На прошедшей недавно конференции Hot Chips 2023 компания Cerebras, создатель самого большого в мире ИИ-процессора WSE-2, рассказала о своём видении будущего ИИ-систем. По мнению Cerebras, сфокусировать внимание стоит не столько на наращивании сложности отдельных чипов, сколько на решениях проблем, связанных с масштабированием кластеров.
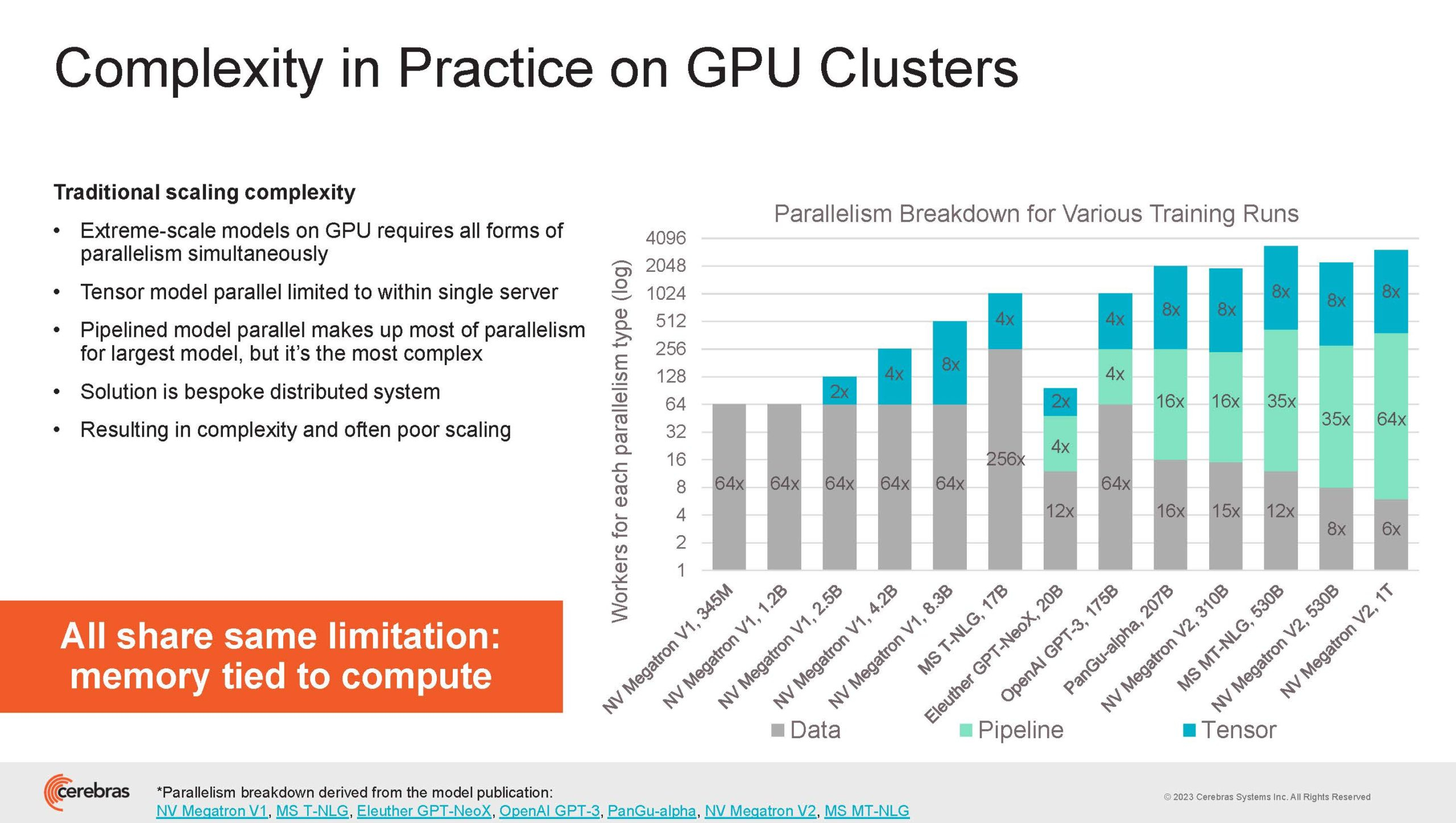
Свою презентацию Cerebras начала с любопытных фактов: за прошедшие пять лет сложность ИИ-моделей возросла в 40 тыс. раз. И этот темп явно опережает темпы развития чипов-ускорителей. Хотя налицо прогресс и в техпроцессах (5x), и в архитектуре (14x), и во внедрении более эффективных для ИИ форматов данных, но наибольший прирост производительности обеспечивает именно возможность эффективного масштабирования.
Источник изображений здесь и далее: Cerebras (via ServeTheHome)
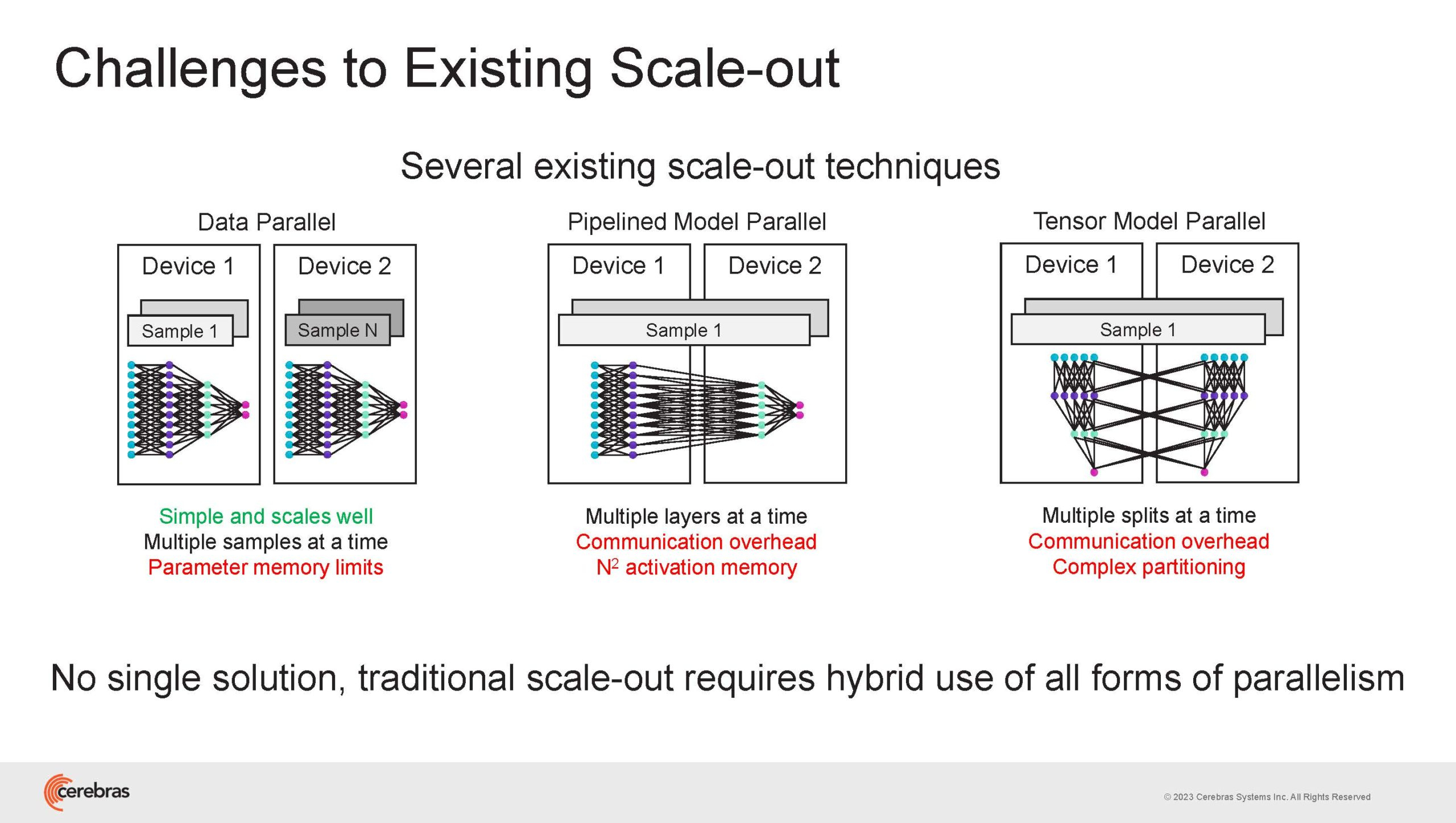
Однако и этого недостаточно — 600-кратный прирост от кластеризации явно теряется на фоне 40-тыс. усложнения самих нейросетей. А дальнейший рост масштабов ИИ-комплексов в их классическом виде, состоящих из множества «малых» ускорителей, неизбежно приводит к проблемам с организацией памяти, интерконнекта и вычислительных мощностей.
В итоге решение любой задачи в таких системах часто упирается в необходимость тончайшей, но при этом далеко не всегда эффективной оптимизации разделения ресурсов. При этом разные методы масштабирования имеют свои проблемы — узким местом могут оказаться и память, и интерконнект, и конкретный подход к организации кластера.
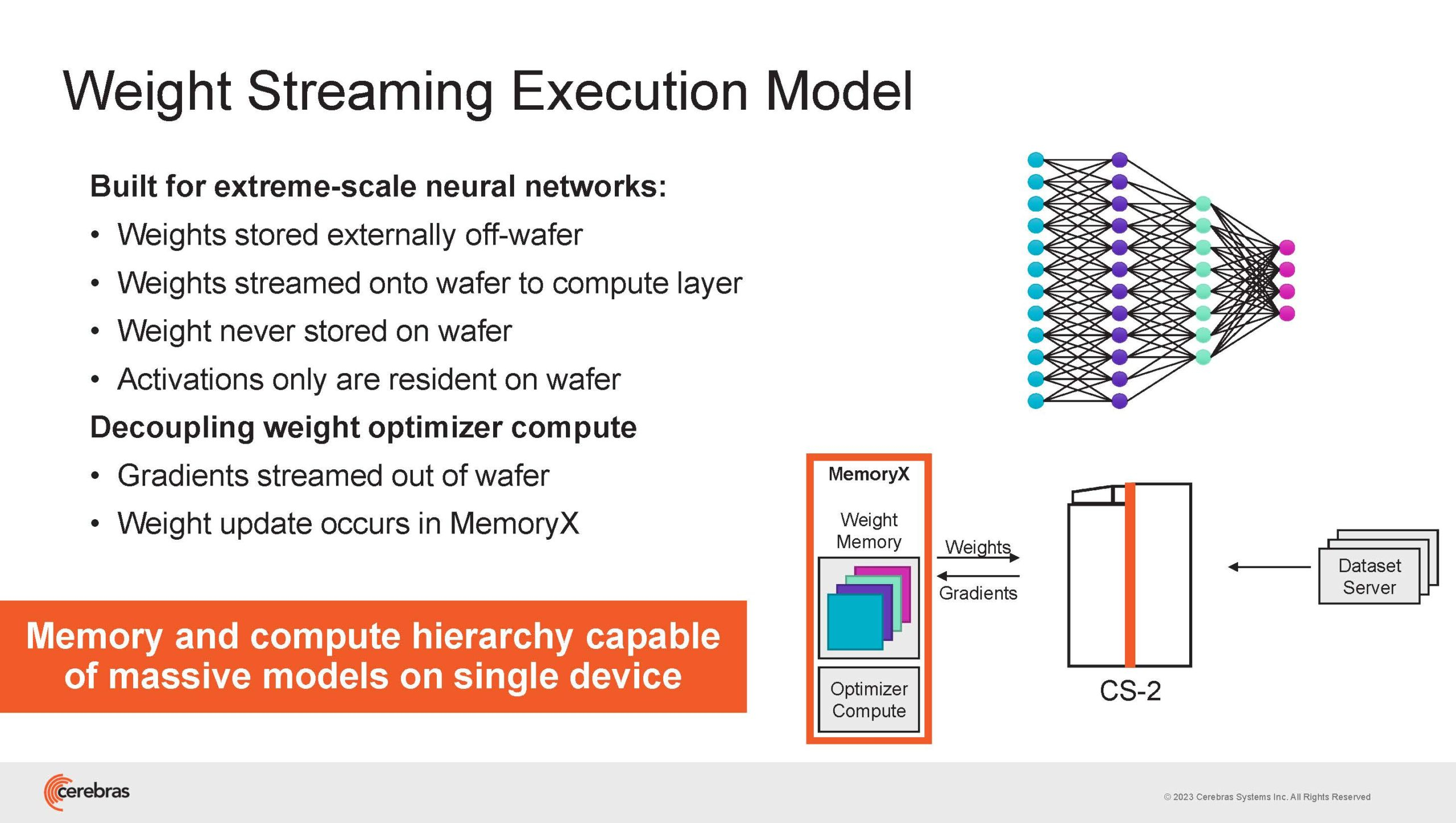
Cerebras же предлагает совершенно иной подход. Выход компания видит в создании огромных чипов-кластеров, таких, как 7-нм Cerebras WSE-2. Этот чип на сегодня можно назвать самым большим в индустрии: его площадь составляет более 45 тыс. мм2, при этом он содержит 2,6 трлн транзисторов и имеет 850 тыс. ядер, дополненных 40 Гбайт сверхбыстрой памяти. Что интереснее, кластер на базе CS-2 представляется с точки зрения исполняемой модели, как единая система.
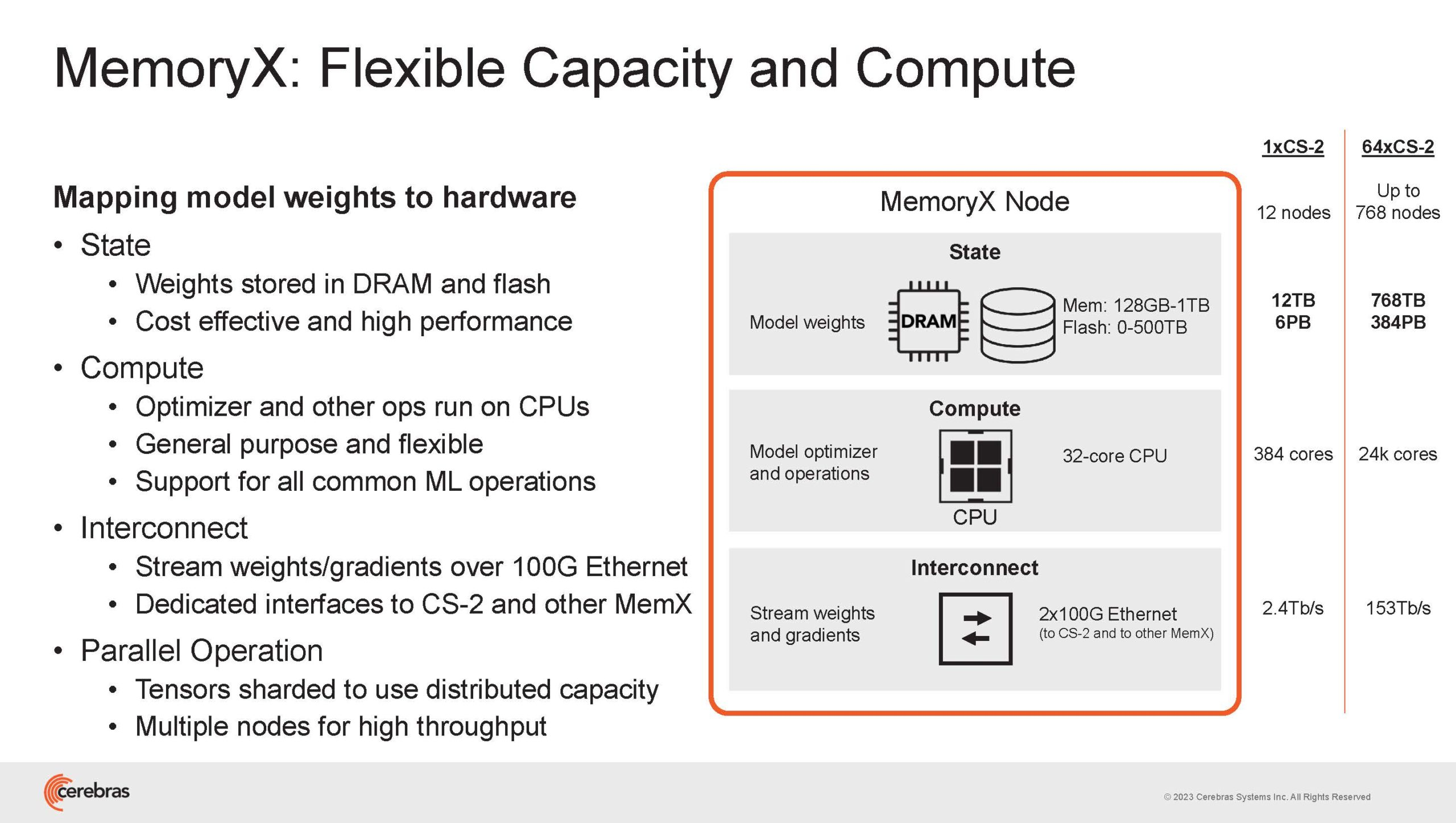
Сама по себе сложность WSE-2 и платформы CS-2 на его основе такова, что позволяет запускать модели практически любых размеров, благо весовые коэффициенты чип в себе не хранит, а подгружает извне с помощью подсистемы MemoryX. При этом сама по себе платформа CS-2 допускает и дальнейшее масштабирование: с помощью интерконнекта SwarmX в единый кластер можно объединить до 192 таких машин, что в теории позволит поднять производительность до 8+ Эфлопс.
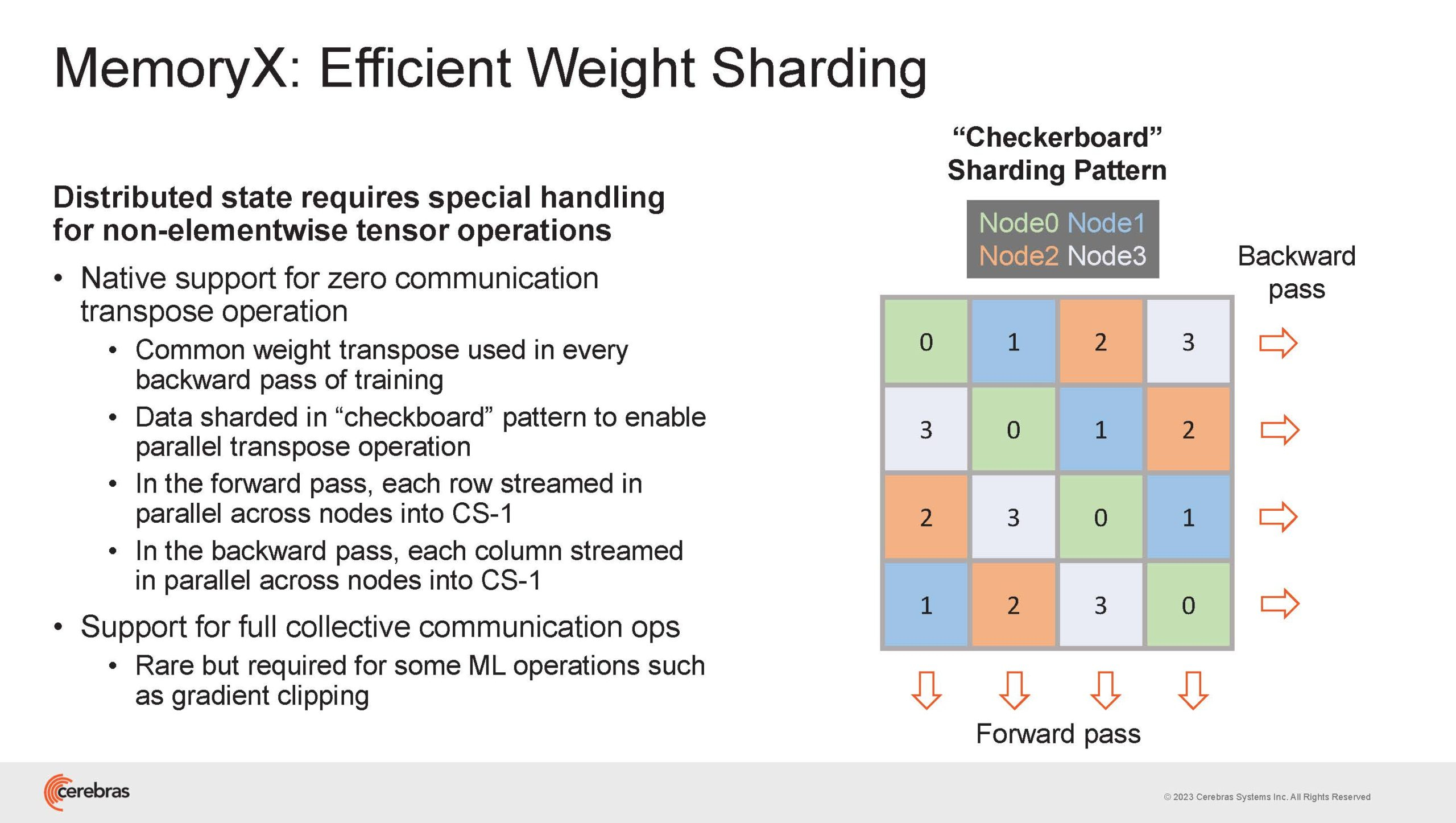
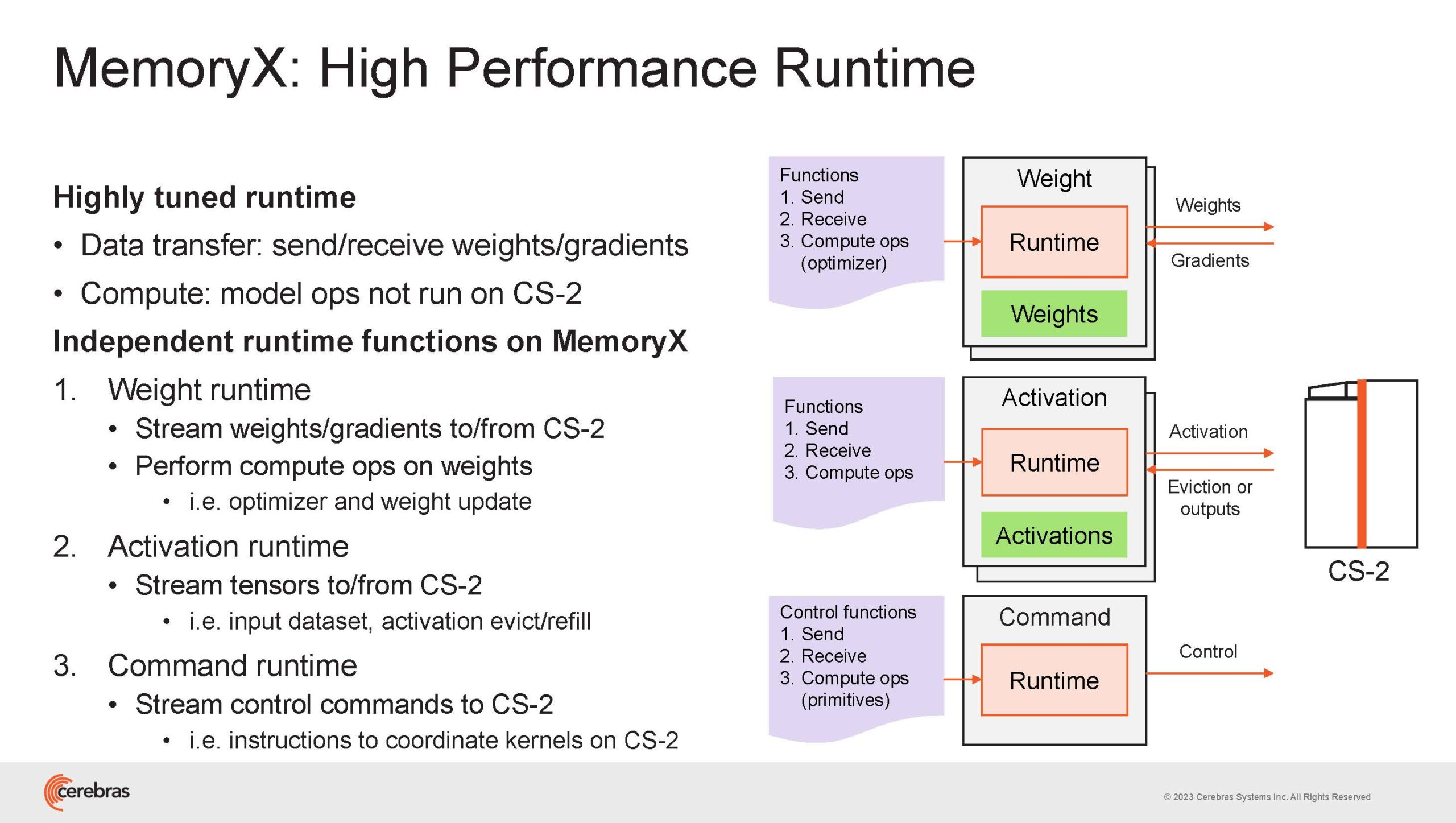
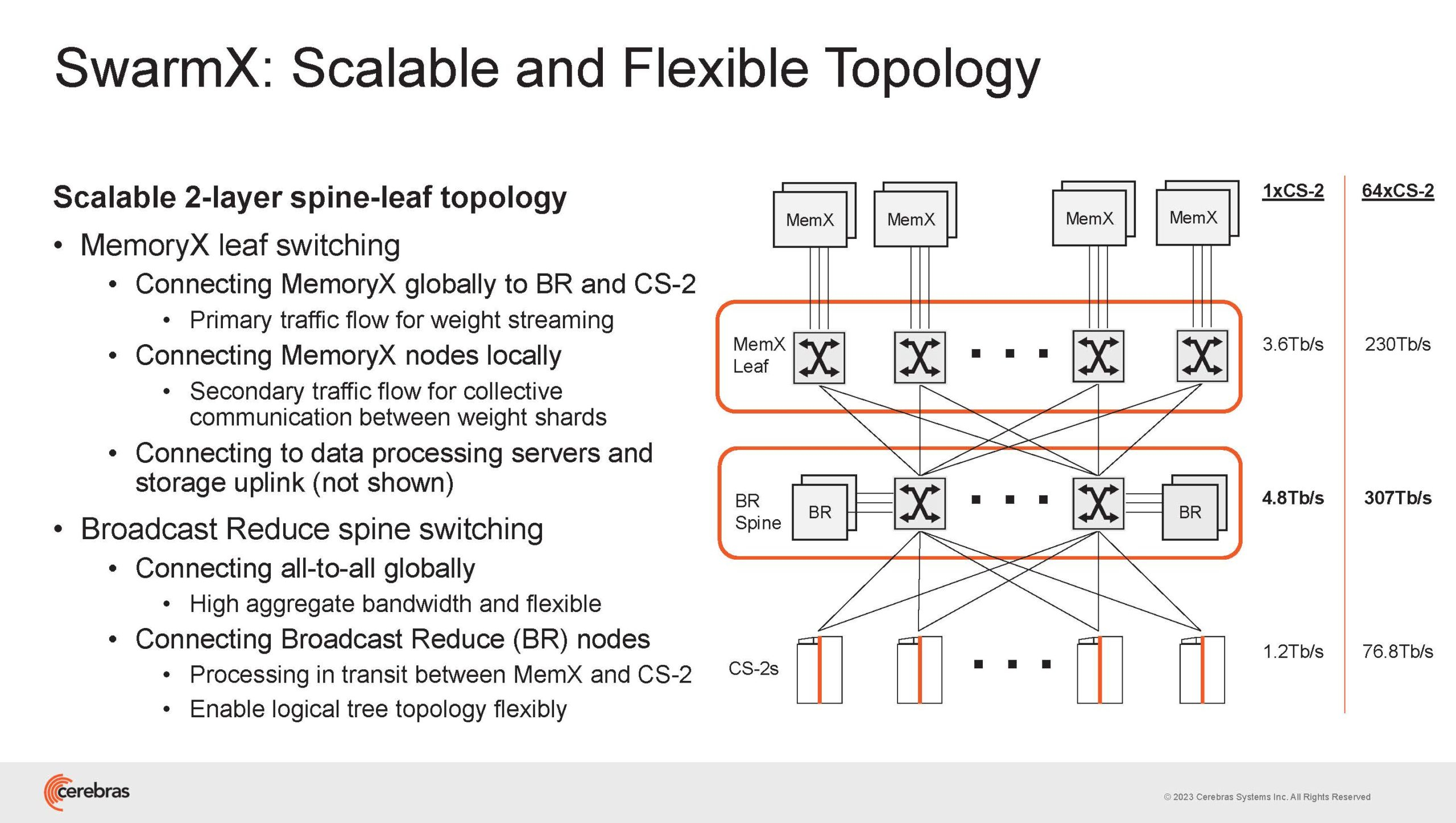
Подсистема MemoryX включает в себя 12 узлов, за оптимизацию модели в ней отвечают 32-ядерные процессоры, а веса хранятся как в DRAM, так и во флеш-памяти — объёмы этих подсистем составляют 12 Тбайт и 6 Пбайт соответственно. Каждый узел имеет по 2 порта 100GbE — один для закачки данных в CS-2, второй для общения с другими MemoryX в кластере. Оптимизация данных производится на процессорах MemoryX, «мегачипы» CS-2 для этого не используются.
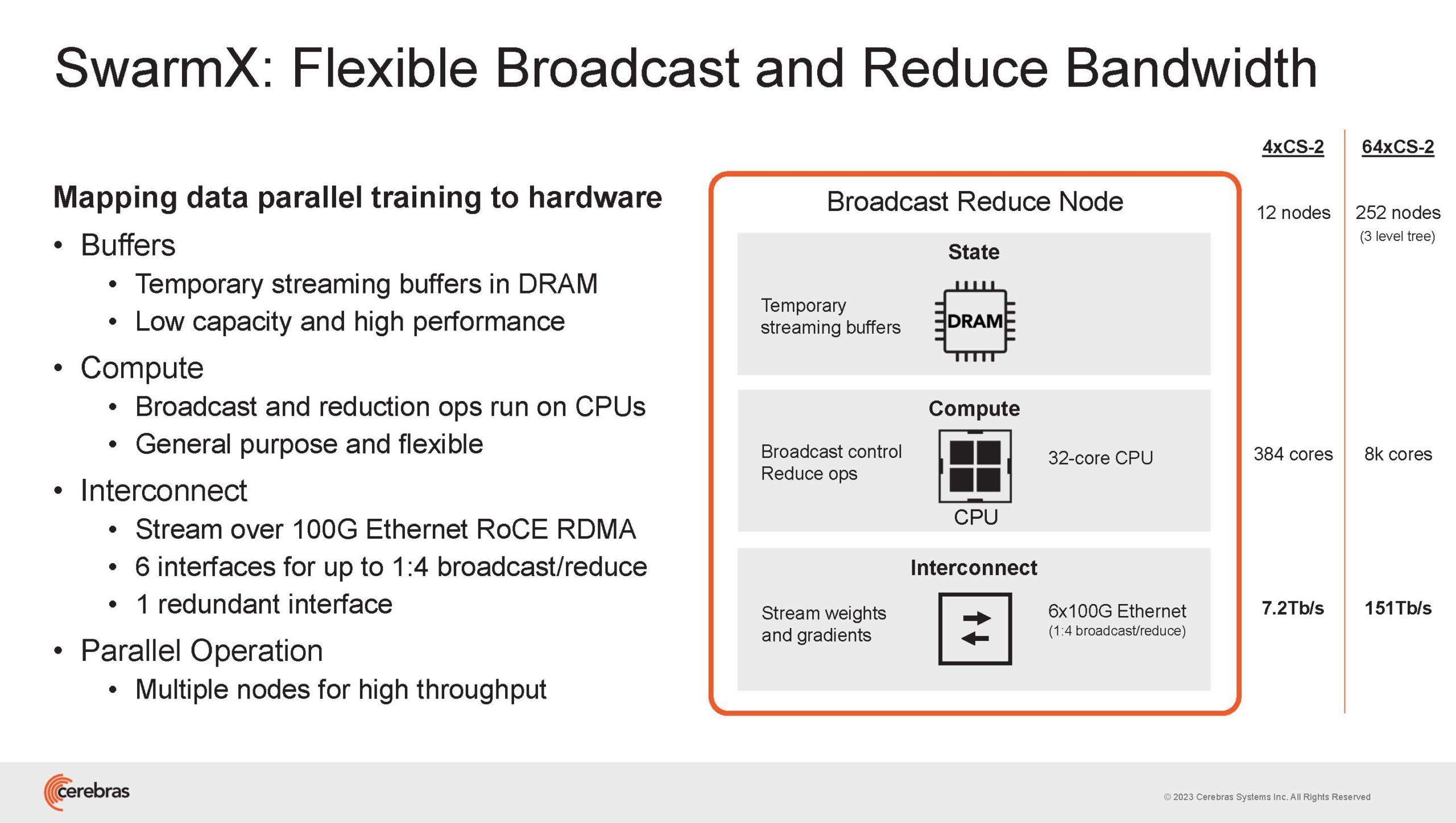
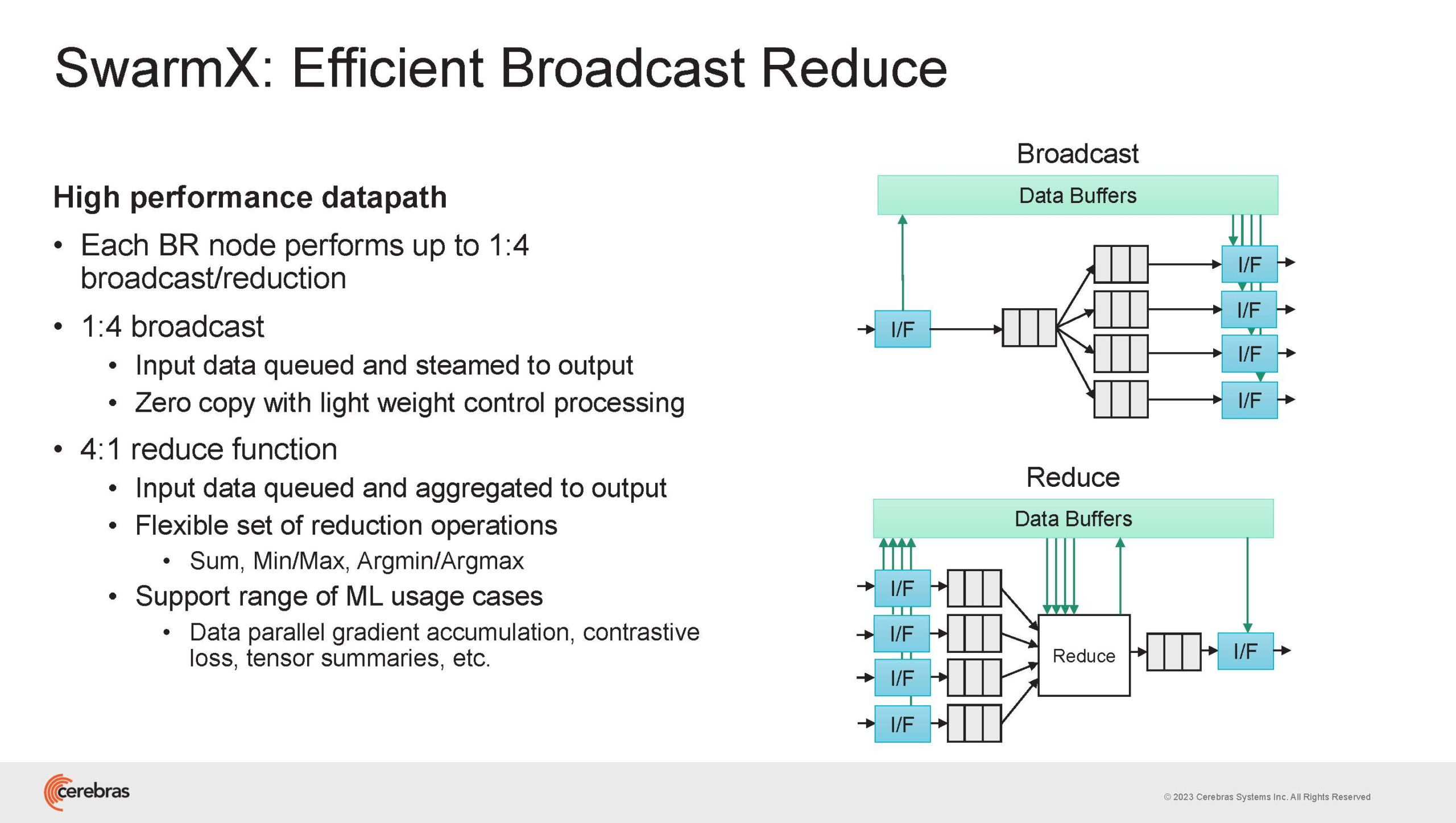
Подсистема интерконнекта SwarmX базируется на 100GbE с поддержкой RoCE DRMA, но имеет ряд особенностей: на каждые четыре системы CS-2 приходтся 12 узлов SwarmX c производительностью интерконнекта 7,2 Тбит/с. Трансляция и редуцирование данных осуществляются с коэффициентом 1:4, причём и здесь используются силы собственных 32-ядерных процессоров, а не ресурсы CS-2. Топологически SwarmX имеет двухслойную конфигурацию spine-leaf и обеспечивает соединение типа all-to-all, при этом каждая CS-2 имеет свой канал с пропускной способностью 1,2 Тбит/с.
Сочетание MemoryX и SwarmX позволяет делать кластеры на базе CS-2 крайне гибкими: размер модели ограничивается лишь ёмкостью узлов MemoryX, а степень параллелизма — их количеством. При этом интерконнект обладает достаточной степенью избыточности, чтобы говорить об отсутствии единых точек отказа.
Таким образом, Cerebras имеет на руках всё необходимое для запуска самых сложных моделей искусственного интеллекта. Уже сравнительно немолодой кластер Andromeda, включающий всего 16 платформ CS-2, способен «натаскивать» за считанные недели нейросети размерностью до 13 млрд параметров. При этом масштабирование по размеру модели не требует серьёзного вмешательства в программный код, в отличие от классического подхода для ускорителей NVIDIA. Фактически для сетей и с 1, и со 100 млрд параметров используется один и тот же код.
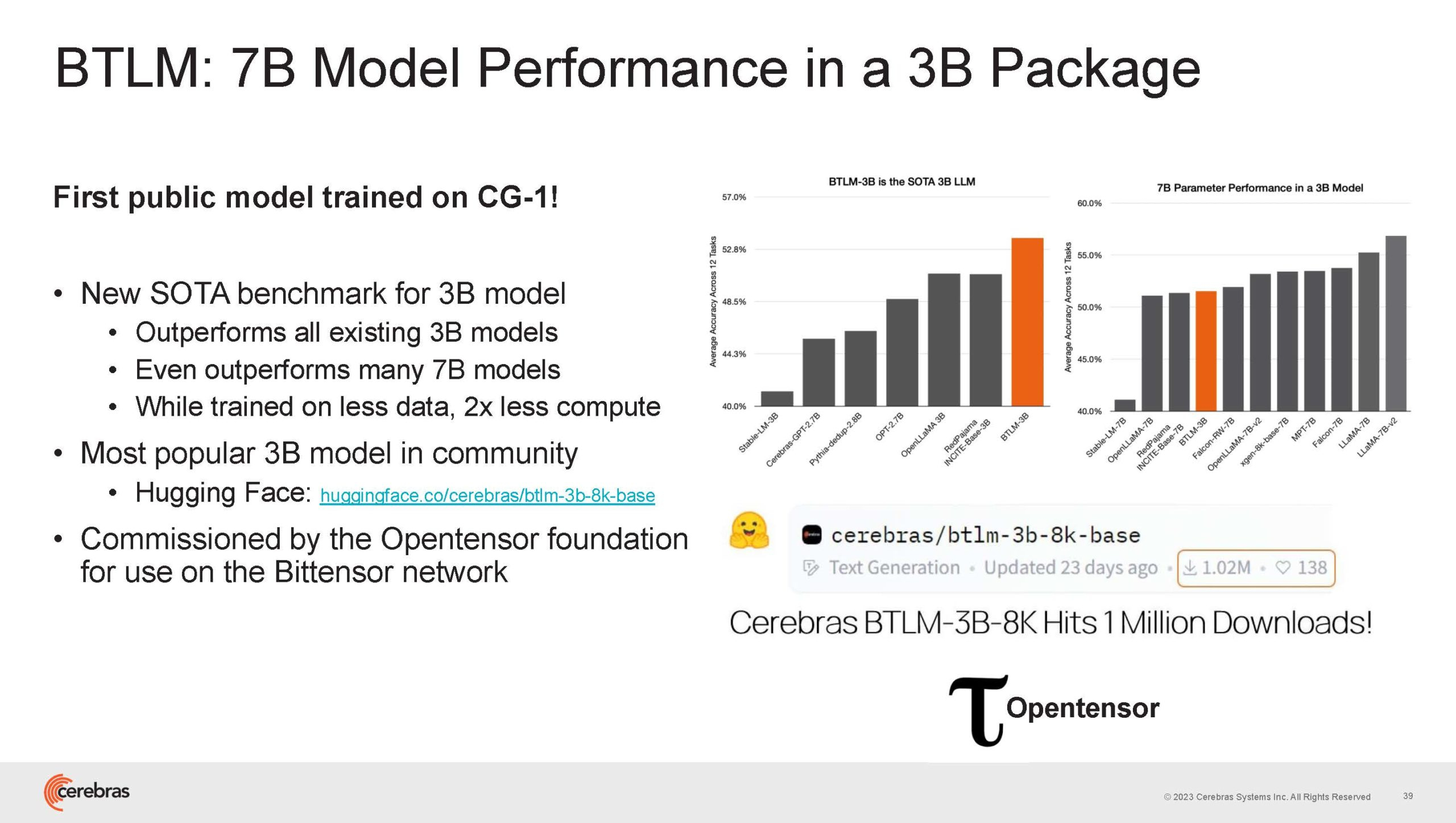
Более мощный 64-узловой комплекс Condor Galaxy 1 (CG-1), располагающий 54 млн ИИ-ядер и развивающий до 4 Эфлопс уже доказал, что подход к масштабированию, продвигаемый Cerebras, оправдывает себя. Он успешно обучил первую публичную модель с 3 млрд параметров, причём по возможностям она приближается к моделям с 7 млрд параметров. И это не предел: напомним, в текущем воплощении сочетание подсистем MemoryX и интерконнекта SwarmX допускает объединение в единый кластер до 192 узлов CS-2.
Компания считает, что она полностью готова к наплыву ещё более сложных нейросетей, а предлагаемая ей архитектура в явном виде лишена многих узких мест, свойственных традиционным GPU-архитектурам. Насколько успешным окажется такой подход в более отдалённой перспективе, покажет время.
Источник: