Материалы по тегу: hardware
|
02.10.2024 [10:24], Сергей Карасёв
AMD представила процессоры EPYC Embedded 8004: до 64 ядер Zen 4c, 6 каналов DDR5-4800 и 96 линий PCIe 5.0Компания AMD анонсировала процессоры EPYC Embedded 8004 (Siena) для встраиваемых систем с интенсивными вычислительными нагрузками. Чипы подходит для сетевого оборудования, маршрутизаторов, устройств обеспечения безопасности, корпоративных и облачных теплых/холодных хранилищ и промышленных периферийных изделий. В основу процессоров положена оптимизированная архитектура Zen 4 — Zen 4c, которая отличается повышенной энергоэффективностью. В семейство EPYC Embedded 8004 вошли чипы с 12, 16, 24, 32, 48 и 64 ядрами, поддерживающими технологию многопоточности. Показатель TDP варьируется от 100 до 200 Вт. 
Источник изображений: AMD Базовая частота у новинок варьируется от 2,3 до 2,65 ГГц, а максимальная частота составляет 3,0 или 3,1 ГГц. Процессоры поддерживают шесть каналов памяти DDR5-4800, максимальный объём которой может составлять 1152 Гбайт в конфигурации 12 × 96 Гбайт. Доступны 96 линий PCIe 5.0. Среди особенностей отмечено наличие DMA-движка, NTB, возможность сброса DRAM на NVMe-накопитель для защиты данных в случае потери питания, поддержка двух SPI ROM (для BIOS и безопасного загрузчика), поддержка Yocto Linux, а также наличие механизма криптографической аттестации процессора, который препятствует неавторизованной замене CPU. 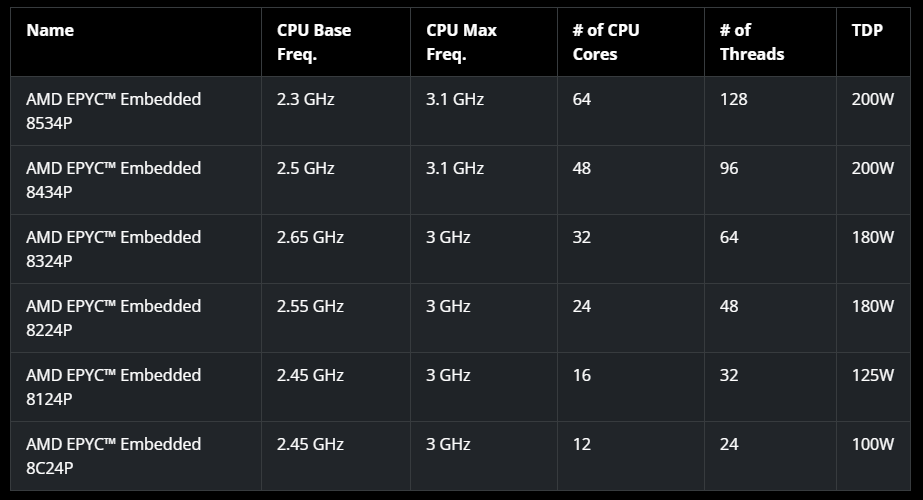 Новые чипы имеют настраиваемый показатель cTDP (configurable TDP). У младшей версии EPYC Embedded 8C24P с 12 ядрами стандартное значение в 100 Вт может быть снижено до 70 Вт, тогда как у старшей модификации EPYC Embedded 8534P с 64 ядрами стандартную величину в 200 Вт можно регулировать в диапазоне от 155 до 225 Вт. Процессоры EPYC Embedded 8004 выполнены в компактном форм-факторе SP6, который на 19 % меньше по сравнению с EPYC Embedded 9004. Жизненный цикл чипов составляет семь лет.
01.10.2024 [15:39], Руслан Авдеев
Конкурент NVIDIA — Cerebras Systems выходит на IPO на биржу NasdaqСтартап Cerebras Systems Inc., разрабатывающий ИИ-суперускорители размером с целую кремниевую пластину, подал заявку для выхода на публичные торги. По данным Silicon Angle, шаг вполне ожидаемый — компания подала проект документации в Комиссию по ценным бумагам и биржам США (SEC) ещё летом текущего года. На прошлой неделе сообщалось, что компания надеется привлечь в ходе IPO от $750 млн до $1 млрд, а оценочная стоимость компании составит до $8 млрд. На Nasdaq компания намерена выйти под тикером CBRS. Флагманским продуктом компании является суперчип WSE-3 с 4 трлн транзисторов, формирующих 900 тыс. ядер и 44 Гбайт SRAM. Компания утверждает, что WSE-3 может обучать ИИ-модели значительно быстрее, чем традиционные чипы. При этом энергоэффективность WSE-3 значительно лучше, поскольку один большой чип просто эффективнее во всех отношениях множества более компактных. Компания поставляет WSE-3 в составе модуля CS-3 размером с небольшой холодильник, также вмещающего и охлаждающее оборудование, модули питания и прочие компоненты. Клиенты могут использовать до 2048 CS-3 в одном ИИ-кластере. 
Источник изображения: Cerebras Cerebras пока не приносит прибыли, но рассчитывает на быстрый рост выручки. С 2022 по 2023 годы продажи компании выросли более чем втрое с $24,62 млн до $78,7 млн. Чистый убыток за те же периоды составил $177,72 млн и $127,16 млн соответственно. В 2024 году за первые шесть месяцев выручка составит $136,4 млн при убытке $66,6 млн. Однако отмечается очень большая концентрация продаж — 87 % продукции в I полугодии предназначалось компании G42 (ныне Core42) из ОАЭ. Более того, этот же заказчик до середины следующего года закупит ускорителей на почти $1,5 млрд. При этом у G42 есть 5 % акций Cerebras, столько же имеется только у основателя компании Эндрю Фельдмана (Andrew Feldman). Среди других известных инвесторов есть глава OpenAI Сэм Альтман (Sam Altman) также является акционером Cerebras, как и сооснователь Sun Microsystems Энди Бехтольшайм (Andy Bechtolsheim). Впрочем, Cerebras уже готовится сотрудничать с Aramco и другими компаниями. В документах, посвящённых выходу на IPO, Cerebras заявила, что намерена сохранить рост выручки, привлекая больше клиентов и расширяя технологическое портфолио, создавая новые продукты и форм-факторы. Ещё одним потенциальным источникам роста стал недавний запуск облачного сервиса для инференса. При этом Reuters сообщает, что ранее в этом году некоторые инвесторы ушли с рынка акций ИИ-компаний из-за опасений того, что тот слишком раздут. Попытка Cerebras выйти на IPO покажет, сохранился ли в должной мере интерес к отрасли. Компанию поддерживает ряд крупных инвесторов, включая Abu Dhabi Growth Fund и Coatue Management. Андеррайтерами предложения, помимо прочих, являются Citigroup, Barclays, UBS Investment, Wells Fargo Securities и Mizuho.
01.10.2024 [10:12], Сергей Карасёв
Huawei представила All-Flash массивы OceanStor Dorado V7Компания Huawei анонсировала системы хранения данных OceanStor Dorado следующего поколения (V7), относящиеся к классу All-Flash. В семейство вошли модели high-end-класса OceanStor Dorado 8000/18000, решения среднего уровня OceanStor Dorado 5000/6000, а также версия начального уровня OceanStor Dorado 3000. В основу СХД положена полностью взаимосвязанная архитектура SmartMatrix 4.0 типа «активный — активный», которая обеспечивает стабильную работу систем даже в случае отказа семи из восьми контроллеров. Реализована поддержка протоколов FC, iSCSI, NFS, CIFS, FC-NVMe, NVMe over RoCE, NDMP, S3, NFS over RDMA. 
Источник изображения: Huawei По заявлениям Huawei, решение Dorado 18000 обеспечивает в три раза большую производительность по сравнению с массивами предыдущего поколения, чему способствует разгрузка CPU на аппаратном уровне. В частности, применяются карты SmartNIC на базе DPU для разделения потоков данных и управления. Модернизированный интеллектуальный алгоритм взаимодействия FlashLink между контроллерами и DPU обеспечивает более 100 млн IOPS и «чрезвычайно низкую задержку в 0,03 мс» в системе, насчитывающей до 32 контроллеров. СХД обеспечивают гарантированную доступность данных на уровне 99,9999 %. Кроме того, реализована защита от программ-вымогателей с эффективностью до 99,99 %. Заявлена совместимость между разными СХД на уровне поколений. Это означает, что в одном кластере могут быть задействованы системы V7, ранее выпущенные V6 и будущие V8. Максимальная общая вместимость достигает 500 Пбайт. Интегрированная непрерывная защита данных на уровне ввода-вывода гарантирует, что информация может быть восстановлена в любой момент времени.
01.10.2024 [09:17], Сергей Карасёв
Isambard 2, один из первых Arm-суперкомпьютеров, отправился на покой30 сентября 2024 года, по сообщению Datacenter Dynamics, прекращена эксплуатация британского вычислительного комплекса Isambard 2. Это был один из первых в мире суперкомпьютеров, построенных на процессорах с архитектурой Arm. Система отправилась на покой после примерно шести лет работы. Isambard 2 назван в честь Изамбарда Кингдома Брюнеля — британского инженера, ставшего известной фигурой в истории Промышленной революции. Проект Isambard 2 реализован совместно компанией Cray, Метеорологической службой Великобритании и исследовательским консорциумом GW4 Alliance, в который входят университеты Бата, Бристоля, Кардиффа и Эксетера. Запуск суперкомпьютера состоялся в мае 2018 года. В основу Isambard 2 положены узлы Cray XC50. Задействованы 64-битные процессоры Marvell ThunderX2 с архитектурой Arm v8-A и ускорители NVIDIA P100. Общее количество вычислительных ядер — 20 992. Это одна из немногих систем на базе серии чипов ThunderX. 
Источник изображения: Marvell Technology/YouTube «После шести лет службы суперкомпьютер Isambard 2 наконец-то отправляется на пенсию. С мая 2018-го он был первым в мире серийным суперкомпьютером на базе Arm, использующим процессоры ThunderX2. Сегодня ему на смену приходит Isambard 3, содержащий Arm-чипы NVIDIA Grace», — сообщил профессор Саймон Макинтош-Смит (Simon McIntosh-Smith), руководитель проекта, глава группы микроэлектроники в Университете Бристоля. В основу Isambard 3 лягут 384 суперпроцессора NVIDIA Grace. Эта система, как ожидается, обеспечит в шесть раз более высокую производительность и в шесть раз лучшую энергоэффективность по сравнению с Isambard 2. Пиковое быстродействие FP64 у нового суперкомпьютера составит 2,7 Пфлопс при энергопотреблении менее 270 кВт. В дальнейшем вычислительные мощности Isambard 3 планируется наращивать. Комплекс будет применяться при решении сложных задач в области ИИ, медицины, астрофизики, биотехнологий и пр.
30.09.2024 [10:24], Сергей Карасёв
В облаке Vultr появились ускорители AMD Instinct MI300XVultr, крупнейший в мире частный облачный провайдер, объявил о том, что в составе его инфраструктуры теперь доступны ускорители AMD Instinct MI300X и открытый программный стек AMD ROCm. Клиенты могут использовать их для ресурсоёмких задач ИИ и НРС-нагрузок. Отмечается, что благодаря объединению платформы Vultr Serverless Inference с ускорителями Instinct MI300X даже небольшие предприятия получают возможность применять передовые технологии ИИ, которые ранее им были недоступны. Новое решение ориентировано на заказчиков из различных отраслей, включая здравоохранение, финансовые услуги, производство, энергетику, медиа, розничную торговлю и телекоммуникации. На сайте Vultr отмечается, что изделия Instinct MI300X обеспечивают ИИ-производительность в режиме TF32 до 653,7 Тфлопс, FP16 — 1307,4 Тфлопс, INT8 — 2614,9 TOPS, FP8 — 2614,9 Тфлопс. При НРС-нагрузках теоретическое пиковое быстродействие достигает 81,7 Тфлопс FP64 и 163,4 Тфлопс FP32. 
Источник изображения: Vultr Ускорители AMD интегрируются с Vultr Kubernetes Engine for Cloud GPU для формирования кластеров Kubernetes с ускорением на базе GPU. Компания Vultr говорит о высоком соотношении цены и производительности, гибких возможностях масштабирования и оптимизации для инференса. Нужно отметить, что ранее об использовании ускорителей Instinct MI300X в составе своей облачной инфраструктуры объявила корпорация Oracle. Новые инстансы BM.GPU.MI300X.8 могут использоваться в том числе для обработки больших языковых моделей (LLM), насчитывающих сотни миллиардов параметров.
30.09.2024 [09:14], Руслан Авдеев
Microsoft при поддержке ESB на время запитает свой дублинский ЦОД от водородных топливных ячеек GeoPuraMicrosoft приступила к тестовому использованию экобезопасного «зелёного» водорода, обеспечивающего нулевые выбросы при генерации электроэнергии. Испытания пройдут в дата-центре компании в Дублине (Ирландия) совместно с поставщиком водородных решений ESB. Топливные ячейки мощностью 250 кВт проработают в течение восьми недель. Точно такие же ячейки проходят испытание и в дублинском ЦОД Equinix. Они рассматриваются в качестве экобезопасной замены дизель-генераторам. Проекты с Microsoft и Equinix являются частью целой серии испытаний в 2024–2025 гг. ESB рассчитывает продемонстрировать универсальность водородных технологий для различных сфер использования. В Microsoft уверены, что первый эксперимент позволит продемонстрировать, как водородная энергетика сможет помочь декарбонизации IT-индустрии, в частности, ирландских ЦОД. Сейчас в стране фактически действует мораторий на строительство новых дата-центров в районе Дублина, поскольку ЦОД потребляют уже 21 % энергии в стране. 
Источник изображения: Microsoft В Microsoft давно экспериментируют с водородными топливными элементами для ЦОД. В начале 2024 года компания заявила, что совместный проект с Caterpillar в Вайоминге (США) позволил небольшому ЦОД успешно проработать 48 часов на одних только водородных элементах. Руководство ESB тоже уверено, что «зелёный» водород будет играть важную роль в экобезопасной энергосистеме будущего, а совместный проект с Microsoft продемонстрирует потенциал технологии для дата-центров. Впрочем, в 2023 году Microsoft добилась разрешения на строительство газовой электростанции мощностью 170 МВт в дублинском кампусе. Тогда она заявила, что та будет применяться только для резервного электроснабжения объекта.
29.09.2024 [18:32], Руслан Авдеев
Microsoft потратит $2,7 млрд на облачную и ИИ-инфраструктуру в БразилииКомпания Microsoft будет способствовать развитию облачной и ИИ-инфраструктуры Бразилии, расширяя свои собственные дата-центры в стране. По данным Datacenter Dynamics, компания объявила о намерении потратить $2,7 млрд на соответствующие проекты в течение трёх лет. В частности, в штате Сан-Паулу предполагается расширить облачную инфраструктуру в нескольких кампусах ЦОД. В Бразилии у компании есть облачный регион Brazil South в штате Сан-Паулу (введён в эксплуатацию в 2014 году), а в 2020 году IT-гигант запустил Brazil Southeast в Рио-де-Жанейро. Глава Microsoft Сатья Наделла (Satia Nadella) уже заявил о поддержке ИИ-трансформации страны и сообщил, что новые инвестиции компании в облака и ИИ обеспечат доступ к современным технологиям, а программы обучения будут способствовать получению новых навыков, которые станут драйвером процветания людей и экономики Бразилии в эру ИИ. По данным компании, речь идёт о крупнейшей в истории компании единовременной инвестиции в стране. В числе прочего предусмотрено обучение 5 млн человек навыкам работы с ИИ в последующие три года. Ещё в 2014 году Microsoft запустила облачный регион São Paulo Azure в бразильском муниципалитете Кампинас, а в 2021 году его расширили до трёх зон доступности. В 2023 году появилась информация, что компания дополнительно работает над объектами в городах Ортоландия (Hortolândia) и Сумаре (Sumaré) в штате Сан-Паулу. Также в 2020 году было объявлено о намерении открыть второй облачный регион в Рио-де-Жанейро, но позже проект переквалифицировали в «регион с зарезервированным доступом». 
Источник изображения: Pedro Menezes/unsplash.com В 2023 году Microsoft подписала с AES Brasil контракт на поставки возобновляемой энергии сроком на 15 лет, забор энергии предусмотрен с ветроэлектростанции Cajuína Wind Complex, находящейся в штате Риу-Гранди-ду-Норти (Rio Grande do Norte). Коммерческая эксплуатация началась в июле 2024 года. Инвестирует в бразильскую цифровую инфраструктуру не только Microsoft. Пару недель назад появилась информация о том, что $1,8 млрд на расширение ЦОД в стране готовится выделить и AWS, а Scala Data Centers построит в бразильском штате Риу-Гранди-ду-Сул (Rio Grande do Sul) мегакампус ЦОД на 4,75 ГВт.
29.09.2024 [14:31], Сергей Карасёв
NetApp представила All-Flash СХД ASA A-Series с эффективной ёмкостью до 67 ПбайтКомпания NetApp анонсировала новые высокопроизводительные СХД семейства ASA A-Series класса All-Flash, оптимизированные для блочного хранения. Дебютировали модели ASA A1K, ASA A90 и ASA A70, которые, как утверждается, обеспечивают доступность данных на уровне 99,9999 %. Все новинки имеют 12-узловую конфигурацию и используют два контроллера в режиме «активный — активный». Модель ASA A1K получила исполнение 2 × 2U (плюс дисковая полка NS224 на 24 накопителя), а варианты ASA A90 и ASA A70 — 4U с 48 внутренними отсеками для SSD. У всех СХД максимальная конфигурация может включать 1440 накопителей. Эффективная ёмкость достигает 67 Пбайт с учётом компрессии 5:1. Доступны 18 слотов расширения PCIe. Говорится о поддержке 24 портов 200GbE и 36 портов 100GbE/40GbE. Младшая версия также поддерживает 48 портов 25GbE/10GbE/1GbE, две другие — 56. Среднее энергопотребление составляет 2718 Вт (с полкой NS224) у ASA A1K, 1950 Вт у ASA A90 и 1232 Вт у ASA A70. 
Источник изображения: NetApp Заявлена совместимость с NVMe/TCP, NVMe/FC, FC, iSCSI, а также с платформами Windows Server, Linux, Oracle Solaris, AIX, HP-UX, VMware. Вместе с выпуском новых СХД компания NetApp усовершенствовала свой сервис Data Infrastructure Insights (ранее Cloud Insights) с целью улучшения возможностей мониторинга и анализа. Клиентам предоставляются дополнительные инструменты по управлению оптимизацией и надежностью инфраструктуры хранения данных, что позволяет повысить эффективность и производительность. Вместе с тем средства NetApp ONTAP Autonomous Ransomware Protection with AI (ARP/AI) обеспечивают обнаружение программ-вымогателей с точностью 99 %.
29.09.2024 [00:30], Алексей Степин
Рождение экосистемы: Intel объявила о доступности ИИ-ускорителей Gaudi3 и решений на их основеПро ускорители Gaudi3 компания Intel достаточно подробно рассказала ещё весной этого года — 5-нм новинка стала дальнейшим развитием идей, заложенных в предыдущих поколениях Gaudi. Объявить о доступности новых ИИ-ускорителей Intel решила одновременно с анонсом новых серверных процессоров Xeon 6900P (Granite Rapids), которые в видении компании являют собой «идеальную пару». Впрочем, в компании признают лидерство NVIDIA, так что обещают оптимизировать процессоры для работы с ускорителями последней. А вот ускорителей Falcon Shores, вполне вероятно, с новой политикой Intel потенциальные заказчики не дождутся. 
Источник изображений здесь и далее: Intel На данный момент главной новостью является то, что в распоряжении Intel не просто есть некий ИИ-ускоритель с более или менее конкурентоспособной архитектурой и производительностью, а законченное и доступное заказчикам решение, уже успевшее привлечь внимание крупных производителей и поставщиков серверного оборудования. 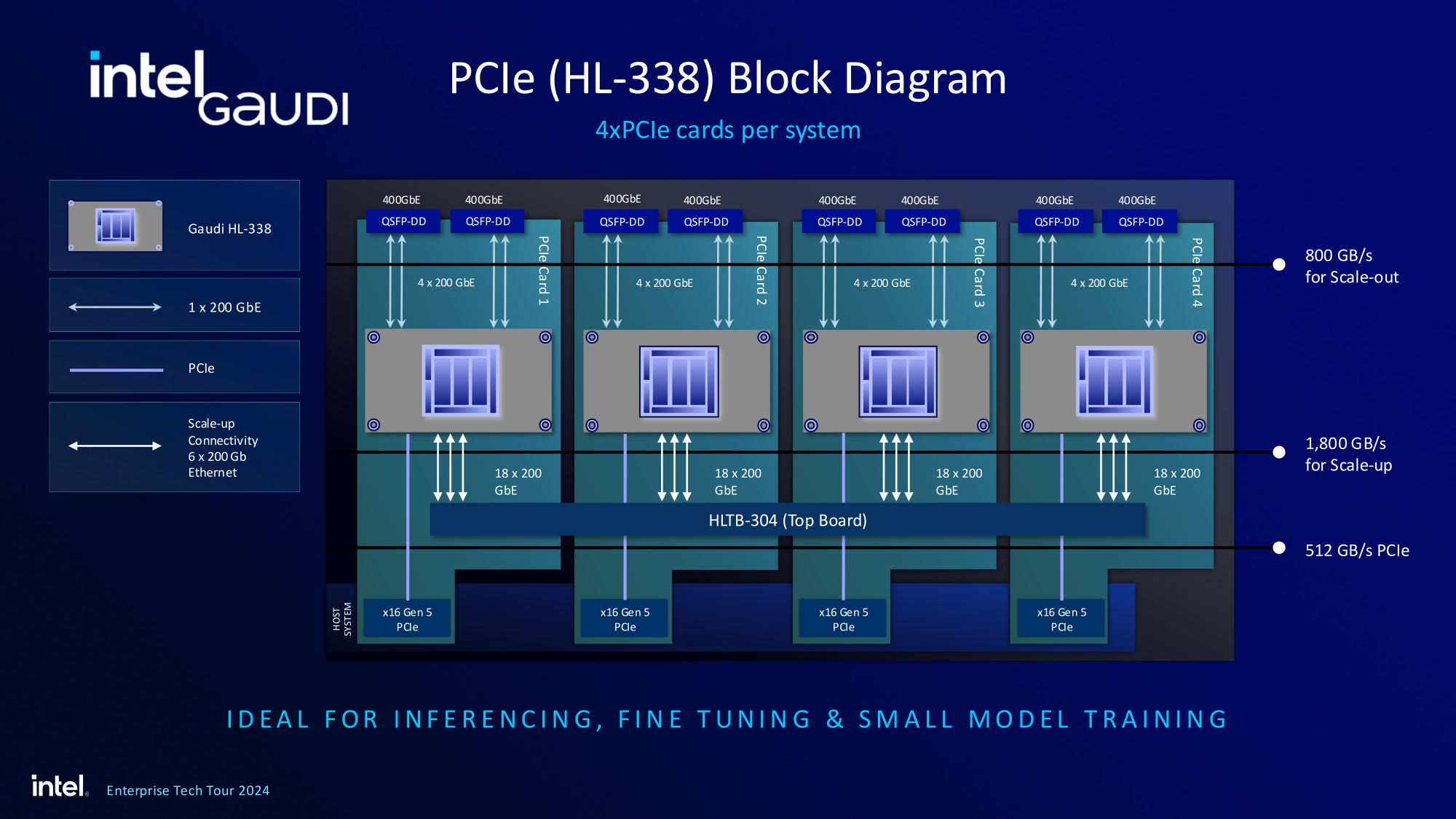 Впрочем, на презентации были продемонстрированы любопытные слайды, в частности, касающиеся архитектуры и принципов работы блоков матричной математики (MME), тензорных ядер (TPC), а также устройство подсистемы памяти. 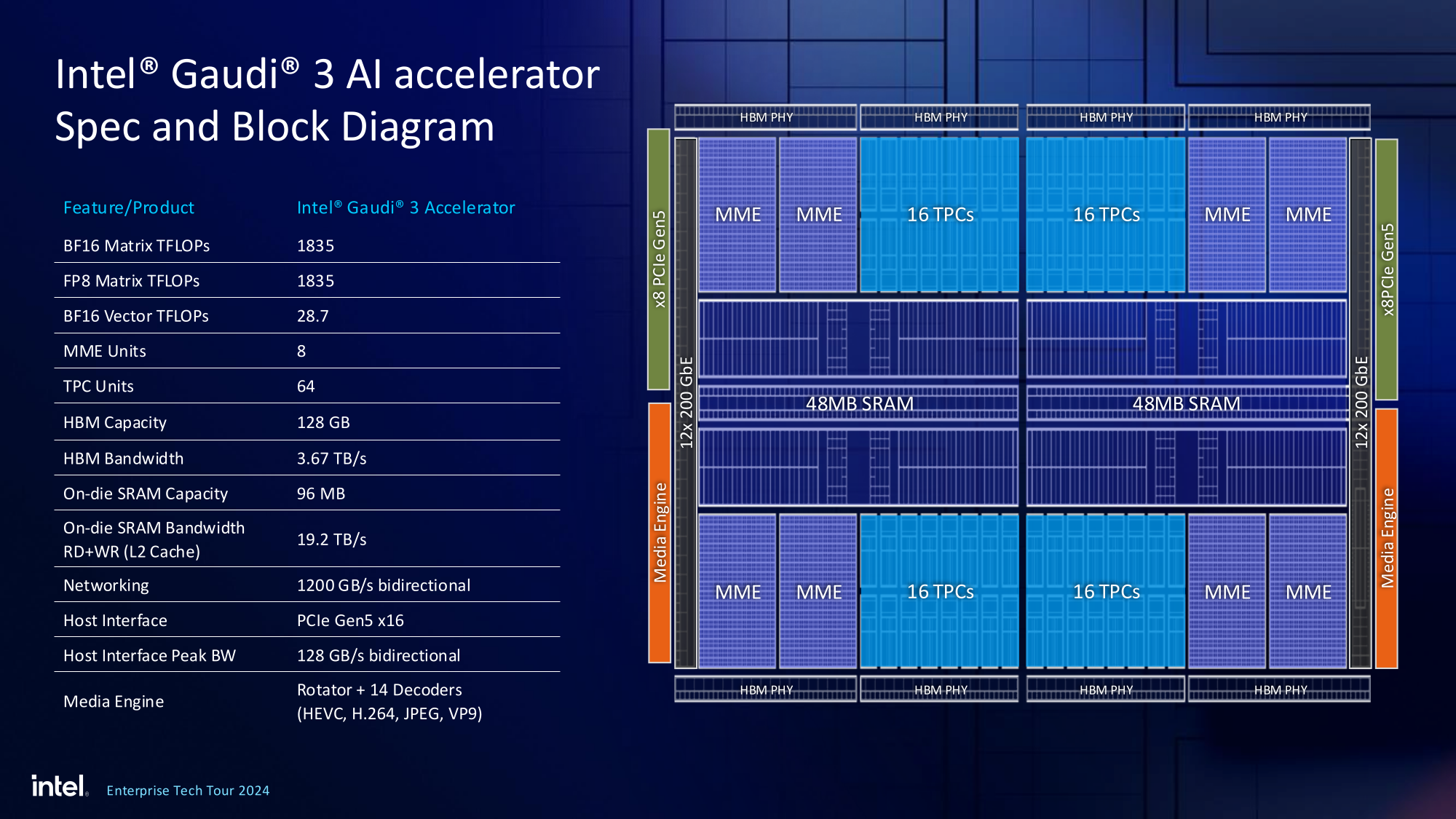 В последнем случае любопытен максимальный отход от иерархических принципов построения в пользу единого унифицированного пространства памяти, включающего в себя кеши L2 и L3, а также набортные HBM2e-стеки ускорителя. Общение с сетевым интерконнектом при этом организовано из пространства L3, что должно минимизировать задержки.  При этом сетевые порты доступны операционной системе как NIC через драйвер Gaudi3, с управлением посредством RDMA verbs. Благодаря большому количеству таких виртуальных NIC, организация интерконнекта внутри сервера-узла не требует никаких коммутаторов, а совокупная внутренняя производительность при этом достигает 67,2 Тбит/с.  Хотя основой экосистемы Gaudi3 станут в первую очередь ускорители HL-325L и UBB-платы HLB-325, есть у Intel и PCIe-вариант в виде FHFL-платы HL-338: 1,835 Пфлопс в режиме FP8 при теплопакете 600 Вт. Оно имеет только 22 200GbE-контроллера, а в остальном повторяет конфигурацию HL-325L с восемью блоками матричной математики (MME).  Эти ускорители получат пару портов QSFP-DD, каждый из которых будет поддерживать скорость 400 Гбит/с, а между собой платы в пределах одного сервера смогут общаться при помощи специального бэкплейна. 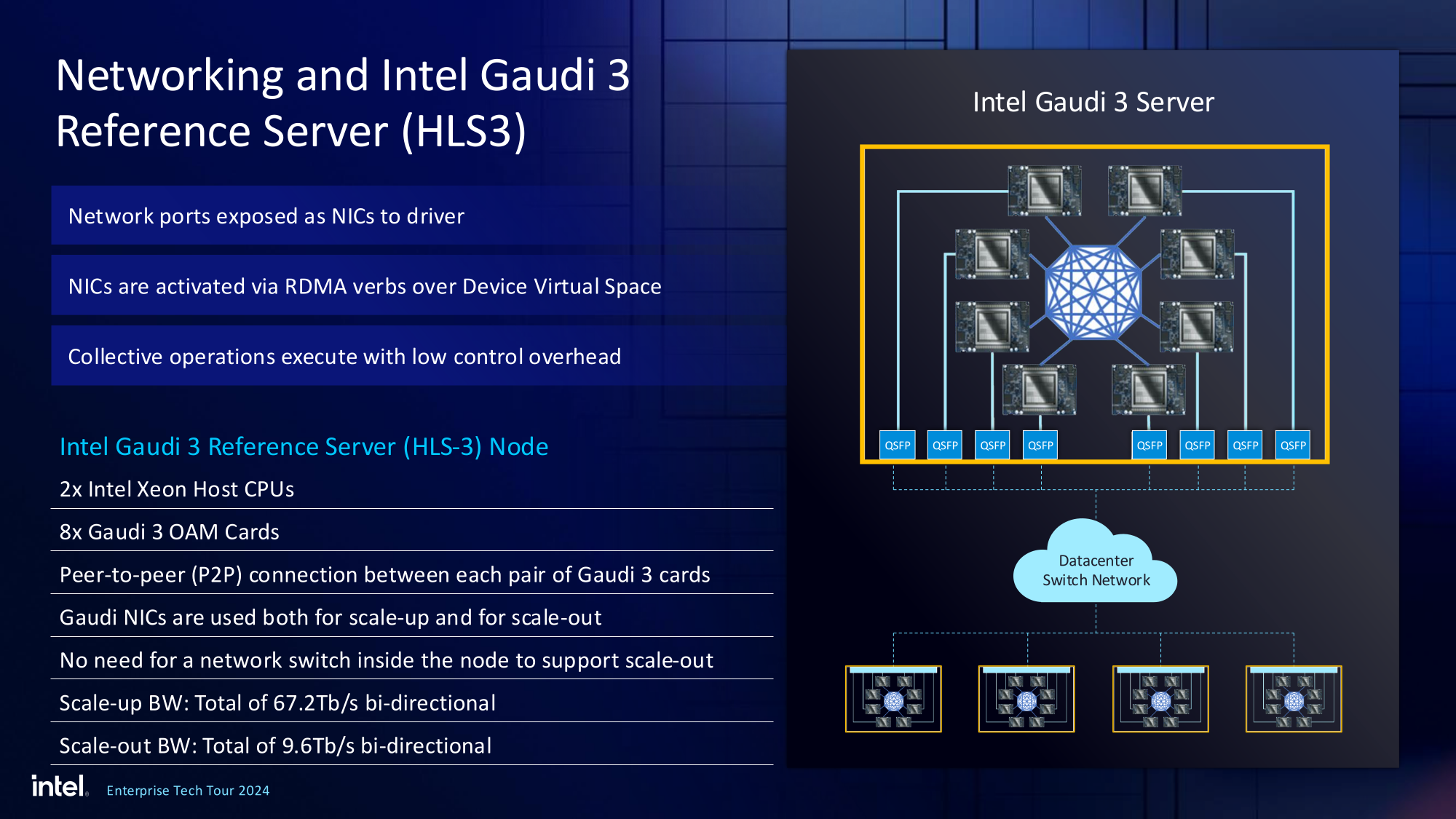 Важно то, что Gaudi3 успешно прошёл путь от анонса до становления сердцем полноценной аппаратно-программной экосистемы, в том числе благодаря ставке на программное обеспечение с открытым кодом. В настоящее время Intel в содействии с партнёрами могут предложить широчайший по масштабу спектр решений на базе Gaudi3 — от рабочих станций и периферийных серверов до вычислительных узлов, собирающихся в стойки, кластеры и даже суперкластеры. 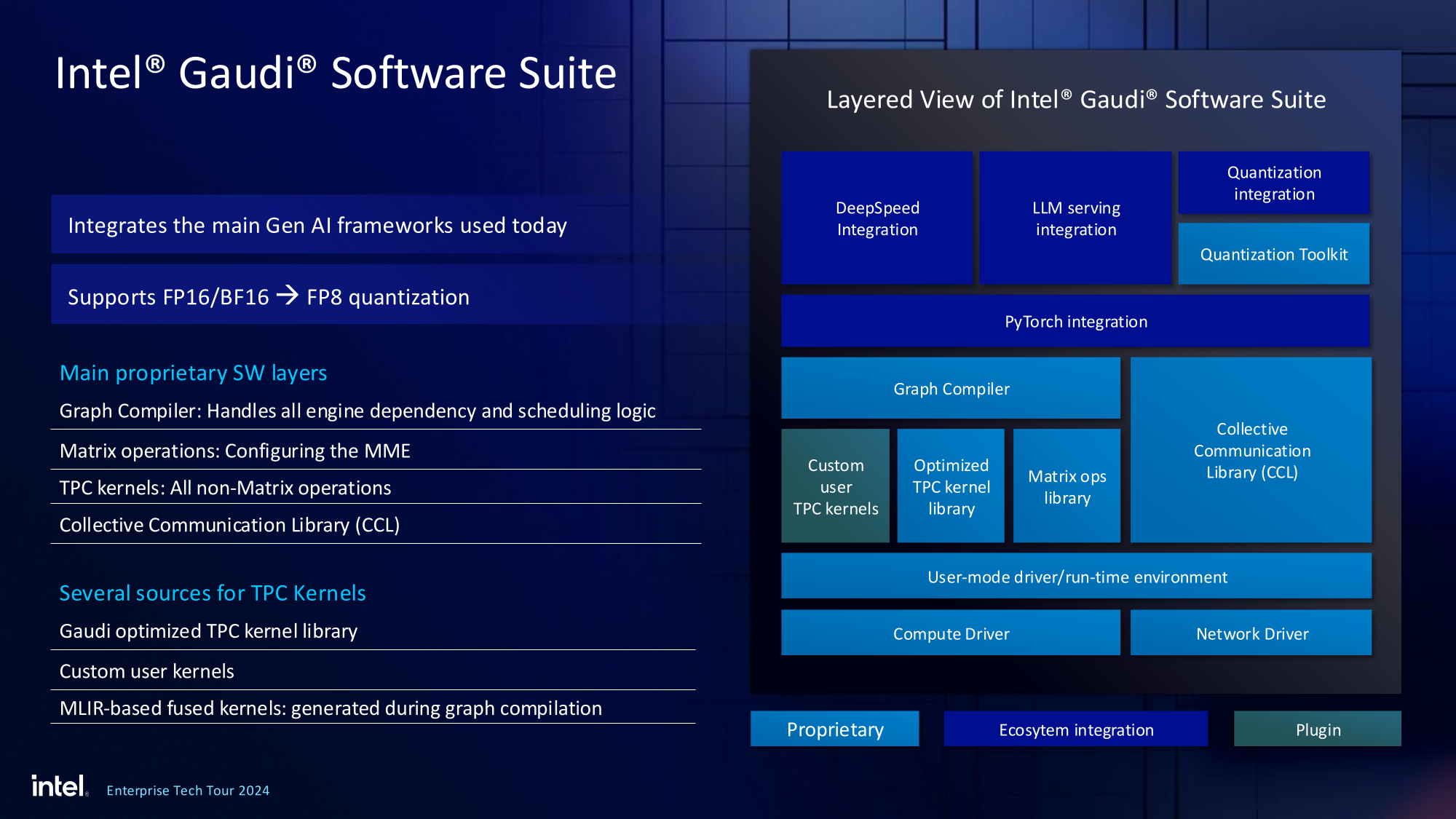 В числе крупнейших партнёров Intel по новой экосистеме есть Dell и Supermicro, представившие серверные системы c Gaudi3. Начало массовых поставок этих систем запланировано на октябрь 2024 года. Вряд ли такие серверы будут развёртываться по одному, поэтому Intel рассказала о возможностях масштабирования Gaudi3-платформ.  Один узел с восемью OAM-модулями HL-325L, развивающий 14,7 Пфлопс в режиме FP8 и располагающий 1 Тбайт HBM станет основой для 32- и 64-узловых кластеров с 256 и 512 Gaudi3 на борту, благо нехватка пропускной способности сетевой части Gaudi3 не грозит — она составляет 9,6 Тбайт/с для одного узла. Из таких кластеров может быть составлен суперкластер с 4096 ускорителями или даже мегакластер, где их число достигнет 8192. Производительность в этом случае составит 15 Эфлопс при объёме памяти 1 Пбайт и совокупной производительности сети 9,8 Пбайт/с. 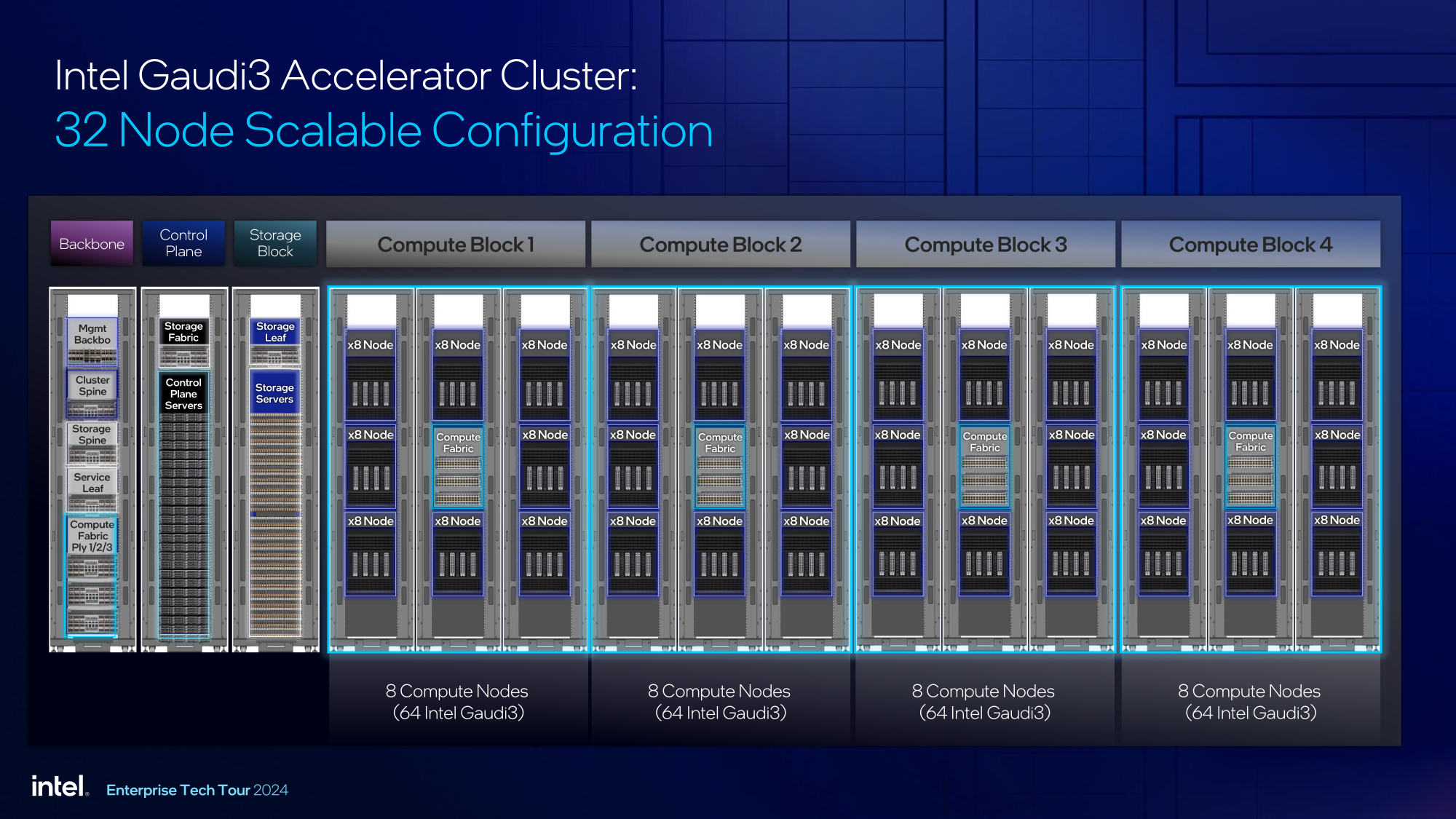 Типовой 32-узловой кластер на базе Gaudi3 Intel — это решение средней плотности с 15 стойками, содержащими не только вычислительные узлы, но и управляющие серверы, сетевые коммутаторы и подсистему хранения данных. Благодаря тому, что Intel в качестве интерконнекта для Gaudi3 избрала открытый и широко распространённый стандарт Ethernet (200GbE RoCE, 24 контроллера на ускоритель), не должно возникнуть проблем с совместимостью и привязкой к аппаратному обеспечению единственного вендора, как это имеет место быть c NVIDIA InfiniBand и NVLink.  Вкупе с программным обеспечением, основой которого является открытый OneAPI, и развитой системой техподдержки, системы на базе Gaudi3 станут надёжной основой для развёртывания ИИ-систем класса RAG, позволяющих заказчику в кратчайшие сроки запускать сети LLM с собственными датасетами без переобучения модели с нуля, говорит компания.  Именно в сферах, так или иначе связанных с большими языковыми моделями, Gaudi3 и системы на его основе должны помочь Intel укрепить свои позиции. Компания приводит данные, что Gaudi3 производительнее H100 примерно в 1,19 раза без учёта энергоэффективности, но в пересчёте «ватт на доллар» эти ускорители превосходят NVIDIA H100 уже в два раза.  Правда, H100 арсенал NVIDIA уже не ограничивается, но с массовой доступности новых решений Intel они могут оказаться привлекательнее. К тому же платформа совместима со всеми основными фреймворками, библиотеками и средствами управления. Впрочем, на примере AMD прекрасно видно, насколько индустрия привязана к решениям NVIDIA, причём в первую очередь программным.
28.09.2024 [23:24], Сергей Карасёв
Индия запустила сразу пять суперкомпьютеров за два дня
a100
amd
atos
cascade lake-sp
epyc
eviden
hardware
hpc
intel
milan
nvidia
xeon
индия
метео
суперкомпьютер
Премьер-министр Индии Нарендра Моди, по сообщению The Register, объявил о вводе в эксплуатацию трёх новых высокопроизводительных вычислительных комплексов PARAM Rudra. Запуск этих суперкомпьютеров, как отмечается, является «символом экономической, социальной и промышленной политики» страны. Вдаваться в подробности о технических характеристиках машин Моди во время презентации не стал. Однако некоторую информацию раскрыли организации, которые займутся непосредственной эксплуатацией этих НРС-систем. Один из суперкомпьютеров располагается в Национальном центре радиоастрофизики Индии (NCRA). Данная машина оснащена «несколькими тысячами процессоров Intel» и 90 ускорителями NVIDIA A100, 35 Тбайт памяти и хранилищем вместимостью 2 Пбайт. Ещё один НРС-комплекс смонтирован в Центре фундаментальных наук имени С. Н. Бозе (SNBNCBS): известно, что он обладает быстродействием 838 Тфлопс. Оператором третьей системы является Межуниверситетский центр ускоренных вычислений (IUAC): этот суперкомпьютер с производительностью на уровне 3 Пфлопс использует 24-ядерные чипы Intel Xeon Cascade Lake-SP. Ёмкость хранилища составляет 4 Пбайт. Упомянут интерконнект с пропускной способностью 240 Гбит/с. The Register отмечает, что указанные характеристики в целом соответствуют описанию суперкомпьютеров Rudra первого поколения. Согласно имеющейся документации, такие машины используют:
Ожидается, что машины Rudra второго поколения получат поддержку процессоров Xeon Sapphire Rapids и четырёх GPU-ускорителей. Суперкомпьютеры третьего поколения будут использовать 96-ядерные Arm-процессоры AUM, разработанные индийским Центром развития передовых вычислений: эти изделия будут изготавливаться по 5-нм технологии TSMC. 
Источник изображения: pixabay.com Между тем компания Eviden (дочерняя структура Atos) сообщила о поставках в Индию двух новых суперкомпьютеров. Один из них установлен в Индийском институте тропической метеорологии (IITM) в Пуне, второй — в Национальном центре среднесрочного прогнозирования погоды (NCMRWF) в Нойде. Эти системы, построенные на платформе BullSequana XH2000, предназначены для исследования погоды и климата. В создании комплексов приняли участие AMD, NVIDIA и DDN. Система IITM, получившая название ARKA, обладает быстродействием 11,77 Пфлопс: 3021 узел с AMD EPYC 7643 (Milan), 26 узлов с NVIDIA A100, NVIDIA Quantum InfiniBand и хранилище на 33 Пбайт (ранее говорилось о 3 Пбайт SSD + 29 Пбайт HDD). В свою очередь, суперкомпьютер NCMRWF под названием Arunika обладает производительностью 8,24 Пфлопс: 2115 узлов с AMD EPYC 7643 (Milan), NVIDIA Quantum InfiniBand и хранилище DDN EXAScaler ES400NVX2 (2 Пбайт SSD + 22 Пбайт HDD). Кроме того, эта система включает выделенный блок для приложений ИИ и машинного обучения с быстродействием 1,9 Пфлопс (точность не указана), состоящий из 18 узлов с NVIDIA A100. |
|