Лента новостей
|
23.10.2025 [23:43], Владимир Мироненко
Инвесторы остались недовольны замедлением роста выручки от ПО IBM — акции упали, несмотря на рост показателейКорпорация IBM опубликовала финансовые результаты за III квартал 2025 года, завершившийся 30 сентября, которые превзошли ожидания Уолл-стрит, и повысила свой прогноз в связи с благоприятными условиями для развития ИИ-технологий. Однако акции компании упали на 5 %, поскольку инвесторы остались недовольны замедлением роста выручки от продаж в ключевом сегменте облачного ПО, пишет Reuters, Выручка IBM выросла за отчётный период год к году на 9 % до $16,33 млрд, что выше консенсус-прогноза аналитиков, опрошенных LSEG, равного $16,09 млрд. Скорректированная прибыль (Non-GAAP) на акцию равняется $2,65 при целевом показателе аналитиков от LSEG в размере $2,45 на акцию. Чистая прибыль (GAAP) за квартал составила $1,74 млрд, тогда как годом ранее у компании были убытки в $330 млн, обусловленные пенсионными выплатами в размере $2,7 млрд. Глава IBM Арвинд Кришна (Arvind Krishna) охарактеризовал минувший квартал как успешный: благодаря росту показателей во всех сегментах компания превзошла прогнозы экспертов по выручке, прибыли и свободному денежному потоку. «Клиенты по всему миру продолжают использовать наши технологии и экспертные знания для повышения производительности своих операций и создания реальной бизнес-ценности с помощью ИИ», — отметил он. Кришна сообщил, что портфель заказов компании в сфере ИИ, объединяющий бронирование с фактическими продажами различных продуктов и услуг на базе ИИ, вырос по сравнению с предыдущим кварталом на $7,5 млрд, превысив $9,5 млрд. 
Источник изображения: IBM Выручка IBM от разработки ПО выросла год к году на 10 % до $7,21 млрд, что соответствует прогнозу StreetAccount. При этом выручка в категории гибридного облачного ПО, включающей Red Hat, увеличилась на 14 %, тогда как в предыдущем квартале её рост составил 16 %. Замедление роста выручки стало поводом для недовольства инвесторов. Кришна заверил аналитиков в ходе телефонной конференции, что подразделение гибридного облака вернется к росту в среднем на 15 % или близко к этому уровню к началу 2026 года. «Замедление роста выручки и продаж Red Hat… разочарует тех, кто надеялся на ускорение роста в этом высокорентабельном сегменте», — заявил Майкл Эшли Шульман (Michael Ashley Schulman), директор по инвестициям Running Point Capital. Как пишет SiliconANGLE, с его мнением совпало мнение аналитика Evercore ISI Амита Дарьянани (Amit Daryanani) и аналитика Jeffries Брента Тилла (Brent Thill), который в своей записке для инвесторов сообщил, что перспективы софтверного бизнеса IBM в значительной степени зависят от того, сможет ли Red Hat найти способ возобновить рост: «Ускорение роста бизнеса IBM в сфере ПО в ближайшие несколько кварталов будет зависеть от динамики развития Red Hat, которая остаётся краеугольным камнем стратегии роста IBM в сфере ПО, и руководство подтверждает уверенность в сохранении роста на уровне около 15 %». 
Источник изображения: IBM Выручка подразделения по автоматизации увеличилась год к году на 24 %, выручка подразделения по обработке данных и ИИ — на 8 %. Выручка от обработки транзакций снизилась на 1 % год к году. Выручка от консалтинговых услуг составила $5,3 млрд, превысив прогноз Уолл-стрит в $5,24 млрд. В сегменте инфраструктуры выручка увеличилась на 17 % до $3,56 млрд. При этом продажи мейнфреймов IBM Z выросли на 61 %. Новый мейнфрейм z17, ориентированный на ИИ, широко используется в финансовой отрасли, позволяя поддерживать строгие правила хранения и шифрования данных в процессе внедрения ИИ-технологий, сообщил агентству Reuters финансовый директор IBM Джим Кавано (Jim Kavanaugh). ИИ также внёс свой вклад в рост выручки, поскольку, как отметил Кришна, СХД являются ключевой частью ИИ-инфраструктуры, поэтому у IBM их активно покупают, пишет The Register. IBM повысила свой прогноз выручки и заявила, что теперь ожидает её роста «более чем» на 5 % по сравнению с «как минимум» 5 %, ожидавшимся ранее. Также ожидается, что свободный денежный поток за год составит $14 млрд, что выше прогноза в $13,5 млрд, сделанного в предыдущем квартале. 
Источник изображения: IBM Кришна cообщил, что IBM сотрудничает с гиперскейлерами, а также является одним из крупных клиентов CoreWeave. «Мы также часто используем инфраструктуру AWS, Azure и GCP, — сказал он. — У нас есть прекрасная возможность выполнять как консалтинговые проекты, так и развёртывать наше ПО на этих инфраструктурах для наших клиентов». Он рассказал, что один из «очень крупных клиентов в сфере медицинского страхования» предпочитает не использовать публичное облако, «но его вполне устраивает возможность использовать частные инстансы в облаке и разворачивать там модели, разворачивать там наши программные стеки и добиваться роста. Поэтому мы, как правило, так и поступаем». По мнению The Register, это свидетельствует в пользу того, что IBM не собирается закупать ускорители в больших количествах или состязаться с гиперскейлерами в объёме капвложений, предпочитая брать вычислительные мощности в аренду.
23.10.2025 [17:05], Руслан Авдеев
OpenAI на проводе: поставщик газовых турбин GE Vernova рассчитывает неплохо заработать на ИИ ЦОД гиперскейлеров
general electric
hardware
openai
гиперскейлер
полезные ископаемые
сша
финансы
электропитание
энергетика
Акции производителя турбин GE Vernova показали рекордное падение после рекордного же роста в этом году из-за опасений компании по поводу будущего рынка. Впрочем, компания надеется на растущий спрос со стороны дата-центров, сообщает Bloomberg. Тем не менее, GE Vernova по-прежнему не уверена в целесообразности расширения производственных мощностей, хотя и полагает, что капитальные расходы предприятий сектора энергетика достигнут пика уже в следующем году. При этом заявление GE Vernova обрушило и акции конкурентов: Vertiv Holdings и Eaton. Спрос на электроэнергию быстро растёт благодаря развитию энергоёмких ИИ ЦОД, новых производств и общей электрификации экономики. Внимание экспертов приковано к тому, как крупные энергокомпании реализуют потенциал роста и избегут ряда рисков. GE Vernova намерена всё активнее поставлять технологическим компаниям, строящим ЦОД, свои газовые турбины. Впрочем, пока около 90 % заказов поступает от обычных клиентов вроде коммунальных компаний и независимых производителей энергии. Примерно 10 % приходятся на гиперскейлеров — $600 млн в 2024 году и $900 млн в этом, с учётом заказов за IV квартал сумма год к году фактически удвоится. Вместе с тем на IT-гигантов также приходится около трети оплаченных предварительных заказов для проектов на ранней стадии реализации. Однако здесь есть важный нюанс — технологические компании нередко финансируют контракты, не будучи конечными операторами турбин. Они лишь принимают участие в проектах, чтобы обеспечить рост отрасли соответствующими их ожиданиям темпами. По словам GE Vernova, турбины практически распроданы уже на весь 2028 год. На 2027 год распределены заказы на значительную часть трансформаторов. Компания также заявила, что намерена купить за $5,3 млрд 50 % акций производителя трансформаторов Prolec GE. 
Источник изображения: GE Vernova В III квартале заказы в энергетическом бизнесе компании выросли на 50 % году к году до $7,8 млрд, заказы в сегменте электрификации выросли на 102 % до $5,1 млрд. Также компания объявила, что портфель её энергетических заказов и запросов вырос с 55 до 62 ГВт, цены на газовые генераторы растут ускоренными темпами, а рентабельность по будущим заказам улучшается. Ожидается, что предварительные запросы превратятся в настоящие заказы в течение 2026 года, что обеспечит компании увеличение и выручки, и прибыли. Глава GE Vernova отметил, что в последние недели часто виделся с руководителем OpenAI Сэмом Альтманом (Sam Altman) и его командой. OpenAI является неотъемлемой частью амбициозного плана по развитию бизнеса GE Vernova. Речь идёт как о партнёрстве в сфере генерации энергии, так и поставках электрического оборудования. Компания уже стала ключевым поставщиком энергетического оборудования почти всем ключевым гиперскейлерам, включая OpenAI и Oracle (Crusoe и не только), Google (NextEra) и xAI. По словам экспертов, сейчас главной проблемой GE Vernova являются ограниченные возможности производства, меняющаяся тарифная политика, которая уже обошлась компании в $300–$400 млн, и регуляторы, из-за которых, в частности, упали заказы на ветряки. У бизнеса может появиться сильный конкурент. Компания ProEnergy предложила запитать ЦОД от своих газовых генераторов на основе старых авиадвигателей. Они будут доступны тысячами после списания с авиалайнеров.
23.10.2025 [15:25], Руслан Авдеев
Подводный ЦОД с надводной ветрогенерацией: HiCloud развернула в Шанхае новый демо-модуль мощностью 2,3 МВтКитайская HiCloud, занимающаяся строительством подводных ЦОД, запустила демо-проект с подключение своих объектов напрямую к ветряной электростанции морского базирования, о чём говорилось ранее в текущем году. Дополнительно она объявила о планах увеличения мощности подводной инфраструктуры дата-центров до 500 МВт, сообщает Datacenter Dynamics. Пока же демонстрационная площадка поддерживает лишь 2,3 МВт. Она расположена неподалёку от Шанхая, близ пилотной зоны свободной торговли Lingang Special Area of China (Shanghai) Pilot Free Trade Zone. Где именно находятся ветряные турбины, пока не разглашается. Компания заявила, что проект знаменует собой новую эпоху для района Lingang Special Area в деле глубокой интеграции цифровой экономики, новой энергетики и морской экономики. Проект — лишь первый этап плана HiCloud по созданию крупномасштабного подводного дата-центра, работающего на прибрежной ветроэнергетике. В ходе мероприятия подписано соглашение о сотрудничестве с Shenergy Group, Shanghai Telecom, Shanghai INESA и CCCC Third Harbor Engineering Company. Компании договорились о совместной работе над подводным дата-центром мощностью 500 МВт. 
Источник изображения: HiCloud Сама HiCloud является подразделением компании Highlander. Ранее она развернула подводные модули ЦОД у побережья провинции Хайнань (Китай). Впервые эксперимент с подводными дата-центрами стартовал там в 2021 году, в 2023 году компания запустила первый коммерческий проект. В феврале 2025 года к объекту HiCloud в Хайнане добавился ещё один модуль с 400 серверами. Разместить ЦОД в океане пытаются и другие компании. Например, Microsoft в 2015 году запустила первый в мире подводный ЦОД в рамках инициативы Project Natick у тихоокеанских берегов США. В 2018 году она разместила ещё один ЦОД у Оркнейских островов в Северном море, но в 2024 году отказалась от реализации подводных инициатив. Также подводными дата-центрами занимаются Subsea Cloud и NetworkOcean.
23.10.2025 [13:50], Руслан Авдеев
Неудобные вопросы: казначейство Великобритании выясняет, почему сбой AWS по ту сторону океана нарушил работу госведомств Соединённого Королевства
aws
lloyds banking
software
банк
великобритания
госуслуги
информационная безопасность
кии
конфиденциальность
облако
сбой
От правительства Великобритании потребовали ответить, почему многочасовой сбой в работе сервисов AWS (Amazon) на другом берегу Атлантики нарушил функциональность информационных систем британских структур, включая налоговую службу HMRC и Lloyds Banking Group, сообщает Computer Weekly. Многочасовой сбой 20 октября во флагманском регионе AWS US-East-1 в Северной Вирджинии (США) нарушил работу компаний и организаций по всему миру, в том числе и в Соединённом Королевстве. Поэтому в Великобритании и других странах растёт обеспокоенность тем, что частный и государственный сектора зависят от заокеанских служб — вновь появились призывы сохранить услуги национального значения под локальным контролем. Так, Казначейству Великобритании уже предложено отчитаться о том, почему предоставленные в январе этого года полномочия не помогли гарантировать надёжность сервисов в секторе финансовых услуг. В частности, почему платформа AWS (и не только она), которая является облачным провайдером большого числа финансовых учреждений Великобритании, до сих пор не включена в список критически важных третьих сторон (Critical Third Parties, CTP), который позволяет требовать от сторонних компаний соблюдения тех же высоких стандартов, что и от финансовых учреждений. Также чиновников попросили уточнить, не беспокоит ли их тот факт, что ключевые фрагменты британской IT-инфраструктуры размещены за рубежом, с учётом последствий недавнего сбоя. Также предлагается объяснить, какую работу проводят совместно с HMRC, чтобы предотвратить аналогичные сбои в будущем. В Министерстве финансов Великобритании заявили журналистам, что работают с регуляторами над внедрением режима CTP. В AWS же предложили спросить у самой HMRC, почему сбой в США так повлиял на неё. 
Источник изображения: Tom Athawes/unspalsh.com У AWS с 2016 года есть собственный облачный регион в Великобритании, причём платформа позволяет британским структурам получать доступ к локальным версиям публичных облачных сервисов. В AWS придерживаются «модели общей ответственности», при которой клиенты должны сами внимательно выбирать сервисы для размещения в облаке. Утверждается, что такой подход обеспечивает гибкость и контроль со стороны клиента. По мнению некоторых экспертов, сбой свидетельствует о том, что часть инфраструктуры HMRC и Lloyds зависела от американских мощностей, и это мог быть осознанный выбор британских структур, а не вина AWS. С другой стороны, инцидент показал, как сложна и взаимосвязана современная облачная инфраструктура. Заказчики могли не знать какие сервисы размещены в рамках их пакетов услуг в Великобритании и насколько они устойчивы. Например, Microsoft в своё сообщила, что не может гарантировать суверенитет данных полиции Великобритании, хранящихся и обрабатываемых на её платформе. Позже выяснилось, что данные британской полиции могут обрабатываться более чем в 100 странах, причём пользователи об этом не знали. 
Источник изображения: Jud Mackrill/unsplash.com В Forrester сообщают, что AWS осознаёт проблему и намерена запустить в Европе «идеальную копию» своих сервисов в рамках предложения суверенного облака. Первый изолированный регион предусмотрен в Германии. Фактически, единственный надёжный способ избавиться от иностранной зависимости — физическая и логическая изоляция облачных регионов, используемых клиентами. По словам экспертов, чем более «концентрированной» становится инфраструктура, тем более хрупкой и зависимой от внешнего управления она становится. Если Европа настроена на обретение цифрового суверенитета, ей необходимо скорее принять необходимые для этого меры. В частности, следует переосмыслить систему закупок, финансировать суверенные альтернативы и сделать обеспечение надёжности базовым требованием. Ранее эксперты пришли к выводу, что сбой в работе AWS наглядно продемонстрировал опасную зависимость всего мира от нескольких облачных гигантов из США. Европа так и не смогла избавиться от бремени американских гиперскейлеров, которые открыто признают, что даже не могут гарантировать суверенитет данных. При этом к AWS есть вопросы и у других британских регуляторов.
23.10.2025 [09:43], Руслан Авдеев
Amazon намерена построить в Вашингтоне мини-реакторы X-Energy на 960 МВт, но пока предлагает полюбоваться на рендеры будущих АЭСНесмотря на технические и нормативные препятствия, Amazon всё ещё считает, что малые модульные реакторы (SMR) являются оптимальным ответом на дефицит электричества для её дата-центров. Осенью 2024 года компания объявила об инвестициях $500 млн в «атомный» стартап X-Energy, а на днях появилась информация, что его реакторы Xe-100 обеспечат штату Вашингтон поставки до 960 МВт «чистой» электроэнергии, сообщает The Register. Правда, строительство начнётся не раньше конца текущего десятилетия, а сами SMR заработают уже 2030-х годов. В частности, 80-МВт реакторы планируется развернуть на объекте Cascade Nuclear Energy Center близ Ричленда (Richland). Реализация проекта предусмотрена в три этапа, каждый из которых обеспечит 320 МВт. В Amazon утверждают, что SMR компании X-Energy будут меньше, быстрее в установке и дешевле в эксплуатации, чем традиционные реакторы. Компания настолько уверена в технологии, что намерена развернуть к 2039 году SMR общей мощностью 5 ГВт. В этом ей помогут Doosan Enerbility и Korea Hydro and Nuclear Power. Правда, сама технология не опробована в реальных условиях, а один из ранних проектов SMR закрылся из-за высоких эксплуатационных расходов. Кроме того, реакторы компании ещё даже не получили одобрения Комиссии по ядерному регулированию (Nuclear Regulatory Commission, NRC) США, которое необходимо для начала строительства. Разрешение на начало строительства планируется получить лишь к концу 2026 года. Впрочем, Amazon активно делится 3D-рендермаи будущих электростанций. 
Источник изображения: Amazon Ставку на SMR делают и другие операторы ЦОД. Например, Oracle намерена установить не менее трёх реакторов мощностью около гигаватта, но деталей о них пока немного. Поддерживаемый Google стартап Kairos Power намерен разместить 50-МВт реактор возле Ок-Риджской национальной лаборатории (ORNL). Демонстрационный образец Kairos Hermes 2 должен заработать не раньше 2030 года. Правда, одобрение NRC в этом случае уже получено, так что у Kairos больше шансов раньше представить рабочую модель. Впрочем, для запуска реактора всё равно потребуется дополнительное разрешение. Но и от традиционных АЭС гиперскейлеры не отказываются. В прошлом году AWS приобрела «атомный» кампус Cumulus Data за $650 млн при АЭС Susquehanna, которая может предоставить дата-центрам до 960 МВт. Microsoft вкладывает средства в возвращение к жизни энергоблока Unit-1 атомной электростанции Three Mile Island. Ожидается, что он снова заработает в 2027 году. Google тоже не прочь перезапустить АЭС DAEC, а Meta✴ попросту выкупила всю энергию АЭС Clinton Clean Energy Center на 20 лет вперёд.
23.10.2025 [00:40], Владимир Мироненко
Умение Альтмана играть на самолюбии руководителей позволило OpenAI заключить сделки на сотни миллиардов долларовГлава OpenAI Сэм Альтман (Sam Altman) оказался умелым стратегом. Чтобы обеспечить компанию чуть ли не бесконечными вычислительными мощностями, он организовал целую серию сделок на сотни миллиардов долларов, натравив друг на друга гигантов Кремниевой долины. Альтман сыграл на их самолюбии и желании нажиться на будущем росте OpenAI. Все они теперь делают ставку на успех стартапа, который пока невероятно далёк от прибыльности, пишет The Wall Street Journal. Но выйти из игры они уже не могут — OpenAI должна выжить любой ценой. А NVIDIA даже готова расплатиться по долгам OpenAI, если что-то пойдёт не так. За последние два месяца цены на акции Oracle, NVIDIA, AMD и Broadcom резко взлетали вверх после объявления о сделках, связанных с OpenAI. В общей сложности их рыночная стоимость выросла на $630 млрд в первый день торгов после этих объявлений. Каждый раз за этим следовал более масштабный рост акций технологических компаний, способствуя росту фондового рынка США до рекордных высот. «Самые успешные люди, которых я знаю, верят в себя почти до самообмана», — написал в 2019 году Альтман в блоге «Как достичь успеха», а затем добавил: «Одной веры в себя недостаточно — нужно ещё и уметь убеждать других в своей вере». В этом году OpenAI планирует получить выручку в размере $13 млрд, что несопоставимо со счетами на $650 млрд, которые компания получит только в рамках сделок с NVIDIA и Oracle, согласно подсчётам The Wall Street Journal. С учётом соглашений с AMD, Broadcom и другими провайдерами облачных услуг, такими как Microsoft, общая сумма затрат приближается к $1 трлн. Обязательства на такие объёмы поставок чипов и километровых ЦОД до того, как OpenAI сможет себе это позволить, вызывают опасения, что энтузиазм в отношении ИИ превращается в пузырь, зависящий от успеха всего одной компании. Некоторые партнёры даже помогают OpenAI оплачивать свои чипы, заключая циклические сделки. 
Источник изображения: Rain Bennett / Unsplash В прошлом году Альтман спросил гендиректора Microsoft Сатью Наделлу (Satya Nadella), готова ли его компания инвестировать не менее $100 млрд в создание новых ЦОД OpenAI в рамках будущего проекта Stargate. Тот ответил отказом. Такой же ответ он получил от TSMC. Последней он представил проект стоимостью $7 трлн по строительству новых заводов по производству микросхем по всему миру. Ситуация изменилась, когда Альтману удалось заручиться поддержкой гендиректора SoftBank Масаёси Сона (Masayoshi Son). Сон согласился возглавить проект стоимостью $500 млрд. После объявления Белого дома США о поддержке проекта Stargate, акции SoftBank подскочили на 11 %, как и акции других технологических партнёров, участвующих в проекте. Практически сразу NVIDIA предложила OpenAI организовать похожий проект и помочь с его финансированием, но без участия SoftBank. В последующие после анонса недели и месяцы OpenAI получила сотни предложений о потенциальных площадках для строительства, что подготовило почву для её следующих шагов. В свою очередь Microsoft расторгла договоры аренды некоторых ЦОД в США, ссылаясь на отказ от поддержки нагрузок OpenAI. Вместе с тем она, являясь на тот момент главным инвестором OpenAI, разрешила ей найти дополнительные вычислительные мощности у других поставщиков и сосредоточила усилия на привлечении клиентов. После этого OpenAI заключила контракт с Oracle на $300 млрд, что привело к рекордному за четверть века росту акций последней. Внутри Microsoft сделку раскритиковали — не было уверенности, что Oracle справится, поскольку строительство гигантских ЦОД обязывает OpenAI выплачивать в среднем $60 млрд/год, что более чем вчетверо превышает её текущую выручку. 
Источник изображения: Ross Sneddon / Unsplash Между тем переговоры OpenAI и NVIDIA по их собственному проекту создания ИИ-инфраструктуры зашли в тупик. Всё изменилось в июне, когда стало известно о сделке между Google и OpenAI. А после появления сообщения о том, что OpenAI начала арендовать ускорители TPU у Google для поддержки ChatGPT, гендиректор NVIDIA Дженсен Хуанг (Jensen Huang) практически сразу позвонил Альтману, чтобы узнать, правда ли это, и дал понять, что готов возобновить переговоры. В итоге NVIDIA подписала соглашение о предоставлении в аренду OpenAI до 5 млн своих чипов, что по сегодняшним ценам обойдётся в $350 млрд. Также NVIDIA готова инвестировать до $100 млрд, чтобы помочь стартапу оплатить сделку. Более того, в рамках сделки NVIDIA также обсуждает предоставление гарантий по некоторым кредитам, которые OpenAI планирует взять на строительство собственных ЦОД, сообщили источники WSJ. Этим шагом NVIDIA может возложить на себя миллиардные долговые обязательства, если стартап не сможет вовремя погасить кредиты. Несмотря на заключённые с NVIDIA и другими компаниями контракты, OpenAI продолжала расширять свою вычислительную базу. Всего через несколько недель компания подписала с AMD контракт на 6 ГВт, в рамках которого может также получить до 10 % её акций. После объявления 6 октября о сделке с OpenAI акции AMD выросли на рекордные 24 %. Неделю спустя OpenAI официально представила проект по разработке ИИ-чипа совместно с Broadcom, над которым они работали с начала 2024 года. После объявления о сделке OpenAI с NVIDIA переговоры о заключении крупного соглашения ускорились. Сделка с Broadcom сопоставима по масштабу со сделкой с NVIDIA — до 10 ГВт вычислительной мощности для OpenAI к 2029 году.
22.10.2025 [21:00], Руслан Авдеев
От винта! ProEnergy предложила запитать ЦОД от старых авиадвигателей
general electric
hardware
авиация
дефицит
полезные ископаемые
сша
утилизация
цод
экология
электропитание
энергетика
Строители ЦОД столкнулись с серьёзным дефицитом энергии, пытаясь строить всё более крупные объекты для ИИ-инициатив. На помощь готова прийти компания ProEnergy, предложившая альтернативу классическим источникам энергии — бывшие в употреблении авиационные двигатели, сообщает IEEE Spectrum. Некоторые ЦОД уже используют газовые генераторы ProEnergy PE6000 во время строительства и первых лет эксплуатации. После присоединения к энергосети турбины становятся резервными источниками питания, причём иногда не только для ЦОД, но и для местных коммунальных компаний. Впрочем, идея не нова. Производители газотурбинных установок вроде GE Vernova и Siemens Energy давно используют адаптированные авиационные двигатели для создания стационарных генераторов, у которых уже есть своя ниша на рынке — они легче, компактнее и проще в обслуживании, чем обычные газотурбинные установки. Правда, по словам экспертов Axford Turbine Consultants, чтобы заставить авиационный двигатель вырабатывать электроэнергию, приходится приложить немало усилий. Газовая турбина LM6000 компании GE Vernova была создана на основе успешного турбовинтового двигателя GE CF6-80C2, широко применяемого в коммерческих самолётах. Двигатель появился в 1985 году, а LM6000 — пятью годами позже. В конструкцию пришлось внести немало изменений, в том числе позволяющих вместо авиационного топлива работать на природном газе. Кроме того, важен и экологический аспект, поскольку классический двигатель выбрасывает немало оксидов азота в ходе работы. 
Источник изображения: ProEnergy Так или иначе, Generative Power Solutions утверждает, что классических газовых турбин просто не хватает, сроки поставок LM6000 составляют 3–5 лет. То же можно сказать и об «авиационной» турбине SGT-A35 компании Siemens Energy. Сроки ожидания некоторых популярных моделей ещё больше. Так, PE6000 обещают поставить в 2027 году. Производители, конечно, видят спрос со стороны дата-центров, но расширять производство пока опасаются из-за возможного краха ИИ-сектора. Переделанный двигатель от ProEnergy может обеспечить до 48 МВт, чего достаточно для небольших и средних ЦОД или 20–40 тыс. домохозяйств. ProEnergy предлагает готовые к развёртыванию установки PE6000 на базе отремонтированных и доработанных б/у двигателей CF6-80C2. ProEnergy продаёт двухтурбинные блоки стандартной конфигурации. Они включают газовые турбины, собственно генераторы и множество других компонентов вроде систем охлаждения воздуха, поступающего в турбины в жаркие дни и т. п. Компания специализируется исключительно на модели CF6-80C2 для оптимизации и упрощения проектирования и обслуживания. 
Источник изображения: ProEnergy Первоначально PE6000 предназначался для коммунальных служб для компенсации нагрузок в часы пик. Из-за бума ЦОД операторы последних хотят сами приобретать генерирующие мощности, работающие на природном газе и готовые к эксплуатации в течение 5 минут после запуска. Замена нуждающегося в обслуживании двигателя осуществляется в течение 72 ч., а уровень выбросов ниже норм Агентства по охране окружающей среды США. С 2020 года ProEnergy выпустила 75 комплектов PE6000, на очереди ещё 52. В компании рассчитывают, что в следующие 10 лет около 1 тыс. авиадвигателей выведут из эксплуатации, поэтому недостатка в них не будет. Популярности модели способствует не только резкий рост количества дата-центров, но и необходимость подолгу ждать подключения к электросети — иногда до 8–10 лет. В этих условиях турбины на основе авиадвигателей выступают как промежуточная технология, которая будет работать, пока коммунальная компания не будет готова обеспечить присоединение. По такому пути, например, пошла xAI, которая смогла в кратчайшие сроки запустить свои ИИ ЦОД, но столкнулась с противодействием экоактивистов.
22.10.2025 [17:09], Владимир Мироненко
AWS пожертвовала компактностью GB300 NVL72, лишь бы снизить зависимость от NVIDIAAmazon Web Services (AWS) нашла выход, как использовать собственные Nitro DPU K2v5/6 (EFA) в новейших стоечных системах NVIDIA GB300 NVL72, которые, как считает гиперскейлер, превосходит адаптеры NVIDIA ConnectX-7/8 по производительности. В связи с тем, что в стойках NVIDIA Oberon используются укороченные лотки высотой 1U, AWS размещает NIC в отдельной стойке JBOK, предназначенной только для сетевых карт, пишет SemiAnalysis. Причина кроется в невозможности установить в 1U сразу девять фирменных адаптеров (8 × EFA + 1 × ENA/EBS). Для серверных систем GB200 NVL предыдущего поколения AWS выбрала вариант NVL36×2, поскольку только в этом случае использовались 2U-узлы, где достаточно места для всех NIC. Однако сдвоенная конфигурация менее эффективна, чем нативная конструкция NVL72. NVIDIA сама была не очень довольна вариантами NVL36. Meta✴, например, и вовсе «растянула» NVL36×2 на шесть стоек, чтобы обойтись воздушным охлаждением. 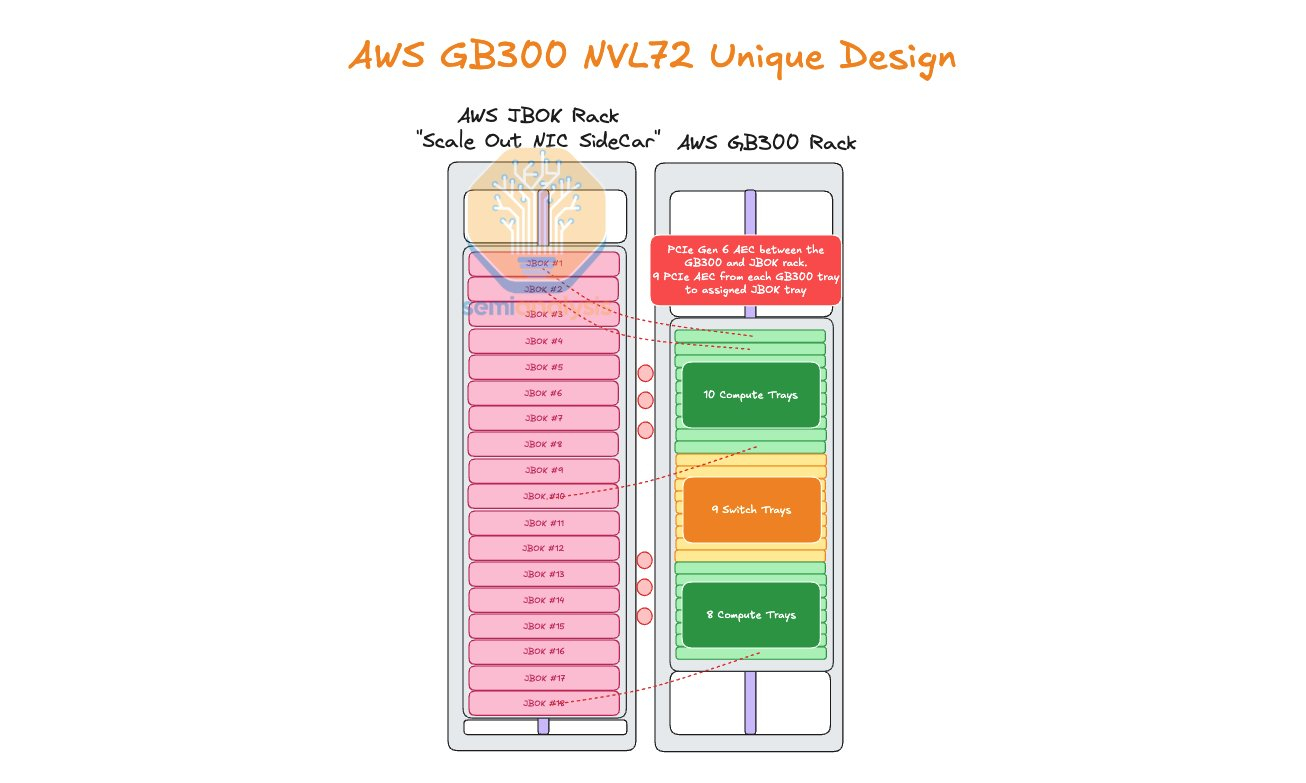
Источник изображения: SemiAnalysis AWS в случае Blackwell Ultra предпочла остановиться на NVL72-варианте, а DPU вынести в отдельную стойку — всего 18 узлов высотой 2U, по 9 NIC в каждом. С узлами NVIDIA они соединены активными электрическими кабелями (AEC) и портами OSFP-XD для передачи сигналов PCIe 6.0. По словам AWS, её адаптеры лучше справляются с нагрузками, чем ConnectX-8 (RoCEv2), что отчасти спорно. В любом случае таким образом компания снижается зависимость от NVIDIA. 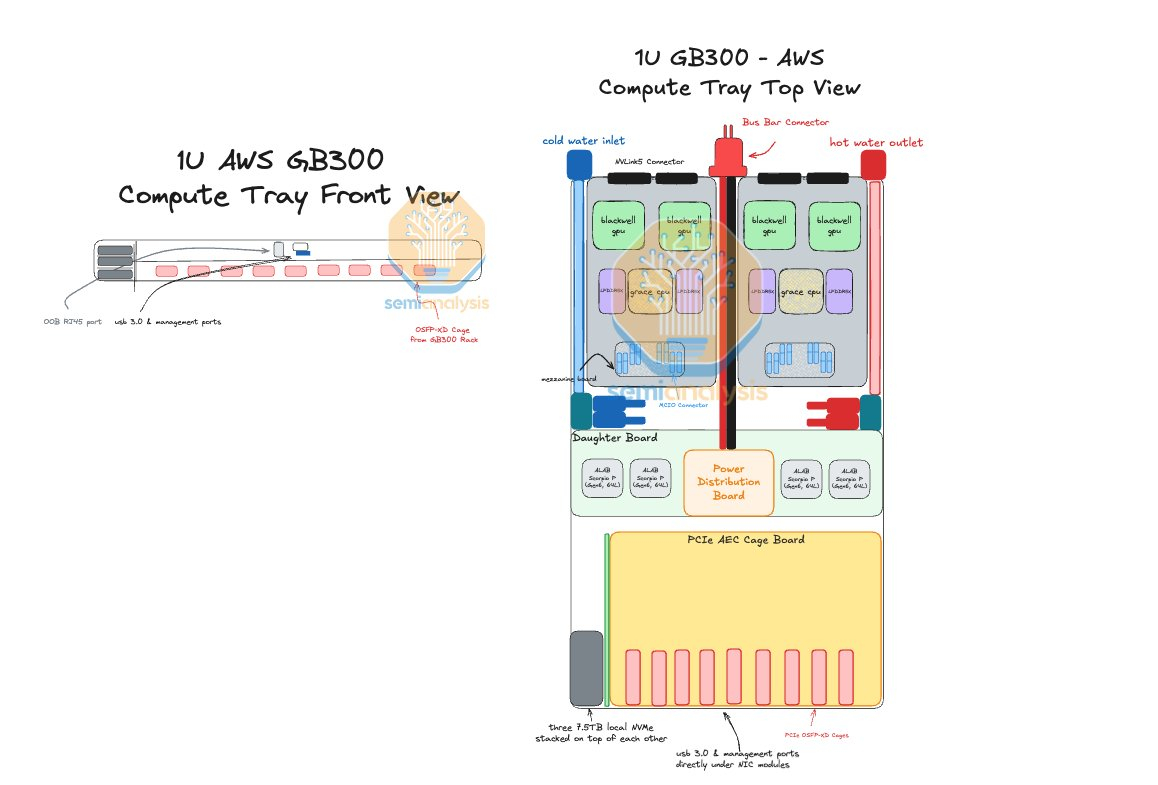
Источник изображения: SemiAnalysis С точки зрения SemiAnalysis, доработка GB300 в AWS помогает устранить единую точку отказа в референсной архитектуре NVIDIA, где каждый ускоритель взаимодействует только с одним сетевым адаптером ConnectX-8, тогда как в конфигурации AWS каждый ускоритель общается с двумя NIC. У AWS накоплен богатый опыт разработки собственного оборудования для ЦОД. Ранее компания в партнёрстве с Broadcom разрабатывала специализированные сетевые коммутаторы. Также недавно представленные ею EC2-инстансы P6-B200 и P6e-GB200 оснащены собственным сетевым стеком Elastic Fabric Adapter (EFAv4) на базе собственных контроллеров Nitro, который оптимизирует обработку сетевых пакетов и снижает задержки для высокопроизводительных приложений.
22.10.2025 [14:13], Руслан Авдеев
Oracle и OpenAI помогли поставить новый рекорд на рынке ЦОД США: в III квартале было арендовано больше мощностей, чем за весь 2024 годТолько в III квартале 2025 года гиперскейлерами арендовано больше мощностей дата-центров в США, чем за весь 2024 год. В отчёте TD Cowen указывается, что рекордный объём аренды ЦОД достиг 7,4 ГВт, а портфель будущих сделок составляет порядка 10,2 ГВт, сообщает Datacenter Dynamics. Это самый большой рост спроса за всю историю отрасли. Совокупный объём аренды гиперскейлерами за текущий год составит приблизительно 11,3 ГВт, тогда как за весь 2024 год он составил 7 ГВт. При поквартальном учёте рост ещё заметнее — во II квартале 2025 года было арендовано всего 2 ГВт. Огромную долю рынка заняла Oracle. В III квартале она арендовала порядка 5,4 ГВт на нескольких площадках, мощности предназначены в основном для OpenAI. В TD Cowen отмечают, что Oracle и OpenAI являются основными драйверами спроса, но значительно активнее, чем раньше, ведут себя и Google, Meta✴, Microsoft, AWS, а также Anthropic. 
Источник изображения: Point3D Commercial Imaging Ltd./unsplash.com Google ведёт переговоры об аренде гигаваттных масштабов, Meta✴ ведёт переговоры об аренде гигаваттных мощностей помимо площадки в Луизиане, Anthropic активно работает над гигаваттными проектами отдельно от Amazon (AWS) и Google. Microsoft наращиваетнедостающие мощности за счёт внешних арендаторов и масштабирования облачного бизнеса. Наконец, Amazon (AWS) активно масштабирует Project Rainier. Второе место в рейтинге TD Cowen заняла Google, которая арендовала 600 МВт только в III квартале, на третьем — Anthropic с показателем 528 МВт за квартал. В начале июня TD Cowen сообщала, что аренда ЦОД возвращается к значительным масштабам после замедления в начале 2025 года. Amazon и Microsoft отложили или отменили проекты ЦОД, но утверждали, что это не является признаком общей системной проблемы. Тем временем Oracle активно анонсирует новые запланированные мощности, в том числе — очередную облачную сделку с OpenAI на сумму $300 млрд.
22.10.2025 [12:35], Руслан Авдеев
Сбой в работе AWS показал опасную зависимость мира от нескольких облачных гигантов из СШАМасштабный сбой в работе облака AWS в понедельник коснулся множества сервисов по всему миру во многих секторах экономики и общественной деятельности. Инцидент вызвал разговоры о зависимости пользователей от крупных облачных провайдеров из США, необходимости повышения цифрового суверенитета и диверсификации рисков, сообщает Datacenter Knowledge. В компании объявили, что причина — в «эксплуатационном инциденте» в регионе us-east-1, именно там расположен крупнейший кластер ЦОД провайдера. Облачный регион находится в т.н. «Аллее ЦОД» в Северной Вирджинии и состоит из 158 объектов общей мощностью 2,544 ГВт. По оценкам Amazon, более 90 % компаний из рейтинга Fortune 100 используют именно облачные сервисы AWS. Сбой стал крупнейшим инцидентом в работе интернета с тех пор, как в 2024 году из-за ошибки обновления Crowdstrike из строя по всему миру вышли миллионы систем Microsoft. По словам IDC, последний инцидент демонстрирует, как масштабные вычисления могут привести к масштабным проблемам. Хотя предприятия в целом приняли идею отказа от собственной инфраструктуры ЦОД, происшествие привлекает внимание к необходимости диверсификации рисков. Это может привести к созданию распределённых архитектур, охватывающих несколько облачных регионов в рамках пакетного предложения одного провайдера, и более широкому использованию нескольких облаков разных провайдеров одновременно. 
Оригинал: xkcd.com/2347 Эксперты обеспокоены зависимостью предприятий всего мира от американских гиперскейлеров — последствия инцидента носят трансграничный характер и касаются не только клиентов одного поставщика облачных сервисов. Многие уже задаются вопросом — стоит ли сохранять зависимость государственных учреждений, от налоговых служб государство до крупных банков службам, расположенным на другом побережье Атлантического океана. Европа так и не смогла избавиться от бремени американских гиперскейлеров, которые открыто признают, что даже не могут гарантировать суверенитет данных. Как заявляют в британской Asanti Data Centres, многие организации активно приняли концепцию публичных облаков, но сбой показал, что может случиться, когда всё построено на одном фундаменте. Проблема затронула не только структуры, напрямую использующие сервисы AWS, но и всех остальных в цепочке поставок услуг. Большинство организаций ведут дела с клиентами AWS, в результате чего речь идёт о каскадном, общесистемном ущербе. 
Источник изображения: Oğuzhan Akdoğan/unspalsh.com В IDC подчёркивают, что роль в купировании негативных эффектов от будущих инцидентов может сыграть ИИ. Хотя у AWS в целом довольно хорошая репутация среди пользователей, на устранение последствий инцидента потребовалось слишком много времени, поэтому возникают сомнения, сможет ли AWS поддерживать репутацию по мере роста бизнеса и усложнения технологий. ИИ может помочь, создавая агентов, способных заранее выявлять и устранять проблемы до того, как они негативно скажутся на клиентах. Стоит отметить, что концентрация облачных ресурсов в одном месте может действительно крайне негативно сказаться на деятельности целых государств. Недавний пожар в южнокорейском ЦОД показывает, к каким катастрофическим последствиям для государственных услуг может привести консолидация облачных мощностей в одном месте. Более того, даже концентрация крупных ЦОД разных операторов в одном месте грозит тем, что сбой одного из них приведёт к проблемам у соседних. Особенно в случае ИИ ЦОД. |
|