Материалы по тегу: cpu
|
14.12.2021 [19:41], Алексей Степин
Серверы на базе «Эльбрус» не прошли тесты Сбербанка, но не всё потеряноВ рамках программы импортозамещения СберТех провёл тестирование серверов на базе процессоров Эльбрус-8С. По результатам системы признаны работоспособными, но не отвечающими предъявляемым требованиям по целому ряду параметров. Все пожелания и замечания переданы МЦСТ, разработчику Эльбрус. Банковские информационные системы — критически важная часть любого государства. Поэтому неудивительно стремление использовать в них решения собственной разработки, дабы меньше зависеть от чужих чипов и серверов. Примеры Huawei это подтверждают, но в данной заметке речь пойдёт не о китайских процессорах, а о российских. Лаборатория СберТех провела полноценное тестирование серверов на базе процессоров Эльбрус-8С, результаты которого, к сожалению, трудно назвать удовлетворительными. 
Фото: МЦСТ Это первое полномасштабное испытание процессоров Эльбрус в «полевых условиях», то есть, на уровне реальных серверов и задач, которые эти серверы должны выполнять. В испытаниях приняли участие платформы с двумя и четырьмя чипами Эльбрус-8С (VLIW, 8C/8T, 1,3 ГГц, 16 Мбайт L3-кеш, 70 Вт TDP, 28 нм). В качестве оппонентов выступили «типичные системы» на базе Intel Xeon Gold 6230 (x86-64, Cascade Lake-SP, 20C/40T, 2,1-3,9 ГГц, 27,5 Мбайт кеш, 125 Ватт TDP, 14 нм), которых в Сбере тысячи и тысячи. 
Изображения: YouTube/ElbrusTV По итогам тестирования серверы признаны работоспособными, но показавшими неудовлетворительный уровень производительности. Озвучены основные выводы: «мало памяти, медленная и устаревшая память, мало ядер, низкая тактовая частота». Особенно низкой оказалась производительность в приложениях, использующих Java.  Если в тестах PGbench/PostreSQL Xeon опередил Эльбрус в 1,7-3,3 раза, то в тестах на время отклика Java-приложения разница составила 23-26 раз. Запуск приложения, который по нормативам СберТеха должен укладываться в 60 секунд, занял у серверов Эльбрус 220 секунд в двухпроцессорном варианте и 164 секунды — в четырёхпроцессорном.  Кроме того, в рамках стандартных спецификаций компании системы на базе Эльбрус-8С смогли пройти всего по 7 параметрам из 44 предъявляемых. Если отсутствие монтажных стоечных рельсов можно отнести к «мелким претензиям», которые легко решаются, то отсутствие системы удалённого управления — недоработка весьма серьёзная, поскольку затраты на увеличение штата ИТ-специалистов окажутся непомерно велики. 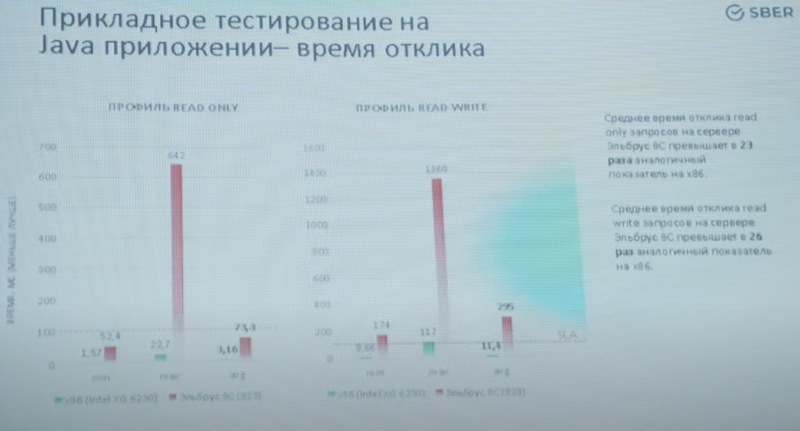 Стоит, однако, отметить, что Эльбрус-8С уже устарел в рамках собственной экосистемы: МЦСТ обещает представить на тестирование усовершенствованные варианты серверов на базе Эльбрус-8СВ с более высокой частотой (1,5 против 1,3 ГГц), удвоенной производительностью в операциях над числами с плавающей запятой, а также использующие память DDR4-2400 (до 1 Тбайт на сервер) вместо окончательно устаревшей DDR3-1600. Однако массовые поставки таких серверов при заказе 1-5 тыс. единиц возможны не ранее IV квартала 2022 года при заказе в III квартале 2021 года. 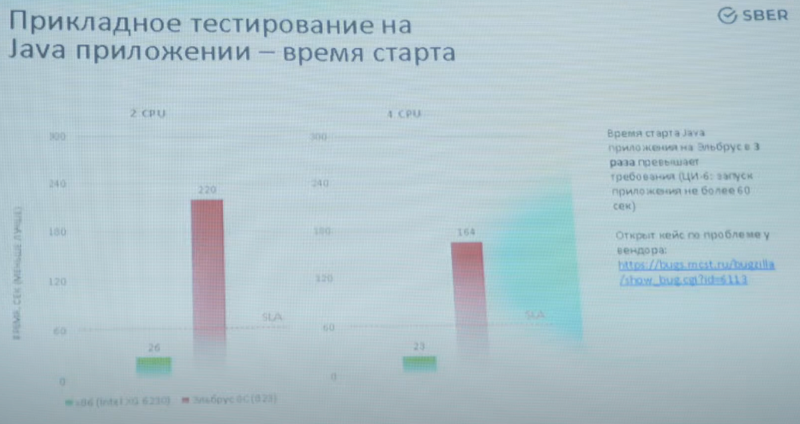 Признана необходимость проведения тестов систем на базе Эльбрус под управлением ОС, сертифицированных ФСТЭК по профилю не ниже ОС.А4 (использование для обработки персональных данных и ГИС). Также отмечена необходимость введения полноценной поддержки технологий виртуализации, а не только контейнеризации.  Отметим также, что МЦСТ успешно завершила разработку Эльбрус-16С, в котором ряд фундаментальных недостатков, присущих процессорам Эльбрус-8С/8СВ успешно устранён. Новый чип будет иметь 16 ядер с возросшей до 2 ГГц частотой, восьмиканальный контроллер памяти DDR4-3200 (до 16 Тбайт на сервер), контроллер 10GbE и интегрированный контроллер PCIe 3.0 (32 линии). Последний снимает серьёзные ограничения по пропускной способности чипов Эльбрус-8C/CB к периферийным устройствам. Также с 8 до 48 Гбайт/с возрастёт скорость межпроцессорного обмена данными. 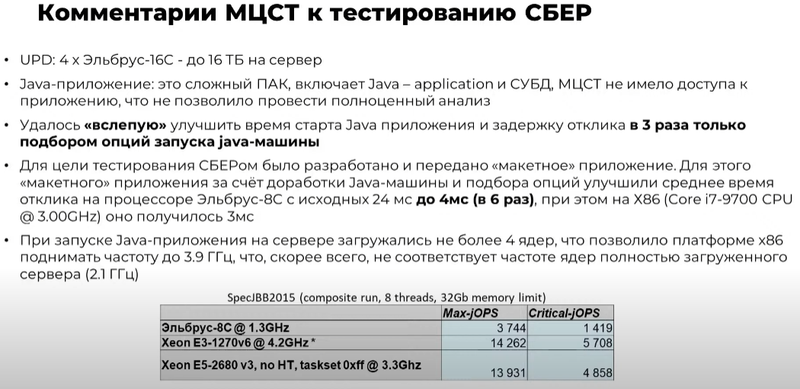 Представитель МЦСТ отметил, что низкие результаты в Java-тестах отчасти обусловлены «слепым тестированием», в котором разработчикам не были предоставлены данные, необходимые для полноценной оптимизации Java-машины. Простым подбором опций МЦСТ удалось улучшить показатели в три раза, а «макет» оптимизированного приложения СберТеха позволил сократить время отклика с 24 до 4 мс, что практически равнозначно показателям систем на базе процессоров Intel (Core i7-9700, 3 мс).
04.12.2021 [03:42], Игорь Осколков
Процессор Amazon Graviton3: 64 ядра Arm, 5-нм техпроцесс, чиплетная компоновка и DDR5 с PCIe 5.0Анонсированный на днях Arm-процессор Graviton3, создававшийся специально для нужд Amazon и AWS, неожиданно оказался по ряду параметров на голову выше ещё даже не вышедших EPYC и Xeon следующего поколения. И это не самый хороший сигнал для AMD, Intel, Qualcomm и прочих производителей. 
Amazon Graviton3. Фото: Ian Colle Graviton3 — первый массовый (самой Amazon и рядом избранных клиентов он используется уже не один месяц) серверный процессор с поддержкой DDR5 и PCIe 5.0. CPU выполнен по 5-нм техпроцессу TSMC и содержит примерно 55 млрд транзисторов. Для удешевления он использует BGA-корпусировку и чиплетную компоновку из семи отдельных кристаллов — два PCIe-контроллера и четыре двухканальных контроллера DDR5 вынесены за пределы собственно CPU. 
Узел EC2 C7g. Здесь и ниже изображения Amazon AWS Более того, их упаковка использует передовые решения с каналами длиной менее 55 мкм, что вдвое меньше, чем у других серверных CPU. Уменьшение длины проводников положительно сказывается на энергоэффективности, которая очень важна для любого гиперскейлера. Этим же объясняется и относительно небольшое по современным меркам число ядер (всего 64) и их частота (2,6 ГГц). Всё это позволило добиться энергопотребления примерно в 100 Вт. 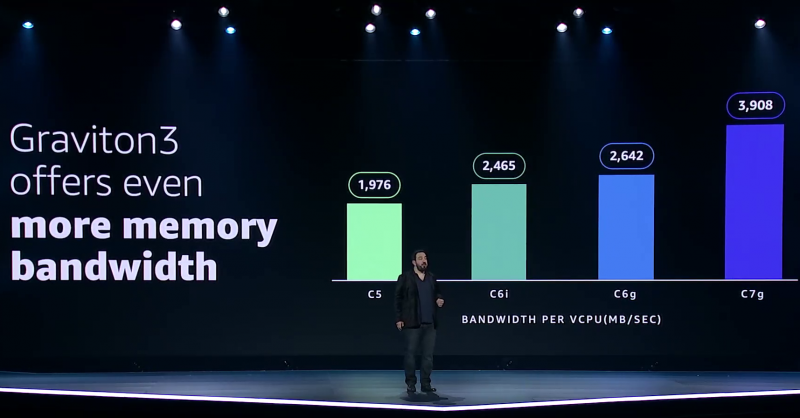 Есть и ещё один важный плюс в сохранении числа ядер — переход на DDR5-4800 позволил не только достичь пиковой суммарной пропускной способности памяти в 300 Гбайт/с на чип, но и повысить реальную скорость работы с памятью каждого vCPU (фактически ядра) в полтора раза по сравнению с прошлым поколением. Та же ситуация и с PCIe 5.0 — для достижения той же пропускной способности, что ранее, нужно вдвое меньше линий.  Для удешевления используются готовые IP-блоки сторонних компаний и, судя по всему, ядра тоже несильно отличаются от референсов Arm. А вот какие именно, узнаем не сразу, поскольку Amazon явно не указала, будут ли это Neoverse V1 (Zeus) или N2 (Perseus). Вероятно, это всё же V1 (ARMv8.5-A), поскольку по описанию Graviton3 похожи именно на эту архитектуру. Новые ядра стали значительно «шире» прежних — они забирают 8 инструкций, декодируют от 5 до 8 из них и отправляют на исполнение сразу 15 инструкций. Соответственно и число исполнительных блоков по сравнению с Neoverse-N1 (Graviton2) практически удвоилось. 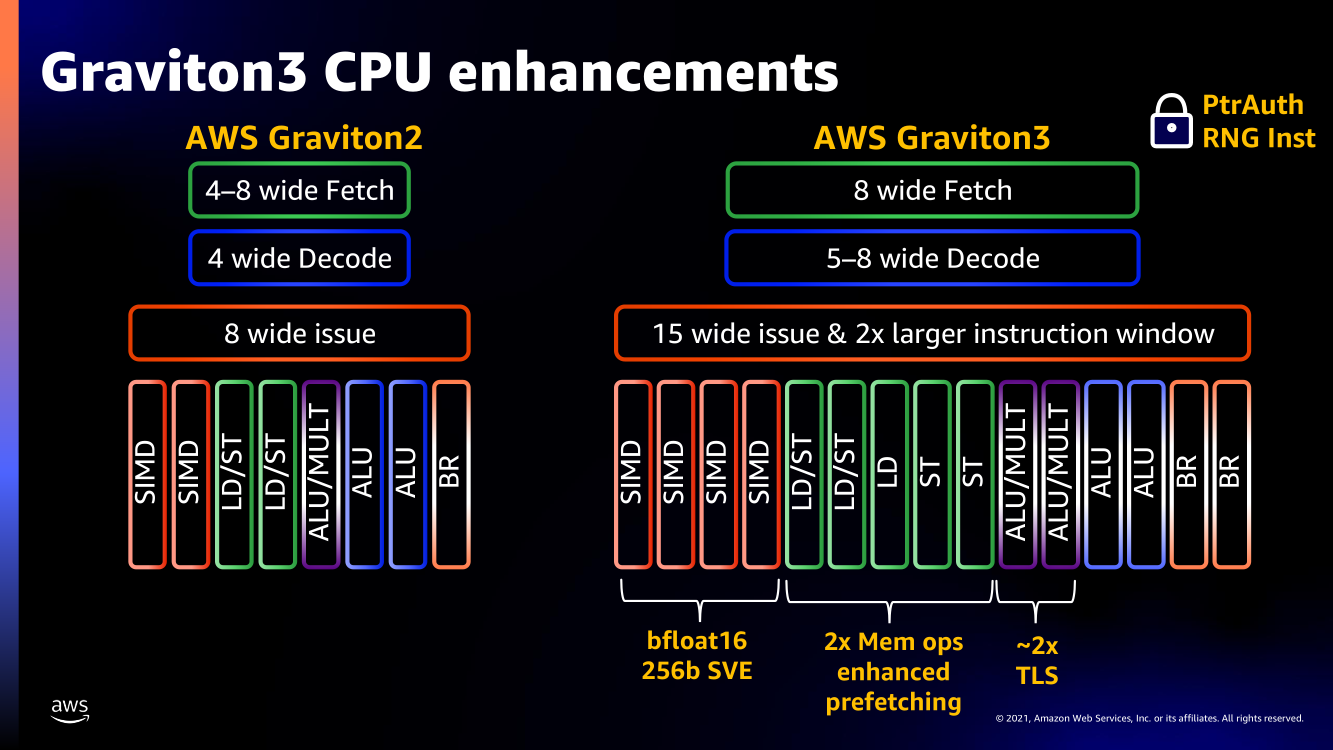  Кроме того, они обзавелись поддержкой 256-бит векторных инструкций SVE, что повысило не только скорость выполнения «классических» FP-операций (например, для задач медиакодирования и шифрования), но и благодаря поддержке bfloat16 позволило утверждать Amazon, что новые чипы годятся и для инференса. Среди упомянутых ранее мер защиты есть, например, принудительное шифрование оперативной памяти, изолированные кеши для каждого vCPU (ядра), аппаратная защита стека. 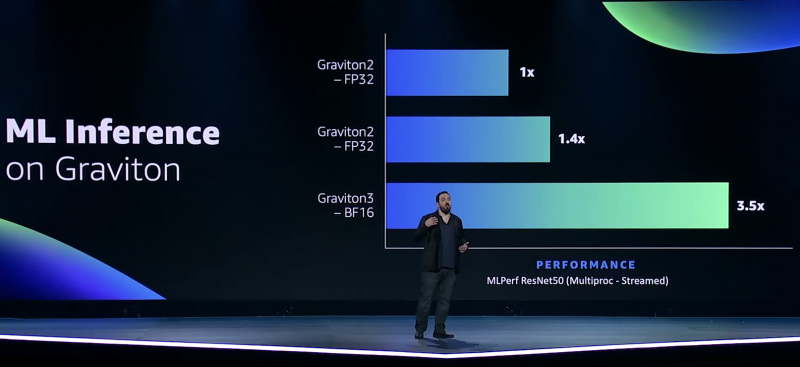
В подписи второго столбца явная опечатка В целом, средний прирост производительности Graviton3 по сравнению с Graviton2 составил 25 %, но в некоторых задачах он достигает 60 %. И всё это при сохранении того же уровня энергопотребления и тепловыделения. Всё это позволило уместить в одном 1U-узле с воздушным охлаждением сразу три процессора Graviton3. И они разительно отличаются от грядущих 128-ядерных процессоров Altra Max и EPYC Bergamo, которые Ampere и AMD позиционируют как решения для гиперскейлеров. Зато в чём-то похожи на Yitian 710 от Alibaba Cloud. 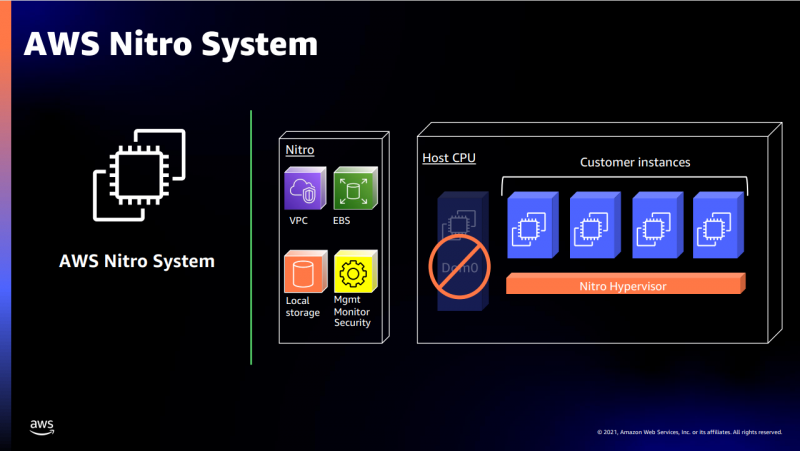 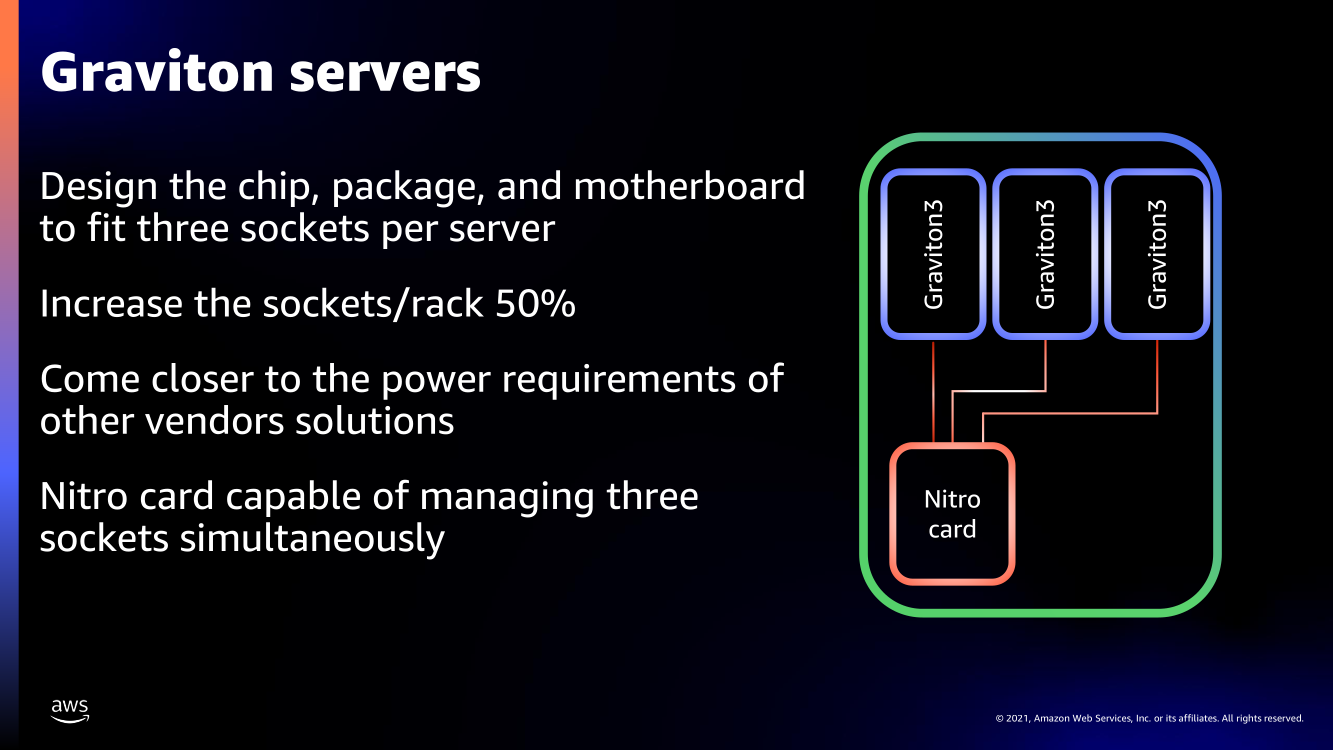 Но CPU — это лишь часть платформы, фундамент для которой несколько лет назад заложило появление чипов Nitro. Их сейчас стоило бы назвать DPU/IPU, хотя на момент их появления такого понятия, можно сказать, и не было. Nitro берёт на себя все задачи по обслуживанию гипервизора, обеспечению безопасности, работе с хранилищем и сетью и т.д., высвобождая, с одной стороны, все ресурсы CPU, памяти и SSD для обработки задачи клиента, а с другой — позволяя практически полностью дезагрегировать всю инфраструктуру. 
Узел с Nitro SSD Впрочем, Amazon пошла ещё дальше — теперь она самостоятельно закупает NAND-чипы и производит SSD, тоже под управлением Nitro. То есть у компании под контролем практически полный стек современных аппаратных решений: CPU, DPU, SSD, ИИ-ускорители для обучения (Trainium) и инференса (Inferentia). Она активно переносит на него собственные сервисы и предлагает их клиентам. И именно это и должно обеспокоить крупных вендоров, поскольку их решения вряд ли позволят добиться такого же уровня TCO, а гиперскейлеров, желающих перейти на аналогичную модель, немало.  UPD 06.12.21: презентация новых процессоров стала доступна публично, поэтому в материал добавлены некоторые иллюстрации, а в галерее ниже приведены результаты тестов производительности.
08.11.2021 [20:00], Игорь Осколков
AMD анонсировала процессоры EPYC Milan-X с 3D V-Cache: 804 Мбайт кеша и 64 ядра Zen3AMD анонсировала серию своих серверных процессоров под кодовым названием Milan-X. Новинки являются развитием EPYC 7003 (Milan), представленных весной этого года, и рассчитаны в первую очередь на высокопроизводительные вычисления (HPC). Главным же отличием от «обычных» Milan станет резко увеличенный объём кеш-памяти, что позволило AMD снова назвать свои процессоры самими быстрыми в мире. 
AMD EPYC Milan-X с 3D V-Cache (Здесь и ниже изобржаения AMD) Откуда берётся цифра в 804 Мбайт? Математика простая. На каждое ядро Zen3 приходится по 32 Кбайт L1-кеша для инструкций и данных + 512 Кбайт L2-кеша. На восемь ядер в CCX-комплексе приходится 32 Мбайт общего L3-кеша. И вот к ним добавляются ещё 64 Мбайт 3D V-Cache — в максимальной конфигурации на 8 CCX получается суммарно 768 Мбайт 3D V-Cache в дополнение к иерархии нижележащих кешей. Таким образом, конкретно по этому показателю побит рекорд IBM z15, хотя данный CPU ориентирован на совсем другие задачи.   А вот среди x86-64 равных Milan-X сейчас нет. Более того, по словам AMD, реализация 3D V-Cache на текущий момент является уникальной в индустрии. Дополнительный кеш имеет непосредственно подключение к CCX по медным каналами, что позволяет значительно повысить плотность упаковки и энергоэффективность, снизить задержки и улучшить температурный режим. Правда, детальные характеристики V-Cache пока не приводятся.  Что важно, новинки будут совместимы с имеющимися SP3-платформами для Milan, что упростит тестирование и валидацию — для них будет выпущено обновление BIOS. Увы, пока данные по частотам, TDP и цене компания не приводит — выпуск Milan-X запланирован на I квартал 2022 года. Но в сносках к презентации, в частности, упоминаются не только 64-ядерные Milan-X, но и 16-ядерные. Надо полагать, что такие «бутерброды» будут дороже обычных CCX, поскольку здесь цена брака будет выше.   Также заявлена совместимость с имеющимся ПО, но и с разработчиками уже ведётся активная работа по дополнительной оптимизации их решений. Наибольшую выгоду от увеличенного кеша получат нагрузки, для которых критична скорость работы с памятью и задержки доступа. Среди таковых AMD упоминает метод конечных элементов, структурный анализ, вычислительную гидродинамику и автоматизированные системы проектирования электроники (EDA). Для последних на примере Synopsys VCS рост производительности составил 66%.
26.10.2021 [22:45], Игорь Осколков
Получена первая партия российских серверных Arm-процессоров Baikal-S: 48 ядер, 6 каналов DDR4-3200 и 80 линий PCIe 4.0Компания «Байкал Электроникс» сообщила о получении первой партии инженерных образцов серверных Arm-процессоров Baikal-S объёмом 400 шт. Следующую партию компания ожидает получить в первом квартале следующего года, а первые массовые поставки (партия более 10 тыс. шт.) должны начаться до конца третьего квартала. Инженерные платы для разработчиков, созданы «Гаоди рус» (Dannie Group) и выпущены компанией «Рутек». Baikal-S, изготавливаемый по 16-нм техпроцессу на TSMC, имеет 48 ядер Arm Cortex-A75 на базе достаточно свежей 64-бит архитектуры ARMv8.2-A, которая была анонсирована в 2017 году. Частота составляет до 2,2 ГГц, а уровень TDP равен 120 Вт. Заявленный диапазон рабочих температур простирается от 0 до +70 °C. Производительность в HPL составляет 385 Гфлопс, а рейтинг в SPEC CPU2006 INT — до 600. Ориентировочная цена одного процессора ожидается на уровне $3 тыс.  L1-кеш имеет объём по 64 Кбайт для данных и инструкций, а L2 — 512 Кбайт на ядро. Любопытно, что в дополнение к L3-кешу (по 2 Мбайт на кластер) есть ещё и L4-кеш на 32 Мбайт. Контроллер памяти имеет шесть каналов DDR4-3200 ECC и обслуживает до 128 Гбайт на канал (суммарно 768 Гбайт на сокет). Кроме того, каждый процессор имеет 80 линий PCIe 4.0, из которых 48 линий делятся тремя интерфейсами CCIX x16. Также есть пара 1GbE-интерфейсов. 
Источник: CNews При этом новинка поддерживает аппаратную виртуализацию, Arm TrustZone и позволяет создавать четырёхсокетные платформы. Всё это делает её привлекательным решением не только для традиционных серверов и СХД, но и для и HCI- и HPC-систем. С экосистемой ПО проблемы вряд ли будут. Во-первых, для «малого» Байкал-М уже сейчас есть отечественные ОС и другие продукты. Во-вторых, серверные платформы Arm в мире развивают сразу несколько игроков, да и сама Arm стимулирует процесс разработки и портирования ПО. Кроме того, «Байкал Электроникс» имеет тесные связи с ГК Astra Linux.
19.10.2021 [19:39], Алексей Степин
Alibaba Cloud представила серверный 128-ядерный Armv9-процессор Yitian 710Эпоха неоспоримого господства x86-64 в серверах, похоже, постепенно всё же подходит к концу. Ampere, AWS, Fujitsu, HiSilicon, Phytium и другие производители Arm-процессоров дают бой x86-64 и выигрывает его, пусть и не во всех областях. Эффективность серверных Arm-решений уже неоспорима, количество ядер уже перевалило за сотню, а теперь ещё один крупный провайдер облачных услуг, китайская компания Alibaba Cloud, анонсировала свой вариант высокопроизводительного CPU на базе Arm. Первые попытки Arm проникнуть на рынок серверов или рабочих станций были робкими и неуверенными, но за последние несколько лет ситуация сильно изменилась: уверенно показывают себя такие интересные чипы, как Ampere Altra, недавно доросшие уже до 128 ядер, Amazon активно предлагает инстансы на базе Graviton2, а Huawei даже открывает первый в России ЦОД на базе своих чипов Kunpeng 920.  Более того, мощные многоядерные Arm-процессоры обрастают собственной инфраструктурой: появляются собственные процессорные разъёмы, системные платы, не уступающие x86-моделям, и даже варианты в виде рабочих станций для разработчиков программного обеспечения, без которого любая платформа мертва. Тем интереснее выглядит анонс Alibaba Cloud. Компания сообщила о выпуске нового процессора, который послужит основой для её облачных. И по ряду характеристик можно видеть, что это весьма передовые решения. Новинка носит название Yitian 710, она имеет собственный процессорный сокет и инфраструктуру сопутствующей «обвязки» (есть и референс-дизайн сервера, Panjiu). Впрочем, интереснее то, что эти процессоры — как и Altra Max — могут иметь до 128 ядер.  Но если текущее поколение Ampere Altra базируется на наборе инструкций Armv8.2 с некоторыми заимствованиями из v8.3 и v8.4, то китайский гигант использует более новый вариант, Armv9. Эта версия архитектуры была анонсирована только весной этого года, она, как минимум, на треть быстрее v8, поддерживает аппаратную ускорение работы контейнеров и виртуальных машин, а также наделена востребованными нынче векторными инструкциями со средствами ускорения машинного обучения (SVE2). 5-нм процессоры Yitian 710 поставляются с июля этого года. Они содержат примерно 60 млрд транзисторов и могут иметь тактовую частоту до 3,2 ГГц, а также включают 128 Мбайт L3-кеша, восьмиканальный контроллер DDR5-4400 и 96 линий PCIe 5.0. TDP равен 250 Вт. Так что это один из самых передовых на сегодня серверных процессоров не только в плане чистой производительности. Сама Alibaba называет свое детище универсальным, одинаково хорошо подходящим для нагрузок общего назначения, развёртывания СХД и ИИ-нагрузок, но, разумеется, приоритет отдаётся задачам, характерным для облачных сред. 
Alibaba Cloud: Yitian 710 превосходит всех ARM-соперников и в своём классе является лучшим Ввиду санкционных трений решение Alibaba Cloud разработать собственный мощный процессор выглядит вполне обоснованно, как и принятое ранее решение о создании собственной ИИ-платформы Hanguang 800. И это не единственные разработки Alibaba Cloud. Компания собирается сделать открытым дизайн не только четырёх чипов XuanTie (RISC-V), но и некоторых будущих ядер. Открыт будет и сопутствующий набор ПО, так что Alibaba Cloud всерьёз намеревается вырастить вокруг своего «кремния» развитую инфраструктуру аппаратного и программного обеспечения.
30.09.2021 [16:15], Сергей Карасёв
128-ядерный Arm-процессор Ampere Altra Max оказался на треть дешевле флагманских Xeon и EPYCРесурс Phoronix раскрыл стоимость многоядерных процессоров Ampere Altra Max, предназначенных для использования в высокопроизводительных серверах. Наблюдатели отмечают, что эти изделия, насчитывающие до 128 вычислительных ядер, предлагаются по цене ниже флагманских серверных чипов Intel Xeon и AMD EPYC. Arm-процессоры Ampere Altra Max M128-30 с частотой 3,0 ГГц изготавливаются по 7-нм технологии и предлагают 128 линий PCIe 4.0 и восемь каналов оперативной памяти DDR4-3200. Тесты Phoronix показывают, что в целом ряде задач чипы Ampere Altra Max M128-30 могут вполне конкурировать со старшими моделями Intel Xeon Ice Lake и AMD EPYC Milan. 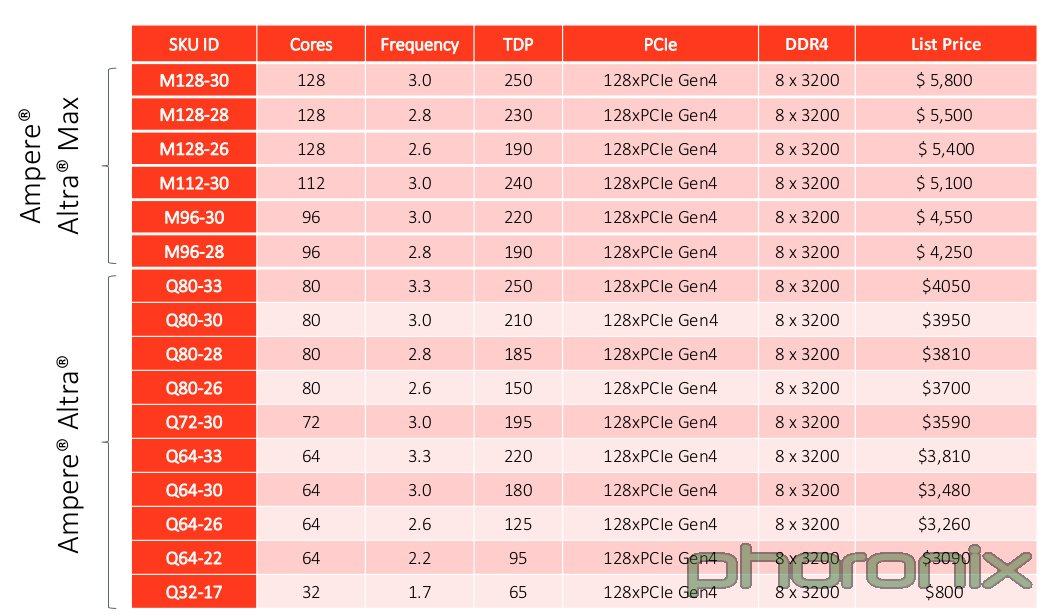
Источник: Phoronix Итак, сообщается, что цена Ampere Altra Max M128-30 составляет $5800. Для сравнения: чип Intel Xeon Platinum 8380 сейчас предлагается за $8099, тогда как AMD EPYC 7763 стоит $8600. Процессор Ampere Altra Q80-30 с 80 вычислительными ядрами можно приобрести по цене $3950, а самая младшая 32-ядерная модель Ampere Altra Q32-17 стоит всего $800. Правда, надо учитывать, что всё это рекомендованные цены, а у AMD с Intel намного больше возможностей по их снижению для конечных заказчиков.
22.09.2021 [21:16], Алексей Степин
Выпущена тестовая партия европейских высокопроизводительных RISC-V процессоров EPI EPAC1.0Наличие собственных высокопроизводительных процессоров и сопровождающей их технической инфраструктуры — в современном мире вопрос стратегического значения для любой силы, претендующей на первые роли. Консорциум European Processor Initiative (EPI), в течение долгого времени работавший над созданием мощных процессоров для нужд Евросоюза, наконец-то, получил первые весомые плоды. О проекте EPI мы неоднократно рассказывали читателям в 2019 и 2020 годах. В частности, в 2020 году к консорциуму по разработке мощных европейских процессоров для систем экза-класса присоединилась SiPearl. Но сегодня достигнута первая серьёзная веха: EPI, насчитывающий на данный момент 28 членов из 10 европейских стран, наконец-то получил первую партию тестовых образцов процессоров EPAC1.0. 
Источник изображений: European Processor Initiative (EPI) По предварительным данным, первичные тесты новых чипов прошли успешно. Процессоры EPAC имеют гибридную архитектуру: в качестве базовых вычислительных ядер общего назначения в них используются ядра Avispado с архитектурой RISC-V, разработанные компанией SemiDynamics. Они объединены в микро-тайлы по четыре ядра и дополнены блоком векторных вычислений (VPU), созданным совместно Барселонским Суперкомпьютерным Центром (Испания) и Университетом Загреба (Хорватия). 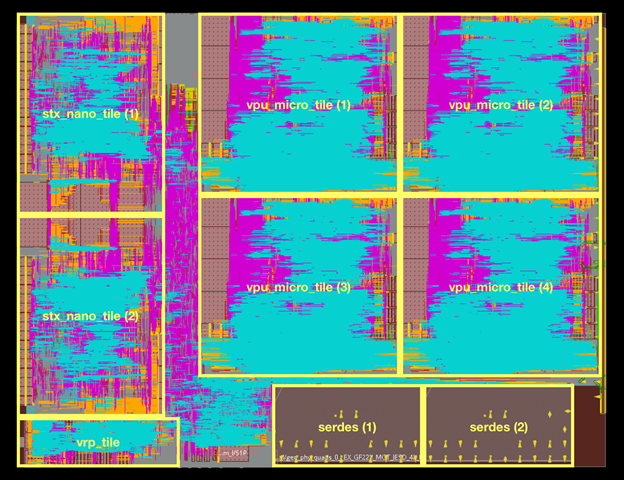
Строение кристалла EPAC1.0 Каждый такой тайл содержит блоки Home Node (интерконнект) с кешем L2, обеспечивающие когерентную работу подсистем памяти. Имеется в составе EPAC1.0 и описанный нами ранее тензорно-стенсильный ускоритель STX, к созданию которого приложил руку небезызвестный Институт Фраунгофера (Fraunhofer IIS). Дополняет картину блок вычислений с изменяемой точностью (VRP), за его создание отвечала французская лаборатория CEA-LIST. Все ускорители в составе нового процессора связаны высокоскоростной сетью, использующей SerDes-блоки от EXTOLL. 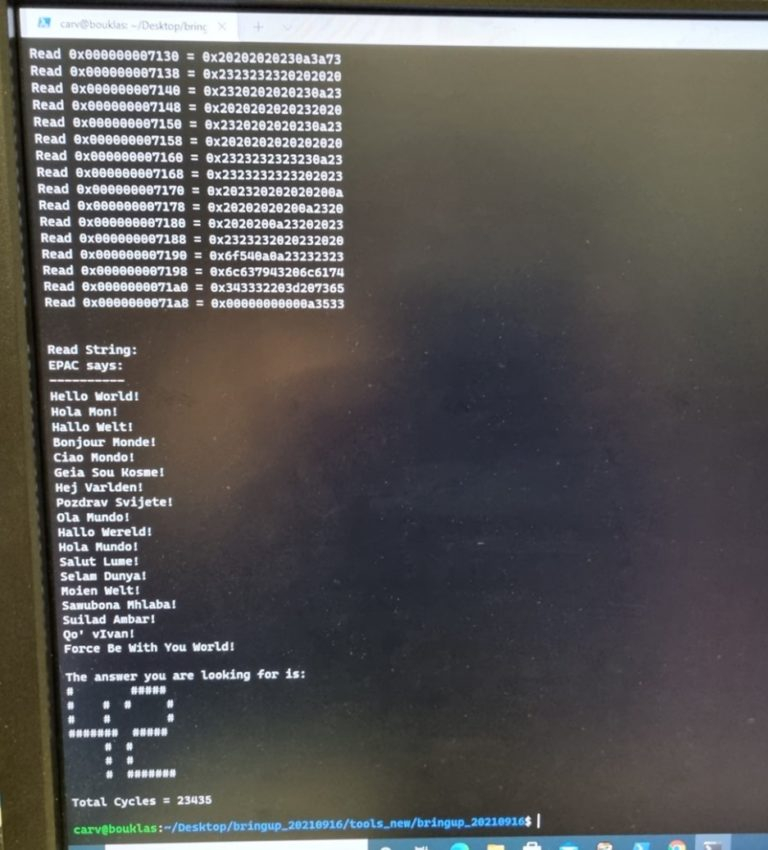 Первые 143 экземпляра EPAC произведены на мощностях GlobalFoundries с использованием 22-нм техпроцесса FDX22 и имеют площадь ядра 27 мм2. Используется упаковка FCBGA 22x22. Тактовая частота невысока, она составляет всего 1 ГГц. Отчасти это следствие использования не самого тонкого техпроцесса, а отчасти обусловлено тестовым статусом первых процессоров. Но новорожденный CPU жизнеспособен: он успешно запустил первые написанные для него программы, в числе прочего, ответив традиционным «42» на главный вопрос жизни и вселенной. Ожидается, что следующее поколение EPAC будет производиться с использованием 12-нм техпроцесса и получит чиплетную компоновку.
08.09.2021 [19:00], Алексей Степин
Intel представила процессоры Xeon E-2300: Rocket Lake-E для серверов и рабочих станций начального уровняВ современном мире нагрузки на процессор год от года становятся всё сложнее и объёмнее, и не только крупные ЦОД нуждаются в архитектурных новшествах и новых наборах инструкций — малому бизнесу также требуются чипы нового поколения. Корпорация Intel ответила на это выпуском новых процессоров Xeon серии E-2300 и соответствующей платформы для них. Новинки стали быстрее и получили долгожданную поддержку PCI Express 4.0. Платформа Xeon E-2x00 не обновлялась достаточно давно: процессоры серии E-2200 были представлены ещё в 2019 году. На тот момент это был действительно прорыв в сегменте чипов Intel начального уровня — они впервые получили до 8 ядер Coffee Lake-S, а поддерживаемый объём памяти вырос с 64 до 128 Гбайт. Однако на сегодня таких возможностей уже может оказаться недостаточно: у E-2200 нет AVX-512 с VNNI, шина PCIe ограничена версией 3.0, а графическое ядро HD Graphics P630 и по меркам 2019 года быстрым назвать было нельзя. 
Источник изображений: Intel 10 новых процессоров Xeon E-2300, анонсированных Intel сегодня, должны заполнить пустующую нишу младших бизнес-решений. Нововведений в новой платформе не так уж мало, как может показаться на первый взгляд, ведь максимальное количество процессорных ядер у Xeon E-2300 по-прежнему восемь. Однако их максимальная частота выросла до 5,1 ГГц. Изменился процессорный разъём, теперь это LGA1200. 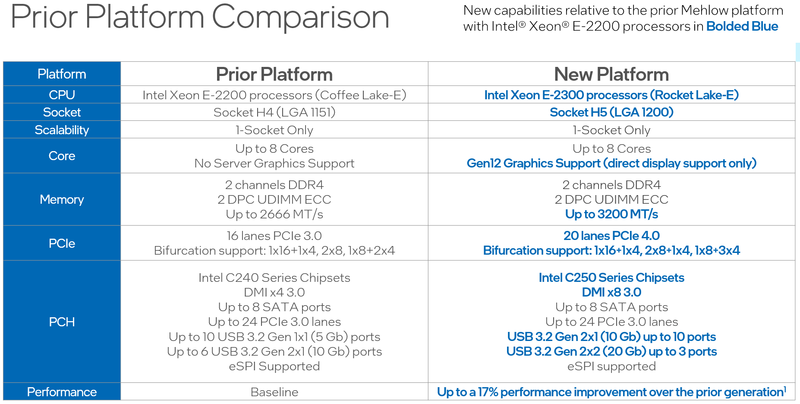 Ядра 11-го поколения Rocket Lake-E (Cypress Cove) по-прежнему используют 14-нм техпроцесс, но оптимизированная микроархитектура позволила Xeon E-2300 быть быстрее соответствующих моделей предыдущего поколения на 17%, и это без учёта качественных нововведений — теперь у них есть AVX-512 с поддержкой инструкций VNNI, ускоряющих работу нейросетей. Нововведения касаются и вопросов информационной безопасности, в которой малый бизнес нуждается не меньше крупного. Как и «большие» Xeon на базе Ice Lake-SP, процессоры Xeon E-2300 получили «взрослую» поддержку защищённых анклавов SGX объёмом до 512 Мбайт, что существенно выше максимально доступных для прошлого поколения Xeon E 64 Мбайт. Максимальный объём памяти остался прежним, но скорость подросла — до 128 Гбайт DDR4-3200 ECC UDIMM в двух каналах (2DPC).  Весьма важно также появление нового графического ядра с архитектурой Xe-LP. Конечно, высокой 3D-производительности от него ждать не стоит, но даже в этом оно на шаг впереди устаревшей архитектуры. К этому стоит добавить поддержку HDMI 2.0b и DP 1.4a, аппаратное декодирование 12-бит HEVC и VP9 и 10-бит AV1, а также кодирование в 8-бит AVC и 10-бит HEVC и VP9. 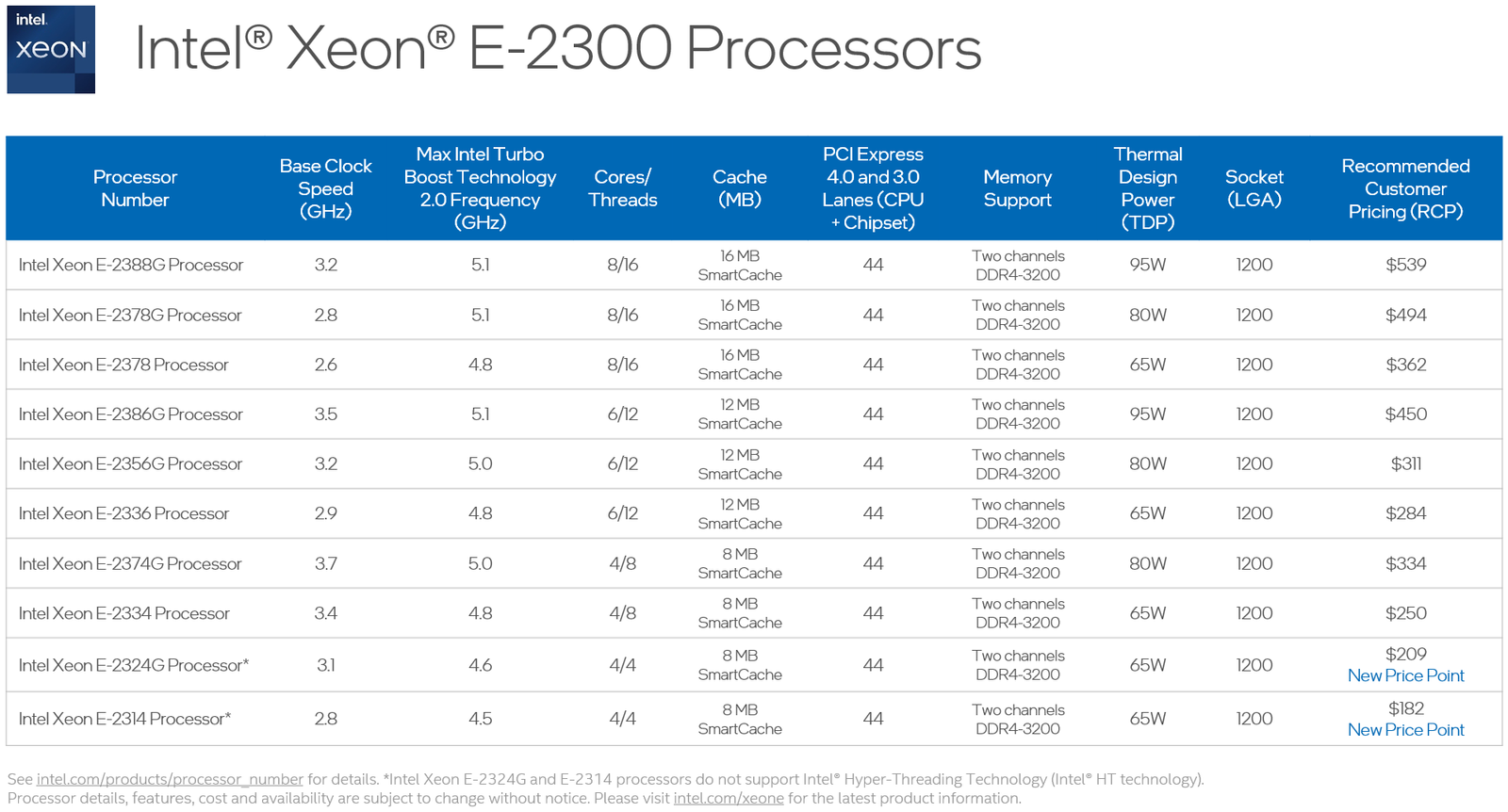 Поддержка PCIe 4.0 пришла и на платформу Xeon E — новые процессоры могут предложить 20 линий PCIe 4.0, причём с поддержкой бифуркации. Ещё 24 линии PCIe 3.0 включает чипсет серии C250. В нём же имеется поддержка 8 портов SATA-3 и USB 3.2 Gen 2x2 — до трёх портов со скоростью 20 Гбит/с. Сетевая часть может быть реализована как на базе недорогих чипов i210, так и более производительных i225 (2,5 Гбит/с) или x550 (10 Гбит/с).  В новой серии, как уже было сказано, представлено 10 процессоров, стоимостью от $182 до $539 и теплопакетами от 65 до 95 Вт. Лишь две младшие модели в списке не имеют поддержки Hyper-Threading. Все Xeon E-2300 располагают встроенным движком Manageability Engine 15 и поддержкой Intel Server Platform Services 6, облегчающей развёртывание и удалённое управление. Свои решения на базе новой платформы представят все ведущие производители серверного оборудования.
01.09.2021 [23:58], Андрей Галадей
Ветераны индустрии основали стартап Ventana для создания чиплетных серверных процессоров RISC-VСтартап Ventana Micro Systems, похоже, намерен перевернуть рынок серверов. Компания заявила о разработке высокопроизводительных процессоров на архитектуре RISC-V для центров обработки данных. Первые образцы фирменных CPU будут переданы клиентам во второй половине следующего года, а поставки начнутся в первой половине 2023 года. При этом процессоры получат чиплетную компоновку — различные модули и кристаллы на общей подложке. Основные процессорные ядра разработает сама Ventana, а вот остальные чиплеты будут создаваться под нужды определённых заказчиков. CPU-блоки будут иметь до 16 ядер, которые, как обещается, окажутся быстрее любых других реализаций RV64. Использование RISC-V позволит разрабатывать сверхмощные решения в рекордные сроки и без значительного бюджета. Ядра будут «выпекаться» на TSMC по 5-нм нормам, но для остальных блоков могут использовать другие техпроцессы и фабрики. Ventana будет следить за процессом их создания и упаковывать до полудюжины блоков в одну SoC. Для соединения ядер, кеша и других компонентов будет использоваться фирменная кеш-когерентная шина, которая обеспечит задержку порядка 8 нс и скорость передачи данных 16 Гбит/с на одну линию. Основными заказчиками, как ожидается, станут гиперскейлеры и крупные IT-игроки, которым часто требуется специализированное «железо» для ЦОД, 5G и т.д. Сегодня Ventana объявила о привлечении $38 млн в рамках раунда B. Общий же объём инвестиций составил $53 млн. Компания была основана в 2018 году. Однако это не совсем обычный стартап — и сами основатели, и команда являются настоящими ветеранами индустрии. Все они имеют многолетний опыт работы в Arm, AMD, Intel, Samsung, Xilinx и целом ряде других крупных компаний в области микроэлектроники. Часть из них уже имела собственные стартапы, которые были поглощены IT-гигантами.
24.08.2021 [04:11], Алексей Степин
IBM представила процессоры Telum: 8 ядер, 5+ ГГц, L2-кеш 256 Мбайт и ИИ-ускорительФинансовые организации, системы бронирования и прочие операторы бизнес-критичных задач любят «большие машины» IBM за надёжность. Недаром литера z в названии систем означает Zero Downtime — нулевое время простоя. На конференции Hot Chips 33 компания представила новое поколение z-процессоров, впервые в истории получившее собственное имя Telum (дротик в переводе с латыни). «Оружейное» название выбрано неспроста: в новой архитектуре IBM внедрила и новые, ранее не использовавшиеся в System z решения, предназначенные, в частности, для борьбы с фродом. 
Пластина с кристаллами IBM Telum Одни из ключевых заказчиков IBM — крупные финансовые корпорации и банки — давно ждали встроенных ИИ-средств, поскольку их системы должны обрабатывать тысячи и тысячи транзакций в секунду, и делать это максимально надёжно. Одной из целей при разработке Telum было внедрение инференс-вычислений, происходящих в реальном времени прямо в процессе обработки транзакции и без отсылки каких-либо данных за пределы системы.  Поэтому инференс-ускоритель в Telum соединён напрямую с подсистемой кешей и использует все механизмы защиты процессора и памяти z/Architecture. И сам он тоже несёт ряд характерных для z подходов. Так, управляет работой акселератора отдельная «прошивка» (firmware), которую можно менять для оптимизации задач конкретного клиента. Она выполняется на одном из ядер и собственно ускорителе, который общается с данным ядром, и отвечает за обращения к памяти и кешу, безопасность и целостность данных и управление собственно вычислениями. 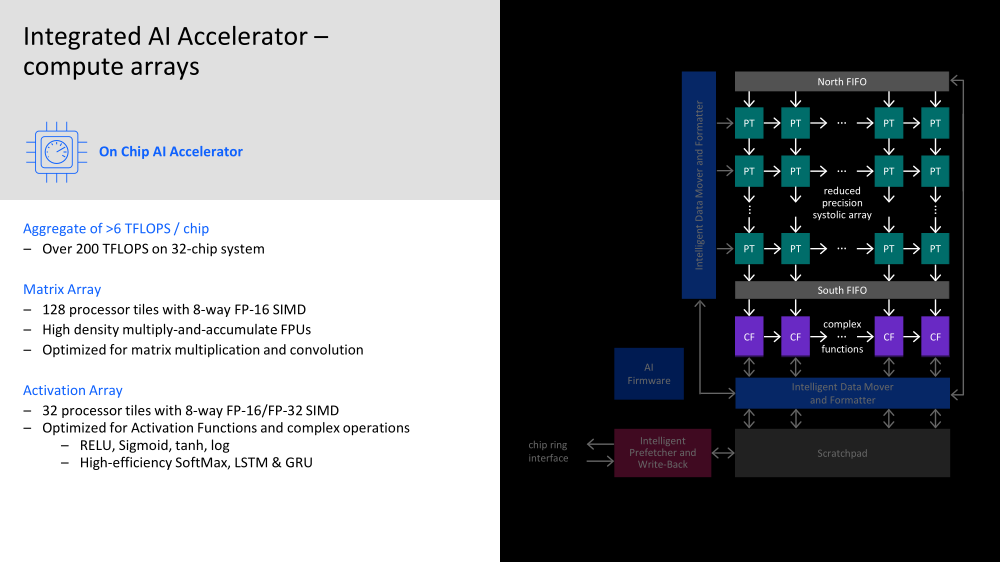 Акселератор включает два вида движков. Первый имеет 128 SIMD-блоков для MAC-операций с FP16-данными и нужен для перемножения и свёртки матриц. У второго всего 32 SIMD-блока, но он может работать с FP16/FP32-данными и оптимизирован для функций активации сети и других, более комплексных задач. Дополняет их блок сверхбыстрой памяти (scratchpad) и «умный» IO-движок, ответственный за перемещение и подготовку данных, который умеет переформатировать их на лету. 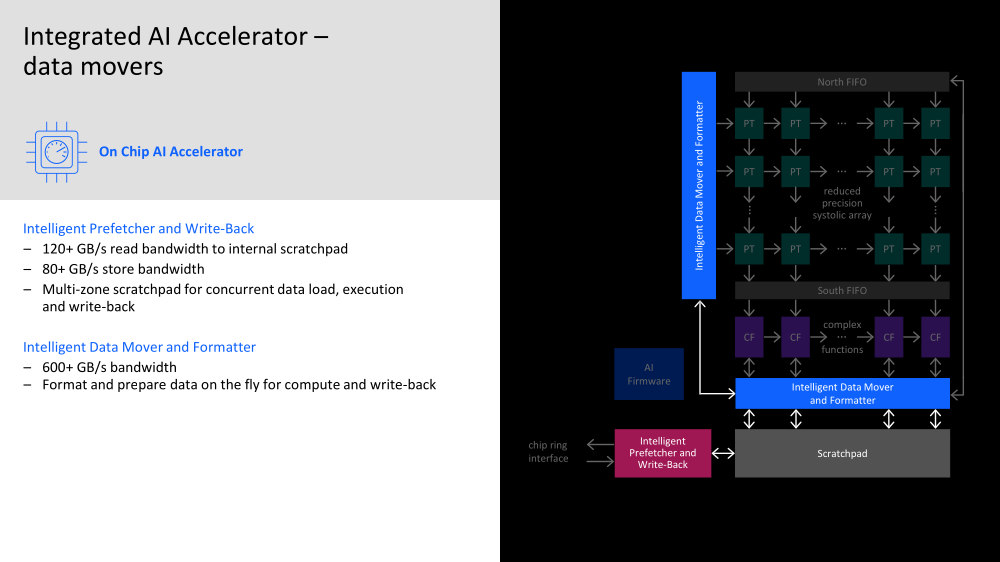 Scratchpad подключён к блоку, который подкачивает данные из L2-кеша и отправляет обратно результаты вычислений. IBM отдельно подчёркивает, что наличие выделенного ИИ-ускорителя позволяет параллельно использовать и обычные SIMD-блоки в ядрах, явно намекая на AVX-512 VNNI. Впрочем, в Sapphire Rapids теперь тоже есть отдельный AMX-блок в ядре, который однако скромнее по функциональности. 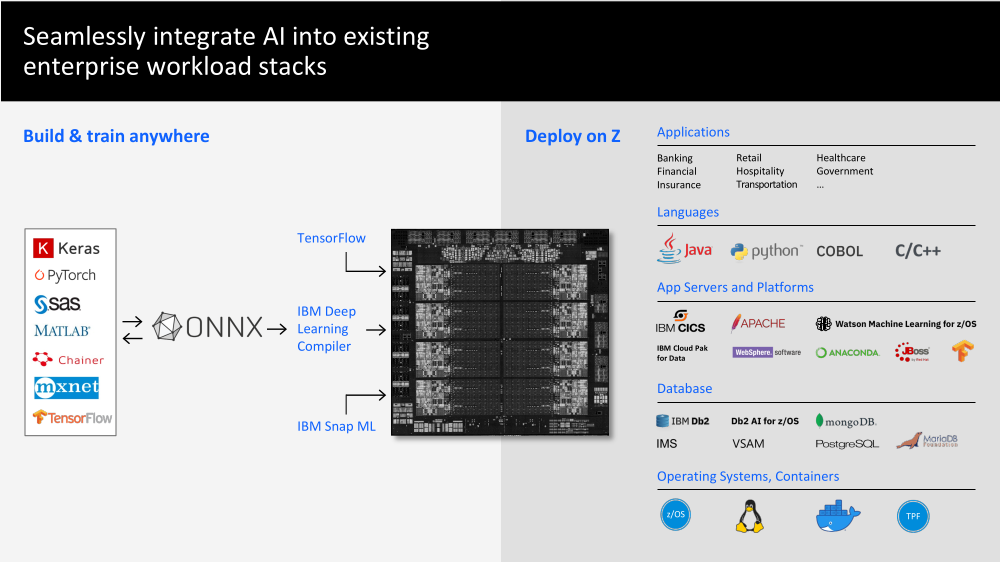 Доступ к ускорителю возможен из пространства пользователя, в том числе в виртуализированном окружении. Для работы с новым ускорителем компания предлагает IBM Deep Learning Compiler, который поможет оптимизировать импортируемые ONNX-модели. Также есть готовая поддержка TensorFlow, IBM Snap ML и целого ряда популярных средств разработки. На процессор приходится один ИИ-ускоритель производительностью более 6 Тфлопс FP16. 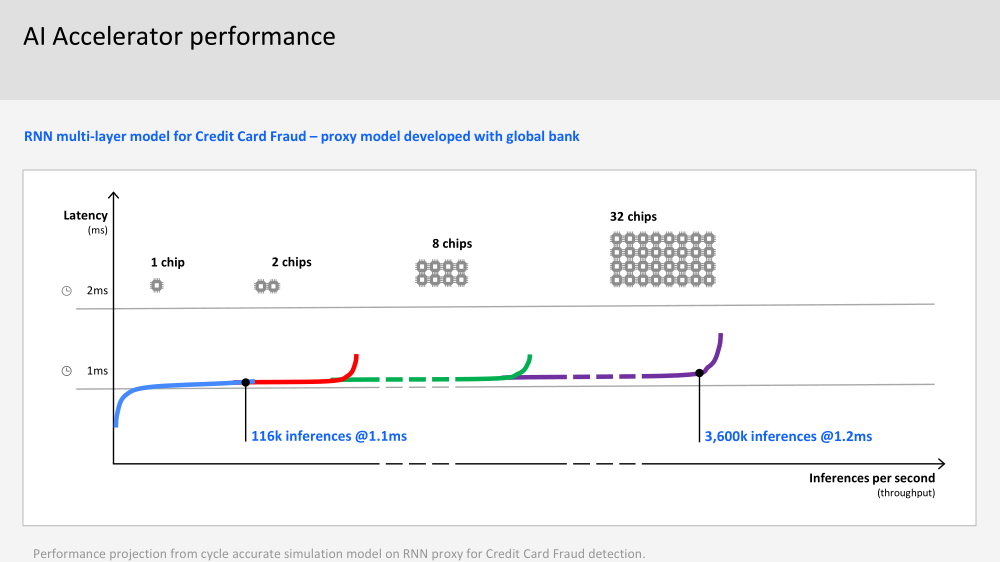 На тестовой RNN-модели для защиты от фрода чип может выполнять 116 тыс. инференс-операций с задержкой в пределах 1,1 мс, а для системы из 32 процессоров этот показатель составляет уже 3,6 млн инференс-операций, а латентность при этом возрастает всего лишь до 1,2 мс. Помимо ИИ-акселератора также имеется общий для всех ядер ускоритель (де-)компрессии (gzip) + у каждого ядра есть ещё и движок для CSMP. Ну и ускорители для сортировки и шифрования тоже никуда не делись.  За надёжность отвечают сотни различных механизмов проверки и перепроверки работоспособности. Так, например, регистры и кеш дублируются, позволяя в случае сбоя ядра сделать его полную перезагрузку и продолжить выполнение задач ровно с того места, где оно прервалось. А для оперативной памяти, которая в обязательном порядке шифруется, используется режим Redundant Array of Memory (RAIM), своего рода RAID-массив, где одна кеш-линия «размазывается» сразу между восемью модулями.  Telum, унаследовав многое от своего предшественника z15, всё же кардинально отличается от него. Процессор содержит восемь ядер с поддержкой «умного» глубокого внеочередного исполнения и SMT2, работающих на частоте более 5 ГГц. Каждому ядру полагается 32 Мбайт L2-кеша, так что на его фоне другие современные CPU выглядят блекло. Но не всё так просто. 
IBM Telum Между собой кеши общаются посредством двунаправленной кольцевой шины с пропускной способностью более 320 Гбайт/с, формируя таким образом виртуальный L3-кеш объёмом 256 Мбайт и со средней задержкой в 12 нс. Каждый чип Telum может содержать один (SCM) или два (DCM) процессора. А в одном узле может быть до четырёх чипов, то есть до восьми CPU, объединённых по схеме каждый-с-каждым с той же скоростью 320 Гбайт/с.  Таким образом, в рамках узла формируется виртуальный L4-кеш объёмом уже 2 Гбайт. Плоская топология кешей, по данным IBM, обеспечивает новым процессорам меньшую латентность в сравнении с z15. Масштабирование возможно до 32 процессоров, но отдельные узлы связаны несколькими подключениями со скоростью «всего» 45 Гбайт/с в каждую сторону.  В целом, IBM говорит о 40% прироста производительности в сравнении с z15 в пересчёте на сокет. Telum содержит 22 млрд транзисторов и имеет TDP на уровне 400 Вт в нормальном режиме работы. Процессор будет производиться на мощностях Samsung с использованием 7-нм техпроцесса EUV. Он станет основной для мейнфреймов IBM z16 и LinuxNOW. Программной платформой всё так же будут как традиционная z/OS, так и Linux. |
|
