Материалы по тегу: инференс
|
30.08.2024 [13:11], Руслан Авдеев
ИИ-ускорители Intel Gaudi 3 дебютируют в облаке IBM CloudКомпании Intel и IBM намерены активно сотрудничать в сфере облачных ИИ-решений. По данным HPC Wire, доступ к ускорителям Intel Gaudi 3 будет предоставляться в облаке IBM Cloud с начала 2025 года. Сотрудничество обеспечит и поддержку Gaudi 3 ИИ-платформой IBM Watsonx. IBM Cloud станет первым поставщиком облачных услуг, принявшим на вооружение Gaudi 3 как для гибридных, так и для локальных сред. Взаимодействие компаний позволит внедрять и масштабировать современные ИИ-решения, а комбинированное использование Gaudi 3 с процессорами Xeon Emerald Rapids откроет перед пользователями дополнительные возможности в облаках IBM. Gaudi 3 будут применяться и в задачах инференса на платформе Watsonx — клиенты смогут оптимизировать исполнение таких нагрузок с учётом соотношения цены и производительности. Для помощи клиентам в различных отраслях, в том числе тех, деятельность которых жёстко регулируется, компании предложат возможности IBM Cloud для гибкого масштабирования нагрузок, а интеграция Gaudi 3 в среду IBM Cloud Virtual Servers for VPC позволит компаниям, использующим аппаратную базу x86, быстрее и безопаснее использовать свои решения, чем до интеграции. 
Источник изображения: Intel Ранее сообщалось, что модель Gaudi 3 готова бросить вызов ускорителям NVIDIA. В своё время Intel выступила с заявлением о 50 % превосходстве новинки в инференс-сценариях над NVIDIA H100, а также о 40 % преимуществе в энергоэффективности при значительно меньшей стоимости. Позже Intel публично раскрыла стоимость новых ускорителей, нарушив негласные правила рынка.
29.08.2024 [01:00], Владимир Мироненко
NVIDIA вновь показала лидирующие результаты в ИИ-бенчмарке MLPerf InferenceNVIDIA сообщила, что её платформы показали самые высокие результаты во всех тестах производительности уровня ЦОД в бенчмарке MLPerf Inference v4.1, где впервые дебютировал ускоритель семейства Blackwell. Ускоритель NVIDIA B200 (SXM, 180 Гбайт HBM) оказался вчетверо производительнее H100 на крупнейшей рабочей нагрузке среди больших языковых моделей (LLM) MLPerf — Llama 2 70B — благодаря использованию механизма Transformer Engine второго поколения и FP4-инференсу на Tensor-ядрах. Впрочем, именно B200 заказчики могут и не дождаться. Ускоритель NVIDIA H200, который стал доступен в облаке CoreWeave, а также в системах ASUS, Dell, HPE, QTC и Supermicro, показал лучшие результаты во всех тестах в категории ЦОД, включая последнее дополнение к бенчмарку, LLM Mixtral 8x7B с общим количеством параметров 46,7 млрд и 12,9 млрд активных параметров на токен, использующую архитектуру Mixture of Experts (MoE, набор экспертов). 
Источник изображения: NVIDIA Как отметила NVIDIA, MoE приобрела популярность как способ привнести большую универсальность в LLM, поскольку позволяет отвечать на широкий спектр вопросов и выполнять более разнообразные задачи в рамках одного развёртывания. Архитектура также более эффективна, поскольку активируются только несколько экспертов на инференс — это означает, что такие модели выдают результаты намного быстрее, чем высокоплотные (Dense) модели аналогичного размера. Также NVIDIA отмечает, что с ростом размера моделей для снижения времени отклика при инференсе объединение нескольких ускорителей становится обязательными. По словам компании, NVLink и NVSwitch уже в поколении NVIDIA Hopper предоставляют значительные преимущества для экономичного инференса LLM в реальном времени. А платформа Blackwell ещё больше расширит возможности NVLink, позволив объединить до 72 ускорителей. 
Источник изображения: NVIDIA Заодно компания в очередной раз напомнила о важности программной экосистемы. Так, в последнем раунде MLPerf Inference все основные платформы NVIDIA продемонстрировали резкий рост производительности. Например, ускорители NVIDIA H200 показали на 27 % большую производительность инференса генеративного ИИ по сравнению с предыдущим раундом. А Triton Inference Server продемонстрировал почти такую же производительность, как и у bare-metal платформ. Наконец, благодаря программным оптимизациям в этом раунде MLPerf платформа NVIDIA Jetson AGX Orin достигла более чем 6,2-кратного улучшения пропускной способности и 2,5-кратного улучшения задержки по сравнению с предыдущим раундом на рабочей нагрузке GPT-J LLM. По словам NVIDIA, Jetson способен локально обрабатывать любую модель-трансформер, включая LLM, модели класса Vision Transformer и, например, Stable Diffusion. А вместо разработки узкоспециализированных моделей теперь можно применять универсальную GPT-J-6B модель для обработки естественного языка на периферии.
28.08.2024 [00:10], Владимир Мироненко
NVIDIA представила шаблоны ИИ-приложений NIM Agent Blueprints для типовых бизнес-задачNVIDIA анонсировала NIM Agent Blueprints, каталог предварительно обученных, настраиваемых программных решений, предоставляющий разработчикам набор инструментов для создания и развёртывания приложений генеративного ИИ для типовых вариантов использования, таких как аватары для обслуживания клиентов, RAG, виртуальный скрининг для разработки лекарственных препаратов и т.д. Предлагая бесплатные шаблоны для частых бизнес-задач, компания помогает разработчикам ускорить создание и вывод на рынок ИИ-приложений. NIM Agent Blueprints включает примеры приложений, созданных с помощью NVIDIA NeMo, NVIDIA NIM и микросервисов партнёров, примеры кода, документацию по настройке и Helm Chart'ы для быстрого развёртывания. Предприятия могут модифицировать NIM Agent Blueprints, используя свои бизнес-данные, и запускать приложения генеративного ИИ в ЦОД и облаках (в том числе в рамках NVIDIA AI Enterprise), постоянно совершенствуя их благодаря обратной связи. На текущий момент NIM Agent Blueprints предлагают готовые рабочие процессы (workflow) для систем обслуживания клиентов, для скрининга с целью автоматизированного поиска необходимых соединений при разработке лекарств и для мультимодального извлечения данных из PDF для RAG, что позволит обрабатывать огромные объёмы бизнес-данных для получения более точных ответов, благодаря чему ИИ-агенты чат-боты службы станут экспертами по темам компании. С примерами можно ознакомиться здесь. 
Источник изображения: NVIDIA Каталог NVIDIA NIM Agent Blueprints вскоре станет доступен у глобальных системных интеграторов и поставщиков технологических решений, включая Accenture, Deloitte, SoftServe и World Wide Technology (WWT). А такие компании как Cisco, Dell, HPE и Lenovo предложат полнофункциональную ИИ-инфраструктуру с ускорителями NVIDIA для развёртывания NIM Agent Blueprints. NVIDIA пообещала, что ежемесячно будут выпускаться дополнительные шаблоны для различных бизнес-кейсов.
27.08.2024 [17:46], Руслан Авдеев
ИИ-ускорители Rebellions Rebel Quad получат 144 Гбайт памяти Samsung HBM3eЮжнокорейский стартап Rebellions представила на днях план развития своих ИИ-ускорителей. Как сообщает Business Korea, компания ускорит выпуск ИИ-чипов нового поколения, которые получат 4-нм модули памяти HBM3e производства Samsung. Samsung же будет отвечать за объединение чипов и HBM в одной упаковке. Изначально к концу 2024 года планировалось наладить выпуск продукта Rebel Single с одним модулем памяти, но потом было решено выпустить гораздо более производительный вариант Rebel Quad с четырьмя 12-слойными (12-Hi) модулями HBM3e суммарной ёмкостью 144 Гбайт, тоже к концу текущего года. Новинка придёт на смену ускорителю ATOM, который оснащён всего лишь 16 Гбайт GDDR6. Использование ёмкой и быстрой HBM3e-памяти считается одним из главных преимуществ Rebel Quad, по этому показателю новинки сравнимы с последними ускорители NVIDIA семейства Blackwell. При этом обещано, что новинки будут значительно энергоэффективнее решений NVIDIA и даже ускорителей Groq. Это по-прежнему серверные ускорители для обработки LLM вроде ChatGPT, но подойдут ли они для обучения ИИ-моделей, пока не уточняется. 
Источник изображения: Rebellions Сейчас Rebellions ориентируется на поставки комплексных ИИ-решений «стоечного уровня». В рамках концепуии Rebellion Scalable Design (RDS) будет предложены программно-аппаратные комплексы, которые позволят органично взаимодействовать многочисленным ускорителями и серверам с максимальной производительностью и энергоэффективностью. Речь идёт о решении, теоретически способном конкурировать с NVIDIA CUDA.
27.08.2024 [12:08], Сергей Карасёв
Стартап FuriosaAI представил эффективный ИИ-ускоритель RNGD для LLM и мультимодальных моделейЮжнокорейский стартап FuriosaAI на мероприятии анонсировал специализированный чип RNGD (произносится как «Renegade»), который позиционируется в качестве альтернативы ускорителям NVIDIA. Новинка предназначена для работы с большими языковыми моделями (LLM) и мультимодальным ИИ. FuriosaAI основана в 2017 году тремя инженерами, ранее работавшими в AMD, Qualcomm и Samsung. Своё первое решение компания выпустила в 2021 году: чип Warboy представляет собой высокопроизводительный ЦОД-ускоритель, специально разработанный для рабочих нагрузок компьютерного зрения. Новое изделие RNGD, как утверждает FuriosaAI, является результатом многолетних инноваций. Чип изготавливается по 5-нм техпроцессу TSMC. ИИ-ускоритель на базе RNGD выполнен в виде карты расширения PCIe 5.0 x16. Он наделён 48 Гбайт памяти HBM3 с пропускной способностью до 1,5 Тбайт/с и 256 Мбайт памяти SRAM (384 Тбайт/с). Показатель TDP находится на уровне 150 Вт, что позволяет использовать устройство в системах с воздушным охлаждением. Для сравнения: у некоторых ускорителей на базе GPU величина TDP достигает 1000 Вт и более. 
Источник изображения: FuriosaAI Утверждается, что RNGD обеспечивает производительность до 512 Тфлопс в режиме FP8 и до 256 Тфлопс в режиме BF16. Быстродействие INT8/INT4 достигает 512/1024 TOPS. Карта позволяет эффективно запускать открытые LLM, такие как Llama 3.1 8B. Говорится, что один PCIe-ускоритель RNGD обеспечивает пропускную способность от 2000 до 3000 токенов в секунду (в зависимости от длины контекста) для моделей с примерно 10 млрд параметров. В системе можно объединить до восьми карт для работы с моделями, насчитывающими около 100 млрд параметров. RNGD основан на архитектуре свёртки тензора (Tensor Contraction Processor, TCP), которая, как отмечается, обеспечивает оптимальный баланс между эффективностью, программируемостью и производительностью. Программный стек состоит из компрессора моделей, сервисного фреймворка, среды выполнения, компилятора, профилировщика, отладчика и набора API для простоты программирования и развёртывания. Говорится, что чипы RNGD можно настроить для выполнения практически любой рабочей нагрузки LLM или мультимодального ИИ.
19.08.2024 [12:52], Сергей Карасёв
Ola представила индийские ИИ-чипы Bodhi 1, Ojas и Sarv 1Компания Ola-Krutrim, дочернее предприятие одного из крупнейших в Индии производителей электрических двухколёсных транспортных средств Ola Electric, по сообщению Tom's Hardware, объявила о разработке первых в стране специализированных чипов для задач ИИ. Анонсированы изделия Bodhi 1, Ojas и Sarv 1. Впоследствии выйдет решение Bodhi 2. Но, судя по всему, речь всё же идёт о совместной работе с Untether AI. Чип Bodhi 1 предназначен для инференса, благодаря чему может использоваться при обработке больших языковых моделей (LLM) и визуальных приложений. По заявлениям Ola Electric, Bodhi 1 обеспечивает «лучшую в своём классе энергоэффективность», что является критически важным параметром для ресурсоёмких ИИ-систем. Чип Sarv 1, в свою очередь, ориентирован на облачные платформы и дата-центры, обрабатывающие ИИ-нагрузки. Процессор Sarv 1 базируется на наборе инструкций Arm. Изделие Ojas предназначено для работы на периферии и может быть оптимизировано под специфичные задачи — автомобильные приложения, Интернет вещей, мобильные сервисы и пр. В частности, сама Ola Electric намерена применять Ojas в своих электрических скутерах следующего поколения для повышения эффективности зарядки, улучшения функциональности систем помощи водителю (ADAS) и пр. 
Источник изображения: Tom's Hardware В рамках презентации Ola Electric продемонстрировала, что её ИИ-решения обеспечивают более высокие производительность и энергоэффективность, нежели ускорители NVIDIA. При этом индийская компания не уточнила, с какими именно ускорителями производилось сравнение. Ожидается, что процессоры Bodhi 1, Ojas и Sarv 1 выйдут на массовый рынок в 2026 году, тогда как Bodhi 2 появится в 2028-м. О том, где планируется изготавливать изделия, пока ничего не сообщается. Одновременно с анонсом индийских чипов производитель ИИ-ускорителей Untether AI объявил о сотрудничестве с Ola-Krutrim, в рамках которого была продемонстрирована производительность текущих решений speedAI и было объявлено о совместной разработке будущих ИИ-ускорителей для ЦОД, которые будут использованы для тюнинга и инференса ИИ-моделей Krutrim. В Индии активно развивается как ИИ-индустрия (в том числе на государственном уровне), так и рынок ЦОД. Попутно страна пытается добиться технологической независимости как от азиатских, так и от западных IT-гигантов.
16.08.2024 [16:56], Руслан Авдеев
Закупочная ёмкость SSD для ИИ-нагрузок превысит 45 Эбайт в 2024 годуСпрос на ИИ-системы и соответствующие серверы привёл к росту заказов на SSD корпоративного класса в последние два квартала. По данным TrendForce, производители компонентов для твердотельных накопителей налаживают производственные процессы, готовясь к массовому выпуску накопителей нового поколения, которые появятся на рынке в 2025. Увеличение заказов корпоративных SSD от пользователей ИИ-серверов привело к росту контрактных цен на эту категорию товаров на более чем 80 % с IV квартала 2023 года по III квартал 2024. При этом SSD играют ключевую роль в развитии ИИ, поскольку только они годятся для эффективной работы с моделями. Помимо собственно хранения данных модели они также нужны для создания контрольных точек во время обучения, чтобы в случае сбоев можно было быстро «откатить» модель и возобновить обучение. Благодаря высокой скорости записи и чтения, а также повышенной надёжности в сравнении с HDD, для тренировки моделей обычно выбирают TLC-накопители ёмкостью 4–8 Тбайт. Эффективность RAG и больших языковых моделей (LLM), особенно для генерации медиаконтента, зависят и от ёмкости, и от производительности накопителей, поэтому для инференса более предпочтительны TLC/QLC-накопители ёмкостью от 16 Тбайт. 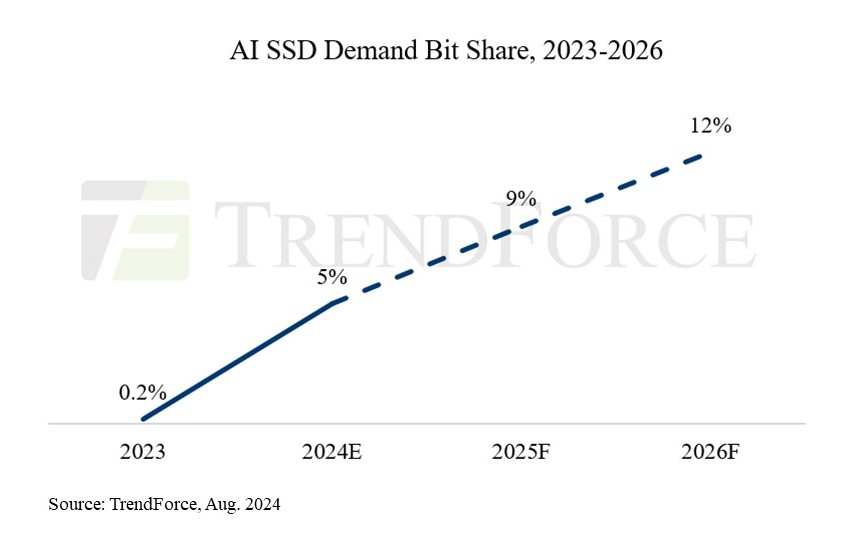
Источник изображения: TrendForce Со II квартала 2024 года спрос на SSD для ИИ-серверов ёмкостью больше 16 Тбайт значительно вырос. С повышением доступности ускорителей NVIDIA H100/H20/H200 клиенты начали наращивать спрос и на TLC SSD на 4 и 8 Тбайт. В агентстве считают, что закупочная ёмкость SSD для в 2024 году превысит 45 Эбайт, а в следующие несколько лет спрос на серверные SSD будет увеличиваться более чем на 60 % ежегодно. В частности, на SSD для ИИ-нагрузок потенциально уйдёт до 9 % всей NAND-памяти в 2025, тогда как в 2024 году этот показатель, как ожидается, составит 5 %.
05.07.2024 [09:18], Владимир Мироненко
Потрать доллар — получи семь: ИИ-арифметика от NVIDIANVIDIA заявила, что инвестиции в покупку её ускорителей весьма выгодны, передаёт ресурс HPCwire. По словам NVIDIA, компании, строящие огромные ЦОД, получат большую прибыль в течение четырёх-пяти лет их эксплуатации. Заказчики готовы платить миллиарды долларов, чтобы не отстать в ИИ-гонке. «Каждый доллар, вложенный провайдером облачных услуг в ускорители, вернётся пятью долларами через четыре года», — заявил Иэн Бак (Ian Buck), вице-президент HPC-подразделения NVIDIA на конференции BofA Securities 2024 Global Technology Conference. Он отметил, что использование ускорителей для инференса несёт ещё больше выгоды, позволяя получить уже семь долларов за тот же период. Как сообщается, инференс ИИ-моделей Llama, Mistral и Gemma становится всё масштабнее. Для удобства NVIDIA упаковывает открытые ИИ-модели в оптимизированные и готовые к запуску контейнеры NIM. Компания отметила, что её новейшие ускорители Blackwell оптимизированы для инференса. Они, в частности, поддерживают типы данных FP4/FP6, что повышает энергоэффективность оборудования при выполнении рабочих нагрузок ИИ с низкой интенсивностью. 
Источник изображений: NVIDIA Провайдеры облачных услуг планируют строительство ЦОД на пару лет вперёд и хотят иметь представление о том, какими будут ускорители в обозримом будущем. Бак отметил, что провайдерам важно знать, как будут выглядеть ЦОД с серверами на базе чипов Blackwell и чем они будут отличаться от дата-центров на Hopper. Скоро на смену Blackwell придут ускорители Rubin. Их выпуск начнётся в 2026 году, так что гиперскейлерам уже можно готовиться к обновлению дата-центров. Как ожидается, чипы Blackwell, первые партии которых будут поставлены к концу года, будут в дефиците. «С каждым новым технологическим переходом возникает… сочетание проблем спроса и предложения», — отметил Бак. По его словам, операторы ЦОД постепенно отказываются от инфраструктуры на базе CPU, освобождая место под большее количество ускорителей. Ускорители Hopper пока остаются в ЦОД и всё ещё будут основными «рабочими лошадками» для ИИ, но вот решения на базе архитектур Ampere и Volta уже перепродаются.  Microsoft и Google сделали ставку на ИИ и сейчас работают над более функциональными большими языковыми моделями, причём Microsoft (и OpenAI) в значительной степени полагается на ускорители NVIDIA, тогда как Google опирается на TPU собственной разработки для использования в своей ИИ-инфраструктуре. Пока что самая крупная модель насчитывает порядка 1,8 трлн параметров, но по словам Бака, это только начало. В дальнейшем появятся модели с триллионами параметров, вокруг которой будут построены более мелкие и более специализированные модели. Так, свежая GPT-модель (вероятно, речь о GPT-4o) включает 16 отдельных нейросетей. NVIDIA уже адаптирует свои ускорители к архитектуре Mixture of Experts (MoE, набор экспертов), где процесс обработки запроса пользователя делится между несколькими специализированными «экспертными» нейросетями. GB200 NVL72, по словам Бака, идеально подходит для MoE благодаря множеству ускорителей связанных быстрым интерконнектом, каждый из которых может обрабатывать часть запроса и быстро делится ответом с другими.
29.06.2024 [21:18], Владимир Мироненко
Omdia: ИИ-приложения станут основной нагрузкой в ЦОД и подстегнут рост расходов на серверыВ настоящее время ИИ является основным драйвером инвестиций в ЦОД, капитальные затраты на которые в этом году вырастут почти на 30 %, пишет The Register со ссылкой на исследование Omdia. Согласно прогнозу аналитиков, в течение нескольких лет ИИ станет основной серверной рабочей нагрузкой в ЦОД. Приложения ИИ являются наиболее быстрорастущей категорией среди нагрузок, исходя из количества развёртываемых в год серверов. Согласно данным Omdia, рост расходов на серверы в прошлом году полностью приходится на ИИ-оборудование. В 2024 году спрос на использование ИИ ускорил инвестиции в ЦОД — капитальные затраты, «подкреплённые корпоративными денежными резервами крупных гиперскейлеров», как ожидает Omdia, вырастут на 28,5 %. По подсчётам Omdia, продажи серверов в этом году вырастут на 74 % до $210 млрд с $121 млрд в 2023 году. В дальнейшем количество серверов для обучения ИИ будет расти примерно на 5 % в год до чуть менее 1 млн/год в 2029 году. А количество серверов для инференса будет расти со скоростью 17 % в год, и к 2029 году годовые поставки достигнут 4 млн шт. Это объясняется тем, что серверы для обучения ИИ в основном нужны небольшому количеству гиперскейлеров. Они сосредоточены на достижении максимальной эффективности своего ИИ-оборудования и у них нет потребности закупать много серверов. 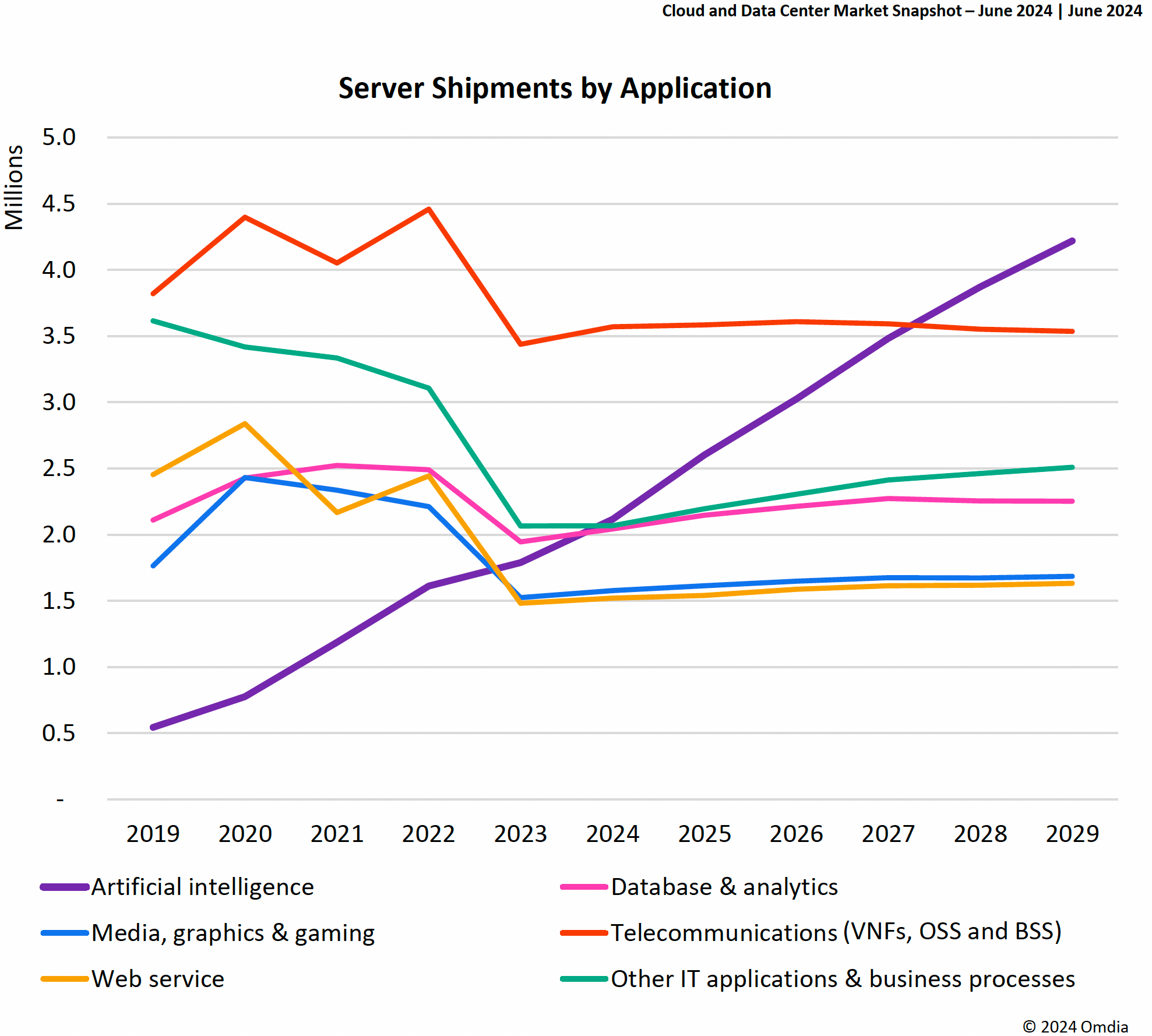
Источник изображений: Omdia В Omdia считают, что обучение ИИ можно классифицировать как деятельность в области НИОКР, и поэтому, оно будет подлежать плановому распределению бюджета, то есть реинвестированию доли доходов. А количество серверов, необходимых для инференса, наоборот, будет расти по мере увеличения аудитории пользователей приложений ИИ. Как утверждают в Omdia, в основном в течение следующих пяти лет будут продолжать быстро расти продажи ИИ-серверов, а рост поставок других типов серверов будет значительно меньше. 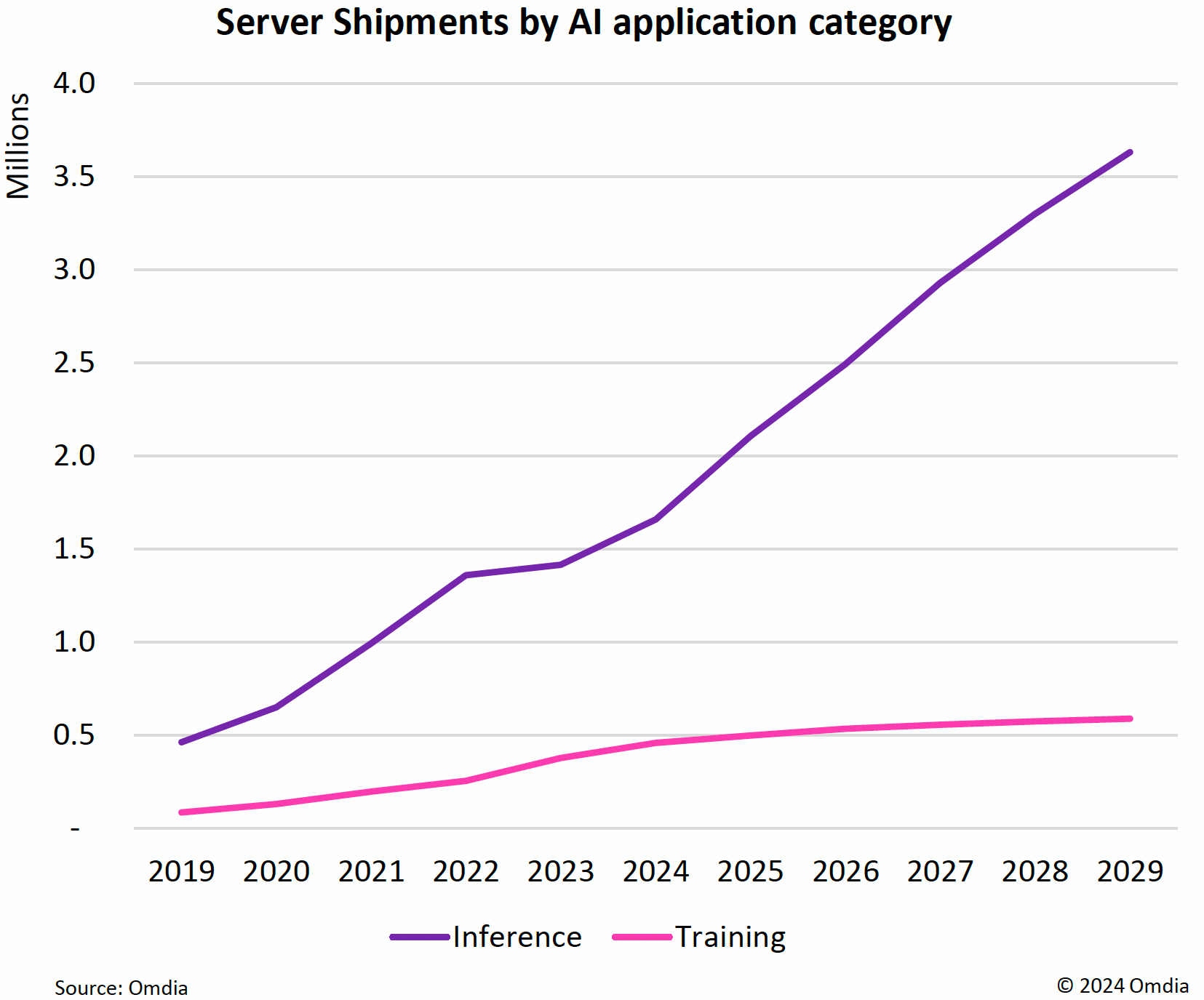 Прогнозируется, что расходы на управление температурным режимом в ЦОД вырастут в 2024 году на 22 % год к году до $9,4 млрд. Побочным эффектом роста спроса на более мощное серверное оборудование стал бум внедрения СЖО. По прогнозам Omdia, общий доход от СЖО превысит к концу этого года отметку в $2 млрд, а к 2028 году будет больше $5 млрд. Доходы от инфраструктуры распределения электроэнергии в этом году впервые превысят $4 млрд, а доходы от источников бесперебойного питания вырастут на 10 % до $13 млрд.
26.06.2024 [01:00], Игорь Осколков
Etched Sohu — самый быстрый в мире ИИ-ускоритель, но только для трансформеровСтартап Etched, основанный в 2022 году выпускниками Гарварда, анонсировал самый быстрый, по его словам, ИИ-ускоритель Sohu. Секрет высокой производительности очень прост — Sohu представляет собой узкоспециализированный 4-нм ASIC, который умеет работать только с моделями-трансформерами. При этом в длинном анонсе новинки обещана чуть ли не революция в мире ИИ. Etched прямо говорит, что делает ставку на трансформеры, и надеется, что не прогадает. Данная архитектура ИИ-моделей была создана в недрах Google в 2017 году, но сама Google распознать её потенциал, по-видимому, вовремя не смогла. Сейчас же, по словам Etched, практически все массовые ИИ-модели являются именно трансформерами, а стремительно набирать популярность этот подход начал всего полтора года назад с выходом ChatGPT, хотя в Etched «предугадали» важность трансформеров ещё до выхода детища OpenAI. 
Источник изображений: Etched Etched в целом справедливо отмечает, что подавляющее большинство ИИ-ускорителей умышленно создаётся так, чтобы быть достаточно универсальными и уметь работать с различными типами и архитектурами ИИ-моделей. Это ведёт к взрывному росту транзисторного бюджета и уменьшению общей эффективности. Так, по словам Etched, загрузка ускорителя на базе GPU работой на практике составляет около 30 %, а у Sohu она будет на уровне 90 %.  Тут есть некоторое лукавство, потому что Etched в основном говорит о «больших» ускорителях, ориентированных и на обучение тоже, тогда как Sohu предназначен исключительно для инференса. На практике же бывают и гибридные подходы. Например, у AWS есть не только Trainium, но Inferentia. Meta✴ использует чипы NVIDIA для обучения, но для инференса разрабатывает собственные ускорители MTIA. Cerebras практически отказалась от инференса, а Groq — от обучения моделей. Корректнее было бы сравнить именно инференс-ускорители, пусть даже никто из упомянутых Etched конкурентов не ориентирован исключительно на трансформеры. 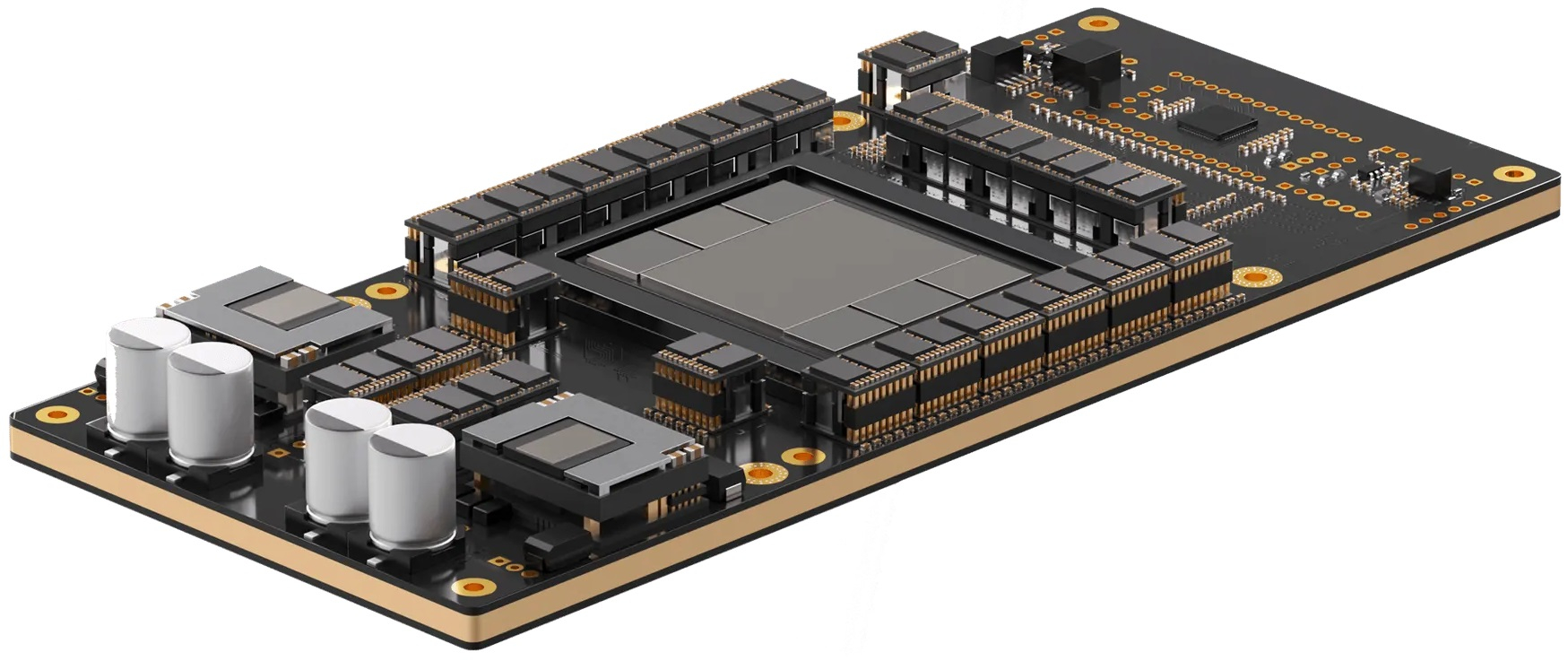 Также стартап критикует громоздкую программную экосистему для современного генеративного ИИ, к тому же не всегда открытую. Важность оптимизации ПО хороша видна на примере NVIDIA TensorRT-LLM. Но крупным компаниям этого мало, они готовы вкладывать немало средств в глубокую оптимизацию, чтобы ещё чуть-чуть повысить производительность. Дело доходит до выяснения того, у какого регистра задержка меньше при работе с каким тензорным ядром, говорит Etched. Стартап обещает, что его заказчикам не придётся заниматься такими изысканиями — весь программный стек будет open source. Впрочем, на примере AMD ROCm видно, что открытость ещё не означает мгновенный успех у пользователей. 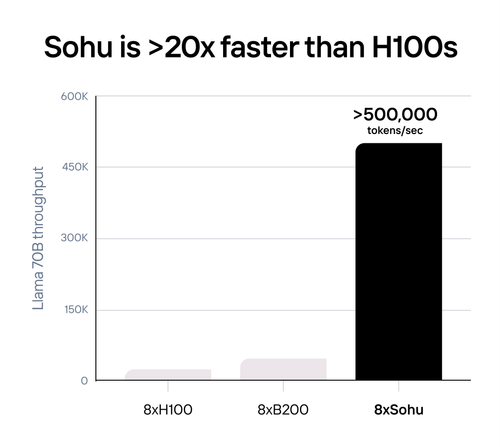 Технические характеристики Sohu не раскрываются. Явно говорится лишь о наличии 144 Гбайт HBM3e. Обещанная производительность сервера с восемью ускорителями Sohu составляет 500 тыс. токенов в секунду для Llama 70B: FP8 без разреженности, параллелизм на уровне модели, 2048 токенов на входе и 128 токенов на выходе. Иными словами, один такой сервер Sohu заменяет сразу 160 ускорителей NVIDA H100, говорит Etched. А вот про масштабируемость своих платформ компания пока ничего не говорит. Зато хвастается, что первые заказчики уже зарезервировали Sohu на десятки миллионов долларов. |
|