Материалы по тегу: cpu
|
19.08.2021 [16:00], Игорь Осколков
Intel представила Xeon Sapphire Rapids: четырёхкристалльная SoC, HBM-память, новые инструкции и ускорителиВ рамках Architecture Day компания Intel рассказала о грядущих серверных процессорах Sapphire Rapids, подтвердив большую часть опубликованной ранее информации и дополнив её некоторыми деталями. Intel позиционирует новинки как решение для более широкого круга задач и рабочих нагрузок, чем прежде, включая и популярные ныне микросервисы, контейнеризацию и виртуализацию. Компания обещает, что CPU будут сбалансированы с точки зрения вычислений, работой с памятью и I/O. Новые процессоры, наконец, получили чиплетную, или тайловую в терминологии Intel, компоновку — в состав SoC входят четыре «ядерных» тайла на техпроцессе Intel 7 (10 нм Enhanced SuperFIN). Каждый тайл объединён с соседом посредством EMIB. Их системные агенты, включающие общий на всех L3-кеш объём до 100+ Мбайт, образуют быструю mesh-сеть с задержкой порядка 4-8 нс в одну сторону. Со стороны процессор будет «казаться» монолитным.  Каждые ядро или поток будут иметь свободный доступ ко всем ресурсам соседних тайлов, включая кеш, память, ускорители и IO-блоки. Потенциально такой подход более выгоден с точки зрения внутреннего обмена данными, чем в случае AMD с общим IO-блоком для всех чиплетов, которых в будущих EPYC будет уже 12. Но как оно будет на самом деле, мы узнаем только в следующем году — выход Sapphire Rapids запланирован на первый квартал 2022-го, а массовое производство будет уже во втором квартале.  Ядра Sapphire Rapids базируются на микроархитектуре Golden Cove, которая стала шире, глубже и «умнее». Она же будет использована в высокопроизводительных ядрах Alder Lake, но в случае серверных процессоров есть некоторые отличия. Например, увеличенный до 2 Мбайт на ядро объём L2-кеша или новый набор инструкций AMX (Advanced Matrix Extension). Последний расширяет ИИ-функциональность CPU и позволяет проводить MAC-операции над матрицами, что характерно для такого рода нагрузок.  Для AMX заведено восемь выделенных 2D-регистров объёмом по 1 Кбайт каждый (шестнадцать 64-байт строк). Отдельный аппаратный блок выполняет MAC-операции над тремя регистрами, причём делаться это может параллельно с исполнением других инструкций в остальной части ядра. Настройкой параметров и содержимого регистров, а также перемещением данных занимается ОС. Пока что в процессорах представлен только MAC-блок, но в будущем могут появиться блоки и для других, более сложных операций. 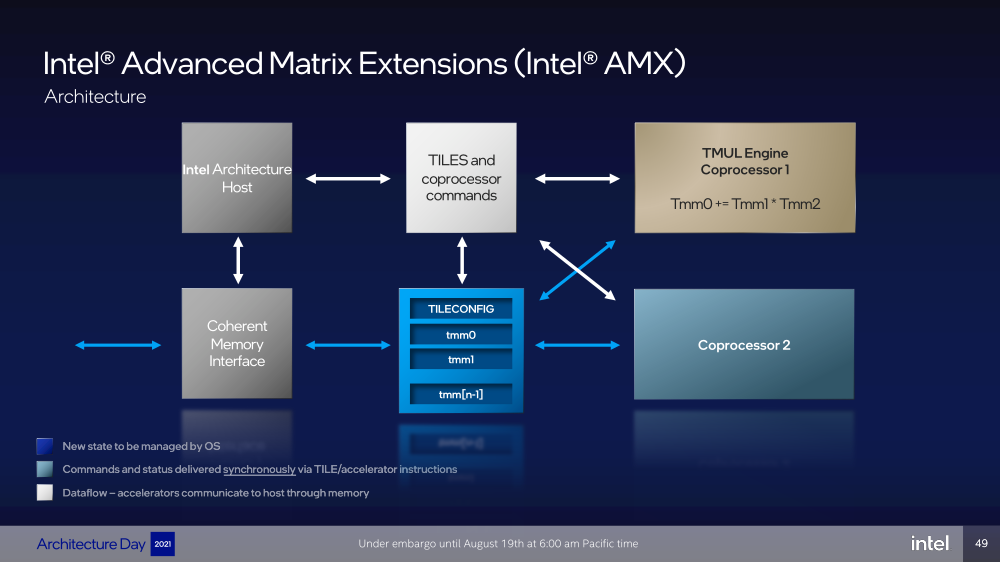 В пике производительность AMX на INT8 составляет 2048 операций на цикл на ядро, что в восемь раз больше, чем при использовании традиционных инструкций AVX-512 (на двух FMA-портах). На BF16 производительность AMX вдвое ниже, но это всё равно существенный прирост по сравнению с прошлым поколением Xeon — Intel всё так же пытается создать универсальные ядра, которые справлялись бы не только с инференсом, но и с обучением ИИ-моделей. Тем не менее, компания говорит, что возможности AMX в CPU будут дополнять GPU, а не напрямую конкурировать с ними.  К слову, именно Sapphire Rapids должен, наконец, сделать BF16 более массовым, поскольку Cooper Lake, где поддержка этого формата данных впервые появилась в CPU Intel, имеет довольно узкую нишу применения. Из прочих архитектурных обновлений можно отметить поддержку FP16 для AVX-512, инструкции для быстрого сложения (FADD) и более эффективного управления данными в иерархии кешей (CLDEMOTE), целый ряд новых инструкций и прерываний для работы с памятью и TLB для виртуальных машин (ВМ), расширенную телеметрию с микросекундными отсчётами и так далее.  Последние пункты, в целом, нужны для более эффективного и интеллектуального управления ресурсами и QoS для процессов, контейнеров и ВМ — все они так или иначе снижают накладные расходы. Ещё больше ускоряют работу выделенные акселераторы. Пока упомянуты только два. Первый, DSA (Data Streaming Accelerator), ускоряет перемещение и передачу данных как в рамках одного хоста, так и между несколькими хостами. Это полезно при работе с памятью, хранилищем, сетевым трафиком и виртуализацией. 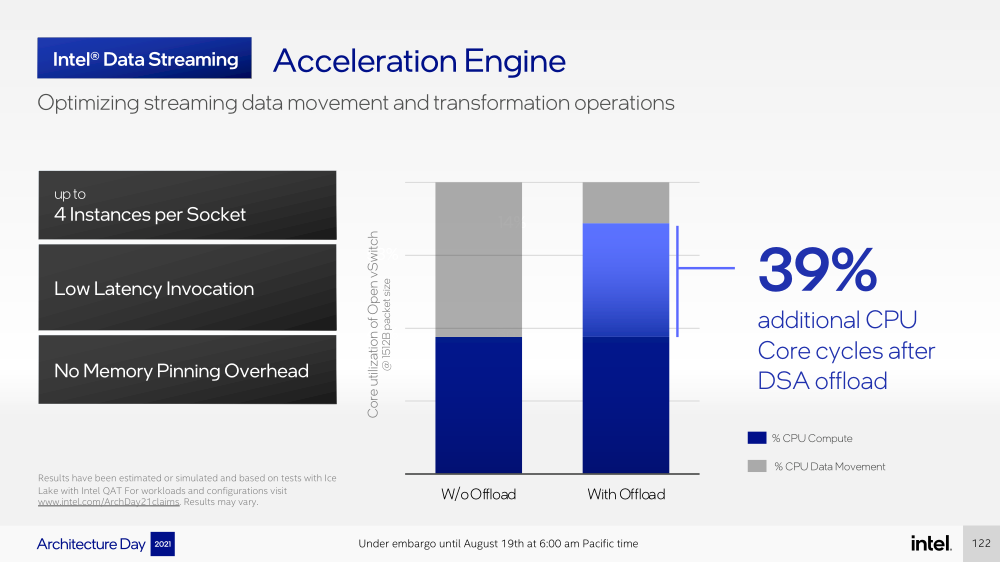 Второй упомянутый ускоритель — это движок QAT (Quick Assist Engine), на который можно возложить операции или сразу цепочки операций (де-)компрессии (до 160 Гбит/с в обе стороны одновременно), хеширования и шифрования (до 400 Гбитс/с) в популярных алгоритмах: AES GCM/XTS, ChaChaPoly, DH, ECC и т.д. Теперь блок QAT стал частью самого процессора, тогда как прежде он был доступен в составе некоторых чипсетов или в виде отдельной карты расширения. Это позволило снизить задержки и увеличить производительность блока. 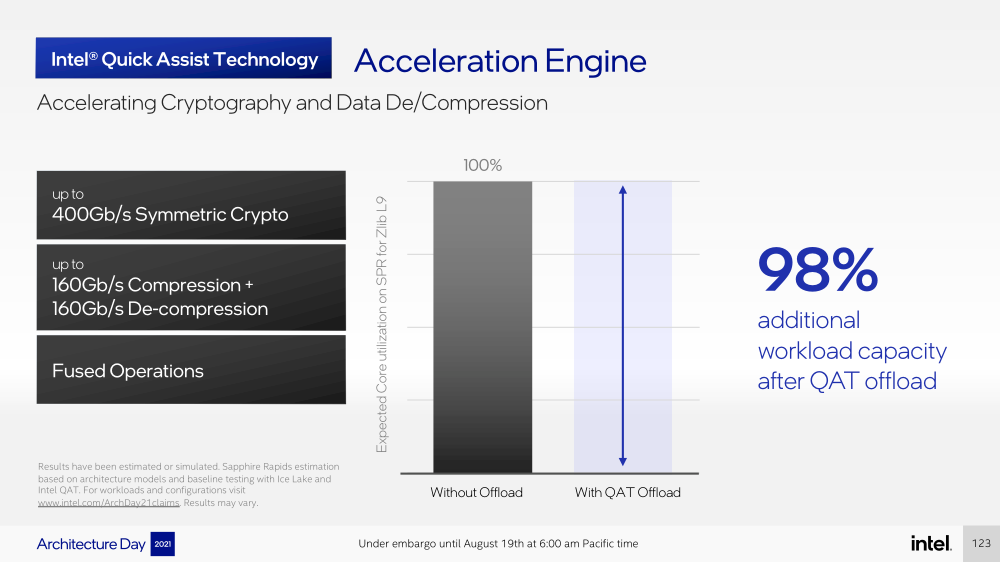 Кроме того, QAT можно будет задействовать, например, для виртуализации или Intel Accelerator Interfacing Architecture (AiA). AiA — это ещё один новый набор инструкций, предназначенный для более эффективной работы с интегрированными и дискретными ускорителями. AiA помогает с управлением, синхронизацией и сигнализацией, что опять таки позволит снизить часть накладных расходов при взаимодействии с ускорителями из пространства пользователя. 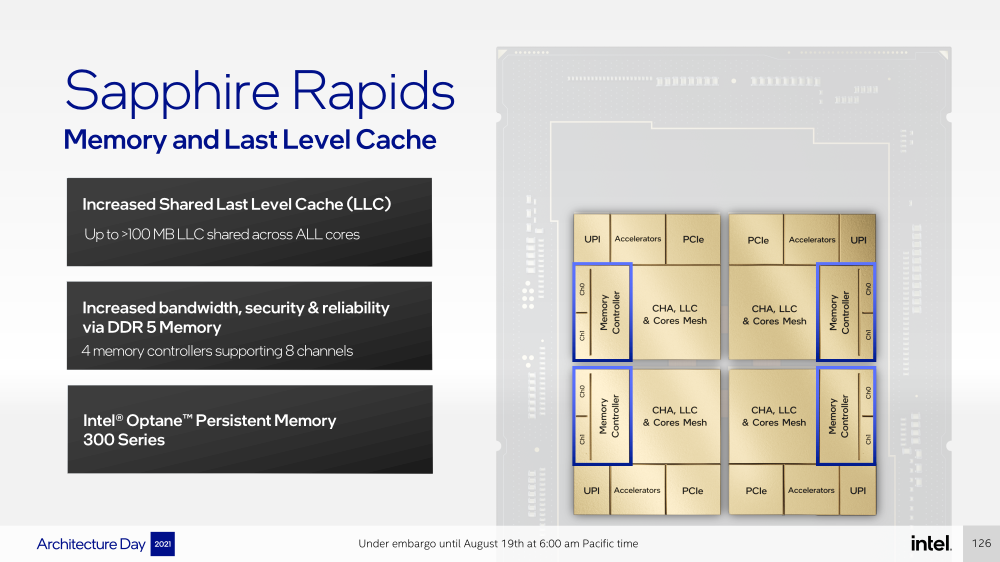 Подсистема памяти включает четыре двухканальных контроллера DDR5, по одному на каждый тайл. Надо полагать, что будут доступные четыре же NUMA-домена. Больше деталей, если не считать упомянутой поддержки следующего поколения Intel Optane PMem 300 (Crow Pass), предоставлено не было. Зато было официально подтверждено наличие моделей с набортной HBM, тоже по одному модулю на тайл. HBM может использоваться как в качестве кеша для DRAM, так и независимо. В некоторых случаях можно будет обойтись вообще без DRAM. 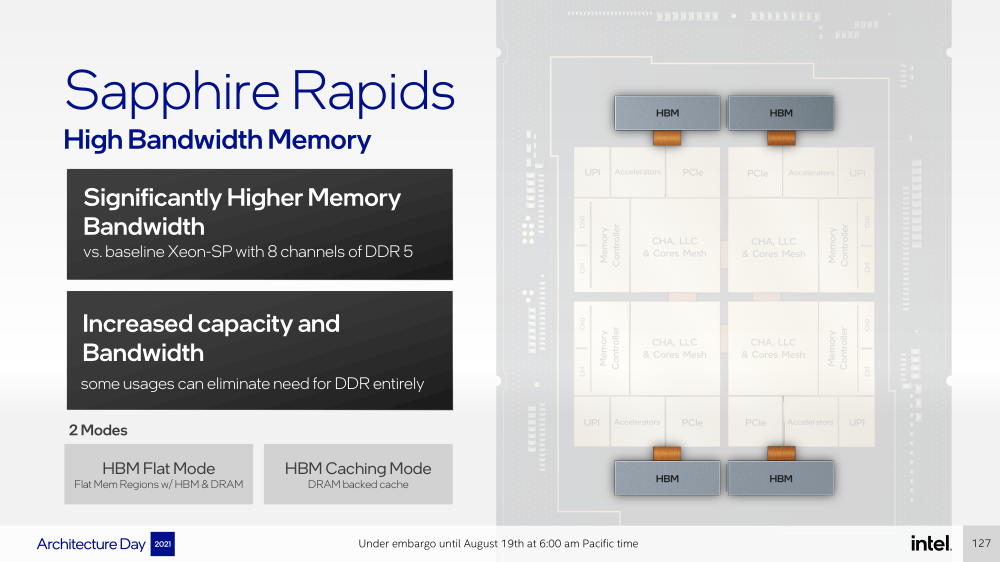 Про PCIe 5.0 и CXL 1.1 (CXL.io, CXL.cache, CXL.memory) добавить нечего, хотя в рамках другого доклада Intel ясно дала понять, что делает ставку на CXL в качестве интерконнекта не только внутри одного узла, но и в перспективе на уровне стойки. Для объединения CPU (бесшовно вплоть до 8S) всё так же будет использоваться шина UPI, но уже второго поколения (16 ГТ/с на линию) — по 24 линии на каждый тайл. 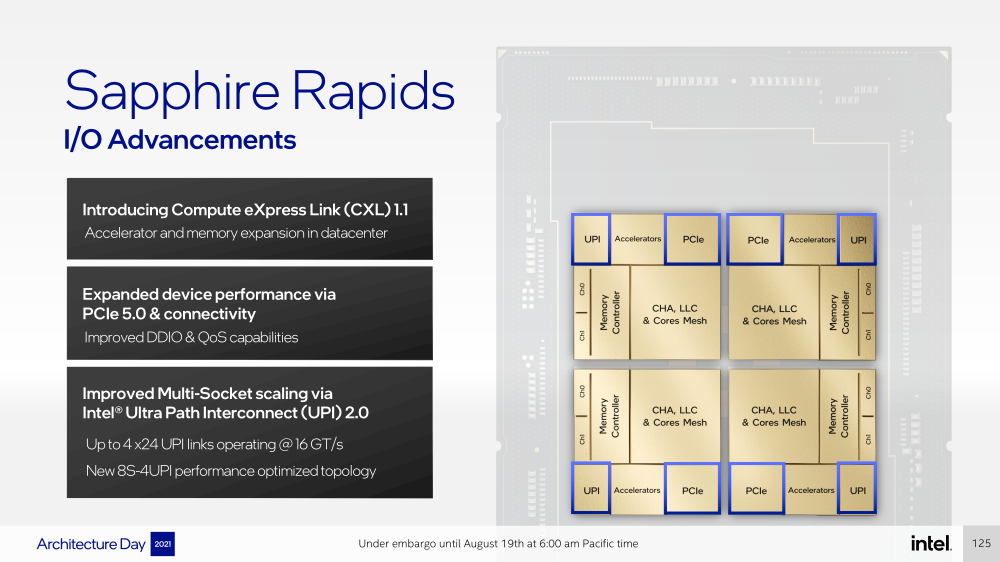 Конкретно для Sapphire Rapids Intel пока не приводит точные данные о росте IPC в сравнении с Ice Lake-SP, ограничиваясь лишь отдельными цифрами в некоторых задачах и областях. Также не был указан и ряд других важных параметров. Однако AMD EPYC Genoa, если верить последним утечкам, даже по чисто количественным характеристикам заметно опережает Sapphire Rapids.
30.07.2021 [21:05], Алексей Степин
Конец эпохи: Intel окончательно прекратила поставки процессоров ItaniumПервая попытка Intel покорить рынок массовых 64-бит систем окончилась неудачей — любопытная сама по себе архитектура Itanium (IA64) была несовместима со сложившейся экосистемой x86. Однако лишь сегодня в истории можно окончательно поставить точку: компания прекратила последние отгрузки процессоров Itanium. Сейчас поддержка 64-бит вычислений привычна и является частью любого достаточно современного процессора. Но так было не всегда: в конце 90-х и начале 2000-х ограничения, накладываемые 32-бит разрядностью хотя и были очевидны, рынок высокопроизводительных 64-бит процессоров для серверов и рабочих станций принадлежал компаниям Sun, Silicon Graphics, DEC и IBM. Все они имели RISC-архитектуру и не имели совместимости с x86. 
Форм-фактор Itanium: нечто среднее между слотовыми Pentium II/III и привычным PGA/LGA Itanium, или IA64, совместная разработка Intel и Hewlett-Packard, должна была вернуть этим компаниям первенство в сфере мощных CPU. И ставка была сделана на уникальную архитектуру EPIC (разновидность VLIW) с явным параллелизмом команд. Сама по себе IA64 обладала рядом преимуществ, однако требовала тонкой проработки ПО на уровне компилятора, поскольку процессоры EPIC во многом полагаются именно на него, а не на аппаратный планировщик. 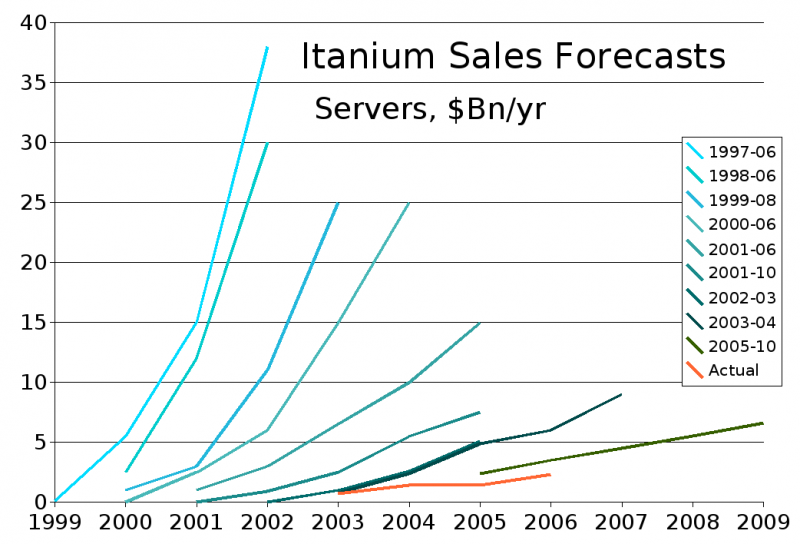
Itanium: радужные надежды и суровая реальность (красная линия) Отказ от последнего позволял потратить освободившийся транзисторный бюджет на более важные, по мнению Intel и HP, цели — например, на увеличение производительности вычислений с плавающей запятой. Но инфраструктура программного обеспечения к моменту анонса Itanium уже была весьма развитой. При этом новое, 64-бит ПО ещё надо было создать и, что гораздо важнее и сложнее, правильным образом оптимизировать, а уже имевшееся на новых CPU работало медленно из-за необходимости эмуляции x86. Компании пытались развивать IA64 до 2017 года, когда были представлены чипы Itanium Kittson с 8 ядрами и частотой до 2,66 ГГц, но то, что затея с новой архитектурой оказалась неудачной, было понятно уже после анонса первых процессоров AMD x86-64, полностью совместимых как с 32-бит, так и с 64-бит приложениями x86. В начале 2021 года Линус Торвальдс объявил о фактической смерти архитектуры и поддержка IA64 была исключена из новых ядер Linux. А сегодня можно говорить об окончательном завершении эры Itanium. 
Раритет: Supermicro i2DML-iG2 в форм-факторе EATX с поддержкой Itanium 2. Найти такую плату почти невозможно Сама Intel ещё в 2019-ом официально поставила на Itanium крест, но из-за сложившейся экосистемы заказы на процессоры принимались вплоть до 30 января 2020 года. А вчера компания официально объявила о прекращении поставок последних партий Itanium. Теперь ещё одна процессорная архитектура стала достоянием истории, хотя HPE формально будет поддерживать её до 2025 года. Сами CPU нередко встречаются на онлайн-аукционах, например, на Ebay, но даже для энтузиастов они малоинтересны — найти подходящую системную плату невероятно сложно, а стоить она может намного дороже самих процессоров, да и форм-фактор имеет специфический.
02.06.2021 [19:14], Игорь Осколков
Южная Корея намерена разработать собственные CPU и ИИ-чипы для суперкомпьютеров и серверовЮжная Корея намерена добиться большей независимости в сфере разработки и производства чипов для серверов и суперкомпьютеров, в первую очередь для нужд внутри страны. По сообщению Министерства науки и ИКТ Южной Кореи, пять гиперскейлеров подписали меморандум о взаимопонимании с пятью производителями микросхем. Меморандум предполагает расширение использования отечественных технологий, в частности, ИИ-ускорителей в центрах обработки данных на территории страны. Производители и разработчики чипов — SK Group, Rebellions, FuriosaAI и Исследовательский институт электроники и телекоммуникаций — также согласились создать для этого новый технологический центр в Кванджу на юго-западе страны. 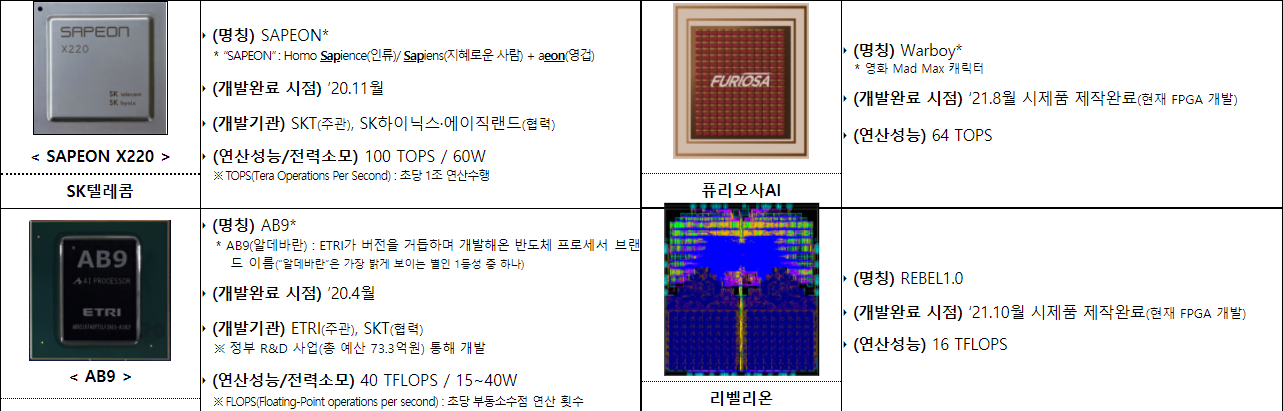 Отечественные чипы получат компании Naver Cloud, Douzone Bizon, Kakao Enterprise, NHN и KT. Все они являются крупными игроками на местном рынке и, каждая в своей области, довольно успешно конкурируют с зарубежными IT-гигантами. Это во многом напоминает ситуацию в Китае и Японии, которые также имеют сильных локальных игроков и вкладываются в разработку собственной микроэлектроники, чтобы быть менее зависимыми от США, как минимум, в области суперкомпьютинга. Несколько недель назад правительство объявило о пакете поддержки в размере 510 трлн вон ($451 млрд) для увеличения производства микросхем в стране, что принесёт пользу не только Samsung и SK Hynix, но и небольшим компаниям. Также ранее сообщалось, что Южная Корея намерена к 2030 году построить суперкомпьютер экзафлопсного класса на базе преимущественно «домашних» компонентов.
12.04.2021 [19:26], Игорь Осколков
NVIDIA анонсировала серверные Arm-процессоры Grace и будущие суперкомпьютеры на их базеВ рамках GTC’21 NVIDIA анонсировала Arm-процессоры Grace серверного класса, которые станут компаньонами будущих ускорителей компании. Это не означает полный отказ от x86-64, но это позволит компании предложить клиентам более глубоко оптимизированные, а, значит, и более быстрые решения. NVIDIA говорит, что новый CPU позволит на порядок повысить производительность систем на его основе в ИИ и HPC-задачах в сравнении с современными решениями. Процессор назван в честь Грейс Хоппер (Grace Hopper), одного из пионеров информатики и создательницы целого ряда основополагающих концепций и инструментов программирования. И это имя нам уже встречалось в контексте NVIDIA — в конце 2019 года компания зарегистрировала торговую марку Hopper для MCM-решений.  Компания не готова раскрыть полные технически характеристики новинки, которая станет доступна в начале 2023 года, но приводит некоторые интересные детали. В частности, процессор будет использовать Arm-ядра Neoverse следующего поколения (надо полагать, уже на базе ARMv9), которые позволят получить в SPECrate2017_int_base результат выше 300. Для сравнения — система с парой современных AMD EPYC 7763 в том же бенчмарке показывает результат на уровне 800. Вторая особенность Grace — использование памяти LPDRR5X (с ECC, естественно). В сравнении с DDR4 она будет иметь вдвое большую пропускную способность (ПСП) и в 10 раз меньшее энергопотребление. Число и скорость каналов памяти не уточняются, но говорится о суммарной ПСП в более чем 500 Гбайт/с на процессор. А у того же EPYC 7763 теоретический пик ПСП чуть больше 200 Гбайт/с. Очевидно, что другие процессоры к моменту выхода NVIDIA Grace тоже увеличат и производительность, и пропускную способность памяти. Гораздо более интересный вопрос, сколько линий PCIe 5.0 они смогут предложить. Если допустить, что у них будет 128 линий, то общая скорость для них составит чуть больше 500 Гбайт/с. 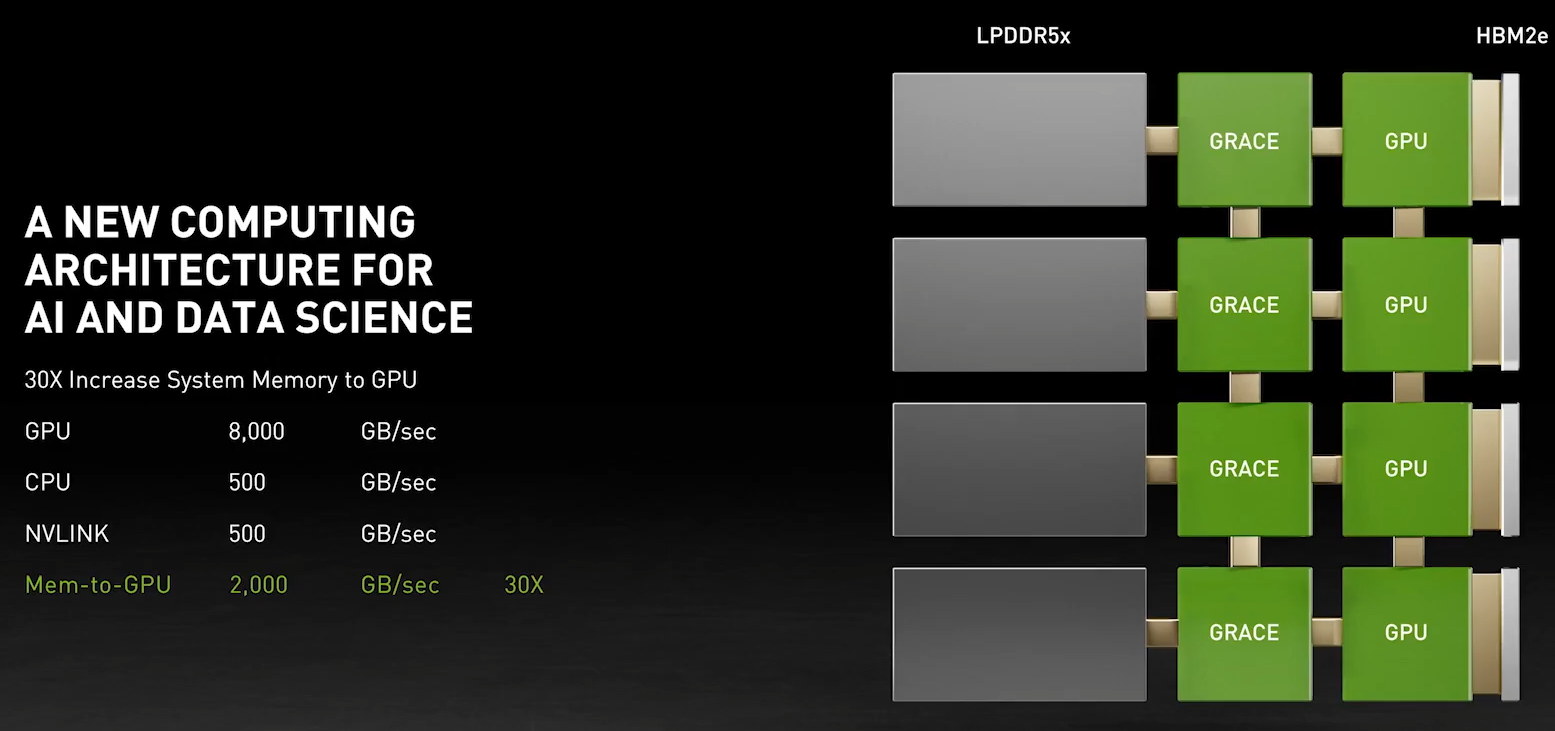 И NVIDIA этого мало — процессоры Grace получат прямое, кеш-когерентное подключение к GPU по NVLInk 4.0 (14x) с суммарной пропускной способностью боле 900 Гбайт/с. GPU тоже, как и прежде, будут общаться напрямую друг с другом по NVLink. Скорость связи между двумя CPU превысит 600 Гбайт/с, а в сборке из четырёх модулей CPU+GPU суммарная скорость обмена данными между системной памятью процессоров и GPU в такой mesh-сети составит 2 Тбайт/с. Но самое интересное тут то, что у памяти CPU (LPDDR5X) и GPU (HBM2e) в такой системе будет единое адресное пространство. Собственно говоря, таким образом компания решает давно назревшую проблему дисбаланса между скоростью обмена данными и доступным объёмом памяти в различных частях вычислительного комплекса. Для сравнения можно посмотреть на архитектуру нынешних DGX A100 или HGX. У каждого ускорителя A100 есть 40 или 80 Гбайт набортной памяти HBM2e (1555 или 2039 Гбайт/с соответственно) и NVLInk-подключение на 600 Гбайт/c, которое идёт к коммутатору NVSwitch, имеющего суммарную пропускную способность 1,8 Тбайт/с. Всего таких коммутаторов шесть, а объединяют они восемь ускорителей. Внутри этой NVLInk-фабрики сохраняется достаточно высокая скорость обмена данными, но как только мы выходим за её пределы, ситуация меняется. 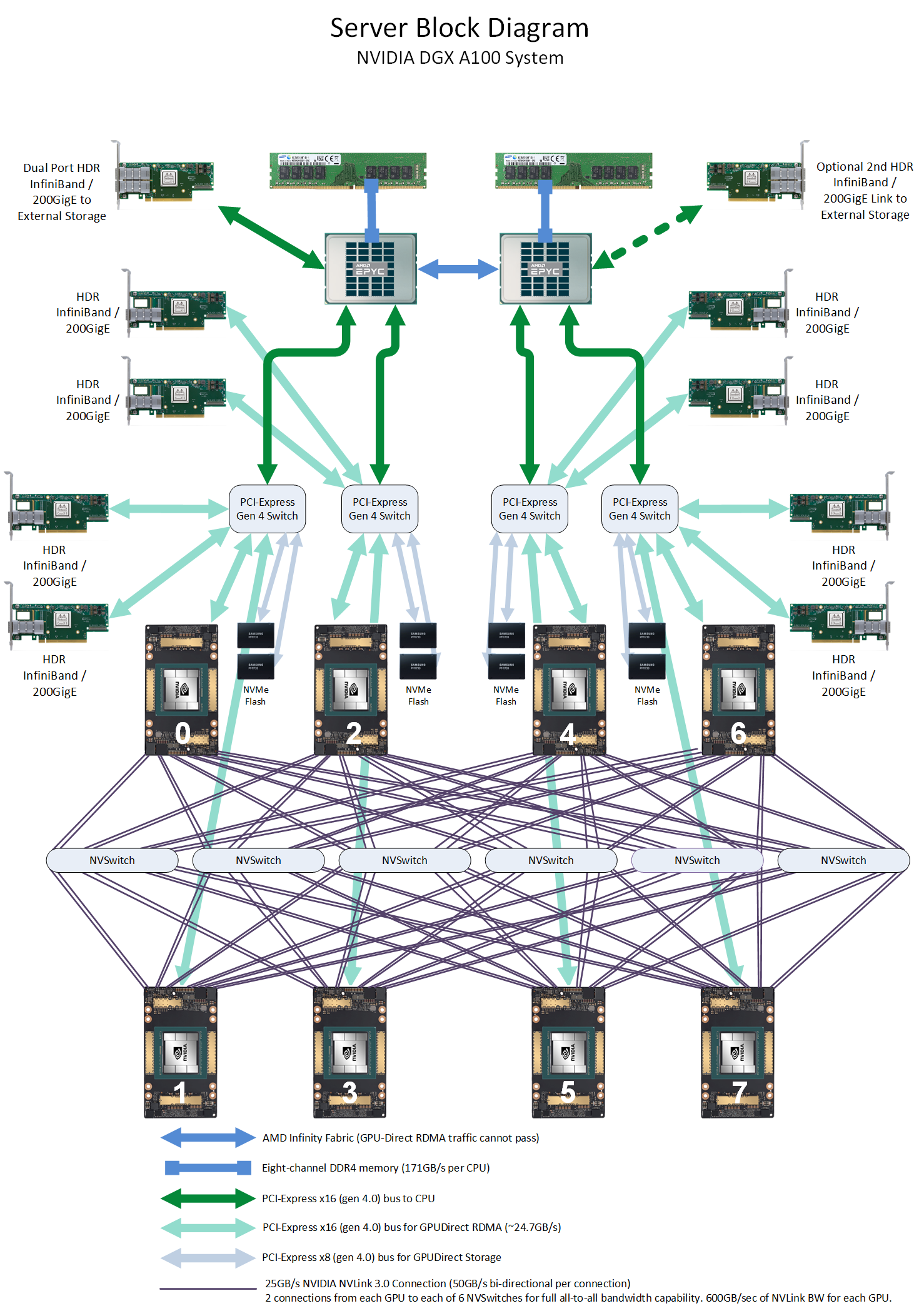
Схема NVIDIA DGX A100. Источник: Microway Каждый ускоритель A100 имеет второй интерфейс — PCIe 4.0 x16 (64 Гбайт/с), который уходит к PCIe-коммутатору, каковых в DGX A100 имеется четыре. Коммутаторы, в свою очередь, объединяют между собой сетевые 200GbE-адаптеры (суммарно в дуплексе до 1,6 Тбайт/с для связи с другими DGX A100), NVMe-накопители и CPU. У каждого CPU может быть довольно много памяти (от 512 Гбайт), но её скорость ограничена упомянутыми выше 200 Гбайт/c.  Узким местом во всей этой схеме является как раз PCIe, поэтому переход исключительно на NVLInk позволит NVIDIA получить большой объём памяти при сохранении приемлемой ПСП, не тратясь лишний раз на дорогую локальную HBM2e у каждого GPU. Впрочем, если компания не переведёт на NVLink и собственные будущие DPU Bluefield-3 (400GbE), которые будут скармливать связке CPU+GPU по, например, GPUDirect Storage данные из внешних NVMe-oF хранилищ и объединять узлы DGX POD, то PCIe 5.0 в составе Grace стоит ждать. Это опять-таки упростит и повысит эффективность масштабирования.  В целом, всё это необходимо из-за быстрого роста объёма ИИ-моделей — в GPT-3 уже 175 млрд параметров, а в течение пары лет можно ожидать модели уже с 0,5-1 трлн параметров. Им потребуются не только новые решения для обучения, но и для инференса. То же касается и физических расчётов — модели становятся всё больше и требовательнее + ИИ здесь тоже активно внедряется. Параллельно с разработкой Grace NVIDIA развивает программную экосистему вокруг Arm и своих решений, готовя почву для будущих систем на их основе.  Одной из такой систем станет суперкомпьютер Alps в Швейцарском национальном компьютерном центре (Swiss National Computing Centre, CSCS), который придёт на смену Piz Daint (12 место в нынешнем рейтинге TOP500). Этот суперкомпьютер серии HPE Cray EX, в частности, сможет в семь раз быстрее обучить модель GPT-3, чем машина NVIDIA Selene (5 место в TOP500). Впрочем, на нём будут выполняться и классические HPC-задачи в области метеорологии, физики, химии, биологии, экономики и так далее. Ввод в эксплуатацию намечен на 2023 год. Тогда же в США появится аналогичная машина от HPE в Лос-Аламосской национальной лаборатории (LANL). Она дополнит систему Crossroads, использующую исключительно процессоры Intel Xeon Sapphire Rapids.
17.02.2021 [00:43], Игорь Осколков
Российские процессоры Эльбрус-16С, Эльбрус-12С и Эльбрус-2С3 получат ядра шестого поколения архитектуры E2KНа мероприятии Elbrus Tech Day компания МСЦТ рассказала о текущих достижениях и планах развития серии российских процессоров Эльбрус. Сейчас наиболее современным CPU этой линейки является Эльбрус-8СВ на базе архитектуры E2K (Эльбрус 2000) пятого поколения, но в ближайшие годы появятся сразу три SoC шестого поколения: Эльбрус-16С, Эльбрус-2С3 и Эльбрус-12С.  Эльбрус-8СВ является эволюционным развитием Эльбрус-8. Оба чипа используют 28-нм техпроцесс, но за счёт оптимизаций у 8СВ удалось поднять частоту, что вкупе с поддержкой широких векторных инструкций и более современного стандарта памяти дало двукратный рост теоретической пиковой производительности. Впрочем, для программ, не использующих SIMD, прирост пропорционален увеличению тактовой частоты + они всё равно выигрывают от увеличения скорости работы памяти. 
На базе этих и других процессоров компания МЦСТ разрабатывает референсные дизайны материнских плат различных форм-факторов, которые можно лицензировать для дальнейшей кастомизации. Часть партнёров компании разрабатывает собственные материнские платы и изделия на их основе. В скором времени на TSMC будет размещён заказ на изготовление очередной партии Эльбрус-8СВ объёмом 10 тыс. штук. В целом, вокруг уже имеющихся CPU сложилась достаточно заметная экосистема как аппаратных, так и программных продуктов и решений. 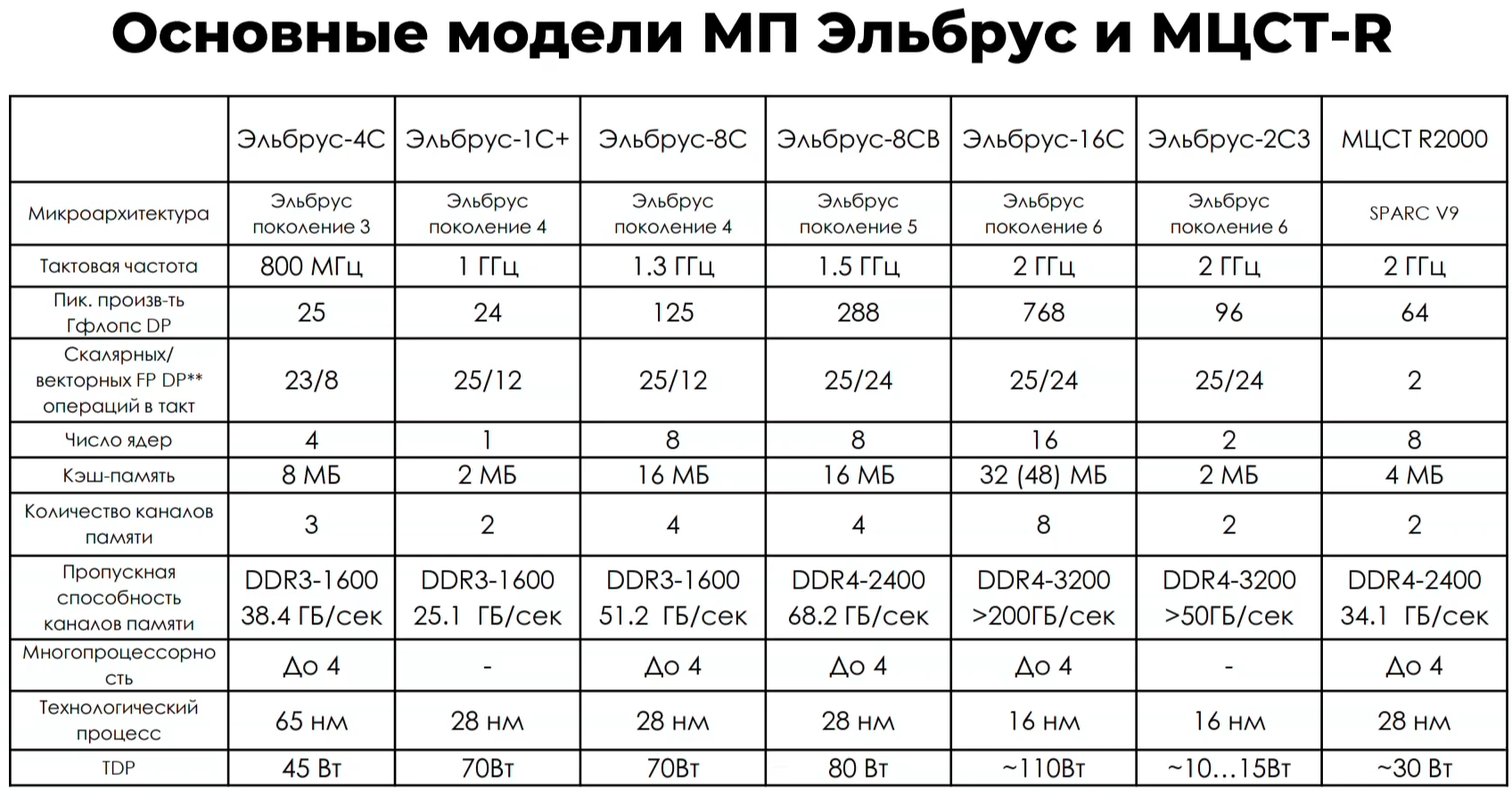 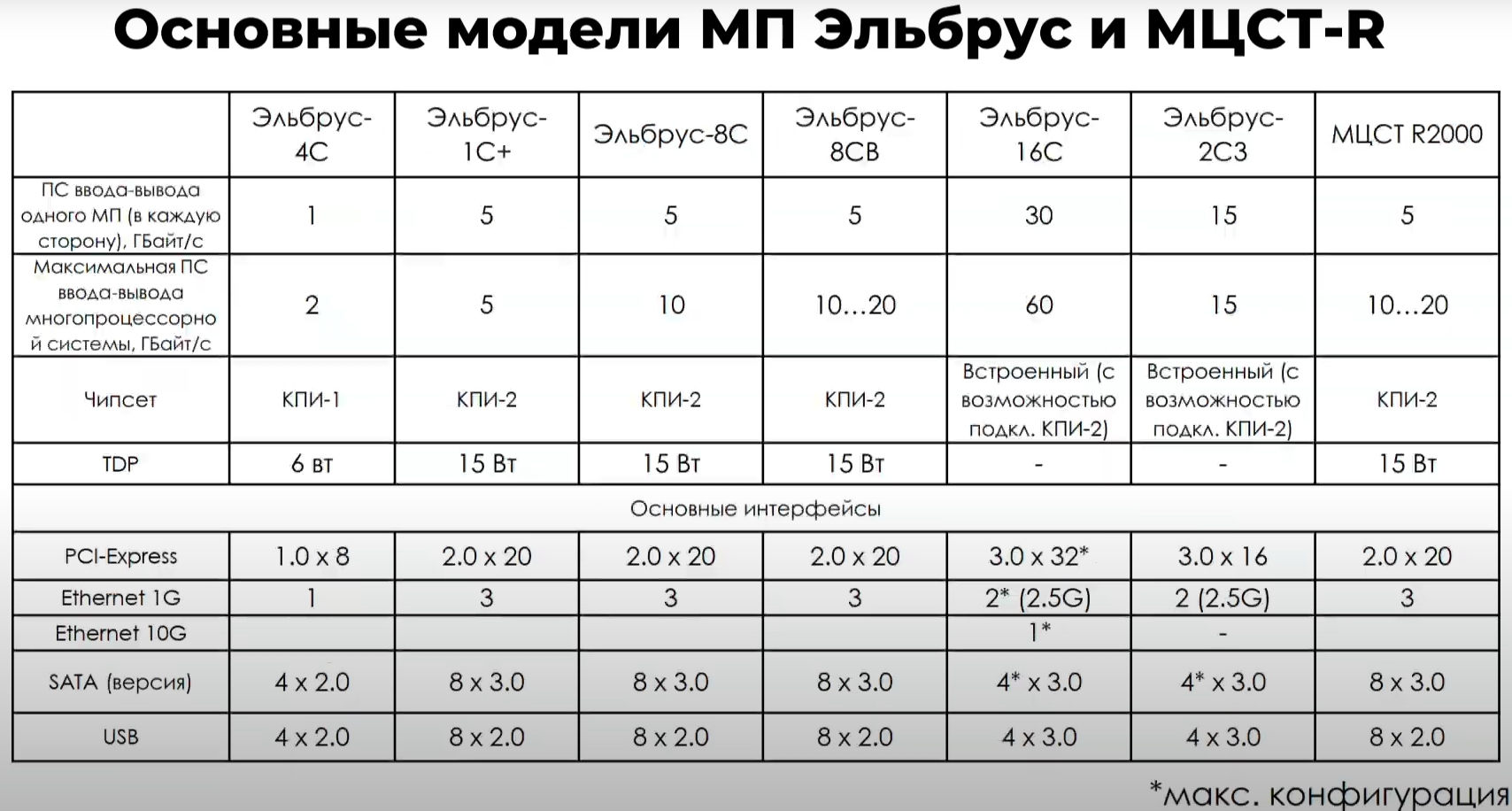 Следующее поколение процессоров будет разнообразнее. Помимо 16-ядерного Эльбрус-16С, ориентированного на высокопроизводительные серверные системы, будет и модель попроще, которая появится позже остальных — Эльбрус-12С. Этот 12-ядерный CPU рассчитан на серверы начального уровня, а также рабочие станции. А главное отличие от 16С будет в цене. Наконец, ещё один чип, двухъядерный Эльбрус-2С3, ориентирован на мобильные системы, в том числе планшетные компьютеры.  
Эльбрус-16С Все чипы будут изготавливаться на TSMC по 16-нм техпроцессу FinFET и будут основаны на шестом поколении архитектуры E2K. Строго говоря, это уже не процессоры, а полноценные SoC с интегрированными контроллерами для различной периферии, и для работы им не требуется внешний чип южного моста, как было ранее. В случае Эльбрус-16С площадь кристалла составляет 618 мм2 (25,3 × 24,4 мм), упакован он в корпус HFCBGA4804 с габаритами 63 × 78 мм. Кристалл содержит 12 млрд транзисторов, а его мощность не превышает 130 Вт. 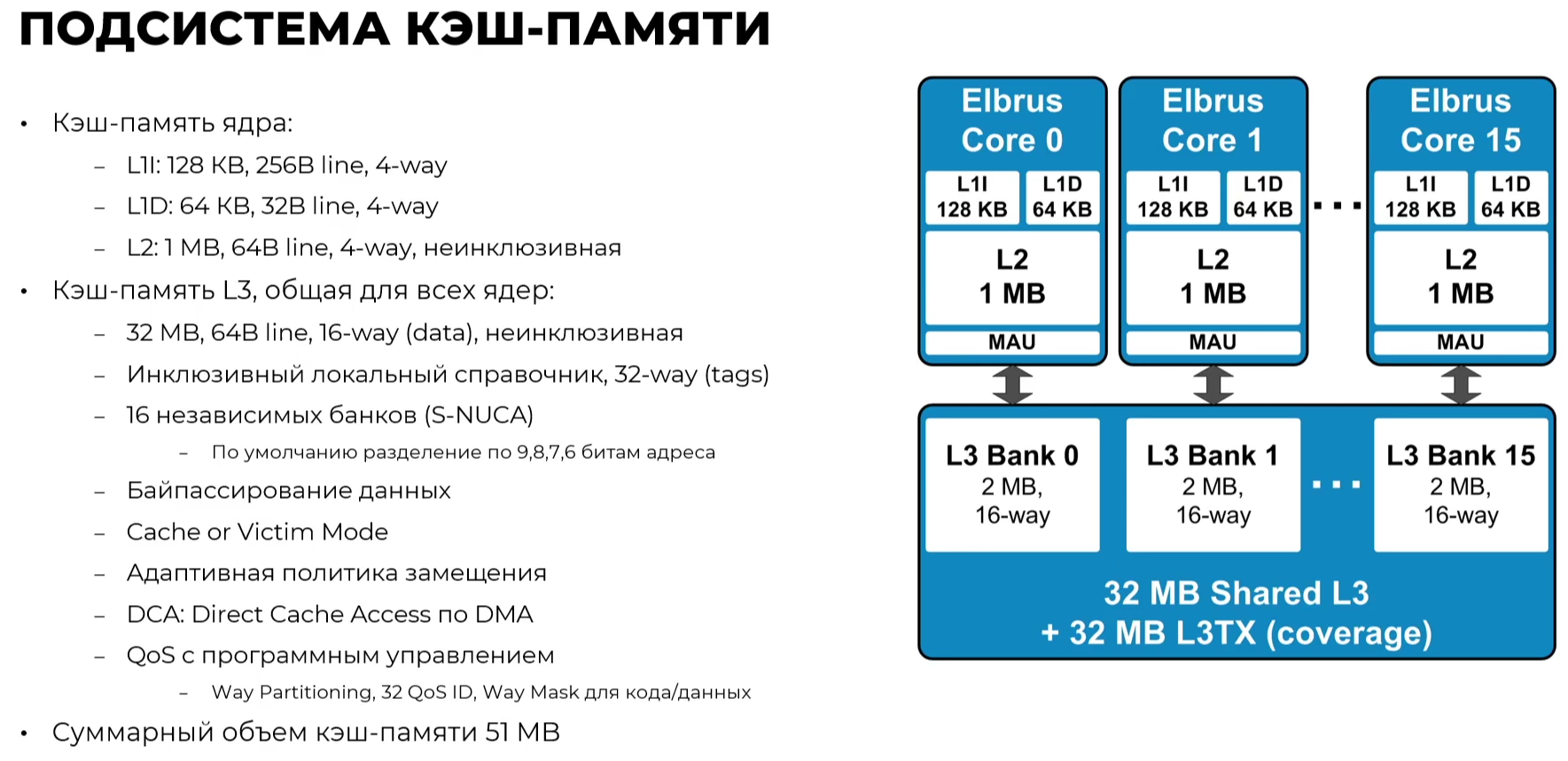 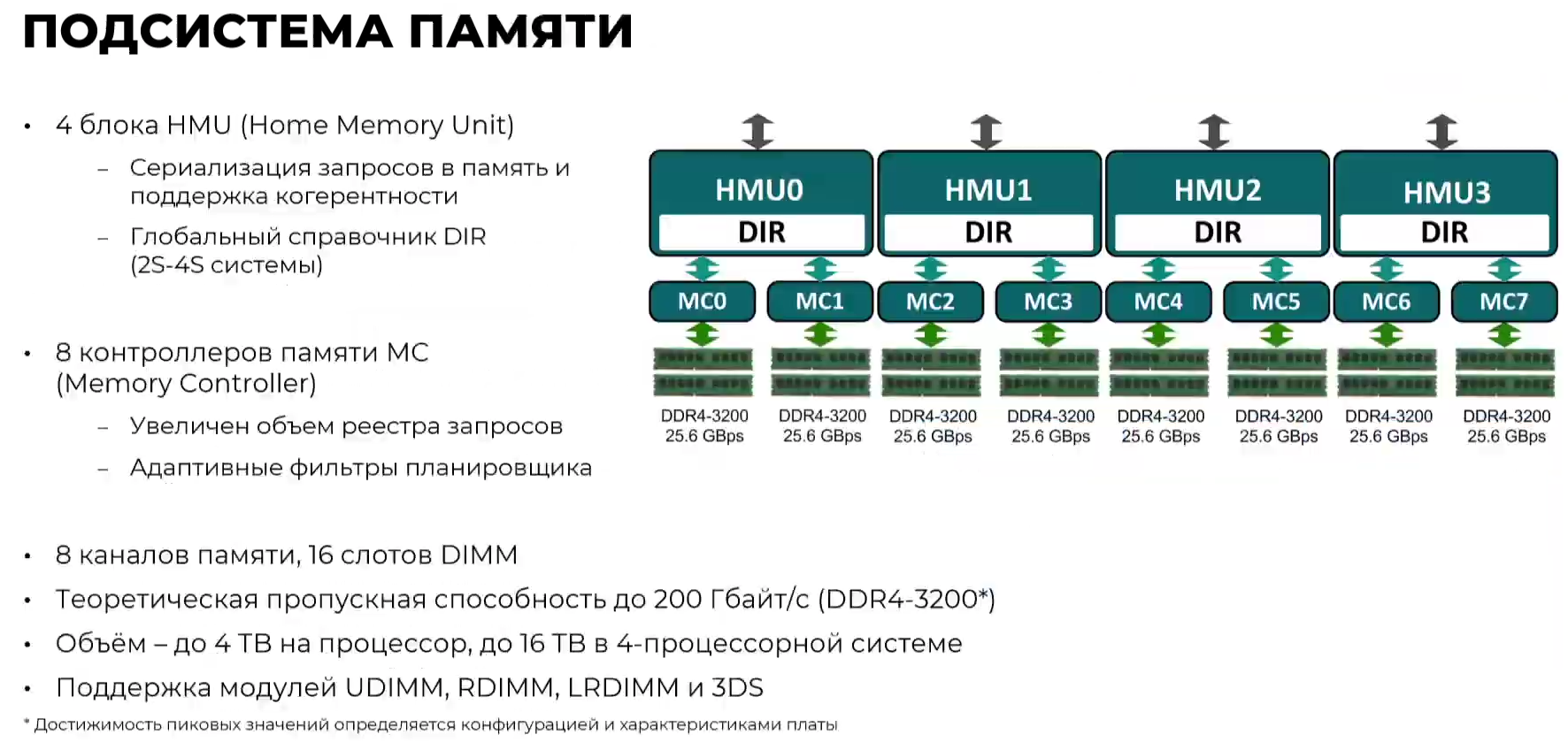 Значительная часть изменений в архитектуре коснулась подсистемы памяти. В частности, были увеличены размеры кешей, суммарный объём которых достиг 51 Мбайт: общий для всех L3-кеш 32 Мбайт, увеличенный до 1 Мбайт L2-кеш, L1-кеш для инструкций на 128 Кбайт + L1-кеш данных на 64 Кбайт. Контроллер памяти стал восьмиканальным, получил поддержку модулей DDR4-3200 и 2DPC, что даёт до 4 Тбайт RAM на сокет с суммарной пропускной способностью до 200 Гбайт/с. 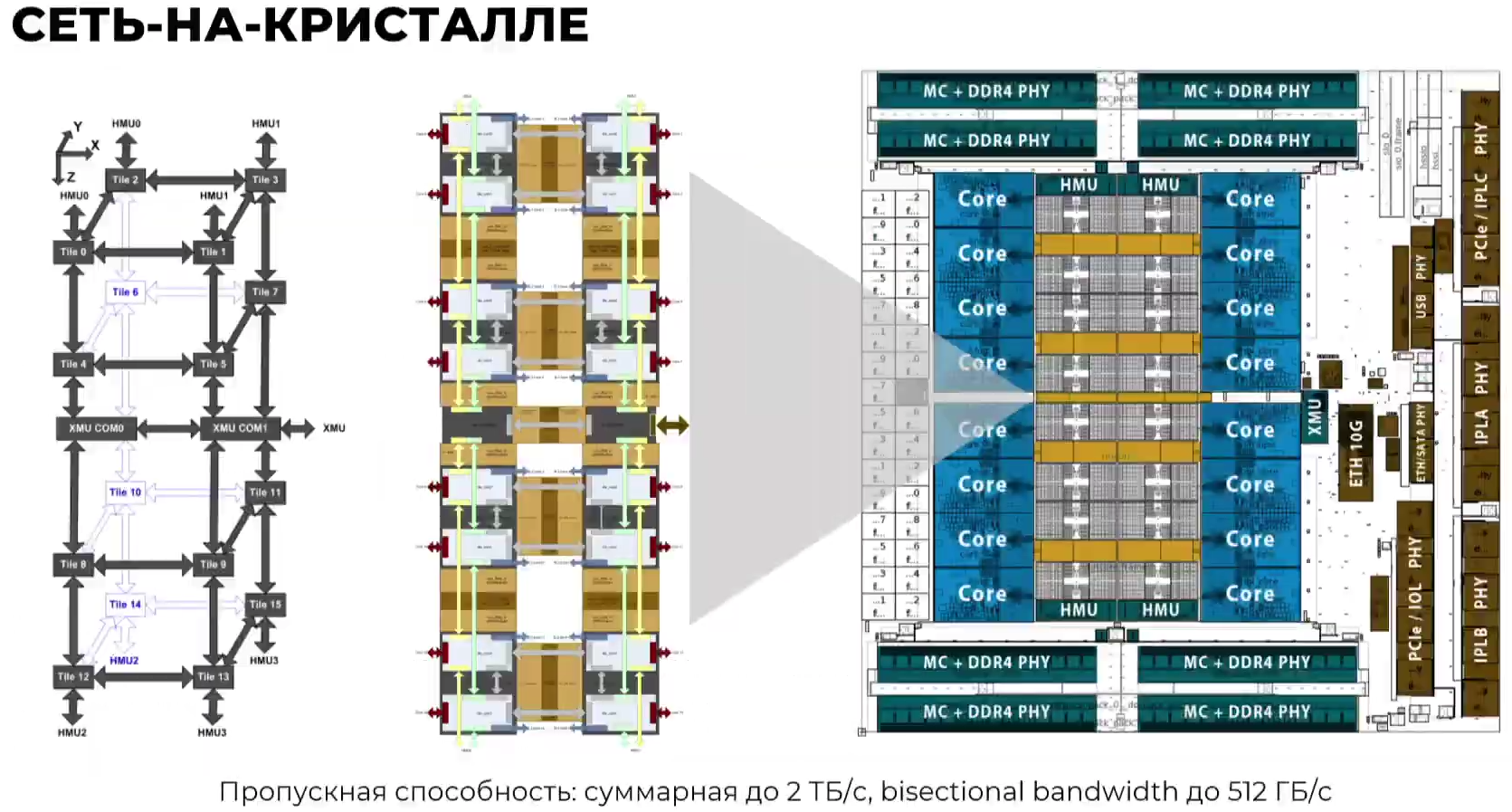 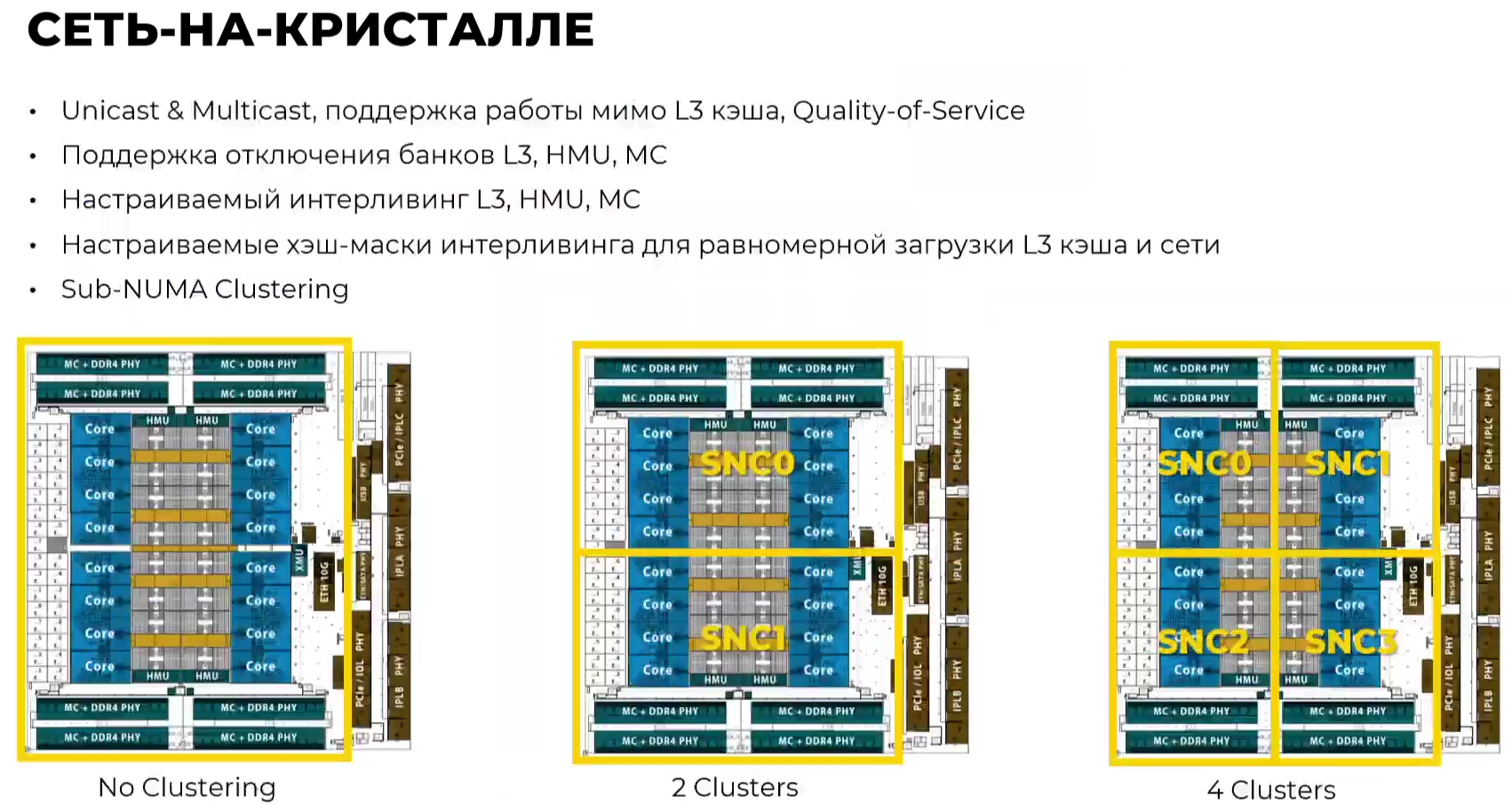 Первые инженерные образцы Эльбрус-16С, полученные в конце прошлого года, уже выдают в бенчмарке stream скорость порядка 70-80% от максимально возможной. Контроллеры попарно подключены к четырём агентам (HMU), «прикреплённым» к внутренней mesh-шине с пропускной способностью 2 Тбайт/с, объединяющей память и ядра. Чип можно разделить на два или четыре NUMA-домена, что полезно для ряда задач.  Одной из таких задач является виртуализация, и в Эльбрус-16С она, наконец, стала полноценной — новые процессоры поддерживают аппаратную виртуализацию практически всех важных ресурсов, в том числе и для режима x86-трансляции, который тоже никуда не делся. Для CPU прошлых поколений всё ещё можно использовать контейнеризацию, но МЦСТ занимается и подготовкой паравиртуализированного ядра и сопутствующих компонентов, включая KVM, QEMU, libvirt и virt-manager. 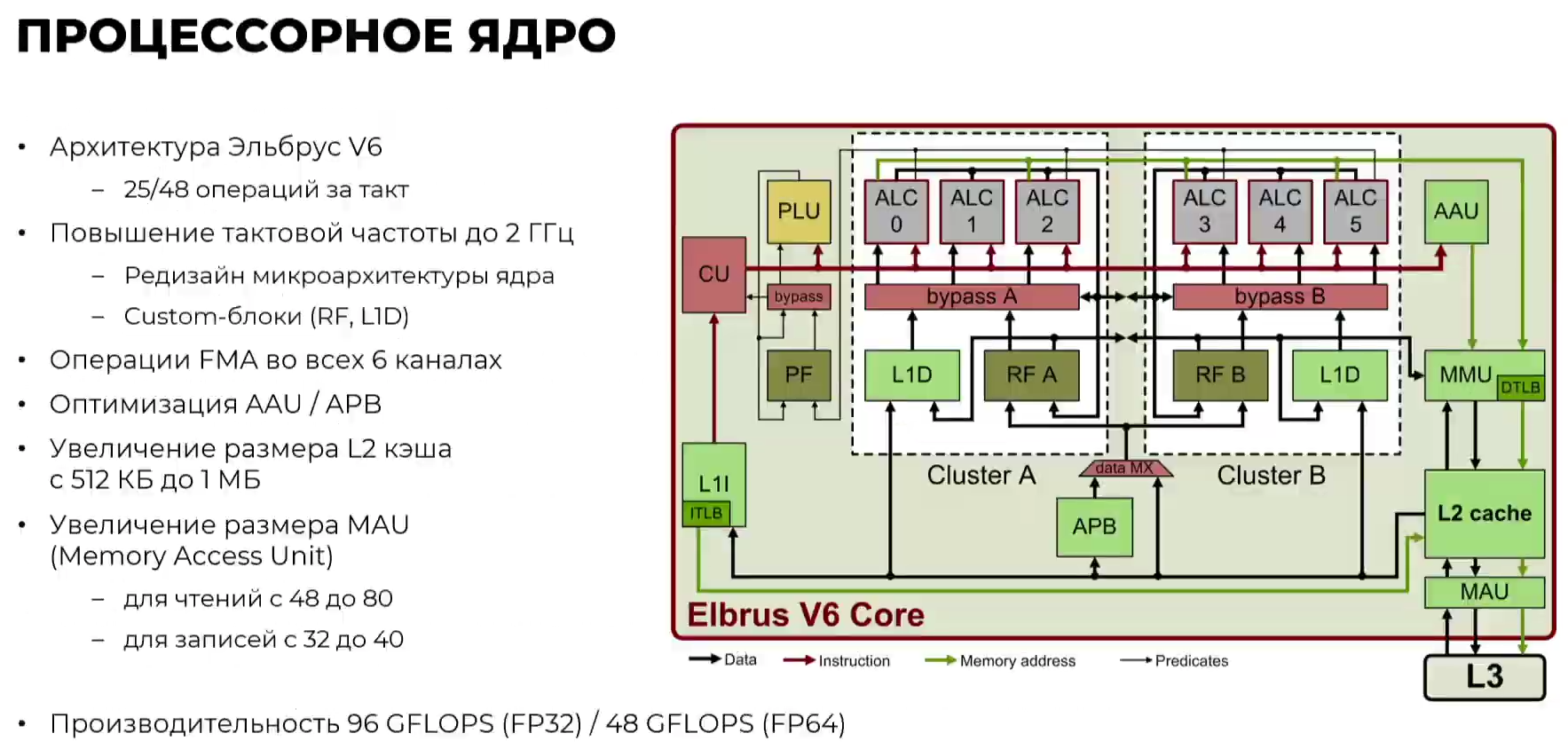 Для самих ядер был произведён редизайн микроархитектуры, что дало повышение скорости работы и новые возможности. В частности, появились новые SIMD-инструкции в дополнение к имеющимся, поддержка FMA по стандарту IEEE 754-2008 (требуется в современных стандартах C), динамическая оптимизация (касается планирования, что важно для VLIW), новый контроллер прерываний (необходим для виртуализации) и так далее. 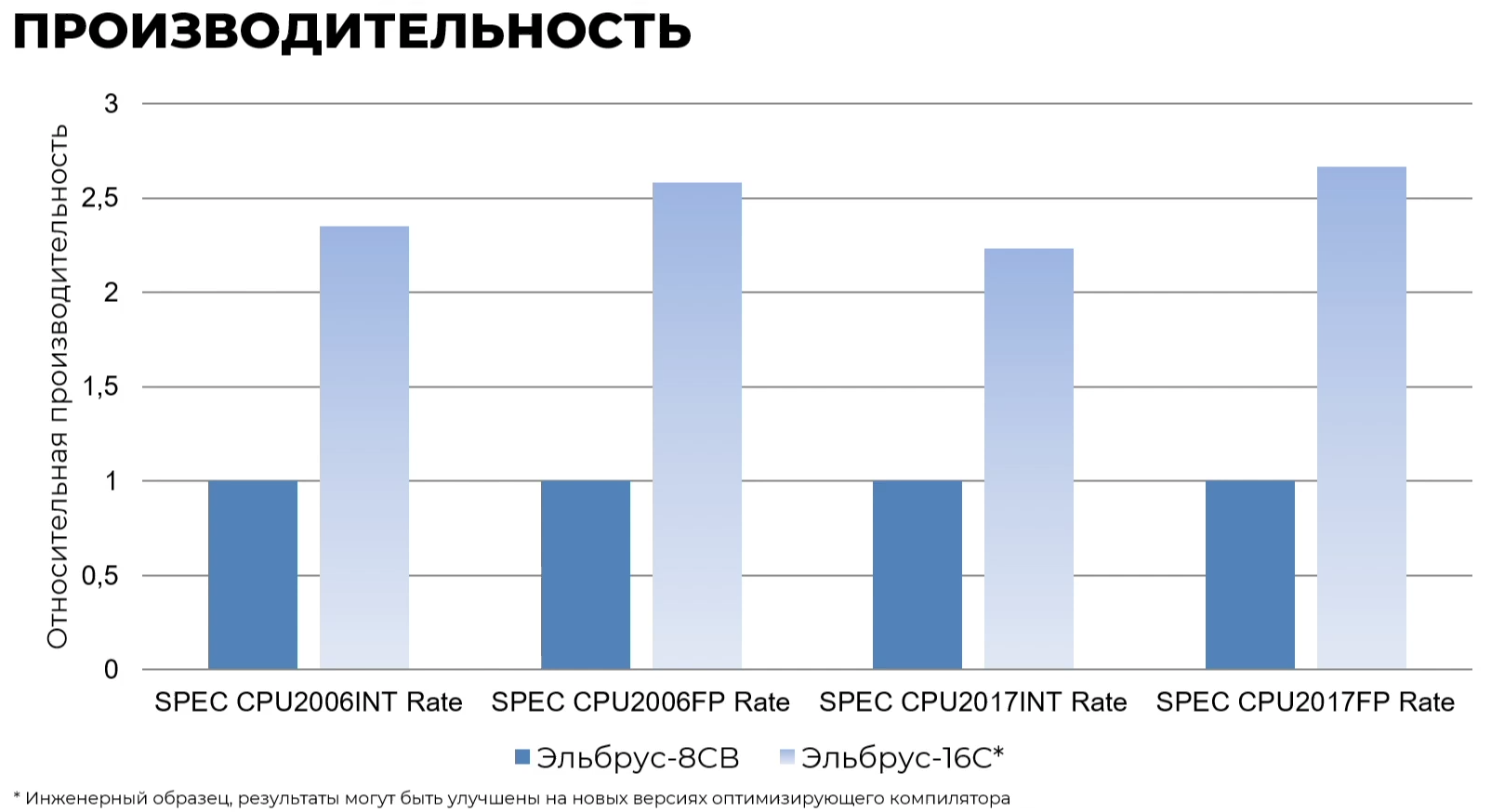 Пиковая теоретическая производительность ядра составляет 96 Гфлопс для вычислений одинарной точности и 48 Гфлопс — для двойной. Для всего CPU это 1,5 Тфлопс и 768 Гфлопс соответственно. Предварительные тесты показывают прирост производительности в 2-2,5 раза в сравнении с Эльбрус-8СВ, но надо помнить, что очень много зависит от оптимизаций со стороны компилятора. Само ядро хоть и стало сложнее, но оно всё равно проще, чем ядра современных x86-64 процессоров. 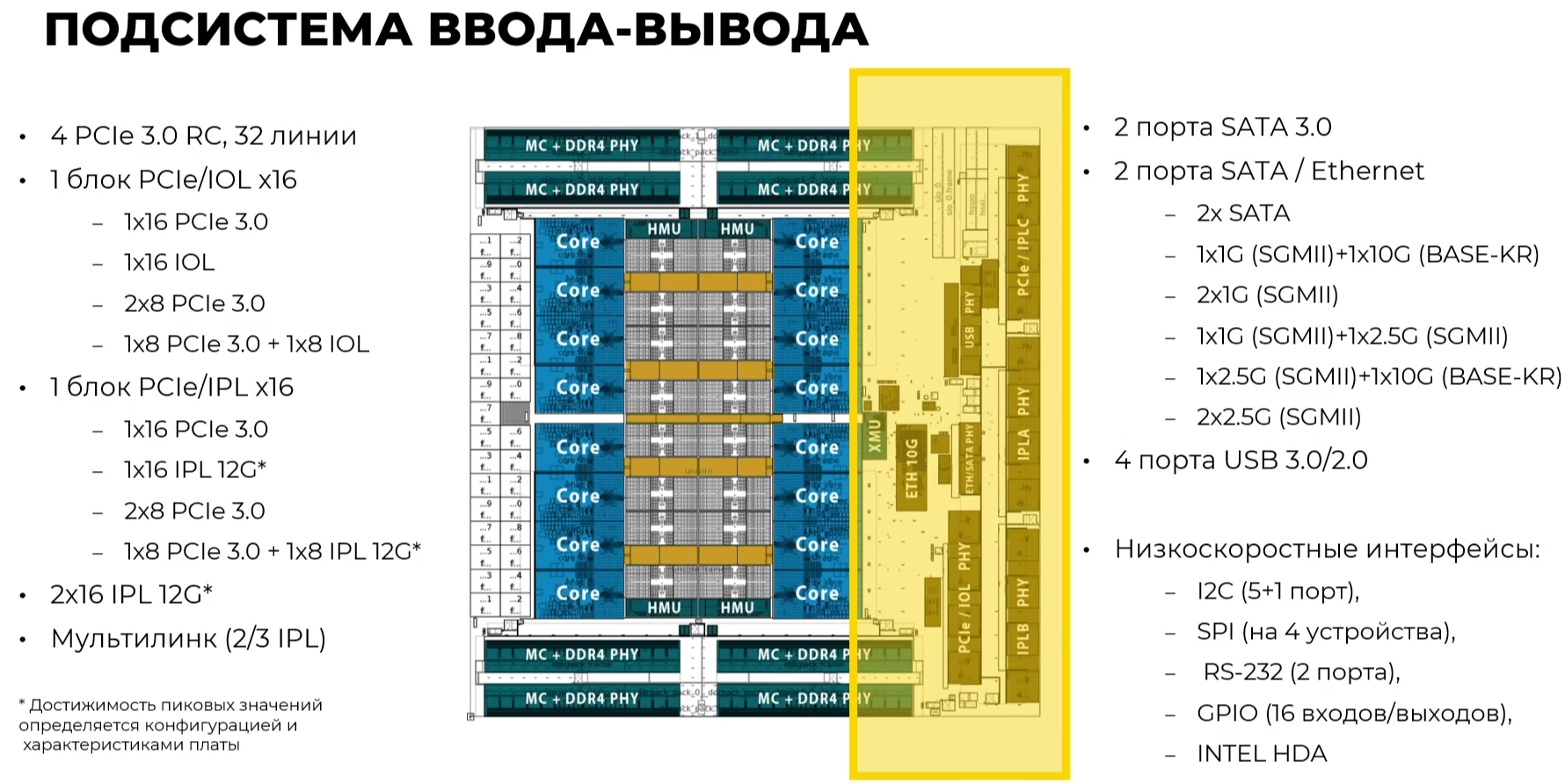 Слабым местом новых чипов, на наш взгляд, является IO-блок. В состав SoC входят четыре root-комплекса PCIe 3.0, которые в сумме дают 32 линии. Из них 8 или 16 линий можно выделить на подключение внешнего южного моста, если не хватает того, что встроен в сам чип. Он предоставляет 2 порта SATA 3.0, 4 порта USB 3.0/2.0 и два мульти-порта, дающих или пару SATA, или пару Ethernet с максимальной конфигурацией 10GbE + 2.5GbE. 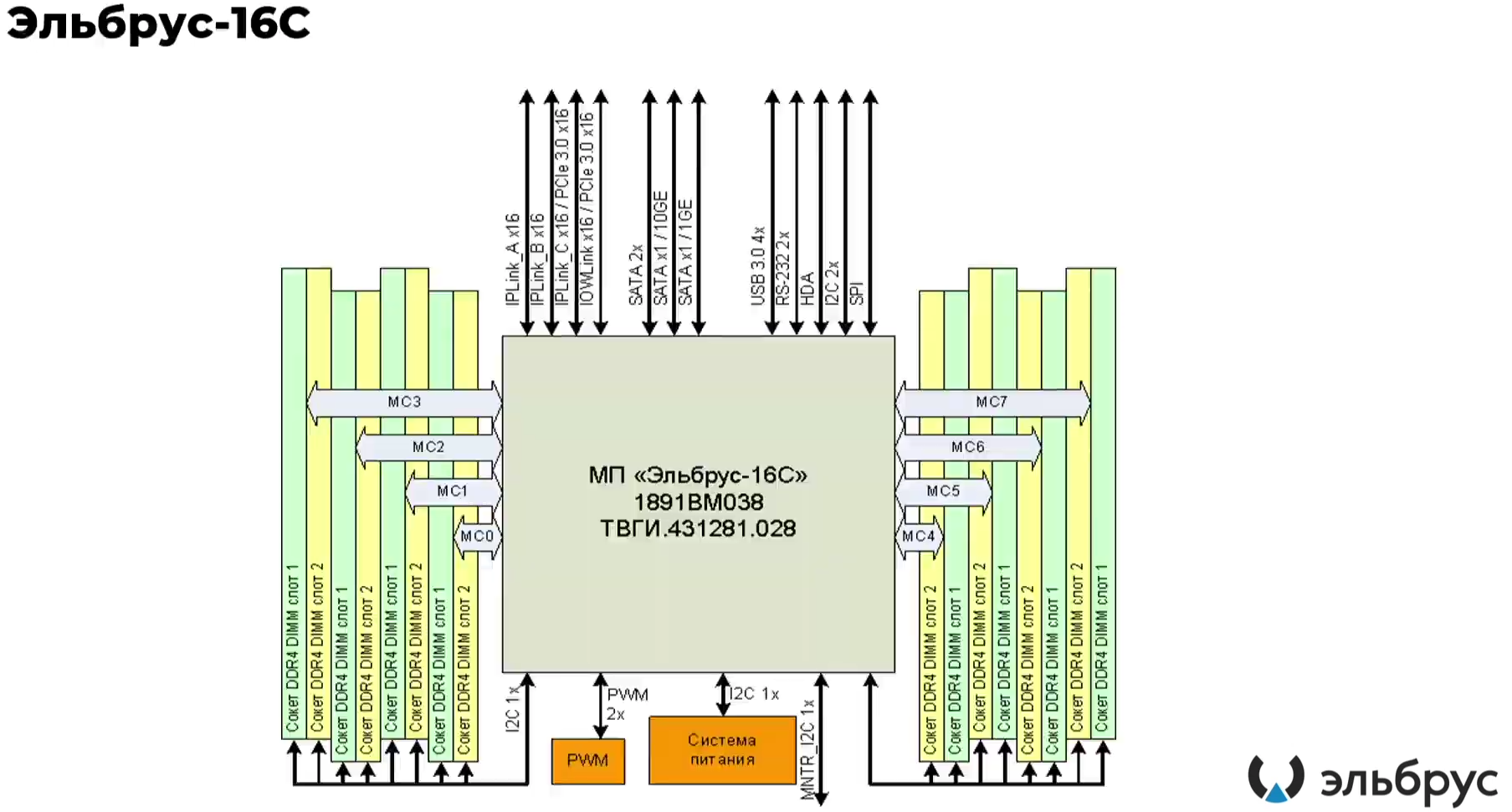 Ещё 8 линий PCIe можно отдать на канал для межпроцессорной связи (IPL) в дополнение к двумя каналам, которые есть всегда. В двухсокетной системе, таким образом, можно объединить CPU двумя или тремя IPL. Правда, скорость одного такого канала составляет всего 12 Гбит/с (на инженерных образцах пока достигли 10 Гбит/с), что значительно меньше, чему у UPI или Infinity Fabric. Всего в одной системе может быть объединение до четырёх процессоров.   Помимо прочего, в чипах реализованы различные RAS-функции для повышения надёжности работы. Также улучшен мониторинг процессора и управление его питанием и охлаждением. Вероятно, теперь уже все системы на базе новых CPU будут комплектоваться BMC-контроллером — ASPEED AST2500 и в перспективе AST2600 — с собственной прошивкой на базе OpenBMC и с встроенной микро-ОС, упрощающей инициализацию и работу с оборудованием. Референсный дизайн двухсокетной платы 2Э16С-SPRC появится в середине этого года, а однопроцессорной Micro-ATX — к концу. 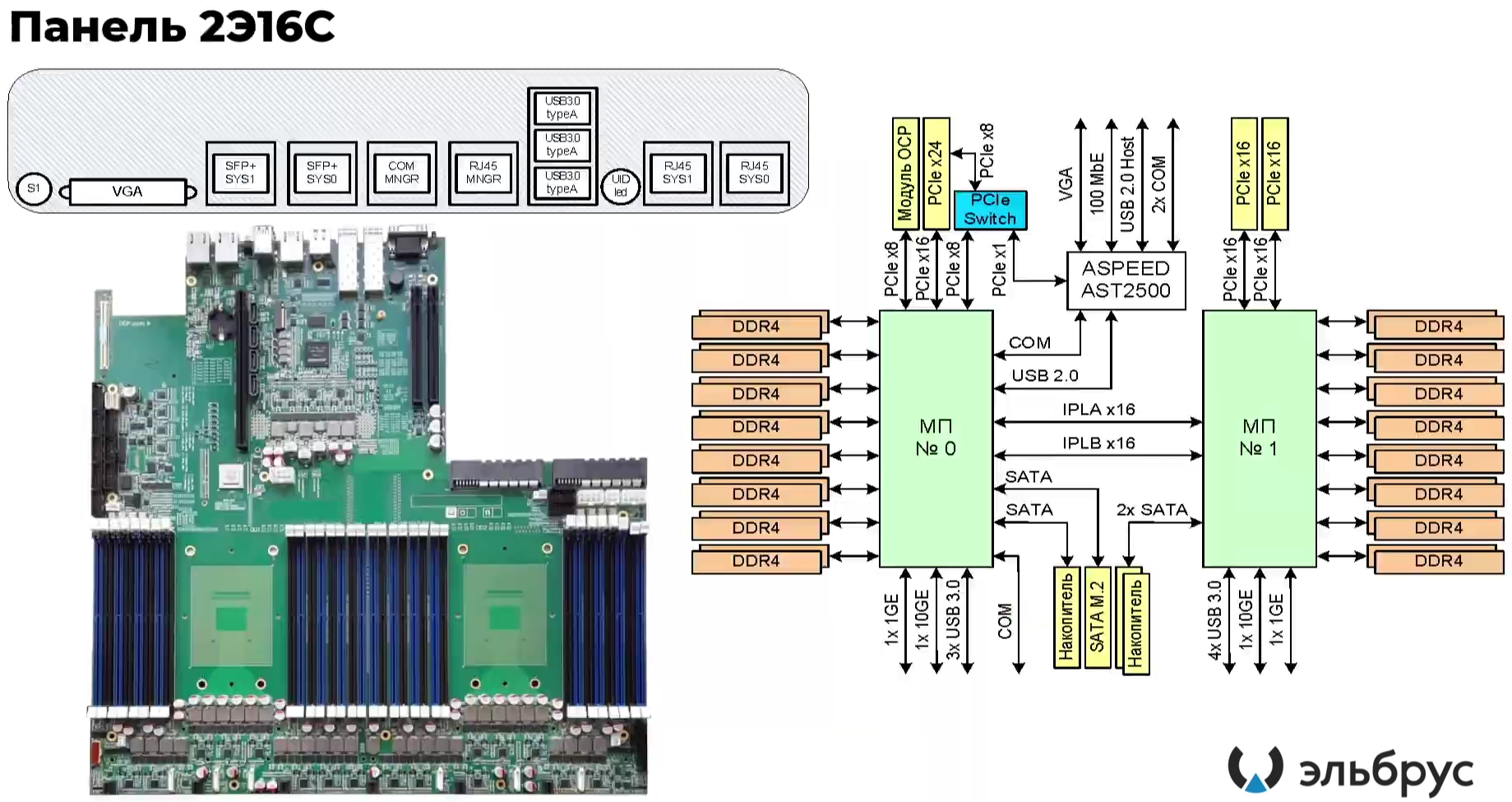 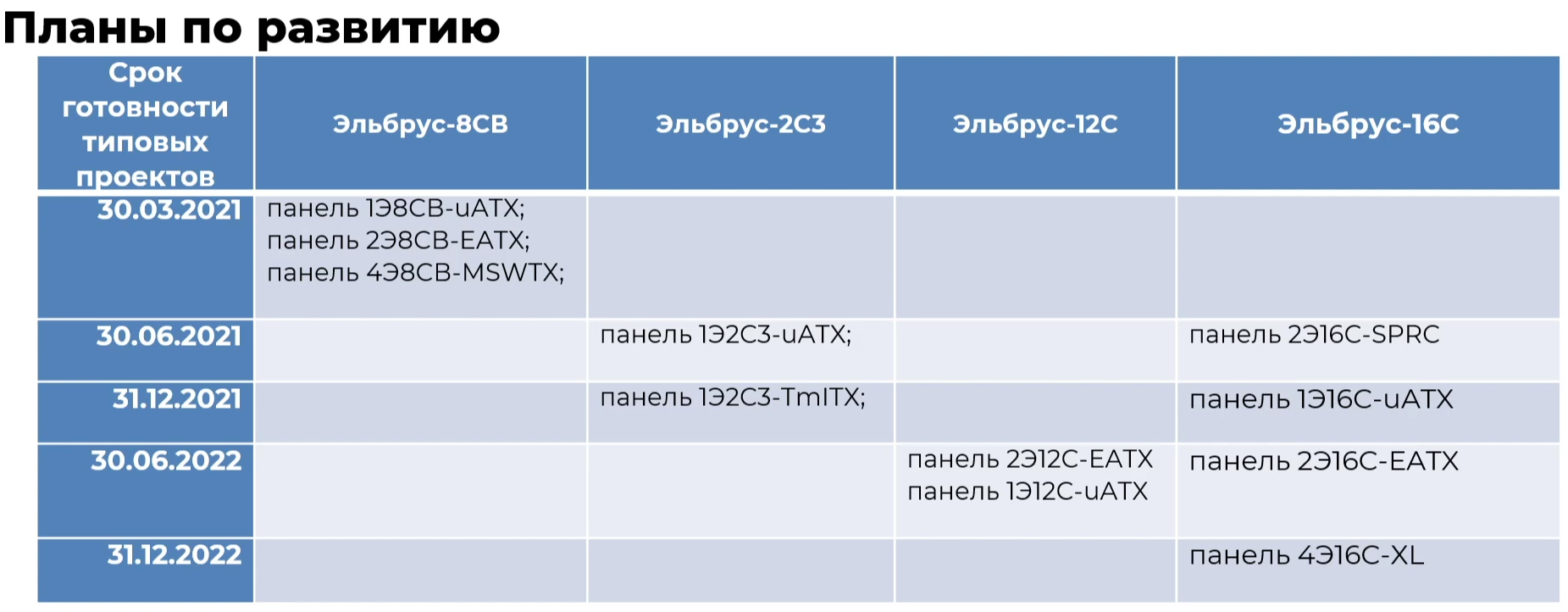 В 2022 году появятся и другие варианты двух- и четырёхсокетных систем с Эльбрус-16С, а также одно- и двухсокетные платы для Эльбрус-12С. Партнёры МЦСТ, надо полагать, тоже не будут сидеть без дела. Напомним, что формально окончание разработки Эльбрус-16С намечено на конец этого года. Для Эльбрус-2С3 и Эльбрус-12С точные сроки озвучены не были. И если 12-ядерная модель, скорее всего, очень похожа на 16-ядерную, то младший чип серии заметно от них отличается.  Эльбрус-2С3 имеет всего два ядра шестого поколения с тактовой частотой 2 ГГц, два канала памяти DDR4-3200 и производительность до 192/96 Гфлопс FP32/FP64. У него есть 16 линий PCIe 3.0. В его состав входит 3D-ядро Imagination PowerVR GX6650 (300 Гфлопс), ряд (де)кодеров видео, а также 2D-ядро собственной разработки. Есть четыре видеовыхода (из них 2 HDMI) и поддержка 4K-вывода. Для этой SoC компанией в течение 2021 года будут подготовлены первые платы Micro-ATX и Mini-ITX. 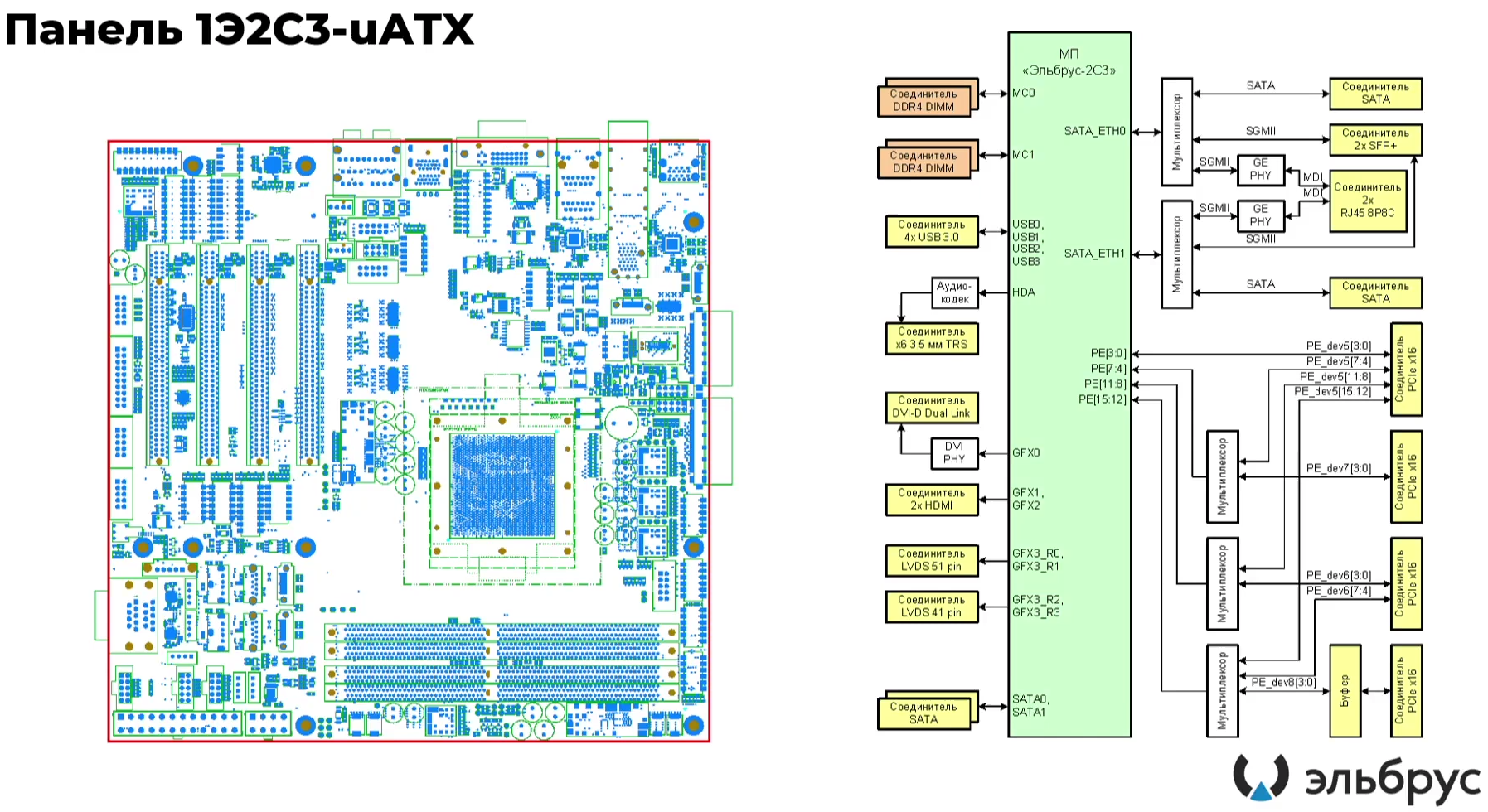 Характеристики будущих процессоров Эльбрус-32С пока до конца не определены, но примерные очертания будущего продукта уже есть. CPU должен иметь производительность не ниже 1,5/3/6 Тфлопс для вычислений FP64/FP32/FP16 и содержать от 32 ядер с частотой более 2 ГГц. Возможно, будет и 64 ядра седьмого поколения E2K. Объём L3-кеша должен как минимум удвоиться, а контроллер памяти, возможно, получит поддержку DDR5 объёмом не менее 4 Тбайт/сокет. Предполагается возможность работы как минимум двухсокетных конфигураций.  Дальнейшее развитие могут получить виртуализация и фирменная технология безопасных вычислений с попутным добавлением новых инструкций. Уже сейчас разработчики хотят предоставить 64 линии PCIe 5.0, что открывает путь к использованию CXL 2.0. К встроенным контроллерам, помимо NVMe, без которого уже точно не обойтись, могут добавиться 100GbE и USB 3.1 или более новые. Будущие кристаллы перейдут на техпроцесс не толще 7 нм, а их площадь вырастет до 600 мм2.
01.02.2021 [22:16], Алексей Степин
Cделка IBM и Inspur, похоже, спасает архитектуру POWER от вымиранияКогда говорят о противостоянии серверных процессоров, как правило, называют AMD и Intel, а с недавних пор ещё и ARM. Некогда крупный игрок, IBM со своими процессорами серии POWER, упоминается существенно реже, и на то есть причины — за прошедшее десятилетие дела у компании шли не слишком хорошо. Но, если верить аналитикам IT Jungle, ситуация с POWER не так проста и не так плоха. Если верить отчётам самой IBM, доходы снизились на рекордную величину за последние пять лет, упали даже продажи мейнфреймов. Доходы в сегменте аппаратного обеспечения за прошедший год у IBM упали на 18% относительно 2019 года, а у подразделения Power Systems называют даже цифру 43,3%. Однако как считают некоторые аналитики, дела в секторе серверов на базе процессоров POWER могут обстоять не так плохо, как это может показаться на первый взгляд.  Платформа IBM POWER самобытна и весьма интересна сама по себе: так, уже не новые процессоры POWER9 поддерживают четыре потока на ядро против традиционных двух у x86, а в некоторых вариантах способны работать даже в режиме SMT8. Более новые POWER10 также поддерживают восьмипоточный режим; кроме того, они работают с прогрессивным форматом оперативной памяти OMI и имеют контроллер PCI Express 5.0. 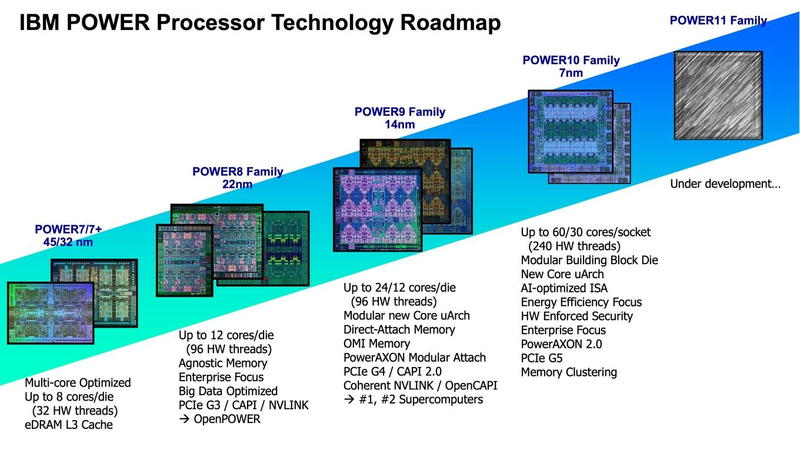
Планы развития архитектуры POWER Здесь следует немного углубиться в историю. Китайская компания Inspur, один из крупнейших среднеазиатских производителей серверного оборудования, всегда мечтала о «большом железе». В 2014 году ей удалось добиться договорённости с IBM о праве запускать фирменное ПО последней (в частности, базы данных DB2 и сервер приложений WebSphere) на 32-процессорных Itanium-системах. А месяцем позднее Inspur присоединилась к консорциуму OpenPower с целью создания серверов уже на базе архитектуры POWER. В 2017 начинается «война санкций», при этом приличного самостоятельного открытого клона POWER-процессора консорциум так и не создал. Известно, что китайская Suzhou PowerCore Technology, входящая в OpenPower, занималась адаптацией POWER под более «толстые» техпроцессы. Сейчас компания активно нанимает сотрудников и открывает новое подразделение в США. Однако чем именно она занимается и связан ли этот рост с полным открытием POWER ISA, не до конца ясно. 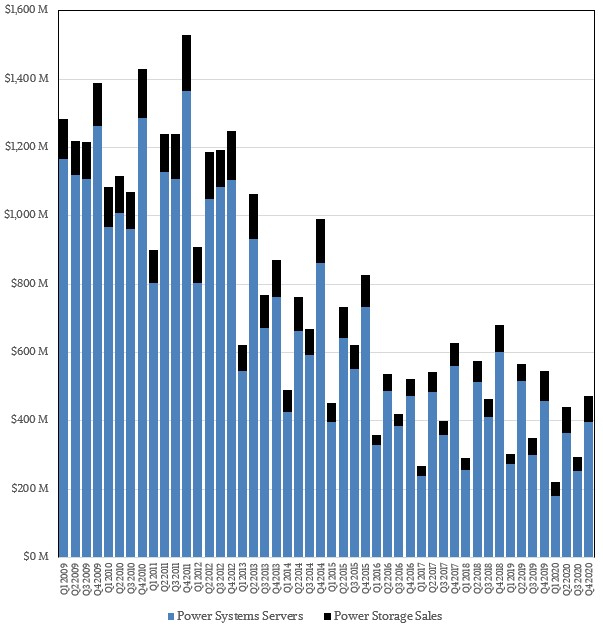
Структура продаж POWER-систем по мнению ресурса IT Jungle До ввода санкций IBM и Inspur успевают создать совместное предприятие (51% Inspur + 49% IBM), которое, что интересно, тоже называется IBM — Inspur Business Machines. Цель новой компании, в которую вложили порядка 1 млрд юаней ($150 млн) — создание мощных серверных систем на базе архитектуры POWER для крупного бизнеса. Поставками же POWER-процессоров для Inspur занималась, в частности, всё та же Suzhou. Судя по косвенным данным, сделка для Inspur оказалась весьма успешна. Кроме того, компания вообще чувствует себя отлично, поставляя также x86-серверы как малому и среднему бизнесу, так и китайским гигинтам Alibaba, Baidu и Tencent. К сентябрю 2020 года продажи Inspur составят $7,71 млрд, что на 43% больше, нежели у IBM с её $5,4 млрд. 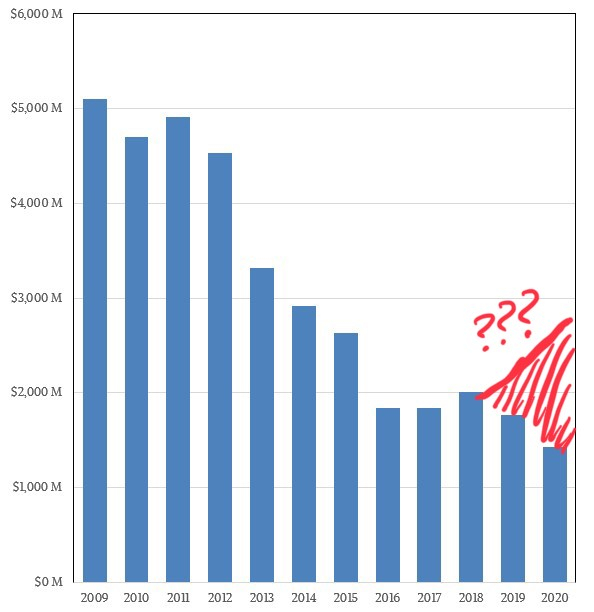
С учётом поставок Inspur общий объём продаж POWER-серверов может выглядеть так по мнению IT Jungle К настоящему моменту IBM публикует только свои цифры продаж систем на базе POWER, и графики выглядят достаточно удручающе. Из-за санкций IBM не может продавать POWER-системы в КНР напрямую, а Inspur Business Machines — может. Из $8 млрд продаж Inspur примерно 10-12% может приходиться на системы с процессорами POWER, а это от $800 до $960 млн, и эти цифры сопоставимы с продажами серверов самой IBM. Иными словами, платформа POWER, скорее всего, отнюдь не находится в процессе вымирания. Более того, после неудачных 2016 и 2017 годов объёмы продаж таких серверов могли, как минимум, вернуться к показателям 2015 года. Также вполне вероятно, что и Google производит для себя серверы на базе POWER — соответствующие предложения появились в Google Cloud уже достаточно давно. Похожее решение есть и в Microsoft Azure.
13.01.2021 [19:03], Игорь Осколков
Qualcomm поглощает Nuvia, разработчика серверных Arm-процессоровQualcomm Incorporated объявила, что её дочерняя компания Qualcomm Technologies, Inc. заключила окончательное соглашение о приобретении NUVIA примерно за $1,4 млрд. Решения компании должны дополнить экосистему Snapdragon, включающую GPU, ИИ-движки, DSP и мультимедийные ускорители. Сделка ждёт одобрения со стороны регуляторов. Любопытно, что Qualcomm говорит об использовании решений NUVIA во флагманских смартфонах, ноутбуках следующего поколения, системах автопилотирования и приборных панелях авто, а также для сетевой инфраструктуры и подключённых устройств. Однако NUVIA разрабатывала SoC Orion c Arm-процессором Phoenix собственного дизайна, которая ориентирована на совершенно другой сегмент — на облачных провайдеров и гиперскейлеров. Компания обещала, что её чипы будут быстрее и энергоэффективнее AMD EPYC и Intel Xeon. Осенью она получила дополнительные $240 млн для производства первых чипов. 
Источник изображений: NUVIA У двух крупных игроков, Qualcomm и Broadcom, с серверными Arm-процессорами не заладилось. Первая забросила Centriq, а наследие проекта Vulcan второй в результате череды слияний и поглощений оказалось в руках Marvell, которая этими же руками проект, судя по всему, и похоронила. Так что на этом рынке к концу 2020 года осталось только два заметных игрока: Ampere, уже представившая свои чипы (очень неплохие, надо сказать), и подающие надежды NUVIA. Из альтернатив остаются Amazon Graviton2, который доступен только в облаке AWS, и Kunpeng от Huawei, которая находится под санкциями США и будущее её несколько туманно. Qualcomm, судя по сегодняшнему релизу, пока не очень заинтересована в развитии серверных Arm-процессоров. Вероятно, она надеется, что NUVIA поможет ей догнать Apple — Qualcomm традиционно отставала от последней в выводе на рынок SoC на базе новых архитектур Arm. Среди основателей NUVIA числится Джерард Уильямс III (Gerard Williams III), который почти десять лет руководил разработкой Arm-чипов в Apple, был научным сотрудником Arm и ведущим дизайнером Texas Instruments. В конце 2019 года Apple подала к нему иск. Двое других основателей NUVIA имеют не менее солидный послужной список: Ману Гулати (Manu Gulati) и Джон Бруно (John Bruno) в разное время работали в AMD, Apple и Google, в том числе в должности архитектора. К компании также присоединились бывший вице-президент Intel по маркетингу Джон Карвилл (Jon Carvill), работавший в Facebook✴, Qualcomm, Globalfoundries, AMD и ATI, а также Энтони Скарпино (Anthony Scarpino), проработавший 24 года в ATI и AMD.
21.12.2020 [18:41], Алексей Степин
128-ядерные супепроцессоры Tachyum Prodigy стали на шаг ближе к реальностиЛетом уходящего года компания Tachyum объявила о том, что собирается отправить Xeon «на свалку истории». Сделать это должен 128-ядерный процессор нового поколения Prodigy. Хотя массово он пока не производится, компания продолжает активно работать над проектом и совсем недавно объявила начало предзаказов на эмуляторы нового процессора, как программные, так и базирующиеся на ПЛИС. Также она продемонстрировала рабочий UEFI для будущих CPU. 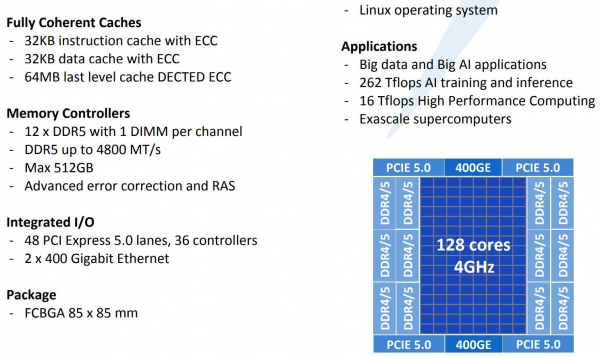 Молодая словацкая компания замахнулась на многое. Её процессор должен получить до 128 ядер, работающих на частоте до 4 ГГц. Чтобы «накормить» его данными, предусмотрен 12-канальный контроллер памяти DDR5. С периферией Prodigy будет общаться посредством 48 линий PCIe 5.0, но также получит и два контроллера Ethernet класса 400G. Характеристики весьма впечатляют.  Разработчики заявляют, что Prodigy найдёт своё место в системах класса Big Data и мощных системах машинного обучения. Если верить Tachyum, производительность разрабатываемого процессора должна достигнуть 16 и 8 Тфлопс на классичесих вычислениях FP32/FP64. В режиме машинного обучения и инференса возможности новой архитектуры выглядят ещё внушительнее, поскольку речь идёт о цифре 262 Тфлопс. 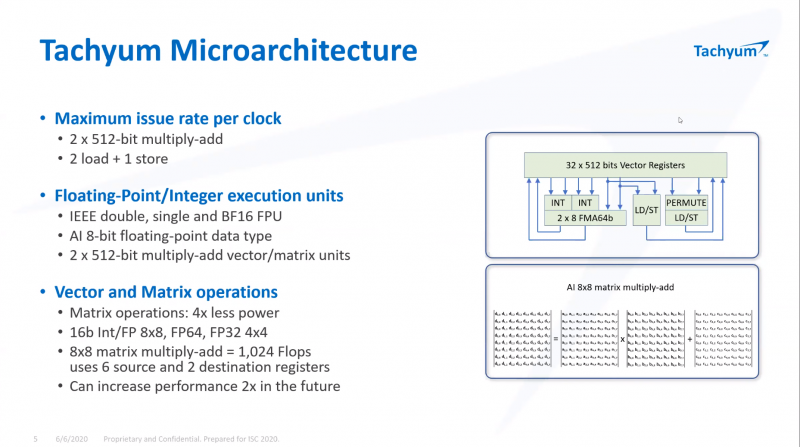 Столь громкие анонсы в истории вычислительной техники часто заканчивались «на бумаге», но Tachyum действительно работает над реализацией Prodigy. Как это обычно бывает, новая процессорная архитектура отрабатывается разработчиками с помощью эмуляции — как чисто программной, так и базирующейся на мощных ПЛИС. Это позволяет понять возможности и особенности поведения архитектуры, пусть и работающей с меньшей производительностью.  В начале декабря Tachyum объявила об открытии предзаказов на ПЛИС-эмулятор Prodigy, позволяющий начать разработку программного обеспечения для будущих систем на базе нового процессора уже сейчас. Поставки должны начаться в первом квартале 2021 года. В середине месяца Tachyum анонсировала и возможность заказа программного эмулятора Prodigy. Главная ценность такого эмулятора — более низкая стоимость в сравнении с вариантом на базе ПЛИС. Любой процессор неработоспособен без сопутствующего системного программного обеспечения — BIOS или, что сейчас встречается намного чаще, UEFI. В начале месяца Tachyum объявила о том, что передаст OEM и ODM-партнёрам UEFI, разработанное для новой архитектуры. При этом ПО будет поставляться не только в бинарном виде, разработчики получат и исходные коды. 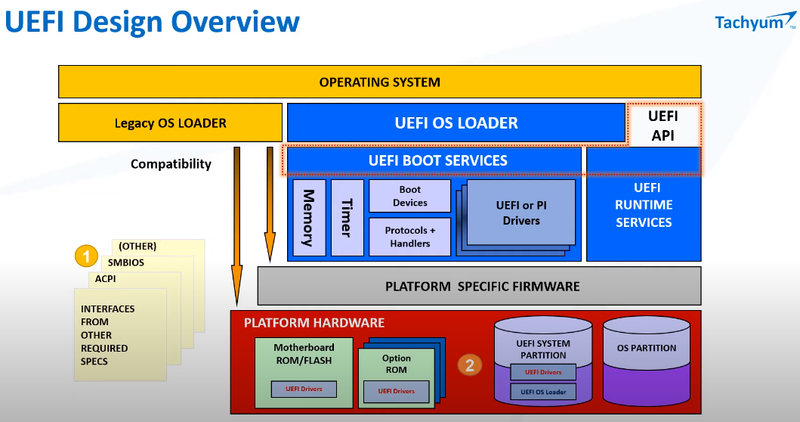 К настоящему времени, таким образом, компания предлагает программные и ПЛИС-эмуляторы нового процессора, и сопутствующее программное обеспечение. К чести Tachym, разработан не только UEFI — имеется и ядро Linux с поддержкой новой архитектуры, набор средств разработки, включая компиляторы (в том числе, для ИИ-задач) и отладчики кода. Успешно продемонстрирована возможность работы на Prodigy бинарного кода, созданного для архитектур x86, ARM и RISC-V. Первые чипы Prodigy должны появиться уже в следующем году. Если запуск будет успешным, Tachym может сильно изменить привычную картину мира в сфере HPC и ИИ, ведь новая архитектура обещает быть производительнее классических Xeon и EPYC при на порядок более низком энергопотреблении, втрое более низкой стоимостью в пересчёте на MIPS, и вчетверо более низкой стоимостью владения. Более того, Prodigy угрожает даже ускорителям, обеспечивая сравнимый или более высокий уровень производительности в задачах, где последние традиционно сильны, например, в системах машинного обучения. Остаётся лишь пожелать Tachyum удачи в столь смелом начинании.
13.11.2020 [18:00], Алексей Степин
Южная Корея близка к созданию собственного процессора для суперкомпьютеровМощные многоядерные процессоры, могущие служить основой суперкомпьютерных комплексов и кластерных систем могут разрабатывать, а тем более производить, не так уж много стран. Но любое государство, претендующее на независимость в IT, хорошо понимает, что в современном мире такая возможность может оказаться ключевой. Именно поэтому создан консорциум European Processor Initiative, именно для этого КНР, Япония и Россия разрабатывают свои многоядерные чипы. Теперь в игру вступает и Южная Корея. Концепция процессора для сферы супервычислений может отличаться кардинально: так, Европа и Япония предпочитают архитектуру ARM, Европа присматривается и к RISC-V, а Россия делает основную ставку на VLIW (семейство «Эльбрус»). Японские процессоры Fujitsu A64FX тоже основаны на ARM, но заметно отличаются от всех остальных чипов: набор инструкций SVE, HBM-память и встроенный интерконнект.  Южнокорейский институт электроники и телекоммуникаций (ETRI), ведущий свой проект совместно с ARM, объявил о том, что стал ещё на шаг ближе к созданию собственного уникального процессора класса HPC. Уникальность южнокорейской разработки в том, что она должна обеспечивать как высокую производительность в традиционных суперкомпьютерных задачах, обычно использующих вычисления двойной точности (FP64), так и невысокий уровень энергопотребления в «низкоточных» задачах (инференс, машинное обучение и тому подобные сценарии). 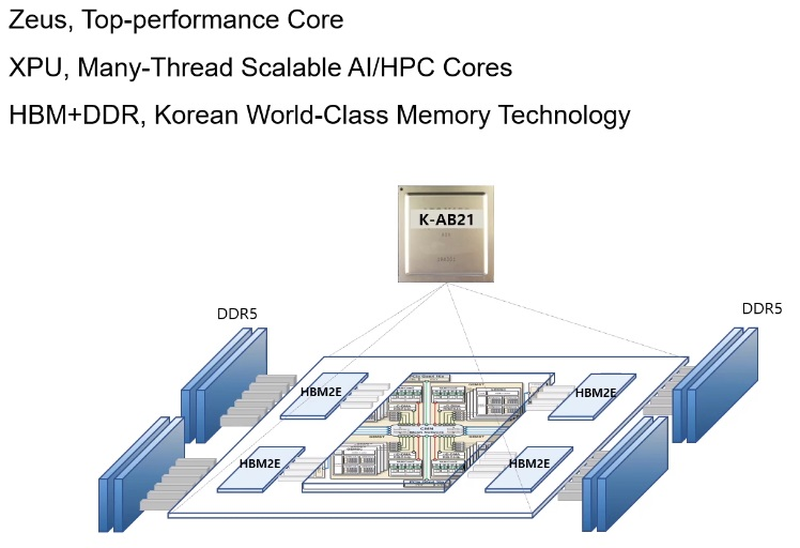 Спецификации, поставленные перед южнокорейскими разработчиками, довольно серьёзны: финальный вариант процессора должен обеспечивать 2,5-кратное превосходство над классическими ускорителями (обычно на базе графических чипов), но при этом быть на 60% экономичнее них. Это должно достигаться за счёт уникальной реализации управления питанием и тактовыми частотами отдельных компонентов процессора. Речь идёт как об аппаратной составляющей, так и о разработке собственного программного стека, позволяющего тонко манипулировать режимами работы нового ЦП. Заявлена возможность интеграции собственных блоков ускорителей, совместимых с уже существующими фреймворками за счёт поддержки OpenMP и OpenCL. Процессор в полной мере сохранит классический режим вычислений с двойной точностью. Текущий прототип получил название K-AB21, причём AB означает «Artificial Brain» (искусственный мозг) — разработчики заявляют, что за счет активного использования матричных ядер (XPU) им удалось достичь производительности 16 Тфлопс на процессор. Это обещает до 1600 Тфлопс на стойку. Процессор с такой производительностью должен открыть Южной Корее дорогу к собственным суперкомпьютерам экзафлопсного класса. 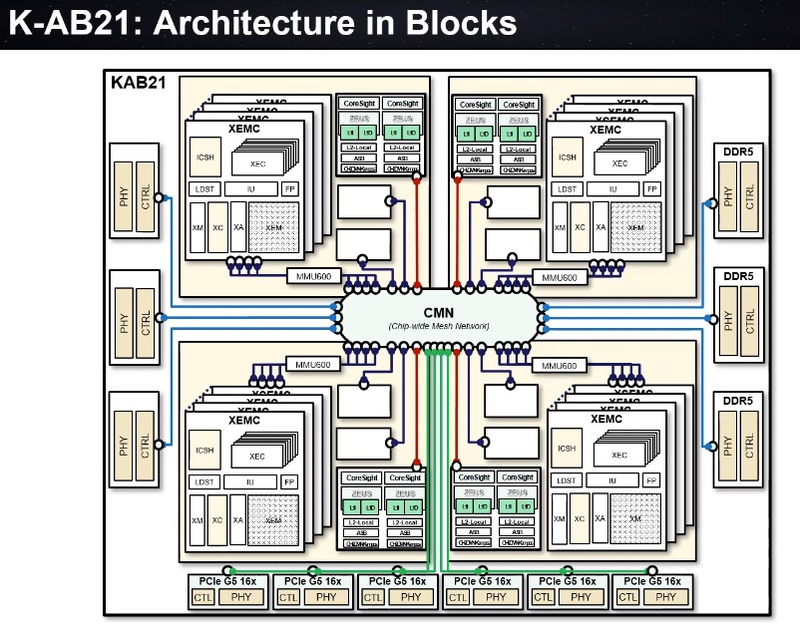 Компоновкой K-AB21 отчасти напоминает Fujitsu A64FX, поскольку также предусматривает наличие пула HBM2 в виде четырёх сборок, однако это не единственная его память. HBM выступает скорее в роли ещё одного уровня кеша, а основной объём составляют модули DDR5. Вычислительная часть состоит из классических ARM-ядер Zeus и многопоточных масштабируемых ядер XPU собственной разработки ETRI. Их-то разработчики и называют «матричными ядрами», поскольку работа с матричной математикой главная задача этих ядер. Группы таких ядер, называемые доменами XEMC на схеме (всего их в каждом процессоре 4), имеют свой MMU, а также собственные подсистемы кешей и программируемых блоков логики с поддержкой SMT. За соединение частей процессора между собой отвечает внутренняя сеть с ячеистой (mesh) топологией. Текущая реализация K-AB21 также включает в себя шесть контроллеров шины PCI Express 5.0, каждый на 16 линий. В настоящее время разработчики заняты финализацией отдельных элементов дизайна K-AB21, но в целом разработка близка к завершению. Полноценная реализация «в кремнии» ожидается к концу 2021 года, что для проекта такого масштаба достаточно быстро и позволит Южной Корее вовремя войти в эру суперкомпьютеров экза-класса. В настоящее время самым мощным южнокорейским кластером является Nurion, занимающий 17 место в Top500. Однако это система Cray CS500 на базе Intel Xeon Phi 7250, которая целиком базируется на технологиях США, а выпуск собственного HPC-процессора позволит Южной Корее стать более независимой в этом аспекте.
23.09.2020 [16:00], Алексей Степин
Intel представила новые 10-нм индустриальные процессоры: от Atom x6000E до Core i7 Tiger LakeНа мероприятии Intel Industrial Summit компания показала новые решения для периферийных вычислений и промышленных систем: платформу Atom x6000E, а также новые процессоры Pentium и Celeron серий N/J и индустриальные версии Core i3/i5/i7 11-го поколения известного как Tiger Lake. Для x6000E, Pentium и Celeron используется классический, «старый» 10 нм, а кристаллы Tiger Lake производятся с использованием «нового» 10 нм, так называемого SuperFIN. Платформа Intel Atom x6000E (Elkhart Lake) универсальна и позволяет решать широкий круг задач. Она может применяться в производящей промышленности и энергетике, в системах управления «умного города», в здравоохранении и медицине и во многих других отраслях, где требуется обработка достаточно серьёзных входных потоков данных в реальном времени. При этом платформа отвечает самым строгим требованиям безопасности.  По сравнению с предыдущими процессорами Atom аналогичного назначения в серии x6000E однопоточная производительность возросла в 1,7 раза, многопоточная — в 1,5 раза, а производительность графической подсистемы вдвое. Для повышенной временной точности в новинках реализована поддержка технологий Intel Time Coordinated Computing (TCC) и Time-Sensitive Networking (TSN).  Как и полагается современной SoC для периферийных вычислений, в составе x6000E имеются блоки критографических ускорителей, а для IoT имеется интегрированный микроконтроллер ARM Cortex-M7, отвечающий за работу Intel Programmable Services Engine (Intel PSE). Он работает независимо от остальных блоков и предоставляет возможности удалённого управления SoC, обработки низкоскоростного ввода-вывода от различных сенсоров, запуск приложений реального времени и синхронизацию. Есть также и чисто аппаратные средства обеспечения ИТ-безопасности, объединённые под именем Intel Safety Island. 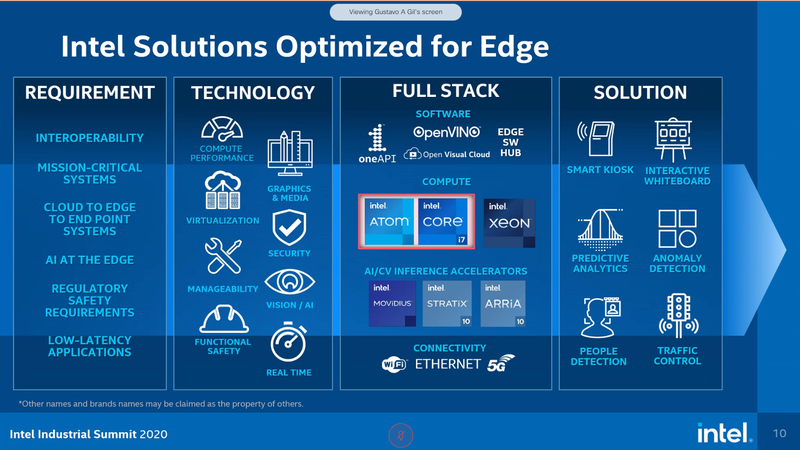 Также в целях обеспечения надёжности реализован широкий спектр средств удалённого мониторинга и управления, как в режиме in-band, так и в out-of-band. Включение, выключение, сброс и перезагрузку можно выполнять даже если система в целом не отвечает. Модели Atom x6427FE и x6200FE отвечают стандартам функциональной безопасности IEC 61508 и ISO 13849, они прошли соответствующую сертификацию, так что использовать их можно и в системах жизнеобеспечения, в комплексах управления АЭС или нефтеперабатывающего предприятия. 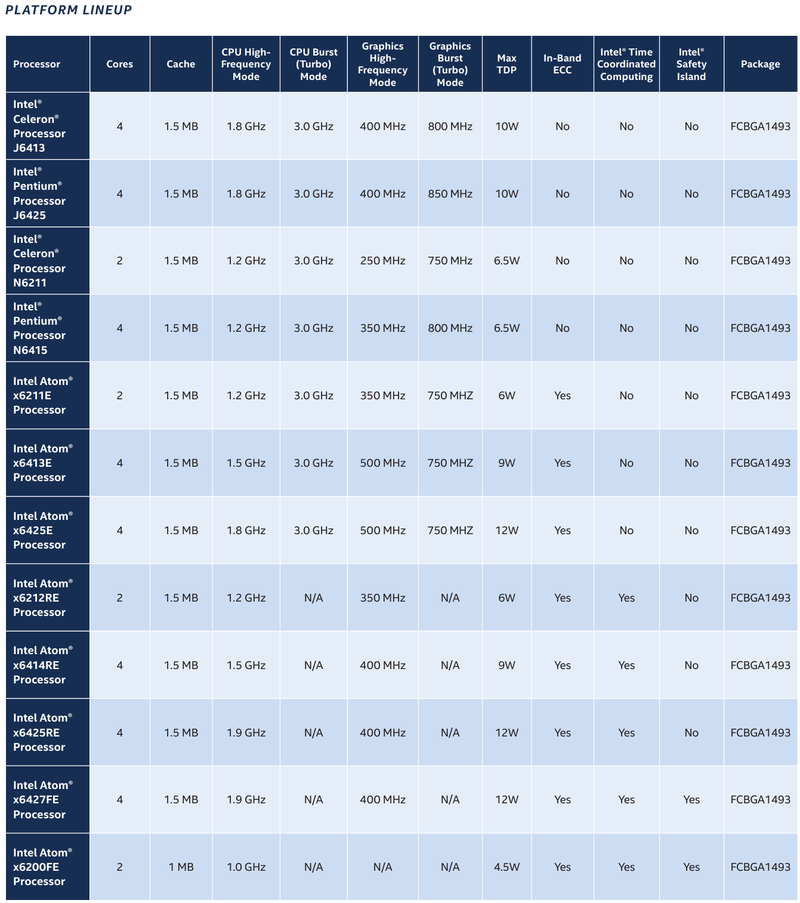 Серия Intel Atom x6000E включает в себя процессоры с двумя или четырьмя ядрами, их частотный диапазон составляет от 1,0 до 1,9 ГГц, в турборежиме частота может временно увеличиваться до 3,0 ГГц. Аналогичные частотные формулы имеют и Pentium/Celeron, базирующиеся на ядрах Tiger Lake (11 поколение). Контроллер памяти может работать либо с LPDDR4x (4×32 бита, максимум 4267 Мт/с, 16 Гбайт при 3200 МГц, всего до 64 Гбайт) или DDR4 (2×64 бита, 3200 Мт/с, максимум 32 Гбайт, всего до 64 Гбайт), есть поддержка in-band ECC для обычных модулей без ECC. Объём кеша составляет 1 Мбайт у самой младшей модели, во всех остальных случаях он равен 1,5 Мбайт. 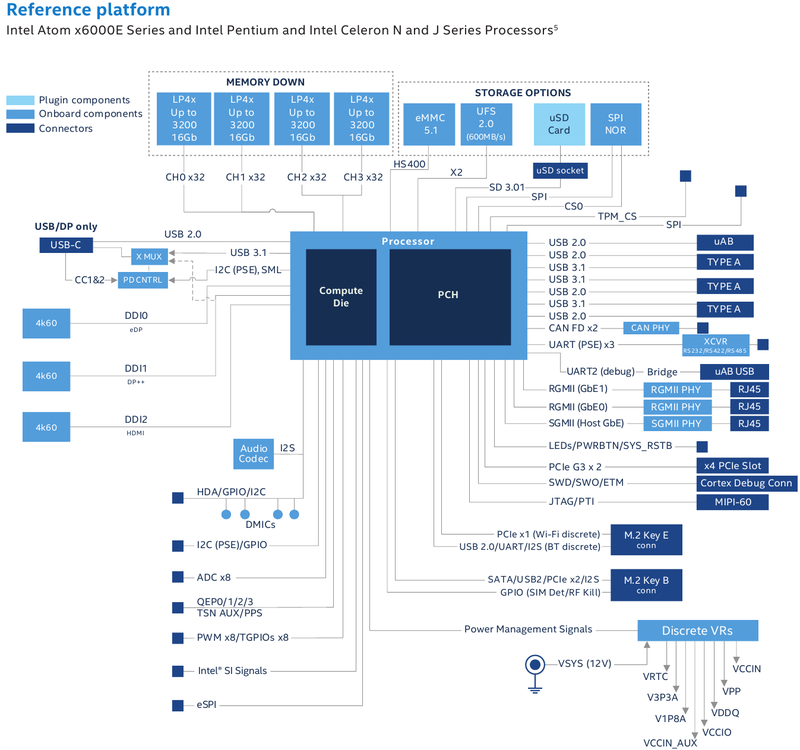 В соответствии с современными требованиями к графике, новинки Atom поддерживают подключение до трёх независимых дисплеев с разрешением 4K при 60 Гц, для этого служат интерфейсы Display Port 1.3 и HDMI 2.0b. Также поддерживается подключение экранов по eDP или MIPI DSI. Сам графический движок Intel UHD Graphics может иметь конфигурацию с 16 или 32 исполнительными блоками, работающими на частоте до 400 МГц, а в турборежиме — и до 800 МГц. Они поддерживают различные режимы вычислений для работы в качестве инференс-системы. Новые SoC Intel выполнены в едином корпусе FCBGA1493, однако под крышкой скрываются два кристалла — вычислительный и PCH. 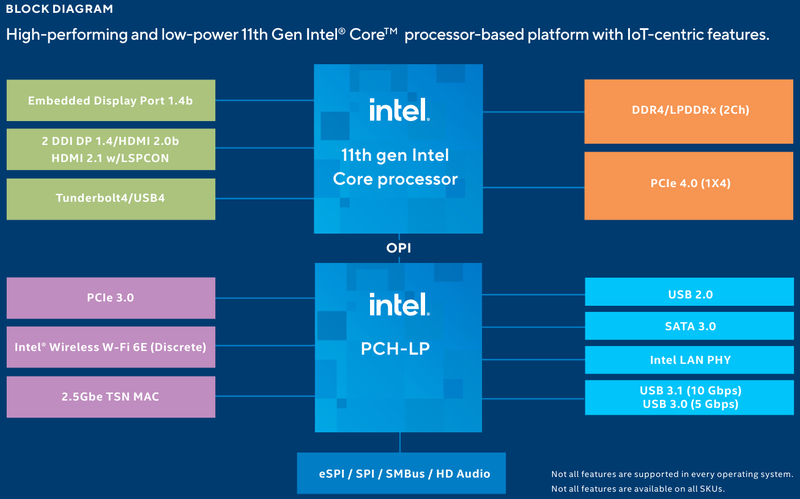 У более мощных процессоров с ядрами Tiger Lake графика тоже намного мощнее, она представлена блоками Iris Xe, которых в составе чипа может быть до 96, к тому же новая графическая архитектура лучше подходит для систем принятия решений (инференс) и задач машинного зрения. Такая графическая подсистема может одновременно обрабатывать до 40 потоков видео в формате 1080p при 30 кадрах в секунду, а выводить — либо четыре потока 4K, либо два, но уже в 8K. Подобные мощности позволяют использовать Tiger Lake в системах, для которых требуется детерминированная, строго синхронизированная по времени работа, либо в гибких системах машинного зрения с ИИ-компонентами. Безопасности способствует возможность полного шифрования содержимого оперативной памяти. 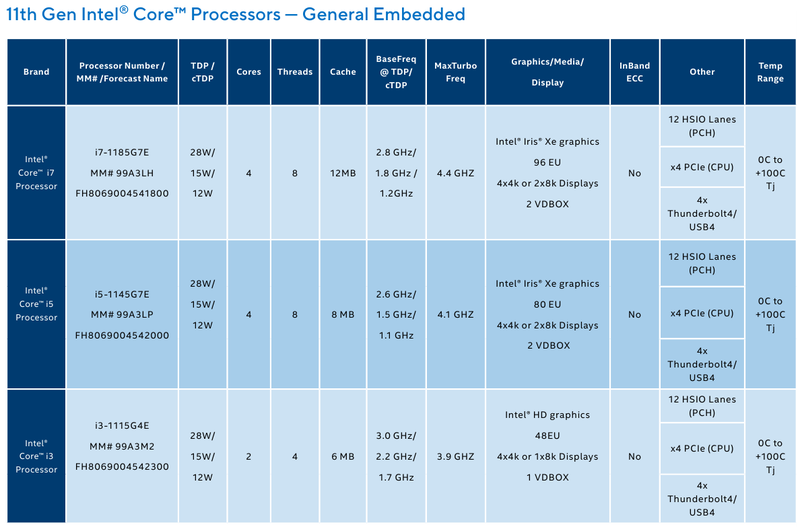 Коммуникационные возможности новых промышленных процессоров Intel также соответствуют требованиям времени: новые SoC несут на борту три MAC-контроллера, способных работать на скорости 2,5 Гбит/с, причём, в моделях с поддержкой TSN обеспечивается режим реального времени с минимальными задержками. Также общение «с внешним миром» происходит посредством 8 линий PCI Express 3.0, четырех портов USB 3.1 и 10 портов USB 2.0. Имеется два порта для подключения флеш-накопителей с интерфейсом UFS 2.0. В референсной платформе Intel реализована и поддержка UART и JTAG (разъём MIPI-60). 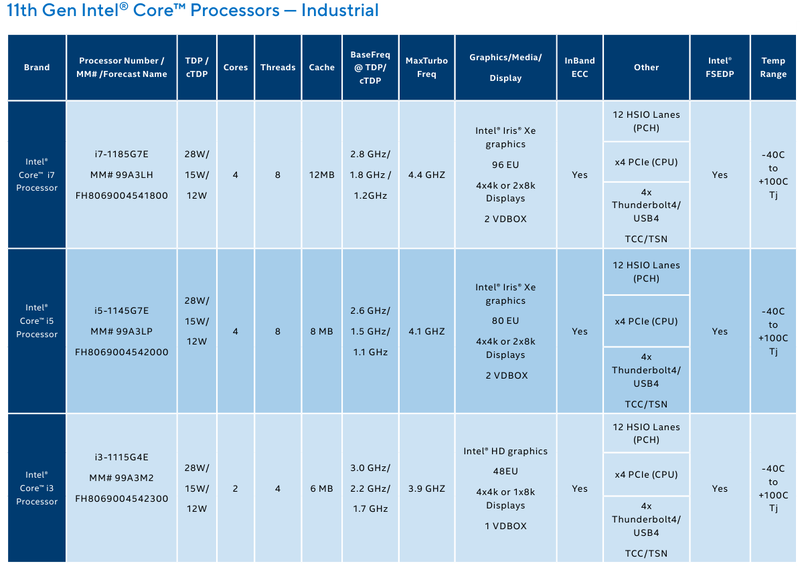 У более мощных Tiger Lake из серий i3/i5/i7 возможности несколько иные: встроенных MAC два, один из которых работает в режиме 1GbE, другой поддерживает cкорость 2,5GbE, в некоторых моделях дополнен поддержкой Time-Sensitive Networking. Поддерживается подключение дискретного сетевого контроллера I225LM/IT. Что касается беспроводной части, то имеется поддержка Wi-Fi со скоростями до 1,73 Гбит/с, а также Bluetooth 5.0. Для расширения инференс-способностей поддерживается подключение дополнительного ускорителя Intel из серии Movidius. Также реализованы стандарты PCIe 4.0 (четыре линии) и Thunderbolt/USB 4 (четыре порта).  Теплопакеты достаточно скромные: от 4,5 до 12 Ватт у Atom, до 28 Ватт у Tiger Lake. Улучшенный техпроцесс позволяет последним быть существенно быстрее аналогичных Core 8 поколения, в зависимости от характера нагрузки это до 23% (однопоточная) или до 19% (многопоточная), а графическая подсистема и вовсе практически в три раза быстрее за счёт новой архитектуры.  Новые процессоры имеют широкий спектр программной поддержки. В первую очередь, это, естественно, Microsoft Windows 10 IoT Enterprise и Yocto Project Linux, разрабатываемая сообществом Yocto совместно с Intel. Поддерживается также запуск Ubuntu, Wind River Linux LTS и Android 10 (только 64-битная версия). Для Tiger Lake также заявлена совместимость с Wind River VxWorks. 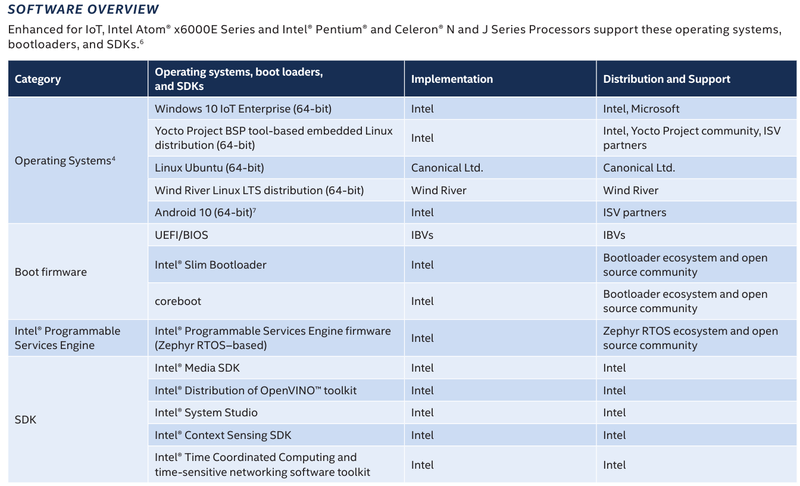 В качестве загрузчика может использоваться как обычный BIOS/UEFI, так и открытые Intel Slim Bootloader и coreboot. Часть, отвечающая за подсистемы безопасности и реального времени, работает под управлением Zephyr RTOS, также открытой. В число партнёров Intel, отвечающих за код BIOS, входят American Metatrends, Thundersoft, Byosoft, Insyde и Phoenix. 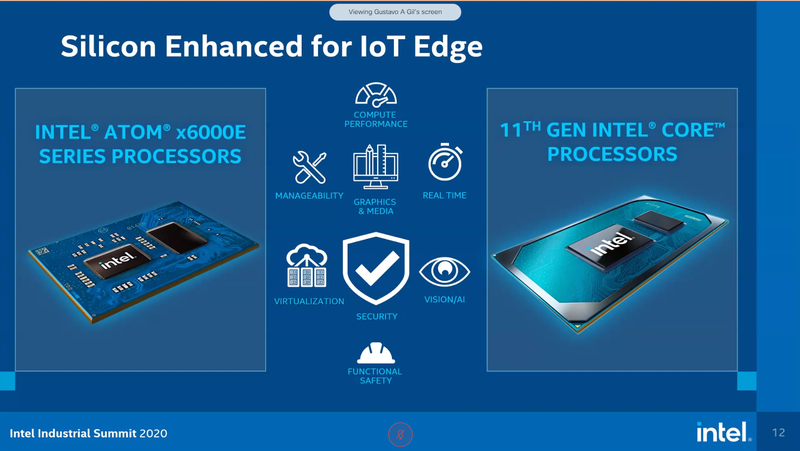 Для создания ПО компания предлагает расширенный комплект разработчика: инструменты для реализации Time Coordinated Computing, Intel Media SDK, набор Intel для OpenVINO, Intel System Studio и Intel Context Sensing SDK. Intel понимает всю важность рынка периферийных вычислений, за которым, судя по всему, будущее промышленности: любая производственная задача будет неизбежно порождать серьёзные потоки данных и требовать от системы управления минимальных задержек. Именно поэтому периферийные вычислительные устройства, к которым относятся и новые процессоры Intel, столь важны. Неудивительно, что компания уделяет много внимания как аппаратным возможностям, так и программным компонентам в новой платформе. |
|
