Материалы по тегу: mlperf
|
11.11.2023 [15:23], Сергей Карасёв
MLPerf: Intel улучшила производительность Gaudi2, но лидером остаётся NVIDIA H100Консорциум MLCommons обнародовал результаты тестирования различных аппаратных решений в бенчмарке MLPerf Training 3.1, который оценивает производительность на ИИ-операциях. Отмечается, что корпорация Intel смогла существенно увеличить быстродействие своего ускорителя Habana Gaudi2, но безоговорочным лидером остаётся NVIDIA H100. Тесты проводились на платформе Xeon Sapphire Rapids. Отмечается, что для некоторых задач Intel реализовала поддержку FP8-вычислений, благодаря чему производительность поднялась в два раза по сравнению с показателями, которые этот же ускоритель демонстрировал ранее. Согласно результатам тестов, в бенчмарке GPT-3 ускоритель Gaudi2 ровно в два раза проигрывает решению NVIDIA H100. То же самое касается теста Stable Diffusion: при этом нужно отметить, что Gaudi2 использовал формат BF16, а H100 — FP16. В ResNet эти ускорители демонстрируют сопоставимую производительность. В тесте BERT чип H100 при использовании FP8-вычислений показал значительное преимущество перед Gaudi2, который использовал формат BF16. 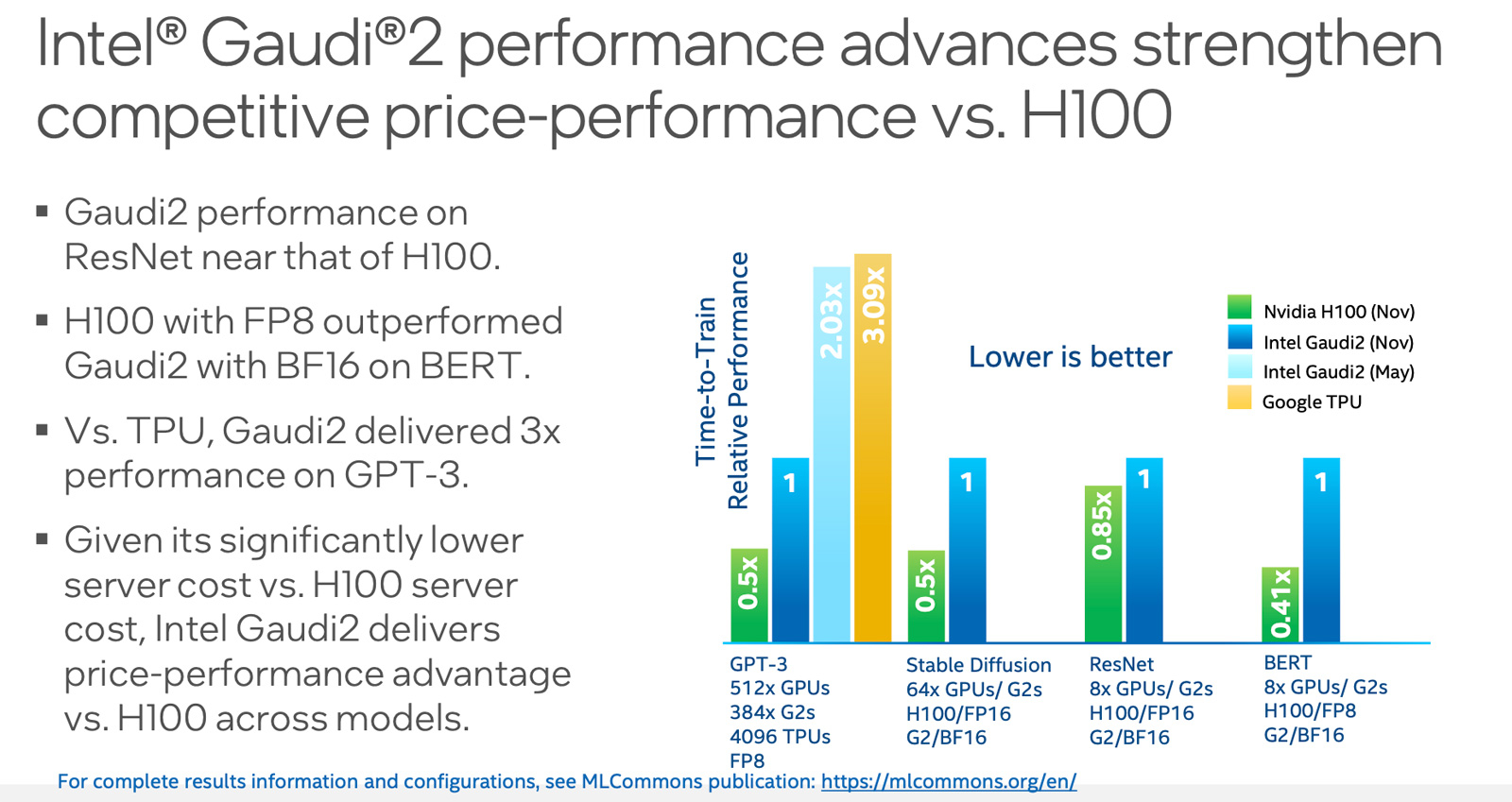
Источник изображения: MLCommons Сама Intel отмечает, что с внедрением поддержки FP8 система с 384 ускорителями Gaudi2 способна завершить обучение GPT-3 за 153,58 мин. При использовании 64 чипов Gaudi2 тест Stable Diffusion может быть завершён за 20,2 мин (BF16). Для тестов BERT и ResNet-50 на восьми ускорителях Gaudi2 (BF16) результат составляет 13,27 и 15,92 мин соответственно. Вместе с тем стоимость и доступность ускорителей Intel, как считается, существенно лучше, чем у решений NVIDIA.
08.11.2023 [20:00], Игорь Осколков
Счёт на секунды: ИИ-суперкомпьютер NVIDIA EOS с 11 тыс. ускорителей H100 поставил рекорды в бенчмарках MLPerf TrainingВместе с публикацией результатов MLPerf Traning 3.1 компания NVIDIA официально представила новый ИИ-суперкомпьютер EOS, анонсированный ещё весной прошлого года. Правда, с того момента машина подросла — теперь включает сразу 10 752 ускорителя H100, а её FP8-производительность составляет 42,6 Эфлопс. Более того, практически такая же система есть и в распоряжении Microsoft Azure, и её «кусочек» может арендовать каждый, у кого найдётся достаточная сумма денег. 
Изображения: NVIDIA Суммарно EOS обладает порядка 860 Тбайт памяти HBM3 с агрегированной пропускной способностью 36 Пбайт/с. У интерконнекта этот показатель составляет 1,1 Пбайт/с. В данном случае 32 узла DGX H100 объединены посредством NVLink в блок SuperPOD, а за весь остальной обмен данными отвечает 400G-сеть на базе коммутаторов Quantum-2 (InfiniBand NDR). В случае Microsoft Azure конфигурация машины практически идентичная с той лишь разницей, что для неё организован облачный доступ к кластерам. Но и сам EOS базируется на платформе DGX Cloud, хотя и развёрнутой локально.   В рамках MLPerf Training установила шесть абсолютных рекордов в бенчмарках GPT-3 175B, Stable Diffusion (появился только в этом раунде), DLRM-dcnv2, BERT-Large, RetinaNet и 3D U-Net. NVIDIA на этот раз снова не удержалась и добавила щепотку маркетинга на свои графики — когда у тебя время исполнения теста исчисляется десятками секунд, сравнивать свои результаты с кратно меньшими по количеству ускорителей кластерами несколько неспортивно. Любопытно, что и на этот раз сравнивать H100 приходится с Habana Gaudi 2, поскольку Intel не стесняется показывать результаты тестов. 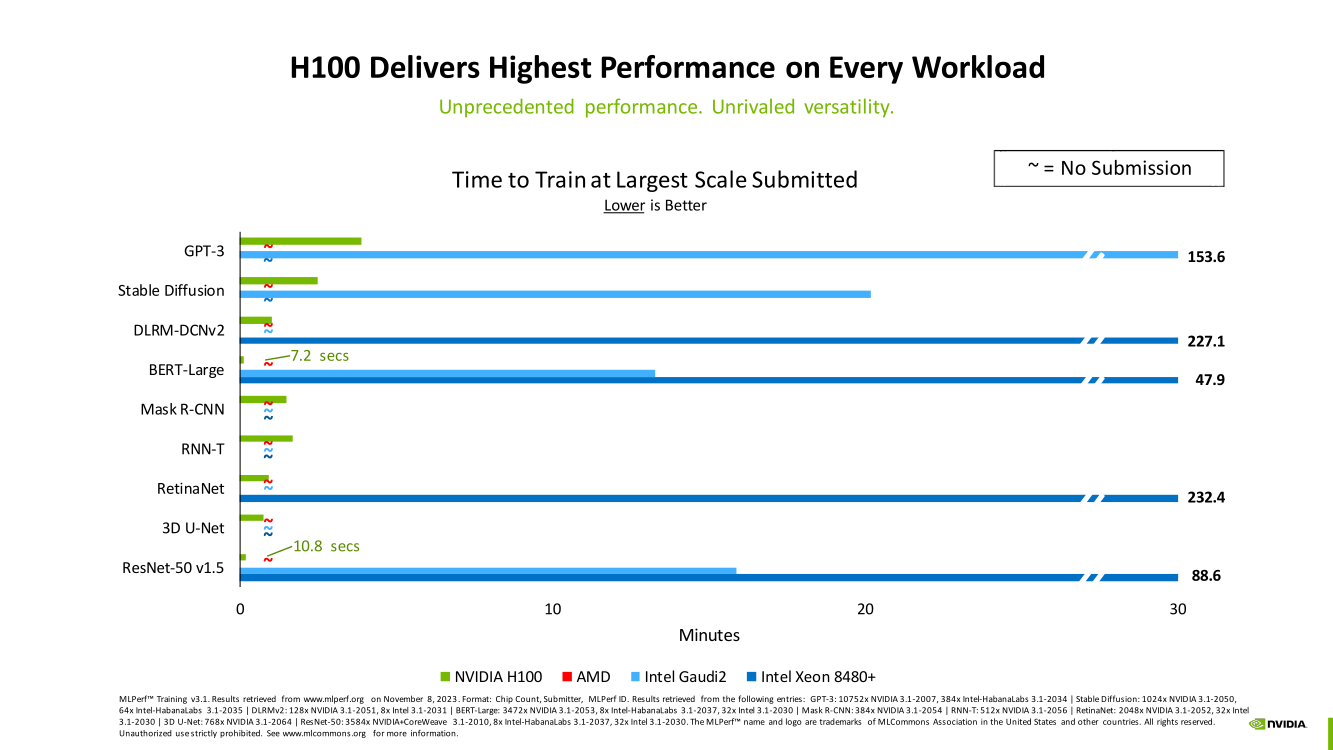 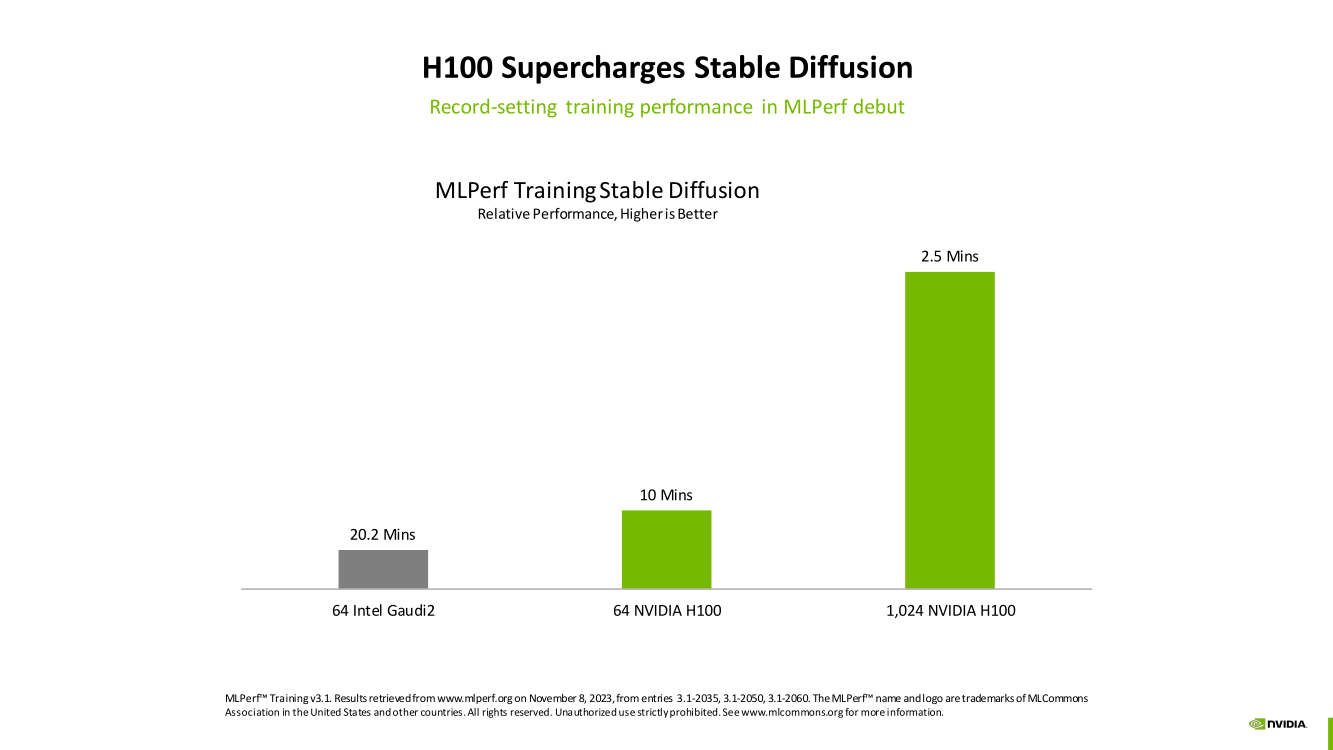 NVIDIA очередной раз подчеркнула, что рекорды достигнуты благодаря оптимизациям аппаратной части (Transformer Engine) и программной, в том числе совместно с MLPerf, а также благодаря интерконнекту. Последний позволяет добиться эффективного масштабирования, близкого к линейному, что в столь крупных кластерах выходит на первый план. Это же справедливо и для бенчмарков из набора MLPerf HPC, где система EOS тоже поставила рекорд. 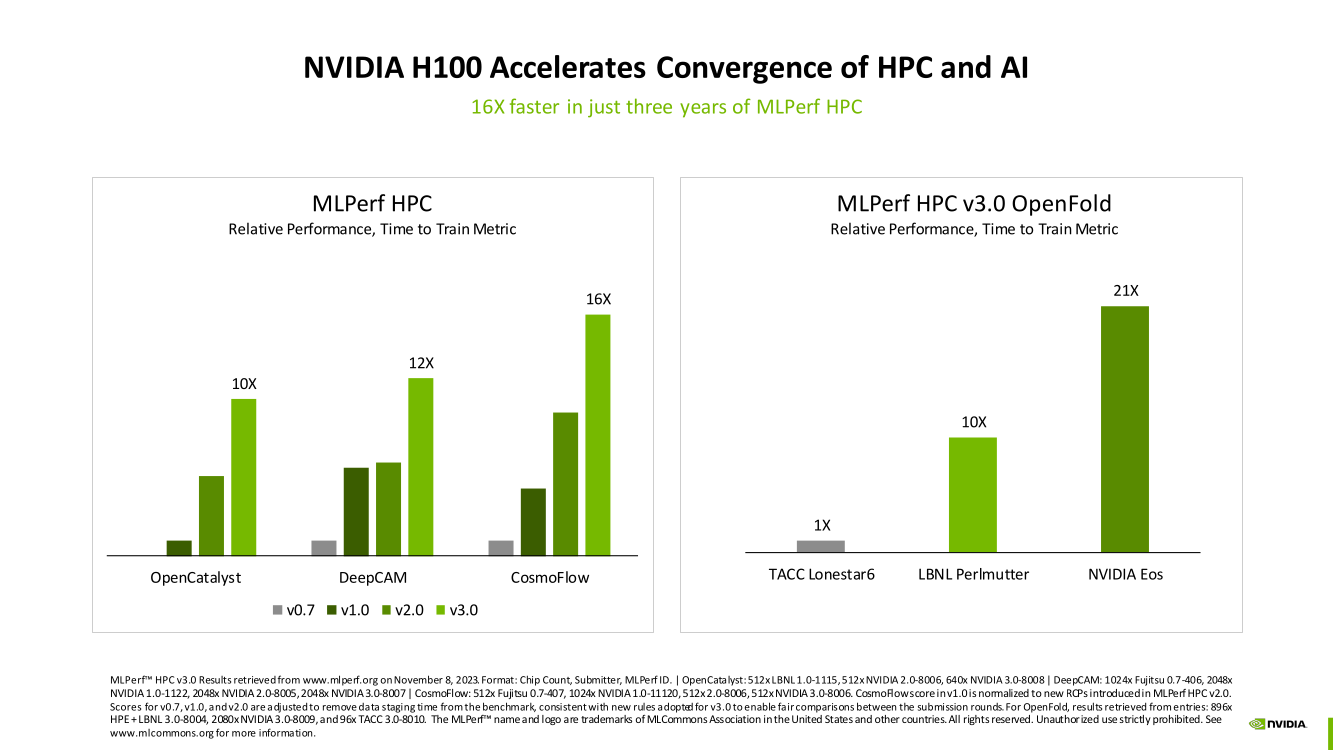 |
|