Материалы по тегу: h100
|
21.10.2023 [16:44], Сергей Карасёв
Gcore развернула кластер генеративного ИИ с ускорителями NVIDIAПровайдер облачных и периферийных сервисов Gcore, по сообщению ресурса Datacenter Dynamics, запустил вычислительный кластер для решения задач в области генеративного ИИ. Площадка, расположенная в Люксембурге, использует ускорители NVIDIA. Ранее Gcore уже развернула в Люксембурге ИИ-платформу на базе Graphcore IPU (Intelligence Processing Unit). Кроме того, компания оперирует такими системами в Амстердаме (Нидерланды) и Уэльсе (Великобритания). Новый кластер позволит клиентам ускорить решение задач в сферах генеративного ИИ и машинного обучения. Запущенная в Люксембурге площадка объединяет 20 серверов с ускорителями NVIDIA A100. До конца текущего года будут добавлены 128 узлов на базе NVIDIA H100 и ещё 25 серверов с изделиями A100. О текущей и планируемой производительности кластера данных пока нет. Отмечается лишь, что заказчики смогут разворачивать на базе платформы крупномасштабные ИИ-модели. 
Источник изображения: NVIDIA На сегодняшний день Gcore имеет точки присутствия в более чем в 140 регионах на шести континентах, а также более чем 20 облачных локаций. Компания была основана в 2014 году, а услуги CDN и хостинга начала предоставлять в 2016 году.
05.10.2023 [21:30], Сергей Карасёв
Британская NexGen Cloud вложит $1 млрд в создание европейского ИИ-супероблака из 20 тыс. NVIDIA H100Британская компания NexGen Cloud, по сообщению ресурса Datacenter Dynamics, намерена инвестировать $1 млрд в проект AI Supercloud: речь идёт о развёртывании так называемого ИИ-супероблака в Европе. Создание платформы начнётся в текущем месяце. NexGen Cloud уже оформила заказы на оборудование на сумму приблизительно $576 млн. В полностью завершённом виде система объединит 20 тыс. ускорителей NVIDIA H100. Завершение создания платформы запланировано на июнь 2024 года. Доступ к системе будет предоставляться через гиперстек NexGen Cloud. Ресурсы AI Supercloud будут доступны предприятиям и государственным заказчикам, которые должны оставаться в европейской юрисдикции. Предполагается, что супероблако позволит клиентам решать ресурсоёмкие задачи ИИ, оставаясь конкурентоспособными на глобальном рынке. 
Источник изображения: NVIDIA Проект финансируется благодаря партнёрству NexGen Cloud и Moore and Moore Investments Group (MMI) за счёт средств частных инвесторов. Отмечается, что NexGen Cloud является участником партнёрской сети NVIDIA. Компания, основанная в 2020 году, предоставляет услуги по модели «инфраструктура как сервис» (IaaS): заказчикам предлагаются высокопроизводительные решения для облачных вычислений на базе GPU.
05.10.2023 [13:06], Сергей Карасёв
ИИ-провайдер 6Estates развернул свою первую систему NVIDIA DGX BasePOD на базе DGX H100Компания 6Estates, сингапурский провайдер ИИ-решений для корпоративных заказчиков, объявила о развёртывании первой системы NVIDIA DGX BasePOD на основе DGX H100. Кластер будет применяться для решения ресурсоёмких задач в области ИИ. Фирма 6Estates, созданная на базе Национального университета Сингапура и Университета Цинхуа, специализируется на предоставлении предприятиям решений, использующих LLM. Кроме того, 6Estates является участником программы NVIDIA Inception по поддержке стартапов в области ИИ. DGX BasePOD — это референсная архитектура, которая объединяет вычислительные мощности, сетевые инструменты, СХД, необходимое ПО и другие компоненты в интегрированную ИИ-инфраструктуру на основе NVIDIA DGX. 6Estates планирует использовать BasePOD на базе DGX H100 для своего нового предложения Model Solutions, которое даёт предприятиям возможность создавать персонализированные LLM и приложения для конкретных задач. Кроме того, 6Estates получит доступ к комплексному пакету фреймворков и ИИ-инструментов NVIDIA AI Enterprise. 
Источник изображения: 6Estates Используя DGX H100, 6Estates существенно сократит время обучения моделей и обеспечит более быстрое предоставление услуг Model Solutions корпоративным клиентам. Кластер также будет поддерживать существующие решения 6Estates в области ИИ, в частности, специализированную платформу, которая автоматизирует обработку и анализ неструктурированных документов без шаблонов, а также автоматизирует рабочие процессы для кредиторов и торговых компаний.
29.09.2023 [22:57], Руслан Авдеев
Французская iliad Group приобрела ИИ-кластер NVIDIA DGX SuperPOD из 1016 ускорителей H100 и задумала создать универсальный ИИФранцузская ГК iliad Group заявила о приобретении системы NVIDIA DGX SuperPOD для предоставления участникам европейского рынка IT «самого мощного» в регионе облачного ИИ-суперкомпьютера, включающего 1016 ускорителей H100 (127 систем DGX последнего поколения). За покупку отвечал облачный провайдер Scaleway, а сама машина разместилась в ЦОД Datacenter 5 в окрестностях Парижа. 
Фото: iliad Group Это только первый шаг компании на пути к достижению краткосрочной цели по предоставлению новых вычислительных мощностей клиентам. Для того, чтобы удовлетворить любые запросы клиентов, Scaleway обеспечила предоставление вычислительных мощностей небольшими блоками, по паре связанных серверов DGX H100 в каждом. В ближайшие месяцы Scaleway продолжит наращивать вычислительные способности платформы. Кроме того, iliad анонсировала создание в Париже ИИ-лаборатории, в которую уже инвестировано более €100 млн. Её главой стал миллиардер Ксавье Ниль (Xavier Niel), фактически контролирующий iliad Group. Лаборатория, как сообщается, привлекла известных исследователей из крупнейших международных компаний. Основной целью лаборатории станет помощь в создании универсального ИИ, а результаты исследований в этом направлении будут доступны публично.
28.09.2023 [02:09], Владимир Мироненко
Oracle запустила bare-metal инстансы с NVIDIA H100Несмотря на нехватку на рынке ускорителей NVIDIA H100 ещё один провайдер представил продукты на их основе. Облачная служба Oracle Cloud Infrastructure (OCI) объявила о доступности bare-metal инстансов OCI Compute на базе NVIDIA H100, предназначенных для крупномасштабных приложений искусственного интеллекта (ИИ) и высокопроизводительных вычислений (HPC). Инстанс OCI Compute BM.GPU.H100.8 содержит восемь ускорителей H100, каждый из которых имеет 80 Гбайт памяти HBM2, 16 локальных накопителей NVMe ёмкостью 3,84 Тбайт каждый, два 56-ядерных процессора Intel Xeon Sapphire Rapids (2,0/3,8 ГГц), 2 Тбайт памяти DDR5, а также восемь 400G-адаптеров. Также в этом году компании смогут воспользоваться OCI Supercluster для создания кластеров, включающих до 50 тыс. ускорителей H100. Эта опция поначалу будет доступна в регионах Лондона и Чикаго, а в будущем число регионов с её поддержкой будет увеличено. При этом в OCI доступен и сервис NVIDIA DGX Cloud, который также включает кластеры на базе H100. 
Изображение: Oracle Oracle также сообщила, что в начале 2024 года представит инстансы с новейшими ускорителями NVIDIA L40S. Например, инстанс BM.L40S.4 предложит четыре L40S с двумя 56-ядерными процессорами Intel Xeon, 1 Тбайт RAM, 15,36 Тбайт NVMe-хранилища и сетевое подключение 400 Гбит/с.
22.09.2023 [12:29], Сергей Карасёв
Цукерберг создаст суперкомпьютер для биомедицинских исследований на ускорителях NVIDIA H100«Инициатива Чан Цукерберг» (CZI), благотворительная организация основателя Facebook✴ Марка Цукерберга (Mark Zuckerberg), намерена создать высокопроизводительный вычислительный кластер с ускорителями NVIDIA. Об этом сообщает ресурс Datacenter Dynamics. Говорится, что в основу платформы лягут более тысячи изделий NVIDIA H100. Кластер планируется использовать для биомедицинских исследований с применением средств ИИ. Суперкомпьютер будет использоваться для разработки открытых моделей человеческих клеток. При этом планируется применять прогностические методы, обученные на больших наборах данных, таких как те, которые интегрированы в программный инструмент Chan Zuckerberg CELL by GENE (CZ CELLxGENE). Модели также будут обучаться на данных, полученных исследовательскими институтами CZ Science, таких как атлас расположения и взаимодействия белков OpenCell и клеточный атлас Tabula Sapiens, созданный Биоцентром Чана Цукерберга в Сан-Франциско (Biohub San Francisco). 
Источник изображения: pixabay.com Разработка цифровых моделей, способных предсказывать поведение различных типов клеток, поможет исследователям лучше понять здоровое состояние организма и изменения, происходящие при различных заболеваниях.
17.09.2023 [19:04], Сергей Карасёв
NVIDIA за квартал отгрузила 900 тонн ускорителей H100Во II четверти 2024 финансового года, которая была закрыта 30 июля, компания NVIDIA реализовала продукцию для дата-центров на сумму около $10,32 млрд — это на 171 % больше результата за предыдущий год. Аналитики Omdia, как сообщает ресурс Tom's Hardware, подсчитали, что за эти три месяца NVIDIA отгрузила свыше 300 тыс. флагманских ускорителей H100. Изделия H100 на архитектуре Hopper предназначены для ресурсоёмких приложений ИИ, а также задач НРС. Однако из-за стремительного развития платформ генеративного ИИ такие ускорители оказались в дефиците: выполнение новых заказов откладывается до 2024 года. 
Источник изображения: NVIDIA По оценкам Omdia, во II квартале NVIDIA поставила более 900 тонн ускорителей H100. В своих расчётах аналитики полагают, что вес одного устройства с радиатором охлаждения превышает 3 кг. Таким образом, получается, что в течение рассматриваемого периода компания реализовала более 300 тыс. изделий. Ускорители H100 предлагаются в нескольких вариантах исполнения — в виде карты расширения PCIe и в формате модуля SXM. При этом масса (с учётом радиатора) различается: так, например, для карты она указана на отметке 1,2 кг. В случае SXM-изделий показатель не приводится, но, как отмечает Tom's Hardware, он не превышает 2 кг. Если предположить, что 80 % поставок H100 составляют модули, а 20 % — карты, то средний вес одного ускорителя должен составить около 1,84 кг. Omdia заявляет, что оценила общую массу в 900 тонн на основе количества H100, которые, по её мнению, NVIDIA поставила во II квартале. Таким образом, как отмечается, фактически суммарный вес может оказаться меньше, но речь всё равно идёт о сотнях тонн. Omdia прогнозирует, что до конца 2023 года темпы отгрузок Н100 сохранятся. Иными словами, NVIDIA сможет за год поставить около 1,2 млн таких ускорителей, а их суммарный вес достигнет 3600 тонн.
11.09.2023 [19:00], Сергей Карасёв
Много памяти, быстрая шина и правильное питание: гибридный суперчип GH200 Grace Hopper обогнал H100 в ИИ-бенчмарке MLPerf InferenceКомпания NVIDIA сообщила о том, что суперчип NVIDIA GH200 Grace Hopper и ускоритель H100 лидируют во всех тестах производительности ЦОД в бенчмарке MLPerf Inference v3.1 для генеративного ИИ, который включает инференс-задачи в области компьютерного зрения, распознавания речи, обработки медицинских изображений, а также работу с большими языковыми моделями (LLM). Ранее NVIDIA уже объявляла о рекордах H100 в новом бенчмарке MLPerf. Теперь говорится, что суперчип GH200 Grace Hopper впервые прошёл все тесты MLPerf. Вместе с тем системы, оснащенные восемью ускорителями H100, обеспечили самую высокую пропускную способность в каждом тесте MLPerf Inference. Решения NVIDIA прошли обновленное тестирование в области рекомендательных систем (DLRM-DCNv2), а также выполнили первый эталонный тест GPT-J — LLM с 6 млрд параметров. Примечательно, что GH200 оказался до 17 % быстрее H100, хотя чип самого ускорителя в обоих продуктах один и тот же. NVIDIA объясняет это несколько факторами. Во-первых, у GH200 больше набортной памяти — 96 Гбайт против 80 Гбайт. Во-вторых, ПСП составляет 4 Тбайт/с, а сам чип является гибридным, так что для передачи данных между LPDDR5x и HBM3 не используется PCIe. В-третьих, GH200 при низкой нагрузке на CPU умеет отдавать часть энергии ускорителю, оставаясь в заданных рамках энергопотребления. Правда, в тестах GH200 работал на полную мощность, т.е. с TDP на уровне 1 кВт (UPD: NVIDIA уточнила, что реально потребление GH200 под полной нагрузкой составляет 750–800 Вт). 
Источник изображений: NVIDIA Отдельно внимание уделено оптимизации ПО — на днях NVIDIA анонсировала открый программный инструмент TensorRT-LLM, предназначенный для ускорения исполнения LLM на продуках NVIDIA. Этот софт даёт возможность вдвое увеличить производительность ускорителя H100 в тесте GPT-J 6B (входит в состав MLPerf Inference v3.1). NVIDIA отмечает, что улучшение ПО позволяет клиентам с течением времени повышать производительность ИИ-систем без дополнительных затрат. 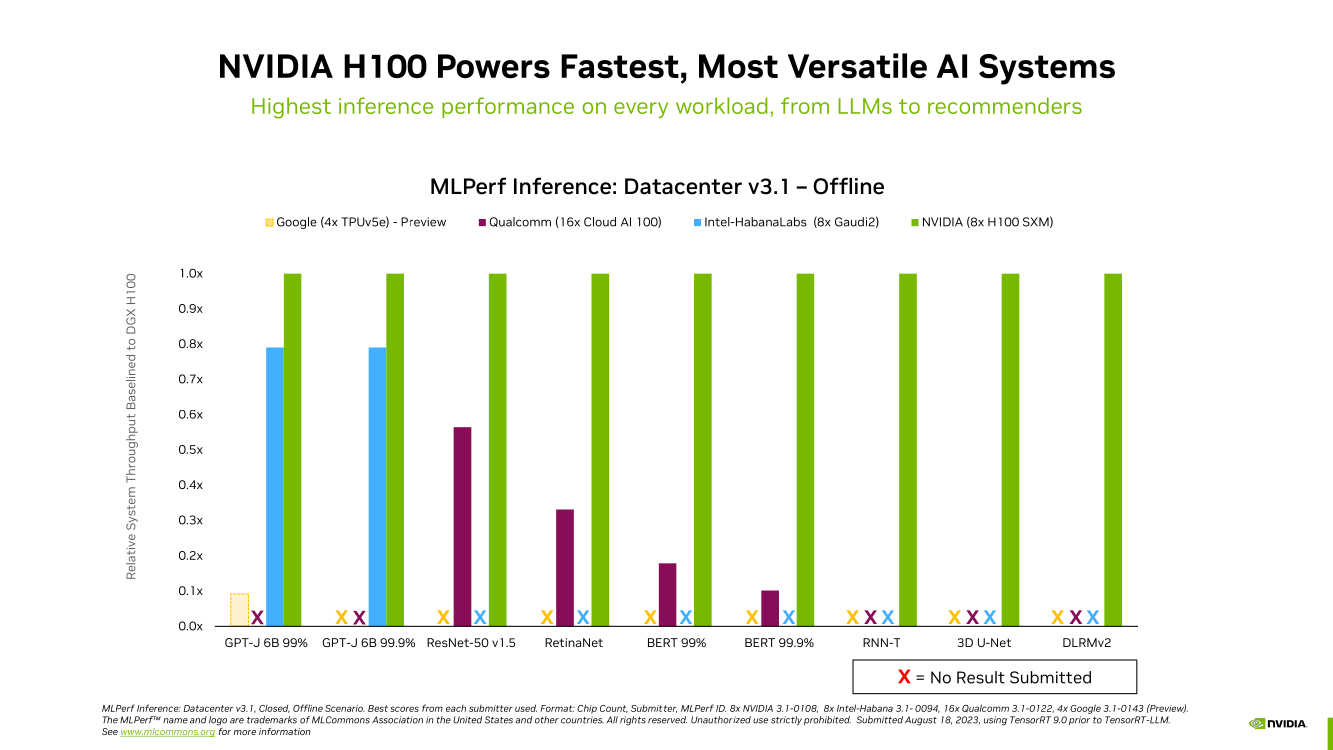 Также отмечается, что модули NVIDIA Jetson Orin благодаря новому ПО показали прирост производительности до 84 % на задачах обнаружения объектов по сравнению с предыдущим раундом тестирования MLPerf. Ускорение произошло благодаря задействованию Programmable Vision Accelerator (PVA), отдельного движка для обработки изображений и алгоритмов компьютерного зрения работающего независимо от CPU и GPU.  Сообщается также, что ускоритель NVIDIA L4 в последних тестах MLPerf выполнил весь спектр рабочих нагрузок, показав отличную производительность. Так, в составе адаптера с энергопотреблением 72 Вт этот ускоритель демонстрирует в шесть раз более высокое быстродействие, нежели CPU, у которых показатель TDP почти в пять раз больше. Кроме того, NVIDIA применила новую технологию сжатия модели, что позволило продемонстрировать повышение производительности в 4,4 раза при использовании BERT LLM на ускорителе L4. Ожидается, что этот метод найдёт применение во всех рабочих нагрузках ИИ. В число партнёров при проведении тестирования MLPerf вошли поставщики облачных услуг Microsoft Azure и Oracle Cloud Infrastructure, а также ASUS, Connect Tech, Dell Technologies, Fujitsu, Gigabyte, Hewlett Packard Enterprise, Lenovo, QCT и Supermicro. В целом, MLPerf поддерживается более чем 70 компаниями и организациями, включая Alibaba, Arm, Cisco, Google, Гарвардский университет, Intel, Meta✴, Microsoft и Университет Торонто.
30.08.2023 [17:09], Владимир Мироненко
Google объявила о скорой доступности инстансов A3 на базе NVIDIA H100Google Cloud сообщила, что в следующем месяце станут доступны инстансы Google Compute Engine A3 на базе платформы NVIDIA HGX H100 с восемью ускорителями H100, двумя процессорами Intel Xeon Sapphire Rapids, 2 Тбайт, а также интерконнектом NVLink и адаптерами Google Titanium. Платформ обеспечивает высокую производительность для всех видов ИИ-приложений, в том числе для обучения и обслуживания особенно требовательных рабочих нагрузок ИИ и больших языковых моделей (LLM). В блоге Google Cloud отмечено, что сочетание ускорителей NVIDIA с ведущими инфраструктурными технологиями Google Cloud обеспечивает масштабируемость и производительность и является огромным шагом вперёд в возможностях ИИ: обучение происходит в 3 раза быстрее, а пропускная способность сети в 10 раз выше, чем у предыдущего поколения. Инстансы A3 также поддерживают масштабирование до 26 тыс. ускорителей H100. 
Изображение: NVIDIA Незадолго до этого Google Cloud объявила NVIDIA партнёром года по генеративному ИИ (Generative AI Partner of the Year). Компании сотрудничают по разным направлениям: от проектирования инфраструктуры до реализации программного обеспечения, чтобы упростить создание и развёртывание приложений ИИ на платформе Google Cloud. PaxML, платформа Google для создания больших языковых моделей, теперь оптимизирована для решений NVIDIA и доступна в реестре NVIDIA NGC. Google использовала PaxML для создания внутренних моделей, включая DeepMind, а также исследовательских проектов. Кроме того, компании сервис Google Dataproc позволяет задействовать решения NVIDIA для ускорения работы Apache Spark. H100 вскоре также появятся на платформе Vertex AI. Наконец, было обещано, что в облаке Google появятся NVIDIA DGX Cloud и новейшие гибридные чипы GH200. Впрочем, вместе с анонсом A3 Google представила ИИ-инстансы на базе собственных ускорителей TPU v5e.
29.08.2023 [17:50], Сергей Карасёв
10 тыс. ускорителей NVIDIA H100: Tesla запустила один из мощнеших ИИ-суперкомпьютеров в миреКомпания Tesla, по сообщению Tom's Hardware, в минувший понедельник, 28 августа 2023 года, запустила вычислительный кластер для решения ресурсоемких задач, связанных с ИИ. В основу платформы положены 10 тыс. ускорителей NVIDIA H100. Отмечается, что система обеспечивает пиковую производительность в 340 Пфлопс FP64 для технических вычислений и 39,58 Эфлопс INT8 для приложений ИИ. Таким образом, по производительности FP64 кластер превосходит суперкомпьютер Leonardo, который располагается на четвёртой позиции в нынешнем рейтинге Тор500 с показателем 304 Пфлопс. Фактически кластер Tesla на базе NVIDIA H100 является одной из самых мощных платформ в мире. Он подходит не только для обработки алгоритмов ИИ, но и для НРС-задач. Благодаря данной системе Tesla значительно расширит свои ресурсы для создания полноценного автопилота. А это поможет компании Илона Маска получить конкурентные преимущества перед другими разработчиками умных транспортных средств. На формирование кластера потрачено около $300 млн. 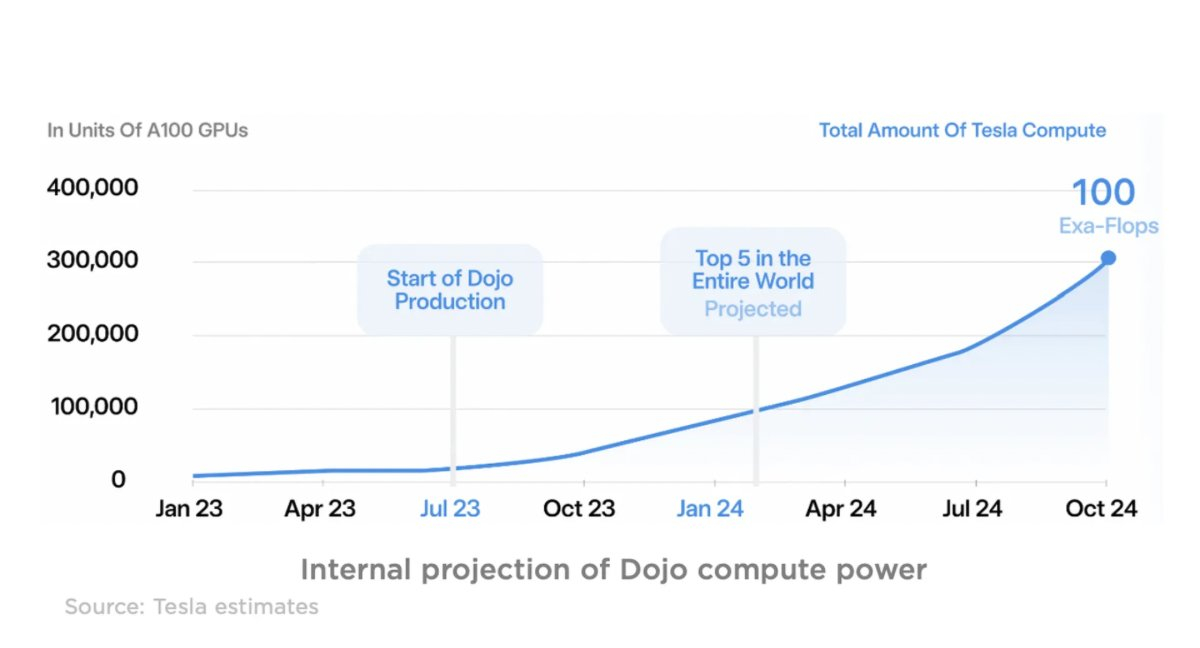
Изображение: Twitter / Sawyer Merritt Однако на рынке сформировался дефицит ускорителем NVIDIA H100. На этом фоне Tesla создаёт ИИ-суперкомпьютер Dojo, в основу которого лягут специализированные чипы собственной разработки — Tesla D1. К концу следующего года, по словам Илона Маска, производительность ИИ-систем Tesla может быть доведена до 100 Эфлопс. Стоимость проекта оценивается в $1 млрд. На обучение ИИ-моделей Tesla намерена потратить более $2 млрд в текущем году и примерно такую же сумму в 2024-м. |
|