Материалы по тегу: инференс
|
25.03.2024 [21:23], Владимир Мироненко
Samsung поставит Naver ИИ-ускорители Mach-1 на $752 млнКомпания Samsung Electronics поставит в этом году ведущей южнокорейской интернет-компании Naver Corp. ИИ-ускорители Mach-1 следующего поколения собственной разработки. Сумма контракта составит до ₩1 трлн (около $752 млн), сообщил ресурс KED Global со ссылкой на отраслевые источники. Это позволит Naver значительно сократить зависимость от поставок ускорителей NVIDIA. В октябре прошлого года Naver вынужденно стала использовать процессоры Intel Xeon вместо ускорителей NVIDIA. Смена оборудования Naver происходит на фоне роста недовольства технологических компаний увеличением цен на ускорители NVIDIA и их глобальной нехваткой. По словам Samsung, Mach-1 был разработан для поддержки Transformer-моделей и позволяет выполнять инференс больших языковых моделей (LLM) даже с маломощной памятью вместо энергоёмкой HBM, что делает его в восемь раз энергоэффективнее традиционных ускорителей на базе GPU. При этом Mach 1 на порядок дешевле чипов NVIDIA. По словам источников, бизнес-подразделение Samsung System LSI и Naver находятся в заключительной стадии переговоров о поставке 150–200 тыс. ИИ-ускорителей Mach-1, цена которых может составить ₩5 млн ($3756) за штуку. Цены и точный объём поставок пока не согласованы. Сообщается, что Naver будет использовать Mach-1 для инференса вместо ускорителей NVIDIA в картографическом сервисе AI Naver Place. Naver готова покупать эти чипы и в дальнейшем, если первая партия покажет «хорошую производительность», отметили источники, по словам которых Samsung также ведёт переговоры о поставках Mach-1 с Microsoft и Meta✴. 
Источник изображения: Samsung Для Samsung сделка с Naver важна с точки зрения конкуренции с SK hynix, доминирующей в сегменте памяти HBM, спрос на которую в связи с популярностью генеративного ИИ резко вырос. Samsung сообщила о разработке первой в отрасли памяти HBM3E 12-Hi, массовое производство которой начнётся в I половине этого года. Кроме того, SK Group поддерживает разработку ИИ-ускорителей Sapeon, а Samsung сотрудничает с Rebellions. По оценкам Omdia, глобальный рынок ИИ-ускорителей вырастет с $6 млрд в 2023 году до $143 млрд к 2030 году.
23.03.2024 [22:33], Сергей Карасёв
Akamai внедрит в своей сети ПО Neural Magic для ускорения ИИ-нагрузокCDN-провайдер Akamai Technologies объявил о заключении соглашения о стратегическом партнёрстве с компанией Neural Magic, разработчиком специализированного ПО для ускорения рабочих нагрузок, связанных с ИИ. Сотрудничество призвано расширить возможности глубокого обучения на базе распределённой вычислительной инфраструктуры Akamai. Компания Akamai реализует комплексную стратегию по трансформации в распределённого облачного провайдера. В частности, в начале 2023 года Akamai запустила платформу Connected Cloud на базе Linode: это более распределённая альтернатива сервисам AWS или Azure. А в феврале 2024 года была представлена система Gecko (Generalized Edge Compute), которая позволяет использовать облачные вычисления на периферии. 
Источник изображения: pixabay.com В рамках сотрудничества с Neural Magic провайдер предоставит клиентам высокопроизводительную инференс-платформу. Утверждается, что софт Neural Magic даёт возможность запускать ИИ-модели на обычных серверах на базе CPU без дорогостоящих ускорителей на основе GPU. ПО позволяет ускорить выполнение ИИ-задач с помощью технологий автоматического разрежения моделей (model sparsification). Софт Neural Magic дополнит возможности Akamai по масштабированию, обеспечению безопасности и доставке приложений на периферии. Это позволит компаниям развёртывать ИИ-сервисы в инфраструктуре Akamai c более низкими задержками и повышенной производительностью без необходимости аренды GPU-ресурсов. Платформа Akamai и Neural Magic особенно хорошо подходит для ИИ-приложений, в которых большие объёмы входных данных генерируются близко к периферии.
21.03.2024 [00:51], Владимир Мироненко
Облачный ИИ-суперкомпьютер AWS Project Ceiba получит 21 тыс. суперчипов NVIDIA GB200
aws
b100
dgx cloud
gb200
gtc 2024
hardware
nvidia
ии
инференс
информационная безопасность
облако
суперкомпьютер
Amazon Web Services (AWS) и NVIDIA объявили о расширении сотрудничества, в рамках которого ускорители GB200 и B100 вскоре появятся в облаке AWS. Кроме того, компании объявили об интеграции Amazon SageMaker с NVIDIA NIM для предоставления клиентам более быстрого и дешёвого инференса, о появлении в AWS HealthOmics новых базовых моделей NVIDIA BioNeMo, а также о поддержке AWS обновлённой платформы NVIDIA AI Enterprise. Сотрудничество двух компаний позволило объединить в единую инфраструктуру их новейшие технологии, в том числе многоузловые системы на базе чипов NVIDIA Blackwell, ПО для ИИ, AWS Nitro, сервис управления ключами AWS Key Management Service (AWS KMS), сетевые адаптеры Elastic Fabric (EFA) и кластеры EC2 UltraCluster. Предложенная инфраструктура и инструменты позволят клиентам создавать и запускать LLM с несколькими триллионами параметров быстрее, в больших масштабах и с меньшими затратами, чем позволяли EC2-инстансы с ускорителями NVIDIA прошлого поколения. AWS предложит кластеры EC2 UltraClusters из суперускорителей GB200 NVL72, которые позволят объединить тысячи чипов GB200. GB200 будут доступны и в составе инстансов NVIDIA DGX Cloud. AWS также предложит EC2 UltraClusters с ускорителями B100. Amazon отмечает, что сочетание AWS Nitro и NVIDIA GB200 ещё больше повысит защиту ИИ-моделей: GB200 обеспечивает шифрование NVLink, EFA шифрует данные при передаче между узлами кластера, а KMS позволяет централизованно управлять ключами шифрования. 
Источник изображения: NVIDIA Аппаратный гипервизор AWS Nitro, как и прежде, разгружает CPU узлов, беря на себя обработку IO-операций, а также защищает код и данные во время работы с ними. Эта возможность, доступная только в сервисах AWS, была проверена и подтверждена NCC Group. Инстансы с GB200 поддерживают анклавы AWS Nitro Enclaves, что позволяет напрямую взаимодействовать с ускорителем и данными в изолированной и защищённой среде, доступа к которой нет даже у сотрудников Amazon. 
Источник изображения: NVIDIA Чипы Blackwell будут использоваться в обновлённом облачном суперкомпьютере AWS Project Ceiba, который будет использоваться NVIDIA для исследований и разработок в области LLM, генерация изображений/видео/3D, моделирования, цифровой биологии, робототехники, беспилотных авто, предсказания климата и т.д. Эта первая в своём роде машина на базе GB200 NVL72 будет состоять из 20 736 суперчипов GB200, причём каждый из них получит 800-Гбит/с EFA-подключение. Пиковая FP8-производительность системы составит 414 Эфлопс.
20.03.2024 [22:19], Сергей Карасёв
Samsung создала лабораторию по разработке ИИ-чипов нового поколенияКомпания Samsung Electronics, по сообщению Bloomberg, сформировала лабораторию, специалистам которой предстоит заняться разработкой чипов следующего поколения для ИИ-приложений. Новое подразделение получило название Samsung Semiconductor AGI Computing Lab: его офисы будут располагаться в Южной Корее и США. Главной задачей лаборатории является проектирование полупроводниковых чипов, способных справляться с высокими вычислительными нагрузками, связанными с развитием так называемого «общего искусственного интеллекта» (Artificial General Intelligence, AGI). Речь идёт о системах, которые по возможностям смогут как минимум не уступать человеческому мозгу, а, возможно, и превосходить его. 
Источник изображения: pixabay.com Современные ИИ-модели функционируют в рамках набора данных, на которых производилось обучение. Концепция AGI, в свою очередь, предполагает, что ИИ-система может выполнять задачи, для которых она изначально не обучалась. Такие модели должны обладать достаточной степенью самосознания и способностью осваивать новые навыки без вмешательства человека. Иными словами, AGI — это универсальный ИИ, способный решать сложные задачи, применяя обобщенные когнитивные способности. Фактически такая нейросеть может стать полноценной альтернативой человеческому мозгу. Однако для поддержания работы AGI потребуются чипы нового поколения, обладающие необходимой производительностью при сравнительно небольшом энергопотреблении. Для достижения таких характеристик Samsung планирует переосмыслить все аспекты архитектуры процессоров, включая память, интерконнект и даже упаковку. На первом этапе новая лаборатория сосредоточится на разработке чипов для больших языковых моделей (LLM) с упором на инференс. Руководителем Samsung Semiconductor AGI Computing Lab назначен Дон Хёк Ву (Dong Hyuk Wu), который ранее занимал должность старшего инженера-программиста Google.
19.03.2024 [03:18], Владимир Мироненко
Всё своё ношу с собой: NVIDIA представила контейнеры NIM для быстрого развёртывания оптимизированных ИИ-моделейКомпания NVIDIA представила микросервис NIM, входящий в платформу NVIDIA AI Enterprise 5.0 и предназначенный для оптимизации запуска различных популярных моделей ИИ от NVIDIA и её партнёров. NVIDIA NIM позволяет развёртывать ИИ-модели в различных инфраструктурах: от локальных рабочих станций до облаков. Предварительно созданные контейнеры и Helm Chart'ы с оптимизированными моделями тщательно проверяются и тестируются на различных аппаратных платформах NVIDIA, у поставщиков облачных услуг и на дистрибутивах Kubernetes. Это обеспечивает поддержку всех сред с ускорителями NVIDIA и гарантирует, что компании смогут развёртывать свои приложения генеративного ИИ где угодно, сохраняя полный контроль над своими приложениями и данными, которые они обрабатывают. Разработчики могут получить доступ к моделям посредством стандартизированных API, что упрощает разработку и обновление приложений. 
Источник изображений: NVIDIA NIM также может использоваться для оптимизации исполнения специализированных решений, поскольку не только использует NVIDIA CUDA, но и предлагает адаптацию для различных областей, таких как большие языковые модели (LLM), визуальные модели (VLM), а также модели речи, изображений, видео, 3D, разработки лекарств, медицинской визуализации и т.д. NIM использует оптимизированные механизмы инференса для каждой модели и конфигурации оборудования, обеспечивая наилучшую задержку и пропускную способность и позволяя более просто и быстро масштабироваться по мере роста нагрузок. 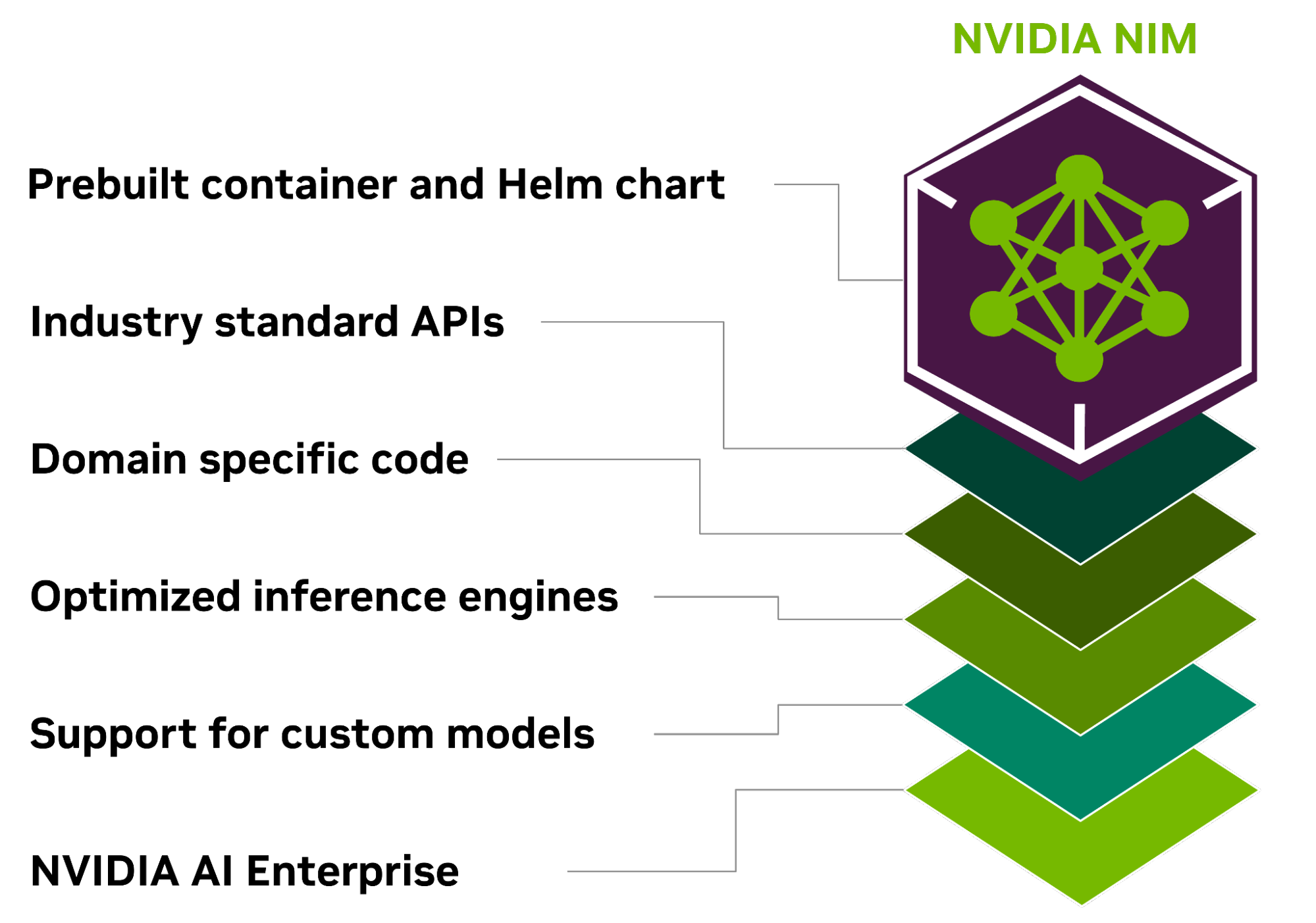 В то же время NIM позволяет дообучить и настроить модели на собственных данных, поскольку можно не только воспользоваться облачными API NVIDIA для доступа к готовым моделями, но и самостоятельно развернуть NIM в Kubernetes-средах у крупных облачных провайдеров или локально, что сокращает время разработки, сложность и стоимость подобных проектов и позволяет интегрировать NIM в существующие приложения без необходимости глубокой настройки или специальных знаний.
19.03.2024 [02:16], Владимир Мироненко
NVIDIA AI Enterprise 5.0 предложит микросервисы, которые ускорят развёртывание ИИNVIDIA представила свежую версию платформы для работы с ИИ-приложениями NVIDIA AI Enterprise 5.0, которая включает микросервисы на базе загружаемых программных контейнеров для быстрого развёртывания приложений генеративного ИИ. NVIDIA отметила, что уже микросервисы адаптируются ведущими поставщиками ПО и платформ кибербезопасности, а все функции AI Enterprise 5.0 вскоре будут доступны в облачных маркетплейсах AWS, Google Cloud, Microsoft Azure и Oracle Cloud. Микросервисы позиционируются компанией как эффективный инструмент для создания разработчиками современных корпоративных приложений в глобальном масштабе. Работая прямо в браузере, разработчики могут используют для создания приложений облачные API. NVIDIA AI Enterprise 5.0 теперь включает предназначенные для развёртывания моделей ИИ микросервисы NIM и микросервисы CUDA-X. Сюда входит и NVIDIA cuOpt, ИИ-микросервис для задачи логистики, который позволяет значительно ускорить оптимизации маршрута и расширить возможности динамического принятия решений, снижая затраты, экономя время и позволяя сократить выбросы CO2. 
Источник изображения: NVIDIA NIM оптимизирует инференс-нагрузки для различных популярных моделей ИИ от NVIDIA и партнёров. Используя ПО NVIDIA для инференса, включая Triton Inference Server, TensorRT и TensorRT-LLM, NIM позволяет сократить развёртывание моделей с недель до минут и вместе с тем обеспечивает безопасность и управляемость в соответствии с отраслевыми стандартами, а также совместимость с инструментами управления корпоративного уровня. В настоящее время компания работает над расширением возможностей AI Enterprise. С выходом версии NVIDIA AI Enterprise 5.0 платформа получила ряд дополнений. В частности, она теперь включает NVIDIA AI Workbench, набор инструментов для разработчиков, обеспечивающих быструю загрузку, настройку и запуск проектов генеративного ИИ. ПО теперь общедоступно и поддерживается NVIDIA. NVIDIA AI Enterprise 5.0 также теперь поддерживает платформу Red Hat OpenStack. Кроме того, в NVIDIA AI Enterprise 5.0 расширена поддержка широкого спектра новейших ускорителей NVIDIA, сетевого оборудования и ПО для виртуализации.
15.03.2024 [22:43], Алексей Степин
Tenstorrent под руководством Джима Келлера представила свои первые ИИ-ускорители Grayskull на базе RISC-VКанадский разработчик микрочипов Tenstorrent, возглавляемый легендарным Джимом Келлером (Jim Keller), наконец, представил свои первые решения на базе архитектуры RISC-V — ИИ-процессоры Grayskull и ускорители на их основе, Grayskull e75 и e150. Оба варианта доступны для приобретения уже сейчас по цене $599 за младшую версию и $799 за старшую. Данные решения предназначены для инференс-систем, разработки и отладки ПО. В комплект разработчика входят инструменты TT-Buda и TT-Metalium. В первом случае речь идёт о высокоуровневом стеке, предназначенном для компиляции и запуска ИИ-моделей на аппаратном обеспечении Tenstorrent, а во втором — о низкоуровневой программной платформе, обеспечивающей прямой доступ к аппаратным ресурсам. Поддерживается PyTorch, ONNX и другие фреймворки. Создатели делают особенный упор на простоте программирования в сравнении с классическими GPU. Поддерживается широкий спектр ИИ-моделей, но Tenstorrent особенно выделяет BERT, ResNet, Whisper, YOLOv5 и U-Net. 
Источник изображений здесь и далее: Tenstorrent Архитектура Grayskull базируется на RISC-V, в настоящий момент максимальное количество фирменных ядер Tensix достигает 120, работают они на частотах вплоть до 1,2 ГГц. Каждое такое ядро содержит пять полноценных ядер RISC-V, блок тензорных операций, блок SIMD для векторных операций, а также ускорители сетевых операций и сжатия/декомпрессии данных. Дополнительно каждое ядро может иметь до 1,5 Мбайт сверхбыстрой памяти SRAM. Между собой ядра общаются напрямую.  В случае Grayskull e150 процессор работает в полной конфигурации со 120 ядрами и 120 Мбайт SRAM, объём внешней памяти LPDDR4 составляет 8 Гбайт (ПСП 118,4 Гбайт/с). Ускоритель выполнен в формате полноразмерной платы расширения с теплопакетом 200 Вт и интерфейсом PCIe 4.0 x16. У младшей модели, Grayskull e75, активных ядер только 96, их частота снижена до 1 ГГц, а пропускная способность внешней памяти при том же объёме снижена до 102,4 Гбайт/с. При этом теплопакет составляет всего 75 Вт, что позволило выполнить ускоритель в виде низкопрофильной платы расширения и обойтись без дополнительного питания.  Чипы Wormhole тоже используют Tensix. В составе Wormhole n300 таких ядер 128 (2 × 64), частота равна 1 ГГц при теплопакете 300 Вт. Объём SRAM составляет 1,5 Мбайт на ядро, а внешняя подсистема памяти включает 24 Гбайт GDDR6 и с ПСП 576 Гбайт/с. Wormhole n150 оснащены 72 ядрами Tensix, 108 Мбайт SRAM и 12 Гбайт GDDR6 с ПСП 288 Гбайт/с. TDP составляет 160 Вт. От Grayskull эти решения отличаются возможностью масштабирования путём прямого объединения плат. Также есть по паре сетевых интерфейсов 200GbE. Возможна работа с форматами FP8/16/32, TF32, BFP2/4/8, INT8/16/32 и UINT8. Чипы Tenstorrent Grayskull и Wormhole лежат в основе уникальных масштабируемых платформ собственной разработки — AICloud и Galaxy. В первом случае используются процессоры Grayskull, поскольку Wormhole на рынке должен появиться позже. Платформа предназначена в качестве аппаратной для ИИ и HPC-нагрузок в облаке Tenstorrent. 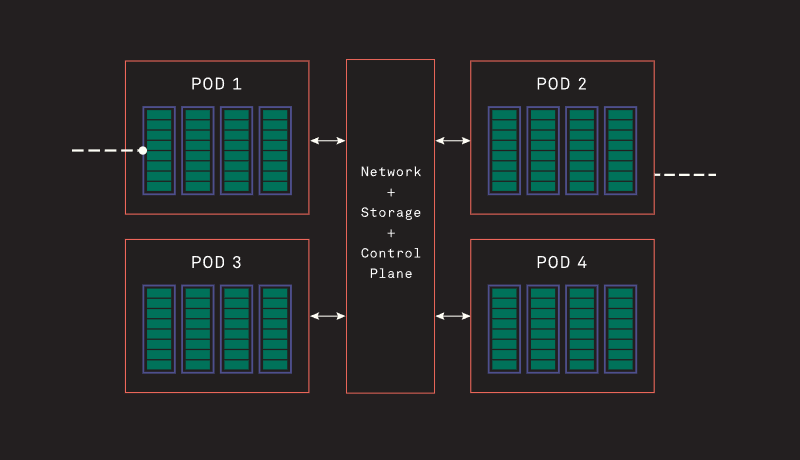 Каждый 4U-узел AICloud высотой содержит восемь карт (16 чипов) и способен предоставить в распоряжение пользователей от 30 до 60 vCPU и от 256 до 1024 Гбайт памяти, вкупе с дисковым пространством объёмом 100–400 Гбайт. Восемь таких узлов составляют стойку, а четыре стойки — кластер Server Pod. Четыре таких кластера объединены общей системой интерконнекта, управления и СХД (до 200 Тбайт), дальнейшее масштабирование уже выходит на уровень ЦОД. 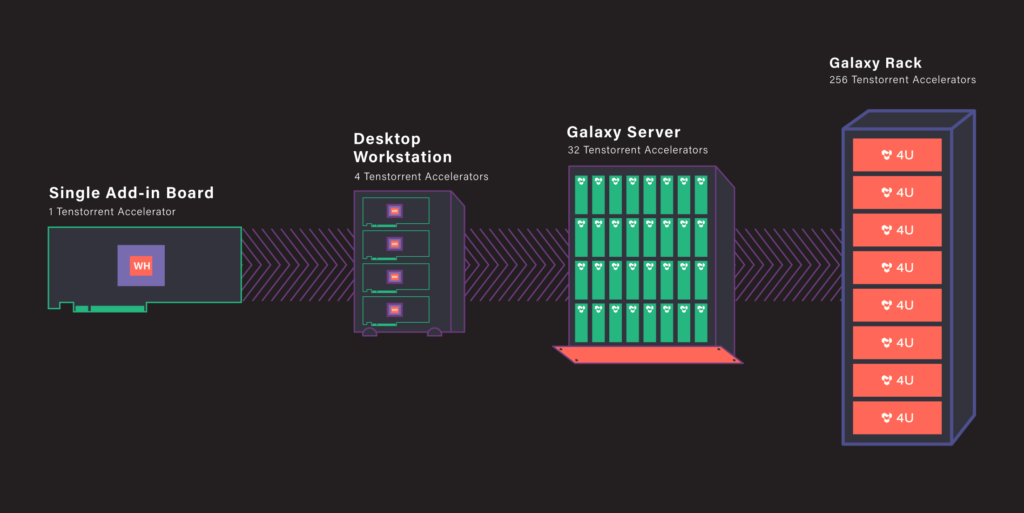 В Tenstorrent Galaxy упор сделан на возможность создания высокопроизводительных ИИ-систем с быстрым интерконнектом на базе Ethernet. Строительным блоком здесь являются 80-ядерные модули Wormhole. 4U-сервер вмещает 32 таких модуля, что в совокупности даёт 2560 ядер Tensix и 384 Гбайт глобально адресуемой GDDR6. Наличие 16 каналов 200GbE в каждом модуле обеспечивает производительность интерконнекта на уровне 3,2 Тбитс. На уровне стойки высотой 48U это дает 256 чипов Wormhole, общий объём SRAM в этом случае достигает 30,7 Гбайт, а GDDR6 — 3 Тбайт. Производительность стойки оценивается разработчиками в 20 Попс (Петаопс), а совокупная скорость интерконнекта — в 76,8 Тбит/с. Расплатой за универсальность и производительность станет энергопотребление, достигающее 60 КВт.
26.02.2024 [23:34], Владимир Мироненко
Groq LPU способен успешно конкурировать с ускорителями NVIDIA, AMD и IntelСтартап Groq сообщил о значительных достижениях в области инференса с использованием ускорителя LPU, разработанного для запуска больших языковых моделей (LLM), таких как GPT, Llama и Mistral. Groq LPU имеет один массивно-параллельный тензорный процессор TSP, который обеспечивает производительность до 750 TOPS INT8 и до 188 Тфлопс FP16. LPU Groq оснащён локальной SRAM объемом 230 Мбайт с пропускной способностью 80 Тбайт/с. Как сообщает компания, при запуске модели Mixtral 8x7B ускоритель LPU обеспечил скорость инференса 480 токенов в секунду, что является одним из ведущих показателей инференса в отрасли. В таких моделях, как Llama 2 70B с длиной контекста 4096 токенов, Groq может обеспечить скорость инференса 300 токенов/с, тогда как в меньшей модели Llama 2 7B с 2048 токенами контекста скорость инференса составляет 750 токенов/с. 
Изображение: Groq Согласно рейтингу бенчмарка LLMPerf, LPU Groq превосходит результаты систем облачных провайдеров на базе традиционных ИИ-ускорителей в деле запуска LLM Llama в конфигурациях от 7 до 70 млрд параметров. Groq лидирует по скорости инференса и занимает второе место по показателю задержки. 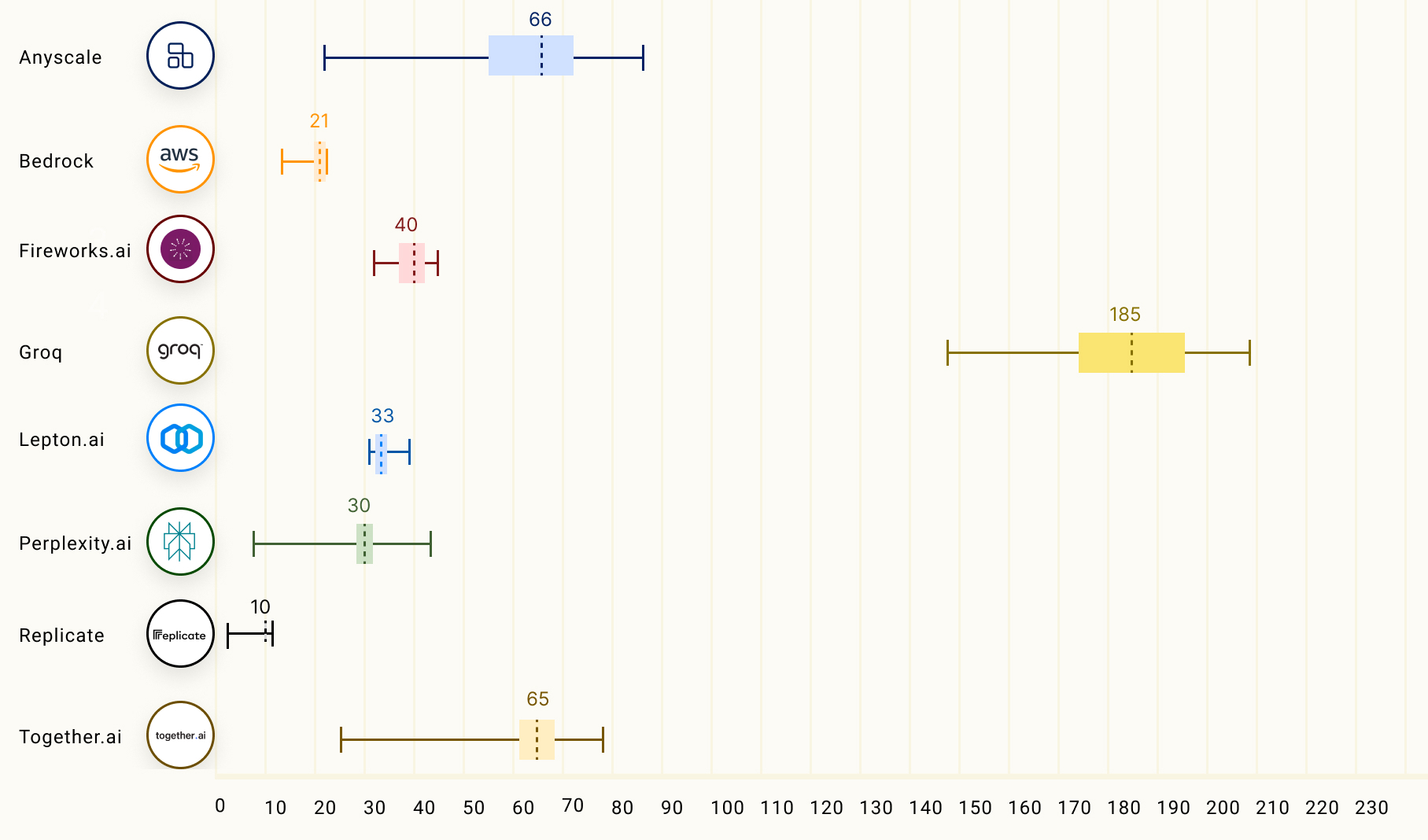
Источник: The Ray Team Для сравнения, бесплатный чат-бот ChatGPT на базе GPT-3.5 обеспечивает обработку около 40 токенов/с. Текущие LLM с открытым исходным кодом, такие как Mixtral 8x7B, могут превосходить GPT 3.5 в большинстве тестов, и теперь могут работать со скоростью почти 500 токенов/с. 
Источник: The Ray Team Опубликованные данные наглядно подтверждают, что предлагаемый Groq ускоритель LPU Groq значительно превосходит системы для инференса, предлагаемые NVIDIA, AMD и Intel, говорит компания. Groq не раскрывает имена своих заказчиков, но в настоящее время её ИИ-решения используются, например, Аргоннской национальной лабораторией Министерства энергетики США.
04.02.2024 [21:02], Сергей Карасёв
Meta✴ намерена активно внедрять собственные ИИ-ускорители Artemis в качестве альтернативы решениям NVIDIA и AMDВ 2024 году компания Meta✴, по сообщению The Register, после многих лет разработки может начать массовое внедрение собственных ИИ-чипов. Они станут альтернативой ускорителям NVIDIA и AMD, что поможет снизить зависимость от продукции сторонних поставщиков. В 2024 году компания намерена потратить до $37 млрд на развитие своей инфраструктуры. В настоящее время для поддержания ИИ-нагрузок Meta✴ применяет такие решения, как NVIDIA H100. Ожидается, что к концу 2024 года компания будет иметь в своём распоряжении 350 тыс. этих ускорителей. Вместе с тем Meta✴ проявляет интерес и к изделиям AMD Instinct MI300. Ранее компания высоко оценила возможности Qualcomm Cloud AI 100, но отказалась от них из-за несовершенства ПО. Не приглянулись Meta✴ и чипы Esperanto. Сейчас Meta✴ ведёт разработку собственных ИИ-ускорителей. 
Источник изображения: Meta✴ Весной 2023 года стало известно, что компания создала свой первый ИИ-процессор. Чип под названием MTIA (Meta✴ Training and Inference Accelerator; на изображении) представляет собой ASIC в виде набора блоков, функционирующих в параллельном режиме. Задействованы 64 вычислительных элемента в виде матрицы 8 × 8, каждый из которых объединяет два ядра с архитектурой RISC-V. Конструкция включает 128 Мбайт памяти SRAM, а также до 64/128 Гбайт памяти LPDDR5. Показатель TDP равен 25 Вт. Заявленная производительность на операциях INT8 достигает 102,4 TOPS, на операциях FP16 — 51,2 Тфлопс. Процессор производится по 7-нм технологии TSMC. 
Источник изображения: Meta✴ Как теперь сообщается, в 2024-м Meta✴ намерена начать активное использование собственных ИИ-ускорителей с кодовым именем Artemis. В их основу лягут компоненты MTIA первого поколения. Чип Artemis, оптимизированный для инференса, будет применяться наряду с ускорителями сторонних поставщиков. При этом, как отметили представители компании, изделия Artemis обеспечат «оптимальное сочетание производительности и эффективности при рабочих нагрузках, специфичных для Meta✴». 
Источник изображения: Meta✴ Компания пока не раскрывает ни архитектуру Artemis, ни конкретные рабочие нагрузки, которые будет поддерживать чип. Участники рынка полагают, что Meta✴ будет запускать готовые ИИ-модели на собственных специализированных ASIC, чтобы высвободить ресурсы ускорителей для развивающихся приложений. По данным SemiAnalysis, Artemis получит улучшенные ядра, а компоненты LPDDR5 уступят место более быстрой памяти, использующей технологию TSMC CoWoS. Нужно добавить, что Amazon и Google уже несколько лет используют собственные чипы для ИИ-задач. Например, Amazon недавно ИИ-ускорители Trainium2 и Inferenetia2, тогда как Google в 2023 году представила сразу два новых ускорителя: Cloud TPU v5p и TPU v5e. А Microsoft сообщила о создании ИИ-ускорителя Maia 100.
10.01.2024 [19:40], Сергей Карасёв
Новые чипы Ambarella привнесут возможности генеративного ИИ в периферийные устройстваКомпания Ambarella сообщила о том, что её SoC обеспечат поддержку генеративного ИИ на периферии. Ожидается, что это позволит расширить возможности множества систем и приложений, включая робототехнику и средства видеоаналитики. Отмечается, что по сравнению с ускорителями на базе GPU и другими специализированными решениями, чипы Ambarella представляют собой полноценные «системы на чипе», которые обеспечивают до трёх раз более высокую энергоэффективность на каждый токен. Изначально Ambarella обеспечит оптимизированные возможности генеративного ИИ на своих SoC среднего и высокого классов. Это, в частности, изделие CV72 для устройств с энергопотреблением до 5 Вт. Кроме того, функции генеративного ИИ будут поддерживать чипы новой серии N1 с «производительностью серверного уровня» при энергопотреблении до 50 Вт. 
Источник изображения: Ambarella Чипы N1 основаны на архитектуре Ambarella CV3-HD, изначально разработанной для приложений автономного вождения. Утверждается, что изделие N1 способно обрабатывать модель Llama2-13B с выводом до 25 токенов в секунду в однопоточном режиме при потребляемой мощности менее 50 Вт. Все изделия Ambarella используют новую платформу для разработчиков Cooper. Чтобы ускорить вывод конечных продуктов на рынок, Ambarella предварительно портировала и оптимизировала популярные большие языковые модели, такие как Llama-2 и LLava. |
|