Материалы по тегу: cpu
|
22.09.2020 [20:32], Игорь Осколков
От периферии до облаков: Arm представила серверные платформы Neoverse V1 Zeus и N2 Perseus с поддержкой SVE, PCIe 5.0, DDR5 и HBMКомпания Arm объявила о расширении своего портфолио серверных решений семейства Neoverse, представив сразу два варианта платформы. Новая серия V и её первенец V1 под кодовым именем Zeus вместе с N2 (Perseus) получат поддержку SIMD-расширений SVE и формата bfloat16, а также интерфейсы PCIe 5.0, DDR5 и HBM. Однако отличия между ними весьма существенны. В Neoverse V1 в отличие от N2 Arm отказывается от традиционной оптимизации сразу по трём направлениям — энергопотребление, производительность и площадь кристалла — и делает упор на мощность. Вероятно, основой для них станут вариации Cortex-X1. Эти чипы будут потреблять больше энергии и будут физически больше, но взамен предложат значительное увеличение размеров буферов, кешей, окон и очередей. Показатель IPC для одного потока будет увеличен на впечатляющие 50% в сравнении с Neoverse N1. 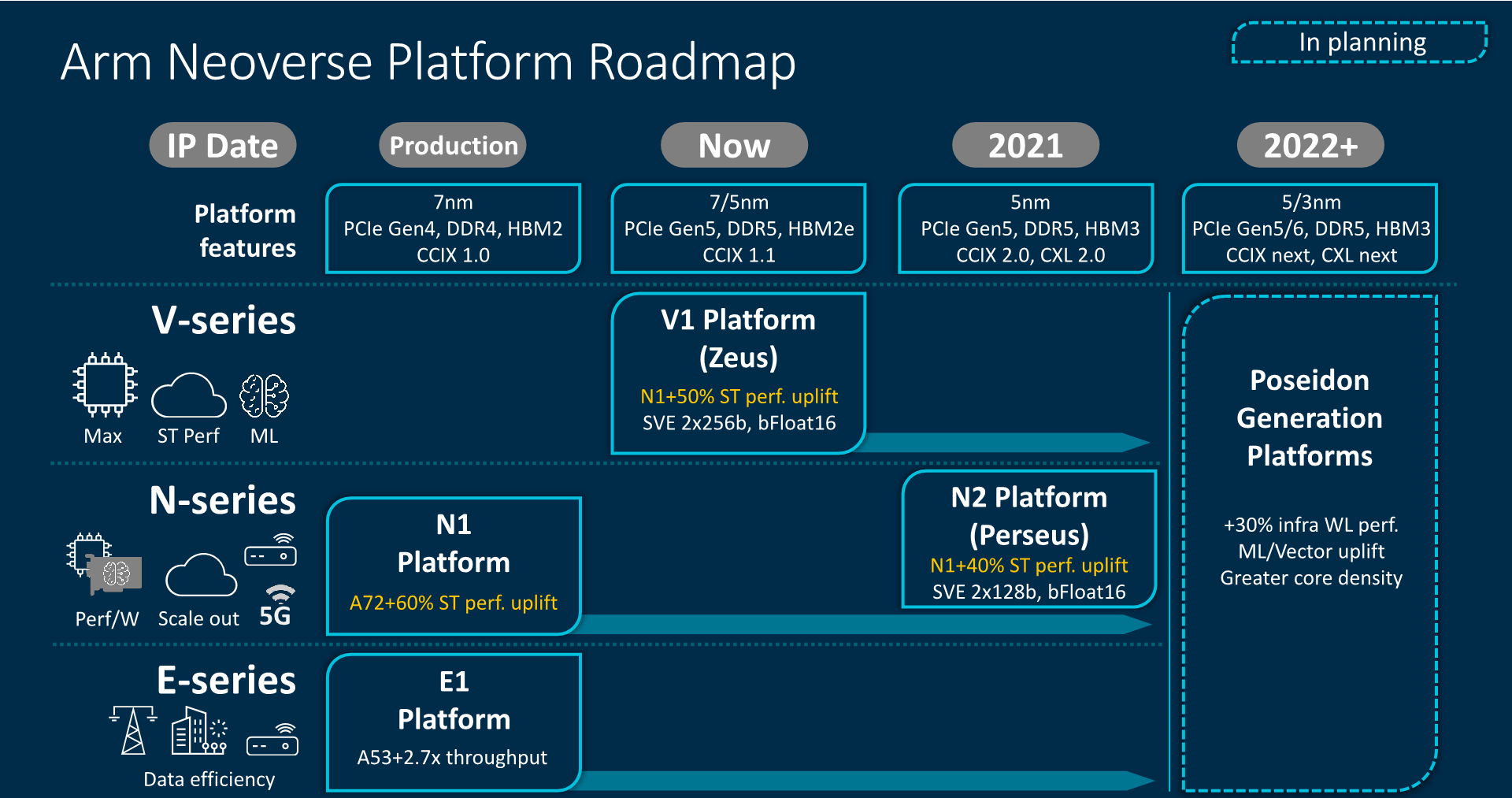 А новые техпроцессы 5 и 7 нм позволят повысить частоты будущих процессоров. Так что они потенциально смогут соревноваться с грядущими платформами x86-64 не только по показателю производительность на Ватт, но и в чистой производительности. Поспособствует этому и долгожданное официальное появление векторных инструкций Scalable Vector Extension (SVE) в составе самого ядра. Их отличительной чертой (от SSE/AVX) является нефиксированная ширина — производители конкретных SoC могут реализовать поддержку от 128 до 2048 бит с шагом в 128 бит. При этом SVE-код будет работать на любом из них, просто скорость обработки данных будет разной. 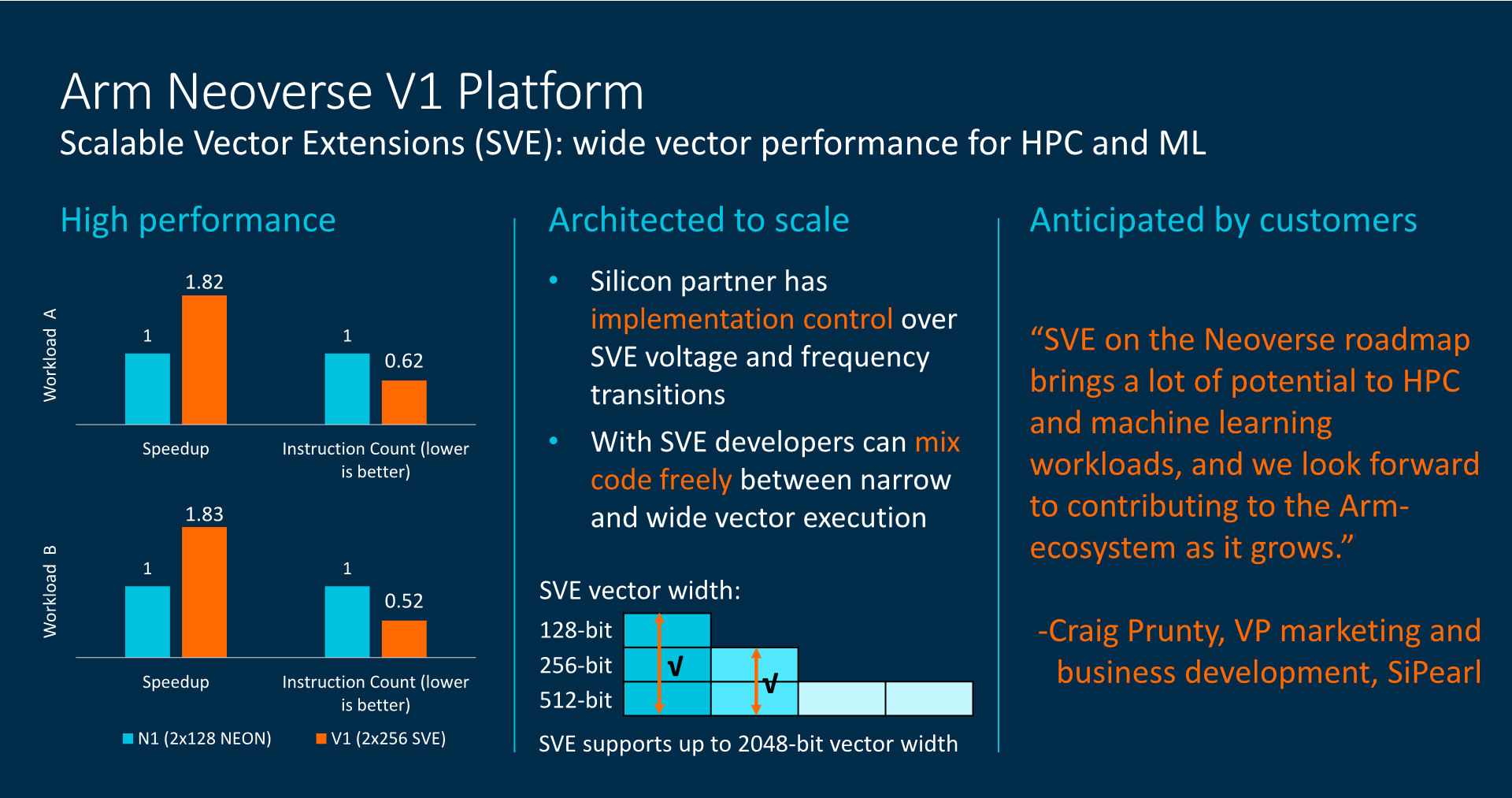 Конкретно в V1 Arm заложила два блока SVE-256. Это явно хуже пары SVE-512 в Fujitsu A64FX, единственном «кремнии», который уже поддерживает новые инструкции, но всё равно в два раза лучше, чем у N1 с двумя «старыми» 128-бит NEON. Так что мы вполне можем увидеть в будущем ориентированные на высокопроизводительные вычисления решения от других компаний. Этому поспособствует и поддержка памяти HBM2e. Опять-таки, в A64FX она была нужна именно для того, чтобы SVE-блоки не «голодали». Кроме того, обновлённые спецификации SVE включают и поддержку формата bfloat16, актуального для нейронных сетей. 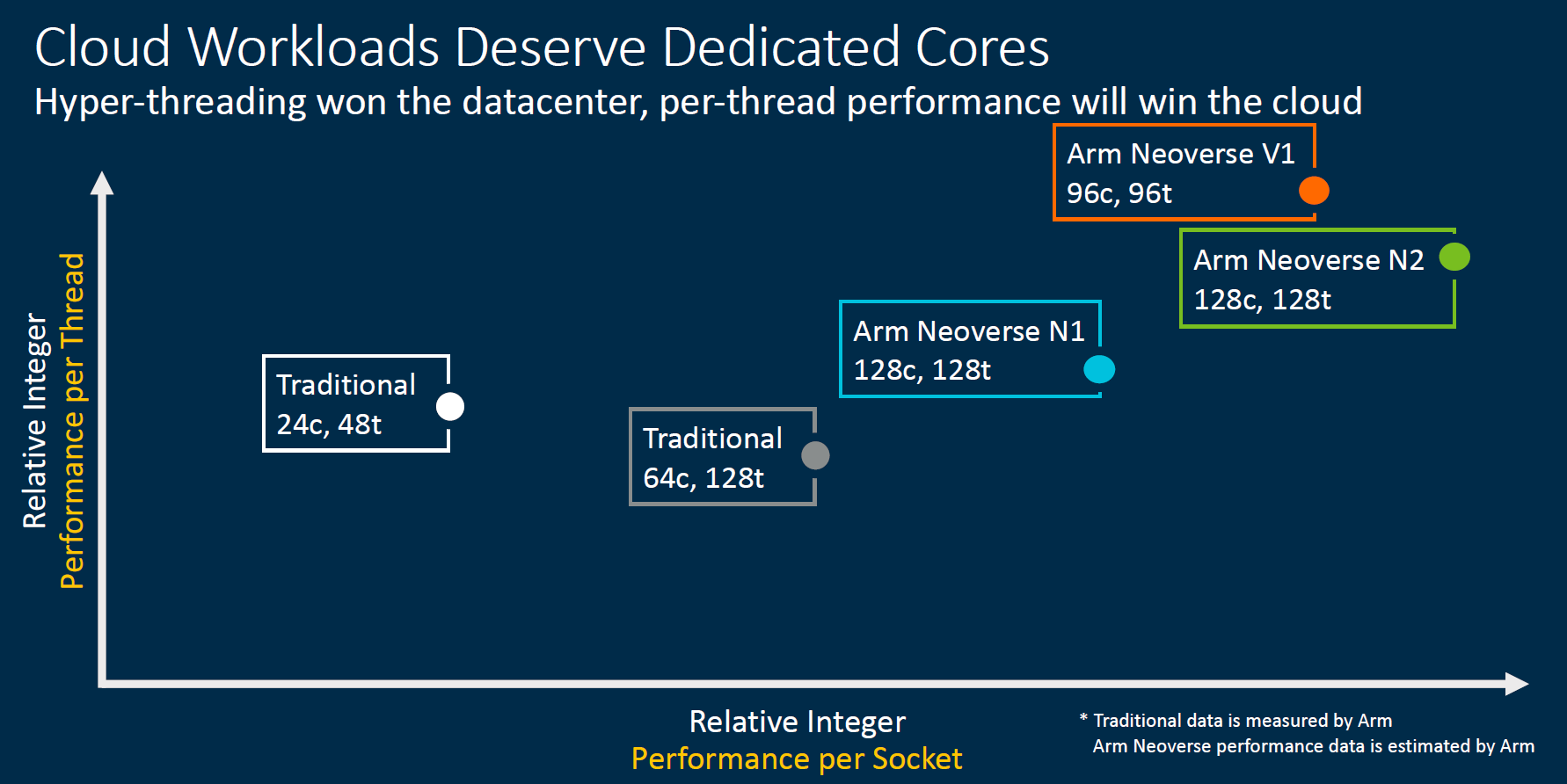 Arm Neoverse V1 формально доступен уже сейчас. Первыми процессорами на базе этой архитектуры должны стать 72-ядерные SiPearl Rhea, которые вместе с другими чипами, уже на базе открытой архитектуры RISC-V, лягут в основу будущих европейских суперкомпьютеров. Таким образом Евросоюз надеется получить большую независимость от технологий США. Впрочем, объявленная сделка между NVIDIA и Arm может расстроить эти планы. Следующим крупным лицензиатом V1 может стать Ampere, которая готовится выпустить в 2022 году процессоры Siryn. 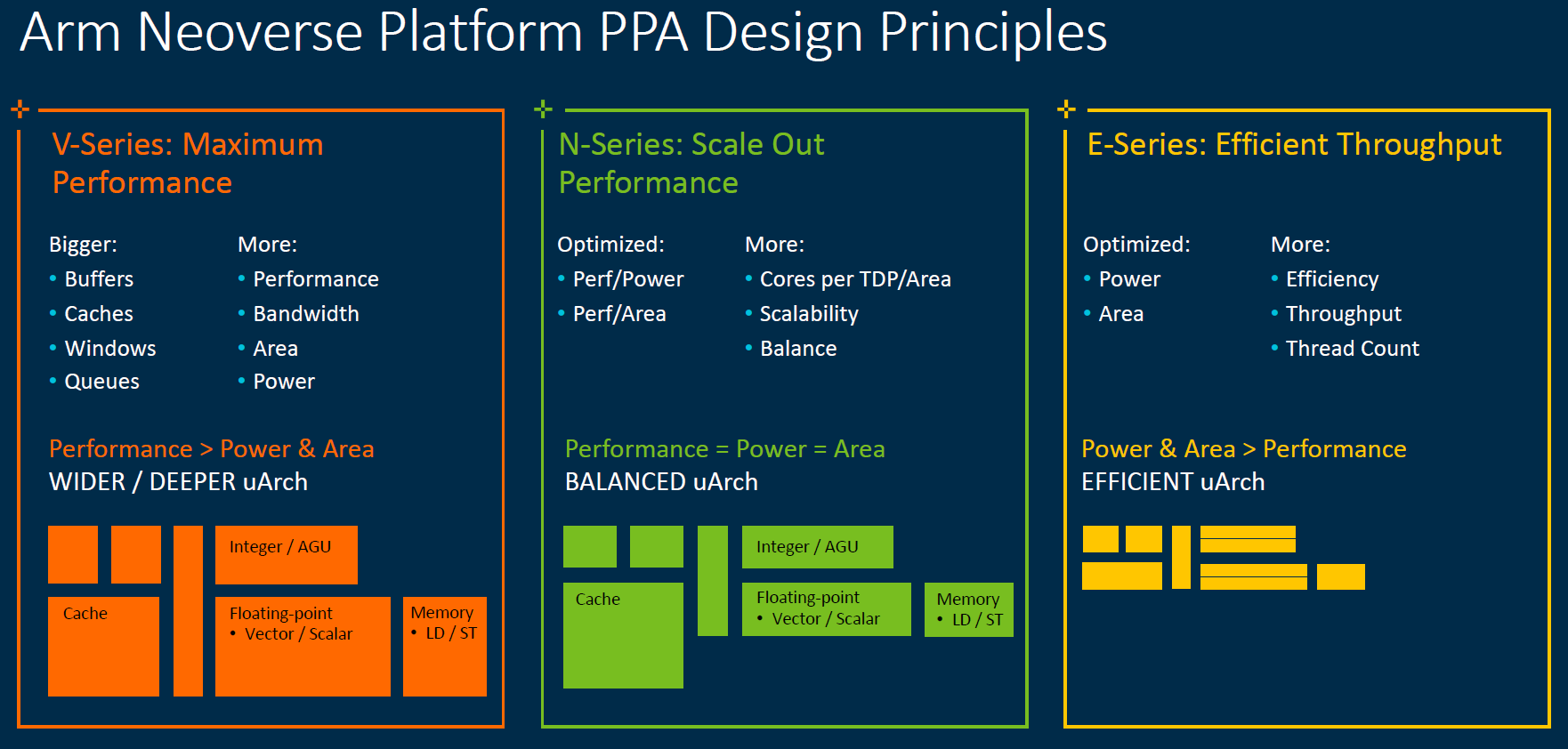 Что касается архитектуры Neoverse N2, то она появятся уже в следующем году, а лицензирование начнётся в конце этого. Она также получит поддержку SVE и bfloat16, но в виде двух 128-бит блоков. Будет внедрена поддержка HBM3, CXL 2.0 и CCIX 2.0. В N2 Arm придерживается своего традиционного подхода, так что прирост IPC в однопотоке составит «всего лишь» до 40% в сравнении с N1, но при этом сохранятся те же уровень энергопотребления и площадь ядра. Можно предположить, что основной для неё станет Cortex-A78. 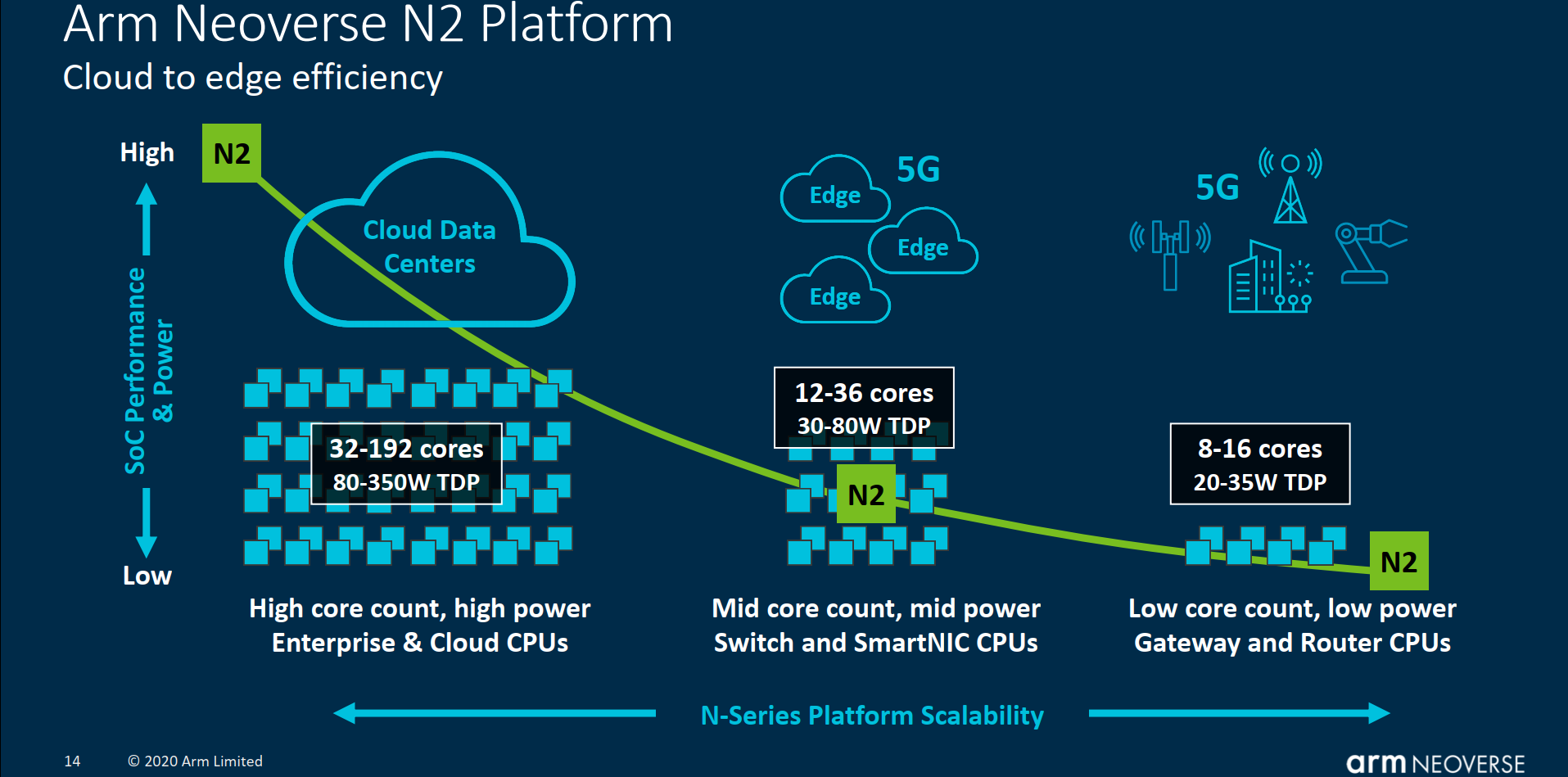 Именно N2 должна стать наиболее массовой платформой благодаря масштабируемости. Arm видит различные варианты дизайнов будущих SoC. От 8 до 16 ядер с TDP 20-35 Вт пойдут в экономичные решения на самой границе сети, варианты на 12-36 ядер с TDP от 30 до 80 Вт могут стать основой периферийных вычислений, а сборки с числом ядер от 32 до 192 и с TDP от 80 до 350 Вт займут место в мощных серверах, включая облачные. Пока что единственным более-менее массовым решением на базе Neoverse N1 владеет Amazon — в мае в AWS появились инстансы на базе 64-ядерных Graviton2.  После 2022 года выйдет следующее поколение Neoverse под кодовым именем Poseidon. Про него пока говорится в общих чертах, что оно станет производительнее на 30%, получит улучшения по части векторных инструкций и машинного обучения, обзаведётся поддержкой будущих версий CCIX и CXL, а также предложит более плотную упаковку ядер.
18.08.2020 [22:16], Алексей Степин
Серверные ARM-процессоры Marvell ThunderX3: 60 ядер в SCM, 96 ядер в MCM, SMT4 в подарокПоследние дни оказались богатыми на анонсы новых процессоров. Компания IBM представила новейшие POWER10 с поддержкой памяти OMI DDR5 и PCI Express 5.0, Intel анонсировала Xeon Ice Lake-SP, которые, наконец, получили поддержку PCIe 4.0. Третьей в этом списке можно назвать Marvell, которая на мероприятии Hot Chips 32 рассказала подробности о последнем, третьем поколении ARM-процессоров ThunderX, формально анонсированном ещё весной этого года. 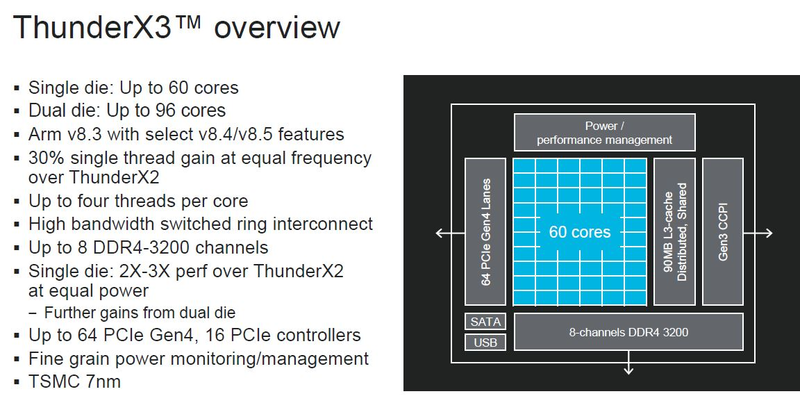
Источник изображений: ServeTheHome Процессоры с архитектурой ARM покорили сегмент мобильных устройств, но в последние несколько лет интереснее другая тенденция — данная архитектура ложится в основу всё новых и новых «крупных» процессоров, предназначенных для серверного применения. И как показывает практика, когда-то считавшаяся «слабой» архитектура оказывается вовсе не такой. 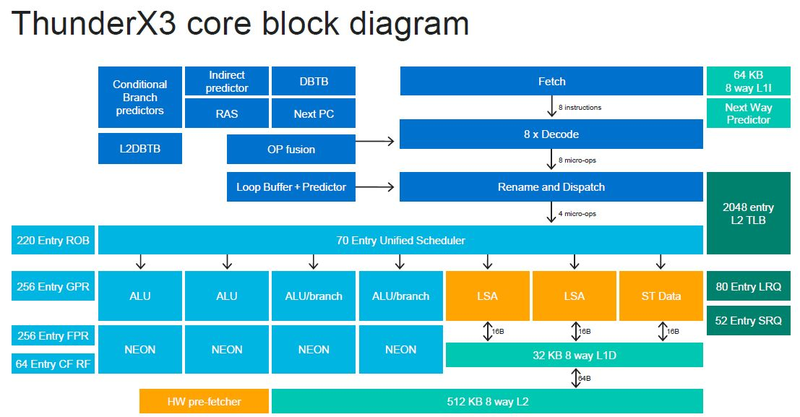 Она успешно соперничает с x86, особенно там, где необходима высокая плотность упаковки вычислительных мощностей и высокая энергоэффективность. Примеры AWS Graviton2 и кастомных процессоров Google тому доказательством, а разработка Fujitsu, процессор A64FX, и вовсе лежит в основе мощнейшего суперкомпьютера планеты, японского кластера Fugaku. 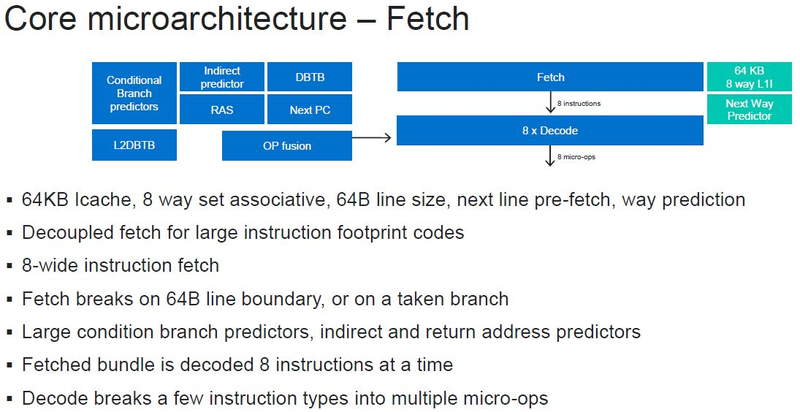 Одной из компаний, прилагающих серьёзные усилия к освоению серверного рынка с помощью архитектуры ARM, является Marvell. Если первые процессоры ThunderX, доставшиеся в наследство от Broadcom, сложно назвать успешным, то уже второе поколение показало себя неплохо, и, судя по всему, третье, наконец, готово к массовому внедрению. Напомним, в отличие от домашних проектов AWS и Google, процессоры ThunderX3 должны получить развитую поддержку многопоточности, на уровне SMT4, что больше, чем у x86, но меньше, чем у POWER10. 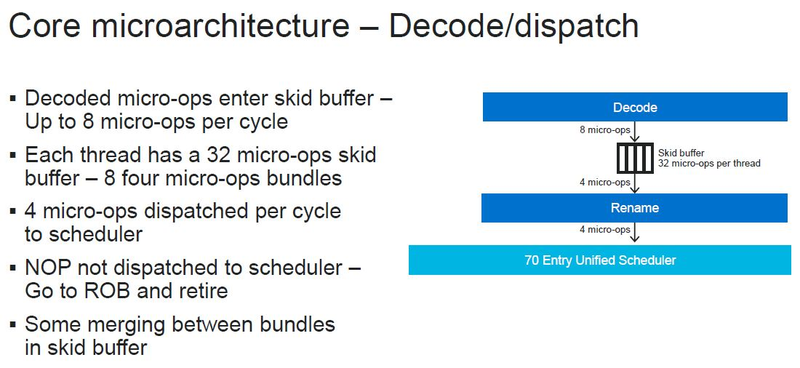 При этом максимальное количество ядер у ThunderX3 впечатляет. Теперь известно, что о 96 ядрах речь идёт только в двухкристалльной компоновке (этим подход Marvell напоминает IBM POWER10, также существующий в двух вариантах). Один кристалл может нести до 60 ядер, что меньше, чем у Graviton2, но, во-первых, ненамного, а во-вторых, с лихвой компенсируется наличием SMT. SMT4 может дать 240 или 384 потока в зависимости от версии, и наверняка это понравится крупным облачным провайдерам, поскольку позволит разместить беспрецедентное количество VM в рамках одного сокета. 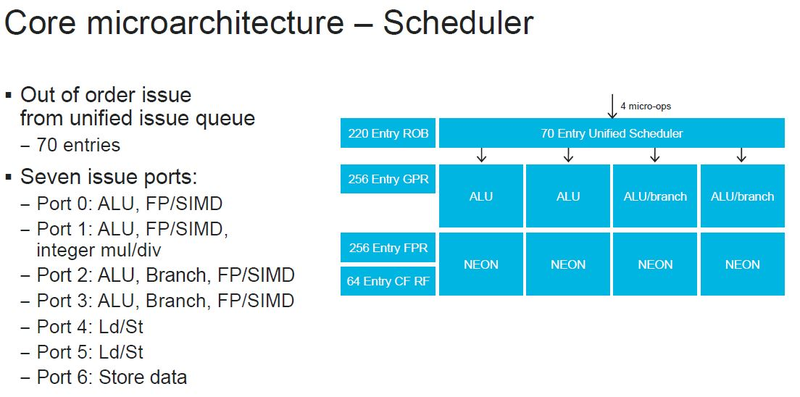 Однопоточная производительность не осталась без внимания. Компания заявила о 30% превосходстве над ThunderX2 в пересчёте на поток. В целом же, третье поколение ThunderX должно быть в 2-3 раза быстрее второго. Архитектурно процессор основывается на наборе инструкций ARM v8.3, однако сказано о частичной поддержке ARM v8.4/8.5. 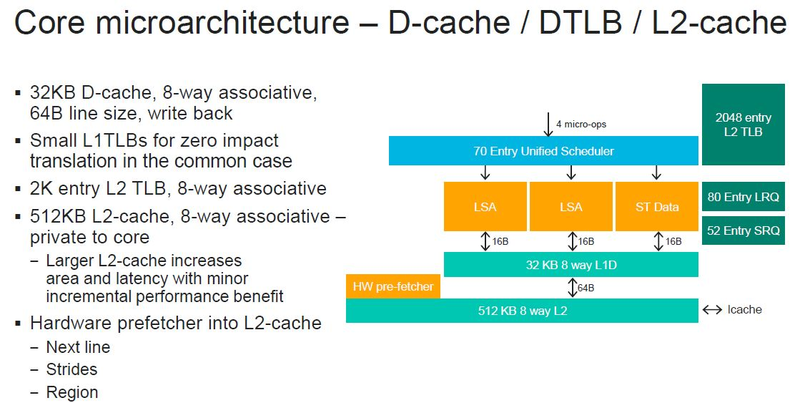 В споре о том, что эффективнее для связи ядер между собой, кольцевые шины или единая mesh-сеть, единого мнения нет. Intel предпочитает первый подход, но Marvell остановила свой выбор на втором. Как обычно, на внешнем кольце расположены кеш (80 Мбайт L3 на кристалл), блоки управление питанием, а также контроллеры памяти, PCI Express и межпроцессорной шины (в данном случае CCPI). 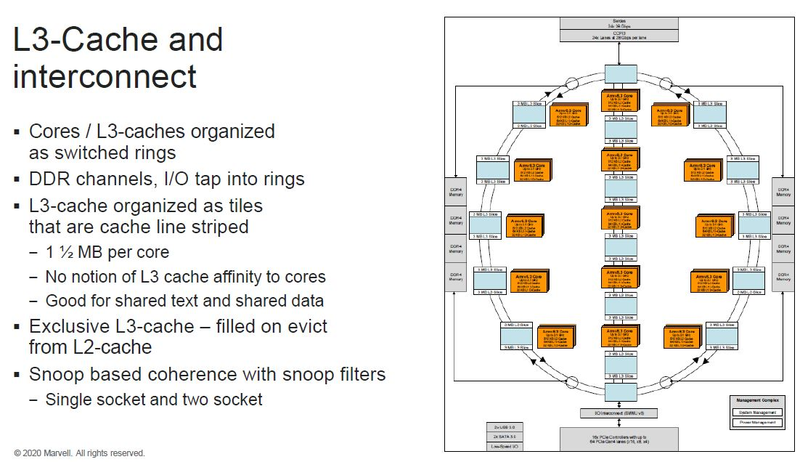 Поддержка SMT4 реализована полностью аппаратно. С точки зрения операционной системы каждый поток ThunderX3 выглядит, как обычный процессор с архитектурой ARM. При этом реализация столь развитой многопоточности привела всего лишь к 5% увеличению площади кристалла в сравнении с однопоточной реализацией.  Разделение ресурсов ядра у нового процессора динамическое, осуществляется оно в четырёх точках: выборка, когда потока с меньшим количеством инструкций получают более высокий приоритет; выполнение, работающее по такому же принципу; планирование, которое базируется на «возрасте» потока; наконец, «отставка» — здесь приоритет получают потоки с наибольшим количеством инструкций. Оптимизация многопоточности позволяет Marvell говорить о практически линейной масштабируемости новых процессоров, по крайней мере, в пределах одного разъёма. В зависимости от числа инструкций на ядро коэффициент прироста может варьироваться от x1,28 до 2,21. 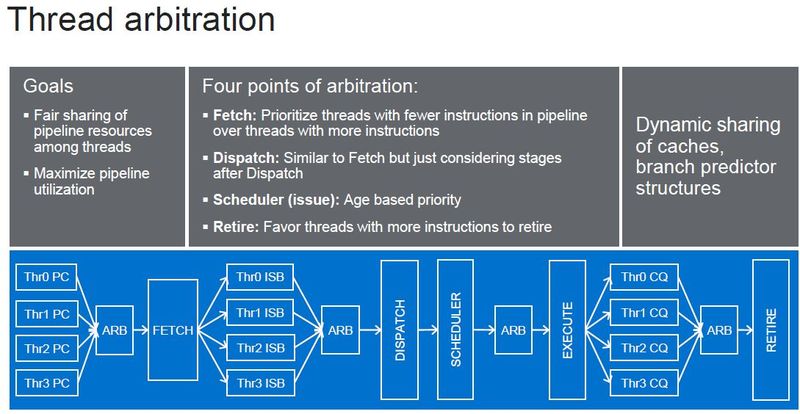 Подсистема ввода-вывода у новинок достаточно развитая. Контроллер памяти имеет 8 каналов и поддерживает DDR4-3200. За поддержку PCI Express отвечают 16 раздельных контроллеров, поддерживающих четвёртую версию стандарта. Это должно обеспечивать высокий уровень производительности при подключении 16 NVMe-накопителей, на каждый из которых придётся по четыре линии PCIe. 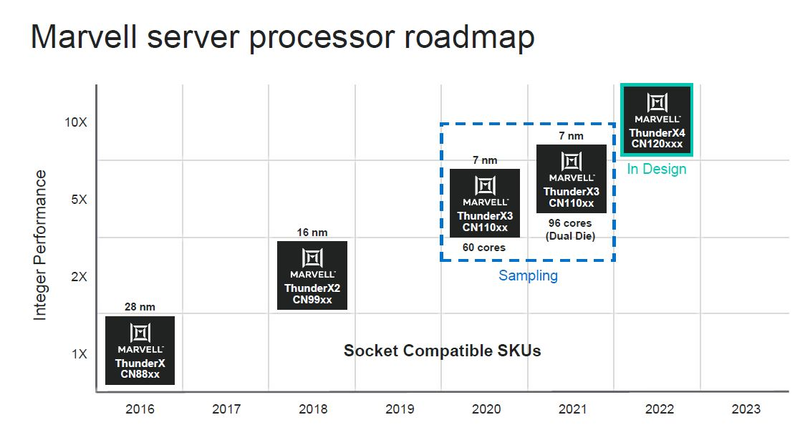 Заявлено о «тонком» управлении питанием, но деталей Marvell не приводит и остаётся только догадываться, насколько эта подсистема ThunderX3 продвинута. Производится новый процессор на мощностях TSMC с использованием техпроцесса 7 нм. Версия с одним 60-ядерным кристаллом выйдет на рынок уже в этом году, а вариант с двумя кристаллами и большим общим количеством ядер начнет поставляться позже, в 2021 году. Компания уже работает над ThunderX4, ожидается что эти процессоры будут использовать техпроцесс 5 нм и увидят свет в 2022 году.
17.08.2020 [15:32], Алексей Степин
Подробности о процессорах IBM POWER10: SMT8, OMI DDR5, PCIe 5.0 и PowerAXON 2.0Мы внимательно следим за судьбой и развитием архитектуры POWER, которая наряду с ARM представляет определённую угрозу для x86 в сфере серверов и суперкомпьютеров — недаром одна из самых мощных в мире HPC систем, суперкомпьютер Ок-Риджской национальной лаборатории Summit, использует процессоры POWER9. Ранее ожидалось что по ряду причин выход следующей в семействе архитектуры, POWER10, откладывается до 2021 года, хотя IBM и продвигала активно новые решения вроде универсального стандарта оперативной памяти OMI. Однако официальный анонс IBM POWER10 состоялся сегодня, а немецкий портал Hardwareluxx выложил слайды презентации компании.  Как компания уже отмечала ранее, она делает упор на большие системы и гибридные облака. С учётом этих тенденций и были разработаны новые процессоры. Поскольку в крупных облачных ЦОД упаковка вычислительных плотностей достигает уже невиданного ранее уровня, всё острее встаёт вопрос с энергоэффективностью и отводом тепла. Но именно здесь, как считает IBM, POWER10 и должен показать себя с наилучшей стороны — новые процессоры производятся с использованием 7-нм техпроцесса и могут демонстрировать трёхкратное преимущество в энергоэффективности в сравнении с POWER9. 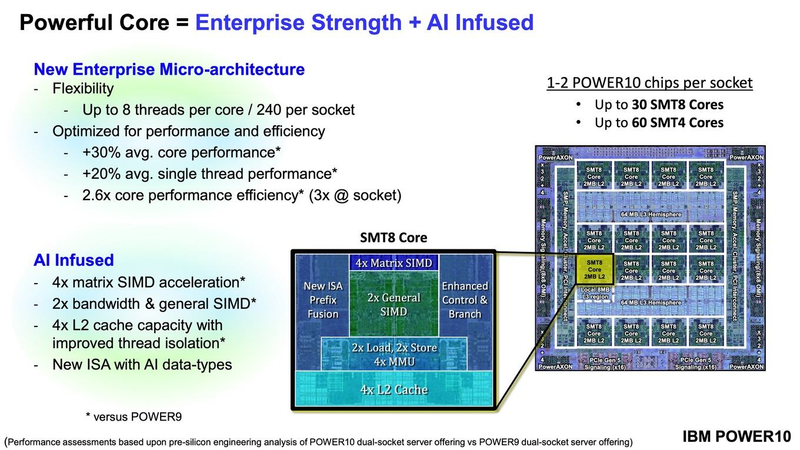 POWER10 — первый коммерческий процессор IBM, использующий нормы производства 7 нм; любопытно, что теперь Intel отстаёт не только от AMD, которая стала пионером в использовании столь тонкого техпроцесса в «крупных» серверных процессорах, но и от IBM. В отличие от AMD EPYC, производимых на мощностях TSMC, новинки IBM «куются» в полупроводниковых кузнях Samsung. Площадь кристалла, состоящего из 18 миллиардов транзисторов, у новых процессоров достигает 602 мм2, что меньше, чем у новейших графических ядер, но всё равно цифра довольно солидная. 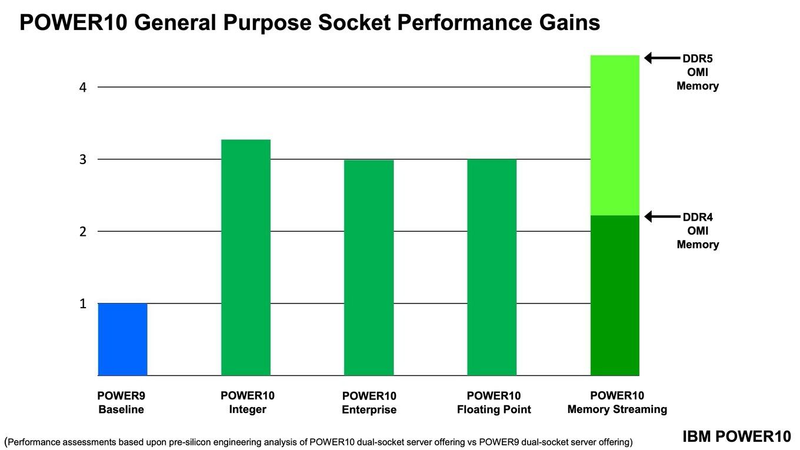 Техпроцесс POWER10 является совместной разработкой Samsung и IBM. В нём реализованы некие особенности, которые, предположительно, должны позитивно сказаться на характеристиках отдельных транзисторов. Не забыта и мода на установку нескольких кристаллов в один корпус: POWER10 доступны как в классическом варианте (SCM), так и в виде сборки из двух кристаллов (DCM), так что для каждого сценария использования можно выбрать подходящий вариант. В варианте SCM тактовая частота ядер составляет 4 ГГц, количество процессорных разъёмов в системе может достигать 16. В версии DCM частота снижена до 3,5 ГГц. 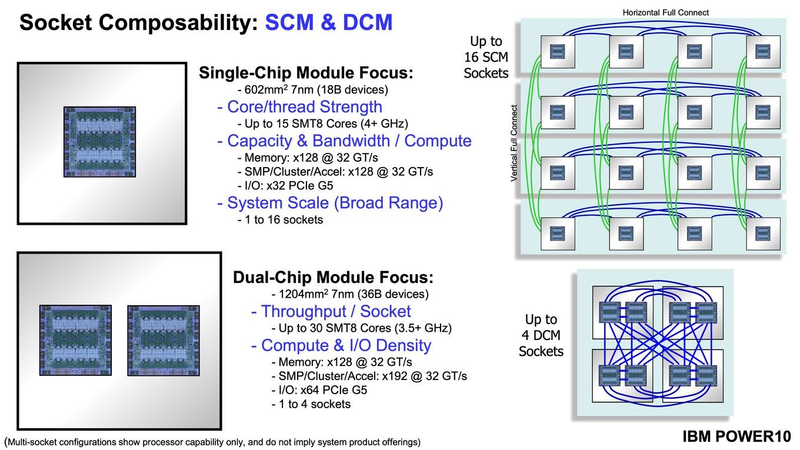 Базовый кристалл POWER10 имеет 16 вычислительных ядер, хотя используется из них только 15, каждое ядро дополнено 2 Мбайт кеша L2, а общий объём кеша L3 может достигать внушительных 120 Мбайт. Степень параллелизма была увеличена с SMT4 до SMT8, так что процессор может исполнять одновременно до 120 потоков, хотя, естественно, не в любой задаче такое распараллеливание ресурсов ядер будет эффективным. Производительность блоков SIMD была существенно увеличена, они вдвое быстрее аналогичных блоков POWER9, а на матричных операциях — быстрее в четыре раза. 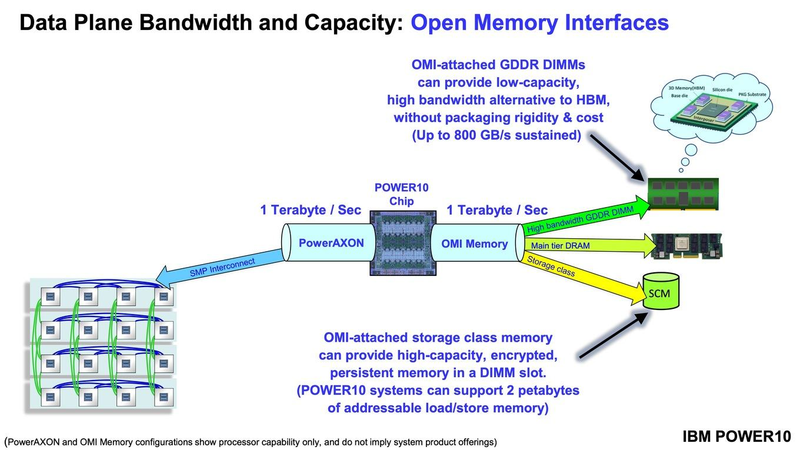 За общение процессора с «внешним миром» отвечают интерфейсы PowerAXON 2.0 и PCI Express 5.0, в первом случае поддерживается открытый стандарт OpenCAPI, во втором реализовано 64 линии со скоростью 32 ГТ/с на линию, как и предписано стандартом. Компоновка связей у DCM и SCM разная. В первом случае сокетов может быть только 4, зато используется топология «каждый с каждым», а вот в 16-сокетном варианте SCM «по диагонали» между собой процессоры напрямую не общаются. 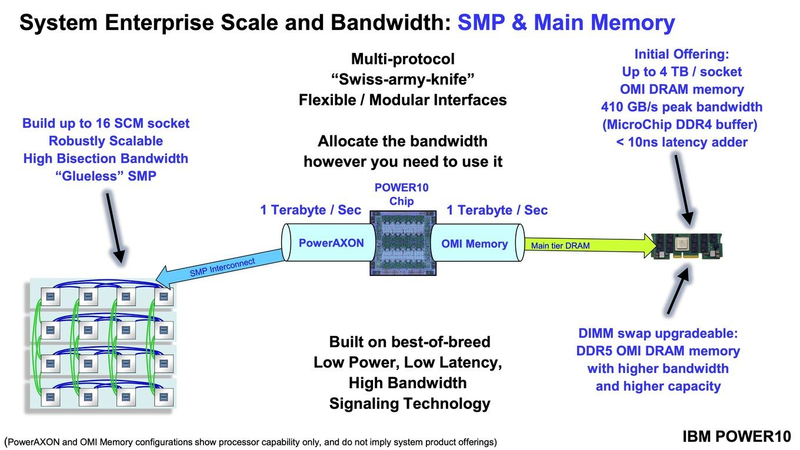 Интерфейс PowerAXON универсален, он использовался, в числе прочего, для реализации протокола NVLink для подключения ускорителей на базе графических процессоров NVIDIA. Проблем с пропускной способностью быть не должно, у каждого процессора в системе PowerAXON обеспечивает до 1 Тбайт/с. Кроме подключения ускорителей и общения процессоров между собой, у PowerAXON есть и ещё одно интересное и важное применение, о котором ниже. 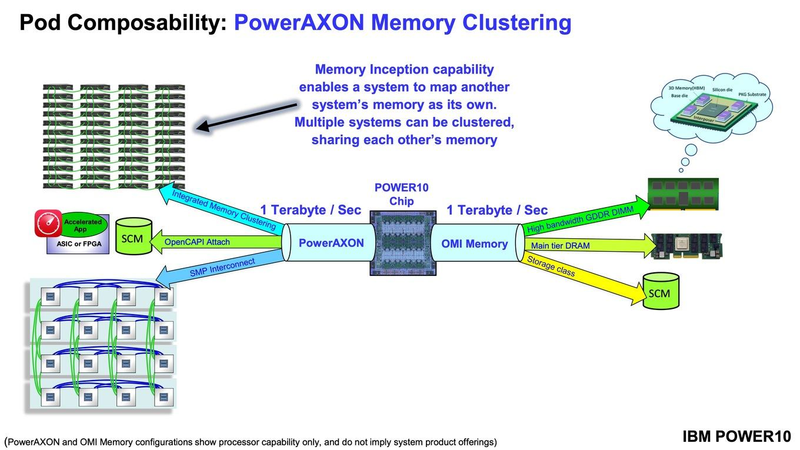 О преимуществах унифицированного интерфейса OMI, позволяющего «малой кровью» модернизировать подсистему памяти, мы уже рассказывали читателям ранее. В новом процессоре эти возможности задействованы полностью. Каждый базовый кристалл POWER10 имеет 16 линков OMI x8, общая пропускная способность достигает 1 Тбайт/с. Латентность, разумеется, возросла, поскольку контроллер DDR у OMI, по сути, внешний, но прирост небольшой и составляет менее 10 наносекунд. Универсальность и возможность модернизации этот недостаток искупают с лихвой. В текущем варианте пиковая пропускная способность достигает 410 Гбайт/с на разъём, объём — 4 Тбайт на разъём, однако с внедрением более быстрых типов памяти (DDR5, GDDR или даже HBM) может быть достигнута цифра 800 Гбайт/с на разъём. Отдельно упоминается возможность работы с SCM, но без конкретики. На данный момент такая память массово представлена только 3D XPoint в виде Intel Optane DCPMM. 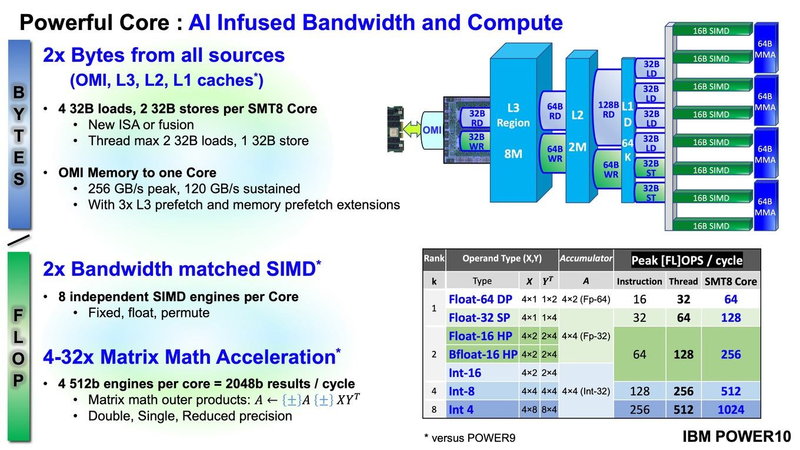 Любопытна технология Memory Clustering. С помощью PowerAXON система может обращаться к оперативной памяти в другой системе, как к собственной. Латентность при этом составляет 50 ‒ 100 нс, для систем типа NUMA совсем немного. Общий объем на одну систему POWER10 может достигать 2 Пбайт; с учётом применения систем IBM для запуска таких «пожирателей памяти», как SAP HANA такие объемы очень к месту. 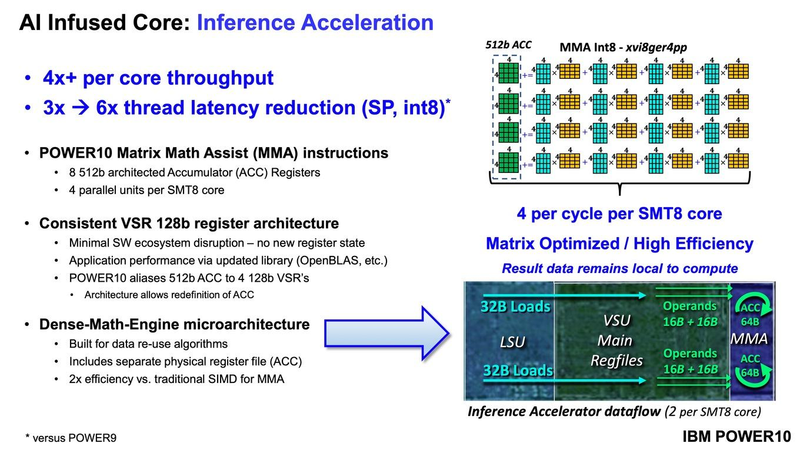 Следуя текущей моде на машинное обучение, разработчики реализовали в POWER10 развитую поддержку форматов вычислений, отличных от традиционных FP32/64. Блок плавающих вычислений в новом процессоре носит название Matrix Math Accelerator. В сравнении с POWER9 он быстрее в 10, 15 и 20 раз в режимах FP32, BFloat16 и INT8 соответственно. Иными словами, именно для инференс-систем POWER10 станет хорошим выбором. 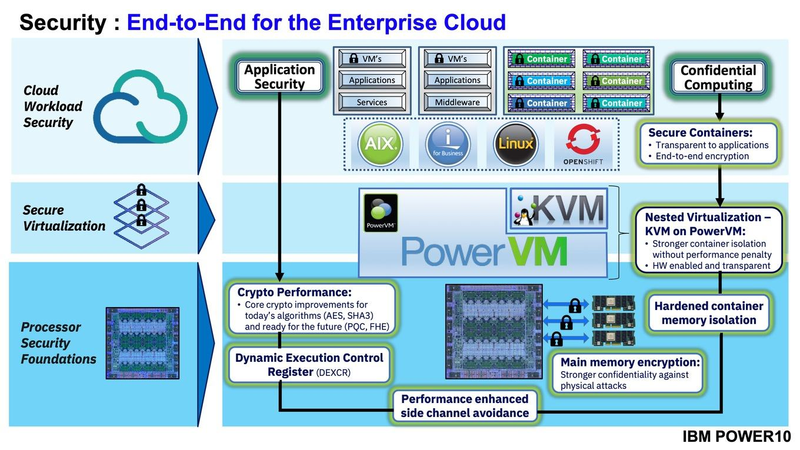 Поскольку одним из применений POWER10 компания видит облачные комплексы, серьёзное внимание уделено обеспечению безопасности. Новые процессоры поддерживают полное шифрование содержимого оперативной памяти, а для ускорения криптографических процедур в их составе есть соответствующие аппаратные блоки, причём не только для широко распространённого стандарта AES. Они достаточно гибки, чтобы поддерживать и шифрование будущего класса quantum safe. Также поддерживается защита и изоляция контейнеров на аппаратном уровне. Успешная атака на один контейнер в пределах машины не означает и успеха с другими контейнерами.  В качестве программной основы IBM предлагает Red Hat OpenShift, и архитектура POWER10 была соответствующим образом оптимизирована, чтобы показывать наилучшие результаты именно с этой средой. В целом, можно уверенно сказать: новые процессоры Голубого Гиганта получились интересными и весьма достойно выглядящими решениями даже на фоне успеха AMD EPYC.  Официальный анонс состоялся сегодня, но развёртывание массового производства должно занять определённое время, так что появления первых серверов на базе IBM POWER10 стоит ожидать не ранее начала следующего, 2021 года. А планы компании говорят о том, что POWER11 уже находится в разработке.
12.08.2020 [01:04], Илья Коваль
ARM-процессоры NUVIA Phoenix обещают быть быстрее и энергоэффективнее AMD EPYC и Intel XeonМощными серверными ARM-процессорами сейчас уже никого не удивить: A64FX трудятся в самом быстром в мире суперкомпьютере Fugaku, ThunderX и Altra стараются быть универсальными, а Graviton2 осваивается в облаке Amazon. Вот с последним как раз и хочет побороться NUVIA, молодой, но перспективный разработчик процессоров. SoC NUVIA Orion, в составе которого будет ARM-процессор Phoenix, ориентирован в первую очередь на облачных провайдеров и гипескейлеров, то есть на весьма «жирный» кусок рынка серверных процессоров, где сейчас доминирует Intel и архитектура x86-64 вообще. В этом сегменте, где число активных серверов исчисляется миллионами, крайне важны не расходы на закупку, а расходы на обслуживание и содержание такого огромного парка. 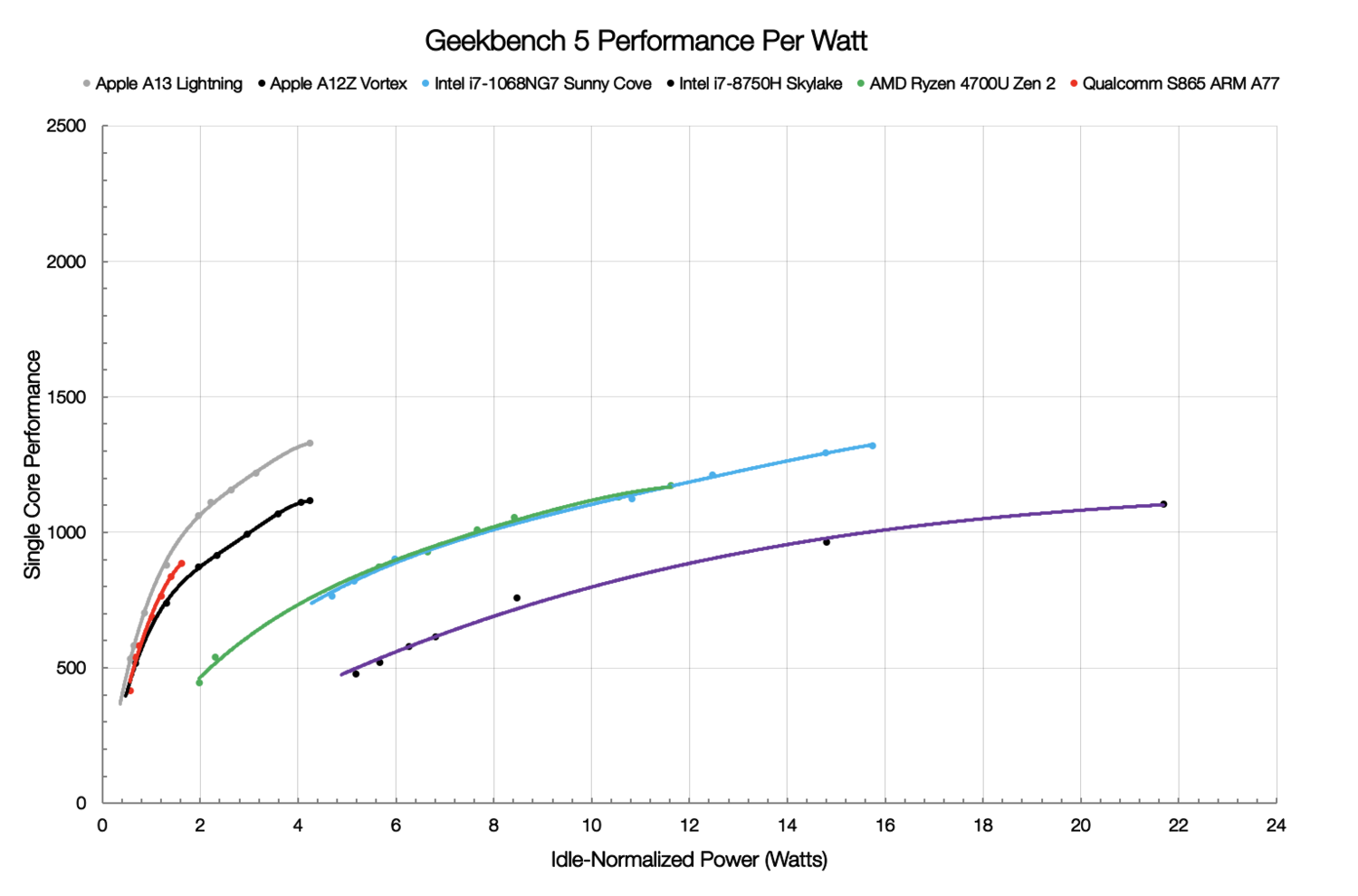
Источник изображений: NUVIA Одним из основных пунктов являются затраты на энергопотребление (питание и охлаждение), поэтому в NUVIA справедливо считают, что таким заказчикам нужен быстрый и энергоэффективный процессор. Решения на базе x86-64 компания к таковым не причисляет: они действительно имеют высокую производительность, однако рост мощности непропорционален росту TDP и потребления, и в этом их основная проблема в отличие от ARM. Для подкрепления своей точки зрения NUVIA провела собственные тесты в Geekbench 5 современных мобильных платформ ARM и x86-64. Выбор бенчмарка обусловлен тем, что он включает современные и разнообразные нагрузки на CPU. А мобильные платформы выбраны потому, что они, как и сервера в ЦОД гиперскейлеров, имеют вынужденные ограничения по питанию и охлаждению. И действительно, та же Facebook✴ для собственных платформ стремится к значению в 400 – 600 Вт на шасси. 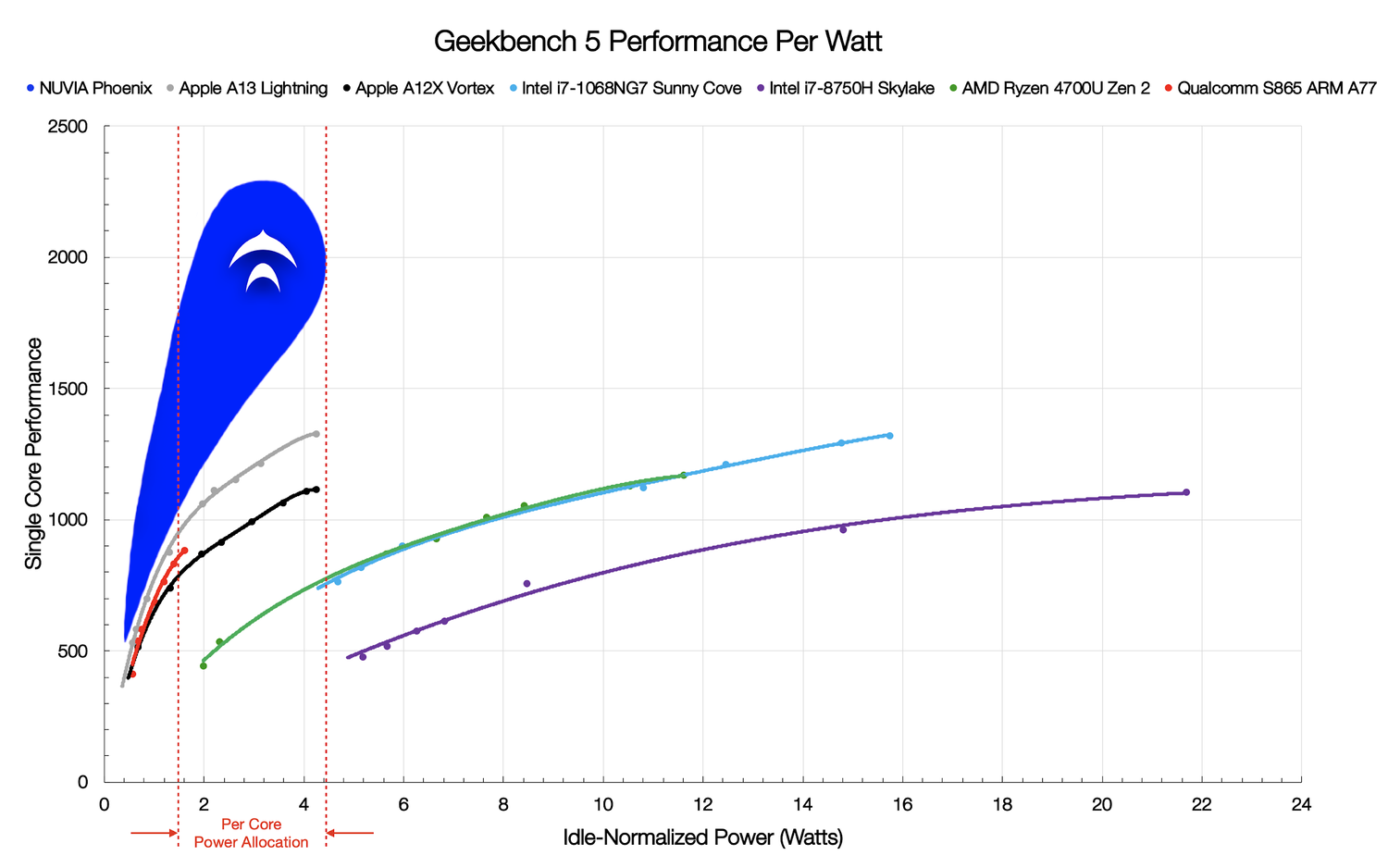 Приведённый график наглядно показывает, что производительность ядер ARM-процессоров нарастает намного быстрее при увеличении мощности. И именно к этому и стремится NUVIA — ядра Phoenix будут быстрее на 50-100% других и при этом в три-четыре раза экономичнее ядер x86-64. Но надо учесть, что сама NUVIA ориентируется на потребление в диапазоне примерно от 0,5 до 5 Вт на ядро. Компания полагает, что в ближайшее время все серверные процессоры будут иметь от 64 до 128 ядер и TDP на уровне 250 – 300 Вт, так что её SoC с такими параметрами ядер вписывается в эти параметры.
24.07.2020 [00:50], Игорь Осколков
Phytium Tengyun S2500: 64-ядерный ARM-чип для восьмипроцессорных системКак сообщает cnTechPost, Phytium, китайский разработчик процессоров, анонсировал новый 64-ядерный чип Tengyun S2500, ориентированный на высокопроизводительные вычисления (HPC). Компания и прежде была известна разработками в этой области — её процессоры легли в основу суперкомпьютеров Tiahne, занимавших первые строчки рейтинга TOP500. 
Изображения: cnTechPost В отличие от своего предшественника FT-2000+/64, тоже 64-ядерного, ядра новинки в дополнение к L2-кешу объёмом 512 Кбайт получили общий L3-кеш на 64 Мбайт. Кроме того, чип поддерживает восемь каналов памяти DDR4-3200. Отличительной чертой Tengyun S2500 является возможность объединения — судя по всему, бесшовного — от двух до восьми процессоров в рамках одной системы. Для связи между CPU используется несколько линий собственной шины со скоростью 800 Гбит/с.  В основе CPU лежат ядра FTC663, работающие на частоте 2 – 2,2 ГГц. Они же используются в представленном в прошлом году младшем чипе Phytium FT2000/4. Ядра серии FTC600 базируются на модифицированной архитектуре ARMv8 и включают переделанные блоки для целочисленных вычислений и вычислений с плавающей запятой, ASIMD-инструкции, новый динамический предсказатель переходов, поддержку виртуализации, а также традиционные для китайских CPU блоки шифрования и безопасности, соответствующие локальным стандартам.  Энергопотребление новинок достигает 150 Вт. Изготавливаться они будут на TSCM по техпроцессу 16-нм FinFET. Начало массового производства запланировано на четвёртый квартал этого года. Тогда же появятся и 14-нм десктопные чипы Phytium Tengrui D2000, которым через года не смену придут Tengrui D3000. Выход 7-нм серверных процессоров Phytium Tengyun S5000 запланирован на третий квартал 2021 года, а 5-нм чипы Tengyun S6000 появятся уже в 2022-ом.
25.06.2020 [21:10], Алексей Степин
ISC 2020: Tachyum анонсировала 128-ядерные ИИ-процессоры Prodigy и будущий суперкомпьютер на их основеМашинное обучение в последние годы развивается и внедряется очень активно. Разработчики аппаратного обеспечения внедряют в свои новейшие решения поддержку оптимальных для ИИ-систем форматов вычислений, под этот круг задач создаются специализированные ускорители и сопроцессоры. 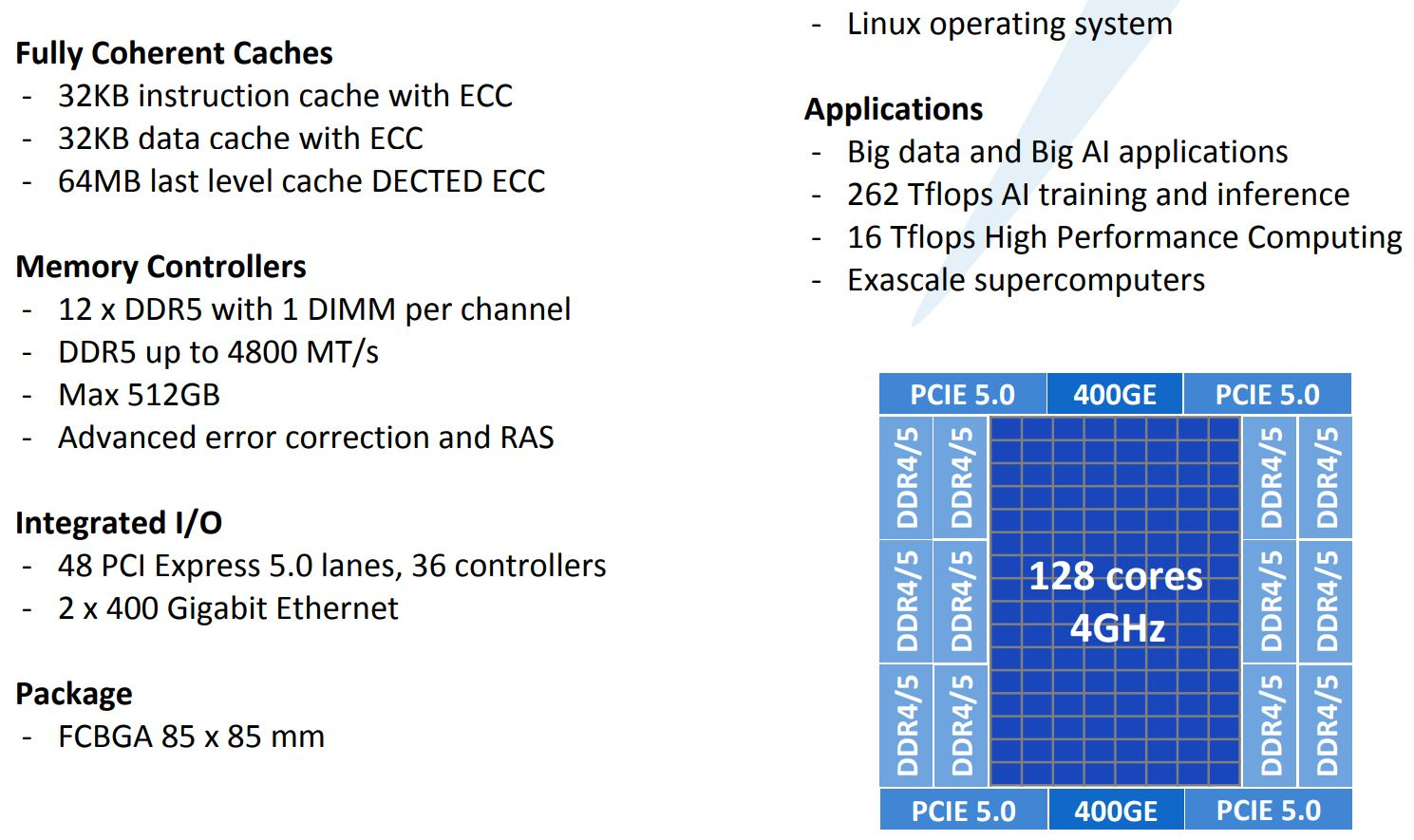 Словацкая компания Tachyum достаточно молода, но уже пообещала выпустить процессор, который «отправит Xeon на свалку истории». О том, что эти чипы станут основой для суперкомпьютеров нового поколения, мы уже рассказывали читателям, а на конференции ISC High Performance 2020 Tachyum анонсировала и сами процессоры Prodigy, и ИИ-комплекс на их основе.  Запуск готовых сценариев машинного интеллекта достаточно несложная задача, с ней справляются даже компактные специализированные чипы. Но обучение таких систем требует куда более внушительных ресурсов. Такие ресурсы Tachyum может предоставить: на базе разработанных ею процессоров Prodigy она создала дизайн суперкомпьютера с мощностью 125 Пфлопс на стойку и 4 экзафлопса на полный комплекс, состоящий из 32 стоек высотой 52U.  Основой для новой машины является сервер-модуль собственной разработки Tachyum, системная плата которого оснащается четырьмя чипами Prodigy. Каждый процессор, по словам разработчиков, развивает до 625 Тфлопс, что дает 2,5 Пфлопс на сервер. Компания обещает для новых систем трёхкратный выигрыш по параметру «цена/производительность» и четырёхкратный — по стоимости владения. При этом энергопотребление должно быть на порядок меньше, нежели у традиционных систем такого класса. 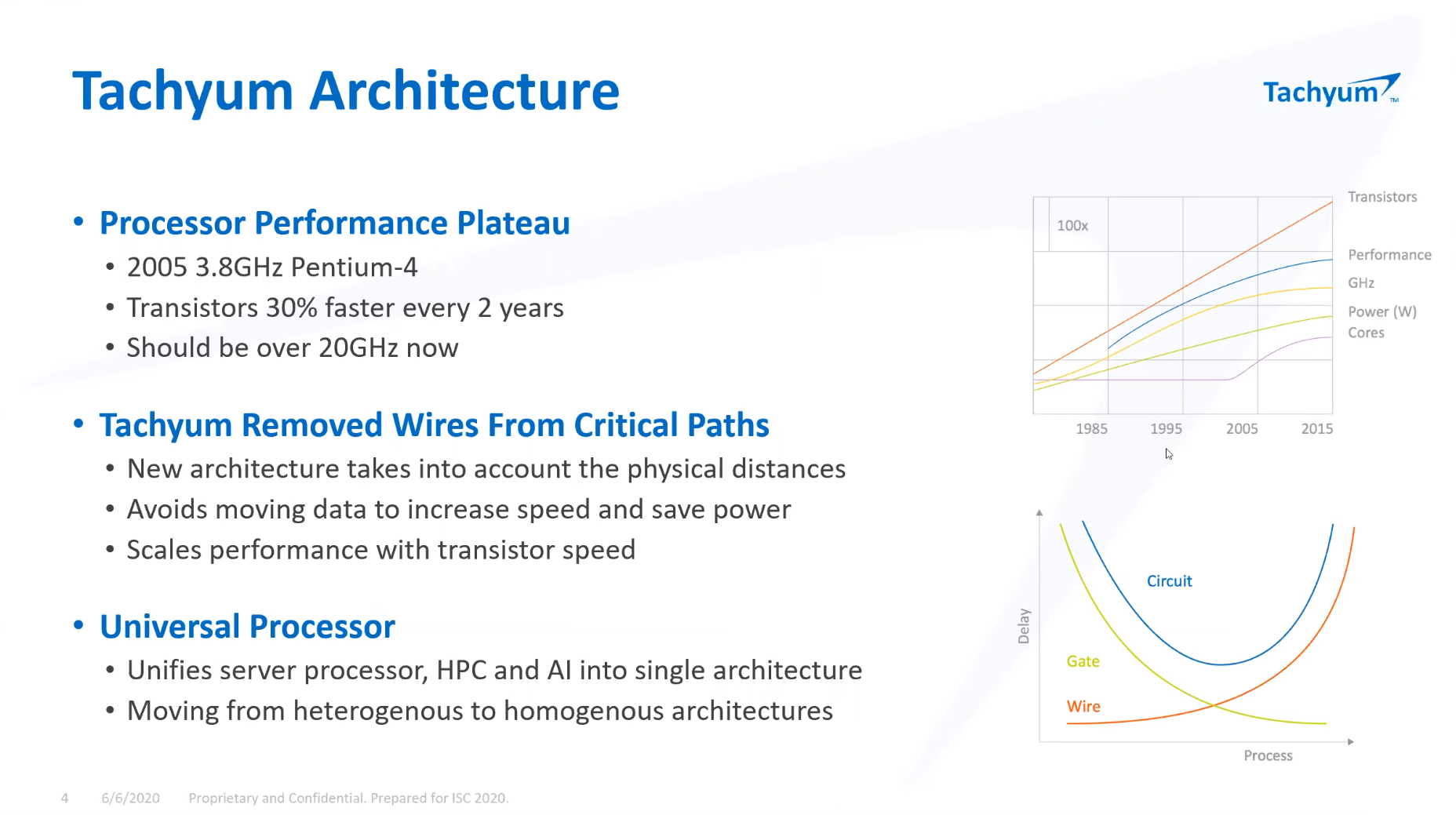 Архитектура Prodigy представляет существенный интерес: это не узкоспециализированный чип, вроде разработок NVIDIA, а универсальный процессор, сочетающий в себе черты ЦП, ГП и ускорителя ИИ-операций. Структура кристалла построена вокруг концепции «минимального перемещения данных». При разработке Tachyum компания принимала во внимание задержки, вносимые расстоянием между компонентами процессора, и минимизировала их. 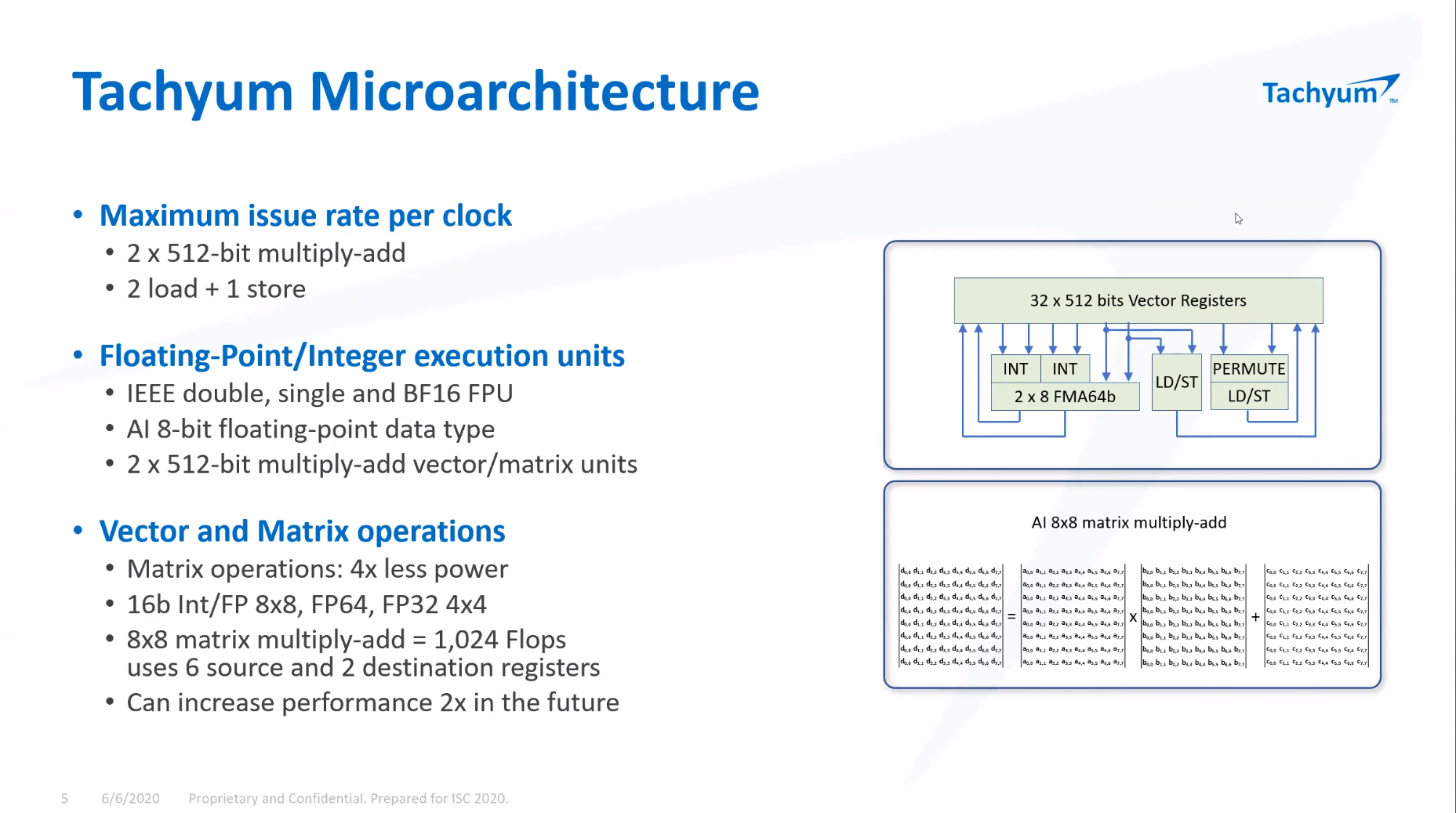 Процессор Prodigy может выполнять за такт две 512-битные операции типа multiply-add, 2 операции load и одну операцию store. Соответственно то, что каждое ядро Prodigy имеет восемь 64-бит векторных блока, похожих на те, что реализованы в расширениях Intel AVX-512 IFMA (Integer Fused Multiply Add, появилось в Cannon Lake). Блок вычислений с плавающей точкой поддерживает двойную, одинарную и половинную точность по стандартам IEEE. Для ИИ-задач имеется также поддержка 8-битных типов данных с плавающей запятой. 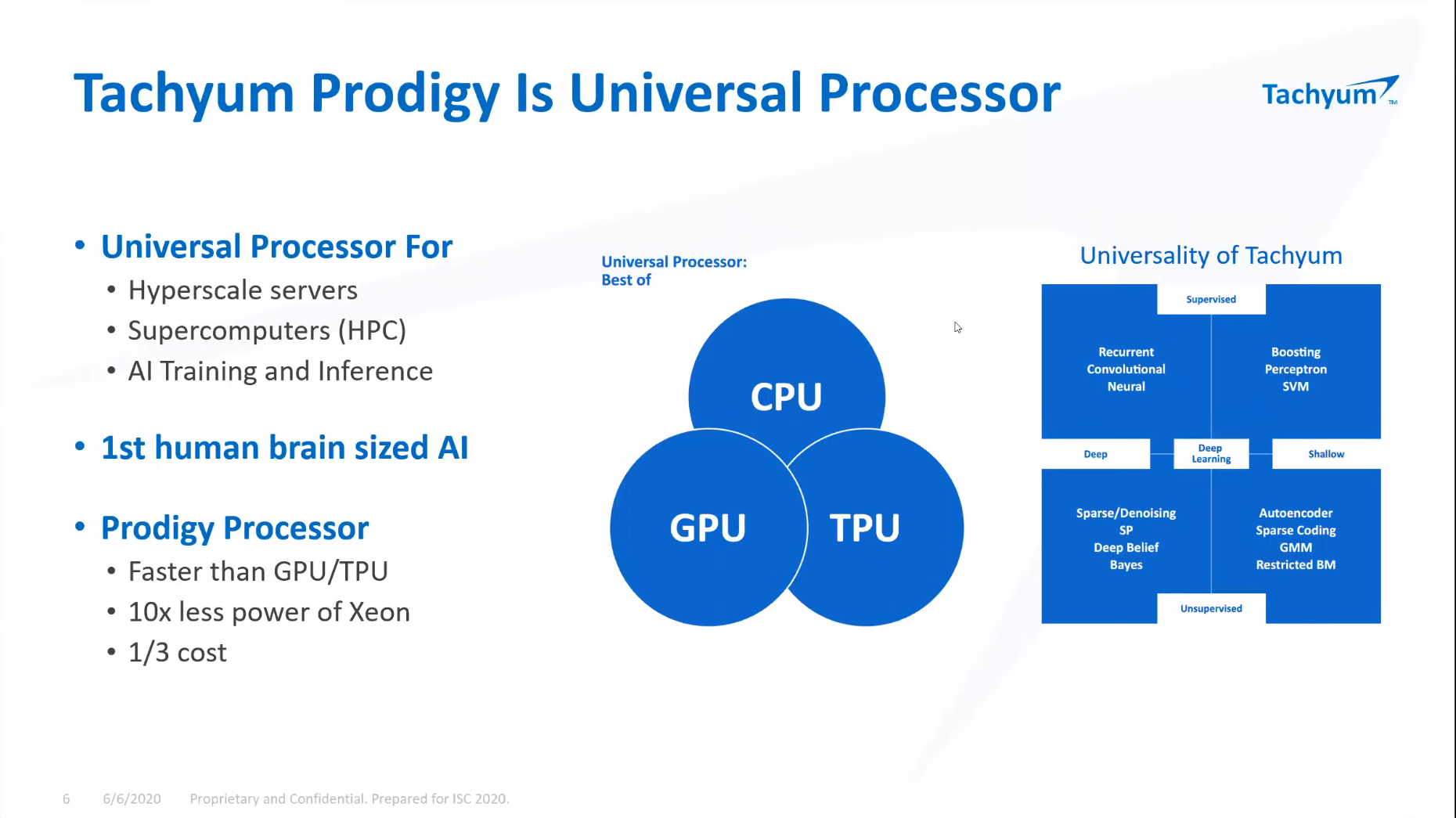 Векторные и матричные операции — сильная сторона Prodigy. На перемножении-сложении матриц размерностью 8 × 8 ядро развивает 1024 Флопс, используя 6 входных и 2 целевых регистра (в сумме есть тридцать два 512-бит регистра). Это не предел, разработчик говорит о возможности увеличения скорости выполнения этой операции вдвое. Tachyum обещает, что система на базе Prodigy станет первым в мире ИИ-кластером, способным запустить машинный интеллект, соответствующий человеческому мозгу.  С учётом заявлений о 10-кратной экономии электроэнергии и 1/3 стоимости от стоимости Xeon, это заявление звучит очень сильно. Но Prodigу — не бумажный продукт-однодневка. Tachyum разработала не только сам процессор, но и всю необходимую ему сопутствующую инфраструктуру, включая и компилятор, в котором реализованы оптимизации в рамках «минимального перемещения данных». Новинка разрабона с использованием 7-нм техпроцесса, максимальное количество ядер с вышеописанной архитектурой — 64. Помимо самих ядер, кристалл T864 содержит восьмиканальный контроллер DDR5, контроллер PCI Express 5.0 на 64 (а не 72, как ожидалось ранее) линии и два сетевых интерфейса 400GbE. При тактовой частоте 4 ГГц Prodigy развивает 8 Тфлопс на стандартных вычислениях FP32, 1 Пфлоп на задачах обучения ИИ и 4 Петаопа в инференс-задачах. Самая старшая версия, Tachyum Prodigy T16128, предлагает уже 128 ядер с частотой до 4 ГГц, 12 каналов памяти DDR5-4800 (но только 1DPC и до 512 Гбайт суммарно), 48 линий PCI Express 5.0 и два контроллера 400GbE. Производительность в HPC-задачах составит 16 Тфлопс, а в ИИ — 262 Тфлопс на обучении и тренировке.  Системные платы для Prodigy представлены, как минимум, в двух вариантах: полноразмерные четырёхпроцессорные для сегмента HPC и компактные однопроцессорные для модульных систем высокой плотности. Полноразмерный вариант имеет 64 слота DIMM и поддерживает модули DDR5 объёмом до 512 Гбайт, что даёт 32 Тбайт памяти на вычислительный узел. Сам узел полностью совместим со стандартами 19″ и Open Compute V3, он может иметь высоту 1U или 2U и поддерживает питание напряжением 48 Вольт. Плата имеет собственный BIOS UEFI, но для удалённого управления в ней реализован открытый стандарт OpenBMC.  Tachyum исповедует концепцию универсальности, но всё-таки узлы для HPC-систем на базе Prodigy могут быть нескольких типов — универсальные вычислительные, узлы хранения данных, а также узлы управления. В качестве «дисковой подсистемы» разработчики выбрали SSD-накопители в формате NF1, подобные представленному ещё в 2018 году накопителю Samsung. Таких накопителей в корпусе системы может быть от одного до 36; поскольку NF1 существенно крупнее M.2, поддерживаются модели объёмом до 32 Тбайт, что даёт почти 1,2 Пбайт на узел. Стойка с модулями Prodigy будет вмещать до 50 модулей высотой 1U или до 25 высотой 2U. Согласно идее о минимизации дистанций при перемещении данных, сетевой коммутатор на 128 или 256 портов 100GbE устанавливается в середине стойки.  Такая конфигурация работает в системе с числом стоек до 16, более масштабные комплексы предполагается соединять между собой посредством коммутатора высотой 2U c 64 портами QSFP-DD, причём поддержка скорости 800 Гбит/с появится уже в 2022 году. 512 стоек могут объединяться посредством высокопроизводительного коммутатора CLOS, он имеет высоту 21U и также получит поддержку 800 Гбит/с в дальнейшем. Компания активно поддерживает открытые стандарты: применён загрузчик Core-Boot, разработаны драйверы устройств для Linux, компиляторы и отладчики GCC, поддерживаются открытые приложения, такие, как LAMP, Hadoop, Sparc, различные базы данных. В первом квартале 2021 года ожидается поддержка Java, Python, TensorFlow, PyTorch, LLVM и даже операционной системы FreeBSD.  Любопытно, что существующее программное обеспечение на системах Tachyum Prodigy может быть запущено сразу в виде бинарных файлов x86, ARMv8 или RISC-V — разумеется, с пенальти. Производительность ожидается в пределах 60 ‒ 75% от «родной архитектуры», для достижения 100% эффективности всё же потребуется рекомпиляция. Но в рамках контрактной поддержки компания обещает помощь в этом деле для своих партнёров. Разумеется, пока речи о полномасштабном производстве новых систем не идёт. Эталонные платформы Tachyum обещает во второй половине следующего года. Как обычно, сначала инженерные образцы получают OEM/ODM-партнёры компании и системные интеграторы, а массовые поставки должны начаться в 4 квартале 2021 года. Однако ПЛИС-эмуляторы Prodigy появятся уже в октябре этого года, инструментарий разработки ПО — и вовсе в августе.  Планы у Tachyum поистине наполеоновские, но её разработки интересны и содержат целый ряд любопытных идей. В чём-то новые процессоры можно сравнить с Fujitsu A64FX, которые также позволяют создавать гомогенные и универсальные вычислительные комплексы. Насколько удачной окажется новая платформа, говорить пока рано.
23.06.2020 [19:23], Алексей Степин
128 ядер ARM: Ampere Computing анонсировала процессоры Altra MaxНа первый взгляд, позиции архитектуры x86 в мире высокопроизводительных вычислений выглядят незыблемыми: примерно 94% всех систем класса HPC используют в качестве основы процессоры Intel и ещё 2,2% занимает AMD. Однако запуск кластера Fugaku доказал, что ARM — соперник весьма и весьма опасный. Система на базе процессоров Fujitsu A64FX использует именно архитектуру ARM. И наступление ARM продолжается и на других фронтах: к примеру, AWS предлагает инстансы на собственных ARM-процессорах Graviton2. Не дремлет Ampere Computing, анонсировавшая сегодня новые процессоры Altra и Altra Max.  Разработкой мощных многоядерных процессоров с архитектурой ARM компания занимается довольно давно: в конце прошлого года она уже рассказывала о втором поколении своих продуктов, чипах QuickSilver. В их основу лег дизайн ядра ARM Neoverse N1 (ARM v8.2+), количество самих ядер достигло 80, появилась поддержка интерфейса PCI Express 4.0, чего, например, до сих пор нет в процессорах Intel Xeon Scalable. Серверные процессоры с архитектурой ARM доказали своё превосходство в энергоэффективности перед x86, что сделало их отличным выбором для облачных сервисов — в таких ЦОД плотность упаковки вычислительных мощностей максимальна и такие параметры, как удельная производительность, энергопотребление и тепловыделение играют крайне важную роль. Новые процессоры Ampere под кодовым именем Altra нацелены именно на этот сектор рынка. 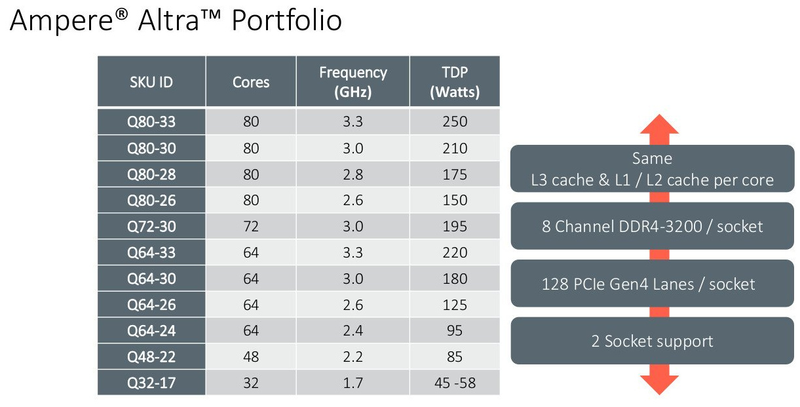 В основе Altra также лежит ядро Neoverse N1 — оно же применено и в проекте Amazon Graviton2 — но Ampere Computing намеревается охватить с помощью Altra остальных крупных провайдеров облачных услуг, которые также заинтересованы в высокоплотных энергоэффективных ЦП. При этом утверждается, что Altra превосходит Graviton2; по крайней мере, на бумаге это выглядит убедительно. Всего в серии Altra анонсировано 12 процессоров, с количеством ядер от 32 до 80, частотами от 1,7 до 3,3 ГГц и теплопакетами от 45 до 250 Ватт. Все они располагают восьмиканальным контроллером памяти DDR4-3200 (до 4 Тбайт на процессор) и предоставляют в распоряжение системы 128 линий PCI Express 4.0, чем пока могут похвастаться разве что AMD Rome. Применена очень простая система наименований: например, «Q72-30» означает, что перед нами 72 ядерный процессор поколения QuickSilver с частотой 3 ГГц.  Altra следует большинству современных тенденций в процессоростроении: процессоры располагают солидным массивом кешей (1 Мбайт на ядро, 32 Мбайт L3), ядра имеют два 128-битных блока инструкций SIMD, а также поддерживают популярные в задачах машинного интеллекта и инференс-комплексах форматы вычислений INT8 и FP16. Что касается удельной энергоэффективности, то ядро AMD Rome потребляет около 3 Ватт при полной нагрузке на частоте 3 ГГц, а для Altra Q80-30 этот показатель равен 2,6 Ватта; турборежима у Altra, впрочем, нет и максимальные частоты справедливы для всех ядер.  В настоящий момент компания поставляет образцы платформ Altra двух типов: однопроцессорную Mt. Snow и двухпроцессорную Mt. Jade. В число партнёров компании входят такие производители, как GIGABYTE и Wiwynn, заявлен также ряд контрактов с производителями более низких эшелонов. В основе Mt. Jade, вероятнее всего, лежит системная плата GIGABYTE MP32-AR0, о ней мы уже рассказывали нашим читателям.  Цены новых решений пока не разглашаются, однако, заинтересованные в процессорах Ampere провайдеры уже в течение двух месяцев тестируют новые платформы; в их число входят такие компании, как Packet и CloudFlare, причём Packet уже предоставляет своим клиентам «ранний доступ» к услугам, запускаемым на новых платформах Ampere. Более массовых поставок следует ожидать в августе и сентябре текущего года. 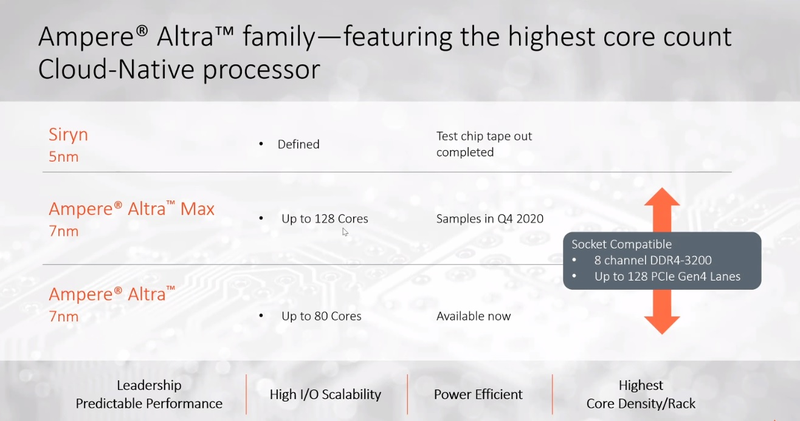 80 ядер — весьма солидное количество, даже в арсенале AMD таких процессоров ещё нет, семейство EPYC всё ещё ограничено 64 ядрами, но с SMT. Однако на достигнутом Ampere не останавливается и позднее в этом году планирует представить миру настоящего монстра — 128-ядерный процессор Altra Max, на базе всё той же архитектуры QuickSilver/Neoverse. Этот чип имеет кодовое имя Mystique, он будет базироваться на новом дизайне кристалла, однако отличия здесь количественные, качественно это всё та же Altra, но с большим количеством ядер, оптимизированная с учётом возможностей сохранённой неизменной подсистемой памяти. Сохранится даже совместимость по процессорному разъёму. Образцы Altra Max если и существуют, то только в лаборатории Ampere Computing, а публичного появления сэмплов этих процессоров следует ожидать не ранее 4 квартала с началом производства в 2021 году. 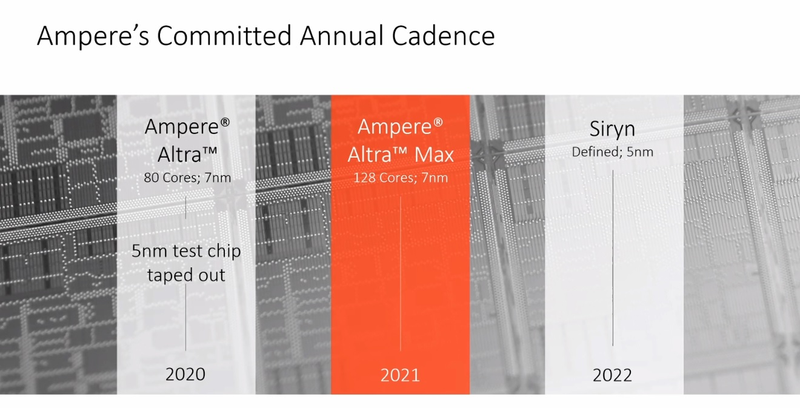 Таким образом, можно утверждать, что технологическая ступень 7 нм компанией освоена. Она штурмует новую высоту — образцы процессоров Siryn, построенные с использованием 5-нм техпроцесса TSMC должны появиться ближе к концу следующего года. Некоторые блоки Siryn уже существуют в кремнии. Эти процессоры получат и новую платформу, а, возможно, и поддержку таких технологий, как PCI Express 5.0 и DDR5.
18.06.2020 [16:00], Алексей Степин
Intel представила Xeon Cooper Lake, третье поколение Scalable-процессоровКрупнейший в мире производитель процессоров с архитектурой x86, компания Intel, представила новую платформу, нацеленную на быстро растущий рынок машинного обучения, аналитики и периферийных вычислений. Хотя платформа состоит из нескольких компонентов, главным из них являются новые процессоры Intel Xeon Scalable — это уже третье поколение серии Scalable.  Первое поколение Xeon Scalable (Skylake) отличалось наличием поддержки векторных расширений с длиной 512 бит, хотя эта поддержка была наиболее полной в других процессорах с разъёмом LGA 3647, ныне почивших Xeon Phi 72xx. Во втором поколении Xeon Scalable, известном под кодовым именем Cascade Lake, появились расширения AVX-512 VNNI (Vector Neural Network Instructions, они же DL Boost), и это был первый реверанс в сторону машинного обучения со стороны Intel — расширения позволялил работать с INT8 и подходили для инференса.  Третье поколение, получившее имя Cooper Lake, ещё больше продвинулось в сторону поддержки нетипичных для традиционной архитектуры x86 форматов вычислений. Главным нововведением здесь является поддержка формата bfloat16, который часто используется в комплексах машинного обучения и системах принятия решений (инференс). Он требует меньше вычислительных мощностей, нежели традиционные форматы FP32/64, но при этом в большинстве случаев обеспечивает достаточную точность вычислений, а итоговый выигрыш в производительности может быть почти двухкратным.  Популярные фреймворки, такие как TensorFlow и Pytorch, уже давно поддерживают bfloat16, а Intel-оптимизированные версии доступны в комплекте Intel AI Analytics Toolkit. Компания также оптимизировала среды OpenVINO и ONNX с учётом возможностей новых процессоров Xeon Scalable. Собственно говоря, самое главное в Cooper Lake то, что их теперь можно использовать и для обучения нейронных сетей, а не только для инференса. Intel отдельно подчёркивает универсальность новых CPU. 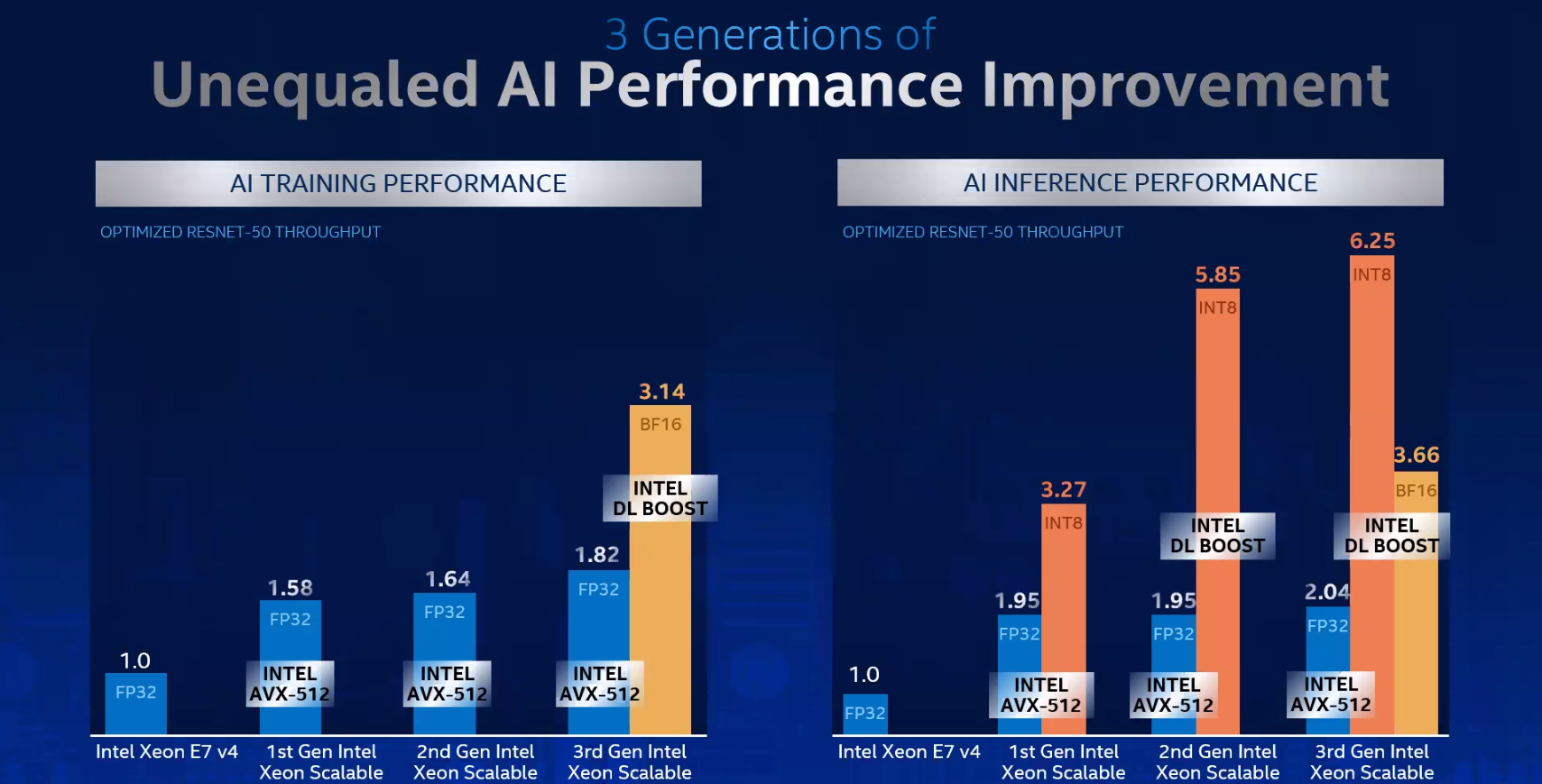 Что касается самих процессоров, то максимальное количество ядер сохранилось, их в серии Xeon Gold 53xx/63xx и Xeon Platinum 83xx по-прежнему 28 при поддержке SMT2. Однако улучшения есть, и достаточно серьёзные. Серия Xeon Platinum поддерживает память до DDR4-3200 (1DPC) и DDR4-2933 (2DPC), хотя младшие пяти- и шеститысячники так же ограничены 2666 и 2933 MT/с. Зато все они поддерживают память Intel Optane DCPMM 2-го поколения. Число каналов память осталось прежним, их шесть. Существенное отличие от Cascade Lake в том, что теперь у всех CPU есть 6 линий UPI — они могут может «бесшовно» устанавливаться в системы с четырьмя или восемью процессорными разъёмами. Другое важное отличие — серия 53xx теперь имеет два FMA-порта для AVX-512, а не один как раньше. Часть новинок поддерживает Intel Speed Select. 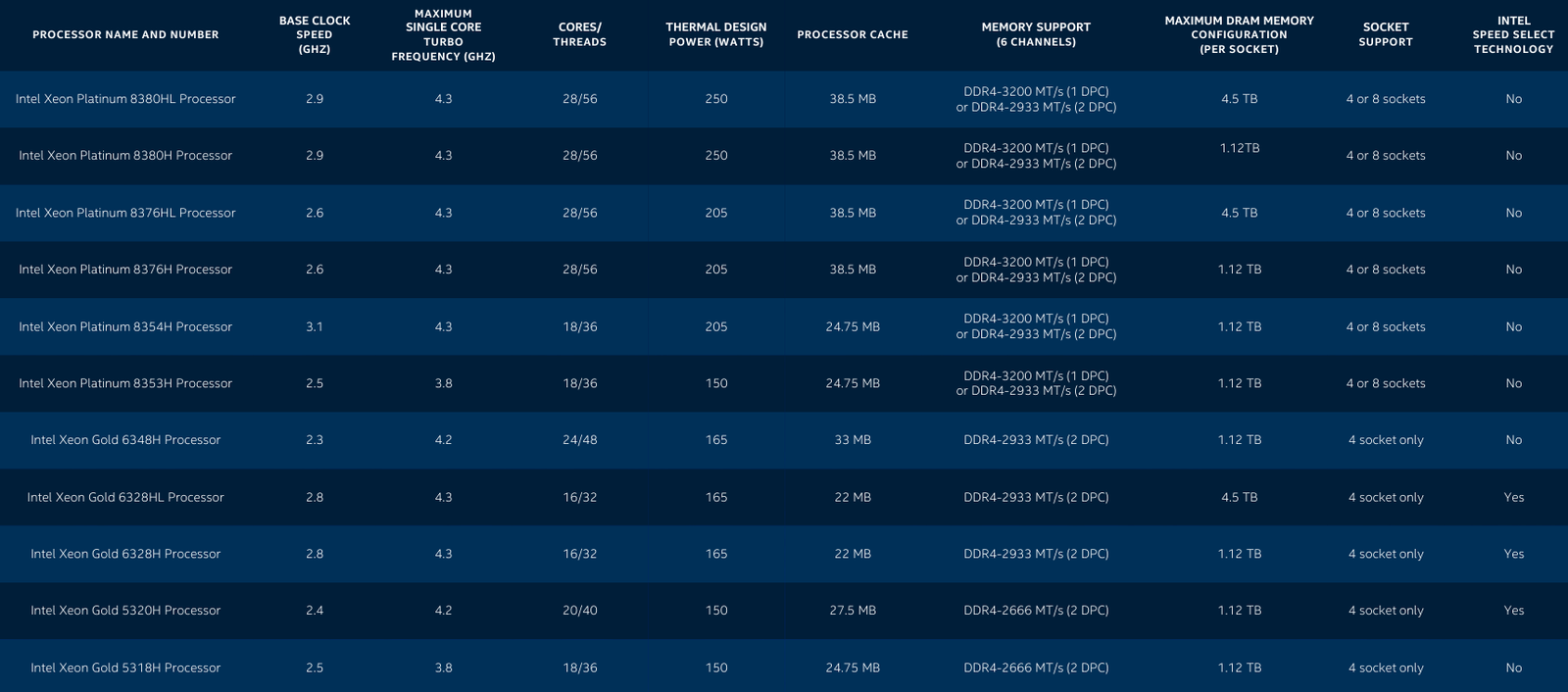 У «ёмких» моделей с суффиксом HL максимальный объём оперативной памяти достиг 4,5 Тбайт, а у базовых H — до 1,12 Тбайт. Несколько подросли тактовые частоты, в серии есть модели с частотной формулой 2,9 ‒ 4,3 ГГц, причём большая часть новинок имеет частоту в турборежиме более 4 ГГц. Исключение — модели с пониженным энергопотреблением. Всё это делает новые процессоры привлекательными для крупных предприятий, облачных провайдеров и гиперскейлеров вообще. Если даже на секунду забыть все новововведения для ИИ, Cooper Lake всё равно останется многосокетной платформой, а это значит, что он подходит для работы с большими СУБД, анализа больших объёмов данных в реальном времени, OLTP и виртуализации. В области 4S/8S-платформ у Intel давно крепкие позиции, так что новинки наверняка приглянутся определённому кругу заказчиков. Но массовыми Cooper Lake в текущем виде не станут. 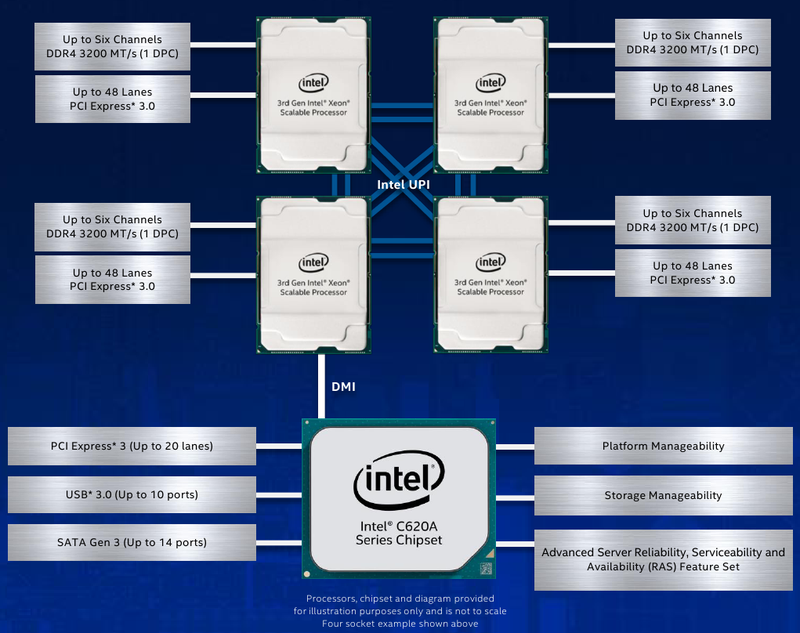 Основной системный чипсет — Intel C620A, то есть обновлённый Lewisburg. В серию пока входит всего три модели, две из которых поддерживают технологию Intel QAT, ускоряющую работы по компресии и шифрованию. Так это обновление уже имеющихся чипсетов, поддержки PCI Express 4.0 нет. Сами процессоры Xeon Scalable третьего поколения по-прежнему могут предоставить в распоряжение системы до 48 линий PCIe 3.0. С учётом того, что ориентированы они на 4-сокетные системы, этого может быть вполне достаточно.  Однако другие процессоры Xeon Scalable «Ice Lake», для одно-двухсокетных платформ Whitley, которые Intel планирует представить позднее в этом году, уже получат поддержку PCI Express 4.0. Также известно, что четвёртое поколение Xeon Scalable под именем Sapphire Rapids получит набор новых матричных расширений (Advanced Matrix Extensions, AMX), которые, вероятно, буду напоминать тензорные ядра. Она увидит свет уже в 2021 году. Для массовых одно- и двухсокетных платформ пока предлагается использовать Cascade Lake Refresh. Вместе с Intel Xeon Cooper Lake компания также анонсировала второе поколение памяти Intel Optane DCPMM 200, накопители Intel D7-P5500 и D7-5600 с интерфейсом PCIe 4.0 и новую FPGA Intel Stratix 10 NX.
24.02.2020 [17:00], Константин Ходаковский
Intel представила семейство процессоров Intel Xeon Cascade Lake RefreshВместе с серией продуктов для инфраструктуры сетей 5G, включающей систему на кристалле Atom P5900 для базовых станций, структурированную платформу ASIC Diamond Mesa для ускорения сетей 5G, серию сетевых контроллеров Ethernet 700 и программное решение OpenNESS для лёгкого развёртывания облачных периферийных микросервисов, корпорация Intel расширила и серию серверных процессоров Intel Xeon Scalable 2-го поколения.  Intel Xeon Scalable 2-го поколения являются основой платформенной инфраструктуры в центрах обработки данных. На сегодняшний день чипов Xeon Scalable продано в общей сложности более 30 миллионов. Появление этих процессоров позволило трансформировать ядро сети: сегодня на их долю приходится 50 % всех виртуализированных окружений по всему миру, а к 2023 году это число дополнительно увеличится.  Как мы уже сообщали, новая серия серверных процессоров Intel включает 18 моделей с более высокими частотами (до 4 ГГц в режиме Turbo Boost), увеличенным количеством ядер и объёмом кеша в различной комбинации этих параметров. Но главное изменение — это существенно сниженная стоимость. Например, Xeon Gold 6238R предложит 28 ядер и базовую частоту 2,2/4 ГГц, тогда как его предшественник в лице Xeon Gold 6238 использует 22 ядра с частотой 2,1/3,7 ГГц при одинаковой стоимости.  Флагманом семейства станет Xeon Gold 6258R с 28 ядрами, поддержкой Hyper-Threading, базовой частотой 2,7 ГГц и уровнем TDP не более 205 Вт. В обозначении моделей новых процессоров, как правило, присутствует литера «R», то есть Refresh. Серия оптимизированных ЦП для высочайшей производительности отдельных ядер теперь представляет собой такой перечень. Все процессоры поддерживают Intel Optane DC Persistent Memory (жирным помечены новые модели):
Серия ЦП, оптимизированных для производительности на Ватт, представляет собой такой перечень. Все процессоры Platinum и Gold поддерживают Intel Optane DC Persistent Memory, а остальные — нет (жирным помечены новые модели):
Также компания представила новый чип в семействе энергоэффективных, рассчитанных на долгий цикл процессоров, — Silver 4210T (10 ядер, 2,3/3,2 ГГц, 13,75 Мбайт, 95 Вт, $554). Как и старая 8-ядерная модель Silver 4209T, новая тоже не поддерживает Intel Optane DC Persistent Memory. И наконец для односокетных серверов, где принципиальную роль играет стоимость, представлена 16-ядерная модель Gold 6208U (2,9/3,9 ГГц, 22 Мбайт, 150 Вт, $989, поддержка Intel Optane DC Persistent Memory). Запуск новых моделей призван сделать предложения Intel более конкурентоспособными по сравнению с 7-нм чипами AMD EPYC Rome — неслучайно затронуты были наиболее ходовые процессоры. Самое производительное (и дорогое) семейство Xeon Platinum 9000 с количеством ядер от 32 до 56 обновлено не было. Повышение показателя цены/производительности — главный повод к запуску Cascade Lake R (снижение наблюдается кратное). В новой серии процессоры разделены между семействами Bronze, Silver и Gold. Неслучайно процессоров Platinum в ней нет: старшие модели, в том числе и 28-ядерный флагман, вошли в семейство Gold. Поэтому Intel законно поставила на «новинки» более низкие ценники. Ранее компания уже серьёзно пересмотрела свои серверные предложения. Она, по сути, отказалась от процессоров серии M, которые, в отличие от стандартных решений, ограниченных объёмом ОЗУ в 1,5 Тбайт, позволяют работать в системах с 2 Тбайт памяти. Клиентам, нуждающимся в таком объёме ОЗУ, теперь предлагается использовать процессоры класса выше — L, поддерживающие уже 4,5 Тбайт. Для этого компания уравняла цены моделей L с M. Впрочем, не все OEM-производители спешат обесценить свои запасы и задерживают снижение цен.  Помимо процессоров Intel также представила 17 обновлённых решений Select Solutions, в которых реализована поддержка этих новых продуктов для ускорения наиболее важных рабочих нагрузок у заказчиков. Ведущие отраслевые производители уже начинают поставки новых платформ на базе Intel Xeon 2-го поколения Refresh.
19.02.2020 [17:16], Алексей Степин
Calxeda: взлёт и падение первого разработчика серверных процессоров ARMАрхитектура ARM активно прокладывает себе путь в серверные системы и даже в суперкомпьютеры. Но судьба первой компании, рискнувшей сделать ставку на ARM, вовсе не так радужна. В 2011 году компания Calxeda опубликовала сведения о 32-бит серверном процессоре на базе ARM Cortex-A9. В 2020 году можно считать, последний гвоздь в крышку гроба этих CPU забит — в ядре Linux поддержка платформ Calxeda будет в ближайшее время прекращена. Но мы считаем, что те, кто первыми бросил вызов могуществу x86, заслуживают памяти.  Ещё первая разработка Calxeda, четырёхъядерный процессор ARM Cortex-A9, о котором мы писали в 2011 году, позволял создавать серверы формата 2U со 120 процессорами (480 ядер совокупно). Компания называла свою затею «первопроходческой инициативой» и планировала развернуть вокруг своих разработок целую экосистему — и спрос на такие решения был. 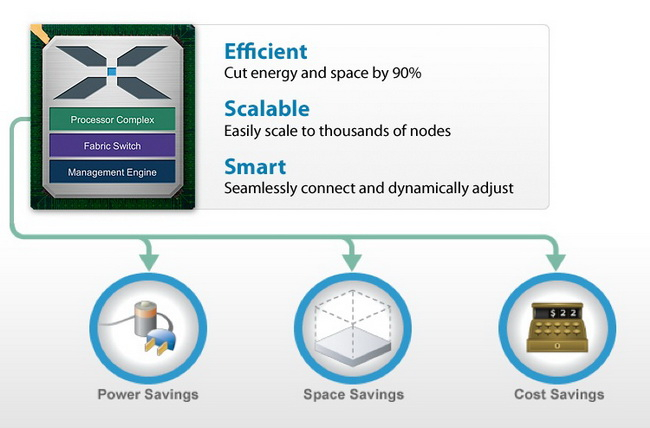
Преимущества платформы Calxeda по мнению компании: экономичность, компактность, низкая стоимость Проект поддержал солидный список из венчурных фондов и производителей полупроводников: ARM, Advanced Technology Investment Company, Battery Ventures, Flybridge Capital Partners и Highland Capital Partners, а первым ключевым партнёром для Calxeda стала Canonical — разработчик операционной системы Ubuntu. 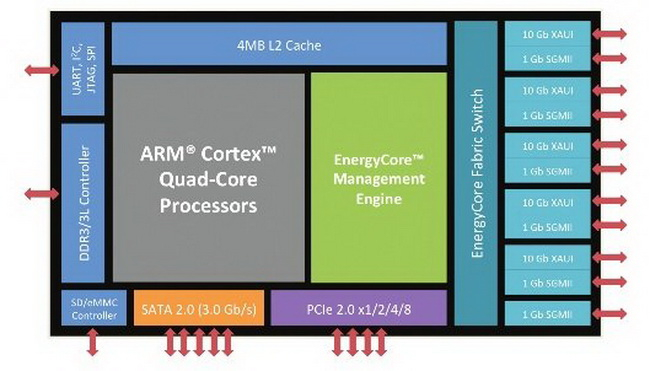
Архитектура первого серверного процессора Calxeda EnergyCore ECX-1000 К концу 2011 года проект оформился окончательно. CPU получил название EnergyCore, стали известны тактовые частоты (1,1 ‒ 1,4 ГГц) и другие подробности: наличие 4 Мбайт кеша L3, интегрированного коммутатора с производительностью 80 Гбит/с, отдельного ядра для управления энергопотребления. Энергопотребление одного узла на базе EnergyCore, в состав которого, помимо процессора, входило 4 Гбайт памяти и SSD-накопитель, могло составлять всего 5 ватт. Неудивительно, что разработкой заинтересовалась Hewlett-Packard, объявившая о намерении использовать EnergyCore в своих новых серверах. Говорилось о 4U-шасси, содержащих 288 чипов Calxeda EnergyCore. 
Эталонный дизайн вычислительного узла с четырьмя Calxeda EnergyCore К сожалению, в 2012 году было объявлено о том, что OEM-серверы на базе чипов Calxeda появятся только ближе к концу года. Но HP уже располагает такими системами под названием Redstone; они используются для разработки энергоэффективной серверной архитектуры в проекте Moonshot. 
Мини-кластер HP Redstone Осенью того же года Calxeda объявляет о выпуске новой платформы Midway. В ней используется более совершенная архитектура ARM Cortex-A15 с поддержкой аппаратных средств виртуализации. Опубликованы планы на 2014 год, в них фигурирует поддержка 64-битной архитектуры ARM v8. Наконец, на конференции Strata + HadoopWorld в Нью-Йорке компания Penguin Computing демонстрирует успешную работу Hadoop на платформе UDX1, построенной с использованием Calxeda EnergyCore. 
Типичный дизайн сервера на базе процессоров Calxeda. Производитель Boston, модель Viridis 2013 год. Intel не собирается уступать и в противовес Calxeda и AMD, работающими над созданием экономичных ARM-процессоров, выпускает первую систему на чипе на базе архитектуры Broadwell. К сожалению, это последний год деятельности Calxeda. Исчерпав резервы денежных средств, пионер на рынке ARM-серверов объявляет о прекращении своей работы. По мнению экспертов, причин краха две — компания слишком рано начала наступление на серверный рынок, ещё не готовый к пришествию ARM, а также сделала ставку на 32-битные процессоры в то время, как серверный рынок уже успел привыкнуть к 64-битным чипам, хотя бы потому, что они поддерживают большие объемы оперативной памяти. Кроме того, даже сама ARM относительно недавно, наконец, ввела спецификации ServerReady для упрощения внедрения в серверный сегмент. Крах Calxeda также негативно сказался на общее отношение к серверным ARM в индустрии, которая сама по себе всегда была консервативна. В частности, в разговоре на SC19 представитель одного из ведущих производителей серверов отметил, что неуспех первых ARM-платформ и фактически впустую потраченные средства надолго отпугнули корпорацию даже от экспериментов в этой области. 
Последние из могикан: вскоре для них не останется работы Уже выпущенные серверы с процессорами Calxeda ещё работают. Но дни их уже сочтены: на рынке серверных процессоров с архитектурой ARM появляются другие игроки, изначально сделавшие ставку на мощные 64-битные варианты. К 2020 году встретить сервер Calxeda в работе удаётся очень редко — и разработчики ядра Linux объявляют о том, что вскоре откажутся от поддержки инфраструктуры Calxeda. Будет также убрана поддержка KVM-виртуализации для всех 32-битных процессоров ARM. Это не первая история неуспеха ARM в серверном сегмента. Два крупнейших производителя SoC, Broadcom и Qualcomm, в итоге отказались от затеи. Наработки первой после долгих скитаний воплотились в ThunderX, а процессоры Centriq второй так толком и не увидели свет. Собственные CPU Marvell не снискали большой популярности, так что компания в итоге купила ThunderX. ThunderX 2 вместе с Fujitsu A64FX пока остаются единственными крупными игроками на этом рынке, если не считать ряда внутренних разработок вроде AWS Graviton, которые не предназначены для свободной продажи. Конкуренцию им в ближайшее время должны составить Ampere eMAG и Huawei KunPeng. |
|