Материалы по тегу: hpc
|
10.05.2024 [23:47], Сергей Карасёв
Eviden представила семейство ИИ-серверов BullSequana AIКомпания Eviden (дочерняя структура Atos) анонсировала серверы серии BullSequana AI, предназначенные для решения ИИ-задач. В зависимости от модификации и уровня производительности устройства подходят для различных сценариев использования — от НРС-платформ до периферийных вычислений. Наиболее производительными серверами семейства являются решения BullSequana AI 1200H. Они могут применяться в составе облачных и гибридных инфраструктур, а также в дата-центрах заказчиков. По сути, это суперкомпьютер корпоративного уровня, специально разработанный для ресурсоёмких задач, таких как точная настройка ИИ-систем или обучение больших языковых моделей (LLM). Конфигурация BullSequana AI 1200H включает суперчипы NVIDIA Grace Hopper, а также интерконнект NVIDIA Quantum-2 InfiniBand. Задействовано программное обеспечение Eviden Jarvice XE, Eviden Smart Energy Management Suite, Eviden Smart Management Center и NVIDIA AI Enterprise. 
Источник изображения: Eviden Серверы BullSequana AI 1200H, насчитывающие в общей сложности 1456 ускорителей NVIDIA H100, выбраны для модернизации французского суперкомпьютера Jean Zay. Производительность этого НРС-комплекса увеличится более чем в три раза — с 36,85 до 125,9 Пфлопс. Кроме того, в новое семейство серверов вошли производительные устройства BullSequana AI 800, системы BullSequana AI 600 с воздушным и гибридным охлаждением, модели BullSequana AI 200 для частных и гибридных облачных сред, а также BullSequana AI 100 для периферийных вычислений. 
Источник изображения: Eviden В целом, как отмечается, каждая модель BullSequana AI предлагает различные уровни производительности, масштабируемости и гибкости. Таким образом, заказчики могут подобрать наиболее подходящий для себя вариант в зависимости от конкретного варианта использования, бюджета и размера бизнеса.
10.05.2024 [13:53], Владимир Мироненко
Lenovo установит в Италии 1,2-Пфлопс суперкомпьютер Cassandra на базе Intel Xeon Max для климатических исследованийКомпания Lenovo сообщила о возобновлении сотрудничества с Европейско-Средиземноморским центром по изменению климата (CMCC), базирующимся в Лечче (Италия), и подписании контракта на установку в этом году новой мощной системы высокопроизводительных вычислений (HPC) Cassandra, предназначенной для исследования изменения климата с помощью повышенных вычислительных возможностей и оптимизации использования энергии. Cassandra включает 180 узлов SD650 V3 с двумя процессорами Intel Xeon Max 9480 (Sapphire Rapids с HBM) на узел и имеет пиковую FP64-производительность 1,2 Пфлопс. Благодаря использованию технологии жидкостного охлаждения Lenovo Neptune Direct Water-Cooling, способной отводить до 98 % тепла, Cassandra потребляет на 15 % ниже электроэнергии, чем аналогичные решения с воздушным охлаждением. Благодаря повышенной эффективности СЖО температура процессоров не достигает критических значений, что позволяет избежать снижения максимальной частоты ядер процессоров, говорит Lenovo. Установкой Cassandra в суперкомпьютерном центре CMCC (SCC) будет заниматься Ricca IT, сертифицированный партнёр Lenovo. В суперкомпьютерном центре CMCC уже имеется HPC-система от Lenovo под названием Juno, установленная в 2022 году, с FP64-производительностью около 1,13 Пфлопс и построенная на базе процессоров Intel и ускорителей NVIDIA. 
Источник изображения: cmcc.it Cassandra будет использоваться для климатического моделирования системы Земли, океана, работы как глобальных, так и региональных систем сезонного прогнозирования, а также запуска приложения по исследованию изменения климата на основе ИИ. CMCC также планирует интегрировать во II полугодии в суперкомпьютер два ИИ-узла с восемью ускорителями NVIDIA H100 в каждом.
10.05.2024 [11:32], Сергей Карасёв
Суперкомпьютер в стойке GigaIO SuperNODE обзавёлся поддержкой AMD Instinct MI300XКомпания GigaIO анонсировала новую модификацию системы SuperNODE для рабочих нагрузок генеративного ИИ и приложений НРС. Суперкомпьютер в стойке теперь может комплектоваться ускорителями AMD Instinct MI300X, благодаря чему значительно повышается производительность при работе с большими языковыми моделями (LLM). Решение SuperNODE, напомним, использует фирменную архитектуру FabreX на базе PCI Express, которая позволяет объединять различные компоненты, включая GPU, FPGA и пулы памяти. По сравнению с обычными серверными кластерами SuperNODE даёт возможность более эффективно использовать ресурсы. Изначально для SuperNODE предлагались конфигурации с 32 ускорителями AMD Instinct MI210 или 24 ускорителями NVIDIA A100. Новая версия допускает использование 32 изделий Instinct MI300X. Утверждается, что архитектура FabreX в сочетании с технологией интерконнекта AMD Infinity Fabric наделяет систему SuperNODE «лучшими в отрасли» возможностями в плане задержек при передаче данных, пропускной способности и управления перегрузками. Это позволяет эффективно справляться с обучением LLM с большим количеством параметров. 
Источник изображения: GigaIO Отмечается, что SuperNODE значительно упрощает процесс развёртывания и управления инфраструктурой ИИ. Традиционные конфигурации обычно включают в себя сложную сеть и необходимость синхронизации нескольких серверов, что создаёт определённые технических сложности и приводит к дополнительным временным затратам. Конструкция SuperNODE с 32 мощными ускорителями в рамках одной системы позволяет решить указанные проблемы.
08.05.2024 [13:24], Сергей Карасёв
ИИ-суперкомпьютер в чемодане — GigaIO представила платформу GryfКомпания GigaIO совместно с SourceCode анонсировала вычислительную систему Gryf. Это, как утверждается, первый в мире суперкомпьютер для ИИ-нагрузок, выполненный в виде чемодана на колёсиках. Изделие имеет габариты 228,6 × 355,6 × 622,3 мм и весит около 25 кг. Применяется фирменная система интерконнекта FabreX на базе PCI Express. Конфигурация Gryf предусматривает использование модулей (Sled) четырёх типов: это вычислительный узел (Compute Sled), блок ускорителя (Accelerator Sled), узел хранения (Storage Sled) и сетевой блок (Network Sled). Они могут компоноваться в различных сочетаниях, но общее количество модулей в рамках одного экземпляра Gryf не превышает шести. В состав Compute Sled входят процессор AMD EPYC 7313 Milan (16C/32T; 3,0–3,7 ГГц; 155 Вт), 256 Гбайт DDR4-3200, системный накопитель NVMe M.2 SSD вместимостью 256 Гбайт и два 100GbE-порта QSFP56/QSFP28. Может применяться ОС Linux Rocky 8/9 или Ubuntu 20/24. В свою очередь, Accelerator Sled содержит ускоритель NVIDIA L40S (48 Гбайт). Модуль Storage Sled объединяет восемь накопителей NVMe E1.L SSD суммарной вместимостью 246 Гбайт. 
Источник изображения: GigaIO Наконец, Network Sled предоставляет два разъёма QSFP56 100GbE и шесть 25GbE-портов SFP28. Вся система получает питание от двух блоков мощностью 2500 Вт каждый. Применены шесть вентиляторов охлаждения диаметром 60 мм. Диапазон рабочих температур — от 10 до +32 °C. Одно устройство Gryf обеспечивает производительность до 91,6 Тфлопс FP32, до 733 Тфлопс FP16 и до 1466 Тфлопс FP8. При этом в единый комплекс могут быть связаны до пяти экземпляров Gryf, что позволяет масштабировать быстродействие для выполнения тех или иных задач.
07.05.2024 [14:05], Сергей Карасёв
Самый производительный японский суперкомпьютер Fugaku будет работать в тандеме с квантовой системой IBMКорпорация IBM сообщила о том, что её квантовая платформа Quantum System Two будет интегрирована с суперкомпьютером Fugaku в рамках совместного проекта с японским Институтом физико-химических исследований (RIKEN). Кроме того, IBM будет работать над новым ПО для выполнения квантово-классических задач. Напомним, вычислительный комплекс Fugaku на базе Arm-процессоров Fujitsu A64FX в 2020 году стал самым высокопроизводительным суперкомпьютером в мире. В текущем рейтинге ТОР500 эта НРС-система занимает четвёртое место с быстродействием приблизительно 442 Пфлопс. В свою очередь, квантовый компьютер IBM Quantum System Two был представлен в конце 2023 года. В нём применяется 133-кубитный квантовый процессор Heron. Отмечается, что Quantum System Two будет единственной квантовой системой, размещённой рядом с Fugaku в Центре вычислительных наук RIKEN в Кобе (Япония). Такая связка поможет в разработке приложений нового поколения для квантово-ориентированных суперкомпьютеров. 
Источник изображения: IBM Совместная инициатива IBM и RIKEN стала частью проекта, поддерживаемого японской Организацией по развитию новых энергетических и промышленных технологий (NEDO). Целью программы является демонстрация преимуществ гибридных вычислительных платформ при выполнении сложных и ресурсоёмких задач в эпоху «после 5G». «С точки зрения HPC, квантовые компьютеры — это системы, которые позволяют ускорить научные приложения, обычно выполняемые на суперкомпьютерах. Кроме того, квантовые платформы дают возможность решать задачи, которые не по силам традиционным вычислительным комплексам», — отмечает доктор Мицухиса Сато (Mitsuhisa Sato), руководитель подразделения RIKEN Quantum HPC Collaborative Platform. При этом Fujitsu совместно с RIKEN уже развернули в Осакском университете (Osaka University) собственный 64-кубитный квантовый компьютер с облачным доступом.
06.05.2024 [10:08], Сергей Карасёв
В AlmaLinux сформировано подразделение по НРС и ИИУчастники проекта AlmaLinux объявили о формировании специальной группы по интересам (SIG), которая займётся развитием направления НРС и ИИ. Подразделение под названием AlmaLinux HPC and AI SIG возглавляет Хайден Барнс (Hayden Barnes) — менеджер сообщества open source по задачам ИИ в корпорации HPE. AlmaLinux фактически заполняет пробел, оставшийся после прекращения выпуска стабильных версий CentOS Linux. Поддержка этой ОС прекратилась в конце 2021 года, а не в 2029-м, как ожидалось. Место CentOS заняла CentOS Stream, вечная бета-версия RHEL. 
Источник изображения: AlmaLinux Группа HPC and AI SIG в составе AlmaLinux, как отмечается, состоит из экспертов по HPC и ИИ, которые выбрали эту ОС в качестве программной основы для своих проектов. В их число входят специалисты компаний — поставщиков оборудования для НРС-систем, участники ИИ-проектов open source, а также администраторы, развёртывающие AlmaLinux в исследовательских организациях. Подразделение сформировано с тем, «чтобы гарантировать, что у пользователей есть ресурсы и поддержка сообщества, необходимые для максимизации преимуществ AlmaLinux» в рамках инициатив, связанных с НРС и ИИ. Участники SIG намерены взаимодействовать, внедрять инновации и обмениваться знаниями внутри сообщества AlmaLinux. За пределами экосистемы AlmaLinux специалисты новой группы намерены развивать партнёрские отношения и сотрудничать с иными заинтересованными сторонами. AlmaLinux рассчитывает «оставаться в авангарде технологических достижений» в сферах НРС и ИИ.
05.05.2024 [14:09], Сергей Карасёв
HPE представила СХД среднего уровня Cray Storage Systems C500 для задач НРС и ИИКомпания HPE анонсировала СХД Cray Storage Systems C500. Утверждается, что данное решение привносит передовые технологии хранения в вычислительные кластеры начального и среднего уровня для задач НРС и ИИ. Новая система может масштабироваться до полезной ёмкости в несколько петабайт. Устройство Cray Storage Systems C500 построено на основе того же ПО, что и высокопроизводительные системы Cray ClusterStor E1000, которые применяются в передовых суперкомпьютерах. В то же время есть некоторые отличия, которые позволяют снизить затраты на приобретение и эксплуатацию оборудования. Так, если в E1000 для блока управления системой (SMU) используется контроллер типоразмера 2U24, то в C500 применяется более экономичный сервер HPE ProLiant DL325 Gen11 формата 1U. В составе E1000 задействованы контроллер хранения 2U24 с 24 накопителями NVMe SSD для работы с метаданными (MDU) и контроллер 2U24 с 24 изделиями NVMe SSD в качестве масштабируемого флеш-хранилища (SSU-F). В свою очередь, C500 объединяет оба контроллера в один конвергентный узел MDU/SSU-F стандарта 2U24. 
Источник изображения: HPE Базовая конфигурация Cray Storage Systems C500 обеспечивает полезную ёмкостью от 22 Тбайт до 513 Тбайт на основе 24 устройств NVMe SSD. При этом производительность при чтении, как утверждается, достигает 80 Гбайт/с, при записи — 60 Гбайт/с. Дополнительно могут быть добавлены модули 2U24 NVMe или 5U84 HDD, что позволит нарастить полезную ёмкость до 2,6 Пбайт в варианте All-Flash или до 4 Пбайт в гибридной конфигурации SSD/HDD. Кроме того, как отмечается, HPE внедряет улучшения ПО и новые функциональные возможности, которые упрощают развёртывание и управление хранилищем.
05.05.2024 [13:56], Сергей Карасёв
Власти США продали на аукционе 5,34-ПФлопс суперкомпьютер Cheyenne из-за растущего числа сбоев и протечек СЖОАдминистрация общих служб США (GSA) реализовала на аукционе НРС-систему под названием Cheyenne, которая была введена в строй в Центре суперкомпьютерных вычислений NCAR-Wyoming (NWSC) штата Вайоминг в 2016 году. Стоимость лота составила $480 085, тогда как затраты на строительство машины оцениваются как минимум в $25 млн. Cheyenne стал одним из последних суперкомпьютеров компании Silicon Graphics International (SGI). Корпорация HPE приобрела эту фирму после того, как Cheyenne был смонтирован, но до фактического запуска системы в эксплуатацию. На момент начала работы производительность комплекса составляла 5,34 Пфлопс, что соответствовало 20 месту в актуальном тогда списке ТОР500. Cheyenne представляет собой кластер SGI ICE XA с 4032 узлами, каждый из которых содержит два процессора Intel Xeon E5-2697v4 Broadwell (18C/36; 2,3 ГГц). Таким образом, суммарное количество ядер достигает 145 152. Применяется оперативная память DDR4-2400 ECC общей ёмкостью 313 Тбайт (4890 модулей на 64 Гбайт). В состав машины изначально входило хранилище данных вместимостью 40 Пбайт. Энергопотребление — приблизительно 1,7 МВт. Задействована система жидкостного охлаждения. 
Источник изображения: GSA Две стойки управления с воздушным охлаждением состоят из 26 серверов типоразмера 1U (20 со 128 Гбайт ОЗУ и ещё 6 с 256 Гбайт ОЗУ), 10 коммутаторов и двух блоков питания. Суперкомпьютер эксплуатировался с 12 января 2017 года по 31 декабря 2023-го, решая задачи в области изменений климата и в других сферах, связанных с науками о Земле. Cheyenne превзошёл свой запланированный срок службы: в заявлении NWSC говорилось, что он будет эксплуатироваться до 2021 года. Однако к концу 2023-го количество сбоев и проблем стало слишком большим. В описании лота говорится, что «примерно 1 % узлов столкнулись с отказами за последние шесть месяцев», в основном из-за модулей памяти. Кроме того, система испытывает ограничения по техническому обслуживанию из-за неисправных быстроразъёмных соединений, вызывающих протечки воды. Таким образом, «учитывая затраты и время простоя, связанные с устранением проблем», дальнейшее использование комплекса признано нецелесообразным, в связи с чем он пущен с молотка. Вместе с тем, как отмечает Tom's Hardware, новый владелец суперкомпьютера может реализовать его основные компоненты на вторичном рынке. Например, стоимость чипов Xeon E5-2697 v4 на eBay составляет около $50, а модулей DDR4-2400 ECC ёмкостью 64 Гбайт — примерно $65. То есть, по самым скромным подсчётам, только эти компоненты могут принести новому владельцу суперкомпьютера приблизительно $700 тыс. без учёта затрат на демонтаж и вывоз машины массой 43 т, а также на тестирование компонентов. Впрочем, массовый выброс на рынок CPU и RAM в таких объёмах приведёт к снижению цен.
30.04.2024 [21:59], Руслан Авдеев
Водородные элементы запитают суперкомпьютерный центр Texas Advanced Computing CenterДемонстрационная платформа на водородных топливных элементах, запущенаная в Остине (Техас), запитает ЦОД суперкомпьютерного центра Texas Advanced Computing Center (TACC). Проект стал частью инициативы H2@Scale и будет моделью для будущих масштабных водородных проектов, объединяющих производство, распределение, хранение и использование данного вида топлива, передаёт Datacenter Dynamics. Объект, расположенный в одном из кампусов Техасского университета, представляет собой плод сотрудничества GTI Energy, её «дочки» Frontier Energy, университетского Центра электромеханики, а также пары десятков акционеров, представляющих промышленные предприятия. Площадка будет генерировать водород, путём электролиза, используя энергию солнца и ветра, а также переработку метана с хранилищ отходов. Полученный водород будет применяться в топливных ячейках и для заправки парка электромобилей Toyota Mirai и БПЛА, тоже применяющих водородные топливные элементы. Техасский университет не первое десятилетие работает над соответствующими технологиями и намерен поставлять для проекта квалифицированные кадры и инженерные данные. Помимо текущего проекта, исследовательская площадка пригодится и для развития других решений в «зелёной» водородной индустрии. А основанный в 2001 году центр TACC стал пристанищем для нескольких суперкомпьютеров, включая Frontera, JetStream2, Lonestar6, Maverick2 и Stampede3. Не так давно анонсировано строительство кластера Vista на ускорителях NVIDIA. 
Источник изображения: Техасский университет Инициативу H2@Scale в Техасском университете начали реализовать в 2020 году. В задачи входит продвижение пилотных проектов, связанных с «возобновляемым» водородом в качестве экологически чистого и экономически эффективного источника топлива. В числе промышленных партнёров университета есть Air Liquide, CenterPoint Energy, Chart Industries, Chevron, ConocoPhillips, Hitachi Energy, Low-Carbon Resources Initiative, McDermott, Mitsubishi Heavy Industries America, OneH2, ONE Gas, ONEOK, Shell, SoCalGas, Texas Commission on Environmental Quality, Toyota и WM. Государственно-частные проекты в рамках инициативы H2@Scale поддерживает Министерство энергетики США. Техасский университет отмечает, что штат имеет оптимальные условия для реализации водородных проектов, уже имея значительную водородную инфраструктуру, включая около 1500 км подходящих трубопроводов. Но эксперименты H2@Scale ведутся и в других местах. Так, в январе Caterpillar Electric Power и Microsoft объявили об успешном эксперименте, в ходе которого для питания дата-центра применялись исключительно водородные топливные ячейки в течение 48 часов.
30.04.2024 [12:21], Владимир Мироненко
Правительство Франции решило выкупить часть активов Atos, чтобы сохранить контроль над критически важными технологиямиФранцузский IT-холдинг Atos сообщил о получении 27 апреля от правительства Франции письма о намерении (non-binding letter of intent, LOI) приобрести у неё 100 % активов в области передовых вычислений, критически важных систем и продуктов кибербезопасности подразделения по работе с большими данными и кибербезопасности BDS (Big Data & Security) по ориентировочной цене от €700 млн до €1 млрд. Оборот этой части бизнеса BDS составил в 2023 году около €1 млрд при общем обороте всего подразделения в размере €1,5 млрд. Ранее испытывающая финансовые трудности Atos вела переговоры о продаже всего подразделения BDS с Airbus, но в итоге они ни к чему не привели, равно как и попытка продать подразделение ЦОД и хостинга Tech Foundations компании EP Equity Investment (EPEI) за ориентировочно €2 млрд. В результате Atos поддержала предложение правительства, которое намерено защитить суверенные стратегические активы Франции. Проведение юридической экспертизы потенциальной сделки государством начнётся в ближайшее время. Необязывающее предложение правительства о покупке должно быть оформлено к началу июня 2024 года. 
Источник изображений: Atos Письмо о намерениях предусматривает ограниченное эксклюзивное обязательство, распространяющееся на прямые предложения в рамках, указанных в письме о намерениях (прямо разрешающее обмен информацией и глобальные предложения в контексте плана финансовой реструктуризации) до 31 июля 2024 года и заключение глобального соглашения о реструктуризации. Компания также представила пересмотренную программу реструктуризации на основе скорректированного бизнес-плана на 2024–2027 гг., где снижены ожидаемые показатели работы. В частности, в 2024 году компания планирует получить €9,8 млрд выручки, что на 3,3 % меньше по сравнению с 2023 годом, тогда как 9 апреля объявила о прогнозе выручки в размере €9,9 млрд (падение на 2,0 %). Операционная прибыль Atos должна за год составить €0,3 млрд или 2,9 % от выручки по сравнению с €0,4 млрд или 4,3 % от выручки, о которых сообщалось ранее. 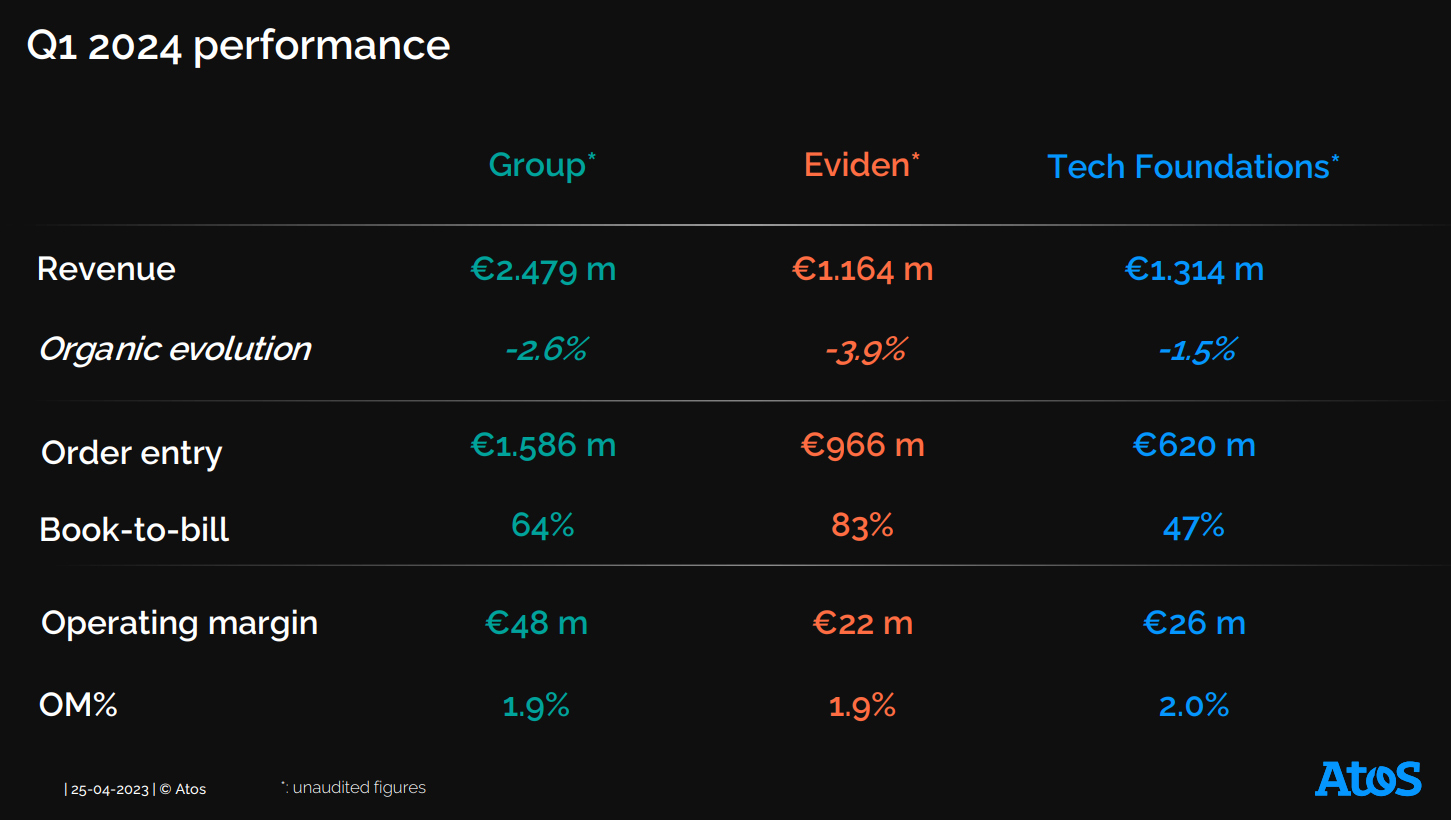 Согласно скорректированному плану, в 2027 году выручка Atos должна составить €11,0 млрд по сравнению с €11,4 млрд, о которых сообщалось ранее. Ожидаемый среднегодовой темп роста выручки за период 2023–2027 гг. составит 2,3 %, хотя ранее ожидался прирост на уровне 3,1 %. Операционная прибыль компании в 2027 году должна составить €1,1 млрд или 9,9 % от выручки по сравнению с прежним прогнозом в размере €1,2 млрд или 10,3 % от выручки. Скорректированный бизнес-план учитывает текущие тенденции бизнеса и более слабые рыночные условия в некоторых ключевых областях деятельности, а также отражает задержки в заключении новых контрактов и дополнительных работах, поскольку клиенты ожидают окончательного решения по финансовой реструктуризации компании. Также были учтены отсрочка с возвратом к органическому росту выручки до июля 2025 года, снижение рентабельности, более высокие накладные расходы, увеличение затрат на реструктуризацию в 2025 году и т.д. Согласно пересмотренной концепции финансовой реструктуризации, для финансирования бизнеса в период 2024–2025 гг. необходимо €1,1 млрд денежных средств по сравнению с €600 млн согласно предыдущему плану. Средства должны быть предоставлены в виде займа и/или собственного капитала существующими заинтересованными сторонами или сторонними инвесторами. Как и прежде, компания считает, что ей потребуется €300 млн в виде новой возобновляемой кредитной линии и €300 млн в виде дополнительных банковских гарантийных линий. Сроки погашения оставшегося долга должны быть продлены на 5 лет. 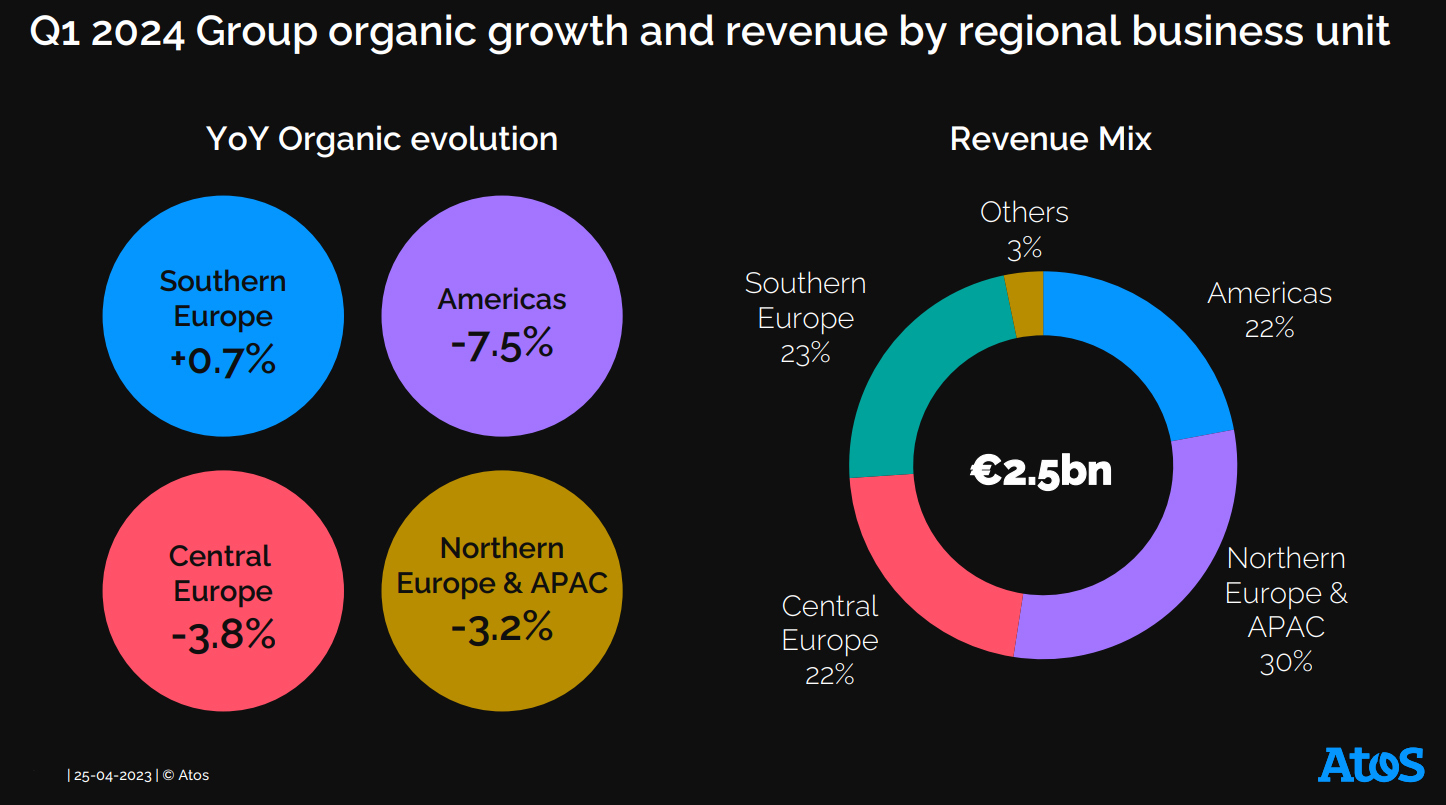 Компания отметила, что письмо о намерениях, полученное от французского государства, не влияет на ключевые параметры реструктуризации. Если соглашение будет достигнуто, предполагается, что доходов от такой сделки не будет до II полугодия 2025 года. Соглашение о финансовой реструктуризации должно будет включать продление уже согласованного в общих чертах промежуточного финансирования в размере €450 млн и дополнительное промежуточное финансирование в размере €350 млн с июля 2024 года до окончательной реализации соглашения о финансовой реструктуризации. Компания сообщила, что будет принимать предложения инвесторов по данным вопросам до 3 мая. Также с акционерами и финансовыми кредиторами будут проведены консультации в соответствии с требованиями французского законодательства. На конец 2023 года чистый долг компании составлял €2,23 млрд., а общая сумма выплат по кредитам достигла €4,8 млрд. Комментируя действия правительства, министр экономики, финансов, промышленного и цифрового суверенитета Франции Брюно Лё Мэр (Bruno Le Maire) сообщил в интервью французскому телеканалу LCI (La Chaîne Info), что Atos осуществляет ряд видов деятельности, которые являются стратегическими для французской нации, для суверенитета страны и для обороны в областях кибербезопасности, HPC и атомной энергетики. Эта суверенная деятельность должна оставаться под исключительным контролем Франции, отметил чиновник. «Мы берём на себя инициативу, потому что роль государства заключается в защите стратегических интересов Atos и предотвращении зависимости чувствительных, решающих технологий, таких как суперкомпьютеры или оборонные решения, от иностранных интересов в любое время», — подчеркнул Лё Мэр. |
|