Материалы по тегу: cpu
|
29.08.2023 [22:18], Алексей Степин
Intel поделилась некоторыми подробностями о 144-ядерных Xeon Sierra ForestНа конференции Hot Chips 2023 корпорация Intel рассказала о новых чипах Xeon, в том числе о создаваемых специально под нужды гиперскейлеов процессорах Sierra Forest. Они не только получат чиплетную компоновку и до 144 ядер на CPU, но и будут обладать рядом архитектурных особенностей, делающих эти процессоры уникальными. Стоит начать с того, что подход, применённый к Sierra Forest, кардинально отличается от подхода AMD, которая в процессорах EPYC Bergamo просто применила оптимизированные по площади кристалла ядра Zen 4c. Архитектурно эти ядра во всём подобны Zen 4, хотя и лишены некоторых возможностей. 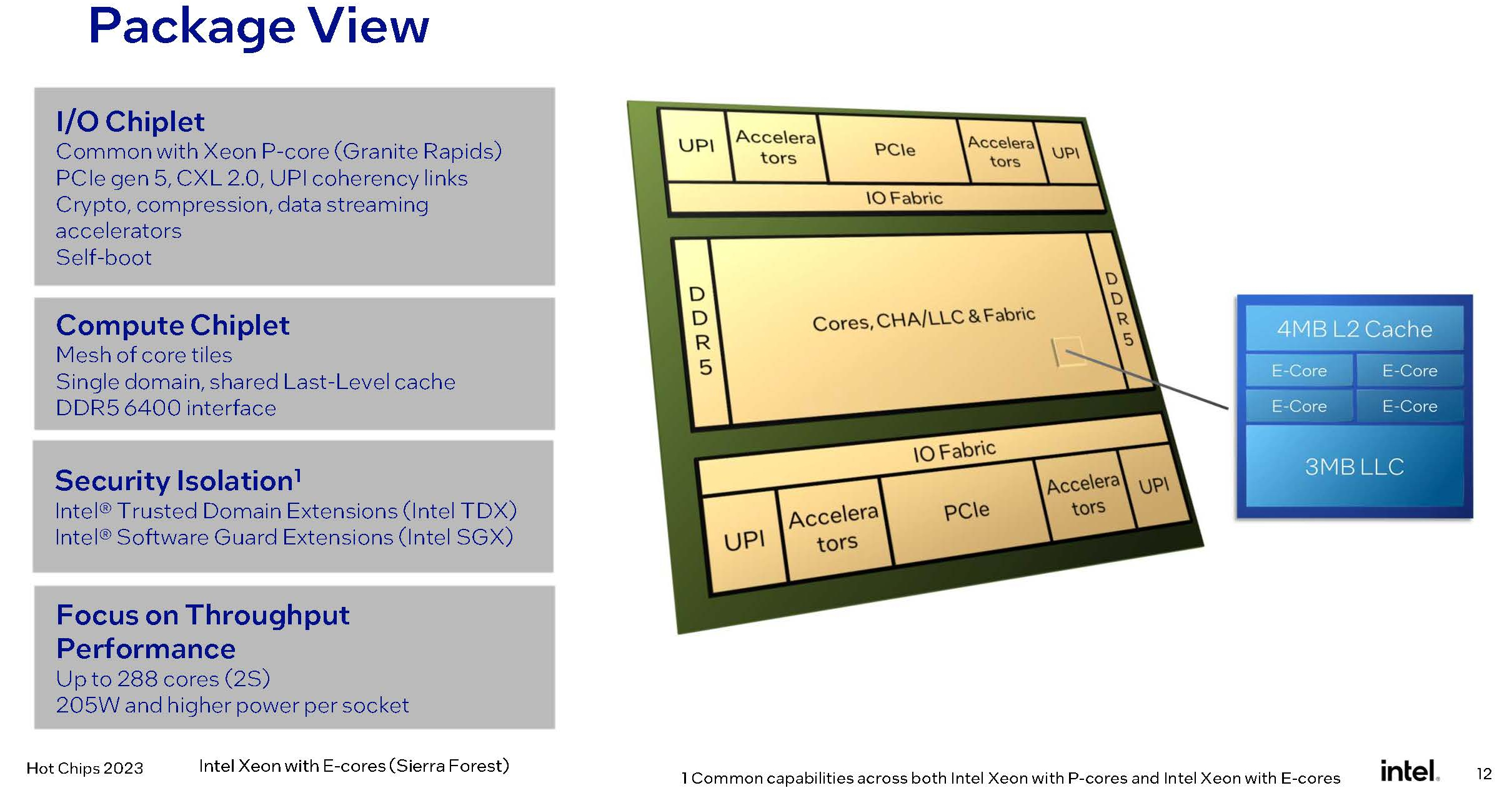
Изображения: Intel (via ServeTheHome) Совсем другое дело Sierra Forest — это первые Xeon, построенные на базе исключительно энергоэффективных Е-ядер, базирующихся на микроархитектуре под кодовым названием Crestmont (Sierra Glenn). И эта архитектура, в основе которой лежит техпроцесс Intel 3, изначально оптимизирована с учётом достижения максимальных энергоэффективности и горизонтальной масштабируемости. 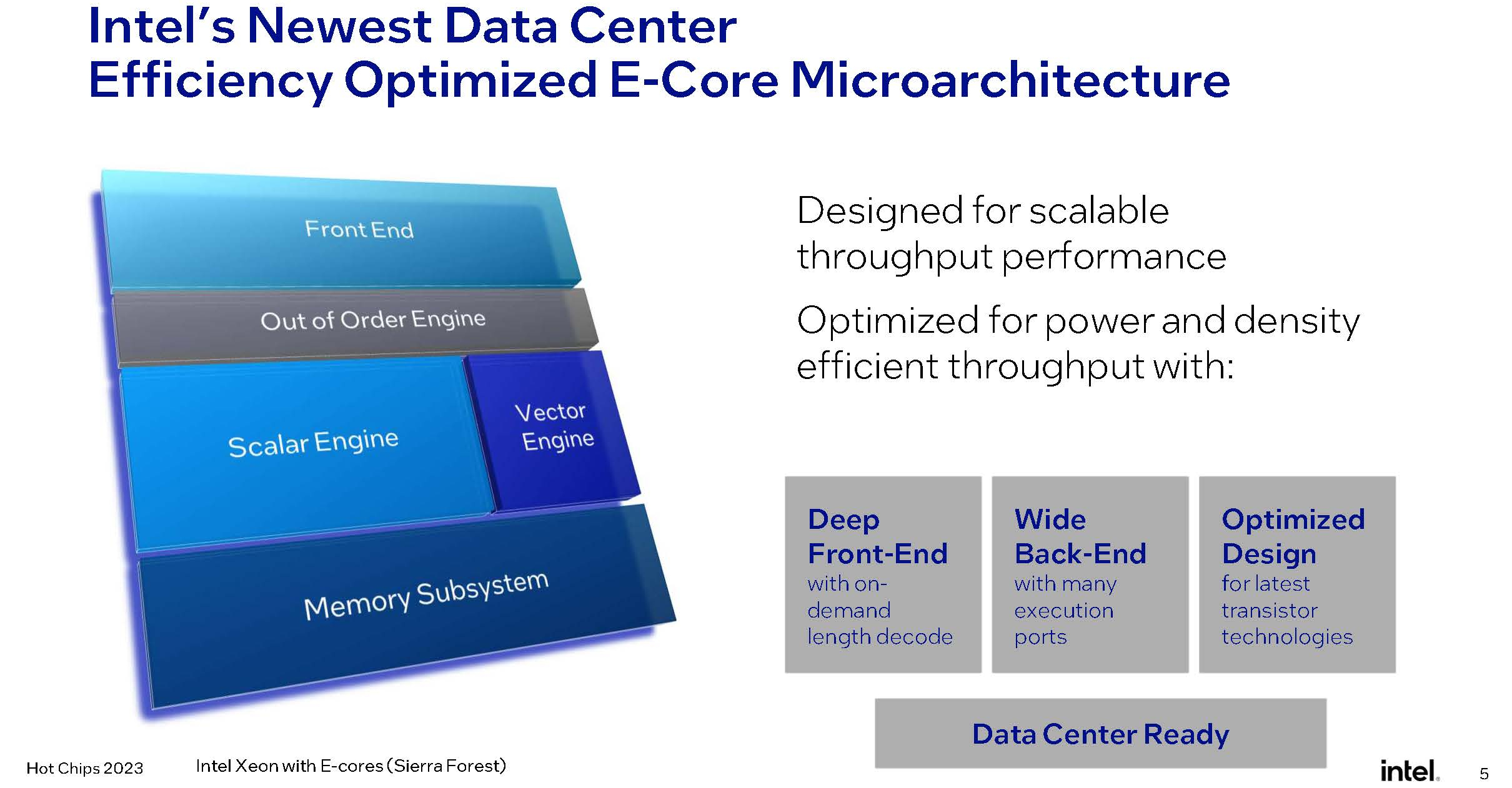 Intel говорит о 2,5-кратном превосходстве в плотности упаковки в пересчёте на стойку и 2,4-кратном преимуществе в производительности на Вт в сравнении с Sapphire Rapids. Новые E-ядра могут быть сгруппированы в кластеры по 2 или 4 ядра, в отличие от Gracemont, не поддерживающего кластеризацию менее чем по 4 ядра. 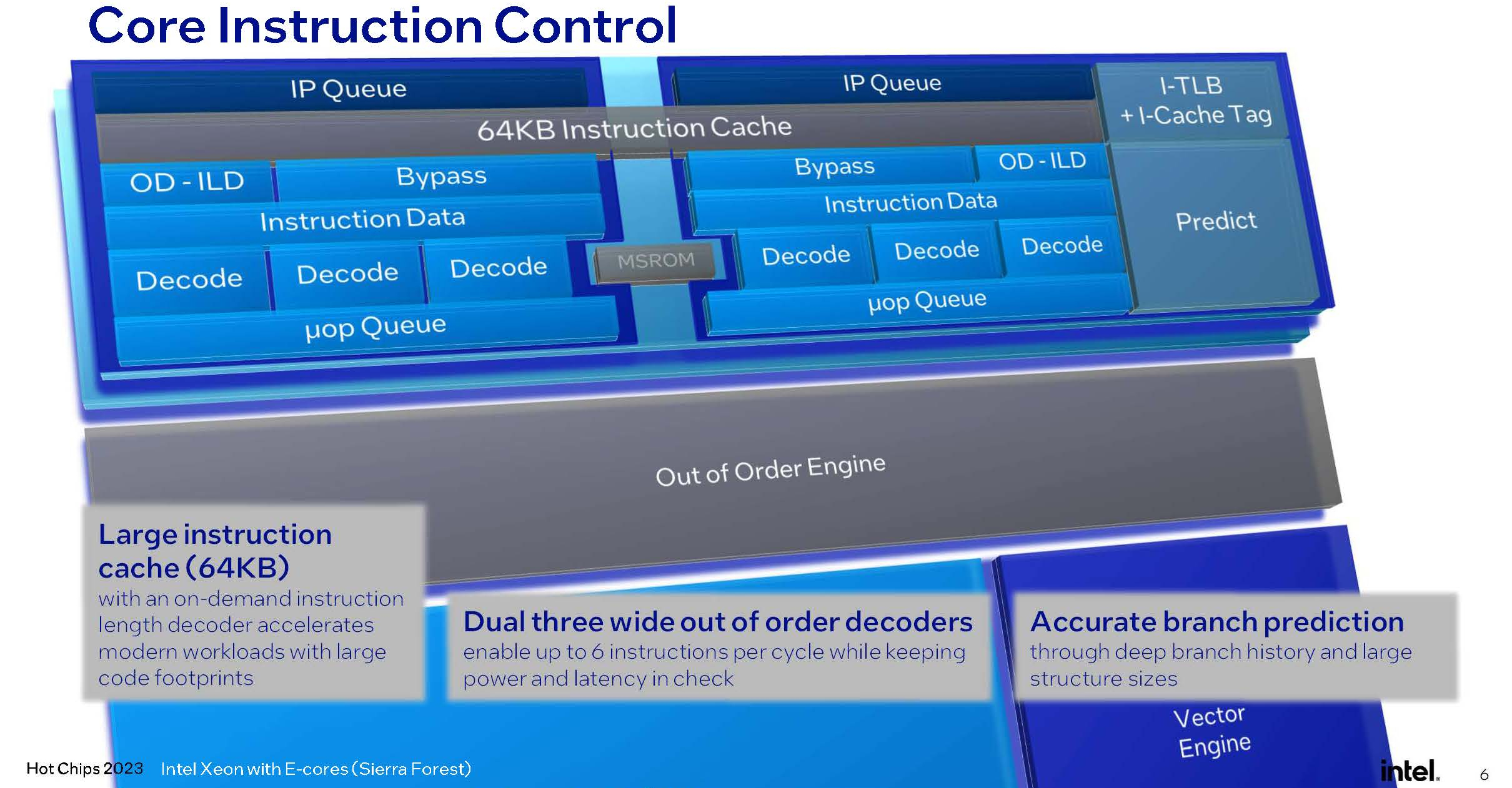 В зависимости от компоновки и модели, таким образом, 4 Мбайт общего кеша L2 может приходиться на те же 2 или 4 ядра, что позволит заказчикам выбрать процессор с учётом используемых сценариев: с максимизацией количества ядер, либо с меньшим числом ядер, но с более высокой производительностью на ядро.  Новые ядра нельзя назвать упрощёнными: они характеризуются развитыми подсистемами фронт- и бэкэнда, довольно объёмным кешем инструкций (64 Кбайт), сдвоенным внеочередным декодером, способным декодировать до 6 инструкций за такт, и конвейером, рассчитанным на выполнение до 8 микроопераций за такт. Также реализован достаточно продвинутый механизм предсказания ветвлений с высокой глубиной хранения истории, причём вмещает этот механизм достаточно объёмные структуры.  Следует отметить, что поддержки Hyper-Threading новые ядра не имеют, поэтому количество одновременно исполняемых потоков не превысит 144, что меньше, нежели у AMD Bergamo, где наличие такой поддержки позволяет говорить о 256 потоках. Однако в поддержке актуальных наборов инструкций и форматов данных Intel будущим чипам Sierra Forest не отказала. 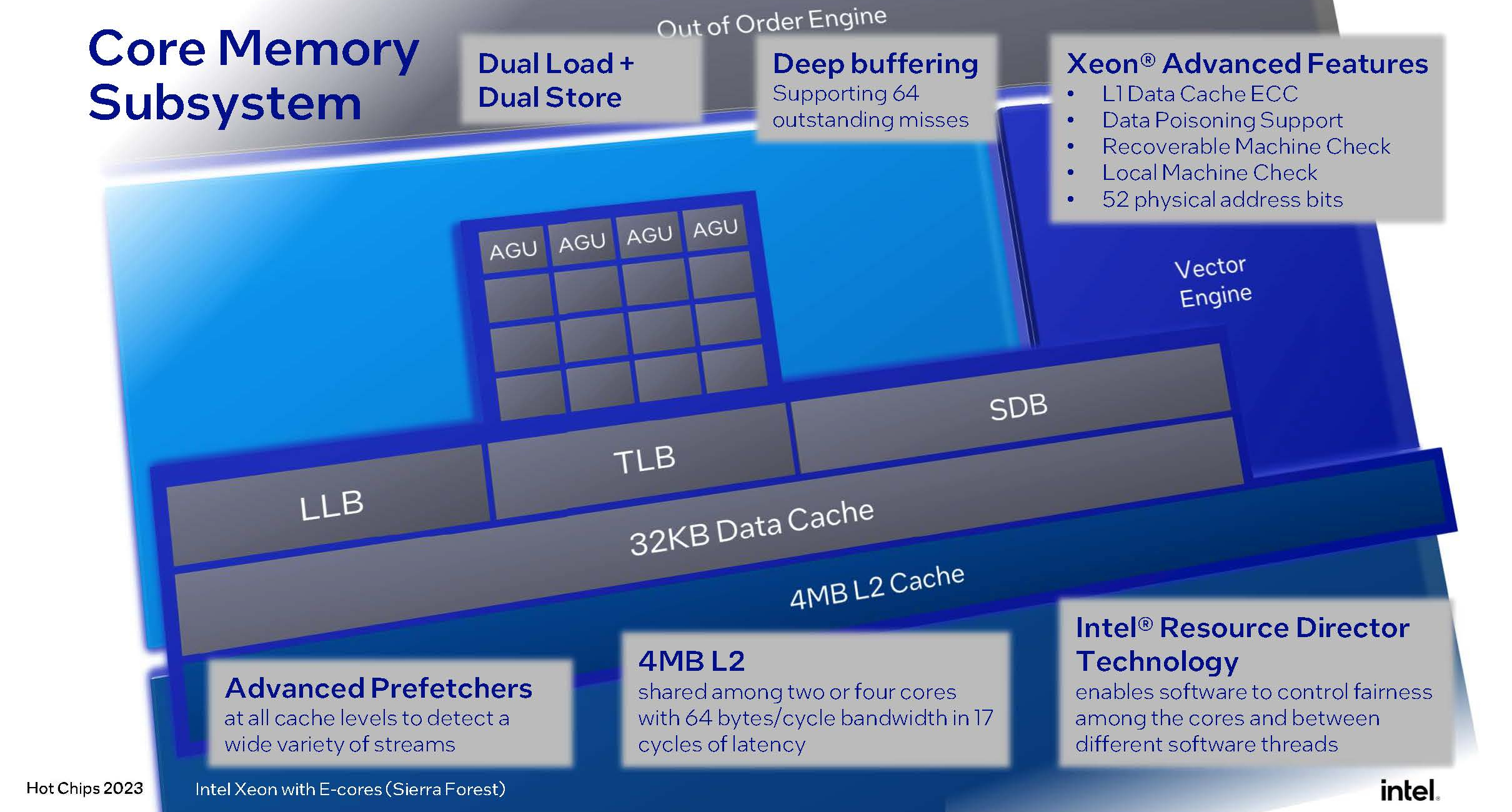 Новые процессоры научатся работать с BF16, а также поддерживают продвинутые наборы инструкций вроде AVX-IFMA и AVX-DOT-PROD-INT8, однако не AVX-512. Не будет и матричных расширений AMX — два последних набора останутся прерогативой P-ядер Redwood Cove. Впоследствии Intel планирует сгладить эту разницу с помощью AVX10, но не в поколении Sierra Forest. В качестве мер по обеспечению повышенной безопасности в новых Е-ядрах реализованы технологии Intel CET, VT-rp, поддерживаются доверенные домены (технология Trusted Domain Extensions, TDX), а также расширения SGX.  Базовой единицей компоновки Sierra Forest станет тайл, содержащий 2 или 4 ядра, 4 Мбайт кеша L2, а также «кусок» (slice) кеша LLC объёмом 3 Мбайт. LLC делится между всеми ядрами в процессоре, но его также можно будет разбить на кластеры для отдельных NUMA-узлов. Сшивка тайлов в чиплет будет осуществляться за счёт логически монолитной, но при этом модульной меш-сети, за связь же чиплетов между собой отвечают мостики EMIB. По краям чиплета расположится подсистема памяти — контроллеры DDR5-6400. В этом тоже есть отличие от подхода AMD. В случае Sierra Forest и Granite Rapids IO-тайл будет одинаковым для обоих процессоров, но он не будет содержать контроллеры памяти, а лишь HSIO-линии (PCIe 5.0, UPI) и некоторую другую обвязку. К слову, оба Xeon нового поколения, наконец, станут полноценными SoC. 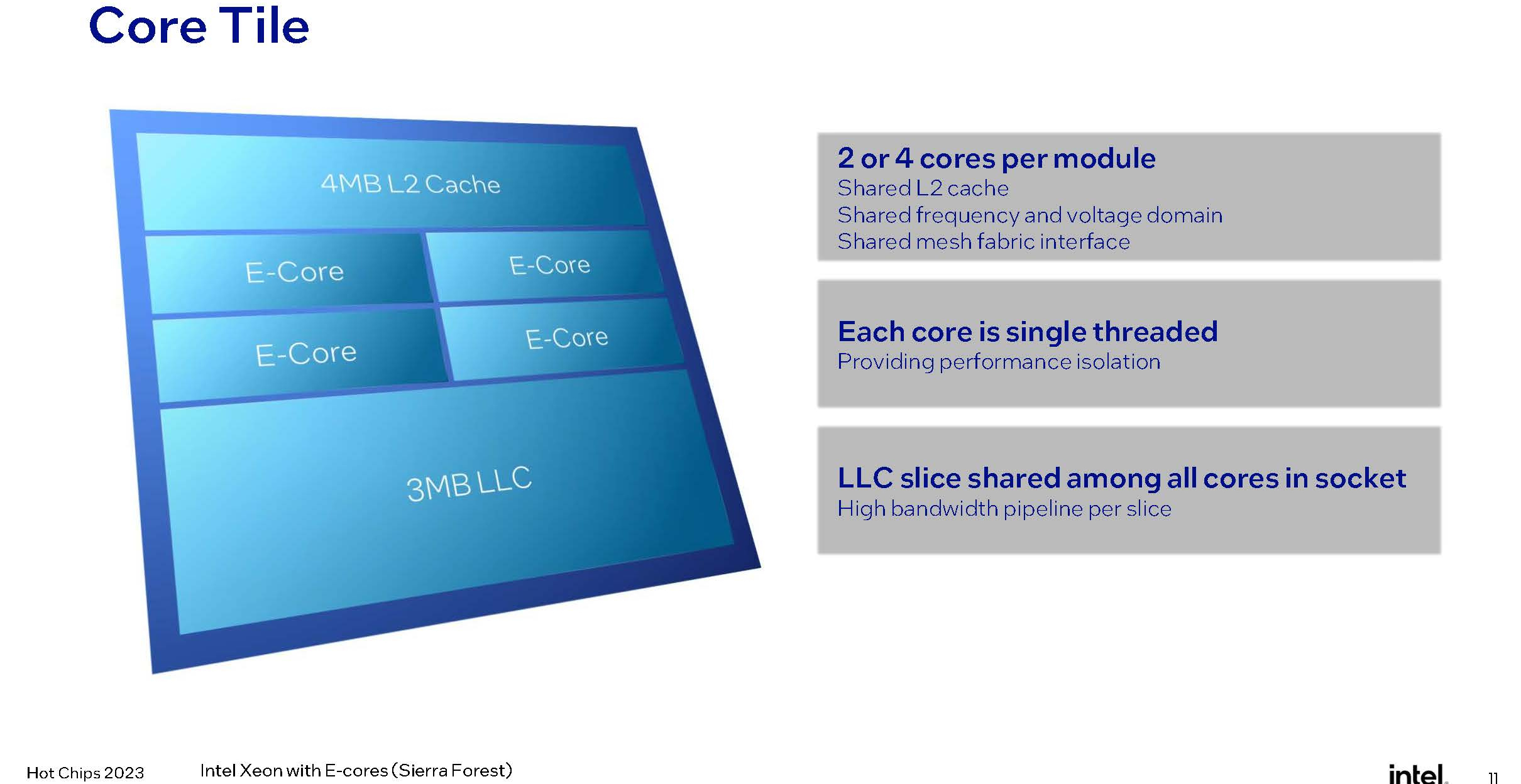 На уровне платформы Sierra Forest будет поддерживать только двухпроцессорные конфигурации, что ограничит максимальную конфигурацию системы 288 ядрами. Платформу Birch Stream они будут делить с Granite Rapids, но последние получат поддержку 8S-конфигураций. Теплопакет Sierra Forest, согласно опубликованным слайдам, не превысит 205 Вт на процессор. Это не так уж много — для сравнения, 128-ядерные AMD EPYC Bergamo имеют TDP 360 Вт.  В целом, Sierra Forest чем-то напоминает концепцией решения Ampere Computing — это процессор с максимально возможным в рамках используемого пакета технологий количеством относительно несложных ядер, ориентированный на использование в облачных средах, в т.ч. хорошо подходящий для одновременного запуска множества виртуальных машин. Однако в отличие от AmpereOne он позволит использовать всё богатство накопленного для платформы x86 программного обеспечения без необходимости пересборки. В сочетании с высокой заявленной энергоэффективностью это может отвлечь внимание потенциальных заказчиков от решений на базе Arm.
29.08.2023 [17:00], Сергей Карасёв
Intel Xeon следующего поколения получат 12 каналов DDR5 и 136 линий PCIe 5.0/CXL 2.0Корпорация Intel на конференции Hot Chips 2023, по сообщению The Register, рассказала о процессорах Xeon следующего поколения для платформы Birch Stream, известных под кодовыми обозначениями Sierra Forest и Granite Rapids. Эти изделия получат ряд улучшений в плане поддержки оперативной памяти и интерфейсов ввода/вывода. А ещё они, наконец-то, станут полноценными SoC, которые не требуют дополнительной обвязки для старта и работы. Нынешние чипы Xeon Sapphire Rapids предлагают восемь каналов памяти DDR5-4800 (1DPC) и DDR5-4400 (2DPC), а также 80 линий PCIe 5.0/CXL 1.1. Вместе с тем конкурирующие AMD EPYC Genoa имеют 12 каналов памяти DDR5-4800 и 128 линий PCIe 5.0. При этом с 2DPC у Genoa не всё гладко. Процессоры Xeon следующего поколения обеспечат поддержку DDR5 DIMM и MCR DRAM, причём с поддержкой 2DPC, а также 136 линий PCIe 5.0/CXL 2.0 (с упором на Type-3) и 6 линий UPI. В марте нынешнего года Intel сообщала, что Granite Rapids смогут работать с памятью MCR-8800. Пропускная способность ОЗУ по сравнению с Sapphire Rapids возрастёт практически в три раза. 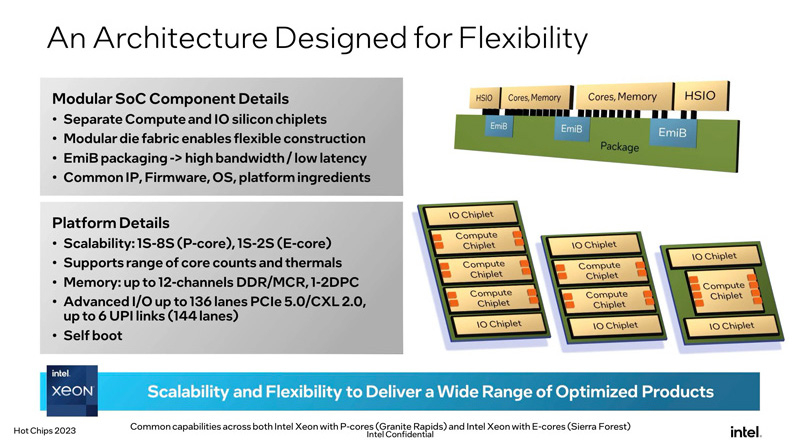
Источник изображений: Intel Впрочем, главной особенностью Sierra Forest и Granite Rapids станет полный переход на чиплетную компоновку. В них два IO-тайла, которые и предоставляют HSIO-линии, «сшиты» посредством EMIB с вычислительными тайлами, которых может быть от одного до трёх. Это позволит консолидировать основную функциональность на уровне платформы (Birch Stream), которая едина для обоих процессоров и физически, и электрически, и логически. Впрочем, важное отличие есть: Sierra Forest рассчитаны на одно- и двухсокетные системы, тогда как Granite Rapids поддерживают и 8S-конфигурации.  Чипы Sierra Forest с ядрами E (с высокой энергетической эффективностью) ориентированы на горизонтально масштабируемые рабочие нагрузки, а изделия Granite Rapids с ядрами P (с высокой производительностью) предназначены для приложений с интенсивными вычислениями. При этом компания, несмотря на имеющиеся возможности, не намерена создавать гибридные процессоры с P- и E-ядрами. В случае Sierra Forest компания сосредоточилась на повышении плотности размещения ядер с минимальным ущербом для производительности. Заказчикам на выбор будут доступны два варианта: два или четыре ядра на один блок L2-кеша объёмом 4 Мбайт, причём с возможностью более тонко контролировать, какие данные будут туда попадать. 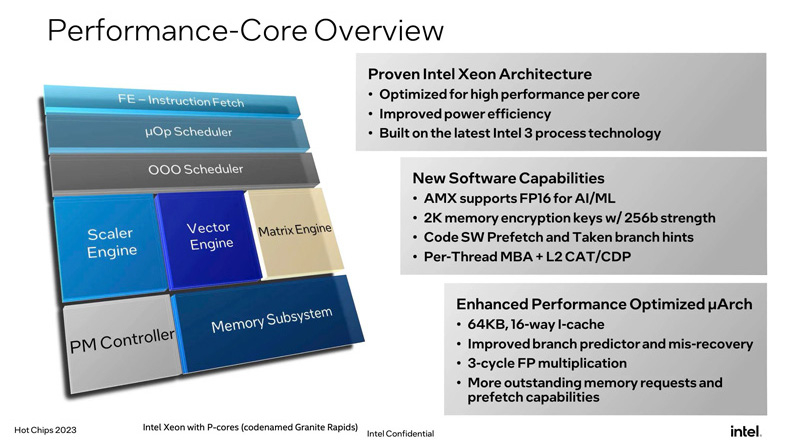 Процессоры будут изготавливаться по 7-нм технологии Intel 3. В семейство войдут решения, насчитывающие до 144 ядер, но это максимум для Sierra Forest (будут и более простые модели), а вот лимит под ядрам для Granite Rapids так и не был назван. Для Sierra Forest заявлена поддержка BF16 и FP16, а вот AVX-512 они лишены напрочь. Частично упростит унификацию кода для разных процессоров появление AVX10, но полноценно эти инструкции будут реализованы лишь в будущих поколениях. В случае с Granite Rapids упомянута поддержка Advanced Matrix Extensions (AMX) с FP16 для задач ИИ и машинного обучения.
29.08.2023 [14:20], Сергей Карасёв
AMD EPYC Siena для периферийных вычислений получат до 64 ядер Zen4Компания AMD, по сообщению ресурса ServeTheHome, поделилась информацией о процессорах EPYC Siena, предназначенных для использования в телекоммуникационной сфере и системах периферийных вычислений. В основу этих изделий положена микроархитектура Zen 4 — AMD придерживается стратегии формирования различных чиплетных сборок вокруг унифицированного IO-блока. В состав Siena войдут до 64 вычислительных ядер с возможностью одновременной обработки до 128 потоков инструкций. Говорится о поддержке шести каналов оперативной памяти DDR5 DRAM. Величина TDP новых процессоров составит от 70 до 225 Вт. По имеющейся информации, чипы будут функционировать на тактовой частоте от 2,2 до 2,55 ГГц. Объём кеша L3 будет достигать 128 Мбайт, что в два раза меньше по сравнению с процессорами AMD EPYC Rome с 64 ядрами. 
Источник изображений: AMD (via ServeTheHome) Предполагается, что Siena будут использовать новую платформу SP6, которая значительно проще, чем SP5, применяемая для чипов EPYC серии 9000. Системы на платформе Siena смогут использовать модули DDR5-4800. Поначалу в семейство Siena войдут как минимум шесть моделей — с 8, 16, 24, 32, 48 и 64 ядрами. Процессоры, как ожидается, появятся на рынке в конце текущего или в начале следующего года. Чипы предназначены для серверов с низким энергопотреблением, которым не требуется максимальная производительность. 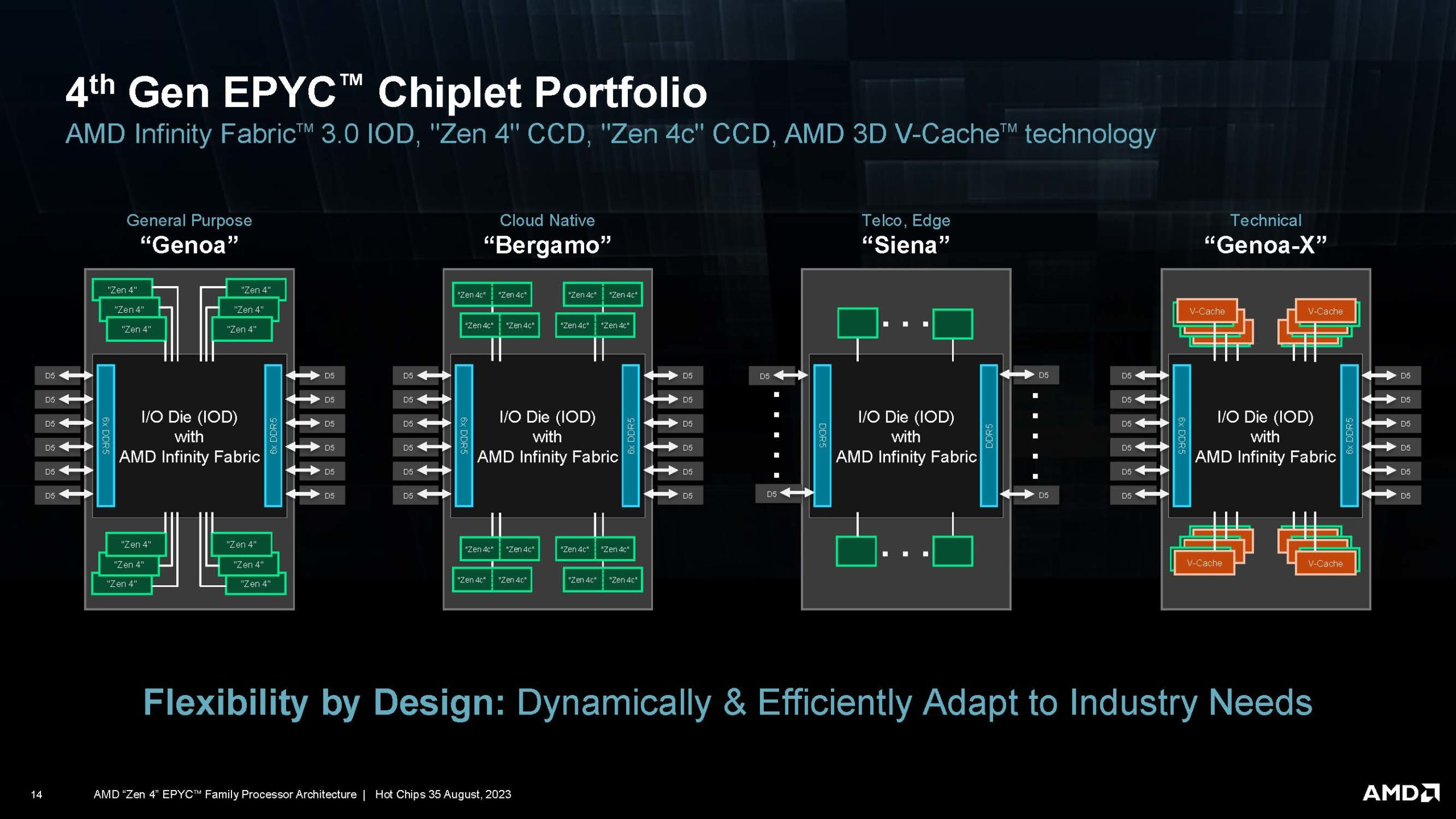
30.06.2023 [21:39], Владимир Мироненко
Глава Oracle считает, что архитектура Intel x86 теряет актуальность для серверовВ 2023 году Oracle планирует потратить значительные средства на приобретение чипов AMD и Ampere Computing для новой инфраструктуры, отметив, что «старая архитектура Intel x86 достигает своего предела». «В этом году Oracle купит GPU и CPU у трёх компаний, — сообщил на прошедшем в среду мероприятии глава Oracle Ларри Эллисон (Larry Ellison). — Мы будем покупать GPU у NVIDIA, мы покупаем у неё на миллиарды долларов США. И потратим в три раза больше на центральные процессоры от Ampere и AMD. Мы по-прежнему тратим больше денег на традиционные чипы». Oracle сообщила, что впервые за 14 лет существования специализированных ПАК Exadata для СУБД она полностью отказалась от процессоров Intel в пользу чипов AMD. В платформе 12-го поколения Exadata X10M в рамках двух предложений Oracle Exadata Machine и управляемого решения Oracle Exadata Cloud@Customer будут использоваться AMD EPYC Genoa. Одной из причин такого перехода, пусть и далеко не самой важной, считается отказ Intel от Optane. 
Источник изображения: Oracle С момента запуска Exadata в 2008 году Oracle полагалась на процессоры Intel Xeon. Но ситуация начала меняться c выходом X9M в 2021 году. Для Oracle Exadata Machine и Oracle Exadata Cloud@Customer компания выбрала чипы Intel Xeon Ice Lake-SP, а в начале 2022 года для облачного решения Oracle Exadata Cloud Infrastructure решила использовать чипы AMD. При этом EPYC Milan использовались в серверах для обеспечения работы баз данных, а Ice Lake-SP — для СХД. Кроме того, на днях Oracle сделала важный шаг — перенесла свою флагманскую СУБД Oracle Database на архитектуру Arm, т.е. на процессоры компании Ampere Computing, в которую в своё время инвестировала. Эллисон отметил, что чипы Ampere Altra намного энергоэффективнее решений AMD и NVIDIA, что поможет ЦОД Oracle соответствовать будущим регуляциям. «Мы перешли на новую архитектуру и к новому поставщику, — сообщил Эллисон. — Мы думаем, что это будущее. Старая архитектура Intel x86 после многих десятилетий на рынке подошла к своему пределу». 
Источник изображения: Oracle Тем не менее, эксперты полагают, что ставка Oracle на архитектуру Arm не помешает её отношениям с AMD в ближайшее время, тем более что Intel и AMD планируют бороться с Arm-процессорами с помощью оптимизированных для облачных платформ чипов с высокой плотностью ядер и улучшенной энергоэффективностью: EPYC Bergamo и Xeon Sierra Forest. Кроме того, разработка, перенос и рефакторинг ПО для Arm требует времени и средств. В свою очередь, представитель Intel сообщил ресурсу CRN в четверг, что компания поставляет Oracle процессоры Xeon Sapphire Rapids «в течение многих месяцев и планирует продолжать поставки Xeon текущего и следующего поколения в будущем». Компании связывают долгие годы совместной работы над аппаратными и программными решениями для клиентов, а сейчас Intel поставляет чипы для облачной инфраструктуры Oracle OCI.
19.05.2023 [10:10], Сергей Карасёв
Ampere представила процессоры AmpereOne: до 192 ядер Arm, 8 каналов DDR5 и 128 линий PCIe 5.0Компания Ampere анонсировала процессоры серии AmpereOne, предназначенные для использования в серверах и оборудовании для дата-центров. Утверждается, что по сравнению с изделиями предыдущих поколений — Ampere Altra и Ampere Altra Max — новые чипы обеспечивают более высокие показатели производительности и энергоэффективности, а также обладают улучшенной масштабируемостью. Процессоры AmpereOne основаны на кастомизированных ядрах собственной разработки Ampere с набором инструкций Arm. Задействована чиплетная компоновка. Изготавливаются решения на предприятии TSMC на основе комбинации технологий с нормами 5 и 7 нм. 
Источник изображений: Ampere В семейство AmpereOne вошли пять моделей — со 136, 144, 160, 172 и 192 ядрами. Каждое ядро способно обрабатывать один поток инструкций. Объём кеша L2 составляет 2 Мбайт в расчёте на ядро; размер кеша L1 — 16 Кбайт для инструкций и 64 Кбайт для данных. Кроме того, есть 64 Мбайт системного кеша. Тактовая частота достигает 3,0 ГГц. 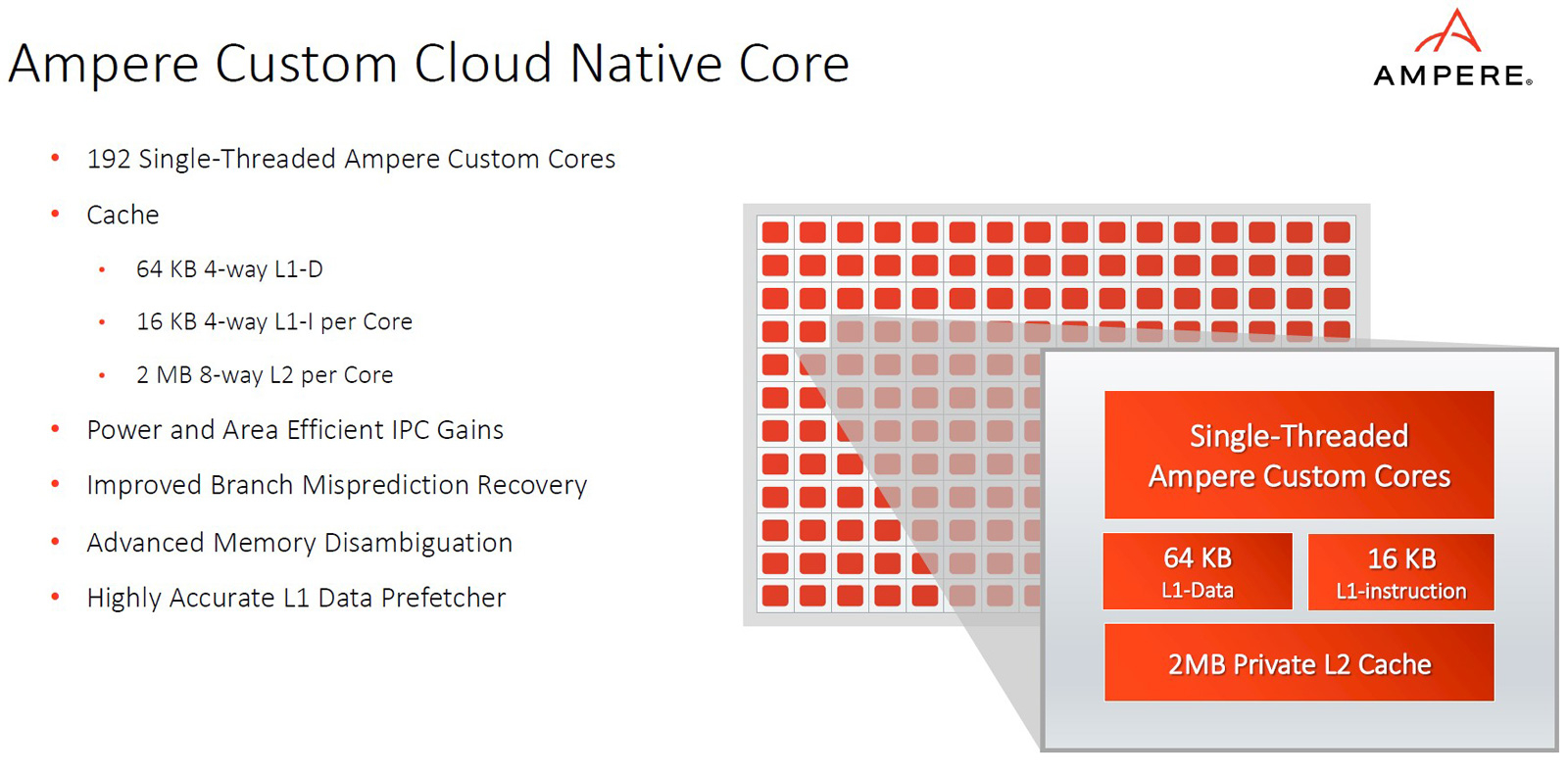
 Конструкция AmpereOne включает восемь каналов памяти DDR5 с поддержкой ECC: сервер может быть оборудован 16 слотами DIMM с возможностью использования до 8 Тбайт ОЗУ. Доступны 128 линий PCIe 5.0. Упомянута поддержка Armv8.6+ и SBSA 5. Чипы имеют исполнение FCLGA (5964-Pin).  Ampere отмечает, что процессоры AmpereOne ориентированы прежде всего на облачные платформы и среды виртуализации. Они обеспечивают высокую плотность вычислений и возможность формирования виртуальных машин, использующих от одного vCPU. Кроме того, достигается высокая производительность при ИИ-нагрузках (BF16). Заявленное энергопотребление AmpereOne составляет 1,8 Вт в расчёте на ядро, или от 200 до 350 Вт на сокет в зависимости от модификации решения. 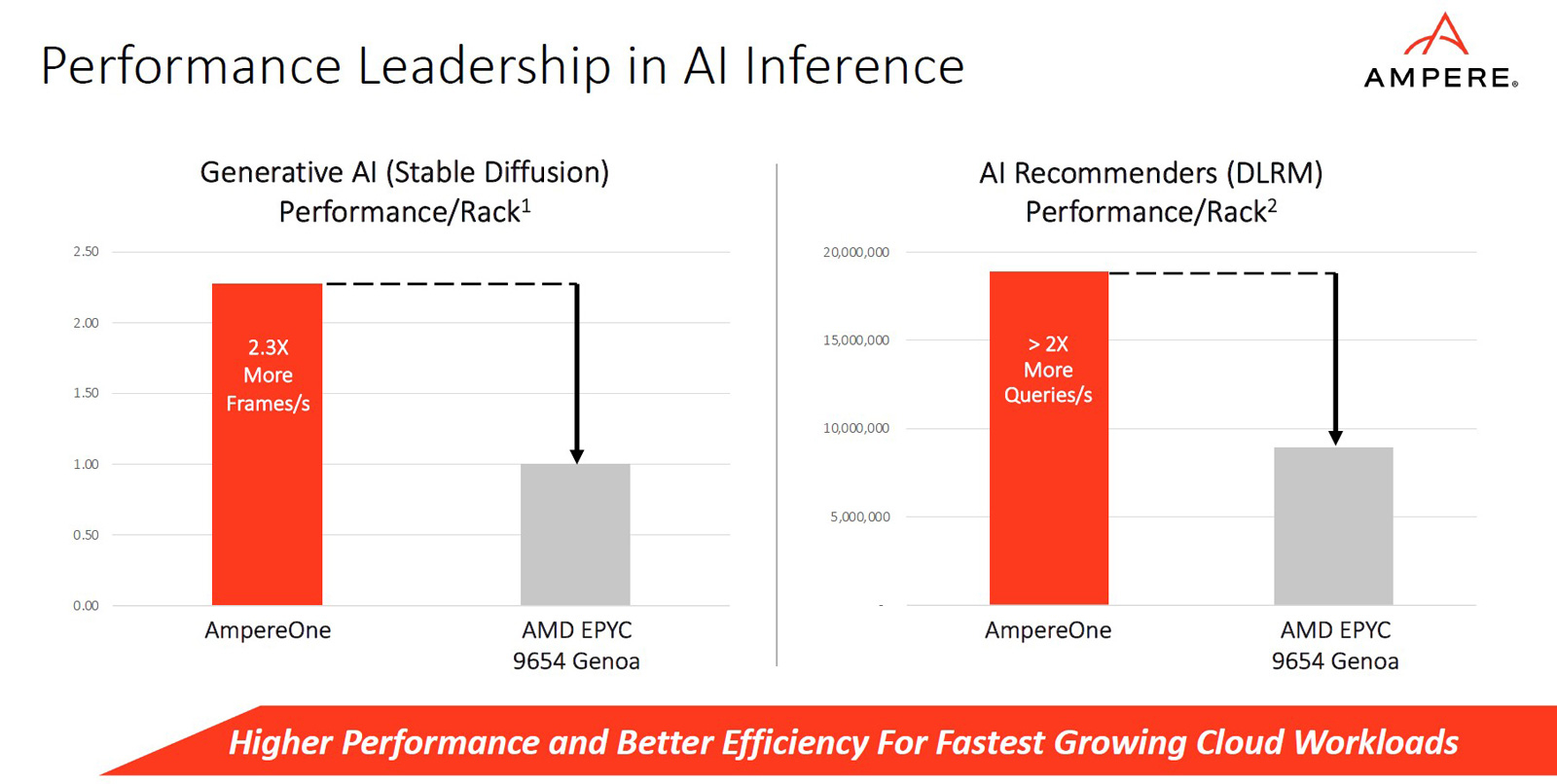
16.05.2023 [09:23], Сергей Карасёв
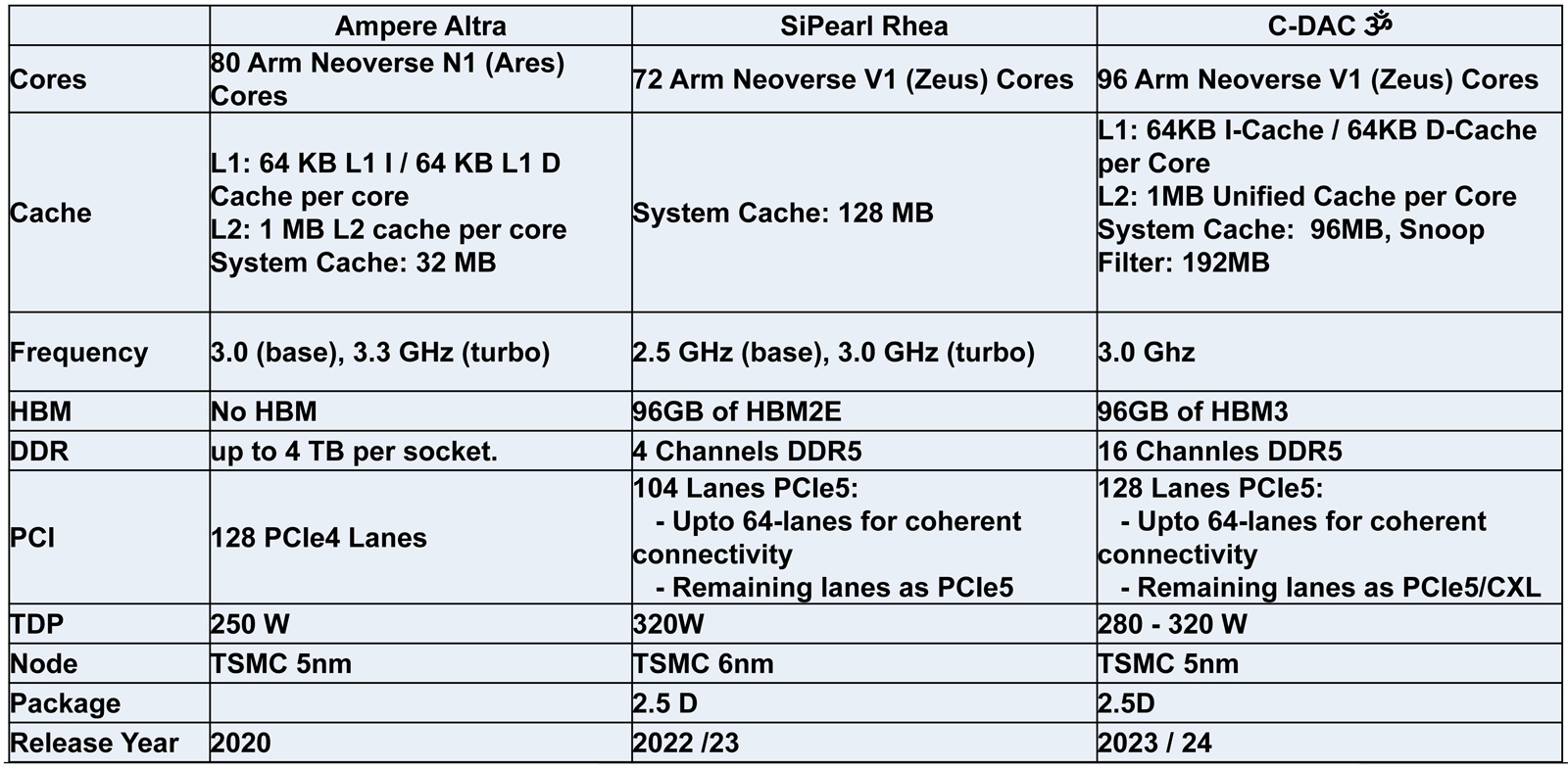
Индия представила свой первый серверный процессор AUM: 96 ядер и 96 Гбайт памяти HBM3Центр развития передовых вычислений (C-DAC) Департамента электроники и информационных технологий Министерства коммуникаций и информационных технологий Индии представил первый в стране процессор для серверов и НРС-систем. Изделие под названием AUM выйдет на коммерческий рынок в текущем или следующем году. Решение имеет чиплетную компоновку на базе двух модулей A48Z, каждый из которых насчитывает 48 вычислительных ядер Zeus с архитектурой Arm. Таким образом, суммарное количество ядер достигает 96. Тактовая частота составляет 3,0 ГГц (до 3,5 ГГц в турбо-режиме); показатель TDP варьируется от 280 до 320 Вт. 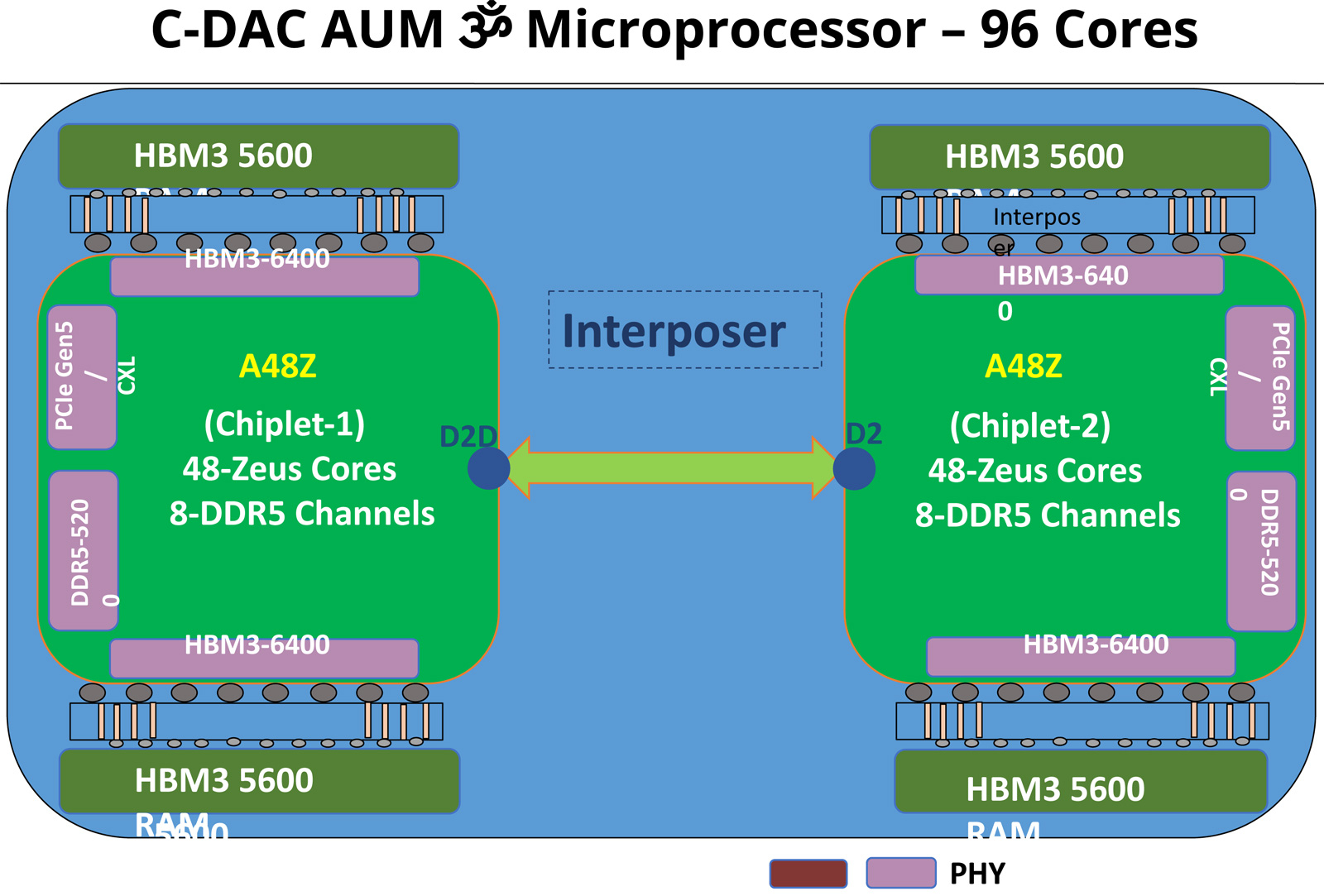
Источник изображений: C-DACC-DAC Новинка будет изготавливаться на предприятии TSMC по 5-нм технологии. Чип содержит 96 Мбайт кеша L2 и 96 Мбайт системного кеша. Изделие получило 96 Гбайт памяти HBM3 и 8-канальный контроллер DDR5-5200; кроме того, имеется доступ к 64 Гбайт памяти HBM3-5600. Таким образом, задействована трёхуровневая подсистема памяти. Упомянуты до 128 линий PCIe 5.0 с поддержкой CXL. 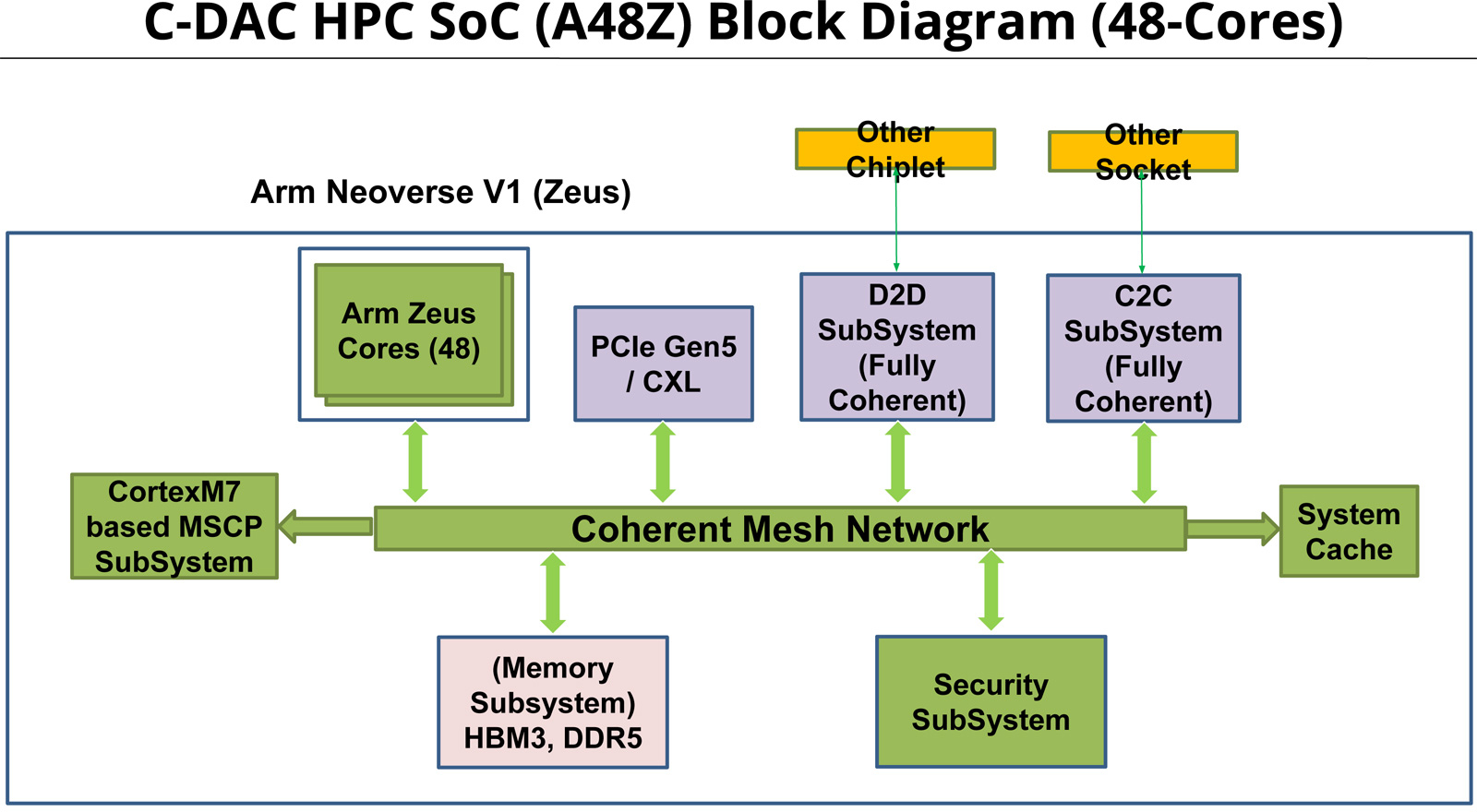 Процессор AUM может применяться в двухсокетных серверах. Заявленная производительность превышает 4,6 Тфлопс в расчёте на разъём. Реализованы различные средства обеспечения безопасности, в том числе функция Secure Boot и криптографические алгоритмы. 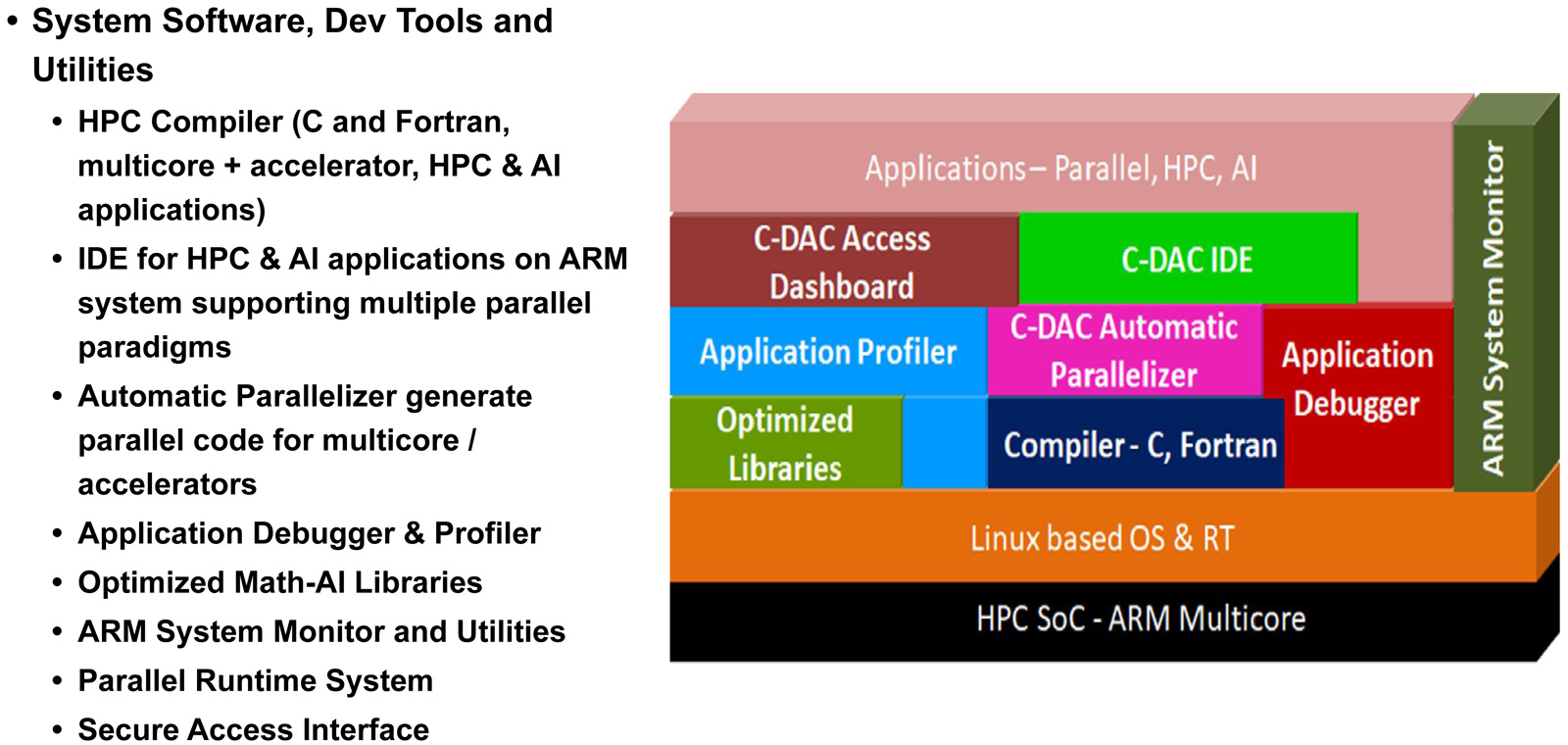
22.03.2023 [00:09], Алексей Степин
NVIDIA показала сдвоенный серверный суперпроцессор Grace SuperchipПроект NVIDIA Grace весьма амбициозен: компания всерьёз намерена ворваться с его помощью на рынок высокопроизводительных серверных процессоров, где всё ещё доминируют решения Intel и AMD. Об этом чипе было объявлено ещё на конференции GTC 2022, а на GTC 2023 глава компании, наконец, показал его вживую. В рамках продолжающегося роста плотности упаковки вычислительных мощностей в современных ЦОД на первый план выдвинулась не голая производительность, а соотношение производительности к уровню энергопотребления и тепловыделения. По сочетанию этих параметров x86 далеко не оптимальна, и тут у NVIDIA есть все шансы. С анонсом Grace Superchip NVIDIA провозглашает (впрочем, уже не в первый раз) смерть «закона Мура» — пришло время оптимизации и отказа от устаревших, по мнению компании, вычислительных архитектур. 
Источник изображений здесь и далее: NVIDIA Процессор NVIDIA Grace воплощает в себе все современные тенденции, начиная с отказа от монолитного кристалла. Сборка Grace Superchip состоит из двух кристаллов, каждый из которых включает в себя 72 ядра Arm Neoverse V2 (Arm v9), поддерживающих векторные расширения SVE2 и оптимизированные для ИИ форматы BF16/INT8. Кристаллы соединены между собой шиной NVLink-C2C, обеспечивающей пропускную способность 900 Гбайт/с.  В сборку интегрированы чипы памяти LPDDR5x общим объёмом до 960 Гбайт, причём каждый кристалл имеет свою шину доступа к памяти с производительностью 500 Гбайт/с. При этом с точки зрения ПО Grace Superchip представляется единым 144-ядерным процессором с ПСП на уровне 1 Тбайт/с. 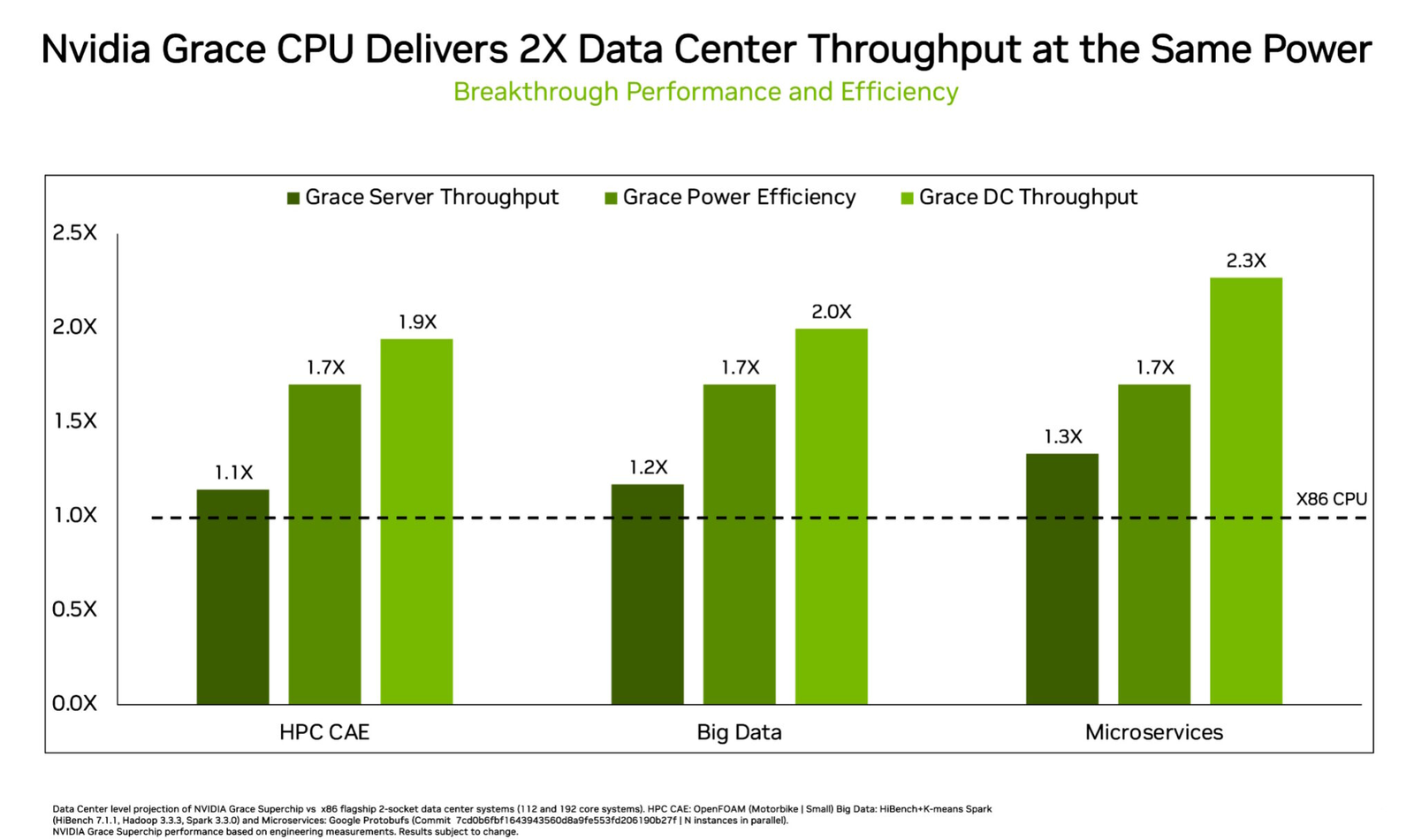 Для достижения схожих параметров в мире x86 требуется двухпроцессорная платформа AMD Genoa, куда более сложная технически и гораздо менее энергоэффективная, но при этом обладающая всеми недостатками NUMA-систем. Достаточно сравнить энергопотребление: 900 Вт против 500 у нового решения NVIDIA. 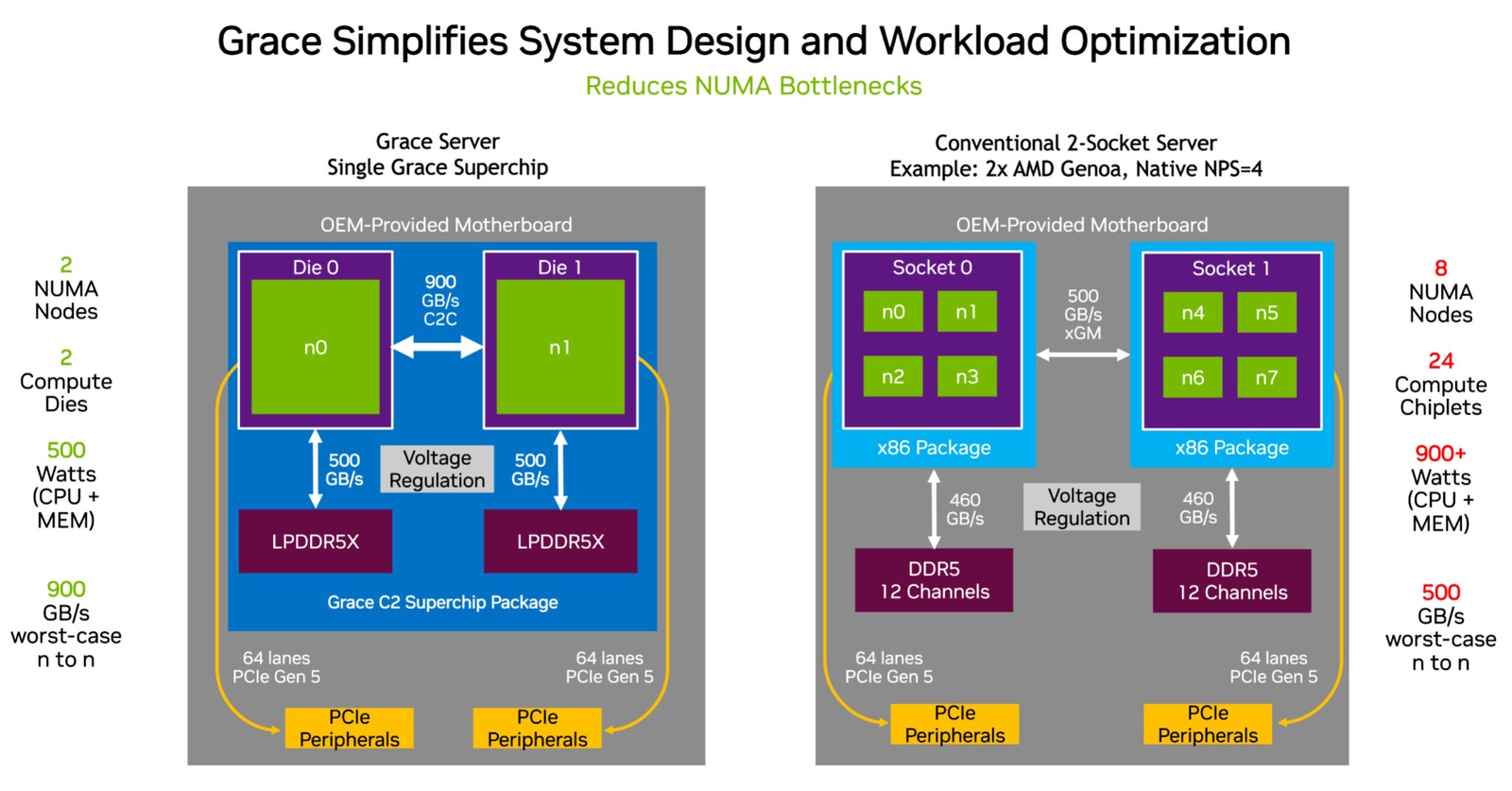 NVIDIA есть чем гордиться: при сопоставимом уровне энергопотребления Grace Superchip превосходит своих конкурентов из мира x86 в 2,3 раза при запуске микросервисов, вдвое опережает их в приложениях с интенсивным обменом данными с памятью и почти вдвое — в задачах симуляции вычислительной гидродинамики. В ряде других научно-технических задач преимущество может быть и более чем двукратным. 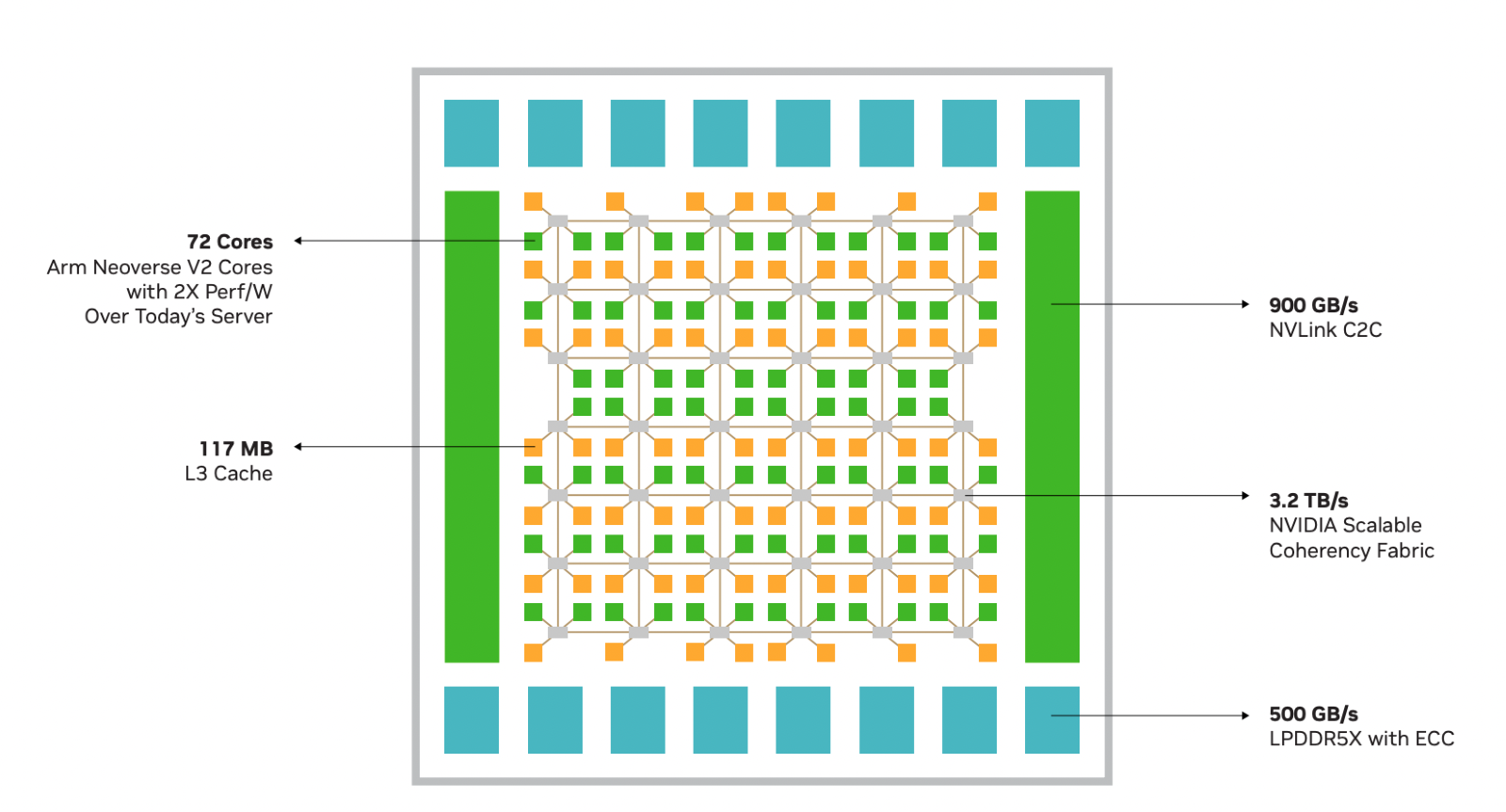 Это достигнуто в том числе благодаря изначальной оптимизации дизайна процессора с упором на максимальную производительность передачи данных. Внутренне Grace организован по принципу меш-сети с распределённой системой кеширования на базе специальных узлов коммутации CSN (Cache Switch Nodes). Называется эта сеть Scalable Coherency Fabric, она имеет пропускную способность 3,2 Тбайт/с, а объём кеша L3 составляет 117 Мбайт на кристалл и 234 Мбайт совокупно.  Сервер на базе NVIDIA Grace не только может потреблять меньше энергии, но и будет существенно проще конструктивно, поскольку модуль Grace Superchip содержит не только процессорные ядра и память, но также и регуляторы напряжения. От платформы на базе нового процессора требуется только PCIe 5.0 — у нового чипа есть два набора по 64 линии. Причём линии с поддержкой CXL 2.0, так что проблем с расширением доступного объёма памяти новинка испытывать не будет.  Даже компактные серверы высотой 1U смогут вместить две сборки Grace Superchip, что даст 288 ядер и почти 2 Тбайт оперативной памяти — труднодостижимый в таких габаритах показтель для более традиционных конструктивов процессоров и системных плат. Сравнительно невысокий теплопакет позволит таким решениям обходиться традиционным воздушным охлаждением.  При этом есть и вариант Grace Hopper, сочетающий в одном модуле кристалл Grace и новейший GPU H100, причём параметрами PCI Express последний ограничен не будет благодаря NVLink-C2C. NVIDIA уже начала первичные поставки Grace, а начало полномасштабного производства ожидается во второй половине года. Новыми процессорами заинтересовались крупные производители оборудования, включая ASUS, Atos, GIGABYTE, HPE, QCT, Supermicro, Wistron и ZT Systems.  Лос-Аламосская национальная лаборатория объявила, что использует NVIDIA Grace в новом суперкомпьютере Venado, который поможет учёным в исследованиях новых материалов и возобновляемых источников энергии. Ряд крупных европейских и азиатских ЦОД также рассматривает перспективы применения новых процессоров NVIDIA. В частности, одной из систем на базе Grace станет кластер Alps в Швейцарском национальном компьютерном центре.
28.02.2023 [00:08], Игорь Осколков
Xeon EE для 5G: Intel представила процессоры Sapphire Rapids со встроенным ускорителем vRAN BoostНа MWC 2023 компания Intel, как и обещала когда-то, представила специализированное решение для ускорения внедрения 5G и 4G, которое упрощает развёртывание виртуализированных сетей радиодоступа (vRAN) — процессоры Xeon Sapphire Rapids с интегрированным ускорителем vRAN Boost. Новинки, по словам компании, оптимизированы для сигнальной обработки и обработки пакетов, балансировки, ИИ и машинного обучения, а также динамического управления энергопотреблением.  Новинки позволят телеком-провайдерами консолидировать уже развёрнутые сети 4G/5G, удвоив ёмкость vRAN (по сравнению с Ice Lake-SP), а также вдвое улучшить энергоэффективность обработки L1-трафика в режиме реального времени благодаря расширенным возможностям сбора телеметрии и управления состоянием отдельных ядер (переход в сон и обратно) с низким уровнем задержки, а также гибкого перераспределения сетевых и иных нагрузок между ядрами.  Компания предложит заказчикам две серии Xeon EE (Enhanced Edge) с числом ядер до 20 или до 36 шт. и восемью каналами памяти, DDR5-4000 и DDR5-4400 соответственно. В обоих случаях речь об односокетных платформах. Некоторые модели также имеют поддержку AMX-инструкций и расширенный диапазон рабочих температур. Компанию новинкам составят FPGA Agilex 7, eASIC N5X и сетевые контроллеры E810 (Columbiaville). 
Источник: Intel Xeon EE используют расширения AVX (в частности, AVX512-FP16) для обработки сигналов и аппаратные блоки ускорения vRAN Boost для прямой коррекции ошибок (FEC, Forward Error Correction) и дискретного преобразования Фурье (DFT, Discrete Fourier Transformation), что позволяет снизить энергопотребление на величину до 20 % по сравнению с обычными Sapphire Rapids, поскольку для них и более ранних CPU требуются дискретные ускорители вроде ACC100. Для работы с новыми функциями предлагается DPDK и VPP, а драйверы совместимы с O-RAN ALLIANCE Accelerator Abstraction Layer (AAL) API. Также поддерживается и референсная платформа Intel FlexRAN.  В целом же, Intel продолжает продвигать идею замены специализированного 4G/5G-оборудования на как можно более стандартные серверы, что приводит к снижению совокупной стоимости владения (TCO) и повышает функциональность, гибкость и масштабируемость сетей нового поколения благодаря переходу к программно определяемым решениям. Среди ключевых партнёров компания называет Advantech, Capgemini, Canonical, Dell Technologies, Ericsson, HPE, Mavenir, Quanta Cloud Technology, Rakuten Mobile, Red Hat, SuperMicro, Telefonica, Verizon, VMware, Vodafone и Wind River.  На MWC 2023 также были показаны анонсированные на днях edge-серверы Dell на базе новых Xeon EE. Кроме того, Intel при сотрудничестве с SK Telecom разработала референсную программную платформу Intel Infrastructure Power Manager для ядра 5G-сети, которая позволяет ещё больше снизить (до -30 %) фактическое энергопотребление процессоров. Наконец, компания на пару с Samsung продемонстрировала работу 5G UPF (User Plane Function) на скорости 1 Тбит/с, для чего оказалось достаточно двухсокетного сервера с Sapphire Rapids, который, судя по всему, всё же был снабжён ускорителями.
20.01.2023 [15:28], Алексей Степин
NVIDIA Grace Superchip получит 144 Arm-ядра, 960 Гбайт набортной памяти LPDDR5x и 128 линий PCIe 5.0, а TDP составит 500 ВтGrace можно назвать одним из самых амбициозных проектов NVIDIA. О намерении ворваться на рынок мощных серверных процессоров компания объявила ещё на GTC 2022, но до недавних пор о чипах Grace были доступны лишь общие сведения. Однако ситуация меняется. NVIDIA явно располагает рабочим «кремнием», и на днях опубликовала пару деталей о Grace Superchip. Ожидается, что официальный анонс новинки состоится в марте этого года на GTC 2023. Эта сборка включает в себя два 72-ядерных кристалла Grace, использующих ядра Arm Neoverse V2. Данное ядро использует набор инструкций Armv9, а также имеет четыре 128-битных блока векторных расширений SVE2, блоки для работы с матрицами и поддержку BF16/INT8. Объём кеша L1 составляет по 64 Кбайт для инструкций и данных, L2 — 1 Мбайт на ядро, а общий объём L3 на сборку достигает 234 Мбайт. 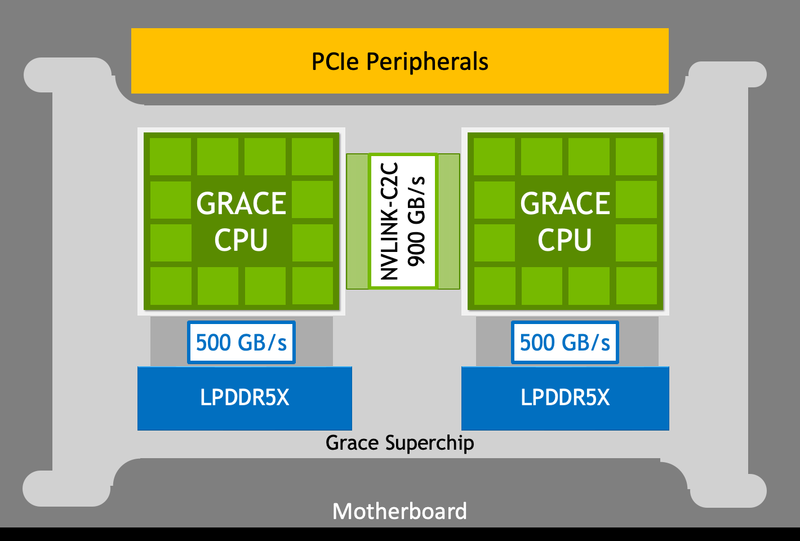
Блок-схема сборки Grace Superchip. Источник изображений здесь и далее: NVIDIA Между собой кристаллы соединены шиной NVLink C2C с пропускной способность 900 Гбайт/с, и работают они как единый 144-ядерный процессор. Но это ещё не всё: каждый из кристаллов соединен со своим банком памяти LPDDR5x ECC шиной с пропускной способностью 500 Гбайт/с (т.е. суммарно на чип получается 1 Тбайт/с). Совокупный объём памяти может достигать 960 Гбайт. 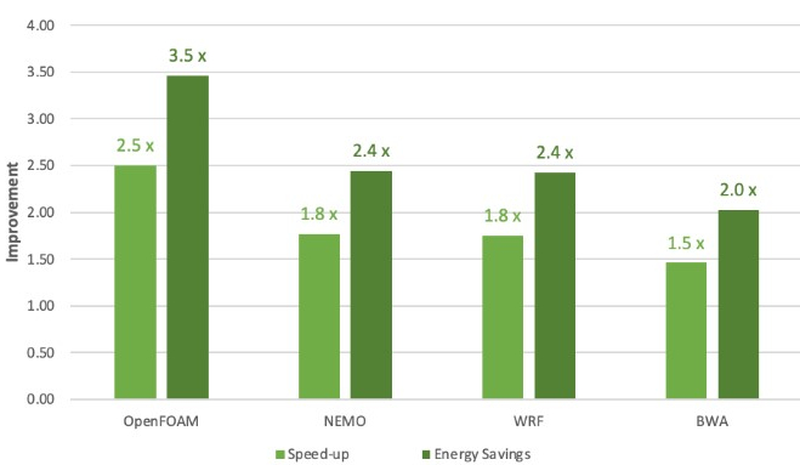
Сравнение производительности и энергоэффективности Grace Superchip с двумя AMD EPYC 7763 (Milan) Сборка Grace Superchip общается с внешним миром посредством восьми комплексов PCIe 5.0 x16 (всего 128 линий, поддерживается бифуркация). Чип при теплопакете 500 Вт (вместе с набортной памятью) способен развивать 7,1 Тфлопс на вычислениях двойной точности. С учетом интегрированной памяти это делает Grace Superchip интересной альтернативой AMD Genoa. 
Программная экосистема платформы NVIDIA Grace. По клику открывается полноразмерная версия. Помимо данных о производительности в режиме FP64 компания уже опубликовала результаты тестов новинки в HPC-нагрузках, где сравнила своё детище с двухсокетной системой на базе AMD EPYC 7763. Выигрыш в производительности составляет от 1,5x до 2,5x, но что не менее важно — Grace Superchip намного эффективнее энергетически, здесь преимущество может достигать 3,5x. В условиях высокоплотных ЦОД или HPC-кластеров это может стать решающим.
11.01.2023 [03:00], Игорь Осколков
Асимметричный ответ: Intel официально представила процессоры Xeon Sapphire RapidsIntel официально представила серверные процессоры Xeon семейства Sapphire Rapids (SPR), выход которых изрядно задержался, а также ускорители ранее известные как Ponte Vecchio и теперь объединённые вместе с HBM-версиями SPR в отдельную HPC-серию Max. В этом поколении Intel не смогла догнать AMD EPYC Genoa по числу ядер, числу каналов памяти и линий PCIe, но заготовила ассиметричный, хотя и очень странно реализованный ответ. Всего представлено 52 модели с числом P-ядер от 8 до 60 и с TDP от 125 до 350 Вт. По числу ядер это существенный апгрейд по сравнению с Ice Lake-SP (до 40 ядер), да и IPC вырос у Golden Cove на 15 % в сравнении с Sunny Cove. Но это существенный проигрыш в сравнении с Genoa (до 96 ядер), особенно если учитывать их максимальный TDP в 360 Вт (cTDP до 400 Вт). Правда, у Sapphire Rapids есть ещё и экономичный режим работы, в котором энергопотребление снижается на 20 %, а производительность для некоторых нагрузок — всего на 5 %. 
Изображения: Intel Sapphire Rapids предлагают 8 каналов памяти DDR5-4800 (1DPC) и DDR5-4400 (2DPC). 2DPC у Genoa пока что нет. Кроме того, контроллеры поддерживают и модули Optane PMem 300 (Crow Pass), но с учётом того, что производство 3D XPoint прекращено, достаться они могут не всем (впрочем, не всем они и нужны). Ну а маленькая серия Max также включает 64 Гбайт набортной HBM2e-памяти (1,2 Тбайт/с). Остались и отличия в максимальном объёме SGX-анклавов в зависимости от модели CPU. 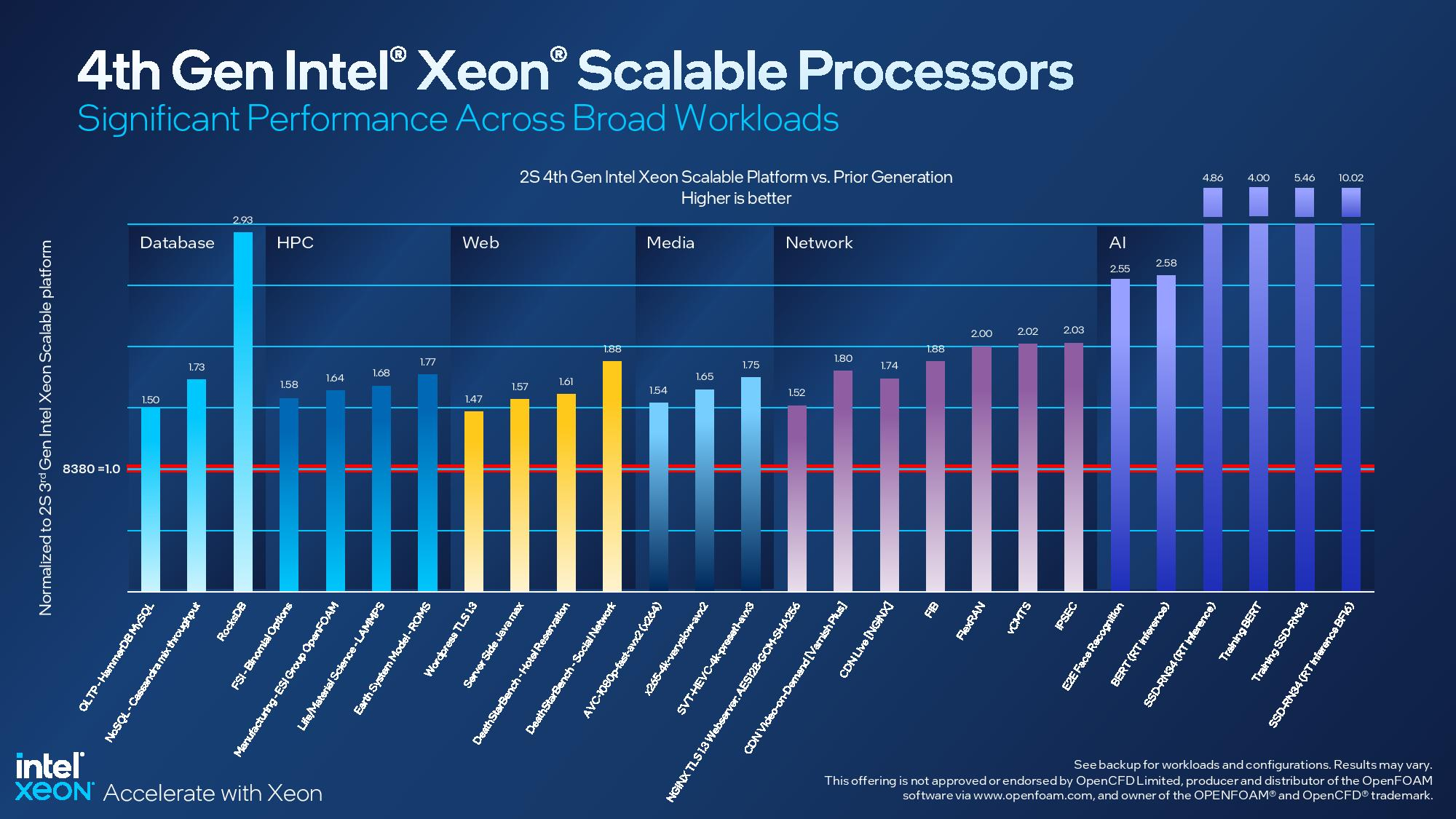 Однако по числу ядер на узел всё равно лидирует Intel. Если AMD поддерживает только 2S-конфигурации, то Intel снова предлагает и 4S, и 8S (а с момента выхода Cooper Lake-SP прошло немало времени) — на процессор доступно до 4 линий UPI 2.0 (16 ГТ/с в сравнении с 11,2 ГТ/с у Ice Lake-SP). В 2S-платформах Sapphire Rapids также формально обгоняет Genoa по числу линий PCIe 5.0, которых тут по 80 шт. на сокет. Формально потому, что в случае Genoa при желании всё же можно получить 160 линий, пожертвовав скоростью шины между CPU, но в односокетном варианте EPYC в любом случае интереснее Xeon. 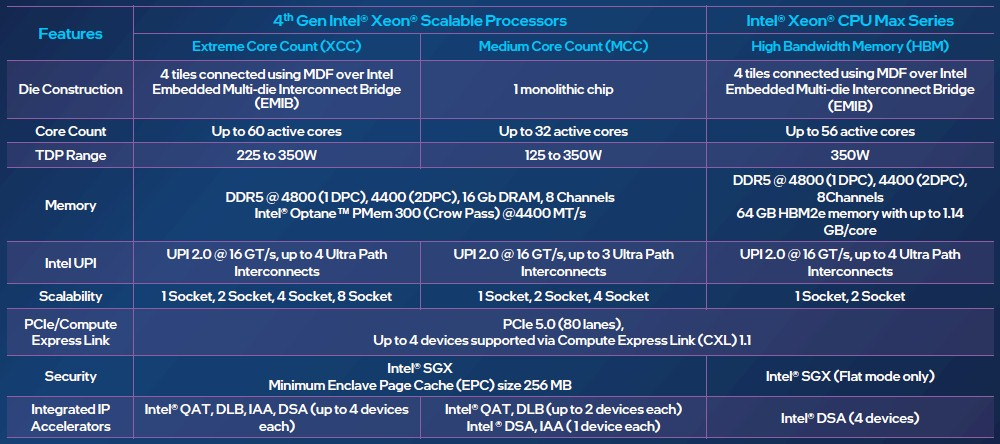 Без нюансов тут не обошлось. Так, при бифуркации до 8 x2 скорость падает до PCIe 4.0. Зато каждый root-комплекс поддерживает CXL 1.1, тогда как у Genoa CXL есть только у половины! Впрочем, поддержка всё равно ограничена 4x CXL-устройствами на CPU. Что ещё более странно, официально заявлена поддержка только устройств Type 1 и Type 2, но не Type 3, хотя последние весьма пригодились бы в ряде конфигураций, где требуется больше относительно недорогой, пусть и несколько более медленной, RAM. 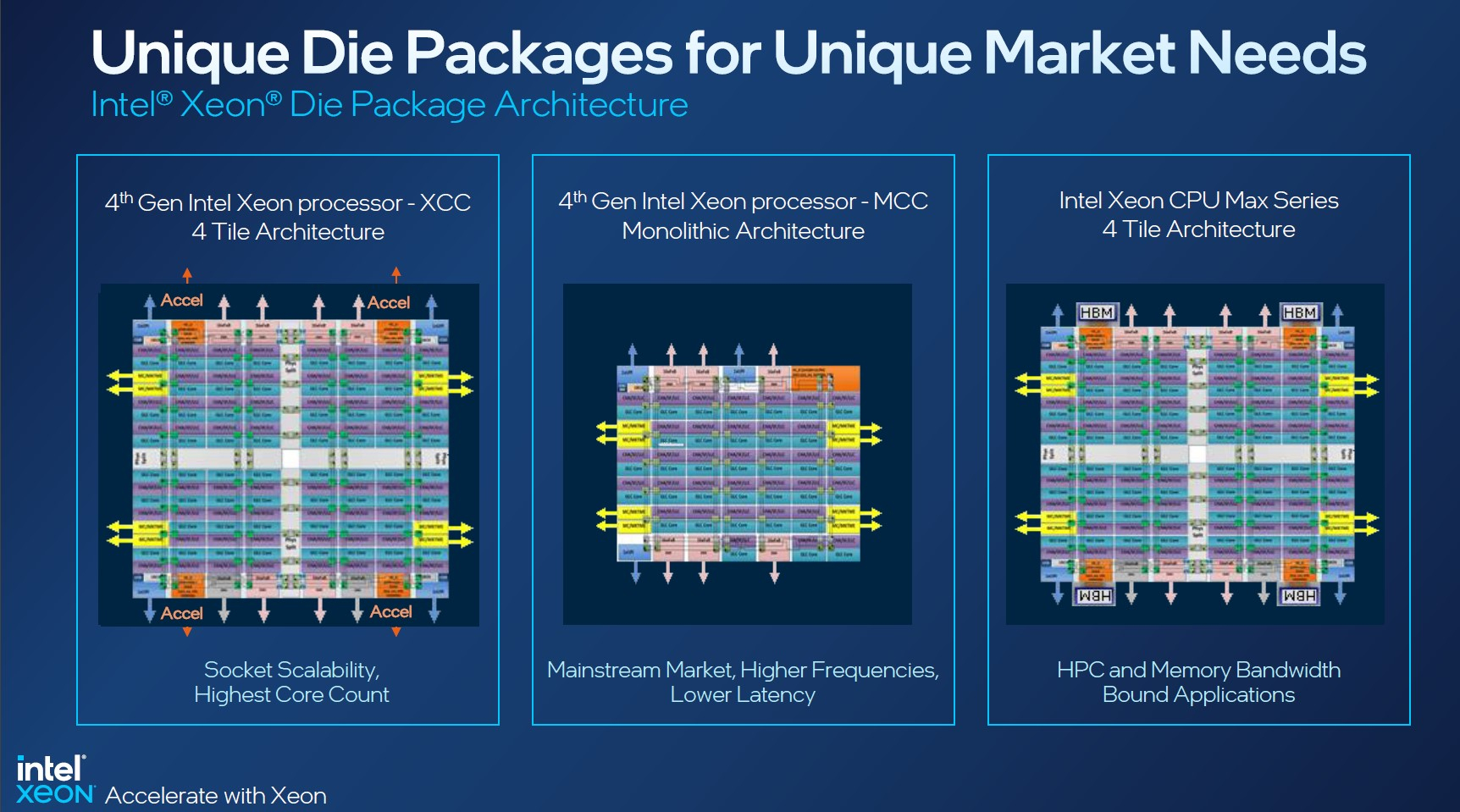 Сохранилось традиционное разделение на серии Platinum (8000), Gold (6000/5000), Silver (4000) и Bronze (3000), к которым теперь добавилась серия Max (9400). Список суффиксов, означающих оптимизацию под те или иные задачи и наличие каких-то особенностей, стал чуть шире: Y (SST-PP 2.0), Q (рассчитаны на работу с СЖО), U (односокетные общего назначения), T (увеличенный жизненный цикл), H (in-memory СУБД, аналитика, виртуализация), N (сетевые решения, в том числе для 5G), облачные P/V/M (IaaS/Paa/медиа), S (СХД и HCI). 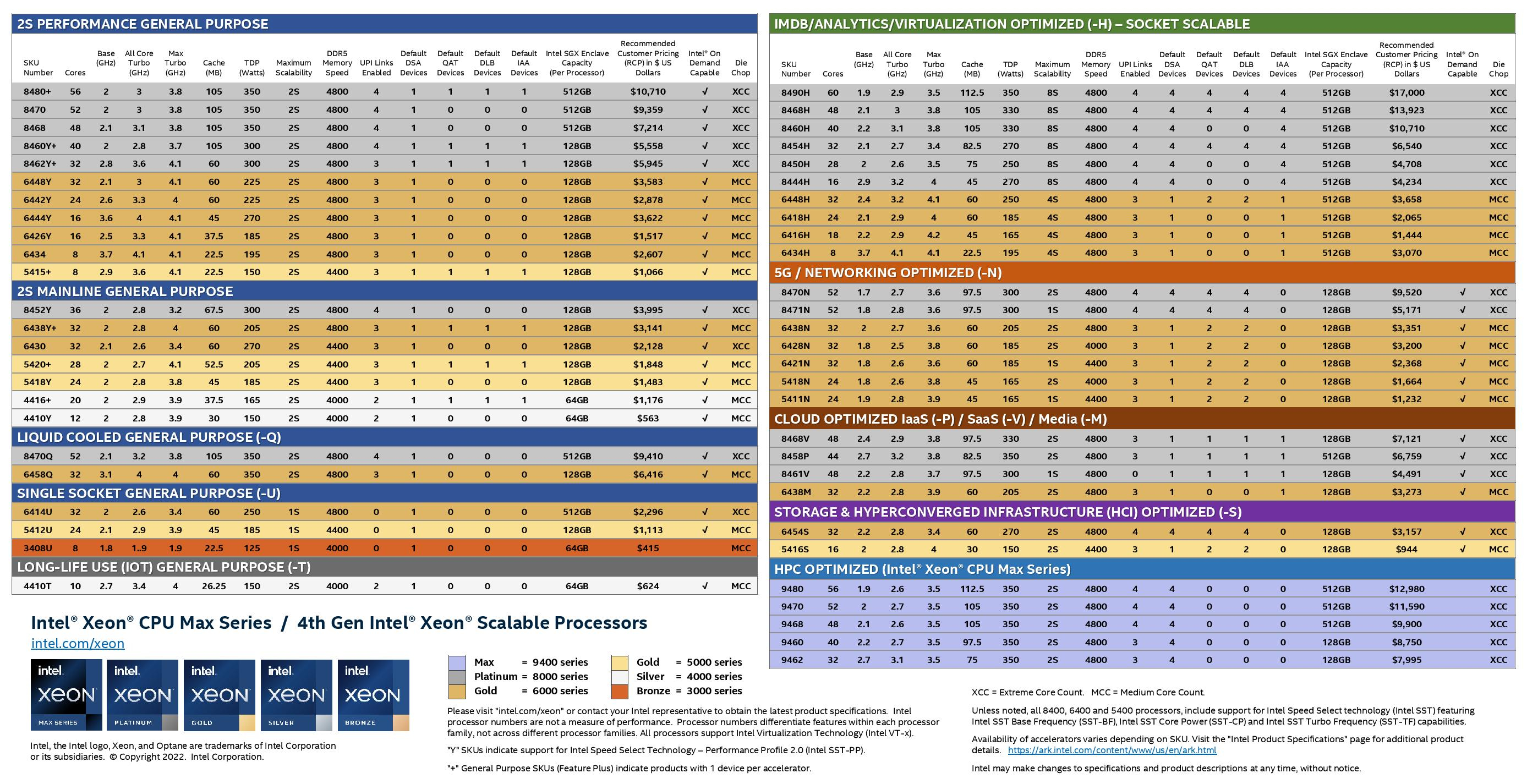 Но некоторые модели также имеют в названии «+». И вот тут начинается самое интересное! Все процессоры получили «традиционную» (в сравнении с Genoa) реализацию AVX-512, включая DL Boost, а также целый новый набор ИИ-инструкций AMX (до 10 раз быстрее обучение и инференс в сравнении с Ice Lake-SP). Есть и всяческие Speed Select, DDIO, TDX, CET и т.д. Но Sapphire Rapids также получили четыре отдельных ускорителя:
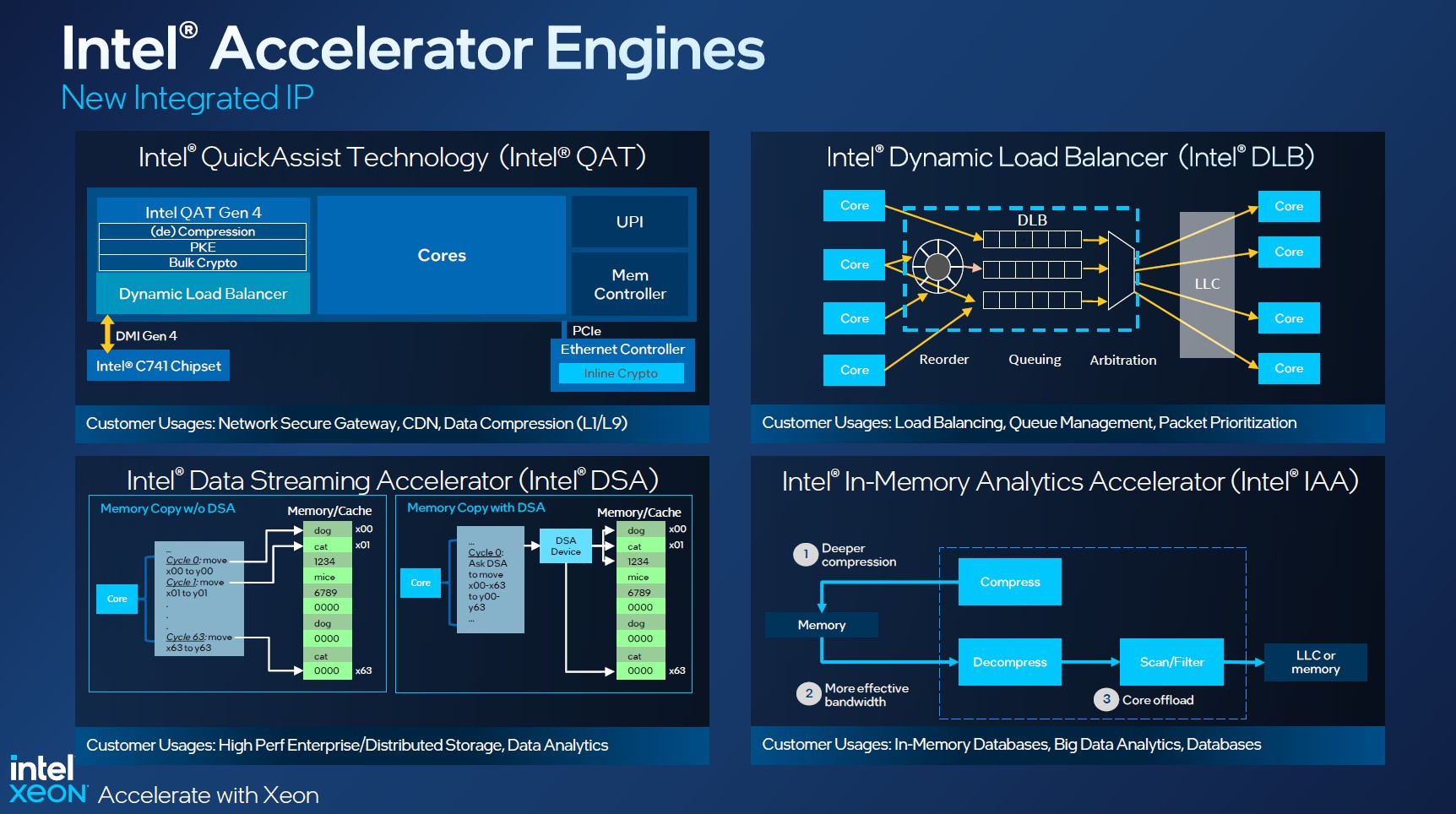 Intel заявляет, что средний прирост производительности Sapphire Rapids в сравнении с Ice Lake-SP составил 1,53 раза. А вот для ряда нагрузок, которые могут задействовать новые ускорители прирост производительности на Вт составляет уже до 2,9 раз! То есть Intel продолжает придерживаться стратегии создания максимально универсальных CPU для различных нагрузок. И действительно, спорить с гибкостью Sapphire Rapids трудно. Но какой ценой это достигается? Т.е. буквально: во сколько это обойдётся заказчику? Ответа пока нет.  Дело в том, что в зависимости от модели отличается число доступных и число активированных ускорителей. Фактически в новом поколении используется два вида кристаллов: XCC, «сшитые» из четырёх отдельных тайлов, и монолитные MCC (до 32 ядер, причём 32-ядерных моделей в серии большинство). У каждого тайла в XCC есть по одному блоку QAT, DSA, DLB и IAA, т.е. суммарно на CPU приходится до четырёх ускорителей каждого типа. В случае MCC может быть по два QAT и DLB и по одному DSA и IAA на процессор. Например, у тех моделей, что помечены «+», активно по одному блоку каждого типа, а минимум один DSA активен есть вообще у всех CPU.  За не активированные по умолчанию ускорители придётся заплатить в рамках программы Intel On Demand (SDSi), причём есть опции как с единовременным платежом за постоянную активацию, так и с оплатой по факту использования (это удобно в случае облаков и платформ по типу HPE Greenlake). Исключением являются H-модели, куда входит и самый дорогой ($17000) 60-ядерный процессор 8490H с полностью разблокированными ускорителями и поддержкой 8S-конфигураций, а также процессоры Max, которым доступно только четыре DSA-блока и 2S-платформы, например, 56-ядерный 9480 ($12980). 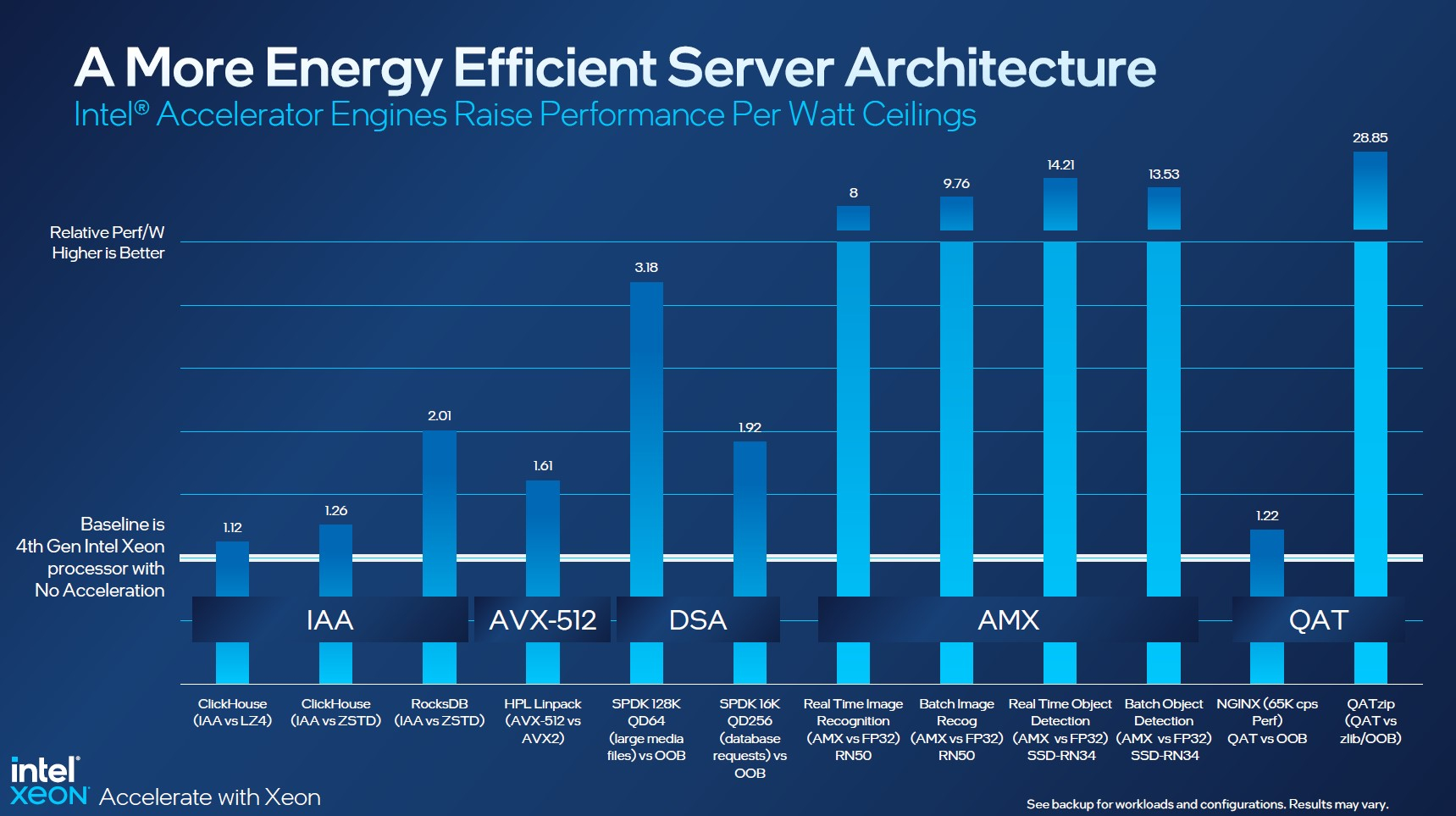 С одной стороны, желание Intel предоставить больше гибкости заказчикам, а заодно чуть увеличить выход годных к продаже процессоров, понятно. С другой — не очень-то и похоже, что CPU без «лишних» ускорителей отдаются с какой-то существенной скидкой. При этом транзисторный бюджет на них всё равно расходуется. Кроме того, есть ещё момент востребованности этих ускорителей и готовности ПО. У Intel есть и опыт ресурсы для помощи разработчикам, но процесс адаптации в любом случае не мгновенен.  Впрочем, у Intel по сравнению с AMD есть и ещё одно важное преимущество — в среднем более высокая доступность процессоров для большинства заказчиков. Так что с Sapphire Rapids может повториться та же история, что с Ice Lake-SP, когда вендоры здесь и сейчас готовы были предложить Intel-платформы.  В целом же, в новом семействе наиболее любопытны Xeon Max, которые, по словам Intel, по сравнению с прошлым поколением в 3,7 раз производительнее в задачах, завязанных на пропускную способность памяти (а это целый пласт HPC-нагрузок), и которые не так уж дороги. Правда, и здесь без приключений не обошлось — несчастный суперкомпьютер Aurora ожидает утомительный апгрейд его 10 тыс. узлов c простых Xeon Sapphire Rapids на Xeon Max — по полчаса на каждый узел. |
|