Материалы по тегу: суперкомпьютер
|
01.10.2024 [09:17], Сергей Карасёв
Isambard 2, один из первых Arm-суперкомпьютеров, отправился на покой30 сентября 2024 года, по сообщению Datacenter Dynamics, прекращена эксплуатация британского вычислительного комплекса Isambard 2. Это был один из первых в мире суперкомпьютеров, построенных на процессорах с архитектурой Arm. Система отправилась на покой после примерно шести лет работы. Isambard 2 назван в честь Изамбарда Кингдома Брюнеля — британского инженера, ставшего известной фигурой в истории Промышленной революции. Проект Isambard 2 реализован совместно компанией Cray, Метеорологической службой Великобритании и исследовательским консорциумом GW4 Alliance, в который входят университеты Бата, Бристоля, Кардиффа и Эксетера. Запуск суперкомпьютера состоялся в мае 2018 года. В основу Isambard 2 положены узлы Cray XC50. Задействованы 64-битные процессоры Marvell ThunderX2 с архитектурой Arm v8-A и ускорители NVIDIA P100. Общее количество вычислительных ядер — 20 992. Это одна из немногих систем на базе серии чипов ThunderX. 
Источник изображения: Marvell Technology/YouTube «После шести лет службы суперкомпьютер Isambard 2 наконец-то отправляется на пенсию. С мая 2018-го он был первым в мире серийным суперкомпьютером на базе Arm, использующим процессоры ThunderX2. Сегодня ему на смену приходит Isambard 3, содержащий Arm-чипы NVIDIA Grace», — сообщил профессор Саймон Макинтош-Смит (Simon McIntosh-Smith), руководитель проекта, глава группы микроэлектроники в Университете Бристоля. В основу Isambard 3 лягут 384 суперпроцессора NVIDIA Grace. Эта система, как ожидается, обеспечит в шесть раз более высокую производительность и в шесть раз лучшую энергоэффективность по сравнению с Isambard 2. Пиковое быстродействие FP64 у нового суперкомпьютера составит 2,7 Пфлопс при энергопотреблении менее 270 кВт. В дальнейшем вычислительные мощности Isambard 3 планируется наращивать. Комплекс будет применяться при решении сложных задач в области ИИ, медицины, астрофизики, биотехнологий и пр.
28.09.2024 [23:24], Сергей Карасёв
Индия запустила сразу пять суперкомпьютеров за два дня
a100
amd
atos
cascade lake-sp
epyc
eviden
hardware
hpc
intel
milan
nvidia
xeon
индия
метео
суперкомпьютер
Премьер-министр Индии Нарендра Моди, по сообщению The Register, объявил о вводе в эксплуатацию трёх новых высокопроизводительных вычислительных комплексов PARAM Rudra. Запуск этих суперкомпьютеров, как отмечается, является «символом экономической, социальной и промышленной политики» страны. Вдаваться в подробности о технических характеристиках машин Моди во время презентации не стал. Однако некоторую информацию раскрыли организации, которые займутся непосредственной эксплуатацией этих НРС-систем. Один из суперкомпьютеров располагается в Национальном центре радиоастрофизики Индии (NCRA). Данная машина оснащена «несколькими тысячами процессоров Intel» и 90 ускорителями NVIDIA A100, 35 Тбайт памяти и хранилищем вместимостью 2 Пбайт. Ещё один НРС-комплекс смонтирован в Центре фундаментальных наук имени С. Н. Бозе (SNBNCBS): известно, что он обладает быстродействием 838 Тфлопс. Оператором третьей системы является Межуниверситетский центр ускоренных вычислений (IUAC): этот суперкомпьютер с производительностью на уровне 3 Пфлопс использует 24-ядерные чипы Intel Xeon Cascade Lake-SP. Ёмкость хранилища составляет 4 Пбайт. Упомянут интерконнект с пропускной способностью 240 Гбит/с. The Register отмечает, что указанные характеристики в целом соответствуют описанию суперкомпьютеров Rudra первого поколения. Согласно имеющейся документации, такие машины используют:
Ожидается, что машины Rudra второго поколения получат поддержку процессоров Xeon Sapphire Rapids и четырёх GPU-ускорителей. Суперкомпьютеры третьего поколения будут использовать 96-ядерные Arm-процессоры AUM, разработанные индийским Центром развития передовых вычислений: эти изделия будут изготавливаться по 5-нм технологии TSMC. 
Источник изображения: pixabay.com Между тем компания Eviden (дочерняя структура Atos) сообщила о поставках в Индию двух новых суперкомпьютеров. Один из них установлен в Индийском институте тропической метеорологии (IITM) в Пуне, второй — в Национальном центре среднесрочного прогнозирования погоды (NCMRWF) в Нойде. Эти системы, построенные на платформе BullSequana XH2000, предназначены для исследования погоды и климата. В создании комплексов приняли участие AMD, NVIDIA и DDN. Система IITM, получившая название ARKA, обладает быстродействием 11,77 Пфлопс: 3021 узел с AMD EPYC 7643 (Milan), 26 узлов с NVIDIA A100, NVIDIA Quantum InfiniBand и хранилище на 33 Пбайт (ранее говорилось о 3 Пбайт SSD + 29 Пбайт HDD). В свою очередь, суперкомпьютер NCMRWF под названием Arunika обладает производительностью 8,24 Пфлопс: 2115 узлов с AMD EPYC 7643 (Milan), NVIDIA Quantum InfiniBand и хранилище DDN EXAScaler ES400NVX2 (2 Пбайт SSD + 22 Пбайт HDD). Кроме того, эта система включает выделенный блок для приложений ИИ и машинного обучения с быстродействием 1,9 Пфлопс (точность не указана), состоящий из 18 узлов с NVIDIA A100.
20.09.2024 [20:25], Руслан Авдеев
20 тонн HDD в труху — накопители хранилища Alpine уходящего на покой суперкомпьютера Summit отправили в измельчительПо словам специалистов Национальной лаборатории Ок-Ридж (ORNL) Министерства энергетики США, суперкомпьютеры и их компоненты утилизируются точно так же, как и ненужная бумага — буквально отправляются в измельчитель. И совсем скоро сотрудникам лаборатории предстоит разобрать суперкомпьютер Summit, который морально устарел, хотя всё ещё входит в десятку самых производительных систем мирового рейтинга TOP500. Summit хотели вывести из эксплуатации ещё в 2023 году, но из-за довольно высокой производительности пока решено оставить его в строю почти до ноября 2024 года в рамках программы SummitPLUS. Впрочем, часть комплекса уже модернизируется. Так, на смену хранилищу Alpine придёт Alpine 2. Данные из Alpine были переданы в другие СХД суперкомпьютерного центра Oak Ridge Leadership Computing Facility (OLCF). 19 ноября Alpine2 переключат в режим «только для чтения», а потом изменят конфигурацию хранилища для использования в других проектах. Alpine, основанная на параллельной файловой системе IBM Spectrum Scale, создавалась для временного хранения данных Summit и других систем. По словам учёных, Summit строили для симуляции процессов в сверхновых и термоядерных реакторах и вряд ли где-либо ещё есть такая же концентрация жёстких дисков в одном месте, как в системах ORNL, за исключением, возможно, гиперскейлеров. Другими словами, даже разборка Alpine, которая началась ещё летом — чрезвычайно трудоёмкий процесс, поскольку накопители приходится извлекать вручную и по одному. 
Источник изображения: ORNL Alpine состояло из 40 стоек на площади около 130 м2. Хранилище суммарной ёмкостью 250 Пбайт включало 32 494 HDD. Речь идёт о почти 20 т оборудования. Чтобы обеспечить по-настоящему безопасное удаление данных, HDD отвозят для физического уничтожения. За этот процесс отвечает компания ShredPro Secure. HDD буквально крошатся металлическими зубьями до небольших фрагментов. На переработку одного диска уходит приблизительно 10 с, а за день можно уничтожить до 3,5 тыс. накопителей. Полученные остатки окончательно утилизируются в рамках программы по переработке металла ORNL, так что лаборатория ещё и получает деньги за сдачу вторичного сырья. Вывод из эксплуатации крупных вычислительных систем — постоянно совершенствуемый процесс, который с годами становится всё эффективнее. В последний раз крупное хранилище (Atlas) утилизировали в 2019 году, оно включало около 20 тыс. HDD. Утилизация своими силами заняла около 9 месяцев и оказалась очень дорогой. ShredPro Secure справилась гораздо быстрее, а сам процесс оказался гораздо дешевле. Поэтому компании в итоге отдали на уничтожение ещё около 10 тыс. HDD из других систем. Правда, теперь ORNL раздумывает над покупкой собственного измельчителя, чтобы дополнительно повысить безопасность и сэкономить ещё больше в долгосрочной перспективе.
17.09.2024 [23:07], Игорь Осколков
Швейцария ввела в эксплуатацию гибридный суперкомпьютер Alps: 11 тыс. NVIDIA GH200, 2 тыс. AMD EPYC Rome и щепотка A100, MI250X и MI300AШвейцарская высшая техническая школа Цюриха (ETH Zurich) провела церемонию официального запуска суперкомпьютера Alps в Швейцарском национальном суперкомпьютерном центре (CSCS) в Лугано. Система, построенная HPE, уже заняла шестую строчку в последнем рейтинге TOP500 и имеет устоявшеюся FP64-производительность 270 Пфлопс (теоретический пик — 354 Пфлопс). К ноябрю будут введены в строй остальные модули машины, и её максимальная производительность составит порядка 500 Пфлопс. 
Источник изображений: CSCS В июньском рейтинге TOP500 участвовал раздел из 2688 узлов HPE Cray EX254n с «фантастической четвёркой» NVIDIA Quad GH200. Если точнее, это всё же «старый» вариант ускорителя с H100 (96 Гбайт HBM3), 72-ядерным Arm-процессором Grace и 128 Гбайт LPDDR5x — суммарно 10 752 Grace Hopper. Данный раздел потребляет 5,2 МВт и в Green500 находится на 14 месте. Узлы, конечно же, используют СЖО. Это основной, но не единственный раздел суперкомпьютера. Ещё в 2020 году HPE развернула 1024 двухпроцессорных узла с 64-ядерными AMD EPYC 7742 (Rome) и 256/512 Гбайт RAM. Его производительность составляет 4,7 Пфлопс. Кроме того, в состав Alps входят 144 узла с одним 64-ядерным AMD EPYC, 128 Гбайт RAM и четырьмя NVIDIA A100 (80 или 96 Гбайт HBM2e).  Наконец, машина получит 24 узла с одним 64-ядерным AMD EPYC, 128 Гбайт RAM и четырьмя AMD Instinct MI250X (128 Гбайт HBM2e) и 128 узлов с четырьмя гибридными ускорителями AMD Instinct MI300A. Большая часть узлов будет объединена интерконнектом HPE Slingshot-11: 200G-подключение на узел или ускоритель. Более точную конфигурацию системы раскроют в ноябре. Lustre-хранилище для будущей машины обновили ещё в прошлом году. Основной СХД является Cray ClusterStor E1000 с подключением Slingshot-11. Так, было добавлено 100 Пбайт полезной HDD-ёмкости (8480 × 16 Тбайт) с пропускной способностью 1 Тбайт/с (300 тыс. IOPS на запись, 1,5 млн IOPS на чтение) и 5 Пбайт SSD, а также резервные ёмкости. За архивное хранение отвечают две ленточные библиотеки объёмом 130 Пбайт каждая.  Особенностью системы является её геораспределённость (фактически узлы размещены в четырёх местах) и облачная модель использования. Так, метеослужба страны MeteoSwiss получила в своё распоряжение выделенный виртуальный кластер, что уже позволило перейти на использование метеомодели более высокого разрешения, которая лучше отражает сложный рельеф Швейцарии. Кроме того, для подстраховки часть узлов Alps размещена на территории Федеральной политехнической школы Лозанны (EPFL). Alps приходит на смену суперкомпьютеру Piz Daint (Cray XC50/40, 21,2 Пфлопс), о завершении жизненного цикла которого было объявлено в конце июля 2024 года. В CSCS пока останутся машины Arolla + Tsa (для нужд MeteoSwiss) и Blue Brain 5 (решает задачи реконструкции и симуляции мозга). Alps же помимо традиционных HPC-нагрузок, будет использоваться для разработки ИИ-решений.
13.09.2024 [10:22], Сергей Карасёв
Некогда самый мощный в мире суперкомпьютер Summit уйдёт на покой в ноябреВысокопроизводительный вычислительный комплекс Summit, установленный в Окриджской национальной лаборатории (ORNL) Министерства энергетики США, будет выведен из эксплуатации в ноябре 2024 года. Обслуживать машину становится всё дороже, а по эффективности она уступает современным суперкомпьютерам. Summit был запущен в 2018 году и сразу же возглавил рейтинг мощнейших вычислительных систем мира TOP500. Комплекс насчитывает 4608 узлов, каждый из которых оборудован двумя 22-ядерными процессорами IBM POWER9 с частотой 3,07 ГГц и шестью ускорителями NVIDIA Tesla GV100. Узлы соединены через двухканальную сеть Mellanox EDR InfiniBand, что обеспечивает пропускную способность в 200 Гбит/с для каждого сервера. Энергопотребление машины составляет чуть больше 10 МВт. 
Источник изображения: ORNL FP64-быстродействие Summit достигает 148,6 Пфлопс (Linpack), а пиковая производительность составляет 200,79 Пфлопс. За шесть лет своей работы суперкомпьютер ни разу не выбывал из первой десятки TOP500: так, в нынешнем рейтинге он занимает девятую позицию. 
Источник изображения: ORNL Отправить Summit на покой планировалось в начале 2024-го. Однако затем была запущена инициатива SummitPLUS, и срок службы вычислительного комплекса увеличился практически на год. Отмечается, что этот суперкомпьютер оказался необычайно продуктивным. Он обеспечил исследователям по всему миру более 200 млн часов работы вычислительных узлов. В настоящее время ORNL эксплуатирует ряд других суперкомпьютеров, в число которых входит Frontier — самый мощный НРС-комплекс в мире. Его пиковое быстродействие достигает 1714,81 Пфлопс, или более 1,7 Эфлопс. При этом энергопотребление составляет 22 786 кВт: таким образом, система Frontier не только быстрее, но и значительно энергоэффективнее Summit. А весной этого года из-за растущего количества сбоев и протечек СЖО на аукционе был продан 5,34-ПФлопс суперкомпьютер Cheyenne.
12.09.2024 [11:20], Сергей Карасёв
Начался монтаж модульного ЦОД для европейского экзафлопсного суперкомпьютера JUPITERЮлихский исследовательский центр (Forschungszentrum Jülich) объявил о начале фактического создания модульного дата-центра для европейского экзафлопсного суперкомпьютера JUPITER (Joint Undertaking Pioneer for Innovative and Transformative Exascale Research). Европейское совместное предприятие по развитию высокопроизводительных вычислений (EuroHPC JU) заключило контракт на создание JUPITER с консорциумом, в который входят Eviden (подразделение Atos) и ParTec. В рамках партнёрства за создание модульного ЦОД отвечает Eviden. После завершения строительства комплекс, как ожидается, объединит около 125 стоек BullSequana XH3000. Общая площадь ЦОД составит примерно 2300 м2. Он будет включать порядка 50 компактно расположенных контейнеров. Благодаря модульной конфигурации ускоряется монтаж систем, а также снижаются расходы на строительство объекта. Суперкомпьютер JUPITER получит энергоэффективные высокопроизводительные европейские Arm-процессоры SiPearl Rhea. CPU-блок будет включать 1300 узлов и иметь производительность около 5 Пфлопс (FP64). Кроме того, в состав машины войдут порядка 6000 узлов с NVIDIA Quad GH200, а общее количество суперчипов GH200 Grace Hopper составит почти 24 тыс. Именно они и обеспечат FP64-производительность на уровне 1 Эфлопс. Узлы объединит интерконнект NVIDIA InfiniBand NDR (DragonFly+). 
Источник изображений: Юлихский исследовательский центр Хранилище системы будет включать два раздела: быстрый ExaFLASH и ёмкий ExaSTORE. ExaFLASH будет базироваться на сорока All-Flash СХД IBM Elastic Storage System 3500 с эффективной ёмкостью 21 Пбайт («сырая» 29 Пбайт), скоростью записи 2 Тбайт/с и скоростью чтения 3 Тбайт/с. ExaSTORE будет иметь «сырую» ёмкость 300 Пбайт, а для резервного копирования и архивов будет использоваться ленточная библиотека ёмкостью 700 Пбайт.  «Первые контейнеры для нового европейского экзафлопсного суперкомпьютера доставлены компанией Eviden и установлены на площадке ЦОД. Мы рады, что этот масштабный проект, возглавляемый EuroHPC, всё больше обретает форму», — говорится в сообщении Юлихского исследовательского центра.  Ожидаемое быстродействие JUPITER на операциях обучения ИИ составит до 93 Эфлопс, а FP64-производительность превысит 1 Эфлопс. Стоимость системы оценивается в €273 млн, включая доставку, установку и обслуживание НРС-системы. Общий бюджет проекта составит около €500 млн, часть средств уйдёт на подготовку площадки, оплату электроэнергии и т.д.
11.09.2024 [18:55], Игорь Осколков
Oracle анонсировала зеттафлопсный облачный ИИ-суперкомпьютер из 131 тыс. NVIDIA B200Oracle и NVIDIA анонсировали самый крупный на сегодняшний день облачный ИИ-кластер, состоящий из 131 072 ускорителей NVIDIA B200 (Blackwell). По словам компаний, это первая в мире система производительностью 2,4 Зфлопс (FP8). Кластер заработает в I половине 2025 года, но заказы на bare-metal инстансы и OCI Superclaster компания готова принять уже сейчас. Заказчики также смогут выбрать тип подключения: RoCEv2 (ConnectX-7/8) или InfiniBand (Quantum-2). По словам компании, новый ИИ-кластер вшестеро крупнее тех, что могут предложить AWS, Microsoft Azure и Google Cloud. Кроме того, компания предлагает и другие кластеры с ускорителями NVIDIA: 32 768 × A100, 16 384 × H100, 65 536 × H200 и 3840 × L40S. А в следующем году обещаны кластеры на основе GB200 NVL72, объединяющие более 100 тыс. ускорителей GB200. В скором времени также появятся и куда более скромные ВМ GPU.A100.1 и GPU.H100.1 с одним ускорителем A100/H100 (80 Гбайт). Прямо сейчас для заказы доступны инстансы GPU.H200.8, включающие восемь ускорителей H200 (141 Гбайт), 30,7-Тбайт локальное NVMe-хранилище и 200G-подключение. Семейство инстансов на базе NVIDIA Blackwell пока включает лишь два варианта. GPU.B200.8 предлагает восемь ускорителей B200 (192 Гбайт), 30,7-Тбайт локальное NVMe-хранилище и 400G-подключение. Наконец, GPU.GB200 фактически представляет собой суперускоритель GB200 NVL72 и включает 72 ускорителя B200, 36 Arm-процессоров Grace и локальное NVMe-хранилище ёмкостью 533 Тбайт. Агрегированная скорость сетевого подключения составляет 7,2 Тбит/с. 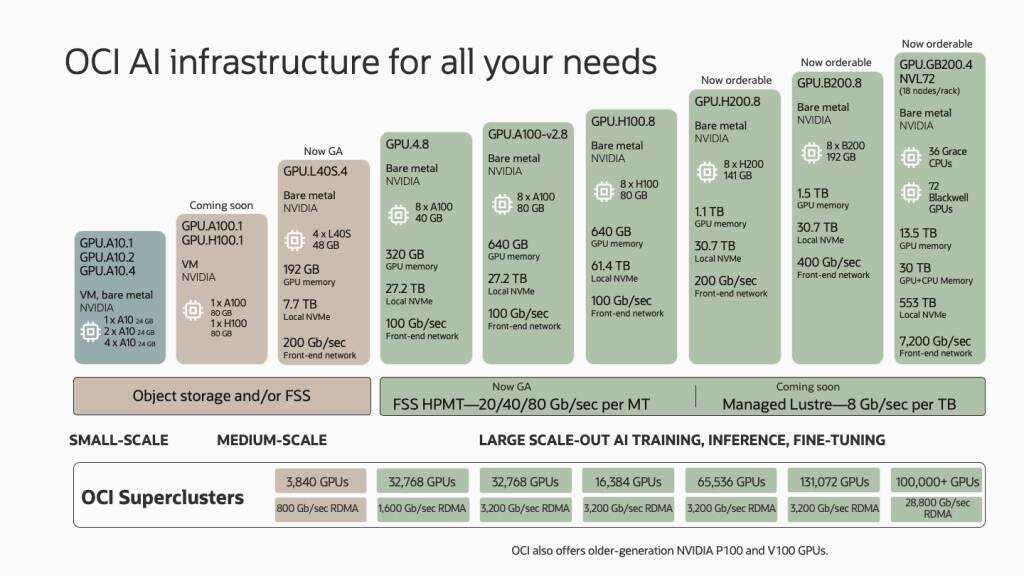
Источник изображения: Oracle Для всех новых инстансов Oracle подготовит управляемое Lustre-хранилище с производительностью до 8 Гбит/с на каждый Тбайт. Кроме того, компания предложит расширенные средства мониторинга и управления, помощь в настройке инфраструктуры для достижения желаемого уровня реальной производительности, а также набор оптимизированного ПО для работы с ИИ, в том числе для Arm.
10.09.2024 [14:55], Сергей Карасёв
TACC ввёл в эксплуатацию Arm-суперкомпьютер Vista на базе NVIDIA GH200 для ИИ-задачТехасский центр передовых вычислений (TACC) при Техасском университете в Остине (США) объявил о том, что мощности нового НРС-комплекса Vista полностью доступны открытому научному сообществу. Суперкомпьютер предназначен для решения ресурсоёмких задач, связанных с ИИ. Формальный анонс машины Vista состоялся в ноябре 2023 года. Тогда говорилось, что Vista станет связующим звеном между существующим суперкомпьютером TACC Frontera и будущей системой TACC Horizon, проект которой финансируется Национальным научным фондом (NSF). Vista состоит из двух ключевых частей. Одна из них — кластер из 600 узлов на гибридных суперчипах NVIDIA GH200 Grace Hopper, которые содержат 72-ядерный Arm-процессор NVIDIA Grace и ускоритель H100/H200. Обеспечивается производительность на уровне 20,4 Пфлопс (FP64) и 40,8 Пфлопс на тензорных ядрах. Каждый узел содержит локальный накопитель вместимостью 512 Гбайт, 96 Гбайт памяти HBM3 и 120 Гбайт памяти LPDDR5. Интероконнект — Quantum 2 InfiniBand (400G). Второй раздел суперкомпьютера объединяет 256 узлов с процессорами NVIDIA Grace CPU Superchip, содержащими два кристалла Grace в одном модуле (144 ядра). Узлы укомплектованы 240 Гбайт памяти LPDDR5 и накопителем на 512 Гбайт. Интерконнект — Quantum 2 InfiniBand (200G). Узлы произведены Gigabyte, а за интеграцию всей системы отвечала Dell. 
Источник изображения: TACC Общее CPU-быстродействие Vista находится на отметке 4,1 Пфлопс. В состав комплекса входит NFS-хранилише VAST Data вместимостью 30 Пбайт. Суперкомпьютер будет использоваться для разработки и применения решений на основе генеративного ИИ в различных секторах, включая биологические науки и здравоохранение.
03.09.2024 [14:09], Руслан Авдеев
Бразильская Petrobras купит пять суперкомпьютеров Lenovo за $89 млнБразильская государственная нефтегазовая компания Petrobras намерена потратить $89 млн на покупку пяти новых супекомпьютеров Lenovo, которая смогла выиграть тендер, предложив лучшую по сравнению с Atos и Dell цену. По данным Datacenter Dynamics, системы разместят на территории принадлежащего компании инновационного центра Cenpes в Рио-де-Жанейро. Ожидается, что сборка начнётся в текущем году, а в ввод в эксплуатацию состоится в следующем. Немного технической информации доступно только об одном суперкомпьютере производительностью до 73 Пфлопс, который заменит принадлежащие компании машины Fênix, Atlas и Dragão. В марте 2023 года Petrobras внедрила свой первый ИИ-суперкомпьютер Tatu, построенный Atos на основе 224 ускорителей NVIDIA с 80 Гбайт памяти. А в 2022 году компания развернула систему Pegasus. 
Источник изображения: Davi Costa/unsplash.com Неназванная 73-Пфлопс система будет наиболее масштабной из пяти новых суперкомпьютеров и, как сообщают в Petrobras, станет самой «экоэффективной» в Латинской Америке. Компания намерена использовать суперкомпьютер для обработки сейсмоданных и создания симуляций процессов под земной поверхностью. Это поможет выявлять новые запасы нефти и газа. Как сообщают в компании, покупка новых суперкомпьютеров является для Petrobras делом стратегической важности, она позволит компании оставаться технологическим лидером нефтегазового сектора. Обновление парка суперкомпьютеров входит в стратегический план компании на 2024–2028 гг., который, помимо финансирования модернизации Cenpes, включает обязательства, связанные с декарбонизацией и энергетическим переходом.
03.09.2024 [11:04], Сергей Карасёв
Стартап xAI Илона Маска запустил ИИ-кластер со 100 тыс. ускорителей NVIDIA H100Илон Маск (Elon Musk) объявил о том, что курируемый им стартап xAI запустил кластер Colossus, предназначенный для обучения ИИ. На сегодняшний день в состав этого вычислительного комплекса входят 100 тыс. ускорителей NVIDIA H100, а в дальнейшем его мощности будут расширяться. Напомним, xAI реализует проект по созданию «гигафабрики» для задач ИИ. Предполагается, что этот суперкомпьютер в конечном итоге будет насчитывать до 300 тыс. новейших ускорителей NVIDIA B200. Оборудование для платформы поставляют компании Dell и Supermicro, а огромный дата-центр xAI расположен в окрестностях Мемфиса (штат Теннесси). «В эти выходные команда xAI запустила кластер Colossus для обучения ИИ со 100 тыс. карт H100. От начала до конца всё было сделано за 122 дня. Colossus — самая мощная система обучения ИИ в мире», — написал Маск в социальной сети Х. 
Источник изображения: WebProNews По его словам, в ближайшие месяцы вычислительная мощность платформы удвоится. В частности, будут добавлены 50 тыс. изделий NVIDIA H200. Маск подчёркивает, что Colossus — это не просто еще один кластер ИИ, это прыжок в будущее. Основное внимание в рамках проекта будет уделяться использованию мощностей Colossus для расширения границ ИИ: планируется разработка новых моделей и улучшение уже существующих. Ожидается, что по мере масштабирования и развития система станет важным ресурсом для широкого сообщества ИИ, предлагая беспрецедентные возможности для исследований и инноваций. Запуск столь производительного кластера всего за 122 дня — это значимое достижение для всей ИИ-отрасли. «Удивительно, как быстро это было сделано, и для Dell Technologies большая честь быть частью этой важной системы обучения ИИ», — сказал Майкл Делл (Michael Dell), генеральный директор Dell Technologies. |
|