Материалы по тегу: h100
|
17.10.2024 [14:36], Руслан Авдеев
Nebius, бывшая Yandex, представила облачную ИИ-платформу с ускорителями NVIDIA H100 и H200ИИ-компания Nebius, сформированная из бывшей Yandex N.V., представила облачную платформу с современными ускорителями NVIDIA. Как уточняет Datacenter Dynamics, речь идёт о моделях NVIDIA H100 и H200, а также L40S. В скором будущем компания рассчитывает добавить и новейшие суперускорители GB200 NVL72. 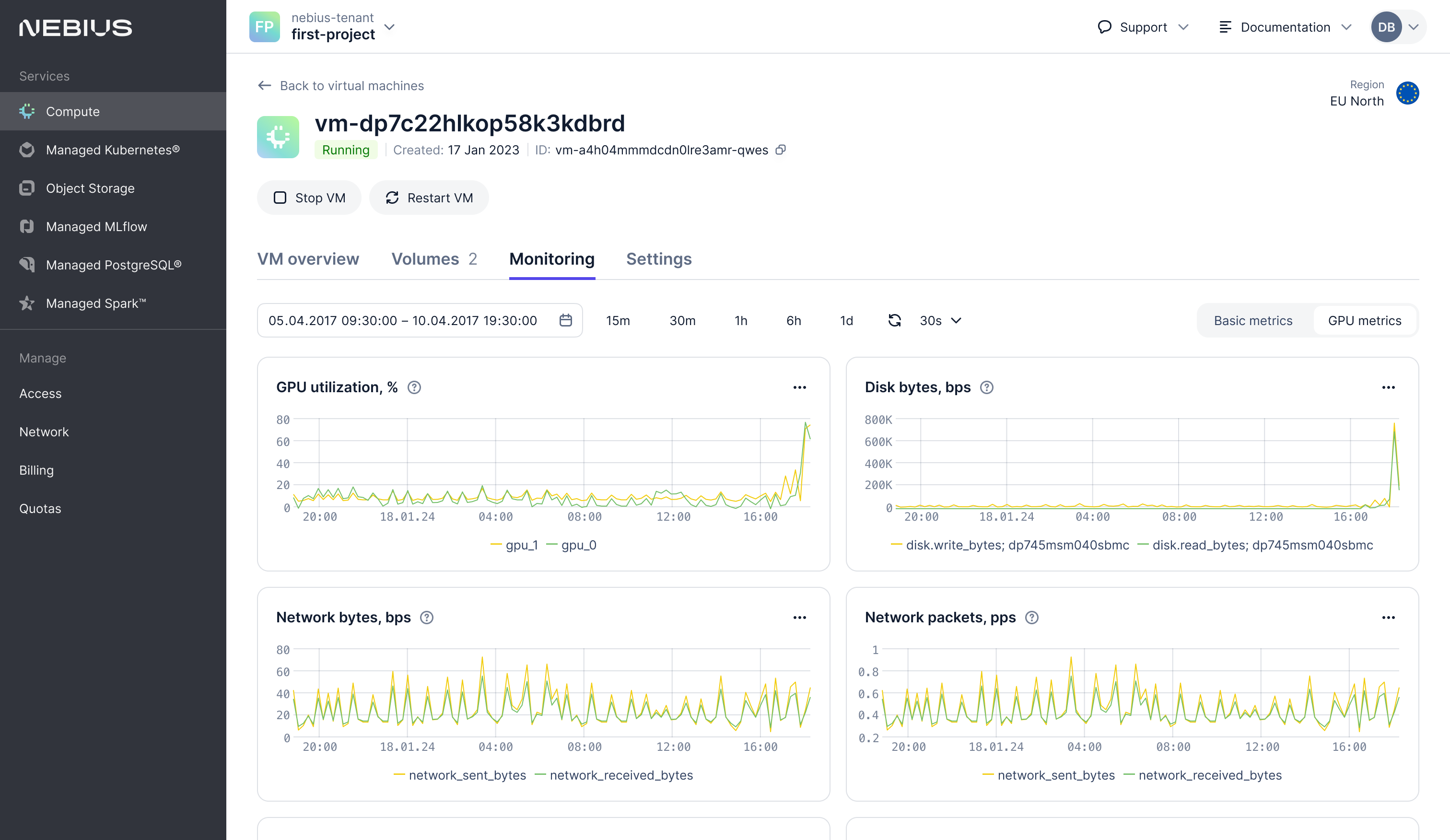
Источник изображения: Nebius Облачное хранилище обеспечивает агрегированную скорость чтения до 100 Гбайт/с и 1 млн IOPS. Платформа также предлагает управляемые Apache Spark и MLFlow, а ВМ по умолчанию включают ИИ-библиотеки и драйверы. По словам компании, она прислушалась к запросам клиентов, нуждавшихся в самостоятельном доступе и инфраструктуре, отлично от просто «базовой». Речь идёт о крупномасштабных кластерах с InfiniBand-подключением на базе эталонной архитектуры NVIDIA, но с кастомизированным оборудованием и проприетарной программной облачной платформой. После введения антироссийских санкций Nebius дистанцировалась от «Яндекса», основная часть активов которого была продана группе российских инвесторов. У Nebius остался дата-центр в Финляндии, ёмкость которого она намерена утроить в обозримом будущем. Там разместятся более 60 тыс. ускорителей. В августе сообщалось, что компания увеличила облачную выручку на 60 % год к году во II квартале.
03.09.2024 [11:04], Сергей Карасёв
Стартап xAI Илона Маска запустил ИИ-кластер со 100 тыс. ускорителей NVIDIA H100Илон Маск (Elon Musk) объявил о том, что курируемый им стартап xAI запустил кластер Colossus, предназначенный для обучения ИИ. На сегодняшний день в состав этого вычислительного комплекса входят 100 тыс. ускорителей NVIDIA H100, а в дальнейшем его мощности будут расширяться. Напомним, xAI реализует проект по созданию «гигафабрики» для задач ИИ. Предполагается, что этот суперкомпьютер в конечном итоге будет насчитывать до 300 тыс. новейших ускорителей NVIDIA B200. Оборудование для платформы поставляют компании Dell и Supermicro, а огромный дата-центр xAI расположен в окрестностях Мемфиса (штат Теннесси). «В эти выходные команда xAI запустила кластер Colossus для обучения ИИ со 100 тыс. карт H100. От начала до конца всё было сделано за 122 дня. Colossus — самая мощная система обучения ИИ в мире», — написал Маск в социальной сети Х. 
Источник изображения: WebProNews По его словам, в ближайшие месяцы вычислительная мощность платформы удвоится. В частности, будут добавлены 50 тыс. изделий NVIDIA H200. Маск подчёркивает, что Colossus — это не просто еще один кластер ИИ, это прыжок в будущее. Основное внимание в рамках проекта будет уделяться использованию мощностей Colossus для расширения границ ИИ: планируется разработка новых моделей и улучшение уже существующих. Ожидается, что по мере масштабирования и развития система станет важным ресурсом для широкого сообщества ИИ, предлагая беспрецедентные возможности для исследований и инноваций. Запуск столь производительного кластера всего за 122 дня — это значимое достижение для всей ИИ-отрасли. «Удивительно, как быстро это было сделано, и для Dell Technologies большая честь быть частью этой важной системы обучения ИИ», — сказал Майкл Делл (Michael Dell), генеральный директор Dell Technologies.
29.08.2024 [16:41], Руслан Авдеев
Илон Маск показал ИИ-суперкластер Tesla Cortex из 50 тыс. ускорителей NVIDIAИлон Маск (Elon Musk) продолжает наращивать вычислительные мощности своих компаний. Как сообщает Tom’s Hardware, он поделился сведениями об ИИ-суперкластере Cortex. По данным Tom's Hardware, недавнее дополнение завода Giga Texas компании Tesla будет состоять из 70 тыс. ИИ-серверов, а также потребует 130 МВт энергии на обеспечение вычислений и охлаждения на момент запуска, к 2026 году мощность вырастет до 500 МВт. На опубликованном в социальной сети X видео Илона Маска показан машинный зал: по 16 IT-стоек в ряд, по два ряда на коридор. Каждая стойка вмещает восемь ИИ-серверов, а в середине каждого ряда видны стойки без таковых. В видео можно разглядеть порядка 16–20 рядов, поэтому довольно грубый подсчёт позволяет предположить наличие около 2 тыс. серверов с ускорителями, т.е. менее 3 % от запланированной ёмкости. В ходе июльского финансового отчёта Tesla Илон Маск рассказал, что Cortex будет крупнейшим обучающим кластером Tesla на сегодняшний день и будет состоять из 50 тыс. ускорителей NVIDIA H100 и 20 тыс. ускорителей Tesla D1 собственной разработки. Это меньше, чем Маск прогнозировал раньше, в июне он сообщал, что Cortex будет включать 50 тыс. D1. Правда, сообщалось, что на момент запуска будут применяться только решения NVIDIA, а разработки Tesla появятся позже. 
Источник изображения: Alexander Shatov/unsplash.com Кластер Cortex предназначен в первую очередь для обучения автопилота Full Self Driving (FSD), сервиса Cybertaxi и роботов Optimus, ограниченное производство которых должно начаться в 2025 году для использования на заводах компании. Также Маск анонсировал планы потратить $500 млн на суперкомпьютер Dojo в Буффало (штат Нью-Йорк), также принадлежащий Tesla. Первым же в «коллекции» Маска заработал Memphis Supercluster, принадлежащий xAI и оснащённый 100 тыс. NVIDIA H100. Со временем эта система получит 300 тыс. ускорителей NVIDIA B200, но задержки с их производством заставили отложить реализацию проекта на несколько месяцев.
27.07.2024 [23:44], Алексей Степин
Не так просто и не так быстро: учёные исследовали особенности работы памяти и NVLink C2C в NVIDIA Grace HopperГибридный ускоритель NVIDIA Grace Hopper объединяет CPU- и GPU-модули, которые связаны интерконнектом NVLink C2C. Но, как передаёт HPCWire, в строении и работе суперчипа есть некоторые нюансы, о которых рассказали шведские исследователи. Им удалось замерить производительность подсистем памяти Grace Hopper и интерконнекта NVLink в реальных сценариях, дабы сравнить полученные результаты с характеристиками, заявленными NVIDIA. Напомним, для интерконнекта изначально заявлена скорость 900 Гбайт/с, что в семь раз превышает возможности PCIe 5.0. Память HBM3 в составе GPU-части имеет ПСП до 4 Тбайт/с, а вариант с HBM3e предлагает уже до 4,9 Тбайт/с. Процессорная часть (Grace) использует LPDDR5x с ПСП до 512 Гбайт/с. В руках исследователей оказалась базовая версия Grace Hopper с 480 Гбайт LPDDR5X и 96 Гбайт HBM3. Система работала под управлением Red Hat Enterprise Linux 9.3 и использовала CUDA 12.4. В бенчмарке STREAM исследователям удалось получить следующие показатели ПСП: 486 Гбайт/с для CPU и 3,4 Тбайт/с для GPU, что близко к заявленным характеристиками. Однако результат скорость NVLink-C2C составила всего 375 Гбайт/с в направлении host-to-device и лишь 297 Гбайт/с в обратном направлении. Совокупно выходит 672 Гбайт/с, что далеко от заявленных 900 Гбайт/с (75 % от теоретического максимума). 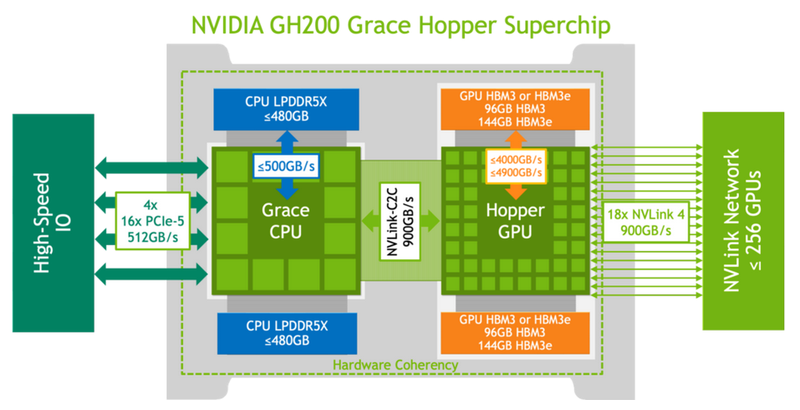
Источник: NVIDIA Grace Hopper в силу своей конструкции предлагает два вида таблицы для страниц памяти: общесистемную (по умолчанию страницы размером 4 Кбайт или 64 Кбайт), которая охватывает CPU и GPU, и эксклюзивную для GPU-части (2 Мбайт). При этом скорость инициализации зависит от того, откуда приходит запрос. Если инициализация памяти происходит на стороне CPU, то данные по умолчанию помещаются в LPDDR5x, к которой у GPU-части есть прямой доступ посредством NVLink C2C (без миграции), а таблица памяти видна и GPU, и CPU. 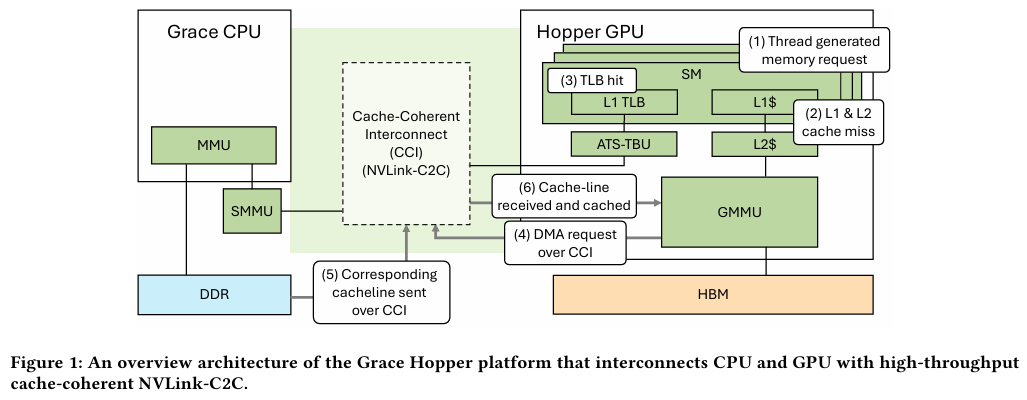
Источник: arxiv.org Если же памятью управляет не ОС, а CUDA, то инициализацию можно сразу организовать на стороне GPU, что обычно гораздо быстрее, а данные поместить в HBM. При этом предоставляется единое виртуальное адресное пространство, но таблиц памяти две, для CPU и GPU, а сам механизм обмена данными между ними подразумевает миграцию страниц. Впрочем, несмотря на наличие NVLink C2C, идеальной остаётся ситуация, когда GPU-нагрузке хватает HBM, а CPU-нагрузкам достаточно LPDDR5x. 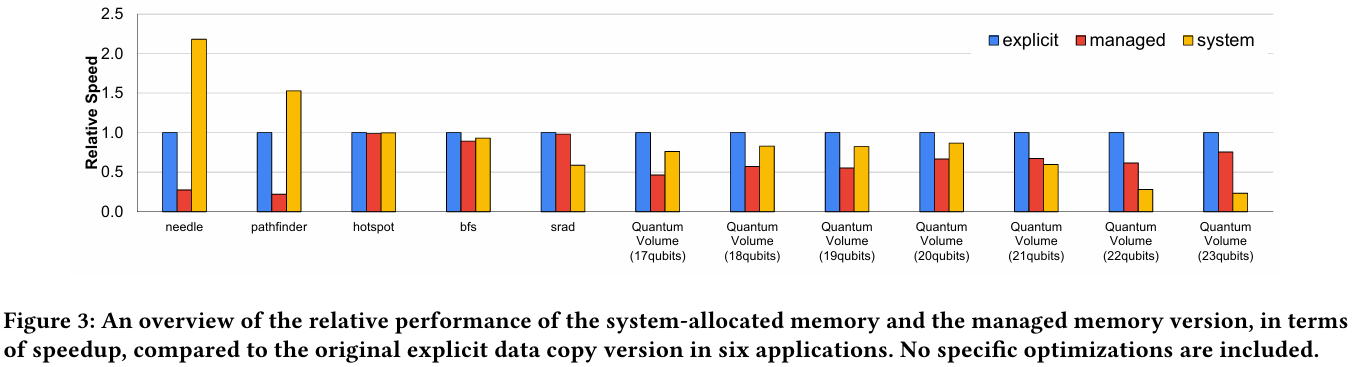
Источник: arxiv.org Также исследователи затронули вопрос производительности при использовании страниц памяти разного размера. 4-Кбайт страницы обычно используются процессорной частью с LPDDR5X, а также в тех случаях, когда GPU нужно получить данные от CPU через NVLink-C2C. Но как правило в HPC-нагрузках оптимальнее использовать 64-Кбайт страницы, на управление которыми расходуется меньше ресурсов. Когда же доступ в память хаотичен и непостоянен, страницы размером 4 Кбайт позволяют более тонко управлять ресурсами. В некоторых случаях возможно двукратное преимущество в производительности за счёт отсутствия перемещения неиспользуемых данных в страницах объёмом 64 Кбайт. В опубликованной работе отмечается, что для более глубокого понимания механизмов работы унифицированной памяти у гетерогенных решений, подобных Grace Hopper, потребуются дальнейшие исследования.
23.07.2024 [01:20], Владимир Мироненко
Стартап xAI Илона Маска запустил ИИ-кластер в Теннеси [Обновлено]Илон Маск объявил в соцсети X (ранее Twitter) о запуске стартапом xAI в дата-центре в Мемфисе «самого мощного в мире кластера для обучения ИИ», который будет использоваться для создания «самого мощного в мире по всем показателям искусственного интеллекта к декабрю этого года», пишет Tom's Hardware. Однако, судя по всему, на практике сейчас работает лишь очень небольшая часть кластера. «Отличная работа команды @xAI, команды @X, @Nvidia и компаний поддержки, которые начали обучение с кластером Memphis Supercluster примерно в 4:20 утра по местному времени. 100 тыс. H100 с жидкостным охлаждением в единой RDMA-фабрике — это самый мощный кластер обучения ИИ в мире!», — сообщил миллиардер в своём аккаунте. Как указали в xAI, новая вычислительная система будет использоваться для обучения новой версии @grok, которая будет доступна премиум-подписчикам @x. Ранее появились сообщения о том, что оборудование для ИИ-кластера будут поставлять Dell и Supermicro. Комментируя нынешнее заявление Маска, гендиректор Supermicro Чарльз Лян (Charles Liang) подтвердил, что большая часть оборудования для ИИ-кластера была поставлена его компанией. 
Источник изображений: xAI В мае этого года Маск поделился планами построить гигантский суперкомпьютер для xAI для работы над следующей версией чат-бота Grok, который будет включать 100 тыс. ускорителей Nvidia H100. А в следующем году Илон Маск планирует запустить ещё один кластер, который будет содержать 300 тыс. ускорителей NVIDIA B200. Для его создания Маск намеревался привлечь Oracle, планируя выделить $10 млрд на аренду ИИ-серверов компании, но затем отказался от этой идеи, так как его не устроили предложенные Oracle сроки реализации проекта. Как отметил ресурс Tom's Hardware, новый ИИ-кластер стартапа xAI превосходит все суперкомпьютеры из TOP500 с точки зрения количества ускорителей. Самые мощные в мире суперкомпьютеры, такие как Frontier (37 888 ускорителей AMD), Aurora (60 000 ускорителей Intel) и Microsoft Eagle (14 400 ускорителей NVIDIA), похоже, значительно уступают кластеру xAI. Впрочем, технические детали о сетевой фабрике нового кластера пока не предоставлены.  Но, как выясняется, не всё в заявлении Маска соответствует действительности. Аналитик Dylan Patel (Дилан Пател) из SemiAnalysis обвинил Маска во лжи, поскольку в настоящее время кластеру доступно 7 МВт мощности, чего хватит для работы примерно 4 тыс. ускорителей. С 1 августа будет доступно 50 МВт, если xAI наконец подпишет соглашение с властями Теннесси. А подстанция мощностью 150 МВт все ещё находится в стадии строительства, которое завершится в IV квартале 2024 года. Как отмечает местное издание commercial appeal, поскольку речь идёт об объекте мощностью более 100 МВт, для его подключения требуется разрешение коммунальных компаний Memphis Light, Gas and Water (MLGW) и Tennessee Valley Authority (TVA). Контракт на подключение ЦОД к энергосети с TVA не был подписан. Более того, для охлаждения ЦОД, по оценкам MLGW, потребуется порядка 4,9 тыс. м3 воды ежедневно. UPD: Дилан Пател удалил исходный твит, но уточнил текущее положение дел. От энергосети кластер сейчас потребляет 8 МВт, однако рядом с площадкой установлены мобильные генераторы (14 × 2,5 МВт), так что сейчас в кластере активны около 32 тыс. ускорителей, а в полную силу он зарабатает в IV квартале. Если контракт с TVA будет подписан, то к 1 августу кампус получит ещё 50 МВт от сети, а к концу году будет подведено 200 МВт. Для работы 100 тыс. H100 требуется порядка 155 МВт.
03.07.2024 [08:32], Владимир Мироненко
Крупный европейский криптомайнер Northern Data обдумывает вывод на биржу подразделений ЦОД и ИИКомпания Northern Data, деятельность которой связана с майнингом криптовалюты, предоставлением услуг высокопроизводительных вычислений (HPC) и ИИ, обдумывает возможность проведения IPO подразделений Taiga и Ardent, предоставляющих услуги облачных вычислений и ЦОД соответственно, пишет Bloomberg. По данным источников Bloomberg, IPO может состояться на площадке Nasdaq. В настоящее время компания ведёт переговоры с банками для проведения публичного размещения акций. По оценкам банков, капитализация этих подразделений может составить $10–$16 млрд. Как и многие компании, занимающиеся майнингом криптовалют, Northern Data рассматривает HPC и ИИ как прибыльное дополнение к своей основной деятельности. В прошлом году Northern Data разделила свой бизнес на три подразделения — Arden, Taiga и Peak Mining, сосредоточив в последнем все операции по майнингу криптовалют. Согласно информации на сайте компании, у неё имеется 11 дата-центров. Peak Mining, американское подразделение компании по майнингу биткоинов, строит и разрабатывает дата-центры суммарной ёмкостью почти 700 МВт, что в случае реализации всех планов сделает его одним из крупнейших майнеров криптовалюты в США. Taiga уже владеет 24,5 тыс. ускорителей NVIDIA, включая H100, A100 и A6000. Они в основном находятся в трёх ЦОД в Швеции и Норвегии и на 100 % запитаны от «зелёных» источников энергии. В понедельник компания объявила, что первой в Европе приобрела 2 тыс. ускорителей NVIDIA H200, дополненных DPU BlueField-3 и ConnectX-7. Они будут размещены в одном из европейских ЦОД с PUE менее 1,2. Запуск первого кластера намечен на IV квартал, а его производительность составит порядка 32 Пфлопс (точность вычислений не указана). Пиковая теоретическая FP64-производительность такого количества ускорителей H200 составляет 68 Пфлопс. 
Источник изображения: Northern Data В свою очередь Ardent занимается дизайном и строительством высокоплотных ЦОД, ориентированных на HPC- и ИИ-нагрузки. Компания использует СЖО, а заявленный уровень PUE не превышает 1,15. При этом Ardent обещает 100 % доступность своих площадок. Как сообщается, Northern Data в ноябре получила кредитное финансирование на сумму €575 млн от компании Tether Group, занимающейся стейблкоинами, а в январе завершила приобретение у Tether компании Damoon за €400 млн, рассчитавшись с помощью облигаций, конвертируемых в акции, выпущенные Northern Data AG. В результате Tether стала основным инвестором Northern Data. Полученные средства Northern Data использует для закупок самых востребованных чипов NVIDIA. Благодаря этому к концу лета компанией будет развёрнуто около 20 тыс. NVIDIA H100.
30.06.2024 [14:28], Сергей Карасёв
В Австралии запущен ИИ-суперкомпьютер Virga [Обновлено]Государственное объединение научных и прикладных исследований Австралии (CSIRO) сообщило о вводе в эксплуатацию высокопроизводительного вычислительного комплекса Virga. Система, предназначенная для ИИ-задач, ускорит научные открытия, а также поможет развитию промышленности и экономики страны. Суперкомпьютер располагается в дата-центре Hume компании CDC в Канберре. Его созданием занималась компания Dell: в основу положены серверы PowerEdge XE9640, оснащённые двумя процессорами Intel Xeon Sapphire Rapids 8452Y (36C/72T, 2,0/3,2 ГГц, 300 Вт), до 512 Гбайт RAM и четырьмя 61,44-Тбайт NVMe SSD. Задействованы ИИ-ускорители NVIDIA H100 с 96 Гбайт памяти HBM3 — всего 448 шт. Система занимает 14 стоек, а в качестве интерконнекта используется Infiniband NDR. Dell заключила контракт на создание Virga в 2023 году: сумма изначально составляла $9,65 млн, однако фактическое строительство комплекса обошлось в $10,85 млн. Новый суперкомпьютер придёт на смену НРС-системе CSIRO предыдущего поколения под названием Bracewell, но унаследует от неё BeeGFS-хранилище, также построенное на оборудовании Dell. В нынешнем рейтинге TOP500 машина занимает 72 место с пиковой и практической FP64-производительностью 18,46 Пфлопс и 14,94 Пфлопс соответственно. Комплекс Virga получил своё имя в честь метеорологического эффекта «вирга» — это дождь, который испаряется, не достигая земли: видеть его можно в виде полос, выходящих из-под облаков. Систему Virga планируется использовать для таких задач, как прогнозирование пожаров, разработка вакцин нового поколения, проектирование гибких солнечных панелей, анализ медицинских изображений и пр. 
Источник изображения: CSIRO Пока подробные технические характеристики Virga и показатели быстродействия не раскрываются. Отмечается лишь, что в составе комплекса применена гибридная система прямого жидкостного охлаждения. Говорится также, что CDC оперирует двумя кампусами дата-центров Hume. Площадка Hume Campus One объединяет три ЦОД и имеет мощность 21 МВт, тогда как в состав Hume Campus Two входят два объекта суммарной мощностью 51 МВт.
27.06.2024 [12:58], Сергей Карасёв
В Японии запущен суперкомпьютер TSUBAME4.0 с ускорителями NVIDIA H100 для ИИ-задачГлобальный научно-информационный вычислительный центр (GSIC) Токийского технологического института (Tokyo Tech) в Японии объявил о вводе в эксплуатацию вычислительного комплекса TSUBAME4.0, созданного компанией HPE. Новый суперкомпьютер будет применяться в том числе для задач ИИ. В основу машины легли 240 узлов HPE Cray XD665. Каждый из них несёт на борту два процессора AMD EPYC Genoa и четыре ускорителя NVIDIA H100 SXM5 (94 Гбайт HBM2e). Объём оперативной памяти DDR5-4800 составляет 768 Гбайт. Задействован интерконнект Infiniband NDR200. Вместимость локального накопителя NVMe SSD — 1,92 Тбайт. В состав НРС-комплекса входит подсистема хранения данных HPE Cray ClusterStor E1000. Сегмент на основе HDD имеет ёмкость 44,2 Пбайт — это в 2,8 раза больше по сравнению с суперкомпьютером предыдущего поколения TSUBAME 3.0. Кроме того, имеется SSD-раздел ёмкостью 327 Тбайт. Пиковая производительность TSUBAME4.0 достигает 66,8 Пфлопс (FP64), что в 5,5 больше по отношению к системе третьего поколения. Быстродействие на операциях половинной точности (FP16) поднялось в 20 раз по сравнению с TSUBAME3.0 — до 952 Пфлопс. 
Источник изображения: Tokyo Tech На сегодняшний день TSUBAME4.0 является вторым по производительности суперкомпьютером в Японии после Fugaku. Эта система в нынешнем рейтинге TOP500 занимает четвёртое место с показателем 442 Пфлопс. Лидером в мировом масштабе является американский комплекс Frontier — 1,21 Эфлопс.
21.06.2024 [12:05], Сергей Карасёв
«ИИ-гигафабрику» для xAI построят Dell и SupermicroОборудование для мощнейшего ИИ-суперкомпьютера компании xAI, курируемой Илоном Маском (Elon Musk), как сообщает Datacenter Dynamics, будут поставлять Dell и Supermicro. Речь идёт о серверах, оборудованных высокопроизводительными ускорителями NVIDIA. После анонса акции обеих компаний выросли в цене. Напомним, что xAI реализует проект по созданию самого мощного в мире вычислительного комплекса, ориентированного на задачи ИИ. Строительство суперкомпьютера будет осуществляться в несколько этапов. Так, в ближайшее время должна быть запущена система, содержащая 100 тыс. ускорителей NVIDIA H100. А летом 2025 года планируется ввести в эксплуатацию кластер из 300 тыс. новейших ускорителей NVIDIA B200. О том, что участие в масштабном проекте xAI принимает корпорация Dell, сообщил её генеральный директор Майкл Делл (Michael Dell). Эти сведения подтвердил и сам Маск: по его словам, Dell «соберёт половину стоек, которые войдут в состав суперкомпьютера». За строительство оставшейся части системы будет отвечать Supermicro. По имеющейся информации, огромный дата-центр xAI, прозванный «ИИ-гигафабрикой», расположится в окрестностях Мемфиса (штат Теннесси). О том, в какой пропорции работы по строительству машины будут распределены между Dell и Supermicro, на данный момент нет. Стоимость проекта оценивается в миллиарды долларов. 
Фото: Michael Dell xAI в настоящее время арендует около 16 тыс. ускорителей NVIDIA H100 в облаке Oracle Cloud, а также использует веб-сервисы Amazon и свободные мощности на ЦОД-площадках X/Twitter. В мае 2024 года стартап осуществил раунд финансирования Series B, в ходе которого было привлечено $6 млрд. В результате, рыночная стоимость xAI достигла $24 млрд. Создаваемый суперкомпьютер будет использоваться в том числе для поддержания работы чат-бота xAI Grok следующего поколения.
12.06.2024 [18:00], Владимир Мироненко
Уже рутина: NVIDIA снова улучшила результаты в ИИ-бенчмарке MLPerf TrainingВычислительные платформы NVIDIA снова продемонстрировали высокую производительность, на этот раз в свежих тестах MLPerf Training v4.0. Так, суперкомпьютер NVIDIA EOS-DFW более чем утроил свою производительность в LLM-тесте на базе GPT-3 175B по сравнению с прошлогодним результатом. Как сообщается, 11 616 ускорителей NVIDIA H100, объединённых 400G-интерконнектом NVIDIA Quantum-2 InfiniBand, позволили суперкомпьютеру EOS достичь столь значительного результата благодаря более масштабному и комплексному подходу к проектированию системы. А это позволяет более эффективно обучать и запускать крупные модели, экономя время и ресурсы, говорит компания. А более современный ускоритель H200 с улучшенной подсистемой памяти в MLPerf Training быстрее H100 на 14 %, а в GNN-тестах (RGAT) узлы с H200 оказались быстрее узлов с H100 сразу на 47 %. 
Источник изображений: NVIDIA По словам компании, поставщики услуг LLM могут всего за четыре года, инвестировав $1, получить $7, используя модель Llama 3 70B на серверах на базе NVIDIA HGX H200, если исходить из того, что обслуживание обходится в $0,60 за миллион токенов, а пропускная способность HGX H200 составляет 24 тыс. токенов в секунду. 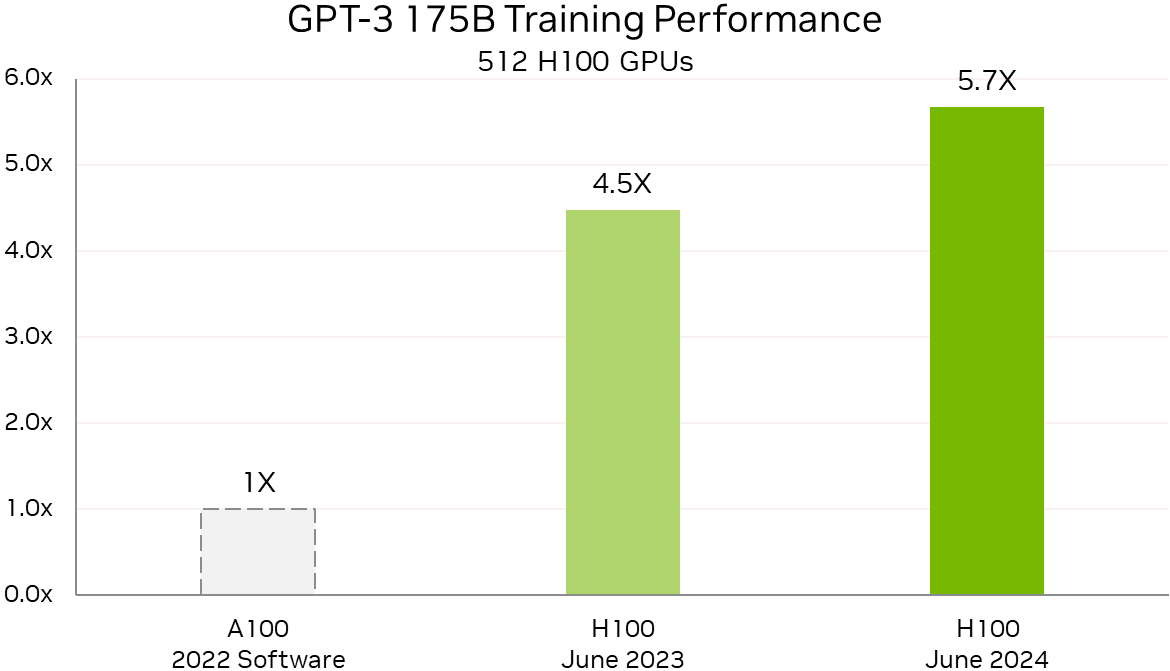 Росту производительности также способствовало совершенствование и оптимизация ПО. Так, кластер из 512 чипов H100 за год стал на 27 % быстрее, а рост производительности с увеличением количества ускорителей теперь более линеен. В новом тесте MLPerf Training по тюнингу LLM (LoRA применительно к Meta✴ Llama 2 70B) системы NVIDIA показали эффективное масштабирование при количестве ускорителей от 8 до 1024. NVIDIA также увеличила производительность обучения Stable Diffusion v2 почти на 80 % при тех же масштабах систем, что были представлены в прошлом тестировании. 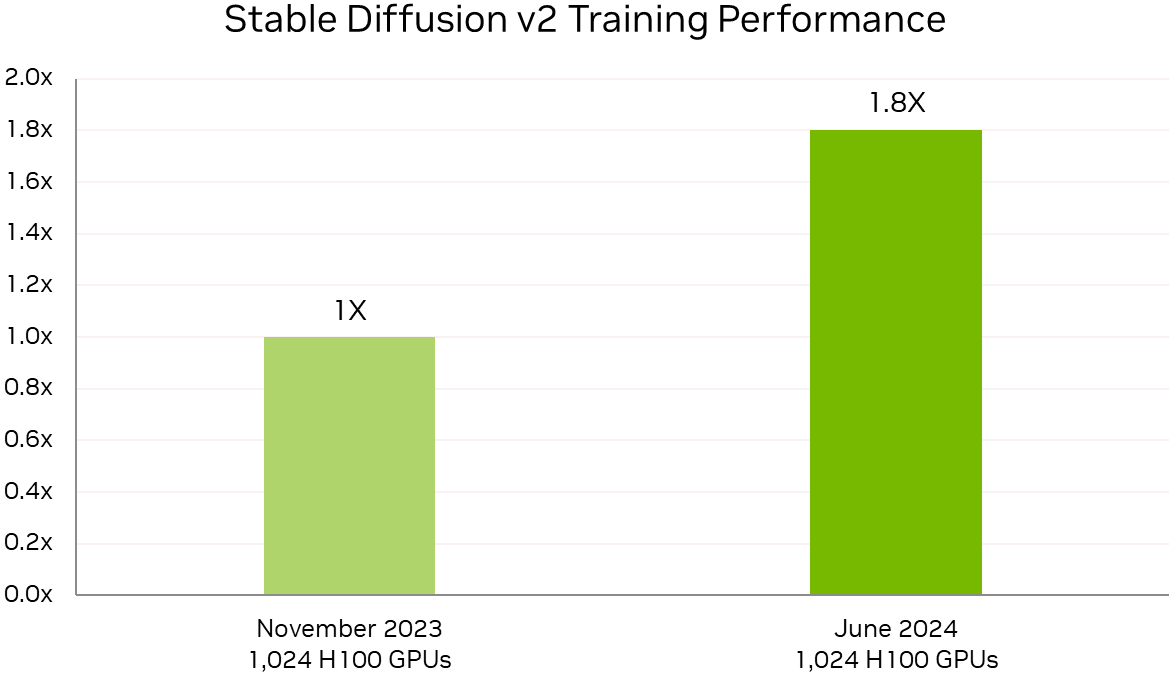 NVIDIA отметила, что для компаний, запускающих приложения на базе LLM, высокая производительность имеет большое значение. Возможность обучать и настраивать более мощные модели — и быстрее их развёртывать и запускать — позволит получить лучшие результаты и более высокий доход. А с выходом платформы NVIDIA Blackwell скоро появится возможность как обучения, так и инференса моделей генеративного ИИ с триллионом параметров. |
|