Лента новостей
|
27.08.2019 [11:00], Геннадий Детинич
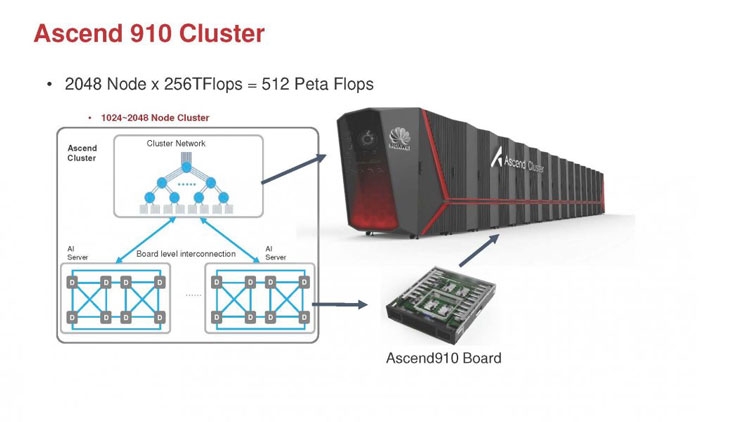
Huawei Ascend 910: китайская альтернатива ИИ-платформам NVIDIAГлубокое машинное обучение ― это сравнительно новая область приложения для вычислительных архитектур. Как всё новое, ML заставляет искать альтернативные пути решения задач. В этом поиске китайские разработчики оказались на равных и даже в привилегированных условиях, что привело к появлению в Китае мощнейших ИИ-платформ. Как всем уже известно, на конференции Hot Chips 31 компания Huawei представила самый мощный в мире ИИ-процессор Ascend 910. Процессоры для ИИ каждый разрабатывает во что горазд, но все разработчики сравнивают свои творения с ИИ-процессорами компании NVIDIA (а NVIDIA с процессорами Intel Xeon). Такова участь пионера. NVIDIA одной из первых широко начала продвигать свои модифицированные графические архитектуры в качестве ускорителей для решения задач с машинным обучением.  Гибкость GPU звездой взошла над косностью x86-совместимой архитектуры, но во время появления новых подходов и методов тренировки машинного обучения, где пока много открытых дорожек, она рискует стать одной из немногих. Компания Huawei со своими платформами вполне способна стать лучшей альтернативой решениям NVIDIA. Как минимум, это произойдёт в Китае, где Huawei готовится выпускать и надеется найти сбыт для миллионов процессоров для машинного обучения. 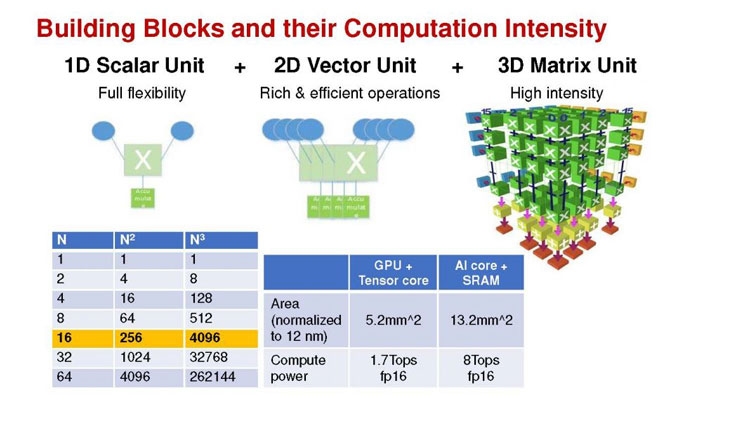 Мы уже публиковали анонс наиболее мощного ускорителя для ML чипа Huawei Ascend 910. Сейчас посмотрим на это решение чуть пристальнее. Итак, Ascend 910 выпускается компанией TSMC с использованием второго поколения 7-нм техпроцесса (7+ EUV). Это техпроцесс характеризуется использованием сканеров EUV для изготовления нескольких слоёв чипа. На конференции Huawei сравнивала Ascend 910 с ИИ-решением NVIDIA на архитектуре Volta, выпущенном TSMC с использованием 12-нм FinFET техпроцесса. Выше на картинке приводятся данные для Ascend 910 и Volta, с нормализацией к 12-нм техпроцессу. Площадь решения Huawei на кристалле в 2,5 раза больше, чем у NVIDIA, но при этом производительность Ascend 910 оказывается в 4,7 раза выше, чем у архитектуры Volta. 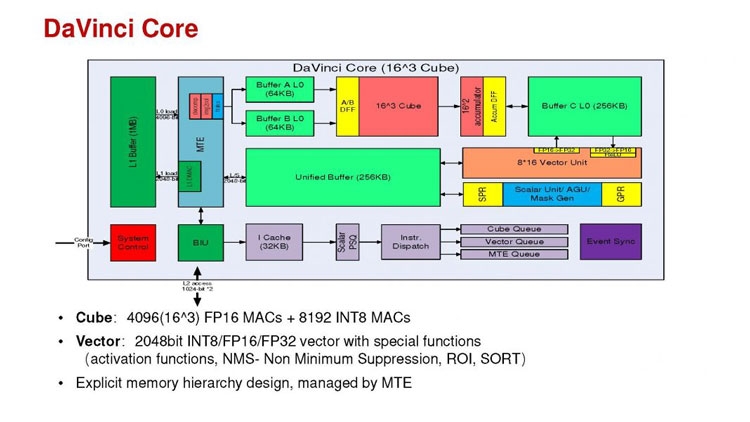 Также на схеме видно, что Huawei заявляет о крайне высокой масштабируемости архитектуры. Ядра DaVinci, лежащие в основе Ascend 910, могут выпускаться в конфигурации для оперирования скалярными величинами (16), векторными (16 × 16) и матричными (16 × 16 × 16). Это означает, что архитектура и ядра DaVinci появятся во всём спектре устройств от IoT и носимой электроники до суперкомпьютеров (от платформ с принятием решений до машинного обучения). Чип Ascend 910 несёт матричные ядра, как предназначенный для наиболее интенсивной работы. 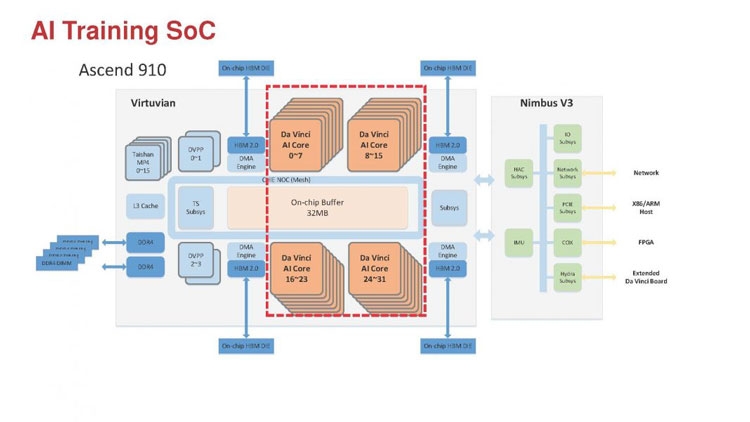 Ядро DaVinci в максимальной конфигурации (для Ascend 910) содержит 4096 блоков Cube для вычислений с половинной точностью (FP16). Также в ядро входят специализированные блоки для обработки скалярных (INT8) и векторных величин. Пиковая производительность Ascend с 32 ядрами DaVinci достигает 256 терафлопс для FP16 и 512 терафлопс для целочисленных значений. Всё это при потреблении до 350 Вт. Альтернатива от NVIDIA на тензорных ядрах способна максимум на 125 терафлопс для FP16. Для решения задач ML чип Huawei оказывается в два раза производительнее. 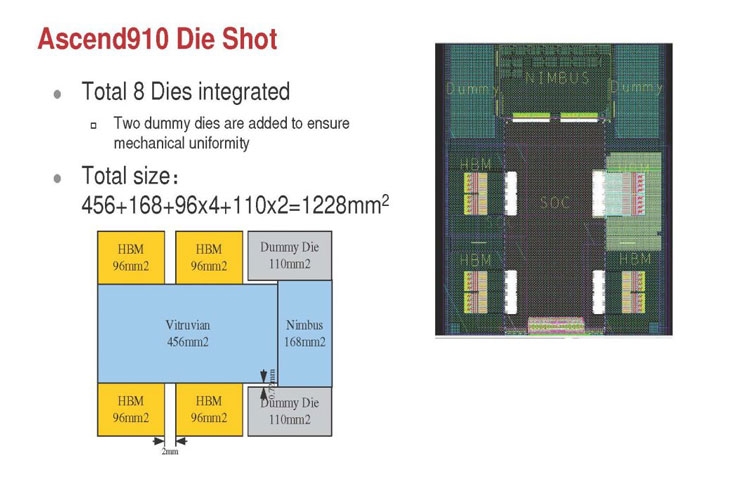 Помимо ядер DaVinci на кристалле Ascend 910 находятся несколько других блоков, включая контроллер памяти HBM2, 128-канальный движок для декодирования видеопотоков. Мощный чип для операций ввода/вывода Nimbus V3 выполнен на отдельном кристалле на той же подложке. Рядом с ним для механической прочности всей конструкции пришлось расположить два кристалла-заглушки, каждый из которых имеет площадь 110 мм2. С учётом болванок и четырёх чипов HBM2 площадь всех кристаллов достигает 1228 мм2. 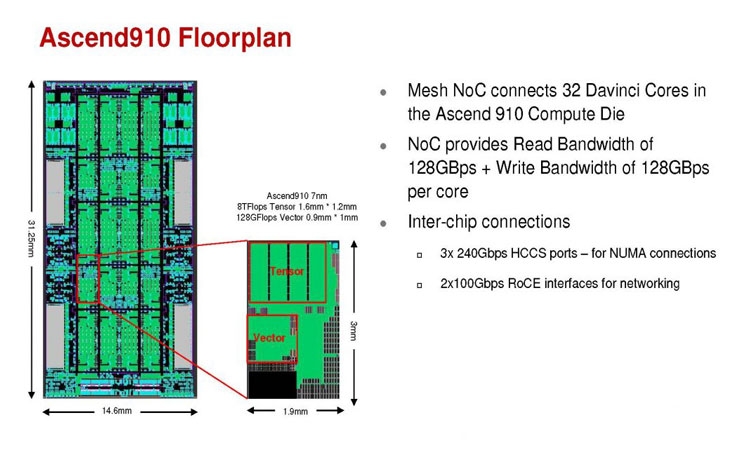 Для связи ядер и памяти на кристалле создана ячеистая сеть в конфигурации 6 строк на 4 колонки со скоростью доступа 128 Гбайт/с на каждое ядро для одновременных операций записи и чтения. Для соединения с соседними чипами предусмотрена шина со скоростью 720 Гбит/с и два линка RoCE со скоростью 100 Гбит/с. К кеш-памяти L2 ядра могут обращаться с производительностью до 4 Тбайт/с. Скорость доступа к памяти HBM2 достигает 1,2 Тбайт/с.  В каждый полочный корпус входят по 8 процессоров Ascend 910 и блок с двумя процессорами Intel Xeon Scalable. Спецификации полки ниже на картинке. Решения собираются в кластер из 2048 узлов суммарной производительностью 512 петафлопс для операций FP16. Кластеры NVIDIA DGX Superpod обещают производительность до 9,4 петафлопс для сборки из 96 узлов. В сравнении с предложением Huawei это выглядит бледно, но создаёт стимул рваться вперёд. 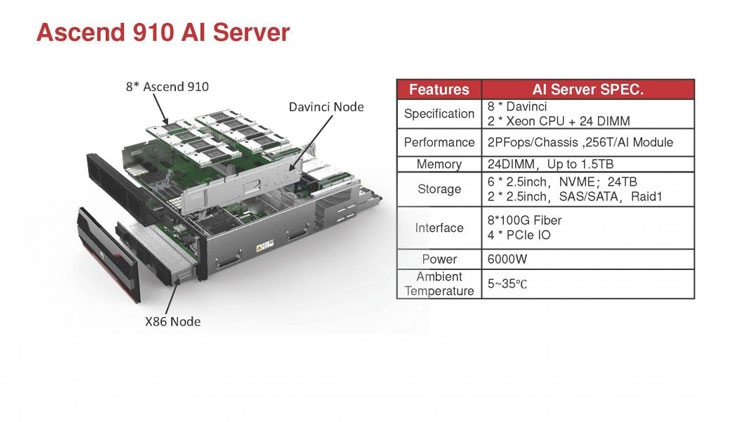
24.08.2019 [06:14], Андрей Галадей
IBM передала наработки по архитектуре Power сообществуКорпорация IBM сообщила, что переводит архитектуру набора команд (ISA) Power в разряд открытых решений. То есть, за неё не нужно будет платить, как это было в последние 6 лет. Отмечается, что с 2013 года действовал консорциум OpenPOWER, который лицензировал связанную с Power интеллектуальную собственность. Но теперь все наработки и патенты будут переданы сообществу безвозмездно. Сама же организация OpenPOWER Foundation будет переподчинена Linux Foundation, что позволит создать площадку для развития архитектуры без привязки к чипмейкеру или иной компании. Как отмечается, OpenPOWER Foundation включает в себя более 350 компаний, а сообществу передали свыше 3 млн строк кода системных прошивок, спецификаций и схем. Всё это позволит создавать Power-совместимые чипы всем желающим. 
pixabay.com Помимо собственно процессоров, компания передала сообществу и смежные технологии для разработки расширений на основе интерфейсов OpenCAPI (Open Coherent Accelerator Processor Interface) и OMI (Open Memory Interface). Первая технология должна устранить «узкие места» во взаимодействии CPU, GPU, ASIC, а также других чипов и контроллеров. Вторая же должна ускорить оперативную память. Это позволит создавать на базе архитектуры Power специализированные чипы для искусственного интеллекта. Важно отметить, что процессоры Power позволяют создавать современные серверы и суперкомпьютеры. К примеру, суперкомпьютеры Summit и Sierra работают как раз на таких чипах. А это, на минуточку, первый и второй номера в мировом рейтинге таких систем. Напомним, на процессорах с архитектурой Power (хотя и специализированных) работали в том числе и консоли Sony PlayStation 3, Xbox 360, а также старые ПК и ноутбуки Apple.
02.08.2019 [14:32], Геннадий Детинич
Intel хоронит шину Omni-PathДовольно неожиданно компания Intel отказалась от развития интерконнекта Omni-Path, которую она продвигала в серверных и HPC-платформах сначала для соединения узлов, в том числе для гиперконвергентных систем. Первое поколение шины Omni-Path с пропускной способностью до 100 Гбит/с на порт появилось несколько лет назад. Но ожидаемого второго поколения решений с пропускной способностью до 200 Гбит/с уже не будет. 
Ускорители Intel Xeon Phi с интегрированными контроллером и шиной Omni-Path Информацию о прекращении разработки и выпуска продукции Intel OmniPath Architecture 200 (OPA200) компания подтвердила, например, нашим коллегам с сайта HPCwire. Компания продолжит поддержку и поставку решений с шиной OPA100, но поставок продуктов с архитектурой OPA200 на рынок больше не будет. В принципе, сравнительно слабая поддержка шины Intel OmniPath со стороны клиентов рынка высокопроизводительных систем намекала на нечто подобное. Большей популярностью у строителей суперсистем и не только продолжает пользоваться InfiniBand и её новое HDR-воплощение с той же пропускной способностью до 200 Гбит/с. В свете ликвидации OPA200 становится понятно, почему Intel схватилась с NVIDIA за право поглощения компании Mellanox. Но не вышло: приз ушёл к NVIDIA. «Вообще, половина инсталляций в TOP500 использует Ethernet, но в основном 10/25/40 Гбит/с, и лишь совсем чуть-чуть может похвастаться 100 Гбит/с. InfiniBand установлен почти в 130 машинах, а Omni-Path есть чуть больше чем в 40. Остальное — проприетарные разработки». Что остаётся Intel? У лидера рынка микропроцессоров есть I/O-активы. Компания около 8 лет активно выстраивает направление для развития коммуникаций в ЦОД. За это время она поглотила разработчика коммутационных ASIC компанию Fulcrum Microsystems, подразделение по разработке адаптеров и коммутаторов InfiniBand компании QLogic и коммуникационное подразделение компании Cray. Относительно свежей покупкой Intel стала компания Barefoot Networks, разработчик решений для Ethernet-коммутаторов. Похоже, Intel решила вернуться к классике: InfiniBand (что менее вероятно) и Ethernet (что более вероятно), а о проприетарных шинах в виде той же Omni-Path решила забыть. В конце концов, Ethernet-подразделение компании славится своими продуктами. Новое поколения Intel Ethernet 800 Series способно заменить OPA100.
27.07.2019 [15:15], Геннадий Детинич
Alibaba представила 16-ядерный RISC-V процессор XT 910 для «умной» периферии и edge-платформНа днях дочернее подразделение корпорации Alibaba Group компания Pingtouge Semiconductor на тематической конференции в Шанхае представила первый фирменный процессор для «умной» периферии. Китайская разработка XuanTie 910 оказалось уникальной по целому ряду причин, о которых мы поговорим ниже. Но прежде обозначим главное, на чём настаивают китайские источники. Процессор XuanTie 910 поможет китайским компаниям всех уровней сбросить зависимость от ядер ARM и других проприетарных разработок (читай ― сведут на нет опасность санкций со стороны США), поскольку ядра XuanTie 910 используют открытую архитектуру RISC-V с открытым набором команд.  Производительность моделей процессоров семейства XuanTie 910 может варьироваться в широких пределах. 64-бит ядра собираются в кластеры по четыре штуки. В процессоре может быть до четырёх таких кластеров, то есть в максимальной конфигурации XuanTie 910 имеет 16 ядер RISC-V. Больше вряд ли необходимо, но в случае надобности разработчики наверняка смогут увеличить число ядер в процессоре. Относительно небольшое число ядер в процессорах XuanTie 910 объясняется назначением платформы ― стать основой вещей с подключением к Интернету, ассистентов (умных колонок и прочего), самоуправляемых автомобилей, периферии с подключением к сетям 5G, платформ с элементами ИИ и тому подобных решений для перифейрийных (edge) вычислений и платформ. По словам разработчиков, XuanTie 910 сегодня является самым производительным решением на архитектуре RISC-V. Это решение на частоте 2,5 ГГц, изготовленное с использованием 12-нм техпроцесса, как заявлено, обеспечивает производительность на уровне 7,1 CoreMark/МГц, что на 40 % больше, чем для существующих сегодня конкурирующих процессоров на архитектуре RISC-V. Если точнее, то сравнение было с 64-бит ядром SiFive U74, которое достигает 5,1 CoreMark/МГц (на ядро). Оно тоже позиционируется как самое мощное решение RISC-V, способное исполнять полноценные ОС вроде Linux. Для сравнения — отечественный процессор Байкал-Т1, согласно нашим прошлогодним тестам, имеет производительность 5,4 CoreMark/МГц (на ядро). 
onties.com Удивительным в этом сообщении наших коллег с EE Times представляется информация о 12-нм техпроцессе, который был задействован для производства XuanTie 910. Этот техпроцесс широко использует только компания GlobalFoundries. В этом случае Alibaba 100-процентно подставляется под санкции США, что нивелирует всякий смысл выбора открытой архитектуры. Впрочем, выводы делать рано, подождём подробности. Из других интересных особенностей ядер XuanTie 910 отметим 12-уровневый конвейер с внеочередным исполнением команд. За один цикл конвейер может исполнять сразу до 8 инструкций, причём и инструкции загрузки (load), и сохранения (store). Важно, что разработчики добавили в архитектуру RISC-V и процессор 50 новых расширенных инструкций для лучшей работы арифметических операций, доступа к памяти и поддержки многоядерности. Эти инструкции и ряд других решений китайцы сделают достоянием сообщества разработчиков с открытым кодом. Всё (или почти всё) будет выложено на GitHub, вероятно, в сентябре. Компании важно получить как можно более широкую поддержку со стороны независимых программистов, чему открытость RISC-V будет только способствовать. Примечательно, что новость о выходе XT 910 исчезла с сайта RISC-V Foundation через несколько часов после выхода. Среди других заметных китайских участников RISC-V Foundation есть Huawei, MediaTek, Huami (партнёр Xiaomi), а также инвестгруппа Xiamen SIG. Сейчас Китай активно развивает импортозамещение. Согласно планам правительства, в 2020 году 40% спроса на полупроводниковую продукцию должны удовлетворить местные производители. В прошлом году, по данным TrendForce, лишь 15% пришлось на «домашние» процессоры.
16.04.2019 [17:05], Андрей Созинов
AMD Ryzen Embedded R1000: двухъядерные процессоры для встраиваемых системКомпания AMD расширила ассортимент своих продуктов для встраиваемых систем, представив новую серию процессоров Ryzen Embedded R1000. Новинки, по словам самой AMD, предлагают новый класс производительности в области встраиваемых систем, а также предлагают лучшее соотношение цены и производительности по сравнению с конкурентными решениями. 
Источник изображений: AMD Всего было представлено два процессора: Ryzen Embedded R1606G и R1505G. Новинки весьма похожи друг на друга и отличаются между собой только тактовыми частотами ядер и встроенного GPU. Оба процессора располагают парой ядер Zen с поддержкой SMT, то есть работают на четыре потока. В качестве встроенного GPU в обеих новинках выступает Vega 3. В случае процессора Ryzen Embedded R1606G частоты ядер составляют 2,6/3,5 ГГц, а GPU — 1,2 ГГц. Младший Ryzen Embedded R1505G во всём медленнее на 200 МГц, то есть предлагает 2,4/3,3 и 1 ГГц соответственно.  Объём кеша второго и третьего уровней составляет 1 и 4 Мбайт соответственно. Поддерживается оперативная память DDR4 с частотой до 2400 МГц. Также есть поддержка до двух 10-гигабитных портов Ethernet. Есть возможность подключения до трёх дисплеев. Максимальный поддерживаемый формат видео — 4K с частотой 60 FPS.  Производители систем на базе новинок AMD смогут самостоятельно настроить уровень TDP чипов в пределах от 12 до 25 Вт. Это, конечно же, будет несколько влиять на производительность, однако позволит использовать чипы как в более мощных компьютерах, так и в более экономичных, и даже безвентиляторных системах. По словам AMD, новинки могут найти применение в самых различных устройствах: от тонких клиентов до промышленных систем и игровых систем, вроде предстоящей Atari VCS.  Также AMD отмечает высокую производительность своих новинок. В качестве примера приводятся результаты тестирования в Cinebench R15 и 3DMark11. Здесь оба процессора серии Ryzen Embedded R1000 смогли опередить чипы Intel Core i3-8145U поколения Whiskey Lake и Core i3-7100U поколения Kaby Lake.
02.04.2019 [20:00], Геннадий Детинич
Intel представила процессоры Xeon D-1600: почта, телеграф, мостыВ 2015 году компания Intel представила процессоры Xeon семейства D. Первой появилась серия Xeon D-1500. Процессоры Xeon D получили архитектуру уровня Intel Core (Broadwell), став на ступеньку выше Xeon на архитектуре Atom. Целевое назначение Xeon D при этом не изменилось ― они всё так же были ориентированы на создание микросерверов, встраиваемых решений, систем для хранения данных малого и среднего уровней и сетевого оборудования. В 2018 году компания выпустила серию Xeon D-2100 на архитектуре Skylake. Тем самым в семейство Xeon D добавились решения повышенной производительности. Сегодня Intel представила третью серию Xeon D ― процессоры D-1600, которые возвращают нас к истокам семейства, главной целью которого был захват рынка производительной периферии с акцентом на плотность и сниженное потребление.  Процессоры Intel Xeon D-1600 получили меньшее число ядер, чем у их предшественников в лице Xeon D-1500. Диапазон числа физических ядер у моделей Xeon D-1600 сократился с 4–16 до 2–8. Максимальный тепловой пакет при этом остался тем же ― 65 Вт, тогда как минимальное значение TDP снизилось с 35 Вт до 27 Вт. Снижение числа ядер и сохранение максимального уровня TDP говорит о росте производительности в пересчёте на одно ядро. Во многом это достигается за счёт прироста как базовой частоты (в 1,2–1,5 раза), так и за счёт увеличения частоты при автоматическом разгоне до 3,2 ГГц, тогда как модели Xeon D-1500 в режиме турбо ограничивались частотой до 2,7 ГГц. Определённым образом Intel откатилась назад по шкале эволюции, понизив градус многоядерности в пользу наращивания однопоточной производительности. Собственно, этого требует позиционирование новой серии и активное развитие виртуализации сетевых функций (NFV). Для этого стала важнее скорость реакции сетевой платформы, что хорошо отрабатывается повышением тактовых частот.  Архитектурных изменений в моделях Xeon D-1600 не очень много, если они вообще есть (пока предполагаем, что архитектура осталась прежней ― Broadwell). Интегрированный контроллер памяти остался двухканальным с поддержкой модулей DDR4 с частотой до 2400 МГц суммарным объёмом до 128 Гбайт. Также поддерживается память DDR3L-1600. Уточним, процессоры Xeon D ― это однокристальная платформа, фактически SoC, что чрезвычайно удобно для тех областей, на которые нацелены эти решения.  Встроенные в процессоры интерфейсы представлены 24 линиями PCIe 3.0, 8 линиями PCIe 2.0, 6 портами SATA 6 Гбит/с, 4 портами USB 3.0, 4 портами USB 2.0 и 4 портами Ethernet 10 Гбит/с. Кстати, об Ethernet. На кристалл Xeon D-1600 интегрирован контроллер Intel серии Ethernet 700. На это намекают не только четыре интерфейса Ethernet 10GbE, но также поддержка технологии Intel QuickAssist.  У старшей серии Xeon D-2100 модели Xeon D-1600 взяли то, чего не было у моделей Xeon D-1500 ― это поддержка технологии Intel QuickAssist (QAT). Технология QAT поддержана в моделях Xeon D-1600 с индексом «N». Наличие QAT означает, что процессор несёт встроенный аппаратный ускоритель для работы с криптографией, компрессией и обработки сетевого трафика. Поддерживается целый ряд популярных алгоритмов, что существенно разгружает вычислительные ядра и даёт ощутимый прирост производительности. Например, обработка трафика TLS/IPSec плюс компрессия происходит со скоростью 30 Гбит/с плюс 30 000 операций в секунду, как и расшифровка ключами RSA с такой же производительностью. 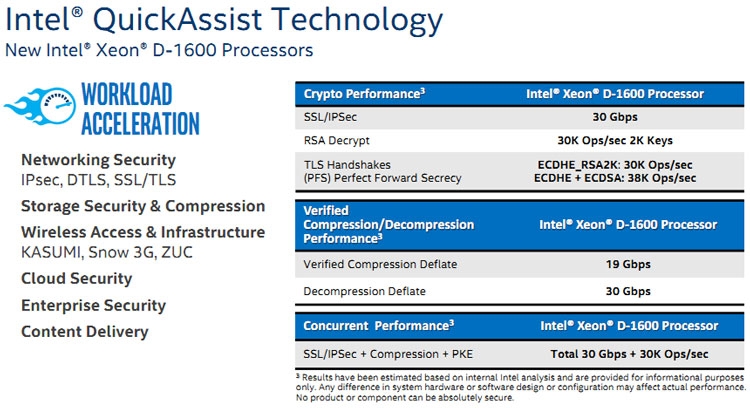 Поставки процессоров Xeon D-1600 компания Intel начнёт во втором квартале текущего года. Решения на основе новинок попадут на рынок к середине года или во второй его половине. По представлениям Intel, вычислительное и коммуникационное оборудование на базе Xeon D-1600 станет оптимальным выбором для развёртывания инфраструктуры для реализации и поддержки сотовой связи поколения 5G, а также для организации периферийных (пограничных) вычислений, когда обработка сырых данных (видео, сбор информации с датчиков, включая автомобильную электронику) происходит на месте и минимизирует пересылку в центры по обработке информации. Кроме того, они могут быть использованы в системах хранения данных. 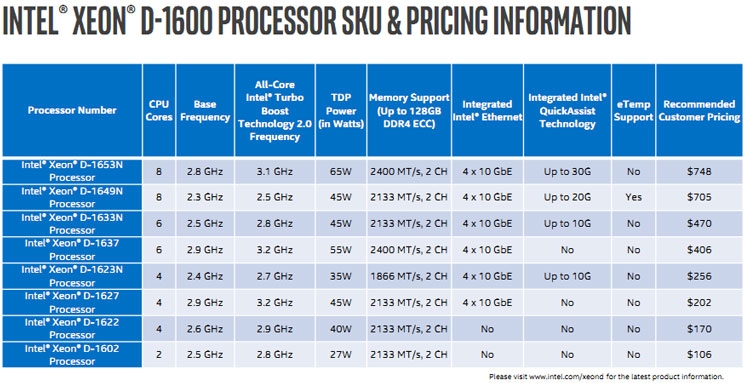 Процессоры Intel Xeon D 1600 представлены в рамках большого обновления решений для ЦОД, которое включает «взрослые» Intel Xeon Cascade Lake AP и SP с поддержкой памяти Optane в формате DDR4-модулей и новых инструкций для ИИ, модульные FPGA Agilex и сетевые контроллеры 100GbE Intel Ethernet 800. Подробности по ссылкам ниже.
23.02.2019 [20:20], Геннадий Детинич
Анонс серверных платформ ARM Neoverse E1 и N1: шах и мат, IntelУж извините за столь кричащий заголовок, но ARM давно мечтает сказать нечто подобное в отношении серверных платформ Intel. Пока получается не очень. Как говорят в самой ARM, не вышло с первого раза, попробуем во второй. Не получится во второй раз, на третий точно всё будет как надо. А сейчас и повод-то отличный! Разработчики оригинальных ядер ARM из одноимённой компании ударили сразу с двух направлений: по масштабируемым сетевым платформам (Neoverse E1) и по масштабируемым серверным (Neoverse N1). Очевидно, что пока «мата» в этой партии явно не будет. Intel крепко держится за серверные платформы и одновременно тянет руки к периферийным как в виде распределённых вычислительных ресурсов в составе базовых станций, так и в виде обычных периферийных ЦОД. Тем не менее, шансы объявить Intel «шах» у ARM определённо есть.  Рассчитанную на несколько лет вперёд стратегию Neoverse компания ARM представила в середине октября прошлого года. Она предполагает три крупных этапа, в ходе которых будут выходить доступные для широкого лицензирования 64-битные ядра ARM Ares (7 нм), Zeus (7 и 5 нм) и Poseidon (5 нм). Планируется, что каждый год производительность решений будет возрастать на 30 %. Сама компания ARM, напомним, не выпускает процессоры и SoC, а лишь продаёт лицензии на ядра и архитектуру, которые клиенты компании обустраивают нужными им контроллерами и интерфейсами. У ARM настолько многочисленная армия клиентов, что она ожидает буквально цунами из сотен и тысяч миллиардов ядер в год уже в недалёком будущем. Когда-нибудь в этот водоворот ядер будут вовлечены и серверные платформы, а затем количество перейдёт в качество.  Разработка и анонс ядер Neoverse N1 ― это явление народу 7-нм ядер Ares. Процессоры могут нести от 4 до 128 ядер, объединённых согласованной ячеистой сетью. Платформа N1 может служить периферийным компьютером с 8-ядерным процессором с потреблением менее 20 Вт, а может стать сервером в ЦОД на 128-ядерных процессорах с потреблением до 200 Вт. Степень масштабируемости должна впечатлять. Кроме этого, как сообщают в ARM, производительность ядер N1 на облачных нагрузках в 2,5 раза выше, чем у 16-нм ядер предыдущего поколения Cosmos (Cortex-A72, A75 и A53). Кстати, прошлой осенью на платформе Cosmos компания Amazon представила фирменный процессор Graviton. 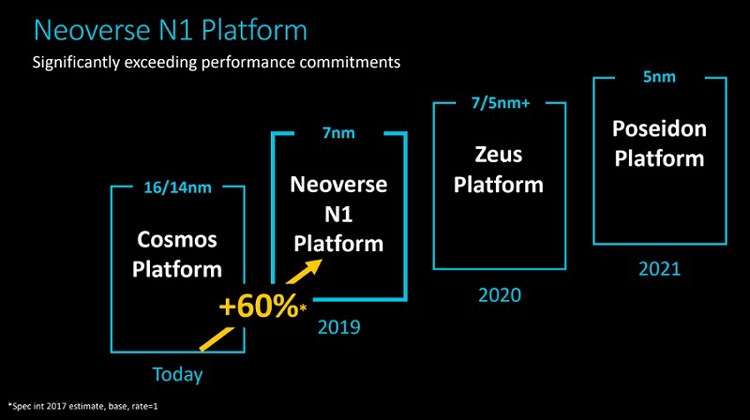 Производительность N1 при обработке целочисленных значений оказывается на 60 % больше, чем на ядрах Cortex-A72 Cosmos. При этом энергоэффективность ядер N1 также на 30 % выше, чем у ядер Cortex-A72. Как поясняют разработчики, платформа Neoverse N1 построена на «таких инфраструктурных расширениях, как виртуализация серверного класса, современная поддержка сервисов удалённого доступа, управление питанием и производительностью и профилями системного уровня». 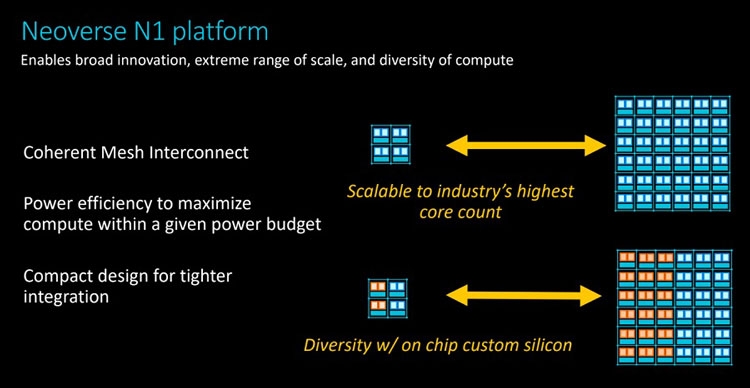 Когерентная ячеистая сеть (Coherent Mesh Network, CMN), о которой выше уже говорилось, разработана с учётом высокого соответствия вычислительным возможностям ядер. По словам ARM, сеть обменивается с ядрами такой служебной информацией, которая позволяет устанавливать объём загрузки в память данных для упреждающей выборки, распределяет кеш между ядрами и определяет, как он может быть использован, а также делает много других вещей, которые способствуют оптимизации вычислений. Интересно отметить, что в составе процессоров на платформе Neoverse N1 может быть существенно больше 128 ядер, но с оптимальной работой возникнут проблемы. Точнее, вычислительная производительность упрётся в пропускную способность памяти. Так, ARM рекомендует для CPU с числом ядер от 64 до 96 использовать 8-канальный контроллер DDR4, а для 96–128 ядерных версий ― контроллер памяти DDR5. Платформа Neoverse E1 ― это решение для сетевых шлюзов, коммутаторов и сетевых узлов, которое, например, облегчит переход от сетей 4G к сетям 5G с их возросшей требовательностью к каналам передачи данных. Так, Neoverse E1 обещает рост пропускной способности в 2,7 раза, увеличение эффективности при передаче данных в 2,4 раза, а также более чем 2-кратный рост вычислительной мощности по сравнению с предыдущими платформами (ядрами). С масштабируемостью ядер E1 тоже всё в порядке, они позволят создать решение как для базовых станций начального уровня с потреблением менее 35 Вт, так и маршрутизатор с пропускной способностью в сотни гигабайт в секунду. Что же, ARM расставила на доске новые фигуры. Будет интересно узнать, кто же начнёт игру?
31.01.2019 [20:33], Сергей Карасёв
Intel ставит крест на процессорах ItaniumКорпорация Intel опубликовала документ, по сути, знаменующий закат эпохи процессоров Itanium, на которые некогда возлагались большие надежды.  В обнародованном уведомлении речь идёт о грядущем прекращении производства чипов Itanium 9700, известных под кодовым именем Kittson. Массовые поставки этих изделий были начаты в 2017 году. Семейство включает четыре модели — Itanium 9720, Itanium 9740, Itanium 9750 и Itanium 9760 с четырьмя и восемью вычислительными ядрами. В документе Intel говорится, что приём заказов на все перечисленные процессоры прекратится через год — 30 января 2020-го. Поставки будут полностью свёрнуты 29 июля 2021 года. 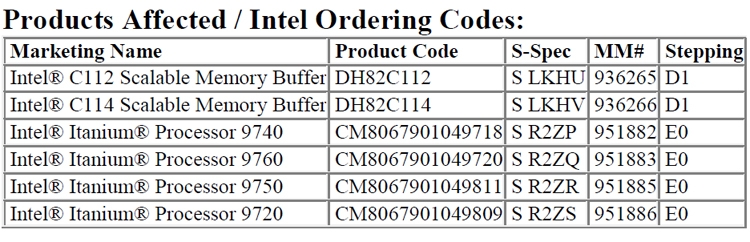 Таким образом, Intel ставит крест на решениях Itanium. Ещё в момент выхода Kittson говорилось, что эти изделия станут последними в семействе Itanium. Добавим, что впервые чипы Itanium дебютировали в мае 2001 года. Но продажи чипов оказались менее успешными, чем предполагалось. Основными причинами этому были проблемы с производительностью и малое количество оптимизированного программного обеспечения.
22.08.2018 [13:00], Геннадий Детинич
Раскрыты спецификации ARM-процессоров Fujitsu A64FX для суперкомпьютера Post-KПримерно через три года начнётся коммерческая эксплуатация суперкомпьютера Post-K, который компании Fujitsu и RIKEN разрабатывают на смену предыдущей совместной системы суперкомпьютера K (начал работать в 2011 году). Новая система Post-K обещает 100-кратно поднять производительность на уровне приложений. И сделано это будет благодаря переходу Fujitsu на ARM-совместимые ядра и новую архитектуру с масштабируемыми векторными инструкциями (Scalable Vector Extensions).  На прошедшей на днях конференции Hot Chips 30 (2018) компания Fujitsu впервые обнародовала спецификации новых процессоров, которые получили обозначение A64FX. Ни «A», ни «64», ни «FX» не имеют отношение к компании AMD, хотя в названии новых суперпроцессоров Fujitsu что-то немного согревает душу. Это процессоры с поддержкой 64-разрядных команд ARM и векторных инструкций длиной до 512 бит. Каждый процессор Fujitsu A64FX будет нести 48 вычислительных ядер и 4 вспомогательных ядра, разделённые на четыре блока, соединённых внутренней кольцевой шиной. Для связи с другими процессорами Fujitsu использует две линии внешнего интерфейса Tofu с пропускной способностью 28 Гбит/с. Строение процессора и внешний скоростной интерфейс обещают значительное наращивание параллелизма в вычислениях. 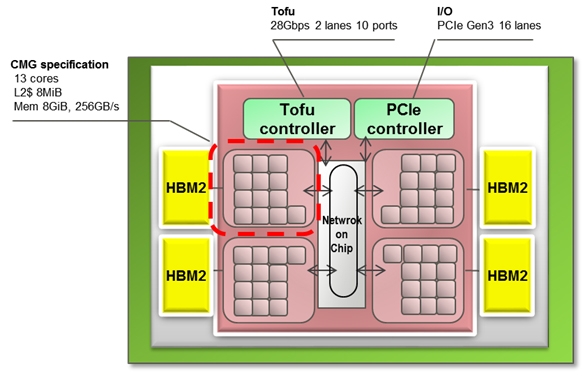
Fujitsu Каждый из 13-ядерных блоков поддержан кеш-памятью L2 объёмом 8 Мбайт. Кроме этого каждый из блоков напрямую обращается к модулю стековой памяти HBM2 объёмом 8 Гбайт. Суммарный объём памяти HBM2 у каждого процессора насчитывает 32 Гбайт, а общая скорость доступа достигает 1024 Гбайт/с. Поскольку память HBM2 можно рассматривать в качестве кеш-памяти третьего уровня, все или большинство операций выполняются в процессоре, что обещает отличный прирост производительности.  Процессор Fujitsu A64FX выпускается с использованием 7-нм техпроцесса, очевидно, что на линиях компании TSMC. Он насчитывает 8,7 млрд транзисторов. Пиковая производительность процессора для операций с двойной точностью достигает 2,7 терафлопс. Процессор без потерь на переход может вычислять операции с одинарной точностью и половинной, соответственно, в два и четыре раза быстрее. Также, за что надо благодарить тему машинного обучения, процессор A64FX оптимизирован для обработки 16- и 8-битных целочисленных значений. 
29.07.2018 [13:00], Геннадий Детинич
Американские ВВС получили самый большой в мире нейроморфный суперкомпьютерЗвучит громко, но это именно так. Лаборатория Air Force Research Laboratory (AFRL) в городе Ром, штат Нью-Йорк, получила в своё распоряжение самый большой в мире компьютер по числу задействованных в системе нейроморфных процессоров IBM TrueNorth. Система представлена полочными компьютерами высотой 4U (7 дюймов) для стандартной серверной стойки. Каждый компьютер располагает 64 процессорами IBM TrueNorth. В пересчёте на человеческие в буквальном смысле единицы измерения мозга — это 64 млн нейронов и 16 млрд синапсов. Всего в стойке может разместиться 512 млн цифровых нейронов. Примерно столько нейронов в коре головного мозга собаки. 
AFRL Система под именем «Blue Raven» на базе IBM TrueNorth для Лаборатории ВВС США представлена пока 64-процессорным решением с общим потреблением 40 Вт. Это, кстати, в 4 раза больше ожидаемого. Аналогичный 16-процессорный компьютер, переданный в 2016 году Ливерморской национальной лаборатории им. Лоуренса, потреблял всего 2,5 Вт или 156 мВт на один процессор. Возможно таким образом была повышена производительность системы, которая при потреблении 70 мВт способна работать с производительностью 46 млрд синаптических операций в секунду. 
IBM По оценкам IBM, работа процессоров TrueNorth с необозначенным датасетом на CIFAR-100 по распознаванию наборов изображений характеризуется производительностью свыше 1500 кадров в секунду с потреблением 200 мВт или свыше 7000 кадров в секунду на ватт. Ускоритель NVIDIA Tesla P4 (Pascal GP104), например, обрабатывает датасет Resnet-50 с производительностью 27 кадров в секунду на ватт. 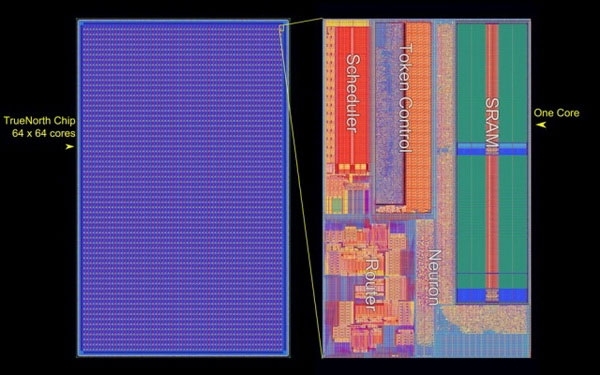
Структура процессора IBM TrueNorth Вообще, в Лаборатории AFRL, похоже, работают увлечённые люди. Новым проектом «Blue Raven» руководит тот же человек (Mark Barnell), который несколько лет назад отметился запуском суперкомпьютера Condor Cluster на базе сотен игровых консолей Sony PlayStation 3. Какими расчётами в AFRL будет заниматься суперкомпьютер с «мозгами» не уточняется. Пока учёные будут изучать круг задач, решаемый подобными системами. Ожидается, что принятая на «вооружение» научным отделом ВВС США вычислительная система обеспечит дальнейшее приоритетное развитие технологий в этой стране. |
|
|||||||||||||






