Материалы по тегу: cpu
|
13.12.2022 [21:52], Алексей Степин
Ventana анонсировала первый по-настоящему серверный RISC-V процессор Veyron V1: 192 ядра с частотой 3,6 ГГцАрхитектура RISC-V достаточно молода и обычно ассоциируется с экономичными чипами на платах, подобных Raspberry Pi. Однако технически она позволяет создавать и мощные процессоры, способные поспорить с лучшими решениями на базе архитектур Arm и x86. На саммите RISC-V компания Ventana Micro Systems анонсировала целое семейство высокопроизводительных процессоров, первенцем в котором стал чип Veyron V1, который, по словам разработчиков, сможет потягаться в однопоточной производительности с самыми современными CPU класса High-End. 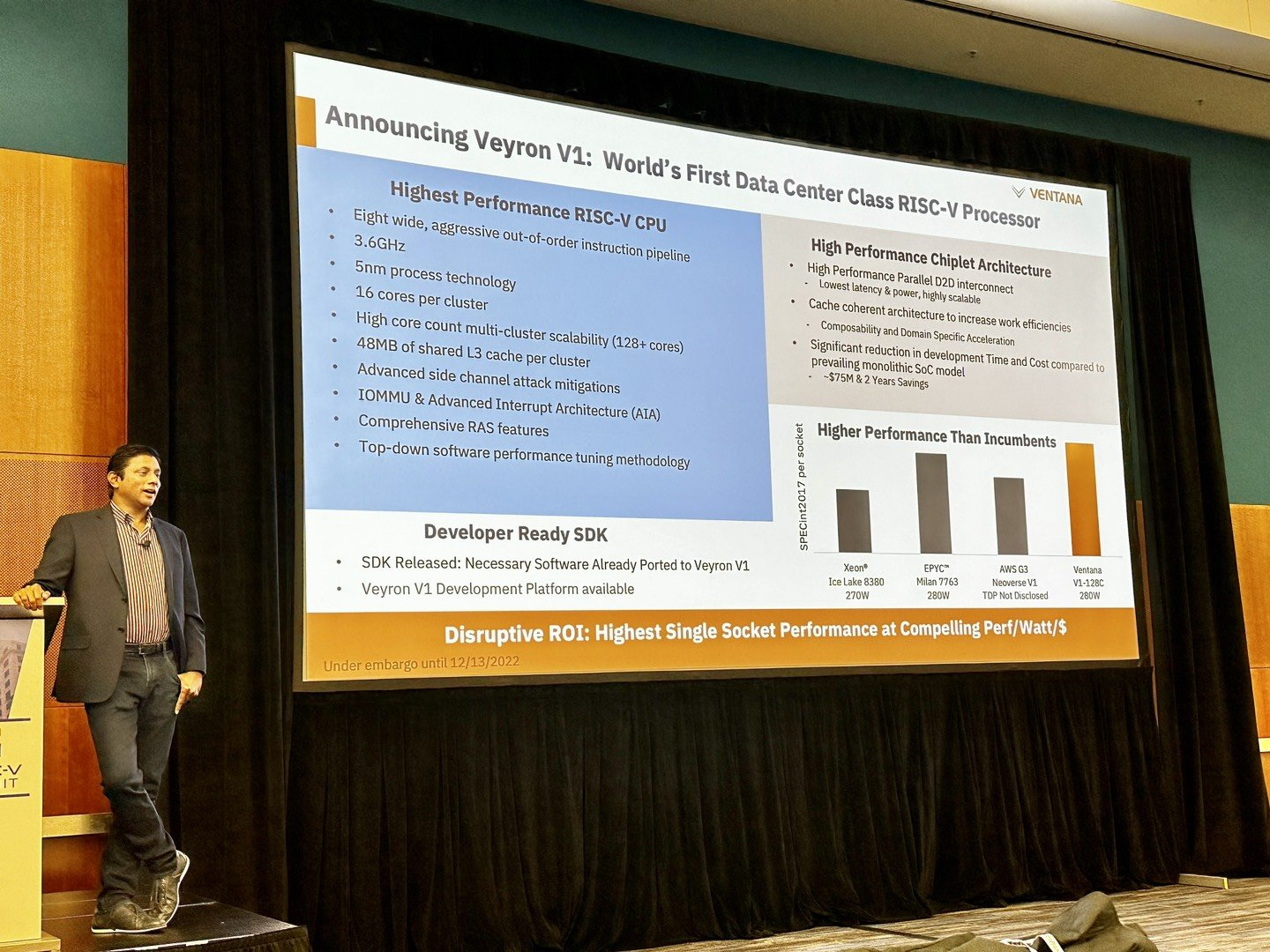
Veyron V1 должен стать самым быстрым процессором с архитектурой RISC-V. Источник: Twitter@risc_v Новинка нацелена на рынок гиперскейлеров, причём благодаря чиплетному дизайну новый процессор изначально разрабатывался как кастомизируемый под задачи заказчика. Veyron V1 будет предлагаться в виде своеобразного набора-конструктора, включающего в себя один или несколько вычислительных чиплетов Veyron, I/O-хаба и интерконнекта, позволяющего связать все компоненты воедино. Это, по словам разработчиков, должно серьёзно ускорить и удешевить процесс внедрения новой процессорной платформы, снизив расходы на разработку чипов на 75 %, а время создания — до не более чем двух лет. 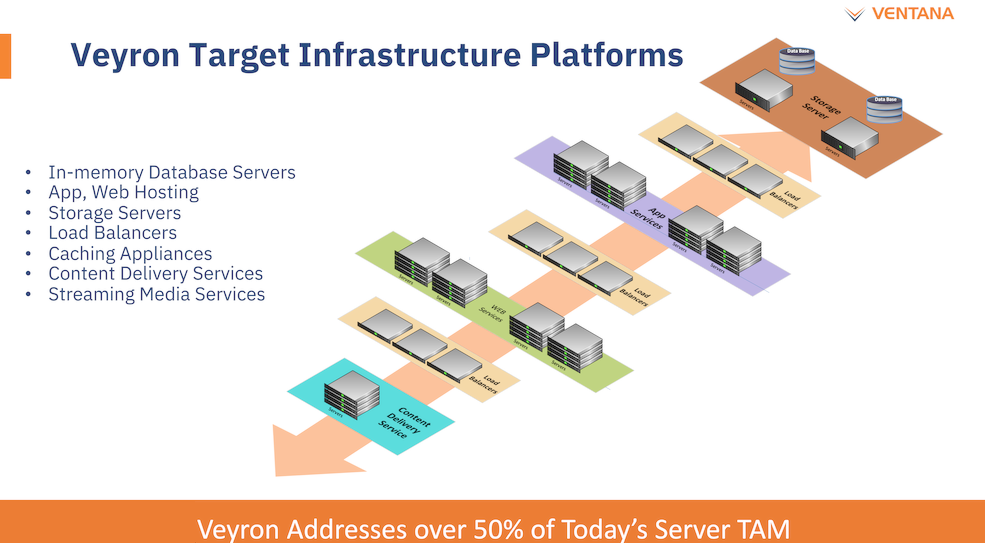
Платформа Veyron V1 универсальна и покрывает широкий спектр задач. Источник здесь и далее: StorageReview Вычислительный чиплет Veyron V1 использует продвинутые 64-битные ядра RISC-V и располагает 2 Мбайт кеша L2, а также многопоточным контроллером памяти. Предусмотрены конфигурации чиплета с 6, 8, 12 или 16 ядрами с частотой в районе 3 ГГц, что сопоставимо с решениями Google и AWS. Использоваться процессор может не только в ЦОД, но и в различных встраиваемых системах, базовых станциях 5G или даже клиентских рабочих станциях. 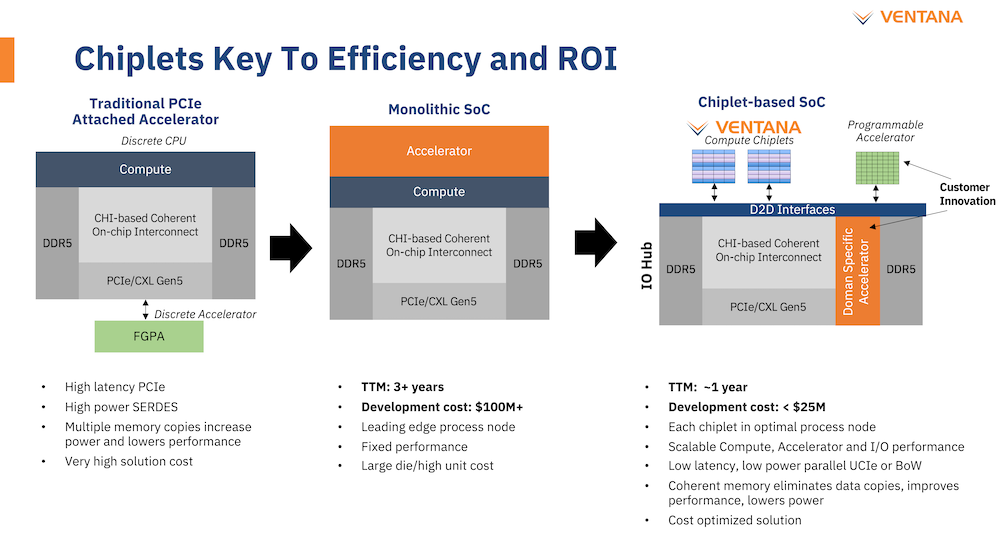
Чиплетная архитектура ускорит цикл разработки и внедрения, а также упростит задачу подключения кастомных ускорителей Архитектурно дизайн Veyron V1 использует агрессивный конвейер шириной восемь инструкций и с внеочередным исполнением. Чип способен работать на частоте до 3,6 ГГц благодаря использованию 5 нм техпроцесса TSMC. I/O-хаб может производиться с использованием более дешёвых 12 или даже 16-нм техпроцессов. Для соединения компонентов процессора разработан специальный низколатентный интерконнект D2D. 
Платформа разработки Veyron V1 и её технические характеристики Каждый чиплет включает в себя до 16 ядер, предусмотрена возможность масштабирования процессора до 192 ядер в 12 чиплетах. Общий объём разделяемого кеша L3 составляет 48 Мбайт. Заявлен высокий уровень защищённости архитектуры от атак по сторонним каналам. Разработчики заявляют о беспрецедентно низком энергопотреблении: 128 ядер V1 уложатся в 280 Вт; AMD EPYC 7763 потребляет столько же при вдвое меньшем числе ядер. 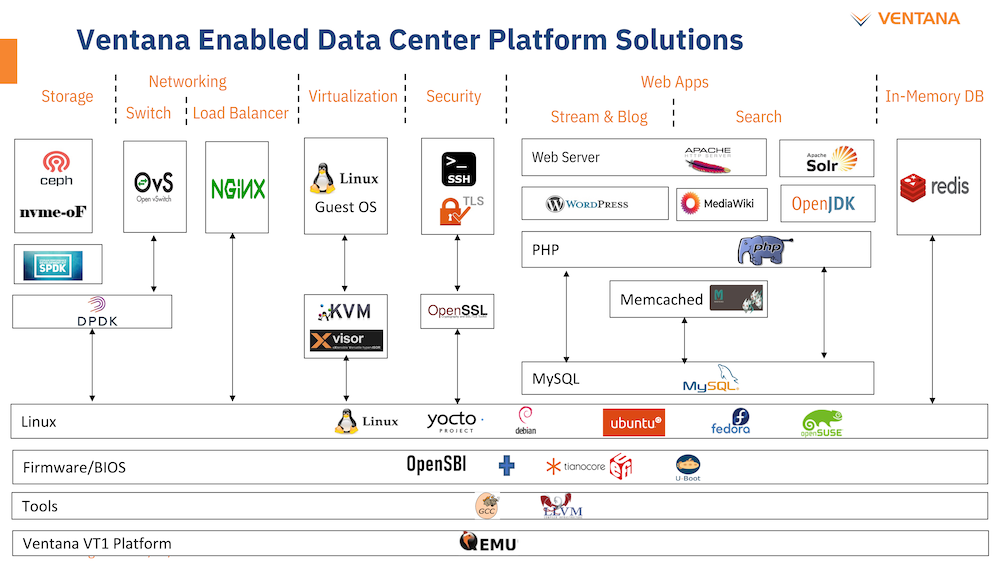
Ventana поддержит новую платформу на всех уровнях разработки системного и прикладного ПО Анонс Ventana нельзя назвать «бумажным» — компания говорит о доступности комплектов разработчика, причём сразу в двух типах шасси: в настольном и в серверном корпусе высотой 2U. Конфигурация включает в себя 16-ядерную версию V1, 128 гбайт памяти DDR5, подключенной с помощью интерфейса CXL (PCIe 5.0) x16, два свободных слота расширения PCIe 5.0 x16, загрузочный накопитель NVMe M.2 и 8 NVMe SFF SSD формата 2,5" для хранения данных. Для удалённого управления предусмотрен 1GbE-порт. 
Большая часть критически важного программного обеспечения уже портирована на архитектуру RISC-V Компания не забыла и о поддержке со стороны программного обеспечения: платформы разработчика Ventana Veyron V1 будут сопровождаться полноценным SDK с основным ПО, уже портированным на новую архитектуру. В список входят компиляторы GCC и LLVM, отладчик OpenOCD/GDB, исходные коды и бинарные файлы загрузчиков U-Boot и Tianocore UEFI EDK2.1. Поддерживается ряд дистрибутивов Linux, а также другое системное и прикладное ПО. Ожидается, что новые системы будут доступны в начале следующего года.
29.11.2022 [17:12], Алексей Степин
AWS представила Arm-процессор Graviton3E, оптимизированный для задач ИИ и HPCОдин из крупнейших облачных провайдеров, компания Amazon Web Services объявила о доступности новых инстансов EC2 на базе процессора Graviton3E. Новый чип — наследник анонсированного в конце 2021 года Graviton3, 5-нм 64-ядерного процессора на дизайне Arm Neoverse V1 (Zeus) с поддержкой DDR5 и PCI Express 5.0. Graviton3 использует набор команд Armv8.4 c расширениями Neon (4×128 бит) и SVE (2×256 бит) и поддерживает работу с популярными в сфере машинного обучения форматами данных INT8 и BF16. В сравнении c Graviton2 процессор быстрее на 25-60 % при сохранении аналогичного уровня тепловыделения. Дизайн серверов AWS предусматривает наличие трёх процессоров на узел высотой 1U. 
Изображения: AWS Новый процессор Graviton3E представляет собой дальнейшее развитие Graviton3. Чип оптимизирован с учётом потребностей рынка высокопроизводительных вычислений и основное внимание в его архитектуре уделено повышению производительности на операциях с плавающей запятой и вычислениях с использованием векторной математики. AWS, к сожалению, пока не раскрывает деталей относительно архитектуры Graviton3E, но прирост производительности на векторных операциях относительно обычного Graviton3 может достигать 35 %. Помимо классического теста HPL новый процессор хорошо проявляет себя в тестах, имитирующих медико-биологические и финансовые задачи.  Сценарии нагрузок, характерные для HPC, как правило, активно оперируют перемещением крупных объемов данных. Чтобы оптимизировать этот процесс, в новых инстансах AWS использует сеть на базе Elastic Fabric с новыми адаптерами Elastic Network Adapter (ENA). Такая сеть оперирует т. н. Scalable Reliable Datagram (SRD) вместо всем привычных TCP-пакетов. SRD позволяет организовать повторную отправку пакетов за микросекунды вместо миллисекунд в классическом Ethernet. Сердцем же новых инстансов AWS стало пятое поколение аппаратных гипервизоров Nitro 5. В сравнении с предыдущим поколением, Nitro 5 обладает вдвое более высокой вычислительной производительностью, на 50 % повышенной пропускной способностью памяти, а также позволяет обрабатывать на 60 % больше сетевых пакетов при сниженной на 30 % латентности. 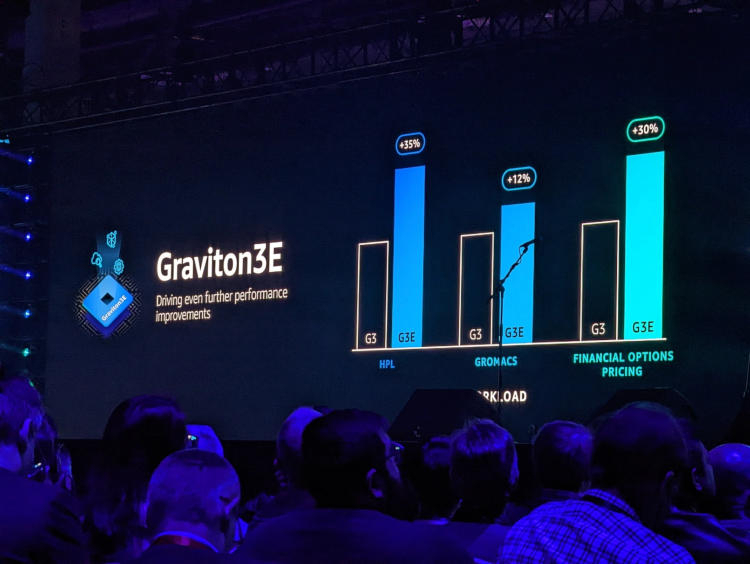
Здесь и далее источник изображений: AWS Инстансы Hpc7g с процессорами Graviton3E получат внутреннюю сеть с пропускной способностью 200 Гбит/с и станут доступны в различных конфигурациях вплоть до 64 vCPU и 128 ГиБ памяти. Аналогичные параметры имеют инстансы C7gn, предназначенные для задач с интенсивным сетевым трафиком: виртуальных маршрутизаторов, сетевых экранов, балансировщиков нагрузки и т.п. Также компания анонсировала инстансы R7iz, в которых используются процессоры Intel Xeon Scalable четвёртого поколения (Sapphire Rapids) с постоянной частотой всех ядер 3,9 ГГц. Они могут иметь конфигурацию до 128 vCPU с 1 ТиБ памяти.
14.11.2022 [00:00], Игорь Осколков
Игра по новым правилам: AMD представила Genoa, четвёртое поколение серверных процессоров EPYCВсего за десять лет AMD совершила почти невозможное — практически полностью потеряла серверный рынок, а теперь не просто успешно его отвоёвывает, но и предлагает комплексное портфолио решений. Анонс четвёртого поколения процессоров EPYC под кодовым именем Genoa — это не технологическая победа над Intel, поскольку AMD даже не думала бороться с Sapphire Rapids и уж тем более с Ice Lake-SP, а ориентировалась на Granite Rapids. Но годовая задержка с выпуском Sapphire Rapids позволила AMD не только в более спокойном темпе доделывать чипы Genoa, которые вышли на полгода позже, чем задумывалось ранее, но и поработать с разработчиками и заказчиками. Компании удалось вернуть их доверие — победа в умах гораздо важнее, чем просто технологическое превосходство. А оно неоспоримо. 
Источник: AMD EPYC Genoa заключены в корпус 72×75 мм, содержат до 90 млрд транзисторов и состоят из 13 чиплетов: 12 CCD, изготовленных по 5-нм техпроцессу TSMC плюс один, изрядно увеличившийся в размерах, IO-блок, сделанный там же, но уже по 6-нм нормам. Отказ от услуг GlobalFoundries, которая так и не смогла освоить тонкие техпроцессы, случился как нельзя кстати, поскольку IO-блок становится крайне важным компонентом при таком количестве ядер, которые необходимо вовремя накормить данными. И Genoa интересны в первую очередь с точки зрения полноты и разнообразия IO, а не рекордного количества ядер. IO-чиплет оснащён новыми SerDes-блоками, которые обслуживают и PCIe 5.0, и Infinity Fabric 3.0 (IF/GMI3). Формально каждому чипу полагается 128 линий PCIe 5.0, но реальная конфигурация чуть сложнее. Во-первых, у каждого чипа есть ещё восемь (2 x4) бонусных линий PCIe 3.0 для подключения нетребовательных устройств и обвязки, но в 2S-конфигурации таких линий будет только 12. Во-вторых, для 2S можно задействовать три (3Link) или четыре (4Link) IF-подключения, получив 160 или 128 свободных линий PCIe 5.0 соответственно. 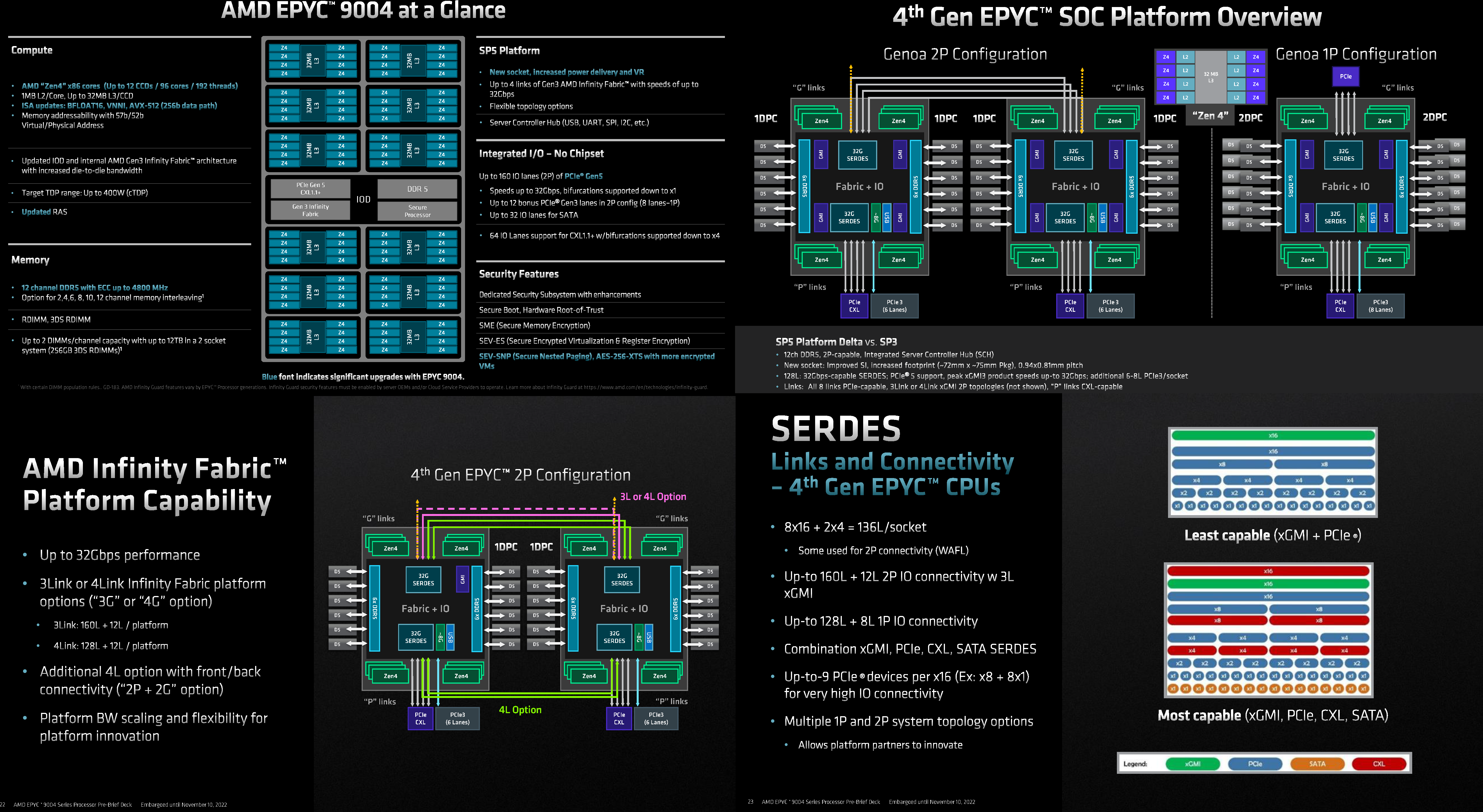
Изображения: AMD (via SemiAnalysis) В-третьих, каждый root-комплекс x16 может быть поделён между девятью устройствами (вплоть до x8 + восемь x1). Часть линий можно отдать на SATA (до 32 шт.), хотя это довольно расточительно. Но главное не это! Из 128 линий 64 поддерживают в полном объёме CXL 1.1 и частично CXL 2.0 Type 3, причём возможна бифуркация вплоть до x4. Ради такой поддержки CXL выход Genoa задержался на два квартала, но оно того определённо стоило — к процессору можно подключать RAM-экспандеры. И решения SK Hynix уже валидированы для новой платформы. CXL-память будет выглядеть как NUMA-узел (без CPU) — задержки обещаны примерно те же, что и при обращении к памяти в соседнем сокете, а пропускная способность одного CXL-подключения x16 почти эквивалентна двум каналам DDR5. При этом для CXL-памяти прозрачно поддерживаются всё те же функции безопасности, включая SME/SEV/SNP (теперь ключей стало аж 1006, а алгоритм обновлён до 256-бит AES-XTS). Отдельно для CXL-памяти внедрена поддержка SMKE (secure multi-key encryption), с помощью которой гипервизор может оставлять зашифрованными выбранные области SCM-устройств (до 64 ключей) между перезагрузками. 
Изображения: AMD (via SemiAnalysis) Такая гибкость при работе с памятью крайне важна для тех же гиперскейлеров. DDR5 по сравнению с DDR4 вчетверо плотнее, вполовину быстрее и… пока значительно дороже. И здесь AMD снова пошла им навстречу, добавив поддержку 72-бит памяти, а не только стандартной 80-бит, сохранив и расширив механизмы коррекции ошибок. 10-% разница в количестве DRAM-чипов при сохранении той же ёмкости на масштабах в десятки и сотни тысяч серверов выливается в круглую сумму. Кроме того, в Genoa сглажена разница в производительности между одно- и двухранговыми модулями с 25 % (в случае Milan) до 4,5 %. Что примечательно, AMD удалось сохранить сопоставимый уровень задержки обращений к памяти между поколениями CPU: 118 нс против 108 нс, из которых только 3 нс приходится на IO-блок, а 10 нс уже на саму память. Теоретическая пиковая пропускная способность памяти составляет 460,8 Гбайт/с на сокет. Однако тут есть нюансы. Genoa имеет 12 каналов памяти DDR5-4800, которые способны вместить до 6 Тбайт RAM. Однако сейчас фактически доступен только режим 1DPC, а вот 2DPC, судя по всему, появится только в следующем году. Genoa поддерживает модули (3DS) RDIMM и предлагает чередование с шагом в 2, 4, 6, 8, 10 или 12 каналов. 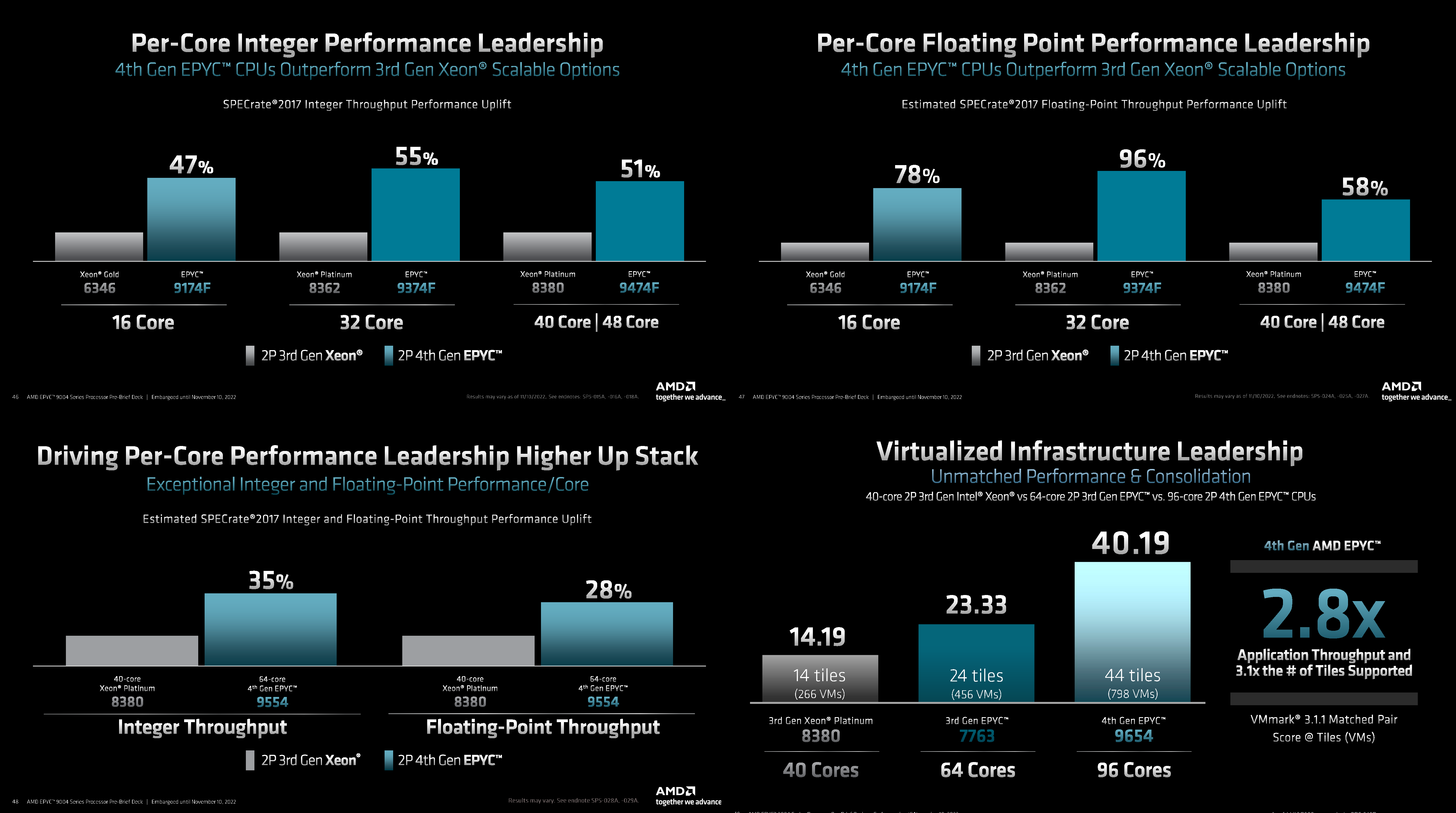
Изображения: AMD (via SemiAnalysis)
Каждый чип можно разбить на два (NPS2) или четыре (NPS4) равных NUMA-домена, а при большом желании и «прибить» L3-кеш к ядрам в том же CCD, получив уже 12 доменов. Но, по словам AMD, это нужно лишь в редких случаях, чтобы выжать ещё несколько процентов производительности. И это снова возвращает нас к особенностям IO-блока. Дело в том, что у каждого CCD есть сразу два GMI-порта. Но в конфигурациях с 8 и 12 CCD используется только один из них, а вот в случае 4 CCD — оба. Интересно, задействует ли AMD «лишние» порты для подключения других блоков. Впрочем, AMD, имея столь гибкие возможности конфигурации моделей, ограничилась относительно скромным начальным набором CPU, которые включает всего 18 моделей с числом ядер от 16 до 96, из которых четыре имеют индекс P (односокетные, чуть дешевле) и четыре — F (выше частота, больше объём L3-кеша). Модельный ряд условно делится на три группы: повышенная производительность на ядро (F-серия), повышенная плотность ядер и повышенный показатель TCO (с относительно малым количеством ядер). 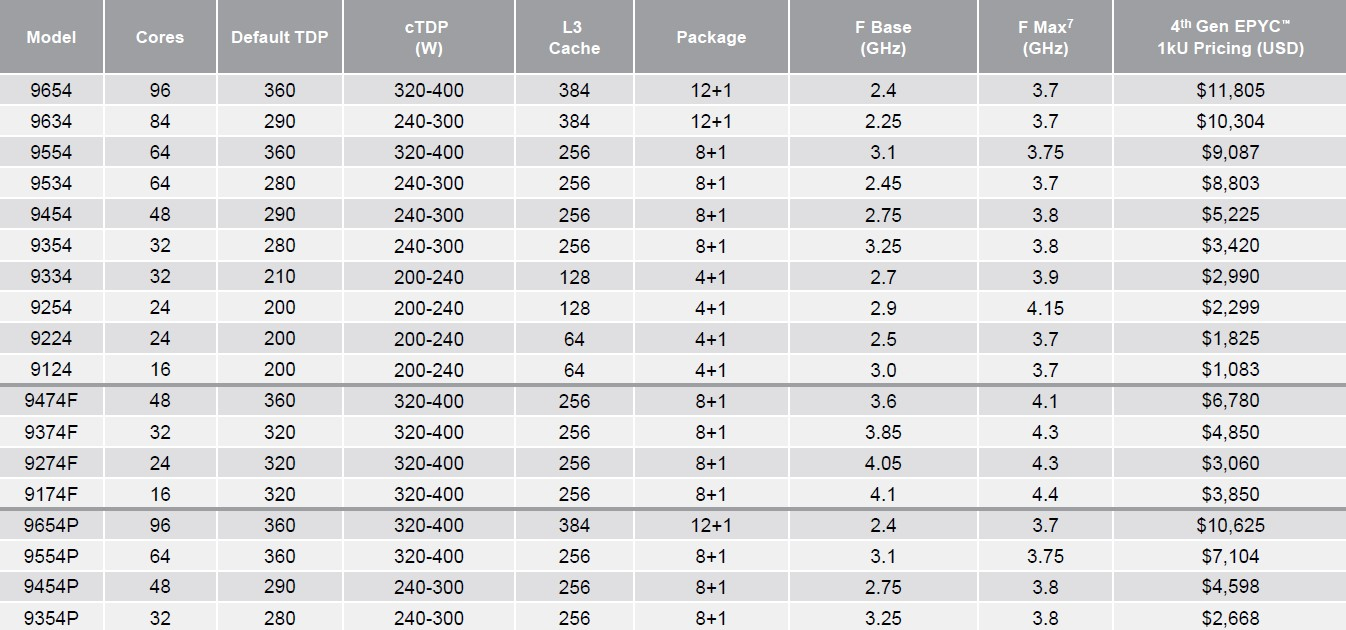
Источник: AMD (via ServeTheHome) На первый взгляд может показаться, что и цены на новинки заметно выросли, но это не совсем так. Например, у топовых моделей условная стоимость одного ядра (а их стала в полтора раза больше) так и крутится около «магического» значения в $123. Но с учётом возросшей производительности на ценовую политику AMD просто грех жаловаться. Прирост IPC между Zen3 и Zen4 составил 14 %, в том числе благодаря увеличению L2-кеша до 1 Мбайт на ядро (L1 и L3 остались без изменений), но не только. Есть и другие улучшения. Например, обновлённый контроллер прерываний AVIC позволяет практически полностью насытить не только 200G, но 400G NIC. С учётом чуть возросших частот и просто катастрофической разнице в количестве ядер топовый вариант Genoa не только значительно обгоняет Milan, но и в два-три раза быстрее старшего Ice Lake-SP. Дело ещё в и том, что Genoa обзавелись поддержкой AVX-512, в том числе инструкций VNNI (DL Boost), которыми так долго хвасталась Intel, а также BF16. Но реализация сделана иначе. У Intel используются «полноценные» 512-бит блоки, дорогие с точки зрения энергопотребления и затрат кремния. AMD же пошла по старому пути, используя 256-бит операции и несколько циклов, что позволяет не так агрессивно сбрасывать частоты. 
Изображения: AMD (via SemiAnalysis) Переход на новый техпроцесс, а также обновлённые подсистемы мониторинга и управления питанием позволили сохранить TDP в разумных пределах от 200 Вт до 360 Вт (cTDP до 400 Вт), что всё ещё позволяет обойтись воздушным охлаждением — всего + 80 Вт для старших процессоров при полуторакратном росте числа ядер. Таким образом, AMD имеет полное право заявлять, что Genoa лидирует по производительности, плотности размещения вычислительных мощностей, энергоэффективности и, в целом, по уровню TCO. У Intel же пока преимущество в более высокой доступности продукции в сложившейся геополитической обстановке. Отдельный вопрос, как AMD будет распределять имеющиеся мощности по выпуску Genoa между гиперскейлерами, корпоративным сектором и HPC-сегментом. Впрочем, компания в любом случае меняет рынок, иногда неожиданным образом. В частности, VMware, которая когда-то из-за EPYC изменила политику лицензирования, была вынуждена дополнительно оптимизировать свои продукты для Genoa. В конце концов, где вы раньше видели 2S-платформу со 192 ядрами и 384 потоками?
10.11.2022 [01:55], Игорь Осколков
Intel объединила HBM-версии процессоров Xeon Sapphire Rapids и ускорители Xe HPC Ponte Vecchio под брендом MaxВ преддверии SC22 и за день до официального анонса AMD EPYC Genoa компания Intel поделилась некоторыми подробностями об HBM-версии процессоров Xeon Sapphire Rapids и ускорителях Ponte Vecchio, которые теперь входят в серию Intel Max. 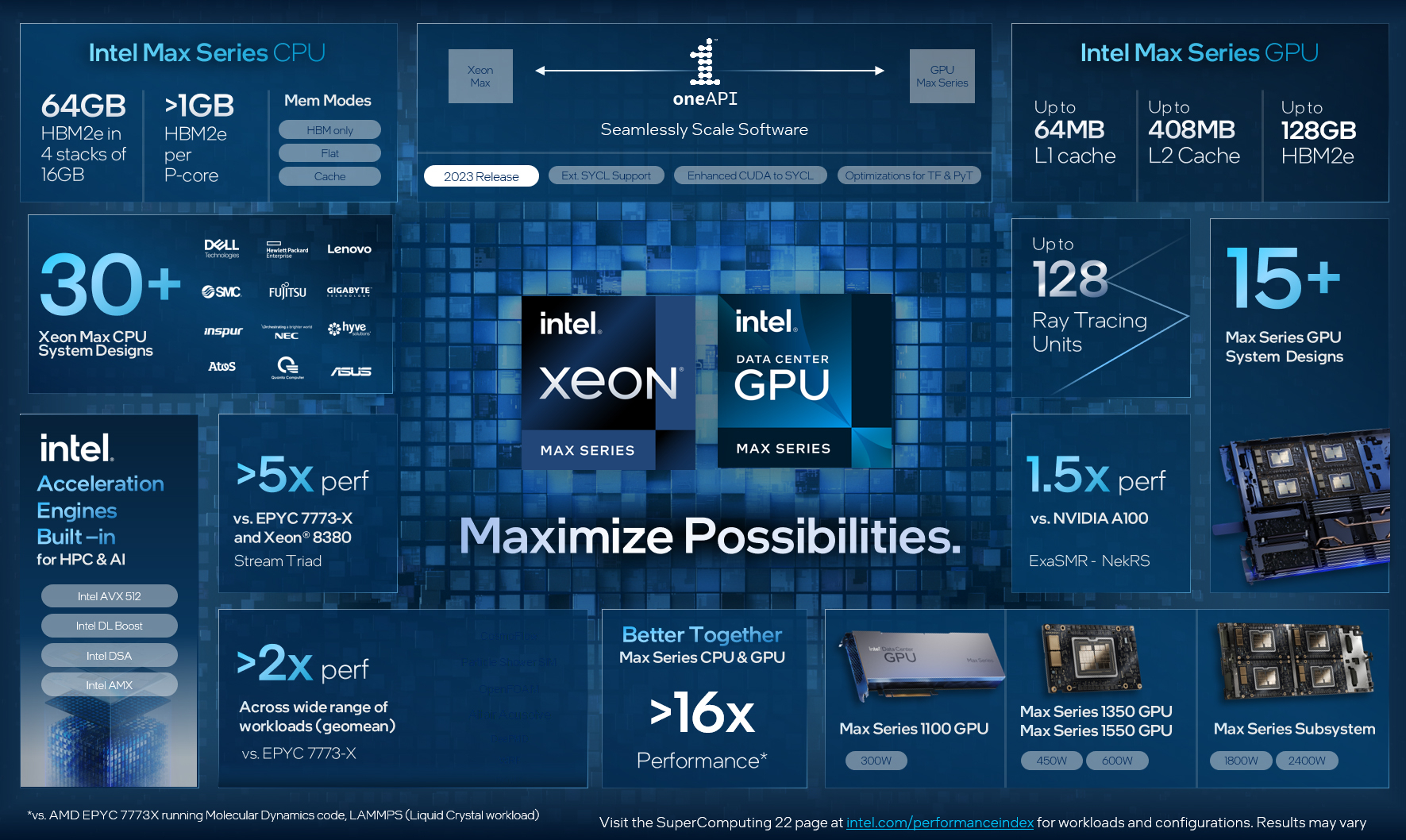
Изображения: Intel Intel Xeon Max предложат до 56 P-ядер, 112,5 Мбайт L3-кеша, 64 Гбайт HBM2e-памяти (четыре стека) с пропускной способностью порядка 1 Тбайт/с, 8 каналов памяти (DDR5-4800 в случае 1DPC, суммарно до 6 Тбайт), а также интерфейсы PCIe 5.0, CXL 1.1, UPI 2.0 и целый ряд различных технологий ускорения для задач HPC и ИИ: AVX-512, DL Boost, AMX, DSA, QAT и т.д. Заявленный уровень TDP составляет 350 Вт.  Первым процессором с набортной HBM-памятью был Arm-чип Fujitsu A64FX (48 ядер, 32 Гбайт HBM2), лёгший в основу суперкомпьютера Fugaku. Intel поднимает планку, давая более 1 Гбайт быстрой памяти на каждое ядро. А поскольку процессор состоит из четырёх отдельных чиплетов, возможно создание четырёх NUMA-доменов с выделенными HBM- и DDR-контроллерами. Но и монолитный режим тоже имеется. А поддержка CXL даёт возможность задействовать RAM-экспандеры. 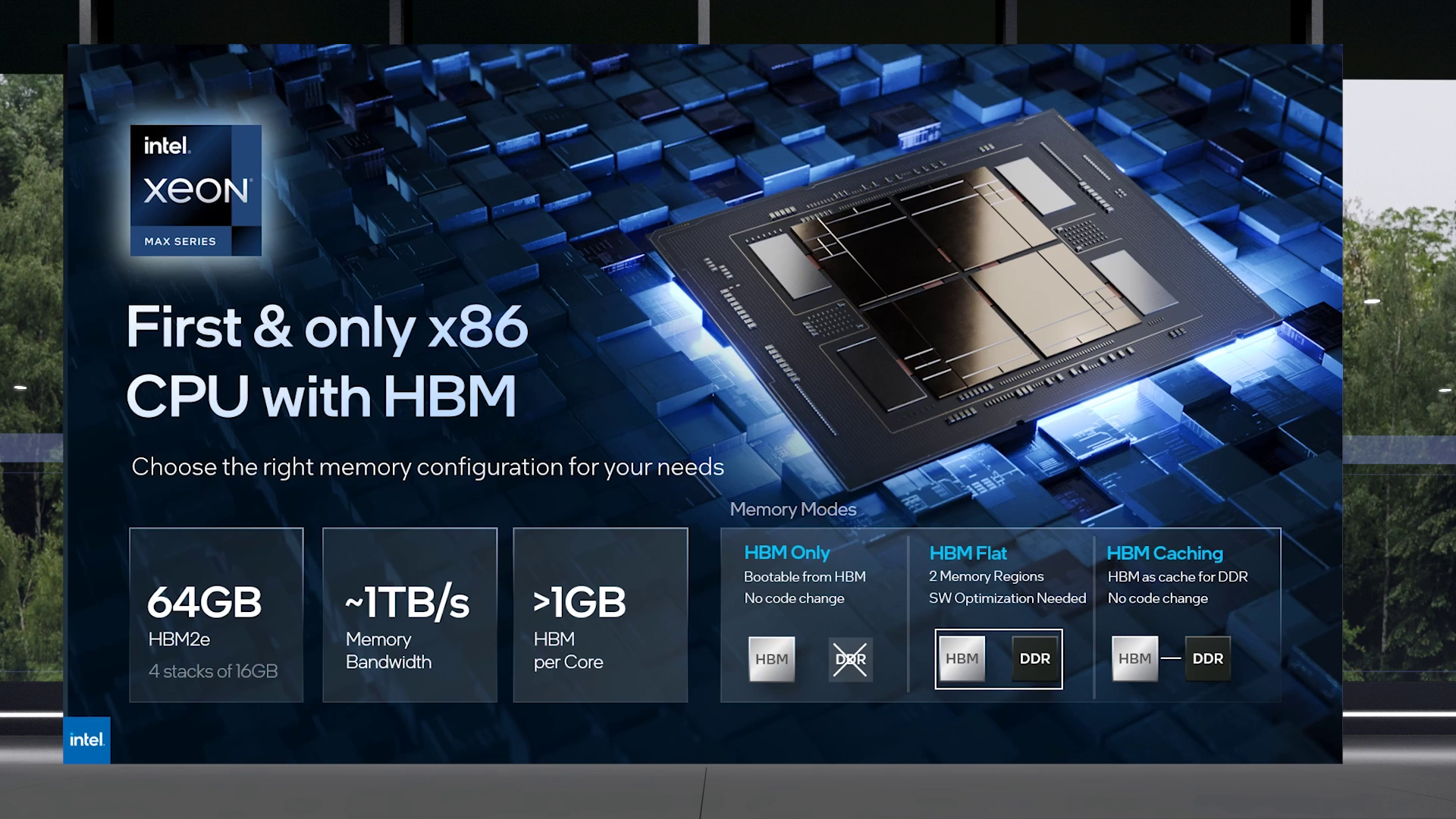 Intel Xeon Max поддерживают 2S-платформы, что суммарно даёт уже 128 Гбайт HBM-памяти, которых вполне хватит для целого ряда задач. Новые процессоры действительно могут обходиться без DIMM. Но есть и два других режима. В первом HBM-память работает в качестве кеша для обычной памяти, и для системы это происходит прозрачно, так что никаких модификаций для ПО (как в случае отсутствия DIMM вообще) не требуется. Во втором режиме HBM и DDR представлены как отдельные пространства, так что тут дорабатывать ПО придётся, зато можно добиться более эффективного использования обоих типов памяти.
В презентации Intel сравнивает новые Xeon Max с AMD EPYC Milan-X – в зависимости от задачи прирост составляет от +20 % до 4,8 раз. Но, во-первых, уже сегодня эти тесты потеряют всякий смысл в связи с презентацией EPYC Genoa (которые, к слову, должны получить AVX-512), а во-вторых, в следующем году AMD обещает представить Genoa-X с 3D V-Cache. Intel же явно не оставляет попытки создать как можно более универсальный процессор.  Что касается Ponte Vecchio, которые теперь называются Max GPU, то практически ничего нового относительно строения и особенностей данных ускорителей Intel не сказала: до 128 ядер Xe (только теперь стало известно об аппаратном ускорении трассировки лучей, что важно для визуализации), 64 Мбайт L1-кеша и аж 408 Мбайт L2-кеша (из них 120 Мбайт приходится на Rambo-кеш в двух стеках), 16 линий Xe Link, 8 HBM2e-контроллеров на 128 Гбайт памяти и пиковая FP64-производительность на уровне 52 Тфлопс. Все эти характеристики относятся к старшей модели Max Series 1550 в OAM-исполнении с TDP в 600 Вт.  Max Series 1350 предложит 112 ядер Xe и 96 Гбайт HBM2e, но и TDP у этой модели составит всего 450 Вт. Для обеих OAM-версий также будут доступны готовые блоки из четырёх ускорителей (по примеру NVIDIA RedStone), объединённых по схеме «каждый с каждым», так что в сумме можно получить 512 Гбайт HBM2e с ПСП в 12,8 Тбайт/с. Ну а самый простой ускоритель в серии называется Max Series 1100. Это 300-Вт PCIe-плата с 56 Xe-ядрами, 48 Гбайт HBM2e и мостиками Xe Link.  Intel утверждает, что ускорители Max до двух раз быстрее NVIDIA A100 в некоторых задачах, но и здесь история повторяется — нет сравнения с более современными H100. Хотя предварительный доступ к этим ускорителям у Intel есть, поскольку именно Sapphire Rapids являются составной частью платформы DGX H100. В целом, Intel прямо говорит, что наибольшей эффективности вычислений позволяет добиться связка CPU и GPU серии Max в сочетании с oneAPI. Всего на базе решений данной серии готовится более 40 продуктов.
Пока что приоритетным для Intel проектом является 2-Эфлопс суперкомпьютер Aurora, для которого пока что создан тестовый кластер Sunspot со 128 узлами, содержащими ускорители Max. Следующим ускорителем Intel станет Rialto Bridge, который появится в 2024 году. Также компания готовит гибридные (XPU) чипы Falcon Shores, сочетающие CPU, ускорители и быструю память. Аналогичный подход применяют AMD и NVIDIA.
28.09.2022 [12:37], Алексей Степин
AMD анонсировала Ryzen Embedded V3000 — процессоры для встраиваемых систем с архитектурой Zen 3Семейство процессоров AMD Ryzen Embedded V получило долгожданное обновление: компания представила чипы V3000 с архитектурой Zen 3. Процессоры предназначены для широкого круга задач и могут использоваться в системах хранения данных, маршрутизаторах, сетевых брандмауэрах и коммутаторах — для этого у них достаточно как производительности, так и возможностей подсистем ввода-вывода. Новые чипы отличаются высокой энергоэффективностью: их номинальный теплопакет составляет от 15 до 45 Ватт в зависимости от модели; более тонкая настройка TDP позволяет регулировать потребление в диапазоне 10-54 Ватта. Это очень полезная возможность для периферийных систем, часто обходящихся пассивным охлаждением в виде оребренного корпуса. 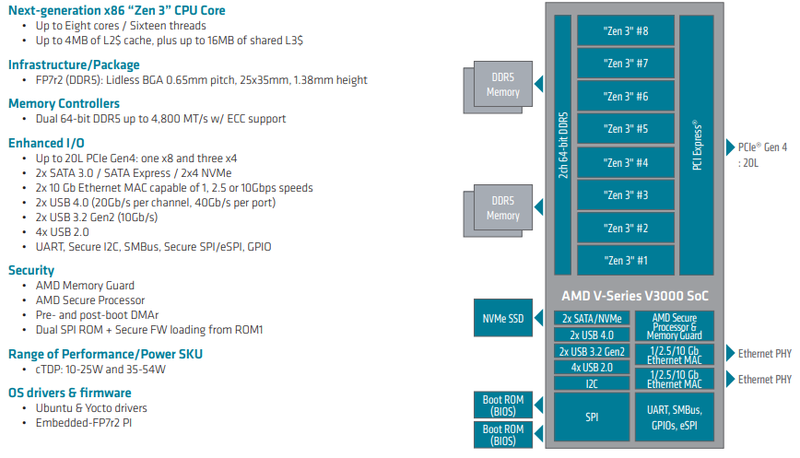
Источник изображений здесь и далее: AMD Всего в серии Ryzen Embedded V3000 представлено пять новых процессоров с количеством ядер от четырёх до восьми. Они отличаются базовой частотой от 1,9 до 3,5 ГГц, объёмами кешей, а также диапазоном рабочих температур: например, в серии есть модель V3C18I, способная функционировать в окружающей среде с температурой от -40 до +105 °C. В остальном новые процессоры очень похожи: все они используют компактные корпуса BGA, у всех максимальная частота в турборежиме составляет 3,8 ГГц, все чипы способны работать с памятью DDR5-4800, имеют 20 линий PCIe 4.0 и два интегрированных MAC-блока 10GbE. 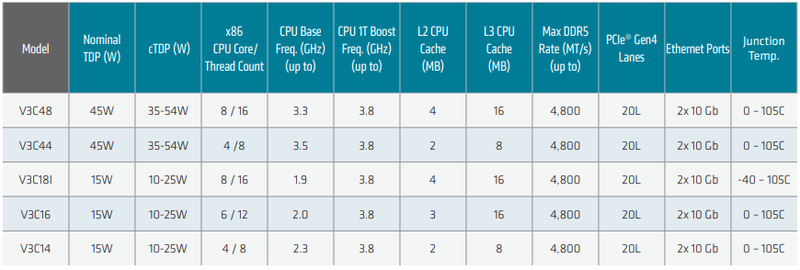
Модельный ряд Ryzen Embedded V3000 Новые процессоры AMD могут похвастаться повышенной защищённостью за счёт поддержки технологий AMD Memory Guard и AMD Platform Secure Boot. Компания-производитель рассчитывает на долгую службу новинок — жизненный цикл Ryzen Embedded V3000 составляет 10 лет. Также они будут иметь драйверную поддержку для будущих версий Linux Ubuntu и Yocto. Поставки новых чипов Ryzen Embedded V3000 ведущим OEM- и ODM-производителям оборудования уже начаты. AMD считает, что эти процессоры станут идеально сбалансированным выбором для СХД и сетевых устройств, как сочетающие в себе достаточно высокую производительность и низкий уровень тепловыделения, особенно важный в ограниченном пространстве серверных стоек.
23.09.2022 [19:58], Алексей Степин
Google заявила, что использует процессоры SiFive Intelligence X280 на RISC-V вместе со своим TPUАрхитектура RISC-V продолжает понемногу набирать популярность и завоевывать внимание ведущих игроков на рынке информационных технологий. На мероприятии AI Hardware Summit в совместном выступлении ведущего архитектора SiFive и архитектора Google TPU было отмечено, что Google уже использует процессоры с ядрами Intelligence X280. Эти ядра — один из вариантов воплощения архитектуры RISC-V, из продвигаемых SiFive. Анонс Intelligence X280 состоялся ещё в апреле 2021 года, когда SiFive выпустила апдейт 21G1, основной упор в котором был сделан на максимизацию характеристик уже существующих ядер RISC-V в области операций с плавающей запятой. 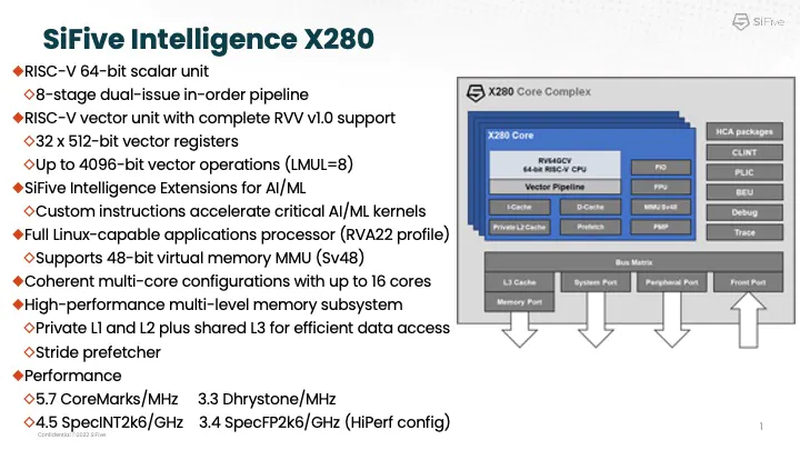
Процессорное ядро Intelligence X280 и его возможности. Источник: SiFive Как следует из названия, данный вариант процессора оптимизирован под задачи машинного интеллекта: ядра RISC-V в нём дополнены векторными конвейерами RISC-V Vector (RVV) с производительностью 4,5 Тфлопс BF16 и 9,2 Топс INT8 на ядро. Одной из самых интересных технологий в Intelligence X280 является интерфейс Vector Coprocessor Interface eXtension (VCIX). 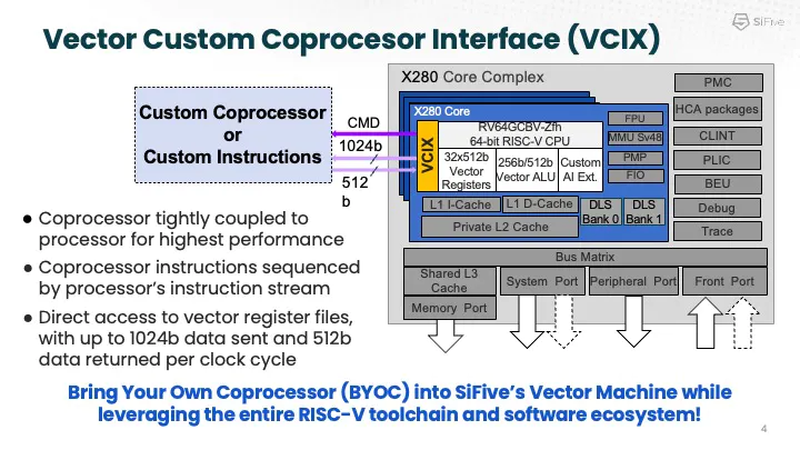
Устройство VCIX. Источник: SiFive Он позволяет подключать внешние ускорители векторных операций напрямую к регистровому файлу X280, минуя основную шину и кеши. Такой подход минимизирует накладные расходы и не требует использования специальных средств при программировании системы, поскольку связка из X280 и подключённого по VCIX ускорителя работает полностью прозрачно в рамках стандартных средств разработки SiFive. 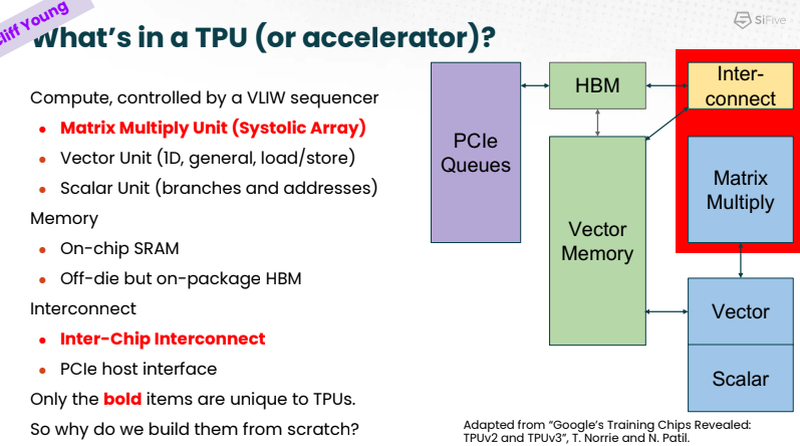
Сильные стороны Google TPU. Источник: SiFive На саммите в Санта-Кларе разработчики SiFive и Google TPU рассказали, что процессоры Intelligence X280 используются в качестве хост-процессоров к ускорителям систолической векторной математики Google MXU; правда, о масштабах внедрения RISC-V в Google сведений приведено не было. 
Разделение труда Intelligence X280 и Google TPU. Источник: SiFive Ранее уже появлялась информация, что Google активно тестирует ASIC сторонних разработчиков в связке со своим TPU, в частности, чипы Broadcom, дабы разгрузить его от второстепенных задач и сделать упор на сильных сторонах — матричной математике и быстром интерконнекте. Похоже, SiFive Intelligence X280 решает задачу интеграции подобного рода задач более изящно: как отметил в выступлении Клифф Янг (Cliff Young), архитектор Google TPU, с помощью VCIX можно построить машину, позволяющую усидеть на двух стульях (build a machine that lets you have your cake and eat it too).
14.09.2022 [22:28], Игорь Осколков
Arm анонсировала серверные ядра Neoverse V2 Demeter, именно они легли в основу процессоров NVIDIA GraceArm анонсировала новые ядра в серии Neoverse, принадлежащие к семейству Armv9 — Neoverse V2 с кодовым названием Demeter (Деметра). В семействе Neoverse V-ядра относятся к высокопроизводительным решениям, ориентированным на гиперскейлеров, облачных провайдеров и поставщиков HPC-решений. Одним из первых продуктов на базе новой платформы станет 72-ядерный серверный процессор NVIDIA Grace, выход которого запланирован на следующий год. 
Источник: Arm Arm пока что не приводит точные характеристики V2-ядер, но говорит о возросшей производительности как целочисленных вычислений, так и вычислений с плавающей запятой. Для новинок заявлена поддержка SVE2-инструкций, наличие четырёх 128-бит векторных блоков, а также блоки для работы с матрицами и поддержка BF16/INT8. Кроме того, ядра получат увеличенный до 2 Мбайт L2-кеш, а также новые механизмы аппаратной защиты и, по-видимому, улучшенные криптографические движки. 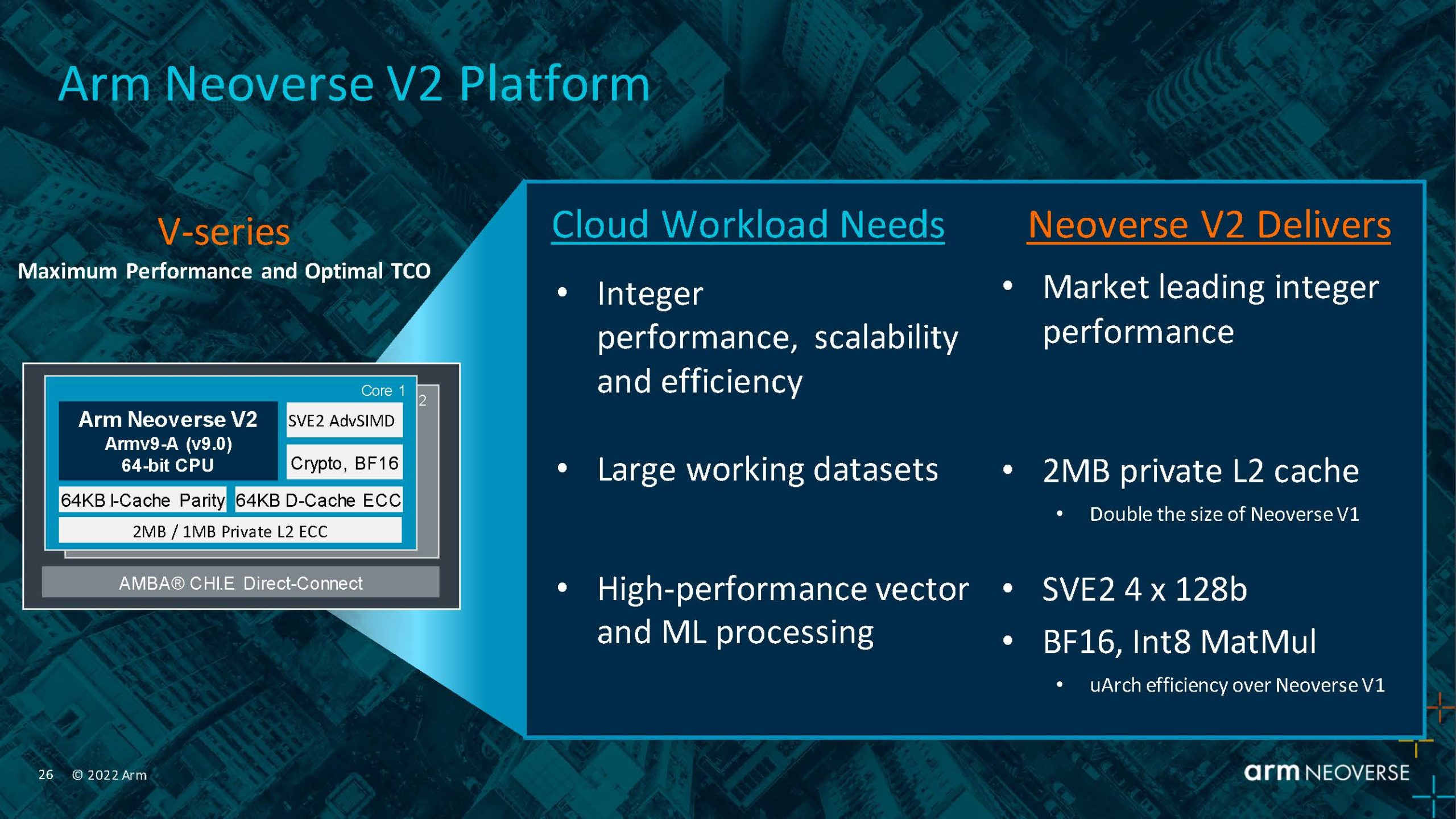
Источник: ServeTheHome  Объединять ядра и кеши будет когерентная mesh-шина CMN-700 с суммарной пропускной способностью до 4 Тбайт/с, которая может обслуживать до 512 Мбайт кеш-памяти. А за обслуживание связей с другими кристаллами всё так же будет отвечать шина AMBA CHI. Будет предложена поддержка (LP)DDR5(X), CXL 2.0, PCIe 5.0 и UCIe. Также Arm пообещала и далее вкладываться в развитие инициативы SystemReady и совместную с партнёрами оптимизацию системного и прикладного ПО — всё ради упрощения перехода конечных пользователей с x86 на Arm. 
Источник: ServeTheHome  Впрочем, как отмечает ServeTheHome, в ходе презентации Arm напирала скорее на прирост эффективности с точки зрения именно целочисленных вычислений, что актуально для облаков. x86-лагерь сдавать позиции в этой области не хочет — конкуренцию Arm составят AMD EPYC Bergamo и Intel Xeon Sierra Forest. Но в 2023 году Arm представит следующее поколение высокопроизводительных ядер Neoverse V3 (Poseidon) c PCIe 6.0 и CXL 3.0, а также «сбалансированную» платформу Neoverse N3 и энергоэффективные ядра Neoverse E следующего поколения.
20.08.2022 [22:30], Алексей Степин
NVIDIA поделилась некоторыми деталями о строении Arm-процессоров Grace и гибридных чипов Grace HopperНа GTC 2022 весной этого года NVIDIA впервые заявила о себе, как о производителе мощных серверных процессоров. Речь идёт о чипах Grace и гибридных сборках Grace Hopper, сочетающих в себе ядра Arm v9 и ускорители на базе архитектуры Hopper, поставки которых должны начаться в первой половине следующего года. Многие разработчики суперкомпьютеров уже заинтересовались новинками. В преддверии конференции Hot Chips 34 компания раскрыла ряд подробностей о чипах. Grace производятся с использованием техпроцесса TSMC 4N — это специально оптимизированный для решений NVIDIA вариант N4, входящий в серию 5-нм процессов тайваньского производителя. Каждый кристалл процессорной части Grace содержит 72 ядра Arm v9 с поддержкой масштабируемых векторных расширений SVE2 и расширений виртуализации с поддержкой S-EL2. Как сообщалось ранее, NVIDIA выбрала для новой платформы ядра Arm Neoverse. 
Источник: NVIDIA Процессор Grace также соответствует ряду других спецификаций Arm, в частности, имеет отвечающий стандарту RAS v1.1 контроллер прерываний (Generic Interrupt Controller, GIC) версии v4.1, блок System Memory Management Unit (SMMU) версии v3.1 и средства Memory Partitioning and Monitoring (MPAM). Базовых кристаллов у Grace два, что в сумме даёт 144 ядра — рекордное количество как в мире Arm, так и x86. 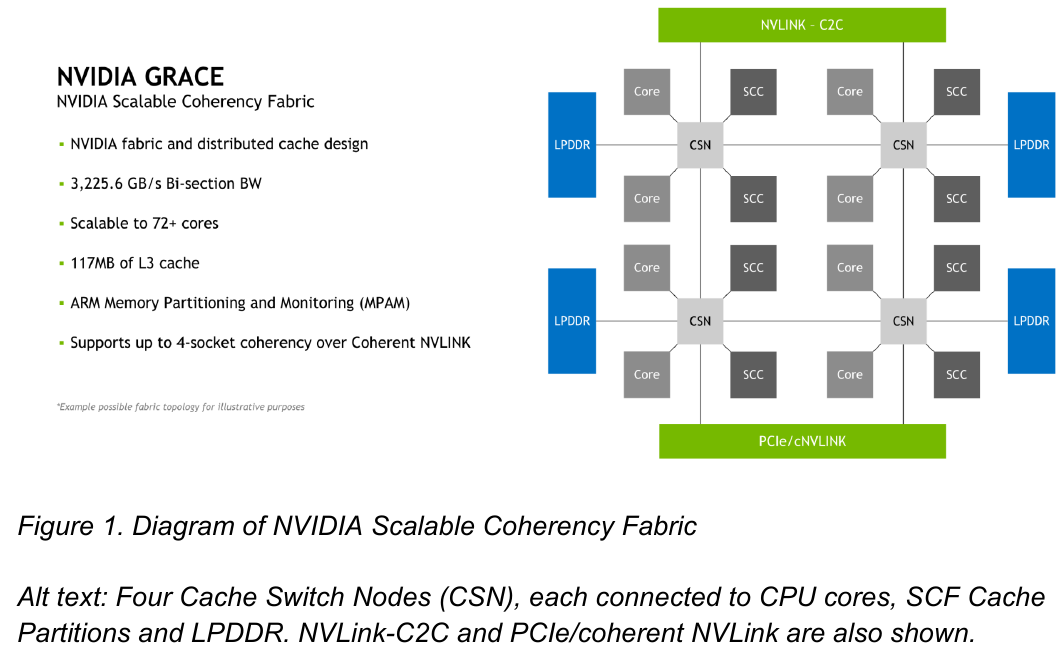
Внутренняя организация кластеров ядр в Grace. Источник: NVIDIA Внутренние блоки Grace соединяются посредством фабрики Scalable Coherency Fabric (SCF), вариации NVIDIA на тему сети CMN-700, применяемой в дизайнах Arm Neoverse. Производительность данного интерконнекта составляет 3,2 Тбайт/с. В случае Grace он предполагает наличие 117 Мбайт кеша L3 и поддерживает когерентность в пределах четырёх сокетов (посредством новой версии NVLink). Но SCF поддерживает масштабирование. Пока что в «железе» она ограничена двумя блоками Grace, а это уже 144 ядра и 234 Мбайт L3-кеша. Ядра и кеш-разделы (SCC) рапределены по внутренней mesh-фабрике SCF. Коммутаторы (CSN) служат интерфейсами для ядер, кеш-разделов и остальными частями системы. Блоки CSN общаются непосредственно друг с другом, а также с контроллерами LPDDR5X и PCIe 5.0/cNVLink/NVLink C2C. 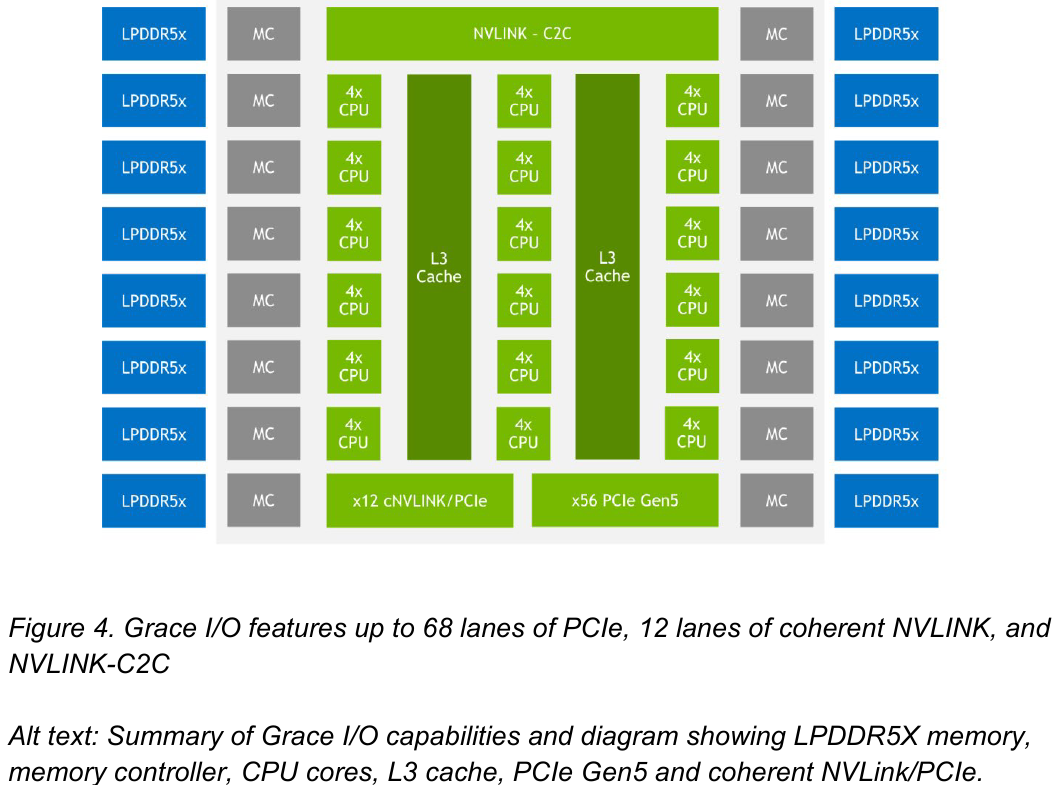
Блок-схема кристалла Grace. Источник: NVIDIA В чипе реализована поддержка PCI Express 5.0. Всего контроллер поддерживает 68 линий, 12 из которых могут также работать в режиме cNVLink (NVLink с когерентностью). x16-интерфейс посредством бифуркации может быть превращен в два x8. Также на приведённой NVIDIA диаграмме можно видеть целых 16 двухканальных контроллеров LPDDR5x. Заявлена ПСП на уровне свыше 1 Тбайт/с для сборки (до 546 Гбайт/с на кристалл CPU). 
Источник: NVIDIA Основной же межчиповой связи NVIDIA видит новую версию NVLink — NVLink-C2C, которая в семь раз быстрее PCIe 5.0 и способна обеспечить двунаправленную скорость передачи данных на уровне до 900 Гбайт/с, будучи при этом в пять раз экономичнее. Удельное потребление у новинки составляет 1,3 пДж/бит, что меньше, нежели у AMD Infinity Fabric с 1,5 пДж/бит. Впрочем, существуют и более экономичные решения, например, UCIe (~0,5 пДж/бит). 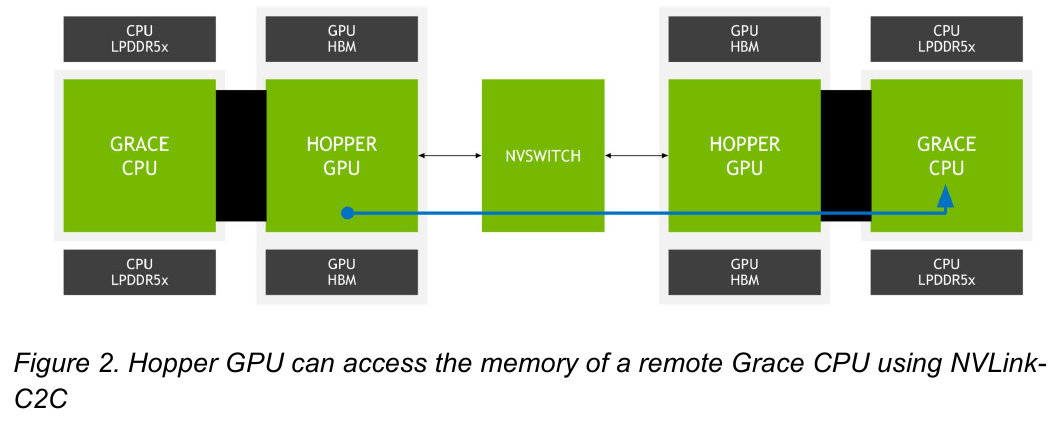
Новый вариант NVLink обеспечит кластер на базе Grace Hopper единым пространством памяти. Источник: NVIDIA NVLink-C2C позволяет реализовать унифицированный «плоский» пул памяти с общим адресным пространством для Grace Hopper. В рамках одного узла возможно свободное обращение к памяти соседей. А вот для объединения нескольких узлов понадобится уже внешний коммутатор NVSwitch. Он будет занимать 1U в высоту, и предоставлять 128 портов NVLink 4 с агрегированной пропускной способностью до 6,4 Тбайт/с в дуплексе. 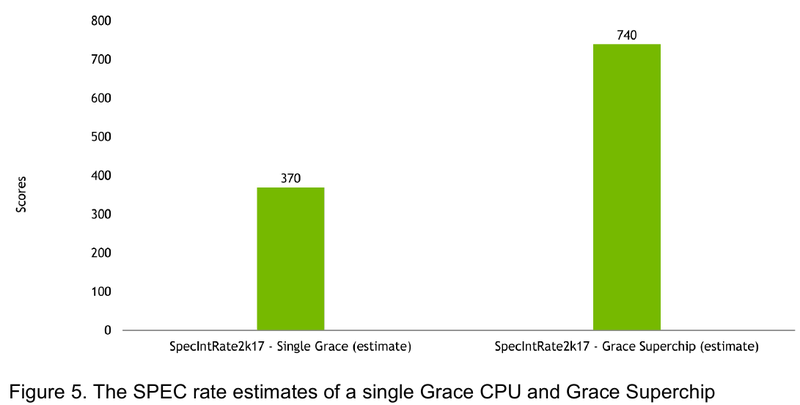
Источник: NVIDIA Производительность Grace также обещает быть рекордно высокой благодаря оптимизированной архитектуре и быстрому интерконнекту. Даже по предварительным цифрам, опубликованным NVIDIA, речь идёт о 370 очках SPECrate2017_int_base для одного кристалла Grace и 740 очках для 144-ядерной сборки из двух кристаллов — и это с использованием обычного компилятора GCC без тонких платформенных оптимизаций. Последняя цифра существенно выше результатов, показанных 128-ядерными Alibaba T-Head Yitian 710, также использующим архитектуру Arm v9, и 64-ядерными AMD EPYC 7773X.
04.08.2022 [15:54], Владимир Мироненко
Разработчик серверных чипов Prodigy с невероятными характеристиками обвинил в своих бедах CadenceКак сообщает The Register, cтартап Tachyum подал в суд на Cadence Design Systems, обвинив компанию в саботаже при выполнении контракта на поставку IP-блоков для будущих 5-нм серверных процессоров Prodigy. По словам Tachyum, старшие 128-ядерные CPU Prodigy с частотой 5,7 ГГц будут втрое быстрее AMD EPYC 7763 и NVIDIA H100. В иске утверждается, что заключённая в 2019 году сделка на предоставление решений Cadence для процессоров Prodigy, была сорвана, поскольку Cadence не смогла предоставить необходимые технологии для вывода продукта на рынок. Заказанные Tachyum блоки не относятся к разряду новшеств, и инженеры Cadence уверяли Tachyum, что стандартные компоненты могли быть без труда интегрированы в процессор. Однако график поставок был нарушен, и дошло даже до того, что Cadence посоветовала Tachyum не использовать её компоненты или вообще приобрести аналоги у других поставщиков. 
Источник изображения: Tachyum Стартап добавил в иске, что Cadence усугубила ущерб, прекратив доступ Tachyum к ПО eDAcard, тем самым вынудив понести расходы на лицензирование другого ПО и переобучение своих инженеров. Срыв сроков и прочие препятствия привели к задержке выхода Prodigy примерно на два года. Tachyum потребовал возместить упущенную выгоду в размере $206 млн и ещё $27 млн дополнительных затрат на поиск альтернативных решений в сжатые сроки. 
Источник изображения: Tachyum Tachyum также указала, что из-за срыва сроков она потеряла возможность получения заказов на поставку чипов для испанского суперкомпьютера MareNostrum 5 стоимостью €151,41 млн. В итоге Барселонский суперкомпьютерный центр (BSC), с которым был подписан меморандум о взаимопонимании, предпочёл компанию Atos. Последняя выбрала ускорители NVIDIA и процессоры Intel, поскольку ни одна европейская компания не могла бы поставить чипы, отвечающие ключевым критериям отбора. В иске Tachyum отмечает, что тогдашний генеральный директор Cadence Лип-Бу Тан (Lip-Bu Tan) входил в совет директоров двух конкурентов Tachyum — SambaNova и Nuvia (поглощена Qualcomm) — и активно участвовал в фондах Walden International и Walden Catalyst, которые инвестировали в другие «кремниевые» стартапы. Ещё один член совета директоров Cadence, Янг Сон (Young Sohn), также является директором одного из этих инвестфондов. По мнению Tachyum, налицо явный конфликт интересов.
13.07.2022 [16:13], Алексей Степин
128-ядерный Arm-процессор Alibaba T-Head Yitian 710 показал отличные результаты в SPEC CPU2017Не секрет, что китайские гиганты, такие, как Huawei и Alibaba Cloud, разрабатывают собственные серверные процессоры на базе архитектуры Arm. Однако информации об этих чипах, как правило, не очень много и пользоваться общепринятыми на западе тестами и рейтингами разработчики не спешат, что, к слову, характерно и для китайских суперкомпьютеров. Alibaba Cloud представила чип Yitian 710 ещё осенью прошлого года. Этот процессор построен на базе архитектуры Armv9 и максимально может иметь 128 ядер с частотой до 3,2 ГГц. Однако результаты проверки чипа в популярном тесте SPEC CPU2017 были опубликованы только сейчас. 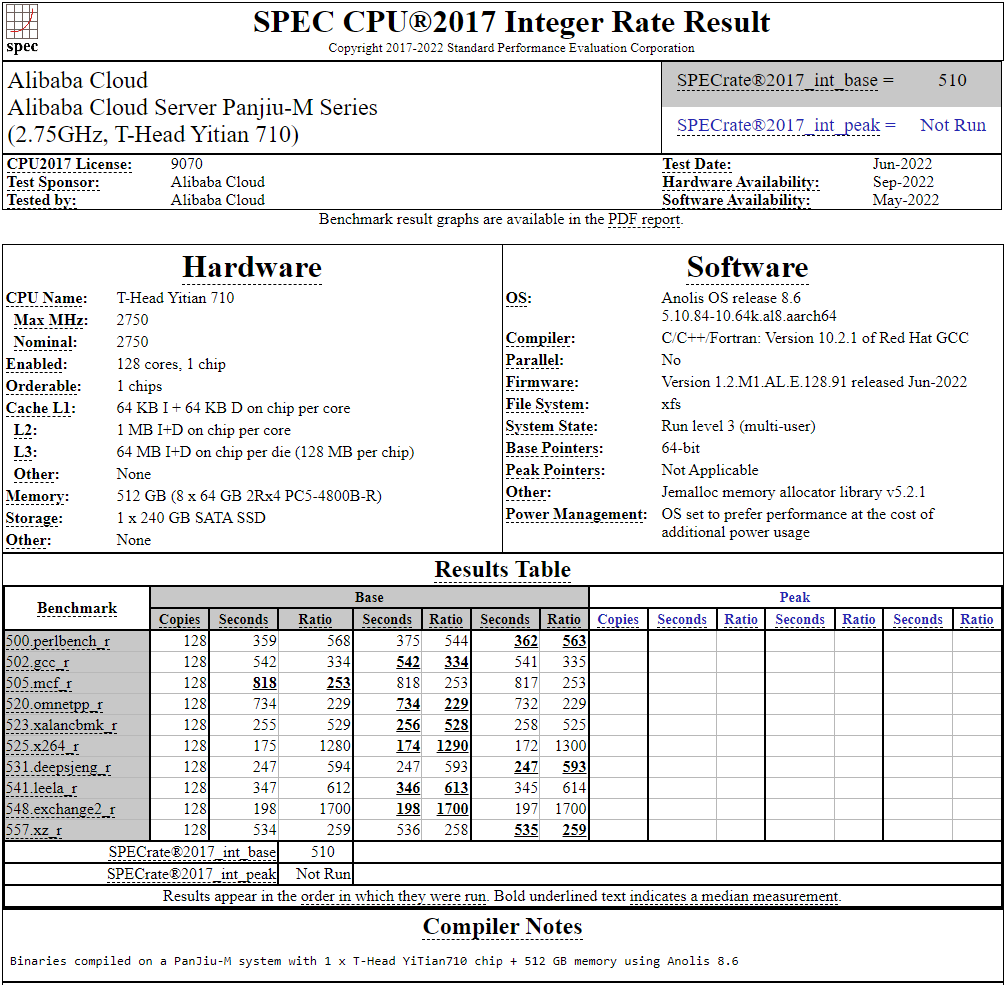 Процессор тестировался в составе референс-сервера Panjiu. Применялась 128-ядерная версия с частотой 2,75 ГГц, 1 Мбайт кеша L2 на ядро и 64 Мбайт кеша L3 на кристалл (128 Мбайт на сборку). Последнее позволяет говорить о том, что Alibaba также использует в своих процессорах чиплетную компоновку. 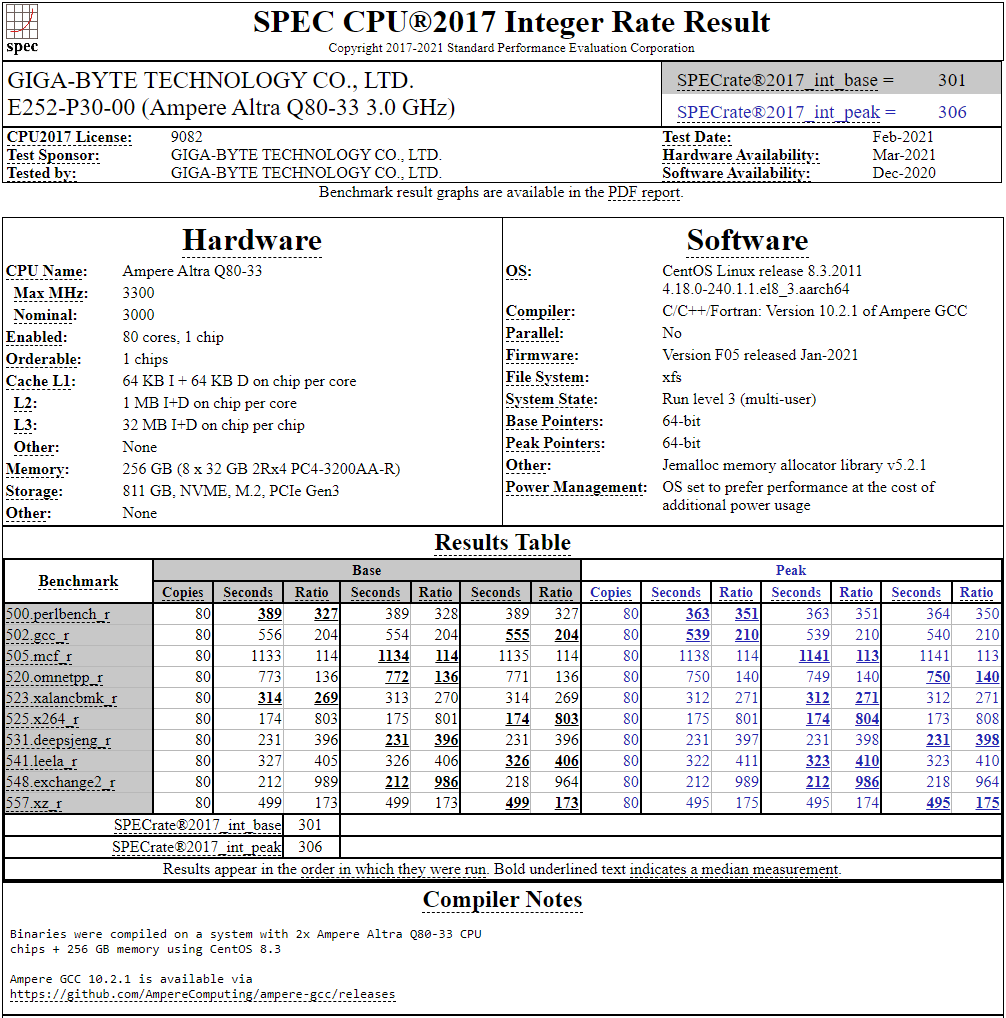 Результаты оказались существенно более высокими, нежели у Ampere Altra Q80-33; правда, стоит сделать скидку на то, что у Ampere использовалась 80-ядерная версия, а не более новая 128-ядерая Altra Max. Но в аутсайдерах оказался также и AMD EPYC 7773X (64 ядер/128 потоков, 2,2-3,5 ГГц, 768 Мбайт L3), показавший 440 очков против 510 у Yitian 710. Увеличенный объём кеша не слишком помог детищу «красных». 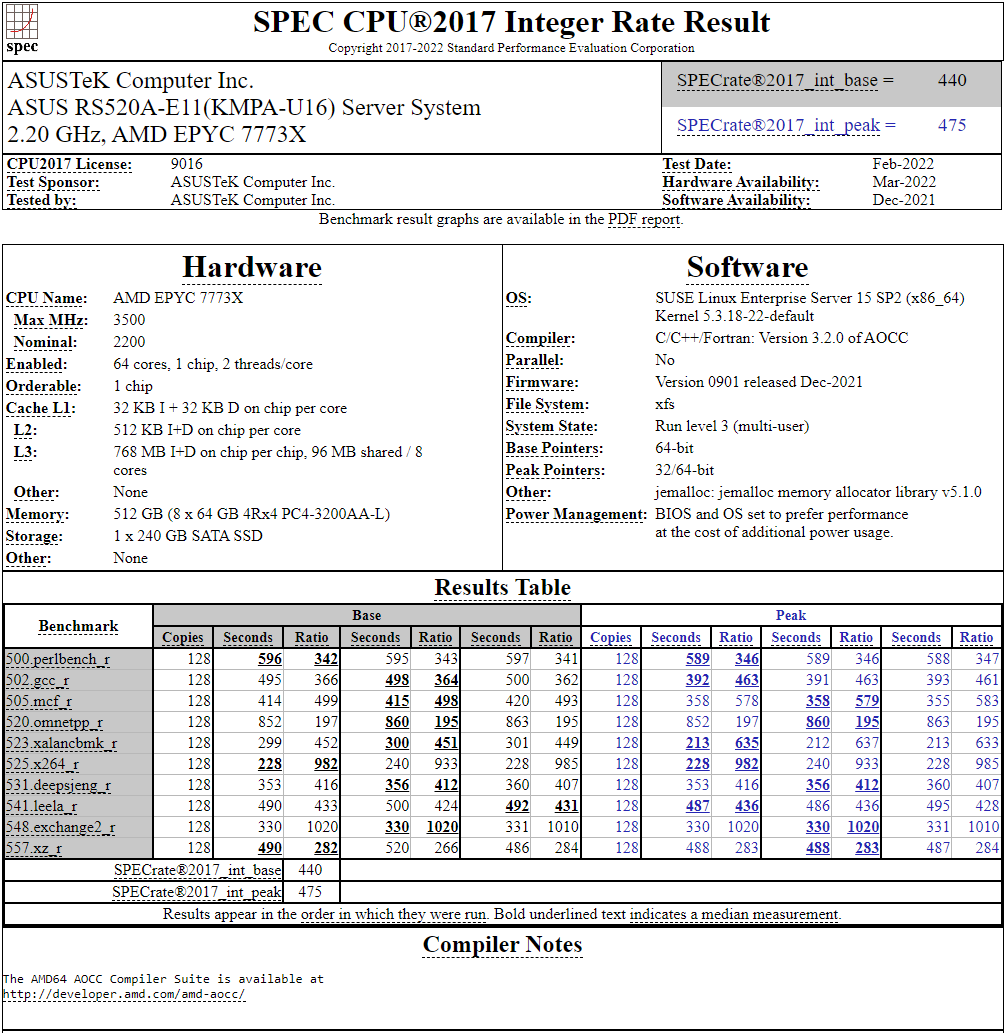 Таким образом, процессор на базе архитектуры Armv9 занял первое место там, где традиционно господствовали решения с архитектурой x86 — достаточно взглянуть на Топ-20 в рейтинге CPU2017 Integer. Можно сказать, что 128-ядерный процессор не вполне корректно сравнивать с 64-ядерным с поддержкой SMT, однако если технологии и архитектура позволяют разместить вдвое больше полноценных ядер в сопоставимом по размеру с AMD EPYC корпусе, так ли это важно? 
Текущий Tоп-20 целочисленной производительности в SPEC CPU2017 К сожалению, пока речь идёт только о целочисленных вычислениях. По неизвестной причине, Alibaba Cloud не опубликовала результаты CPU2017 Floating Point, где сравнение вышло бы существенно интереснее. В любом случае, монополия AMD на первые места пошатнулась; что же касается Intel, то в классе однопроцессорных систем самым мощным вариантом является 36-ядерный Xeon Platinum 8351N, который заведомо проиграет 64-128 ядерным монстрам AMD, Ampere, а теперь уже и Alibaba Cloud. |
|
