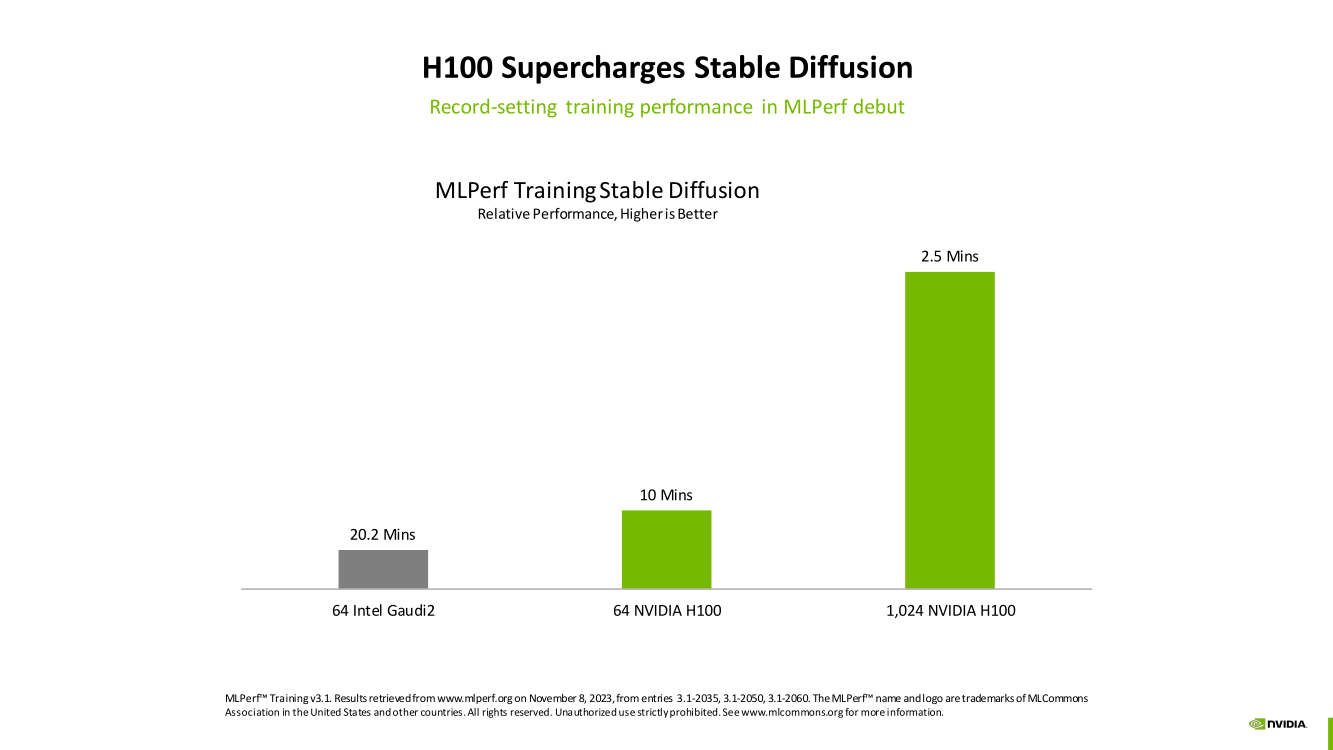 NVIDIA очередной раз подчеркнула, что рекорды достигнуты благодаря оптимизациям аппаратной части (Transformer Engine) и программной, в том числе совместно с MLPerf, а также благодаря интерконнекту. Последний позволяет добиться эффективного масштабирования, близкого к линейному, что в столь крупных кластерах выходит на первый план. Это же справедливо и для бенчмарков из набора MLPerf HPC, где система EOS тоже поставила рекорд. 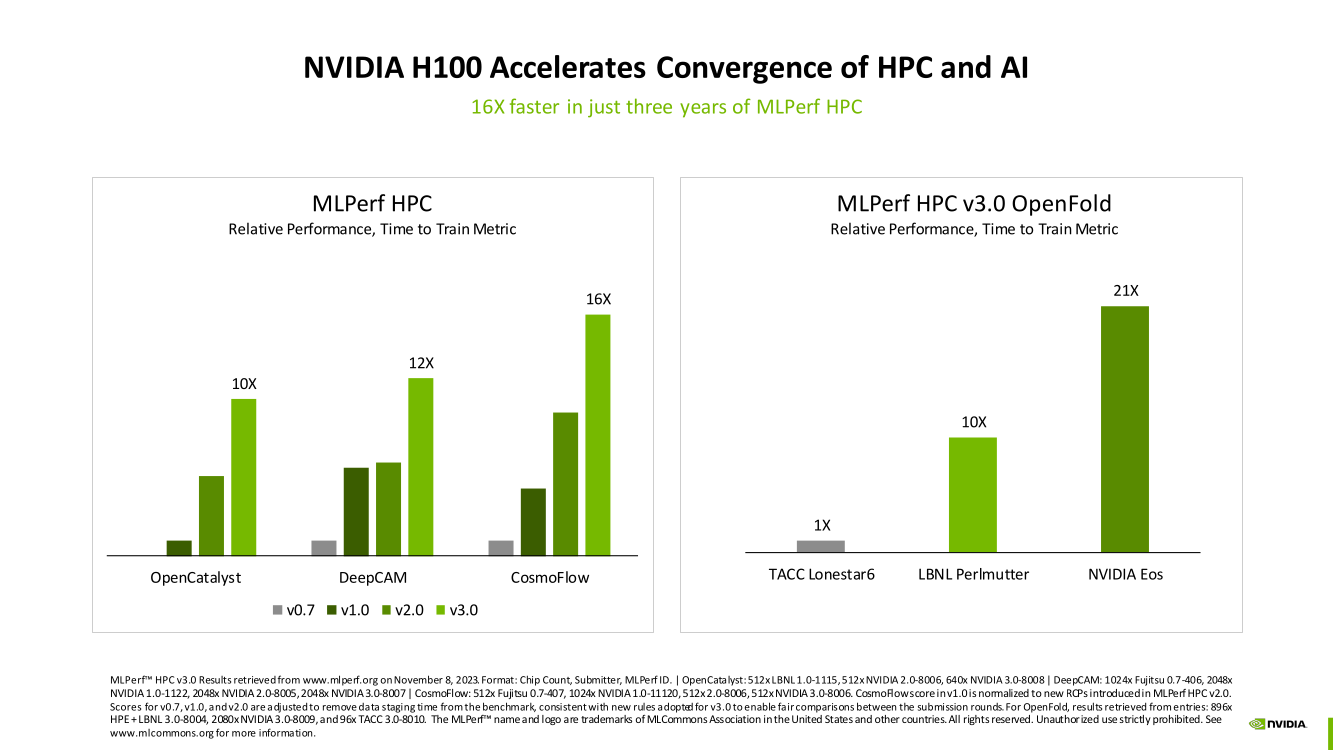
02.11.2023 [01:35], Владимир Мироненко
Бронь на ИИ: AWS предложила клиентам заранее заказывать кластеры с ускорителями NVIDIA H100Облачный провайдер Amazon Web Services (AWS) объявил о запуске новой модели потребления EC2 Capacity Blocks for ML, предназначенной для предприятий, желающих зарезервировать доступ к ускорителям вычислений для обработки кратковременных рабочих нагрузок ИИ. Решение Amazon EC2 Capacity Blocks for ML позволяет клиентам зарезервировать доступ к «сотням» ускорителей NVIDIA H100 в кластерах EC2 UltraClusters, которые предназначены для высокопроизводительных рабочих нагрузок машинного обучения. Клиенты просто указывают желаемый размер кластера, дату начала и окончания доступа. Таким образом повышается предсказуемость доступности ИИ-ресурсов и в то же время нет необходимости оплачивать доступ к мощностям, когда они не используются. AWS тоже в выигрыше, поскольку такой подход позволяет более полно использовать имеющиеся ресурсы. 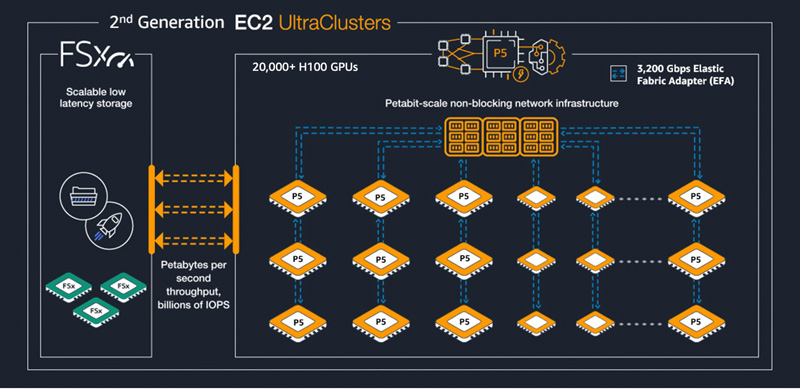
Источник изображения: AWS В рамках EC2 Capacity Blocks предлагаются кластеры, включающие от 1 до 64 инстансов EC2 P5 с подключением на базе Elastic Fabric Adapter (EFA) второго поколения. Кластеры можно зарезервировать на срок от 1 до 14 дней, но не позднее чем за восемь недель до начала использования. Это делает их идеальными для обучения и тюнинга ИИ-моделей, краткосрочных экспериментов или для обработки пикового потока запросов, например, при запуске нового продукта, сообщила AWS. Хольгер Мюллер (Holger Mueller), аналитик компании Constellation Research Inc., отметил, что креативный подход AWS позволяет максимизировать эффективность имеющихся ресурсов ускорителей, которые сейчас пользуются пиковым спросом, а доступ к ним обходится дорого. По его словам, подход заимствован из эпохи мейнфреймов, и впервые был использован ещё в 1970-х годах, когда доступ распределялся по времени между сотнями пользователей с различными рабочими нагрузками. Клиенты могут использовать консоль AWS, CLI или SDK, чтобы найти и зарезервировать доступные кластеры. При использовании EC2 Capacity Blocks клиенты платят только за то время, которое они зарезервировали. Решение доступно в регионе AWS Восток США (Огайо). В дальнейшем число регионов и локальных зон AWS с доступностью этого решения будет расширено.
31.10.2023 [20:58], Руслан Авдеев
Voltage Park закупила 25 тыс. ускорителей NVIDIA H100, чтобы сбалансировать спрос и предложение на дефицитные ресурсы для ИИПровайдер ИИ-инфраструктуры Voltage Park объявил о приобретении 24 тыс. ускорителей NVIDIA H100. Как сообщает The Register, компания намерена сдавать их в аренду корпоративным клиентам, небольшим стартапам и исследовательским структурам уже в следующем году. Первые счастливчики в лице Imbue уже получили доступ, а формирование кластеров для Character.ai и Atomic AI находится на финальной стадии. В компании подчеркнули, что мало кто понимает, насколько недостаток вычислительных мощностей вредит инновациям — для реализации многих проектов в сфере ИИ и машинного обучения требуется или ждать месяцы своей очереди для доступа к ускорителям, или, если позволяет бюджет, платить доступ здесь и сейчас заоблачные суммы. Компания рассчитывает сбалансировать спрос и предложение. 
Источник изображения: NVIDIA Voltage Park привлекла $500 млн. Ускорители купят у некоммерческой организации, поддерживаемой миллиардером Джедом Маккалебом (Jed MacCaleb), сколотившим состояние на крипторынке, а теперь заинтересовавшимся космическими проектами. Внедрение нового оборудования намечено в Техасе, Вирджинии и Вашингтоне. Компания намерена расширить портфолио долгосрочных и краткосрочных тарифов, а в начале следующего года появится возможность даже почасовой аренды мощностей отдельных ускорителей. Доступ к одному ускорителю у Voltage Park будет стоить от $1,89/час, но полные условия, в том числе особенности инфраструктуры, не раскрываются. Для сравнения — инстанcы AWS EC2 P5 с восемью NVIDIA H100 обойдутся в $98,32/час при доступе по запросу или же в $43,16/час при заключении контракта на три года. Voltage Park по запросу будет предоставлять мощности от 1 до 8 ускорителей, для доступа к 8–248 H100 придётся подписать краткосрочный договор аренды. Наконец, годовой контракт даёт доступ к 4088 ускорителям ($67,7 млн/год). Это далеко не единственная компания, выросшая на фоне высокого спроса на продукцию NVIDIA и AMD. Например, CoreWeave при сотрудничестве с NVIDIA построила собственный кластер, включающий более 22 тыс. ускорителей H100.
28.10.2023 [14:12], Сергей Карасёв
AlphaCool выпустила однослотовый водоблок за €300 для ускорителя NVIDIA H100Компания AlphaCool анонсировала водоблок ES H100 80GB HBM PCIe, предназначенный для использования в составе системы жидкостного охлаждения ускорителя NVIDIA H100. Новинка, получившая однослотовое исполнение, уже доступна для заказа по ориентировочной цене €300. Изделие полностью изготовлено из высококачественной хромированной меди. Верхняя часть водоблока выполнена из углеродного волокна. Новинка специально спроектирована для серверов с ограниченным внутренним пространством. В частности, коннекторы расположены в задней части изделия, благодаря чему упрощается прокладка шлангов. Это позволяет интегрировать решение в водяной контур даже в самых тесных корпусах. 
Источник изображений: AlphaCool Задействованы фитинги стандарта G1/4". Габариты составляют 261,89 × 95,71 × 19,40 мм, а тыльная панель из алюминия чёрного цвета имеет размеры 261,89 × 95,71 × 4,00 мм. Максимальная рабочая температура — 60 °C. В комплект поставки входят термопрокладки толщиной 1 мм и термопаста Alphacool Apex с теплопроводностью 17 Вт/м·К. 
25.10.2023 [12:15], Сергей Карасёв
Taiga Cloud развернёт ИИ-платформу Gigabyte с 10 тыс. ускорителями NVIDIA H100Компания Northern Data Group объявила о том, что её облачное подразделение Taiga Cloud заключило соглашение о стратегическом сотрудничестве с Gigabyte. Партнёрство предполагает создание в европейском регионе НРС-площадки для решения ресурсоёмких задач, связанных с генеративным ИИ. Речь идёт об использовании ускорителей NVIDIA. В частности, Gigabyte по заказу Taiga Cloud создала архитектуру из NVIDIA DGX SuperPod, насчитывающих 512 ускорителей NVIDIA H100. Четыре таких блока (2048 ускорителей) связаны посредством NVIDIA BlueField и NVIDIA Quantum-2 InfiniBand, а всего таких блоков будет пять, т.е. суммарно оператор получит 10 240 ускорителей. Gigabyte поставит в интересах Taiga Cloud в общей сложности 20 вычислительных блоков с ускорителями NVIDIA H100 на общую сумму €400 млн. В результате, Taiga Cloud станет одним из крупнейших в Европе независимых поставщиков облачных услуг на основе оборудования NVIDIA — с более чем 19 тыс. ускорителей H100, A100 и RTX A6000. 
Источник изображения: NVIDIA Предполагается, что развёртывание площадки поможет заказчикам ускорить инновации в области генеративного ИИ. Облачная платформа с ускорителями NVIDIA H100 повысит скорость обучения больших языковых моделей (LLM). Таким образом, клиенты смогут выводить свои продукты на коммерческий рынок в более сжатые сроки, что обеспечит конкурентное преимущество и даст возможность повысить выручку. |
|