Материалы по тегу: fpga
|
07.02.2024 [20:00], Алексей Степин
Ryzen + Versal: AMD представила платформу Embedded+Как правило, основное внимание AMD привлекает своими процессорами с архитектурой x86, будь то Ryzen или EPYC. Тем не менее, другие направления, такие как встраиваемые платформы или решения для периферийных вычислений, для компании также играют важную роль. Вчера AMD анонсировала новую платформу Embedded+, главной особенностью которой является сочетание хорошо знакомой и отлично себя зарекомендовавшей архитектуры Zen+ с наработками бывшей Xilinx в лице SoC Versal AI Edge. 
Источник изображений: AMD via AnandTech В данном случае речь идёт об использовании соответствующих чипов в рамках одной системной платы, представляющей собой практически законченное изделие, предназначенное для использования в сценариях, требующих низкого энергопотребления при достаточно серьёзных вычислительных возможностях, особенно в традиционных для ИИ форматах. Сфера применения такого решения крайне широка и включает в себя любые задачи, требующие обработки массивов данных, поступающих в реальном времени с различных сенсорных систем и датчиков. Это могут быть как медицинские устройства, так и решения «умной промышленности» или автономный транспорт. 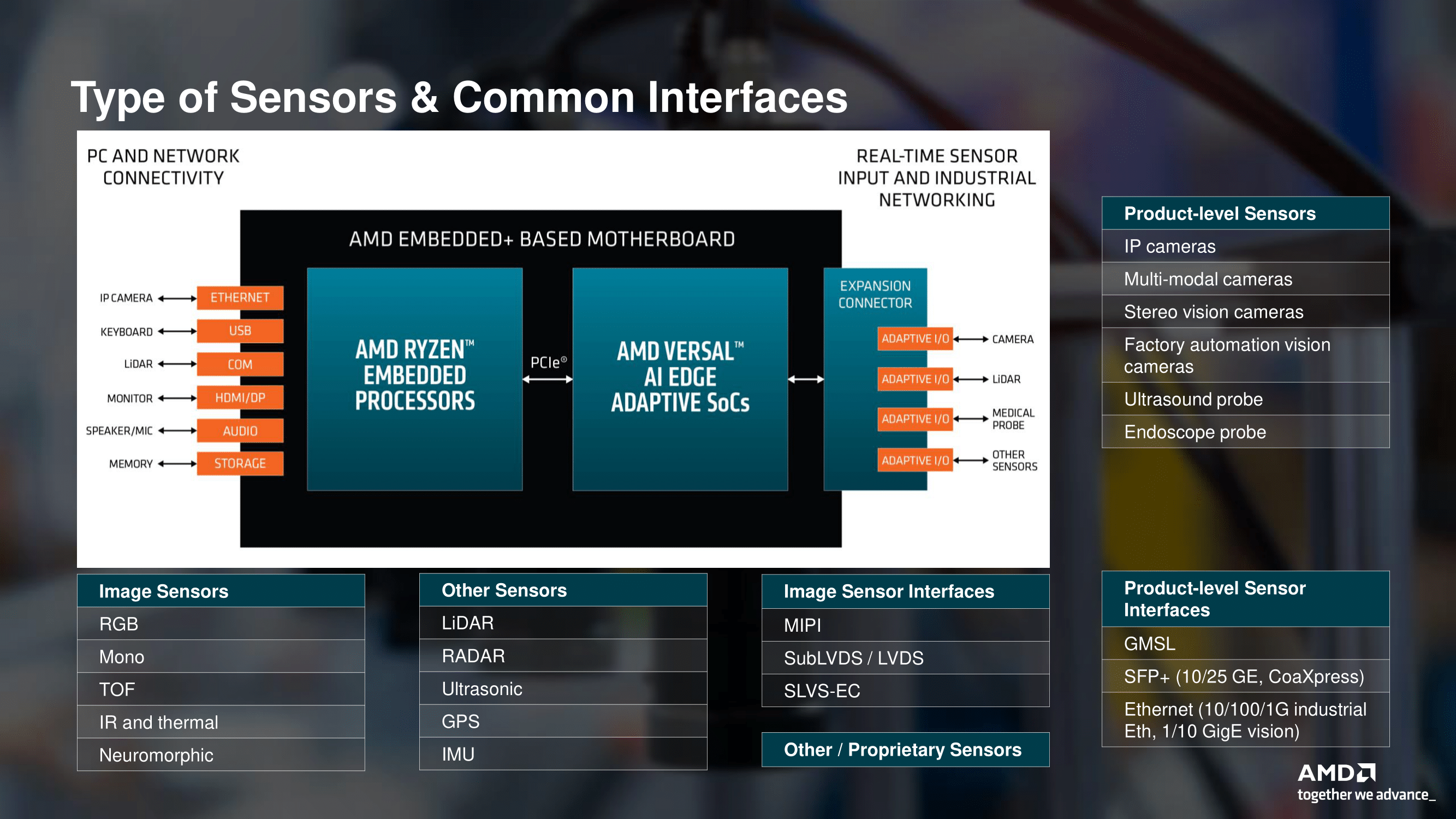 Во всех упомянутых случаях требуется низкая латентность, и платформа AMD Embedded+ соответствует подобного рода требованиям. Также она является поистине универсальной, поскольку несёт в своём составе как x86-ядра процессора Ryzen Embedded, так и ядра Arm в составе чипа Versal, а для уникальных задач можно использовать программируемую FPGA-логику. Новую платформу характеризует широкий спектр поддерживаемых интерфейсов ввода-вывода, начиная со стандартных Ethernet, USB и HDMI/Display Port, заканчивая интерфейсами различных сенсоров, такими, как MIPI и LVDS, а также GMSL. Речь идёт не только о сенсорах машинного зрения, но и о различных радарах, лидарах, ультразвуковых датчиках, приёмниках GPS и тому подобных устройствах.  Одновременно с анонсом самой платформы AMD представила готовое решение на её основе — плату Sapphire VPR-4616-MB. Решение имеет форм-фактор mini-ITX и несёт на борту Ryzen Embedded R2314 и Versal AI Edge 2302. Первый имеет конфигурацию с четырьмя x86-ядрами и шестью блоками Radeon Vega. В составе второго имеется по паре ядер Arm Cortex-A72 и Cortex-R5F, последние предназначены для работы в режиме реального времени. Программируемая часть содержит 329 тысяч логических ячеек и свыше 150 тысяч LUT. Чип способен развивать до 23 Топс на операциях в формате INT8 за счёт 34 собственных движков ИИ, ещё 5 Топс может выдать программируемая логика. 464 движка DSP делают данное решение хорошо подходящим для реализации машинного зрения, в том числе в системах автопилота. 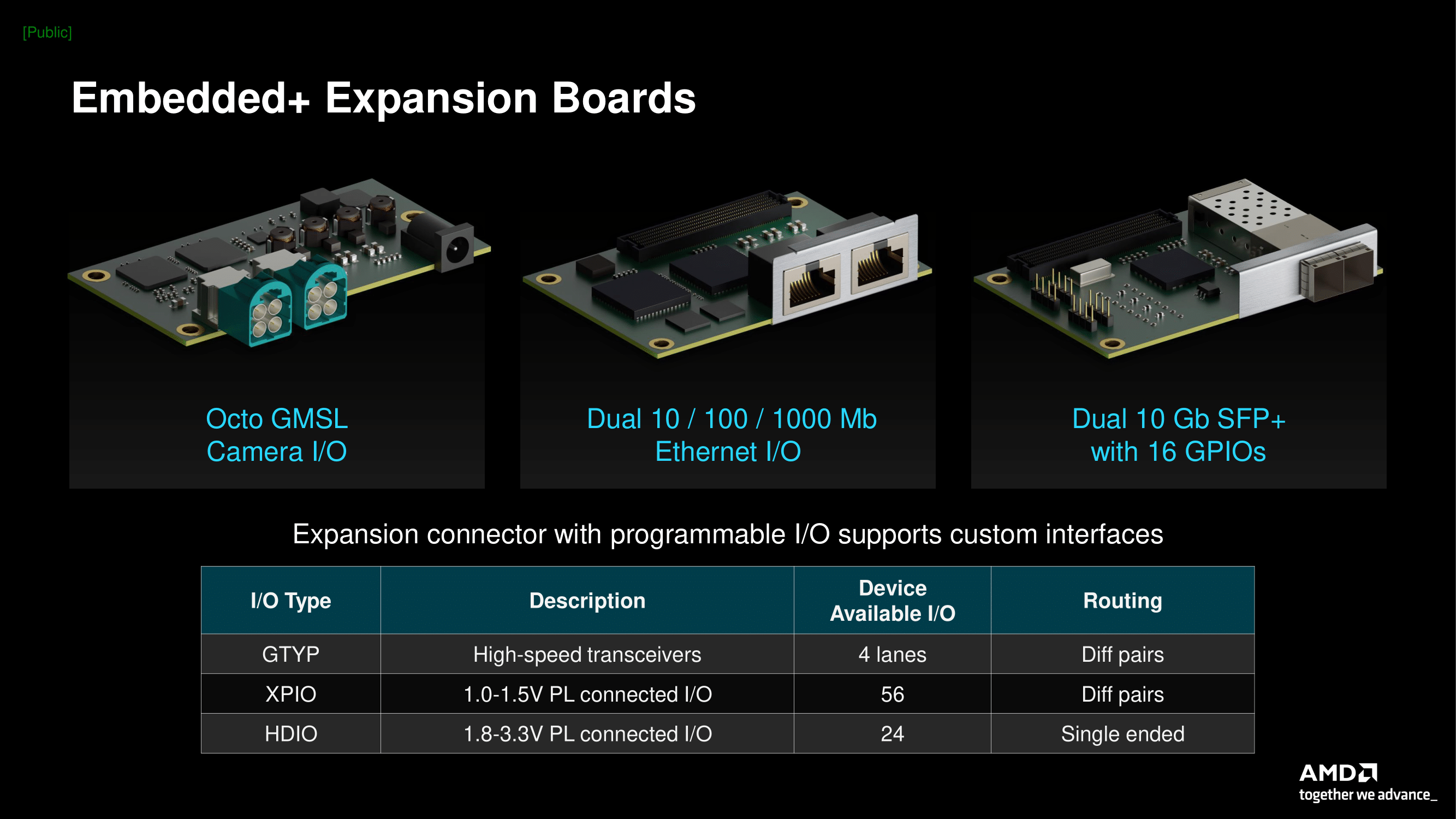 Плата имеет специальный разъём расширения, к нему подключаются различные модули с интерфейсами машинного зрения, Ethernet и GPIO. Объём оперативной памяти, которым можно укомплектовать решение, достигает 64 Гбайт, доступна установка накопителя M.2 и SATA, имеется отдельный слот M.2 2230 для реализации беспроводной связи.
14.12.2023 [22:30], Владимир Мироненко
FPGA + Orin: Lattice и NVIDIA будут сотрудничать в деле ускорения ИИ-вычислений на периферииLattice Semiconductor представила на конференции для разработчиков Lattice Developers Conference новую эталонную платформу для ускорения разработки периферийных ИИ-решений использованием платформ NVIDIA Jetson Orin и IGX Orin. Сотрудничество Lattice с NVIDIA нацелено на повышение эффективности подключения сенсоров к приложениям для ИИ-обработки, что позволит расширить возможности сообщества разработчиков открытых платформ. Согласно пресс-релизу, эталонная open source плата, основанная на энергоэффективных FPGA Lattice и аппаратной платформе NVIDIA Orin, предназначена для удовлетворения потребностей разработчиков в подключении к разнообразным датчикам и интерфейсам, при разработке масштабируемых высокопроизводительных периферийных ИИ-приложений с низким уровнем задержкидля нужд здравоохранения, робототехники, встраиваемых систем визуализации и т.д. Эталонная плата пока доступна лишь избранным клиентам, но Lattice планирует расширить доступ к решению и примерам приложений в I половине 2024 года. 
Источник изображения: Lattice Semiconductor «Мы рады сотрудничеству с NVIDIA, которое позволит расширить возможности наших эталонных решений, предлагая больше инноваций нашим клиентам и экосистеме, чтобы помочь упростить и ускорить внедрение периферийных приложений ИИ», — заявил директор по стратегии и маркетингу Lattice Semiconductor. В свою очередь директор по управлению встраиваемыми ИИ-продуктами NVIDIA отметил, что сотрудничество с Lattice позволит ускорить инновации в области обработки показаний датчиков и упростить развёртывание приложений ИИ «от периферии до облака».
30.03.2023 [19:45], Владимир Мироненко
В 2023 году Intel выпустит Xeon Emerald Rapids и подготовит полтора десятка FPGA, а чипы Sierra Forest и Granite Rapids появятся уже в 2024 годуВ ходе мероприятия для инвесторов Intel подтвердила свои планы по противодействию процессорам AMD EPYC Bergamo, в которых будет использоваться архитектура с высокой плотностью ядер Zen4c, а также всё нарастающему давлению Arm. Intel придерживается планов по созданию собственных архитектур с производительными и энергоэффективными ядрами для чипов Xeon. Intel объявила, что рассчитывает выпустить следующее, пятое по счёту поколение процессоров Xeon Scalable под кодовым названием Emerald Rapids (EMR), преемников Sapphire Rapids (SPR), в IV квартале 2023 года. Компания также продемонстрировала чип Emeralds Rapids, состоящий из двух чиплетов (тайлов в терминологии Intel). Sapphire Rapids, напомним, имеется четыре тайла меньших размеров. Сообщается, что образцы Emerald Rapids уже доступны избранным заказчикам. Не вдаваясь особо в технические подробности, компания рассказала, что Emerald Rapids будет работать в том же диапазоне TDP, что и Sapphire Rapids, что повысит общую производительность платформы в пересчёте на Вт. 
Изображения: Intel Учитывая то, что Emerald Rapids будет использовать ту же платформу LGA 4677, что и Sapphire, заказчики смогут заменить Sapphire на Emerald в существующих решениях. Такой подход позволит легко модернизировать уже внедрённые системы, а в случае производителей оборудования — ускорить вывод Emerald Rapids на рынок. Emerald Rapids будет построен на том же техпроцессе Intel 7. Это означает, что прирост производительности должен быть обеспечен за счёт архитектурных улучшений. Intel сообщила о «повышенной плотности ядер», поэтому можно предположить, что у Emerald Rapids будет больше ядер в сравнении с Sapphire Rapids. 
Emerald Rapids Вслед за Emerald Rapids компания планирует начать в 2024 году поставки чипов следующего поколения Granite Rapids (GNR) на базе производительных P-ядер. Сообщается, что вычислительные тайлы Granite Rapids будут выпускаться с использованием техпроцесса Intel 3. Intel также впервые сообщила, что Granite Rapids будут поддерживать MCR DIMM (DDR5-8800+) и обеспечат ПСП в пределах 1,5 Тбайт/с (12 каналов памяти). Ещё одной особенностью станет полный переход на чиплетную компоновоку с независимым IO-тайлом. Первые образцы Granite Rapids уже тестируются некоторыми заказчиками. 
Emerald Rapids В первой половине 2024 года должен выйти и процессор Sierra Forest (SRF), первый Intel Xeon с энергоэффективными E-ядрами (следующее за Gracemont поколение) общим числом до 144 единиц. Сообщается, что Sierra Forest и Granite Rapids будут использовать одну и ту же платформу Birch Stream. Следует отметить, что чипы Sierra Forest появятся несколько раньше, чем Granite Rapids, и тоже будут использовать техпроцесс Intel 3, а также IO-тайлы. Отмечается, что Sierra Forest даже в текущем виде оказались на удивление стабильно работающими. Более того, их уже тестирует как минимум один заказчик Intel. 
Sierra Forest На смену Sierra Forest придут в 2025 году чипы Clearwater Forest (CWF), которые станут первыми в семействе Intel Xeon, основанными на техпроцессе Intel 18A. По словам Intel, её заказчики не хотят серверные процессоры смешанной архитектуры, то есть требуют чипы либо только с P-ядрами, либо только с E-ядрами. Sierra Forest сейчас является, пожалуй, наиболее важным продуктом для Intel и для демонстрации производственных возможностей, и для сохранения заказчиков среди гиперскейлеров. 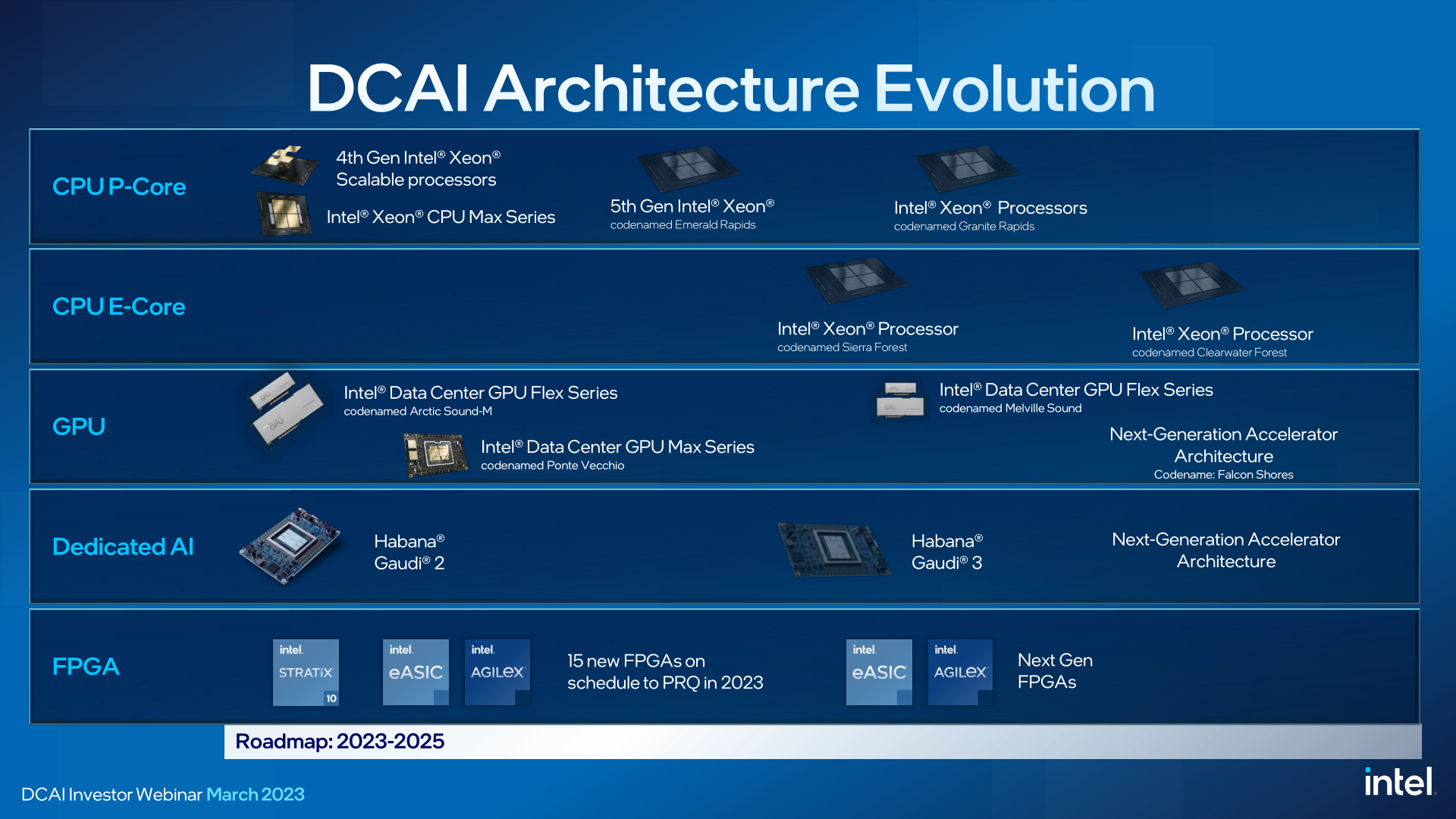 Что касается ускорителей, то компания в этом году планирует подготовить сразу 15 различных FPGA в сериях Agilex и Stratix, а также eASIC. Intel, как уже говорилось ранее, не забрасывает работу над специализированными ускорителями Habana, но грядущие Gaudi3 от нынешних Gaudi2 будут отличаться переходом с 7-нм на 5-нм техпроцесс. Отменённых Rialto Bridge в планах более нет, да и Falcon Shores тоже не упоминаются. При этом Intel считает, что к 2027 году в области ИИ-чипов соотношение между CPU и GPU будет на уровне 60/40.
24.11.2020 [18:54], Игорь Осколков
«ВКонтакте» использует FPGA Intel Arria для обработки изображений на летуГод назад на Intel Experience Day 2019 «ВКонтакте» поделилась результатами первых экспериментов по использованию FPGA-ускорителей для обработки изображений на лету. За прошедшее время компания внедрила ПЛИС в свою инфраструктуру, ускорив работу и сэкономив место в хранилище, где уже находится 1,2 Эбайта различного контента. У «ВКонтакте» почти 100 млн активных пользователей, которые ежеминутно загружают порядка 100 Гбайт изображений. Для каждого из них после загрузки генерируется более десятка копий различных формата и размера, которые используются в разных частях социальной сети. Основная проблема в том, что на таких масштабах все эти дополнительные изображения отъедают очень много места — до двух третей от общего объёма. 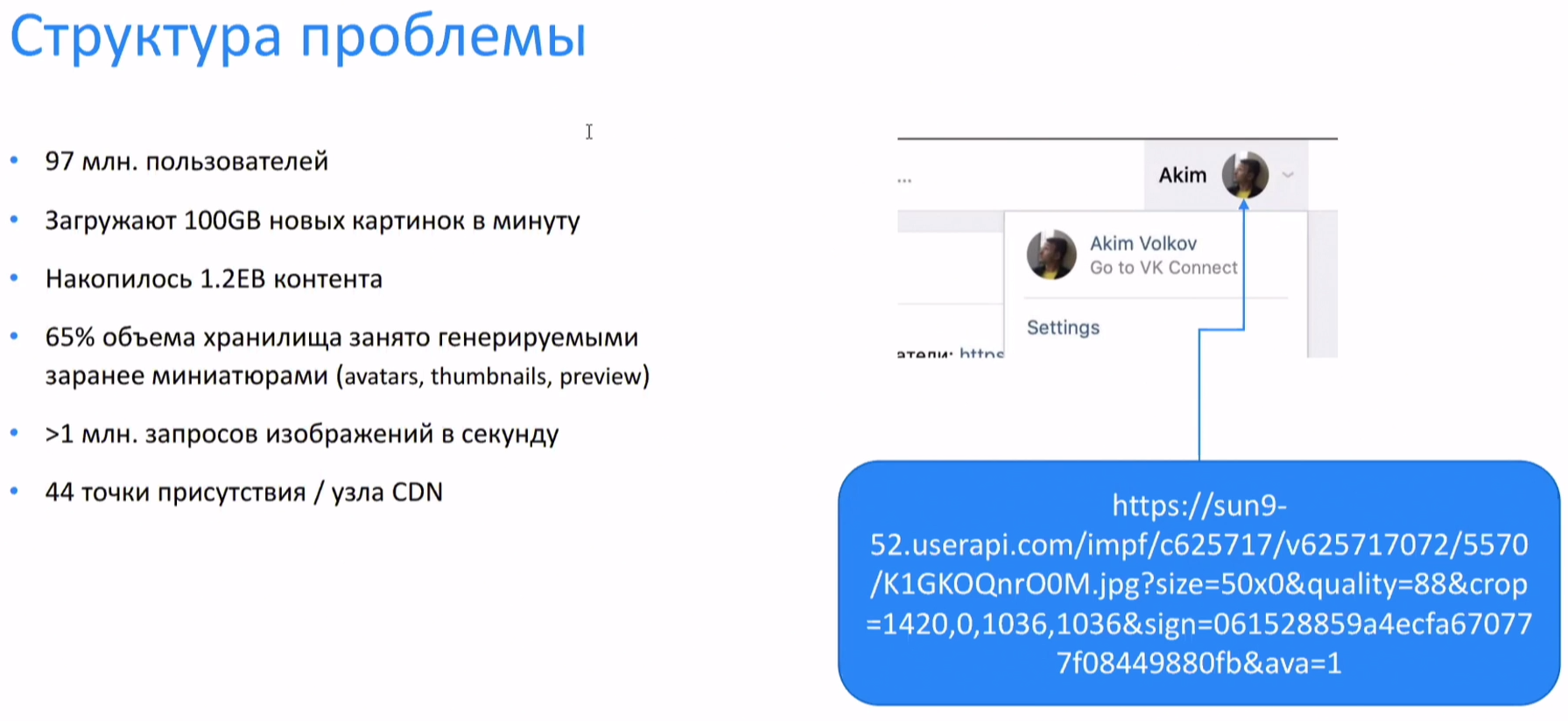 Оптимальнее было бы генерировать их на лету, однако это очень существенная вычислительная нагрузка. Тестовые машины с Intel Xeon E5-2620 v4, которые на тот момент составляли значительную часть серверного парка, могли обработать до 200-220 изображений в секунду, чего явно было недостаточно. Поэтому и было принято решение попробовать для решения этой задачи FPGA, в данном случае это Arria 10. 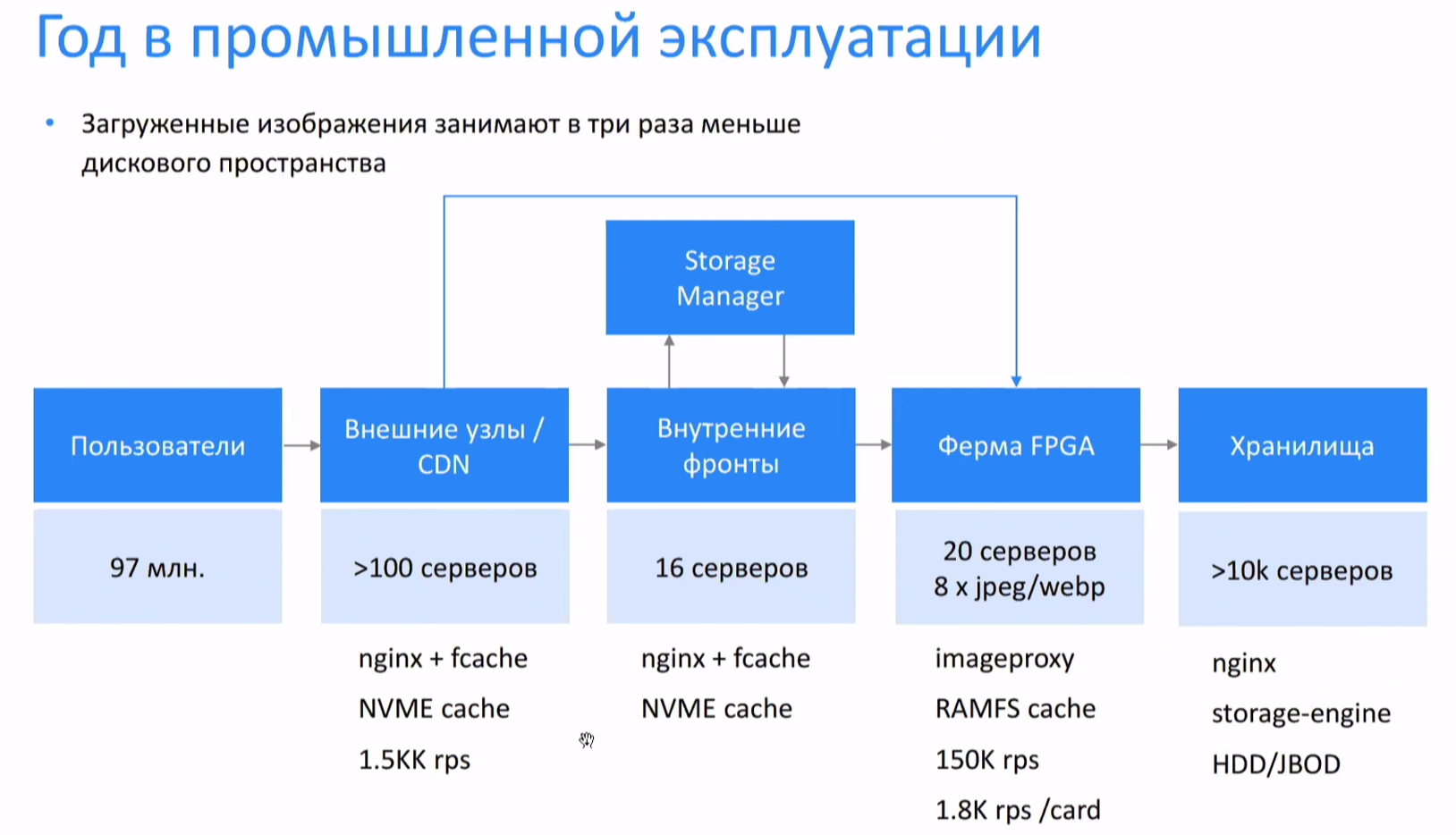 Теперь изображения с нужными характеристиками можно сформировать, указав параметры в URL. Если оно уже не закешировано на одной из конечных точек для отдачи контента, то запрос уходит «вниз» и из хранилища (а это более 10 тыс. серверов) извлекается оригинал и отправляется на FPGA-ферму, которая состоит всего из 20 серверов с ПЛИС, которых достаточно для удовлетворения всех запросов. На FPGA изображения конвертируются и отправляются «наверх», где кешируются и отдаются клиенту. Основными форматами, с которыми работает FPGA-ферма, являются JPEG и WebP, но компания рассматривает и другие, более современные. Кроме того, VK планирует изучить возможности FPGA для декодирования медиафайлов, сжатия данных (zstd) со стороны хранилища, а также опробовать в деле более современные модели ПЛИС.
16.10.2020 [23:17], Юрий Поздеев
DPU в стиле Intel: сетевые адаптеры с Xeon D, FPGA, HBM и SSDМир сетевых карт становится умнее. Это следующий шаг в дезагрегации ресурсов центров обработки данных. Наличие расширенных возможностей сетевых карт позволяет разгрузить центральный процессор, при этом специализированные сетевые адаптеры обеспечивают более совершенные функции и безопасность. В этой новости мы познакомим вас сразу с двумя адаптерами: Silicom SmartNIC N5010 и Inventec SmartNIC C5020X. Silicom FPGA SmartNIC N5010 предназначена для систем крупных коммуникационных провайдеров. Операторы все чаще стремятся заменить проприетарные форм-факторы от поставщиков телекоммуникационного оборудования на более стандартные варианты. В рамках этого мы видим, что производители ПЛИС не прочи освоить и эту нишу.  В Silicom FPGA SmartNIC N5010 используется Intel Stratix 10 DX с 8 Гбайт памяти HBM. Поскольку пропускная способность памяти становится все большим аспектом производительности системы, HBM будет продолжать распространяться за пределы графических процессоров и FPGA. В SmartNIC и DPU память HBM может использоваться для размещения индексных таблиц поиска и других функций для интенсивных сетевых нагрузок. Помимо HBM SmartNIC N5010 имеет еще 32 Гбайт памяти DDR4 ECC. SmartNIC N5010 потребляет до 225 Вт, что предполагает несколько вариантов исполнения карты, в том числе и с активным охлаждением.  Самая интересная особенность новой карты — 4 сетевых порта по 100 Гбит/с. На плате SmartNIC N5010 установлены две базовые сетевые карты Intel E810 (Columbiaville). На приведенной схеме можно заметить, что используется интерфейс PCIe Gen4 x16, причем их тут сразу два. Для работы четырех 100GbE-портов уже недостаточно одного интерфейса PCIe 4.0 x16. Второй порт PCIe 4.0 x16 может быть подключен через дополнительный кабель к линиям второго процессора, чтобы избежать межпроцессорного взаимодействия для передачи данных.  Вторая новинка, Inventec FPGA SmartNIC C5020X, совмещает на одной плате процессор Intel Xeon D и FPGA Intel Stratix 10. Этот адаптер предназначен для разгрузки центрального процессора в серверах крупных облачных провайдеров. На плате установлен процессор Intel Xeon D-1612 с 32-Гбайт SSD и 16 Гбайт DDR4, подключение к ПЛИС Intel Stratix 10 DX 1100 осуществляется через PCIe 3.0 x8. Нужно отметить, что FPGA Stratix имеет свои собственные 16 Гбайт памяти DDR4, а также обеспечивает сетевые подключения 25/50 Гбит/с и оснащен интерфейсом PCIe 4.0 x8, через который адаптер подключается к хосту. 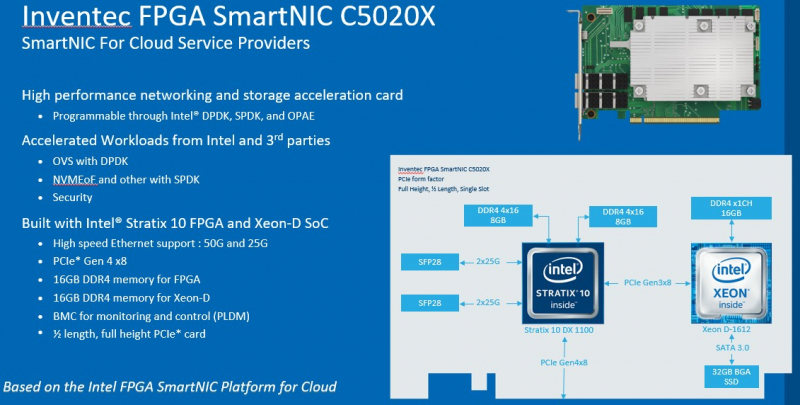 У Inventec уже есть решение на базе Arm (Inventec X250), которое использует ПЛИС Arria 10 GX660 вместе с сетевым адаптером Broadcom Stingray BCM8804, которое имеет аналогичный форм-фактор и TPD не более 75 Вт. Однако для некоторых организаций наличие единой x86 платформы, включая SmartNIC, упрощает развертывание, поэтому вариант C5020X для таких компаний более предпочтителен. Решение получилось очень интересным, однако вряд ли его можно назвать адаптером для массового рынка, как Intel Columbiaville. На примере этого адаптера Intel показала, что может объединить элементы своего портфеля для создания комплексных решений. Inventec FPGA SmartNIC C5020X является хорошей альтернативой предложению на базе Broadcom, что позволит крупным облачным провайдерам диверсифицировать свои платформы.  Несмотря на то, что обе новинки классифицируются как «умные» сетевые адаптеры SmartNIC, вторая, пожалуй, уже ближе к DPU, если сравнивать её с адаптерами NVIDIA DPU, в которых сетевая часть дополнена Arm-процессором и GPU-ускорителем. В данном случае есть и x86-ядра общего назначения, и ускоритель, хотя и на базе ПЛИС. Впрочем, устоявшегося определения DPU и списка критериев соответствия этому классу процессоров пока нет. |
|