Лента новостей
|
29.07.2018 [13:00], Геннадий Детинич
Американские ВВС получили самый большой в мире нейроморфный суперкомпьютерЗвучит громко, но это именно так. Лаборатория Air Force Research Laboratory (AFRL) в городе Ром, штат Нью-Йорк, получила в своё распоряжение самый большой в мире компьютер по числу задействованных в системе нейроморфных процессоров IBM TrueNorth. Система представлена полочными компьютерами высотой 4U (7 дюймов) для стандартной серверной стойки. Каждый компьютер располагает 64 процессорами IBM TrueNorth. В пересчёте на человеческие в буквальном смысле единицы измерения мозга — это 64 млн нейронов и 16 млрд синапсов. Всего в стойке может разместиться 512 млн цифровых нейронов. Примерно столько нейронов в коре головного мозга собаки. 
AFRL Система под именем «Blue Raven» на базе IBM TrueNorth для Лаборатории ВВС США представлена пока 64-процессорным решением с общим потреблением 40 Вт. Это, кстати, в 4 раза больше ожидаемого. Аналогичный 16-процессорный компьютер, переданный в 2016 году Ливерморской национальной лаборатории им. Лоуренса, потреблял всего 2,5 Вт или 156 мВт на один процессор. Возможно таким образом была повышена производительность системы, которая при потреблении 70 мВт способна работать с производительностью 46 млрд синаптических операций в секунду. 
IBM По оценкам IBM, работа процессоров TrueNorth с необозначенным датасетом на CIFAR-100 по распознаванию наборов изображений характеризуется производительностью свыше 1500 кадров в секунду с потреблением 200 мВт или свыше 7000 кадров в секунду на ватт. Ускоритель NVIDIA Tesla P4 (Pascal GP104), например, обрабатывает датасет Resnet-50 с производительностью 27 кадров в секунду на ватт. 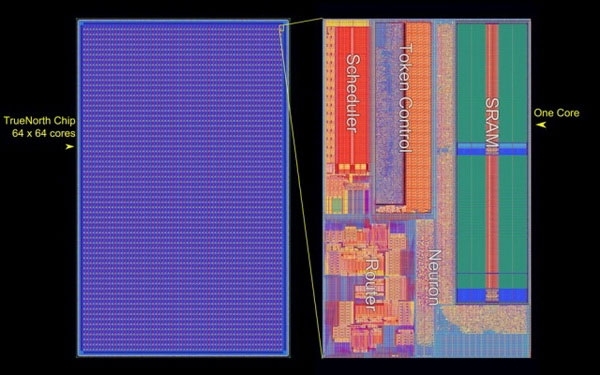
Структура процессора IBM TrueNorth Вообще, в Лаборатории AFRL, похоже, работают увлечённые люди. Новым проектом «Blue Raven» руководит тот же человек (Mark Barnell), который несколько лет назад отметился запуском суперкомпьютера Condor Cluster на базе сотен игровых консолей Sony PlayStation 3. Какими расчётами в AFRL будет заниматься суперкомпьютер с «мозгами» не уточняется. Пока учёные будут изучать круг задач, решаемый подобными системами. Ожидается, что принятая на «вооружение» научным отделом ВВС США вычислительная система обеспечит дальнейшее приоритетное развитие технологий в этой стране.
07.07.2018 [13:35], Андрей Созинов
Китайский серверный процессор Hygon Dhyana построен на архитектуре AMD ZenКитайская компания Hygon начала производство x86-совместимых серверных процессоров Dhyana, построенных на микроархитектуре AMD Zen. Эти процессоры стали плодом совместной работы китайского производителя с компанией AMD, а именно лицензирования технологий последней, связанных с архитектурой x86. Компания AMD утверждает, что она не продаёт свои окончательные проекты чипов китайским партнёрам, а лишь позволяет создавать им свои собственные процессоры на основе её разработок, которые будут адаптированы именно к китайскому рынку. Но это лишь слова, и в реальности процессоры Hygon Dhyana настолько похожи на процессоры AMD Epyc, что разработчики Linux в обновление ядра для обеспечения их поддержки добавили лишь идентификаторы поставщика и номера семейств. А коды поддержки для новых китайских процессоров были полностью заимствованы у Epyc. То есть между процессорами практически нет разницы. 
Источник изображений: AMD Новые китайские серверные процессоры появились как раз во время обостряющейся торговой войны между Китаем и США, так что собственное производство процессоров является стратегически важным для КНР. Также начать производство собственных процессоров Китай подстегнуло то, что в 2015 году администрация Обамы запретила Intel продавать Поднебесной процессоры Xeon из-за того, что они помогают в развитии её ядерной программы.  То, что AMD смогла создать франшизу, которая позволяет китайским производителям процессоров создавать и продавать x86-совместимые процессоры, на этом фоне выглядит ещё более удивительно. Как это удалось американской компании? Если вкратце, то AMD создала в Китае совместное предприятие с местными частными и государственными компаниями. В итоге получилось достаточно сложная структура, но она позволяет лицензировать AMD технологии, связанные с архитектурой x86, не нарушая какие-либо законы или соглашения, с той же Intel.
29.06.2018 [13:00], Геннадий Детинич
Опубликованы финальные спецификации CCIX 1.0: разделяемый кеш и PCIe 4.0Чуть больше двух лет назад в мае 2016 года семёрка ведущих компаний компьютерного сектора объявила о создании консорциума Cache Coherent Interconnect for Accelerators (CCIX, произносится как «see six»). В число организаторов консорциума вошли AMD, ARM, Huawei, IBM, Mellanox, Qualcomm и Xilinx, хотя платформа CCIX объявлена и развивается в рамках открытых решений Open Compute Project и вход свободен для всех. В основе платформы CCIX лежит дальнейшее развитие идеи согласованных (когерентных) вычислений вне зависимости от аппаратной реализации процессоров и ускорителей, будь то архитектура x86, ARM, IBM Power или нечто уникальное. Скрестить ежа и ужа — вот едва ли не буквальный смысл CCIX. 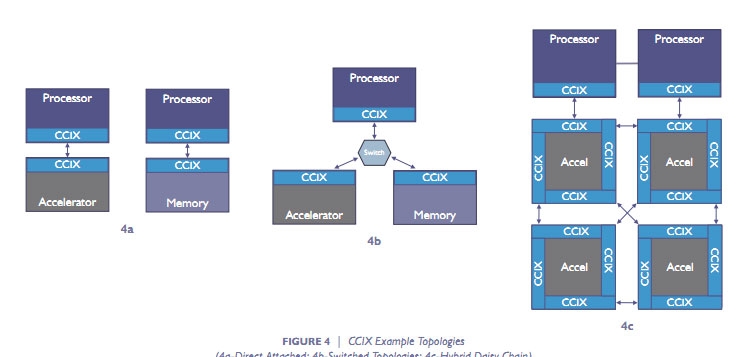
Варианты топологии CCIX На днях консорциум сообщил, что подготовлены и представлены финальные спецификации CCIX первой версии. Это означает, что вскоре с поддержкой данной платформы на рынок может выйти первая совместимая продукция. По словам разработчиков, CCIX позволит организовать новый класс подсистем обмена данными с согласованием кеша с низкими задержками для следующих поколений облачных систем, искусственного интеллекта, больших данных, баз данных и других применений в инфраструктуре ЦОД. Следующая ступенька в производительности невозможна без эффективных гетерогенных (разнородных) вычислений, которые смешают в одном котле исполнение кода общего назначения и спецкода для ускорителей на базе GPU, FPGA, «умных» сетевых карт и энергонезависимой памяти. 
Решение CCIX IP компании Synopsys Базовые спецификации CCIX Base Specification 1.0 описывают межчиповый и «бесшовный» обмен данными между вычислительными ресурсами (процессорными ядрами), ускорителями и памятью во всём её многообразии. Все эти подсистемы объединены разделяемой виртуальной памятью с согласованием кеша. В основе спецификаций CCIX 1.0, добавим, лежит архитектура PCI Express 4.0 и собственные наработки в области быстрой коррекции ошибок, что позволит по каждой линии обмениваться данными со скоростью до 25 Гбайт/с. 
Тестовая платформа с поддержкой CCIX Synopsys на FPGA матрице Но главное, конечно, не скорость обмена, хотя это важная составляющая CCIX. Главное — в создании программируемых и полностью автономных процессов по обмену данными в кешах процессоров и ускорителей, что реализуется с помощью новой парадигмы разделяемой виртуальной памяти для когерентного кеша. Это радикально упростит создание программ для платформ CCIX и обеспечит значительный прирост в ускорении работы гетерогенных платформ. Вместо механизма прямого доступа к памяти (DMA), со всеми его тонкостями для обмена данными, на платформе CCIX достаточно будет одного указателя. Причём обмен данными в кешах будет происходить без использования драйвера на уровне базового протокола CCIX. Ждём в готовой продукции. Кто первый, AMD, ARM или IBM? 
Тестовый набор CCIX 
Рабочая демо-система с неназванным CPU и FPGA, соединённых шиной CCIX
09.11.2017 [13:07], Сергей Карасёв
Начались коммерческие поставки 10-нм серверных чипов Qualcomm Centriq 2400Компания Qualcomm Datacenter Technologies, подразделение Qualcomm Incorporated, объявила о старте коммерческих поставок первых в мире 10-нанометровых серверных процессоров — решений семейства Centriq 2400. О разработке чипов Centriq 2400 стало известно ещё в декабре прошлого года. Позднее Qualcomm раскрыла детали об этих изделиях. И вот теперь настало время массовых поставок процессоров. 
Источник изображений: Qualcomm В основу Centriq 2400 положены 64-битные вычислительные ядра с кодовым именем Falkor, обладающие поддержкой команд ARMv8. Количество таких ядер в составе чипов может достигать 48. Максимальная тактовая частота — 2,6 ГГц.  При изготовлении изделий применяется 10-нанометровая технология Samsung FinFET. Процессоры насчитывают до 18 млрд транзисторов. Каждая пара ядер снабжена 512 Кбайт общей кеш-памяти L2, а объём кеша L3 у чипов достигает 60 Мбайт.  В состав Centriq 2400 вошли 6-канальный контроллер памяти с поддержкой DDR4-2667 МГц ECC (до двух модулей на канал), 32 линии PCI Express 3.0, интерфейсы SATA, USB и пр. 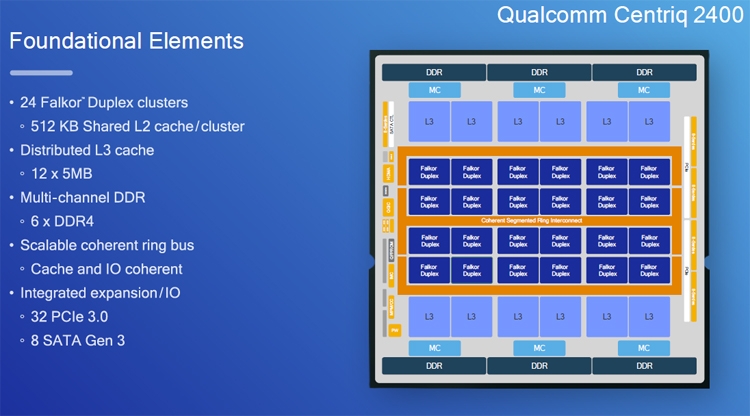 Процессоры ориентированы на современные облачные платформы и центры обработки данных. Более подробную информацию о технических характеристиках можно найти здесь. Что касается стоимости, то изделие Qualcomm Centriq 2460, насчитывающее 48 вычислительных ядер, обойдётся заказчикам в 1995 долларов США.
30.09.2017 [00:15], Алексей Степин
Терафлопс в космосе: на МКС тестируется компьютер HPE SpaceborneБытует мнение, что в космической отрасли используется всё самое лучшее, включая компьютерные компоненты. Это не совсем так: вы не встретите в космических аппаратах 18-ядерных Xeon и ускорителей Tesla. Во-первых, энергетические резервы за пределами Земли строго ограничены, и даже на МКС никто не будет тратить несколько киловатт на питание «космического суперкомпьютера». Во-вторых, практически вся электроника, работающая за пределами атмосферы, выпускается в специальном радиационно-стойком исполнении. Чаще всего за счёт техпроцессов «кремний на диэлектрике» (SOI) и «сапфировая подложка» (SOS), используется также биполярная логика вместо менее стойкой к внешним излучениям CMOS. 
Мини-кластер в космическом исполнении. Охлаждение жидкостное Мощными в космосе считаются такие решения, как BAE Systems серии RAD, особенно новая RAD5500 (от 1 до 4 ядер, 45-нм SOI, PowerPC, 64 бита). Четырёхъядерный вариант RAD5545 развивает производительность более 3,7 гигафлопс при потреблении около 20 ватт. Иными словами, вычислительные мощности в космосе тоже растут, но совсем иными темпами, нежели на Земле. Тому подтверждением служит недавно вступивший в строй на борту Международной космической станции компьютер HPE Spaceborne. Если на Земле мощность суперкомпьютеров измеряется десятками и сотнями петафлопс, то Spaceborne куда скромнее — судя по проведённым тестам, его вычислительная мощность достигает 1 терафлопса. Достигнута она путём сочетания современных процессоров Intel с ускорителями NVIDIA Tesla P100 (NVLink-версия). 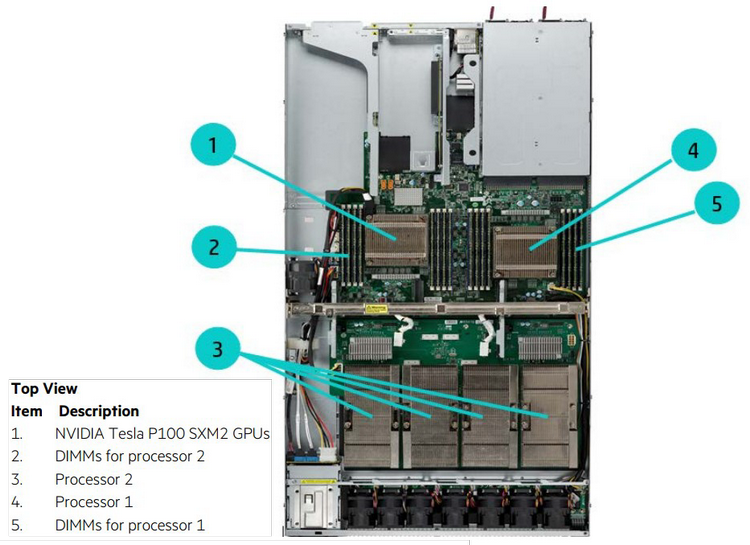
Конфигурация каждого из узлов Spaceborne Для космических систем это большое достижение, и не стоит иронизировать над этим показателем производительности. Интересно, что сама по себе система Spaceborne, доставленная на борт станции миссией SpaceX CRS-12, является своего рода экспериментом на тему «как чувствуют себя в космосе обычные компьютерные комплектующие». Это связка из двух серверов HPE Apollo 40 на базе Intel Xeon, объединённая сетью со скоростью 56 Гбит/с. 14 сентября на систему было подано питание (48 и 110 вольт), а недавно проведены первые тесты High Performance LINPACK. 
Системы охлаждения и электропитания Spaceborne Пока Spaceborne не будет использоваться для анализа научных данных или управления какими-либо системами станции. Его миссия — продемонстрировать то, насколько живучи обычные серверы в космосе. Результаты постоянных тестов будут сравниваться с аналогичной системой, оставшейся на Земле. Тем не менее, достижение первого терафлопса в космосе является своеобразным мировым рекордом. Это маленький шаг для супервычислений, но большой для всей космической индустрии, поскольку за Spaceborne явно последуют его более совершенные и мощные потомки.
05.09.2017 [17:44], Андрей Крупин
«Ростелеком» запустил личный кабинет для операторов связи«Ростелеком» объявил о развёртывании в федеральном масштабе системы «Личный кабинет оператора», позволяющей российским телекоммуникационным компаниям дистанционно заказывать и подключать лицензируемые услуги связи, обмениваться с поставщиком бухгалтерскими документами, узнавать о новых сервисах в режиме онлайн и решать прочие задачи. Новый сервис обеспечивает структурированный учёт информации о взаимодействии, автоматизирует обмен расчётными данными, позволяет сократить сроки обработки заявок и ускорить процесс предоставления новых услуг операторам-партнёрам «Ростелекома». Ожидается, что использование нового инструмента уменьшит число телефонных переговоров и объем рутинного и ручного труда персонала как со стороны операторов связи, так и со стороны «Ростелекома», что позволит существенно сократить сроки заключения договоров и соглашений, а в дальнейшем — и сроки реагирования на различные запросы клиентов.  «Запуск личного кабинета для операторов связи — важный элемент построения технологического партнёрства на телекоммуникационном рынке. «Ростелеком» выполняет функцию не только инфраструктурного оператора, но создателя основы для эффективного межоператорского сотрудничества. Новый сервис позволит повысить прозрачность и оперативность взаимодействия операторов, а также предоставит нашим партнёрам лёгкий дистанционный доступ к телеком-инфраструктуре национального оператора связи и даст возможность пользоваться технологическими достижениями компании», — говорится в сообщении «Ростелекома». В «Ростелекоме» видят огромные перспективы нового сервиса на рынке и поэтому планируют развивать и совершенствовать его функциональные возможности.
04.04.2017 [13:34], Сергей Юртайкин
HPE отделила подразделение IT-услугКорпорация Hewlett Packard Enterprise (HPE) закрыла сделку по передаче бизнеса в области корпоративных IT-услуг конкурирующей компании Computer Sciences. В результате слияния подразделения HPE Enterprise Services, специализирующегося на услугах консалтинга, аутсорсинга и системной интеграции, с Computer Sciences появилась компания DXC Technology. HPE оценивает свои доход от сделки в $13,5 млрд. Сюда входят стоимость доли HPE в новой компании, дивиденды для акционеров и переданные DXC долги и другие обязательства. 
Источник изображения: HPE Объединение HPE Enterprise Services и Computer Sciences было анонсировано в мае 2016 года. Тогда сообщалось, что сделка создаст поставщика IT-услуг с годовой выручкой в $26 млрд, а оставшийся у HPE бизнес (продажа серверов, систем хранения данных, сетевого оборудования, облачных инфраструктур и др. ) будет приносить компании доход в $33 млрд. В совет директоров DXC Technology вошла генеральный директор HPE Мег Уитмен (Meg Whitman). Компании планируют тесно сотрудничать друг с другом. При этом HPE обещает сохранить и развивать созданное недавно подразделение технических услуг Pointnext. После закрытия сделки с Computer Sciences компания HPE понизила прогноз по доходам. К примеру, по итогам текущего финансового года вендор ожидает прибыль на уровне 27–37 центов на акцию, тогда как прежде предсказывал 60–70 центов.
07.12.2016 [14:50], Андрей Крупин
Видео: как работает дата-центр «Яндекса» в ФинляндииКомпания «Яндекс» разместила на своей странице видеохостинга YouTube ролик, рассказывающий об особенностях работы самого энергоэффективного центра обработки данных (ЦОД) российского интернет-гиганта, расположенного в городе Мянтсяля в шестидесяти километрах от Хельсинки (Финляндия). Финский центр обработки данных «Яндекса» является одиннадцатым по счёту ЦОД компании и первым, созданным в соответствие с концепцией GreenField, предполагающей проектирование и строительство здания под дата-центр «с нуля». Площадь вычислительного комплекса составляет 3400 кв. м, его проектная мощность достигает 40 МВт. Объект подключён к двум независимым магистральным источникам электроэнергии по 110 киловольт каждый. Для резервирования энерговводов предусмотрено резервное питание от семи установок DRUPS, за счёт кинетической энергии вращающихся барабанов обеспечивающих автономную работу систем дата-центра на момент запуска дизель-генераторных источников бесперебойного питания. Особенностью дата-центра «Яндекса» в Финляндии является система охлаждения, функционирующая по принципу Free Cooling (для охлаждения оборудования применяется наружный воздух) и позволяющая использовать тепло от серверов в полезных целях — для отопления жилых домов Мянтсяля. Серверы финского ЦОД «Яндекса» охлаждаются уличным воздухом, который впоследствии нагнетается в теплообменники, а те, в свою очередь, нагревают воду до 30-45 градусов. После этого станция донагрева увеличивает температуру воды до 55-60 градусов, которая затем поступает в городскую сеть. Такое сотрудничество с городом позволяет «Яндексу» экономить до трети расходов на электроэнергию, потребляемую дата-центром. «Яндекс» намерен и впредь совершенствовать систему охлаждения серверов уличным воздухом. Задействованные в финском ЦОД энергоэффективные технологии и инновационные решения компания планирует использовать в строящемся во Владимире центре обработки данных. Запуск нового дата-центра ожидается в первом квартале 2017 года.
18.08.2016 [09:50], Валерий Косихин
IDF 2016: Intel анонсировала Knights Mill — новую архитектуру ускорителей Xeon Phi для задач глубинного обученияНа конференции Intel Developer Forum, которая в данный момент проходит в Сан-Франциско, была названа следующая версия архитектуры MIC (Many Integrated Cores), основанные на которой продукты пополнят семейство ускорителей параллельных вычислений Xeon Phi — Knights Mill. От Intel давно не поступало новостей касательно планов по развитию этой линейки устройств. На сегодняшний день Intel выпустила два поколения Xeon Phi — Knights Corner в 2013 году и Knights Landing в 2016-м. Согласно предыдущим заявлениям, третье поколение получит кодовое название Knights Hill, а соответствующие чипы будут производиться по технологической норме 10 нм. В кратком выступлении, которое Intel посвятила анонсу Knights Mill, не пояснили, как новинка соотносится с прошлыми планами. Возможно, что Knights Mill является промежуточной остановкой на пути к Knights Hill. По другой версии, новый продукт олицетворяет ответвление от основного пути развития, предназначенное для специфической ниши — глубинного обучения.  Глубинное обучение — одно из направлений задач машинного обучения, которое предполагает моделирование абстрактных понятий за счет построения многократно ветвящихся графов. На практике это применяется в программах компьютерного зрения, распознавания объектов, человеческой речи и т.п. Определяющий признак, который сделает Knights Mill подходящей платформой для глубинного обучения — то, что Intel довольно расплывчато обозначила термином «переменная точность». Скорее всего, речь идет о поддержке формата чисел с плавающей запятой FP16 (половинная точность) либо других форматов с еще меньшей разрядностью. FP16 является приоритетным форматом для задач глубинного обучения, поскольку они не требуют более высокой точности, а процессор достигает более высокой пропускной способности при условии, что FP16 поддерживается им «в железе». Поддержка половинной точности реализована в GPU последнего поколения от AMD и NVIDIA, и ускорители вычислений Tesla на базе архитектуры Pascal специально оптимизированы для высокой скорости в работе с FP16. Появление чипов Knights Mill упрочит позиции Intel в конкуренции с NVIDIA на этом рынке. При этом разработчики указывают на ряд преимуществ архитектуры MIC по сравнению с графическими процессорами. Xeon Phi, начиная с поколения Kings Landing, существуют в сокетном форм-факторе, который позволяет загружать ОС непосредственно с MIC без необходимости в отдельном CPU традиционной архитектуры. Также, наряду с массивом высокоскоростной набортной памяти MCDRAM (разновидность HBM) Knights Landing, как и его потомок Knights Mill, может напрямую адресовать внешние модули DDR4 SDRAM. NVIDIA Tesla не может похвастаться такими функциями.  Массовое производство чипов Knights Mill намечено на 2017 г. Судя по графику на слайде Intel (который, впрочем, вряд ли отражает какие-либо твердые числа), Knights Mill удвоит показатели быстродействия, характерные для предыдущего поколения Xeon Phi. Это, в свою очередь, сигнализирует о применении техпроцесса 10 нм, и в таком случае не исключено, что Knights Mill — это просто новое название для ранее анонсированной архитектуры Knights Hill.
20.06.2016 [19:30], Илья Гавриченков
Intel представила процессоры Xeon Phi Knights LandingМногоядерные ускорители вычислений Intel Xeon Phi продолжают своё развитие. Об их очередном поколении с кодовым именем Knights Landing разработчик рассказывает уже почти три года, а с конца прошлого года даже поставляет образцы систем с ними своим избранным партнёрам. Однако до официального анонса дело дошло только сейчас. В рамках проходящей в эти дни в Германии конференции ISC High Performance 2016 компания Intel официально объявила о выходе принципиально новых Xeon Phi на базе дизайна Knights Landing, ключевое свойство которых заключается в том, что теперь это — не сопроцессоры, а полноценные x86-процессоры, способные взять на себя роль центрального компонента системы. Иными словами, новые Xeon Phi могут работать полностью самостоятельно, не нуждаясь ни в каком дополнительном управляющем CPU. И это очень важное улучшение, так как проведённое коренное изменение архитектуры ликвидирует узкое место — шину PCI Express, которую используют для передачи данных предшествующие и конкурирующие ускорители вычислений, например, базирующиеся на GPU. 
Источник изображений: Intel Knights Landing воплощают собой уже третье поколение многоядерной x86-архитектуры Intel. Предыдущее поколение, известное под кодовым именем Knights Corner, базировалось на Pentium-подобных ядрах P54C. Новая же версия ускорителей переехала на модифицированную 14-нм микроархитектуру Airmont, известную по процессорам Atom. Однако в Knights Landing ядра Airmont попарно объединены в модули, которые включают также мегабайтный L2-кеш и четыре блока VPU (Vector Processing Unit), отвечающих за поддержку векторных инструкций AVX-512. Всего в новых процессорах Xeon Phi содержится до 36 таких модулей, то есть, общее число ядер в ускорителе может достигать 72. При этом каждое ядро дополнительно поддерживает технологию Hyper-Threading и способно выполнять до четырёх потоков одновременно, что наделяет Xeon Phi впечатляющим арсеналом средств для работы с параллельными вычислениями. Учитывая, что в Knights Landing производительность на поток по сравнению с Knights Corner выросла примерно втрое только за счёт смены микроархитектуры, обновление ускорителей Xeon Phi дало им возможность дотянуться до планки в 3 Тфлопс. Процессоры Knights Landing снабжены также интегрированной памятью MCDRAM с пропускной способностью до 500 Гбайт/с и объёмом 16 Гбайт, которая может взаимодействовать с системной шестиканальной DDR4-памятью по нескольким принципиально различным алгоритмам. Упоминания заслуживает и реализация в новых Xeon Phi отдельного двухпортового 100 Гбит/с-контроллера Omni-Path, который предполагается использовать для высокоскоростного объединения узлов, основанных на Knights Landing, в вычислительные кластеры. Объявленная сегодня линейка процессоров Xeon Phi поколения Knights Landing включает четыре модели с числом ядер от 64 до 72 и частотой от 1,3 до 1,5 ГГц. 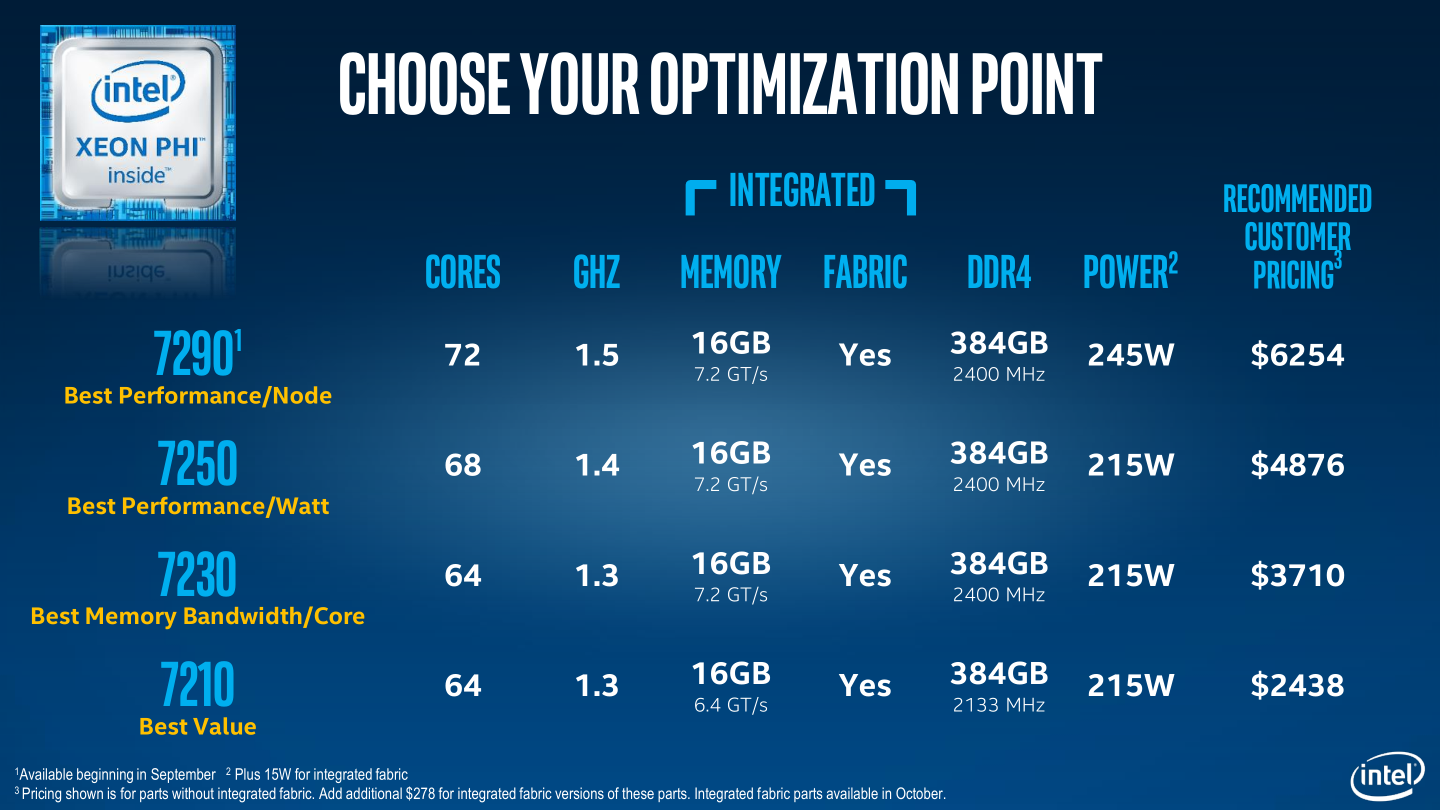 Стоит отметить, что в настоящее время для заказчиков доступны лишь три младшие модели: Xeon Phi 7250, 7230 и 7210. Самая же мощная 72-ядерная версия ускорителя, Xeon Phi 7290, обещана к сентябрю. Также пока Intel не поставляет варианты с интегрированным контроллером Omni-Path, который по плану появится в перечисленных моделях в октябре этого года. Высокая производительность процессоров Xeon Phi, простая масштабируемость систем на их основе, а также полная совместимость с x86-экосистемой и знакомым всем средствами разработки, делает новинки отличным вариантом для использования в массе областей, где требуются параллельные высокопроизводительного вычисления. И особенно Intel подчёркивает применимость построенных на Xeon Phi кластеров в системах машинного обучения и искусственного интеллекта, то есть тех областях, где в последнее время высокую активность развила NVIDIA, реализующая свои ускорители семейства Tesla. В подтверждение лидирующих характеристик Knights Landing, компания Intel приводит информацию о кратном превосходстве системы на базе Xeon Phi 7250 над системой, в которой используется конкурирующий ускоритель вычислений NVIDIA Tesla K80 и пара центральных процессоров Xeon E5-2697 v4.  При этом, Intel говорит не только о достигающем пятикратного размера преимуществе Xeon Phi в производительности. Согласно информации компании, конфигурация с процессором Xeon Phi 7250 оказывается в восемь раз экономичнее и в девять — дешевле. Учитывая всё сказанное, Intel ожидает, что внедрение новых Xeon Phi пойдёт очень быстрыми темпами. До конца года производитель намеревается продать более ста тысяч процессоров, а готовые системы на базе Knights Landing будут поставлять более 50 компаний, включая Dell, Fujitsu, Hitachi, HP, Inspur, Lenovo, NEC, Oracle, Quanta, SGI, Supermicro, Colfax и другие. Кстати, в этом списке место нашлось и для российского интегратора — группы компаний РСК — которая собирается поставлять высокоплотные кластерные решения на базе Xeon Phi, оснащённые системами жидкостного охлаждения. |
|